resize to[a4paper]
Data Synopses Management based on a Deep Learning Model
Abstract
Pervasive computing involves the placement of processing units and services close to end users to support intelligent applications that will facilitate their activities. With the advent of the Internet of Things (IoT) and the Edge Computing (EC), one can find room for placing services at various points in the interconnection of the aforementioned infrastructures. Of significant importance is the processing of the collected data to provide analytics and knowledge. Such a processing can be realized upon the EC nodes that exhibit increased computational capabilities compared to IoT devices. An ecosystem of intelligent nodes is created at the EC giving the opportunity to support cooperative models towards the provision of the desired analytics. Nodes become the hosts of geo-distributed datasets formulated by the IoT devices reports. Upon the datasets, a number of queries/tasks can be executed either locally or remotely. Queries/tasks can be offloaded for performance reasons to deliver the most appropriate response. However, an offloading action should be carefully designed being always aligned with the data present to the hosting node. In this paper, we present a model to support the cooperative aspect in the EC infrastructure. We argue on the delivery of data synopses distributed in the ecosystem of EC nodes making them capable to take offloading decisions fully aligned with data present at every peer. Nodes exchange their data synopses to inform their peers. We propose a scheme that detects the appropriate time to distribute the calculated synopsis trying to avoid the network overloading especially when synopses are frequently extracted due to the high rates at which IoT devices report data to EC nodes. Our approach involves a Deep Learning model for learning the distribution of calculated synopses and estimate future trends. Upon these trends, we are able to find the appropriate time to deliver synopses to peer nodes. We provide the description of the proposed mechanism and evaluate it based on real datasets. An extensive experimentation upon various scenarios reveals the pros and cons of the approach by giving numerical results.
Index Terms:
Edge Computing, Internet of Things, Data Management, Data Synopsis, Deep LearningI Introduction
Pervasive computing targets to the creation of smart environments around end users saturated with computing and communication capabilities to support novel applications. Pervasive services aim to be invisible, however, intelligent enough to facilitate users activities. Today, we are witnessing the provision of huge infrastructures where pervasive applications can be hosted. Such infrastructures deal with the Internet of Things (IoT) and Edge Computing (EC). Both of them try to ‘surround’ end users with smart devices, collect and process data to create knowledge adopted by various applications. It becomes obvious that in this new era of the Web, there are numerous opportunities to support intelligent and invisible services in a close distance with users. Hence, we are able to reduce the latency in the provision of the discussed services and increase the performance. The first ‘actor’ in this setting is the IoT device that may directly interact with users and their environment to collect data and perform simple processing activities [34]. IoT devices can, then, report their data in an upwards mode, to the EC infrastructure and Cloud for further processing. EC involves an ecosystem of heterogeneous nodes that become the hosts of the collected data and act as processing points to deliver analytics and knowledge [34]. We can observe a high number of distributed datasets present at the network edge opening the room for defining advanced services and support real time applications. The aim is to serve users or applications requests in the minimum time with the maximum performance. As the maximum performance we denote the provision of responses that fully match to the incoming requests. Obviously, responses are provided upon the available data and should be aligned with them.
As the EC supports a distributed environment with numerous datasets present at the ecosystem of nodes, the use of cooperative models is imposed to make nodes capable of exchanging data, queries/tasks, etc. The interaction between EC nodes aims at detecting the appropriate line of actions to efficiently respond to the incoming requests for processing. The reaserch community has already focused not only on the management of queries/tasks [20], [21], [22], [23], [24] but also on the management of the collected data [1]. However, due to the distributed nature of the EC, nodes should have a view on the data present in peers especially when we want to support efficient decision making locally. For instance, a data allocation action demands for the knowledge of the remote data at least in the form of synopses. Data synopses can be exchanged between EC nodes without burdening the network as they usually convey high level statistical information about the available data. The delivery of synopses seems to be more efficient than the exchange of large pieces of data, i.e., data migration between nodes [9]. Actually, we have two solutions for responding to queries/tasks requests when the relevant data are note present at the node receiving the request. The first solution deals with the queries/tasks migration upon the decision of finding the most appropriate node as seen by the corresponding synopsis. The second solution deals with the migration of the relevant data from the owner/peer to the node receiving the request. Evidently, the former model should be supported by an intelligent mechanism for exchanging the necessary statistical information for the data present in the ecosystem while the latter scheme burdens the network with large messages increasing the possibility of bottlenecks.
In this paper, we support the autonomous nature and the cooperation between EC nodes to serve queries/tasks demanded by users or applications. We focus on the first of the aforementioned solutions (i.e., queries/tasks migration) and propose a scheme for exchanging data synopses in the ecosystem to efficiently support decisions related to offloading actions. Synopses are updated every time new data arrive in an EC node, however, they should distributed when their ‘magnitude’ exhibit that significant new information is present. We propose a monitoring mechanism for the updated synopses and a model that detects when significant changes are present at every dataset. When this is true, we decide to deliver the synopses to peer nodes to have them informed about the new status of every dataset. We rely on a Deep Machine Learning (DML) model to learn the distribution behind the calculated synopses being able to estimate their future trends. Hence, in a proactive manner, we are able to estimate the appropriate time for delivering the updated synopses. More specifically, we adopt a Long Short Term Memory (LSTM) network which is a specific type of Recurrent Neural Networks (RNNs) [18]. The adopted LSTM is capable of incorporating data from the previous step to the upcoming steps of processing. Hence, LSTMs are capable of identifying dependencies on data that ‘legacy’ neural networks cannot do. The detection of such dependencies are critical in our scenario as synopses are updated in an ‘incremental’ manner, i.e., new data arrivals are affecting the statistical information of datasets that is related to the previously delivered synopses. We consider the trade off between the frequency of synopses distribution and the ‘magnitude’ of updates. We can accept the limited freshness of updates for gaining benefits in the performance of the network. We also define an uncertainty driven model under the principles of Fuzzy Logic (FL) [35] to decide when an EC node should distribute the synopsis of its dataset. The uncertainty is related to the ‘threshold’ (upon the differences of the available data after getting reports from IoT devices) over which the node should disseminate the current synopsis. We monitor the ‘statistical significance’ of synopses updates before we decide to distributed them in the network. We consider the trade off between the frequency of the distribution and the ‘magnitude’ of updates. We can accept the limited freshness of updates for gaining benefits in the performance of the network. We apply our scheme upon past, historical observations (i.e., synopses updates) as well as upon future estimations. Both, the view on the past and the view on the future (derived by the proposed LSTM) are fed into our Type-2 FL System (T2FLS) to retrieve the Degree of Distribution (DoD). Two DoD values (upon historical values and future estimations) are smoothly aggregated through a geometrical mean function [32] to finally decide the dissemination action. Our contributions are summarized by the following list:
-
•
We support monitoring activities for detecting the magnitude of the updated synopses;
-
•
We deliver an LSTM for learning the distribution and dependencies on continuous updates of data synopses for estimating their future realizations;
-
•
We propose an uncertainty driven model for detecting the appropriate time to distribute data synopses to peers;
-
•
We report on the experimental evaluation of the proposed models through a large set of simulations.
