Decoding News Bias: Multi Bias Detection in News Articles
Abstract.
News Articles provides crucial information about various events happening in the society but they unfortunately come with different kind of biases. These biases can significantly distort public opinion and trust in the media, making it essential to develop techniques to detect and address them. Previous works have majorly worked towards identifying biases in particular domains e.g., Political, gender biases. However, more comprehensive studies are needed to detect biases across diverse domains. Large language models (LLMs) offer a powerful way to analyze and understand natural language, making them ideal for constructing datasets and detecting these biases. In this work, we have explored various biases present in the news articles, built a dataset using LLMs and present results obtained using multiple detection techniques. Our approach highlights the importance of broad-spectrum bias detection and offers new insights for improving the integrity of news articles.
1. Introduction
Over the last decade, rapid technological advancements and increased internet accessibility have led to a significant shift in how information is distributed, with a growing preference for online news articles over traditional print media (Krieger et al., 2022; Gonçalves et al., 2021). Today, news articles serve as a vital source of information for millions of people globally (Hamborg et al., 2019). They play a crucial role in spreading awareness, educating the public, and providing real-time updates on various events. As such, they significantly influence public opinion, shaping how people perceive societal, political, and global matters (Hamborg et al., 2019). This power to inform and influence makes the integrity and impartiality of news articles critically important.
However, news articles are often subject to various forms of media bias. These biases can skew the information presented, leading to misleading narratives and polarizing views. Biases in news articles may manifest in several forms, including political bias, where certain political parties or ideologies are unreasonably favored; gender bias, which portrays or criticizes individuals based on gender-related attributes; entity bias, favoring specific organizations or people; racial bias, where content favors or marginalizes certain racial or cultural groups and other kinds of biases. The presence of such biases can significantly distort the objectivity of news, misguiding readers and perpetuating misinformation.
Detecting biases in news articles is essential for promoting transparency and fostering critical thinking. Identifying these biases allows readers to better evaluate the information they consume, making informed decisions rather than being influenced by skewed content. Moreover, news article providers can benefit by improving their content’s credibility and gaining the trust of a wider audience. By highlighting biases, they can maintain higher ethical standards and work towards providing more balanced and objective reporting.
In recent years, Large Language Models (LLMs) have demonstrated impressive capabilities in understanding and generating natural language (Naveed et al., 2023). These advancements have opened new possibilities in analyzing and processing text at an unprecedented scale and accuracy. However, leveraging LLMs specifically for detecting biases in news reporting remains relatively underexplored.
This study make following key contributions:
-
•
Extending the Scope: We broaden the scope of the bias detection problem by identifying and analyzing different types of biases that may occur in news articles.
-
•
Dataset Annotation Method: We introduce a preliminary method for dataset annotation using LLMs, recognizing that further research is required to thoroughly assess the reliability and consistency of LLM-driven annotations.
-
•
Experimental Results: We experimented with different transformer based models on the curated dataset to assess their effectiveness in identifying news biases, providing a comparative analysis of existing methods.
The rest of this paper is structured as follows: Section 2 presents a detailed review of the related works in bias detection and the use of LLMs for natural language tasks. Section 3 discusses our methodology for bias detection, including how we build and annotate the dataset. Section 4 details the experiments conducted and the corresponding results derived from the techniques applied to the dataset. Section 5 offers the concluding remarks of the study and lastly, we address the study’s limitations and explores potential future research directions.
2. Related Works
Recent studies have predominantly focused on detecting political bias and media bias in news articles. Media bias, particularly bias by word choice and framing, has been a central topic of research. For instance, Krieger et al. introduced DA-RoBERTa, a domain-adaptive model that detects media bias, particularly bias by word choice, achieving state-of-the-art performance in detecting biased language through a domain-adaptive pre-training approach. Similarly, Gaussian Mixture Models (GMM) have been employed to assess article-level bias by analyzing sentence-level features, such as bias frequency and bias sequence, effectively capturing the probabilistic nature of bias (Chen et al., 2020).
