Deep ad-hoc beamforming
Abstract
Far-field speech processing is an important and challenging problem. In this paper, we propose deep ad-hoc beamforming, a deep-learning-based multichannel speech enhancement framework based on ad-hoc microphone arrays, to address the problem. It contains three novel components. First, it combines ad-hoc microphone arrays with deep-learning-based multichannel speech enhancement, which reduces the probability of the occurrence of far-field acoustic environments significantly. Second, it groups the microphones around the speech source to a local microphone array by a supervised channel selection framework based on deep neural networks. Third, it develops a simple time synchronization framework to synchronize the channels that have different time delay. Besides the above novelties and advantages, the proposed model is also trained in a single-channel fashion, so that it can easily employ new development of speech processing techniques. Its test stage is also flexible in incorporating any number of microphones without retraining or modifying the framework. We have developed many implementations of the proposed framework and conducted an extensive experiment in scenarios where the locations of the speech sources are far-field, random, and blind to the microphones. Results on speech enhancement tasks show that our method outperforms its counterpart that works with linear microphone arrays by a considerable margin in both diffuse noise reverberant environments and point source noise reverberant environments. We have also tested the framework with different handcrafted features. Results show that although designing good features lead to high performance, they do not affect the conclusion on the effectiveness of the proposed framework.
keywords:
Adaptive beamforming , ad-hoc microphone array , channel selection , deep learning , distributed microphone array1 Introduction
Deep learning based speech enhancement has demonstrated its strong denoising ability in adverse acoustic environments [Wang & Chen, 2018], which has attracted much attention since its first appearance [Wang & Wang, 2013]. Although many positive results have been observed, existing deep-learning-based speech enhancement and its applications were studied mostly with a single microphone or a conventional microphone array, such as a linear array in a portable equipment. Its performance drops when the distance between the speech source and the microphone (array) is enlarged. Finally, how to maintain the enhanced speech at the same high quality throughout an interested physical space becomes a new problem.
Ad-hoc microphone arrays provide a potential solution to the above problem. As illustrated in Fig. 1, an ad-hoc microphone array is a set of randomly distributed microphones. The microphones collaborate with each other. Compared to the conventional microphone arrays, an ad-hoc microphone array has the following two advantages. First, it has a chance to enhance a speaker’s voice with equally good quality in a range where the array covers. Second, its performance is not limited to the physical size of application devices, e.g. cell-phones, gooseneck microphones, or smart speaker boxes. Ad-hoc microphone arrays also have a chance to be widespread in real-world environments, such as meeting rooms, smart homes, and smart cities. The research on ad-hoc microphone arrays is an emerging direction [Markovich-Golan et al., 2012, Heusdens et al., 2012, Zeng & Hendriks, 2014, Wang et al., 2015, O’Connor et al., 2016, O’Connor & Kleijn, 2014, Tavakoli et al., 2016, Jayaprakasam et al., 2017, Tavakoli et al., 2017, Zhang et al., 2018, Wang & Cavallaro, 2018, Koutrouvelis et al., 2018]. It contains at least the following three fundamental problems:
-
1.
Channel selection. Because the microphones may distribute in a large area, taking all microphones into consideration may not be the best way, since that the microphones that are far away from the speech source may be too noisy. Channel selection aims to group a handful microphones around a speaker into a local microphone array from a large number of randomly distributed microphones.
-
2.
Device synchronization. Because the microphones are distributed in different positions and maybe also different devices, their output signals may have different time delay, clock rates, or adaptive gain controllers. Device synchronization aims to synchronize the signals from the microphones, so as to fascinate its following specific applications.
-
3.
Task-driven multichannel signal processing. It aims to maximize the performance of a specific task by, e.g., adapting a multichannel signal processing algorithm designed for a conventional array to an ad-hoc array. The tasks include speech enhancement, multi-talker speech separation, speech recognition, speaker recognition, etc.
However, current research on ad-hoc microphone arrays is still at the beginning. For example, some work discussed a so called message passing problem between microphones where it assumes that the ground-truth noise spectrum is known [Heusdens et al., 2012] or the steering vectors from speech sources to microphones are known [Zeng & Hendriks, 2014]. Some work focused on the channel selection problem in an ideal scenario where perfect noise estimation and voice activity detection are available [Zhang et al., 2018]. Although some work tried to jointly conduct noise estimation and channel selection by advanced mathematical formulations, it has to make many assumptions such as the ground-truth distances between microphones, ground-truth geometry of the array, and free-space signal transmission model without reverberation [O’Connor et al., 2016].
A possible explanation for the above difficulty is that an ad-hoc microphone array lacks so much important prior knowledge while contains so many interferences that we finally have little information about the array except the received signals in the extreme case. To overcome the difficulty, we may consider the way of learning the priors, parameters, or hidden variables of the array instead of making unrealistic assumptions. Supervised deep learning, which learns prior knowledge and parameters by neural networks, provides us this opportunity as it did for the supervised speech separation with the conventional microphone arrays [Wang & Chen, 2018].
In this paper, we propose a framework named deep ad-hoc beamforming (DAB) which brings deep learning to ad-hoc microphone arrays. It has the following four novelties:
-
1.
A supervised channel selection framework is proposed. It first predicts the quality of the received speech signal of each channel by a deep neural network. Then, it groups the microphones that have high speech quality and strong cross-channel signal correlation into a local microphone array. Several channel selection algorithms have been developed, including a one-best channel selection method and several N-best channel selection methods with the positive integer either predefined or automatically determined according to different channel selection criteria.
-
2.
A simple supervised time synchronization framework is proposed. It first picks the output of the best channel as a reference signal, then estimates the relative time delay of the other channels by a traditional time delay estimator, and finally synchronize the channels according to the estimation result, where the best channel is selected in a supervised manner.
-
3.
A speech enhancement algorithm is implemented as an example. The algorithm applies the channel selection and time synchronization frameworks to deep beamforming. It is designed to demonstrate the overall effectiveness and flexibility of DAB. Its implementation is straightforward without a large modification of existing deep beamforming algorithms.
-
4.
The effects of acoustic features on performance are studied. It is known that the performance of deep-learning-based speech enhancement relies heavily on acoustic features. In this paper, we further emphasize its importance on DAB by carrying out the first study on the effects of different handcrafted features on the performance. In this study, a variant of short term Fourier transform (STFT) and the common multi-resolution cochleagram (MRCG) features are used for comparison.
We have conducted an extensive experimental comparison between DAB and its deep-learning-based multichannel speech enhancement counterpart with linear microphone arrays, in scenarios where the speech sources and microphone arrays were placed randomly in typical physical spaces with random time delay, and the noise sources were either diffuse noise or point source noise. Experimental results with noise-independent training show that DAB outperforms its counterpart by a large margin. Its experimental conclusion is consistent across different hyperparameter settings and handcrafted features, though a good handcrafted feature do improve the overall performance.
The core idea of the proposed method has been released at [Zhang, 2018]. The main difference between the method here and [Zhang, 2018] is that we have added the time synchronization module, more channel selection algorithms and experiments on the point source noise environment here, which are incremental extensions that do not affect the fundamental claim of the novelty of the paper, compared to some related methods published after [Zhang, 2018].
This paper is organized as follows. Section 2 presents mathematical notations of this paper. Section 3 presents the signal model of ad-hoc microphone arrays. Section 4 presents the framework of the proposed DAB. Section 5 presents the channel selection module of DAB. Section 6 presents the application of DAB to speech enhancement. Section 7 evaluates the effectiveness of the proposed method. Finally, Section 8 concludes our findings.
1.1 Related work
Current deep-learning-based techniques employ either a single microphone or a conventional microphone array to pick up speech signals. Here, the conventional microphone array means that the microphone array is fixed in a single device. Deep-learning-based single-channel speech enhancement, e.g. [Wang & Wang, 2013, Zhang & Wu, 2013b, Lu et al., 2013, Wang et al., 2014, Huang et al., 2015, Xu et al., 2015, Weninger et al., 2015, Williamson et al., 2016, Zhang & Wang, 2016b], employs a deep neural network (DNN), which is a multilayer perceptron with more than one nonlinear hidden layer, to learn a nonlinear mapping function from noisy speech to clean speech or its ideal time-frequency masks. This field progresses rapidly. We list some of the recent progress as follows. Phase spectrum, which was originally believed to be helpless to speech enhancement, has shown to be helpful in the deep learning methodology [Zheng & Zhang, 2018, Tan & Wang, 2019]. Some end-to-end speech enhancement methods have been proposed, including the representative gated residual networks [Tan et al., 2018], fully-convolutional time-domain audio separation network [Luo & Mesgarani, 2019], and full convolutional neural networks [Pandey & Wang, 2019]. The long-term difficulty of the nonlinear distortion of the enhanced speech for speech recognition has been overcome as well [Wang et al., 2019]. Some solid theoretical analysis on the generalization ability of the deep learning based speech enhancement has been made [Qi et al., 2019].
Deep-learning-based multichannel speech enhancement has two major forms. The first form [Jiang et al., 2014] uses a microphone array as a feature extractor to extract spatial features as the input of the DNN-based single-channel enhancement. The second form [Heymann et al., 2016, Erdogan et al., 2016], which we denote bravely as deep beamforming, estimates a monaural time-frequency (T-F) mask [Wang et al., 2014, Heymann et al., 2016, Higuchi et al., 2016] using a single-channel DNN so that the spatial covariance matrices of speech and noise can be derived for adaptive beamforming, e.g. minimum variance distortionless response (MVDR) or generalized eigenvalue beamforming. It is fundamentally a linear method, whose output does not suffer from nonlinear distortions. Due to its success on speech recognition, it has been extensively studied, including the aspects of the integration with the spatial-clustering-based masking [Nakatani et al., 2017], acoustic features [Wang & Wang, 2018], model training [Xiao et al., 2017, Tu et al., 2017, Higuchi et al., 2018, Zhou & Qian, 2018], mask estimations [Erdogan et al., 2016], post-processing [Zhang et al., 2017], rank-1 estimation of steering vectors [Taherian et al., 2019], etc.
The effectiveness of deep learning based speech enhancement lies strongly on acoustic features. The earliest studies take the concatenation of multiple acoustic features, such as STFT and Mel frequency captral coefficient (MFCC), as the input [Wang & Wang, 2013, Zhang & Wu, 2013a] for the sake of mining the complementary information between the features. Later on, Chen et al. [2014] found that cochleagram feature based on gammatone filterbanks is a strong noise-robust acoustic feature, after a wide comparison between 17 acoustic features covering gammatone-domain, autocorrelation-domain, and modulation-domain features, as well as linear prediction features, MFCC variants, pitch-based features, etc, in various adverse acoustic environments. Because STFT has a perfect inverse transform, the log spectral magnitude becomes popular [Xu et al., 2015]. Recently, Delfarah & Wang [2017] performed another feature study in room reverberant situations, where log spectral magnitude and log mel-spectrum features were further added to the comparison. The conclusions in [Chen et al., 2014] and [Delfarah & Wang, 2017] are consistent. Although learnable features are becoming a new trend [Tan et al., 2018, Luo & Mesgarani, 2019, Pandey & Wang, 2019], very recent research results demonstrate that handcrafted acoustic features are still competitive to the learnable filters, e.g. [Ditter & Gerkmann, 2020, Pariente et al., 2020]. For multichannel speech enhancement, interaural time difference, interaural level difference [Jiang et al., 2014], interaural phase difference, and their variants [Yang & Zhang, 2019] are widely used spatial features. See [Wang & Chen, 2018, Section 4] for an excellent summary on the acoustic features.
