Deep Neural Network Identification of Limnonectes Species and New Class Detection Using Image Data
Abstract
As is true of many complex tasks, the work of discovering, describing, and understanding the diversity of life on Earth (viz., biological systematics and taxonomy) requires many tools. Some of this work can be accomplished as it has been done in the past, but some aspects present us with challenges which traditional knowledge and tools cannot adequately resolve. One such challenge is presented by species complexes in which the morphological similarities among the group members make it difficult to reliably identify known species and detect new ones. We address this challenge by developing new tools using the principles of machine learning to resolve two specific questions related to species complexes. The first question is formulated as a classification problem in statistics and machine learning and the second question is an out-of-distribution (OOD) detection problem. We apply these tools to a species complex comprising Southeast Asian stream frogs (Limnonectes kuhlii complex) and employ a morphological character (hind limb skin texture) traditionally treated qualitatively in a quantitative and objective manner. We demonstrate that deep neural networks can successfully automate the classification of an image into a known species group for which it has been trained. We further demonstrate that the algorithm can successfully classify an image into a new class if the image does not belong to the existing classes. Additionally, we use the larger MNIST dataset to test the performance of our OOD detection algorithm. We finish our paper with some concluding remarks regarding the application of these methods to species complexes and our efforts to document true biodiversity. This paper has online supplementary materials.
Key Words: Convolutional Neural Network; Frogs; Image Classification; Out of Distribution Detection; Species Complex; Tuberculation.
1 Introduction
1.1 Background and Motivation
We are facing a biodiversity crisis. At present we have discovered, identified, and described only a very small fraction of the organisms with which we share this planet (e.g., \citeNPSweetlove2011). Unfortunately, because of habitat loss, climate change, and other anthropogenic influences, it is likely that we will lose this diversity faster than we can recognize it (e.g., \shortciteNPCowieetal2022). Our ability to accurately identify and delineate biological diversity is critically important because it influences our understanding of true biological richness and informs conservation efforts to safeguard these natural resources. Two critical tasks involved in understanding biological diversity are (1) the ability to correctly identify an individual organism to the taxonomic rank of species, and (2) the ability to detect individuals that may represents new species that are undescribed and therefore unrecognized by the scientific community. Traditionally, we have relied on the expertise of taxonomic specialists who drew from an understanding of morphology and natural history to identify new species. In recent decades, tools such as DNA sequencing and phylogenetic analyses have been employed by systematists in this pursuit. These new methods have advanced our rate of species discovery (e.g., \shortciteNPYAMASAKI2017177) and revealed species complexes in which morphological similarity has obfuscated true diversity (e.g., \shortciteNPFreudensteinetal2016).
We consider a species complex to be a group of two or more phylogenetically related species-level taxa that share such morphological similarity that group members cannot easily be distinguished from one another (\shortciteNPScherzetal2019 and \shortciteNPdeSousa-Paulaetal2021). Examples of species complexes can be found across all domains of life and present unique challenges to taxonomists and conservation biologists alike who would benefit from a new suite of tools that facilitate the recognition and detection of both known and unknown species.
In this paper, we focus on one such species complex comprising a group of Southeast Asian stream frogs. The frogs allied to the Limnonectes kuhlii (abbreviated as L. kuhlii) complex were considered to be a single species for about 200 years. Broadly distributed throughout Southeast Asia these frogs share a tremendous amount of morphological and ecological similarities. On the basis of DNA evidence alone, molecular phylogenetic studies (e.g., \shortciteNPYeetal2007, \citeNPMcLeod2008, \citeNPMCLEOD2010, \shortciteNPMatsuietal2010, and \shortciteNPStuartetal2020) recovered more than 22 unique evolutionary lineages representing potentially new species within the L. kuhlii complex. Using these data in combination with morphological evidence, subsequent taxonomic studies have described several new species from within the L. kuhlii complex (e.g., L. megastomias in \citeNPMcLeod2008, L. nguyenorum in \shortciteNPMcLeodetal2012, L. isanensis in \shortciteNPSuwannapoometal2017, and L. fastigatus in \shortciteNPStuartetal2020). Figure 1 shows four examples of frogs from four different clades (i.e., lineages).
Despite these advances, delineating species boundaries and describing additional new species within this complex has been confounded by the high degree of morphological similarity among the genetically distinct lineages. One of the diagnostic morphological characters that has proven useful in distinguishing between species in the L. kuhlii complex is the texture of the skin on the frog’s hind legs. This texture (created by the patterning of raised tubercles) is traditionally described qualitatively on the spectra of “smooth to rough” or “dense to sparse”, but without quantification of any kind. The pattern of tuberculation is consistent within a species but varies between species (\shortciteNPMcLeodetal2011, \shortciteNPMcLeodetal2012, and \shortciteNPStuartetal2020). The consistent yet subjectively qualitative nature of this character opens the door for applying machine-learning-based methods to standardize and automate species recognition and the detection of new species. Thus our specific research questions in this paper are: 1) whether machine-learning methods can use a qualitative character, such as the pattern of tuberculation on frog legs, to classify individuals into known classes (viz., species), and 2) whether a machine-learning-based tool can be developed to detect new classes (viz., new species). Figure 2 shows examples of the texture of the frog legs from the four clades for the four samples as shown in Figure 1, which highlights visible differences in tubercle structure on the hind limbs.
 |
 |
| (a) Clade 4 | (b) Clade 5 |
 |
 |
| (c) Clade 8 | (d) Clade 12 |
 |
 |
 |
 |
| (a) Clade 4 | (b) Clade 5 | (c) Clade 8 | (d) Clade 12 |
1.2 Research Questions
The first research question can be formulated as an image classification problem. Thus, deep-learning techniques can be applied. Deep learning has proven to be a powerful tool in resolving image classification problems across diverse applications (e.g., \shortciteNPKrizhevskyetal2012, and \citeNPRawatetal2017). \shortciteNNorouzzadehetal2018 applied a deep-learning method to monitor wildlife using camera-trap images, and \shortciteNWangetal2021 applied deep-learning algorithm on CT images to screen for COVID-19 disease. Whereas the application of machine learning is commonly used in species identification (e.g., iNaturalist, www.inaturalist.org, and PictureThis, www.picturethisai.com) and there has been some application of machine-learning and deep-learning methods to detect species from audio files of frog calls (e.g., \shortciteNPHuangetal2009, \shortciteNPHassanetal2017, and \shortciteNPXieetal2017), no study has applied these methods to problems associated with species complexes and new species detection. In this paper, we develop a convolutional neural network (CNN) model that can serve as an automatic identifier or classifier based on image/pattern recognition. This tool works in such a way that a photograph of an individual frog can be classified into one of the existing species using an existing set of images.
