supplement.pdf
Deep Learning for Omnidirectional Vision: A Survey and New Perspectives
Abstract
Omnidirectional image (ODI) data is captured with a field-of-view, which is much wider than the pinhole cameras and contains richer spatial information than the conventional planar images. Accordingly, omnidirectional vision has attracted booming attention due to its more advantageous performance in numerous applications, such as autonomous driving and virtual reality. In recent years, the availability of customer-level cameras has made omnidirectional vision more popular, and the advance of deep learning (DL) has significantly sparked its research and applications. This paper presents a systematic and comprehensive review and analysis of the recent progress in DL methods for omnidirectional vision. Our work covers four main contents: (i) An introduction to the principle of omnidirectional imaging, the convolution methods on the ODI, and datasets to highlight the differences and difficulties compared with the 2D planar image data; (ii) A structural and hierarchical taxonomy of the DL methods for omnidirectional vision; (iii) A summarization of the latest novel learning strategies and applications; (iv) An insightful discussion of the challenges and open problems by highlighting the potential research directions to trigger more research in the community.
Index Terms:
Omnidirectional vision, deep learning (DL), Survey, Introductory, Taxonomy1 Introduction
With the rapid development of 3D technology and the pursuit of realistic visual experience, research interest in computer vision has gradually shifted from traditional 2D planar image data to omnidirectional image (ODI) data, also known as the 360∘ image, panoramic image, or spherical image data. ODI data captured by the cameras yields a field-of-view (FoV), which is much wider than the pinhole cameras; therefore, it can capture the entire surrounding environment by reflecting richer spatial information than the conventional planar images. Due to the immersive experience and complete view, ODI data has been widely applied to numerous applications, e.g., augmented reality(AR)virtual reality (VR), autonomous driving, and robot navigation. In general, raw ODI data is represented as, e.g., the equirectangular projection (ERP) or cubemap projection (CP) to be consistent with the imaging pipelines [1], [2]. As a novel data domain, ODI data has both domain-unique advantages (wide FoV of spherical imaging, rich geometric information, multiple projection types) and challenges (severe distortion in the ERP type, content discontinuities in the CP format). This renders the research on omnidirectional vision valuable yet challenging.
Recently, the availability of customer-level cameras has made omnidirectional vision more popular, and the advance in deep learning (DL) has significantly promoted its research and applications. In particular, as a data-driven technology, the continual release of public datasets, e.g., SUN360 [3], Salient 360 [4], Stanford2D3D [5], Pano-AVQA [6] and PanoContext [7], have rapidly enabled the DL methods to accomplish remarkable breakthroughs and often achieve the state-of-the-art (SoTA) performances on various omnidirectional vision tasks. Moreover, various deep neural network (DNN) models have been developed based on diverse architectures, ranging from convolutional neural networks (CNNs) [8], recurrent neural networks (RNNs) [9], generative adversarial networks (GANs) [10], graph neural networks (GNNs) [11], to vision transformers (ViTs) [12]. In general, SoTA-DL-methods focus on four major aspects: (I) convolutional filters used to extract features from the ODI data (omnidirectional video (ODV) can be considered as a temporal set of ODIs), (II) network design by considering the input numbers and projection types, (III) novel learning strategies, and (IV) practical applications.
This paper presents a systematic and comprehensive review and analysis of the recent progress in DL methods for omnidirectional vision. Previously, Zou et al. [13] only focused on the algorithms of reconstructing room layout from a single ODI based on the Manhattan assumption. Similarly, Silveira et al. [14] merely reviewed recent 3D scene geometry recovery approaches based on the ODIs. Moreover, there exist some limited reviews of the FoV-adaptive video streaming methods [15], [16], especially on the topic of projection types, visual distortion problems, and efficient network structures. Recently, Chiariotti et al. [17] provided a more extensive review of the existing literature about ODV streaming systems. Unlike them, we highlight the importance of DL and probe the recent advances for omnidirectional vision, both methodically and comprehensively. The structural and hierarchical taxonomy proposed in this study is shown in Fig. 1.
In summary, the major contributions of this study can be summarized as follows: (I) To the best of our knowledge, this is the first survey to comprehensively review and analyze the DL methods for omnidirectional vision, including the omnidirectional imaging principle, representation learning, datasets, a taxonomy, and applications, to highlight the differences and difficulties with the 2D planner image data. (II) We summarize most, if not all but representative, published top-tier conference/journal works (over 200 papers) in the last five years and conduct an analytical study of recent trends of DL for omnidirectional vision, both hierarchically and structurally. Moreover, we offer insights into the discussion and challenge of each category. (III) We summarize the latest novel learning strategies and potential applications for omnidirectional vision. (IV) As DL for omnidirectional vision is an active yet intricate research area, we provide insightful discussions of the challenges and open problems yet to be solved and propose the potential future directions to spur more in-depth research by the community. Meanwhile, we have summarized representative methods and their key strategies for some popular omnidirectional vision tasks in Table. II, Table. III, Table. IV, Table. V, and Table. VI. To provide a better intra-task comparison, we present some representative methods’ quantitative and qualitative results on benchmark datasets and all statistics are derived from the original papers. Due to the lack of space, we show the experimental results in Sec. 2 of the suppl. material. (V) We create an open-source repository that provides a taxonomy of all the mentioned works and code links. We will keep updating our open-source repository with new works in this area and hope it can shed light on future research. The repository link is https://github.com/VLISLAB/360-DL-Survey.


The rest of the paper is organized as follows. In Sec. 2, we introduce the imaging principle of ODI, convolution methods for omnidirectional vision, and some representative datasets. Sec. 3 introduces the existing DL approaches for various tasks and provides taxonomies to categorize the relevant papers. Sec. 4 covers novel learning paradigms for the tasks in omnidirectional vision, e.g., unsupervised learning, transfer learning, and reinforcement learning. Sec. 5 then scrutinizes the applications, followed by Sec. 6, where we discuss open problems and future directions. Finally, we conclude this paper in Sec. 7.
2 Background
2.1 Omnidirectional Imaging
2.1.1 Acquisition
A normal camera has an FoV less than and thus captures view at most a hemisphere. However, an ideal camera can capture lights falling on the focal point from all directions, making the projection plane a whole spherical surface. In practice, most cameras can not achieve it, which excludes top and bottom regions due to dead angles111https://en.wikipedia.org/wiki/Omnidirectional_(360-degree)_camera. According to the number of lenses, cameras can be categorized into three types: (i) Cameras with one fisheye lens, which is impossible to cover the whole spherical surface. However, if the intrinsic and extrinsic parameters are known, an ODI can be achieved by projecting multiple images into a sphere and stitching them together; (ii) Cameras with dual fisheye lenses located at opposite positions, each of which covers over FoV, such as Insta360 ONE222https://www.insta360.com/product/insta360-one and LG 360 CAM333https://www.lg.com/sg/lg-friends/lg-360-CAM. This type of cameras have minimum demand for lenses, which are cheap and convenient, favoured by industries and customers. Images from the two cameras are then stitched together to obtain an omnidirectional image, but the stitching process might lead to edge blurring; (iii) Cameras with more than two lenses, such as Titan (eight lenses)444https://www.insta360.com/product/insta360-titan/. In addition, GoPro Omni555https://gopro.com/en/us/news/omni-is-here is the first camera rig to place six regular cameras onto six faces of a cube and its synthesized results have higher precision and less blur in edges. This type of cameras are professional-level.
2.1.2 Spherical Imaging
We first define the spherical coordinate , where ,, and represent the latitude, longitude, and radius of the sphere, respectively. We also define the Cartesian coordinate . The transformation between spherical coordinate and Cartesian coordinate can be formulated as follows [18]:
| (1) |
Equirectangular Projection (ERP)666https://en.wikipedia.org/wiki/Equirectangular_projection is a representation by uniformly sampling grids from the spherical surface, as shown in Fig. 3(a). The horizontal unit angle is and the vertical unit angle is . In particular, if the horizontal and vertical unit angle are equal, the width is twice of height . In a word, each pixel coordinate in ERP can be mapped to the spherical coordinate and vice versa. Cubemap Projection (CP) projects the spherical surface to six cube faces with FoV, equal-side length , and focal length , as shown in Fig. 3(b). We denote the cube faces as , , representing back, down, front, left, right, and up, respectively. By setting the cube center as the origin, the extrinsic matrix of each face can be simplified into or rotation matrix and zero translation matrix [19]. Given a pixel on the plane , we transform to the front plane (identical to the Cartesian coordinates) and calculate with Eq. 1.

Tangent Projection is the gnomonic projection [24], a non-conformal projection from points on the sphere surface with the sphere center to points in a tangent plane with center 777https://mathworld.wolfram.com/GnomonicProjection.html, as shown in Fig. 3(c). For a pixel on the ERP image , we first calculate its corresponding point on the unit sphere, following the transformation in ERP format. The projection from to is defined as:
| (2) |
where is the spherical coordinate of the tangent plane center , and is the intersection coordinate of the tangent plane and the extension line of . The inverse transformations are formulated as:
| (3) |
where and . With Eqs. 2 and 3, we can build one-to-one forward and inverse mapping functions between the spherical coordinates and pixels on the tangent images [25].
Icosahedron approximates a sphere surface through a Platonic solid [26]. Compared with ERP and CP, icosahedron projection has resolved the spherical distortion well. While some practical applications need less distortion representations, we can increase the number of subdivisions to further mitigate the spherical distortion. Specifically, each face in an icosahedron can be subdivided into four smaller faces to achieve higher resolution and less distortion [26]. There exist some CNNs that are specifically designed to process an icosahedron [27, 28]. It is noteworthy that the choice of subdivision degree needs to achieve a trade-off between efficiency and accuracy.
Other projections. For CP, different sampling locations on the cube faces decide different spatial sampling rates, resulting in the distortions. To address this problem, Equi-Angular Cubemap (EAC) projection 888https://blog.google/products/google-ar-vr/bringing-pixels-front-and-center-vr-video/ is proposed to keep the sampling uniform. Besides, some projections can transform the spherical surface into non-spatial domains, e.g., 3D rotation group (SO3) [29] and spherical Fourier transformation (SFT) [30].
2.1.3 Spherical Stereo
Spherical stereo is about two viewpoints displaced with a known horizontal or vertical baseline [18]. Due to the spherical projection, spherical stereo is more irregular than stereo with traditional pinhole cameras. According to Eq. 1, we define the baseline as , and the derivative correspondence between the spherical coordinates and Cartesian coordinates can be formulated as follows:
| (4) |
2.2 Convolution Methods on ODI
As the natural projection surface of an ODI is a sphere, standard CNNs are less capable of processing the inherent distortions when the spherical image is projected back to a plane. Numerous CNN-based methods have been proposed to enhance the extraction of ”unbiased” information from spherical images. These methods can be classified into two prevailing categories: (i) Applying 2D convolution filters on planar projections; (ii) Directly leveraging spherical convolution filters in the spherical domain. In this subsection, we analyze these methods in detail.
2.2.1 Planar Projection-based Convolution
As the most common sphere-to-plane projection, ERP introduces severe distortions, especially at the poles. Considering it provides global information and takes less computation cost, Su et al. [20] proposed a representative method named Spherical Convolution, which leverages regular convolution filters with the adaptive kernel size according to the spherical coordinates. However, as shown in Fig. 4(a), the regular convolution weights are only shared along each row and can not be trained from scratch. Inspired by Spherical Convolution, SphereNet [21] proposes another typical method that processes the ERP by directly adjusting the sampling grid locations of convolution filters to achieve the distortion invariance and can be trained end-to-end, as depicted in Fig. 4(b). This is conceptually similar to those in [22], [23], as shown in Fig. 4(c) and (d). In particular, before ODIs are widely applied, Cohen et al. [29] have discussed the spatially varying distortions introduced by ERP and proposed a rotation-invariant spherical CNN approach to learn an SO3 representation. By contrast, KTN [31, 32] learns a transfer function to achieve that the convolution kernel, which is learnt from the conventional planar images, can be directly applied on ERP without retraining. In [33], the ERP is represented as a weighted graph, and a novel graph construction method is introduced by incorporating the geometry of the omnidirectional cameras into the graph structure to mitigate the distortions. [19, 34] focused on directly applying traditional 2D CNNs on CP and tangent projection, which are distortion-less.
2.2.2 Spherical Convolution
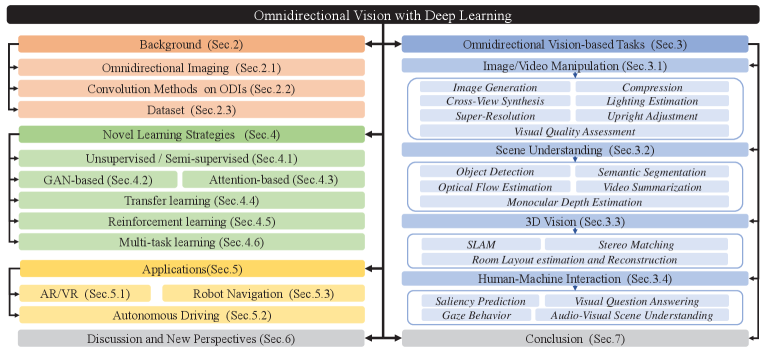
Some methods have explored the special convolution filters in the spherical domain. Esteves et al. [36] proposed the first spherical CNN architecture, which considers the convolution filters in the spherical harmonic domain, to address the problem of 3D rotation equivariance in standard CNNs. Unlike [36], Yang et al. [35] proposed a representative framework to map spherical images into the rotation-equivariant representations based on the geometry of spherical surfaces. As shown in Fig. 5(a), SGCN [35] represents the input spherical image as a graph based on the GICOPix [35]. Moreover, it explores the isometric transformation equivariance of the graph through GCN layers. A similar strategy is proposed in [37] and [38]. In [37], the gauge equivariant CNNs are proposed to learn spherical representations from the icosahedron. By contrast, Shakerinava et al. [38] extended the icosahedron to all the pixelizations of platonic solids and generalized the gauge equivariant CNNs on the pixelized spheres. Due to a trade-off between efficiency and rotation equivariance, DeepSphere [39] models the sampled sphere as a graph of connected pixels and designs a novel graph convolution network (GCN) to balance the computational efficiency and sampling flexibility by adjusting the neighboring pixel numbers of the pixels on the graph. Compared with the methods above, another representative ODI representation is proposed in SpherePHD [27]. As shown in Fig. 5(b), SpherePHD represents the spherical image as the spherical polyhedron and provides specific convolution and pooling methods.
2.3 Dataset
| Dataset | Size | Data Type | Resolution | GT | Purpose |
| Stanford2D3D [5] | 70496 RGB+1413 ERP images | Real | 1080 1080 | Object Detection, Scene Uderstanding | |
| Structured3D [40] | 196k images | Synthetic | 512 1024 | ✗ | Object Detection, Scene Understanding, Image Synthesis, 3D Modeling |
| SUNCG [41] | 45622 scenes | Synthetic | N/A | ✗ | Depth Estimation |
| 360-Sport [42] | 342 360∘ videos | Real | N/A | Visual Pilot | |
| Wild-360 [43] | 85 360∘ videos | Real | N/A | Video Saliency |
The performance of the DL-based approaches is closely related to the qualities and quantities of the datasets. With the development of spherical imaging devices, a large number of ODI and ODV datasets are publicly available for various vision tasks. Especially, most ODV data is collected from public video sharing platforms like Vimeo and Youtube. In Table. I, we list some representative ODI and ODV datasets used for different purposes and we also show their properties, e.g., size, resolution, data source. Complete summary of datasets can be found in the suppl. material. According to the data source, there are two categories of datasets: real-world datasets and synthetic datasets. Most real-world datasets only provide images of 2D projection modality and are applied to some specific task. However, Stanford2D3D [5] contains three modalities, including 2D, 2.5D, that are suitable for cross-modal learning. Moreover, some datasets are selected from the existing ones, such as PanoContext [7] collected from SUN360 [3]. For the synthetic datasets, images are complete and high-quality without natural noise, and the annotations are easier to obtain than that in the real-world scenes. For instance, SUNCG [41] is created via the Plannar5D platform, and all the 3D scenes are composed of individually labeled 3D object meshes. Structured3D [40] and OmniFlow [44] utilize the rendering engine to generate photo-realistic images containing 3D structure annotations and corresponding optical flows. Similar to real-world datasets, there are also some datasets, e.g., omni-SYNTHIA [45], extracted from the large synthetic ones for specific tasks.
