Deep Hedging: Learning to Remove the Drift under Trading Frictions with Minimal Equivalent Near-Martingale Measures
Abstract
We present a machine learning approach for finding minimal equivalent martingale measures for markets simulators of tradable instruments, e.g. for a spot price and options written on the same underlying. We extend our results to markets with frictions, in which case we find “near-martingale measures” under which the prices of hedging instruments are martingales within their bid/ask spread.
By removing the drift, we are then able to learn using Deep Hedging a “clean” hedge for an exotic payoff which is not polluted by the trading strategy trying to make money from statistical arbitrage opportunities. We correspondingly highlight the robustness of this hedge vs estimation error of the original market simulator. We discuss applications to two market simulators.
1 Introduction
A long-standing challenge in quantitative finance is the development of market models for the dynamics of tradable instruments such as a spot price and options thereon. The classic approach to developing such models is to find model dynamics in a suitable parameter space under which the respective risk-neutral drift could be computed somewhat efficiently, c.f. for example [12], [15], [10] for the case of equity option markets. With this approach, realistic dynamics or estimation of statistically valid parameters are an afterthought.
This article proposes to reverse this process by starting out with training a realistic model of the market under the statistical measure – and then find an equivalent “near-martingale” measure under which the drifts of tradable instruments are constrained by their marginal costs such that there are no statistical arbitrage opportunities, that is, trading strategies which produce positive expected gains. In the absence of trading costs, this means finding an equivalent martingale measure to “remove the drift”.
Indeed, we will show that absence of statistical arbitrage under a given measure is equivalent to the conditional expectation of the returns under this measure
being constrained by their marginal bid/ask prices. This result is of independent interest.
The main motivation for the present work is the application of our Deep Hedging algorithm to construct hedging strategies for contingent claims by trading in hedging instruments which include derivatives such as options. When described first in [3], we relied on markets simulated with classic quantitative finance models. In [1] we proposed a method to build market simulators of options markets under the statistical measure. Under this measure, we will usually find statistical arbitrage in the sense that an empty initial portfolio has positive value. This reflects the realities of historic data: at the time of writing the S&P 500 had moved upwards over the last ten years, giving a machine the impression that selling puts and being long the market is a winning strategy. However, naively exploiting this observation risks falling foul of the “estimation error” of the mean returns of our hedging instruments. In the context of hedging a portfolio of exotic derivatives, the presence of statistical arbitrage is undesirable as an optimal strategy will be a combination of a true hedge, and a strategy which does not depend on our portfolio, but tries to take advantage of the opportunities seen the market. It is therefore not robust against estimation error of said drifts. Hence we propose using the method presented here to generate a “clean” hedge by removing the drift of the market to increase robustness against errors in the estimation of returns of our hedging instruments.
While our examples focus on simulating equity option markets – in this case amounting to a stochastic implied volatility model – our approach is by no means limited to the equities case. In fact, it is entirely model agnostic and can be applied to any market simulator which generates paths of tradable instruments under the same numeraire which are free of classic arbitrage.
In particular, our approach can be applied to “black box” neural network based simulators such as those using Generative Adversarial Networks (GANs) described in [1] or Variational Autoencoders as in [5]. Such simulators use machine learning methods to generate realistic paths from the statistical measure, but clearly no analytic expression to describe the market dynamics can be written. Our method allows constructing an equivalent risk neutral measure through further applications of machine learning methods.
1.1 Summary of our Approach
Given instrument returns across discrete time steps , and convex costs associated with trading units of each instrument, we propose using our Deep Hedging algorithm introduced in [3] to find a trading strategy and cash amount which maximize the optimized certainty equivalent of a utility ,
Let denote the “marginal cost” of trading in our market. We then define an equivalent measure by setting
Under the market has no statistical arbitrage opportunities in the sense that there is no strategy which has positive expected returns, i.e.
| (1) |
In the absence of transaction costs, is an equivalent martingale measure. In the presence of transaction costs, we show that removing statistical arbitrage is equivalent to the measure being an equivalent near-martingale measure, in the sense that the drift of all tradable instruments must be dominated by the transaction costs. Moreover, is minimal among all equivalent (near-) martingale measures with respect to the -divergence from where is the Legendre-Fenchel transform of .
The key insight of our utility-based risk-neutral density construction is that it relies only on solving the optimization problem of finding and , not on any particular dynamics for the market under the measure. Therefore, it lends itself to the application of modern machine learning methods. As mentioned above, this is particularly useful in the case of removing statistical arbitrage from a “black box” market simulator, such as the GAN based approach discussed in [1]. Through the choice of utility function, we are able to control the risk neutral measure we construct.
We demonstrate the power of this approach with two examples of option market simulators for spot and a number of volatilities. Specifically, we train a Vector Autoregressive (VAR) model of the form
for a vector of log spot returns and log volatilities , and also a neural network based GAN simulator, and then in both cases use our approach to construct the above measure such that the resulting spots and option prices are near-martingale, and free from statistical arbitrage.
1.2 Related Work
We are not aware of attempts to numerically solve for a risk-neutral density with the approach discussed here, as an application to stochastic implied volatility or otherwise. To our knowledge, ours is the first practical approach for implementing general statistically trained market models under risk-neutral measures.
The classic approach to stochastic implied volatilities is via the route of identifying analytically a risk-neutral drift given the other parameters of the specified model. The first applicable results for a term structure of implied volatilities are due to [12]. The first viable approach to a full stochastic implied volatility model for an entire fixed strike and fixed maturity option surface was presented in[15], using as parametrization also discrete local volatilities. Wissel describes the required continuous time drift adjustment for a diffusion driving a grid of such discrete local volatilities as a function of the free parameters. Unnaturally, in his approach the resulting spot diffusion takes only discrete values at the strikes of the options at each maturity date and the approach is limited to a set grid of options defined in cash strikes and fixed maturities.