The second research question can be formulated as an out-of-distribution detection (OOD) problem (e.g., \shortciteNPhendrycks2017a, and \shortciteNPliang2018enhancing). The developed new class detection (NCD) tool allows for an image to be “rejected”, suggesting the detection of a potential new species. CNN and OOD techniques are well developed in the machine-learning discipline. For example, \shortciteNLeeetal2018 presents a simple unified framework for detecting OOD samples under the setting of adversarial attacks to neural network. The applications of CNN and OOD tools to biological research in the context of species complexes are new, and our approach provides quantitative tools to biological scientists working in the area. Our NCD methods extend the framework in \shortciteNLeeetal2018 and customize it for the frog NCD problem.
1.3 Overview
The rest of the paper is organized as follows. Section 2 describes the collection and preprocessing of the frog image data used in this study. Section 3 describes the CNN model for classification and describes a new method for NCD. Section 4 presents the classification and NCD results for the frog datasets and the NCD results for the MNIST dataset (\citeNPDeng2012) for further validation. Section 5 contains some concluding remarks.
2 Description of Image Data and Preprocessing
In this paper, we use image data collected from a subset of lineages identified as part of the Limnonectes kuhlii complex (\citeNPMCLEOD2010). We chose to build our neural network using samples representing lineages 4 (Limnonectes fastigatus, \shortciteNPStuartetal2020), 5 (Limnonectes kiziriani, \shortciteNPPhametal2018), 8 (Limnonectes bannaensis, \shortciteNPYeetal2007), and 12 (Limnonectes taylori, \shortciteNPMatsuietal2010) based on the relatively large number of sample images available. A cleaned subset of those images is used to develop and evaluate the classifier for the species.
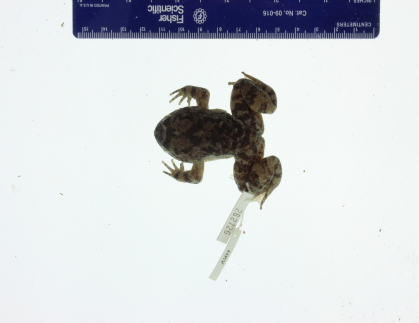
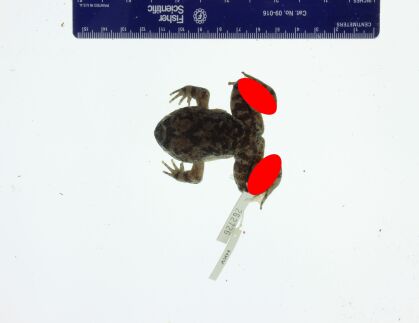
Our first question is whether a deep-learning algorithm applied to the texture (tuberculation) of the skin on the hind legs complex can successfully differentiate among species in the L. kuhlii complex. We therefore focus on images of the legs of the frogs. In order to utilize these raw images, some data preprocessing is needed to ensure consistency among the images. We found that raw specimen photographs vary in clarity due to noise factors such as the inclusion of scale bars and specimen tags as shown in Figure 3(a). In order to reduce image noise we cropped out the legs of the frog (indicated by two red ellipses in Figure 3(b)). We first manually label the two frog legs with red ellipses. Then the red part is cropped as shown in Figure 3(c). In addition, the white background is replaced by black as shown in Figure 3(d). To increase the sample size, the left and right legs are treated as two different images after pre-processing. Those images with legs obstructed by noise items, for example, specimen tags, or non-specimen structures such as human fingers, were removed from the sample set. A summary of image counts is given in Table 1. In total, we have 193 images, which we consider to be a moderate sample size for implementing some deep-learning models.
 |
 |
| (a) Original Image | (b) Leg Mark |
 |
 |
| (c) Legs with Mixed Background | (d) Adjusted Black Background |
After the image pre-processing, we resize our images to be in color pixels. For each individual pixel, there are three channels for red, green, and blue color components, with numbers ranging from 0 to 255. For example, represents a white pixel and represents a black pixel. Thus, all the pixels in an image forms a 3-dimensional (3-D) tensor with size .
Some notations are needed for later development. The (3-D) image tensor with size is denoted as , where is the index for image. For notation convenience, we use a class label ranging from 1 to 4 to represent the clades, as shown in Table 1. For example, class label 1 corresponds to clade 4. We let be the class label of the image and takes values in , where is the number of label classes. Here, as shown in Table 1. The data are denoted by and is the index for the sample. The total number of samples/images is 193, as shown in Table 1.
| Clade | Clade 4 | Clade 5 | Clade 8 | Clade 12 | Total |
|---|---|---|---|---|---|
| Number of leg images | 44 | 22 | 77 | 50 | 193 |
| Class label | 1 | 2 | 3 | 4 |
3 Methods Development
3.1 Convolutional Neural Network for Classification
In this section, we develop a classifier that can predict the species based on frog leg images. We use on deep neural networks (e.g., \citeNPGoodfellowetal2016). In particular, we use the convolutional neural networks (CNN) for the prediction that can provide classification based directly on the images of frog legs. In the literature, the CNN has been found to be a powerful tool in image classification. A CNN consists of an input layer, an output layer, and multiple hidden layers. The hidden layers consist of convolutional layers, pooling layers, and fully connected layers. Sometimes normalization layers and dropout layers are also used. More details can be found in Chapter 9 of \citeNGoodfellowetal2016.
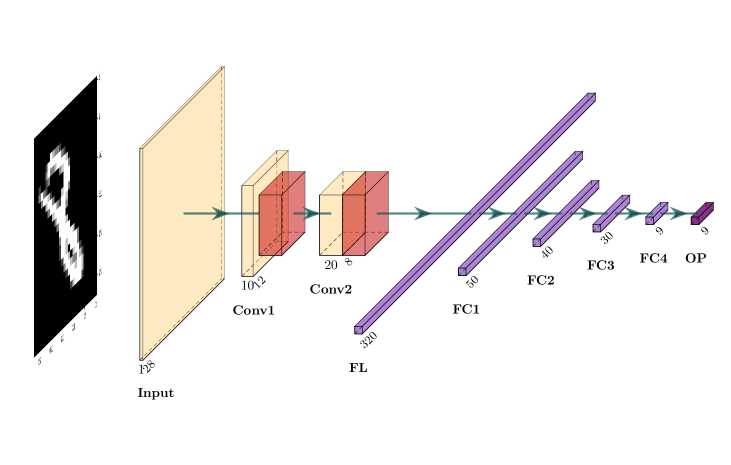
Here we introduce the network architecture used for the frog images. Figure 4 illustrates the structure of the CNN used in this paper, which is a relatively simple structure due to the limited number of images, compared to the magnitude of tens of thousands of images in some other applications. We also tried CNN with more complicated structures. However, the prediction results are not getting better. For the CNN structure in Figure 4, the input image is , which is a tensor. The kernel size for the convolution is . After the convolution, we do maximum pooling. The kernel size for the maximum pooling is with a stride of to reduce the image size. Between each convolutional layer, batch normalization is applied. For each fully connected layer, the random dropout rate is set to 0.8.