The paper is organized as follows. Section II presents the related work while Section III formulates our problem and provides the main notations adopted in our model. In Section IV, we present the envisioned mechanism and explain its functionalities. In Section V, we deliver our experimental evaluation and conclude the paper in Section VI by presenting our future research directions.
II Related Work
Resource management at EC has been studied in the past to reveal the requirements for hosting and processing data. This is because data processing demands for specific resources according to the complexity of the requested queries/tasks. The appropriate allocation of the available resources will guarantee the increased performance and the timely provision of the outcomes. A number of efforts try to deal with the resource management problem [6], [13], [39], [43]. Their aim is to address the challenges on how we can offload various tasks/queries and data to EC nodes taking into consideration a set of constraints, e.g., time requirements, communication needs, nodes’ performance, the quality of the provided responses and so on and so forth. A relevant study in the domain reveals that processing nodes may adopt the following three (3) schemes to perform the execution of queries/tasks [43]:
-
•
An integration model for aggregating data reported by multiple devices [44]. EC nodes have the opportunity to locally process the collected data before they transfer them to the Cloud. This approach limits the time for the provision of the final response as the processing is performed in close distance with end users;
-
•
A ‘cooperative’ scheme though which EC nodes interact with other devices (e.g., IoT devices, EC nodes) having processing capabilities to offload a subset of tasks [45]. In any case, the distance between the interacting devices should be low, otherwise, their interaction may be problematic;
-
•
A ‘centralized’ approach where EC nodes act as execution points for queries/tasks offloaded by IoT devices [36]. This approach sees EC nodes having increased computational resources compared to IoT devices, thus, they can perform more complicated processing. Arguably, EC nodes should incorporated a monitoring mechanism to detect possible overloading cases and take specific mitigation actions.
Additionally, for speeding up the processing at the EC nodes while being aligned with the requirements of requests, various efforts have proposed the use of caching [10], context-aware web browsing [37] and pre-processing actions [40].
Evidently, queries/tasks are executed upon huge volumes of data. The processing of large scale data demands for efficient techniques to timely deliver the outcomes. The support of synopses management is already identified by the research community as a means for having a view upon the data avoiding to perform time consuming activities, Synopses convey statistical information about the underlying data [4] and can be maintained in an incremental approach. The research community has connected the term ‘synopsis’ with (i) approximate query estimation [11]: the target is to estimate, in real time, responses given the query and without having any view on data. Obviously, the final goal is to detect the data that better ‘match’ to the incoming queries; (ii) approximate join estimation [5], [16]: join operations are usually time concuming and more complex compared to other types of operations (e.g., a simple select upon the available data). Hence, approximate solutions may limit the time required to conclude any join operation taking into consideration the trade off between the accuracy of results and the conclusion time; (iii) aggregates calculation [12], [15], [17], [28]: the aim is to provide aggregate statistics over the available data; (iv) data mining schemes [2], [3], [38]: there are services demanding for synopses instead of the individual data points, e.g., clustering, classification. This means that any decision is retrieved upon the high level statistical information for the available data. In any case, the adoption of data synopses aims at the processing of only a subset of the actual data. Synopses act as ‘representatives’ of data and usually involve summarizations or the selection of a specific subset [27]. Any limited representation may heavily reduce the need for increased bandwidth of the network and can be easily transferred in the minimum possible time. Examples techniques for the delivery of synopses deal with sampling [27], load shedding [7], [41], sketching [8], [33] and micro cluster based summarization [2]. The easiest one is sampling. It targets to the probabilistic selection of a subset of the actual data. Obviously, the appropriate selection of samples plays a significant role in the success of the decision making model where samples are processed. Load shedding aims to drop some data when the system identifies a high load, thus, to avoid bottlenecks. Sketching involves the random projection of a subset of features that describe the data incorporating mechanisms for the vertical sampling of the stream. Micro clustering targets to the management of the multi-dimensional aspect of any data stream towards to the processing of the data evolution over time. Other statistical techniques are histograms and wavelets [4].