More recently, a number of works have shown that when representing an option surface with a Lévy kernel we can derive suitable Heath-Jarrow-Morton conditions on the parameters of the diffusion of the Lévy kernel such that the resulting stock price is arbitrage-free, c.f. [10] and the references therein. Simulation of the respective model requires solving the respective Fourier equations for the spot price and options at each step in the path.
1.3 Outline
The rest of the article is organised as follows. In Section 2 we describe the theoretical framework and introduce the key method for constructing a risk-neutral measure in the firctionless case, which is then extended to the case with market frictions in Section 3. Then, in Section 4 we describe some of the consequences of the approach from a practical persective, and in Section 5 we provide numerical experiments demonstrating the effectiveness of the method in practice.
2 Frictionless risk-neutral case
Consider a discrete-time simulated financial market with finite time horizon where we trade over time steps where is the maximum maturity of all tradable instruments. Fix a probability space and a probability measure under which the market is simulated, which we will refer to as the “statistical” measure. For each , we denote by the state of the market at time , including relevant information from the past. The state represents all information available to us, including mid-prices of all tradable instruments, trading costs, restrictions and risk limits.
The sequence of states generates a sequence of -algebras forming a filtration. Being generative means that any -measurable function can be written as a function of as .
To simplify notation, we stipulate that the total number of instruments at each timestep is always . Let be the and -valued, -adapted stochastic process of mid-prices of the liquid instruments available to trade at . As above, is a function of , and we also assume that is in . Note that can represent a wide class of instruments, including primary assets such as single equities, indices, and liquid options.
For each instrument we observe at time a final mark-to-market mid-value which will usually be the sum of any cashflows along the path, and which is also assumed to be a function of . That means must contain sufficient information from the past along the path: for example, if the th instrument tradable at is a call option with relative strike and time-to-maturity on a spot price process , then the final value of this th instrument is the payoff on the path, . Whilst for simplicity, we assume that all options mature within the time horizon, we can easily extend our method to the case where options are allowed to mature after by valuing them in at mid-prices.
We further assume that discounting rates, funding, dividends, and repo rates are zero. Extension to the case where they are non-zero and deterministic is straightforward.
At each time step we may chose an action to trade in the hedging instruments based on the information available in the state , i.e. . The -valued, -adapted stochastic process defines a trading strategy over the time horizon. To ease notation, it will be useful to define for an action , where the operation is applied elementwise. We also use to refer to the th unit vector.
We start with the frictionless case, where the actions are unconstrained, i.e. the set of admissible actions is equal to for all . In this case the terminal gain of implementing a trading strategy with is given by
| (2) |
Our slightly unusual notation of taking the performance of each instrument to maturity reflects our ambition to look at option market simulators for “floating” implied volatility surfaces where the observed financial instruments change from step to step. If the instruments tradable at each time step are, in fact, the same fixed strike and maturity instruments, then
| (3) |
where starting with .
2.1 Optimized certainty equivalents
In order to assess the performance of a trading strategy, we are looking for risk-adjusted measures of performance instead of plain expected return. We will focus on the following case: let be a strictly concave, strictly increasing utility function which is and normalized to both and .111 Note that the normalization is a convenience which is always achievable: If is concave and strictly increasing, then satisfies these assumptions. Examples of such utility functions are the adjusted mean-volatility function proposed in [9], or the exponential utility . We make the further assumption that for all . (This condition is not met when is the exponential utility and the market contains a Black & Scholes process with negative drift.222 To see this, assume , , , and let for positive and , and standard normal. Then . )
For a given utility function, define now the optimized certainty equivalent (OCE) of the expected utility, introduced in [2] as
| (4) |
The functional satisfies the following properties:
-
(i)
Monotone increasing: if then . A better payoff leads to higher expected utility.
-
(ii)
Concave: for . Diversification leads higher utility.
-
(iii)
Cash-Invariant: for all . Adding cash to a position increases its utility by the same amount.
This above properties mean that is a convex risk measure. Note that the assumptions and imply that for all and hence . Furthermore, is finite for all bounded variables , since by monotonicity we have .
Cash invariance means that , i.e. is the minimum amount of cash that needs to be added to a position in order to make it acceptable, in the sense that . The cash-invariance property of the OCE means in particular that optimizing does not depend on our initial wealth.
A classic example of such an OCE measure is the case where is the exponential utility with risk aversion level . In this case we obtain the entropy
We now consider the application of the optimized certainty equivalent to the terminal gains of a trading strategy. To this end, define
| (5) |
Lemma 2.1.
Suppose the market exhibits classic arbitrage. Then no finite maximizers of exist.
Proof.
Assume that is a classic arbitrage opportunity with and for a set for some . Note that . Let . Then
The last term is optimized by as it solves . Therefore, which tends to infinity as . Hence, no finite maximizer of (5) exists. ∎
2.2 Utility-based risk neutral densities
In the absence of classic arbitrage, we are now able to use the optimized certainty equivalent framework to construct an equivalent martingale measure. Before moving on to our main result, we will need the following lemma.
Lemma 2.2.
Let be concave and . Assume that for all and that for some . Then
| (6) |
Proof.
Define such that since is concave. As a difference between two variables . Since maximizes the expectation of , we also have . Using the dominated convergence shows that and therefore that taking expectations and derivatives in (6) can be exchanged. ∎
Now we give the main result allowing the construction of utility-based equivalent martingale measures.
Proposition 2.3.
Let and be finite maximizers of
| (7) |
Then,
| (8) |
is an equivalent martingale density, i.e. the measure defined via is an equivalent martingale measure.333 We note that if is not strictly increasing, then is an absolutely continuous, but possibly not equivalent density. An example is the CVaR “utility”.
Proof.
We follow broadly the discussion in Section 3.1 of [6].