3 Omnidirectional Vision Tasks
3.1 Image/Video Manipulation
3.1.1 Image Generation
Insight: Image generation aims to restore or synthesize the complete and clean ODI data from the partial or noisy data.
For image generation on ODI, there exist four popular research directions: (i) panoramic depth map completion; (ii) ODI completion; (iii) panoramic semantic map completion; (iv) view synthesis on ODI. In this subsection, we provide a comprehensive analysis of some representative works.
Depth Completion: Due to the scarcity of real-world sparse-to-dense panoramic depth maps, this task mainly utilizes simulation techniques to generate artificially sparse depth maps as the training data. Liu et al. [46] proposed a representative two-stage framework to achieve panoramic depth completion. In the first stage, a spherical normalized convolution network is proposed to predict the initial dense depth maps and confidence maps from the sparse depth inputs. Then the output of the first stage is combined with corresponding ODIs to generate the final panoramic dense depth maps through a cross-modal depth completion network. Especially, BIPS [47] proposes a GAN framework to synthesize RGB-D indoor panoramas from the limited input information about a scene captured by the camera and depth sensors in arbitrary configurations. However, BIPS ignores a large distribution gap between synthesized and real LIDAR scanners, which could be better addressed with domain adaptation techniques.
ODI Completion: It aims to fill in missing areas to generate complete and plausible ODIs. Considering the high degree of freedom involved in generating an ODI from a single limited FoV image, Hara et al. [48] leveraged a fundamental property of the spherical structure, scene symmetry, to control the degree of freedom and improve the plausibility of the generated ODI. On the opposite of [48], Akimoto et al. [49] proposed a transformer-based framework to synthesize the ODIs with arbitrary resolution from a fixed limited FoV image and encouraged the diversity of synthesized ODIs. In addition, Sumantri et al. [50] proposed a first pipeline to reconstruct the ODIs from a set of unknown FoV images without any overlap, including two steps: (i) FoV estimation of input images relative to the panorama; (ii) ODI synthesis with the input images and estimated FoVs.
Semantic Scene Completion (SSC): It aims to reconstruct the indoor scenes with both the occupancy and semantic labels of the whole room. Existing works, e.g., [51], are mostly based on the RGB-D data and LiDAR scanners. As the first work to accomplish the SSC task using the ODI data, [52] used only a single ODI and its corresponding depth map as the input and generates a voxel grid from the input panoramic depth map. This voxel grid is partitioned into eight overlapping views, and each partitioned grid, representing a single view of a regular RGB-D sensor, is submitted to the 3D CNN model [53], pre-trained on the standard 2.5D synthetic RGB-D data. These partial inferences are aligned and ensembled to obtain the final result.
| Method | Publication | Input | View synthesis | Localization | Highlight |
| Lu [54] | CVPR’20 | Image | ✗ | Utilizing depth and semantics | |
| Li [55] | ICCV’21 | Video | ✗ | 3D point cloud representation with depth and semantics | |
| Zhai [56] | CVPR’17 | Image | Pretraining semantic segmentation task with transfer learning | ||
| Regmi [57] | ICCV’19 | Image | Two stage training: Satellite-view synthesis and feature matching | ||
| Toker [58] | CVPR’21 | Image | End-to-end training for view synthesis and feature matching | ||
| Shi [59] | NIPS’19 | Image | ✗ | Polar transform | |
| Zhu [60] | CVPR’22 | Image | ✗ | Attention-based transformer and remove uninformative patches | |
| Shi [61] | CVPR’20 | Image | ✗ | Adding orientation estimation during localization | |
| Zhu [62] | CVPR’21 | Image | ✗ | Proposing that multiple satellite images can cover one ground image |
View Synthesis: View synthesis aims to generate ODIs from unknown viewpoints. OmniNeRF, proposed by Hsu et al. [63], is the first and representative learning approach for panoramic view synthesis. To generate a novel view ODI, it first projects an ODI to the 3D domain with an auxiliary depth map and a derived gradient image, and then translates the view position to re-project the 3D coordinates to 2D space. The neural radiance fields (NeRF) [64] is used to learn the pixel-based representations and solve the information missing problem caused by viewpoint translation. A similar strategy, proposed by [65], leverages a conditional generator to synthesize the novel view. With video as the input, Pathdreamer [66] designs a hierarchical architecture to conduct the non-observed view synthesis from one previous observation and the trajectory of future viewpoints.
3.1.2 Cross-view Synthesis and Geo-localization
Insight: Cross-view synthesis aims to synthesize ground-view ODIs from the satellite-view images while geo-localization aims to match the ground-view ODIs and satellite-view images to determine their relations.
Ground-view, a.k.a., street-view images are usually panoramic to provide complete surrounding information, while satellite views are planar images captured to cover almost every corner of the world. There exist a few methods to synthesize ground-view images from satellite-view images. Lu et al. [54] proposed a representative work including three stages: satellite stage, geo-transformation stage, and street-view stage. The satellite stage predicts depth maps and segmentation maps from satellite images. The geo-transformation stage transforms the output of the satellite stage into the panoramas. Finally, the street-view stage predicts the street-view panoramas from the segmentation maps via a GAN. Sat2Vid [55], the first work for cross-view video synthesis, also employs three stages to generate street-view ODVs using voxel grids with semantics and depth cues transformed from satellite images with trajectory. This is conceptually similar to that in [54].
In general, the framework for geo-localization consists of two modules: cross-synthesis module and retrieval module. Shi et al. [59] proposed a representative contrastive learning pipeline to calculate the distance between the ground-view ODIs and satellite-view images in the embedding space, similar to [58, 57]. In particular, in [58], a ground-view ODI is synthesized from the polar transformation of the satellite view via a GAN, supervised by the corresponding ground-view ground truth. Meanwhile, an extra retrieval branch is applied to constrain the latent representations of two domains. Using conditional GANs, Regmi et al. [57] skillfully synthesized the satellite-view image from the ground-view ODI. To learn a robust satellite query representation, they fused the features from the satellite-view synthesis and ground-view ODI, and then matched the query feature with satellite-view features in the embedding space. As the latest work, TransGeo [60] is the first ViT-based framework to extract the position information from the satellite images and ground-view ODIs. With an attention mechanism, TransGeo removes uninformative patches in the satellite-view images and surpasses previous CNN-based methods.
Discussion: Most cross-view synthesis and geo-localization methods assume that a reference image is precisely centered at the location of any query image. Nonetheless, in practice, the two views are usually not perfectly aligned in terms of orientation [61] and spatial location[62]. Therefore, how to apply cross-view synthesis and geo-localization methods under challenging conditions is a valuable research direction.
3.1.3 Compression
Compared with conventional perspective images, omnidirectional data records richer geometrical information with a higher resolution and wider FoV, making it more challenging to achieve effective compression. The early approaches for ODI compression directly utilize the existing perspective methods to compress the perspective projections of the ODIs. For instance, Simone et al. [67] proposed an adaptive quantization method to solve the frequency shift in the viewport image blocks when projecting the ODI to the ERP. By contrast, OmniJPEG [68] first estimates the region of interest in the ODI and then encodes the ODI based on the geometrical transformation of the region content with a novel format called OmniJPEG, which is an extension of JPEG format [69] and can be viewable on legacy JPEG decoders. Considering the ERP distortion, a graph-based coder is proposed by [70] to adapt the sphere surface. To make the coding progress computationally feasible, the graph partitioning algorithm based on rate distortion optimization [71] is introduced to achieve a trade-off between the distortion of reconstructed signals, the signal smoothness on each sub-graph, and the coding cost of partitioning description. As a representative CNN-based ODI compression work, OSLO [72] applies HEALPix [73] to define a convolution operation directly on the sphere and adapt the standard CNN techniques to the spherical domain. The proposed on-the-sphere representation outperforms the similar learnable compression models on the ERP.
For ODV compression, Li et al. [74] proposed a representative work aiming to optimize the ODV encoding progress. They analyzed the distortion impacts of restoring spherical domain signals from the different planar projection types and then applied the rate distortion optimization based on the distortion of signal in spherical domain. Similarly, Wang et al. [75] proposed a spherical coordinates transform-based motion model to address the distortion problem in projections. Another representative method [76] maps the ODV to the rhombic dodecahedron (RD) map and directly applies the planar perspective videos encoding methods on the RD map. Specifically, the rate control-based algorithms are proposed to achieve better qualities and smaller bitrate errors for ODV compression [77], [78]. Zhao et al. [78] utilized game theory to find optimal inter/intra-frame bitrate allocations while Li et al. [77] proposed a novel bit allocation algorithm for ERP with the coding tree unit (CTU) level. Similar to [20], the CTUs in the same row have the same weight to reduce the distortion influence.
Potential and Challenges: Based on the aforementioned analysis, only a few DL-based methods exist in this research domain. Most works combine the traditional planar coding methods with geometric information in the spherical domain. There remain some challenges for DL-based ODI/ODV compression. DL-based image compression methods require the effective metrics as the constraint, e.g., peak signal-to-noise ratio (PSNR), and structural similarity (SSIM). However, due to spherical imaging, traditional metrics are weak to measure the qualities of ODI. Furthermore, the planar projections of the ODI are high memory and distorted, which increase the computation cost and compression difficulty. Future research might consider extending more effective metrics based on the spherical geometric information and restoring a high-quality compressed ODI from a partial input.
3.1.4 Lighting Estimation
Insight: It aims to predict the high dynamic range (HDR) illumination from low dynamic range (LDR) ODIs.
Illumination recovery is widely employed in many real-world tasks ranging from scene understanding, reconstruction to editing. Hold-Geoffroy et al. [79] proposed a representative framework for outdoor illumination estimation. They first trained a CNN model to predict the sky parameters from viewports of outdoor ODIs, e.g., sun position and atmospheric conditions. They then reconstructed illumination environment maps for the given test images according to the predicted illumination parameters. Similarly, in [80], a CNN model is leveraged to predict the location of lights in the viewports, and the CNN is fine-tuned to predict the light intensities, i.e., environment maps, from the ODIs. In [81], geometric and photometric parameters of indoor lighting are regressed from the viewports of ODI, and the intermediate latent vectors are used to reconstruct the environment maps. Another representative method, called EMLight [82], consists of a regression network and a neural projector. The regression network outputs the light parameters, and the neural projector converts the light parameters into the illumination map. In particular, the ground truths of the light parameters are decomposed by a Gaussian map generated from the illumination via a spherical Gaussian function.
Discussion and Potential: From the aforementioned analysis, previous works for lighting estimation on ODIs take a single viewport as the input. The reason might be that the viewports are distortion-less and low-cost with low resolution. However, they suffer from severe drop of spatial information. Hence, it could be beneficial to apply contrastive learning to learn the robust representations from the multiple viewports or components of the tangent images.
3.1.5 ODI Super-Resolution (SR)
Existing Head-Mounted Display (HMD) devices [83] require at least the ODI with 2160010800 pixels for immersive experience, which can not be directly captured by current camera systems [84]. One alternative way is to capture low resolution (LR) ODIs and super-resolve them into high resolution (HR) ODIs efficiently. LAU-Net [85], as the first work to consider the latitude difference for ODI SR, introduces a multi-level latitude adaptive network. It splits an ODI into different latitude bands and hierarchically upscales these bands with different adaptive factors, which are learned via a reinforcement learning scheme. Beyond considering SR on the ERP, Yoon et al. [28] proposed a representative work, SphereSR, to learn a unified continuous spherical local implicit image function and generate an arbitrary projection with arbitrary resolution according to the spherical coordinate queries. For ODV SR, SMFN [86] is the first DNN-based framework, including a single-frame and multi-frame joint network and a dual network. The single-frame and multi-frame joint network fuses the features from adjacent frames, and the dual network constrains the solution space to find a better answer.
3.1.6 Upright Adjustment
Insight: Upright adjustment aims to correct the misalignment of the orientations between the camera and scene to improve the visual quality of ODI and ODV while they are used with a narrow field-of-view (NFoV) display, such as the VR application.
The standard approach of upright adjustment follows two steps: (i) estimating the position of the pole of the ODI; (ii) applying a rotation matrix to align the estimated north pole. The early representative work [87] estimates the camera rotation according to the geometric structures in the panoramas, e.g., curving straight lines and vanishing points. However, these methods are limited to the Manhattan [88] or Atlanta world [89] assumption and rely on necessary prior knowledge of geometric structures. Recently, DL-based upright adjustment has been widely studied. Without any specific assumption on the scene structure, DeepUA [90] proposes a representative CNN-based framework to estimate the 2D rotations of multiple NFoV images sampled from the ODI and then estimate the 3D camera rotation through the geometric relationship between 3D and 2D rotations. By contrast, Deep360Up [91] directly takes ERP image as the input and synthesizes the upright version according to the estimated up-vector orientation. In particular, Jung et al. [92] proposed a two-stage pipeline for ODI upright adjustment. First, the feature map is extracted by a CNN model from the rotated ERP image. The feature map is then mapped into a spherical graph. Finally, a GCN is applied to estimate the 3D camera rotation, which is the location of the point on the spherical surface corresponding to the north pole.
3.1.7 Visual Quality Assessment
Due to the ultra-high resolution and sphere representation of omnidirectional data, visual quality assessment (V-QA) is valuable for the optimization of exiting image/video processing algorithms. We next introduce some representative works on ODI-QA and ODV-QA, respectively.
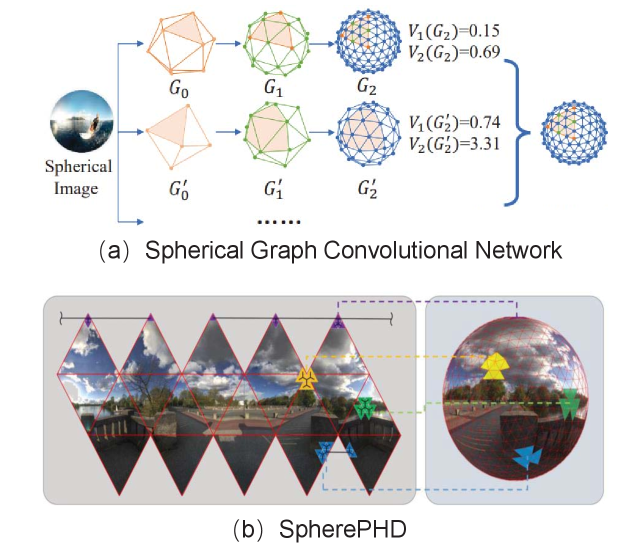
For the ODI-QA, according to the availability of the reference images, it can be further classified into two categories: full-reference (FR) ODI-QA and no-reference (NR) ODI-QA. In exiting methods on FR ODI-QA, some works focus on extending the conventional FR image quality assessment metrics, e.g., PSNR and SSIM, to the omnidirectional domain, e.g., [95], [96]. These works introduce special geometric structures of the ODI and its projection representations to traditional quality assessment metrics and measure the objective quality more accurately. In addition, there are a few DL-based approaches for FR ODI-QA. As the representative work shown in Fig. 6(a), Lim et al. [93, 97] proposed a novel adversarial learning framework, consisting of a quality score predictor and a human perception guider, to automatically assess the image quality following the human perception. NR ODI-QA, also called blind ODI-QA, predicts the ODI quality without expensive reference ODIs. Considering multi-viewport images in the ERP format, Xu et al. [98] applied a novel viewport-oriented GCN to process the distortion-less viewports in ERP images and aggregated these features to estimate the quality score via an image quality regressor. A similar strategy is applied in [99, 100]. By contrast, [2] extracted the features from CP images and their corresponding eye movement (EM) and head movement (HM) hotspot maps and provided a good projection-based potential, that is extracting the features from the multiple projection formats and fusing the features to improve the performance on blind ODI-QA, as shown in Fig. 6(b).
