Deep-Learning-Aided Successive-Cancellation Decoding of Polar Codes
Abstract
A deep-learning-aided successive-cancellation list (DL-SCL) decoding algorithm for polar codes is introduced with deep-learning-aided successive-cancellation (DL-SC) decoding being a specific case of it. The DL-SCL decoder works by allowing additional rounds of SCL decoding when the first SCL decoding attempt fails, using a novel bit-flipping metric. The proposed bit-flipping metric exploits the inherent relations between the information bits in polar codes that are represented by a correlation matrix. The correlation matrix is then optimized using emerging deep-learning techniques. Performance results on a polar code of length with information bits concatenated with a -bit cyclic redundancy check show that the proposed bit-flipping metric in the proposed DL-SCL decoder requires up to fewer multiplications and up to fewer additions, without any need to perform transcendental functions, and by providing almost the same error-correction performance in comparison with the state of the art.
Index Terms:
5G, polar codes, deep learning, SC, SCL, SC-Flip, SCL-Flip.I Introduction
Polar codes represent a class of error-correcting codes that are proven to achieve channel capacity for any binary symmetric channel under the low-complexity successive-cancellation (SC) decoding [1]. Recently, polar codes are selected for use in the enhanced mobile broadband (eMBB) control channel of the fifth generation of cellular technology (5G standard), where codes with short block length are used [2]. The error-correction performance of short polar codes under SC decoding does not satisfy the requirements of the 5G standard. SC list (SCL) decoding was introduced in [3] to improve the error-correction performance of SC decoding by keeping a list of candidate message words at each decoding step. In addition, it was observed that under SCL decoding, the error-correction performance is significantly improved when the polar code is concatenated with a cyclic redundancy check (CRC) code [3]. However, the decoding complexity of SCL grows as the list size increases.
Unlike SCL decoding, SC flip (SCF) decoding [4] performs multiple SC decoding attempts in series where in each attempt, the first-order erroneous information bit in the initial SC decoding attempt is flipped. Similar to SCL decoding, SCF decoding uses a CRC code to determine whether a decoding attempt is successful or not and a bit-flipping metric is used to identify the erroneous information bit. Several methods have been proposed to improve the error-correction performance of SCF [5, 6, 7]. However, the bit-flipping metric of a given information bit is oversimplified where only the log-likelihood ratio (LLR) corresponding to that bit is considered. To overcome this problem, dynamic SCF (DSCF) decoding [8] defines a more accurate bit-flipping metric, which utilizes the LLR values of all the previously decoded information bits. It was shown in [8] that at practical signal-to-noise ratio (SNR) values, DSCF decoding can achieve an error-correction performance comparable to SCL decoding, while maintaining an average decoding complexity close to that of SC decoding. But the bit-flipping metric in DSCF decoding requires costly exponential and logarithmic computations, which hinders the algorithm to be efficiently implemented in hardware.
In this paper, the likelihood of the correct decoding of each information bit under SC or SCL decoding is estimated by exploiting the inherent correlations among all the information bits. These correlations are expressed in the form of a trainable correlation matrix. Consequently, a bit-flipping metric based on the proposed correlation matrix is introduced. It only requires the computation of multiplication and addition operations in the LLR domain, preventing completely the needs to use costly transcendental functions as required by DSCF decoding. Motivated by recent developments that exploit deep learning (DL) to decode polar codes [9, 10, 11, 12, 13], DL techniques are applied to optimize the correlation matrix. Thus the proposed decoding algorithm is called deep-learning-aided SCL (DL-SCL) decoding with DL-SC decoding being its specific case when the list size is one. Performance results on a polar code of length with information bits concatenated with a -bit CRC show that the proposed bit-flipping metric in the proposed DL-SCL decoder requires up to fewer multiplications and up to fewer additions in comparison with the decoder that uses the bit-flipping metric in [8]. Moreover, the proposed decoder with the proposed bit-flipping metric does not require to perform any transcendental functions and can provide almost the same error-correction performance in comparison with the decoder that uses the bit-flipping metric in [8].
