Deconditional Downscaling with Gaussian Processes
Abstract
Refining low-resolution (LR) spatial fields with high-resolution (HR) information, often known as statistical downscaling, is challenging as the diversity of spatial datasets often prevents direct matching of observations. Yet, when LR samples are modeled as aggregate conditional means of HR samples with respect to a mediating variable that is globally observed, the recovery of the underlying fine-grained field can be framed as taking an “inverse” of the conditional expectation, namely a deconditioning problem. In this work, we propose a Bayesian formulation of deconditioning which naturally recovers the initial reproducing kernel Hilbert space formulation from Hsu and Ramos [1]. We extend deconditioning to a downscaling setup and devise efficient conditional mean embedding estimator for multiresolution data. By treating conditional expectations as inter-domain features of the underlying field, a posterior for the latent field can be established as a solution to the deconditioning problem. Furthermore, we show that this solution can be viewed as a two-staged vector-valued kernel ridge regressor and show that it has a minimax optimal convergence rate under mild assumptions. Lastly, we demonstrate its proficiency in a synthetic and a real-world atmospheric field downscaling problem, showing substantial improvements over existing methods.
1 Introduction
Spatial observations often operate at limited resolution due to practical constraints. For example, remote sensing atmosphere products [2, 3, 4, 5] provide measurement of atmospheric properties such as cloud top temperatures and optical thickness, but only at a low resolution. Devising methods to refine low-resolution (LR) variables for local-scale analysis thus plays a crucial part in our understanding of the anthropogenic impact on climate
When high-resolution (HR) observations of different covariates are available, details can be instilled into the LR field for refinement. This task is referred to as statistical downscaling or spatial disaggregation and models LR observations as the aggregation of an unobserved underlying HR field. For example, multispectral optical satellite imagery [6, 7] typically comes at higher resolution than atmospheric products and can be used to refine the latter.
Statistical downscaling has been studied in various forms, notably giving it a probabilistic treatment [8, 9, 10, 11, 12, 13], in which Gaussian processes (GP) [14] are typically used in conjunction with a sparse variational formulation [15] to recover the underlying unobserved HR field. Our approach follows this line of research where we do not observe data from the underlying HR groundtruth field. On the other hand, deep neural network (DNN) based approaches [16, 17, 18] study this problem from a different setting, where they often assume that both HR and LR matched observations are available for training. Then, their approaches follow a standard supervised learning setting in learning a mapping between different resolutions.
However, both lines of existing methods require access to bags of HR covariates that are paired with aggregated targets, which in practice might be infeasible. For example, the multitude of satellites in orbit not only collect snapshots of the atmosphere at different resolutions, but also from different places and at different times, such that these observations are not jointly observed. To overcome this limitation, we propose to consider a more flexible mediated statistical downscaling setup that only requires indirect matching between LR and HR covariates through a mediating field. We assume that this additional field can be easily observed, and matched separately with both HR covariates and aggregate LR targets. We then use this third-party field to mediate learning and downscale our unmatched data. In our motivating application, climate simulations [19, 20, 21] based on physical science can serve as a mediating field since they provide a comprehensive spatiotemporal coverage of meteorological variables that can be matched to both LR and HR covariates.
Formally, let be a general notation for bags of HR covariates, the field of interest we wish to recover and the LR aggregate observations from the field . We suppose that and are unmatched, but that there exists mediating covariates , such that are jointly observed and likewise for as illustrated in Figure 1. We assume the following aggregation observation model with some noise . Our goal in mediated statistical downscaling is then to estimate given and , which corresponds to the deconditioning problem introduced in [1].

Motivated by applications in likelihood-free inference and task-transfer regression, Hsu and Ramos [1] first studied the deconditioning problem through the lens of reproducing kernel Hilbert space (RKHS) and introduced the framework of Deconditional Mean Embeddings (DME) as its solution.
In this work, we first propose a Bayesian formulation of deconditioning that results into a much simpler and elegant way to arrive to the DME-based estimator of Hsu and Ramos [1], using the conditional expectations of . Motivated by our mediated statistical downscaling problem, we then extend deconditioning to a multi-resolution setup and bridge the gap between DMEs and existing probabilistic statistical downscaling methods [9]. By placing a GP prior on the sought field , we obtain a posterior distribution of the downscaled field as a principled Bayesian solution to the downscaling task on indirectly matched data. For scalability, we provide a tractable variational inference approximation and an alternative approximation to the conditional mean operator (CMO) [22] to speed up computation for large multi-resolution datasets.
From a theoretical stand point, we further develop the framework of DMEs by establishing it as a two-staged vector-valued regressor with a natural reconstruction loss that mirrors Grünewälder et al. [23]’s work on conditional mean embeddings. This perspective allows us to leverage distribution regression theory from [24, 25] and obtain convergence rate results for the deconditional mean operator (DMO) estimator. Under mild assumptions, we obtain conditions under which this rate is a minimax optimal in terms of statistical-computational efficiency.
Our contributions are summarized as follows:
-
•
We propose a Bayesian formulation of the deconditioning problem of Hsu and Ramos [1]. We establish its posterior mean as a DME-based estimate and its posterior covariance as a gauge of the deconditioning quality.
-
•
We extend deconditioning to a multi-resolution setup in the context of the mediated statistical downscaling problem and bridge the gap with existing probabilistic statistical downscaling methods. Computationally efficient algorithms are devised.
-
•
We demonstrate that the DMO estimate minimises a two-staged vector-valued regression and derive its convergence rate under mild assumptions, with conditions for minimax optimality.
-
•
We benchmark our model against existing methods for statistical downscaling tasks in climate science, on both synthetic and real-world multi-resolution atmospheric fields data, and show improved performance.
2 Background Materials
2.1 Notations
Let be a pair of random variables taking values in non-empty sets and , respectively. Let and be positive definite kernels. The closure of the span of their canonical feature maps and for and respectively induces RKHS and endowed with inner products and .
We observe realizations of bags from conditional distribution , with bag-level covariates sampled from . We concatenate them into vectors and .
For simplicity, our exposition will use the notation without bagging – i.e. where – when the generality of our contributions will be relevant to the theory of deconditioning from Hsu and Ramos [1], in Sections 2, 3 and 4. We will come back to a bagged dataset formalism in Sections 3.3 and 5, which corresponds to our motivating application of mediated statistical downscaling.
With an abuse of notation, we define feature matrices by stacking feature maps along columns as and and we denote Gram matrices as and . The notation abuse is a shorthand for the elementwise RKHS inner products when it is clear from the context.
Let denote the real-valued random variable stemming from the noisy conditional expectation of some unknown latent function , as . We suppose one observes another set of realizations from , which is sampled independently from . Likewise, we stack observations into vectors , and define feature map .
2.2 Conditional and Deconditional Kernel Mean Embeddings
Marginal and Joint Mean Embeddings
Kernel mean embeddings of distributions provide a powerful framework for representing and manipulating distributions without specifying their parametric form [26, 22]. The marginal mean embedding of measure is defined as and corresponds to the Riesz representer of expectation functional . It can hence be used to evaluate expectations . If the mapping is injective, the kernel is said to be characteristic [27], a property satisfied for the Gaussian and Matérn kernels on [28]. In practice, Monte Carlo estimator provides an unbiased estimate of [29].
Extending this rationale to embeddings of joint distributions, we define and , which can be identified with the cross-covariance operators between Hilbert spaces and . They correspond to the Riesz representers of bilinear forms and . As above, empirical estimates are obtained as and . Again, notation abuse is a shorthand for element-wise tensor products when clear from context.