Show that with zero expectation: optimality of and imply first . Secondly, lemma 2.2 shows for arbitrary that with
| (9) |
Show that : for the previous statement, set where is -measurable, and where denotes the th unit vector. We obtain
| (10) |
Show that : recall that . Since is concave and strictly increasing, is decreasing and positive. Then,
since and were assumed to be finite, and since the previous step with implies .
Positivity of : since is decreasing and positive we have and therefore , since being almost surely finite implies that .
has unit expectation: optimality of and implies
| (11) |
and therefore that .
∎
The density provides an equivalent martingale density. It is minimal among all equivalent martingale densities in the following sense: the Legendre-Fenchel transform of the convex function is defined as.
The associated -divergence between two distributions and with is then
It is a non-symmetric measure of the similarity between two probability distributions.
Corollary 2.4.
Let be the Legrendre-Fenchel transform of , and define as in (8). Then, is a minimizer of the -divergence
| (12) |
over all equivalent martingale densities.
Proof.
The Legrende-Fenchel transform of the convex function is which implies that for all ,
| (13) |
Let be the set of equivalent martingale densities. Equation (13) implies for and ,
| (14) |
Let . For a given the sup in is attained by which yields
| (15) |
for all and all as claimed above. Applying (15) to yields that equality of both sides of (14), proving our claim that is indeed a minimizer of (12).
∎
Thus, finding the -minimal equivalent martingale measures is the dual problem of maximizing the expected utility. The key observation is that we now have a numerically efficient method to solving the primal problem via the application of machine learning methods.
In the case of the exponential utility, the -divergence is the relative entropy of with respect to ,
The measure is the minimal entropy martingale measure (MEMM) introduced by [7], given by
The measure is unique due to the strict convexity of the function .
Remark 1.
In the case where the returns are normally distributed, and the utility is the exponential utility, then the optimization is easily shown to be equivalent to solving the classic mean-variance objective of Markowitz [11] , and in this case the found martingale measure removes the drift while preserving the covariance of the returns.
Direct Construction of Equivalent Martingale Measures
An alternative to the above construction is described in [6] Section 3.1, as follows.
Proposition 2.5.
Define as above and fix some initial wealth . Let be a finite maximizer of
| (16) |
Then, the measure with density
| (17) |
is an equivalent martingale measure.
Proof.
We prove that is a martingale measure.444We follow broadly section 3.1 in [6].
Show for all . For an arbitrary we get
| (18) |
where follows from Lemma 2.2. Given that was arbitrary above also implies .
We first prove that : recall that . Since is concave and increasing, for . Then,
since was assumed to be finite.
Positivity of : since is decreasing and positive we have and therefore , since being almost surely finite implies that ∎
Remark 2.
We note that the assumption of finiteness of again excludes markets with classic arbitrage opportunities.555 Assume that is a classic arbitrage opportunity with and for a set for . Then , e.g. no finite maximizer of exists. If is the exponential utility, then coincides with the previously defined density of the MEMM in (8).
We note that while this approach is somewhat more direct it depends on initial wealth – except in the case of the exponential utility – and lacks the interpretation of the density as a minimizer of some distance to .
We now briefly discuss some extensions of the previous results to the cases of unbounded assets, and continuous time processes.
Unbounded Assets
As pointed out in [6] Section 3.1, the requirement can be enforced at the cost of interpretability of our previous results by passing over to bounded asset prices: to this end define the random variable and set , which are now bounded.
We can then show with the same steps as before that we can construct an equivalent martingale measure in this case as follows.
Proposition 2.6.
Let and be maximizers of the bounded problem
| (19) |
Then,
| (20) |
is an equivalent martingale density for the unscaled problem, i.e. for all .
Moreover, minimizes the scaled -divergence
| (21) |
over all equivalent martingale densities.
Proof.
We cover the main differences to the previous case: first, we see that
| (22) |
Then,
| (23) |
showing that is an equivalent martingale density. Using (13) with for and yields as before
| (24) |
Equality in follows as before. ∎
Continuous Time
We note that our method of proof also works in a continuous time: let where (i.e. the classic setup with fixed instruments). Assume that maximize and that which again excludes markets with classic arbitrage. Then, then same statement as above is true with virtually the same proof.
Let and notice that if then has derivative which is the Arrow-Pratt coefficient of absolute risk aversion of , c.f. [6] section 2.3. Standard calculus shows that
| (25) |
Under our assets are driftless and satisfy for a -Brownian motion . This implies the well-known result
| (26) |
3 Transaction costs and trading constraints
The previous section enables us to simulate markets from a martingale measure in the absence of trading frictions. In practise, trading strategies will be subject to trading cost and constraints such as liquidity and risk limits. Our use-case is training a Deep Hedging agent. We therefore now extend the previous results to the case of generalized cost functions which will cover both trading cost and most trading constraints.
A generalized cost function is a non-negative, -measurable function with values in , which is convex in , lower semi-continuous, and normalized to . To impose convex restrictions on our trading activity, we set transaction cost to infinity outside the admissible set. Indeed, let be be a convex set of admissible trading actions, and an initial const function. We then use . (We note that this construction is lower semi-continuous.) As example, let us assume the th instrument is not tradable in . We then impose whenever .
In reverse, if is a generalized cost function, we may call the convex set of admissible actions. Note also that by construction .
Example 3.1.
The simplest trading costs are proportional. Assume that and are observable Black & Scholes delta and vega of the mid-prices for the trading instruments available at , and that the cost of trading units of is proportional to its delta and vega with cost factors and for buying and selling, respectively. We also impose that we may trade at most units of vega per time step. The corresponding cost function is given by
| (27) |
Example 3.2.
