Deep Learning Assisted Antenna Selection in Untrusted Relay Networks
Abstract
This letter mainly studies the transmit antenna selection(TAS) based on deep learning (DL) scheme in untrusted relay networks. In previous work, we discover that machine learning (ML)-based antenna selection schemes have small performance degradation caused by complicated coupling relationship between achievable secrecy rate and the channel gains. To solve the issue, we here introduce deep neural network (DNN) to decouple the complicated relationship. The simulation results show the DNN scheme can achieve better decoupling and thus perform almost the same performance with conventional exhausted searching scheme.
Index Terms:
transmit antenna selection, untrusted relay networks, DNNI introduction
In recent years, artificial intelligence (AI) has made great success in many fields such as pattern recognitions and signal processing, and the intelligence communication is considered a sightful way for wireless communication after 5G [1]. Currently, the research of AI is advancing into physical layer security in wireless communication so as to reduce the complexity and solve other existing problems to improve the system performance [2].
Especially, the ML technology has become one of most popular AI technologies in physical layer security [3]. For example, the ML schemes are conducted for the antenna selection in wiretap networks [4]. In [5], the author studied resource allocation in multi-channel cognitive networks using DNN method. DL algorithm was proposed in [6] to improve the performance of the belief propagation algorithm for decoding. In [7], an unsupervised deep learning was used in Multiple-Input Multiple-Output (MIMO) encoder system.
In our previous work [8], we applied ML schemes, namely, support vector machine(SVM), naive-bayes(NB), and k-nearest neighbors(k-NN), to implement TAS for the optimization problem in (8). However, ML-based scheme has a little system degradation due to nonlinear coupling. In this paper, since the DNN can solve the various nonlinear distortions, we believe that the DL application is a useful and promising way to achieve decoupling in antenna selection. Our main contributions are as follows:
-
•
We focus on DL scheme to enhance physical layer security in untrusted relay networks.
-
•
Compared to our previous work in [8], we extend our research by DNN to achieve decoupling and further get better system performance.
II System and Signal Model
We consider half-duplex two-hop untrusted relay networks, consisting of a source (S), a destination (D) and an untrusted amplifying-and-forward (AF) relay (R) equipped with , , antennas, respectively. For simplicity, we assume for our initial work. We note that only the source S is employed to process the transmit antenna selection. Further, all channels are subject to independent and identically distributed (i.i.d) Rayleigh fading.
In this system, there is no direct link between S and D because of shadowing or long distance; Therefore the communication is implemented via R. We denote as the channel vector from S to R. Further define and as the channel gains from R to D and from D to R. Here, since the channel reciprocity is considered, we have = . Due to the high cost of RF chain, only antennas among of S are activated to perform transmission. Assume that the available antennas are labeled as and the selected antennas are with the indices where for . Therefore, the practical propagation channel from S to R can be denoted as . In order to maximize the received SNR for the relay R, the source S adopts matched filter precoding. In this case, the precoding vector for S’s transmission is , where represents the -norm of a vector.
Owing to the relay is untrustworthy, we adopt the destination-aided jamming (DAJ) technique[9] and divide the transmission into two time-slots.
In the first time slot, S transmits its precoded signal, to R with being the confidential signal, and simultaneously D emits cooperative jamming signal to R in the same frequency. The received signal at R, , is presented by [9]
| (1) |
where and are both with unit power; and are the transmitted powers from and ; denotes the complex additive white Gaussian noise (AWGN) received at R, following -distribution. In this letter, all the AWGNs received both at R in the first time slot and at D in the second time slot are assumed with unit power spectral density (PSD), i.e., . Hence, the signal-to-noise ratio (SNR) at different nodes can be adjusted by the transmitted power. With the cooperative jamming signal as the second item in (II), the eavesdropping capability of R is degraded.
From (II), the instantaneous received signal-to-interference-plus-noise ratio (SINR) at R can be denoted as
| (2) |
In the second time slot, the relay R re-transmits the received signal to D after amplifying it with an amplification factor . Let be the transmitted power by R. Therefore, with in (II), the amplification factor can be denoted as
| (3) |
Then the received signal at D from R is given by
| (4) |
where is the complex AWGN received at D, which is also assumed to be -distributed.
Since the second item in (II) is transmitted by D itself, D can perform self-interference cancellation with perfect channel state information (CSI) available. Consequently, the instantaneous SINR at D can be presented as
| (5) |
In physical-layer security based untrusted relay system, the achievable secrecy rate can be defined as [10]
| (6) |
where . Note that, for simplification, we neglect this operator for the following derivation but consider it for simulation.
When we select only one antenna, namely , to implement the transmission. Therefore, in (II) can be further replaced with .