Conditional Mean Embeddings
Similarly, one can introduce RKHS embeddings for conditional distributions referred to as Conditional Mean Embeddings (CME). The CME of conditional probability measure is defined as . As introduced by Fukumizu et al. [27], it is common to formulate conditioning in terms of a Hilbert space operator called the Conditional Mean Operator (CMO). satisfies by definition and , where denotes the adjoint of . Plus, the CMO admits expression , provided [27, 26]. Song et al. [30] show that a nonparametric empirical form of the CMO writes
| (1) |
where is some regularisation ensuring the empirical operator is globally defined and bounded.
Deconditional Mean Embeddings
Introduced by Hsu and Ramos [1] as a new class of embeddings, Deconditional Mean Embeddings (DME) are natural counterparts of CMEs. While CME allows to take the conditional expectation of any through inner product , the DME denoted solves the inverse problem111the slightly unusual notation is taken from Hsu and Ramos [1] and is meant to contrast the usual conditioning and allows to recover the initial function of which the conditional expectation was taken, through inner product .
The associated Hilbert space operator, the Deconditional Mean Operator (DMO), is thus defined as the operator such that . It admits an expression in terms of CMO and cross-covariance operators provided and and . A nonparametric empirical estimate of the DMO using datasets and as described above, is given by where is a regularisation term and can be interpreted as a mediation operator. Applying the DMO to expected responses , Hsu and Ramos [1] are able to recover an estimate of as
| (2) |
Note that since separate samples can be used to estimate , this naturally fits a mediating variables setup where and the conditional means are not jointly observed.
3 Deconditioning with Gaussian processes
In this section, we introduce Conditional Mean Process (CMP), a stochastic process stemming from the conditional expectation of a GP. We provide a characterisation of the CMP and show that the corresponding posterior mean of its integrand is a DME-based estimator. We also derive in Appendix B a variational formulation of our model that scales to large datasets and demonstrate its performance in Section 5.
For simplicity, we put aside observations bagging in Sections 3.1 and 3.2, our contributions being relevant to the general theory of DMEs. We return to a bagged formalism in Section 3.3 and extend deconditioning to the multiresolution setup inherent to the mediated statistical downscaling application. In what follows, is a measurable space, a Borel space and feature maps and are Borel-measurable functions for any , . All proofs and derivations of the paper are included in the appendix.
3.1 Conditional Mean Process
Bayesian quadrature [31, 32, 14] is based on the observation that the integral of a GP with respect to some marginal measure is a Gaussian random variable. We start by probing the implications of integrating with respect to conditional distribution and considering such integrals as functions of the conditioning variable . This gives rise to the notion of conditional mean processes.
Definition 3.1 (Conditional Mean Process).
Let with integrable sample paths, i.e. a.s. The CMP induced by with respect to is defined as the stochastic process given by
| (3) |
By linearity of the integral, it is clear that is a Gaussian random variable for each . The sample paths integrability requirement ensures is well-defined almost everywhere. The following result characterizes CMP as a GP on .
Proposition 3.2 (CMP characterization).
Suppose and and let . Then is a Gaussian process a.s. , specified by
| (4) |
. Furthermore, a.s.
Intuitively, the CMP can be understood as a GP on the conditional means where its covariance is induced by the similarity between the CMEs at and . Resorting to the kernel defined on , we can reexpress the covariance using Hilbert space operators as . A natural nonparametric estimate of the CMP covariance thus comes using the CMO estimator from (1) as . When , the mean function can be written as for which we can also use empirical estimate . Finally, one can also quantify the covariance between the CMP and its integrand , i.e. . Under the same assumptions as Proposition 3.2, this covariance can be expressed using mean embeddings, i.e. and admits empirical estimate .
3.2 Deconditional Posterior
Given independent observations introduced above, and , we may now consider an additive noise model with CMP prior on aggregate observations . Let be the kernel matrix induced by on and let be the cross-covariance between and . The joint normality of and gives
| (5) |
Using Gaussian conditioning, we can then readily derive the posterior distribution of the underlying GP field given the aggregate observations corresponding to . The latter can naturally be degenerated if observations are paired, i.e. . This formulation can be seen as an example of the inter-domain GP [33], where we utilise the observed conditional means as inter-domain inducing features for inference of .
Proposition 3.3 (Deconditional Posterior).
Given aggregate observations with homoscedastic noise , the deconditional posterior of is defined as the Gaussian process where
| (6) | ||||
| (7) |
Substituting terms by their empirical forms, we can define a nonparametric estimate of the as
| (8) |
which, when , reduces to the DME-based estimator in (2) by taking the noise variance as the inverse regularization parameter. Hsu and Ramos [1] recover a similar posterior mean expression in their Bayesian interpretation of DME. However, they do not link the distributions of and its CMP, which leads to much more complicated chained inference derivations combining fully Bayesian and MAP estimates, while we naturally recover it using simple Gaussian conditioning.
Likewise, an empirical estimate of the deconditional covariance is given by
| (9) |
Interestingly, the latter can be rearranged to write as the difference between the original kernel and the kernel undergoing conditioning and deconditioning steps . This can be interpreted as a measure of reconstruction quality, which degenerates in the case of perfect deconditioning, i.e. .
3.3 Deconditioning and multiresolution data
Downscaling application would typically correspond to multiresolution data, with bag dataset where . In this setup, the mismatch in size between vector concatenations and prevents from readily applying (1) to estimate the CMO and thus infer the deconditional posterior. There is, however, a straightforward approach to alleviate this: simply replicate bag-level covariates to match bags sizes . Although simple, this method incurs a cost due to matrix inversion in (1).
Alternatively, since bags are sampled from conditional distribution , unbiased Monte Carlo estimators of CMEs are given by . Let denote their concatenation along columns. We can then rewrite the cross-covariance operator as and hence take as an estimate for . Substituting empirical forms into and applying Woodbury identity, we obtain an alternative CMO estimator that only requires inversion of a matrix. We call it Conditional Mean Shrinkage Operator and define it as
| (10) |
This estimator can be seen as a generalisation of the Kernel Mean Shrinkage Estimator [34] to the conditional case. We provide in Appendix C modifications of (8) and (9) including this estimator for the computation of the deconditional posterior.
4 Deconditioning as regression
In Section 3.2, we obtain a DMO-based estimate for the posterior mean of . When the estimate gets closer to the exact operator, the uncertainty collapses and the Bayesian view meets the frequentist. It is however unclear how the empirical operators effectively converge in finite data size. Adopting an alternative perspective, we now demonstrate that the DMO estimate can be obtained as the minimiser of a two-staged vector-valued regression. This frequentist turn enables us to leverage rich theory of vector-valued regression and establish under mild assumptions a convergence rate on the DMO estimator, with conditions to fulfill minimax optimality in terms of statistical-computational efficiency. In the following, we briefly review CMO’s vector-valued regression viewpoint and construct an analogous regression problem for DMO. We refer the reader to [35] for a comprehensive overview of vector-valued RKHS theory. As for Sections 3.1 and 3.2, this section contributes to the general theory of DMEs and we hence put aside the bag notations.
Stage 1: Regressing the Conditional Mean Operator
As first introduced by Grünewälder et al. [23] and generalised to infinite dimensional spaces by Singh et al. [25], estimating is equivalent to solving a vector-valued kernel ridge regression problem in the hypothesis space of Hilbert-Schmidt operators from to , denoted as . Specifically, we may consider the operator-valued kernel defined over as . We denote the -valued RKHS spanned by with norm , which can be identified to 222. Singh et al. [25] frame CMO regression as the minimisation surrogate discrepancy , to which they substitute an empirical regularised version restricted to given by
| (11) |
This -valued kernel ridge regression problem admits a closed-form minimiser which shares the same empirical form as the CMO, i.e. [23, 25].