Consider trading cost which apply only to net delta and vega traded, e.g.
| (28) |
The terminal gain of implementing a trading policy with cost function is given by
| (29) |
The marginal cost of trading small quantities of the th asset in are given as
| (30) |
They define the marginal cost function
| (31) |
3.1 Statistical arbitrage and near-martingale measures
Under the statistical measure we expect there to be statistical arbitrage opportunities, i.e. trading strategies such that we expect to make money:
| (32) |
In the absence of transaction costs, the market will be free from statistical arbitrage if and only if we are under a martingale measure.666 Assume that there is a such that . Set . Then the strategy is a statistical arbitrage strategy. Since the gains of trading with transaction costs are almost surely never greater than the gains in the absence of transaction costs, it is clear that if is an equivalent martingale measure for the market, then there are no statistical arbitrage opportunities under transaction cost, either, i.e. for all policies (equality is acheived with ). Taking the limit to small transaction cost, it becomes inutitively clear that as well for marginal cost. In fact, inuitively it makes sense that the market is free of statistical arbitrage with full cost if and only if it is free of statistical arbitrage with marginal cost .
Here is our formal result:
Proposition 3.3.
We call a near martingale measure if any of the following equivalent conditions hold:
-
•
the measure is free from statistical arbitrage with full cost ;
-
•
the measure is free from statistical arbitrage with marginal cost ; and
-
•
the expected return from any hedging instrument is within its marginal bid/ask spread in the sense that
(33) with defined in (30).
Proof.
Assume first there are no statistical arbitrage opportunities with full cost . We will show (33). Let arbitrary and let the policy with unit vector at and zero elsewhere; for ease of notation we will also write for simply the unit vector, seen at a time .
Assume now that (33) holds, and let be arbitrary. Then by construction of our marginal cost (31) and (33). Hence, there is no statistical arbitrage with cost . Since it is also clear that if there is no statistical arbitrage with marginal cost , then there is also no statistical arbitrage with full cost . ∎
Remark 3.
Under the conditions of the above theorem the conditional expectation defines a martingale “micro-price” [14] within the bid–ask spread.
In the absence of trading costs or trading constraints then equality is acheived. That is, the market is free from statistical arbitrage if and only if
resulting in the classic formulation of the price process being a martingale under .
3.2 Utility-based near-martingale measures under trading frictions
We now proceed with constructing a near-martingale measure via the same duality as in the zero transaction cost case. Define again the function
| (34) |
just as in (7), but this time with marginal transaction costs.
Proposition 3.4.
Let and be finite maximizers of . Then
| (35) |
is an equivalent density, and the measure defined by is a near-martingale measure. Moreover, the density minimizes the -divergence among all equivalent near-martingale densities.
Proof.
To show that is a equivalent near- martingale density most of the previous proof applies as before, except of course (9) since is not an equivalent martingale measure. Instead, we will show that there is no statistical arbitrage under . Let therefore be arbitrary, and denote by the strategy with unit vector in and zero otherwise; for notational simplicity we will also use to refer simply the unit vector, in .
Define . Consider the derivative : we recall that . Therefore
Since are optimal we must have . Given that was arbitrary we obtain
| (36) |
This is in fact a more precise statement than (33).
We now show that minimizes the -divergence among all measures . We apply (13) again with and . This yields
| (37) |
where the last inequality holds since does not admit statistical arbitrage. The right hand side is maximized in ). For the left hand side, apply again (15) which yields
| (38) |
This proves that is -minimal among all near-martingale measures. ∎
Considering that any equivalent true martingale measure is also a near-martingale measure, this result is a formalization of the intuitive notion that in order to avoid statistical arbitrage we do not truly have to find a full martingale measure, but that we only have to “bend” the drifts of our trading instruments enough to be dominated by prevailing trading cost.
4 Learning to Simulate Risk-Neutral Dynamics
The key insight of our utility-based risk-neutral density construction is that it relies only on solving the optimization problem of find and , not on specifying any particular dynamics for the market under the measure. Therefore, it can be done in a data-driven, model agnostic way, lending itself to the application of modern machine learning methods. Specifically, given a set of samples from a market simulator, we may make the sample set risk neutral by numerically solving the optimization problem on the paths, and then using our formulation to reweight the paths so that the resulting weighted sample is a (near-)martingale. As mentioned above, this is particularly useful in the case of removing statistical arbitrage from a “black box” market simulator, such as the GAN based approach discussed in [1].
Our approach enables the adaptation of GAN and other advanced machine learning approaches so that they can not only simulate realistic samples from the statistical measure, but also from an equivalent risk neutral measure. Moreover, through the choice of utility function, we are able to control the risk neutral measure we construct.
We solve the stochastic control problem (7) through an application of the ‘Deep Hedging’ methods of [3]: we can pose (7) as a reinforcement learning problem and use a neural network to represent our trading policy , and since the function is fully differentiable, use stochastic gradient methods to find , and hence .
4.1 Deep Hedging under Risk-Neutral Dynamics
Our primary application is in the pricing and hedging of exotic options via utility-based Deep Hedging. With a portfolio of derivatives represented by the random variable to hedge, the Deep Hedging problem under the statistical measure is to maximize the optimized certainty equivalent
| (39) |
over strategies and . An optimal solution is called an optimal hedge for . We note that in the presence of statistical arbitrage . Deep Hedging under a near-martingale measure then is
| (40) |
Since under we have we note that represents an indifference price for in the sense of [3] section 3.
In the case of hedging under exponential utility with zero transaction costs, it is straightforward to show that the optimal hedge for the derivative under the statistical measure can be written as
| (41) |
where is an optimal hedge for under the minimal entropy martingale measure (MEMM), and where is an optimal statistical arbitrage strategy, i.e. an optimal “hedge” for an empty initial portfolio. In this sense we may regard as a net hedging strategy for .
