Decomposition-based Unsupervised Domain Adaptation for Remote Sensing Image Semantic Segmentation
Abstract
Unsupervised domain adaptation (UDA) techniques are vital for semantic segmentation in geosciences, effectively utilizing remote sensing imagery across diverse domains. However, most existing UDA methods, which focus on domain alignment at the high-level feature space, struggle to simultaneously retain local spatial details and global contextual semantics. To overcome these challenges, a novel decomposition scheme is proposed to guide domain-invariant representation learning. Specifically, multiscale high/low-frequency decomposition (HLFD) modules are proposed to decompose feature maps into high- and low-frequency components across different subspaces. This decomposition is integrated into a fully global-local generative adversarial network (GLGAN) that incorporates global-local transformer blocks (GLTBs) to enhance the alignment of decomposed features. By integrating the HLFD scheme and the GLGAN, a novel decomposition-based UDA framework called De-GLGAN is developed to improve the cross-domain transferability and generalization capability of semantic segmentation models. Extensive experiments on two UDA benchmarks, namely ISPRS Potsdam and Vaihingen, and LoveDA Rural and Urban, demonstrate the effectiveness and superiority of the proposed approach over existing state-of-the-art UDA methods. The source code for this work is accessible at https://github.com/sstary/SSRS.
Index Terms:
Remote Sensing, Semantic Segmentation, Unsupervised Domain Adaptation, Global-Local Information, High/Low-Frequency DecompositionI Introduction
Driven by the rapid development of Earth Observation (EO) technology, semantic segmentation has become one of the most important tasks in practical remote sensing applications, such as land cover monitoring, land planning, and natural disaster assessment [1, 2]. In the era of deep learning, semantic segmentation models are normally trained by exploiting labeled datasets in a fully supervised manner [3, 4, 5, 6]. However, their impressive performance is limited by the availability of high-quality annotated samples generated by the costly and laborious labeling process [7, 8]. Furthermore, these supervised methods show poor generalization when the trained models are applied to data in other domains or unseen scenarios due to discrepancies between heterogeneous domains [9]. To circumvent the domain shift, the Unsupervised Domain Adaption (UDA) approach has been investigated, which aims to transfer knowledge from the source domain and achieve the desired semantic segmentation performance in the target domain [10, 11, 12].
Generally speaking, the core idea of UDA is to learn domain-invariant features through domain alignment based on optimization principles such as discrepancy metrics [13] and adversarial learning [14, 15, 16, 17]. In particular, the adversarial-based methods were developed upon the generative adversarial network (GAN) that alternately trains a generator and a discriminator for domain alignment. In semantic segmentation tasks, adversarial-based methods attempt to align two domains at image-level [18, 19], feature-level [20, 21] or output-level [22, 23, 24, 25]. Since global context modeling is important for remote sensing vision tasks, transformer [26], with its superiority by its ability to model long-range contextual information, has facilitated many GAN-based UDA methods by enhancing feature alignment [27, 28].
Notably, UDA on semantic segmentation of remote sensing images presents unique challenges. The ground objects and their spatial relationships are complex in fine-resolution remote sensing images [29]. Further, it becomes more evident when ground objects are collected from different locations. Larger-scale variations and more complicated boundaries can be observed as shown in Fig. 1. Nevertheless, it has been also observed that cross-domain remote sensing images share certain similarities in both local and global contexts. Therefore, we argue that both detailed local features and abstract global contexts are crucial for domain alignment in semantic segmentation. The former includes the fine structure (e.g., corners and edges) [30], small-scale spatial variations and patterns, and precise layouts of parts of objects or complete small objects. In contrast, the latter encompasses types of landscapes, significant geographical features (e.g., mountains and rivers), and the spatial relationships between ground objects. However, existing UDA methods generally capture global contexts by aligning high-level features [20, 21, 31] or learn local contexts by designing loss functions [32, 33, 34]. The latter exploits local constraints as an auxiliary way to learn global domain-invariant representations. Therefore, they struggle to simultaneously preserve and align local spatial details and global contextual semantics. From the perspective of model structure, existing methods primarily focus on the decoder and discriminator of the GAN framework, neglecting the encoder stage, which contains richer multiscale global and local domain-invariant semantic information. This oversight leads to a gap in knowledge transfer across domains.
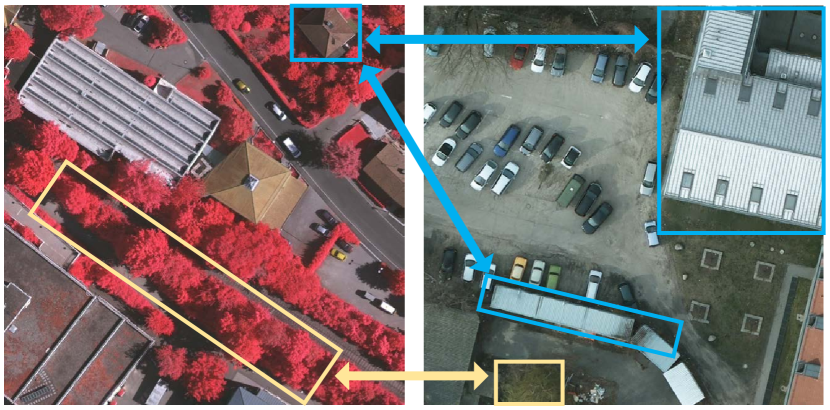
To address these problems, we propose a decomposition-driven UDA method based on a global-local GAN model, namely De-GLGAN, considering alignment in low-frequency global representations and high-frequency local information. Firstly, we propose a high/low-frequency decomposition (HLFD) scheme that decomposes the feature map into high-frequency and low-frequency components through a CNN-based extractor and a window-based attention module, respectively. By aligning high- and low-frequency information simultaneously, the generator can learn more transferable features from the source domain. In particular, the HLFD scheme with a frequency alignment loss can be easily embedded into other UDA approaches to facilitate the learning of domain-invariant representations. To further exploit the decomposed information in an adversarial learning framework, a novel GAN model named GLGAN is proposed by exploiting a decoder and a global-local discriminator (GLDis), both of which are derived from the global-local transformer block (GLTB) [35]. With the exploration of global contexts and local spatial information, the former facilitates the generation of accurate segmentation maps, whereas the latter efficiently distinguishes the origins of segmentation maps. The contributions of this work are summarized in the following:
-
•
A novel decomposition-based adaptation scheme is proposed to learn high- and low-frequency domain-invariant features at multiple scales using a frequency alignment loss for model optimization. To the best of our knowledge, this is the first work that introduces the idea of frequency decomposition into UDA for remote sensing image semantic segmentation.
-
•
We implement the decomposition-based adaptation scheme into a fully global-local adversarial learning-based UDA framework. It facilitates domain alignment by capturing cross-domain dependency relationships at different levels while exploiting global-local context modeling between two domains.
-
•
Extensive experiments on two UDA benchmarks, i.e., ISPRS Potsdam and Vaihingen, and LoveDA Rural and Urban confirm that the proposed De-GLGAN is more effective in overcoming the domain shift problem in cross-domain semantic segmentation than existing UDA methods.
The remainder of this paper is organized as follows. We first review the related works in Sec. II while Sec. III introduces the proposed HLFD and GLGAN in detail. After that, Sec. IV elaborates on the experiment setup, experimental results and related analysis. Finally, the conclusion is given in Sec. V.
II Related Work
II-A Cross-Domain Semantic Segmentation in Remote Sensing
Leveraging encoder-decoder-based networks, numerous methods of semantic segmentation have emerged in the field of remote sensing [36]. Most existing methods are developed based on CNNs with residual learning and attention mechanisms to boost the representation learning [37]. To address the limitations of CNNs in modeling global representations, many transformer-based methods [38, 39] have been integrated under the encoder-decoder framework, leveraging the global context modeling capability of the self-attention mechanism [26, 40]. Recently developed remote sensing foundation models attempt to achieve domain-generalized performance by leveraging large-scale datasets and vision models [41, 42, 43]. For downstream tasks on specific remote sensing datasets, transfer learning or fine-tuning is required.
In contrast to the straightforward semantic segmentation task, cross-domain semantic segmentation focuses on transferring knowledge from the source domain to the target domain. According to the transfer strategy, existing cross-domain semantic segmentation models can be divided into two main categories, namely the self-training approach [44, 45] and the adversarial training approach [14, 21]. The former generates pseudo-labels as the supervision information of the target domain using a model trained on the labeled source domain [46]. However, pseudo-labeling inevitably introduces noise into model training, typically requiring a pre-defined threshold to filter out low-confidence pseudo-labels. Alternatively, the adversarial training approach focuses on aligning distributions of two domains at the image feature or output levels. The key to this method lies in the stability of the training process. Recently, there has been an increase in methods that integrate self-training techniques with adversarial learning to address UDA challenges, using a multi-stage training strategy [44, 47, 48]. This work aims to develop a versatile and efficient framework based on adversarial training. Compared to these methods, this work develops an effective one-stage UDA framework with promising performance based on adversarial training.
II-B GAN-based UDA in Remote Sensing
GAN-based UDA algorithms have been proven effective in cross-domain semantic segmentation for remote sensing imagery. [49] proposed the first GAN-based model designed for cross-domain semantic segmentation from aerial imagery. On this basis, TriADA [44] introduced a triplet branch to improve the CNN-based feature extraction by simultaneously aligning features from the source and target domains. Recently, a self-training approach that employs high-confidence pseudo-labels was applied to incorporate category information [48, 33, 50]. Furthermore, SADA [31] and CS-DDA [20] developed subspace alignment methods to constitute a shared subspace with high-level features. To improve the high-level feature extraction, attention mechanisms were introduced into GAN-based UDA. More specifically, CAGAN [51] developed a covariance-based channel attention module to compute weighted feature maps, whereas CCAGAN [32] used a category-certainty attention module to align the category-level features. MASNet [52] stored domain-invariant prototypical representations by employing a feature memory module while MBATA-GAN [21] aligned high-level features by constructing a cross-attention-based transformer. Compared with the methods above, this work attempts to fully explore global-local context modeling in the generator and discriminator, as shown in Table I. Therefore, it can capture cross-domain global semantics and local detailed contexts while boosting the learning of domain-invariant features.
| Generator | Discriminator | Method |
| Local | Local | HighDAN [16], MBATA-GAN [21], CCAGAN [32], TriADA [44], GANAI [49], CAGAN [51], MASNet [52] |
| Global | Local | ALE-UDA [28], MuGCDA [53] |
| Global | Global | TransGAN [54], Swin-GAN [55], HyperViTGAN [56], SWCGAN [57] |
| Global-Local | Global-Local | GLGAN (Ours) |
II-C Decomposition-based UDA in Remote Sensing
The core idea of decomposition-based UDA is to project features into different subspaces before performing domain alignment in the corresponding subspaces. For instance, ToMF-B [58] decomposed the cross-domain features into task-related features and task-irrelevant features by analyzing the gradients of the predicted score corresponding to the labels. Furthermore, ST-DASegNet [59] introduced a domain disentangled module to extract cross-domain universal features and improve single-domain distinct features in a self-training framework whereas DSSFNet [60] decoupled building features to learn domain-invariant semantic representations and domain-specific style information for building extraction. However, these techniques mainly concentrate on aligning high-level abstract features, overlooking the relationship between high/low-frequency details and the characteristics of ground objects. Therefore, it is crucial to address this shortfall by delving into frequency decomposition technology.