Further research has explored linguistic and context-oriented features to identify subtle word-level bias in media leveraging demographic insights of annotators to enhance bias detection (Spinde et al., 2021). Additionally, Aggarwal et al. have gone beyond mere detection and proposed systems to assess the short-term impact of media bias on public opinion, as seen in research analyzing biased reporting in the context of Twitter posts by Indian media outlets.
Political bias detection research has largely aimed at uncovering partisan leanings in news content. For example, a framework has been used to analyze the framing and structure of news across sources, showing improved performance over traditional models (Nadeem and Raza, 2021). Another method incorporated headline attention mechanisms to detect bias, enhancing accuracy with neural networks (Gangula et al., 2019). Additionally, adversarial media adaptation has focused on emphasizing content over source bias, improving the prediction of political ideologies in news articles (Baly et al., 2020).
In recent years, there has been a growing interest in incorporating Large Language Models (LLMs) into bias detection systems to enhance their capabilities. One prominent example is BiasScanner, an application that leverages a pre-trained LLM to detect biased sentences in news articles and provides explanations for its decisions (Menzner and Leidner, 2024).
One study explored GPT-4’s ability to classify political bias from web domains, showing strong correlation with human-verified sources like Media Bias/Fact Check (MBFC). While promising for scalable bias detection, GPT-4 abstained from classifying less popular sources, highlighting the need for combining LLMs with human oversight (Hernandes, 2024). Another study used GPT-3.5 for annotating politically biased news articles, blending LLMs with expert-driven rules for identifying bias indicators (Raza et al., 2024).
Moreover, there are a few studies which have incorporated LLMs in detecting fake news (Boissonneault and Hensen, 2024; Teo et al., 2024; Jiang et al., 2024). While fake news detection and bias detection seem similar, they address distinct issues. Fake news detection focuses on identifying completely false or misleading content designed to deceive, using fact-checking or external validation. In contrast, bias detection uncovers partiality or slant in how factual information is framed.
However, while these effective in specific bias detection tasks, there is still a gap in exploring diverse types of biases. Most studies focus on singular forms of bias, such as political or word-choice bias, without addressing a more comprehensive range of biases that may exist in news articles. Additionally, none of these approaches have leveraged LLMs to build a multi-label dataset capable of detecting various types of biases in a single framework. Given the limitations of prior work, our research proposes a new approach that explores multiple forms of bias using LLMs, thus enabling a broader, multi-label bias detection framework that has yet to be fully explored in the literature.
3. Methodology
In this section, we will first outline the various types of biases along with their definitions to ensure a clear understanding of each bias. Afterward, we will delve into the process of dataset creation, discuss how the labels were extracted, and detail the techniques applied to the collected and filtered data.
3.1. Bias Definitions
In prior studies, labeling datasets often relied on simplified techniques, such as left-center-right categorization or a binary biased-unbiased approach. However, these methods overlook the more nuanced and distinct types of biases present in news content. To address this, we chose to label each major form of bias individually, ensuring a more detailed and accurate representation. Below is a list of the various biases along with their definitions:

-
•
Political Bias: This refers to articles that unreasonably favor or criticize a political party, ideology, or government policy.
-
•
Gender Bias: This bias occurs when individuals or groups are evaluated or treated based on their gender, particularly with a focus on appearances or stereotypical roles.
-
•
Entity Bias: Entity bias manifests when reporting disproportionately criticizes or praises specific individuals, corporations, or other entities, regardless of objective facts.
-
•
Racial Bias: This is evident when articles favor or disfavor individuals or groups based on race, nationality, ethnicity, or culture.
-
•
Religious Bias: The unfair favoring or critique of a particular religion or its followers. News articles may show religious bias by unfairly portraying certain faiths as superior or inferior, or by emphasizing the actions of specific religious groups in a misleading way.
-
•
Regional Bias: This bias occurs when individuals or events are depicted unfairly based on their geographic location, often leading to unequal or skewed coverage.
-
•
Sensationalism: The use of exaggerated or shocking headlines and content to attract attention, often at the expense of factual accuracy. This bias prioritizes emotional appeal and drama over balanced, objective reporting, potentially distorting the reader’s perception of the event.
3.2. Dataset Collection
To develop a robust model for bias detection, we curated a diverse dataset of news articles across six key domains: Hollywood, Fashion, Finance, Religion, Politics and Sports.