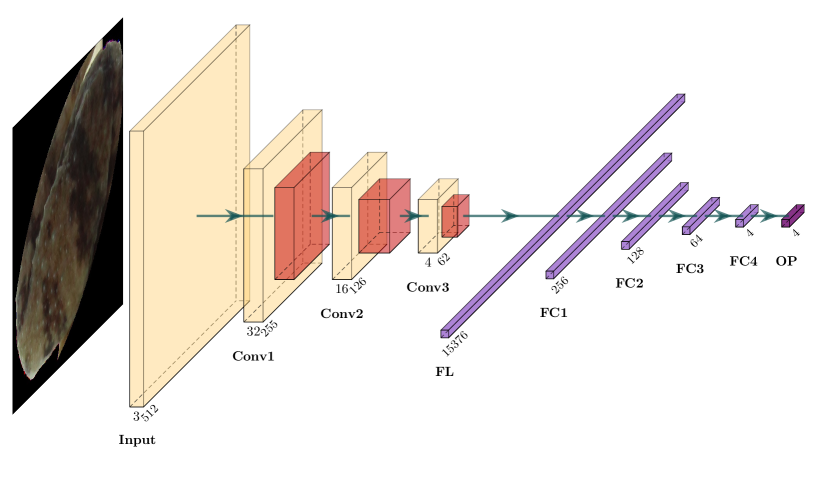
As shown in Figure 4, we have three convolutional layers after the input layer, which are labeled as Conv1, Conv2, and Conv3, respectively. The number of filters we use in Conv1, Conv2, and Conv3 are 32, 16, and 4, respectively. After application of Conv3, we obtain a tensor and it is flattened to a vector. The flattened vector then goes through four fully connected layers, labeled by FC1, FC2, FC3, and FC4, respectively. The lengths of those four output vectors are 256, 128, 64, and 4, respectively. For convenience, we denote the outputs of those fully connected layers by
| (1) |
respectively. Here, is the index for the input image. In the output layer, as labeled “OP” in Figure 4, we use the softmax function to map to a probability. That is
| (2) |
where . Here, is the index for class label.
Let be the set of indexes for samples used in model training and let be the set of indexes for samples used in testing. Note that we do not have a validation set because of the small sample size and the fact that we do not have hyper-parameters in the model training. Let be the set of all parameters in the CNN model. The categorical entropy is used as the loss function, that is,
| (3) |
where and is the indicator function. PyTorch (\shortciteNPPyTorch) is used for training the model to find the that minimizes the loss function.
To measure the model prediction accuracy, we use -fold cross validation. We have an unbalanced classification problem. If we split the data randomly across all four species, the training set may not have all four species. To ensure that all four species are in our training set and the testing set consists of equal proportions from each of the four species for each fold, we use a balanced cross validation. For each species with class label , we denote the index set by . The process for balanced cross validation is described as follows.
By using a balanced cross validation, we can ensure that each class always appears in both the training and testing sets.
3.2 New Class Detection
In this section, we describe our algorithms for new class detection (NCD) for frog species. To evaluate the performance of our NCD algorithm, we take one of the classes in frog clades, say class , as the samples from the out-of-distribution (OOD) population. Then the rest of the three classes are used to build the model.
For a trained deep-learning model, the outputs of the intermediate layers, such as those in (1), represent the extracted features from the sample. If a new sample does not belong to one of existing classes in the training set, then one would expect those extracted features would be different from those features from samples from existing classes. Thus, detecting new classes based on the outputs of intermediate layers can be treated as detecting outliers based on these multivariate outputs. Similar ideas have been used in the literature (e.g., \shortciteNPLeeetal2018). In this paper, we customize this idea for the our frog species detection problem and use parametric discriminant analyses for NCD.
Suppose we already have a trained deep neural network classification model, such as the one in Figure 4 (but with 3 outputs for FC4 and OP layers to match the dimension). Let be one of those outputs in (1). For those three classes that used for modeling for the frog data, we split them into the training set () and the testing set (). The samples that we set aside for OOD testing is denoted by . We prepare three datasets for the NCD problem.
Then we assume given class follows a multivariate normal distribution. That is, the distribution of is modeled as , where the mean is estimated by
| (4) |
Here is the number of samples in and is the number of samples in .
For the OOD detection, we consider both linear discriminate analysis (LDA) and quadratic discriminant analysis (QDA). For LDA, the variance-covariance matrix are estimated by
| (5) |
which is common across all class labels. For QDA, each class has different , which is
Note that the estimate for the variance-covariance matrix, , may not be positive definite. In such cases, we use the estimator from \citeNLEDOIT2004365, which works for non-positive definite cases by modifying the sample covariance matrix as,
| (6) |
Here in (6) is the identical matrix, and are are scalars. Note that is a nonnegative definite matrix and adding to its diagonal terms will make positive definite.
Specifically, are are determined by the following optimization problem,
| (7) |
Here is the squared Frobenius norm for matrices, and the expectation is taken with respect to the distribution . The idea behind (7) is to find a matrix that is guaranteed to be positive definite and it is as close to as possible.
Intuitively, those ’s from the OOD samples should be far away from the center of distribution of , while those ’s from the ID samples should be close to the center of distribution of , Thus, we use the Mahalanobis distance-based confidence score of to measure the distance of to its nearest class (e.g., \shortciteNPDenouden2018ImprovingRA). That is, for LDA, we compute
and for QDA, we compute
For a sample with that is beyond a threshold, it will classified as a new class. So the data for the NCD problem is denoted as . We train a logistic regression model as
| (8) |
where is the probability. With the logistic regression and the area under the receiver operating characteristic curve (AUC), a threshold can be determined. Note that to learn the logistic model, training samples from the OOD set are needed.
4 Data Analysis Results
In this section, we presents numeric results for the frog data by applying the methods described in Section 3. Because the frog dataset is relatively small, we also use a larger dataset, namely the MNIST data (\citeNPDeng2012), for illustration of the NCD methods and providing more insights.
4.1 Model Testing Results on Frog Data
We first fit the CNN model as in Figure 4 to all the frog image data as summarized in Table 1. We use balanced cross validation as described in Section 3.1 with , which leads to 80% for training and 20% for testing. Table 2 shows the accuracy of each fold and the overall accuracy for the testing set is around 73.1%, which is reasonably good, given that the size of training set is only around 150. To gain insights on mis-classifications, Table 3 shows the overall confusion matrix. We can see that the model mainly mis-classifies clades 4 and 5 to other clades, which may be caused by limited sample size.