Stage 2 : Regressing the Deconditional Mean Operator
The DMO on the other hand is defined as the operator such that , . Since deconditioning corresponds to finding a pseudo-inverse to the CMO, it is natural to consider a reconstruction objective . Introducing a novel characterization of the DMO, we propose to minimise this objective in the hypothesis space of Hilbert-Schmidt operators which identifies to . As per above, we denote the empirical CMO learnt in Stage 1, and we substitute the loss with an empirical regularised formulation on
| (12) |
Proposition 4.1 (Empirical DMO as vector-valued regressor).
The minimiser of the empirical reconstruction risk is the empirical DMO, i.e.
Since it requires to estimate the CMO first, minimising (12) can be viewed as a two-staged vector value regression problem.
Convergence results
Following the footsteps of [25, 24], this perspective enables us to state the performance of the DMO estimate in terms of asymptotic convergence of the objective . As in Caponnetto and De Vito [36], we must restrict the class of probability measure for and to ensure uniform convergence even when is infinite dimensional. The family of distribution considered is a general class of priors that does not assume parametric distributions and is parametrized by two variables: controls the effective input dimension and controls functional smoothness. Mild regularity assumptions are also placed on the original spaces , their corresponding RKHS and the vector-valued RKHS . We discuss these assumptions in details in Appendix D. Importantly, while can be infinite dimensional, we nonetheless have to assume the RKHS is finite dimensional. In further research, we will relax this assumption.
Theorem 4.2 (Empirical DMO Convergence Rate).
Denote . Assume assumptions stated in Appendix D are satisfied. In particular, let and be the parameters of the restricted class of distribution for and respectively and let be the Hölder continuity exponent in . Then, if we choose , where , we have the following result,
-
•
If , then with
-
•
If , then with
This theorem underlines a trade-off between the computational and statistical efficiency with respect to the datasets cardinalities , and the problem difficulty . For , smaller means less samples from at fixed and thus computational savings. But it also hampers convergence, resulting in reduced statistical efficiency. At , convergence rate is a minimax computational-statistical efficiency optimal, i.e. convergence rate is optimal with smallest possible . We note that at this optimal, and which means less samples are required from . does not improve the convergence rate but only increases the size of and hence the computational cost it bears.
5 Deconditional Downscaling Experiments
We demonstrate and evaluate our CMP-based downscaling approaches on both synthetic experiments and a challenging atmospheric temperature field downscaling problem with unmatched multi-resolution data. We denote the exact CMP deconditional posterior from Section 3 as cmp, the cmp using with efficient shrinkage CMO estimation as s-cmp and the variational formulation as varcmp. They are compared against vbagg [9] — which we describe below — and a GP regression [14] baseline (gpr) modified to take bags centroids as the input. Experiments are implemented in PyTorch [37, 38], all code and datasets are made available333https://github.com/shahineb/deconditional-downscaling and computational details are provided in Appendix E.
Variational Aggregate Learning
vbagg is introduced by Law et al. [9] as a variational aggregate learning framework to disaggregate exponential family models, with emphasis on the Poisson family. We consider its application to the Gaussian family, which models the relationship between aggregate targets and bag covariates by bag-wise averaging of a GP prior on the function of interest. In fact, the Gaussian vbagg corresponds exactly to a special case of cmp on matched data, where the bag covariates are simply one hot encoded indices with kernel where is the Kronecker delta. However, vbagg cannot handle unmatched data as bag indices do not instill the smoothness that is used for mediation. For fair analysis, we compare variational methods varcmp and vbagg together, and exact methods cmp/s-cmp to an exact version of vbagg, which we implement and refer to as bagg-gp.
5.1 Swiss Roll
The scikit-learn [39] swiss roll manifold sampling function allows to generate a 3D manifold of points mapped with their position along the manifold . Our objective will be to recover for each point by only observing at an aggregate level. In the first experiment, we compare our model to existing weakly supervised spatial disaggregation methods when all high-resolution covariates are matched with a coarse-level aggregate target. We then proceed to withdraw this requirement in a companion experiment.

5.1.1 Direct matching
Experimental Setup
Inspired by the experimental setup from Law et al. [9], we regularly split space along height times as depicted in Figure 2 and group together manifold points within each height level, hence mixing together points with very different positions on the manifold. We obtain bags of samples where the th bag contains points and their corresponding targets . We then construct bag aggregate targets by taking noisy bag targets average , where . We thus obtain matched weakly supervised bag learning dataset . Since each bag corresponds to a height-level, the center altitude of each height split is a natural candidate bag-level covariate that informs on relative positions of the bags. We can augment the above dataset as . Using these bag datasets, we now wish to downscale aggregate targets to recover the unobserved manifold locations and be able to query the target at any previously unseen input .
Models
We use a zero-mean prior on and choose a Gaussian kernel for and . Inducing points location is initialized with K-means++ procedure for varcmp and vbagg such that they spread evenly across the manifold. For exact methods, kernel hyperparameters and noise variance are learnt on by optimising the marginal likelihood. For varcmp, they are learnt jointly with variational distribution parameters by maximising an evidence lower bound objective. While CMP-based methods can leverage bag-level covariates , baselines are restricted to learn from . Adam optimiser [40] is used in all experiments.
Results
We test models against unobserved groundtruth by evaluating the root mean square error (RMSE) to the posterior mean. Table 1 shows that cmp, s-cmp and varcmp outperform their corresponding counterparts i.e. bagg-gp and vbagg, with statistical significance confirmed by a Wilcoxon signed-rank test in Appendix E. Most notably, this shows that the additional knowledge on bag-level dependence instilled by is reflected even in a setting where each bag is matched with an aggregate target.
| Matching | cmp* | s-cmp* | varcmp* | bagg-gp | vbagg | gpr |
|---|---|---|---|---|---|---|
| Direct | 0.330.06 | 0.25 0.04 | 0.180.04 | 0.600.01 | 0.220.04 | 0.700.05 |
| Indirect | 0.800.14 | 1.050.04 | 0.870.07 | 1.130.11 | 1.460.34 | 1.040.05 |
5.1.2 Indirect matching
Experimental Setup
We now impose indirect matching through mediating variable . We randomly select bags which we consider to be the first ones without loss of generality and split into and , such that no pair of covariates bag and aggregate target are jointly observed.
Models
CMP-based methods are naturally able to learn from this setting and are trained by independently drawing samples from and . Baseline methods however require bags of covariates to be matched with an aggregate bag target. To remedy this, we place a separate prior and fit regression model over . We then use the predictive posterior mean to augment the first dataset as . This dataset can then be used to train bagg-gp, vbagg and gpr.
Results
For comparison, we use the same evaluation as in the direct matching experiment. Table 1 underlines an anticipated drop in RMSE for all models, but we observe that bagg-gp and vbagg suffer most from the mediated matching of the dataset while cmp and varcmp report best scores by a substantial margin. This highlights how using a separate prior on to mediate and turns out to be suboptimal in contrast to using the prior naturally implied by CMP. While it is more computationally efficient than cmp, we observe a relative drop in performance for s-cmp.
5.2 Mediated downscaling of atmospheric temperature
Given the large diversity of sources and formats of remote sensing and model data, expecting directly matched observations is often unrealistic [41]. For example, two distinct satellite products will often provide low and high resolution imagery that can be matched neither spatially nor temporally [2, 3, 4, 5]. Climate simulations [20, 21, 19] on the other hand provide a comprehensive coarse resolution coverage of meteorological variables that can serve as a mediating dataset.
For the purpose of demonstration, we create an experimental setup inspired by this problem using Coupled Model Intercomparison Project Phase 6 (CMIP6) [19] simulation data. This grants us access to groundtruth high-resolution covariates to facilitate model evaluation.