III Proposed Method
In this section, we will first present the principle of frequency decomposition and introduce the HLFD module inspired by GLTB. After that, we propose the overall structure of De-GLGAN before elaborating on its generator and discriminator (GLDis). Finally, the loss functions used in training will be presented.
III-A Preliminary: Frequency Decomposition
Before introducing our proposed UDA framework, we first revisit the basics of the multi-head self-attention (MHSA) design and the convolutional operation (Conv) from a frequency perspective. We employ the discrete Fourier transform (DFT) to analyze the feature maps regarding specific frequency components generated by MHSA and Conv, respectively. Let and represent an image in the spatial domain and its corresponding label, where denotes the number of classes. We transform into the frequency spectrum using the DFT : and revert the signals of the image from frequency back to the spatial domain using the inverse DFT : . For a mask , the low-pass filtering of size can be formally defined as [61]:
| (1) |
where
| (2) |
where stands for the Hadamard product, and denotes the value of at position .
Similarly, the high-pass filtering is defined as
| (3) |
where
| (4) |
According to the definitions in Eq. (2) and Eq. (4), the low-frequency components are shifted to the center of the frequency spectrum while the high-frequency components are shifted away from the center of the frequency spectrum.
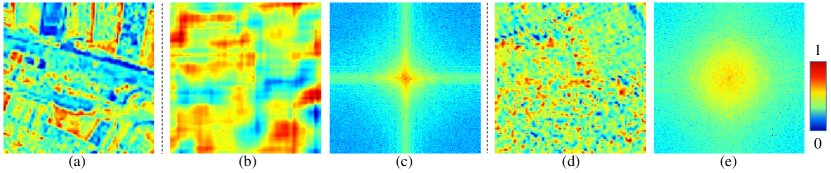
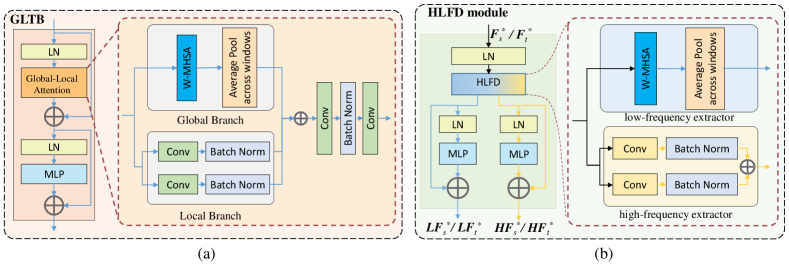
Fig. 2 illustrates the contrasting behaviors that MHSA and Conv demonstrate. As shown in Fig. 2(b) and (d), MHSA aggregates feature maps, whereas Conv disperses them. Furthermore, as depicted in Fig. 2(c) and (e), Fourier analysis of feature maps reveals that MHSA focuses on low-frequency components, while Conv amplifies high-frequency components. In other words, MHSAs function as low-pass filters, while Conv serves as high-pass filters. Consequently, MHSA and Conv complement each other and can be jointly employed for frequency decomposition. More details can be found in [62].
Based on the discussions above, we propose to utilize the existing GLTB for the frequency decomposition. In particular, the global-local attention in GLTB consists of two parallel branches, namely the global and local branches, as presented in Fig. 3(a). The former captures the global context between windows by exploiting the window-based multi-head self-attention (W-MHSA) [40] while maintaining the spatial consistency of ground objects through Average Pooling across windows, while the latter has a structure of two parallel convolutional layers with kernel sizes of and , respectively. Each convolutional layer is followed by a batch normalization operation. The global-local attention leverages its two branches to investigate and incorporate global-local contextual information. Hereby, the outputs from the global and local branches are fused together before the resulting global-local context is further characterized by two convolution layers and a batch normalization operation.
It is observed that GLTB satisfies the requirements for frequency decomposition that needs a branch based on MHSA and a branch based on Conv. Therefore, we propose the HLFD module as depicted in Fig. 3(b) by exploiting the GLTB structure to decompose multiscale features. However, in sharp contrast to GLTB, which is utilized for global-local information aggregation, the HLFD module utilizes two parallel branches for the decomposition. More specifically, a low-frequency extractor is designed to capture the low-frequency components by utilizing the W-MHSA while a high-frequency extractor is employed to extract high-frequency components using Conv operation. The output low- and high-frequency components are then processed by a LayerNorm (LN) layer and a multilayer perceptron (MLP), respectively. Finally, a novel model called De-GLGAN is established by capitalizing on the GLTB and HLFD modules.
III-B Pipeline
Typical UDA tasks involve a labeled source dataset and an unlabeled target dataset where represents an image in the source domain with its corresponding label whereas denotes the unlabeled image in the target domain. Furthermore, and stand for the sample size of the source domain and the target domain, respectively. As the source domain and target domain possess different marginal and conditional distributions, i.e., , the domain shift problem occurs. We assume that certain inherent similarities exist between different domains, which is valid as both domains share the same segmentation output space [11, 21].
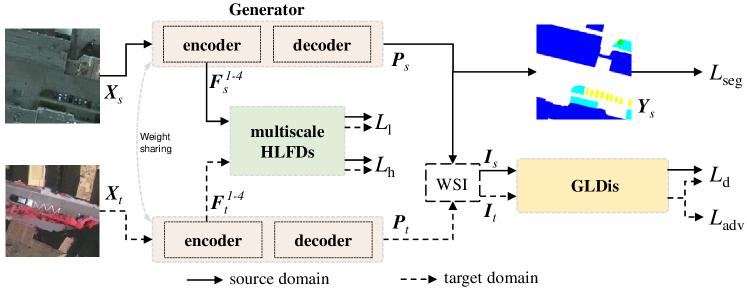
As depicted in Fig. 4, the proposed De-GLGAN is designed by capitalizing upon frequency decomposition and global-local context utilization. Specifically, multiscale HLFD modules are presented to align cross-domain representations by exploiting multiscale features generated by the encoder. Moreover, the global-local discriminator named GLDis further exploits the decomposed features to learn multiscale domain-invariant representations. In particular, the GLDis attempts to mimic the decoder to learn the domain-specific output space using the global-local representations.
III-C Encoder and Multiscale High/Low-Frequency Decomposition Modules
As illustrated in Fig. 5, the encoder comprises a Patch Partition layer and four successive stages. More specifically, the first stage contains one embedding layer followed by the SwinTBs, whereas the following three stages are equipped with one merging layer followed by each SwinTB. We denote by and the training images from the source and target domains, respectively. Furthermore, stands for the number of image channels, whereas and represent the height and width of the image, respectively. and are first split into non-overlapping patches of size by the Patch Partition layer. After that, the first-stage Embedding layer is applied to project these patches onto the encoding space before the SwinTBs gather image information on these patch tokens. As shown in Fig. 5, the SwinTB consists of four LN layers, two MLPs, one W-MHSA and one shifted window-based multi-head self-attention (SW-MHSA) [26, 40]. After the first stage, three more successive stages are applied to generate the multiscale features denoted as and both of size where is the encoding dimension with being the stage index. After that, these multiscale features are then fed into the corresponding HLFD module for frequency decomposition. Notably, the images from the source and the target domain are fed into the generator successively, that is, and are generated and collected, respectively.
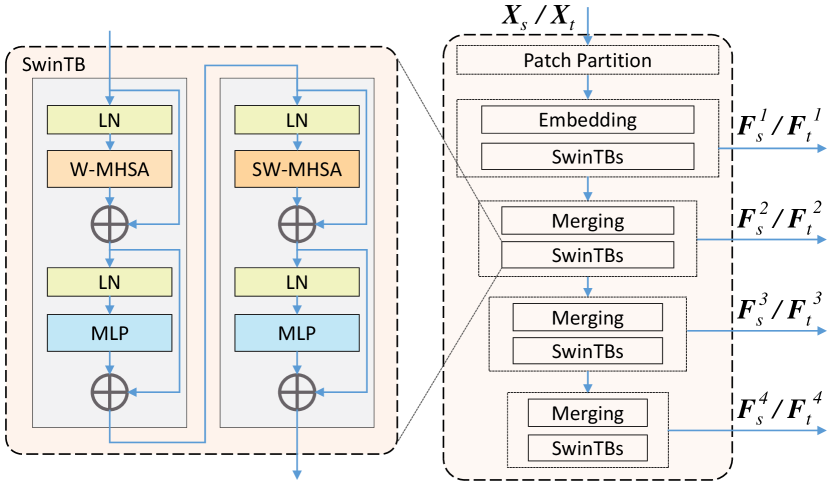
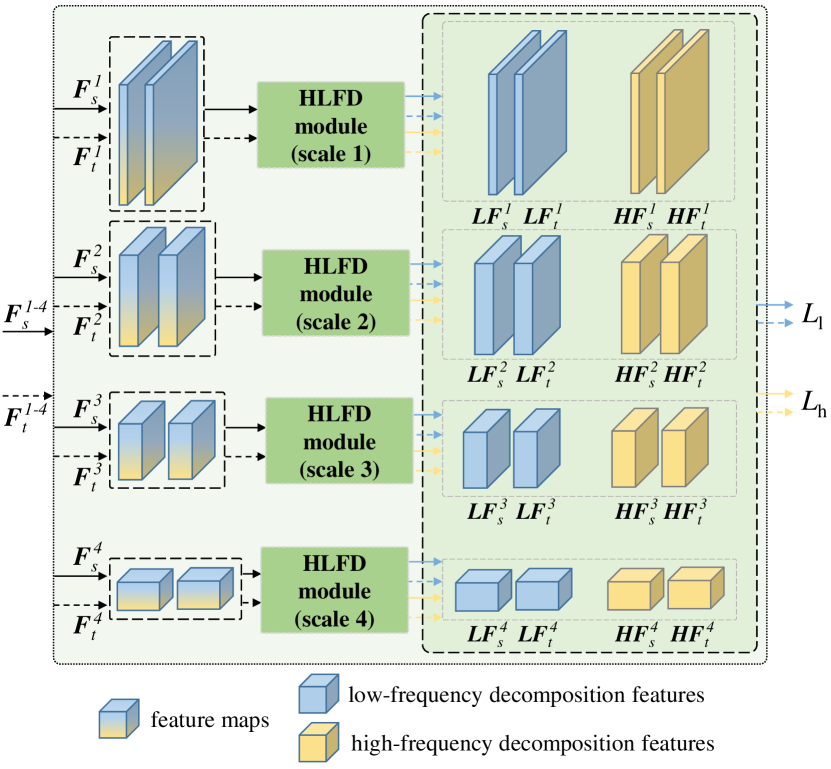
HLFD modules are employed to decompose the multiscale feature maps and , as illustrated in Fig. 6. The feature map at each scale, including the features from the source domain and the target domain, will be decomposed into the high or low-frequency feature maps by the corresponding scale HLFD. After that, the final outputs of the HLFD modules denoted as and are used to compute the frequency alignment loss , which will be elaborated in Sec. III-F.
III-D Global-Local Decoder
The decoder is developed based on GLTB [35] and designed to exploit the decomposed features by gradually extracting global and local information, as shown in Fig. 7(a). Specifically, the high-level feature maps derived from the encoder are first fed into an individual GLTB whose output is processed by two stages of weighted sum operation and GLTB. In particular, GLTB is able to capture the global context and local details simultaneously. After that, the weighted sum operation is employed to extract domain-invariant features by adaptively fusing the residual features and those from the previous GLTB. After the first three stages of the GLTB-based decoding, a weighted sum operation is used to fuse the residual connection from the first stage of the encoder and the deep global-local feature derived from previous GLTB before a classifier produces the final segmentation maps denoted by and of size for the source and target domains, respectively, where stands for the number of ground object categories.