A consequence of this is that the hedge found by solving the Deep Hedging problem under the statistical measure will be a sum of a true hedge, and a component which does not depend on and is simply seeking profitable opportunities in the market. Solving the optimization problem under the risk neutral measure will then directly remove the statistical arbitrage component of the strategy, leaving a “clean” hedge for the derivative, which is not sensitive to the estimation of the mean returns of our hedging instruments.
5 Numerical implementations
To demonstrate our approach we apply it to two market simulators. First, we discuss a simple, but usable multivariate “PCA” vector autoregressive model for spot and a form of implied volatilities. Secondly, we also present results for a Generative Adversarial Network based simulator based on the ideas presented in [1].
5.1 Vector Autoregressive market simulator
For the first numerical experiment, we build a VAR market simulator as follows. For the simulation we use discrete local volatilies (DLVs) as arbitrage-free parametrization of option prices. We do not use the underlying model dynamics; the only use of DLVs is arbitrage-free parametrization of the option surface. We briefly recap the relevant notation: assume thaty are time-to-maturities and relative strikes.777See [4] for the use of inhomogeneous strike grids. Also define the additonal boundary strikes and .
For and we denote by the price of the call option with payoff at maturity . Define , and . The discrete local volatility surface for and is defined by
| (42) |
where we set whenever the square root is imaginary. We also set if occurs. We recall that a given surface of option prices is free of static arbitrage if and only if . Moreover, given a surface of finite discrete local volatilities, we can reconstruct the surface of arbitrage-free call prices by solving the implicit finite difference scheme implied by (42). This involves inverting sequentially tridiagonal matrices, an operation which is “on graph” in modern automatic adjoint differentiation (AAD) machine learning packages such as TensorFlow, see [4] for further details.
For a given time series of vectors of historical log spot returns and log DLVs
| (43) |
we estimate a vector autoregression model of the form
| (44) |
where each is a coefficient matrix, is an intercept, and is a volatility matrix.
Constructing – we train the model to historical data from EURO STOXX 50, using standard regression techniques from the Statsmodels Python package [13]. Once the model has been trained, we can simulate new sample paths of log spot returns and discrete local volatilities by sampling new noise variables and stepping the model forward. We then convert the DLVs to option prices using the methods detailed above, so that we can simulate market states of spot and option prices.
We generate paths, of length 30 days from a VAR model, where each path consists of spot and both put and call option prices on a grid of maturities and relative strikes .
Constructing – we construct the risk neutral measure by solving 34 with the exponential utility, using proportional transaction costs for all instruments set to . To parametrize our policy action, we use a two layer feedforward neural network, with 64 units in each layer and ReLU activation functions. We train for 2000 epochs on the training set of paths.
Assessing Performance – Figure 1 compares out-of-sample the expected value of the option payoffs vs. their prices for the full grid of calls and puts under both the statistical and the risk-free measure in relation to trading cost.
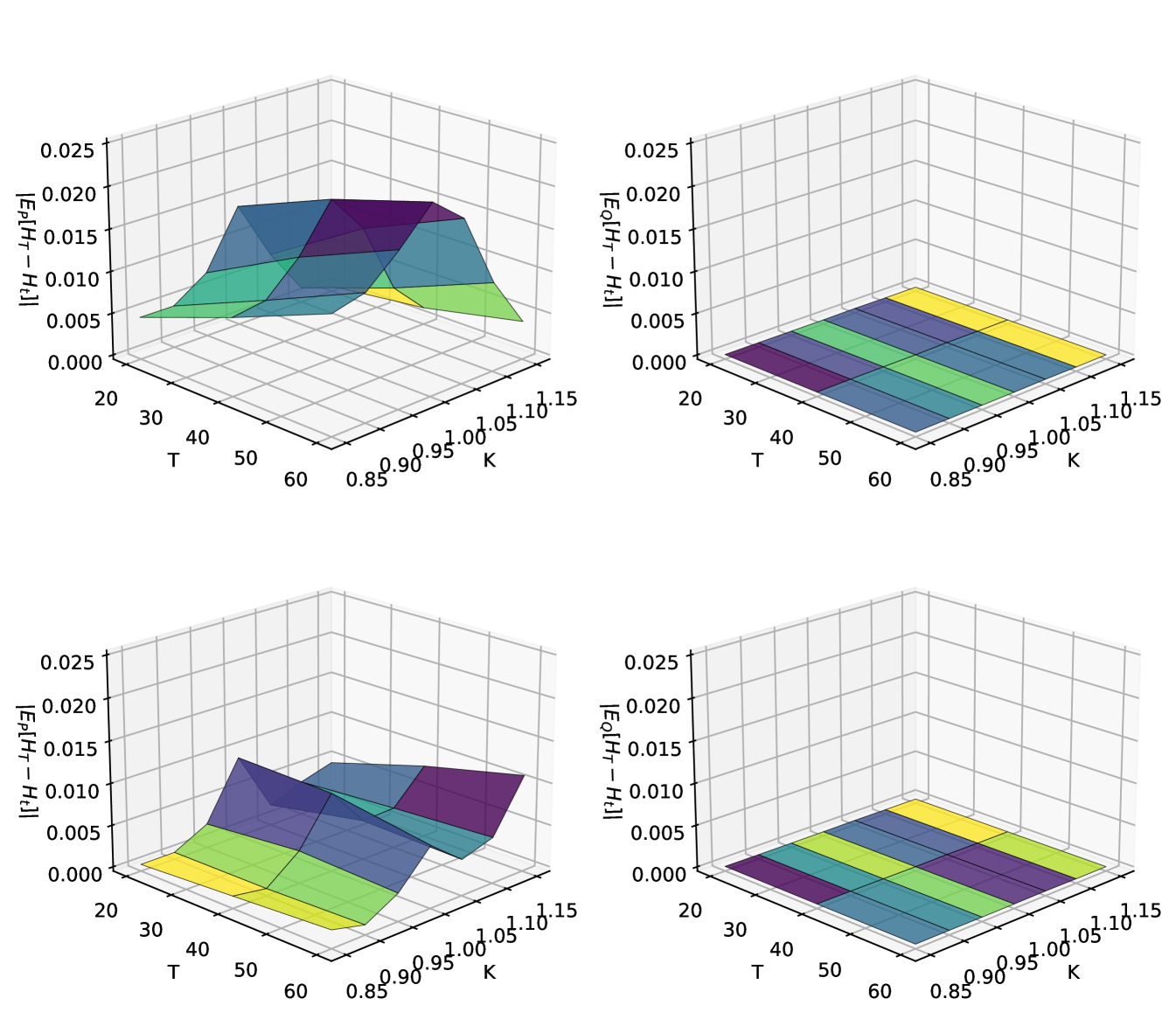
The expected payoff under the changed measure has been flattened to zero, and now lies within the transaction cost level, so that the tradable drift has been removed.