III Conventional And Machine Learning-based Antenna Selection Scheme
In conventional antenna selection, the source S can be aware of all CSIs, such as and . Then, S traverses all the possible antenna combinations, and computes the corresponding secrecy rate. The maximum secrecy rate and the corresponding antenna selection scheme are the solutions for TAS problem. The optimization problem can be formulated as
| (8) |
where denote the index set for all possible combinations for selected antennas, with size .
As can be seen from the analysis of (II), there exists quite an involved coupling relationship for with and . It is hard for ML scheme to achieve decoupling since the ML schemes usually deal with some linear problems; in this case more misclassification is led to and degradation of system performance is emerged [8]. Considering the superiority of DNN to solve nonlinearity, we will introduce DNN method to decouple the above complicated relationship and achieve the optimal antenna selection in untrusted relay networks.
IV DNN-based antenna selection scheme
The DNN structure we utilize here has 3 layers consisting of an input layer, hidden layers and an output layer and every layer has their own neurons [11]. Three procedures for DNN-based TAS scheme are as follows.
IV-A Data sets generation
First, we generate a training data set and a testing data set, each of which containing diverse real channel state information(CSI) data samples, e.g. . To be specific, the -th training or testing data samples can be denoted as for .
Then, we generate normalized feature vector by normalizing . The -th element of , , can be generated as
| (9) |
where is the -th element of ; denotes the expected value operation.
Furthermore, we calculate secrecy rate of each antenna combination in as the KPI, and we choose the target antennas that achieves the maximum secrecy rate.
IV-B Construct DNN model
We construct DNN model on Tensorflow platform.
In input layer of the training DNN model, each item of the normalized training feature vector obtained in (9) corresponds to each neuron as the input.
In output layer of the DNN model, selected labels corresponds to each neuron as the output. Meanwhile, The one-hot encoding is choosed for the labels. It means that when there is combinations, it needs bits to encode labels. The processed label has only one bit equaling to 1 and other bits equaling to 0. For example, when selecting 1 antenna from 6 antennas, the selected label 6 can be coded as 000001 and 4 can be coded as 000100; when selecting 2 antenna from 6 antennas, the selected label 10 can be coded as 000000000100000 and 14 can be coded as 000000000000010.
Then, we set a series of parameters, such as learning rate, model training times, batch size and the neurons of input layer, hidden layer and output layer and so on. We adopt rectified linear units (ReLU) function as the hidden layer function; In addition, we apply RMSProp optimizer as the model optimizer method. For last layer’s neuron to next layer’s neuron , it can be denoted as , The weight matrix of last layer’s output to the next layer’s neuron is ; is the bias parameter. In addition, the RMSProp optimizer as the model optimizer method is applied.
IV-C Start model training and predication
We train DNN model to extract its features and set up internal parameters. After the model is established, we perform label prediction of normalized testing feature vector by DNN.
When DNN model carries out label predicting, the normalized testing feature vector obtained in (9) is regarded as input, and the probability of each antenna (i.e., ) corresponding each output layer’s neuron is regarded as output. For example, when it is single antenna selection, the label which make the highest probability will be selected; when it is two antenna selection, the label combination which make the highest probability will be selected.
The reason for setting up probability of each antenna is that we use logistic function equation as the output layer function, where correspond the input elements of the output layer.
V Simulation Results And Analysis
In this section, we present some simulation results to verify the efficiency of the DNN-based schemes. The size of both training data and testing data are set 2000007. The source S is configured with antennas, and or antennas will be selected out. For simplicity, we set .
The experiment is carried out in Tensorflow platform which exploiting GPU processing power, thus solving the large amount of data more efficiently. By looking for the maximum classification accuracy as possible, those parameters are adjusted and confirmed. The amount of the input layer, hidden layer, output layer of DNN architecture is set to 1, 1, 1, repectively; the batch size is 128; the learning rate is 0.01; when selecting 1 antenna from 6 antennas, the neurons of input layer, hidden layer and output layer are set 7, 1500, 6 or set 7, 1500, 15 when selecting 2 antenna from 6 antennas.
V-A System Performance
The system performance simulation is conducted in terms of secrecy rate defined in (6) and secrecy outage probability (SOP). The SOP can be defined as
| (10) |
where is the probability, is the target SOP and .