Finally, the supervised segmentation loss and the adversarial loss are also derived in the generator optimization stage. More specifically, is computed based on the source labels while is calculated using the adversarial strategy. More details about the loss functions will be provided in Sec. III-F.
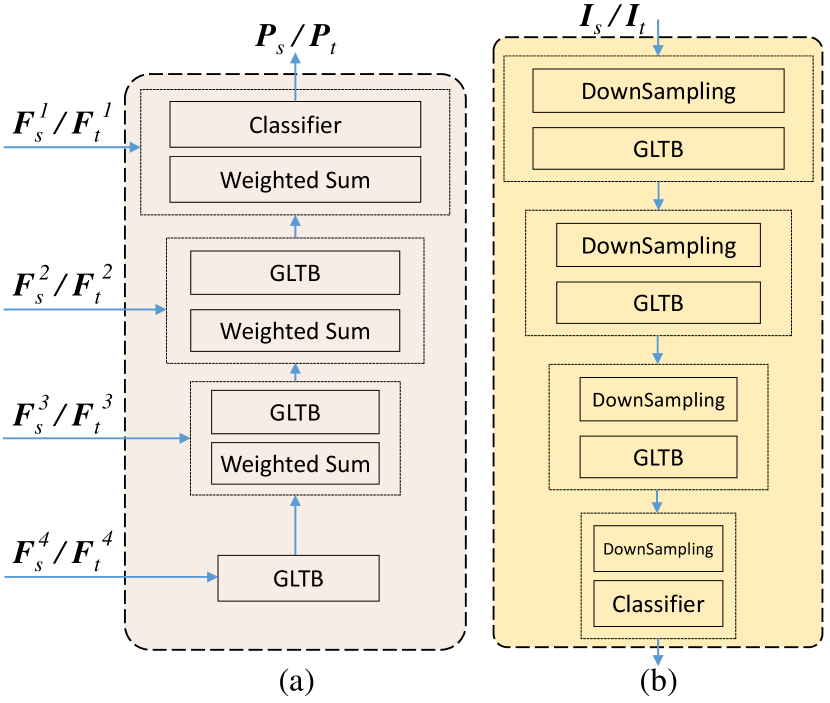
III-E Global-Local Discriminator
In the proposed discriminator, GLDis, we employ GLTB to exploit the semanftic output space produced by the generator. As shown in Fig. 7, the GLDis and the decoder are similar in structure but different in function. Specifically, it first down-samples the weighted self-information (WSI) distribution and derived from and before feeding the down-sampled data into a GLTB. Given the output segmentation maps of the source domain and the target domain , the corresponding self-information is defined as and , respectively. Consequently, the WSI maps and are calculated as follows:
| (5) | |||
| (6) |
where the dimensions of , , and are , and represents the index position of one pixel. These information maps are regarded as the disentanglement of the Shannon Entropy. After the first GLTB, the resulting data is further processed by two successive stages of down-sampling, followed by the GLTB, which is designed to gradually gather the global and local information in the segmentation map-generated features. Finally, the resulting data is down-sampled and processed by a classifier, which predicts the domain to which the input segmentation maps belong. Despite its appearance similar to the decoder structure, GLDis is tailored to learn domain-specific representations using an adversarial strategy. More specifically, the decoder upsamples the abstract semantic features, whereas GLDis down-samples the structured output space to identify the domain to which each input belongs. The final output of GLDis is used to compute a cross-entropy loss denoted by in the discriminator training stage. More details about the loss function will be presented in the next section.
III-F Loss Functions
The proposed De-GLGAN capitalizes on four loss functions, namely the segmentation loss , the typical adversarial loss , the frequency alignment loss , and the cross-entropy loss . These loss functions are defined as follows.
III-F1 Generator
, and are proposed to optimize the generator. In particular, is computed directly using images from the source domain and their corresponding labels. Mathematically, takes the following form:
| (7) |
where is the category set whose cardinality is the number of categories , of size denotes the labels from the source domain, and is a scalar, representing the weighting coefficient for the segmentation loss. is computed to align decomposed cross-domain features generated by multiscale HLFDs as follows:
| (8) |
where the sizes of , , and are , is the encoding dimension with being the stage index, is a scalar, representing the weighting coefficient, and stands for the average pooling, which gathers spatial information for each channel . The frequency alignment loss function is designed to efficiently align the feature maps across the source and target domains.
To align the structured output space, the WSI distribution is adopted in the proposed training process to calculate the adversarial loss as follows:
| (9) |
where is a scalar, representing the weighting coefficient for the adversarial loss while denotes the GLDis. Note that the artificial labels and are assigned to samples drawn from the source domain and the target domain, respectively. In Eq. (9), the label in the superscript (h,w,0) is set to intentionally mislead GLDis. Therefore, the discriminator is motivated to bridge the prediction gap between the source and target domains.
Finally, the following overall objective function is proposed to optimize the generator:
| (10) |
III-F2 GLDis
The discriminator GLDis is optimized with the following cross-entropy loss to identify to which domain a given segmentation map belongs.
| (11) |
III-F3 Overall Loss Function
Finally, the overall loss function proposed for De-GLGAN is given as follows:
| (12) |
where and are with the size of , and and denote GLDis and the generator, respectively. Eq. (12) is designed to minimize the segmentation loss in the generator for the source images while maximizing the output space similarity of the source and target domains. Notably, the generator and the discriminator are trained in a classical GAN-based manner, whereas the generator and GLDis are trained alternatively. More specifically, the generator is first trained using Eq. (10) with the parameters of GLDis being held constant before GLDis is updated with Eq. (11). The overall optimization process of De-GLGAN is presented in Algorithm 1 for better understanding. Finally, the well-trained generator is used for testing in the target domain.
IV Experiments And Discussions
IV-A Datasets Description
IV-A1 ISPRS Potsdam and Vaihingen
This dataset [63] involves fine-resolution images obtained from two cities. The images in both datasets were obtained from aerial photography but of different Ground Sampling Distance (GSD). More specifically, the images of Potsdam have clearer ground objects with a GSD of cm as compared to a GSD of cm for Vaihingen. Furthermore, images in Potsdam possess richer spectrum information from four frequency bands, namely, InfraRed, Red, Green and Blue (IRRGB), whereas images in Vaihingen only three bands, namely, InfraRed, Red and Green channels (IRRG). All images in ISPRS Potsdam and Vaihingen are provided with semantic labels, including six ground object classes, namely, Building (Bui.), Tree (Tre.), Low Vegetation (Low.), Car, Impervious Surface (Imp.) and Clutter/Background.
Potsdam: There are very fine-resolution true orthophotos of size in Potsdam dataset. In the experiments, we divided these orthophotos into a training set of images and a test set of images.
Vaihingen: The Vaihingen dataset contains very fine-resolution true orthophotos of size pixels. In our experiments, these orthophotos are divided into a training set of images and a test set of images.
Fig. 8(a-c) illustrates two groups of images sampled from the Potsdam and Vaihingen datasets. Visual inspection of Fig. 8(a-c) confirms large discrepancies across the two datasets. However, since the scene categories of Potsdam and Vaihingen are similar, the category distributions are close as shown in Fig. 8(d). Therefore, the domain shift in UDA tasks constructed on Potsdam and Vaihingen mainly comes from geographical location and image mode. In the sequel, we divide the Potsdam dataset into two subsets, namely, “P-IRRG” and “P-RGB”, taking into account the data size and image channels as compared to those of Vaihingen. P-IRRG contains infrared, red, green bands while P-RGB contains red, green and blue bands. The Vaihingen dataset forms only one dataset denoted as “V-IRRG” including infrared, red, green bands. By treating these three subsets as the source and target domains, we design the first three UDA tasks with increasing levels of difficulty as listed in Table II.
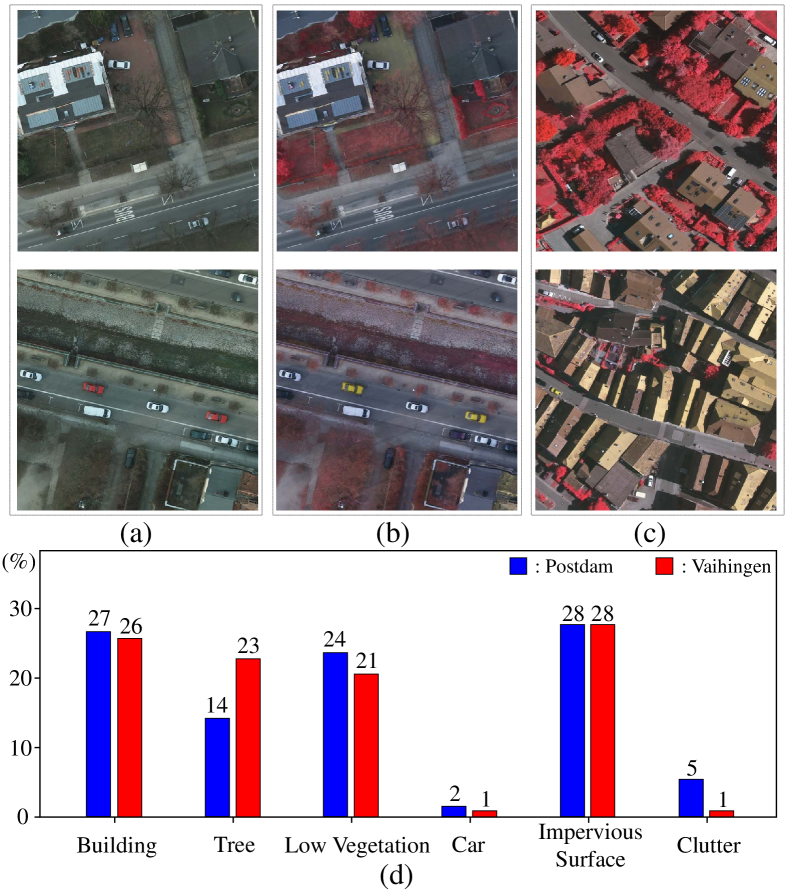
It is worth noting that these three tasks exhibit different levels of domain shifts. For instance, Task , i.e., P-IRRG to V-IRRG, suffers from the domain shift caused by large discrepancies in the spatial resolution, the ground object style and the illumination environment, though the images from both domains possess the same spectrum information. In contrast, the domain shift problem in Task , i.e., P-RGB to V-IRRG, is caused by the frequency band difference in addition to all discrepancies in Task . Finally, Task , i.e., V-IRRG to P-RGB, encounters the same domain shift problem as Task with a greater challenge as the size of the Vaihingen dataset in the source domain is much smaller than that of the Potsdam dataset in the target domain. In summary, these three UDA tasks were designed to explore the effectiveness of the UDA method under consideration in cross-location, in-image mode, and cross-image mode UDA tasks.

IV-A2 LoveDA Rural and Urban
The LoveDA dataset contains two scenes, namely Rural and Urban. The Rural and Urban comprise and high-resolution optical remote sensing images, respectively. All images are with the size of pixels. The images provide three channels, namely Red, Green, and Blue (RGB), with a ground sampling distance of cm. The dataset encompasses seven landcover categories, including Background (Bac.), Building (Bui.), Road, Water (Wat.), Barren (Bar.), Forest (For.), and Agriculture (Agr.) [64]. These images were collected from three cities in China (Nanjing, Changzhou, and Wuhan).
Rural: The images are divided into two parts, with images for training and images for testing. Specifically, the training set contains images indexed from to , while the test set spans images from to .