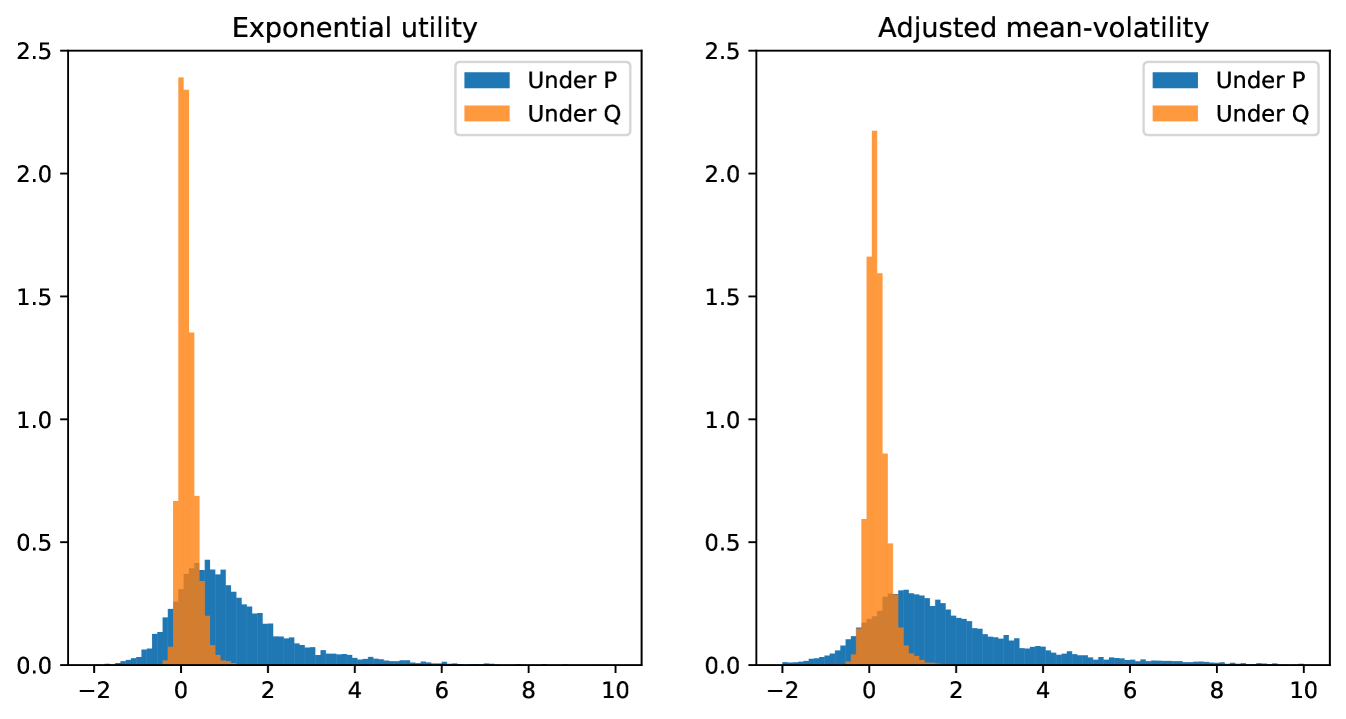
To further confirm that statistical arbitrage has indeed been eliminated from the market simulator under , we train a second strategy under the new measure, with identical neural network architecture and the same utility function but incresed transaction cost . Figure 2 shows the distributions of terminal gains of respective estimated optimal strategies under and . We compare the method using the exponential utility, and the adjusted mean-volatility utility . In both cases, the distribution of gains is now tightly centred at zero confirming that statistical arbitrage has been removed.
5.2 GAN market simulator
To demonstrate the flexibility of our approach, we now apply it to a more data driven simulator for spot and option prices based on Generative Adversarial Networks (GANs) [8] as in[1].