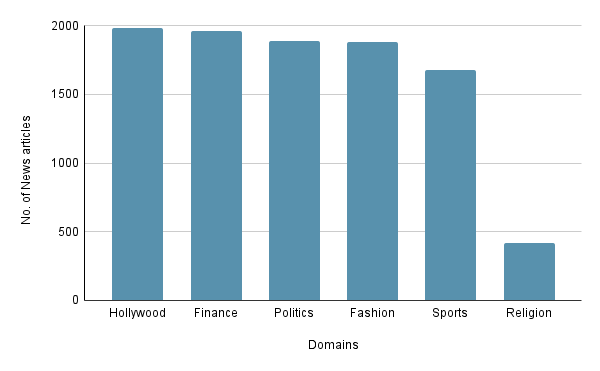
These domains were deliberately selected because we believe they are more likely to exhibit one or more types of biases, making them ideal for testing the model’s ability to detect biases across different contexts. This diversity ensures that the model is exposed to varied instances of bias, enhancing its generalizability and performance. We utilized an API provided by Aylein (https://aylien.com/) to gather full-text news articles. Figure 9 shows the number of news articles fetched for each of the domains. A total of 9790 articles were collected, with approximately 1850 articles from each domain except religion domain which has only 415 articles. We believe this is because religion is a highly niche and personal subject and therefore not a lot of news articles are published as compared to other domains. We labeled the dataset as discussed in Section 3.3. We filtered the dataset by only keeping those examples which had at least one bias from 7 bias categories and discarded others. This process reduced the dataset size to 4886 samples.
Additionally, Figures 7 to 7 presents word clouds for each of the domains, offering a visual summary of the common themes and frequently used words in the news articles. These word clouds provide a quick overview of the linguistic patterns and key topics within each domain, helping us better understand the nature of the articles.
3.3. Label Extraction
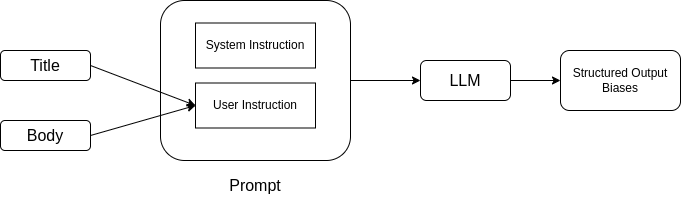
Manually labeling a large dataset for various biases is both labor-intensive and prone to inconsistencies. To address this challenge and automate the labeling process, we propose leveraging a Large Language Model (LLM) with increased language understanding capabilities (Naveed et al., 2023). The overall flow of the label extraction process is illustrated in Figure 1.
LLM Selection: We selected GPT-4o mini for its strong performance in language understanding tasks, alongside its cost-effectiveness, making it suitable for labeling large datasets. Its capacity to accurately interpret nuanced language constructs ensures both consistency and reliability in the generated outputs.
Prompting Techniques: Several prompting techniques exist for LLMs, including zero-shot prompting, few-shot prompting (Brown, 2020), instruction-based prompting, chain-of-thought prompting (Wei et al., 2022), and contextualized prompting with external knowledge (Lewis et al., 2020). In this study, we opted for instruction-based prompting due to its simplicity and feasibility, especially given the cost constraints associated with the total number of prompt tokens. The prompt was designed with clear and structured user and system instructions to ensure reliable results.
User and System Instruction: We provided the model with a detailed system instruction that included specific definitions for each type of bias. The instruction was designed to clearly outline the task and how the results should be formatted. The bias definitions were included in the instruction, and an example output format was provided to guide the model. Additionally, the title and body of each news article were passed through the user instruction. The prompt template and its description is given in the Appendix A. Using this approach, the GPT-4omini model labeled the entire dataset of 9790 articles, drawn from six distinct domains. The entire process took approximately 6 hours, providing an efficient, scalable, and consistent labeling mechanism across the dataset.