For the ODV-QA, Li et al. [94] proposed a representative viewport-based CNN approach, including a viewport proposal network and a viewport quality network, as shown in Fig. 6(c). The viewport proposal network generates several potential viewports and their error maps, and viewport quality network rates the V-QA score for each proposed viewport. The final V-QA score is calculated by the weighted average of all viewport V-QA scores. [101] is another representative that considers the temporal changes of spatial distortions in ODVs and fuses a set of spatio-temporal objective quality metrics from multiple viewports to learn a subjective quality score. Similarly, Gao et al. [102] modeled the spatial-temporal distortions of ODVs and proposed a novel FR objective metric by integrating three existing ODI-QA objective metrics.
3.2 Scene Understanding
3.2.1 Object Detection
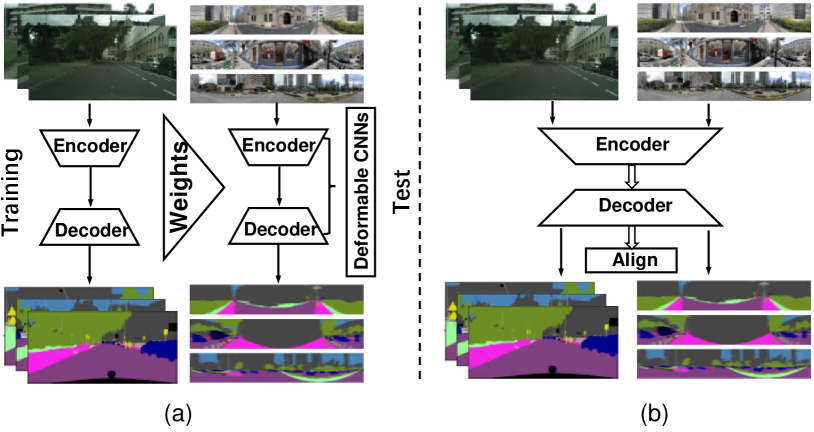
Compared with the perspective images, DL-based object detection on ODIs remains two main difficulties: (i) traditional convolutional kernels are weak to process the irregular planar grid structures in the ODI projections; (ii) the criterias adopted in conventional 2D object detection do not fit well to the spherical images. To address the first difficulty, distortion-aware structures are proposed, e.g., multi-scale feature pyramid network in [105], multi-kernel layers in [106]. However, the detection flows of these two methods are similar to the methods for 2D domain, which take the whole ERP image as input and predict the regions of interest (ROIs) to obtain the final bounding boxes. Considering the wide FoV of ERP, Yang et al. [107] proposed a representative framework, which can leverage the conventional 2D images to train a panoramic detector. The detecting progress consists of three sub-steps: stereo-projection, YOLO detectors, and bounding box post processing. Especially, they generated four stereographic projections with a FoV from an ERP and the four result maps predicted by the YOLO detectors. Finally, the sub-window detected bounding boxes are re-projected to the ERP and re-aligned into the final distortion-less bounding boxes.
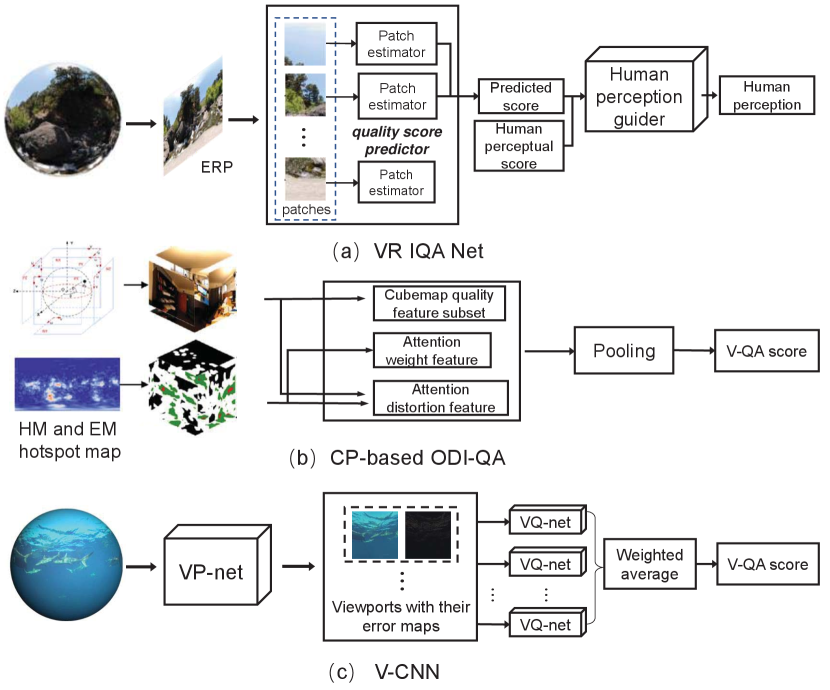
To tackle the second difficulty, a novel kind of spherical bounding boxe (SphBB) and spherical Intersection over Union (SphIoU) for ODI object detection are introduced in [103], as shown in the first row of Fig. 7. SphBB is represented by the coordinates , of the object centers and the unbiased FoVs , of the objective occupation. SphIoU is similar to planar IoU and calculated by the IoU between two SphBBs. Concretely, FoVBBs are moved to the equator that is undistorted. Similarly, Cao et al. [104] proposed a novel IoU calculation method without any extra movement, called FoV-IoU. As shown in the second row of Fig. 7, FoV-IoU better approximates the exact computation of IoU between two FoV-BBs compared with the SphIoU.
3.2.2 Semantic Segmentation
| Method | Publication | Input | Dataset | Deformable | Supervision | Highlight |
| Tateno [108] | ECCV’2018 | ERP | Stanford2d3d | U | Distortion-aware convolution | |
| Zhang [45] | ICCV’2019 | Tangent | Stanford2D3D/Omni-SYNTHIA | S | Orientation-aware convolutions | |
| Lee [27] | CVPR’2019 | Tangent | SYNTHIA/Stanford2D3D | S | Icosahedral geodesic polyhedron | |
| Viu [110] | ICRA’2020 | ERP | SUN360 | S | Equirectangular convolutions | |
| Yang [111] | CVPR’2021 | ERP | PASS/WildPASS | ✗ | U | Concurrent attention networks |
| Zhang [112] | CVPR’2022 | ERP | Stanford2D3D/DensePASS | U | Deformable MLP | |
| Zhang [113] | T-ITS’2022 | ERP | DensePASS/VISTAS | ✗ | D | Uncertainty-aware adaptation |
DL-based omnidirectional semantic segmentation has been widely studied because ODI can encompass exhaustive information about the surrounding space. There are many practically remaining challenges, e.g., distortions in the planar projections, object deformations, computed complexity, and scarce labeled data. We next introduce some representative methods for ODI semantic segmentation via supervised learning and unsupervised learning.
Due to the lack of real-world datasets, Deng et al. [114] firstly generated ODIs from an existing dataset of urban traffic scenes and then designed an approach, called zoom augmentation, to transform the conventional images into fisheye images. Meanwhile, they proposed a CNN-based framework with a special pooling module to integrate the local and global context information and handle complex scenes in the ODIs. Considering that CNNs have inherently limited ability to handle the distortions in ODIs, Deng et al. [115] proposed a method, called Restricted Deformable Convolution, to model geometric transformations and learn a convolutional filter size from the input feature map. Zoom augmentation was also applied to [115] for enriching the train data. As the first framework to conduct semantic segmentation on the real-world outdoor ODIs, SemanticSO [116] builds a distortion-aware CNN model using the equirectangular convolutions [117].
Due to the time-consuming and expensive cost of ground truth annotations for ODIs, endeavours have been made to synthesize ODI datasets from the conventional images and utilize knowledge transfer to adopt models directly trained with the perspective images. PASS [118] is the first work to bypass fully dense panoramic annotations and aggregate features represented by conventional perspective images to fulfill the pixel-wise segmentation in panoramic imagery. Based on the PASS, DS-PASS [119] further re-uses the knowledge learned from perspective images and adapts the model learned from the 2D domain to panoramic domain. Meanwhile, in DS-PASS, the sensitivity to spatial details is enhanced by implementing attention-based lateral connections to perform segmentation accurately. To reduce the domain gap between the ODI and perspective image, Yang et al. [111] proposed a representative cross-domain transfer framework that designs an efficient concurrent attention network to capture the long-range dependencies in ODI imagery and integrates the unlabeled ODIs and labeled perspective images into training. A similar strategy was applied in [120], [121] and [109]. Particularly, in [109], a shared attention module is used to extract features from the 2D domain and panoramic domain, and two domain adaption modules are used to ”teach” the panoramic branch by the perspective branch. For unsupervised semantic segmentation, there also exist some works considering the geometric structure of ODI [108]. For instance, Zhang et al. [45] proposed an orientation-aware CNN framework based on the icosahedron mesh representation of ODI and introduced an efficient interpolation approach of the north-aligned kernel convolutions for features on the sphere.
3.2.3 Monocular Depth Estimation
| Method | Publication | Supervision | Input types | Architecture | Loss functions |
| Zioulis [122] | ECCV’18 | S | ERP | Rectangular filters | l2 loss+smooth loss |
| Pintore [123] | CVPR’21 | S | ERP | Slice-based representation and LSTM | BerHu loss [124] |
| Zhuang [125] | AAAI’22 | S | ERP | Dilated filters | BerHu loss |
| Wang [19] | CVPR’20 | S | ERP+CP | Two-branch network and bi-projection fusion | BerHu loss |
| Rey-Area [34] | CVPR’22 | S | Tangent | Perspective network+Alignment+Blending | Energy function |
| Li [25] | CVPR’22 | S | Tangent | Geometric embedding+Transformer | BerHu loss |
| Jin [126] | CVPR’20 | S | ERP | Structure information as prior and regularizer | l1 loss+cross entropy loss |
| Wang [127] | ACCV’18 | Self-S | CP | Depth estimation+camera motion estimation | photometric + pose loss |
| Zioulis [18] | 3DV’19 | Self-S | ERP | View synthesis in horizontal, vertical and trinocular ones | photometric +smooth loss |
| Yun [128] | AAAI’22 | S+Self-S | ERP | ViT+pose estimation | SSIM [129]+gradient +L1+photometric loss |
| Tateno [108] | ECCV’18 | D | ERP | Distortion-aware filters | BerHu loss |
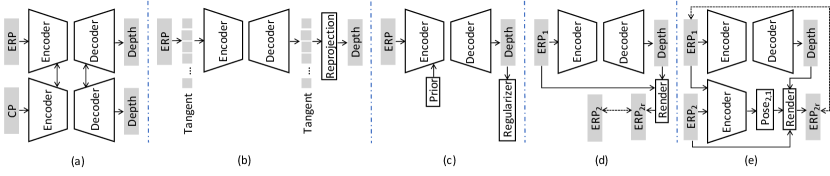
Thanks to the emergence of large-scale panoramic depth datasets, monocular depth estimation has evolved rapidly. As shown in Fig. 9, there are several trends: (i) Tailored networks, e.g., distortion-aware convolution filters [108] and robust representations [123]; (ii) Different projection types of ODIs [19], [130], [25], as depicted in Fig. 9(a), (b); (iii) Inherent geometric priors [131], [126], as shown in Fig. 9(c); (iv) Multiple views [18] or pose estimation [128], as shown in Fig. 9 (d), (e), respectively.
Tailored networks: To reduce the influence of the stretch distortion, Zioulis et al. [122] proposed the first work by directly using the ODIs. It follows [20] to transfer regular square convolution filters into row-wise rectangles and vary filter sizes to address the distortions at the poles. Tateno et al. [108] proposed a deformable convolution filter that samples the pixel grids on the tangent planes according to unit sphere coordinates. Recently, Zhuang et al. [125] proposed a novel framework to combine different dilated convolutions and extend the receptive field in the ERP images. In comparison, Pintore et al. [123] proposed a framework, named SliceNet, with regular convolution filters to work on the ERP directly. SliceNet reduces the input tensor only along the vertical direction to collect a sequence of vertical slices and adopts an LSTM [132] network to recover the long- and short-term spatial relationships among slices.
Different projection formats: There are some attempts to address the distortion in the ERP via other distortion-less projection formats, e.g., CP, tangent projection. As a representative work, BiFuse [19] introduces a two-branch pipeline, where one branch processes the ERP input and another branch extracts the features from CP, to simulate the peripheral and foveal vision of human, as shown in Fig. 9 (a). Then, a fusion model is proposed to combine the semantic and geometric information of the two branches. Inspired by BiFuse, UniFuse [133] designs a more effective fusion module to combine the two kinds of features and unidirectionally feeds the CP features to the ERP features only at the decoding stage. To better extract the global context information, GLPanoDepth [134] converts ERP input into a set of CP images and then exploits a ViT model to learn the long-range dependencies. As the tangent projection produces less distortion than CP, 360MonoDepth [34] trains the SoTA depth estimation models in 2D domain [135] with tangent images and re-projects predicted tangent depth maps into the ERP with alignment and blending, as shown in Fig. 9(b). However, directly re-projecting the tangent images back to the ERP format will cause overlapping and discontinuity. Therefore, OmniFusion [25] (the SoTA method by far) introduces additional 3D geometric embeddings to mitigate the discrepancy in patch-wise features and aggregates patch-wise information with an attention-based transformer.
Geometric Information Prior: Some methods add extra geometric information priors to improve the performance, e.g., edge-plane information, surface normal, boundaries, as shown in Fig. 9(c). Eder et al. [131] assumed that each scene is piecewise planar and the principal curvature of each planar region, which is the second derivative of depth, should be zero. Consequently, they proposed a plane-aware learning scheme that jointly predicts depth, surface normal, and boundaries. Similar to [131], Feng et al. [136] proposed a framework to refine depth estimation using the surface normal and uncertainty scores. For a pixel with higher uncertainty, its prediction is mainly aggregated from the neighboring pixels. Particularly, Jin et al. [126] demonstrated that the representations of geometric structure, e.g., corners, boundaries, and planes, can provide the regularization for depth estimation and benefit it as the prior information well.
Multiple Views: As ODI depth annotations are expensive, some works leverage the multiple viewpoints to synthesize data and obtain competitive results. Zioulis et al. [18] explored the spherical view synthesis for self-supervised monocular depth estimation. As shown in Fig. 9(d), in [18], after predicting the ERP format depth map, stereo viewpoints in vertical and horizontal baselines are synthesized by the depth-image-based rendering. Synthesized images are supervised by real images with the same viewpoints via photometric image reconstruction loss. To improve accuracy and stability simultaneously, Yun et al. [128] proposed a joint learning framework to estimate monocular depth via supervised learning and estimate poses via self-supervised learning from the adjacent frames of ODV, as shown in Fig. 9(e).
Discussion: Based on the aforementioned analysis, most methods only consider indoor scenes due to two main reasons: (i) Some geometric priors are ineffective in the wild, e.g., the plane assumption; (ii) Outdoor scenes are more challenging due to the scale ambiguity in approximately infinite regions (e.g., sky), and objects in various shapes and sizes [130].