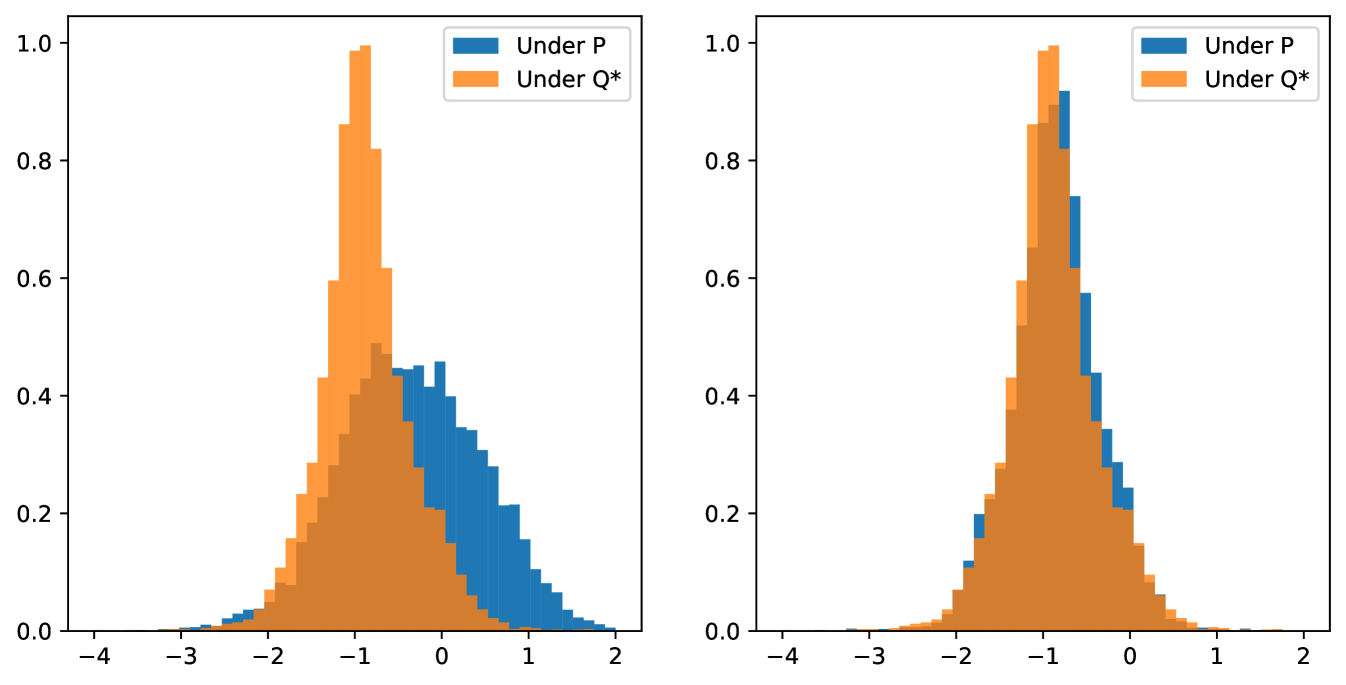
We illustrate the effect on Deep Hedging of changing measure with the following numerical experiment. We hedge a short position in a digital call option, with market instruments being the spot and at the money call options with maturities and days. We first train a network under the zero portfolio to find a maximal statistical arbitrage strategy, then use this to construct the risk neutral density. We then train two Deep Hedging networks to hedge the digital, one under the original, unweighted, market and one under the risk neutral market. All networks are trained to maximize exponential utility. Figure 3 compares the final hedged PNL of the two strategies on the left, and the PNL of the strategies, with the statistical arbitrage component subtracted, on the right (i.e. vs. ). The distribution of PNL from the risk neutral hedge is clearly less wide tailed, and the righthand plot demonstrates that we have removed the statistical arbitrage element as the distributions now align.
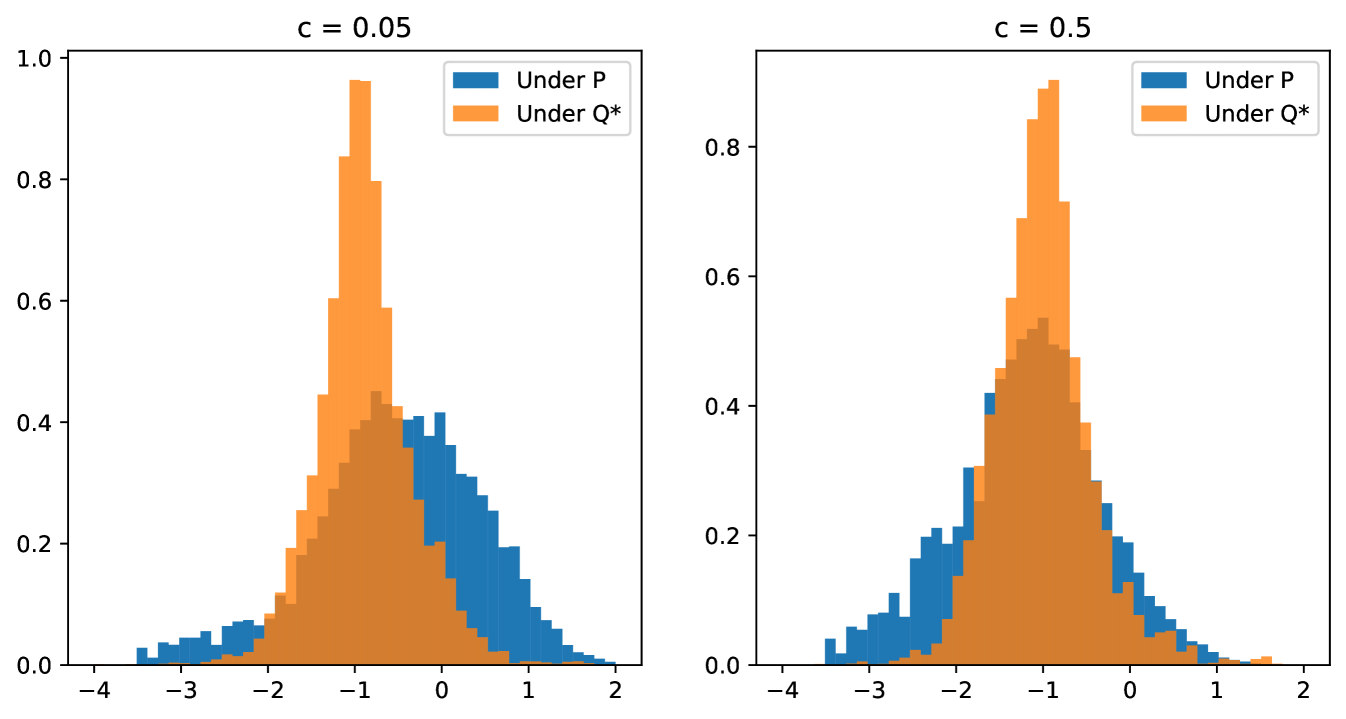
Robustness of – by removing the statistical arbitrage component of the strategy, the risk neutral hedge represents a more robust hedge with respect to uncertainty in the market simulator, i.e. when the future distribution of the market at model deployment differs slightly from the distribution of the training data generated by the market simulator. Consider the case where the future market returns follow a distribution , which is similar to in the sense that for some small where is the relative entropy. For illustration, we can construct such a measure by simply perturbing the weights of the simulated paths slightly.
