Deep Neural Networks are Adaptive to Function Regularity and Data Distribution in Approximation and Estimation
Abstract
Deep learning has exhibited remarkable results across diverse areas. To understand its success, substantial research has been directed towards its theoretical foundations. Nevertheless, the majority of these studies examine how well deep neural networks can model functions with uniform regularity. In this paper, we explore a different angle: how deep neural networks can adapt to different regularity in functions across different locations and scales and nonuniform data distributions. More precisely, we focus on a broad class of functions defined by nonlinear tree-based approximation. This class encompasses a range of function types, such as functions with uniform regularity and discontinuous functions. We develop nonparametric approximation and estimation theories for this function class using deep ReLU networks. Our results show that deep neural networks are adaptive to different regularity of functions and nonuniform data distributions at different locations and scales. We apply our results to several function classes, and derive the corresponding approximation and generalization errors. The validity of our results is demonstrated through numerical experiments.
1 Introduction
Deep learning has achieved significant success in practical applications with high-dimensional data, such as computer vision (Krizhevsky et al., 2012), natural language processing (Graves et al., 2013; Young et al., 2018), health care (Miotto et al., 2018; Jiang et al., 2017) and bioinformatics (Alipanahi et al., 2015; Zhou and Troyanskaya, 2015). The success of deep learning demonstrates the power of neural networks in representing and learning complex operations on high-dimensional data.
In the past decades, the representation power of neural networks has been extensively studied. Early works in literature focused on shallow (two-layer) networks with continuous sigmoidal activations (a function is sigmoidal, if as , and as ) for a universal approximation of continuous functions in a unit hypercube (Irie and Miyake, 1988; Funahashi, 1989; Cybenko, 1989; Hornik, 1991; Chui and Li, 1992; Leshno et al., 1993; Barron, 1993; Mhaskar, 1996). The universal approximation theory of feedforward neural networks with a ReLU activation was studied in Lu et al. (2017); Hanin (2017); Daubechies et al. (2022); Yarotsky (2017); Schmidt-Hieber (2017); Suzuki (2018). In particular, the approximation theories of ReLU networks have been established for the Sobolev (Yarotsky, 2017), Hölder (Schmidt-Hieber, 2017) and Besov (Suzuki, 2018) functions. These works guarantee that, the Sobolev, Hölder, or Besov function class can be well approximated by a ReLU network function class with a properly chosen network architecture. The approximation error in these works was given in terms of certain function norm. Furthermore, the works in Gühring et al. (2020); Hon and Yang (2021); Liu et al. (2022a) proved the approximation error in terms of the Sobelev norm, which guaranteed the approximation error for the function and its derivatives simultaneously. In terms of the network architecture, feedforward neural networks were considered in the vast majority of approximation theories. Convolutional neural networks were considered in Zhou (2020); Petersen and Voigtlaender (2020), and convolutional residual networks were considered in Oono and Suzuki (2019); Liu et al. (2021).
It has been widely believed that deep neural networks are adaptive to complex data structures. Recent progresses have been made towards theoretical justifications that deep neural networks are adaptive to low-dimensional structures in data. Specifically, function approximation theories have been established for Hölder and Sobolev functions supported on low-dimensional manifolds (Chen et al., 2019a; Schmidt-Hieber, 2019; Cloninger and Klock, 2020; Nakada and Imaizumi, 2020; Liu et al., 2021). The network size in these works crucially depends on the intrinsic dimension of data, instead of the ambient dimension. In the task of regression and classification, the sample complexity of neural networks (Chen et al., 2019b; Nakada and Imaizumi, 2020; Liu et al., 2021) depends on the intrinsic dimension of data, while the ambient dimension does not affect the rate of convergence.
This paper answers another interesting question about the adaptivity of deep neural networks: How does deep neural networks adapt to the function regularity and data distribution at different locations and scales? The answer of this question is beyond the scope of existing function approximation and estimation theory of neural networks. The Sobolev and Hölder functions are uniformly regular within the whole domain. The analytical technique to build the approximation theory of these functions relies on accurate local approximations everywhere within the domain. In real applications, functions of interests often exhibit different regularity at different locations and scales. Empirical experiments have demonstrated that deep neural networks are capable of extracting interesting information at various locations and scales (Chung et al., 2016; Haber et al., 2018). However, there are limited works on theoretical justifications of the adaptivity of neural networks.
In this paper, we re-visit the nonlinear approximation theory (DeVore, 1998) in the classical multi-resolution analysis (Mallat, 1999; Daubechies, 1992). Nonlinear approximations allow one to approximate functions beyond linear spaces. The smoothness of the function can be defined according to the rate of approximation error versus the complexity of the elements. In many settings, such characterization of smoothness is significantly weaker than the uniform regularity condition in the Sobolev or Hölder class (DeVore, 1998).