It has been demonstrated that directly applying the DL-based methods for 2D optical flow estimation on ODI will obtain the unsatisfactory results [137]. To this end, Xie et al. [138] introduced a small diagnostic dataset FlowCLEVR and evaluated the performance of three kinds of tailored convolution filters, namely the correlation, coordinate and deformable convolutions, for estimating the omnidirectional optical flow. The domain adaptation frameworks [139, 140] benefit from the development of optical flow estimation in the perspective domain. Similar to [137], OmniFlowNet [139] is built on FlowNet2 and the convolution operation is inspired by [117]. Especially, as the extension of [141], LiteFlowNet360 [140] uses kernel transformation techniques to solve the inherent distortion problem caused by the sphere-to-plane projection. A representative pipeline is proposed by [142], consisting of a data augmentation method and a flow estimation module. The data augmentation method overcomes the distortions introduced by ERP, and the flow estimation module exploits the cyclicity of spherical boundaries to convert long-distance estimation into a relatively short-distance estimation.
3.2.4 Video Summarization
Insight: Video summarization aims to generate representative and complete synopsis by selecting the parts containing the most critical information of the ODV.
Compared with the methods for 2D video summarization, only a few works have been proposed for ODV summarization. Pano2Vid [143] is the representative framework that contains two sub-steps: detecting candidate events of interest in the entire ODV frames and applying dynamic programming to link detected events. However, Pano2Vid requires observing the whole video and is less capable for video streaming applications. Deep360Pilot [42] is the first framework to design a human-like online agent for automatic ODV navigation of viewers. Deep360pilot consists of three steps: object detection to obtain the candidate objects of interest, training RNN to choose the important object, and capturing exciting moments in ODV. AutoCam [144] generates the normal NFoV videos from the ODVs following human behavior understanding. An similar strategy was applied by Yu et al. [145]. They built a deep ranking model for spatial summarization to select NFOV shots from each frame in the ODV and generated a spatio-temporal highlight video by extending the same model to the temporal domain. Moreover, Lee [146] proposed a novel deep ranking neural network model for summarizing ODV both spatially and temporally.
Discussion: Based on the above analysis, only a few methods exist in this research domain. As a temporal-related task, applying the transformer mechanism to ODV summarization could be beneficial. In addition, previous works only considered the ERP format, which suffer from the most severe distortion problems. Therefore, it is better to consider the CP, tangent projection or sphere format as the input for ODV summarization.
3.3 3D Vision
| Method | Publication | Architecture | Highlight | Projection | Task |
| Zhang [147] | ICCV’21 | Mask RCNN+ODN +LIEN+HorizonNet | Context relation modeling | ERP | Layout+ object +semantic labels |
| Yang [148] | CVPR’19 | Two ResNet on ceiling and floor | Projection feature fusion | ERP, ceiling | Layout |
| Zou [149] | CVPR’18 | CNN+3D layout regressor | Boundary+Corner map prediction | ERP | Layout |
| Tran [150] | CVPR’21 | HorizonNet+EMA | Semi-supervised learning | ERP | Layout |
| Pintore [151] | ECCV’20 | ResNet+RNN | Atlanta World indoor Model | ERP, ceiling | Layout |
| Sun [152] | CVPR’19 | ResNet+RNN | 1D representation of layout | ERP | Layout |
| Sun [153] | CVPR’21 | ResNet+ efficient height compression | Latent horizontal feature | ERP | Layout, depth +semantic labels |
| Wang [154] | CVPR’21 | HorizonNetL2D transformation | Differentiable depth rendering | ERP | Layout |
3.3.1 Room Layout estimation and Reconstruction
Insight: Room Layout estimation and reconstruction consists of multiple sub-tasks such as layout estimation, 3D object detection and 3D object reconstruction. This comprehensive task aims to facilitate holistic scene understanding based on a single ODI.
As the indoor panoramas can cover wider surrounding environment and capture more context cues than conventional perspective images, they are beneficial to scene understanding and widely applied into room layout estimation and reconstruction. Zou et al. [13] summarized that the general procedure of layout estimation and reconstruction contains three sub-steps: edge-based alignment, layout elements prediction, and 3D layout elements recovery, as shown in Fig. 10. The representative work, proposed by Zhang et al. [147], conducts the first DL-based pipeline for holistic 3D scene understanding that recovers 3D room layout and detailed information, e.g., shape, pose, and location of objects from a single ODI. In [147], a context-based GNN is designed to predict the relationships across the objects and room layout and achieves the SoTA performance on both geometry accuracy of room layout and 3D object arrangement.
For the alignment, this pre-possessing step provides indoor geometric information as the prior knowledge to ease the network training. Several SoTA approaches [148, 149, 150] follow the ”Manhattan world” assumption, in which all walls are aligned with a canonical coordinate system, and the floor plane direction is estimated by selecting long line segments and voting for the three mutually orthogonal vanishing directions. In contrast, AtlantaNet [151] predicts the 3D layout from less restrictive scenes that are not limited to ”Manhattan World” assumption. AtlantaNet follows ”Atlanta World” assumption and projects an gravity-aligned ODI into two horizontal planes to predict a 2D room footprint on the floor plan and a room height to recover the 3D layout.
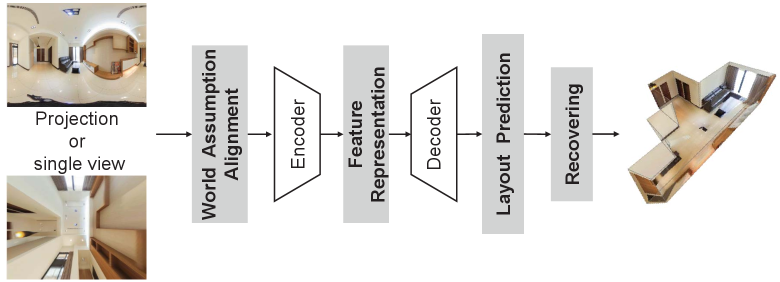
For the layout element prediction, the primary task is to estimate layout boundaries and corner positions. On the one hand, the related methods usually choose different projections of ODIs as the input. For instance, some methods [149, 152, 153] predict the layout only from ERP images. Besides the ERP, Yang et al. [148] added a perspective ceiling-view image, which is obtained from the ERP through an equirectangular-to-perspective (E2P) conversion, as an extra input. They then extracted the features from the two formats by a two-branch network and fused the two-modal features to predict the layout elements. The advantage of [148] is that it directly uses the multi-projection model to jointly predict a Manhattan-world floor plan instead of estimating the number of corners. On the other hand, recent methods varied in their ways of feature representation. For instance, HorizonNet [152] represents the room layout of the ODI as three 1D embedding vectors and recovers 3D room layouts from 1D predictions with low computation cost. Differently, Wang et al. [154] converted the layout into ’horizon-depth’ through ray casting of a few points. This transformation maintains the simplicity of layout estimation and improves the generalization capacity to unseen room layouts.
For final recovery, the general strategy [149, 148, 152] is to reconstruct the layout by the optimization of mapping each pixel between walls and corners. In particular, it defines the weighted loss of probability maps of floors, ceilings, and corners. The major difficulty is the layout boundary occlusions when the camera position is not ideal for the entire display. To address this problem, HorizonNet [152] observes the occlusions by examining the orientation of the first Principal Component Analysis (PCA) component of adjacent walls and recovers occluded parts according to the long-term dependencies of global geometry.
3.3.2 Stereo Matching
Human binocular disparity depends on the difference between the projections on the retina, that is, a sphere projection rather than a planar projection. Therefore, stereo matching on the ODIs is more similar to the human vision system. In [155], they discussed the influence of omnidirectional distortion on the CNN-based methods and compared the quality of disparity maps predicted from the perspective and omnidirectional stereo images. The experimental results show that stereo matching based on the ODIs is more advantageous for numerous applications, e.g., robotics, AR/VR, and several other applications. General stereo matching algorithms follow four steps: (i) matching cost computation, (ii) cost aggregation, (iii) disparity computation with optimization, and (iv) disparity refinement. As the first DNN-based omnidirectional stereo framework, SweepNet [156] proposes a wide-baseline stereo system to compute the matching cost map from a pair of images captured by cameras with ultra-wide FoV lenses and uses a global sphere sweep at the rig coordinate system to generate an omnidirectional depth map directly. By contrast, OmniMVS [157] takes four 220∘ FoV fisheye views as the input to train an end-to-end DNN model and uses a 3D encoder-decoder block to regularize the cost volume. The method proposed in [158], as the extension of OmniMVS, provides a novel regularization of cost volume based on the uncertainty of prior guidance. Another representative work, 360SD-Net [159], is the first end-to-end trainable network for omnidirectional stereo depth estimation with the top-bottom ODI pairs as the input. It mitigates the distortion in the ERP images through an additional polar angle coordinate input and a learnable cost volume.
3.3.3 SLAM
SLAM is an intricate system that adopts multiple cameras, e.g., monocular, stereo, or RGB-D, combined with sensors onboard a mobile agent to reconstruct the environment and estimate the agent pose in real-time. SLAM is often used in real-time navigation and reality augmentation, e.g., Google Earth. The stereo information, such as key points [160] and dense or semi-dense depth maps[161], is indispensable to build an accurate modern SLAM system. Specifically, compared with traditional monocular SLAM [162] or multi-view SLAM [163], the omnidirectional data can provide the richer texture and structure information due to a large FoV, and the omnidirectional SLAM avoids the influence of discontinued frames in the surrounding environment and enjoys the technical advantage of complete positioning and mapping. Caruso et al. [164] proposed a representative monocular SLAM method for omnidirectional cameras in which the direct image alignment and pixel-wise distance filtering are directly formulated. Zachary et al. [165] proposed a general framework that accepts multiple types of sensor data and is capable of iterative updates of camera pose and pixel-wise depth. DeepFactors [166] performs joint optimization of the pose and depth variables to detect the loop closure. As the omnidirectional data has rich geometry and texture information, further works may consider how to cultivate the full potential of DL and utilize these imaging advantages to construct a fast and accurate SLAM system.
3.4 Human Behavior Understanding
3.4.1 Saliency Prediction
| Method | Input | Publication | EM | HM | Highlight | Contribution |
| Dai [167] | IMG | ICASSP’20 | CP 2D CNN | Dilated convolution | ||
| Lv [168] | IMG | ACM MM’20 | Spherical images GCN | GCN with spherical interpolation | ||
| Chao [169] | IMG | TMM’21 | Multi-viewports 2D CNN | Different FoV viewports | ||
| Abdelaziz [170] | IMG | ICCV’21 | ERP 2D CNN self-attention mechanism | Contrastive learning to maximize the mutual information | ||
| Xu [171] | IMG | TIP’21 | ✗ | ERP deep reinforcement learning | Generative adversarial imitation learning | |
| Nguyen [172] | VID | ACM MM’18 | ✗ | ERP 2D CNN LSTM | Transfer learning | |
| Chen [43] | VID | CVPR’18 | ✗ | CP 2D CNN convLSTM | Spatial-temporal network Cube Padding | |
| Zhang [173] | VID | ECCV’18 | ERP spherical CNN | Spherical crown convolution kernel | ||
| Xu [174] | VID | TPAMI’19 | ✗ | ERP deep reinforcement learning | Deep reinforcement learning | |
| Zhu [175] | VID | TCSVT’21 | ✗ | Image patches GCN | Graph convolution and feature alignment | |
| Qiao [176] | VID | TMM’21 | ✗ | Multi-viewports 2D CNN convLSTM | Multi-Task Deep Neural Network |
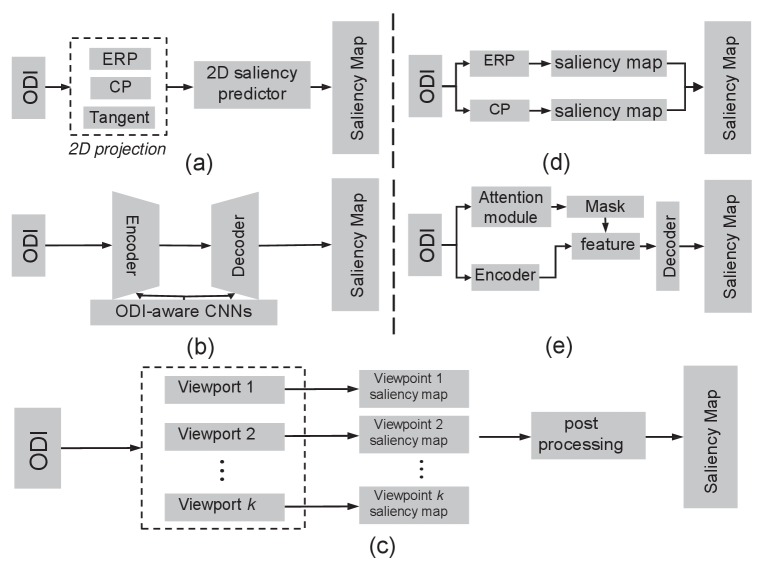
Recently, there have been several research trends in ODI saliency prediction, building on DL progress: (i) From 2D traditional convolutions to 3D specific convolutions; (ii) From single feature to multiple features; (iii) From single ERP input to multi-type inputs; (iv) From normal CNN-based learning to novel learning strategies. In Table. VI, numerous DL-based methods have been proposed for ODI saliency prediction. In the following, we introduce and analyze some representative networks, as shown in Fig. 11.
(i) To directly apply 2D deep saliency predictors on ODIs and reduce the unsatisfactory distortion in ODIs, many works [177, 167] convert ODIs into 2D projection format. As the first attempt of DNNs on ODI saliency prediction, SalNet360 [177] subdivides an ERP into a set of six CP patches as the input because CP avoids the heavy distortions near the poles like ERP. Then SalNet360 combines predicted saliency maps and per-pixel spherical coordinates of these patches to output a resulting saliency map in ERP format. Differently, a few works [178, 168] propose the ODI-aware convolution filters for saliency prediction, and learn the relationships between the features from a non-distorted space. The representative work, SalGCN [168], transfers the ERP image to a spherical graph signal representation, generates the spherical graph signal representation of the saliency map and finally reconstructs the ERP format saliency map through the spherical crown-based interpolation. SalGFCN [179] proposes a SoTA method that is composed of a residual U-Net architecture based on the dilated graph convolutions and attention mechanism in the bottleneck. (ii) The viewports are the rectangular windows on ERP with different narrow FoVs caused by observers’ head movement. Due to less distortions in viewports, some works [180, 181] choose a set of viewports on ERP as the input and extract the multiple independent features from these viewports. The final omnidirectional saliency map is generated by a set of viewport saliency maps and refined via an equator biased post-processing. Different from most prior multi-feature works extracting the low-level geometric features, Mazumdar et al. [180] introduced a 2D detector to find important objects first, and this kind of local information can improve the performance of the overall saliency map. Recently, Chao et al. [169] utilized three different FoVs in each viewport to extract rich salient features and better combined the local and global information. Furthermore, stretch weighted maps are applied in the loss function to avoid the disproportionate impact of stretching in the north and south poles of the ERP image.
(iii) ODI saliency prediction methods with multi-type inputs focus on the projection transformations of the ODIs, which has been mentioned in the Sec 2.1. These methods aim to utilize the properties of different projection formats to achieve the better performance than the single ERP input [177, 182, 183]. Due to the geometric distortions in the poles of ERP format, Djemai et al. [182] introduced a set of CP images, which are projected by five different rotational ERP images into the CNN-based approach. However, boundary-distortion and discontinuity in CP images cause the lack of global information in the extracted features. To address the problem, SalBiNet360 [183] simultaneously takes ERP and CP images as the input. It constructs a bifurcated network to predict global and local saliency maps, respectively. The final saliency output is the fusion of the global and local saliency maps. Furthermore, Zhu [184] provided a groundbreaking multi-domain model, which decomposes the ERP image using spherical harmonics in the frequency domain and combines frequency components with multiple viewports of the ERP images in the spatial domain to extract features.
