Deep Attention-guided Graph Clustering
with Dual Self-supervision
Abstract
Existing deep embedding clustering methods fail to sufficiently utilize the available off-the-shelf information from feature embeddings and cluster assignments, limiting their performance. To this end, we propose a novel method, namely deep attention-guided graph clustering with dual self-supervision (DAGC). Specifically, DAGC first utilizes a heterogeneity-wise fusion module to adaptively integrate the features of the auto-encoder and the graph convolutional network in each layer and then uses a scale-wise fusion module to dynamically concatenate the multi-scale features in different layers. Such modules are capable of learning an informative feature embedding via an attention-based mechanism. In addition, we design a distribution-wise fusion module that leverages cluster assignments to acquire clustering results directly. To better explore the off-the-shelf information from the cluster assignments, we develop a dual self-supervision solution consisting of a soft self-supervision strategy with a Kullback-Leibler divergence loss and a hard self-supervision strategy with a pseudo supervision loss. Extensive experiments on nine benchmark datasets validate that our method consistently outperforms state-of-the-art methods. Especially, our method improves the ARI by more than 10.29% over the best baseline. The code will be publicly available at https://github.com/ZhihaoPENG-CityU/DAGC.
Index Terms:
Unsupervised learning, deep embedding clustering, feature fusion, self-supervision.I Introduction
Clustering is one of the fundamental tasks in data analysis, which aims to categorize samples into multiple groups according to their intrinsic similarities, and has been successfully applied to many real-world applications such as image processing [1, 2, 3, 4, 5], face recognition [6, 7, 8], and object detection [9, 10, 11]. Recently, with the booming of deep learning, numerous researchers have paid attention to deep embedding clustering analysis, which could effectively learn a clustering-friendly representation by extracting intrinsic patterns from the latent embedding space. For example, Hinton and Salakhutdinov [12] developed a deep auto-encoder (DAE) framework that first conducts embedding learning and then performs K-means [13] to obtain clustering results. Xie et al. [14] designed a deep embedding clustering method (DEC) to perform embedding learning and cluster assignment jointly. Guo et al. [15] improved DEC by introducing a reconstruction loss to preserve data structure. Although these DAE-based approaches obtain impressive improvement, they neglect the underlying topological structure among data, which has demonstrated its importance in various works [16, 17, 18].
Recently, a series of works have been proposed to use graph convolutional networks (GCNs) [19] to exploit the topological structure information. For instance, Kipf et al. [20] incorporated GCN into DAE and variational DAE, and proposed graph auto-encoder (GAE) and variational graph auto-encoder (VGAE), respectively. Pan et al. [21] designed an adversarially regularized graph auto-encoder network (ARGA) to promote GAE. Wang et al. [22] incorporated graph attention networks [23] into GAE for attributed graph clustering. Bo et al. [24] fused GCN into DEC to consider the node content and topological structure information at the same time.
However, these works still suffer from the following drawbacks. First, they equate the importance of the features extracted from DAE and GCN, e.g., in [24], the DAE and GCN features of a typical layer are averaged. Such a simple fusion strategy is not a good choice since those features contain different characteristic information. Second, they neglect the multi-scale information embedded in different layers, which may lead to inferior clustering results. Third, they output two probability distributions capable of obtaining the final clustering results; however, the complex real-world datasets are usually agnostic and vastly different, so it is difficult to decide which one should be used to get the final clustering results. To the best of our knowledge, this is a decision-making dilemma for those kinds of deep graph clustering methods. Last but not least, the previous approaches fail to adequately exploit the available information from the high-confidence clustering assignments.
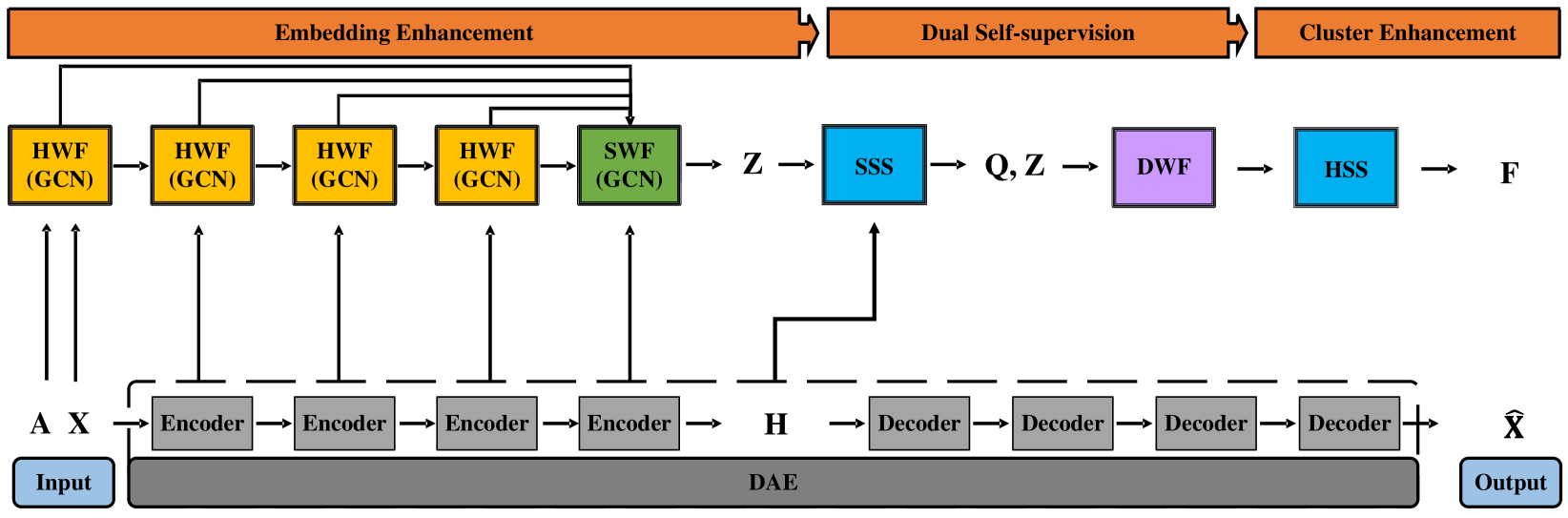
To address the above-mentioned drawbacks, we propose a novel deep embedding clustering method, focusing on exploiting the available off-the-shelf information from feature embeddings and cluster assignments. As shown in Figure 1, the proposed method consists of a heterogeneity111Here, ‘heterogeneity’ indicates the discrimination of feature structure, e.g., the DAE-based feature structure and the GCN-based feature structure.-wise fusion (HWF) module, a scale-wise fusion (SWF) module, a distribution-wise fusion (DWF) module, a soft self-supervision (SSS) strategy, and a hard self-supervision (HSS) strategy. A preliminary version of this work was published in ACM Multimedia 2021 [25], which can be regarded as a special case of the current version that focuses on embedding enhancement via the HWF and SWF modules. However, the conference paper suffers from the decision-making dilemma concerning two learned probability distributions from DAE and GCN, i.e., which one should be selected as the final clustering assignment result. In summary, the main contributions of this journal paper are as follows:
-
•
To handle the decision-making dilemma, we propose a learning-aware fusion module to adaptively fuse the learned data probability distributions to predict the clustering results.
-
•
In addition, for the two learned distributions, we improve the soft self-supervision strategy to better preserve the distribution consistency alignment.
-
•
Moreover, for the aforementioned fused distribution, we develop a hard self-supervision strategy with a pseudo supervision loss to employ the high-confidence clustering assignments to improve clustering performance.
-
•
Extensive experiments on nine benchmark datasets validate that our method consistently outperforms the conference version [25]. For instance, on DBLP, our method improves the ARI by more than 14.80%. In addition, the ablation studies and visualizations quantitatively and qualitatively validate the effectiveness of this method.
We organize the rest of this paper as follows. Section II briefly reviews the related works. Section III introduces the proposed network architecture, followed by the experimental results and analyses in Section IV. Finally, we conclude this paper in Section V.
Notation: Throughout the paper, scalars are denoted by italic lower case letters, vectors by bold lower case letters, matrices by bold upper case ones, and operators by calligraphy ones, respectively. Let be the input data, be the node set, be the edge set, and be the undirected graph. denotes the adjacency matrix, denotes the degree matrix, and denotes the identity matrix. We summarize the main notations in Table I.
| Notations | Descriptions | |
| The input matrix | ||
| The reconstructed matrix | ||
| The adjacency matrix | ||
| The degree matrix | ||
| The GCN feature from the layer | ||
| The encoder feature from the layer | ||
| The HWF weight matrix | ||
| The HWF combined feature | ||
| The SWF weight matrix | ||
| The DAE extracted feature | ||
| The distribution obtained from DAE | ||
| The distribution obtained from SWF | ||
| The auxiliary distribution | ||
| The DWF weight matrix | ||
| The DWF combined feature | ||
| n | The number of samples | |
| d | The dimension of | |
| The dimension of the latent feature | ||
| l | The number of network layers | |
| k | The number of clusters | |
| The number of neighbors for KNN graph | ||
| r | The threshold value for pseudo supervision | |
| The concatenation operation | ||
II Related Work
DAE is a typical deep neural network that allows computational models composed of multiple processing layers to learn data representations with multiple levels of abstraction. Recently, benefiting from the powerful representation ability of DAE, deep embedding clustering has achieved remarkable development [26, 27, 28, 29, 30, 31, 32]. For example, Hinton and Salakhutdinov [12] used DAE to extract the feature representation of input data, on which K-means [13] is performed to obtain the clustering results. [14] jointly conducted embedding learning and cluster assignment in an iterative optimization manner. The improved DEC (IDEC) [15] enhanced the clustering performance by adding a reconstruction loss function into DEC. A series of works [2, 3, 33] introduced multi-view information into the DAE framework to further improve embedding learning. However, these DAE-based methods neglect the underlying topological structure among data, which has demonstrated its effectiveness for data clustering [16, 17, 34, 35, 18], thus limiting their performance.
