Data-Free Likelihood-Informed Dimension Reduction of Bayesian Inverse Problems
Abstract
Identifying a low-dimensional informed parameter subspace offers a viable path to alleviating the dimensionality challenge in the sampled-based solution to large-scale Bayesian inverse problems. This paper introduces a novel gradient-based dimension reduction method in which the informed subspace does not depend on the data. This permits an online-offline computational strategy where the expensive low-dimensional structure of the problem is detected in an offline phase, meaning before observing the data. This strategy is particularly relevant for multiple inversion problems as the same informed subspace can be reused. The proposed approach allows controlling the approximation error (in expectation over the data) of the posterior distribution. We also present sampling strategies that exploit the informed subspace to draw efficiently samples from the exact posterior distribution. The method is successfully illustrated on two numerical examples: a PDE-based inverse problem with a Gaussian process prior and a tomography problem with Poisson data and a Besov- prior.
1 Introduction
The Bayesian approach to inverse problems builds a probabilistic representation of the parameter of interest conditioned on observed data. Denoting the parameter and data by and , respectively, the solution to the inverse problem is encapsulated in the posterior distribution, which has the probability density function (pdf)
| (1) |
where denotes the prior density, is the likelihood function, and is the marginal density of the data that can be expressed as
| (2) |
This way, one can encode the posterior into summary statistics, for example, moments, quantiles, or probabilities of some events of interest [31, 51, 52], to provide parameter inference and associated uncertainty quantification.
In practice, computing these summary statistics requires dedicated methods to efficiently characterize the posterior distribution. Markov chain Monte Carlo (MCMC) methods [9, 38], originating with the Metropolis-Hastings algorithm [29, 41], and sequential Monte Carlo methods [22] have been developed as workhorses in this context. However, many inverse problems have high-dimensional or infinite-dimensional parameter space, which present a significant hurdle to the applicability of MCMC, SMC, and other related sampling methods in general.
The efficiency of these sampling methods, measured by the required number of posterior density evaluations, may deteriorate with the dimension of the parameter space, see [47, 48] and references therein. Even with the rather strong log-concave assumption, start-of-the-art MCMC methods can still be sensitive to the dimension of the problem, see for instance [20, 24, 25].
One promising way to alleviating the challenge of dimensionality is to exploit the effectively low-dimensional structures of the posterior distribution. Such low-dimensional structures can be used to construct certified low-dimensional approximations of the posterior distribution [50, 54] and efficient MCMC proposals that are robust in the parameter dimension [5, 6, 17, 16, 33]. There exists several ways to detect low-dimensional structures. A widely accepted method is to utilize the regularity of the prior, in which the dominant eigenvectors of the prior covariance operator [40] can be used to define such a low-dimensional subspace. This prior-based dimension reduction also plays a key role in the analysis of high-dimensional integration methods such as [26, 27]. In addition to the prior regularity, the limited accuracy of the observations and the ill-posed nature of the forward model often allow one to express the posterior as a low-dimensional update from the prior. Methods such as the active subspace (AS) [13, 14] and the likelihood-informed subspace (LIS) [18, 19, 54] utilize gradients of the forward model and/or of the likelihood function in order to better identify the low-dimensional structure of the problem. We refer to [19, 54] for an overview and a comparison of the existing methods.
The success of AS and LIS relies on the computation of the gradient or the Hessian of the log-likelihood function. Since the likelihood function depends on the observed data, the resulting subspaces need to be reconstructed each time a new data set is observed. This can add a significant computational burden to the solution of inverse problems. In this paper, we present a new data-free strategy for constructing the informed subspace in which the computationally costly subspace construction can be performed in an offline phase, meaning before observing any data sets. In the subsequent online phase, the data set is observed and the precomputed informed subspace is utilized to accelerate the inversion process. This computational strategy is particularly relevant for real-time systems such as medical imaging where multiple inversions are needed.
The rest of the paper is organized as follows. To begin, we introduce the problem setting in Section 2. In Section 3, we present a new data-free likelihood-informed approach to construct the subspace. Denoting the Fisher information matrix of the likelihood function by , this approach defines the informed subspace as the rank- dominant eigenspace of the matrix
| (3) |
with . This definition makes no particular assumption on the likelihood function, so it can be applied to a wide range of measurement processes, e.g., Gaussian likelihood and Poisson likelihood. It also does not involve any particular data set , and hence can be constructed offline. Given the informed subspace, we approximate the posterior density by
| (4) |
where and denote respectively the informed and the non-informed components of . We prove that the expected Kullback-Leibler (KL) divergence of the full posterior from its approximation is bounded as
| (5) |
where the expectation is taken over the data , being the subspace Poincaré constant of the prior [53, 54] and the -th largest eigenvalue of . This way, a problem with a fast decay in the spectrum of yields an accurate low-dimensional posterior approximation in expectation over the data.
In Section 4, we restrict the analysis to Gaussian likelihood. In this case, we show that the vector-valued extension [53] of the AS method [12], which reduces parameter dimensions via approximating forward models, also leads to the same data-free informed subspace as that obtained using (3). We can further show that, although the likelihood-informed approach and AS employ different approximations to the posterior density, the resulting approximations share the same structure as shown in (4) and follow the same error bound as in (5).
As suggested by (4), the factorized form of the approximate posterior densities allows for dimension-robust sampling. One can explore the low-dimensional intractable parameter reduced posterior using methods such as MCMC, followed by direct sampling of the high-dimensional but tractable conditional prior . This strategy has been previously investigated, see [18, 54] and references therein. We provide a brief summary to this existing sampling strategy in Section 5. Despite the accelerated sampling offered by the informed subspace, the resulting inference results are subject to the dimension truncation error that is bounded in (5). In Section 6, by integrating the pseudo-marginal approach [1, 2] and the surrogate transition approach [11, 38, 39] into the abovementioned sampling strategy, we present new exact inference algorithms that can enjoy the same subspace acceleration while target on the full posterior. Our exact inference algorithms only require minor modifications to the sampling strategy of [18, 54].
While our dimension reduction method readily apply for Gaussian priors, its application to non-Gaussian priors might not be straightforward. In Section 7, we show how to use the propose method for problems with Besov priors [21, 32, 34] which are commonly used in image reconstruction problems.
We demonstrate the accuracy of the proposed data-free LIS and the efficiency of new sampling strategies on a range of problems. These include the identification of the diffusion coefficient of a two-dimensional elliptic partial differential equation (PDE) with a Gaussian prior in Section 8 and Positron emission tomography (PET) with Poisson data and a Besov prior in Section 9.
2 Problem setting
For high-dimensional ill-posed inverse problems, the data are often informative only along a few directions in the parameter space. To detect and exploit this low-dimensional structure, we introduce a projector of rank such that is the informed subspace and the non-informed one. This splits the parameter space as
where the subspaces and are not necessarily orthogonal unless is orthogonal. The fact that the data are only informative in means there exists an approximation to the posterior density under the form
| (6) |
in which the likelihood function is replaced by a ridge function . A ridge function [46] is a function which is constant on a subspace, here . Let and be the components of in and , respectively. We have the parameter decomposition
Using a slight abuse of notation, we factorize the prior density as , where
denote the marginal prior and the conditional prior. The approximate posterior (6) writes
This factorization shows that, under the approximate posterior density, the Bayesian update is effective on the informed subspace (first term ), while the non-informed subspace is characterized by the prior (second term ). This property will be exploited later on to design efficient sampling strategies for exploring both the approximate posterior and the full posterior.
The challenge of dimension reduction is to construct both the low-rank projector and the ridge approximation such that the KL divergence of the full posterior from its approximation
can be controlled. In this work, we specifically focus on constructing a projector which is independent on the data and which allows to bound .
3 Dimension reduction via optimal parameter-reduced likelihood
In this section, we first briefly review the optimal parameter-reduced likelihood and the data-dependent LIS proposed in [54], and then we will introduce the data-free LIS.
3.1 Optimal parameter-reduced likelihood using a given projector
As shown in Section 2.1 of [54], for a given data set and a given projector , the parameter-reduced likelihood function
| (7) |
is an optimal approximation in the sense that it minimizes . We denote by
the resulting approximate posterior density. The marginal density can be expressed as
| (8) |
for all , where is the marginal density of the full posterior. Thus, for any projector and any data , the approximate posterior and the full posterior have the same marginal density on . In summary we have
which shows that the optimal approximation to replaces the conditional posterior with the conditional prior .