(iv) As the first to use GAN to predict the saliency maps for ODIs, SalGAN360 [185] provides a new generator loss, which is designed according to three evaluation metrics to fine-tune the SalGAN [186]. SalGAN360 constructs a different branch with the Multiple Cubic Projection (MCP) as input to simulate undistorted contents. For the attention-based learning on ODI saliency prediction, Zhu et al. proposed RANSP [187] and AAFFN [188]. Both methods contain the part-guided attention (PA) module, which is a normalized part confidence map that can highlight specific regions in the image. Moreover, an attention-aware module is introduced to refine the final saliency map. Especially, RANSP predicts the head fixations while AAFFN predicts the eye fixations.
ODV Saliency Prediction For the saliency prediction in ODVs, the key points are accurate saliency prediction for each frame and the temporal coherence of the viewing process. As videos with dynamic contents are widely used in real applications, deep ODV saliency prediction has received more attention in the community. Nguyen et al. [172] proposed a representative transfer learning framework that shifted a traditional saliency model to a novel saliency model, PanoSalNet, which is similar to [189] and [177]. By contrast, Cheng et al. [43] proposed a spatial-temporal network consisting of a static model and a ConvLSTM module. The static model is inspired by [190] and ConvLSTM [132] is used to aggregate temporal information. They also implemented the Cube Padding technique to connect the cube faces by propagating the shared information across the views. Similar to [180], a viewport saliency prediction model is proposed in [176] which first studies human attention to detect the desired viewports of the ODV and then predict the fixations based on the viewport content. Especially, the proposed Multi-Task Deep Neural Network (MT-DNN) model takes both the viewport content and location of the viewport as the input and its structure follows [43] which employs a CNN and a ConvLSTM to explore both spatial and temporal features. One more representative is proposed by [173], in which the convolution kernel is defined on a spherical crown and the convolution operation corresponds to the rotation of kernel on the sphere. Considering the common planar ERP format, Zhang et al. [173] re-sampled the kernel based on the position of the sampled patches on ERP. There also exist some works based on novel learning strategies. Xu et al. [174] developed the saliency prediction network of head movement (HM) based on deep reinforcement learning (DRL). The proposed DRL-based head movement prediction approach owns offline and online versions. In offline version, multiple DRL workflows determines potential HM positions at each panoramic frame and generate a heat map of the potential HM positions. In online version, the DRL model will estimate the next HM position of one subject according to the currently observed HM position. Zhu et al. [175] proposed a graph-based CNN model to estimate the fraction of the visual saliency via Markov Chains. The edge weights of the chains represent the characteristics of viewing behaviors, and the nodes are feature vectors from the spatial-temporal units.
3.4.2 Gaze Behavior
Gaze following, also called gaze estimation, is related to detecting what people in the scene look at and are absorbed in. As normal perspective images are NFoV captured, gaze targets are always out of the scene. ODI gaze following is proposed to solve this problem because ODIs have a great ability to capture the entire viewing surroundings. Previous 3D gaze following methods can directly detect the gaze target of a human subject in the sphere space but ignore scene information of ODIs, which performs gaze following not well. Gaze360 [191] collects a large-scale gaze dataset using fish-eye lens rectification to pre-process the images. However, due to the distortion caused by the sphere-to-plane projection, the gaze target maybe not be in the 2D sightline of the human subject in long-distance gaze, which is no longer the same in 2D images. Li et al. [192] proposed the first framework for ODI gaze following and also collected the first ODI gaze following dataset, called GazeFollow360. They detected the gaze target within a local region and a distant region. For ODI gaze prediction, Xu et al. [193] built a large-scale eye-tracking dataset for dynamic 360∘ immersive videos and gave a detailed analysis of gaze prediction. They utilized the temporal saliency, spatial saliency and history gaze path for gaze prediction with a combination of CNN and LSTM, which is similar to the architecture proposed by [194].
Challenges and potential: ODI contains richer context information that can boost gaze behaviour understanding. However, some challenges remain. First, there are few specific gaze following and gaze prediction datasets specific for ODI. Data is the ”engine” of DL-based methods, so collecting the quantitative and qualitative datasets is necessary. Second, due to the distortion problem in sphere-to-plane projection types, future research should consider how to correct this distortion via geometric transformation. Finally, both gaze following and gaze prediction in ODI need to understand wider scene information compared with normal 2D images. The spatial context relation should be further explored.
3.4.3 Audio-Visual Scene Understanding
Because ODVs can provide the observers with an immersive understanding of the entire surrounding environments, recent research focuses on audio-visual scene understanding on ODVs. Due to its enabling viewers to experience sound in all directions, the spatial radio of ODV is an essential cue for full scene awareness. As the first work on the omnidirectional spatialization problem, Morgado et al. [195] designed a four-block architecture applying self-supervised learning to generate the spatial radio, given the mono audio and ODV as the joint inputs. They also proposed a representative self-supervised framework [196] for learning representations from the audio-visual spatial content of ODVs. In [197], ODIs combined with the multichannel audio signals are applied to localize sound source object within the visual observation. The self-supervised training method includes two DNN models: one for visual object detection and another for sound source estimation. Both DNN models are trained based on variational inference. Vasudevan et al. [198] simultaneously achieved an audio task, spatial sound super-resolution, and two visual tasks, dense depth prediction, and semantic labeling of the scene. They proposed a cross-modal distillation framework, including a shared encoder and three task-specific decoders, to transfer knowledge from vision to audio. For the audio-visual saliency prediction on ODVs, AVS360 [199] is the first end-to-end framework with two branches to understand audio and visual cues. Especially, AVS360 considers geometric distortion in ODV and extracts the spherical representation from the cube map images. Furthermore, as the first user behavior analysis for audio-visual content in ODV, Chao et al. [200] designed the comparative studies using ODVs with three different audio modalities and demonstrated that audio cues can improve the audio-visual attention in ODV.
Discussion: Based on the above analysis, most works in this research domain process ERP images as normal 2D images and ignore the inherent distortions. Future research may explore how better combine spherical imaging characteristics and geometrical information of ODI with the spatial audio cues to provide a more realistic audio-visual experience.
3.4.4 Visual Question Answering
Visual question answering (VQA) is a comprehensive and interesting task that combines computer vision (CV), natural language processing (NLP), and knowledge representation reasoning (KR). Wider FoV ODIs and ODVs are more valuable and challenging for the VQA research because they can provide stereoscopic spatial information similar to the human visual system. VQA 360∘, proposed in [201], is the first VQA framework on ODI. It introduces a CP-based model with multi-level fusion and attention diffusion to reduce spatial distortion. Meanwhile, the collected VQA 360∘ dataset provides a benchmark for future developments. Furthermore, Yun et al. [6] proposed the first ODV-based VQA work, Pano-AVQA, which combines information from three modalities: language, audio, and ODV frames. The fused multi-modal representations extracted by a transformer network provide a holistic semantic understanding of omnidirectional surroundings. They also provided the first spatial and audio-VQA dataset on ODVs.
Discussion and Challenges: Based on the above analysis, there exist few works for the ODIODV-based VQA. Compared with the methods in 2D domain, the most considerable difficulty is how to leverage the spherical projection types, e.g., icosahedron and tangent images. As more than two dozen datasets and numerous effective networks [202] in the 2D domain have been published, future research may consider how to effectively transfer knowledge to learn more robust DNN models for omnidirectional vision.
4 Novel Learning Strategies
Unsupervised/Semi-supervised Learning. ODI data scarcity problem occurs due to the insufficient yet costly panorama annotations. This problem is commonly addressed by semi-supervised learning or unsupervised learning that can take advantage of abundant unlabeled data to enhance the generalization capacity. For semi-supervised learning, Tran et al.[150] exploited the ‘Mean-Teacher’ model [203] for 3D room layout reconstruction by learning from the labeled and unlabeled data in the same scenario. For unsupervised learning, Djilali et al. [170] proposed the first framework for ODI saliency prediction. It calculates the mutual information between different views from multiple scenes and combines contrastive learning with unsupervised learning to learn latent representations. Furthermore, unsupervised learning can be combined with supervised learning to enhance the generalization capacity. Yun et al. [128] proposed to combine self-supervised learning with supervised learning for depth estimation, alleviating data scarcity and enhancing stability.
GAN. To decrease the domain divergence between perspective images and ODIs, P2PDA [113] and DENSEPASS [109] exploit the GAN frameworks and design an adversarial loss to facilitate semantic segmentation. In image generation, BIPS [47] proposes a GAN framework to synthesize RGB-D indoor panoramas based on the arbitrary configurations of cameras and depth sensors.
Attention Mechanism. For cross-view geo-localization, in [60], ViT [12] is utilized to remove uninformative image patches and enhance the informative image patches to higher resolution. This attention-guided non-uniform cropping strategy can save the computational cost, which is reallocated to informative patches to improve the performance. The similar strategy is adopted in the unsupervised saliency prediction [170]. In [170], a self-attention model is employed to build spatial relationship between the two input and select the sufficiently invariant features.
Transfer Learning. There exist a lot of works to transfer the knowledge learned from the source 2D domain to facilitate learning in the ODI domain for numerous vision tasks, e.g., semantic segmentation [115] and depth estimation [108]. Designing the deformable CNN or MLP on the pre-trained models from perspective images can enhance the model capability for ODIs in numerous tasks, e.g., semantic segmentation [115, 108, 45, 27, 110, 112], video super-resolution [86], depth estimation [108], and optical flow estimation [138]. However, these methods heavily rely on the handcrafted modules, which lack the generalization capability for different scenarios. Unsupervised domain adaptation aims to transfer knowledge from the perspective domain to ODI domain by decreasing the domain gaps between the perspective images and ODIs. P2PDA [113] and BendingRD [112] decrease domain gaps between perspective images and ODIs to effectively obtain pseudo dense labels for the ODIs. Knowledge distillation (KD) is another effective technique that transfers knowledge from a cumbersome teacher model to learn a compact student model, while maintaining the student’s performance. However, we find that few works have applied KD for omnidirectional vision tasks. In semantic segmentation, ECANets [111] performs data distillation via diverse panoramas from all around the globe.
Deep Reinforcement Learning (DRL). In saliency prediction, [171] predicted the head fixation through DRL by interpreting the trajectories of head movements as discrete actions, which are rewarded by correct policies. Besides, in object detection, Pais et al. [204] provided the pedestrians’ positions in the real world by considering the 3D bounding boxes and their corresponding distortion projections into the image. Another application for DRL is to select up-scaling factors adaptively based on the pixel density [85], which addresses the unevenly distributed pixel density in the ERP.
Multi-task Learning. Sharing representations between the related tasks can increase the generalization capacity of the models and improve the performance on all involved tasks. MT-DNN [176] combines the saliency detection task with the viewport detection task to predict the viewport saliency map of each frame and improves the saliency prediction performance in the ODVs. DeepPanoContext [147] empowers panoramic scene understanding by jointly predicting object shapes, 3D poses, semantic categories, and room layout. Similarly, HoHoNet [153] proposes a Latent Horizontal Feature (LHFeat) and a novel horizon-to-dense module to accomplish various tasks, including room layout reconstruction and per-pixel dense prediction tasks, e.g., depth estimation, semantic segmentation.
5 Applications
AR and VR. With the advancement of techniques and the growing demand of interactive scenarios, AR and VR have seen rapid development in recent years. VR aims to simulate real or imaginary environments, where a participant can obtain immersive experiences and personalized content by perceiving and interacting with the environment. With the advantage of capturing the entire surrounding environment with FoV in ODIs, 360 VR/AR facilitates the development of immersive experiences.
[205] gives a detailed SWOT (namely strengths, weaknesses, opportunities, and threats) analysis of 360 VR to make sure that it is suitable to leverage the 360 VR to develop athletes’ decision-making skills. Understanding human behaviors is crucial for the application of 360 VR. [194] proposed a preference-aware framework for viewport prediction, and [193] combined the history scan path with image contents for gaze prediction. In addition, to enhance the immersive experience, Kim et al. [206] proposed a novel pipeline to estimate room acoustic for plausible reproduction of spatial audio with cameras. Importantly, acquiring 3D data is strongly desired in VR/AR to provide the sense of 3D. However, consumer-level depth sensors can only capture perspective depth maps, and panoramic depths need time-consuming stitching technologies. Therefore, monocular depth estimation techniques, e.g., OmniDepth [122] and UniFuse [133], are promising for VR/AR.
Robot Navigation. In addition to SLAM mentioned in Sec. 3.3.3, we further discuss the related applications of ODI/ODV in the field of robot navigation, including the telepresence system, surveillance, and DL-based optimization methods.
The telepresence system aims to overcome the space constraints to enable people to remotely visit and interact with each other. ODI/ODV is gaining popularity by providing a more realistic and natural scene, especially in outdoor activities with open environments [207]. [208] proposed a prototype of an ODV-based telepresence system to support more natural interactions and the remote environment exploration, where real walking in the remote environment can simultaneously control the relevant movement of the robot platform. Surveillance aims to replace humans for security purposes, in which the calibration is vital for sensitive data. Accordingly, Pudics et al. [209] proposed a safe navigation system tailored for obstacle detection and avoidance with a calibration design to obtain the proper distance and direction. Compared with NFoV images, panoramic images can reduce the computational cost significantly by providing complete FoV in a single shot. Moreover, Ran et al. [210] proposed a lightweight framework based on the uncalibrated cameras. The framework can accurately estimate the heading direction by formulating it into a series of classification tasks and avoid redundant computation by saving the calibration and correction processes. To address dark environments, e.g., underground mine, Mansouri et al. [211] presented another DNN model by utilizing online heading rate commands to avoid the collision in the tunnels and calculating depth information online within the scene.
Autonomous Driving. It requires a full understanding of the surrounding environment, which omnidirectional vision excels at. Some works focus on setting up platform for autonomous driving [212, 213]. Specifically, [212] utilized a stereo camera, a polarization camera and a panoramic camera to form a multi-modal visual system to capture omnidirectional landscape. [213] introduced a multi-modal 360∘ perception proposal based on visual and LiDAR scanners for 3D object detection and tracking. In addition to the platform, the emergence of public omnidirectional datasets for autonomous driving are crucial for the application of DL methods. Caeser et al. [214] were the first to introduce the relevant dataset which carries six cameras, five radars and one LiDAR. All devices are with FoV. Recently, OpenMP dataset [215] is captured by six cameras and four LiDARs, which contains scenes in the complex environment, e.g., urban areas with overexposure or darkness. Kumar et al.[216] presented a multi-task visual perception network, which consists of six vital tasks in autonomous driving: depth estimation, visual odometry, senmantic segmentation, motion segmentation, object detection and lens soiling detection. Importantly, as real-time performance is crucial for autonomous driving and embedding systems in vehicles often have limited memory and computational resources, lightweight DNN models are more favored in practice.
6 Discussion and New Perspectives
Cons of Projection Formats. ERP is the most prevalent projection format due to its wide FoV in a planar format. The main challenge for ERP is the increasing stretching distortion towards poles. Therefore, many works were proposed to design specific convolution filters against the distortion [21, 20]. By contrast, CP and tangent images are distortion-less projection formats by projecting a spherical surface into multiple planes. They are similar to the perspective images, and therefore can make full use of many pre-trained models and datasets in the planar domain [25]. However, CP and tangent images suffer from the challenges of higher computational cost, discrepancy and discontinuity.