Graph embedding is a new paradigm for clustering to capture the topological structure among samples [36, 37, 38, 17, 39, 40, 41], and many recent approaches [42, 43, 44, 45, 46] have explored GCN to achieve graph embedding. For instance, Kipf and Welling [20] provided GAE and VGAE methods by incorporating GCN into DAE and variational DAE frameworks, respectively. [21] extended GAE by introducing a designed adversarial regularization. Wang et al. [22] merged GAE and the graph attention network [23] to build a deep attentional embedding framework for attributed graph clustering (DAEGC). The structural deep clustering network (SDCN) [24] fused the node content and topological structure information to achieve deep embedding clustering. Peng et al. [25] designed the attention-driven graph clustering network (AGCN) to merge numerous features to enhance the embedding learning via an adaptive mechanism. The deep fusion clustering network (DFCN) [47] exploited a designed fusion strategy to combine the DAE and GAE frameworks to merge the node attribute and topological structure information. He et al. [48] developed an adaptive graph convolutional clustering (AGCC) model to update the graph structure and the data representation layer by layer.
Optimizing a deep clustering network is a fundamental yet challenging task because there are no ground-truth labels as supervision. Previous works [14, 15, 22, 24, 25] minimize the Kullback-Leibler (KL) divergence to tackle this challenge, and its effectiveness has been proven. Specifically, it first uses the Student’s t-distribution [49, 50] as a kernel function to measure the similarity between the extracted feature and its corresponding centroid vector , in which the measured similarity can be regarded as a probability distribution with its -th element being
| (1) |
where is set to . Then, it implements the KL divergence minimization between and a distribution with the -th element , i.e.,
| (2) |
where is the Kullback-Leibler divergence function that measures the distance between two distributions. Such an auxiliary distribution generation normalizes the high-confidence probability value as a large value, capable of learning the high-confidence assignments. However, previous works fail to sufficiently utilize the available off-the-shelf information from high-confidence clustering assignments, inevitably leading to inferior clustering results.
III Proposed Method
Figure 1 illustrates the architecture of the proposed method, where we will detail the main components in what follows.
III-A Heterogeneity-Wise Fusion
We first exploit a DAE module with a series of encoders and decoders to extract the latent representation by adapting the reconstruction loss, i.e.,
| (3) |
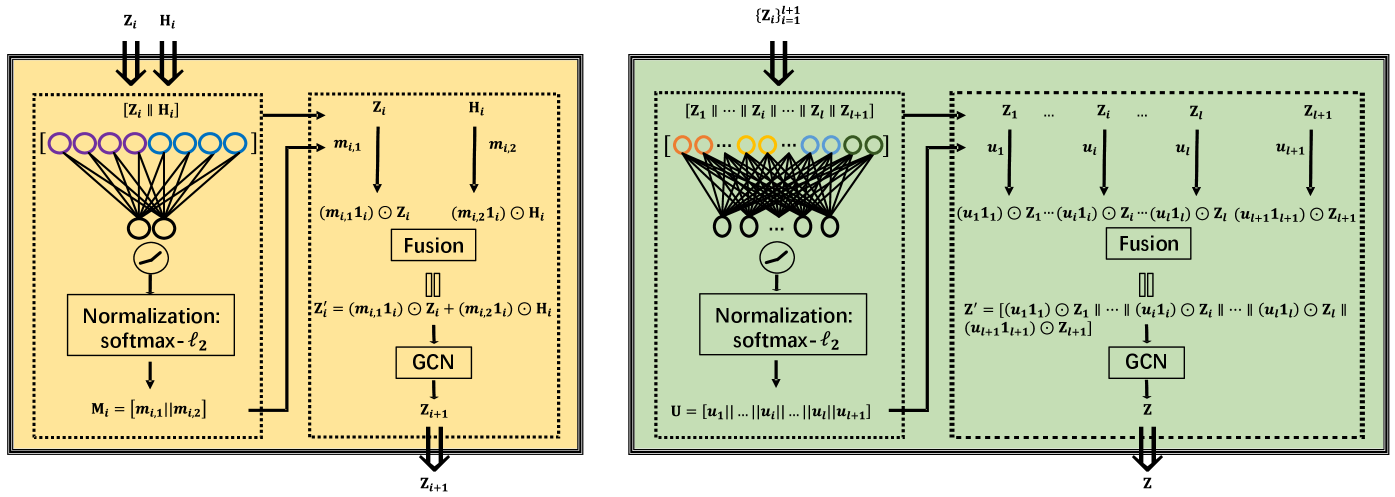
where and denote the input matrix and the reconstructed matrix, respectively. Here, , , , , where and denote the encoder and decoder outputs from the layer, respectively, l denotes the number of encoder/decoder layers, , , , and denote the network weight and bias of the encoder and decoder layer, respectively, and denotes an activation function, such as Tanh or ReLU [51]. Particularly, we set for convenience. In addition, we denote the GCN feature learned from the layer as with being the dimension of the layer, where . Previous works (e.g., SDCN [24]) combine the heterogeneity-wise representation on the layer ( and ) via a fixed fusion strategy (i.e., ) to enhance representation learning. However, such a fusion strategy is simple but unreasonable since the heterogeneity-wise representations and owe different characteristic information. To this end, we propose a learning-aware fusion strategy to develop an adaptive fusion strategy to dynamically weight and . Specifically, to learn the corresponding attention coefficients of and , we first concatenate them as and then build a fully connected layer parametrized by a weight matrix . Afterwards, we apply the LeakyReLU (LReLU) [52] on the product between and , and normalize the output of the LReLU unit via the softmax function and the normalization (i.e., ‘softmax-’ normalization). Formally, we formulate the prediction of the corresponding attention coefficients as
| (4) |
where is the attention coefficient matrix with entries being greater than , and are the weight vectors for measuring the importance of and , respectively, and . Thus, we can adaptively fuse the GCN feature and the DAE feature on the layer as
| (5) |
where denotes the vector of all ones, and denotes the Hadamard product of matrices. Then, we use the resulting matrix as the input of the GCN layer to learn the representation , i.e.,
| (6) |
where denotes the weight matrix from the GCN layer, and normalizes by using renormalization with a self-loop normalized and the corresponding .
III-B Scale-Wise Fusion
As aforementioned, previous works neglect the off-the-shelf multi-scale information embedded in different layers, which is of great importance for embedding learning. To this end, we propose the SWF module to concatenate the multi-scale features from different layers via an attention-based mechanism. The right border of Figure 2 shows the overall architecture of SWF.
We aggregate the multi-scale features with a concatenation manner to dynamically combine various scale features with different dimensions. Afterwards, we build a fully connected layer parametrized by a weight matrix to capture the relationship among the multi-scale features. Formally, we formulate the whole process as
| (7) |
where denotes the concatenation operation of multiple elements. We then conduct the feature fusion as
| (8) |
where is the j-th element of , i.e., . In addition, we use a Laplacian smoothing operator [53] and the softmax function to make the fused feature as a reasonable probability distribution, i.e.,
| (9) |
where denotes the learnable parameters.
III-C Distribution-Wise Fusion
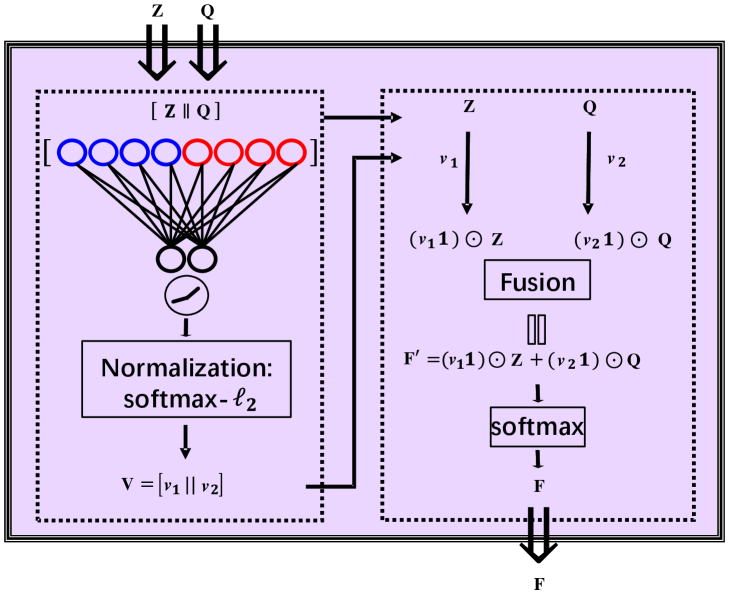
As we obtain the feature from DAE, we can exploit it to calculate its cluster center embedding with K-means. Afterward, we measure the similarity between the extracted feature and its corresponding centroid vector , in which the measured similarity can be regarded as a probability distribution with its -th element being , following Eq. (1). Both and can generate the final clustering results; however, it is challenging to choose which one to obtain the final clustering result within different scenarios. To the best of our knowledge, this is an unsolved decision-making dilemma commonly existing in the previous deep graph clustering methods. To handle this challenge, we propose the DWF module to fuse the learned data probability distributions in an attention-driven manner to predict cluster labels. Figure 3 shows the overall architecture.