| Bias | BERT | DistilBERT | ALBERT | RoBERTa | XLNet | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Political Bias | 0.86 | 0.93 | 0.89 | 0.82 | 0.93 | 0.87 | 0.79 | 0.90 | 0.84 | 0.82 | 0.94 | 0.87 | 0.80 | 0.89 | 0.84 |
| Gender Bias | 0.73 | 0.78 | 0.75 | 0.66 | 0.73 | 0.70 | 0.58 | 0.75 | 0.66 | 0.52 | 0.81 | 0.63 | 0.52 | 0.81 | 0.64 |
| Entity Bias | 0.75 | 0.74 | 0.74 | 0.71 | 0.77 | 0.74 | 0.73 | 0.73 | 0.73 | 0.72 | 0.79 | 0.75 | 0.71 | 0.78 | 0.75 |
| Racial Bias | 0.60 | 0.64 | 0.62 | 0.48 | 0.65 | 0.55 | 0.28 | 0.71 | 0.40 | 0.25 | 0.71 | 0.37 | 0.26 | 0.72 | 0.38 |
| Religious Bias | 0.83 | 0.96 | 0.89 | 0.81 | 0.92 | 0.86 | 0.62 | 0.94 | 0.74 | 0.65 | 0.93 | 0.76 | 0.66 | 0.95 | 0.78 |
| Region Bias | 0.61 | 0.75 | 0.67 | 0.49 | 0.65 | 0.56 | 0.46 | 0.59 | 0.52 | 0.40 | 0.77 | 0.53 | 0.39 | 0.73 | 0.51 |
| Sensational Bias | 0.74 | 0.86 | 0.80 | 0.78 | 0.65 | 0.71 | 0.72 | 0.78 | 0.75 | 0.76 | 0.67 | 0.71 | 0.74 | 0.67 | 0.70 |
4. Experiments
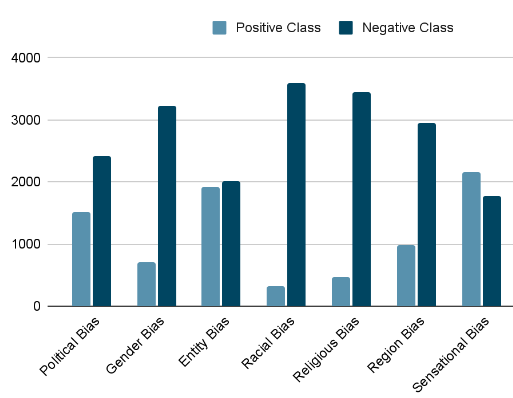
In this study, we evaluated several transformer-based models to classify biases in news articles, specifically focusing on BERT (Devlin, 2018), RoBERTa (Liu, 2019), ALBERT (Lan, 2019), DistilBERT (Sanh, 2019), and XLNet (Yang, 2019). One major challenge was the significant class imbalance present in the dataset, as illustrated in Figure 9, where the number of samples for the positive class is substantially lower than that for the negative class across most biases. To address this issue, we implemented an inverse frequency weighting method, which assigned higher weights to the positive class for each label during training, helping to mitigate the effects of class imbalance.
Experiments were conducted on a T4 GPU using a batch size of 8, leveraging the AdamW optimizer (Loshchilov, 2017), a commonly used variant of the Adam optimizer, designed to better handle overfitting through weight decay. The linear learning rate scheduler was configured with a starting learning rate of , which decays over time to final learning rate to 0, ensuring smooth convergence. Each model was trained for 6 epochs, balancing between model performance and training time efficiency.
In multilabel classification, it is particularly important to retain the distribution of all labels across folds, as each sample can be associated with multiple labels simultaneously. A crucial aspect of this study was the dataset splitting strategy. Rather than randomly splitting the dataset into training, validation, and test sets, which could lead to skewed splits and unrepresentative distributions of the various labels, we used Multilabel Stratified KFold splitting. This method ensures that the label distribution is proportionally maintained across the training, validation, and test sets, preventing the model from learning from biased splits.
5. Results
Following our experiments with various transformer-based models—BERT, RoBERTa, ALBERT, DistilBERT, and XLNet—we evaluated each model’s capacity to classify different types of biases present in news articles. Table 1 provides a summary of the models’ performance across the biases, measured through precision, recall, and F1-score. Our analysis highlights both the models’ effectiveness in detecting explicit bias types and the challenges posed by class imbalance and nuanced biases.