We summarize two potential directions for utilizing CP and tangent images: (i) Redundant computational cost are resulted from large overlapping regions between projection planes. However, the pixel density varies among different sampling positions. The computation can be more efficient through allocating more resources for dense regions (e.g., equator) and less resources for sparse regions (e.g., poles) with reinforcement learning [85]. (ii) Currently, different projection planes are often processed in parallel, which lacks the global consistency. To overcome the discrepancy among different local planes, it is effective to explore an additional branch with ERP as the input [19] or attention-based transformers to construct non-local dependencies [25]. However, these constraints are mainly added to the feature maps, instead of the predictions. Moreover, the discrepancy can be also solved from the distribution consistency of predictions, e.g., the consistent depth range among different planes and the consistent uncertainty scores for the same edges and large gradient regions.
Data-efficient Learning. A challenge for DL methods is the need for large-scale datasets with high-quality annotations. However, for omnidirectional vision, constructing large-scale datasets is expensive and tedious. Therefore, it is necessary to explore more data-efficient methods. One promising direction is to transfer the knowledge learned from models trained on the labeled 2D dataset to models to be trained on the unlabeled panoramic dataset. Specifically, domain adaptation approaches can be applied to narrow the gap between perspective images and ODIs [109]. KD is also an effective solution by transferring learned feature information from a cumbersome perspective DNN model to a compact DNN model learning ODI data [111]. Finally, recent self-supervised methods, e.g., [217], demonstrate the effectiveness of pre-training without the need of additional training annotations.
Physical Constraint. Existing methods for the perspective images are limited in inferring the lighting of the global scene and unseen regions. Owing to the wide FoV of ODIs, complete surrounding environment scenes can be captured. Furthermore, the reflectance can be revealed according to the physical constraints between the lighting and scene structure based on [218]. Therefore, a future direction can be jointly leveraging computer graphics, like ray tracing, and rendering models to help calculate reflectance, which, in turn, contributes to higher-precision global lighting estimation. Additionally, it is promising to process and render ODIs based on the lighting transportation theory.
Multi-modal Omnidirectional Vision. It refers to the process of learning representations from different types of modalities (e.g., text-image for visual question answering, audio-visual scene understanding) using the same DNN model. This is a promising yet practical direction for ominidirectional vision. For instance, [213] introduces a multi-modal perception framework based on the visual and LiDAR information for 3D object detection and tracking. However, existing works in this direction treat ODIs as the perspective images and ignore the inherent distortion in the ODIs. Future works may explore how to utilize the advantage of ODIs, e.g., complete FoV, to assist the representation of other modalities. Importantly, the acquisition of different modalities has obvious discrepancies. For example, capturing RGB images is much easier than that of depth maps. Therefore, a promising direction is to extract available information from one modality and then transfer to another modality via multi-task learning, KD, etc. However, the discrepancy among different modalities should be considered to ensure multi-modal consistency.
Potential for Adversarial Attacks. There exist few studies focusing on adversarial attacks towards omnidirectional vision models. Zhang et al. [219] proposed the first and representative attack approach to fool DNN models by perturbing only one tangent image rendered from the ODI. The proposed attack is sparse as it disturbs only a small part of the input ODI. Therefore, they further proposed a position searching method to search for the tangent point on the spherical surface. There are numerous promising yet challenging research problems in this direction, e.g., analyzing the generalization capacity of attacks among different DNN models for ODIs, white-box attacks for network architectures and training methods, and defenses against attacks.
Potential for Metaverse. Metaverse aims to create a virtual world containing large-scale high-fidelity digital models, where users can freely create contents and obtain immersive interactive experience. Metaverse is facilitated by the AR and VR headsets, in which ODIs are favored due to the complete FoV. Therefore, a potential direction is to generate high-fidelity 2D/3D models from ODIs and simulate the real-world objects and scenes in great details. In addition, to help users obtain immersive experience, techniques that analyze and understand human behavior (e.g., gaze following, saliency prediction) can be further explored and integrated in the future.
Potential for Smart City. Smart city focuses on collecting data from the city with various devices and utilizing information from the data to improve efficiency, security and convenience, etc. Taking advantage of the characteristics of ODI in street-view images can facilitate the development of urban forms comparison. As mentioned in Sec. 3.1.2, a promising direction is to convert street-view images into satellite-view images for urban planning. Except for room layout discussed in Sec. 3.3.1, ODIs can also be applied in more interior designs. To achieve floorplan design, Wang et al. [220] leveraged human-activity maps and editable furniture placements to improve the interaction with users. However, the input of [220] is the boundary of the exterior wall, resulting in limitation of the visualization and manipulation. Future works might consider operating directly on the ODIs to make the interior design observable in all directions, boosting the development of interaction and making professional service accessible.
7 Conclusion
In this survey, we comprehensively reviewed and analyzed the recent progress of DL methods for omnidirectional vision. We first introduced the principle of omnidirectional imaging, convolution methods and datasets. We then provided a hierarchical and structural taxonomy of the DL methods. For each task in the taxonomy, we summarized the current research status and pointed out the opportunities and challenges. We further provided a review of the novel learning strategies and applications. After constructing connections among current approaches, we discussed the pivotal problems to be solved and indicated promising future research directions. We hope this work can provide some insights for researchers and promote progress in the community.
References
- [1] J. Pi, Y. Zhang, L. Zhu, X. Wu, and X. Zhou, “Content-aware hybrid equi-angular cubemap projection for omnidirectional video coding,” VCIP, 2020.
- [2] H. Jiang, G. yi Jiang, M. Yu, Y. Zhang, Y. Yang, Z. Peng, F. Chen, and Q. Zhang, “Cubemap-based perception-driven blind quality assessment for 360-degree images,” TIP, 2021.
- [3] J. Xiao, K. A. Ehinger, A. Oliva, and A. Torralba, “Recognizing scene viewpoint using panoramic place representation,” in CVPR, 2012.
- [4] Y. Rai, J. Gutiérrez, and P. Le Callet, “A dataset of head and eye movements for 360 degree images,” in ACM MMSys, 2017.
- [5] I. Armeni, S. Sax, A. R. Zamir, and S. Savarese, “Joint 2d-3d-semantic data for indoor scene understanding,” arXiv, 2017.
- [6] H. Yun, Y. Yu, W. Yang, K. Lee, and G. Kim, “Pano-avqa: Grounded audio-visual question answering on 360∘ videos,” ICCV, 2021.
- [7] Y. Zhang, S. Song, P. Tan, and J. Xiao, “Panocontext: A whole-room 3d context model for panoramic scene understanding,” in ECCV, 2014.
- [8] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” CVPR, 2016.
- [9] L. R. Medsker and L. Jain, “Recurrent neural networks,” Design and Applications, 2001.
- [10] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” NIPS, 2014.
- [11] F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini, “The graph neural network model,” IEEE TNNLS, 2008.
- [12] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” ICLR, 2020.
- [13] C. Zou, J.-W. Su, C.-H. Peng, A. Colburn, Q. Shan, P. Wonka, H. kuo Chu, and D. Hoiem, “Manhattan room layout reconstruction from a single 360∘ image: A comparative study of state-of-the-art methods,” IJCV., 2021.
- [14] T. L. T. da Silveira, P. G. L. Pinto, J. Murrugarra-Llerena, and C. R. Jung, “3d scene geometry estimation from 360∘ imagery: A survey,” ACM Computing Surveys (CSUR), 2022.
- [15] M. Zink, R. K. Sitaraman, and K. Nahrstedt, “Scalable 360∘ video stream delivery: Challenges, solutions, and opportunities,” Proceedings of the IEEE, 2019.
- [16] M. Xu, C. Li, S. Zhang, and P. L. Callet, “State-of-the-art in 360∘ video/image processing: Perception, assessment and compression,” IEEE J-STSP, 2020.
- [17] A. Yaqoob, T. Bi, and G.-M. Muntean, “A survey on adaptive 360 video streaming: solutions, challenges and opportunities,” IEEE Commun. Surv. Tutor., 2020.
- [18] N. Zioulis, A. Karakottas, D. Zarpalas, F. Alvarez, and P. Daras, “Spherical view synthesis for self-supervised 360 depth estimation,” in 3DV, 2019.
- [19] F.-E. Wang, Y.-H. Yeh, M. Sun, W.-C. Chiu, and Y.-H. Tsai, “Bifuse: Monocular 360 depth estimation via bi-projection fusion,” in CVPR, 2020.
- [20] Y.-C. Su and K. Grauman, “Learning spherical convolution for fast features from 360∘ imagery,” in NIPS, 2017.
- [21] B. Coors, A. P. Condurache, and A. Geiger, “Spherenet: Learning spherical representations for detection and classification in omnidirectional images,” in ECCV, 2018.
- [22] Q. Zhao, C. Zhu, F. Dai, Y. Ma, G. Jin, and Y. Zhang, “Distortion-aware cnns for spherical images.” in IJCAI, 2018.
- [23] R. Khasanova and P. Frossard, “Geometry aware convolutional filters for omnidirectional images representation,” in ICML, 2019.
- [24] T. O’Beirne, “Introduction to geometry,” Physics Bulletin, 1962.
- [25] Y. Li, Y. Guo, Z. Yan, X. Huang, Y. Duan, and L. Ren, “Omnifusion: 360 monocular depth estimation via geometry-aware fusion,” CVPR, 2022.
- [26] M. Eder, M. Shvets, J. Lim, and J.-M. Frahm, “Tangent images for mitigating spherical distortion,” in CVPR, 2020.
- [27] Y. Lee, J. Jeong, J. S. Yun, W. Cho, and K. jin Yoon, “Spherephd: Applying cnns on a spherical polyhedron representation of 360∘ images,” CVPR, 2019.
- [28] Y. Yoon, I. Chung, L. Wang, and K.-J. Yoon, “Spheresr,” CVPR, 2022.
- [29] T. S. Cohen, M. Geiger, J. Köhler, and M. Welling, “Spherical cnns,” arXiv, 2018.
- [30] J. Cruz-Mota, I. Bogdanova, B. Paquier, M. Bierlaire, and J.-P. Thiran, “Scale invariant feature transform on the sphere: Theory and applications,” IJCV, 2012.
- [31] Y.-C. Su and K. Grauman, “Kernel transformer networks for compact spherical convolution,” CVPR, 2019.
- [32] ——, “Learning spherical convolution for 360 recognition,” TPAMI, 2021.
- [33] P. Frossard and R. Khasanova, “Graph-based classification of omnidirectional images,” ICCV Workshops, 2017.
- [34] M. Rey-Area, M. Yuan, and C. Richardt, “360MonoDepth: High-resolution 360∘ monocular depth estimation,” in CVPR, 2022.
- [35] Q. Yang, C. Li, W. Dai, J. Zou, G.-J. Qi, and H. Xiong, “Rotation equivariant graph convolutional network for spherical image classification,” CVPR, 2020.
- [36] C. Esteves, C. Allen-Blanchette, A. Makadia, and K. Daniilidis, “Learning so(3) equivariant representations with spherical cnns,” in ECCV, 2018.
- [37] T. Cohen, M. Weiler, B. Kicanaoglu, and M. Welling, “Gauge equivariant convolutional networks and the icosahedral cnn,” in ICML, 2019.
- [38] M. Shakerinava and S. Ravanbakhsh, “Equivariant networks for pixelized spheres,” in ICML, 2021.
- [39] M. Defferrard, M. Milani, F. Gusset, and N. Perraudin, “Deepsphere: a graph-based spherical cnn,” in ICLR, 2020.
- [40] J. Zheng, J. Zhang, J. Li, R. Tang, S. Gao, and Z. Zhou, “Structured3d: A large photo-realistic dataset for structured 3d modeling,” in ECCV, 2020.
- [41] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser, “Semantic scene completion from a single depth image,” in CVPR, 2017.
- [42] H.-N. Hu, Y.-C. Lin, M.-Y. Liu, H.-T. Cheng, Y.-J. Chang, and M. Sun, “Deep 360 pilot: Learning a deep agent for piloting through 360 sports videos,” in CVPR, 2017.
- [43] H.-T. Cheng, C.-H. Chao, J.-D. Dong, H.-K. Wen, T.-L. Liu, and M. Sun, “Cube padding for weakly-supervised saliency prediction in 360 videos,” in CVPR, 2018.
- [44] R. Seidel, A. Apitzsch, and G. Hirtz, “Omniflow: Human omnidirectional optical flow,” CVPR Workshops, 2021.
- [45] C. Zhang, S. Liwicki, W. Smith, and R. Cipolla, “Orientation-aware semantic segmentation on icosahedron spheres,” in ICCV, 2019.
- [46] R. Liu, G. Zhang, J. Wang, and S. Zhao, “Cross-modal 360∘ depth completion and reconstruction for large-scale indoor environment,” IEEE Trans. Intell. Transp. Syst., 2022.
- [47] C. Oh, W. Cho, D. Park, Y. Chae, L. Wang, and K.-J. Yoon, “Bips: Bi-modal indoor panorama synthesis via residual depth-aided adversarial learning,” arXiv, 2021.
- [48] T. Hara, Y. Mukuta, and T. Harada, “Spherical image generation from a single image by considering scene symmetry,” in AAAI, 2021.
- [49] N. Akimoto, Y. Matsuo, and Y. Aoki, “Diverse plausible 360-degree image outpainting for efficient 3dcg background creation,” arXiv, 2022.
- [50] J. S. Sumantri and I. K. Park, “360 panorama synthesis from a sparse set of images with unknown field of view,” in WACV, 2020.
- [51] L. Roldao, R. De Charette, and A. Verroust-Blondet, “3d semantic scene completion: a survey,” arXiv, 2021.
- [52] A. Dourado, H. Kim, T. E. de Campos, and A. Hilton, “Semantic scene completion from a single 360-degree image and depth map.” in VISIGRAPP, 2020.
- [53] A. Dai, D. Ritchie, M. Bokeloh, S. Reed, J. Sturm, and M. Nießner, “Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans,” in CVPR, 2018.
- [54] X. Lu, Z. Li, Z. Cui, M. R. Oswald, M. Pollefeys, and R. Qin, “Geometry-aware satellite-to-ground image synthesis for urban areas,” in CVPR, 2020.
- [55] Z. Li, Z. Li, Z. Cui, R. Qin, M. Pollefeys, and M. R. Oswald, “Sat2vid: Street-view panoramic video synthesis from a single satellite image,” in ICCV, 2021.
- [56] M. Zhai, Z. Bessinger, S. Workman, and N. Jacobs, “Predicting ground-level scene layout from aerial imagery,” in CVPR, 2017.
- [57] K. Regmi and M. Shah, “Bridging the domain gap for ground-to-aerial image matching,” in ICCV, 2019.
- [58] A. Toker, Q. Zhou, M. Maximov, and L. Leal-Taixé, “Coming down to earth: Satellite-to-street view synthesis for geo-localization,” in CVPR, 2021.
- [59] Y. Shi, L. Liu, X. Yu, and H. Li, “Spatial-aware feature aggregation for image based cross-view geo-localization,” NIPS, 2019.
- [60] S. Zhu, M. Shah, and C. Chen, “Transgeo: Transformer is all you need for cross-view image geo-localization,” arXiv, 2022.
- [61] Y. Shi, X. Yu, D. Campbell, and H. Li, “Where am i looking at? joint location and orientation estimation by cross-view matching,” in CVPR, 2020.
- [62] S. Zhu, T. Yang, and C. Chen, “Vigor: Cross-view image geo-localization beyond one-to-one retrieval,” in CVPR, 2021.
- [63] C.-Y. Hsu, C. Sun, and H.-T. Chen, “Moving in a 360 world: Synthesizing panoramic parallaxes from a single panorama,” arXiv, 2021.
- [64] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” in ECCV, 2020.
- [65] T. Hara and T. Harada, “Enhancement of novel view synthesis using omnidirectional image completion,” arXiv, 2022.
- [66] J. Y. Koh, H. Lee, Y. Yang, J. Baldridge, and P. Anderson, “Pathdreamer: A world model for indoor navigation,” in ICCV, 2021.