Specifically, we first learn the importance of and by an attention-based mechanism, i.e.,
| (10) |
where is the attention coefficient matrix, is a learned weight matrix via a fully connected layer. We then adaptively leverage and as
| (11) |
where denotes the vector of all ones. Finally, we apply the softmax function to normalize with
| (12) |
where is the element of . When the network is well-trained, we can directly infer the predicted cluster label through , i.e.,
| (13) |
where is the predicted label of . In this way, the cluster structure can be represented explicitly in .
III-D Dual Self-supervision
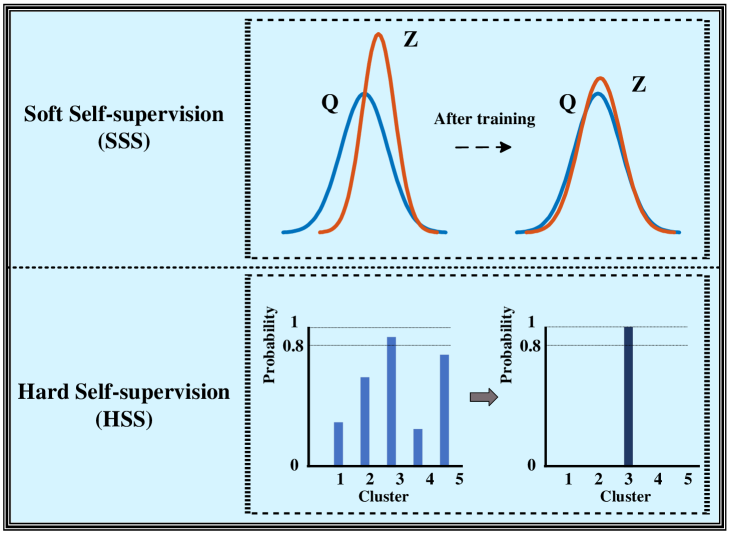
As unsupervised clustering lacks reliable guidance, we propose a novel dual self-supervision scheme that combines a soft self-supervision strategy with a Kullback-Leibler (KL) divergence loss and a hard self-supervision strategy with a pseudo supervision loss to guide the overall network training, as illustrated in Figure 4.
III-D1 Soft Self-supervision
Since we take advantage of the high-confidence assignments to iteratively refine the clusters by utilizing the soft assignments (i.e., the probability distributions and ), we term this supervision strategy as the soft self-supervision strategy. Concretely, since involves the graph information through the HWF and SWF modules, we first derive an auxiliary distribution via by normalizing per cluster after squaring , i.e.,
| (14) |
where is the element of . Then, we minimize the KL divergence not only between a learned distribution and its auxiliary distribution (i.e., and ), but also between both two learned distributions (i.e., ) to promote a highly consistent distribution alignment to train our model, i.e.,
| (15) | ||||
where and are the trade-off parameters.
III-D2 Hard Self-supervision
Although the soft self-supervision strategy has become a helpful tool for unsupervised clustering, it preserves the low-confidence predicted probabilities, limiting the clustering performance. To further make use of the available off-the-shelf information from the cluster assignments, we introduce the pseudo supervision technique [54] and set the pseudo-label as . Considering that the pseudo-labels may contain many incorrect labels, we select the high-confidence ones as supervisory information by a large threshold r, i.e.,
| (16) |
In the experiment, we set . Then, we leverage the high-confidence pseudo-labels to supervise the network training, i.e.,
| (17) |
where is the trade-off parameter, denotes the cross-entropy [55] loss, and transforms to its one-hot form. As shown in Figure 4, the pseudo-labels transfer the cluster assignment to the hard one-hot encoding, we thus name it as hard self-supervision strategy.
In addition, we have empirically observed that only using HSS does not perform well in all scenarios. The reason may be that the distribution probability values are small in some situations, making a weak self-supervision for guiding network training with the HSS strategy. To this end, we combine the SSS and HSS strategies together to drive the network training. Combining Eqs. (3), (15), and (17), our overall loss function can be written as
| (18) |
The whole training process is shown in Algorithm 1.
III-E Computational Complexity Analysis
For the DAE module, the time complexity is . For the GCN module, as the operation can be computed efficiently using sparse matrix computation, the time complexity is only according to [21]. For Eq. (1), the time complexity is based on [14]. For HWF, SWF, and DWF modules, the total time complexity is . Thus, the overall computational complexity of Algorithm 1 in one iteration is about .
| Dataset | Type | Samples | Classes | Edges |
| USPS | Image | 9298 | 10 | 27894 |
| Reuters | Text | 10000 | 4 | 30000 |
| HHAR | Record | 10299 | 6 | 30897 |
| ACM | Graph | 3025 | 3 | 13128 |
| CiteSeer | Graph | 3327 | 6 | 4552 |
| DBLP | Graph | 4057 | 4 | 3528 |
| Amazon Photo | Graph | 7650 | 8 | 119081 |
| PubMed | Graph | 19717 | 3 | 44324 |
| AIDS | Graph | 31385 | 38 | 64780 |
| Datasets | Metrics | K-means [13] | DAE [12] | DEC [14] | IDEC [15] | GAE [20] | VGAE [20] | DAEGC [22] | ARGA [21] | SDCN [24] | AGCN [25] | DFCN [47] | AGCC [48] | Our |
| [Science06] | [ICML16] | [AAAI17] | [NIPS16] | [NIPS16] | [AAAI19] | [IJCAI18] | [WWW20] | [MM21] | [AAAI21] | [TNNLS22] | ||||
| Reuters | ARI | 46.090.02 | 49.550.37 | 48.440.14 | 51.260.21 | 19.610.22 | 26.180.36 | 31.120.18 | 24.500.40 | 55.360.37 | 60.551.78 | 59.800.40 | 62.982.24 | 63.481.10 |
| F1 | 58.330.03 | 60.960.22 | 64.250.22 | 63.210.12 | 43.530.42 | 57.140.17 | 61.820.13 | 51.100.20 | 65.480.08 | 66.160.64 | 69.600.10 | 67.211.61 | 68.811.26 | |
| ACC | 59.980.02 | 74.900.21 | 73.580.13 | 75.430.14 | 54.400.27 | 60.850.23 | 65.500.13 | 56.200.20 | 77.150.21 | 79.301.07 | 77.700.20 | 81.651.52 | 81.680.69 | |
| NMI | 58.860.01 | 49.690.29 | 47.500.34 | 50.280.17 | 25.920.41 | 25.510.22 | 30.550.29 | 28.700.30 | 50.820.21 | 57.831.01 | 59.900.40 | 59.560.94 | 58.941.16 | |
| HHAR | ARI | 27.950.38 | 60.360.88 | 61.250.51 | 62.830.45 | 42.631.63 | 51.470.73 | 60.382.15 | 44.701.00 | 72.840.09 | 77.070.66 | 76.400.10 | 75.581.85 | 77.380.97 |
| F1 | 41.282.43 | 66.360.34 | 67.290.29 | 68.630.33 | 62.640.97 | 71.550.29 | 76.892.18 | 61.100.90 | 82.580.08 | 88.000.53 | 87.300.10 | 85.792.48 | 87.901.11 | |
| ACC | 54.040.01 | 68.690.31 | 69.390.25 | 71.050.36 | 62.331.01 | 71.300.36 | 76.512.19 | 63.300.80 | 84.260.17 | 88.110.43 | 87.100.10 | 86.541.79 | 87.831.01 | |
| NMI | 41.540.51 | 71.420.97 | 72.910.39 | 74.190.39 | 55.061.39 | 62.950.36 | 69.102.28 | 57.101.40 | 79.900.09 | 82.440.62 | 82.200.10 | 82.211.78 | 85.342.11 | |