Experimental Setup
We collect monthly mean 2D atmospheric fields simulation from CMIP6 data [42, 43] for the following variables: air temperature at cloud top (T), mean cloud top pressure (P), total cloud cover (TCC) and cloud albedo (). First, we collocate TCC and onto a HR latitude-longitude grid of size 360720 to obtain fine grained fields (latitudeHR, longitudeHR, altitudeHR, TCCHR, HR) augmented with a static HR surface altitude field. Then we collocate P and T onto a LR grid of size 2142 to obtain coarse grained fields (latitudeLR, longitudeLR, PLR, TLR). We denote by the number of low resolution pixels.
Our objective is to disaggregate TLR to the HR fields granularity. We assimilate the th coarse temperature pixel to an aggregate target T corresponding to bag . Each bag includes HR covariates latitude, longitude, altitude, TCC, . To emulate unmatched observations, we randomly select of the bags and keep the opposite half of LR observations , such that there is no single aggregate bag target that corresponds to one of the available bags. Finally, we choose the pressure field PLR as the mediating variable. We hence compose a third party low resolution field of bag-level covariates latitude, longitude, P which can separately be matched with both above sets to obtain datasets and .

Models Setup
We only consider variational methods to scale to large number of pixels. varcmp is naturally able to learn from indirectly matched data. We use a Matérn-1.5 kernel for rough spatial covariates (latitude, longitude) and a Gaussian kernel for atmospheric covariates (P, TCC, ) and surface altitude. and are both taken as sums of Matérn and Gaussian kernels, and their hyperparameters are learnt along with noise variance during training. A high-resolution noise term is also introduced, with details provided in Appendix E. Inducing points locations are uniformly initialized across the HR grid. We replace gpr with an inducing point variational counterpart vargpr [15]. Since baseline methods require a matched dataset, we proceed as with the unmatched swiss roll experiment and fit a GP regression model with kernel on and then use its predictive posterior mean to obtain pseudo-targets for the bags of HR covariates from .
Results
Performance is evaluated by comparing downscaling deconditional posterior mean against original high resolution field THR available in CMIP6 data [43], which we emphasise is never observed. We use random Fourier features [44] approximation of kernel to scale kernel evaluation to the HR covariates grid during testing. As reported in Table 2, varcmp substantially outperforms both baselines with statistical significance provided in Appendix E. Figure 3 shows the reconstructed image with varcmp, plots for other methods are included in the Appendix E. The model resolves statistical patterns from HR covariates into coarse resolution temperature pixels, henceforth reconstructing a faithful HR version of the temperature field.
| Model | RMSE | MAE | Corr. | SSIM |
|---|---|---|---|---|
| vargpr | 8.020.28 | 5.550.17 | 0.8310.012 | 0.2120.011 |
| vbagg | 8.250.15 | 5.820.11 | 0.8210.006 | 0.1820.004 |
| varcmp | 7.400.25 | 5.340.22 | 0.8480.011 | 0.2120.013 |
6 Discussion
We introduced a scalable Bayesian solution to the mediated statistical downscaling problem, which handles unmatched multi-resolution data. The proposed approach combines Gaussian Processes with the framework of deconditioning using RKHSs and recovers previous approaches as its special cases. We provided convergence rates for the associated deconditioning operator. Finally, we demonstrated the advantages over spatial disaggregation baselines in synthetic data and in a challenging atmospheric fields downscaling problem.
In future work, exploring theoretical guarantees of the computationally efficient shrinkage formulation in a multi-resolution setting and relaxing finite dimensionality assumptions for the convergence rate will have fruitful practical and theoretical implications. Further directions also open up to quantify uncertainty over the deconditional posterior since it is computed using empirical estimates of the CMP covariance. This may be problematic if the mediating variable undergoes covariate shift between the two datasets.
Acknowledgments
SLC is supported by the EPSRC and MRC through the OxWaSP CDT programme EP/L016710/1. SB is supported by the EU’s Horizon 2020 research and innovation programme under Marie Skłodowska-Curie grant agreement No 860100. DS is supported in partly by Tencent AI lab and partly by the Alan Turing Institute (EP/N510129/1).
References
- Hsu and Ramos [2019] Kelvin Hsu and Fabio Ramos. Bayesian Deconditional Kernel Mean Embeddings. Proceedings of Machine Learning Research. PMLR, 2019.
- Remer et al. [2005] L. A. Remer, Y. J. Kaufman, D. Tanré, S. Mattoo, D. A. Chu, J. V. Martins, R.-R. Li, C. Ichoku, R. C. Levy, R. G. Kleidman, T. F. Eck, E. Vermote, and B. N. Holben. The MODIS Aerosol Algorithm, Products, and Validation. Journal of the Atmospheric Sciences, 2005.
- Platnick et al. [2003] S. Platnick, M.D. King, S.A. Ackerman, W.P. Menzel, B.A. Baum, J.C. Riedi, and R.A. Frey. The MODIS cloud products: algorithms and examples from Terra. IEEE Transactions on Geoscience and Remote Sensing, 2003.
- Stephens et al. [2002] Graeme L Stephens, Deborah G Vane, Ronald J Boain, Gerald G Mace, Kenneth Sassen, Zhien Wang, Anthony J Illingworth, Ewan J O’connor, William B Rossow, Stephen L Durden, et al. The CloudSat mission and the A-train: A new dimension of space-based observations of clouds and precipitation. Bulletin of the American Meteorological Society, 2002.
- Barnes et al. [1998] William L. Barnes, Thomas S. Pagano, and Vincent V. Salomonson. Prelaunch characteristics of the Moderate Resolution Imaging Spectroradiometer (MODIS) on EOS-AM1. IEEE Transactions on Geoscience and Remote Sensing, 1998.
- Malenovský et al. [2012] Zbyněk Malenovský, Helmut Rott, Josef Cihlar, Michael E. Schaepman, Glenda García-Santos, Richard Fernandes, and Michael Berger. Sentinels for science: Potential of Sentinel-1, -2, and -3 missions for scientific observations of ocean, cryosphere, and land. Remote Sensing of Environment, 2012.
- Knight and Kvaran [2014] Edward J. Knight and Geir Kvaran. Landsat-8 operational land imager design. Remote Sensing of Environment, 2014.
- Zhang et al. [2020] Yivan Zhang, Nontawat Charoenphakdee, Zhenguo Wu, and Masashi Sugiyama. Learning from aggregate observations. In Advances in Neural Information Processing Systems, 2020.
- Law et al. [2018] Leon Ho Chung Law, Dino Sejdinovic, Ewan Cameron, Tim C.D. Lucas, Seth Flaxman, Katherine Battle, and Kenji Fukumizu. Variational learning on aggregate outputs with Gaussian processes. In Advances in Neural Information Processing Systems, 2018.
- Hamelijnck et al. [2019] Oliver Hamelijnck, Theodoros Damoulas, Kangrui Wang, and Mark A. Girolami. Multi-resolution multi-task Gaussian processes. In Advances in Neural Information Processing Systems, 2019.
- Yousefi et al. [2019] Fariba Yousefi, Michael Thomas Smith, and Mauricio A. Álvarez. Multi-task learning for aggregated data using Gaussian processes. In Advances in Neural Information Processing Systems, 2019.
- Tanaka et al. [2019] Yusuke Tanaka, Toshiyuki Tanaka, Tomoharu Iwata, Takeshi Kurashima, Maya Okawa, Yasunori Akagi, and Hiroyuki Toda. Spatially aggregated Gaussian processes with multivariate areal outputs. Advances in Neural Information Processing Systems, 2019.
