Data–driven predictive control with estimated prediction matrices and integral action
Abstract
This paper presents a data–driven approach to the design of predictive controllers. The prediction matrices utilized in standard model predictive control (MPC) algorithms are typically constructed using knowledge of a system model such as, state–space or input–output models. Instead, we directly estimate the prediction matrices relating future outputs with current and future inputs from measured data, off–line. On–line, the developed data–driven predictive controller reduces to solving a quadratic program with a similar structure and complexity as linear MPC. Additionally, we develop a new procedure for estimating prediction matrices from data for predictive controllers with integral action, corresponding to the rate–based formulation of linear MPC. The effectiveness of the developed data–driven predictive controller is illustrated on position control of a linear motor model.
Index Terms:
Data–driven control, Model predictive control, Markov parameters estimation, Integral controlI Introduction
Data–driven (DD) control design methods have recently gained an increased attention from the control systems community due to the digital technology trends involving big–data and artificial intelligence systems, see, for example, [1, 2] and the references therein. The main idea of data–driven control is to eliminate the standard separation in model–based controller design, i.e., first obtain a system model, by identification or first principles, and then design a controller. Instead, in DD controller design, more freedom is allowed in mixing identification (or estimation) with controller design, and even direct controller synthesis from data.
Much of the existing data–driven methods for controller design, see, e.g., [3, 4, 5, 6] and the references therein, have originated within the field of adaptive control and make use of the so–called model reference control framework. In these approaches, instead of first deriving a system model, measured input–output (I/O) data is directly used to identify a parameterized controller chosen a priori, given a performance requirement, i.e., the reference model. Since it is hard to guarantee closed–loop stability while tuning the controller with these methods without largely compromising performance, an a posteriori data–driven certification procedure has also been reported in [7].
Recently, these ideas have been extended to other types of robust control problems, such as state–feedback stabilization [8], linear quadratic regulator (LQR) design [9, 10], and output feedback with an embedded prediction step [11]. Combining ideas of state–feedback with prediction theory fits well in the framework of model predictive control (MPC) [12], which can also be described by a given performance (whether a reference model or weighting matrices) with a parameterized structure (the prediction matrices, typically constructed using a system model).
MPC approaches based on input–output step–response system models [13] or finite impulse response (FIR) system models [14], have been at the core of the MPC research for a long time. These methods require an identification step to obtain the FIR model (usually by applying some impulses to the system or by differentiating its step response) and an estimation of the system order, and then plugging in these parameters into the prediction matrices. Such an approach, which still resorts to a system identification procedure, is referred to as an indirect data–driven approach to controller design. Another possibility is to combine model–based and data–driven approaches within predictive control algorithms, see, for example, [15] and the references therein, where a linear state–space model is used for describing known system dynamics and a learning data–driven approach is used to model unknown disturbances.
Direct approaches to data–driven predictive control, inspired by [16], were proposed recently in [17] and [18]. These approaches parameterize future predicted outputs as a linear combination of past inputs and outputs, and future inputs, via Hankel matrices of I/O data and a set of coefficients (parameters). Such methods do not require any off–line identification, at the cost of computing the set of coefficients on–line, simultaneously with computing future control inputs and predicted outputs. This makes the number of optimization variables dependent of both the prediction horizon and the size of the Hankel data matrices. It is worth to mention that [17] computes on–line an additive control input that adjusts an unconstrained predictive control law, while [18] computes on–line the constrained predictive control input directly, as in standard MPC. Also, [17] proposes a method to include integral action, while [18] develops solutions for dealing with noisy data. Stability and robustness of Hankel matrices based predictive controllers have been recently studied in [19].
Overall, direct data–driven predictive controllers are sensitive to noisy data, since they do not inherit any of the standard properties of an intermediate step of estimation (and also due to multiplicative noise terms in the prediction step). Another relevant remark to MPC design [12] versus data–driven predictive control (DPC) design is that stability and optimal performance is not anymore easily determined by the cost function tuning. Indeed, while in linear MPC the LQR control law can be recovered if constraints are not active via a suitable terminal penalty, this is no longer the case in DPC, even under the assumption that the full state is measurable.