| USPS | ARI | 54.550.06 | 58.830.05 | 63.700.27 | 67.860.12 | 50.300.55 | 40.960.59 | 63.330.34 | 51.100.60 | 71.840.24 | 73.610.43 | 75.300.20 | 68.503.83 | 75.541.28 |
| F1 | 64.780.03 | 69.740.03 | 71.820.21 | 74.630.10 | 61.840.43 | 53.631.05 | 72.450.49 | 66.101.20 | 76.980.18 | 77.610.38 | 78.300.20 | 74.862.56 | 79.330.74 | |
| ACC | 66.820.04 | 71.040.03 | 73.310.17 | 76.220.12 | 63.100.33 | 56.190.72 | 73.550.40 | 66.800.70 | 78.080.19 | 80.980.28 | 79.500.20 | 77.141.21 | 81.131.89 | |
| NMI | 62.630.05 | 67.530.03 | 70.580.25 | 75.560.06 | 60.690.58 | 51.080.37 | 71.120.24 | 61.600.30 | 79.510.27 | 79.640.32 | 82.800.30 | 75.933.83 | 82.140.15 | |
| ACM | ARI | 30.600.69 | 54.640.16 | 60.641.87 | 62.161.50 | 59.463.10 | 57.720.67 | 59.353.89 | 62.902.10 | 73.910.40 | 74.200.38 | 74.900.40 | 73.730.90 | 76.720.98 |
| F1 | 67.570.74 | 82.010.08 | 84.510.74 | 85.110.48 | 84.651.33 | 84.170.23 | 87.072.79 | 86.101.20 | 90.420.19 | 90.580.17 | 90.800.20 | 90.390.39 | 91.530.42 | |
| ACC | 67.310.71 | 81.830.08 | 84.330.76 | 85.120.52 | 84.521.44 | 84.130.22 | 86.942.83 | 86.101.20 | 90.450.18 | 90.590.15 | 90.900.20 | 90.380.38 | 91.550.40 | |
| NMI | 32.440.46 | 49.300.16 | 54.541.51 | 56.611.16 | 55.381.92 | 53.200.52 | 56.184.15 | 55.701.40 | 68.310.25 | 68.380.45 | 69.400.40 | 68.340.89 | 71.500.80 | |
| CiteSeer | ARI | 06.970.39 | 29.310.14 | 28.120.36 | 25.702.65 | 33.551.18 | 33.130.53 | 37.781.24 | 33.401.50 | 40.170.43 | 43.790.31 | 45.500.30 | 41.822.03 | 47.980.91 |
| F1 | 31.920.27 | 53.800.11 | 52.620.17 | 61.621.39 | 57.360.82 | 57.700.49 | 62.201.32 | 54.800.80 | 63.620.24 | 62.370.21 | 64.300.20 | 60.471.57 | 62.370.52 | |
| ACC | 38.650.65 | 57.080.13 | 55.890.20 | 60.491.42 | 61.350.80 | 60.970.36 | 64.541.39 | 56.900.70 | 65.960.31 | 68.790.23 | 69.500.20 | 68.081.44 | 72.010.53 | |
| NMI | 11.450.38 | 27.640.08 | 28.340.30 | 27.172.40 | 34.630.65 | 32.690.27 | 36.410.86 | 34.500.80 | 38.710.32 | 41.540.30 | 43.900.20 | 40.861.45 | 45.340.70 | |
| DBLP | ARI | 13.433.02 | 12.210.43 | 23.920.39 | 25.370.60 | 22.021.40 | 17.920.07 | 21.030.52 | 22.700.30 | 39.152.01 | 42.490.31 | 47.001.50 | 44.403.79 | 57.291.20 |
| F1 | 36.083.53 | 52.530.36 | 59.380.51 | 61.330.56 | 61.412.23 | 58.690.07 | 61.750.67 | 61.800.90 | 67.711.51 | 72.800.56 | 75.700.80 | 71.842.02 | 80.790.61 | |
| ACC | 39.323.17 | 51.430.35 | 58.160.56 | 60.310.62 | 61.211.22 | 58.590.06 | 62.050.48 | 61.601.00 | 68.051.81 | 73.260.37 | 76.000.80 | 73.452.16 | 81.260.62 | |
| NMI | 16.943.22 | 25.400.16 | 29.510.28 | 31.170.50 | 30.800.91 | 26.920.06 | 32.490.45 | 26.801.00 | 39.501.34 | 39.680.42 | 43.701.00 | 40.362.81 | 51.990.76 | |
| Amazon Photo | ARI | 05.500.44 | 20.800.47 | 18.590.04 | 19.240.07 | 48.824.57 | 56.244.66 | 59.390.02 | 44.184.41 | 31.211.23 | 41.152.78 | 58.980.84 | 29.963.46 | 60.511.58 |
| F1 | 23.960.51 | 47.870.20 | 46.710.12 | 47.200.11 | 68.081.76 | 70.382.98 | 69.970.02 | 64.301.95 | 50.661.49 | 43.685.08 | 71.580.31 | 39.675.22 | 71.682.35 | |
| ACC | 27.220.76 | 48.250.08 | 47.220.08 | 47.620.08 | 71.572.48 | 74.263.63 | 76.440.01 | 69.282.30 | 53.440.81 | 58.531.74 | 76.880.80 | 51.473.04 | 78.751.02 | |
| NMI | 13.231.33 | 38.760.30 | 37.350.05 | 37.830.08 | 62.132.79 | 66.013.40 | 65.570.03 | 58.362.76 | 44.850.83 | 51.763.23 | 69.211.00 | 39.194.07 | 66.271.13 | |
| PubMed | ARI | 28.100.01 | 23.860.67 | 19.550.13 | 20.580.39 | 20.621.39 | 30.151.23 | 29.840.04 | 24.350.17 | 22.302.07 | 31.390.67 | 30.640.11 | OOM | 35.291.02 |
| F1 | 58.880.01 | 64.010.29 | 61.490.10 | 62.410.32 | 61.370.85 | 67.680.89 | 68.230.02 | 65.690.13 | 65.011.21 | 69.730.45 | 68.100.07 | OOM | 72.780.72 | |
| ACC | 59.830.01 | 63.070.31 | 60.140.09 | 60.700.34 | 62.090.81 | 68.480.77 | 68.730.03 | 65.260.12 | 64.201.30 | 69.670.42 | 68.890.07 | OOM | 73.160.69 | |
| NMI | 31.050.02 | 26.320.57 | 22.440.14 | 23.670.29 | 23.843.54 | 30.611.71 | 28.260.03 | 24.800.17 | 22.872.04 | 30.960.99 | 31.430.13 | OOM | 33.291.14 | |
| AIDS | ARI | 05.370.19 | 05.710.66 | 10.713.49 | 13.395.35 | 03.500.79 | 00.440.43 | OOM | 01.790.97 | 0.060.00 | 14.035.76 | 00.480.00 | OOM | 21.407.12 |
| F1 | 11.861.02 | 11.911.54 | 13.811.60 | 12.101.55 | 08.401.23 | 09.132.74 | OOM | 06.011.41 | 02.020.00 | 06.141.80 | 05.510.01 | OOM | 21.771.10 | |
| ACC | 17.110.63 | 21.785.02 | 35.123.69 | 47.325.76 | 15.720.89 | 23.046.08 | OOM | 59.272.54 | 62.250.00 | 59.823.37 | 11.280.02 | OOM | 63.842.81 | |
| NMI | 23.420.57 | 24.292.49 | 24.302.19 | 25.374.90 | 12.662.64 | 01.620.29 | OOM | 04.862.16 | 00.160.00 | 09.082.28 | 04.670.01 | OOM | 34.442.96 |
IV Experiments
We conducted quantitative and qualitative experiments on nine commonly used benchmark datasets to evaluate the proposed model. In addition, we performed ablation studies to investigate the effectiveness of the proposed modules and the adopted strategies. Moreover, we performed a series of parameter analyses to verify the robustness of our method.
IV-A Datasets and Compared Methods
We conducted experiments on one image dataset (USPS [56]), one text dataset (Reuters [57]), one record dataset (HHAR [58]), and six graph datasets (ACM222http://dl.acm.org, CiteSeer333http://CiteSeerx.ist.psu.edu/, DBLP444https://dblp.uni-trier.de, Amazon Photo, PubMed[59], and AIDS[60]), which are briefly summarized in Table II.
We compared the proposed method with the classic clustering method K-means [13], three DAE-based embedding clustering methods [12, 14, 15], and seven GCN-based embedding clustering methods [20, 21, 22, 23, 24, 25, 47], the details of which are listed as follows.