III Preliminaries and Problem Description
We focus on the ecosystem of EC nodes that exhibit cooperative behaviour towards the execution of the received queries/tasks. Without loss of generality, we assume EC nodes depicted by the set . Every node hosts the corresponding dataset, thus, geo-distributed datasets are available as depicted by the following set . Datasets contain multivariate vectors reported by the IoT devices being connected with EC nodes. hosts the reports of ‘its’ IoT devices and formulates a dataset with real-valued contextual multidimensional data vectors. Each data vector involves the data related to dimensions. For instance, IoT devices may monitor a phenomenon and report sensory data related to it (e.g., they could monitor a fire event and report data for temperature, humidity, etc). Any processing activity in is performed upon and targets to the provision of analytics or knowledge. For instance, requests may demand for a regression analysis, classification, the estimation of multivariate and/or uni-variate histograms per attribute, non-linear statistical dependencies between input attributes and an application-defined output attribute, clustering of the contextual vectors, etc. s are also the basis for delivering the discussed synopses. Let us denote a statistical synopsis by . is depicted by -dimensional vectors, i.e., . As mentioned above delivered by is the summarization of upon the data reported by the corresponding IoT devices. Obviously, there are synopses that have to be distributed in the ecosystem of EC nodes.
Let us focus on the behaviour of a specific EC node . A similar approach dictates the behaviour of all the available nodes. Initially, is responsible to calculate locally the corresponding synopsis upon . This happens when the received data change the statistics of the underlying dataset (e.g., concept drift). Afterwards, tries to act in a cooperative manner and decide to exchange regularly. The target is to inform peers about the changes in the statistics of its dataset, thus, to give them the opportunity to be aligned with new trends in . Obviously, , before sending , should take into consideration the trade off between the communication overhead and the ‘freshness’ of delivered to peers. can share up-to-date synopses every time a change (even the smallest one) in the underlying data is realized at the expense of flooding the network with numerous messages. We have to keep in mind that the connection of the IoT and EC infrastructures involves numerous devices exchanging numerous messages to convey data, synopses, knowledge, etc. Hence, the frequency of the delivery of messages plays a significant role in the performance of the network. In any case, a frequent delivery of will give the opportunity to peers to enjoy fresh information increasing the performance of decision making. An intermediate solution is to postpone the delivery of and reduce the sharing rate expecting less network overhead in light of ‘obsolete’ synopses. The delay in delivering can be dictated by the limited updates in as the result of retrieving data that cannot significantly change the statistics of . In this paper, we rely on the second approach and propose a model that monitors and detects where significant changes in the underlying data are present before it decides to deliver the updated . The target is to optimally limit the messaging overhead. Our rationale is to monitor the ‘magnitude’ of the collected statistical synopsis before we decide a dissemination action. In this approach, there are two main problems. The first is related to if past observations are the appropriate basis for initiating the delivery of while the second deals with the uncertainty in the adopted threshold that will ‘fire’ the delivery action. Thresholds are set into any decision making mechanism that tries to detect the appropriate time to initiate an action. For the first problem, we proposed the use of an LSTM/RNN capable of learning the dependencies of data, thus it will be easy to retrieve their future estimates. For the second problem, we proposed the use of a T2FLS to handle the incorporated uncertainty, i.e., our T2FLS results the DoD upon past synopsis observations and its estimated values. The proposed T2FLS tries to bridge the ‘gap’ between past observations and future trends of synopses. In any case, EC nodes are forced to disseminate synopses at pre-defined intervals even if no delivery decision is the outcome from our model. We have to notice that, to avoid bottlenecks in the network, we consider the pre-defined intervals to differ among the group of EC nodes. This ‘simulates’ a load balancing approach avoiding to have too many EC nodes disseminating their synopses at the same time.
Our LSTM/RNN and T2FLS are fed by the most recent . The RRN retrieves future estimates of that are also fed into the proposed T2FLS. To the bast of our knowledge, the proposed model is one of the first attempts that combines a DML with an FL system to deliver a powerful decision making mechanism. The LSTM/RNN undertakes the responsibility of learning the data and their dependencies through time and the T2FLS focuses on the management of uncertainty in decision making. monitors significant changes in as more contextual data are received from IoT devices. Based on the local monitoring activity, implicitly, we incorporate into the network edge the necessary ‘randomness’ in the conclusion of the final decision, thus, potentially avoiding network flooding. The discussed ‘randomness’ is enhanced by different data arriving to the available nodes and their autonomous decision making. Such ‘randomness’ can assist in limiting the possibility of deciding the delivery of synopses at the same time, thus, we can limit the possibility of overloading the network. We consider that at (a discrete time instance) a new arrives in . Afterwards, the corresponding synopsis should be updated to conclude the new . Let be the difference over the current, last sent synopsis and the new, the updated one, . We name this error as the update quantum, i.e., the magnitude of the difference between and . calculates at consecutive time steps and, in a simplistic way, can be concluded by adopting the sum of differences between two consecutive synopsis for every dimension. In any case, we can rely on any desired synopses realization technique. may have a positive or a negative trend, i.e., the new vector can increase or decrease the value of each dimension. For easiness in our calculations, we take into consideration the absolute value of any difference into the available dimensions. EC nodes should delay the delivery of until they see that a significant difference, i.e., a high magnitude depicted by is true. At that time, it is necessary to have the peer nodes informed about the new status of the local dataset. We define the update epoch as the time between disseminating and . The update epoch is realized at pre-defined intervals, (). In this description, we focus on a single interval, e.g., where EC nodes check the last realizations and feed them into our LSTM/RNN and T2FLS to see if they excuse the initiation of the dissemination process. For sure, the dissemination of will be concluded at if no relevant decision is made by our scheme. also ‘reasons’ over the time series of update quanta with . It ‘projects’ the time series to the future through the adoption of our LSTM/RNN. Again, the projection of update quanta is fed into the T2FLS to generate the DoD upon the future estimations of .