3.2 Data-dependent dimension reduction
We denote by a projector built by a data-dependent approach. Ideally, we would like to build that minimizes over the manifold of rank- projectors. However, this non-convex minimization problem can be challenge to solve. Instead, the strategy proposed in [54] minimizes an upper bound of the KL divergence obtained by logarithmic Sobolev inequalities, in which the following assumption on the prior density is adopted.
Assumption 3.1 (Subspace logarithmic Sobolev inequality).
There exists a symmetric positive definite matrix and a scalar such that for any projector and for any continuously differentiable function the inequality
holds, where is the conditional expectation of given by . Here the norm is defined by for any .
Theorem 1 in [54] gives sufficient conditions on the prior density such that Assumption 3.1 holds. In particular, any Gaussian prior with mean and non-singular covariance matrix satisfies Assumption 3.1 with and . As shown in [54, example 2], any Gaussian mixture also satisfies this assumption, but with a constant which might not be accessible in practice. We refer to [28, 36] for nicely written introductions to logarithmic Sobolev inequalities and examples of distributions which satisfy it.
Proposition 3.2.
Proof.
See the proof of Corollary 1 in [54]. ∎
Proposition 3.2 gives an upper bound on . The minimizer of this bound
can be obtained from the leading generalized eigenvectors of the matrix pair , see [53, Proposition 2.6]. Let denotes the -th eigenpair of such that with and for all . The image and the kernel of are respectively defined as
| (11) | ||||
The resulting projector yields an approximate posterior density that satisfies
The above relation can be used to choose the rank to guarantee that the is bounded below some user-defined tolerance. A rapid decay in the spectrum ensures that one can choose a rank that is much lower than the original dimension . Note that the projector may not be unique, unless there exists a spectral gap which ensures the -dimensional dominant eigenspace of is unique.
Remark 3.3 (Coordinate selection).
The projector defined in (11) is, in general, not aligned with the canonical coordinates. However, in some parametrizations—for example, different components of represent physical quantities of different nature—we may prefer coordinate selection than subspace identification to make the dimension reduction more interpretable. Denoting the -th canonical basis vector of by , we let be the projector of rank , which extracts the components of indexed by the index set such that
Using such a projector, the bound (9) becomes
which suggests to define the index set that selects the largest values of .
Because of the dependency on the data set , the projector must be built after a data set has been observed, see Algorithm 1. For scenarios where one wants to solve multiple inverse problems with multiple data sets, the matrix and the resulting projector have to be reconstructed for each data set. This can be a computationally challenging task. In addition, is defined as an expectation over the high-dimensional posterior distribution, which further raises the computational burden.
3.3 Data-free dimension reduction
To overcome the abovementioned computational burden of recomputing the data-dependent projector for every new data set, we present a new data-free dimension reduction method. The key idea is to control the KL divergence in expectation over the marginal density of data. We introduce an -dimensional random vector
where is the marginal density of data defined in (2). Note that the observed data corresponds to a particular realization of . For a given projector independent on the data, replacing with in (9) and taking the expectation over yields
| (12) |
Here, the approximate posterior depends on via the optimal likelihood . Similar to the data-dependent case, the leading generalized eigenvectors of the matrix pair can be used to obtain a projector that minimizes the error bound. However, in this case, the matrix is the expectation of over the marginal density of data, and thus it is independent of observed data. Let denotes the -th eigenpair of such that , with and for all . The data-free projector that minimizes the right-hand side of (12) is given by
| (13) | ||||
When using this projector for defining the approximate posterior , the expectation of the KL divergence can be controlled as
| (14) |
Remark 3.4 (Bound in high probability).
Inequality (14) gives a bound on in expectation. In order to obtain a bound in high probability, let us use the Markov inequality for some . Thus, for a given , the condition is sufficient to ensure that
holds with a probability greater than .
Remark 3.5 (Coordinate selection).
Now we show that the matrix admits a simple expression in terms of the Fisher information matrix associated with the likelihood function. This leads to a computationally convenient way to construct the data-free projector. Recall that the likelihood , seen as a function of , is the pdf of the data conditionned on the parameter . The Fisher information matrix associated with this family of pdf is
| (15) |
We can write
| (16) |
which shows that the matrix is the expectation of the Fisher information matrix over the prior. This expression does not involve any expectation over the posterior density, which is a major advantage compared to the expression (10) of the data-dependent matrix . The methodology presented here is summarized in Algorithm 2.
Example 3.6 (Gaussian likelihood).
Consider the parameter-to-data map is represented by a smooth forward model and corrupted by an additive Gaussian noise with non-singular covariance matrix , i.e.,
The likelihood function takes the form , where is a normalizing constant. The Slepian-Bangs formula gives an explicit expression for the Fisher information matrix , where denotes the Jacobian of the forward model . By relation (16) we obtain
| (17) |
A similar matrix was considered in [18] in the context of data-dependent dimension reduction. The major difference with (17) is that, in [18], the expectation is taken over the posterior density rather than over the prior.
4 Dimension reduction via parameter-reduced forward model
In the previous Section 3, the detection of the data-free informed subspace is based on an approximation of the likelihood function. In this section, we present an alternative strategy which, under Gaussian likelihood assumption, consist in approximating the forward model instead of the likelihood itself. This approach is similar to the vector-valued extension of the AS method [53] and still yields error bounds for the expected KL divergence.
As in Example 3.6, let us start with a Gaussian likelihood of the form
| (18) |
where is a continuously differentiable forward model, is a non-singular covariance matrix and a normalizing constant. Our goal is to build a low-dimensional approximation to the likelihood (18) by replacing the forward model with a ridge approximation . That is, we look for a likelihood approximation of the form
| (19) |
where is a low-rank projector and where is some parameter-reduced function defined over . In general, this approximate likelihood (19) is different than the previous one , see (7), and therefore might not be optimal with respect to the KL divergence as discussed in Section 3.1. The following proposition will guide the construction of the approximate forward model.
Proposition 4.1.
Consider the posterior density with a Gaussian likelihood as in (18). For any approximate forward model , the resulting approximate likelihood defines an approximate posterior density such that
Here the expectation is taken over and is the approximate marginal density of data.
Proof.
See A. ∎
Using an approximate forward model in the form of , Proposition 4.1 ensures that the approximate posterior with as in (19) satisfies
| (20) |
This suggests to construct a ridge approximation to in the sense. To accomplish this, we follow the methodology proposed in [53] for the approximation of multivariate function using gradient information. First, for any projector , the optimal function that minimizes the right-hand side of (20) is the conditional expectation
| (21) |
Then, similarly to Assumption 3.1, we assume that satisfies the following subspace Poincaré inequality.
Assumption 4.2 (Subspace Poincaré inequality).
There exists a symmetric positive definite matrix and a scalar such that for any projector and for any continuously differentiable function the inequality
holds, where is the conditional expectation of defined by .
Assumption 4.2 is weaker than Assumption 3.1, in the sense that any distribution which satisfies the subspace logarithmic Sobolev inequality automatically satisfies the subspace Poincaré inequality with the same and the same , see for instance [54, Corollary 2]. We refer to the recent contributions [4, 43, 49] for examples of probability distribution which satisfy (subspace) Poincaré inequality. As for the logarithmic-Sobolev constant, the Poincaré constant is hard to compute in practice, except the case of Gaussian prior. Using similar arguments as in the proof of Proposition 2.5 in [53], Assumption 4.2 allows to write
| (22) |
holds for any projector , where the matrix is defined by
| (23) |
with the Jacobian matrix of given by
Again, the projector that minimizes the right-hand side of (22) can be constructed via the generalized eigenvalue problem :
| (24) | ||||
Using this projector to construct the approximate forward model in (21) and the approximate likelihood as in (19), Proposition 4.1 and the inequality in (22) yield
| (25) |
The methodology is summarized in Algorithm 3.
The matrix used in this case takes the same form as the matrix in Section 3.3 with the Gaussian likelihood (cf. Example 3.6), and hence results in the same data-free projector. However, the resulting approximate likelihood functions are not the same. Indeed in Section 3.3, the optimal approximate likelihood is given as the conditional expectation of the likelihood function (cf. (7)), whereas here, is defined by the conditional expectation of the forward model (cf. (21)). Using either the parameter-reduced likelihood in (7) or the parameter-reduced forward model in (21) results in the same parameter truncation error bound in terms of expected KL divergence.
Remark 4.3.