- Ville Tanskanen , Krista Longi [2020] Arto Klam Ville Tanskanen , Krista Longi. Non-Linearities in Gaussian Processes with Integral Observations. IEEE international Workshop on Machine Learning for Signal, 2020.
- Rasmussen and Williams [2005] C Rasmussen and C Williams. Gaussian Processes for Machine Learning, 2005.
- Titsias [2009] Michalis K. Titsias. Variational learning of inducing variables in sparse gaussian processes. In AISTATS, 2009.
- Vaughan et al. [2021] Anna Vaughan, Will Tebbutt, J Scott Hosking, and Richard E Turner. Convolutional conditional neural processes for local climate downscaling. Geoscientific Model Development Discussions, pages 1–25, 2021.
- Groenke et al. [2020] Brian Groenke, Luke Madaus, and Claire Monteleoni. Climalign: Unsupervised statistical downscaling of climate variables via normalizing flows. In Proceedings of the 10th International Conference on Climate Informatics, pages 60–66, 2020.
- Vandal et al. [2017] Thomas Vandal, Evan Kodra, Sangram Ganguly, Andrew Michaelis, Ramakrishna Nemani, and Auroop R Ganguly. Deepsd: Generating high resolution climate change projections through single image super-resolution. In Proceedings of the 23rd acm sigkdd international conference on knowledge discovery and data mining, pages 1663–1672, 2017.
- Eyring et al. [2016] Veronika Eyring, Sandrine Bony, Gerald A Meehl, Catherine A Senior, Bjorn Stevens, Ronald J Stouffer, and Karl E Taylor. Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geoscientific Model Development, 2016.
- Flato [2011] Gregory M. Flato. Earth system models: an overview. WIREs Climate Change, 2011.
- Scholze et al. [2012] Marko Scholze, J. Icarus Allen, William J. Collins, Sarah E. Cornell, Chris Huntingford, Manoj M. Joshi, Jason A. Lowe, Robin S. Smith, and Oliver Wild. Earth system models. Cambridge University Press, 2012.
- Muandet et al. [2016a] Krikamol Muandet, Kenji Fukumizu, Bharath Sriperumbudur, and Bernhard Schölkopf. Kernel mean embedding of distributions: A review and beyond. arXiv preprint arXiv:1605.09522, 2016a.
- Grünewälder et al. [2012] Steffen Grünewälder, Guy Lever, Luca Baldassarre, Sam Patterson, Arthur Gretton, and Massimilano Pontil. Conditional Mean Embeddings as Regressors. In Proceedings of the 29th International Coference on International Conference on Machine Learning, 2012.
- Szabó et al. [2016] Zoltán Szabó, Bharath K. Sriperumbudur, Barnabás Póczos, and Arthur Gretton. Learning theory for distribution regression. Journal of Machine Learning Research, 2016.
- Singh et al. [2019] Rahul Singh, Maneesh Sahani, and Arthur Gretton. Kernel instrumental variable regression. In Advances in Neural Information Processing Systems, 2019.
- Song et al. [2013] Le Song, Kenji Fukumizu, and Arthur Gretton. Kernel embeddings of conditional distributions: A unified kernel framework for nonparametric inference in graphical models. IEEE Signal Processing Magazine, 2013.
- Fukumizu et al. [2004] Kenji Fukumizu, Francis R Bach, and Michael I Jordan. Dimensionality reduction for supervised learning with reproducing kernel hilbert spaces. Journal of Machine Learning Research, 2004.
- Fukumizu et al. [2008] Kenji Fukumizu, Arthur Gretton, Xiaohai Sun, and Bernhard Schölkopf. Kernel measures of conditional dependence. In Advances in Neural Information Processing Systems, 2008.
- Sriperumbudur et al. [2012] Bharath K. Sriperumbudur, Kenji Fukumizu, Arthur Gretton, Bernhard Schölkopf, and Gert R. G. Lanckriet. On the empirical estimation of integral probability metrics. Electronic Journal of Statistics, 2012.
- Song et al. [2009] Le Song, Jonathan Huang, Alex Smola, and Kenji Fukumizu. Hilbert space embeddings of conditional distributions with applications to dynamical systems. In Proceedings of the 26th Annual International Conference on Machine Learning, 2009.
- Larkin [1972] FM Larkin. Gaussian measure in Hilbert space and applications in numerical analysis. The Rocky Mountain Journal of Mathematics, 1972.
- Briol et al. [2019] François-Xavier Briol, Chris J Oates, Mark Girolami, Michael A Osborne, Dino Sejdinovic, et al. Probabilistic integration: A role in statistical computation? Statistical Science, 2019.
- Rudner et al. [2020] Tim GJ Rudner, Dino Sejdinovic, and Yarin Gal. Inter-domain deep Gaussian processes. In International Conference on Machine Learning, 2020.
- Muandet et al. [2016b] Krikamol Muandet, Bharath Sriperumbudur, Kenji Fukumizu, Arthur Gretton, and Bernhard Schölkopf. Kernel mean shrinkage estimators. Journal of Machine Learning Research, 2016b.
- Paulsen and Raghupathi [2016] Vern Paulsen and Mrinal Raghupathi. An introduction to the theory of reproducing kernel Hilbert spaces. Cambridge university press, 2016.
- Caponnetto and De Vito [2007] Andrea Caponnetto and Ernesto De Vito. Optimal rates for the regularized least-squares algorithm. Foundations of Computational Mathematics, 2007.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32. 2019.
- Gardner et al. [2018] Jacob Gardner, Geoff Pleiss, Kilian Q Weinberger, David Bindel, and Andrew G Wilson. Gpytorch: Blackbox matrix-matrix Gaussian process inference with GPU acceleration. In Advances in Neural Information Processing Systems, 2018.
- Pedregosa et al. [2011] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 2011.
- Kingma and Ba [2015] Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, ICLR, 2015.
- Watson-Parris et al. [2016] D. Watson-Parris, N. Schutgens, N. Cook, Z. Kipling, P. Kershaw, E. Gryspeerdt, B. Lawrence, and P. Stier. Community Intercomparison Suite (CIS) v1.4.0: a tool for intercomparing models and observations. Geoscientific Model Development, 2016.
- Roberts [2018 v20180730] Malcolm Roberts. MOHC HadGEM3-GC31-HM model output prepared for CMIP6 HighResMIP hist-1950. Earth System Grid Federation, 2018 v20180730. doi: 10.22033/ESGF/CMIP6.6040.
- Voldoire [2019 v20190221] Aurore Voldoire. CNRM-CERFACS CNRM-CM6-1-HR model output prepared for CMIP6 HighResMIP hist-1950. Earth System Grid Federation, 2019 v20190221. doi: 10.22033/ESGF/CMIP6.4040.
- Rahimi et al. [2007] Ali Rahimi, Benjamin Recht, et al. Random features for large-scale kernel machines. In Advances in Neural Information Processing Systems, 2007.
- Kallenberg [2002] Olav Kallenberg. Foundations of Modern Probability. Springer, 2002.
- Micchelli and Pontil [2005] Charles A Micchelli and Massimiliano Pontil. On learning vector-valued functions. Neural computation, 2005.
- Law et al. [2019] Ho Chung Law, Peilin Zhao, Leung Sing Chan, Junzhou Huang, and Dino Sejdinovic. Hyperparameter learning via distributional transfer. In Advances in Neural Information Processing Systems, 2019.
- Steinwart and Christmann [2008] Ingo Steinwart and Andreas Christmann. Support Vector Machines. Springer Publishing Company, Incorporated, 2008.
Appendix A Proofs
A.1 Proofs of Section 3
Proposition A.1.
Let such that . Then, is a full measure set with respect to .
Proof.