An unconstrained solution to an input-output data-driven Subspace Predictive Control algorithm has been derived in [20]. However, the authors suggest to compute the prediction matrices by using a pre-step of QR decomposition of the data matrices, and it is not clear how this computation is affected by noise. They then propose a second step to reduce the state prediction matrix to an estimate of the system order. [21] builds on the input-output GPC approach, including only upper and lower bound type of constraints and proposing an integral action assuming a particular ARIMAX model structure, so they can take the discrete output difference as feedback. Therein, integral prediction matrices are not directly identified from data, instead, they identify the non-integral prediction matrices first, and then they use summation of the specific terms. The method developed in this work do not require any type of system order estimate and we formulate it such that inclusion of constraints follow the model-based approach. We also derive the identification procedure for identifying prediction matrices for rate-based integral action state-space MPC with formal guarantees (Theorem 1) without assuming a specific noise model.
Motivated by the current status in DPC design, in this paper we develop an approach to data–driven predictive control that offers an attractive compromise between indirect and direct approaches to data–driven control. The approach is inspired by the recent data–driven LQR design proposed in [10]. Firstly, instead of identifying a state–space or FIR system model and then building the MPC prediction matrices, the developed approach directly estimates the full prediction matrices from measured data. Estimation of the prediction matrices makes the developed approach less sensitive to noisy data. We also show that these matrices are comprised of the system Markov parameters, so they relate to the MPC approaches using FIR models, but without requiring a priori knowledge of the system order. Moreover, we show that if the state sequence can be measured or the prediction horizon is long enough, then one can recover the corresponding LQR controller by using the derived DPC algorithm. Motivated by the need of off-set free control in practice, another contribution of this paper is the derivation of a rate–based DPC algorithm with integral action, similar to linear MPC with integral action [22]. The performance and robustness of the developed data–driven predictive controller is illustrated for position control of a linear motor model.
II Preliminaries
In this section we recall the standard linear MPC formulation [12] using prediction matrices based on linear discrete–time state–space models, i.e.,
| (1) |
where is the state, is the input, is the output and denotes the discrete–time index. Assuming for simplicity that the regulation objective is to control the output to the origin, in MPC one computes a sequence of optimal control inputs every time instant by minimizing a cost function, e.g.,
| (2) | ||||
where , , , and . Above and are positive definite symmetric weighting matrices of appropriate dimensions, is the prediction horizon (we assume that a control horizon equal to the prediction horizon is used for brevity) and is a terminal weight matrix, which is typically taken equal to the solution of a corresponding discrete–time algebraic Riccati equation (DARE). Moreover, the matrices utilized in (2) are defined as follows:
| (3) | ||||
The unconstrained MPC control law (i.e., if output and input constraints are neglected) can be computed by taking the gradient of with respect to and set it equal to , i.e.:
| (4) | ||||
When output and input constraints are added to the minimization of , the constrained MPC control law is computed on–line, by solving a quadratic program, i.e.,
| (5) | ||||
| subject to: |
where the derivation of the matrices , , and the vector is illustrated next. It is worth mentioning that the terms in (2) that do not depend on are omitted in (5), as they do not influence the corresponding optimum.
Consider linear constraints in the outputs and inputs, i.e.
| (6) | ||||
for suitable matrices and vectors . These constraints can be aggregated as follows
| (7) | ||||
Substituting the future predicted outputs into equation (7) results in
| (8) |
The MPC control law is extracted from as follows:
| (9) |
Next, we will present a data–driven approach to predictive control design, which is based on estimating the prediction matrix and the predicted “free response” directly from measured input–output (or state) data.
III Data–driven predictive control with estimated prediction matrices
Instead of using an identified state–space model to build the prediction matrices and (see (4) and (8)), we aim to directly compute these matrices from I/O data. The data can either be collected whilst controlling the system on–line or obtained off–line from an experiment on the system. Even though collecting data on–line is preferable, as no prior experiment is required, there is no guarantee of persistence of excitation for the inputs generated by a controller. This can yield not only ill–conditioned prediction matrices, but it can strongly degrade initial performance due to the short measurement horizon. Therefore, in this work we assume the data is measured off–line.
III-A Estimating the prediction matrices
We start by showing how to obtain from measured data, using an ARMarkov model as reported in [10, 9, 23]. Suppose the input and output vectors are structured as (for any ):
These vectors can be stacked in the following Hankel matrices:
| (10) | ||||
representing the so–called “past” and “future” I/O data. Above represents some chosen measurement horizon, which we will define later. According to [10, 24], the relation between these matrices can be described as follows:
| (11) | ||||
where , and is the extended controllability matrix . According to [23], as long as , it is guaranteed for an observable system that there exists a matrix such that This allows us to rewrite without state information:
For given and we can obtain the least–squares estimated prediction matrix :
| (12) |
where represents the Moore-Penrose pseudo-inverse, and . Hereby it should be noted that to ensure (12) has a solution.