Urban: We divided the images into images for training and images for testing. The former contains images indexed from to , while the latter spans images from to .
Fig. 9(a) and (b) present two groups of images sampled from the LoveDA Rural and Urban scenes. The discrepancy between the two scenes primarily arises from variations in ground object categories caused by geographical location. To be specific, there is intra-class variance across scene ground objects, such as shape, layout, and scale. Additionally, the class distributions are inconsistent between rural and urban scenes as shown in Fig. 9(c). These differences bring great challenges to the learning of transferable features. Following the common practice reported in the literature [64, 33], we conducted the last two UDA tasks as listed in Table II. During the training stage, the size of the sliding window was set to to collect the training samples dynamically. Therefore, we can obtain Vaihaigen images, Potsdam images, Rural images and Urban images.
| Source Domain | Target Domain | |
| Task 1 | P-IRRG | V-IRRG |
| Task 2 | P-RGB | V-IRRG |
| Task 3 | V-IRRG | P-RGB |
| Task 4 | Rural | Urban |
| Task 5 | Urban | Rural |
| Index | Method | Reference | Description |
| 1 | Source-only | [65] | Images and labels from the source domain are utilized to train the segmentation network before it is tested directly on the target domain. |
| 2 | DANN | [66] | The first UDA method that applies adversarial learning to solve the domain shift problem on the image classification task. |
| 3 | AdasegNet | [11] | This UDA method performs multi-level adversarial learning with two discriminators while assuming that the source and target domains share a similar output space. |
| 4 | Advent | [12] | This UDA method aligns the entropy maps of the output derived by the generator for both domains. |
| 5 | GANAI | [49] | The first UDA method designed for semantic segmentation of remote sensing images based on the GAN. |
| 6 | TriADA | [44] | This UDA method employs a triplet branch for remote sensing images, considering both domains simultaneously to learn a domain-invariant classifier using a domain similarity discriminator. |
| 7 | CCAGAN | [32] | This UDA method, designed for remote sensing images, develops a category-certainty attention module focusing on the misaligned regions in the category level. |
| 8 | MBATA-GAN | [21] | This UDA method develops a mutually boosted attention-based transformer to augment the high-level features and a feature discriminator to learn the transferable features of remote sensing images. |
| 9 | MASNet | [52] | This UDA method stores domain-invariant prototypical representations by employing a feature memory module, bridging the domain distribution discrepancy of two remote sensing domains. |
| 10 | DSSFNet | [60] | This UDA method decouples ground object features to learn domain-invariant semantic representations and domain-specific style information for remote sensing images. |
| 11 | Supervised | [65] | Images and labels from the target domain are used to train and test the segmentation network, which stands for the optimal performance that any UDA method can achieve. |
All models in the experiments were implemented with the PyTorch framework on a single NVIDIA GeForce RTX 3090 GPU with -GB RAM. Furthermore, the generator was optimized with the Stochastic Gradient Descent (SGD) optimizer and the Nesterov acceleration with a momentum of and a weight decay of . The initial learning rate was set to , decreasing with a polynomial decay of power . For GLDis, the Adam optimizer was employed with the learning rate of with a polynomial decay of power . The momentum of Adam is set to . In addition, the multi-level adversarial learning scheme was also adopted with parameters set to their default values derived from AdasegNet [11] in which and were set to and , respectively. Finally, was set to according to the parameter analysis that will be presented in Sec. IV-G.
IV-B Evaluation Metrics
In this work, we adopt three metrics to quantitatively assess the segmentation performance of the cross-domain remote sensing images for all UDA methods, namely, the Overall Accuracy (OA), the F1 score (F1) and the Intersection over Union (IoU), which are defined as follows:
| (13) | |||
| (14) | |||
| (15) | |||
| (16) | |||
| (17) |
where , , and are true positives, false positives, true negatives and false negatives, respectively. Furthermore, the mean F1 score (mF1) and the mean IoU (mIoU) for the main five classes apart from Clutter/Background are calculated to measure the average performance of the UDA methods following the common practice reported in the literature [44, 21].
In addition, the computational complexity of the proposed GLGAN and De-GLGAN is evaluated using the following metrics. First, the giga floating point operation counts (GFLOPs) are employed to evaluate the model complexity. Second, the number of model parameters and the memory footprint are utilized to evaluate the memory requirement. Finally, the frames per second (FPS) is used to evaluate the execution speed. For a computationally efficient method, its first three metrics are usually small, while its FPS value should be large. Each method undergoes training for epochs, with each epoch consisting of batches. During training, the performance of each method is evaluated every 100 batches and recorded. The best-performing model for each method is then selected for subsequent testing based on its highest segmentation performance.
IV-C Experimental settings
In our work, the basic unit of the encoding block in the generator is adopted from the Swin Transformer [40] pretrained on ImageNet. In the experiments, two versions of Swin Transformers, namely Swin-Base and Swin-Large, were applied for image feature extraction. Both Swin-Base and Swin-Large have four stages with the stack of SwinTBs with the embedding dimensions of Swin-Base and Swin-Large being and , respectively. Furthermore, the number of the heads in Swin-Base and Swin-Large are and , respectively. In addition, the window size for W-MHSA and SW-MHSA is . The dimension of both the decoder and GLDis is set to , whereas the window size of the global-local attention is .
IV-D Benchmarking
To confirm the effectiveness of the proposed methods, some representative existing UDA methods were selected for quantitative comparison. Table III summarizes the nine methods evaluated in our following experiments. Notably, in addition to the first three representative methods in the field of computer vision, the other six methods are specifically designed for remote sensing images. Furthermore, we also performed comparison experiments on two non-DA methods for the first three UDA tasks on the ISPRS Potsdam and Vaihingen dataset, namely a deep model without domain adaptation (labeled as “Source-only”) and a supervised deep model (labeled as “Supervised”) trained with labeled data from the target domain. These two non-DA methods stand for the two extreme cases, with the “Supervised” model representing the optimal performance that any UDA method targets and the “Source-only” model standing for the performance lower bound. Furthermore, the classical ResUNet++ [65] is selected for these two non-DA methods by taking into account the balance between segmentation performance and computational complexity. For the aforementioned methods, the same network architectures, training parameters, and evaluation methods were applied to make a fair comparison.
| Method | Backbone | Bui. | Tre. | Low. | Car | Imp. | OA | mF1 | mIoU |
| Non-DA (Source-Only) | ResUNet++ | 76.93 | 70.79 | 40.19 | 7.06 | 56.70 | 63.03 | 50.33 | 37.13 |
| DANN | - | 83.07 | 75.93 | 54.15 | 55.38 | 69.73 | 71.82 | 67.66 | 52.24 |
| AdasegNet | ResNet101 | 87.87 | 79.44 | 56.73 | 57.59 | 76.10 | 76.29 | 71.55 | 57.14 |
| Advent | ResNet101 | 90.85 | 78.78 | 58.31 | 55.07 | 79.53 | 77.63 | 72.51 | 58.68 |
| GANAI | ResNet101 | 87.13 | 77.20 | 52.48 | 58.78 | 74.38 | 73.52 | 69.99 | 55.29 |
| TriADA | ResNet101 | 89.34 | 79.06 | 47.50 | 65.72 | 81.11 | 77.56 | 72.55 | 58.88 |
| CCAGAN | ResNet101 | 89.02 | 78.10 | 59.29 | 65.42 | 79.10 | 76.90 | 74.19 | 60.09 |
| MBATA-GAN | ResNet101 | 90.98 | 79.51 | 63.41 | 66.38 | 82.80 | 80.75 | 76.77 | 63.50 |
| MASNet | ResNet101 | 90.13 | 80.90 | 59.11 | 66.70 | 81.44 | 79.87 | 75.66 | 62.13 |
| DSSFNet | ResNet101 | 92.05 | 80.76 | 60.44 | 66.29 | 82.68 | 80.67 | 76.45 | 63.27 |
| GLGAN | Swin-Base | 91.95 | 80.31 | 67.71 | 65.89 | 84.18 | 81.97 | 78.01 | 65.04 |
| Swin-Large | 92.33 | 81.60 | 69.11 | 67.34 | 84.58 | 82.74 | 78.99 | 66.30 | |
| De-GLGAN | Swin-Base | 93.94 | 80.95 | 70.06 | 70.40 | 86.13 | 83.66 | 80.30 | 68.09 |
| Non-DA (Supervised) | ResUNet++ | 94.84 | 90.15 | 78.25 | 80.16 | 90.47 | 89.66 | 86.77 | 77.20 |
IV-E Results and Discussions
Task 1 (P-IRRG to V-IRRG): The results for Task are summarized in Table IV. Inspection of Table IV suggests that the “Source-Only” method showed the worst performance among all methods under consideration in terms of OA, mF1 and mIoU. Furthermore, all UDA methods demonstrated performance improvement of different degrees. For instance, the simplest DANN achieved improvements of in OA, in mF1 and in mIoU, which confirmed the necessity and effectiveness of the UDA approach. In particular, the baseline Advent showed improved OA, mF1, and mIoU of , and , respectively. Compared with the baseline, the proposed GLGAN achieved great improvements in all performance metrics. Specifically, the OA, mF1 and mIoU attained by GLGAN (Swin-Base) were , and , respectively, which amounts to an improvement of , and as compared to Advent. In addition, GLGAN (Swin-Large) attained higher scores in OA, mF1 and mIoU, by employing a more complex encoder. Among all the unsupervised methods examined, the proposed De-GLGAN achieved the highest scores on all overall matrices with the smallest performance gap as compared to the “Supervised” non-DA method. It is easy to observe in Table IV that the proposed De-GLGAN attained the highest F1 score in four main categories, including for Building, for Low Vegetation, for Cars and for Impervious Surface, which amounts to improvement of for Building, for Low Vegetation, for Cars and for Impervious Surface. Upon comparing the results of GLGAN (Swin-Base) and De-GLGAN (Swin-Base), it becomes evident that improvements are observed across all categories, suggesting that the HLFD module facilitates the learning of transferable features. Finally, Fig. 10 presents the semantic segmentation results achieved by part of the comparative methods. Visual inspection of Fig. 10 reveals that the proposed GLGAN and De-GLGAN are more accurate in differentiating visually similar categories such as Trees and Low Vegetation. Furthermore, the segmentation boundary of ground objects provided by our method is much smoother, with fewer random prediction points than other UDA methods.