IV Uncertainty Driven Proactive Synopses Dissemination
IV-A Estimating Future Trends of Synopses
We select to adopt an LSTM [18], i.e., a specific type of RNNs to capture synopses trends for each dataset. Our LSTM tries to ‘understand’ every synopsis realization based on previous realizations and efficiently learn their distribution. Legacy neural networks cannot perform well in cases where we want to capture the trend of a time series. RNNs and LSTMs are network with loops inside of them making data to persist. We have to notice that the LSTM delivers for each synopsis realization. In our model, we adopt an LSTM for the following reasons: (i) we want to give the opportunity to the proposed model to learn over large sequences of data () and not only over recent data. Typical RNNs suffer from short-term memory and may leave significant information from the beginning of the sequence making difficult the transfer of information from early steps to the later ones; (ii) typical RNNs also suffer from the vanishing gradient problem, i.e., when a gradient becomes very low during back propagation, the network stops to learn; (iii) LSTMs perform better the processing of data compared to other architectures as they incorporate multiple ‘gates’ adopted to regulate the flow of the information. Hence, they can learn better than other models upon time series.
Every LSTM cell in the architecture of the network has an internal recurrence (i.e., a self-loop) in addition to the external recurrence of typical RNNs. It also has more parameters than an RNN and the aforementioned gates to control the flow of data. The self-loop weight is controller by the so-called forget gate, i.e., where is the standard deviation of the unit, represents the bias of the unit, represents the input weights, is the vector of inputs (we can get as many inputs as we want out of recordings), represents the weights of the forget gate and represents the current hidden layer vector. The internal state of an LSTM cell is updated as follows: . Now, , and represent the bias, input weights and recurrent weights of the cell and depicts the external input gate. We perform similar calculations for the external input and the output gates . The following equations hold true:
| (1) |
| (2) |
The output of the cell is calculated as follows:
| (3) |
We adopt a multiple input, single output LSTM. In our case, we consider that the number of inputs/outputs are the three most recent synopsis error observations, i.e., for inputs and . It should be noticed that our LSTM is trained upon real datasets by calculating the synopses of the reports as we reveal in our experimental evaluation section. Past observations are fed into the proposed T2FLS to retrieve the as well as future estimations are adopted by our T2FLS to retrieve the . Hence, our decision making model delivers the appropriate outcomes based on both approaches upon the statistical information of the local synopses.
IV-B The Uncertainty driven Model
For describing the proposed T2FLS, we borrow the notation of our previous efforts (in other domains) presented in [26], [25]. T2FLS is adopted locally at every node at by fusing the past observations and future realizations. is adopted as the indication whether the current update quanta significantly deviate from their past and future short-term trends. The envisioned fusion of update quanta is achieved through a finite set of Fuzzy Rules (FRs). FRs incorporate past quanta or future estimations (two different processes) to reflect the . Actually, we ‘fire’ in two consecutive iterations the T2FLS for the last three (3) quanta realizations, i.e., and the future three (3) quanta estimations, i.e., . Our T2FLS, defines the fuzzy knowledge base for every , e.g., a set of FRs like: ‘when the past/future quanta exhibit a significant difference from the last synopsis delivery, the for initiating the delivery of the new synopsis might be also high’. We rely on Type-2 FL sets as the ‘typical’ Type-1 fuzzy sets and the FRs defined upon them involve uncertainty due to partial knowledge in representing the output of the inference [31]. The limitation of a Type-1 FL system is on handling uncertainty in representing knowledge through FRs [19], [31]. In such cases, uncertainty is observed not only in the environment, e.g., we classify the as ‘low’ or ‘high’, but also on the description of the term, e.g., ‘low’/‘high’, itself. In a T2FLS, membership functions are themselves ‘fuzzy’, which leads to the definition of FRs incorporating such uncertainty [31].
FRs refer to a
non-linear mapping
between three inputs:
(i) when focusing on the past quanta, we take as the following
as inputs into the T2FLS:
;
(ii) when focusing on the future quanta, we take the following
asinputs into the T2FLS:
.
The outputs are & , respectively.
The antecedent part of FRs
is a (fuzzy) conjunction of inputs and
the consequent part of the FRs
is the indicating
the belief that an event actually occurs.
The proposed FRs have
the following structure:
IF is AND is AND is
THEN is ,
IF is AND is AND is
THEN is ,
where and are membership functions for the -th FR mapping and , , , and . For FL sets, we characterize their values through the terms: low, medium, and high. The structure of FRs in the proposed T2FLS involve linguistic terms, e.g., high, represented by two membership functions, i.e., the lower and the upper bounds [30]. For instance, the term ‘high’ whose membership for is a number , is represented by two membership functions defining the interval . This interval corresponds to a lower and an upper membership function and , respectively (e.g., the membership of can be in the interval ). The interval areas for each reflect the uncertainty in defining the term, e.g., ‘high’, useful to determine the exact membership function for each term. Obviously, if , we obtain a FR in a Type-1 FL system. The interested reader could refer to [30] for information on reasoning under Type-2 FIRs. We have to notice that FRs and membership functions for the proposed T2FLS are defined by experts.
IV-C Synopses Update and Delivery
As mentioned, in an iterative manner, our T2FLS is fed by past realizations and future estimations of the update quanta calculated upon the available datasets. The outcomes are depicted by and . We have to combine these two results into the final that exhibits the potential of initiating the delivery of the current synopsis. In other words, we have to combine our view on the past with our estimations of the future before we decide to distribute the updated synopsis to peer nodes. For the aggregation process, we strategically select to rely on a simple methodology that will derive the final outcome in real time. We propose the use of the geometric mean [32] as the function for integrating the two aforementioned views on the updated synopses. The following equation holds true:
| (4) |
with . The rationale behind the adoption of the geometric mean is that it is not affected by extreme values (high or low) and deals with all the inputs. Moreover, the multiplicative approach supported by the geometric mean makes our model to be ‘strict’ approach. FOr instance, when one the two DoD values is zero, the final outcome is zero as well. This way, we want to be sure that there is ‘critical’ amount of magnitude in synopses before they a re distributed in the network. The final decision depends on a threshold . When , we initiate the dissemination action. is a pre-defined threshold that ‘dictates’ when an EC node should pursue the exchange of a synopsis.