III-A1 Estimating : measurable state
If the system state is measurable, an estimate of can be accurately obtained from data. The following ways to estimate it are derived from [10]. The first one uses the estimated and (11), as follows:
| (13) |
Another approach is using the orthogonal complement of the row space of the matrix :
| (14) | ||||
Remark 1
(The LQR equivalence) When the state is measurable, one can also retrieve the stability and (sub–)optimal performance properties of the LQR controller even for a small horizon . Consider the following LQR and MPC cost functions, respectively:
Notice that here is a terminal penalty on the state vector, not on the output. If equals the solution of the associated DARE for the LQR problem, then we obtain the infinite horizon LQR control law as the unconstrained MPC control law111For sufficient large there exists a closed-form solution for (see, e.g., [10]), but then the MPC cost function also converges to the LQR case..
In order to introduce the terminal state penalty in the developed data–driven predictive controller, one can create an unobservable output , where is the Cholesky decomposition of , such that . Thus, we have an augmented output vector which needs only to be re-substituted in (10). This also yields the following performance matrix changes: For sub-optimality it suffices to choose a .
III-A2 Estimating : only I/O data available
If the state is not measurable, the method of [9] can be used to estimate on–line, using previous inputs and measured outputs, as follows:
| (15) | ||||
Since both and can be directly extracted from the matrix obtained in equation (12), then one can compute in real–time as
| (16) |
On–line estimation of depends on the unknown and the estimate accuracy is not guaranteed to improve for any sequence length shorter than .
Remark 2
(Initial inputs and feasibility) If is computed using previous I/O data, it should be noted that due to this poor initial estimation, the predictive control quadratic program may not be feasible at start. This can be circumvented via soft–constraints.
III-B Integral action
Embedding integral action within a model–based predictive controller is known to be beneficial both with respect to tracking time–varying references and removing off–sets. To this end, the rate–based MPC formulation was developed (see, e.g., [22]) by defining an augmented state , where and an incremental input . Then we can construct an augmented system model as follows:
| (17) | ||||
The cost function changes to:
where , and is a known future reference. The actual control input is obtained as . By substituting the integral model (17) into the definitions in equation (3), we obtain
| (18) | ||||
We now formulate a method that allows us to derive these integral action prediction matrices directly from data by manipulating the input used in the experiment.
Theorem 1
Let and , (respectively , ) represent the corresponding row-block w.r.t. output . Then it holds that
| (19) | ||||
Proof:
Consider first the trivial case, , and let :
| (20) | ||||
Next, consider the case , and the previous relation for :
| (21) | ||||
Thus, we obtained the prediction of output as a function of the original prediction matrices, but for the integrated input. The proof for any other follows using the same derivations and is omitted due to space limitation. ∎
The result of Theorem 1 suggests that it is possible to estimate the prediction matrices corresponding to the rate–based predictive control algorithm by manipulating the data fed to the system in the experiment. More specifically, the following procedure can be applied. First, create an input set and form a second input set from such that for any , . Next, perform the experiment on the system using as input and collect the output, which we will denote . Finally, compute as in (12) using for and , but using for the input matrices and , instead of the applied . Using in the experiment, however, could lead to a high magnitude input. An alternative procedure can be used to circumvent this problem, as follows: apply in the experiment, collect and use to compose and . The proof that the developed estimation procedure can still be applied follows the same derivations as above, but we do not include it here due to space limitations.
Remark 3
The implementation of the integral action DPC still requires estimation of . If the states are measurable (see Section III-A1) the unconstrained integral DPC law becomes:
| (22) |
To obtain an estimate of , equations (13) or (14) can be used in combination with the state vector corresponding to the integral action augmented state, i.e., . If the state is not measurable, the unconstrained integral DPC law changes to
which is similar to the method used in Section III-A2. If constraints are added to the optimization problem, the same approaches to estimate or , respectively, apply, as the constraints matrices (8) (corresponding to the integral action formulation) only depend on the estimated prediction matrices.
IV Illustrative examples
IV-A Position control for a linear motor
In this section we provide an illustrative example of the proposed methodology for the position control of a linear motor, see, e.g., [25]. The simplified motion dynamics of the mechanical part of the actuator can be represented by the continuous–time model
where the first state (the output) is the position and the second state is the velocity. The system is discretized with a sampling time of s. In order collect data from the system we set an experiment where the input is a PRBS signal with an amplitude of N at Hz and length 6022 samples. The output is corrupted by a white noise sequence such that the Signal-to-Noise Ratio (SNR) is dB.