Despite the similarity between the approximate likelihood functions given in (7) and (19), these two approaches offer different computational characteristics. Given the data-free informed subspace, the optimal parameter-reduced forward model can be further replaced by a surrogate model constructed in the offline phase. The surrogate model can be obtained using tensor methods [8, 42], the reduced basis method [44], polynomial techniques [35], etc., just to cite a few. All these approximation techniques do not scale well with the apparent parameter dimensions , and thus parameter reduction can greatly improve the scalability of surrogate models.
In contrast, the conditional expectation of the likelihood function in (7) cannot be replaced with offline surrogate models because of the data-dependency of the likelihood.
5 Sampling the approximate posterior
Given a data-free informed subspace, the approximate posterior density has the factorized form
| (26) |
with either in the optimal parameter-reduced likelihood approach of Section 3, or with , in the optimal parameter-reduced forward model approach of Section 4. The factorization (26) naturally suggests a dimension robust way to sampling the approximate posterior. The sampling method consists in first drawing samples from the low-dimensional density using either MCMC or SMC method. Then, for each sample , we simulate a conditional prior sample from . In the end, are samples from the approximate posterior .
We emphasis here that the key is to be able to sample from the conditional prior . This task is rather easy for Gaussian priors. We show in Section 7 how to sample from for non-Gaussian priors with a particular structure that can be exploited.
Remark 5.1.
If the end goal is to compute expectation of some function over of the approximate posterior, the factorization (26) leads to
where are samples from the approximate marginal posterior . This way, if the expectation over the conditional prior can be carried out analytically, one can can simply avoid using conditional prior samples. Alternatively, the conditional expectations can also be approximated via other accurate quadrature rule for . Either way, we assume that integration with respect to the conditional prior is tractable.
In Algorithm 4 we provide the details of an MCMC-based sampling procedure in which the approximate likelihood (defined by either optimal parameter-reduced likelihood or optimal parameter-reduced forward model) can be obtained as sample averages over the conditional prior . To make these approximations generally applicable, we replace the conditional prior with the marginal prior in computing those conditional expectations in the Equations (27) and (28) in Algorithm 4. Note that the typical class of inverse problems equipped with a Gaussian prior is a special case. Since the projector is orthogonal with respect to , the marginal prior coincides with the conditional prior .
| (27) |
| (28) |
| (29) |
A remaining question is how to choose the sample size for computing the conditional expectations in (27) and (28). The following heuristic is developed based on the optimal parameter-reduced forward model. Consider the exact parameter-reduced forward model and its sample-averaged approximation . The sample-averaged approximation defines an approximate posterior density
that satisfies
| (30) |
Here, the expectation is taken jointly over the data and the sample . The above inequality directly follows from Proposition 4.1 and the fact that is the conditional expectation of over . We refer to Theorem 3.2 in [12] for more details on this derivation. Inequality (30) implies that the random approximate posterior can be used in place of , as the bounds on the expected Kullback-Leibler divergence in (20) and (30) are comparable. In addition, this suggests that the sample size in (28) does not have to be large. Even with , (20) and (30) differs only by a factor of 2. For the optimal parameter-reduced likelihood function, it is not obvious how to obtain a similar bound for the sampled-averaged conditional expectation in (27), see for instance the result [54, Proposition 5]. In this case, we adopt the identity (30) as a heuristic.
6 Sampling from the exact posterior
In this section, we present new strategies for sampling the exact posterior by adding minor modifications to Algorithm 4.
6.1 Pseudo-marginal for the optimal parameter-reduced likelihood
For the optimal parameter-reduced likelihood approach, Algorithm 4 replaces the optimal likelihood with the sample-average defined by (27) using frozen (fixed) samples . This way, Algorithm 4 produces samples from an estimation to the posterior approximation . In this section, we first show that replacing the frozen samples with freshly drawing samples at each MCMC iteration yields a pseudo-marginal MCMC [1] which samples exactly from . In addition, we also show that an appropriate recycling of the data generated by this modified algorithm allows obtaining samples from the exact posterior itself.
We propose to modify Algorithm 4 by replacing the acceptance rate in (29) with
| (31) |
Here, are i.i.d. samples from conditioned on the current state of the chain and are i.i.d. samples from conditioned on the proposed candidate . Compared to the previous acceptance rate (29) where where frozen, the new acceptance rate (31) requires to redraw fresh samples at each proposal candidate . This is summarized in Algorithm 5.
In the next proposition we apply the analysis of pseudo-marginal MCMC [1] to show that is the invariant density of the Markov chain constructed by Algorithm 5. The key step is to interpret Algorithm 5 as a classical Metropolis-Hastings algorithm that operates on the product space .
Proposition 6.1.
Algorithm 5 constructs an ergodic Markov chain on the product space with invariant density
| (32) |
The marginal of this target density satisfies so that the sequence is an ergodic Markov chain with the invariant density .
Proof.
See B. ∎
Remark 6.2 (Choosing in Algorithm 5).
The statistical performance of pseudo-marginal methods depends on the variance of the sample-averaged estimate . This variance being inversely proportional to the sample size , a larger may result in better statistical efficiency of the MCMC chain. However, the computational cost per MCMC iteration increases linearly with , while the improvement of the statistical efficiency will not follow the same rate. We refer the readers to [3, 23] for a detailed discussion on this topic and only provide an interpretation as follows. With , the Markov chain constructed by the pseudo-marginal MCMC converges to that of an idealized standard MCMC, which has the acceptance probability defined by the same proposal density and the exact evaluation of . This way, even with a very large , the statistical efficiency of the pseudo-marginal MCMC cannot be improved further beyond that of the idealized standard MCMC. As suggested by [23], the standard deviation of the logarithm of the parameter-reduced likelihood estimate, , can be used to monitor the quality of the sample-averaged estimator.
It is remarkable to observe that, for , the target density (32) becomes the true posterior . This means that Algorithm 5 actually produces samples from . For , we propose to recycle the Markov chain produced by Algorithm 5 in order to generate samples from the exact posterior . This procedure is summarized in Algorithm 6 and a justification is provided in the following proposition.
Proposition 6.3.
Let be a Markov chain generated by Algorithm 5. For any we randomly select according to the probability
| (33) |
and we let . Then is a Markov chain with the exact posterior as invariant density.
Proof.
See C ∎
6.2 Delayed acceptance for the optimal parameter-reduced forward model
For the optimal parameter-reduced forward model, the marginal density of the resulting approximate posterior does not coincide with that of the exact posterior in general. However, we can still modify the approximate inference algorithm 4 using the delayed acceptance technique [11, 38, 39] to explore the exact posterior. The delayed acceptance modifies Algorithm 4 by adding a second stage acceptance rejection within each MCMC iteration. Here we consider the sample-averaged likelihood defined by either (27) (the optimal parameter-reduced likelihood) or (28) (the optimal parameter-reduced forward model), where the marginal prior sample set is prescribed. The following Proposition and Algorithm 7 detail this modification.
Proposition 6.4.
Suppose we have a proposal distribution defined in the parameter reduced subspace . We consider the following two stage Metropolis-Hastings method. In the first stage, we draw a proposal candidate . Then, with the probability
| (34) |
we move the proposal candidate to the next stage. In the second stage, we draw a proposal candidate in the complement subspace and then accept the pair of proposal candidates with the probability
| (35) |
Then, the above procedure constructs an ergodic Markov chain with the full posterior as the invariant density.
Proof.
Remark 6.5.
It worth to note that the delayed acceptance also opens the door to further accelerate the exact inference using surrogate models instead of the original forward model. The approximate likelihood is deterministic and dimension reduced, which makes it possible to further approximate using computationally fast surrogate models. In this case, the same delayed acceptance MCMC (Algorithm 7) can still produce ergodic Markov chains that converge to the full posterior . In contrast, the pseudo-marginal method requires an unbiased Monte Carlo estimate of the exact marginal posterior at every iteration, which is not straightforward to accelerate using surrogate models.
7 Non-Gaussian priors
The dimension reduction techniques presented in Sections 3 and 4 require one to evaluate the marginal prior density and draw samples from the conditional prior . While these tasks are readily doable for Gaussian distributions, it might not be the case in general. In this section, we use Besov priors as an example to present strategies that can extend the proposed dimension reduction methods to some non-Gaussian priors.