| Method | Backbone | Bui. | Tre. | Low. | Car | Imp. | OA | mF1 | mIoU |
| Non-DA (Source-Only) | ResUNet++ | 64.48 | 0.04 | 5.26 | 1.57 | 58.21 | 35.71 | 25.91 | 18.43 |
| DANN | - | 73.20 | 62.46 | 41.50 | 54.94 | 64.39 | 61.85 | 59.30 | 42.94 |
| AdasegNet | ResNet101 | 74.04 | 75.16 | 40.85 | 57.02 | 62.12 | 64.75 | 61.84 | 45.92 |
| Advent | ResNet101 | 83.29 | 77.85 | 42.37 | 49.92 | 65.73 | 67.26 | 63.83 | 48.84 |
| GANAI | ResNet101 | 76.87 | 56.25 | 41.50 | 57.93 | 66.07 | 61.81 | 59.72 | 43.57 |
| TriADA | ResNet101 | 77.86 | 73.85 | 36.57 | 58.70 | 66.48 | 66.09 | 62.69 | 47.20 |
| CCAGAN | ResNet101 | 85.60 | 75.27 | 36.31 | 63.24 | 66.03 | 68.38 | 65.25 | 50.58 |
| MBATA-GAN | ResNet101 | 87.67 | 75.30 | 39.06 | 64.95 | 67.33 | 69.29 | 66.86 | 52.31 |
| MASNet | ResNet101 | 85.31 | 77.79 | 39.69 | 51.92 | 74.44 | 71.59 | 65.83 | 51.43 |
| DSSFNet | ResNet101 | 87.15 | 77.66 | 48.77 | 56.02 | 73.46 | 73.14 | 68.61 | 53.98 |
| GLGAN | Swin-Base | 87.71 | 68.37 | 58.59 | 66.68 | 73.73 | 73.21 | 71.02 | 55.98 |
| Swin-Large | 89.70 | 77.53 | 58.93 | 63.21 | 78.48 | 77.23 | 73.57 | 59.44 | |
| De-GLGAN | Swin-Base | 92.42 | 77.53 | 62.88 | 69.38 | 80.42 | 79.16 | 76.53 | 63.09 |
| Non-DA (Supervised) | ResUNet++ | 94.84 | 90.15 | 78.25 | 80.16 | 90.47 | 89.66 | 86.77 | 77.20 |
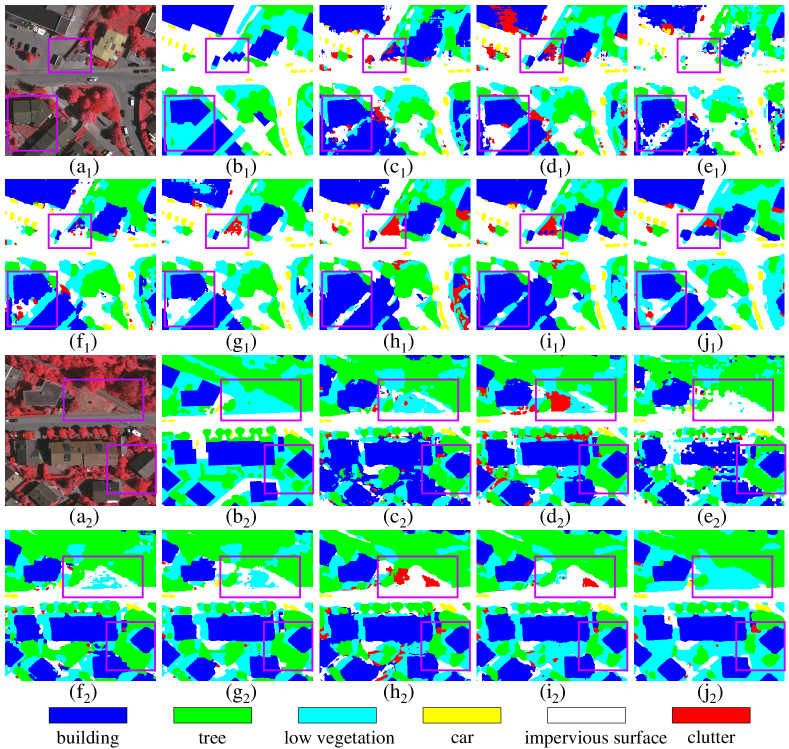

Task 2 (P-RGB to V-IRRG): Table V shows the results for Task that encounters a more severe domain shift problem than Task . In addition to the discrepancies in the spatial resolution, the geographical location and other environmental factors, Task also has to learn image representations from the RGB bands before transferring the learned features to the IRRG bands. Notably, the “Source-only” method showed the worst performance, which is evidenced by its poor OA, mF1, and mIoU of , and , respectively. In sharp contrast, it is observed from Table V that the GLGAN (Swin-Large) achieved OA of , mF1 of , and mIoU of , which stands for an increase of , , and as compared to the corresponding performance of Advent, respectively. Further, the proposed De-GLGAN (Swin-Base) achieved a higher performance than the GLGAN (Swin-Large). It proved the broad applicability of the proposed HLFD, which can steadily improve the performance of the original UDA method in different scenarios. Moreover, these results demonstrate that the proposed GLGAN and De-GLGAN can effectively handle large domain shifts. Furthermore, it is interesting to observe that the De-GLGAN improved the accuracy for Low Vegetation by , but suffered from performance degradation of for Tree. This observation could be explained by the fact that the trees in Potsdam are mostly sparse deciduous trees, while those in Vaihingen have denser foliage and canopy, as shown in Fig. 8. As a result, Tree and Low Vegetation in Potsdam share similar spectral characteristics with Low Vegetation in Vaihingen. Finally, Fig. 11 illustrates some segmentation examples obtained in Task by various methods. It is clearly observed that the “Source-only” method suffered from the worst performance. Furthermore, despite the fact that existing UDA methods showed improvements of different degrees, they incurred deficiencies in the aspects of providing clear boundaries and differentiating visually similar categories. By leveraging its powerful global-local feature extraction capability and frequency decomposition frequency technology, the proposed De-GLGAN achieved segmentation performance close to that of the supervised non-DA method.
| Method | Backbone | Bui. | Tre. | Low. | Car | Imp. | OA | mF1 | mIoU |
| Non-DA (Source-Only) | ResUNet++ | 42.87 | 0.10 | 7.36 | 3.55 | 43.27 | 34.14 | 19.43 | 12.11 |
| DANN | - | 63.70 | 42.50 | 40.26 | 58.21 | 62.10 | 54.53 | 53.35 | 37.00 |
| AdasegNet | ResNet101 | 73.23 | 46.23 | 33.88 | 59.48 | 71.61 | 58.38 | 56.89 | 41.27 |
| Advent | ResNet101 | 71.13 | 46.62 | 31.70 | 66.76 | 70.95 | 57.30 | 57.43 | 41.90 |
| GANAI | ResNet101 | 64.97 | 38.79 | 45.29 | 67.45 | 67.17 | 57.02 | 56.73 | 40.58 |
| TriADA | ResNet101 | 73.95 | 38.06 | 47.87 | 70.46 | 72.55 | 61.34 | 60.58 | 44.99 |
| CCAGAN | ResNet101 | 76.45 | 44.86 | 47.28 | 72.82 | 71.26 | 61.68 | 62.53 | 46.87 |
| MBATA-GAN | ResNet101 | 81.54 | 30.75 | 58.14 | 69.83 | 75.37 | 65.82 | 63.13 | 48.42 |
| MASNet | ResNet101 | 77.89 | 44.87 | 61.89 | 76.04 | 73.97 | 66.42 | 66.93 | 51.51 |
| DSSFNet | ResNet101 | 79.82 | 50.62 | 64.68 | 76.86 | 75.47 | 68.87 | 69.49 | 54.22 |
| GLGAN | Swin-Base | 82.77 | 60.46 | 65.19 | 77.27 | 76.14 | 71.15 | 72.37 | 57.34 |
| Swin-Large | 85.65 | 62.08 | 69.26 | 81.37 | 76.09 | 73.63 | 74.89 | 60.58 | |
| De-GLGAN | Swin-Base | 85.65 | 65.61 | 71.02 | 79.43 | 79.66 | 75.54 | 76.27 | 62.17 |
| Non-DA (Supervised) | ResUNet++ | 92.08 | 74.91 | 80.13 | 90.79 | 89.35 | 84.69 | 85.46 | 75.19 |
Task 3 (V-IRRG to P-RGB): Task suffers from a domain shift problem similar to Task , except that its source domain has a smaller data size than the target domain. From Table VI, it is observed that De-GLGAN achieved the highest OA of , mF1 of , and mIoU of , which stands for an improvement of , , and as compared to Advent, respectively. Furthermore, the segmentation accuracy on Tree and Low vegetation in Task has been substantially improved as compared to Task . This is because these two categories in Vaihingen show much different spectral characteristics, providing more transferable features. Some segmentation samples are presented in Fig. 12 for visual inspection. In sharp contrast to other UDA methods, the proposed methods provided the most accurate semantic information with the smoothest boundaries.

Task 4 (Rural to Urban): Inspection of Table VII suggests that the proposed De-GLGAN achieved the highest OA, mF1 and mIoU among all the unsupervised methods. Compared with the baseline, the proposed De-GLGAN achieved great improvements in all performance metrics. Specifically, the OA, mF1 and mIoU attained were , and , respectively, which amounts to an improvement of , and as compared to Advent. Notably, the proposed methods attained great performance in two categories, including for Background and for Building. These two categories account for more than half of the distribution of Urban scene as presented in Fig. 9(c). It revealed that our approaches effectively learn the transferable features of the dominant object categories in the rural scene, which can aid in identifying these categories in the urban scene. Fig. 13 shows the semantic segmentation results for this task. Visual inspection of Fig. 13 reveals that our method still has fewer random prediction points, maintaining the integrity of the ground objects.
| Method | Backbone | Bac. | Bui. | Road | Wat. | Bar. | For. | Agr. | OA | mF1 | mIoU |
| DANN | - | 53.38 | 60.11 | 56.59 | 74.63 | 58.51 | 64.80 | 65.19 | 61.71 | 61.89 | 45.14 |
| AdasegNet | ResNet101 | 54.76 | 62.77 | 60.84 | 80.75 | 62.28 | 63.23 | 65.57 | 63.02 | 64.31 | 47.87 |
| Advent | ResNet101 | 56.40 | 65.53 | 62.52 | 77.98 | 57.72 | 65.53 | 66.60 | 63.68 | 64.61 | 48.09 |
| GANAI | ResNet101 | 55.54 | 61.04 | 54.76 | 75.42 | 65.31 | 65.01 | 67.31 | 62.98 | 63.48 | 46.86 |
| TriADA | ResNet101 | 57.05 | 63.35 | 65.17 | 80.56 | 65.36 | 67.16 | 71.53 | 66.24 | 67.17 | 50.97 |
| CCAGAN | ResNet101 | 56.91 | 67.45 | 65.68 | 83.00 | 65.10 | 65.93 | 74.93 | 67.78 | 68.43 | 52.55 |
| MBATA-GAN | ResNet101 | 58.66 | 64.95 | 65.90 | 82.54 | 64.35 | 67.72 | 74.18 | 67.93 | 68.47 | 52.52 |
| MASNet | ResNet101 | 59.49 | 71.28 | 64.15 | 83.36 | 63.34 | 69.97 | 75.99 | 69.52 | 69.65 | 53.98 |
| DSSFNet | ResNet101 | 59.25 | 73.95 | 65.84 | 84.44 | 64.12 | 70.74 | 72.89 | 68.90 | 70.18 | 54.60 |
| GLGAN | Swin-Base | 58.06 | 73.11 | 69.99 | 84.09 | 59.70 | 70.66 | 73.64 | 69.13 | 69.89 | 54.32 |
| Swin-Large | 57.83 | 74.45 | 67.90 | 84.57 | 63.08 | 69.09 | 75.68 | 69.50 | 70.37 | 54.80 | |
| De-GLGAN | Swin-Base | 59.53 | 74.49 | 68.80 | 84.66 | 63.71 | 70.50 | 74.83 | 70.01 | 70.93 | 55.50 |
| Method | Backbone | Bac. | Bui. | Road | Wat. | Bar. | For. | Agr. | OA | mF1 | mIoU |
| DANN | - | 67.80 | 49.19 | 24.80 | 57.99 | 26.04 | 7.30 | 28.43 | 55.04 | 37.36 | 24.89 |
| AdasegNet | ResNet101 | 66.47 | 62.36 | 34.59 | 68.49 | 27.85 | 15.05 | 17.04 | 54.85 | 41.69 | 28.82 |
| Advent | ResNet101 | 68.49 | 62.01 | 32.89 | 54.88 | 33.65 | 5.44 | 39.92 | 57.82 | 42.47 | 28.93 |
| GANAI | ResNet101 | 67.75 | 63.08 | 30.20 | 72.08 | 20.00 | 7.62 | 26.21 | 56.64 | 40.99 | 28.80 |
| TriADA | ResNet101 | 69.91 | 66.06 | 53.17 | 57.67 | 18.76 | 22.61 | 54.99 | 62.58 | 49.02 | 34.40 |
| CCAGAN | ResNet101 | 70.34 | 65.28 | 45.76 | 68.60 | 21.97 | 11.72 | 55.33 | 63.45 | 48.43 | 34.48 |
| MBATA-GAN | ResNet101 | 70.00 | 64.77 | 49.93 | 67.46 | 16.03 | 7.19 | 51.53 | 62.12 | 46.70 | 33.27 |
| MASNet | ResNet101 | 68.71 | 67.13 | 41.53 | 55.06 | 19.11 | 12.10 | 49.46 | 60.18 | 44.73 | 30.99 |
| DSSFNet | ResNet101 | 70.88 | 61.88 | 45.79 | 65.88 | 23.94 | 29.88 | 52.54 | 63.01 | 50.11 | 35.01 |
| GLGAN | Swin-Base | 69.68 | 63.65 | 40.80 | 69.87 | 25.72 | 6.65 | 44.15 | 60.90 | 45.79 | 32.27 |
| Swin-Large | 69.74 | 67.80 | 51.73 | 71.91 | 15.10 | 8.20 | 48.63 | 62.20 | 47.59 | 34.34 | |
| De-GLGAN | Swin-Base | 71.48 | 70.96 | 49.92 | 69.12 | 23.79 | 33.60 | 56.83 | 65.22 | 53.67 | 38.58 |


Task 5 (Urban to Rural): Compared with Task , Task is more challenging since the minority categories in the Urban scene, including Water, Forest and Agriculture, are precisely the categories of objects with complex characteristics. Specifically, compared with objects such as Building and Road, they have more complicated and variable boundaries and spatial relationships. From Table VIII, it is observed that the proposed De-GLGAN achieved the highest OA of , mF1 of , and mIoU of , which stands for an improvement of , , and as compared to Advent, respectively. Furthermore, the segmentation accuracy on Building, Forest and Agriculture in Task has been greatly improved. Observing the results of De-GLGAN and GLGAN, we can see that the frequency decomposition technique has a powerful feature extraction capability for this difficult category. By comparing the results of GLGAN and De-GLGAN, it is evident that the frequency decomposition technique excels in feature extraction for the challenging categories. The HLFD module can focus on both local details and global semantics, enabling the extraction of transferable features from a minimal number of category samples. The visualized segmentation samples shown in Fig. 14 indicated that De-GLGAN was more accurate in predicting Agriculture and Forest. It further demonstrates that our method can effectively learn transferable features from a limited number of samples.