Since is a Borel space and is measurable, the existence of a -a.e. regular conditional probability distribution is guaranteed by [45, Theorem 6.3]. Now suppose and let . Since , the conditional expectation must have finite expectation almost everywhere, i.e. . ∎
Proposition 3.2.
Suppose and and let . Then is a Gaussian process a.s. , specified by
| (13) |
. Furthermore, a.s.
Proof of Proposition 3.2.
We will assume for the sake of simplicity that in the following derivations and will return to the case of an uncentered GP at the end of the proof.
Show that is in a space of Gaussian random variables
Let denote a probability space and the space of square integrable random variables endowed with standard inner product. , since is Gaussian, then . We can hence define as the closure in of the vector space spanned by , i.e. .
Elements of write as limits of centered Gaussian random variables, hence when their covariance sequence converge, they are normally distributed. Let , then we have . Let , we also have
| (14) |
In order to switch orders of integration, we need to show that the double integral satisfies absolute convergence.
| (15) | ||||
| (16) | ||||
| (17) |
Since , . Plus, as we assume that , Proposition A.1 gives that a.s. We can thus apply Fubini’s theorem and obtain
| (18) |
As this holds for any , we conclude that . We cannot claim yet though that is Gaussian since we do not know whether it results from a sequence of Gaussian variables with converging variance sequence. We now have to prove that has a finite variance.
Show that has finite variance
We proceed by computing the expression of the covariance between and which is more general and yields the variance.
Let , the covariance of and is given by
| (19) | ||||
| (20) | ||||
| (21) |
Choosing as a constant random variable in the above, we can show that a.s. We can hence apply Fubini’s theorem to switch integration order in the mean terms (21) and obtain that since is centered.
To apply Fubini’s theorem to (20), we need to show that the triple integration absolutely converges. Let , we know that . Using similar arguments as above, we obtain
| (22) |
We can thus apply Fubini’s theorem which yields
| (23) | ||||
| (24) | ||||
| (25) | ||||
| (26) |
where denote random variables with same joint distribution than as defined in the proposition.
and has finite variance a.s., it is thus a centered Gaussian random variable a.s. Furthermore, as this holds for any , then any finite subset of follows a multivariate normal distribution which shows that is a centered Gaussian process on and its covariance function is specified by .
Uncentered case
We now return to an uncentered GP prior on with assumption that . By Proposition A.1, we get that a.s. for .
Let . We can clearly rewrite as the sum of and a centered GP on
| (27) |
which is well-defined almost surely.
It hence comes . Plus since is a constant shift, the covariance is not affected and has the same expression than for the centered GP. Since this holds for any , we conclude that a.s.
Show that
First, we know by Proposition A.1 that -a.e. .By triangular inequality, we obtain -a.e. and hence is well-defined up to a set of measure zero with respect to .
Proposition 3.3.
Given aggregate observations with homoscedastic noise , the deconditional posterior of is defined as the Gaussian process where
| (33) | ||||
| (34) |
Proof of Proposition 3.3.
Recall that
| (35) |
where .
Applying Gaussian conditioning, we obtain that
| (36) | ||||
| (37) |
Since the latter holds for any input , by Kolmogorov extension theorem this implies that conditioned on the data is a draw from a GP. We denote it and it is specified by
| (38) | ||||
| (39) |
Note that we abuse notation
| (40) | ||||
| (41) | ||||
| (42) |
∎
A.2 Proofs of Section 4
Proposition 4.1 (Empirical DMO as vector-valued regressor).
The minimiser of the empirical reconstruction risk is the empirical DMO, i.e.
Proof of Proposition 4.1.
Let , we recall the form of the regularised empirical objective
| (43) |
By [46, Theorem 4.1], if , then it is unique and has form
| (44) |
where is the vector-valued kernel ’s feature map indexed by , such that for any and , we have . (see [35] for a detailed review of vector-valued RKHS). Furthermore, coefficients are the unique solutions to
| (45) |
Since
| (46) |
where denotes the identity operator on . The above simplifies as
| (47) | ||||
| (48) | ||||
| (49) |
where .
Theorem 4.2 (Empirical DMO Convergence Rate).
Denote . Assume assumptions stated in Appendix D are satisfied. In particular, let and be the parameters of the restricted class of distribution for and respectively and let be the Hölder continuity exponent in . Then, if we choose , where , we have the following result,
-
•
If , then with
-
•
If , then with
Appendix B Variational formulation of the deconditional posterior
Inference computational complexity is for the posterior mean and for the posterior covariance. To scale to large datasets, we introduce in the following a variational formulation as a scalable approximation to the deconditional posterior . Without loss of generality, we assume in the following that is centered, i.e. .
B.1 Variational formulation
We consider a set of inducing locations and define inducing points as the gaussian vector , where . We set -dimensional variational distribution over inducing points and define as an approximation of the deconditional posterior . The estimation of the deconditional posterior can thus be approximated by optimising the variational distribution parameters , to maximise the evidence lower bound (ELBO) objective given by
| (58) |
As both and are Gaussians, the Kullback-Leibler divergence admits closed-form. The expected log likelihood term decomposes as
| (59) |
where and are the parameters of the posterior variational distribution given by
| (60) |
Given this objective, we can optimise this lower bound with respect to variational parameters , noise and parameters of kernels and , with an option to parametrize these kernels using feature maps given by deep neural network [47], using a stochastic gradient approach for example. We might also want to learn the inducing locations .
B.2 Details on evidence lower bound derivation
For completeness, we provide here the derivation of the evidence lower bound objective. Let us remind its expression as stated in (58)
| (61) |
The second term here is the Kullback-Leibler divergence of two gaussian densities which has a known and tractable closed-form expression.
| (62) |
The first term is the expected log likelihood and needs to be derived. Using properties of integrals of gaussian densities, we can start by showing that also corresponds to a gaussian density which comes
| (63) | ||||
| (64) | ||||
| (65) |
where
| (66) | ||||
| (67) |
Let’s try now to obtain a closed-form expression of on which we will be able to perform a gradient-based optimization routine. Using Gaussian conditioning on (5), we obtain
| (68) |
We notice that .
Hence we also have .
We can thus simplify (68) as
| (69) |
Then,
| (70) | ||||
| (71) |
Using the trace trick to express the expectation with respect to the posterior variational parameters , we have
| (72) | ||||
| (73) | ||||
| (74) |
And
| (76) | ||||
| (77) |
Hence, it comes that
| (78) | ||||
| (79) |
which can be efficiently computed as it only requires diagonal terms.
Wrapping up, we obtain that
| (80) |
Appendix C Details on Conditional Mean Shrinkage Operator
C.1 Deconditional posterior with Conditional Mean Shrinkage Operator
We recall from Proposition 3.3 that the deconditional posterior is a GP specifed by mean and covariance functions
| (81) | ||||
| (82) |
for any , where we abuse notation for the cross-covariance term
| (83) |
The CMO appears in the cross-covariance term and in the CMP covariance matrix . To derive empirical versions using the Conditional Mean Shrinkage Operator we replace it by .
The empirical cross-covariance operator with shrinkage CMO estimate is given by
| (84) | ||||
| (85) | ||||
| (86) |
where we abuse notation
| (87) | ||||
| (88) |
The empirical shrinkage CMP covariance matrix is given by
| (89) | ||||
| (90) | ||||
| (91) |
where with similar notation abuse
| (92) |
Substituting the latters into (81) and (82), we obtain empirical estimates of the deconditional posterior with shrinkage CMO estimator defined as
| (93) | |||
| (94) |
for any .
Note that as the number of bags increases, it is possible to derive a variational formulation similar to the one proposed in Section B that leverages the shrinkage estimator to further speed up the overall computation.