2 Notations
We first introduce some notations here. Regular lower-case letters, e.g. , , and , indicate scalars. Bold lower-case letters, e.g. and , indicate vectors. Bold capital letters, e.g. and , indicate matrices. Letters in calligraphic fonts, e.g. , indicate sets. () is a vector with all entries being 1 (0). The operator T denotes the transpose. The operator H denotes the conjugate transpose of complex numbers.

3 Signal model of ad-hoc microphone arrays
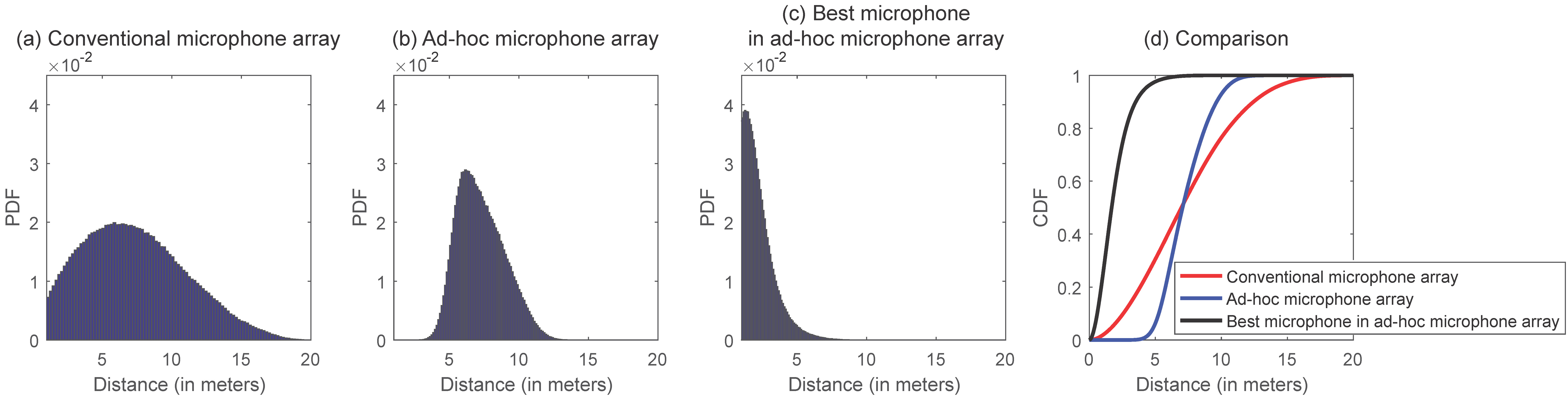
Ad-hoc microphone arrays can significantly reduce the probability of the occurrence of far-field environments. We take the case described in Fig. 2 as an example. When a speaker and a microphone array are distributed randomly in a room, the distribution of the distance between the speaker and an ad-hoc microphone array has a smaller variance than that between the speaker and a conventional microphone array (Figs. 2a and 2b). For example, the conventional array has a probability of 24% to be placed over 10 meters away from the speech source, while the number regarding to the ad-hoc array is only 7%. Particularly, the distance between the best microphone in the ad-hoc array and the speech source is only 1.9 meters on average, and the probability of the distance that is larger than 5 meters is only 2% (Fig. 2c).
Here we build the signal model of an ad-hoc microphone array. All speech enhancement methods throughout the paper operate in the frequency domain on a frame-by-frame basis. Suppose that a physical space contains one target speaker, multiple noise sources, and an ad-hoc microphone array of microphones. The physical model for the signals arrived at the ad-hoc array is assumed to be
| (1) |
where is the short-time Fourier transform (STFT) value of the target clean speech at time and frequency , is the time-invariant acoustic transfer function from the speech source to the array which is an -dimensional complex number:
| (2) |
and are the direct sound and early and late reverberation of the target signal, and is the additive noise:
| (3) | |||
| (4) |
which are the STFT values of the received signals by the -th microphone at time and frequency . Usually, we denote .
After processed by the devices where the microphones are fixed, the signals that the DAB finally receives are:
| (5) |
with . Real-world devices may cause many problems including the unsynchronization of time delay, clock rates, adaptive gain controllers, etc. Here we consider the time unsynchronization problem:
| (6) | ||||
where is the time delay caused by the th device.
4 Deep ad-hoc beamforming: A system overview
A system overview of DAB is shown in Fig. 3. It contains three core components—a supervised channel selection framework, a supervised time synchronization framework, and a speech enhancement module.
The core idea of the channel selection framework is to filter the received signals by a channel-selection vector :
| (7) |
such that the channels that output low quality speech signals can be suppressed or even discarded, where is the output mask of the channel-selection method described in the red box of Fig. 3, and denotes the element-wise product operator. Without loss of generality, we assume the selected channels are .
The time synchronization module first selects the noisy signal from the best channel, assumed to be , as a reference signal by a supervised 1-best channel selection algorithm that will be described in Section 5.2. Then, it estimates the relative time delay of the noisy signals from the selected microphones over the reference signal by a time delay estimator:
| (8) |
where is the time delay estimator with as the reference signal, and is the estimated relative time delay of over . Finally, it synchronizes the microphones according to the estimated time delay:
| (9) |
Note that consists of the relative time delay caused by both the device and the signal transmission through air. Because developing a new accurate time delay estimator is not the focus of this paper, we simply use the classic generalized cross-correlation phase transform [Knapp & Carter, 1976, Carter, 1987] as the estimator, though many other time delay estimators can be adopted as well [Chen et al., 2006]. For example, the deep neural network based time delay estimators [Wang et al., 2018], which were original proposed for the estimation of the signal direction of arrival, can be adopted here too.
The speech enhancement module takes as its input. Many deep-learning-based speech enhancement methods can be used directly or with slight modification as the speech enhancement module. Here we take the MVDR based deep beamforming as an example. Because the deep beamforming is trained in a single-channel fashion as the other parts of DAB, it makes the overall DAB flexible in incorporating any number of microphones in the test stage without retraining or modifying the DAB model. This is an important requirement of real world applications that should also be considered in other DAB implementations. Note that, if , then DAB outputs the noisy speech of the selected single channel directly without resorting to deep beamforming anymore.
In the following two sections, we will present the supervised channel selection framework and speech enhancement module respectively.
5 Supervised channel selection
The channel-selection algorithm is applied to each channel independently. It contains two steps described in the following two subsections respectively.
5.1 Channel-reweighting model
Suppose there is a test utterance of frames, and suppose the received speech signal at the -th channel is :
| (10) |
where is the amplitude spectrogram of at the -th channel.
The channel-reweighting model estimates the channel weight of the th channel by
| (11) |
where is a DNN-based channel-reweighting model, and is the average pooling result of :
| (12) |
To train , we need to first define a training target, and then extract noise-robust handcrafted features, which are described as follows.
5.1.1 Training targets
This paper uses a variant of SNR as the target:
| (13) |
where and are the direct sound and additive noise of the received noisy speech signal in time-domain.
Many measurements may be used as the training targets as well, such as the equivalent form of (13) in the time-frequency domain
| (14) |
performance evaluation metrics including signal-to-distortion ratio (SDR), short-time objective intelligibility (STOI) [Taal et al., 2011], etc., application driven metrics including equal error rate (EER) [Bai et al., 2020a], partial area under the ROC curve [Bai et al., 2020c, b], word error rate, etc, as well as other device-specific metrics including the battery life of a cell phone, etc. For example, if a cell phone is to be out of power, then DAB should prevent the cell phone being an activated channel.
5.1.2 Handcrafted features
Because the STFT feature may not be noise-robust enough, an important issue to the effectiveness of (11) is the acoustic feature. Here we introduce two handcrafted features—enhanced STFT (eSTFT) and multi-resolution cochleagram (MRCG) feature.
1) eSTFT: As shown in the red dashed box of Fig. 3, we first use a DNN-based single-channel speech enhancement method, denoted as DNN1, to generate an estimated ideal ratio mask (IRM) of the direct sound of , denoted as :
| (15) |
where is the estimate of the IRM at the -th channel. The IRM is the training target of DNN1:
| (16) |
where , , and are the amplitude spectrograms of the direct and early reverberant speech, late reverberant speech, and noise components of single-channel noisy speech respectively. Then, we denote the concatenation of the estimated IRM and the noisy feature as the eSTFT feature, which is used to replace in (12).
To discriminate the channel selection model from DNN1, we denote as DNN2. As presented above, both DNN1 and DNN2 are trained on single-channel data only instead of multichannel data from ad-hoc microphone arrays, which is an important merit for the practical use of DAB. In practice, the training data of DNN1 and DNN2 need to be independent so as to prevent overfitting.
2) MRCG: Another alternative of STFT can be MRCG, which has shown to be a noise robust acoustic feature for speech separation [Chen et al., 2014].111Code is downloadable from http://web.cse.ohio-state.edu/pnl/software.html The key idea of MRCG is to incorporate both global information and local information of speech through multi-resolution extraction. The global information is produced by extracting cochleagram features with a large frame length or a large smoothing window (i.e., low resolutions). The local information is produced by extracting cochleagram features with a small frame length and a small smoothing window (i.e., high resolutions). It has been shown that cochleagram features with a low resolution, such as frame length = 200 ms, can detect patterns of noisy speech better than that with only a high resolution, and features with high resolutions complement those with low resolutions. Therefore, concatenating them together is better than using them separately. In this paper, we adopt the implementation in [Zhang & Wang, 2016a].
Because does not need to recover the time-domain signal, many handcrafted acoustic features can be used beyond the above two examples to further improve the estimation accuracy. Some candidate acoustic features are listed in [Chen et al., 2014, Guido, 2018b]. Besides, a large family of wavelet transforms [Mallat, 1989] have not been deeply studied yet. Here we list some possible candidates for DAB: wavelet-packet transform [Sepúlveda et al., 2013], discrete shapelet transform [Guido, 2018a], fractal-wavelet transform [Guariglia & Silvestrov, 2016, Guariglia, 2019], and adaptive multiscale wavelet transform [Zheng et al., 2019].
5.2 Channel-selection algorithms
Given the estimated weights of the test utterance, many advanced sparse learning methods are able to project to , i.e. where is a channel-selection function that enforces sparse constraints on . This section designs several functions as follows.
5.2.1 One-best channel selection (1-best)
The simplest channel-selection method is to pick the channel with the highest SNR:
| (19) |
After the channel selection, DAB outputs the noisy speech from the selected channel directly.
5.2.2 All channels (all-channels)
Another simple channel-selection method is to select all channels with equivalent importance:
| (20) |
This method is an extreme case of channel selection that usually performs well when the microphones are distributed in a small space.
5.2.3 N-best channel selection with predefined (fixed-N-best)
When the microphone number is large enough, there might exist several microphones close to the speech source whose received signals are more informative than the others. It is better to group the informative microphones together into a local array instead of selecting one best channel:
| (23) |
where is the descent order of , and is a user-defined hyperparameter, .
5.2.4 N-best channel selection where is determined on-the-fly (auto-N-best)
5.2.5 Soft N-best channel selection (soft-N-best)
One way to encode the signal quality of the selected channels in (24) is to use soft weights as follows:
| (25) |
5.2.6 Machine-learning-based N-best channel selection (learning-N-best)
The above channel selection methods determine the selected channels by SNR only, without considering the correlation between the channels. As we know, the correlation between the channels, which encodes environmental information and the time delay between the microphones, is important to adaptive beamforming. Here, we develop a spectral clustering based channel selection method that takes the correlation into the design of the affinity matrix of the spectral clustering.
Unlike the other channel selection algorithms, “learning-N-best” should first conduct the time synchronization, which takes as its input. Then, it calculates the covariance matrix of the noisy speech across the channels by
| (26) |
and normalize (26) to an amplitude covariance matrix :
| (27) |
After that, it calculates a new matrix by averaging the amplitude covariance matrix along the frequency axis by
| (28) |
where is the number of the DFT bins. The affinity matrix of the spectral clustering is defined as
| (29) |
where is the identity matrix, and is a hyperparameter with a default value . Following the Laplacian eigenvalue decomposition [Ng et al., 2001] of , it obtains a -dimensional representation of the channels, , where is the representation of the th microphone and denotes the dimension of the representation.