7.1 Besov priors
Besov measure [21, 32, 34] naturally appears in image reconstruction problems in which the detection of edges and interfaces is important. Following [32, 34], we construct Besov priors using wavelet functions and consider functions on the one-dimensional torus . Starting with a suitable compactly supported mother wavelet function , we can define an orthogonal basis
This way, given a smoothness parameter and integrability parameters , a function in the Besov space can be written as
| (36) |
and satisfies
In a Bayesian setting, we can set and define the Besov- prior with the pdf111This pdf is used for demonstrating the intuition rather than a rigorous characterization, as it is defined with respect to the (non-existent) infinite-dimensional Lebesgue measure. However, the finite-dimensional discretization of the Besov measure, which is used in numerical simulations, has a pdf in this form with respect to Lebesgue measure.
| (37) |
where is a scale parameter. One can easily generalize the above definition of Besov priors to multidimensional settings by taking tensor products of the one-dimensional basis and associated coefficients.
We can discretize the Besov prior by truncating the infinite sum in (36) to the first terms. This way, collecting all the coefficients into a parameter vector , where , the discretized Besov- prior can be equivalently expressed as a product-form distribution over the parameter with the pdf
| (38) |
7.2 Dimension reduction via coordinate selection
In general, we do not have closed form expressions for both the marginal and the conditional , unless the projector is aligned with the canonical basis. This leads to the construction of reduced subspace by selecting a subset of canonical basis. As discussed in Remarks 3.3 and 3.5, this task can be achieved by identifying an index set with cardinality such that contains the indices of the largest values of in the data-dependent case or those of in the data-free case. This leads to the projector where is the canonical basis of . Thus, the product-form of (38) yields the marginal prior and the conditional prior
respectively. In this formulation, evaluating the marginal prior density and drawing samples from the conditional prior become straightforward tasks.
Remark 7.1.
For , the tails of defined in (38) are heavier than Gaussian tails, and hence Assumptions 3.1 and 4.2 may not be satisfied. Nonetheless, one can still numerically apply the proposed dimension reduction methods without having the error bounds in (14) and (25). In this case, we set to be the identity matrix in accordance with the fact that the prior components are independent and identically distributed.
Remark 7.2 (Other sparsity-inducing prior).
There exist other shrinkage priors similar to Besov priors, in which the random function is expressed as a weighted linear combination of basis functions and the associated random weights follow other type of heavy tail distributions. For example, the horseshoe prior and the Student’s prior. See [10] for further discussions and references therein. The coordinate selection technique introduced here may also be applicable to those shrinkage priors.
7.3 Dimension reduction via prior normalization
Alternatively, we consider the case where the prior can be defined as the pushforward of the standard Gaussian measure with pdf under a -diffeomorphism , which takes the form
| (39) |
In other words, is the pdf of the random vector where . For the Besov- prior defined in (38), the diffeomorphism has a diagonal form with , where is the cumulative density function (cdf) of defined in (38) and is the cdf of the standard Gaussian. We provide details of the cdf in E.
The invertibility of allows us to reparametrize the Bayesian inverse problem in terms of the variable , which is endowed with the Gaussian prior . With this change of variable, the likelihood function becomes , and thus the matrix used to reduce the dimension of should be
in the data-dependent case and in the data-dependent case. For the optimal parameter-reduced forward model in the Gaussian likelihood case (cf. Section 4), the forward model is replaced by . This way, the matrix should be replaced by
Using either of these matrices, we obtain a projector to reduce the dimension in the variable , where and . In term of the original variable , the dimension reduction method allows one to identify with the observed data, while is informed by the prior only. Since and are nonlinear with respect to , the resulting method can be interpreted as a nonlinear dimension reduction method.
8 Example 1: elliptic PDE
We first validate our methods using an inverse problem of identifying the coefficient of a two-dimensional elliptic PDE from point observations of its solution.
8.1 Problem setup
Consider the problem domain , with boundary . We denote the spatial coordinate by . We model the steady state potential solution field for a given conductivity field and forcing function using the Poisson’s equation
| (40) |
Let denote the top and bottom boundaries, and denote the left and right boundaries. We impose the mixed boundary condition:
and let the forcing function take the form
with , which is the superposition of two Gaussian-shaped sink/source terms centered at and , scaled by a constant . The conductivity field is endowed with a log-normal prior. That is, letting , the Gaussian process prior for is defined by the stochastic PDE (see [37] and references therein):
| (41) |
where is the Laplace operator and is the white noise process. We impose a no-flux boundary condition on the above SPDE and set . Equations (40) and (41) are solved using the finite element method with bilinear basis functions. A mesh with elements is used in this example. This leads to dimensional discretised parameters.
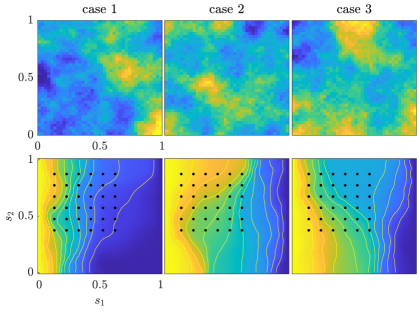
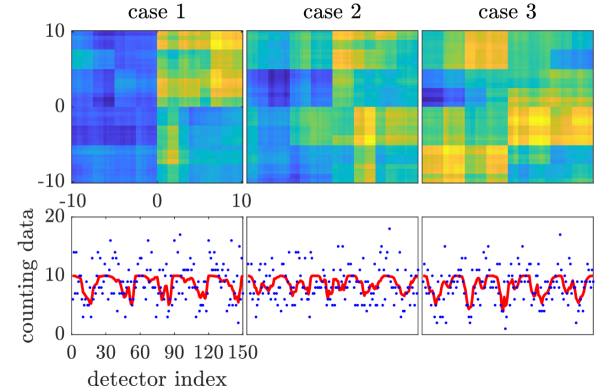
We generate three “true” conductivity fields from the prior distribution and use them to simulate synthetic observed data sets. The true conductivity fields and the simulated potential fields are shown in Figure 1. Observations of the potential fields are measured at the discrete locations shown as black dots in Figure 1. We set the standard derivation of the observation noise to , which corresponds to a signal-to-noise ratio of about .
8.2 Low-dimensional posterior approximations
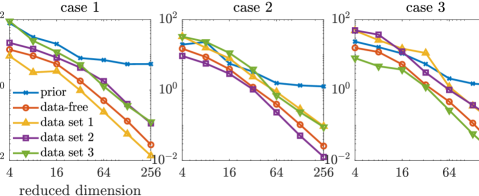
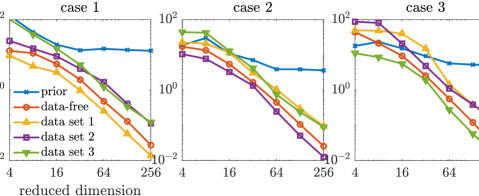
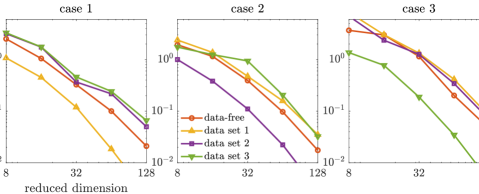
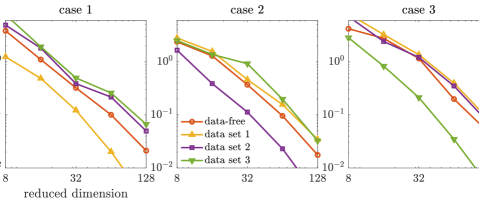
We first compare the approximate posterior densities defined by the data-free dimension reduction with that of the data-dependent dimension reduction and that of the truncated Karhunen–Loéve expansion of the prior. We build five sets of projectors: the data-free projectors as detailed in Section 3.3, three sets of data-dependent projectors (see Section 3.2) that correspond to three synthetic data sets, and projectors defined by leading eigenvectors of the prior covariance (i.e. the truncated Karhunen–Loéve, referred to as the “prior-based projector” from hereinafter). For each of the data sets, the corresponding data-dependent projectors are constructed using the adaptive MCMC algorithm of [54]. Each set consists of projectors with ranks . For each projector, we compute the KL divergences of the full posteriors from the approximated posterior densities defined by the optimal parameter-reduced likelihood (7). The results are shown in the top row of Figure 2. Using the same set of projectors, we also compare the KL divergences of the full posteriors from the resulting approximated posterior densities defined by the optimal parameter-reduced forward model (21). The results are shown in the bottom row of Figure 2.
In these experiments, we estimate the KL divergence using Monte Carlo integration with posterior samples, which yields
where the second sample average accounts for the ratio between normalizing constants. For approximations that are close to the full posterior, using a reasonable number of (independent) posterior samples, e.g., used here, make the standard deviations of the estimated KL divergence insignificant compared with the mean estimates in our numerical examples.