II Preliminaries
II-A Polar Codes, SC Decoding, and SCL Decoding
A polar code of block length with information bits is derived as , where is the polar codeword, is the message word, is the -th Kronecker power of the polarizing matrix , and . The vector consists of a set of the indices of information bits and a set of the indices of frozen bits. The positions of frozen bits are known to both the encoder and the decoder, and their values are set to . In this paper, binary phase-shift keying (BPSK) modulation technique is considered. Therefore, the received signals of the transmitted codeword are represented as , where is an all-one vector of size , and is the additive white Gaussian noise (AWGN) vector with variance and zero mean. The LLR vector of the received signal is then given as .

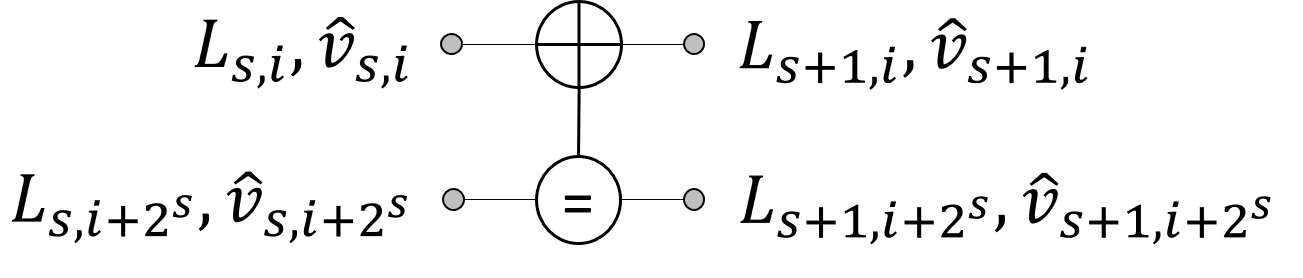
SC decoding can be illustrated on a polar code factor graph representation. Fig. 1(a) shows an example of a factor graph for . To obtain the estimated message word, the LLR values and the hard bit estimations are propagated through all the processing elements (PEs) in the factor graph that are depicted in Fig. 1(b). A PE performs LLR computations as
| (1) |
where and are the LLR value and the hard bit estimation at the -th stage, , and the -th bit, , respectively. The hard bit values of the PE are computed as
| (2) | ||||
where denotes the logical XOR operation.
The LLR values at the -th stage are initialized to . In SC decoding, the hard bit estimations at the -th stage are calculated as
| (3) |
In SCL decoding, at the -th stage, each information bit is estimated as either or and at each decoding step, only most likely candidate paths are allowed to survive. After the last bit is estimated in SCL decoding, the path with the highest reliability metric is selected as the decoding result. If a CRC of length is used to help SCL decoding, after the last bit is estimated, the path that passes the CRC verification is selected as the decoding result.
II-B SCF and DSCF Decoding
SCF decoding is used to decode a polar code that is concatenated with a CRC of length for verification. It starts by performing SC decoding and if the CRC verification fails after the initial SC decoding, it flips the bit estimation of an information bit which has the smallest absolute LLR value [4]. However, this simple bit-flipping metric prevents SCF decoding to obtain a satisfactory error-correction performance [8].
To determine the bit-flipping position, DSCF decoding estimates the probability of the -th bit () being the first-order error bit after the initial SC decoding attempt as
| (4) |
where is defined as
| (5) |
with , . Therefore, the bit-flipping position that maximizes the probability of being correctly decoded after the second SC decoding attempt can be calculated as
| (6) |
Note that cannot be obtained during the course of decoding since the message word is unknown to the decoder [8]. Therefore, DSCF approximates as
| (7) |
It was observed in [8] that the approximation in (7) does not result in a desirable error-correction performance. Therefore, a perturbation parameter is introduced to obtain a better estimation of as
| (8) |
To enable numerically stable computations for a hardware implementation, the bit-flipping metric is defined as [8]
| (9) |
Consequently, the most probable bit-flipping position under DSCF decoding can be found as
| (10) |
III Deep-Learning-Aided Successive-Cancellation Decoding
In this section, a general bit-flipping algorithm for SCL decoding of polar codes is proposed, with the special case of the bit-flipping algorithm for SC decoding when the list size is . Moreover, a new bit-flipping metric is derived that directly utilizes the correlations of the information bits in terms of the likelihood that an information bit is correctly decoded. A training framework is then introduced as the optimization scheme to design the decoder’s parameters followed by the evaluation of the proposed scheme.