The control performance parameters are given by , , and . Also the input force is constrained between , and displacement is limited between . We then perform the estimation of the prediction matrices in (12) and (14) with , and similarly for the integral DPC case.
Fig. 1 portrays the closed–loop results for a sequence of steps using 3 predictive controllers: standard model–based PC, the developed DPC with measured state and measured output, respectively. Also, between s and s we apply a constant disturbance force of amplitude N and we also consider the output corrupted by white noise with SNR = dB. It can be observed that the DPC with measured state converges faster to the reference compared to the DPC with measured output, and it matches the standard MPC result. Due to the poor initial estimation of the output DPC, the initial response is a bit slower. When the disturbance becomes active all 3 predictive controllers result in an off–set, which is considerably larger for the output DPC.
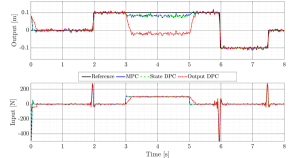
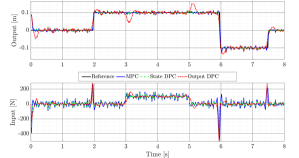
Fig. 2 shows the closed–loop simulation results for the corresponding 3 integral predictive controllers. All controllers successfully remove the off-set caused by the disturbance, while the output integral DPC exhibits longer transients due to the on–line estimation part. This really demonstrates the need of incorporating integral action in data–driven predictive controllers and also, the effectiveness of the developed DPC algorithm.
IV-B UPS system with periodic disturbance
To provide another practical example, the data–driven control algorithm with integral action is also applied to an uninterruptible power supply (UPS). This plant has been studied before in [10].
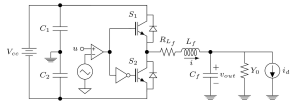
Fig. 3 shows a simplified electrical diagram of the output stage of a single-phase UPS system. The load effect on the system output is modeled by a parallel connection of an uncertain admittance and an unknown periodic disturbance given by the current source . Again for simplicity, the uncertain admittance is presumed to be constant at . The input is a PWM control voltage and the output is the voltage over the capacitor. The states are the inductor current and the capacitor voltage, . The system can be represented as the following state-space model:
| (23) | ||||
The system is discretized with a sampling time of using a zero-order hold. The input voltage is constrained between and there are no output constraints. The closed–loop is set to follow a sinusoidal reference . Additionally, the following control parameters are used:
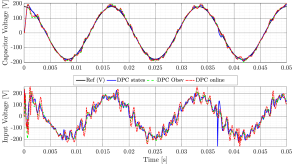
The system is measured off–line using a PRBS with an amplitude of with a length samples at Hz. The experiment is corrupted with output noise such that the SNR is dB, the disturbance current was not present in the experiment. During the simulation, the system is also subjected to an output noise with a SNR of dB. The periodic disturbance is defined as multi–sine with 12 components with random frequencies between and Hz and has an amplitude of . See Fig. 4 for the result of the simulation. The various controllers all achieve reference tracking even for a periodic reference. The total harmonic distortion (THD) caused by the periodic disturbance on the system is between 3.8% and 4%.
V Conclusion
In this work we proposed a new data–driven predictive control approach with estimated prediction matrices and integral action. Our approach lies between the direct data–enabled predictive control and the identified model–based predictive control. In this way, we are able to avoid identification of a complete state–space model and the respective system order, while still enjoying standard properties of least–squares estimation. Also, comparatively to the data–enabled approach, our method deals well with noisy data and requires less in general computations for the on–line implementation. We also presented a formulation that allows direct incorporation of integral action in the DPC algorithm by only manipulating data that is fed to algorithm, without altering the single experiment required for estimation. Simulation results for position control of a linear motor illustrated the effectiveness of our methodology in terms of tracking performance, robustness to noisy measurements and disturbance rejection.
References
- [1] F. Lamnabhi-Lagarrigue, A. Annaswamy, S. Engell, A. Isaksson, P. Khargonekar, R. M. Murray, H. Nijmeijer, T. Samad, D. Tilbury, and P. Van den Hof, “Systems & control for the future of humanity, research agenda: Current and future roles, impact and grand challenges,” Annual Reviews in Control, vol. 43, pp. 1–64, 2017.
- [2] I. Markovsky and P. Rapisarda, “Data-driven simulation and control,” International Journal of Control, vol. 81, no. 12, pp. 1946–1959, 2008.
- [3] A. S. Bazanella, L. Campestrini, and D. Eckhard, Data-driven controller design: the H2 approach. Netherlands: Springer Science & Business Media, 2011.