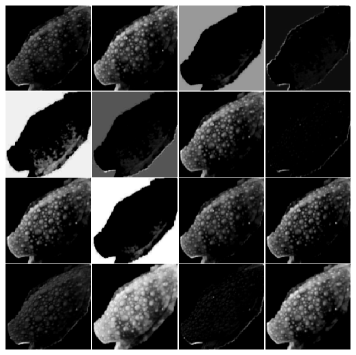
We also plot some output of intermediate layers of the CNN model. Figure 5 plots an input image from one frog and the output of the last two convolution layers (i.e., Conv2 and Conv3) in the CNN model from the input frog image. We can see that different filters pick up different features from the image. Especially from Figure 5(c), we can see that the tuberculation of frog leg are activated in the CNN model, which provides insight that the tuberculation can contribute to classification of frog clades.
| Cross Validation Fold | 1 | 2 | 3 | 4 | 5 | Overall |
|---|---|---|---|---|---|---|
| Accuracy | 0.775 | 0.675 | 0.789 | 0.711 | 0.703 | 0.731 |
| Predicted | |||||
|---|---|---|---|---|---|
| True | Clade 4 | Clade 5 | Clade 8 | Clade 12 | |
| Clade 4 | 27 | 0 | 6 | 11 | |
| Clade 5 | 1 | 9 | 10 | 2 | |
| Clade 8 | 1 | 2 | 70 | 4 | |
| Clade 12 | 8 | 0 | 6 | 35 | |
 |
 |
| (a) Input layer | (b) Conv2: 16-unit layer |
 |
|
| (c) Conv3: 4-unit layer | |
4.2 OOD Testing Results on Frog Data with One OOD Clade
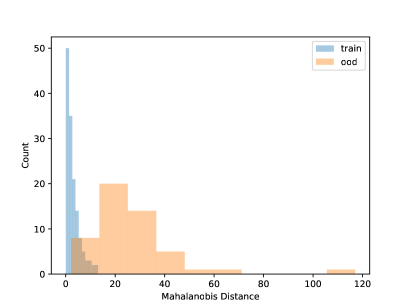
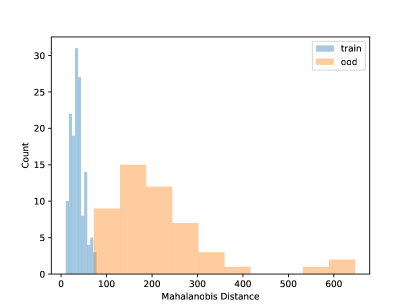
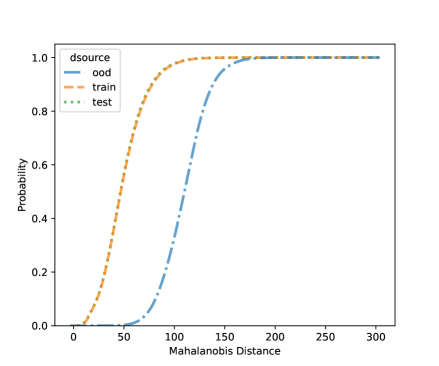
Using the CNN model built in Section 4.1, in this section, we conduct some OOD detections for the frog data with one OOD clade. The data splitting strategy is as described in Section 3.2. That is, we set one clade as the OOD sample and the rest to build the CNN model. Table 4 shows the fitting metrics based on the LDA on the frog data, with each species left out as OOD in each column. The accuracy of detecting OOD samples is high but also depends on the OOD sample size. Generally, more OOD samples will have satisfactory OOD accuracy. Figure 6 shows the visualization of the NCD for clade 5. We can see that the distribution of known species and new species is different. But for the layers with 3 and 64 units, there are no major gaps between the two distributions, which shows it is challenging to do NCD. One reason could be due to the small sample sizes of the OOD sets. Because of the limited sample size, we do not fit the QDA model because the covariance matrix can not be robustly estimated for each class.
| OOD Clade | Clade 4 | Clade 5 | Clade 8 | Clade 12 |
| Number of Legs | 44 | 22 | 77 | 50 |
| Model Building Clades | 5, 8, 12 | 4, 8, 12 | 4, 5, 12 | 4, 5, 8 |
| AUC | 0.963 | 0.791 | 0.969 | 0.999 |
| Confusion matrix |
 |
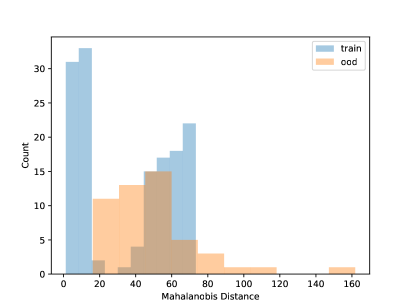 |
| (a) FC4: 3-unit layer | (b) FC3: 64-unit layer |
 |
|
| (c) FC1: 128-unit layer | |
4.3 OOD Testing Results on Frog Data with Multiple OOD Clades
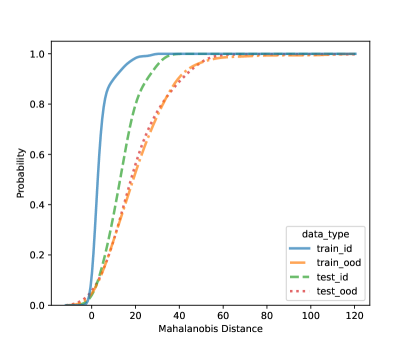
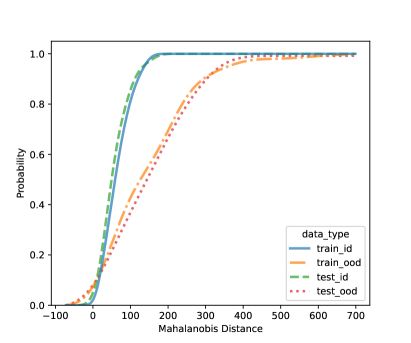
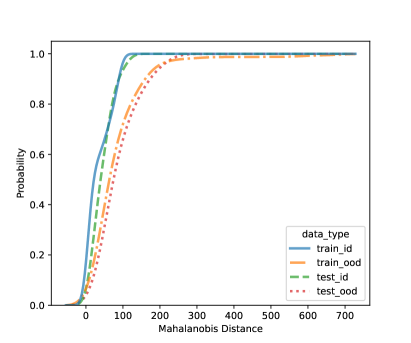
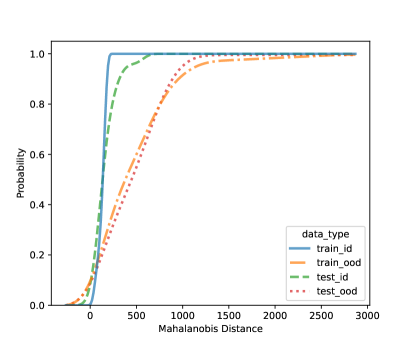
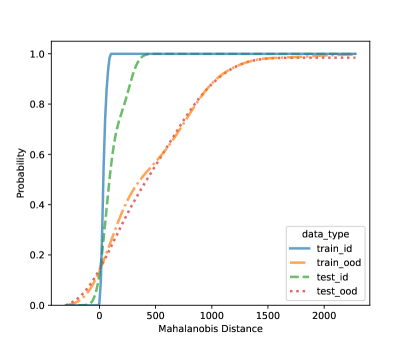
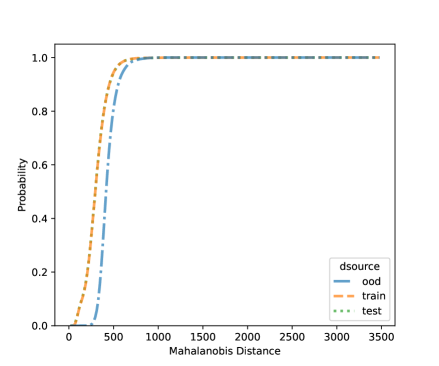
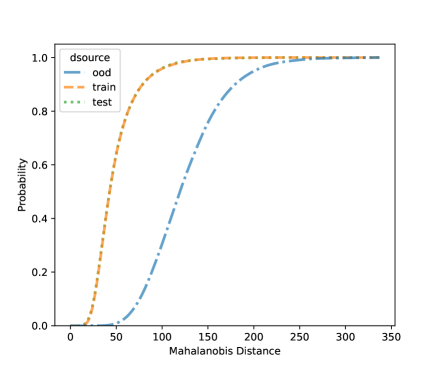
In this section, we present additional results on OOD detection because some new samples were gathered, especially for clades 10, 11, 16, 18, 20, and 21. Because of the availability of additional images on multiple new clades other than clades 4, 5, 8, and 12, we can form an OOD class from multiple OOD clades from those new clades. In particular, the leg image counts for those new clades are 24, 9, 40, 61, 28, and 27, respectively. In total, we have 189 leg images for the OOD class. This section uses images from clades 4, 5, 8, and 12 to train the CNN model, as shown in Figure 4. Figure 7 shows the cumulative distribution of Mahalanobis distance of different fully-connected layers for the LDA and QDA methods. We see that the QDA procedure has slightly better classification power. Table 5 shows the metrics for LDA and QDA for OOD detection based on the frog data. We can see that the QDA method has better overall performance when considering AUC, true positive rate (TPR), and true negative rate (TNR). Overall, the OOD detection ability is good based on the multiple OOD clade data, though there is still room for improvement.