-
•
Model Performance Comparison - BERT consistently outperformed other models across most bias categories, particularly achieving an F1-score of 0.89 in Political Bias detection, which may be attributed to BERT’s robust contextual embedding capabilities. RoBERTa showed a competitive performance, closely following BERT in several categories. However, models like DistilBERT and ALBERT, with fewer parameters, generally exhibited lower F1-scores, particularly in Gender and Sensational Bias detection.
-
•
Class Imbalance Impact and Mitigation - Class imbalance posed a considerable challenge in our dataset, especially in Racial and Region Bias detection, which had notably fewer positive samples. Despite our use of inverse frequency weighting to emphasize the minority classes, models like DistilBERT and XLNet struggled with these biases, achieving F1-scores as low as 0.38 and 0.51 in Racial Bias detection, respectively. This imbalance suggests that additional data or more sophisticated augmentation techniques may be necessary to further alleviate these performance gaps.
-
•
LLM Annotations Reliability - While GPT-4omini provided fairly accurate annotations, we identified several errors in its assessments. In some cases, it incorrectly flagged articles as biased when they did not contain bias particularly in articles with multiple biases. Appendix B includes examples of these misannotations. Improving the accuracy of LLM annotations remains an area of future exploration.
6. Conclusion
In this study, we expanded the framework for bias detection in news articles by identifying various types of biases rather than simply categorizing them as biased or unbiased. Our unique dataset, labeled using large language models (LLMs), represents the first attempt to classify news articles according to seven distinct bias categories prevalent in the media landscape. We applied transformer-based models to this dataset and conducted a comparative analysis of their performance, concluding that BERT emerged as the most effective model overall. This research provides valuable insights into the complexities of bias detection in news media, paving the way for more nuanced approaches in future studies.
Limitations and Future Work
We utilized an LLM, specifically GPT-4omini, to label the dataset, which significantly reduced the time required for annotation. However, relying solely on the LLM for labeling can introduce some discrepancies and inconsistencies. In future work, we aim to explore methods to balance annotation reliability while maximizing the LLM’s capabilities.
Another limitation lies in the dataset itself, particularly the imbalance of samples across bias categories. Although techniques were employed to mitigate the impact of class imbalance, exploring advanced methods to expand and diversify the dataset—especially for underrepresented biases—could lead to more accurate model performance.
Additionally, the dataset splitting method could be further refined. While Multilabel Stratified KFold was used to maintain label distribution, future work could investigate other splitting strategies to prevent potential skewness and better reflect real-world distributions. This, combined with further experimentation on alternative data augmentation techniques, could improve the generalization capabilities of the models. Addressing these limitations would strengthen the reliability of the system and contribute to more accurate and comprehensive bias detection in news articles.
References
- (1)
- Aggarwal et al. (2020) Swati Aggarwal, Tushar Sinha, Yash Kukreti, and Siddarth Shikhar. 2020. Media bias detection and bias short term impact assessment. Array 6 (2020), 100025. https://doi.org/10.1016/j.array.2020.100025
- Baly et al. (2020) Ramy Baly, Giovanni Da San Martino, James Glass, and Preslav Nakov. 2020. We can detect your bias: Predicting the political ideology of news articles. arXiv preprint arXiv:2010.05338 (2020).
- Boissonneault and Hensen (2024) David Boissonneault and Emily Hensen. 2024. Fake News Detection with Large Language Models on the LIAR Dataset. (2024).
- Brown (2020) Tom B Brown. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 (2020).
- Chen et al. (2020) Wei-Fan Chen, Khalid Al-Khatib, Benno Stein, and Henning Wachsmuth. 2020. Detecting media bias in news articles using gaussian bias distributions. arXiv preprint arXiv:2010.10649 (2020).
- Devlin (2018) Jacob Devlin. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Gangula et al. (2019) Rama Rohit Reddy Gangula, Suma Reddy Duggenpudi, and Radhika Mamidi. 2019. Detecting political bias in news articles using headline attention. In Proceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP. 77–84.