- [4] Z.-S. Hou and Z. Wang, “From model-based control to data-driven control: Survey, classification and perspective,” Information Sciences, vol. 235, pp. 3–35, 2013.
- [5] M. C. Campi, A. Lecchini, and S. M. Savaresi, “Virtual reference feedback tuning: a direct method for the design of feedback controllers,” Automatica, vol. 38, no. 8, pp. 1337 – 1346, 2002.
- [6] L. Campestrini, D. Eckhard, A. S. Bazanella, and M. Gevers, “Data-driven model reference control design by prediction error identification,” Journal of the Franklin Institute, vol. 354, no. 6, pp. 2828–2647, 2017.
- [7] G. R. Gonçalves da Silva, A. S. Bazanella, and L. Campestrini, “One-shot data-driven controller certification,” ISA Transactions, vol. 99, pp. 361–373, 2020.
- [8] H. J. Van Waarde, J. Eising, H. L. Trentelman, and M. K. Camlibel, “Data informativity: a new perspective on data-driven analysis and control,” IEEE Transactions on Automatic Control, 2020.
- [9] W. Aangenent, D. Kostic, B. de Jager, R. van de Molengraft, and M. Steinbuch, “Data-based optimal control,” in Proceedings of the American Control Conference, vol. 2, 2005, pp. 1460–1465.
- [10] G. R. Gonçalves da Silva, A. S. Bazanella, C. Lorenzini, and L. Campestrini, “Data-driven LQR control design,” IEEE Control Systems Letters, vol. 3, no. 1, pp. 180–185, 2019.
- [11] C. d. Persis and P. Tesi, “Formulas for data-driven control: Stabilization, optimality, and robustness,” IEEE Transactions on Automatic Control, vol. 65, no. 3, pp. 909–924, 2019.
- [12] J. B. Rawlings, D. Q. Mayne, and M. M. Diehl, Model Predictive Control: Theory, Computation, and Design, 2nd ed. Nob Hill Publishing, 2017.
- [13] D. W. Clarke, C. Mohtadi, and P. S. Tuffs, “Generalized predictive control–Part I. the basic algorithm,” Automatica, vol. 23, no. 2, pp. 137–148, 1987.
- [14] G. Prasath and J. B. Jørgensen, “Model predictive control based on finite impulse response models,” in 2008 American Control Conference. IEEE, 2008, pp. 441–446.
- [15] A. Carron, E. Arcari, M. Wermelinger, L. Hewing, M. Hutter, and M. N. Zeilinger, “Data-driven model predictive control for trajectory tracking with a robotic arm,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3758–3765, 2019.
- [16] I. Markovsky, J. C. Willems, S. Van Huffel, and B. De Moor, Exact and approximate modeling of linear systems: A behavioral approach. SIAM, 2006.
- [17] H. Yang and S. Li, “A data-driven predictive controller design based on reduced hankel matrix,” in 2015 10th Asian Control Conference (ASCC). IEEE, 2015, pp. 1–7.
- [18] J. Coulson, J. Lygeros, and F. Dörfler, “Data-enabled predictive control: In the shallows of the DeePC,” in 2019 18th European Control Conference (ECC). IEEE, 2019, pp. 307–312.
- [19] J. Berberich, J. Köhler, M. A. Muller, and F. Allgower, “Data-driven model predictive control with stability and robustness guarantees,” IEEE Transactions on Automatic Control, 2020.
- [20] W. Favoreel, B. De Moor, and M. Gevers, “SPC: Subspace predictive control,” IFAC Proceedings Volumes, vol. 32, no. 2, pp. 4004–4009, 1999.
- [21] R. Kadali, B. Huang, and A. Rossiter, “A data driven subspace approach to predictive controller design,” Control engineering practice, vol. 11, no. 3, pp. 261–278, 2003.
- [22] L. Wang, Model predictive control system design and implementation using MATLAB®. Springer Science & Business Media, 2009.
- [23] R. K. Lim, M. Q. Phan, and R. W. Longman, “State estimation with ARMarkov models,” Department of mechanical and aerospace engineering, Princeton University, Princeton, NJ, Tech. Rep. 3046, October 1998.
- [24] P. Van Overschee and B. De Moor, Subspace identification for linear systems. Theory, implementation, applications. Springer, Boston, MA, 01 1996, vol. xiv, pp. xiv + 254.
- [25] T. T. Nguyen, M. Lazar, and H. Butler, “Nonlinear model predictive control for ironless linear motors,” in IEEE Conference on Control Technology and Applications. IEEE, 2018, pp. 927–932.