C.2 Ablation Study
In this section we will present an ablation study on the shrinkage CMO estimator. The key is to illustrate that the Shrinkage CMO performs on par with the standard CMO estimator but is much faster to compute.
In the following, we will sample bag data of the form and , i.e there are bags with elements inside each. We first sample bag labels and for each bag , we sample observations .
Recall in standard CME one would need to repeat the number of bag labels to match the cardinality of , i.e estimating CME using data .
Denote as the standard CMO estimator and as the shrinkage CMO estimator. We will compare the RMSE between the two estimator when tested on a grid of test points , i.e comparing the RMSE of the values between and for each . We also report the time in seconds needed to compute the estimator. The following results are ran on a CPU. Kernel hyperparameters are chosen using the median heuristic. The regularisation for both estimator is set to .


Figures 4 and 5 show how shrinkage CMO performed compared to the standard CMO in a small data regime. Now when we increase the data size, we will start to see the major computational differences. (See Figures 6 and 7)


Appendix D Details on Convergence Result
In this section, we provide insights about the convergence results stated in Section 4. These results are largely based on the impactful work of Caponnetto and De Vito [36], Szabó et al. [24] and Singh et al. [25] which we modify to fit our problem setup. Each assumption that we make is adapted from a similar assumption made in those works, for which we provide intuition and a detailed justification. We start by redefining the mathematical tools introduced in these works that are necessary to state our result.
D.1 Definitions and spaces
We start by providing a general definition of covariance operators over vector-valued RKHS, which will allow us to specify a class of probability distributions for our convergence result.
Definition D.1 (Covariance operator).
Let a Polish space endowed with measure , a real separable Hilbert space and an operator-valued kernel spanning a -valued RKHS .
The covariance operator of is defined as the positive trace class operator given by
| (95) |
where denotes the space of bounded linear operators over .
Definition D.2 (Power of self-adjoint Hilbert operator).
Let a compact self-adjoint Hilbert space operator with spectral decomposition on basis of . The th power of is defined as .
Using the covariance operator, we now introduce a general class of priors that does not assume parametric distributions, by adapting to our setup a definition originally introduced by Caponnetto and De Vito [36]. This class captures the difficulty of a regression problem in terms of two simple parameters, and [24].
Definition D.3 ( class).
Let an expected risk function over and . Then given and , we say that is a class probability measure w.r.t. if
-
1.
Range assumption: such that with for some
-
2.
Spectral assumption: the eigenvalues of satisfy for some
The range assumption controls the functional smoothness of as larger corresponds to increased smoothness. Specifically, elements of admit Fourier coefficients such that . In the limit , we obtain . Since ranked eigenvalues are positive and , greater power of the covariance operator give rise to faster decay of the Fourier coefficients and hence smoother operators.
The spectral assumptions can be read as a polynomial decay over the eigenvalues of . Thus, larger leads to enhanced decay and concretely in a smaller effective input dimension.
D.2 Complete statement of the convergence result
The following result corresponds to a detailed version of Theorem 4.2 where all the assumptions are explicitly stated. As such, its proof also constitutes the proof for Theorem 4.2.
Theorem D.4 (Empirical DMO Convergence Rate).
Assume that
-
1.
and are Polish spaces, i.e. separable and completely metrizable topoligical spaces
-
2.
and are continuous, bounded, their canonical feature maps and are measurable and is characteristic
-
3.
is finite dimensional
-
4.
and
-
5.
The operator family is Hölder continuous with exponent
-
6.
is a class probability measure w.r.t. and is a class probability measure w.r.t.
-
7.
, almost surely
Let . Then, if we choose and where , we have
-
•
If , then with
-
•
If , then with
Proof of Theorem 4.2.
Assumption 1
Assume observation model , with and suppose is not constant in .
In this work, the observation model considered is and the objective is to recover the underlying random variable which noisy conditional expectation is observed. The latter presumes that we could bring to ’s resolution. We can model it by introducing “pre-aggregation” observation model such that and is a noise term at individual level satisfying .
Assumption 2
and are Polish spaces.
We also make this assumption.
Assumption 3
and are continuous and bounded, their canonical feature maps are measurable and is characteristic.
We make the same assumptions. The separability of and along with continuity assumptions on kernels allow to propagate separability to their associated RKHS and and to the vector-valued RKHS . Boundedness and continuity on kernels ensure the measurability of the CMO and hence that measures on and can be extended to and . The assumption on being characteristic ensures that conditional mean embeddings uniquely embed conditional distributions and henceforth operators over are identified.
Assumption 4
.
This property stronger is than what the actual conditional mean operator needs to satisfy, but it is necessary to make sure the problem is well-defined. We also make this assumption.
Assumption 5
is a class probability measure, with
As explained by Singh et al. [25], this is further required to bound the approximation error which we also make. Through the definition of the class, this hypothesis assumes the existence of a probability measure over we denote . Since is Polish (proof below), the latter can be constructed as an extension of over the Borel -algebra associated to [48, Lemma A.3.16].
Assumption 6
is a Polish space
Since is continuous and is separable, is a separable Hilbert space which makes it Polish.
Assumption 7
The operator family is
-
•
Uniformly bounded in Hilbert-Schmidt norm, i.e. such that ,
-
•
Hölder continuous in operator norm, i.e. such that ,
where denotes the space of bounded linear operator between and .
Since we assume finite dimensionality of , we make a stronger assumption than the boundedness in Hilbert-Schmidt norm which we obtain as
| (96) | ||||
| (97) | ||||
| (98) |
Hölder continuity is a mild assumption commonly satisfied as stated in [24].
Assumption 8
and is a space of bounded functions almost surely
We assume that the true minimiser of is in to have a well-defined problem. The second assumption here is expressed in terms of probability measure over . We do also assume that there exists such that , almost surely.
Assumption 9
is a class probability measure, with and
This last hypothesis is not required per se to obtain a bound on the excess error of regularized estimate . However, it allows to simplify the bounds and state them in terms of parameters and which characterize efficient input size and functional smoothness respectively.
Furthermore, a premise to this assumption is the existence of a probability measure over that we denote . Since is continuous and separable, it makes a separable and thus Polish. We can then construct by extension of [48, Lemma A.3.16] ∎
This theorem underlines a trade-off between the computational and statistical efficiency w.r.t. the datasets cardinalities and and the problem difficulty .
For , smaller means less samples from at fixed and thus computational savings. But it also hampers convergence, resulting in reduced statistical efficiency. At , convergence rate is a minimax computational-statistical efficiency optimal, i.e. convergence rate is optimal with smallest possible . We note that at this optimal, and hence we require less samples from . does not improve the convergence rate but increases the size of and hence the computational cost it bears.
We also note that larger Hölder exponents , which translates in smoother kernels, leads to reduced . Similarly, since and are strictly decreasing functions over , stronger range assumptions regularity which means smoother operators reduces the number of sample needed from to achieve minimax optimality. Smoother problems do hence require fewer samples.
Larger spectral decay exponent translate here in requiring more samples to reach minimax optimality and undermines optimal convergence rate. Hence problems with smaller effective input dimension are harder to solve and require more samples and iterations.