 |
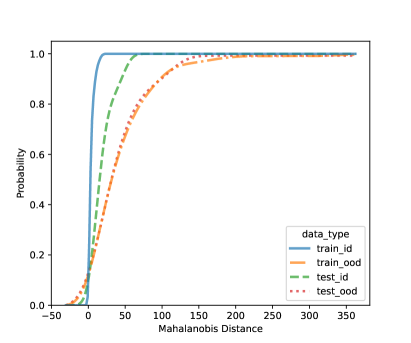 |
| (a) LDA based on FC4: 4-unit layer | (b) QDA based on FC4: 4-unit layer |
 |
 |
| (c) LDA based on FC3: 64-unit layer | (d) QDA based on FC3: 64-unit layer |
 |
 |
| (e) LDA based on FC1: 128-unit layer | (f) QDA based on QDA FC1: 128-unit layer |
| LDA | QDA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Metric | Fitting | Prediction | Metric | Fitting | Prediction | ||||
| AUC | 0.975 | 0.747 | AUC | 0.912 | 0.750 | ||||
| TPR | 0.870 | 0.947 | TPR | 0.758 | 0.789 | ||||
| TNR | 0.961 | 0.208 | TNR | 0.942 | 0.416 | ||||
4.4 OOD Testing Results on the MNIST Data
To better study the performance of our NCD methods, we further test our method by using the much larger MNIST image dataset in \citeNDeng2012, which has tens of thousands of images. The MNIST data are images of handwritten numbers. Although the frog images and MNIST images look different, the general idea of using the features extracted from CNN to do the OOD detection can be applied to different types of image data. Because the input image of the MNIST data is different (much simpler to some extent) from the frog images, we need to slightly modify our CNN model. In particular, we use the CNN architecture as shown in Figure 9, with fewer layers than the CNN for the frog data.
 |
 |
 |
| (a) Clade 10 | (b) Clade 11 | (c) Clade 16 |
 |
 |
 |
| (d) Clade 18 | (e) Clade 20 | (f) Clade 21 |
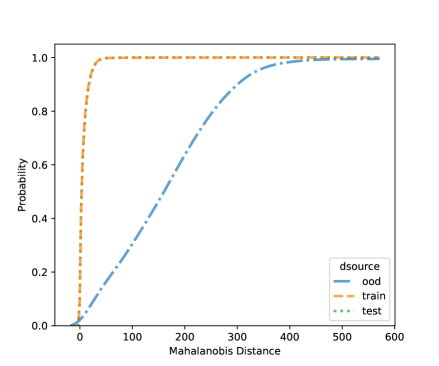
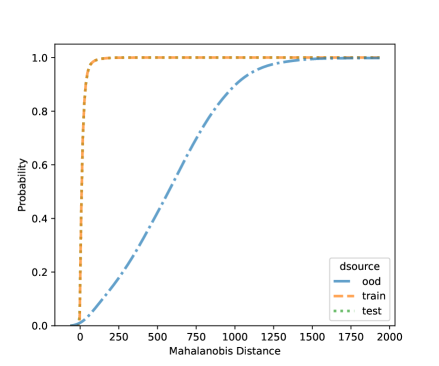
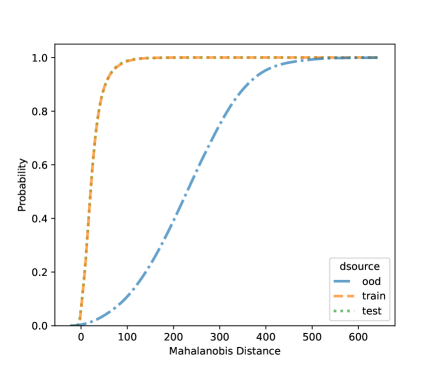
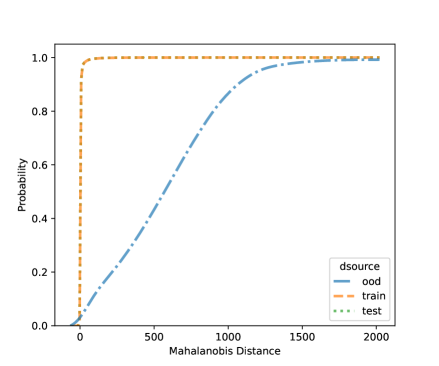
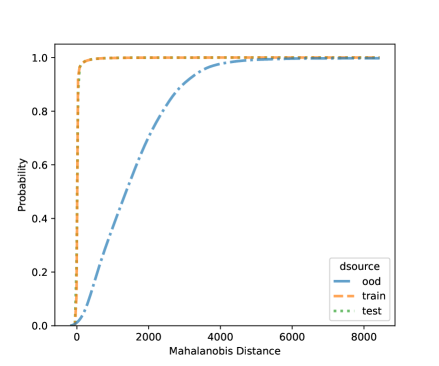
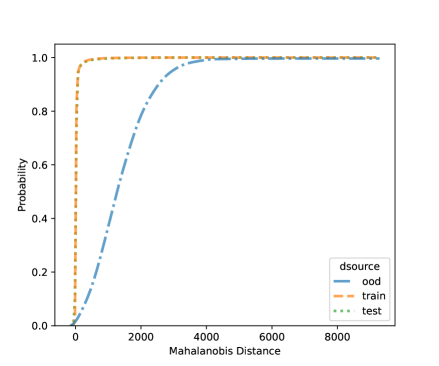
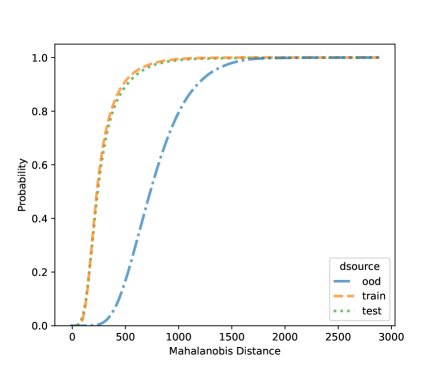
For NCD of the MNIST, we now can consider both classification methods, LDA and QDA. Figures 10 and 11 shows the distribution of the Mahalanobis distance using the MNIST data based on LDA and QDA where the number “9” is left out as OOD. The distribution of the layer’s output of OOD is significantly different from the training and testing data. We see that the QDA procedure has better classification power on layers with 320 and 50 outputs while LDA is better on the final fully connected layer with 8 outputs. One simple idea is when building a logistic model, use the QDA Mahalanobis distance from the layers with 320 and 50 outputs, and the LDA distance from the layer with 8 outputs. Table 6 shows the accuracy results for the LDA and QDA in terms of AUC, TPR, and TNR, based on the MNIST data. We can see that both LDA and QDA have good accuracy for detecting new classes, and QDA has better prediction accuracy than the LDA especially as measured by TPR. In addition, QDA’s performance is more stable when the OOD classes are changing.