V Experimental Setup and Evaluation
V-A Setup and Performance Metrics
We report on the performance of our Uncertainty Driven Synopses Dissemination Model (UDSDM) and compare it with other baseline models and schemes proposed in the relevant literature. Initially, we focus on the percentage of that our model spends till the final decision. The metric is defined as follows: where is the time when the dissemination actions is decided, is the number of experiments and depicts the index of every experiment. When means that the proposed model spends the entire interval to conclude a final decision. When , our model manages to conclude immediately the dissemination action. Additionally, we define the metric i.e., . represents the average magnitude of the difference between the current and the new synopses. Through , we want to depict the ability of the proposed model to ‘react’ even in limited changes in the updated synopses (we target a ). The magnitude is calculated at . The ability of the proposed system to avoid the overloading of the network and limiting the required number of messages is exposed by . The following equation holds true: () where represents the number of times that the model stops in the interval . When means that the proposed model stops frequently, thus, multiple messages conveying the calculated synopses are transferred through the network. When means that our model does not stop frequently, thus, the calculated synopses are delivered close to the expiration of . For our experimentation, we adopt the dataset presented in Intel Berkeley Research Lab [14]. It contains measurements from 54 sensors deployed in a lab. We get the available measurements and simulate the provision of context vectors to calculate the synopses and the update quanta (they are realized in the interval ) in a sequential order. We also pursue a comparative assessment for the UDSDM with: (i) a baseline model (BM) that disseminates synopses when any change is observed over the incoming data; (ii) the Prediction based Model (PM) [29]: PM proceeds with the stopping decision only when the estimation of the future update quanta violates a threshold. For realizing the PM, we adopt the double exponential smoothing method [42]. The method applies a recursive model of an exponential filter twice before it results the final outcome. We perform simulations for adopted to realize the double exponential smoothing scheme and . In every experiment, we run the UDSDM and get numerical results related to the mean of the aforementioned metrics (we adopt for the UDSDM and the PM).
V-B Performance Assessment
In Fig. 1, we present our results for the metric. We observe that the adoption of a low (threshold for deciding the dissemination action) leads to an decreased time for the final decision. This means that the proposed model manages to conclude immediately a fuzzy result upon that ‘fires’ the dissemination action. In addition, and increased leads to a decreased . The higher the is, the lower the becomes. When and are high, the percentage of devoted to conclude the dissemination decision is very low. Compared to the PM, the UDSDM requires less time to conclude the delivery action (except when & ) for the majority of the experimental scenarios. Actually, the proposed system manages to deal with the final decision as soon as it detects that update quanta are aggregated over time even in small amounts. This can be realized in early monitoring rounds due to the dynamic nature of the incoming data. Recall that we adopt a time series that consists of sensory data retrieved by a high number of devices that are, generally, characterized by their dynamic nature.
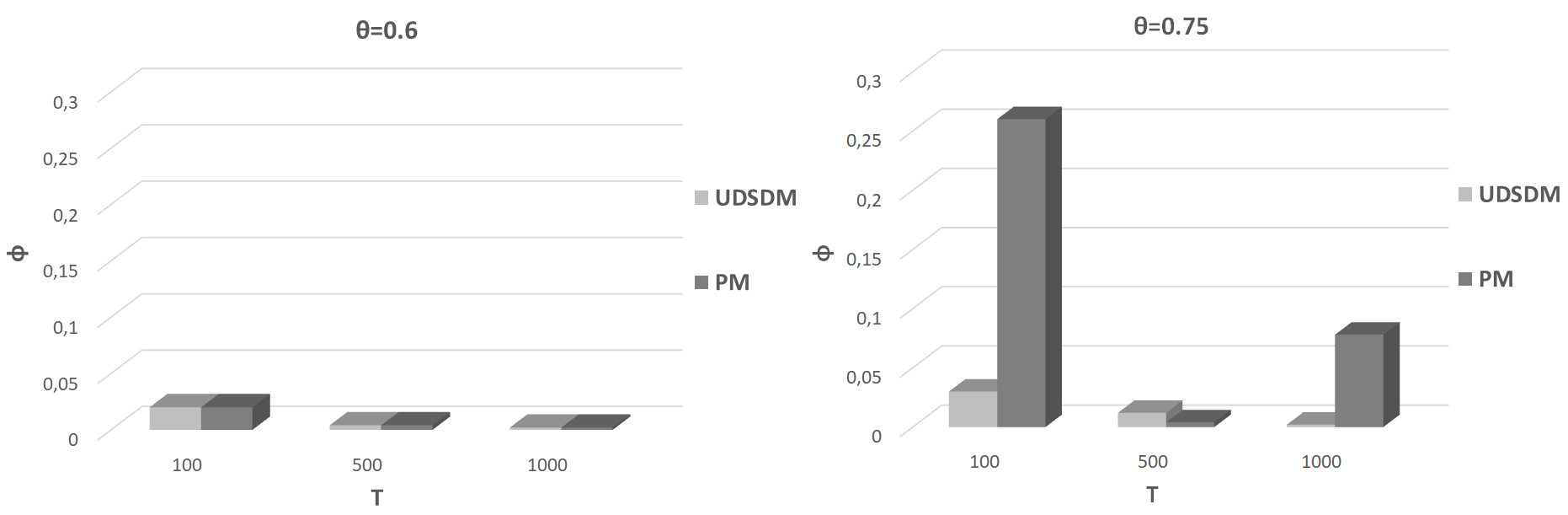
Fig. 2 presents our results related to the metric, i.e., the update quanta at the time when the dissemination action is decided. We observe that the UDSDM requires a lower magnitude than the PM and higher or equal than the BM before it concludes the dissemination action. When , there is ‘stability’ of the required before the dissemination action. When , increases together with . The PM requires a higher synopses magnitude to be collected compared to the remaining two models. These result present the ‘attitude’ of the proposed model to wait and aggregate update quanta in order to alleviate the network from an increased number of messages. However, our model does not wait till the expiration of to report fresh synopses to the network. We can easily observe that the proposed model relies in the middle between the BM and the PM (with an ‘attitude’ to be close to the BM).