“Learning-N-best” conducts agglomerative hierarchical clustering on , and takes the maximal lifetime of the dendrogram as the threshold to partition the microphones into clusters (), denoted as . The maximum predicted SNRs of the microphones in the clusters are denoted as respectively. Finally, it groups the microphones that satisfy the following condition into a local microphone array:
| (32) | |||
| (33) |
where .
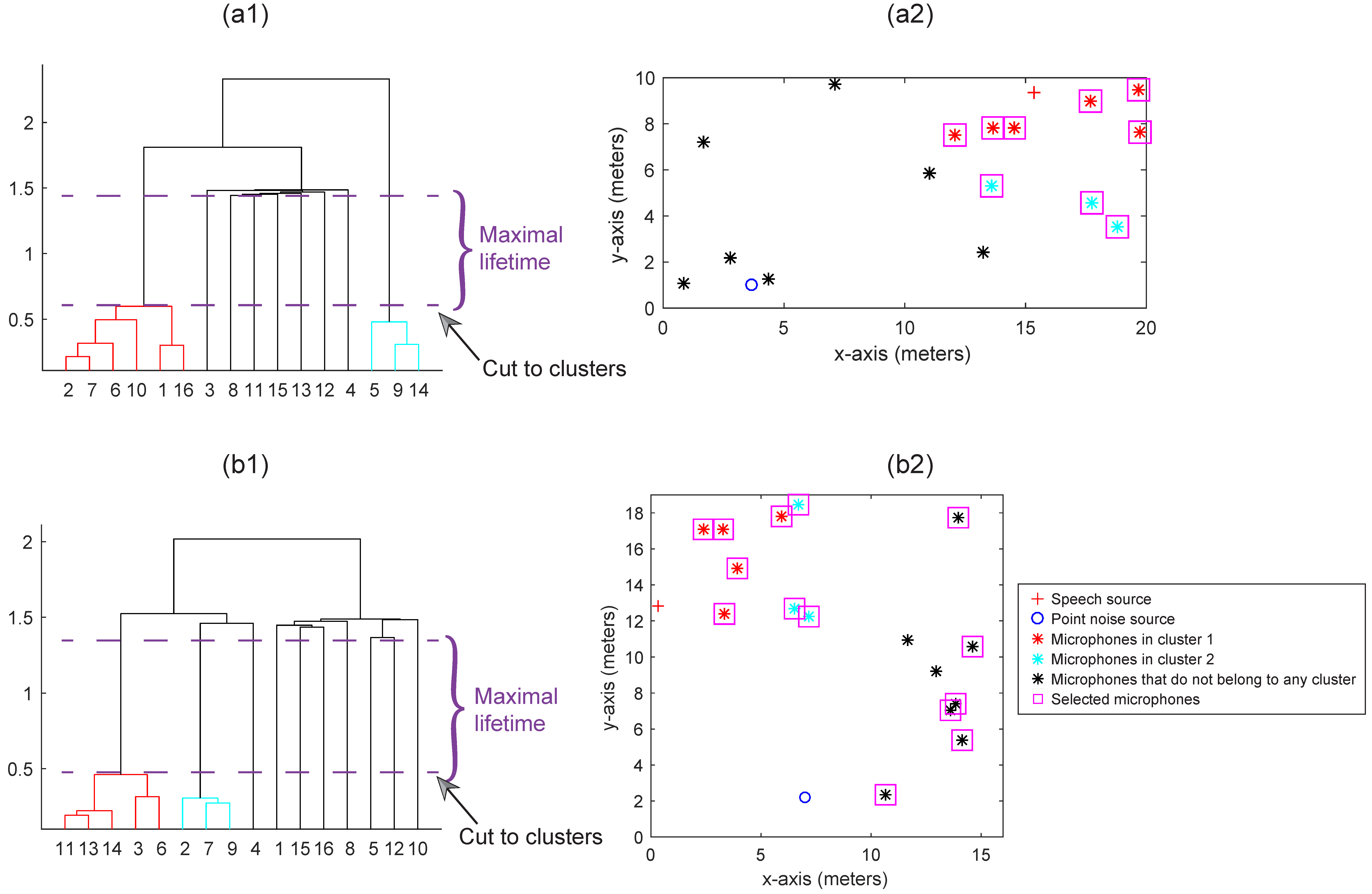
Figure 4 lists two examples of the “learning-N-best” method. From the figure, we see that the microphones around the speech sources are grouped into clusters, while the microphones that are far away from the speech sources have weak correlations, hence they form a number of special clusters that each contains only one microphone. Note that, as shown in Example 2 of Fig. 4, because the selection criterion is determined by (32), there is no guarantee that the clusters that contain more than one microphone will be selected, or the clusters that contain only a single microphone will be discarded.
6 Speech enhancement: An application case
After getting the synchronized signals , we may use existing multichannel signal processing techniques directly or with slight modification for a specific application. Here we use a deep beamforming algorithm [Heymann et al., 2016, Wang & Wang, 2018] directly for speech enhancement as an example.
The deep beamforming algorithm finds a linear estimator to filter by the following equation:
| (34) |
where is an estimate of the direct sound at the reference microphone of the array. For example, MVDR finds by minimizing the average output power of the beamformer while maintaining the energy along the target direction:
| (35) | |||||
where is an -dimensional cross-channel covariance matrix of the received noise signal . (35) has a closed-form solution:
| (36) |
where the variables and are the estimates of and respectively which are derived by the following equations according to [Zhang et al., 2017, Wang & Wang, 2018]:
| (37) | |||
| (38) | |||
| (39) |
where is an estimate of the covariance matrix of the direct sound , is a function returning the first principal component of the input square matrix, and and are defined as the product of individual estimated T-F masks:
| (40) | |||
| (41) |
Note that, in our experiments, when we calculate and , we take all channels of the ad-hoc array into consideration, which empirically results in slight performance improvement over the method that we take only the selected channels into the calculation.
7 Experiments
In this section, we study the effectiveness of DAB in diffuse noise and point source noise environments under the situation where the output signals of the channels have random time delay caused by devices. Specifically, we first present the experimental settings in Section 7.1, then present the experimental results in the diffuse noise and point source noise environments in Section 7.2, and finally discuss the effects of hyperparameter settings on performance in Sections 7.3 and 7.4.
7.1 Experimental settings
Datasets: The clean speech was generated from the TIMIT corpus. We randomly selected half of the training speakers to construct the database for training DNN1, and the remaining half for training DNN2. We used all test speakers for test. The noise source for the training database was a large-scale sound effect library which contains over 20,000 sound effects. The additive noise for the test database was the babble, factory1, and volvo noise respectively from the NOISEX-92 database.
Training data: We simulated a rectangle room for each training utterance. The length and width of the rectangle room were generated randomly from a range of meters. The height was generated randomly from meters. The reverberant environment was simulated by an image-source model.222https://github.com/ehabets/RIR-Generator Its T60 was selected randomly from a range of ] second. A speech source, a noise source, and a single microphone were placed randomly in the room. The SNR, which is the energy ratio between the speech and noise at the locations of their sources, was randomly selected from a range of dB. We synthesized 50,000 noisy utterances to train DNN1, and 100,000 noisy utterances to train DNN2.
Test data: We constructed a rectangle room for each test utterance. The length, width, and height of the room were randomly generated from , , and meters respectively. The additive noise is assumed to be either diffuse noise or point source noise.
For the diffuse noise environment, a speech source and a microphone array were placed randomly in the room. The T60 for generating reverberant speech was selected randomly from a range of ] second. To simulate the uncorrelated diffuse noise, the noise segments at different microphones do not have overlap, and they were added directly to the reverberant speech at the microphone receivers without referring to reverberation. The noise power at the locations of all microphones were maintained at the same level, which was calculated by the SNR of the direct sound over the additive noise at a place of 1 meter away from the speech source, denoted as the SNR at the origin (SNRatO). Note that the SNRs at different microphones were different due to the energy degradation of the speech signal during its propagation. The SNRatO was selected from 10, 15, and 20 dB respectively. We generated 1,000 test utterances for each SNRatO, each noise type, and each kind of microphone array, which amounts to 9 test scenarios and 18,000 test utterances.
For the point source noise environment, a speech source, a point noise source, and a microphone array were placed randomly in the room. The T60 of the room was selected randomly from a range of ] second for generating reverberant speech and reverberant noise at the microphone receivers. The SNRatO was defined as the log ratio of the speech power over the noise power at their source locations respectively. It was chosen from dB. Like the diffuse noise environment, we also generated 1,000 test utterances for each SNRatO, each noise type, and each kind of microphone array.
For both of the test environments, we generated a random time delay from a range of second at each microphone of an ad-hoc microphone array for simulating the time delay caused by devices.
Comparison methods: The baseline is the MVDR-based DB [Heymann et al., 2016] with a linear array of 16 microphones, which is described in Section 6. All DB models employed DNN1 for the single-channel noise estimation. The aperture size of the linear microphone array (i.e. the distance between two neighboring microphones) was set to 10 centimeters.
DAB also employed an ad-hoc array of 16 microphones. We denote the DAB with different channel selection algorithms as:
-
1.
DAB+1-best.
-
2.
DAB+all-channels.
-
3.
DAB+fixed-N-best. We set .
-
4.
DAB+auto-N-best. We set .
-
5.
DAB+soft-N-best. We set .
-
6.
DAB+learning-N-best. We set , , and .
To study the effectiveness of time synchronization (TS) module, we further compared the following systems:
-
1.
DAB+channel selection method. It does not use the TS module.
-
2.
DAB+channel selection method+GT. It uses the ground truth (GT) time delay caused by the devices to synchronize the microphones.
-
3.
DAB+channel selection method+TS. It uses the TS module to estimate the time delay caused by both different locations of the microphones and different devices where the microphones are installed.
We implemented the above comparison methods with different channel selection algorithms. For example, if the channel selection algorithm is “auto-N-best”, then the comparison systems are “DAB+auto-N-best”, “DAB+auto-N-best+GT”, and “DAB+auto-N-best+TS” respectively.
DNN models: For each comparison method, we set the frame length and frame shift to 32 and 16 milliseconds respectively, and extracted 257-dimensional STFT features. We used the same DNN1 for DB and DAB. DNN1 is a standard feedforward DNN. It contains two hidden layers. Each hidden layer has 1024 hidden units. The activation functions of the hidden units and output units are rectified linear unit and sigmoid function, respectively. The number of epochs was set to 50. The batch size was set to 512. The scaling factor for the adaptive stochastic gradient descent was set to 0.0015, and the learning rate decreased linearly from 0.08 to 0.001. The momentum of the first 5 epochs was set to 0.5, and the momentum of other epochs was set to 0.9. A contextual window was used to expand each input frame to its context along the time axis. The window size was set to 7.
DNN2 has the same parameter setting as DNN1 except that DNN2 does not need a contextual window, was trained with a batch size of 32, and took eSTFT as the acoustic feature. All DNNs were well-tuned. Note that although bi-directional long short-term memory may lead to better performance, we simply used the feedforward DNN since the type of the DNN models is not the focus of this paper.
Evaluation metrics: The performance evaluation metrics include STOI [Taal et al., 2011], perceptual evaluation of speech quality (PESQ) [Rix et al., 2001], and signal to distortion ratio (SDR) [Vincent et al., 2006]. STOI evaluates the objective speech intelligibility of time-domain signals. It has been shown empirically that STOI scores are well correlated with human speech intelligibility scores [Wang et al., 2014, Du et al., 2014, Huang et al., 2015, Zhang & Wang, 2016b]. PESQ is a test methodology for automated assessment of the speech quality as experienced by a listener of a telephony system. SDR is a metric similar to SNR for evaluating the quality of enhancement. The higher the value of an evaluation metric is, the better the performance is.