 |
 |
| (a) FC4: 9-unit layer | (b) FC3: 30-unit layer |
 |
 |
| (c) FC2: 40-unit layer | (d) FC1: 50-unit layer |
 |
|
| (e) FL: 320-unit layer | |
 |
 |
| (a) FC4: 9-unit layer | (b) FC3: 30-unit layer |
 |
 |
| (c) FC2: 40-unit layer | (d) FC1: 50-unit layer |
 |
|
| (e) FL: 320-unit layer | |
| OOD Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN Accuracy | 0.980 | 0.971 | 0.980 | 0.733 | 0.979 | 0.867 | 0.976 | 0.928 | 0.974 | 0.984 | |
| LDA | AUC | 0.973 | 0.989 | 0.988 | 0.986 | 0.983 | 0.993 | 0.997 | 0.990 | 0.993 | 0.996 |
| TPR | 0.581 | 0.825 | 0.774 | 0.843 | 0.786 | 0.877 | 0.943 | 0.819 | 0.875 | 0.893 | |
| TNR | 0.979 | 0.987 | 0.988 | 0.990 | 0.994 | 0.995 | 0.998 | 0.993 | 0.994 | 0.996 | |
| QDA | AUC | 0.991 | 0.993 | 0.991 | 0.988 | 0.996 | 0.992 | 0.999 | 0.994 | 0.998 | 0.993 |
| TPR | 0.855 | 0.851 | 0.843 | 0.832 | 0.921 | 0.877 | 0.953 | 0.888 | 0.964 | 0.880 | |
| TNR | 0.984 | 0.992 | 0.985 | 0.985 | 0.993 | 0.988 | 0.998 | 0.994 | 0.994 | 0.994 | |
5 Concluding Remarks
In order for biodiversity conservation to be comprehensively successful we must be able to account for the species we are trying to protect. It is estimated that 86% of existing species on Earth and 91% of species in the ocean still await description (IUCN, www.iucn.org). Although progress towards species discovery, description, and conservation continues to be made, new tools are needed that will allow us address current and future challenges and impediments. Species complexes contribute to this taxonomic backlog because our current tools and knowledge are inadequate to completely resolve them. In an effort to address this, we applied deep learning methods to the morphologically similar, but genetically diverse group of frogs from Southeast Asia referred to the Limnonectes kuhlii complex.
Our first objective was to use the species-specific pattern of skin tuberculation in these frogs as the detection criterion. We chose this morphological feature intentionally to see if a traditionally qualitative character could be treated quantitatively, thereby eliminating the subjectivity of the human observer. Our second objective was to present the model with an “unknown” image and see if it could correctly detect it as a new class (viz., a potentially new and undescribed species). We endeavored to achieve these objectives using a small sample set (193 images representing four classes).
Our results suggest that a CNN model for image classification can achieve good accuracy in identifying a species based on observable, morphological characters. This is especially significant considering our use of a single trait and a limited sample size. Our model also succeeded in capturing a qualitative trait (tuberculation) and evaluating it in a consistent and quantitative manner. The ability to reliably and consistently quantify such a characteristic greatly reduces observer bias and provides a method for collecting standardized data that can be subjected to statistical analyses when evaluating the degree of similarity between two sample groups as is often done in traditional studies of comparative morphology. In an effort to increase the robustness of the CNN model in this application, future iterations could include additional morphological characteristics (e.g., head shape as suggested by \citeNPSchoen2020, and \shortciteNPStuartetal2020) and geospatial data. Ideally, future studies will expand the taxonomic breadth of the model to include all known species in the L. kuhlii complex and increase the sample size of images upon which the model is based. We also envision our model’s framework being applicable to species complexes within any taxon.
With respect to our second objective, our NCD algorithms show effectiveness in recognizing an unknown species, especially considering the limitations of our sample size. Because of the uniqueness of our application, it takes a significant amount of time and budgets to collect frog image data at a large scale. The small sample size problem also prevents us from using famous CNN structures such as VGG (e.g., \citeNPvgg16). Some research, however, suggests that CNN can also work well if the CNN structure is carefully chosen (e.g., \shortciteNPDsouzaetal2020). We expect the accuracy of our procedure to increase as the sample size increases, as demonstrated using the larger MNIST data. The ability to automate the detection of new species while simultaneously providing quantitative character-based evidence for the validity of the species would significantly facilitate and accelerate the processes of taxonomy.
Out research also suggests the need for establishing a public data repository for images. Considering that such repositories already exist (e.g, iNaturalist contains more than 70 million images and 138 million observations, www.inaturalist.org/observations), it is conceivable that these, or others like them could provide the data from which more accurate deep-learning models can be trained. For challenges such as those presented by species complexes, coordinated efforts among members of taxonomic working groups and museums could facilitate this by sharing open source data and images.
At present, anyone with a mobile electronic device (i.e., phone, tablet, etc.) can identify the species that commonly occur around them using mobile apps such as iNaturalist. This ability is facilitated by a platform that utilizes a computer vision model and an image set compiled by citizen scientists around the globe. However, corrections of species identifications still relies on a community of taxonomic experts who can visually vet the images and correct mistakes in identifications. App tools, such as Wildlife Spotter (https://wildspotter.org/), are excellent and have resulted in new species detection and discovery. We envision the refinement of those app tools with machine-learning methods, such as those developed in this paper, would have the ability to provide fine scale species resolution and the ability to correctly identify the members of a species complex. Moreover, we envision these tools to be capable of detecting and provide alerts when a potentially undescribed species is encountered.