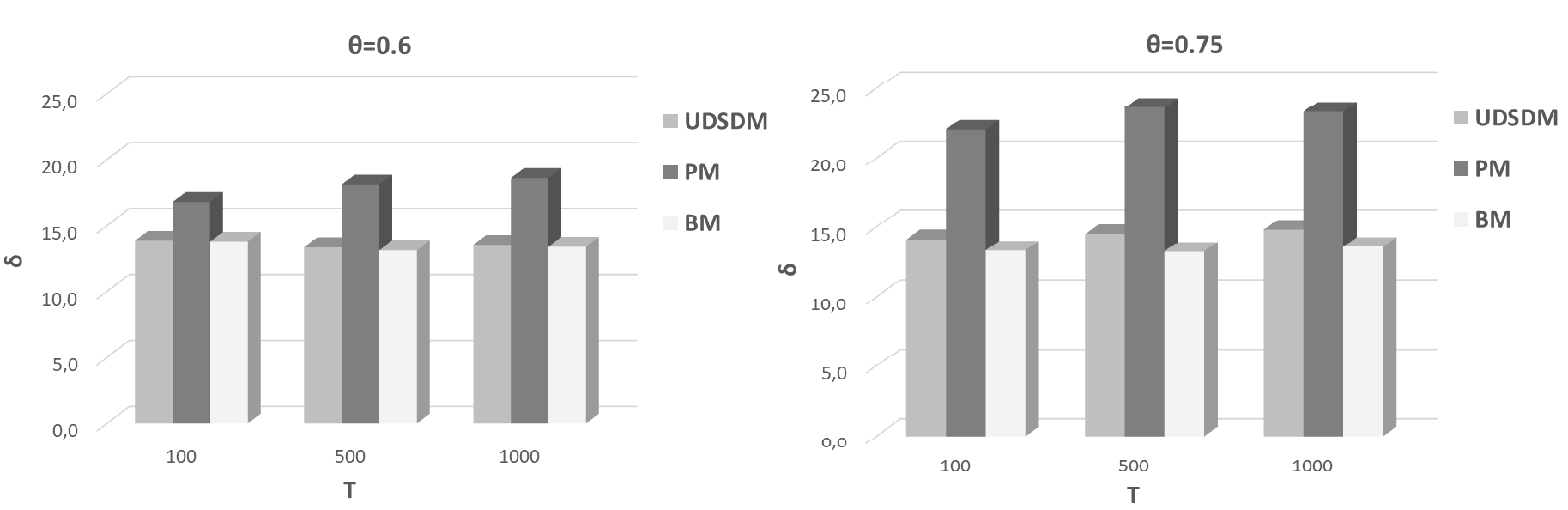
In Fig. 3, we present our results related to the metric. We confirm our observations obtained by the two above discussed metrics, i.e., the UDSDM relies in the middle between the BM and the PM. Our model is mainly affected by the rationale to distribute fresh synopses in the burden of the number of messages circulated in the network. However, it manages to deliver less messages than the BM. We observe a stability in the obtained outcomes exhibiting the capability of the UDSDM to detect changes in synopses quanta and fire the delivery action. The PM requires the less frequency of the delivery, however, in the burden of the freshness of the distributed synopses.
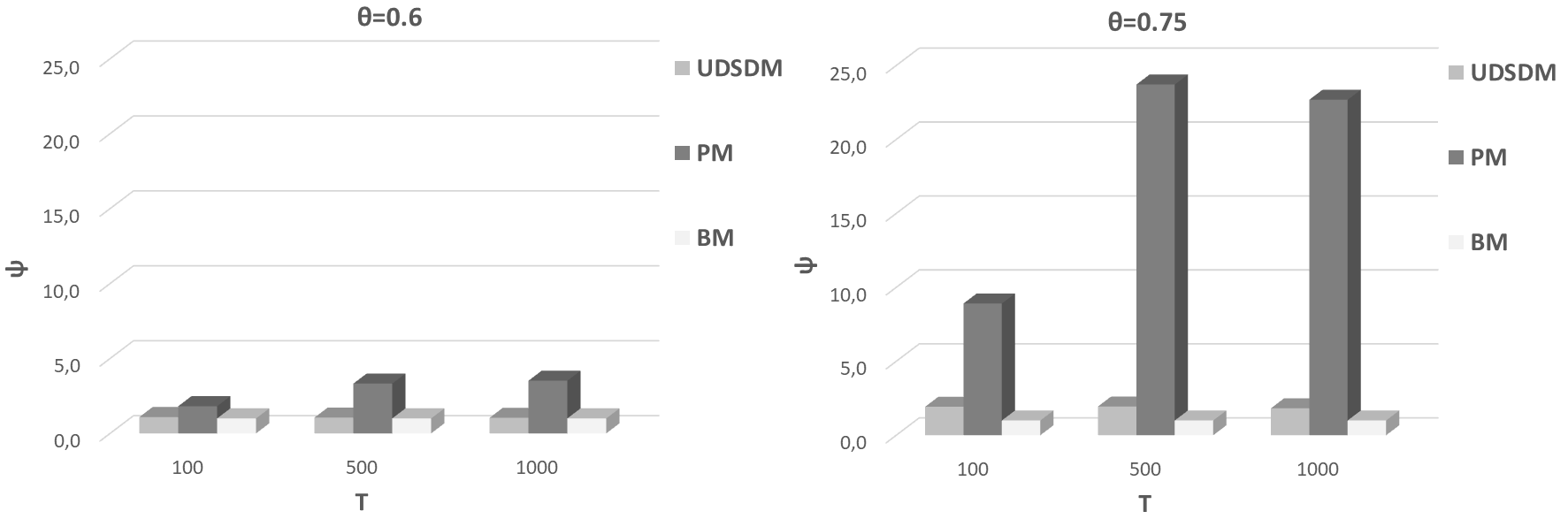
VI Conclusions
Data management at the edge of the network is a significant research subject due to the reduced latency that end users can enjoy if processing is performed at the EC infrastructure. Numerous IoT devices report data towards the Cloud datacenter, thus, advanced data management applications should be provided at the EC as the intermediate point where processing can take place. A number of EC nodes may undertake the responsibility of hosting datasets and processing activities. Nodes should act in a collaborative manner to increase their performance. For instance, EC nodes may exchange processing tasks or data to conclude the desired outcomes as soon as possible. In this paper, we enhance the collaborative aspect of the EC infrastructure and propose a novel model for exchanging data synopses at the edge of network. The target is to have all EC nodes informed about the data present at their peers, thus, to take optimal decisions related to the management of the requested processing activities. We present a deep learning model and an uncertainty driven scheme to reason over the appropriate time to exchange data synopses. The deep learning model manages to learn the distribution of the concluded synopsis as the basis for retrieving future estimations. The uncertainty driven scheme deals with a set of rules applied upon past synopses observations and future estimates. This way, we combine two completely different technologies to realize an efficient system for the management of data synopses at EC. Our aim is to provide a decision making methodology that minimizes the number of messages circulated in the network, however, without jeopardizing the freshness of the exchanged statistical information. We discuss our model adopting the principles of the FL and present the relevant formulations. EC nodes monitor their data and decide when it is the right time to deliver the current data synopsis. Our experimental evaluation shows that the proposed scheme can efficiently assist in the envisioned goals being evidenced by numerical results. In the first place of our future research plans, it is to incorporate a rewarding mechanism for every ‘correct’ decision and present a system that learns on how to learn. Additionally, we want to involve more parameters in the decision making mechanism like a ‘snapshot’ of the current status of every EC node.