7.2 Main results
| SNRatO | Comparison methods | Babble | Factory | Volvo \bigstrut | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| STOI | PESQ | SDR | STOI | PESQ | SDR | STOI | PESQ | SDR \bigstrut | ||
| 10 dB | Noisy | 0.5989 | 1.86 | 1.12 | 0.5969 | 1.80 | 1.20 | 0.6785 | 2.10 | 1.62 \bigstrut[t] |
| DB | 0.6911 | 1.87 | 2.75 | 0.6900 | 1.86 | 3.42 | 0.7766 | 2.16 | 3.95 | |
| DAB (1-best) | 0.7154 | 2.06 | 5.14 | 0.7143 | 2.00 | 5.13 | 0.7892 | 2.31 | 5.23 \bigstrut[b] | |
| DAB (all-channels) | 0.5824 | 1.83 | -0.93 | 0.5760 | 1.78 | -1.55 | 0.6061 | 1.88 | -1.49 \bigstrut[t] | |
| DAB (all-channels+GT) | 0.7206 | 2.06 | 4.40 | 0.7137 | 2.00 | 4.47 | 0.7831 | 2.39 | 4.42 | |
| DAB (all-channels+TS) | 0.7405 | 2.00 | 3.49 | 0.7388 | 1.95 | 3.54 | 0.8039 | 2.32 | 3.25 \bigstrut[b] | |
| DAB (fixed-N-best) | 0.6026 | 1.87 | -0.12 | 0.6022 | 1.82 | -0.33 | 0.6351 | 1.92 | -0.32 \bigstrut[t] | |
| DAB (fixed-N-best+GT) | 0.7451 | 2.12 | 5.10 | 0.7437 | 2.07 | 5.16 | 0.8117 | 2.42 | 5.54 | |
| DAB (fixed-N-best+TS) | 0.7675 | 2.11 | 5.18 | 0.7634 | 2.05 | 5.01 | 0.8460 | 2.43 | 5.97 \bigstrut[b] | |
| DAB (auto-N-best) | 0.5982 | 1.87 | -0.13 | 0.5927 | 1.83 | -0.61 | 0.6573 | 2.00 | 0.82 \bigstrut[t] | |
| DAB (auto-N-best+GT) | 0.7531 | 2.14 | 5.74 | 0.7518 | 2.09 | 5.73 | 0.8164 | 2.46 | 5.97 | |
| DAB (auto-N-best+TS) | 0.7696 | 2.12 | 5.45 | 0.7641 | 2.06 | 5.36 | 0.8405 | 2.44 | 5.85 \bigstrut[b] | |
| DAB (soft-N-best) | 0.5999 | 1.85 | -0.28 | 0.5952 | 1.83 | -0.76 | 0.6645 | 2.01 | 0.84 \bigstrut[t] | |
| DAB (soft-N-best+GT) | 0.7463 | 2.13 | 5.22 | 0.7455 | 2.07 | 5.26 | 0.8055 | 2.42 | 5.50 | |
| DAB (soft-N-best+TS) | 0.7659 | 2.12 | 5.11 | 0.7610 | 2.05 | 5.09 | 0.8363 | 2.43 | 5.65 \bigstrut[b] | |
| DAB (learning-N-best) | 0.5973 | 1.86 | -0.29 | 0.5892 | 1.81 | -0.99 | 0.6488 | 1.98 | 0.21 \bigstrut[t] | |
| DAB (learning-N-best+GT) | 0.7405 | 2.12 | 5.22 | 0.7387 | 2.06 | 5.34 | 0.8026 | 2.43 | 5.35 | |
| DAB (learning-N-best+TS) | 0.7631 | 2.07 | 4.55 | 0.7606 | 2.02 | 4.59 | 0.8330 | 2.41 | 4.97 \bigstrut[b] | |
| 15 dB | Noisy | 0.6410 | 1.97 | 3.05 | 0.6400 | 1.93 | 2.79 | 0.6847 | 2.10 | 2.87 \bigstrut[t] |
| DB | 0.7350 | 2.02 | 4.37 | 0.7396 | 1.99 | 4.61 | 0.7804 | 2.19 | 4.86 | |
| DAB (1-best) | 0.7496 | 2.17 | 6.59 | 0.7527 | 2.14 | 6.45 | 0.7906 | 2.31 | 6.58 \bigstrut[b] | |
| DAB (all-channels) | 0.5977 | 1.85 | -0.52 | 0.5990 | 1.84 | -0.87 | 0.6102 | 1.88 | -0.75 \bigstrut[t] | |
| DAB (all-channels+GT) | 0.7575 | 2.22 | 5.45 | 0.7588 | 2.18 | 5.39 | 0.7887 | 2.42 | 5.23 | |
| DAB (all-channels+TS) | 0.7809 | 2.15 | 4.53 | 0.7869 | 2.12 | 4.54 | 0.8091 | 2.35 | 4.32 \bigstrut[b] | |
| DAB (fixed-N-best) | 0.6218 | 1.89 | 0.27 | 0.6189 | 1.88 | 0.03 | 0.6463 | 1.93 | 0.33 \bigstrut[t] | |
| DAB (fixed-N-best+GT) | 0.7788 | 2.26 | 6.15 | 0.7832 | 2.22 | 6.11 | 0.8172 | 2.43 | 6.37 | |
| DAB (fixed-N-best+TS) | 0.8074 | 2.26 | 6.65 | 0.8095 | 2.21 | 6.36 | 0.8518 | 2.44 | 7.04 \bigstrut[b] | |
| DAB (auto-N-best) | 0.6188 | 1.90 | 0.44 | 0.6142 | 1.87 | -0.13 | 0.6641 | 2.00 | 1.44 \bigstrut[t] | |
| DAB (auto-N-best+GT) | 0.7877 | 2.30 | 6.83 | 0.7946 | 2.26 | 6.92 | 0.8219 | 2.48 | 6.85 | |
| DAB (auto-N-best+TS) | 0.8082 | 2.27 | 6.82 | 0.8140 | 2.23 | 6.81 | 0.8476 | 2.47 | 6.93 \bigstrut[b] | |
| DAB (soft-N-best) | 0.6179 | 1.90 | 0.20 | 0.6140 | 1.88 | -0.29 | 0.6625 | 2.00 | 1.13 \bigstrut[t] | |
| DAB (soft-N-best+GT) | 0.7792 | 2.27 | 6.10 | 0.7858 | 2.24 | 6.18 | 0.8094 | 2.43 | 6.06 | |
| DAB (soft-N-best+TS) | 0.8045 | 2.26 | 6.35 | 0.8090 | 2.22 | 6.28 | 0.8428 | 2.46 | 6.54 \bigstrut[b] | |
| DAB (learning-N-best) | 0.6187 | 1.90 | 0.31 | 0.6154 | 1.87 | -0.24 | 0.6562 | 1.98 | 0.93 \bigstrut[t] | |
| DAB (learning-N-best+GT) | 0.7768 | 2.27 | 6.40 | 0.7799 | 2.24 | 6.30 | 0.8096 | 2.46 | 6.35 | |
| DAB (learning-N-best+TS) | 0.8049 | 2.24 | 5.98 | 0.8100 | 2.20 | 5.90 | 0.8394 | 2.45 | 5.98 \bigstrut[b] | |
| 20 dB | Noisy | 0.6622 | 2.03 | 3.81 | 0.6653 | 2.01 | 3.73 | 0.6860 | 2.12 | 3.71 \bigstrut[t] |
| DB | 0.7539 | 2.09 | 4.90 | 0.7619 | 2.09 | 5.23 | 0.7792 | 2.21 | 5.29 | |
| DAB (1-best) | 0.7768 | 2.25 | 7.25 | 0.7790 | 2.25 | 7.25 | 0.7967 | 2.31 | 7.13 \bigstrut[b] | |
| DAB (all-channels) | 0.6196 | 1.88 | -0.31 | 0.6212 | 1.89 | -0.19 | 0.6213 | 1.89 | -0.50 \bigstrut[t] | |
| DAB (all-channels+GT) | 0.7784 | 2.33 | 5.74 | 0.7834 | 2.32 | 5.68 | 0.7937 | 2.43 | 5.44 | |
| DAB (all-channels+TS) | 0.8057 | 2.27 | 5.21 | 0.8113 | 2.25 | 5.02 | 0.8161 | 2.38 | 4.72 \bigstrut[b] | |
| DAB (fixed-N-best) | 0.6583 | 1.96 | 1.03 | 0.6487 | 1.95 | 0.72 | 0.6553 | 1.94 | 0.57 \bigstrut[t] | |
| DAB (fixed-N-best+GT) | 0.8011 | 2.35 | 6.60 | 0.8046 | 2.34 | 6.33 | 0.8183 | 2.42 | 6.65 | |
| DAB (fixed-N-best+TS) | 0.8352 | 2.37 | 7.36 | 0.8346 | 2.34 | 7.08 | 0.8551 | 2.45 | 7.47 \bigstrut[b] | |
| DAB (auto-N-best) | 0.6632 | 1.99 | 1.78 | 0.6504 | 1.97 | 1.20 | 0.6816 | 2.03 | 2.19 \bigstrut[t] | |
| DAB (auto-N-best+GT) | 0.8098 | 2.40 | 7.28 | 0.8134 | 2.39 | 7.10 | 0.8257 | 2.48 | 7.21 | |
| DAB (auto-N-best+TS) | 0.8361 | 2.39 | 7.67 | 0.8383 | 2.36 | 7.21 | 0.8515 | 2.48 | 7.35 \bigstrut[b] | |
| DAB (soft-N-best) | 0.6610 | 1.99 | 1.52 | 0.6479 | 1.97 | 0.95 | 0.6810 | 2.03 | 2.00 \bigstrut[t] | |
| DAB (soft-N-best+GT) | 0.8018 | 2.37 | 6.70 | 0.8034 | 2.36 | 6.30 | 0.8164 | 2.45 | 6.59 | |
| DAB (soft-N-best+TS) | 0.8317 | 2.38 | 7.16 | 0.8338 | 2.35 | 6.74 | 0.8473 | 2.46 | 7.01 \bigstrut[b] | |
| DAB (learning-N-best) | 0.6564 | 1.97 | 1.30 | 0.6491 | 1.96 | 0.93 | 0.6733 | 2.00 | 1.66 \bigstrut[t] | |
| DAB (learning-N-best+GT) | 0.7968 | 2.38 | 6.74 | 0.8006 | 2.37 | 6.53 | 0.8139 | 2.47 | 6.57 | |
| DAB (learning-N-best+TS) | 0.8309 | 2.36 | 6.74 | 0.8338 | 2.33 | 6.37 | 0.8447 | 2.47 | 6.43 \bigstrut[b] | |
| SNRatO | Comparison methods | Babble | Factory | Volvo \bigstrut | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| STOI | PESQ | SDR | STOI | PESQ | SDR | STOI | PESQ | SDR \bigstrut | ||