| Datasets | SSS | HSS | DWF | SWF | HWF | ARI | F1 | ACC | NMI |
| USPS | ✗ | ✗ | ✗ | ✗ | ✗ | 71.670.44 | 76.880.30 | 78.080.30 | 79.190.44 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 71.710.87 | 76.460.54 | 78.980.97 | 78.870.36 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 70.960.24 | 76.440.17 | 77.700.14 | 78.610.22 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 71.730.71 | 76.310.34 | 79.630.43 | 78.410.29 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 71.900.99 | 76.610.56 | 79.740.79 | 78.640.46 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 74.390.13 | 78.510.09 | 79.110.11 | 82.060.16 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 75.541.28 | 79.330.74 | 81.131.89 | 82.140.15 | |
| Reuters | ✗ | ✗ | ✗ | ✗ | ✗ | 56.374.76 | 65.031.87 | 78.192.02 | 53.743.63 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 61.380.78 | 67.221.15 | 80.190.53 | 57.940.49 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 61.550.64 | 66.540.21 | 80.600.47 | 58.150.49 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 62.701.00 | 66.900.30 | 80.950.46 | 59.420.69 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 63.320.57 | 67.210.18 | 81.280.32 | 60.790.69 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 62.752.00 | 68.741.23 | 81.020.81 | 57.931.50 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 63.481.10 | 68.811.26 | 81.680.69 | 58.941.16 | |
| HHAR | ✗ | ✗ | ✗ | ✗ | ✗ | 73.171.95 | 82.703.97 | 84.182.80 | 80.031.16 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 72.451.02 | 83.250.81 | 84.600.66 | 79.080.85 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 73.240.73 | 83.341.69 | 84.771.21 | 80.100.50 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 72.841.23 | 83.721.10 | 84.950.86 | 79.220.94 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 73.240.52 | 83.740.68 | 85.010.46 | 79.990.47 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 75.910.40 | 86.650.70 | 86.230.81 | 82.610.12 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 77.380.97 | 87.901.11 | 87.831.01 | 85.342.11 | |
| ACM | ✗ | ✗ | ✗ | ✗ | ✗ | 73.910.40 | 90.420.19 | 90.450.18 | 68.310.25 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 73.950.60 | 90.480.26 | 90.470.24 | 68.420.61 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 74.200.38 | 90.580.17 | 90.590.15 | 68.380.45 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 74.580.78 | 90.720.35 | 90.730.33 | 68.940.63 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 74.830.73 | 90.850.33 | 90.850.31 | 69.020.66 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 75.780.64 | 91.180.25 | 91.180.26 | 70.590.68 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 76.720.98 | 91.530.42 | 91.550.40 | 71.500.80 | |
| CiteSeer | ✗ | ✗ | ✗ | ✗ | ✗ | 40.170.43 | 63.620.24 | 65.960.31 | 38.710.32 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 40.931.78 | 60.910.81 | 66.381.72 | 39.071.52 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 43.790.31 | 62.370.21 | 68.790.23 | 41.540.30 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 43.500.47 | 61.250.31 | 68.540.30 | 41.350.58 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 43.720.60 | 61.520.65 | 68.460.40 | 41.250.41 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 47.761.28 | 62.240.80 | 71.860.79 | 45.101.05 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 47.980.91 | 62.370.52 | 72.010.53 | 45.340.70 | |
| DBLP | ✗ | ✗ | ✗ | ✗ | ✗ | 39.152.01 | 67.711.51 | 68.051.81 | 39.501.34 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 37.781.85 | 68.691.65 | 69.651.43 | 35.371.58 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 42.490.31 | 72.800.56 | 73.260.37 | 39.680.42 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 41.720.47 | 72.680.20 | 72.920.21 | 39.260.33 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 42.520.96 | 72.810.59 | 73.430.50 | 39.990.70 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 55.450.60 | 79.830.32 | 80.290.33 | 50.080.56 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 57.291.20 | 80.790.61 | 81.260.62 | 51.990.76 | |
| Amazon Photo | ✗ | ✗ | ✗ | ✗ | ✗ | 31.211.23 | 50.661.49 | 53.440.81 | 44.850.83 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 37.863.46 | 35.864.00 | 54.841.43 | 46.514.93 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 41.152.78 | 43.685.08 | 58.531.74 | 51.763.23 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 41.142.78 | 43.685.08 | 58.521.74 | 51.773.22 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 43.502.29 | 46.204.18 | 60.591.94 | 52.231.67 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 51.812.25 | 66.372.64 | 71.932.08 | 59.091.60 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 60.511.58 | 71.682.35 | 78.751.02 | 66.271.13 | |
| PubMed | ✗ | ✗ | ✗ | ✗ | ✗ | 22.302.07 | 65.011.21 | 64.201.30 | 22.872.04 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 27.651.16 | 67.210.83 | 67.310.78 | 27.771.85 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 31.390.67 | 69.730.45 | 69.670.42 | 30.960.99 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 30.851.10 | 69.050.87 | 68.670.79 | 32.191.29 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 33.211.94 | 70.751.28 | 71.351.39 | 31.471.75 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 32.791.57 | 69.891.20 | 70.561.37 | 31.851.36 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 35.291.02 | 72.780.72 | 73.160.69 | 33.291.14 | |
| AIDS | ✗ | ✗ | ✗ | ✗ | ✗ | 10.153.04 | 4.760.69 | 58.323.33 | 7.670.48 |
| ✗ | ✗ | ✗ | ✗ | ✓ | 10.313.52 | 3.920.67 | 62.250.01 | 6.681.13 | |
| ✗ | ✗ | ✗ | ✓ | ✓ | 10.693.33 | 4.330.99 | 62.320.21 | 7.541.40 | |
| ✗ | ✗ | ✓ | ✓ | ✓ | 11.853.35 | 21.191.39 | 62.290.11 | 32.310.40 | |
| ✗ | ✓ | ✓ | ✓ | ✓ | 12.782.61 | 21.651.51 | 62.250.00 | 32.340.35 | |
| ✓ | ✗ | ✓ | ✓ | ✓ | 15.345.94 | 21.371.60 | 62.611.15 | 32.461.01 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 21.407.12 | 21.771.10 | 63.842.81 | 34.442.96 |
-
•
DAE [12] uses deep auto-encoder to learn latent feature representations and then performs K-means on that feature to obtain clustering results.
-
•
DEC [14] jointly conducts embedding learning and cluster assignment with an iterative procedure.
-
•
IDEC [15] introduces a reconstruction loss into DEC to improve the clustering performance.
- •
-
•
DAEGC [22] achieves a neighbor-wise embedding learning with an attention-driven strategy and supervises the network training with a clustering loss.
-
•
ARGA [21] guides embedding learning with a designed adversarial regularization.
-
•
SDCN [24] fuses DEC and GCN to merge the topological structure information into deep embedding clustering.
-
•
AGCN [25] focuses on enhancing the embedding learning.
-
•
DFCN [47] merges the node attribute and topological structure information based on the DAE and GAE.
-
•
AGCC [48] replaces the graph layer by layer to mine the latent connected relationship between data.
IV-B Implementation Details
IV-B1 Evaluation metrics
We used four metrics to evaluate the clustering performance, including Average Rand Index (ARI), macro F1-score (F1), Accuracy (ACC), and Normalized Mutual Information (NMI). For each metric, a larger value implies a better clustering result.
IV-B2 Graph construction
As those non-graph datasets (i.e., USPS, Reuters, and HHAR) lack the topology graph, we used a typical graph construction approach to generate their graph data. Specifically, we first employed the cosine distance to compute the similarity matrix , i.e.,
| (19) |
where and denote the Frobenius norm and the transpose operation of , respectively. Then, we keep the top- similar neighbors of each sample to construct an undirected -nearest neighbor (KNN [61]) graph. The constructed KNN graph can depict the topological structure of a dataset and hence is used as GCN input.
IV-B3 Training Procedure
Similar to [14, 15, 24, 25], we first pre-trained the DAE module with epochs and the learning rate equal to . Then, we trained the whole network with iterations. We set the dimension of the auto-encoder and the GCN layers to , the batch size to , and the negative input slope of LReLU to . In addition, we set the learning rates of USPS, HHAR, ACM, DBLP, and PubMed datasets with , and Reuters, CiteSeer, and Amazon Photo datasets with . We set to in this paper, where more detailed experiments and analyses of the threshold value are given in Section IV. E. 3). For the method ARGA, we used the parameter settings given by the original paper [21]. For other methods under comparison, we directly cited the results in [25]. We repeated the experiment 10 times to evaluate our method with the mean values and the corresponding standard deviations (i.e., meanstd). The training procedure is implemented by PyTorch on two GPUs (GeForce RTX 2080 Ti and NVIDIA GeForce RTX 3090).
IV-C Clustering Results
Table III provides the clustering results of the proposed method and twelve compared methods with four metrics, where we have the following observations.
-
•
Our method achieves the best clustering results on most benchmark datasets. For example, in the non-graph dataset Reuters, our approach improves the ARI, F1, ACC, and NMI values of SDCN [24] by 8.12%, 3.33%, 4.53%, and 8.12%, respectively. In the graph dataset DBLP, our approach improves 18.14% over SDCN on ARI, 13.08% on F1, 13.21% on ACC, and 12.49% on NMI.
-
•
DAEGC enhances GAE by introducing the neighbor-wise embedding learning with an attention-based strategy, benefiting clustering performance improvement. Such a phenomenon validates the effectiveness of the attention-based mechanism. Differently, our method extends the attention-based mechanism to the heterogeneity-wise, scale-wise, and distribution-wise fusion modules to adaptively utilize the multiple off-the-shelf information, which significantly improves the clustering performance.
-
•
SDCN performs better than the DAE-based (DAE, DEC, IDEC) and GCN-based (GAE, VGAE, ARGA) embedding clustering methods, demonstrating that combining DAE and GCN can contribute to clustering performance. Nevertheless, SDCN () equates the importance of the DAE feature and the GCN feature; () neglects the multi-scale features; and () fails to utilize available off-the-shelf information from the clustering assignment. The proposed method addresses those issues and thus produces significantly better clustering performance than SDCN on all the datasets in almost all metrics.
-
•
Our method typically achieves better clustering performance than AGCN [25], demonstrating the effectiveness of the proposed distribution-wise fusion module and the dual self-supervision solution in guiding the unsupervised clustering network training. For instance, in Amazon Photo, our approach improves 19.36% on ARI, 28.00% on F1, 20.22% on ACC, and 14.51% on NMI.
-
•
Our method provides a significant improvement on DBLP and PubMed, e.g., in DBLP, our approach improves 10.29% over the second-best one on ARI, 5.09% on F1, 5.26% on ACC, and 8.29% on NMI. The possible reason is that DBLP and PubMed belong to datasets with low feature dimensions (i.e., little information), meaning that sufficiently utilizing the available off-the-shelf information plays a great important role in improving the clustering performance.
-
•
Our method does not outperform AGCN in HHAR. The possible reason is that in HHAR, a series of dissimilar nodes are connected in the constructed KNN graph, reducing the graph quality. Although AGCN also uses the KNN graph, its auxiliary distribution was inferred by the output of the conventional auto-encoder. Differently, the proposed method uses the graph convolutional network output to derive for utilizing rich graph information of . Thus, if the graph quality is terrible, the clustering performance of the proposed method may be worse than AGCN.