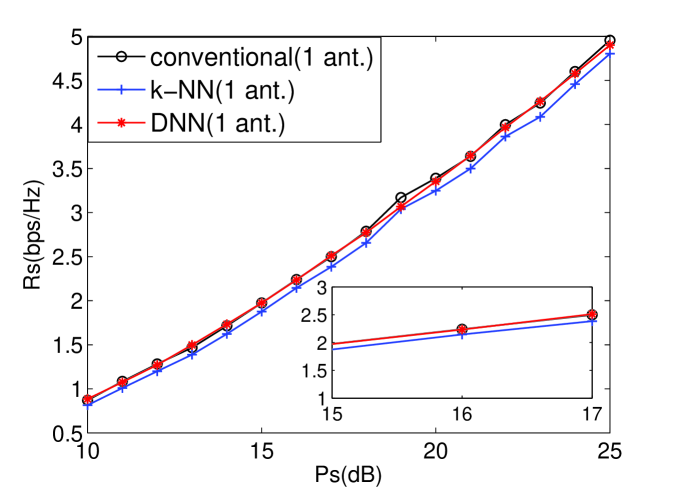
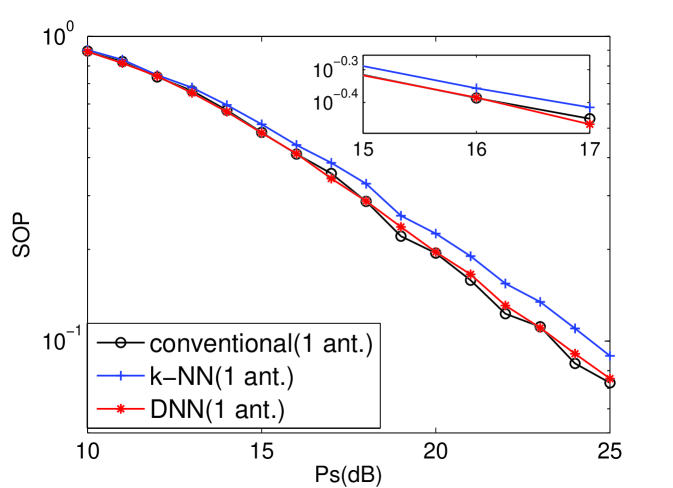
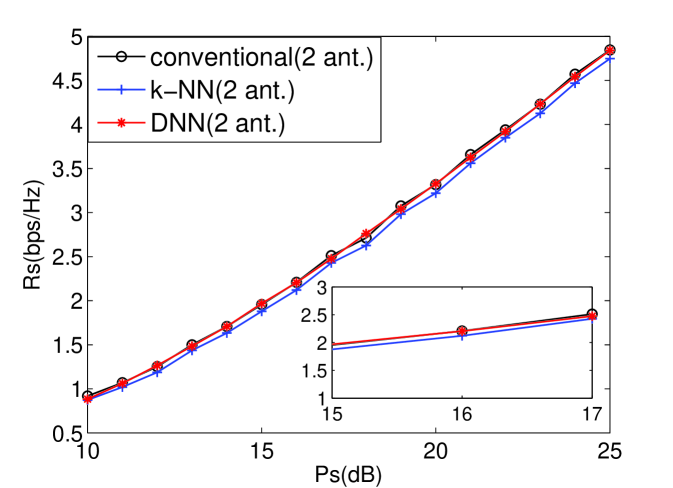
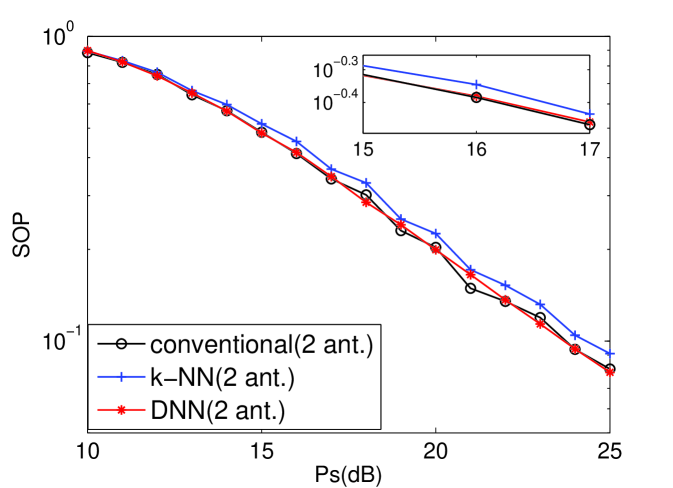
From [8], the k-NN scheme of ML schemes has the highest performance. Therefore, the single antenna for TAS of the k-NN, DNN, and conventional schemes are compared in terms of secrecy rate and SOP as shown in Figs. 1 and 2. In addition, two antennas for TAS of the k-NN, DNN, and conventional schemes are compared in Figs. 3 and 4. And it can indicate that DNN-based TAS scheme outperforms than other ML schemes. Furthermore, the DNN-based scheme achieves almost the same performance with conventional scheme, thus indicating that our proposed DNN-based scheme can achieve decoupling. It is because that each layer of DNN architecture plays a processing unit to solve the the non-linear relationship among the features while the ML schemes merely solve linear relationship. In addition, the DNN shows outstanding modeling capability compared to existing ML methods.[11]
V-B Computational Complexity
As stated in Section III, presents the cardinality of selected antenna combinations, and . Let . The selection complexity for SVM, NB, k-NN, DNN and conventional schemes are , , , and , respectively [12, 4]. We can clearly see that the complexity of DNN and ML schemes are rather lower than that of conventional schemes. It is because that the conventional TAS scheme requires to process the global search and comparison for every antenna combination. However, the complexity of ML-based and DL-based schemes rely on the prediction complexity rather than the training complexity because the model training can be performed offline. Besides, the well-trained DNN architecture only make finite computing processing.