| -5 dB | Noisy | 0.4465 | 1.29 | -6.75 | 0.4336 | 1.19 | -6.08 | 0.6286 | 1.90 | -0.20 \bigstrut[t] |
| DB | 0.5429 | 1.63 | -3.50 | 0.5250 | 1.51 | -2.22 | 0.7406 | 2.04 | 3.82 | |
| DAB (1-best) | 0.5741 | 1.73 | -1.96 | 0.5512 | 1.59 | -1.52 | 0.7647 | 2.25 | 5.16 \bigstrut[b] | |
| DAB (all-channels) | 0.4246 | 1.95 | -8.97 | 0.4194 | 1.73 | -8.10 | 0.5106 | 1.71 | -3.70 \bigstrut[t] | |
| DAB (all-channels+GT) | 0.5756 | 1.70 | -2.41 | 0.5487 | 1.50 | -2.07 | 0.7424 | 2.22 | 3.95 | |
| DAB (all-channels+TS) | 0.5954 | 1.70 | -2.43 | 0.5488 | 1.50 | -2.20 | 0.7775 | 2.22 | 3.30 \bigstrut[b] | |
| DAB (fixed-N-best) | 0.4665 | 1.82 | -6.69 | 0.4619 | 1.66 | -5.83 | 0.5745 | 1.79 | -1.85 \bigstrut[t] | |
| DAB (fixed-N-best+GT) | 0.5891 | 1.74 | -1.99 | 0.5619 | 1.58 | -1.68 | 0.7736 | 2.30 | 5.16 | |
| DAB (fixed-N-best+TS) | 0.6065 | 1.74 | -1.65 | 0.5692 | 1.58 | -1.25 | 0.8124 | 2.33 | 5.57 \bigstrut[b] | |
| DAB (auto-N-best) | 0.4753 | 1.93 | -6.60 | 0.4547 | 1.75 | -6.48 | 0.5773 | 1.86 | -1.18 \bigstrut[t] | |
| DAB (auto-N-best+GT) | 0.6029 | 1.76 | -1.26 | 0.5707 | 1.55 | -1.21 | 0.7745 | 2.32 | 5.55 | |
| DAB (auto-N-best+TS) | 0.6160 | 1.75 | -1.24 | 0.5696 | 1.55 | -1.23 | 0.8047 | 2.32 | 5.21 \bigstrut[b] | |
| DAB (soft-N-best) | 0.4806 | 1.95 | -6.26 | 0.4601 | 1.76 | -6.08 | 0.5822 | 1.87 | -1.05 \bigstrut[t] | |
| DAB (soft-N-best+GT) | 0.6035 | 1.77 | -1.15 | 0.5725 | 1.57 | -1.05 | 0.7681 | 2.29 | 5.08 | |
| DAB (soft-N-best+TS) | 0.6164 | 1.76 | -1.15 | 0.5719 | 1.58 | -1.10 | 0.8013 | 2.32 | 4.92 \bigstrut[b] | |
| DAB (learning-N-best) | 0.4606 | 1.92 | -7.34 | 0.4465 | 1.75 | -6.94 | 0.5654 | 1.83 | -1.80 \bigstrut[t] | |
| DAB (learning-N-best+GT) | 0.5915 | 1.73 | -1.73 | 0.5621 | 1.53 | -1.54 | 0.7617 | 2.29 | 4.91 | |
| DAB (learning-N-best+TS) | 0.6086 | 1.72 | -1.74 | 0.5604 | 1.53 | -1.72 | 0.7967 | 2.29 | 4.39 \bigstrut[b] | |
| 5 dB | Noisy | 0.5678 | 1.68 | 0.11 | 0.5607 | 1.61 | 0.50 | 0.6550 | 1.99 | 2.69 \bigstrut[t] |
| DB | 0.6975 | 1.87 | 2.80 | 0.6856 | 1.85 | 3.19 | 0.7695 | 2.14 | 4.78 | |
| DAB (1-best) | 0.7232 | 2.05 | 5.22 | 0.7187 | 2.00 | 5.53 | 0.7939 | 2.31 | 7.42 \bigstrut[b] | |
| DAB (all-channels) | 0.4942 | 1.79 | -3.59 | 0.4806 | 1.74 | -3.62 | 0.5207 | 1.74 | -2.69 \bigstrut[t] | |
| DAB (all-channels+GT) | 0.7263 | 2.12 | 4.71 | 0.7168 | 2.06 | 4.98 | 0.7770 | 2.37 | 5.71 | |
| DAB (all-channels+TS) | 0.7602 | 2.11 | 4.22 | 0.7481 | 2.05 | 4.31 | 0.8075 | 2.33 | 4.79 \bigstrut[b] | |
| DAB (fixed-N-best) | 0.5522 | 1.80 | -1.80 | 0.5421 | 1.74 | -1.82 | 0.5889 | 1.83 | -0.92 \bigstrut[t] | |
| DAB (fixed-N-best+GT) | 0.7473 | 2.14 | 5.28 | 0.7425 | 2.09 | 5.55 | 0.8117 | 2.42 | 7.22 | |
| DAB (fixed-N-best+TS) | 0.7768 | 2.15 | 5.61 | 0.7734 | 2.11 | 5.81 | 0.8492 | 2.44 | 7.60 \bigstrut[b] | |
| DAB (auto-N-best) | 0.5820 | 1.89 | -0.36 | 0.5901 | 1.86 | 0.39 | 0.6118 | 1.93 | 0.55 \bigstrut[t] | |
| DAB (auto-N-best+GT) | 0.7601 | 2.17 | 5.94 | 0.7568 | 2.12 | 6.29 | 0.8187 | 2.46 | 7.68 | |
| DAB (auto-N-best+TS) | 0.7835 | 2.17 | 6.02 | 0.7751 | 2.12 | 6.32 | 0.8455 | 2.45 | 7.54 \bigstrut[b] | |
| DAB (soft-N-best) | 0.5834 | 1.90 | -0.47 | 0.5915 | 1.85 | 0.25 | 0.6122 | 1.93 | 0.42 \bigstrut[t] | |
| DAB (soft-N-best+GT) | 0.7534 | 2.16 | 5.48 | 0.7510 | 2.10 | 5.83 | 0.8081 | 2.42 | 6.85 | |
| DAB (soft-N-best+TS) | 0.7797 | 2.16 | 5.61 | 0.7714 | 2.11 | 5.91 | 0.8420 | 2.44 | 7.09 \bigstrut[b] | |
| DAB (learning-N-best) | 0.5605 | 1.86 | -1.27 | 0.5617 | 1.82 | -0.86 | 0.5975 | 1.90 | -0.09 \bigstrut[t] | |
| DAB (learning-N-best+GT) | 0.7462 | 2.15 | 5.37 | 0.7397 | 2.09 | 5.71 | 0.8034 | 2.43 | 6.95 | |
| DAB (learning-N-best+TS) | 0.7806 | 2.16 | 5.40 | 0.7672 | 2.10 | 5.38 | 0.8378 | 2.43 | 6.57 \bigstrut[b] | |
| 15 dB | Noisy | 0.6394 | 1.92 | 2.71 | 0.6405 | 1.90 | 2.76 | 0.6700 | 2.02 | 3.16 \bigstrut[t] |
| DB | 0.7534 | 2.11 | 4.85 | 0.7596 | 2.10 | 5.01 | 0.7767 | 2.21 | 5.21 | |
| DAB (1-best) | 0.7868 | 2.26 | 7.48 | 0.7886 | 2.23 | 7.39 | 0.8024 | 2.32 | 7.63 \bigstrut[b] | |
| DAB (all-channels) | 0.5215 | 1.76 | -2.52 | 0.5152 | 1.73 | -2.68 | 0.5183 | 1.76 | -2.69 \bigstrut[t] | |
| DAB (all-channels+GT) | 0.7770 | 2.36 | 6.16 | 0.7763 | 2.33 | 6.12 | 0.7871 | 2.43 | 5.98 | |
| DAB (all-channels+TS) | 0.8173 | 2.35 | 5.77 | 0.8189 | 2.31 | 5.66 | 0.8173 | 2.41 | 5.14 \bigstrut[b] | |
| DAB (fixed-N-best) | 0.5924 | 1.82 | -0.69 | 0.5886 | 1.80 | -0.78 | 0.5911 | 1.83 | -0.81 \bigstrut[t] | |
| DAB (fixed-N-best+GT) | 0.8015 | 2.35 | 6.81 | 0.7999 | 2.32 | 6.77 | 0.8177 | 2.44 | 7.23 | |
| DAB (fixed-N-best+TS) | 0.8434 | 2.40 | 7.68 | 0.8419 | 2.35 | 7.54 | 0.8591 | 2.48 | 7.87 \bigstrut[b] | |
| DAB (auto-N-best) | 0.6503 | 2.01 | 2.22 | 0.6042 | 1.89 | 0.39 | 0.6602 | 2.03 | 2.39 \bigstrut[t] | |
| DAB (auto-N-best+GT) | 0.8156 | 2.40 | 7.93 | 0.8088 | 2.38 | 7.48 | 0.8292 | 2.46 | 7.94 | |
| DAB (auto-N-best+TS) | 0.8405 | 2.41 | 8.08 | 0.8422 | 2.37 | 7.50 | 0.8502 | 2.47 | 8.12 \bigstrut[b] | |
| DAB (soft-N-best) | 0.6499 | 2.01 | 2.13 | 0.6042 | 1.90 | 0.30 | 0.6595 | 2.03 | 2.27 \bigstrut[t] | |
| DAB (soft-N-best+GT) | 0.8088 | 2.39 | 7.44 | 0.8009 | 2.35 | 6.84 | 0.8226 | 2.44 | 7.45 | |
| DAB (soft-N-best+TS) | 0.8379 | 2.40 | 7.79 | 0.8385 | 2.37 | 7.09 | 0.8477 | 2.46 | 7.85 \bigstrut[b] | |
| DAB (learning-N-best) | 0.6272 | 1.95 | 1.25 | 0.5862 | 1.85 | -0.33 | 0.6340 | 1.98 | 1.18 \bigstrut[t] | |
| DAB (learning-N-best+GT) | 0.8028 | 2.39 | 7.30 | 0.7966 | 2.36 | 6.97 | 0.8148 | 2.45 | 7.28 | |
| DAB (learning-N-best+TS) | 0.8415 | 2.42 | 7.28 | 0.8392 | 2.37 | 6.89 | 0.8500 | 2.49 | 7.22 \bigstrut[b] | |
We list the performance of the comparison methods in the diffuse noise and point source noise environments in Tables 1 and 2 respectively. From the tables, we see that the DAB variants given the TS module or the ground-truth time delay outperform the DB baseline significantly in terms of all evaluation metrics. Even the simplest “DAB+1-best” is better than the DB baseline, which demonstrates the advantage of the ad-hoc microphone array.