References
- [1] Amrutha, S. et al., ’Data Dissemination Framework for IoT based Applications’, Indian Journal of Science and Technology, 9(48), 2016, pp. 1–5.
- [2] Aggarwal, C., Han, J., Wang J., Yu, P., ’A Framework for Clustering Evolving Data Streams’, VLDB Conference, 2003.
- [3] Aggarwal, C., Han, J., Wang, J., Yu, P., ’On-Demand Classification of Data Streams’, ACM KDD Conference, 2004.
- [4] Aggarwal, C., Yu, P., ’A Survey of Synopsis Construction in Data Streams’, ch. in ’Data Streams, Models and Algorithms’, ed. Aggarwal, C., Springer Science & Business Media, 2007.
- [5] Alon, N., Gibbons P., Matias Y., Szegedy, M., ’Tracking Joins and Self Joins in Limited Storage’, ACM PODS Conference, 1999.
- [6] Anglano, C., Canonico, M., Guazzone, M., ’Profit-aware Resource Management for Edge Computing Systems’, 1st International Workshop on Edge Systems, Analytics and Networking, 2018, pp. 25–30.
- [7] Babcock, B., Datar, M., Motwani, R., ’Load Shedding Techniques for Data Stream Systems’, Workshop on Management and Processing of Data Streams, 2003.
- [8] Babcock, B., Babu, S., Datar, M., Motwani, R., Widom, J., ’Models and issues in data stream systems’, PODS, 2002.
- [9] Bellavista, P., Corradi, A., Foschini, L., Scotece, D., ’Differentiated Service/Data Migration for Edge Services Leveraging Container Characteristics’, IEEE Access, vol. 7, 2019.
- [10] Bhardwaj, K., Agrawal, P., Gavrilovska, A., Schwan, K., ’AppSachet: Distributed App Delivery from the Edge Cloud’, 7th International Conference Mobile Computing, Applications, and Services, 2015, pp. 89-–106.
- [11] Chakrabarti K., Garofalakis M., Rastogi R., Shim, K., ’Approximate Query Processing with Wavelets’, VLDB Journal, vol. 10(2-3), 2001, pp. 199–223.
- [12] Charikar M., Chen K., Farach-Colton, M., ’Finding Frequent items in data streams’, ICALP, 2002.
- [13] Cherrueau, R. A., Lebre, A., Pertin, D., Wuhib, F., Soares, J., ’Edge Computing Resource Management System: a Critical Building Block! Initiating the debate via OpenStack’, USENIX Workshop on Hot Topics in Edge Computing, 2018, pp. 1–6.
- [14] Chu, D., Deshpande, A., Hellerstein, J., Hong, W., ’Approximate Data Collection in Sensor Networks using Probabilistic Models’, in 22nd International Conference on Data Engineering (ICDE’06), 2006.
- [15] Cormode G., Muthukrishnan, S., ’What’s hot and what’s not: Tracking most frequent items dynamically’, ACM PODS Conference, 2003.
- [16] Dobra A., Garofalakis M. N., Gehrke J., Rastogi, R., ’Sketch-Based Multi-query Processing over Data Streams’, EDBT Conference, 2004.
- [17] Gehrke J., Korn, F., Srivastava, D., ’On Computing Correlated Aggregates Over Continual Data Streams’, SIGMOD Conference, 2001.
- [18] Goodfellow, I., Bengio, Y., Courville, A., ’Deep Learning’, MIT Press, 2016.