III-A A Bit-Flipping Algorithm for SCL decoding
Consider a failure in the SCL decoding with list size as the SCL decoding attempt in which all the decoding paths fail the CRC verification. Let , , be the -th candidate path after the first SCL decoding, be the best path after the first SCL decoding attempt, i.e. the path with the smallest path metric [14], and let be the estimated first erroneous bit of . In the proposed scheme, a secondary SCL decoding attempt is performed by keeping only and fixing all the information bits before the -th bit. This is because all the estimated information bits before -th are believed to be correct, and the -th bit is flipped to correct the first error bit of .
The information bits for the second SCL decoding attempt up to the -th bit are fixed as
| (11) |
for . After the -th information bit, the conventional SCL decoding procedure is performed by estimating each information bit as both and and by keeping the best paths at each decoding step. The path metrics of all the decoding paths are then given as [14]
| (12) |
where , , and is the path metric penalty at the -th bit that is calculated as
| (13) |
where is the LLR value of the -th bit at the -th path.
Note that the bit-flipping metric of DSCF can be used to estimate . However, this approach requires costly logarithmic and exponential functions, hence they are not attractive for an efficient hardware implementation. In the next subsection, a novel bit-flipping metric is proposed that only requires multiplication and addition operations.
III-B The Proposed Bit-Flipping Metric
Unlike the DSCF decoder which relies on the estimation of the probability , for the bit-flipping metric computation, a method is proposed to directly estimate the following likelihood ratio
| (14) |
The value indicates how likely the estimated message bit is correctly decoded given the received signal and the message word . The bit index which is most likely to be the first-order erroneous bit is then obtained as
| (15) |
Similar to , the value of is not available during the decoding process as remains unknown to the decoder. Therefore, the following hypothesis is proposed for the estimation of :
| (16) |
where
| (17) |
and are perturbation parameters such that and , for and .
To enable numerically stable computations, the bit-flipping metric of the proposed decoder can be obtained by transforming the likelihood ratio to the LLR domain as
| (18) |
The most probable bit-flipping index can then be selected as
| (19) |
Note that the bit-flipping metric computation in (18) can be represented in the matrix form as
| (20) |
where and are row vectors of size , and is a matrix of size . Equivalently, is the index of the element in that has the smallest value.
With and , , can be seen as a correlation matrix that captures the inherent relations of the absolute LLR values of all the information bits under SCL decoding. For the sake of simplicity, since only the LLR values of information bits are considered, all of the bit indices used in the rest of this paper are referred to as information bit indices, and therefore have the values in the range of .
III-C Parameter Optimization
Note that is fixed to 1 and is not trainable for all . On the other hand, other elements of the matrix are trainable with a condition that , . In the proposed DL-SCL decoding, the number of trainable parameters of the matrix is , which is too large to efficiently apply heuristic methods such as Monte Carlo simulation for parameter optimization. Therefore, the optimization of is considered as a learning problem and DL techniques are exploited to optimize . The bit-flipping metric of the proposed decoder does not depend on the values of the message word . Thus, all-zero codewords can be used during the training phase. This symmetric property is particularly useful for DL-based decoders of linear block codes, as it simplifies the training process [13, 12, 15].