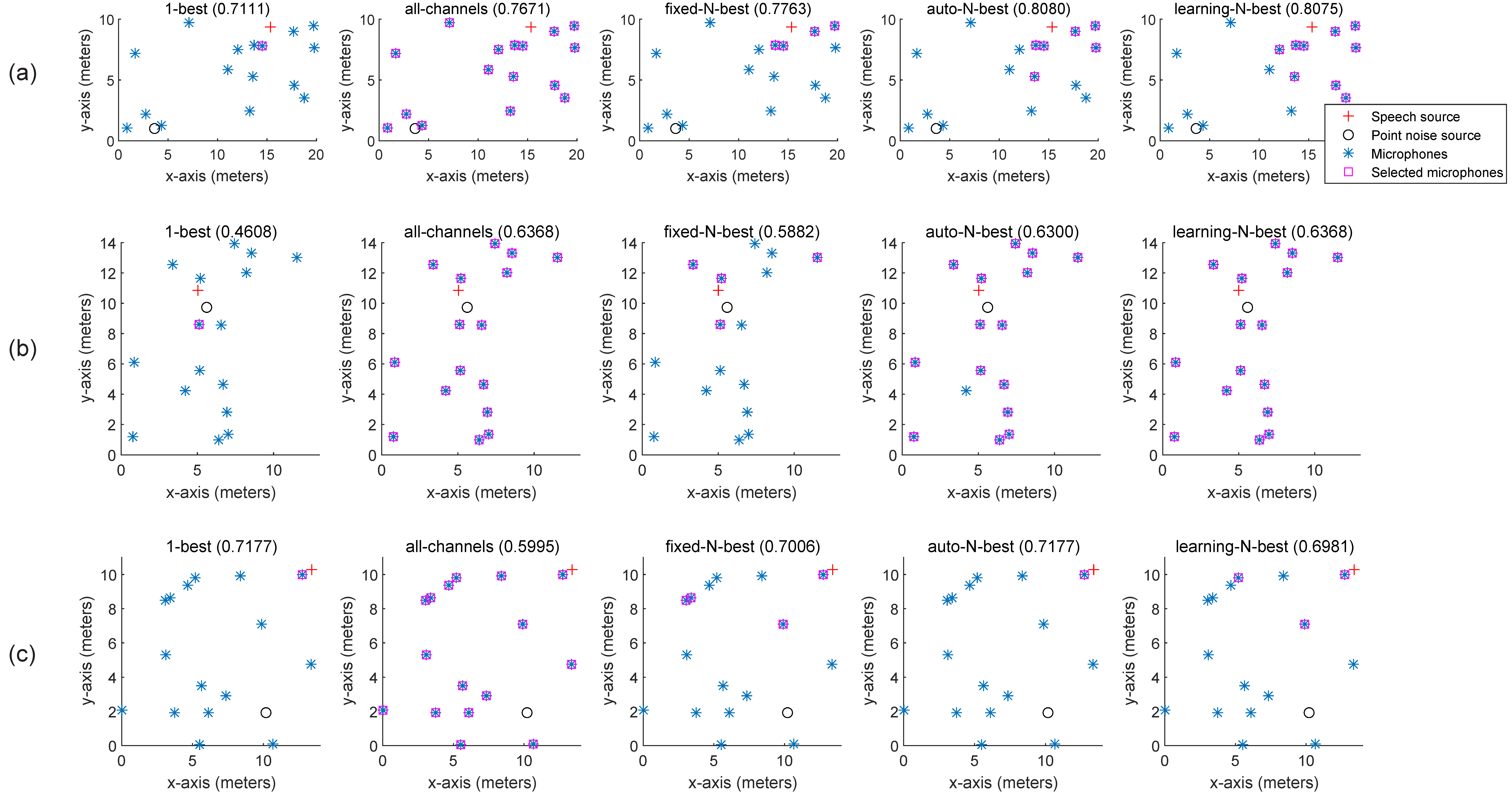
We compare the DB variants with the TS module or the ground-truth time delay for studying the effectiveness of the channel selection algorithms. We find that “auto-N-best” performs the best among the channel selection algorithms in most cases, followed by “soft-N-best”. The “learning-N-best” and “fixed-N-best” algorithms perform equivalently well in general, both of which perform better than the “all-channels” algorithm. Although “1-best” performs the poorest in terms of STOI and PESQ, it usually produces good SDR scores that are comparable to those produced by “auto-N-best”. Note that although “learning-N-best” seems an advanced technique, this advantage does not transfer to superior performance. This may be caused by (32) which is an expansion of the channel selection result of “auto-N-best”. This problem needs further investigation in the future. Comparing “auto-N-best” and “soft-N-best”, we further find that different amplitude ranges of the channels affect the performance, though this phenomenon is not so obvious due to that the nonzero weights do not vary in a large range. As a byproduct, the idea of “soft-N-best” is a way of synchronizing the adaptive gain controllers of the devices. The synchronization of the adaptive gain controllers is not the focus of this paper, hence we leave it for the future study.
We compare the “DAB+channel selection method”, “DAB+channel selection method+GT”, and “DAB+channel selection method+TS” given different channel selection methods for studying the effectiveness of the time synchronization module. We find that the DAB without the TS module does not work at all when there exists a serious time unsynchronization problem caused by devices. “DAB+channel selection method+TS” performs better than “DAB+channel selection method+GT” in terms of STOI, and is equivalently good with the latter in terms of PESQ and SDR in all SNRatO levels, even though the latter was given the ground-truth time delay caused by devices. This phenomenon demonstrates the effectiveness of the proposed TS module. It also implies that the time unsynchronization problem caused by different locations of the microphones affects the performance, though not so serious.
Figure 5 shows three examples of the channel selection results, of which we find some interesting phenomena after looking into the details. Figure 5a is a typical scenario where the speech source is far away from the noise point source. We see clearly from the figure that, although “1-best” is relative much poorer than the other algorithms, all comparison algorithms perform not so bad according to the absolute STOI scores, since that the SNRs at many selectted microphones are relative high. Figure 5b is a special scenario where the speech source is very close to the noise point source. Therefore, the SNRs at all microphones are low. As shown in the figure, it is better to select most microphones as “auto-N-best” and “learning-N-best” do in this case, otherwise the performance is rather poor as “1-best” yields. Figure 5c is a special scenario where there is a microphone very close to the speech source. It can be seen from the channel selection result that the best way is to select the closest microphone, while “all-channels” perform much poorer than the other channel selection algorithms. To summarize the above phenomena, we see that the adaptive channel selection algorithms, i.e. “auto-N-best” and “learning-N-best”, always produce top performance among the comparison algorithms.
7.3 Effect of the number of the microphones in an array
To study how the number of the microphones in an array affects the performance, we repeated the experimental setting in Section 7.1 except that the number of the microphones in an array was reduced to 4. Because the experimental phenomena were consistent across different SNRatO levels and noise types, we list the comparison results of only one test scenario in Tables 3 and 4 for saving the space of the paper. From the tables, we see that, even if the number of the microphones in an array was limited, the DAB variants still perform equivalently well with DB except “DAB+1-best”. Comparing Tables 3 and 4 with Tables 1 and 2, we also find that DAB benefits much more than DB from the increase of the number of the microphones. We take the results in the diffuse noise environment as an example. The STOI score of “DAB+auto-N-best+TS” is improved by relatively 20.22% when the number of the microphones is increased from 4 to 16, while the relative improvement about DB is only 2.56%.
| SNRatO | Comparison methods | Babble \bigstrut | ||
|---|---|---|---|---|
| STOI | PESQ | SDR \bigstrut | ||
| 10 dB | Noisy | 0.5919 | 1.80 | 0.99 \bigstrut[t] |
| DB | 0.6830 | 1.91 | 3.14 | |
| DAB (1-best) | 0.6400 | 1.86 | 2.38 | |
| DAB (all-channels+TS) | 0.7154 | 1.92 | 2.70 | |
| DAB (fixed-N-best+TS) | 0.6821 | 1.90 | 2.58 | |
| DAB (auto-N-best+TS) | 0.7112 | 1.93 | 3.01 | |
| DAB (soft-N-best+TS) | 0.7013 | 1.91 | 2.27 | |
| DAB (learning-N-best+TS) | 0.7135 | 1.92 | 2.82 \bigstrut[b] | |
| SNRatO | Comparison methods | Babble \bigstrut | ||
|---|---|---|---|---|
| STOI | PESQ | SDR \bigstrut | ||
| -5 dB | Noisy | 0.4576 | 1.56 | -6.14 \bigstrut[t] |
| DB | 0.5079 | 1.47 | -5.70 | |
| DAB (1-best) | 0.4996 | 1.57 | -5.10 | |
| DAB (all-channels+TS) | 0.5056 | 1.49 | -6.80 | |
| DAB (fixed-N-best+TS) | 0.5068 | 1.55 | -5.72 | |
| DAB (auto-N-best+TS) | 0.5111 | 1.51 | -6.28 | |
| DAB (soft-N-best+TS) | 0.5140 | 1.53 | -6.19 | |
| DAB (learning-N-best+TS) | 0.5064 | 1.50 | -6.67 \bigstrut[b] | |
7.4 Effect of hyperparameter
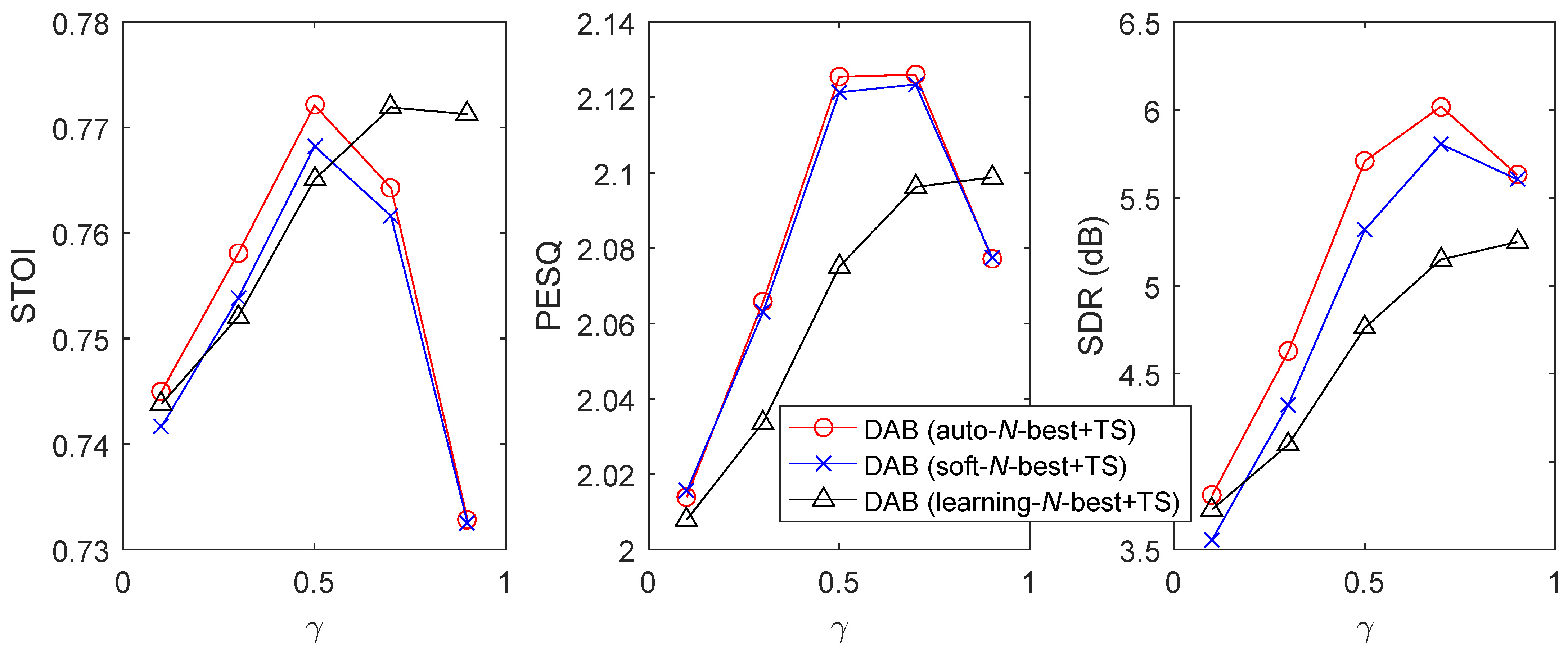
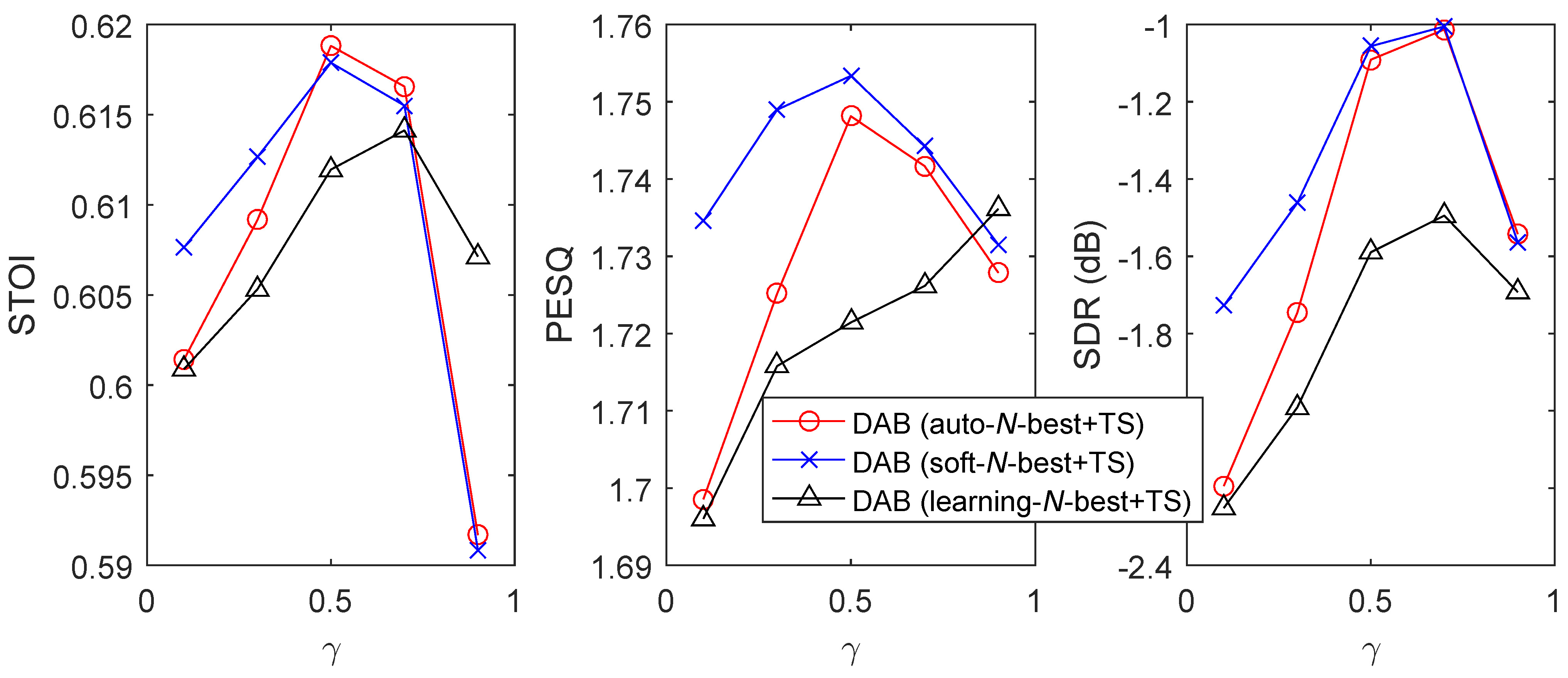
To study how the hyperparameter affects the performance of “DAB+auto-N-best+TS”, “DAB+soft-N-best+TS”, and “DAB+learning-N-best+TS”, we tune from . To save the space of the paper, we only show the results in the babble noise environments at the lowest SNRatO levels in Figs. 6 and 7. From the figures, we observe that “DAB+auto-N-best+TS” and “DAB+soft-N-best+TS” perform similarly if is well-tuned, both of which are better than “DAB+soft-N-best+TS”. The working range of is for “DAB+auto-N-best+TS” and “DAB+soft-N-best+TS”, and for “DAB+learning-N-best+TS”.