- Gonçalves et al. (2021) Tatiana Santos Gonçalves, Pedro Jerónimo, and João Carlos Correia. 2021. Local News and Geolocation Technology in the Case of Portugal. Publications 9, 4 (2021), 53.
- Hamborg et al. (2019) Felix Hamborg, Karsten Donnay, and Bela Gipp. 2019. Automated identification of media bias in news articles: an interdisciplinary literature review. International Journal on Digital Libraries 20, 4 (2019), 391–415.
- Hernandes (2024) Raphael Hernandes. 2024. LLMs left, right, and center: Assessing GPT’s capabilities to label political bias from web domains. arXiv preprint arXiv:2407.14344 (2024).
- Jiang et al. (2024) Bohan Jiang, Zhen Tan, Ayushi Nirmal, and Huan Liu. 2024. Disinformation detection: An evolving challenge in the age of llms. In Proceedings of the 2024 SIAM International Conference on Data Mining (SDM). SIAM, 427–435.
- Krieger et al. (2022) Jan-David Krieger, Timo Spinde, Terry Ruas, Juhi Kulshrestha, and Bela Gipp. 2022. A domain-adaptive pre-training approach for language bias detection in news. In Proceedings of the 22nd ACM/IEEE joint conference on digital libraries. 1–7.
- Lan (2019) Z Lan. 2019. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942 (2019).
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 33 (2020), 9459–9474.
- Liu (2019) Yinhan Liu. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
- Loshchilov (2017) I Loshchilov. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- Menzner and Leidner (2024) Tim Menzner and Jochen L Leidner. 2024. BiasScanner: Automatic Detection and Classification of News Bias to Strengthen Democracy. arXiv preprint arXiv:2407.10829 (2024).
- Nadeem and Raza (2021) MU Nadeem and S Raza. 2021. Detecting Bias in News Articles using NLP Models.
- Naveed et al. (2023) Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. 2023. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435 (2023).
- Raza et al. (2024) Shaina Raza, Mizanur Rahman, and Shardul Ghuge. 2024. Dataset Annotation and Model Building for Identifying Biases in News Narratives.. In Text2Story@ ECIR. 5–15.
- Sanh (2019) V Sanh. 2019. DistilBERT, A Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv preprint arXiv:1910.01108 (2019).
- Spinde et al. (2021) Timo Spinde, Lada Rudnitckaia, Jelena Mitrović, Felix Hamborg, Michael Granitzer, Bela Gipp, and Karsten Donnay. 2021. Automated identification of bias inducing words in news articles using linguistic and context-oriented features. Information Processing & Management 58, 3 (2021), 102505. https://doi.org/10.1016/j.ipm.2021.102505
- Teo et al. (2024) Ting Wei Teo, Hui Na Chua, Muhammed Basheer Jasser, and Richard TK Wong. 2024. Integrating Large Language Models and Machine Learning for Fake News Detection. In 2024 20th IEEE International Colloquium on Signal Processing & Its Applications (CSPA). IEEE, 102–107.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837.
- Yang (2019) Zhilin Yang. 2019. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237 (2019).

Appendix A Prompt
Prompt: The prompt to the LLM consisted of system and user instructions for evaluating news articles for potential biases based on predefined categories. System instructions outline a structured approach for analyzing the text to identify various bias types such as political, gender, entity, racial, religious, regional, sensational, rumor, and inconsistent content. Each bias is classified by severity, using a binary indicator (1 for presence, 0 for absence), ensuring systematic and consistent bias detection. User instruction provide the title and body of a news article as input to the LLM, and the model applies the outlined prompt to detect and categorize biases according to the specified criteria, with the output presented in a clearly defined format that labels each bias category with its corresponding binary value, in strict adherence to the provided output format.
Appendix B LLM Annotations Analysis
In order to check the reliability of the annotations given by the LLM, we performed a qualitative analysis by reviewing a set of articles and their corresponding annotations. Overall, we found that the LLM did a good job assigning most of the biases correctly, especially in cases of gender, entity, racial, and sensational biases. These types of biases are generally more straightforward to identify due to the inherent language used in the articles, making them easier for the LLM to detect.