The comparative results reveal a performance gap between our method and other methods. This is because the proposed framework improves both the generator and discriminator of the GAN framework. In summary, the extensive experiments demonstrated that the proposed GLGAN and De-GLGAN have the capability of overcoming domain shifts, leading to significantly improved semantic segmentation performance on different remote sensing scenarios.
IV-F Ablation Studies
Given that the proposed De-GLGAN incorporates both GLTB and HLFD, we conducted three sets of ablation studies to demonstrate the importance of each component.
1) Global-Local information: To verify the effectiveness of the proposed backbone GLGAN, eight ablation experiments were performed as shown in Table IX. The baseline shown in the first row was obtained with a purely convolutional model composed of an encoder (ResNet101), a decoder (ASPP) and a CNN-based discriminator, whereas the second row shows the case for the baseline with ResNet101 being replaced by the Swin Transformer for feature extraction. Furthermore, the third row shows the case in which the ASPP in the baseline was replaced by the GLTB-based decoder to recover the semantic features and predict the segmentation maps, while the CNN-based discriminator in the baseline was substituted with GLDis in the fourth row. The next three rows, i.e., the fifth row to the seventh row, are pairwise combinations of the Swin Transformer-based encoder, the GLTB-based decoder and GLDis. Inspection of the first four rows in Table IX suggests that each proposed component is of great necessity in the proposed GLGAN. Notably, the result in the second row shows that Swin Transformer only contributes a small part of the superior performance of GLGAN. Furthermore, the ablation experiments shown in the second and fifth rows confirmed the importance of the decoder in learning a transferable output space collocated with the Swin Transformer. Comparison of the results reported in the second and sixth rows, the third and seventh rows, and the fifth and last rows suggest that GLDis was able to improve overall segmentation performance, which provides strong evidence to support our motivation to strengthen the discriminator design under the GAN framework. Therefore, the outstanding performance of GLGAN benefits from the combined effect of all the aforementioned modules. Clearly, GLDis is a better choice than the conventional CNN-based discriminator. Table IX confirmed that the proposed GLGAN is more efficient in image feature extraction and semantic information recovery by effectively exploiting intra- and inter-domain features.
| Generator | GLDis | OA | mF1 | mIoU | |
| encoder | decoder | ||||
| 77.63 | 72.51 | 58.68 | |||
| ✓ | 80.42 | 73.83 | 60.32 | ||
| ✓ | 77.61 | 74.15 | 60.23 | ||
| ✓ | 77.46 | 73.71 | 59.71 | ||
| ✓ | ✓ | 80.51 | 77.27 | 64.03 | |
| ✓ | ✓ | 81.63 | 74.40 | 61.28 | |
| ✓ | ✓ | 78.23 | 75.17 | 61.26 | |
| ✓ | ✓ | ✓ | 81.97 | 78.01 | 65.04 |
| HF | LF | OA | mF1 | mIoU |
| 81.97 | 78.01 | 65.04 | ||
| ✓ | 83.40 | 79.63 | 67.21 | |
| ✓ | 83.38 | 79.79 | 67.45 | |
| ✓ | ✓ | 83.66 | 80.30 | 68.09 |
2) High/Low-frequency information: To verify the effectiveness of the two branches in HLFD, four ablation experiments were performed, as shown in Table X. The baseline shown in the first row was the results provided by GLGAN. The second row shows the case in which only the high-frequency extractor is employed to align the high-frequency information, whereas the third row shows the case in which only the low-frequency extractor is employed to align the low-frequency information. The last row presents the results achieved by utilizing the complete HLFD. Inspection of the results suggests that in UDA tasks, the separate alignment of high- and low-frequency information is very important when learning cross-domain transferable features. We can also draw an inference that besides sharing similarities in global features, the source and target domains also exhibit resemblances in local features, such as the shape of tree crowns and vehicle outlines. These local characteristics of ground objects can be analyzed from a frequency perspective, thereby offering valuable insights for unlabeled target domains.
3) Multiscale features: Eight ablation experiments were performed, as shown in Table XI to verify the necessity of aligning multiscale features. The baseline shown in the first row still included the results provided by GLGAN. According to the experimental results we obtained, we present the ablation experiments in the order shown in Table XI. Specifically, we investigated the impact of a single scale, ranging from shallow features (scale 1) to deep features (scale 4), before progressively incorporating additional scales. There are two interesting conclusions confirmed by Table XI. Firstly, the alignment of multiscale features is necessary. Secondly, deep features hold greater significance compared to shallow features, which has been also reported in the literature [32, 21, 51]. In summary, the proposed GLGAN and De-GLGAN achieved great segmentation performance as compared to other state-of-the-art UDA methods. Both quantitative results and visual inspection confirmed that GLTB-based backbone GLGAN and the frequency decomposition technology can largely bridge the segmentation performance gap between UDA methods and supervised methods.
| Scale 1 | Scale 2 | Scale 3 | Scale 4 | OA | mF1 | mIoU |
| 81.97 | 78.01 | 65.04 | ||||
| ✓ | 82.89 | 78.82 | 66.13 | |||
| ✓ | 83.06 | 78.83 | 66.26 | |||
| ✓ | 82.44 | 79.29 | 66.68 | |||
| ✓ | 83.34 | 79.45 | 66.96 | |||
| ✓ | ✓ | 83.22 | 79.83 | 67.35 | ||
| ✓ | ✓ | ✓ | 83.39 | 80.17 | 67.92 | |
| ✓ | ✓ | ✓ | ✓ | 83.66 | 80.30 | 68.09 |
IV-G Parameter Analysis
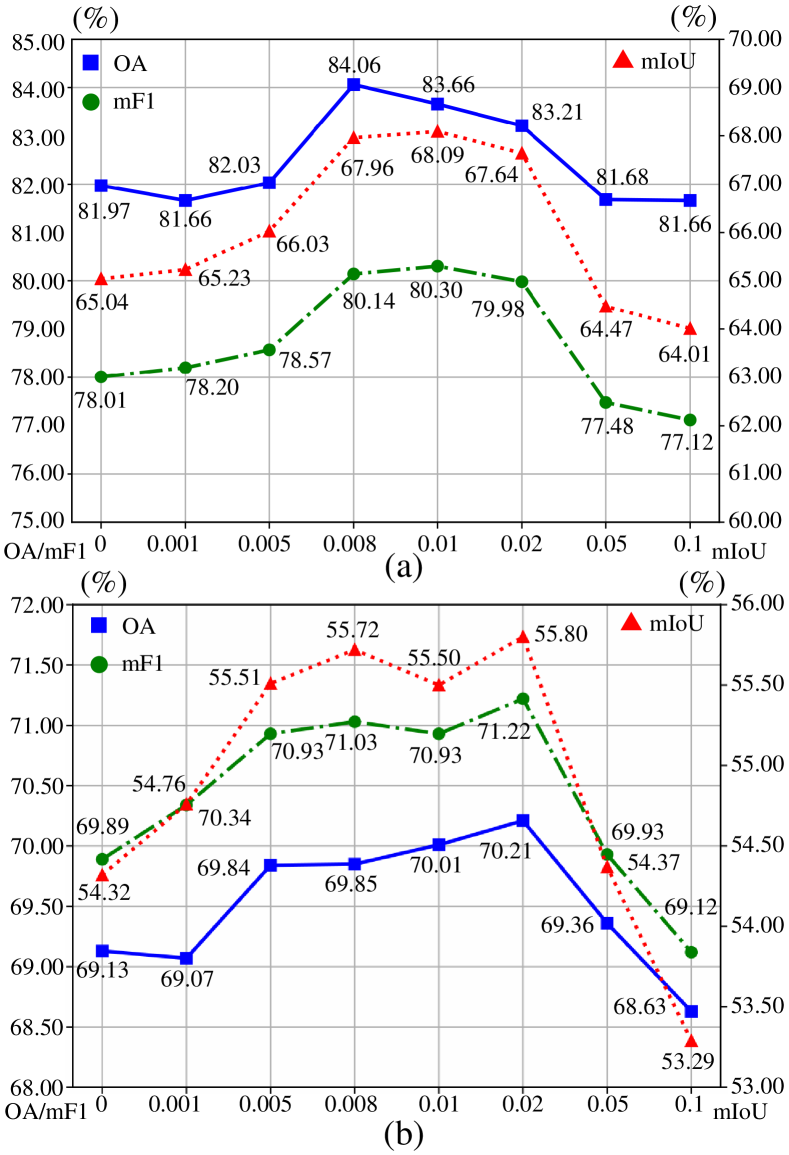
In this section, the sensitivity of hyper-parameter is analyzed. This parameter is designed to regulate the contribution derived from frequency decomposition. Inspection of the results presented in Fig. 15 indicates that a smaller value of diminishes the importance of aligning high/low-frequency information, whereas a larger value may exaggerate the significance of the frequency alignment. Consequently, setting results in notable performance degradation. Conversely, both performance demonstrates less sensitivity to within the range . Therefore, we set in our experiments, which performs effectively across the five UDA tasks, suggesting its strong applicability.