7.5 Effect of handcrafted features on performance
All above experiments were conducted with the eSTFT feature. To study how the handcrafted features affect the performance, we compared the DAB models that took eSTFT and MRCG respectively as the input of the channel-selection model in the babble noise environments at the lowest SNRatO levels. From the comparison results in Tables 5 and 6, we see that eSTFT is slightly better than MRCG in the diffuse noise environment, and significantly outperforms MRCG in the point source noise environment. The effect of different acoustic features for “DAB+1-best+TS” in the point source noise environment is remarkable, which manifests the importance of designing a good handcrafted feature. We also observe that the advantage of the adaptive channel selection algorithms over “DAB+1-best+TS” and “DAB+fixed-N-best+TS” is consistent across the two acoustic features, which demonstrates the robustness of the proposed channel selection algorithms to the choice of the acoustic features.
| SNRatO | Comparison methods | Babble \bigstrut | ||
|---|---|---|---|---|
| STOI | PESQ | SDR \bigstrut | ||
| 10 dB | 1-best (eSTFT) | 0.7154 | 2.06 | 5.14 \bigstrut[t] |
| 1-best (MRCG) | 0.7101 | 2.05 | 5.01 | |
| fixed-N-best+TS (eSTFT) | 0.7675 | 2.11 | 5.18 | |
| fixed-N-best+TS (MRCG) | 0.7617 | 2.10 | 4.96 | |
| auto-N-best+TS (eSTFT) | 0.7696 | 2.12 | 5.45 | |
| auto-N-best+TS (MRCG) | 0.7654 | 2.11 | 5.28 | |
| soft-N-best+TS (eSTFT) | 0.7659 | 2.12 | 5.11 | |
| soft-N-best+TS (MRCG) | 0.7621 | 2.11 | 4.88 | |
| learning-N-best+TS (eSTFT) | 0.7631 | 2.07 | 4.55 | |
| learning-N-best+TS (MRCG) | 0.7606 | 2.07 | 4.48 \bigstrut[b] | |
| SNRatO | Comparison methods | Babble \bigstrut | ||
|---|---|---|---|---|
| STOI | PESQ | SDR \bigstrut | ||
| -5 dB | 1-best (eSTFT) | 0.5741 | 1.73 | -1.96 \bigstrut[t] |
| 1-best (MRCG) | 0.5267 | 1.67 | -3.77 | |
| fixed-N-best+TS (eSTFT) | 0.6065 | 1.74 | -1.65 | |
| fixed-N-best+TS (MRCG) | 0.5838 | 1.67 | -2.55 | |
| auto-N-best+TS (eSTFT) | 0.6160 | 1.75 | -1.24 | |
| auto-N-best+TS (MRCG) | 0.5918 | 1.70 | -2.14 | |
| soft-N-best+TS (eSTFT) | 0.6164 | 1.76 | -1.15 | |
| soft-N-best+TS (MRCG) | 0.5934 | 1.70 | -2.10 | |
| learning-N-best+TS (eSTFT) | 0.6086 | 1.72 | -1.74 | |
| learning-N-best+TS (MRCG) | 0.5956 | 1.70 | -2.27 \bigstrut[b] | |
8 Conclusions and future work
In this paper, we have proposed deep ad-hoc beamforming, which is to our knowledge the first deep learning method designed for ad-hoc microphone arrays.333This claim was made according to the fact that the core idea of the paper has been put on arXiv [Zhang, 2018] in January 2019. DAB has the following novel aspects. First, DAB employs an ad-hoc microphone array to pick up speech signals, which has a potential to enhance the speech signals with equally high quality in a range where the array covers. It may also significantly improve the SNR at the microphone receivers by physically placing some microphones close to the speech source in probability. Second, DAB employs a channel-selection algorithm to reweight the estimated speech signals with a sparsity constraint, which groups a handful microphones around the speech source into a local microphone array. We have developed several channel-selection algorithms as well. Third, we have developed a time synchronization framework based on time delay estimators and the supervised 1-best channel selection. At last, we emphasized the importance of acoustic features to DAB by carrying out the first study on how different acoustic features affect the performance.
Besides the above novelties and advantages, the proposed DAB is flexible in incorporating new development of DNN-based single channel speech processing techniques, since that its model is trained in the single-channel fashion. Its test process is also flexible in incorporating any number of microphones without retraining or revising the model, which meets the requirement of real-world applications. Moreover, although we applied DAB to speech enhancement as an example, we may apply it to other tasks as well by replacing the deep beamforming to other task-specific algorithms.
We have conducted extensive experiments in the scenario where the location of the speech source is far-field, random, and blind to the microphones. Experimental results in both the diffuse noise and point source noise environments demonstrate that DAB outperforms its MVDR based deep beamforming counterpart by a large margin given enough number of microphones. The conclusion is consistent across different acoustic features.
The research on DAB is only at the beginning. There are too many open problems. Here we list some urgent topics as follows. (i) How to synchronize microphones when the clock rates and power amplifiers at different devices are different. (ii) How to design new spatial acoustic features for ad-hoc microphone arrays beyond interaural time difference or interaural level difference. (iii) How to design a model that can be trained with multichannel data collected from ad-hoc microphone arrays, and generalize well to fundamentally different ad-hoc microphone arrays in the test stage. (iv) How to handle a large number of microphones (e.g. over 100 microphones) for a large room that contains many complicated acoustic environments.
Acknowledgments
The author would like to thank Prof. DeLiang Wang for helpful discussions.
This work was supported in part by the National Key Research and Development Program of China under Grant No. 2018AAA0102200, in part by National Science Foundation of China under Grant No. 61831019, 61671381, in part by the Project of the Science, Technology, and Innovation Commission of Shenzhen Municipality under grant No. JCYJ20170815161820095, and in part by the Open Research Project of the State Key Laboratory of Media Convergence and Communication, Communication University of China, China under Grant No. SKLMCC2020KF009.
Appendix A
Proof.
We denote the energy of the direct sound and additive noise components of the test utterance at the -th channel as and respectively, i.e. and . Our core idea is to filter out the signals of the channels whose clean speech satisfies:
| (42) |
Under the assumptions that the estimated weights are perfect and that the statistics of the noise components are consistent across the channels, we have
| (43) |
References
References
- Bai et al. [2020a] Bai, Z., Zhang, X.-L., & Chen, J. (2020a). Cosine metric learning based speaker verification. Speech Communication, 118, 10–20.
- Bai et al. [2020b] Bai, Z., Zhang, X.-L., & Chen, J. (2020b). Partial auc optimization based deep speaker embeddings with class-center learning for text-independent speaker verification. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6819–6823). IEEE.
- Bai et al. [2020c] Bai, Z., Zhang, X.-L., & Chen, J. (2020c). Speaker verification by partial auc optimization with mahalanobis distance metric learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, .
- Carter [1987] Carter, G. C. (1987). Coherence and time delay estimation. Proceedings of the IEEE, 75, 236–255.
- Chen et al. [2006] Chen, J., Benesty, J., & Huang, Y. A. (2006). Time delay estimation in room acoustic environments: an overview. EURASIP Journal on Advances in Signal Processing, 2006, 026503.
- Chen et al. [2014] Chen, J., Wang, Y., & Wang, D. L. (2014). A feature study for classification-based speech separation at very low signal-to-noise ratio. IEEE/ACM Trans. Audio, Speech, Lang. Process., 22, 1993–2002.
- Delfarah & Wang [2017] Delfarah, M., & Wang, D. (2017). Features for masking-based monaural speech separation in reverberant conditions. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25, 1085–1094.
- Ditter & Gerkmann [2020] Ditter, D., & Gerkmann, T. (2020). A multi-phase gammatone filterbank for speech separation via tasnet. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 36–40). IEEE.
- Du et al. [2014] Du, J., Tu, Y., Xu, Y., Dai, L., & Lee, C.-H. (2014). Speech separation of a target speaker based on deep neural networks. In Proc. IEEE Int. Conf. Signal Process. (pp. 473–477).
- Erdogan et al. [2016] Erdogan, H., Hershey, J. R., Watanabe, S., Mandel, M. I., & Le Roux, J. (2016). Improved MVDR beamforming using single-channel mask prediction networks. In Interspeech (pp. 1981–1985).
- Guariglia [2019] Guariglia, E. (2019). Primality, fractality, and image analysis. Entropy, 21, 304.
- Guariglia & Silvestrov [2016] Guariglia, E., & Silvestrov, S. (2016). Fractional-wavelet analysis of positive definite distributions and wavelets on D’(C). In Engineering Mathematics II (pp. 337–353). Springer.