Let be the estimated bit-flipping vector of the information bits with indicating a bit-flip and indicating no bit-flip. From (19), the elements of the vector are defined as
| (21) |
for . In this paper, stochastic-gradient-descent (SGD) based techniques are used to update the values of during training, thus the computation of is modified to enable back-propagation during training [13]. Otherwise, learning is not feasible as the derivative of (21) with respect to , i.e., the -th element of , is always 0.
Let the soft estimation of be
| (22) |
where , and and are the smallest and the second smallest values of , respectively. The objective loss function is then defined as
| (23) |
where is the binary cross-entropy function, and is the scaling factor of the L2 regularization [16].
In this paper, PyTorch [17] is used as the DL framework. Training is done using RMSprop optimizer [18] with a mini-batch size of and a learning rate of . The training set consists of samples of the received channel signals, which are not correctly decoded after the first SCL decoding attempt, and the data is collected at dB. The L2 regularization hyperparameter is set to . The initial values of the non-diagonal elements of are drawn from an i.i.d distribution within the range of before training takes place. The matrix is trained for list sizes 111Optimized matrices are available at https://github.com/nghiadt05/DLSCL-CorMatrices.
III-D Evaluation
In this section, the performance of the proposed DL-SCL decoder in terms of frame-error-rate (FER) and computational complexity is examined. The polar code concatenated with a -bit CRC is considered. The selected polar code and the CRC polynomial are used in the eMBB control channel of the 5G standard [2].
Fig. 2 compares the FER performance of various decoders for . In this figure, DL-SCL denotes the proposed DL-SCL decoding algorithm with list size , and the bit-flipping SCL decoder with the bit-flipping metric proposed in [8] is denoted as SCLF. In addition, the original SCL decoding in [14] is also considered for the comparison. For all the bit-flipping SCL decoders, additional decoding attempts are considered for the secondary SCL decoding. As observed from Fig. 2, the proposed bit-flipping metric in the proposed DL-SCL decoders results in almost no FER performance loss compared to that of the SCLF decoders.
Fig. 3 visualizes the values of the elements in matrix in the form of a heat map222Matrix is shown to exclude the diagonal elements of which have a value of ., where is the identity matrix with the same size as . It can be seen that (and thus ) is a sparse matrix with many of its elements having a value close to . This observation is exploited to reduce the computational complexity of computing the proposed bit-flipping metric, which in turn reduces the computational complexity of the proposed DL-SCL decoding algorithm.

Table I reports the computational complexity of the proposed bit-flipping metric of the DL-SCL decoder in comparison with that of the SCLF decoder in terms of the number of different operations performed. Other than the bit-flipping metric, the proposed DL-SCL decoder and the SCLF decoder are identical. In this table, all the elements of which have a value in the range are set to , thus removing the need to perform additions or multiplications over those elements, without tangibly degrading the error-correction performance. It can be seen that the bit-flipping metric computation in the proposed DL-SCL decoders require up to fewer multiplications and up to fewer additions in comparison with that of the SCLF decoder. Moreover, unlike SCLF decoder, the proposed bit-flipping metric in the DL-SCL decoders does not require the computation of any transcendental functions.
| Decoders | / | ||
|---|---|---|---|
| SCLF | |||
| DL-SCL | |||
| DL-SCL | |||
| DL-SCL | |||
| DL-SCL |
IV Conclusion
In this paper, a deep-learning-aided successive-cancellation list (DL-SCL) decoding algorithm for polar codes is introduced. The proposed decoder improves the performance of successive-cancellation list (SCL) decoding by running additional SCL decoding attempts using a novel bit-flipping scheme. The bit-flipping metric of the proposed decoder is obtained by exploiting the inherent relations between the information bits. These relations are expressed in the form of a trainable correlation matrix, which is optimized using deep-learning (DL) techniques. Performance results on a polar code of length and rate show that the proposed bit-flipping metric in the proposed DL-SCL decoder requires up to fewer multiplications and up to fewer additions in comparison with the state of the art, while providing almost the same error-correction performance.
Acknowledgment
S. A. Hashemi is supported by a Postdoctoral Fellowship from the Natural Sciences and Engineering Research Council of Canada (NSERC).