Beyond our primary goals of species identification and detection, we also recognize that our results suggest that future research should explore the quantification of uncertainty in classification and NCD. With uncertainty quantification, our NCD methods could also be used for estimating detection probability for species abundance estimates (e.g., \shortciteNPMartin-Schwarzeetal2017), or determining whether a prediction is reliable (e.g., \shortciteNPHongetal2022) or robust (e.g., \shortciteNPLianetal2021Robustness) for AI algorithms.
Supplementary Materials
The following supplementary materials are available online.
- Code and data:
-
Computing code and the frog leg image data are available at GitHub repository “FrogLegImages”. The link to the repository is https://github.com/tgh1122334/FrogLegImages.
Acknowledgments
The authors thank the Editor, an Associate Editor, and an anonymous referee for providing helpful suggestions that improved this paper. This research was partially supported by 4-VA, a collaborative partnership for advancing the Commonwealth of Virginia, by National Science Foundation under Grant CNS-1650540 to Virginia Tech, and by the Virginia Tech College of Science Research Equipment Fund. The authors acknowledge the Advanced Research Computing program at Virginia Tech for providing computational resources. This study would not have been possible without the prior efforts of those who gathered specimens from the field and deposited them in accessible museum collections. Specimen loans to DSM were made possible by R. Brown, D. Kizirian, T. Nguyen, T. T. Nguyen, A. Ohler, A. Resetar, K. Thirakhupt, and J. Vindum. We also would like to thank the American Museum of Natural History, California Academy of Science, Chulalongkorn University Museum of Zoology, Field Museum of Natural History, Institute of Ecology and Biological Resources, Muséum National d’Histoire Naturelle, University of Kansas Biodiversity Institute, North Carolina State Museum of Natural Sciences, and the Vietnam National Museum of Nature for providing specimens. DSM also would like to acknowledge the Department of Biology at James Madison University, where some samples were collected.
Conflicts of Interests/Competing Interests
The authors have no conflicts of interests/competing interests.
References
- [\citeauthoryearCowie, Bouchet, and FontaineCowie et al.2022] Cowie, R. H., P. Bouchet, and B. Fontaine (2022). The sixth mass extinction: fact, fiction or speculation? Biological Reviews 97, 640–663.
- [\citeauthoryearde Sousa-Paula, Pessoa, Otranto, and Dantas-Torresde Sousa-Paula et al.2021] de Sousa-Paula, L. C., F. A. C. Pessoa, D. Otranto, and F. Dantas-Torres (2021). Beyond taxonomy: species complexes in new world phlebotomine sand flies. Medical and Veterinary Entomology 35, 267–283.
- [\citeauthoryearDengDeng2012] Deng, L. (2012). The MNIST database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine 29, 141–142.
- [\citeauthoryearDenouden, Salay, Czarnecki, Abdelzad, Phan, and VernekarDenouden et al.2018] Denouden, T., R. Salay, K. Czarnecki, V. Abdelzad, B. Phan, and S. Vernekar (2018). Improving reconstruction autoencoder out-of-distribution detection with Mahalanobis distance. ArXiv abs/1812.02765.
- [\citeauthoryearD’souza, Huang, and YehD’souza et al.2020] D’souza, R. N., P. Y. Huang, and F. C. Yeh (2020). Structural analysis and optimization of convolutional neural networks with a small sample size. Scientific Reports 10, 834.
- [\citeauthoryearFreudenstein, Broe, Folk, and SinnFreudenstein et al.2016] Freudenstein, J. V., M. B. Broe, R. A. Folk, and B. T. Sinn (2016). Biodiversity and the species concept – lineages are not enough. Systematic Biology 66, 644–656.
- [\citeauthoryearGoodfellow, Bengio, and CourvilleGoodfellow et al.2016] Goodfellow, I., Y. Bengio, and A. Courville (2016). Deep learning. MIT Press.
- [\citeauthoryearHassan, Ramli, and JaafarHassan et al.2017] Hassan, N., D. A. Ramli, and H. Jaafar (2017). Deep neural network approach to frog species recognition. In 2017 IEEE 13th International Colloquium on Signal Processing & its Applications (CSPA), pp. 173–178.
- [\citeauthoryearHendrycks and GimpelHendrycks and Gimpel2017] Hendrycks, D. and K. Gimpel (2017). A baseline for detecting misclassified and out-of-distribution examples in neural networks. In International Conference on Learning Representations.
- [\citeauthoryearHong, Lian, Xu, Min, Wang, Freeman, and DengHong et al.2023] Hong, Y., J. Lian, L. Xu, J. Min, Y. Wang, L. J. Freeman, and X. Deng (2023). Statistical perspectives on reliability of artificial intelligence systems. Quality Engineering 35, 56–78.
- [\citeauthoryearHuang, Yang, Yang, and ChenHuang et al.2009] Huang, C.-J., Y.-J. Yang, D.-X. Yang, and Y.-J. Chen (2009). Frog classification using machine learning techniques. Expert Systems with Applications 36, 3737–3743.
- [\citeauthoryearKrizhevsky, Sutskever, and HintonKrizhevsky et al.2012] Krizhevsky, A., I. Sutskever, and G. E. Hinton (2012). Imagenet classification with deep convolutional neural networks. In F. Pereira, C. Burges, L. Bottou, and K. Weinberger (Eds.), Advances in Neural Information Processing Systems, Volume 25.
- [\citeauthoryearLedoit and WolfLedoit and Wolf2004] Ledoit, O. and M. Wolf (2004). A well-conditioned estimator for large-dimensional covariance matrices. Journal of Multivariate Analysis 88(2), 365–411.
- [\citeauthoryearLee, Lee, Lee, and ShinLee et al.2018] Lee, K., K. Lee, H. Lee, and J. Shin (2018). A simple unified framework for detecting out-of-distribution samples and adversarial attacks. NIPS’18: Proceedings of the 32nd International Conference on Neural Information Processing Systems, 7167–7177.
- [\citeauthoryearLian, Freeman, Hong, and DengLian et al.2021] Lian, J., L. Freeman, Y. Hong, and X. Deng (2021). Robustness with respect to class imbalance in artificial intelligence classification algorithms. Journal of Quality Technology 53, 505–525.
- [\citeauthoryearLiang, Li, and SrikantLiang et al.2018] Liang, S., Y. Li, and R. Srikant (2018). Enhancing the reliability of out-of-distribution image detection in neural networks. In International Conference on Learning Representations.
- [\citeauthoryearMartin-Schwarze, Niemi, and DixonMartin-Schwarze et al.2017] Martin-Schwarze, A., J. Niemi, and P. Dixon (2017). Assessing the impacts of time-to-detection distribution assumptions on detection probability estimation. Journal of Agricultural, Biological and Environmental Statistics 22, 465–480.