In particular, we consider perturbations which are unfavourable for the original strategy, where the strategy was over-reliant on the perceived drift in the market, which is no longer present under . Figure 4 shows the new PNL distributions under measures with for What is striking is that a relatively small shift in the measure can significantly worsen the distribution of hedged PNL of the original Deep Hedging model, but that the distribution of PNL of the model trained on the risk neutral measure remains practically invariant, indicating that the model performances more consistently with respect to uncertainty. Naturally, the method provides robustness against estimation errors for mean returns of the underlying assets.
Conclusion
We have presented a numerically efficient method for computing a risk-neutral density for a set of paths over a number of time steps. Our method is applicable to paths of derivatives and option prices in particular, hence we effectively provide a framework for statistically learned stochastic implied volatility via the application of machine learning tools. Our method is generic and does not depend on the market simulator itself, except that it requires that the simulator does not produce classic arbitrage opportunities. It also caters naturally for transaction costs and trading constraints, and is easily extended to multiple assets.
The method is particularly useful to introduce robustness to a utility-based machine learning approach to the hedging of derivatives, where the use of simulated data is essential to train a ‘Deep Hedging’ neural network model. If trained directly on data from the statistical measure, in addition to risk management of the derivative portfolio, the Deep Hedging agent will pursue statistical arbitrage opportunities that appear in the data, thus the hedge action will be polluted by drifts present in the simulated data. By applying our method, we remove any statistical arbitrage opportunities from the simulated data, resulting in a policy from the Deep Hedging agent that seeks to only manage the risk of the derivative portfolio, without exploiting any drifts. This in turn makes the suggested hedge more robust to any uncertainty inherent in the simulated data.
References
- [1] Lanjun Bai, Hans Buehler, Mangnus Wiese and Ben Wood “Deep Hedging: Learning to Simulate Equity Option Markets” In SSRN, 2019 URL: https://ssrn.com/abstract=3470756
- [2] Aharon Ben-Tal and Marc Teboulle “An old-new concept of convex risk measures: The optimized certainty equivalent” In Mathematical Finance 17.3 Wiley Online Library, 2007, pp. 449–476
- [3] H. Buehler, L. Gonon, J. Teichmann and B. Wood “Deep Hedging” In Quantitative Finance 0.0 Routledge, 2019, pp. 1–21 URL: https://ssrn.com/abstract=3120710
- [4] Hans Buehler and Evgeny Ryskin “Discrete Local Volatility for Large Time Steps (Short Version)”, 2016 URL: https://ssrn.com/abstract=2783409
- [5] Hans Buehler et al. “A data-driven market simulator for small data environments” In Available at SSRN 3632431, 2020
- [6] Hans Föllmer and Alexander Schied “Stochastic Finance” De Gruyter, 2008 DOI: doi:10.1515/9783110212075
- [7] Marco Frittelli “The minimal entropy martingale measure and the valuation problem in incomplete markets” In Mathematical finance 10.1 Wiley Online Library, 2000, pp. 39–52
- [8] Ian Goodfellow et al. “Generative adversarial nets” In Advances in neural information processing systems 27, 2014
- [9] V. Henderson and D. Hobson “Utility indifference pricing : an overview”, 2009 URL: https://warwick.ac.uk/fac/sci/statistics/staff/academic-research/henderson/publications/indifference_survey.pdf
- [10] Jan Kallsen and Paul Krühner “On a Heath-Jarrow-Morten approach for Stock Options” In Finance and Stochastics 19, 2015, pp. 583–615 URL: https://arxiv.org/pdf/1305.5621.pdf
- [11] Harry Markowitz “Portfolio Selection” In The Journal of Finance 7.1, 1952, pp. 77–91 DOI: 10.2307/2975974
- [12] Philipp Schönbucher “A market model for stochastic implied volatility” In Phil. Trans. R. Soc. A., 1999, pp. 2071–2092 URL: https://ssrn.com/abstract=182775
- [13] Skipper Seabold and Josef Perktold “statsmodels: Econometric and statistical modeling with python” In 9th Python in Science Conference, 2010
- [14] Sasha Stoikov “The micro-price: a high-frequency estimator of future prices” In Quantitative Finance 18.12 Routledge, 2018, pp. 1959–1966
- [15] Johannes Wissel “Arbitrage-free market models for option prices”, 2007 URL: http://www.nccr-finrisk.uzh.ch/media/pdf/wp/WP428_D1.pdf
Disclaimer
Opinions and estimates constitute our judgement as of the date of this Material, are for informational purposes only and are subject to change without notice. It is not a research report and is not intended as such. Past performance is not indicative of future results. This Material is not the product of J.P. Morgan’s Research Department and therefore, has not been prepared in accordance with legal requirements to promote the independence of research, including but not limited to, the prohibition on the dealing ahead of the dissemination of investment research. This Material is not intended as research, a recommendation, advice, offer or solicitation for the purchase or sale of any financial product or service, or to be used in any way for evaluating the merits of participating in any transaction. Please consult your own advisors regarding legal, tax, accounting or any other aspects including suitability implications for your particular circumstances. J.P. Morgan disclaims any responsibility or liability whatsoever for the quality, accuracy or completeness of the information herein, and for any reliance on, or use of this material in any way.
Important disclosures at: www.jpmorgan.com/disclosures