We observe that the optimal parameter-reduced likelihood and the optimal parameter-reduced forward model result in approximate posteriors with similar accuracy. For sufficiently large ranks (), the most accurate approximate posterior densities are obtained by the data-dependent projectors of the corresponding data set, followed by those obtained by the data-free projectors. We also observe that, for each data set, the data-dependent projectors constructed using other data sets result in less accurate approximations. By allowing a marginal loss of accuracy compared to the data-dependent construction, the data-free construction bypasses the computationally costly online dimension reduction process for every new data set. Compared with the prior-based dimension reduction, which is also an offline method, the data-free construction offers significantly more accurate approximations in this example.
For each of the data sets, we also compare the errors of the approximate posterior densities with the bounds defined in (14) and (25). Note that the right hand sides of (14) and (25) are the same up to the constant in this example. We plot the errors and the bounds (with for Gaussian prior) in Figure 3, in which all approximate posterior densities are defined by the data-free projectors. In this example, we observe that the errors of the approximate posterior densities follow the same trend as their corresponding error bounds. Note that both (14) and (25) give upper bounds on the expected KL divergence, and thus they may not bound the KL divergence for a realization of the data.
8.3 Subspace accelerated sampling
| OL | approximate inference using Algorithm 4 and the optimal parameter-reduced likelihood function in (27) |
|---|---|
| PM | exact inference using the pseudo-marginal method (Algorithms 5 and 6) |
| OF | approximate inference using Algorithm 4 and the optimal parameter-reduced forward model in (28) |
| DA | exact inference using the delayed acceptance algorithm (Algorithm 7) with the approximation defined by the parameter-reduced forward model in (28) |
| H-MALA | exact inference using the Hessian preconditioned Langevin MCMC [45] |
| PCN | exact inference using the preconditioned Crank–Nicolson MCMC [7, 15] |
We demonstrate the sampling performance of various approximate and exact inference algorithms introduced in Sections 5 and 6 using the posterior density conditioned on the first data set. All the methods used in the comparison and their acronyms are summarized in Table 1.
We use the Hessian-preconditioned Metropolis-Adjusted Langevin Algorithm (H-MALA) and the preconditioned Crank–Nicolson (PCN) MCMC as reference MCMC methods for sampling the full-dimensional posterior. Since H-MALA uses the low-rank decomposition of the Hessian matrix of the logarithm of the posterior density computed at the maximum a posteriori point to precondition MCMC, it can also be viewed as a data-dependent subspace-accelerated method. We refer to [17, 45] for a detailed discussion. In order to make a fair comparison with H-MALA, the MCMC algorithm we use on our data-free informed subspace is based on a Langevin proposal preconditioned by the same Hessian matrix used by H-MALA projected onto the data-free informed subspaces.
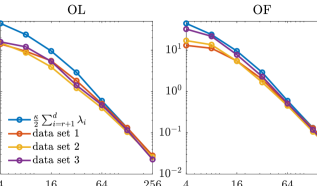
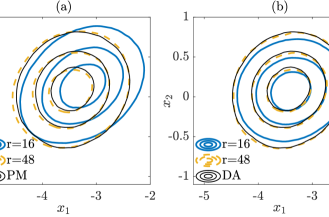
In Figure 4, the contours of the marginal posterior densities (marginalized onto the first two data-free LIS basis vectors) produced by approximate inference methods (with and ) are compared with those produced by their exact inference modifications (with ). We can observe that the results produced by approximate inference methods approach those of their modifications as the rank of informed subspace increases.
To measure the efficiency of various MCMC methods, we use the average integrated autocorrelation times (IACTs) of parameters
where is the IACT of the -th component of . See [38, Section 12.7] for the definition of IACT. The data-free projectors with different ranks and two different sample sizes and are used in this experiment. Here H-MALA and PCN are used as base cases to benchmark those MCMC methods accelerated by the informed subspace. All the methods are simulated for iterations and repeated times to report the mean and the standard deviation of . The initial state of all the simulations are randomly selected from a pre-computed Markov chain of posterior samples to avoid burn-in. The results are reported in Table 2.
For the approximate inference methods (OL and OF), the average IACTs consistently increase with the rank of the projectors, as the sampling performance of the Langevin proposal is expected to decay with the underlying parameter dimension. Both OL and OF produce significantly smaller IACTs compared with the full-dimensional H-MALA.
| IACT | IACT | IACT | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OL | PM | OF | DA | HMALA | PCN | ||||
| 18.91.5 | 16329 | 4.450.20 | 19.71.2 | - | 0.1 | 16417 | 1303139 | ||
| 34.91.1 | 10613 | 2.650.19 | 35.72.1 | - | 0.1 | ||||
| 52.63.0 | 91.85.3 | 1.800.10 | 57.13.1 | 20839 | 0.310.02 | ||||
| 59.42.4 | 91.66.1 | 0.930.03 | 63.02.1 | 20826 | 0.360.02 | ||||
| 60.72.4 | 83.85.6 | 0.690.02 | 66.94.3 | 14610 | 0.460.01 | ||||
| 18.71.0 | 1028.2 | 2.280.10 | 19.31.3 | - | 0.1 | ||||
| 32.71.7 | 72.64.3 | 1.380.05 | 37.82.5 | 25536 | 0.190.02 | ||||
| 48.81.2 | 71.63.0 | 0.970.06 | 55.81.1 | 21438 | 0.310.01 | ||||
| 55.22.1 | 67.43.4 | 0.550.03 | 61.72.8 | 17321 | 0.390.01 | ||||
| 56.03.3 | 64.93.2 | 0.410.02 | 69.93.5 | 14826 | 0.470.01 | ||||
Compared to the OL method, the PM method (the exact inference counterpart for OL) has a different behavior. Here we recall that the sample-averaged parameter-reduced likelihood, , in the PM method is a random estimator, whereas in the OL method is deterministic because of the usage of prescribed samples. The standard deviation of the logarithm of in Table 2 confirms that low-rank projectors have rather large Monte Carlo errors as the approximation accuracy is controlled by the rank truncation (cf. (14)). The exactness of the PM method comes at the cost of Monte Carlo error, which is controlled by the sample size and the rank of the projector. We observe that increasing either the rank or the sample size can narrow the gap between the IACTs produced by PM and its OL counterpart. This experiment clearly suggests that PM needs to balance the sample size and the rank of the projector to achieve the optimal performance.
Compared to the OF method, the DA method (the exact inference counterpart for OF) produces the largest IACTs among all subspace inference methods. This result is not surprising, as the second stage acceptance/rejection of DA necessarily deteriorates the statistical performance [11]. In Table 2, we observe that the second stage acceptance rates, , increase with more accurate approximations obtained with higher projector ranks and larger sample sizes. As the result, the gaps between the IACTs produced by OF and DA are smaller for higher projector ranks and larger sample sizes.
Overall, approximate inference methods have better statistical performance compared to other methods in this example (cf. Table 2) and can obtain reasonably accurate results as shown in Figures 2 and Figure 4. With the additional cost that comes in the form of either Monte Carlo error (PM) or the second stage acceptance/rejection (DA), the exact inference modifications produce Markov chains with larger IACTs. Among all the exact inference methods, PM produces smaller IACTs compared with the full-dimensional H-MALA, PCN, and DA.
It is worth to mention that each iteration of the subspace MCMC method needs number of forward model simulations, whereas H-MALA requires only one forward model simulation per iteration. In this example, approximate inference methods (OL and OF) with still outperforms H-MALA in terms of IACTs per model evaluation. Exact inference methods, however, need more model evaluations than H-MALA to obtain the same number of effective samples (we will show in the subsection another example where H-MALA is outperformed by PM and DA). Notice that the forward model evaluations in each iteration can be embarrassingly parallelized: with parallel computing resources available, the subspace MCMC methods can still be more efficient than H-MALA in terms of the effective sample size per wall-clock time.
9 Example 2: PET with Poisson data
The second example is a two dimensional PET imaging problem, where we aim to reconstruct the density of the object from integer-valued Poisson observed data. We use here a Besov prior for which we access the coordinate selection technique and the prior normalization method presented in Sections 7.2 and 7.3.