- [67] F. D. Simone, P. Frossard, P. Wilkins, N. Birkbeck, and A. C. Kokaram, “Geometry-driven quantization for omnidirectional image coding,” PCS, 2016.
- [68] M. Řeřábek, E. Upenik, and T. Ebrahimi, “Jpeg backward compatible coding of omnidirectional images,” in Applications of digital image processing XXXIX, 2016.
- [69] G. K. Wallace, “The jpeg still picture compression standard,” IEEE TCE, 1992.
- [70] M. Rizkallah, F. D. Simone, T. Maugey, C. Guillemot, and P. Frossard, “Rate distortion optimized graph partitioning for omnidirectional image coding,” EUSIPCO, 2018.
- [71] G. J. Sullivan and T. Wiegand, “Rate-distortion optimization for video compression,” IEEE Signal Process Mag, 1998.
- [72] N. M. Bidgoli, R. G. d. A. Azevedo, T. Maugey, A. Roumy, and P. Frossard, “Oslo: On-the-sphere learning for omnidirectional images and its application to 360-degree image compression,” arXiv, 2021.
- [73] K. M. Gorski, E. Hivon, A. J. Banday, B. D. Wandelt, F. K. Hansen, M. Reinecke, and M. Bartelman, “Healpix: A framework for high-resolution discretization and fast analysis of data distributed on the sphere,” The Astrophysical Journal, 2005.
- [74] Y. Li, J. Xu, and Z. Chen, “Spherical domain rate-distortion optimization for omnidirectional video coding,” IEEE TCSVT, 2019.
- [75] Y. Wang, D. Liu, S. Ma, F. Wu, and W. Gao, “Spherical coordinates transform-based motion model for panoramic video coding,” IEEE J-ESTCS, 2019.
- [76] C.-W. Fu, L. Wan, T. Wong, and A. C.-S. Leung, “The rhombic dodecahedron map: An efficient scheme for encoding panoramic video,” IEEE TMM, 2009.
- [77] L. Li, N. Yan, Z. Li, S. Liu, and H. Li, “-domain perceptual rate control for 360-degree video compression,” IEEE J-STSP, 2020.
- [78] T. Zhao, J. Lin, Y. Song, X. Wang, and Y. Niu, “Game theory-driven rate control for 360-degree video coding,” ACM MM, 2021.
- [79] Y. Hold-Geoffroy, K. Sunkavalli, S. Hadap, E. Gambaretto, and J.-F. Lalonde, “Deep outdoor illumination estimation,” in CVPR, 2017.
- [80] M.-A. Gardner, K. Sunkavalli, E. Yumer, X. Shen, E. Gambaretto, C. Gagné, and J.-F. Lalonde, “Learning to predict indoor illumination from a single image,” ACM TOG, 2017.
- [81] M.-A. Gardner, Y. Hold-Geoffroy, K. Sunkavalli, C. Gagné, and J.-F. Lalonde, “Deep parametric indoor lighting estimation,” ICCV, 2019.
- [82] F. Zhan, C. Zhang, Y. Yu, Y. Chang, S. Lu, F. Ma, and X. Xie, “Emlight: Lighting estimation via spherical distribution approximation,” AAAI, 2021.
- [83] J. P. Rolland and H. Hua, “Head-mounted display systems,” Encyclopedia of optical engineering, 2005.
- [84] C. Ozcinar, A. Rana, and A. Smolic, “Super-resolution of omnidirectional images using adversarial learning,” in MMSP, 2019.
- [85] X. Deng, H. Wang, M. Xu, Y. Guo, Y. Song, and L. Yang, “Lau-net: Latitude adaptive upscaling network for omnidirectional imag super-resolution,” CVPR, 2021.
- [86] H. Liu, Z. Ruan, C. Fang, P. Zhao, F. Shang, Y. Liu, and L. Wang, “A single frame and multi-frame joint network for 360-degree panorama video super-resolution,” arXiv, 2020.
- [87] M. Bosse, R. J. Rikoski, J. J. Leonard, and S. Teller, “Vanishing points and 3d lines from omnidirectional video,” ICIP, 2002.
- [88] C. A. Vanegas, D. G. Aliaga, and B. Benes, “Building reconstruction using manhattan-world grammars,” in CVPR, 2010.
- [89] G. Schindler and F. Dellaert, “Atlanta world: an expectation maximization framework for simultaneous low-level edge grouping and camera calibration in complex man-made environments,” in CVPR, 2004.
- [90] J. Jeon, J. Jung, and S. Lee, “Deep upright adjustment of 360 panoramas using multiple roll estimations,” ACCV, 2018.
- [91] R. Jung, A. S. J. Lee, A. Ashtari, and J. C. Bazin, “Deep360up: A deep learning-based approach for automatic vr image upright adjustment,” VR, 2019.
- [92] R. Jung, S. Cho, and J. Kwon, “Upright adjustment with graph convolutional networks,” ICIP, 2020.
- [93] H. taek Lim, H. G. Kim, and Y. M. Ro, “Vr iqa net: Deep virtual reality image quality assessment using adversarial learning,” ICASSP, 2018.
- [94] C. Li, M. Xu, L. Jiang, S. Zhang, and X. Tao, “Viewport proposal cnn for 360∘ video quality assessment,” CVPR, 2019.
- [95] Y. Sun, A. Lu, and L. Yu, “Weighted-to-spherically-uniform quality evaluation for omnidirectional video,” IEEE SPL, 2017.
- [96] M. Xu, C. Li, Z. Chen, Z. Wang, and Z. Guan, “Assessing visual quality of omnidirectional videos,” IEEE TCSVT, 2019.
- [97] H. G. Kim, H. taek Lim, and Y. M. Ro, “Deep virtual reality image quality assessment with human perception guider for omnidirectional image,” IEEE TCSVT, 2020.
- [98] J. Xu, W. Zhou, and Z. Chen, “Blind omnidirectional image quality assessment with viewport oriented graph convolutional networks,” IEEE TCSVT, 2021.
- [99] W. Zhou, J. Xu, Q. Jiang, and Z. Chen, “No-reference quality assessment for 360-degree images by analysis of multifrequency information and local-global naturalness,” IEEE TCSVT, 2022.
- [100] W. Sun, X. Min, G. Z. S. K. Gu, H. Duan, and S. Ma, “Mc360iqa: A multi-channel cnn for blind 360-degree image quality assessment,” IEEE J-STSP, 2020.
- [101] R. G. de Albuquerque Azevedo, N. Birkbeck, I. Janatra, B. Adsumilli, and P. Frossard, “A viewport-driven multi-metric fusion approach for 360-degree video quality assessment,” ICME, 2020.
- [102] P. Gao, P. Zhang, and A. Smolic, “Quality assessment for omnidirectional video: A spatio-temporal distortion modeling approach,” IEEE TMM, 2022.
- [103] P. Zhao, A. You, Y. Zhang, J. Liu, K. Bian, and Y. Tong, “Spherical criteria for fast and accurate 360 object detection,” in AAAI, 2020.
- [104] M. Cao, S. Ikehata, and K. Aizawa, “Field-of-view iou for object detection in 360 ∘ images,” arXiv, 2022.
- [105] G. Tong, H. Chen, Y. Li, X. Du, and Q. Zhang, “Object detection for panoramic images based on ms-rpn structure in traffic road scenes,” IET Comput. Vis., 2019.
- [106] K.-H. Wang and S.-H. Lai, “Object detection in curved space for 360-degree camera,” in ICASSP, 2019.
- [107] W. Yang, Y. Qian, J.-K. Kämäräinen, F. Cricri, and L. Fan, “Object detection in equirectangular panorama,” in ICPR, 2018.
- [108] K. Tateno, N. Navab, and F. Tombari, “Distortion-aware convolutional filters for dense prediction in panoramic images,” in ECCV, 2018.
- [109] C. Ma, J. Zhang, K. Yang, A. Roitberg, and R. Stiefelhagen, “Densepass: Dense panoramic semantic segmentation via unsupervised domain adaptation with attention-augmented context exchange,” ITSC, 2021.
- [110] J. Guerrero-Viu, C. Fernandez-Labrador, C. Demonceaux, and J. J. Guerrero, “What’s in my room? object recognition on indoor panoramic images,” in ICRA, 2020, 2020.
- [111] K. Yang, J. Zhang, S. Reiß, X. Hu, and R. Stiefelhagen, “Capturing omni-range context for omnidirectional segmentation,” CVPR, 2021.
- [112] J. Zhang, K. Yang, C. Ma, S. Reiß, K. Peng, and R. Stiefelhagen, “Bending reality: Distortion-aware transformers for adapting to panoramic semantic segmentation,” arXiv, 2022.
- [113] J. Zhang, C. Ma, K. Yang, A. Roitberg, K. Peng, and R. Stiefelhagen, “Transfer beyond the field of view: Dense panoramic semantic segmentation via unsupervised domain adaptation,” IEEE Trans. on Intell. Trans. Sys., 2021.
- [114] L. Deng, M. Yang, Y. Qian, C. Wang, and B. Wang, “Cnn based semantic segmentation for urban traffic scenes using fisheye camera,” IV, 2017.
- [115] L. Deng, M. Yang, H. Li, T. Li, B. Hu, and C. Wang, “Restricted deformable convolution-based road scene semantic segmentation using surround view cameras,” IEEE Trans. Intell. Transp. Syst., 2020.
- [116] S. Orhan and Y. Bastanlar, “Semantic segmentation of outdoor panoramic images,” Signal Image Video Process., 2022.
- [117] C. Fernandez-Labrador, J. M. Fácil, A. Pérez-Yus, C. Demonceaux, J. Civera, and J. J. Guerrero, “Corners for layout: End-to-end layout recovery from 360 images,” IEEE Robot. Autom. Lett., 2020.
- [118] K. Yang, X. Hu, L. M. Bergasa, E. Romera, X. Huang, D. Sun, and K. Wang, “Can we pass beyond the field of view? panoramic annular semantic segmentation for real-world surrounding perception,” IV, 2019.
- [119] K. Yang, X. Hu, H. Chen, K. Xiang, K. Wang, and R. Stiefelhagen, “Ds-pass: Detail-sensitive panoramic annular semantic segmentation through swaftnet for surrounding sensing,” IV, 2020.
- [120] A. Jaus, K. Yang, and R. Stiefelhagen, “Panoramic panoptic segmentation: Towards complete surrounding understanding via unsupervised contrastive learning,” IV, 2021.
- [121] K. Yang, X. Hu, Y. Fang, K. Wang, and R. Stiefelhagen, “Omnisupervised omnidirectional semantic segmentation,” IEEE Trans. Intell. Transp. Syst., 2022.
- [122] N. Zioulis, A. Karakottas, D. Zarpalas, and P. Daras, “Omnidepth: Dense depth estimation for indoors spherical panoramas,” in ECCV, 2018.
- [123] G. Pintore, E. Almansa, and J. Schneider, “Slicenet: deep dense depth estimation from a single indoor panorama using a slice-based representation,” CVPR, 2021.
- [124] I. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, and N. Navab, “Deeper depth prediction with fully convolutional residual networks,” in 3DV, 2016.
- [125] C. Zhuang, Z. Lu, Y. Wang, J. Xiao, and Y. Wang, “Acdnet: Adaptively combined dilated convolution for monocular panorama depth estimation,” arXiv, 2021.
- [126] L. Jin, Y. Xu, J. Zheng, J. Zhang, R. Tang, S. Xu, J. Yu, and S. Gao, “Geometric structure based and regularized depth estimation from 360 indoor imagery,” in CVPR, 2020.
- [127] F.-E. Wang, H.-N. Hu, H.-T. Cheng, J.-T. Lin, S.-T. Yang, M.-L. Shih, H.-K. Chu, and M. Sun, “Self-supervised learning of depth and camera motion from 360∘ videos,” in ACCV, 2018.
- [128] I. Yun, H.-J. Lee, and C. E. Rhee, “Improving 360 monocular depth estimation via non-local dense prediction transformer and joint supervised and self-supervised learning,” arXiv, 2021.
- [129] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE TIP, 2004.
- [130] Q. Feng, H. P. Shum, and S. Morishima, “360 depth estimation in the wild-the depth360 dataset and the segfuse network,” in VR, 2022.
- [131] M. Eder, P. Moulon, and L. Guan, “Pano popups: Indoor 3d reconstruction with a plane-aware network,” in 3DV, 2019.
- [132] X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W.-c. Woo, “Convolutional lstm network: A machine learning approach for precipitation nowcasting,” NIPS, 2015.
- [133] H. Jiang, Z. Sheng, S. Zhu, Z. Dong, and R. Huang, “Unifuse: Unidirectional fusion for 360 panorama depth estimation,” IEEE Robot. Autom. Lett., 2021.
- [134] J. Bai, S. Lai, H. Qin, J. Guo, and Y. Guo, “Glpanodepth: Global-to-local panoramic depth estimation,” arXiv, 2022.
- [135] R. Ranftl, A. Bochkovskiy, and V. Koltun, “Vision transformers for dense prediction,” in ICCV, 2021.
- [136] B. Y. Feng, W. Yao, Z. Liu, and A. Varshney, “Deep depth estimation on 360 images with a double quaternion loss,” in 3DV, 2020.
- [137] A. Apitzsch, R. Seidel, and G. Hirtz, “Cubes3d: Neural network based optical flow in omnidirectional image scenes,” arXiv, 2018.
- [138] S. Xie, P. K. Lai, R. Laganière, and J. Lang, “Effective convolutional neural network layers in flow estimation for omni-directional images,” 3DV, 2019.
- [139] C.-O. Artizzu, H. Zhang, G. Allibert, and C. Demonceaux, “Omniflownet: a perspective neural network adaptation for optical flow estimation in omnidirectional images,” ICPR, 2021.
- [140] K. Bhandari, Z. Zong, and Y. Yan, “Revisiting optical flow estimation in 360 videos,” ICPR, 2021.
- [141] T.-W. Hui, X. Tang, and C. C. Loy, “Liteflownet: A lightweight convolutional neural network for optical flow estimation,” CVPR, 2018.
- [142] H. Shi, Y. Zhou, K. Yang, Y. Ye, X. Yin, Z. Yin, S. Meng, and K. Wang, “Panoflow: Learning optical flow for panoramic images,” arXiv, 2022.
- [143] Y. Su, D. Jayaraman, and K. Grauman, “Pano2vid: Automatic cinematography for watching 360∘ videos,” in ACCV, 2016.
- [144] Y. Su and K. Grauman, “Making 360∘ video watchable in 2d: Learning videography for click free viewing,” in CVPR, 2017.
- [145] Y. Yu, S. Lee, J. Na, J. Kang, and G. Kim, “A deep ranking model for spatio-temporal highlight detection from a 360∘ video,” in AAAI, 2018.
- [146] S. Lee, J. Sung, Y. Yu, and G. Kim, “A memory network approach for story-based temporal summarization of 360∘ videos,” in CVPR, 2018.
- [147] C. Zhang, Z. Cui, C. Chen, S. Liu, B. Zeng, H. Bao, and Y. Zhang, “Deeppanocontext: Panoramic 3d scene understanding with holistic scene context graph and relation-based optimization,” ICCV, 2021.
- [148] S.-T. Yang, F.-E. Wang, C.-H. Peng, P. Wonka, M. Sun, and H. kuo Chu, “Dula-net: A dual-projection network for estimating room layouts from a single rgb panorama,” CVPR, 2019.
- [149] C. Zou, A. Colburn, Q. Shan, and D. Hoiem, “Layoutnet: Reconstructing the 3d room layout from a single rgb image,” CVPR, 2018.
- [150] P. V. Tran, “Sslayout360: Semi-supervised indoor layout estimation from 360∘ panorama,” CVPR, 2021.