-
•
Our method obtains the best clustering performance on AIDS with four metrics, where AIDS is a large-scale long-tailed dataset that one class accounts for 62.34% number, and the other thirty-seven classes share 37.66%.



IV-D Ablation Study
We conducted comprehensive ablation studies to validate the effectiveness of the proposed modules and self-supervision strategies. Table IV lists the quantitative results, where the first row of each dataset denotes the baseline that merges the DAE and GCN features in a half-and-half mechanism (i.e., without HWF) and uses the last GCN layer feature (i.e., without SWF and DWF) to conduct the optimization via the reconstruction loss and self-optimizing embedding loss following [14, 15, 22, 24, 25] (i.e., without SSS and HSS). The second, third, and fourth rows denote the baseline that adopts the proposed module HWF, HWF+SWF, and HWF+SWF+DWF, respectively. The fifth, sixth, and seventh rows denote the methods optimized by the introduced hard self-supervision, the soft self-supervision, and both.
IV-D1 Heterogeneity-wise fusion module
By comparing the first and second rows of each dataset in Table IV, we can observe that HWF can typically improve clustering performance in most cases, validating its effectiveness. For example, on Reuters, it produces a 5.01% performance improvement on ARI, 2.19% on F1, 2.00% on ACC, and 4.20% on NMI.
IV-D2 Scale-wise fusion module
We can examine the effectiveness of SWF by comparing the second and third rows of each dataset in Table IV, in which the compared results with four metrics indicate the superiority of the SWF module in most datasets.
IV-D3 Distribution-wise fusion module
By comparing the results of the third and fourth rows of each dataset in Table IV, we observe that DWF also improves clustering performance, benefiting from the adaptive fusion of the information of two distributions.
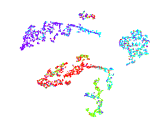
To qualitatively validate the significant performance of the DWF module, we plotted 2D t-distributed stochastic neighbor embedding (t-SNE) [62] visualizations of the distributions , , and on DBLP in Figure 5, where we can see that our adaptively aggregated one is better than others, benefiting from adaptively (due to the DWF module) and effectively (due to the dual self-supervision solution) merging the information of two distributions.
IV-D4 Hard self-supervision strategy
From the results of the fourth and fifth rows of each dataset in Table IV, it can be seen that on the non-graph dataset HHAR and graph dataset DBLP, there is about 2.00% improvement when involving HSS, validating its effectiveness.
IV-D5 Soft Self-supervision Strategy
We can validate the effectiveness of SSS by comparing the results of the fourth and sixth rows of each dataset in Table IV. Specifically, on DBLP, SSS produces 13.73% improvement on ARI, 7.15% on F1, 7.37% on ACC, and 10.82% on NMI. Such impressive improvement is credited to that the SSS strategy refines the cluster assignment by minimizing a Kullback-Leibler divergence loss to promote consistent distribution alignment among distributions , , and .
IV-D6 Dual Self-supervision (DSS)
By comparing the results of the fourth, fifth, sixth, and seventh rows of each dataset in Table IV, we can observe that DSS, which combines HSS and SSS, almost produces the best results on all nine benchmark datasets.
| () | () | () | () | () | () | () | () | () | () | () | () | () | |
| 0.6417 | 0.7669 | 0.0954 | 0.9954 | 0.7091 | 0.7051 | 0.3874 | 0.3896 | 0.4718 | 0.3930 | 0.5666 | 0.8980 | 0.4399 | |
| 0.6166 | 0.7872 | 0.0918 | 0.9958 | 0.7052 | 0.7090 | 0.2780 | 0.2783 | 0.2854 | 0.2824 | 0.8271 | 0.8584 | 0.5131 | |
| 0.8232 | 0.5678 | 0.2532 | 0.9674 | 0.7051 | 0.7091 | 0.2188 | 0.2187 | 0.8826 | 0.2216 | 0.2762 | 0.8585 | 0.5128 | |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 0.6254 | 0.7803 | 0.0686 | 0.9976 | 0.7047 | 0.7095 | 0.2503 | 0.2505 | 0.2572 | 0.2544 | 0.8624 | 0.8582 | 0.5134 | |
| 0.6238 | 0.7816 | 0.0508 | 0.9987 | 0.7060 | 0.7082 | 0.2733 | 0.2741 | 0.2817 | 0.2782 | 0.8327 | 0.8584 | 0.5129 | |
| 0.5919 | 0.8060 | 0.0811 | 0.9967 | 0.7082 | 0.7060 | 0.3903 | 0.3926 | 0.5544 | 0.3956 | 0.4793 | 0.8979 | 0.4402 | |
| AVG | 0.7182 | 0.6704 | 0.1310 | 0.9854 | 0.5916 | 0.7698 | 0.3162 | 0.3157 | 0.5141 | 0.3200 | 0.5821 | 0.8555 | 0.5138 |
| ARI | 0.0836 | 0.5539 | 0.3009 | 0.5500 | 0.5437 | 0.5489 | 0.0836 | 0.3009 | 0.5437 | 0.5453 | 0.5489 | 0.5500 | 0.5489 |
| F1 | 0.4072 | 0.7972 | 0.5781 | 0.7969 | 0.7941 | 0.7964 | 0.4072 | 0.5781 | 0.7941 | 0.7944 | 0.7964 | 0.7969 | 0.7964 |
| ACC | 0.4212 | 0.8023 | 0.6120 | 0.8011 | 0.7981 | 0.8006 | 0.4212 | 0.6120 | 0.7981 | 0.7986 | 0.8006 | 0.8011 | 0.8006 |
| NMI | 0.1778 | 0.4987 | 0.3023 | 0.4996 | 0.4950 | 0.4988 | 0.1778 | 0.3023 | 0.4950 | 0.4965 | 0.4988 | 0.4995 | 0.4988 |
| Metrics | SDCN | AGCN | AGCC | Our | boost |
| ARI (%) | 39.152.01 | 42.490.31 | 44.403.79 | 57.291.20 | 12.89 |
| F1 (%) | 67.711.51 | 72.800.56 | 71.842.02 | 80.790.61 | 07.99 |
| ACC (%) | 68.051.81 | 73.260.37 | 73.452.16 | 81.260.62 | 07.81 |
| NMI (%) | 39.501.34 | 39.680.42 | 40.362.81 | 51.990.76 | 11.63 |
| Parameters (M) | 4.31742 | 4.35658 | 11.86304 | 4.35659 | |
| Time (s) | 253.3905 | 273.1204 | 5420.5255 | 310.6794 |


IV-E Parameters Analysis
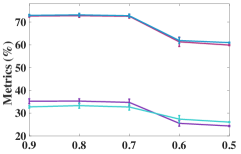
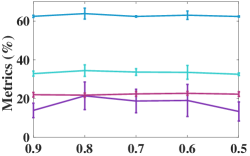
IV-E1 Analysis of the number of neighbors
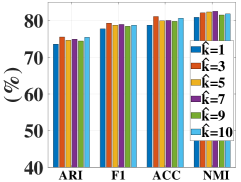
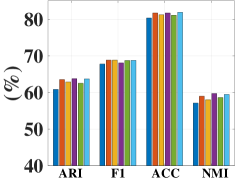
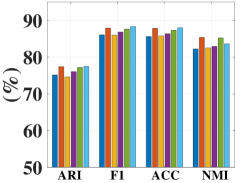
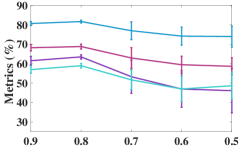
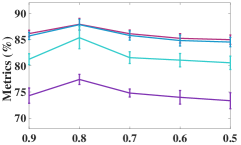
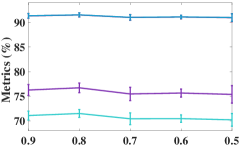
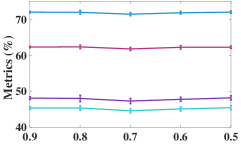
As the number of neighbors directly decides the KNN graph with respect to (w.r.t.) the quality of the adjacency matrix, we tested different on the non-graph datasets, i.e., USPS, Reuters, and HHAR. From Figure 6, we can observe that our model is not sensitive to . In the experiments, we fixed to to construct the KNN graph for the non-graph datasets.
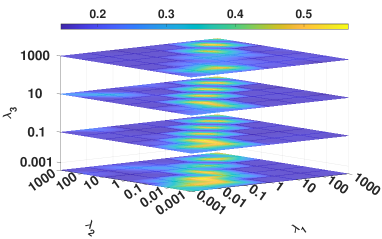
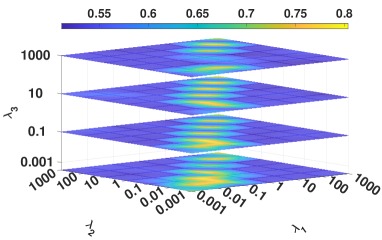
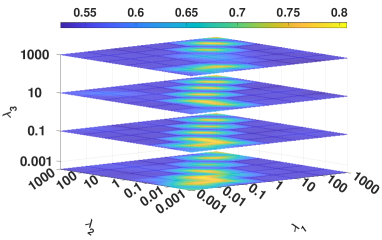
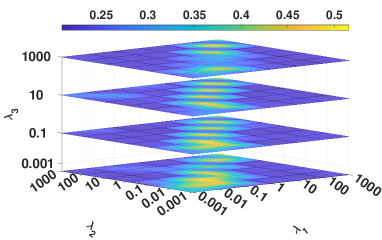
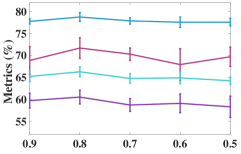
IV-E2 Analysis of hyperparameters
We investigated the influence of the hyperparameters, i.e., , , and , on DBLP. Figure 7 illustrates four metrics results in a 4D figure manner where the color indicates the fourth direction, i.e., the corresponding experimental results. From Figure 7, we have the following observations.