9.1 Problem setup
In PET imaging, the goal is to identify an object of interest located inside a domain subjected to gamma rays. The rays travel through from multiple sources and the detectors count the number of incident photons (thus the data are integer-valued), see Figure 5(a). The object of interest is described by its density of mass which is represented by , where follows a Besov- prior with the Haar wavelet, see Section 7.1. The change of intensity of a gamma ray along the path, , can be modelled using Beer’s law:
| (42) |
where and are the intensities at the detector and at the source, respectively. We assume that all the gamma ray sources have the same intensity, for .
In this example, the domain is discretized into a regular grid with cells and the logarithm of the density is assumed to be piecewise constant. This yields the discretized parameter . The line integrals in (42) are approximated by
where is the length of the intersection between line and cell , and is the discretized density in cell . By discretizing the wavelet basis on the same grid and following the parametrization discussed in Section 7, we can write
where consists of discretized basis functions and consists of associated coefficients. In this setting, follows a product-form Laplace distribution given by (38) with and with the scale parameter arbitrarily set to . Suppose we have a total of number of gamma ray paths and the corresponding matrix , the forward model is defined as
| (43) |
We consider a PET setup shown in Figure 5(a): the problem domain is discretised into a regular grid, five radiation sources with intensity are positioned with equal spaces on one side of a circle, spanning a angle, and each source sends a fan of 30 gamma rays that are measured by detectors. This leads to observations. The model setup is based on the code of [30].
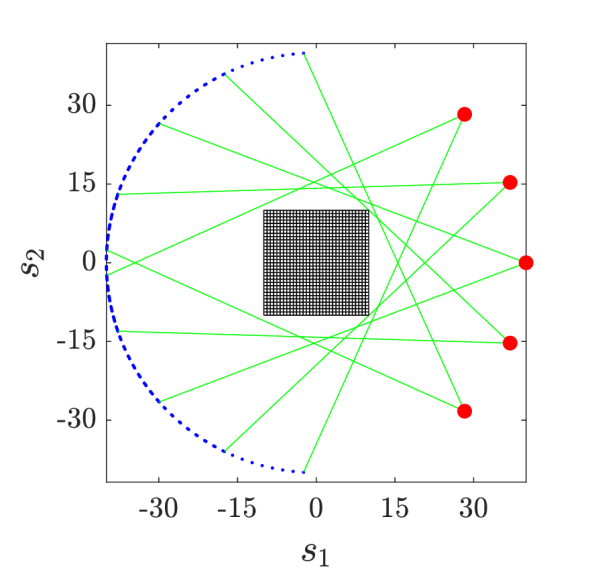
We denote the observed data by where each element is associated with the -th gamma ray in the model. For the -th gamma ray, recall that the intensity at the detector is computed by for some input parameter , and then the probability mass function of observing the counting data is given by
Suppose we can observe the counting data at all the detectors and assume the measurement processes are independent, we can write the likelihood function with the complete data as
| (44) |
As shown in F, the Fisher information matrix of the above likelihood function takes the form
| (45) |
where is a diagonal matrix with along its diagonal. We generate three “true” density functions from the prior distribution and use them to simulate synthetic data sets. The true density functions and the simulated data are shown in Figure 5(b).
9.2 Numerical results using coordinate selection
We first present the results obtained by applying the coordinate selection method (cf. Section 7.2). Similar to the first example, here we will first compare the accuracy of approximate posterior densities defined by various approaches and projectors, and then benchmark the performance of MCMC methods. We adopt the same setup and acronyms as in Example 1 and Table 1.
For the approximate posterior densities, five sets of projectors built from selected coordinates, including the data-free projectors, three sets of data-dependent projectors (corresponding to three data sets), and the prior-based truncated wavelet basis, are considered. Each set consists of projectors with ranks . The KL divergences of the full posteriors from the approximated posterior densities defined by the optimal parameter-reduced likelihood (7) are shown in the top row of Figure 6, while those of the optimal parameter-reduced forward model (21) are shown in the bottom row of Figure 6.
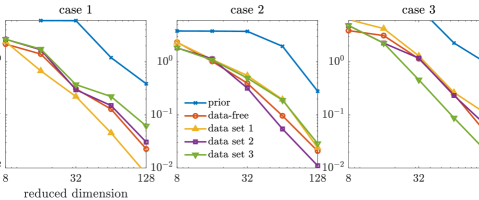
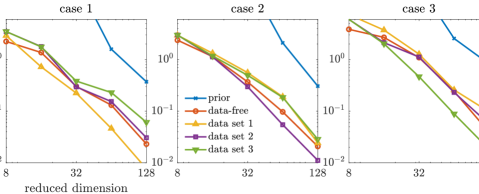
In this example, we observe similar results as the results of the elliptic PDE example. The optimal parameter-reduced likelihood and the optimal parameter-reduced forward model result in approximate posteriors with similar accuracy. The most accurate approximate posterior densities are obtained by the data-dependent projectors of the corresponding data set, followed by those obtained by the data-free projectors. For each data set, the data-dependent projectors constructed using other data sets result in less accurate approximations in general. However, the accuracy gaps between the data-free projectors and the data-dependent projectors (using other data sets) are not as significant as the elliptic PDE example. This can be caused by either the coordinate selection method or the rather large data size in this example. Compared with the prior-based dimension reduction, which is also an offline method, the data-free construction offers significantly more accurate approximations in this example. Overall, the data-free dimension reduction provides reasonably accurate posterior approximations for the Poisson observation process considered here.
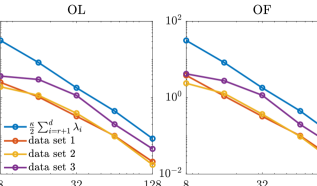
Although it remains an open question if the bounds in (14) and (25) can be applied for Besov priors, we provide a comparison of the errors of the approximate posterior densities (defined by the data-free projectors) with the bounds. The results are shown in Figure 7 with being replaced by . Interesting, we still observe that the errors of the approximate posterior densities follow the same trend as their corresponding bounds.
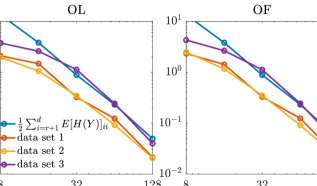
We then compare the performance of various subspace driven inference methods. In Figure 8, the contours of the the marginal posterior densities produced by approximate inference methods (with and ) are compared with those produced by their exact inference modifications (with ). In this example, we observe that the contours produced by approximate inference methods are visually similar to those of exact inference methods. In addition, with increasing ranks, the contours produced by approximate inference methods approach those of the exact inference methods.
| IACT | IACT | IACT | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OL | PM | OF | DA | HMALA | PCN | ||||
| 33.21.7 | 85.12.7 | 1.540.02 | 33.91.1 | 21444 | 0.180.06 | 95.93.3 | 38779 | ||
| 40.01.8 | 54.13.1 | 0.61.007 | 41.02.2 | 87.86.5 | 0.550.01 | ||||
| 45.31.2 | 49.42.6 | 0.45.002 | 46.02.2 | 73.55.8 | 0.660.01 | ||||
| 31.41.9 | 60.06.2 | 0.93.006 | 31.81.4 | 22065 | 0.220.04 | ||||
| 40.82.5 | 47.62.5 | 0.39.004 | 42.82.4 | 88.06.8 | 0.560.01 | ||||
| 46.12.2 | 46.51.4 | 0.29.001 | 46.31.9 | 69.54.0 | 0.670.01 | ||||
We use the average IACTs of the density function, to measure the efficiency of various MCMC methods. The results are reported in Table 3. Here both PCN and H-MALA are implemented to sample the posterior in the transformed coordinate equipped with a Gaussian prior (cf. Section 7.3).
For the approximate inference methods (OL and OF), the average IACTs consistently increase with the rank of the projectors, as the sampling performance of the Langevin proposal is expected to decay with underlying the parameter dimension. Both OL and OF produce significantly smaller IACTs compared with the full-dimensional PCN and H-MALA method. Compared to the OL method, the PM method, has a slightly higher IACTs in this example. This rather mild loss of performance (compared with the elliptic PDE example) is justified by the rather small values of (with ) in Table 3. Compared to the OF method, the DA method, again produces the largest IACTs among all subspace inference methods. However, the loss of performance here is not as severe as the elliptic PDE example, this is also justified by the improved second stage acceptance rates, .
Overall, approximate inference methods have better statistical performance compared to other methods in this example and can obtain reasonably accurate results as shown in Figures 6 and Figure 8. With improved approximation errors, the exact inference methods also produces Markov chains with better mixing. Among all the exact inference methods, PM produces significantly smaller IACTs compared with other methods.