- [19] Hagras, H., ’A hierarchical type-2 fuzzy logic control architecture for autonomous mobile robots’, IEEE TFS, vol. 12, 2004.
- [20] Karanika, A., Oikonomou, P., Kolomvatsos, K., Loukopoulos, T., ’A Demand-driven, Proactive Tasks Management Model at the Edge’, in IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), 2020.
- [21] Kolomvatsos, K., ’An Intelligent Scheme for Assigning Queries’, Springer Applied Intelligence, https://doi.org/10.1007/s10489-017-1099-5, 2018.
- [22] Kolomvatsos, K., ’A Distributed, Proactive Intelligent Scheme for Securing Quality in Large Scale Data Processing’, Springer Computing, 101, 1687–1710, 2019.
- [23] Kolomvatsos, K., Anagnostopoulos, C., ’A Probabilistic Model for Assigning Queries at the Edge’, Computing, Springer, 102, 865–892, 2020.
- [24] Kolomvatsos, K., Anagnostopoulos, C., ’Multi-criteria Optimal Task Allocation at the Edge’, Future Generation Computer Systems, vol. 93, 2019, pp. 358-372.
- [25] Kolomvatsos, K., Anagnostopoulos, C., Hadjiefthymiades, S., ’Data Fusion & Type-2 Fuzzy Inference in Contextual Data Stream Monitoring’, IEEE Transactions on Systems, Man and Cybernetics: Systems, vol. PP, Issue 99, pp.1-15, 2016.
- [26] Kolomvatsos, K., Anagnostopoulos, C., Marnerides, A., Ni, Q., Hadjiefthymiades, S., Pezaros, D., ’Uncertainty-driven Ensemble Forecasting of QoS in Software Defined Networks’, 22nd IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 2017.
- [27] Lakshmi, K. P., Reddy, C. R. K., ’A Survey on Different Trends in Data Streams’, IEEE International Conference on Networking and Information Technology, 2010.
- [28] Manku, G., Motwani, R., ’Approximate Frequency Counts over Data Streams’, VLDB Conference, 2002.
- [29] Martin, R., Vahdat, A., Culler, D., Anderson, T., ’Effects of Communication Latency, Overhead, and Bandwidth in a Cluster Architecture’, 4th Annual International Symposium on Computer Architecture, 1997.
- [30] Mendel, J. M., ’Type-2 Fuzzy Sets and Systems: An Overview’, IEEE Computational Intelligence Magazine, 2(2), 2007.
- [31] Mendel, J. M., ’Uncertain Rule-Based Fuzzy Logic Systems: Introduction and New Directions’, Upper Saddle River, Prentice-Hall, 2001.
- [32] Mesiar, R., Kolesarova, A., Calvo, T., Komornikova, M., ’A Review of Aggregation Functions’, Studies in Fuzziness and Soft Computing, 2008.
- [33] Muthukrishnan, S., ’Data streams: algorithms and applications’, 14th annual ACM-SIAM symposium on discrete algorithms, 2003.
- [34] Najam, S., Gilani, S., Ahmed, E., Yaqoob, I., Imran, M., ’The Role of Edge Computing in Internet of Things’, IEEE Communications Magazine, 2018, doi: 10.1109/MCOM.2018.1700906.
- [35] Novák, V., Perfilieva, I., Močkoř, J., ’Mathematical principles of fuzzy logic’, Dordrecht: Kluwer Academic, 1999.
- [36] Sardellitti, S., Scutari, G., Barbarossa, S., ’Joint Optimisation of Radio and Computational Resources for Multicell Mobile-Edge Computing’, IEEE Transactions on Signal and Information Processing over Networks, vol. 1(2), 2015, pp. 89-–103.
- [37] Savolainen, P., Helal, S., Reitmaa, J., Kuikkaniemi, K., Jacucci, G., Rinne, M., Turpeinen, M., Tarkoma, S., ’Spaceify: A Client-edge-server Ecosystem for Mobile Computing in Smart Spaces’, International Conference on Mobile Computing & Networking, 2013, pp. 211–-214.
- [38] Schweller, R., Gupta, A., Parsons, E., Chen, Y., ’Reversible Sketches for Efficient and Accurate Change Detection over Network Data Streams’, Internet Measurement Conference Proceedings, 2004.
- [39] Shekhar, S., Gokhale, A., ’Dynamic Resource Management Across Cloud-Edge Resources for Performance-Sensitive Applications’, 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, 2017.
- [40] Simoens, P., Xiao, Y., Pillai, P., Chen, Z., Ha, K., Satyanarayanan, ’Scalable crowd-sourcing of video from mobile devices’, 11th annual international conference on Mobile systems, applications, and services, 2013, pp. 139–152.
- [41] Tatbul, N., Zdonik, S., ’A subset-based load shedding approach for aggregation queries over data streams’, International Conference on Very Large Data Bases (VLDB), 2006.
- [42] Vandeput, N., ’Data Science for Supply Chain Forecast’, Independently published, 2018.
- [43] Wang, N., Varghese, B., Matthaiou, M., Nikolopoulos, D., ’ENORM: A Framework for Edge Node Resource Management’, IEEE Transactions on Service Computing, 2017, doi: 10.1109/TSC.2017.2753775.
- [44] Yao, Y., Cao, Q., Vasilakos, A. V., ’EDAL: An Energy-Efficient,Delay-Aware, and Lifetime-Balancing Data Collection Protocol for Wireless Sensor Networks’, IEEE International Conference on Mobile Ad-Hoc and Sensor Systems, 2013, pp. 182-–190.
- [45] Zhou, A., Wang, S., Li, J., Sun, Q., Yang, F., ’Optimal Mobile Device Selection for Mobile Cloud Service Providing’, The Journal of Supercomputing, vol. 72(8), 2016, pp. 3222-–3235.