-
•
The parameters setting of and is critical to the proposed model. Specifically, the highest clustering result occurs when and tend to the same value. This phenomenon reflects the importance of balancing the regularization term in constraining the distribution alignment.
-
•
Our model is robust to the hyperparameter , i.e., our method can obtain the optimal performance in a wide and common parameter range of .
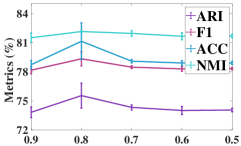
IV-E3 Analysis of the threshold value
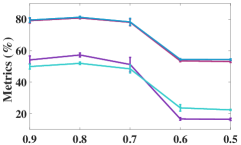
We investigated the effect of the threshold value on clustering performance. Figure 8 shows the clustering results with various thresholds (i.e., , , , , and ). From Figure 8, we have the following conclusions.
-
•
A small threshold value unavoidably degrades the clustering performance compared with the ones using a large threshold value. For example, when we set to or , all four metrics results on DBLP have degraded performance. Apparently, a small threshold value can easily generate a lot of incorrect pseudo-labels.
-
•
A large threshold value is capable of leading to high clustering performance. However, setting to a tremendous value like cannot improve clustering performance. The reason is that with a larger threshold, the number of selected supervised labels will reduce, resulting in weak label propagation. Thus, we set to in this paper.
IV-E4 Analysis of the learned attention-aware weights
We added the results of the learned weight on DBLP to verify the effectiveness of the designed attention mechanism in Table V, where indicates the j-th sample; and indicate the HWF learned weights of and in the i-th layer, respectively; , , , , and indicate the SWF learned weights; and indicate the DWF learned weights of and , respectively; AVG indicates the average value of the weight results. The clustering results of and are inferred through their column indexes of the maximum in each row, and those results of other features are obtained with K-means, where the higher clustering performance, the better the feature representation. We can see that the representation corresponding to a large weight value typically performs better clustering results than the one corresponding to a small weight value, substantiating the effectiveness of the designed attention mechanism in the weighted fusion.
IV-F Time and Space Complexity Analysis
We repeated the experiment 10 times to compare the mean values, the standard deviations (i.e., meanstd), the parameters number, and the running time of the proposed method with the baselines [24, 25, 47] on DBLP in Table VI. Specifically, the experiments are implemented with Python 3.6.12 and Pytorch-1.9.0+cu102 on an NVIDIA GeForce RTX 2080 Ti and an i7-8700K CPU. M and s are the abbreviations of the million and second, respectively. From Table VI, we can observe that our method obtains a significant clustering improvement at the cost of acceptable resource consumption.
IV-G Visual Comparison
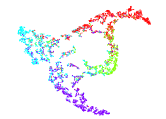
To qualitatively evaluate the effectiveness of the proposed method, we plotted 2D t-SNE visualizations of baselines [24, 25, 47] and the proposed method on DBLP in Figure 9, where we can find that the feature representation obtained by our method shows the best separability for different clusters, i.e., samples from the same class naturally gather together and the gap between different groups is the most obvious one. This phenomenon substantiates that our method produces the most clustering-oriented representation compared with state-of-the-art methods.
V Conclusion
We have presented a novel deep embedding clustering method that simultaneously enhances embedding learning and cluster assignment. Specifically, we first designed heterogeneity-wise and scale-wise fusion modules to learn an informative representation adaptively. Then, we utilized a distribution-wise fusion module to achieve cluster enhancement via an attention-based mechanism. Finally, we proposed a soft self-supervision strategy with a Kullback-Leibler divergence loss and a hard self-supervision strategy with a pseudo supervision loss to utilize the available off-the-shelf information from the cluster assignments. The quantitative and qualitative experiments and analyses demonstrate that our method consistently outperforms state-of-the-art approaches. We also provided comprehensive ablation studies to validate the effectiveness and advantage of our network.
References
- [1] R. Vidal, Y. Ma, and S. Sastry, “Generalized principal component analysis (gpca),” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 12, pp. 1945–1959, 2005.
- [2] Q. Wang, J. Cheng, Q. Gao, G. Zhao, and L. Jiao, “Deep multi-view subspace clustering with unified and discriminative learning,” IEEE Transactions on Multimedia, vol. 23, pp. 3483–3493, 2020.
- [3] Z. Dang, C. Deng, X. Yang, and H. Huang, “Multi-scale fusion subspace clustering using similarity constraint,” in CVPR, 2020, pp. 6658–6667.
- [4] X. Wang, S. Fan, K. Kuang, C. Shi, J. Liu, and B. Wang, “Decorrelated clustering with data selection bias,” in IJCAI, 2021, pp. 2177–2183.
- [5] Y. Jia, H. Liu, J. Hou, and Q. Zhang, “Clustering ensemble meets low-rank tensor approximation,” in AAAI, vol. 35, no. 9, 2021, pp. 7970–7978.
- [6] S. Yang, W. Deng, M. Wang, J. Du, and J. Hu, “Orthogonality loss: learning discriminative representations for face recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 6, pp. 2301–2314, 2020.
- [7] Y. Jia, J. Hou, and S. Kwong, “Constrained clustering with dissimilarity propagation-guided graph-laplacian pca,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2020.
- [8] Y. Wu, L. Du, and H. Hu, “Parallel multi-path age distinguish network for cross-age face recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 9, pp. 3482–3492, 2020.
- [9] Z. Peng, W. Zhang, N. Han, X. Fang, P. Kang, and L. Teng, “Active transfer learning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 4, pp. 1022–1036, 2019.
- [10] Y. Jia, H. Liu, J. Hou, S. Kwong, and Q. Zhang, “Multi-view spectral clustering tailored tensor low-rank representation,” IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [11] Z. Peng, Y. Jia, H. Liu, J. Hou, and Q. Zhang, “Maximum entropy subspace clustering network,” IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [12] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
- [13] J. MacQueen et al., “Some methods for classification and analysis of multivariate observations,” in Proceedings of The Fifth Berkeley Symposium on Mathematical Statistics and Probability, vol. 1. Oakland, CA, USA: Berkeley, 1967, pp. 281–297.
- [14] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised deep embedding for clustering analysis,” in ICML. New York, NY, USA: PMLR, 2016, pp. 478–487.
- [15] X. Guo, L. Gao, X. Liu, and J. Yin, “Improved deep embedded clustering with local structure preservation,” in IJCAI. Melbourne, Australia: AAAI Press, 2017, pp. 1753–1759.
- [16] F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Simplifying graph convolutional networks,” in ICML. PMLR, 2019, pp. 6861–6871.
- [17] D. Kim and A. Oh, “How to find your friendly neighborhood: Graph attention design with self-supervision,” in ICLR. Vienna, Austria: ICLR, 2021, pp. 1–14.
- [18] L. Wu, P. Cui, J. Pei, and L. Zhao, Graph Neural Networks: Foundations, Frontiers, and Applications. Singapore: Springer Singapore, 2022.
- [19] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” ICLR, 2017.
- [20] ——, “Variational graph auto-encoders,” in NIPS workshop. Centre Convencions Internacional Barcelona, Barcelona SPAIN: NIPS, 2016, pp. 1–3.
- [21] S. Pan, R. Hu, S.-f. Fung, G. Long, J. Jiang, and C. Zhang, “Learning graph embedding with adversarial training methods,” IEEE Transactions on Cybernetics, vol. 50, no. 6, pp. 2475–2487, 2019.
- [22] C. Wang, S. Pan, R. Hu, G. Long, J. Jiang, and C. Zhang, “Attributed graph clustering: A deep attentional embedding approach,” in IJCAI. Macao, China: AAAI Press, 2019, pp. 3670–3676.
- [23] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio, “Graph attention networks,” in ICLR. Vancouver Convention Center, Vancouver, BC, Canada: ICLR, 2018, pp. 1–12.
- [24] D. Bo, X. Wang, C. Shi, M. Zhu, E. Lu, and P. Cui, “Structural deep clustering network,” in WWW. Taipei Taiwan: Association for Computing Machinery, New York, NY, United States, 2020, pp. 1400–1410.
- [25] Z. Peng, H. Liu, Y. Jia, and J. Hou, “Attention-driven graph clustering network,” in ACM MM, 2021, pp. 935–943.
- [26] X. Dong, L. Liu, L. Zhu, Z. Cheng, and H. Zhang, “Unsupervised deep k-means hashing for efficient image retrieval and clustering,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 8, pp. 3266–3277, 2020.
- [27] J. Huang, S. Gong, and X. Zhu, “Deep semantic clustering by partition confidence maximisation,” in CVPR, 2020, pp. 8849–8858.
- [28] Z. Wang, Y. Zou, and Z. Zhang, “Cluster attention contrast for video anomaly detection,” in ACM MM. Seattle, United States: ACM, 2020, pp. 2463–2471.
- [29] K. Han, A. Vedaldi, and A. Zisserman, “Learning to discover novel visual categories via deep transfer clustering,” in ICCV. Seoul, Korea: IEEE, 2019, pp. 8401–8409.