9.3 Numerical results using prior normalization
Then, we present the results obtained by applying the prior normalization method (cf. Section 7.3). The KL divergences of the full posteriors from the approximated posterior densities are shown in Figure 9. Here the result of prior-based dimension reduction is not presented, as the prior in the transformed space has an identity covariance matrix. We observe similar results as those obtained by the coordinate selection. We notice that the accuracy gaps between the data-free projectors and the data-dependent projectors (built using other data sets) are more significant compared with those obtained by the coordinate selection. The comparison of the errors of the approximate posterior densities (defined by the data-free projectors) with the bounds in (14) and (25) are provided in Figure 10. Here we have because the transformed coordinate is endowed with a Gaussian prior. We observe that the errors of the approximate posterior densities follow the same trend as their corresponding bounds. The IACTs of various MCMC methods are reported in Table 4. Again, the efficiency of subspace MCMC methods defined by the prior normalization is very close to that defined by the coordinate selection. Overall, both the coordinate selection and the prior normalization can be applied in this example to obtain accurate reduced-dimensional posterior approximations and derive efficient subspace MCMC methods.
| IACT | IACT | IACT | |||||||
|---|---|---|---|---|---|---|---|---|---|
| OL | PM | OF | DA | HMALA | PCN | ||||
| 35.81.7 | 81.46.0 | 1.480.02 | 33.51.8 | 16823 | 0.250.02 | 95.93.3 | 38779 | ||
| 42.82.0 | 55.12.9 | 0.64.006 | 41.21.6 | 86.36.2 | 0.550.01 | ||||
| 45.02.4 | 51.82.0 | 0.46.005 | 44.32.2 | 74.67.4 | 0.650.01 | ||||
| 35.11.9 | 54.14.1 | 0.880.01 | 32.82.8 | 15121 | 0.260.02 | ||||
| 45.01.7 | 49.01.9 | 0.41.003 | 42.02.6 | 83.15.1 | 0.550.01 | ||||
| 45.92.9 | 46.32.2 | 0.29.003 | 44.40.8 | 70.63.7 | 0.660.01 | ||||
10 Conclusion
We present a new data-free strategy for reducing the dimensionality of large-scale statistical inverse problems. Compared to existing gradient-based dimension reduction technique, this new approach identifies the computationally costly subspace construction in an offline phase. Our data-free dimension reduction is certified in the sense that its development is directly guided by factorizable posterior approximations and associated error bounds. The factorizable posterior approximations naturally offer dimension robust sampling methods for exploring the approximate posterior densities. More interestingly, by adding minor modifications to those approximate inference algorithms, we further develop exact inference methods using the pseudo-marginal approach and the delayed acceptance approach. The resulting exact inference methods also scale well with parameter dimensionality, as the backbone of those methods is based on the dimension robust approximate inference methods. We also demonstrate the efficiency of our data-free dimensional reduction and various inference methods on two inverse problems involving a two-dimensional elliptic PDE with a Gaussian process prior and a PET problem with Poisson data and a Besov- prior.
Appendix A Proof of Proposition 4.1
Recall and . By definition of and we have
| (46) |
where is independent on . Next we replace by and we take the expectation over . The first term in the above expression becomes
| (47) |
Next, by definition of , we have
| (48) |
For the last equality we used the fact that is a pdf so that . Using the same arguments, we have
| (49) |
The last equality is obtained by noting that the expectation of the data knowing the parameter is . Combining (47) (48) and (49), we obtain
which concludes the proof.
Appendix B Proof of Proposition 6.1
Consider a Metropolis-Hastings algorithm which targets the pdf defined by (32) using the following proposal density
| (50) |
where is the same proposal density as the one used at step 1 of Algorithm (5). The acceptance probability of this Metropolis-Hastings algorithm is given by
which is precisely defined in (31). Note that the first two steps of Algorithm 5 consists of drawing a sample from the proposal (50). This way, Algorithm 5 can be interpreted as a MCMC algorithm which targets . It remains to show that the marginal distribution is the marginal posterior . We can write
which concludes the proof.
Appendix C Proof of Proposition 6.3
Recall that admits (32) as the invariant density, see Proposition 6.1. It remains to prove that admits as the invariant density. For a given state , we have where is selected with respect to the probability
| (51) |
Thus, we need to prove that the pdf where is the posterior density . We can write
where is the pdf of conditioned on . By construction we have
| (52) |
where denotes the Dirac mass function at point . We can write
which concludes the proof.
Appendix D Proof of Proposition 6.4
To show the result of Proposition 6.4, we first interpret the first stage acceptance/rejection and the conditional prior sampling as a joint proposal acting in the full parameter space . The proposal and the acceptance probability defines an effective proposal distribution
where denotes the Dirac delta and the term in the bracket represents the probability of a proposal candidate being rejected. Then, we can define a joint proposal distribution
for the MH to sample the full posterior.
Following the exactly same derivation in [11], one can show that accepting with the probability
defines a Markov transition kernel with the full posterior as its invariant distribution. Since the above acceptance probability is only used in the case where the first stage proposal candidate is accepted, i.e., , we do not need to consider the Dirac delta term. This way, the above acceptance probability can be simplified as
Substituting the identities
and
into the above equation, we obtain
which is identical to the second stage acceptance probability in (35). Thus, the result follows.
Appendix E Cumulative density function of
Given the pdf , we want to find its normalizing constant and cdf. Using symmetry, the normalizing constant takes the form
and the cdf can be expressed as
We first introduce the change-of-variable so that
This yields
where is the lower incomplete gamma function. Following a similar derivation, we obtain where is the Gamma function. This way, we have the cdf
There are two notable special cases. The Gaussian distribution can be specified using and , in which the cdf can be equivalently expressed using the error function. The Laplace distribution can be specified using , so that the cdf yields a simpler (but equivalent) expression in the form of
Appendix F Derivation of Fisher information matrices
Here we derive the Fisher information matrix for the Poisson likelihood case. Recall the Fisher information matrix
| (53) |
Defining the predata , we can express the gradient of the likelihood function as
where
This way, the Fisher information matrix can be rewritten as
| (54) |
subject to . The term in the brackets of the above equation is the Fisher information matrix of the Poisson distribution, which is a diagonal matrix
Thus, the Fisher information matrix w.r.t. is
| (55) |
where is a diagonal matrix with along its diagonal.
References
References
- [1] Christophe Andrieu, Gareth O Roberts, et al. The pseudo-marginal approach for efficient Monte Carlo computations. The Annals of Statistics, 37(2):697–725, 2009.
- [2] Christophe Andrieu, Matti Vihola, et al. Convergence properties of pseudo-marginal Markov chain Monte Carlo algorithms. The Annals of Applied Probability, 25(2):1030–1077, 2015.
- [3] Christophe Andrieu, Matti Vihola, et al. Establishing some order amongst exact approximations of MCMCs. The Annals of Applied Probability, 26(5):2661–2696, 2016.
- [4] Mario Bebendorf. A note on the Poincaré inequality for convex domains. Zeitschrift für Analysis und ihre Anwendungen, 22(4):751–756, 2003.
- [5] Alexandros Beskos, Mark Girolami, Shiwei Lan, Patrick E Farrell, and Andrew M Stuart. Geometric MCMC for infinite-dimensional inverse problems. Journal of Computational Physics, 335:327–351, 2017.
- [6] Alexandros Beskos, Ajay Jasra, Kody Law, Youssef Marzouk, and Yan Zhou. Multilevel sequential Monte Carlo with dimension-independent likelihood-informed proposals. SIAM/ASA Journal on Uncertainty Quantification, 6(2):762–786, 2018.
- [7] Alexandros Beskos, Gareth Roberts, Andrew Stuart, and Jochen Voss. MCMC methods for diffusion bridges. Stochastics and Dynamics, 8(03):319–350, 2008.
- [8] Marie Billaud-Friess, Anthony Nouy, and Olivier Zahm. A tensor approximation method based on ideal minimal residual formulations for the solution of high-dimensional problems. ESAIM: Mathematical Modelling and Numerical Analysis, 48(6):1777–1806, 2014.
- [9] S. Brooks, A. Gelman, G. Jones, and X. L. Meng, editors. Handbook of Markov Chain Monte Carlo. Taylor & Francis, 2011.
- [10] Carlos M Carvalho, Nicholas G Polson, and James G Scott. Handling sparsity via the horseshoe. In Artificial Intelligence and Statistics, pages 73–80, 2009.