However, we identified some inconsistencies in the classification of religious, regional, and political biases. Specifically, certain articles that mentioned religious practices, regional dynamics, or political figures were misclassified as exhibiting bias, even though the content itself did not demonstrate overt prejudice or discriminatory intent. Examples of the LLM misannotions are provided in Table 2.
For example, articles discussing religious events or political meetings were flagged as having religious or political bias, even though the content merely provided factual reporting without taking a stance or making value judgments. Similarly, articles about regional conflicts or sports conference realignments were misclassified as showing regional bias, despite the focus being on logistical or structural topics, rather than promoting or disparaging specific regions.
These misclassifications likely result from the LLM’s sensitivity to specific keywords (e.g., ”religious ritual” or ”political figures”) that may trigger assumptions of bias, even in neutral contexts. Similarly, discussions of historical tensions or regional fit could be misinterpreted as regional bias, despite their focus on practical matters rather than promoting divisions.
Overall, while the LLM performs well in identifying more overt forms of bias, the occasional misclassification suggests the need for a more nuanced understanding of context, especially when dealing with topics where certain terms or events may be misinterpreted as bias indicators without a clear demonstration of prejudice.
| News Article | Misclassified Bias | Explanation |
|---|---|---|
| In Khargone district, three girls including two sisters drowned in Choral river. Most of these incidents took place when the victims were taking a dip in a river on the occasion of Sarva Pitru Amavasya. Eight persons drowned… | Religious Bias | This article does not exhibit religious bias as it reports tragic drowning incidents during a religious ritual (Sarva Pitru Amavasya) without making negative judgments about the practice. The religious context is mentioned only to explain the timing of the events. It neutrally focuses on the people, locations, and circumstances involved. The purpose is to inform readers, not to promote any bias against the religion. No discrimination or bias is present in the reporting. |
| Several railway stations and religious places in Rajasthan and Madhya Pradesh received a bomb threat after which the security around all the important places was heightened. A letter threatening bomb… | Religious Bias | This article reports on a bomb threat in Rajasthan and Madhya Pradesh, mentioning both railway stations and religious sites without targeting any religion. The threat, attributed to Jaish-e-Mohammed, is discussed in the context of security measures and investigation. The article is neutral and focused on facts, without promoting any religious agenda. |
| Former Vice President Venkaiah Naidu’s office clarified that no political matters discussed during meeting with Odisha Governor Das. Bhubaneswar (Odisha): The office of former Vice-President M Venkaiah Naidu … | Political Bias | This article reports on a meeting between former Vice President M. Venkaiah Naidu and Odisha Governor Raghubar Das, focusing on a clarification denying political motives. It presents a balanced view, mentioning opposition claims without endorsing or dismissing them. The tone remains neutral, avoiding political bias. |
| True equality and justice require more women in politics: Rahul Gandhi “A year ago, we launched the ’Indira Fellowship’ to amplify women’s voices in politics… | Political Bias | This article neutrally reports on Rahul Gandhi’s call for increased women’s participation in politics and the goals of the ’Indira Fellowship’ and ’Shakti Abhiyan.’ It avoids endorsing or criticizing any political ideology. |
| The Biju Janata Dal (BJD) on Thursday (October 3, 2024) alleged that the Odisha Raj Bhawan had turned into a ‘war room’ for the Jharkhand Assembly election. The saffron party claimed that key political manoeuvres were being orchestrated from the August address… | Regional Bias | This article does not have regional bias because it focuses on the political allegations raised by the Biju Janata Dal (BJD) regarding the involvement of Odisha Raj Bhawan in political activities related to the Jharkhand Assembly election. The article reports on the BJD’s concerns and criticisms, which are directed at specific political actions and the governor’s role, rather than making any disparaging comments or generalizations about people from a particular region. |
| Sun Belt officials are preparing for the possibility Texas State leaves the conference sources told the Daily News-Record on Saturday. Those league sources said early in the day it was … | Regional Bias | The article analyzes potential conference realignment in college sports, focusing on logistics and geographic fit without favoring specific regions. However, mentions of historical tensions and regional rivalries could be perceived as highlighting certain areas. Overall, it provides a neutral, analytical perspective on the issue. |