IV-H Visualization of Feature Decomposition
In this section, we will investigate the characteristics of the proposed multiscale HLFD modules by visually inspecting the heatmaps before and after the frequency decomposition. Specifically, multiscale feature maps are first resized to a uniform image size, followed by averaging across all channels. Subsequently, pseudo-color processing is applied. The results are depicted in Fig. 16. Upon inspecting the feature maps before and after the decomposition in both the source and target domains, distinctions become apparent between low- and high-frequency information: low-frequency features possess global characteristics, whereas high-frequency features appear more discrete and localized. In particular, even the fourth scale (high-level) feature maps show significant differences. It fully demonstrates that our HLFD modules successfully decompose high- and low-frequency information.
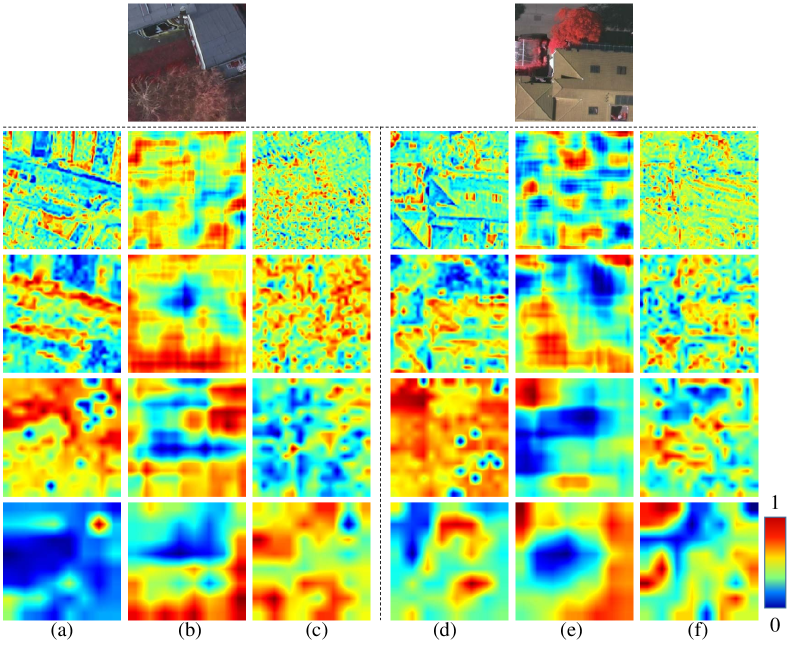
Comparison on the feature maps between the source and target domains reveals that cross-domain high-frequency features share great similarities as well as the cross-domain low-frequency features. It suggests that the model’s capacity to decompose features acquired from the labeled source domain can be successfully applied to the target domain. In other words, the model has learned domain-invariant features from both high- and low-frequency, which correspond to the similarity of spatial details across domains that we emphasized in Sec. I and the global context similarity that the existing works explored. Our work has proved that both of these components are necessary for cross-domain alignment in the UDA method.
IV-I Model Complexity Analysis
Table XII shows the computational complexity of all UDA methods discussed. Compared with the baseline Advent, the proposed general backbone GLGAN (Swin-Base) achieved greatly improved segmentation performance with significantly reduced computational complexity as its hierarchical window-based attention has linear computation complexity to input image size [40]. More specifically, the computational complexity of GLGAN (Swin-Base) is only half that of Advent. Furthermore, GLGAN (Swin-Large) has computational complexity comparable to Advent. However, GLGAN (Swin-Large) requires much more memory to store its parameters. Overall, the proposed GLGAN harvests better performance at the cost of moderately increased computational complexity. The model complexity of De-GLGAN is between GLGAN (Swin-Base) and GLGAN (Swin-Large), yet it exhibits superior performance. It proved that the HLFD module is of great significance in practical application.
| Model | Backbone | Complexity (GFLOPs) | Parameters (M) | Memory (MB) | Speed (FPS) |
| ResUNet++ | ResUNet++ | 241.82 | 35.46 | 4365 | 25.10 |
| AdasegNet | ResNet101 | 47.59 | 42.83 | 2491 | 43.31 |
| Advent | ResNet101 | 47.95 | 43.16 | 2491 | 30.65 |
| GANAI | ResNet101 | 10.27 | 44.55 | 1075 | 6.30 |
| TriADA | ResNet101 | 22.15 | 59.23 | 1075 | 4.54 |
| CCAGAN | ResNet101 | 145.14 | 104.02 | 4503 | 13.04 |
| MBATA-GAN | ResNet101 | 174.20 | 143.90 | 5295 | 8.11 |
| MASNet | ResNet101 | 82.34 | 64.84 | 3648 | 18.22 |
| DSSFNet | ResNet101 | 128.52 | 112.74 | 4836 | 11.13 |
| GLGAN | Swin-Base | 26.13 | 96.72 | 3639 | 12.50 |
| Swin-Large | 45.97 | 159.03 | 4840 | 9.95 | |
| De-GLGAN | Swin-Base | 34.26 | 138.68 | 3841 | 6.22 |
V Conclusion
In this work, a novel decomposition-based UDA approach for remote sensing image semantic segmentation has been proposed. Based on the observation that local detailed features and global contexts are both crucial for reducing domain discrepancy in semantic segmentation, a novel HLFD scheme has been proposed to conduct domain alignment in different subspaces through the decomposition of multiscale features from the frequency perspective. Furthermore, to exploit the global-local cross-domain dependencies, a fully GLGAN has been developed to learn robust domain-invariant representations, leveraging GLTBs. In particular, a novel discriminator, GLDis, has been established to enhance the generator’s representation capability. Finally, a novel UDA framework called De-GLGAN has been established by integrating HLFD and GLGAN for cross-domain semantic segmentation. Extensive experiments on two UDA benchmarks, namely ISPRS Potsdam and Vaihingen, and LoveDA Rural and Urban, have confirmed that the proposed De-GLGAN can substantially outperform existing UDA methods while greatly bridging the performance gap between the existing adversarial training-based UDA approach and the fully-supervised training. Specifically, it can significantly improve the cross-domain transferability and generalization capability of the semantic segmentation model.
In future work, we will investigate the possibility of incorporating the decomposition-based feature learning strategy into fine-tuning visual foundation models on new semantic segmentation datasets. Meanwhile, it is interesting to investigate the integration of the proposed approach with reliable self-training to incorporate category-wise supervision more effectively. Furthermore, it is worth exploring the potential cross-domain applications of GLGAN and the decomposition-based alignment strategy to other tasks, such as image understanding [67, 68] and object detection [69].
References
- Hong et al. [2021] D. Hong, L. Gao, N. Yokoya, J. Yao, J. Chanussot, Q. Du, and B. Zhang, “More diverse means better: Multimodal deep learning meets remote-sensing imagery classification,” IEEE Trans. Geosci. Remote Sens., vol. 59, no. 5, pp. 4340–4354, 2021.
- Zhang and Zhang [2022] L. Zhang and L. Zhang, “Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities,” IEEE Geoscience and Remote Sensing Magazine, vol. 10, no. 2, pp. 270–294, 2022.
- Shan et al. [2022] L. Shan, W. Wang, K. Lv, and B. Luo, “Class-incremental semantic segmentation of aerial images via pixel-level feature generation and task-wise distillation,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–17, 2022.
- Sun et al. [2024] W. Sun, J. Zhang, Y. Lei, and D. Hong, “RSProtoSeg: High spatial resolution remote sensing images segmentation based on non-learnable prototypes,” IEEE Trans. Geosci. Remote Sens., pp. 1–1, 2024.
- Ma et al. [2024a] X. Ma, Q. Wu, X. Zhao, X. Zhang, M.-O. Pun, and B. Huang, “Sam-assisted remote sensing imagery semantic segmentation with object and boundary constraints,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–16, 2024.
- Ma et al. [2024b] X. Ma, X. Zhang, and M.-O. Pun, “RS3Mamba: Visual state space model for remote sensing image semantic segmentation,” IEEE Geoscience and Remote Sensing Letters, pp. 1–1, 2024.
- Li et al. [2021] Y. Li, T. Shi, Y. Zhang, W. Chen, Z. Wang, and H. Li, “Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation,” ISPRS J. Photogramm. Remote Sens., vol. 175, pp. 20–33, 2021.
- Yan et al. [2023] L. Yan, J. Yang, and J. Wang, “Domain knowledge-guided self-supervised change detection for remote sensing images,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023.
- Zhang et al. [2023] X. Zhang, W. Yu, M.-O. Pun, and W. Shi, “Cross-domain landslide mapping from large-scale remote sensing images using prototype-guided domain-aware progressive representation learning,” ISPRS J. Photogramm. Remote Sens., vol. 197, pp. 1–17, 2023.
- Peng et al. [2022] J. Peng, Y. Huang, W. Sun, N. Chen, Y. Ning, and Q. Du, “Domain adaptation in remote sensing image classification: A survey,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 9842–9859, 2022.
- Tsai et al. [2018] Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker, “Learning to adapt structured output space for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7472–7481.
- Vu et al. [2019] T.-H. Vu, H. Jain, M. Bucher, M. Cord, and P. Pérez, “Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2517–2526.
- Liu and Qin [2020] W. Liu and R. Qin, “A multikernel domain adaptation method for unsupervised transfer learning on cross-source and cross-region remote sensing data classification,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 6, pp. 4279–4289, 2020.
- Peng et al. [2021] D. Peng, H. Guan, Y. Zang, and L. Bruzzone, “Full-level domain adaptation for building extraction in very-high-resolution optical remote-sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–17, 2021.
- Huang et al. [2022] Y. Huang, J. Peng, W. Sun, N. Chen, Q. Du, Y. Ning, and H. Su, “Two-branch attention adversarial domain adaptation network for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2022.
- Hong et al. [2023] D. Hong, B. Zhang, H. Li, Y. Li, J. Yao, C. Li, M. Werner, J. Chanussot, A. Zipf, and X. X. Zhu, “Cross-city matters: A multimodal remote sensing benchmark dataset for cross-city semantic segmentation using high-resolution domain adaptation networks,” Remote Sensing of Environment, vol. 299, p. 113856, 2023.
- Huang et al. [2023] Y. Huang, J. Peng, N. Chen, W. Sun, Q. Du, K. Ren, and K. Huang, “Cross-scene wetland mapping on hyperspectral remote sensing images using adversarial domain adaptation network,” ISPRS J. Photogramm. Remote Sens., vol. 203, pp. 37–54, 2023.
- Tasar et al. [2020] O. Tasar, S. Happy, Y. Tarabalka, and P. Alliez, “ColorMapGAN: Unsupervised domain adaptation for semantic segmentation using color mapping generative adversarial networks,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 10, pp. 7178–7193, 2020.
- Li et al. [2022a] J. Li, S. Zi, R. Song, Y. Li, Y. Hu, and Q. Du, “A stepwise domain adaptive segmentation network with covariate shift alleviation for remote sensing imagery,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–15, 2022.
- Zhang et al. [2020] J. Zhang, J. Liu, B. Pan, and Z. Shi, “Domain adaptation based on correlation subspace dynamic distribution alignment for remote sensing image scene classification,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 11, pp. 7920–7930, 2020.