- Guido [2018a] Guido, R. C. (2018a). Fusing time, frequency and shape-related information: Introduction to the discrete shapelet transform’s second generation (dst-ii). Information Fusion, 41, 9–15.
- Guido [2018b] Guido, R. C. (2018b). A tutorial review on entropy-based handcrafted feature extraction for information fusion. Information Fusion, 41, 161–175.
- Heusdens et al. [2012] Heusdens, R., Zhang, G., Hendriks, R. C., Zeng, Y., & Kleijn, W. B. (2012). Distributed MVDR beamforming for (wireless) microphone networks using message passing. In Acoustic Signal Enhancement; Proceedings of IWAENC 2012; International Workshop on (pp. 1–4). VDE.
- Heymann et al. [2016] Heymann, J., Drude, L., & Haeb-Umbach, R. (2016). Neural network based spectral mask estimation for acoustic beamforming. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on (pp. 196–200). IEEE.
- Higuchi et al. [2016] Higuchi, T., Ito, N., Yoshioka, T., & Nakatani, T. (2016). Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on (pp. 5210–5214). IEEE.
- Higuchi et al. [2018] Higuchi, T., Kinoshita, K., Ito, N., Karita, S., & Nakatani, T. (2018). Frame-by-frame closed-form update for mask-based adaptive MVDR beamforming. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 531–535). IEEE.
- Huang et al. [2015] Huang, P.-S., Kim, M., Hasegawa-Johnson, M., & Smaragdis, P. (2015). Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Trans. Audio, Speech, Lang. Process., 23, 2136–2147.
- Jayaprakasam et al. [2017] Jayaprakasam, S., Rahim, S. K. A., & Leow, C. Y. (2017). Distributed and collaborative beamforming in wireless sensor networks: Classifications, trends, and research directions. IEEE Communications Surveys & Tutorials, 19, 2092–2116.
- Jiang et al. [2014] Jiang, Y., Wang, D., Liu, R., & Feng, Z. (2014). Binaural classification for reverberant speech segregation using deep neural networks. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 22, 2112–2121.
- Knapp & Carter [1976] Knapp, C., & Carter, G. (1976). The generalized correlation method for estimation of time delay. IEEE transactions on acoustics, speech, and signal processing, 24, 320–327.
- Koutrouvelis et al. [2018] Koutrouvelis, A. I., Sherson, T. W., Heusdens, R., & Hendriks, R. C. (2018). A low-cost robust distributed linearly constrained beamformer for wireless acoustic sensor networks with arbitrary topology. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 26, 1434–1448.
- Lu et al. [2013] Lu, X., Tsao, Y., Matsuda, S., & Hori, C. (2013). Speech enhancement based on deep denoising autoencoder. In Interspeech (pp. 436–440).
- Luo & Mesgarani [2019] Luo, Y., & Mesgarani, N. (2019). Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM transactions on audio, speech, and language processing, 27, 1256–1266.
- Mallat [1989] Mallat, S. G. (1989). A theory for multiresolution signal decomposition: the wavelet representation. IEEE transactions on pattern analysis and machine intelligence, 11, 674–693.
- Markovich-Golan et al. [2012] Markovich-Golan, S., Gannot, S., & Cohen, I. (2012). Distributed multiple constraints generalized sidelobe canceler for fully connected wireless acoustic sensor networks. IEEE Transactions on Audio, Speech, and Language Processing, 21, 343–356.
- Nakatani et al. [2017] Nakatani, T., Ito, N., Higuchi, T., Araki, S., & Kinoshita, K. (2017). Integrating DNN-based and spatial clustering-based mask estimation for robust MVDR beamforming. In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on (pp. 286–290). IEEE.
- Ng et al. [2001] Ng, A. Y., Jordan, M. I., & Weiss, Y. (2001). On spectral clustering: Analysis and an algorithm. In NIPS.
- O’Connor & Kleijn [2014] O’Connor, M., & Kleijn, W. B. (2014). Diffusion-based distributed MVDR beamformer. In Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on (pp. 810–814). IEEE.
- O’Connor et al. [2016] O’Connor, M., Kleijn, W. B., & Abhayapala, T. (2016). Distributed sparse MVDR beamforming using the bi-alternating direction method of multipliers. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on (pp. 106–110). IEEE.
- Pandey & Wang [2019] Pandey, A., & Wang, D. (2019). A new framework for cnn-based speech enhancement in the time domain. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27, 1179–1188.
- Pariente et al. [2020] Pariente, M., Cornell, S., Deleforge, A., & Vincent, E. (2020). Filterbank design for end-to-end speech separation. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6364–6368). IEEE.
- Qi et al. [2019] Qi, J., Du, J., Siniscalchi, S. M., & Lee, C.-H. (2019). A theory on deep neural network based vector-to-vector regression with an illustration of its expressive power in speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27, 1932–1943.
- Rix et al. [2001] Rix, A. W., Beerends, J. G., Hollier, M. P., & Hekstra, A. P. (2001). Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (pp. 749–752).
- Sepúlveda et al. [2013] Sepúlveda, A., Guido, R. C., & Castellanos-Dominguez, G. (2013). Estimation of relevant time–frequency features using kendall coefficient for articulator position inference. Speech communication, 55, 99–110.
- Taal et al. [2011] Taal, C. H., Hendriks, R. C., Heusdens, R., & Jensen, J. (2011). An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio, Speech, Lang. Process., 19, 2125–2136.
- Taherian et al. [2019] Taherian, H., Wang, Z.-Q., & Wang, D. (2019). Deep learning based multi-channel speaker recognition in noisy and reverberant environments. Proc. Interspeech 2019, (pp. 4070–4074).
- Tan et al. [2018] Tan, K., Chen, J., & Wang, D. (2018). Gated residual networks with dilated convolutions for monaural speech enhancement. IEEE/ACM transactions on audio, speech, and language processing, 27, 189–198.
- Tan & Wang [2019] Tan, K., & Wang, D. (2019). Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 380–390.
- Tavakoli et al. [2016] Tavakoli, V. M., Jensen, J. R., Christensen, M. G., & Benesty, J. (2016). A framework for speech enhancement with ad hoc microphone arrays. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 24, 1038–1051.
- Tavakoli et al. [2017] Tavakoli, V. M., Jensen, J. R., Heusdens, R., Benesty, J., & Christensen, M. G. (2017). Distributed max-SINR speech enhancement with ad hoc microphone arrays. In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on (pp. 151–155). IEEE.
- Tu et al. [2017] Tu, Y.-H., Du, J., Sun, L., & Lee, C.-H. (2017). LSTM-based iterative mask estimation and post-processing for multi-channel speech enhancement. In Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2017 (pp. 488–491). IEEE.
- Vincent et al. [2006] Vincent, E., Gribonval, R., & Févotte, C. (2006). Performance measurement in blind audio source separation. IEEE Trans. Audio, Speech, Lang. Process., 14, 1462–1469.
- Wang & Chen [2018] Wang, D., & Chen, J. (2018). Supervised speech separation based on deep learning: An overview. IEEE/ACM Transactions on Audio, Speech, and Language Processing, .
- Wang & Cavallaro [2018] Wang, L., & Cavallaro, A. (2018). Pseudo-determined blind source separation for ad-hoc microphone networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26, 981–994.
- Wang et al. [2015] Wang, L., Hon, T.-K., Reiss, J. D., & Cavallaro, A. (2015). Self-localization of ad-hoc arrays using time difference of arrivals. IEEE Transactions on Signal Processing, 64, 1018–1033.
- Wang et al. [2019] Wang, P., Tan, K. et al. (2019). Bridging the gap between monaural speech enhancement and recognition with distortion-independent acoustic modeling. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 39–48.
- Wang et al. [2014] Wang, Y., Narayanan, A., & Wang, D. L. (2014). On training targets for supervised speech separation. IEEE/ACM Trans. Audio, Speech, Lang. Process., 22, 1849–1858.
- Wang & Wang [2013] Wang, Y., & Wang, D. L. (2013). Towards scaling up classification-based speech separation. IEEE Trans. Audio, Speech, Lang. Process., 21, 1381–1390.
- Wang & Wang [2018] Wang, Z.-Q., & Wang, D. (2018). All-neural multichannel speech enhancement. to appear in Interspeech, .
- Wang et al. [2018] Wang, Z.-Q., Zhang, X., & Wang, D. (2018). Robust speaker localization guided by deep learning-based time-frequency masking. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27, 178–188.
- Weninger et al. [2015] Weninger, F., Erdogan, H., Watanabe, S., Vincent, E., Le Roux, J., Hershey, J. R., & Schuller, B. (2015). Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr. In International Conference on Latent Variable Analysis and Signal Separation (pp. 91–99). Springer.
- Williamson et al. [2016] Williamson, D. S., Wang, Y., & Wang, D. L. (2016). Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio, Speech, Lang. Process., 24, 483–492.
- Xiao et al. [2017] Xiao, X., Zhao, S., Jones, D. L., Chng, E. S., & Li, H. (2017). On time-frequency mask estimation for MVDR beamforming with application in robust speech recognition. In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on (pp. 3246–3250). IEEE.
- Xu et al. [2015] Xu, Y., Du, J., Dai, L.-R., & Lee, C.-H. (2015). A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio, Speech, Lang. Process., 23, 7–19.
- Yang & Zhang [2019] Yang, Z., & Zhang, X.-L. (2019). Boosting spatial information for deep learning based multichannel speaker-independent speech separation in reverberant environments. In 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (pp. 1506–1510). IEEE.
- Zeng & Hendriks [2014] Zeng, Y., & Hendriks, R. C. (2014). Distributed delay and sum beamformer for speech enhancement via randomized gossip. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22, 260–273.
- Zhang et al. [2018] Zhang, J., Chepuri, S. P., Hendriks, R. C., & Heusdens, R. (2018). Microphone subset selection for MVDR beamformer based noise reduction. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26, 550–563.
- Zhang et al. [2017] Zhang, X., Wang, Z.-Q., & Wang, D. (2017). A speech enhancement algorithm by iterating single-and multi-microphone processing and its application to robust ASR. In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on (pp. 276–280). IEEE.
- Zhang [2018] Zhang, X.-L. (2018). Deep ad-hoc beamforming. arXiv preprint arXiv:1811.01233, . URL: https://arxiv.org/abs/1811.01233v2.
- Zhang & Wang [2016a] Zhang, X.-L., & Wang, D. (2016a). Boosting contextual information for deep neural network based voice activity detection. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24, 252–264.
- Zhang & Wang [2016b] Zhang, X.-L., & Wang, D. (2016b). A deep ensemble learning method for monaural speech separation. IEEE/ACM transactions on audio, speech, and language processing, 24, 967–977.
- Zhang & Wu [2013a] Zhang, X.-L., & Wu, J. (2013a). Deep belief networks based voice activity detection. IEEE Trans. Audio, Speech, Lang. Process., 21, 697–710.
- Zhang & Wu [2013b] Zhang, X.-L., & Wu, J. (2013b). Denoising deep neural networks based voice activity detection. In the 38th IEEE International Conference on Acoustic, Speech, and Signal Processing (pp. 853–857).
- Zheng & Zhang [2018] Zheng, N., & Zhang, X.-L. (2018). Phase-aware speech enhancement based on deep neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27, 63–76.
- Zheng et al. [2019] Zheng, X., Tang, Y. Y., & Zhou, J. (2019). A framework of adaptive multiscale wavelet decomposition for signals on undirected graphs. IEEE Transactions on Signal Processing, 67, 1696–1711.
- Zhou & Qian [2018] Zhou, Y., & Qian, Y. (2018). Robust mask estimation by integrating neural network-based and clustering-based approaches for adaptive acoustic beamforming. In Int Conf on Acoustics, Speech, and Signal Processing, in press. Google Scholar.