- [30] Y. Ou, Z. Chen, and F. Wu, “Multimodal local-global attention network for affective video content analysis,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 5, pp. 1901–1914, 2020.
- [31] X. Wang, Z. Chen, J. Tang, B. Luo, Y. Wang, Y. Tian, and F. Wu, “Dynamic attention guided multi-trajectory analysis for single object tracking,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 12, pp. 4895–4908, 2021.
- [32] Y. Liu, W. Tu, S. Zhou, X. Liu, L. Song, X. Yang, and E. Zhu, “Deep graph clustering via dual correlation reduction,” in AAAI, 2022.
- [33] Y. Hu, Z. Song, B. Wang, J. Gao, Y. Sun, and B. Yin, “Akm 3 c: Adaptive k-multiple-means for multi-view clustering,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 11, pp. 4214–4226, 2021.
- [34] Z. Zhang, J. Wang, J. Ye, and F. Wu, “Rethinking graph convolutional networks in knowledge graph completion,” in WWW, 2022, pp. 798–807.
- [35] H. He, J. Wang, Z. Zhang, and F. Wu, “Compressing deep graph neural networks via adversarial knowledge distillation,” in ACM SIGKDD, 2022.
- [36] X. Wang, M. Zhu, D. Bo, P. Cui, C. Shi, and J. Pei, “Am-gcn: Adaptive multi-channel graph convolutional networks,” in ACM SIGKDD. Virtual Conference: ACM, 2020, pp. 1243–1253.
- [37] Z. Zhang, P. Cui, and W. Zhu, “Deep learning on graphs: A survey,” IEEE Transactions on Knowledge and Data Engineering, 2020.
- [38] B. Chen, Z. Zhang, Y. Li, G. Lu, and D. Zhang, “Multi-label chest x-ray image classification via semantic similarity graph embedding,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 2455–2468, 2021.
- [39] J. He, T. Zhang, Y. Zheng, M. Xu, Y. Zhang, and F. Wu, “Consistency graph modeling for semantic correspondence,” IEEE Transactions on Image Processing, vol. 30, pp. 4932–4946, 2021.
- [40] J. Wang, Z. Zhang, Z. Shi, J. Cai, S. Ji, and F. Wu, “Duality-induced regularizer for semantic matching knowledge graph embeddings,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [41] L. Hu, Z. Dai, L. Tian, and W. Zhang, “Class-oriented self-learning graph embedding for image compact representation,” IEEE Transactions on Circuits and Systems for Video Technology, 2022.
- [42] A. Markovitz, G. Sharir, I. Friedman, L. Zelnik-Manor, and S. Avidan, “Graph embedded pose clustering for anomaly detection,” in CVPR, 2020, pp. 10 539–10 547.
- [43] J. Park, M. Lee, H. J. Chang, K. Lee, and J. Y. Choi, “Symmetric graph convolutional autoencoder for unsupervised graph representation learning,” in ICCV. Seoul, Korea: IEEE, 2019, pp. 6519–6528.
- [44] P. Goyal and E. Ferrara, “Graph embedding techniques, applications, and performance: A survey,” Knowledge-Based Systems, vol. 151, pp. 78–94, 2018.
- [45] G. Li, M. Muller, A. Thabet, and B. Ghanem, “Deepgcns: Can gcns go as deep as cnns?” in ICCV, 2019, pp. 9267–9276.
- [46] Q. Huang, H. He, A. Singh, S.-N. Lim, and A. Benson, “Combining label propagation and simple models out-performs graph neural networks,” in ICLR. Vienna, Austria: ICLR, 2021, pp. 1–19.
- [47] W. Tu, S. Zhou, X. Liu, X. Guo, Z. Cai, E. Zhu, and J. Cheng, “Deep fusion clustering network,” in AAAI, vol. 35, no. 11, 2021, pp. 9978–9987.
- [48] X. He, B. Wang, Y. Hu, J. Gao, Y. Sun, and B. Yin, “Parallelly adaptive graph convolutional clustering model,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [49] F. Helmert, “Die genauigkeit der formel von peters zur berechnung des wahrscheinlichen beobachtungsfehlers director beobachtungen gleicher genauigkeit,” Astronomische Nachrichten, vol. 88, p. 113, 1876.
- [50] Student, “The probable error of a mean,” Biometrika, vol. 6, no. 1, pp. 1–25, 1908.
- [51] X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neural networks,” in AISTATS. Fort Lauderdale, FL, USA: PMLR, 2011, pp. 315–323.
- [52] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier nonlinearities improve neural network acoustic models,” in ICML, vol. 30. Atlanta, USA: Citeseer, 2013, p. 3.
- [53] Q. Li, Z. Han, and X.-M. Wu, “Deeper insights into graph convolutional networks for semi-supervised learning,” in AAAI, vol. 32. Hilton New Orleans Riverside, New Orleans, Louisiana, USA: AAAI Press, 2018, pp. 1–8.
- [54] D.-H. Lee et al., “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks,” in Workshop on challenges in representation learning, ICML, vol. 3, no. 2, 2013, p. 896.
- [55] P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y. Rubinstein, “A tutorial on the cross-entropy method,” Annals of Operations Research, vol. 134, no. 1, pp. 19–67, 2005.
- [56] J. J. Hull, “A database for handwritten text recognition research,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 16, no. 5, pp. 550–554, 1994.
- [57] D. D. Lewis, Y. Yang, T. G. Rose, and F. Li, “Rcv1: A new benchmark collection for text categorization research,” Journal of Machine Learning Research, vol. 5, no. Apr, pp. 361–397, 2004.
- [58] A. Stisen, H. Blunck, S. Bhattacharya, T. S. Prentow, M. B. Kjærgaard, A. Dey, T. Sonne, and M. M. Jensen, “Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition,” in SenSys. New York, NY, United States: ACM, 2015, pp. 127–140.
- [59] S. Wan, Y. Zhan, L. Liu, B. Yu, S. Pan, and C. Gong, “Contrastive graph poisson networks: Semi-supervised learning with extremely limited labels,” NIPS, vol. 34, 2021.
- [60] K. Riesen and H. Bunke, “Iam graph database repository for graph based pattern recognition and machine learning,” in Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR). Springer, 2008, pp. 287–297.
- [61] N. S. Altman, “An introduction to kernel and nearest-neighbor nonparametric regression,” The American Statistician, vol. 46, no. 3, pp. 175–185, 1992.
- [62] L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, no. Nov, pp. 2579–2605, 2008.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae150031-cc79-4908-a746-4937b25b7253/x28.png) |
Zhihao Peng received the B.S. and M.S. degrees in computer science and technology from Guangdong University of Technology, Guangzhou, China, in 2016 and 2019, respectively. He is currently pursuing the Ph.D. degree in department of computer science from City University of Hong Kong, SAR, China. His current research interests include spectral clustering, subspace learning, and domain adaptation in image/text/graph processing with unsupervised learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae150031-cc79-4908-a746-4937b25b7253/x29.png) |
Yuheng Jia received the B.S. degree in automation and the M.S. degree in control theory and engineering from Zhengzhou University, Zhengzhou, China, in 2012 and 2015, respectively, and the Ph.D. degree in computer science from the City University of Hong Kong, SAR, China, in 2019. He is currently an associate professor with the School of Computer Science and Engineering, Southeast University, China. His research interests include machine learning, Bayesian method, spectral clustering and low-rank modeling. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae150031-cc79-4908-a746-4937b25b7253/x30.png)
|
Hui Liu received the B.Sc. degree in communication engineering from Central South University, Changsha, China, the M.Eng. degree in computer science from Nanyang Technological University, Singapore, and the Ph.D. degree from the Department of Computer Science, City University of Hong Kong, Hong Kong. From 2014 to 2017, she was a Research Associate at the Maritime Institute, Nanyang Technological University. She is currently an Assistant Professor with the School of Computing Information Sciences, Caritas Institute of Higher Education, Hong Kong. Her research interests include image processing and machine learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/ae150031-cc79-4908-a746-4937b25b7253/x31.png) |
Junhui Hou (Senior Member) is an Assistant Professor with the Department of Computer Science, City University of Hong Kong. He received the B.Eng. degree in information engineering (Talented Students Program) from the South China University of Technology, Guangzhou, China, in 2009, the M.Eng. degree in signal and information processing from Northwestern Polytechnical University, Xian, China, in 2012, and the Ph.D. degree in electrical and electronic engineering from the School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore, in 2016. His research interests fall into the general areas of multimedia signal processing, such as image/video/3D geometry data representation, processing and analysis, graph-based clustering/classification, and data compression. He received the Chinese Government Award for Outstanding Students Study Abroad from China Scholarship Council in 2015 and the Early Career Award (3/381) from the Hong Kong Research Grants Council in 2018. He is an elected member of IEEE MSA-TC, IEEE VSPC-TC, and IEEE MMSP-TC. He is currently an Associate Editor for IEEE Transactions on Image Processing, IEEE Transactions on Circuits and Systems for Video Technology, Signal Processing: Image Communication, and The Visual Computer. He also served as the Guest Editor for the IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing and Journal of Visual Communication and Image Representation, and as an Area Chair of ACM MM’19-22, IEEE ICME’20, VCIP’20-22, ICIP’22, MMSP’22, and WACV’21. |