- [151] G. Pintore, M. Agus, and E. Gobbetti, “Atlantanet: Inferring the 3d indoor layout from a single image beyond the manhattan world assumption,” in ECCV, 2020.
- [152] C. Sun, C.-W. Hsiao, M. Sun, and H.-T. Chen, “Horizonnet: Learning room layout with 1d representation and pano stretch data augmentation,” CVPR, 2019.
- [153] C. Sun, M. Sun, and H.-T. Chen, “Hohonet: 360 indoor holistic understanding with latent horizontal features,” CVPR, 2021.
- [154] F.-E. Wang, Y.-H. Yeh, M. Sun, W.-C. Chiu, and Y.-H. Tsai, “Led2-net: Monocular 360∘ layout estimation via differentiable depth rendering,” CVPR, 2021.
- [155] J. Seuffert, A. P. Grassi, T. Scheck, and G. Hirtz, “A study on the influence of omnidirectional distortion on cnn-based stereo vision,” in VISIGRAPP, 2021.
- [156] C. Won, J. Ryu, and J. Lim, “Sweepnet: Wide-baseline omnidirectional depth estimation,” ICRA, 2019.
- [157] ——, “Omnimvs: End-to-end learning for omnidirectional stereo matching,” ICCV, 2019.
- [158] ——, “End-to-end learning for omnidirectional stereo matching with uncertainty prior,” IEEE TPAMI, 2021.
- [159] N.-H. Wang, B. Solarte, Y.-H. Tsai, W.-C. Chiu, and M. Sun, “360sd-net: 360∘ stereo depth estimation with learnable cost volume,” ICRA, 2020.
- [160] A. Chiuso, P. Favaro, H. Jin, and S. Soatto, “Structure from motion causally integrated over time,” IEEE TPAMI, 2002.
- [161] R. Mur-Artal and J. D. Tardós, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE T-RO, 2017.
- [162] R. Mur-Artal, J. M. M. Montiel, and J. D. Tardós, “Orb-slam: A versatile and accurate monocular slam system,” IEEE T-RO, 2015.
- [163] S. Urban and S. Hinz, “Multicol-slam-a modular real-time multi-camera slam system,” arXiv, 2016.
- [164] D. Caruso, J. J. Engel, and D. Cremers, “Large-scale direct slam for omnidirectional cameras,” IROS, 2015.
- [165] Z. Teed and J. Deng, “Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras,” in NIPS, 2021.
- [166] J. Czarnowski, T. Laidlow, R. Clark, and A. J. Davison, “Deepfactors: Real-time probabilistic dense monocular slam,” IEEE Robot. Autom. Lett., 2020.
- [167] F. Dai, Y. Zhang, Y. Ma, H. Li, and Q. Zhao, “Dilated convolutional neural networks for panoramic image saliency prediction,” ICASSP, 2020.
- [168] H. Lv, Q. Yang, C. Li, W. Dai, J. Zou, and H. Xiong, “Salgcn: Saliency prediction for 360-degree images based on spherical graph convolutional networks,” ACM MM, 2020.
- [169] F.-Y. Chao, L. Zhang, W. Hamidouche, and O. Déforges, “A multi-fov viewport-based visual saliency model using adaptive weighting losses for 360∘ images,” IEEE TMM, 2021.
- [170] Y. Abdelaziz, D. Djilali, T. Krishna, K. McGuinness, and N. E. O’Connor, “Rethinking 360∘ image visual attention modelling with unsupervised learning,” ICCV, 2021.
- [171] M. Xu, L. Yang, X. Tao, Y. Duan, and Z. Wang, “Saliency prediction on omnidirectional image with generative adversarial imitation learning,” IEEE TIP, 2021.
- [172] A. Nguyen, Z. Yan, and K. Nahrstedt, “Your attention is unique: Detecting 360-degree video saliency in head-mounted display for head movement prediction,” ACM MM, 2018.
- [173] Z. Zhang, Y. Xu, J. Yu, and S. Gao, “Saliency detection in 360∘ videos,” in ECCV, 2018.
- [174] M. Xu, Y. Song, J. Wang, M. Qiao, L. Huo, and Z. Wang, “Predicting head movement in panoramic video: A deep reinforcement learning approach,” IEEE TPAMI, 2019.
- [175] Y. Zhu, G. Zhai, Y. Yang, H. Duan, X. Min, and X. Yang, “Viewing behavior supported visual saliency predictor for 360 degree videos,” IEEE TCSVT, 2021.
- [176] M. Qiao, M. Xu, Z. Wang, and A. Borji, “Viewport-dependent saliency prediction in 360∘ video,” IEEE TMM, 2021.
- [177] R. Monroy, S. Lutz, T. Chalasani, and A. Smolic, “Salnet360: Saliency maps for omni-directional images with cnn,” Signal Process Image Commun, 2017.
- [178] R. Zhang, C. Chen, J. Zhang, J. Peng, and A. M. T. Alzbier, “360-degree visual saliency detection based on fast-mapped convolution and adaptive equator-bias perception,” The Visual Computer, 2022.
- [179] Y. Yang, Y. Zhu, Z. Gao, and G. Zhai, “Salgfcn: Graph based fully convolutional network for panoramic saliency prediction,” VCIP, 2021.
- [180] P. Mazumdar and F. Battisti, “A content-based approach for saliency estimation in 360 images,” ICIP, 2019.
- [181] T. Suzuki and T. Yamanaka, “Saliency map estimation for omni-directional image considering prior distributions,” SMC, 2018.
- [182] I. Djemai, S. A. Fezza, W. Hamidouche, and O. Déforges, “Extending 2d saliency models for head movement prediction in 360-degree images using cnn-based fusion,” ISCAS, 2020.
- [183] D. Chen, C. Qing, X. Xu, and H. Zhu, “Salbinet360: Saliency prediction on 360∘ images with local-global bifurcated deep network,” VR, 2020.
- [184] Y. Zhu, G. Zhai, X. Min, and J. Zhou, “The prediction of saliency map for head and eye movements in 360 degree images,” IEEE TMM, 2020.
- [185] F.-Y. Chao, L. Zhang, W. Hamidouche, and O. Déforges, “Salgan360: Visual saliency prediction on 360 degree images with generative adversarial networks,” ICME Workshop, 2018.
- [186] J. Pan, C. Canton-Ferrer, K. McGuinness, N. E. O’Connor, J. Torres, E. Sayrol, and X. G. i Nieto, “Salgan: Visual saliency prediction with generative adversarial networks,” arXiv, 2017.
- [187] D. Zhu, Y. Chen, T. Han, D. Zhao, Y. Zhu, Q. Zhou, G. Zhai, and X. Yang, “Ransp: Ranking attention network for saliency prediction on omnidirectional images,” ICME, 2020.
- [188] D. Zhu, Y. Chen, D. Zhao, Q. Zhou, and X. Yang, “Saliency prediction on omnidirectional images with attention-aware feature fusion network,” Appl. Intell., 2021.
- [189] M. Assens, X. G. i Nieto, K. McGuinness, and N. E. O’Connor, “Saltinet: Scan-path prediction on 360 degree images using saliency volumes,” ICCV Workshop, 2017.
- [190] B. Zhou, A. Khosla, À. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” CVPR, 2016.
- [191] P. Kellnhofer, A. Recasens, S. Stent, W. Matusik, and A. Torralba, “Gaze360: Physically unconstrained gaze estimation in the wild,” in CVPR, 2019.
- [192] Y. Li, W. Shen, Z. Gao, Y. Zhu, G. Zhai, and G. Guo, “Looking here or there? gaze following in 360-degree images,” ICCV, 2021.
- [193] Y. Xu, Y. Dong, J. Wu, Z. Sun, Z. Shi, J. Yu, and S. Gao, “Gaze prediction in dynamic 360∘ immersive videos,” CVPR, 2018.
- [194] C. Wu, R. Zhang, Z. Wang, and L. Sun, “A spherical convolution approach for learning long term viewport prediction in 360 immersive video,” in AAAI, 2020.
- [195] P. Morgado, N. Vasconcelos, T. R. Langlois, and O. Wang, “Self-supervised generation of spatial audio for 360 video,” in NeurIPS, 2018.
- [196] P. Morgado, Y. Li, and N. Nvasconcelos, “Learning representations from audio-visual spatial alignment,” NeurIPS, 2020.
- [197] Y. Masuyama, Y. Bando, K. Yatabe, Y. Sasaki, M. Onishi, and Y. Oikawa, “Self-supervised neural audio-visual sound source localization via probabilistic spatial modeling,” IROS, 2020.
- [198] A. B. Vasudevan, D. Dai, and L. V. Gool, “Semantic object prediction and spatial sound super-resolution with binaural sounds,” in ECCV, 2020.
- [199] F.-Y. Chao, C. Ozcinar, L. Zhang, W. Hamidouche, O. Déforges, and A. Smolic, “Towards audio-visual saliency prediction for omnidirectional video with spatial audio,” VCIP, 2020.
- [200] F.-Y. Chao, C. Ozcinar, C. Wang, E. Zerman, L. Zhang, W. Hamidouche, O. Déforges, and A. Smolic, “Audio-visual perception of omnidirectional video for virtual reality applications,” ICME Workshop, 2020.
- [201] S.-H. Chou, W.-L. Chao, W.-S. Lai, M. Sun, and M.-H. Yang, “Visual question answering on 360deg images,” in WACV, 2020.
- [202] F. Liu, T. Xiang, T. M. Hospedales, W. Yang, and C. Sun, “Inverse visual question answering: A new benchmark and vqa diagnosis tool,” IEEE TPAMI, 2020.
- [203] A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.” ICLR, 2017.
- [204] G. D. Pais, T. J. Dias, J. C. Nascimento, and P. Miraldo, “Omnidrl: Robust pedestrian detection using deep reinforcement learning on omnidirectional cameras*,” 2019 International Conference on Robotics and Automation (ICRA), 2019.
- [205] A. Kittel, P. Larkin, I. Cunningham, and M. Spittle, “360 virtual reality: A swot analysis in comparison to virtual reality,” Frontiers in Psychology, 2020.
- [206] H. Kim, L. Hernaggi, P. J. B. Jackson, and A. Hilton, “Immersive spatial audio reproduction for VR/AR using room acoustic modelling from 360∘ images,” in VR, 2019.
- [207] Y. Heshmat, B. Jones, X. Xiong, C. Neustaedter, A. Tang, B. E. Riecke, and L. Yang, “Geocaching with a beam: Shared outdoor activities through a telepresence robot with 360 degree viewing,” CHI Conference on Human Factors in Computing Systems, 2018.
- [208] J. Zhang, “A 360∘ video-based robot platform for telepresent redirected walking,” in VAM-HRI, 2018.
- [209] G. Pudics, M. Z. Szabo-Resch, and Z. Vámossy, “Safe robot navigation using an omnidirectional camera,” CINTI, 2015.
- [210] L. Ran, Y. Zhang, Q. Zhang, and T. Yang, “Convolutional neural network-based robot navigation using uncalibrated spherical images †,” Sensors (Basel, Switzerland), 2017.
- [211] S. S. Mansouri, P. S. Karvelis, C. Kanellakis, D. Kominiak, and G. Nikolakopoulos, “Vision-based mav navigation in underground mine using convolutional neural network,” IECON, 2019.
- [212] D. Sun, X. Huang, and K. Yang, “A multimodal vision sensor for autonomous driving,” in Counterterrorism, Crime Fighting, Forensics, and Surveillance Technologies III, 2019.
- [213] J. Beltrán, C. Guindel, I. Cortés, A. Barrera, A. Astudillo, J. Urdiales, M. Álvarez, F. Bekka, V. Milanés, and F. García, “Towards autonomous driving: a multi-modal 360∘ perception proposal,” in ITSC, 2020.
- [214] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in CVPR, 2020.
- [215] X. Zhang, Z. Li, Y. Gong, D. Jin, J. Li, L. Wang, Y. Zhu, and H. Liu, “Openmpd: An open multimodal perception dataset for autonomous driving,” IEEE Trans. Veh. Technol., 2022.
- [216] V. R. Kumar, S. Yogamani, H. Rashed, G. Sitsu, C. Witt, I. Leang, S. Milz, and P. Mäder, “Omnidet: Surround view cameras based multi-task visual perception network for autonomous driving,” IEEE Robot. Autom. Lett., 2021.
- [217] Z. Yan, X. Li, K. Wang, Z. Zhang, J. Li, and J. Yang, “Multi-modal masked pre-training for monocular panoramic depth completion,” arXiv, 2022.
- [218] J. Li, H. Li, and Y. Matsushita, “Lighting, reflectance and geometry estimation from 360∘ panoramic stereo,” CVPR, 2021.
- [219] Y. Zhang, Y. Liu, J. Liu, P. Zhan, L. Wang, and Z. Xu, “Sp attack: Single-perspective attack for generating adversarial omnidirectional images,” in ICASSP, 2022.
- [220] S. Wang, W. Zeng, X. Chen, Y. Ye, Y. Qiao, and C.-W. Fu, “Actfloor-gan: Activity-guided adversarial networks for human-centric floorplan design,” TVCG, 2021.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3551c971-00b5-4fde-a909-38f32b800811/haoai.jpg) |
Hao Ai is a Ph.D. student in the Visual Learning and Intelligent Systems Lab, Artificial Intelligence Thrust, Guangzhou Campus, The Hong Kong University of Science and Technology (HKUST). His research interests include pattern recognition (image classification, face recognition, etc.), DL (especially uncertainty learning, attention, transfer learning, semi- /self-unsupervised learning), omnidirectional vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3551c971-00b5-4fde-a909-38f32b800811/zidongcao.jpg) |
Zidong Cao is a research assistant in the Visual Learning and Intelligent Systems Lab, Artificial Intelligence Thrust, Guangzhou Campus, The Hong Kong University of Science and Technology (HKUST). His research interests include 3D vision (depth completion, depth estimation, etc.), DL (self-supervised learning, weakly-supervised learning, etc.) and omnidirectional vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3551c971-00b5-4fde-a909-38f32b800811/jinjingzhu.jpg) |
JinJing Zhu is a Ph.D. student in the Visual Learning and Intelligent Systems Lab, Artificial Intelligence Thrust, Guangzhou Campus, The Hong Kong University of Science and Technology (HKUST). His research interests include CV (image classification, person re-identification, action recognition, etc.), DL (especially transfer learning, knowledge distillation, multi-task learning, semi-/self-unsupervised learning, etc.), omnidirectional vision, and event-based vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3551c971-00b5-4fde-a909-38f32b800811/haotianbai.jpg) |
Haotian Bai is a research assistant at Visual Learning and Intelligent Systems Lab, AI Thrust, Information Hub, Guangzhou Campus, The Hong Kong University of Science and Technology (HKUST). His research interests include 3D reconstruction (e.g., human and room), CV(especially attention, unsupervised/weakly supervised learning, and domain adaptation), and causal inference. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3551c971-00b5-4fde-a909-38f32b800811/yuchengchen.jpg) |
Yucheng Chen is a Mphil student in the Visual Learning and Intelligent Systems Lab, Artificial Intelligence Thrust, Guangzhou Campus, The Hong Kong University of Science and Technology (HKUST). Her research interests include low-level vision (neural rendering, reflection removal, etc.), DL (especially domain adaptation, transfer learning, semi- /self-unsupervised learning), omnidirectional vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3551c971-00b5-4fde-a909-38f32b800811/wanglin.jpg) |
Lin Wang is an assistant professor in the Artificial Intelligence Thrust, HKUST GZ Campus, HKUST Fok Ying Tung Research Institute, and an affiliate assistant professor in the Dept. of CSE, HKUST, CWB Campus. He got his PhD degree with honor from Korea Advanced Institute of Science and Technology (KAIST). His research interests include computer vision/graphics, machine learning and human-AI collaboration. |