- [\citeauthoryearMatsui, Panha, Khonsue, and KuraishiMatsui et al.2010] Matsui, M., S. Panha, W. Khonsue, and N. Kuraishi (2010). Two new species of the kuhlii complex of the genus Limnonectes from Thailand (Anura, Dicroglossidae). Zootaxa 2615, 1–22.
- [\citeauthoryearMcLeodMcLeod2008] McLeod, D. S. (2008). A new species of big-headed, fanged dicroglossine frog (genus Limnonectes) from Thailand. Zootaxa 1807, 26–46.
- [\citeauthoryearMcLeodMcLeod2010] McLeod, D. S. (2010). Of least concern? systematics of a cryptic species complex: Limnonectes kuhlii (Amphibia: Anura: Dicroglossidae). Molecular Phylogenetics and Evolution 56(3), 991 – 1000.
- [\citeauthoryearMcLeod, Horner, Husted, Barley, and IskandarMcLeod et al.2011] McLeod, D. S., S. Horner, C. Husted, A. Barley, and D. Iskandar (2011). “same-same, but different”: an unusual new species of the Limnonectes kuhlii complex from West Sumatra (anura: Dicroglossidae). Zootaxa 2883, 52–64.
- [\citeauthoryearMcLeod, Kelly, and BarleyMcLeod et al.2012] McLeod, D. S., J. K. Kelly, and A. Barley (2012). “same-same, but different”: Another new species of the Limnonectes kuhlii complex from Thailand (anura: Dicroglossidae). Russian Journal of Herpetology 19, 261–274.
- [\citeauthoryearNorouzzadeh, Nguyen, Kosmala, Swanson, Palmer, Packer, and CluneNorouzzadeh et al.2018] Norouzzadeh, M. S., A. Nguyen, M. Kosmala, A. Swanson, M. S. Palmer, C. Packer, and J. Clune (2018). Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proceedings of the National Academy of Sciences of the United States of America 115, E5716–E5725.
- [\citeauthoryearPaszke, Gross, Massa, Lerer, Bradbury, Chanan, Killeen, Lin, Gimelshein, Antiga, Desmaison, Kopf, Yang, DeVito, Raison, Tejani, Chilamkurthy, Steiner, Fang, Bai, and ChintalaPaszke et al.2019] Paszke, A., S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala (2019). PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pp. 8024–8035. Curran Associates, Inc.
- [\citeauthoryearPham, Le, Ngo, Ziegler, and NguyenPham et al.2018] Pham, C. T., M. D. Le, H. T. Ngo, T. Ziegler, and T. Q. Nguyen (2018). A new species of Limnonectes (Amphibia: Anura: Dicroglossidae) from Vietnam. Zootaxa 4508, 115–130.
- [\citeauthoryearRawat and WangRawat and Wang2017] Rawat, W. and Z. Wang (2017). Deep convolutional neural networks for image classification: A comprehensive review. Neural Computation 29, 2352–2449.
- [\citeauthoryearScherz, Glaw, Hutter, Bletz, Rakotoarison, Köhler, et al.Scherz et al.2019] Scherz, M. D., F. Glaw, C. R. Hutter, M. C. Bletz, A. Rakotoarison, J. Köhler, et al. (2019). Species complexes and the importance of data deficient classification in red list assessments: The case of Hylobatrachus frogs. PLoS ONE 14, e0219437.
- [\citeauthoryearSchoenSchoen2020] Schoen, S. (2020). Splitting up a complex mess: the effectiveness of statistical analysis on delimiting species complexes. Master thesis, James Madison University, Harrisonburg, VA.
- [\citeauthoryearSimonyan and ZissermanSimonyan and Zisserman2014] Simonyan, K. and A. Zisserman (2014). Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556.
- [\citeauthoryearStuart, Schoen, Nelson, Maher, Neang, Rowley, and McleodStuart et al.2020] Stuart, B. L., S. N. Schoen, E. E. M. Nelson, H. Maher, T. Neang, J. J. L. Rowley, and D. S. Mcleod (2020). A new fanged frog in the Limnonectes kuhlii complex (Anura: Dicroglossidae) from northeastern Cambodia. Zootaxa 4894, 451–473.
- [\citeauthoryearSuwannapoom, Yuan, Chen, Hou, Zhao, Wang, Nguyen, Nguyen, Murphy, Sullivan, McLeod, and CheSuwannapoom et al.2017] Suwannapoom, A., Z. H. Yuan, J. M. Chen, M. Hou, H. P. Zhao, L. J. Wang, T. S. Nguyen, T. Q. Nguyen, R. W. Murphy, J. Sullivan, D. S. McLeod, and J. Che (2017). Taxonomic revision of the Chinese Limnonectes (anura dicroglossidae) with a description of a new species from China and Myanmar. Zootaxa 4093, 181–200.
- [\citeauthoryearSweetloveSweetlove2011] Sweetlove, L. (2011). Number of species on earth tagged at 8.7 million. Nature, DOI: 10.1038/news.2011.498.
- [\citeauthoryearWang, Kang, Ma, Zeng, Xiao, Guo, Cai, Yang, Li, Meng, and XuWang et al.2021] Wang, S., B. Kang, J. Ma, X. Zeng, M. Xiao, J. Guo, M. Cai, J. Yang, Y. Li, X. Meng, and B. Xu (2021). A deep learning algorithm using CT images to screen for corona virus disease (COVID-19). European Radiology 31, 6096–6104.
- [\citeauthoryearXie, Zeng, Xu, Zhang, and RoeXie et al.2017] Xie, J., R. Zeng, C. Xu, J. Zhang, and P. Roe (2017). Multi-label classification of frog species via deep learning. In 2017 IEEE 13th International Conference on e-Science (e-Science), pp. 187–193.
- [\citeauthoryearYamasaki, Altermatt, Cavender-Bares, Schuman, Zuppinger-Dingley, Garonna, Schneider, Guillén-Escribà, van Moorsel, Hahl, Schmid, Schaepman-Strub, Schaepman, and ShimizuYamasaki et al.2017] Yamasaki, E., F. Altermatt, J. Cavender-Bares, M. C. Schuman, D. Zuppinger-Dingley, I. Garonna, F. D. Schneider, C. Guillén-Escribà, S. J. van Moorsel, T. Hahl, B. Schmid, G. Schaepman-Strub, M. E. Schaepman, and K. K. Shimizu (2017). Genomics meets remote sensing in global change studies: monitoring and predicting phenology, evolution and biodiversity. Current Opinion in Environmental Sustainability 29, 177–186.
- [\citeauthoryearYe, Fei, Xie, and JiangYe et al.2007] Ye, C.-Y., L. Fei, F. Xie, and J.-P. Jiang (2007). A new ranidae species from China - Limnonectes bannaensis (Ranidae: Anura). Zoological Research 28, 545–555.