- [11] J Andrés Christen and Colin Fox. Markov chain Monte Carlo using an approximation. Journal of Computational and Graphical statistics, 14(4):795–810, 2005.
- [12] Paul G Constantine, Eric Dow, and Qiqi Wang. Active subspace methods in theory and practice: applications to kriging surfaces. SIAM Journal on Scientific Computing, 36(4):A1500–A1524, 2014.
- [13] Paul G Constantine, Carson Kent, and Tan Bui-Thanh. Accelerating Markov chain Monte Carlo with active subspaces. SIAM Journal on Scientific Computing, 38(5):A2779–A2805, 2016.
- [14] Andrea F Cortesi, Paul G Constantine, Thierry E Magin, and Pietro M Congedo. Forward and backward uncertainty quantification with active subspaces: application to hypersonic flows around a cylinder. Journal of Computational Physics, 407:109079, 2020.
- [15] Simon L Cotter, Gareth O Roberts, Andrew M Stuart, David White, et al. MCMC methods for functions: modifying old algorithms to make them faster. Statistical Science, 28(3):424–446, 2013.
- [16] Tiangang Cui, Gianluca Detommaso, and Robert Scheichl. Multilevel dimension-independent likelihood-informed MCMC for large-scale inverse problems. arXiv preprint arXiv:1910.12431, 2019.
- [17] Tiangang Cui, Kody JH Law, and Youssef M Marzouk. Dimension-independent likelihood-informed MCMC. Journal of Computational Physics, 304:109–137, 2016.
- [18] Tiangang Cui, James Martin, Youssef M Marzouk, Antti Solonen, and Alessio Spantini. Likelihood-informed dimension reduction for nonlinear inverse problems. Inverse Problems, 30(11):114015, 2014.
- [19] Tiangang Cui and Xin T Tong. A unified performance analysis of likelihood-informed subspace methods. arXiv preprint arXiv:2101.02417, 2021.
- [20] Arnak S Dalalyan. Theoretical guarantees for approximate sampling from smooth and log-concave densities. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 79(3):651–676, 2017.
- [21] Masoumeh Dashti, Stephen Harris, and Andrew Stuart. Besov priors for Bayesian inverse problems. Inverse Problems & Imaging, 6(2):183, 2012.
- [22] P. Del Moral, A. Doucet, and A. Jasra. Sequential Monte Carlo samplers. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(3):411–436, 2006.
- [23] Arnaud Doucet, Michael K Pitt, George Deligiannidis, and Robert Kohn. Efficient implementation of Markov chain Monte Carlo when using an unbiased likelihood estimator. Biometrika, 102(2):295–313, 2015.
- [24] Alain Durmus, Eric Moulines, et al. High-dimensional Bayesian inference via the unadjusted langevin algorithm. Bernoulli, 25(4A):2854–2882, 2019.
- [25] Raaz Dwivedi, Yuansi Chen, Martin J Wainwright, and Bin Yu. Log-concave sampling: Metropolis-Hastings algorithms are fast. Journal of Machine Learning Research, 20(183):1–42, 2019.
- [26] Ivan G Graham, Frances Y Kuo, James A Nichols, Robert Scheichl, Ch Schwab, and Ian H Sloan. Quasi-Monte Carlo finite element methods for elliptic PDEs with lognormal random coefficients. Numerische Mathematik, 131(2):329–368, 2015.
- [27] Ivan G Graham, Frances Y Kuo, Dirk Nuyens, Robert Scheichl, and Ian H Sloan. Quasi-Monte Carlo methods for elliptic PDEs with random coefficients and applications. Journal of Computational Physics, 230(10):3668–3694, 2011.
- [28] Alice Guionnet and B Zegarlinksi. Lectures on logarithmic Sobolev inequalities. In Séminaire de probabilités XXXVI, pages 1–134. Springer, 2003.
- [29] W. Hastings. Monte Carlo sampling using Markov chains and their applications. Biometrika, 57:97–109, 1970.
- [30] Jere Heikkinen. Statistical inversion theory in x-ray tomography. 2008.
- [31] Jari Kaipio and Erkki Somersalo. Statistical and computational inverse problems, volume 160. Springer Science & Business Media, 2006.
- [32] Ville Kolehmainen, Matti Lassas, Kati Niinimäki, and Samuli Siltanen. Sparsity-promoting Bayesian inversion. Inverse Problems, 28(2):025005, 2012.
- [33] Shiwei Lan. Adaptive dimension reduction to accelerate infinite-dimensional geometric Markov chain Monte Carlo. Journal of Computational Physics, 392:71–95, 2019.
- [34] Matti Lassas, Eero Saksman, and Samuli Siltanen. Discretization-invariant Bayesian inversion and Besov space priors. Inverse problems and imaging, 3(1):87–122, 2009.
- [35] Olivier Le Maître and Omar M Knio. Spectral methods for uncertainty quantification: with applications to computational fluid dynamics. Springer Science & Business Media, 2010.
- [36] Michel Ledoux. Logarithmic Sobolev inequalities for unbounded spin systems revisited. In Séminaire de Probabilités XXXV, pages 167–194. Springer, 2001.
- [37] Finn Lindgren, Håvard Rue, and Johan Lindström. An explicit link between gaussian fields and gaussian Markov random fields: the stochastic partial differential equation approach. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 73(4):423–498, 2011.
- [38] Jun S Liu. Monte Carlo strategies in scientific computing. Springer Science & Business Media, 2001.
- [39] Jun S Liu and Rong Chen. Sequential Monte Carlo methods for dynamic systems. Journal of the American statistical association, 93(443):1032–1044, 1998.
- [40] Youssef M Marzouk and Habib N Najm. Dimensionality reduction and polynomial chaos acceleration of Bayesian inference in inverse problems. Journal of Computational Physics, 228(6):1862–1902, 2009.
- [41] N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller. Equation of state calculations by fast computing machines. Journal of Chemical Physics, 21:1087–1092, 1953.
- [42] Anthony Nouy. Low-Rank Tensor Methods for Model Order Reduction, pages 857–882. Springer International Publishing, Cham, 2017.
- [43] Mario Teixeira Parente, Jonas Wallin, Barbara Wohlmuth, et al. Generalized bounds for active subspaces. Electronic Journal of Statistics, 14(1):917–943, 2020.
- [44] Anthony T Patera, Gianluigi Rozza, et al. Reduced basis approximation and a posteriori error estimation for parametrized partial differential equations, 2007.
- [45] Noemi Petra, James Martin, Georg Stadler, and Omar Ghattas. A computational framework for infinite-dimensional Bayesian inverse problems, part ii: Stochastic newton MCMC with application to ice sheet flow inverse problems. SIAM Journal on Scientific Computing, 36(4):A1525–A1555, 2014.
- [46] Allan Pinkus. Ridge functions, volume 205. Cambridge University Press, 2015.
- [47] G. O. Roberts, A. Gelman, and W. R. Gilks. Weak convergence and optimal scaling of random walk Metropolis algorithms. Annals of Applied Probability, 7:110–120, 1997.
- [48] Gareth O Roberts and Jeffrey S Rosenthal. Optimal scaling for various metropolis-Hastings algorithms. Statistical science, 16(4):351–367, 2001.
- [49] Olivier Roustant, Franck Barthe, Bertrand Iooss, et al. Poincaré inequalities on intervals–application to sensitivity analysis. Electronic journal of statistics, 11(2):3081–3119, 2017.
- [50] Alessio Spantini, Antti Solonen, Tiangang Cui, James Martin, Luis Tenorio, and Youssef Marzouk. Optimal low-rank approximations of Bayesian linear inverse problems. SIAM Journal on Scientific Computing, 37(6):A2451–A2487, 2015.
- [51] A. M. Stuart. Inverse problems: a Bayesian perspective. Acta Numerica, 19:451–559, 2010.
- [52] Albert Tarantola. Inverse problem theory and methods for model parameter estimation, volume 89. SIAM, 2005.
- [53] Olivier Zahm, Paul G Constantine, Clementine Prieur, and Youssef M Marzouk. Gradient-based dimension reduction of multivariate vector-valued functions. SIAM Journal on Scientific Computing, 42(1):A534–A558, 2020.
- [54] Olivier Zahm, Tiangang Cui, Kody Law, Alessio Spantini, and Youssef Marzouk. Certified dimension reduction in nonlinear Bayesian inverse problems. arXiv preprint arXiv:1807.03712, 2018.