- Ma et al. [2023a] X. Ma, X. Zhang, Z. Wang, and M.-O. Pun, “Unsupervised domain adaptation augmented by mutually boosted attention for semantic segmentation of VHR remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–15, 2023.
- Ni et al. [2023] H. Ni, Q. Liu, H. Guan, H. Tang, and J. Chanussot, “Category-level assignment for cross-domain semantic segmentation in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–16, 2023.
- Chen et al. [2023a] J. Chen, P. He, J. Zhu, Y. Guo, G. Sun, M. Deng, and H. Li, “Memory-contrastive unsupervised domain adaptation for building extraction of high-resolution remote sensing imagery,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–15, 2023.
- Huang et al. [2024] Y. Huang, J. Peng, G. Zhang, W. Sun, N. Chen, and Q. Du, “Adversarial domain adaptation network with calibrated prototype and dynamic instance convolution for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., 2024.
- Ning et al. [2024] Y. Ning, J. Peng, Q. Liu, W. Sun, and Q. Du, “Domain invariant and compact prototype contrast adaptation for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., 2024.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, pp. 1–11, 2017.
- Li et al. [2022b] W. Li, H. Gao, Y. Su, and B. M. Momanyi, “Unsupervised domain adaptation for remote sensing semantic segmentation with transformer,” Remote Sensing, vol. 14, no. 19, p. 4942, 2022.
- Zhang et al. [2022] J. Zhang, S. Xu, J. Sun, D. Ou, X. Wu, and M. Wang, “Unsupervised adversarial domain adaptation for agricultural land extraction of remote sensing images,” Remote Sensing, vol. 14, no. 24, p. 6298, 2022.
- Sui et al. [2024] J. Sui, Y. Ma, W. Yang, X. Zhang, M.-O. Pun, and J. Liu, “Diffusion enhancement for cloud removal in ultra-resolution remote sensing imagery,” IEEE Trans. Geosci. Remote Sens., 2024.
- Liu et al. [2018] Y. Liu, B. Fan, L. Wang, J. Bai, S. Xiang, and C. Pan, “Semantic labeling in very high resolution images via a self-cascaded convolutional neural network,” ISPRS J. Photogramm. Remote Sens., vol. 145, pp. 78–95, 2018.
- Song et al. [2019] S. Song, H. Yu, Z. Miao, Q. Zhang, Y. Lin, and S. Wang, “Domain adaptation for convolutional neural networks-based remote sensing scene classification,” IEEE Geoscience and Remote Sensing Letters, vol. 16, no. 8, pp. 1324–1328, 2019.
- Chen et al. [2022] J. Chen, J. Zhu, Y. Guo, G. Sun, Y. Zhang, and M. Deng, “Unsupervised domain adaptation for semantic segmentation of high-resolution remote sensing imagery driven by category-certainty attention,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–15, 2022.
- Ma et al. [2023b] A. Ma, C. Zheng, J. Wang, and Y. Zhong, “Domain adaptive land-cover classification via local consistency and global diversity,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–17, 2023.
- Gao et al. [2023] K. Gao, A. Yu, X. You, C. Qiu, and B. Liu, “Prototype and context enhanced learning for unsupervised domain adaptation semantic segmentation of remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–16, 2023.
- Wang et al. [2022a] L. Wang, R. Li, C. Zhang, S. Fang, C. Duan, X. Meng, and P. M. Atkinson, “UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery,” ISPRS J. Photogramm. Remote Sens., vol. 190, pp. 196–214, 2022.
- Kotaridis and Lazaridou [2021] I. Kotaridis and M. Lazaridou, “Remote sensing image segmentation advances: A meta-analysis,” ISPRS J. Photogramm. Remote Sens., vol. 173, pp. 309–322, 2021.
- Diakogiannis et al. [2020] F. I. Diakogiannis, F. Waldner, P. Caccetta, and C. Wu, “ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data,” ISPRS J. Photogramm. Remote Sens., vol. 162, pp. 94–114, 2020.
- Ma et al. [2022] X. Ma, X. Zhang, and M.-O. Pun, “A crossmodal multiscale fusion network for semantic segmentation of remote sensing data,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 3463–3474, 2022.
- Ma et al. [2024c] X. Ma, X. Zhang, M.-O. Pun, and M. Liu, “A multilevel multimodal fusion transformer for remote sensing semantic segmentation,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–15, 2024.
- Liu et al. [2021] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022.
- Sun et al. [2023] X. Sun, P. Wang, W. Lu, Z. Zhu, X. Lu, Q. He, J. Li, X. Rong, Z. Yang, H. Chang, Q. He, G. Yang, R. Wang, J. Lu, and K. Fu, “RingMo: A remote sensing foundation model with masked image modeling,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–22, 2023.
- Hong et al. [2024] D. Hong, B. Zhang, X. Li, Y. Li, C. Li, J. Yao, N. Yokoya, H. Li, P. Ghamisi, X. Jia, A. Plaza, P. Gamba, J. A. Benediktsson, and J. Chanussot, “Spectralgpt: Spectral remote sensing foundation model,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–18, 2024.
- Wang et al. [2022b] D. Wang, Q. Zhang, Y. Xu, J. Zhang, B. Du, D. Tao, and L. Zhang, “Advancing plain vision transformer toward remote sensing foundation model,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–15, 2022.
- Yan et al. [2019] L. Yan, B. Fan, H. Liu, C. Huo, S. Xiang, and C. Pan, “Triplet adversarial domain adaptation for pixel-level classification of VHR remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 58, no. 5, pp. 3558–3573, 2019.
- Chen et al. [2023b] H. Chen, J. Song, C. Wu, B. Du, and N. Yokoya, “Exchange means change: An unsupervised single-temporal change detection framework based on intra-and inter-image patch exchange,” ISPRS J. Photogramm. Remote Sens., vol. 206, pp. 87–105, 2023.
- Cai et al. [2022] Y. Cai, Y. Yang, Y. Shang, Z. Chen, Z. Shen, and J. Yin, “IterDANet: Iterative intra-domain adaptation for semantic segmentation of remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–17, 2022.
- Zhang et al. [2021] L. Zhang, M. Lan, J. Zhang, and D. Tao, “Stagewise unsupervised domain adaptation with adversarial self-training for road segmentation of remote-sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2021.
- Liang et al. [2023] C. Liang, B. Cheng, B. Xiao, and Y. Dong, “Unsupervised domain adaptation for remote sensing image segmentation based on adversarial learning and self-training,” IEEE Geoscience and Remote Sensing Letters, 2023.
- Benjdira et al. [2019] B. Benjdira, Y. Bazi, A. Koubaa, and K. Ouni, “Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images,” Remote Sensing, vol. 11, no. 11, p. 1369, 2019.
- Shen et al. [2024] Z. Shen, H. Ni, H. Guan, and X. Niu, “Optimal transport-based domain adaptation for semantic segmentation of remote sensing images,” International Journal of Remote Sensing, vol. 45, no. 2, pp. 420–450, 2024.
- Liu et al. [2022] Y. Liu, X. Kang, Y. Huang, K. Wang, and G. Yang, “Unsupervised domain adaptation semantic segmentation for remote-sensing images via covariance attention,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- Zhu et al. [2023] J. Zhu, Y. Guo, G. Sun, L. Yang, M. Deng, and J. Chen, “Unsupervised domain adaptation semantic segmentation of high-resolution remote sensing imagery with invariant domain-level prototype memory,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–18, 2023.
- Xi et al. [2023] Z. Xi, X. He, Y. Meng, A. Yue, J. Chen, Y. Deng, and J. Chen, “A multilevel-guided curriculum domain adaptation approach to semantic segmentation for high-resolution remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–17, 2023.
- Jiang et al. [2021] Y. Jiang, S. Chang, and Z. Wang, “TransGAN: Two pure transformers can make one strong GAN, and that can scale up,” Advances in Neural Information Processing Systems, vol. 34, pp. 14 745–14 758, 2021.
- Wang et al. [2022c] S. Wang, Z. Gao, and D. Liu, “Swin-GAN: generative adversarial network based on shifted windows transformer architecture for image generation,” The Visual Computer, pp. 1–11, 2022.
- He et al. [2022] Z. He, K. Xia, P. Ghamisi, Y. Hu, S. Fan, and B. Zu, “HyperViTGAN: Semisupervised generative adversarial network with transformer for hyperspectral image classification,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 6053–6068, 2022.
- Tu et al. [2022] J. Tu, G. Mei, Z. Ma, and F. Piccialli, “SWCGAN: Generative adversarial network combining Swin Transformer and CNN for remote sensing image super-resolution,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 5662–5673, 2022.
- Zhao et al. [2022] C. Zhao, B. Qin, S. Feng, W. Zhu, L. Zhang, and J. Ren, “An unsupervised domain adaptation method towards multi-level features and decision boundaries for cross-scene hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–16, 2022.
- Zhao et al. [2024] Q. Zhao, S. Lyu, H. Zhao, B. Liu, L. Chen, and G. Cheng, “Self-training guided disentangled adaptation for cross-domain remote sensing image semantic segmentation,” International Journal of Applied Earth Observation and Geoinformation, vol. 127, p. 103646, 2024.
- Chen et al. [2024] J. Chen, J. Zhu, P. He, Y. Guo, L. Hong, Y. Yang, M. Deng, and G. Sun, “Unsupervised domain adaptation for building extraction of high-resolution remote sensing imagery based on decoupling style and semantic features,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–17, 2024.
- Bai et al. [2022] J. Bai, L. Yuan, S.-T. Xia, S. Yan, Z. Li, and W. Liu, “Improving vision transformers by revisiting high-frequency components,” in European Conference on Computer Vision. Springer, 2022, pp. 1–18.
- Wang et al. [2020] H. Wang, X. Wu, Z. Huang, and E. P. Xing, “High-frequency component helps explain the generalization of convolutional neural networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8684–8694.
- Gerke [2014] M. Gerke, “Use of the stair vision library within the ISPRS 2D semantic labeling benchmark (Vaihingen),” 2014.
- Wang et al. [2021] J. Wang, Z. Zheng, A. Ma, X. Lu, and Y. Zhong, “Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation,” arXiv preprint arXiv:2110.08733, 2021.
- Jha et al. [2019] D. Jha, P. H. Smedsrud, M. A. Riegler, D. Johansen, T. De Lange, P. Halvorsen, and H. D. Johansen, “ResUNet++: An advanced architecture for medical image segmentation,” in 2019 IEEE International Symposium on Multimedia (ISM). IEEE, 2019, pp. 225–2255.
- Ganin et al. [2016] Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V. Lempitsky, “Domain-adversarial training of neural networks,” The journal of machine learning research, vol. 17, no. 1, pp. 2096–2030, 2016.
- Rahnemoonfar et al. [2021] M. Rahnemoonfar, T. Chowdhury, A. Sarkar, D. Varshney, M. Yari, and R. R. Murphy, “Floodnet: A high resolution aerial imagery dataset for post flood scene understanding,” IEEE Access, vol. 9, pp. 89 644–89 654, 2021.
- Wang et al. [2024] J. Wang, A. Ma, Z. Chen, Z. Zheng, Y. Wan, L. Zhang, and Y. Zhong, “EarthVQANet: Multi-task visual question answering for remote sensing image understanding,” ISPRS J. Photogramm. Remote Sens., vol. 212, pp. 422–439, 2024.
- Cheng et al. [2023] G. Cheng, X. Yuan, X. Yao, K. Yan, Q. Zeng, X. Xie, and J. Han, “Towards large-scale small object detection: Survey and benchmarks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.