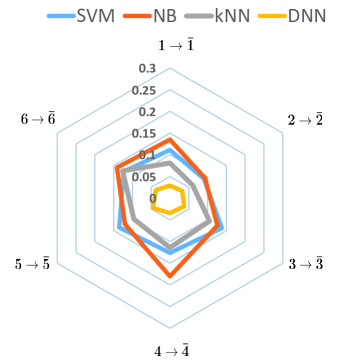
V-C Classification Performance
Actually, TAS is equivalent to a classification system with ML and DL algorithms. In this subsection, we present the misclassification rate for single antenna selection by using the web representation, . The value of each point in polygon denotes the misclassification rate of the corresponding channel index by , where and . From Fig. 5, it can be seen that the DL misclassification rate is greatly lower than the rate for DL, which shows the high classification accuracy and great decoupling capability of the DNN by another aspect.
VI conclusions
In this paper, we applied DNN-based antenna selection scheme to achieve decoupling not being solved by other ML-based schemes (i.e., SVM, NB and k-NN) as well as to reduce the complexity in untrusted relay networks. The simulation results show that our proposed DNN-based scheme can achieve almost the same secrecy rate and SOP as conventional scheme with transmitted power constraint at the relay.
References
- [1] R. Li, Z. Zhao, Z. Xuan, G. Ding, C. Yan, Z. Wang, and H. Zhang, “Intelligent 5G: When cellular networks meet artificial intelligence,” IEEE Wireless Communications, vol. PP, no. 99, pp. 2–10, 2017.
- [2] S. Dorner, S. Cammerer, J. Hoydis, and S. T. Brink, “Deep learning-based communication over the air,” IEEE Journal of Selected Topics in Signal Processing, vol. PP, no. 99, pp. 1–1, 2017.
- [3] T. Oshea, J. Hoydis, T. Oshea, and J. Hoydis, “An introduction to deep learning for the physical layer,” IEEE Transactions on Cognitive Communications & Networking, vol. 3, no. 4, pp. 563–575, 2017.
- [4] D. He, C. Liu, T. Q. S. Quek, and H. Wang, “Transmit antenna selection in MIMO wiretap channels: A machine learning approach,” IEEE Wireless Communications Letters, vol. PP, no. 99, pp. 1–1, 2018.
- [5] W. Lee, “Resource allocation for multi-channel underlay cognitive radio network based on deep neural network,” IEEE Communications Letters, vol. 22, no. 9, pp. 1942–1945, Sep. 2018.
- [6] E. Nachmani, Y. Be’ery, and D. Burshtein, “Learning to decode linear codes using deep learning,” in 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Sep. 2016, pp. 341–346.
- [7] T. J. O’Shea, T. Erpek, and T. C. Clancy, “Deep learning based MIMO communications.” arXiv preprint arXiv:1707.07980, 2017.
- [8] R. Yao, Y. Zhang, N. Qi, and T. A. Tsiftsis, “Machine learning-based antenna selection in untrusted relay networks. available: https://arxiv.org/abs/1812.10318, preprint,” arXiv preprint arXiv:1812.10318, 2018.
- [9] R. Yao, Y. Lu, T. A. Tsiftsis, N. Qi, T. Mekkawy, and F. Xu, “Secrecy rate-optimum energy splitting for an untrusted and energy harvesting relay network,” IEEE Access, vol. 6, pp. 19 238–19 246, 2018.
- [10] T. Mekkawy, R. Yao, T. A. Tsiftsis, F. Xu, and Y. Lu, “Joint beamforming alignment with suboptimal power allocation for a two-way untrusted relay network,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 10, pp. 2464–2474, 2018.
- [11] W. Liu, Z. Wang, X. Liu, N. Zeng, Y. Liu, and F. E. Alsaadi, “A survey of deep neural network architectures and their applications ,” Neurocomputing, vol. 234, pp. 11–26, 2017.
- [12] J. Joung, “Machine learning-based antenna selection in wireless communications,” IEEE Communications Letters, vol. 20, no. 11, pp. 2241–2244, 2016.