Appendix E Additional Experimental Results
E.1 Swiss Roll Experiment
E.1.1 Statistical significance table
| Matching | cmp | bagg-gp | varcmp | vbagg | gpr | s-cmp | |
|---|---|---|---|---|---|---|---|
| Direct | cmp | - | - | - | - | - | - |
| bagg-gp | 0.00006 | - | - | - | - | - | |
| varcmp | 0.00008 | 0.00006 | - | - | - | - | |
| vbagg | 0.00006 | 0.00006 | 0.005723 | - | - | - | |
| gpr | 0.00006 | 0.00006 | 0.00006 | 0.00006 | - | - | |
| s-cmp | 0.00006 | 0.00006 | 0.000477 | 0.014269 | 0.00006 | - | |
| Indirect | cmp | - | - | - | - | - | - |
| bagg-gp | 0.011129 | - | - | - | - | - | |
| varcmp | 0.001944 | 0.015240 | - | - | - | - | |
| vbagg | 0.000089 | 0.047858 | 0.000089 | - | - | - | |
| gpr | 0.025094 | 0.047858 | 0.047858 | 0.851925 | - | - | |
| s-cmp | 0.000089 | 0.002821 | 0.000089 | 0.000140 | 0.052222 | - |
E.1.2 Compute and Resources Specifications
Computations for all experiments were carried out on an internal cluster. We used a single GeForce GTX 1080 Ti GPU to speed up computations and conduct each experiment with multiple initialisation seeds. We underline however that the experiment does not require GPU acceleration and can be performed on CPU in a timely manner.
E.2 CMP with high-resolution noise observation model
E.2.1 Deconditional posterior with high-resolution noise
Beyond observation noise on the aggregate observations as introduced in Section LABEL:sec:_deconditional_posterior, it is natural to also consider observing noise at the high-resolution level, i.e. noises placed on level directly in addition to the one at aggregate level. Let the zero-mean Gaussian process with covariance function
| (99) |
By incorporating this gaussian noise process in the integrand, we can replace the definition of the CMP by
| (100) |
where is the high-resolution noise standard deviation parameter. Essentially, this amounts to consider a contaminated covariance for the HR observation process. This covariance is defined as
| (101) |
Provided the same regularity assumptions as in Proposition 3.2, the covariance of the CMP becomes — the mean and cross-covariance terms are not affected. Similarly be written in terms of conditional mean embeddings, but using as an integrand for the CMEs the canonical feature maps induced by , i.e. for any . Critically, this is reflected in the expression of the empirical CMP covariance which writes
| (102) |
thus, yielding matrix form
| (103) | ||||
| (104) | ||||
| (105) |
which can readily be used in (8) and (9) to compute the deconditional posterior.
This high-resolution noise term introduces an additional regularization to the model that helps preventing degeneracy of the deconditional posterior covariance. Indeed, we have
| (106) | ||||
| (107) | ||||
| (108) |
where on the last line we have used the Woodburry identity. We can see that when , (108) degenerates to . The aggregate observation model noise provides a first layer of regularization at low-resolution. The high-resolution noise supplements it, making for a more stable numerical compuation for the empirical covariance matrix.
E.2.2 Variational deconditional posterior with high-resolution noise
The high-resolution noise observation process can also be incorporated into the variational derivation to obtain a slightly different ELBO objective. We have
| (109) | ||||
| (110) | ||||
| (111) |
The expected loglikelihood with respect to the variational posterior hence writes
| (112) | ||||
| (113) |
E.3 Mediated downscaling of atmospheric temperature
E.3.1 Map visualization of atmospheric fields dataset
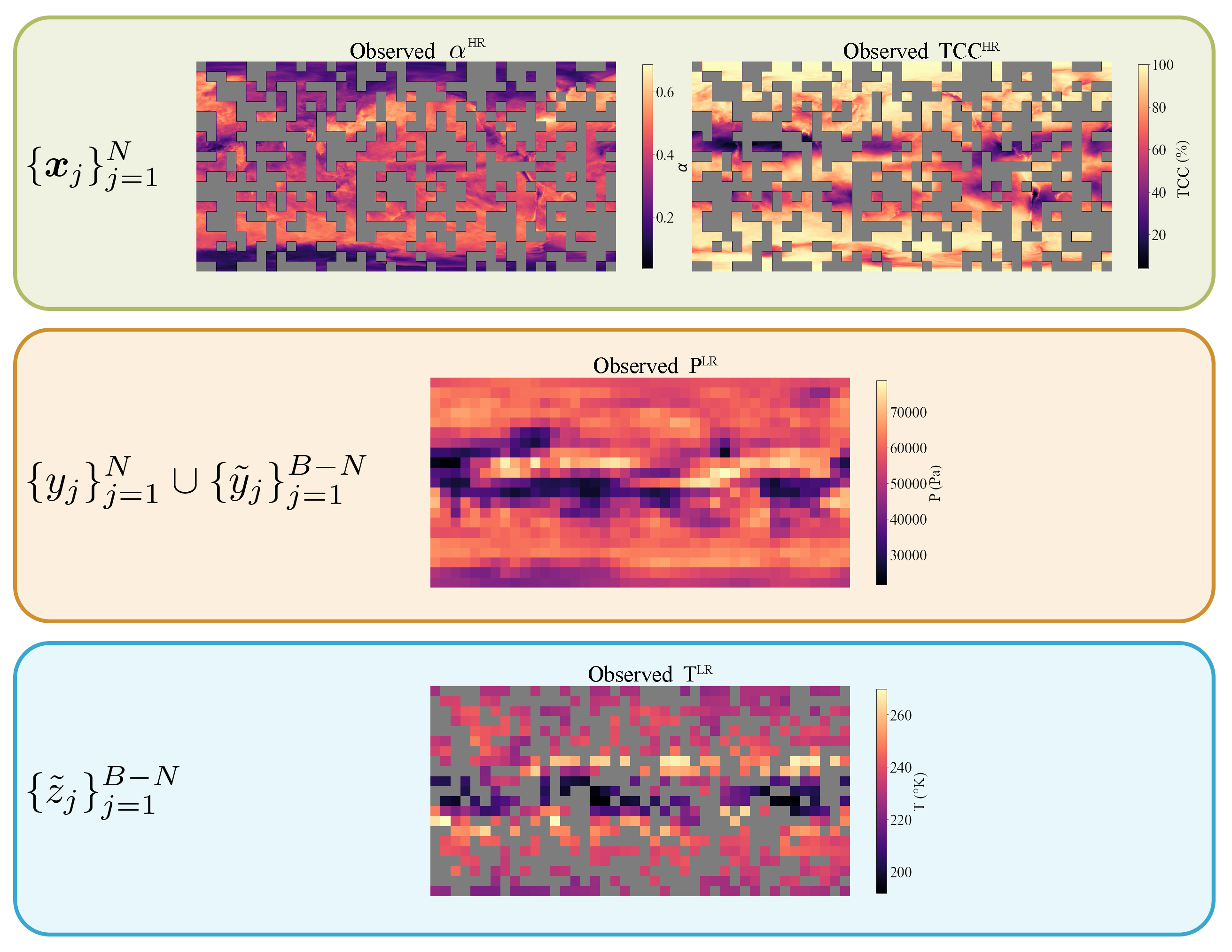
E.3.2 Downscaling prediction maps



E.3.3 Statistical significance table
| Metric | varcmp | vbagg | vargpr | |
|---|---|---|---|---|
| varcmp | - | - | - | |
| RMSE | vbagg | 0.005062 | - | - |
| vargpr | 0.006910 | 0.046853 | - | |
| varcmp | - | - | - | |
| MAE | vbagg | 0.005062 | - | - |
| vargpr | 0.059336 | 0.006910 | - | |
| varcmp | - | - | - | |
| CORR | vbagg | 0.005062 | - | - |
| vargpr | 0.016605 | 0.028417 | - | |
| varcmp | - | - | - | |
| SSIM | vbagg | 0.005062 | - | - |
| vargpr | 0.959354 | 0.005062 | - |
E.3.4 Compute and Resources Specifications
Computations for all experiments were carried out on an internal cluster. We used a single GeForce GTX 1080 Ti GPU to speed up computations and conduct each experiment with multiple initialisation seeds.