References
- [1] E. Arıkan, “Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels,” IEEE Trans. Inf. Theory, vol. 55, no. 7, pp. 3051–3073, July 2009.
- [2] 3GPP, “Multiplexing and channel coding (Release 10) 3GPP TS 21.101 v10.4.0.” Oct. 2018. [Online]. Available: http://www.3gpp.org/ftp/Specs/2018-09/Rel-10/21_series/21101-a40.zip
- [3] I. Tal and A. Vardy, “List decoding of polar codes,” IEEE Trans. Inf. Theory, vol. 61, no. 5, pp. 2213–2226, March 2015.
- [4] O. Afisiadis, A. Balatsoukas-Stimming, and A. Burg, “A low-complexity improved successive cancellation decoder for polar codes,” in 48th Asilomar Conf. on Sig., Sys. and Comp., Nov 2014, pp. 2116–2120.
- [5] C. Condo, F. Ercan, and W. J. Gross, “Improved successive cancellation flip decoding of polar codes based on error distribution,” in IEEE Wireless Commun. and Net. Conf. Workshops, April 2018, pp. 19–24.
- [6] F. Ercan, C. Condo, S. A. Hashemi, and W. J. Gross, “Partitioned successive-cancellation flip decoding of polar codes,” arXiv e-prints, p. arXiv:1711.11093v4, Nov 2017. [Online]. Available: https://arxiv.org/abs/1711.11093
- [7] F. Ercan, C. Condo, and W. J. Gross, “Improved bit-flipping algorithm for successive cancellation decoding of polar codes,” IEEE Trans. on Commun., vol. 67, no. 1, pp. 61–72, Jan 2019.
- [8] L. Chandesris, V. Savin, and D. Declercq, “Dynamic-SCFlip decoding of polar codes,” IEEE Trans. Commun., vol. 66, no. 6, pp. 2333–2345, June 2018.
- [9] S. Cammerer, T. Gruber, J. Hoydis, and S. ten Brink, “Scaling deep learning-based decoding of polar codes via partitioning,” in IEEE Global Commun. Conf., December 2017, pp. 1–6.
- [10] W. Xu, Z. Wu, Y.-L. Ueng, X. You, and C. Zhang, “Improved polar decoder based on deep learning,” in IEEE Int. Workshop on Signal Process. Syst., November 2017, pp. 1–6.
- [11] N. Doan, S. A. Hashemi, and W. J. Gross, “Neural successive cancellation decoding of polar codes,” in 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), June 2018, pp. 1–5.
- [12] N. Doan, S. A. Hashemi, E. N. Mambou, T. Tonnellier, and W. J. Gross, “Neural belief propagation decoding of CRC-polar concatenated codes,” in IEEE Int. Conf. on Commun., May 2019, pp. 1–6.
- [13] N. Doan, S. A. Hashemi, F. Ercan, T. Tonnellier, and W. J. Gross, “Neural dynamic successive cancellation flip decoding of polar codes,” ArXiv, vol. abs/1907.11563, 2019. [Online]. Available: https://arxiv.org/abs/1907.11563
- [14] A. Balatsoukas-Stimming, M. B. Parizi, and A. Burg, “LLR-based successive cancellation list decoding of polar codes,” IEEE Trans. Signal Process., vol. 63, no. 19, pp. 5165–5179, Oct. 2015.
- [15] E. Nachmani, E. Marciano, L. Lugosch, W. J. Gross, D. Burshtein, and Y. Be’ery, “Deep learning methods for improved decoding of linear codes,” IEEE J. of Sel. Topics in Signal Process., vol. 12, no. 1, pp. 119–131, February 2018.
- [16] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, p. 436, May 2015.
- [17] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017.
- [18] G. Hinton, N. Srivastava, and K. Swersky, “Neural networks for machine learning lecture 6a overview of mini-batch gradient descent.” [Online]. Available: https://cs.toronto.edu/csc321/slides/lecture_slides_lec6.pdf