We focus on the tree-based nonlinear approximations with piecewise polynomials (Binev et al., 2007, 2005; Cohen et al., 2001). Specifically, the domain of functions is partitioned to multiscale dyadic cubes associated with a master tree. If we build piecewise polynomials on these multiscale dyadic cubes, we naturally obtain multiscale piecewise polynomial approximations. A refinement quantity is defined at every node to quantify how much the error decreases when the node is refined to its children. A thresholding of the master tree based on this refinement quantity gives rise to a truncated tree, as well as an adaptive partition of the domain. Thanks to the thresholding technique, we can define a function class whose regularity is characterized by how fast the size of the truncated tree grows with respect to the level of the threshold. This is a large function class containing the Hölder and piecewise Hölder functions as special cases.
Our main contributions can be summarized as:
-
1.
We establish the approximation theory of deep ReLU networks for a large class of functions whose regularity is defined according to the nonlinear tree-based approximation theory. This function class allows the regularity of the function to vary at different locations and scales.
-
2.
We provide several examples of functions in this class which exhibit different information at different locations and scales. These examples are beyond the characterization of function classes with uniform regularity, such as the Hölder class.
-
3.
A nonparametric estimation theory for this large function class is established with deep ReLU networks, which is validated by numerical experiments.
-
4.
Our results demonstrate that, when deep neural networks are representing functions, it does not require a uniform regularity everywhere on the domain. Deep neural networks are automatically adaptive to the regularity of functions at different locations and scales.
In literature, adaptive function approximation and estimation has been studied for classical methods (DeVore, 1998), including free-knot spline (Jupp, 1978), adaptive smoothing splines (Wahba, 1995; Pintore et al., 2006; Liu and Guo, 2010; Wang et al., 2013), nonlinear wavelet (Cohen et al., 2001; Donoho and Johnstone, 1998; Donoho et al., 1995), and adaptive piecewise polynomial approximation (Binev et al., 2007, 2005). Based on traditional methods for estimating functions with uniform regularity, these methods allow the smoothing parameter, the kernel band width or knots placement to vary spatially to adapt to the varying regularity. Kernel methods with variable bandwidth were studied in Muller and Stadtmuller (1987) and local polynomial estimators were studied in Fan and Gijbels (1996). Based on traditional smoothing splines with a global smoothing parameter, Wahba (1995) suggested to replace the smoothing parameter by a roughness penalty function. This idea was then studied in Pintore et al. (2006); Liu and Guo (2010) by using piecewise constant roughness penalty, and in Wang et al. (2013) with a more general roughness penalty. A locally penalized spline estimator was proposed and studied in Ruppert and Carroll (2000), in which a penalty function was applied to spline coefficients and was knot-dependent. Adaptive wavelet shrinkage was studied in Donoho and Johnstone (1994, 1995, 1998), in which the authors used selective wavelet reconstruction, adaptive thresholding and nonlinear wavelet shrinkage to achieve adaptation to spatially varying regularity, and proved the minimax optimality. A Bayesian mixture of splines method was proposed in Wood et al. (2002), in which each component spline had a locally defined smoothing parameter. Other methods include regression splines (Fridedman, 1991; Smith and Kohn, 1996; Denison et al., 1998), hybrid smoothing splines and regression splines (Luo and Wahba, 1997), and the trend filtering method (Tibshirani, 2014). The minimax theory for adaptive nonparametric estimator was established in Cai (2012). Most of the works mentioned above focused on one-dimensional problems. For high dimensional problems, an additive model was considered in Ruppert and Carroll (2000). Recently, the Bayesian additive regression trees were studied in Jeong and Rockova (2023) for estimating a class of sparse piecewise heterogeneous anisotropic Hölder continuous functions in high dimension.
Classical methods mentioned above adapt to varying regularity of the target functions through a careful selection of some adaptive parameter, such as the location of knots, kernel bandwidth, roughness penalty and adaptive tree structure. These methods require the knowledge about or an estimation of how the regularity of the target function changes. Compared to classical methods, deep learning solves the regression problem by minimizing the empirical risk in (20), so the same optimization problem can be applied to various functions without explicitly figuring out where the regularity of the underlying function changes. Such kind of automatic adaptivity is crucial for real-world applications.
The connection between neural networks and adaptive spline approximation has been studied in Daubechies et al. (2022); DeVore et al. (2021); Liu et al. (2022b); Petersen and Voigtlaender (2018); Imaizumi and Fukumizu (2019). In particular, an adaptive network enhancement method was proposed in Liu et al. (2022b) for the best least-squares approximation using two-layer neural networks. The adaptivity of neural networks to data distributions was considered in Zhang et al. (2023), where the concept of an effective Minkowski dimension was introduced and applied to anisotropic Gaussian distributions. The approximation error and generalization error for learning piecewise Hölder functions in are developed in Petersen and Voigtlaender (2018) and Imaizumi and Fukumizu (2019), respectively. In the settings of Petersen and Voigtlaender (2018) and Imaizumi and Fukumizu (2019), each discontinuity boundary is parametrized by a -dimensional Hölder function, which is called a horizon function. In this paper, we consider a function class based on nonlinear tree-based approximation, and provide approximation and generalization theories of deep neural networks for this function class, as well as several examples related with practical applications, which are not implied by existing works. For piecewise Hölder functions, our setting only assumes the boundary of each piece has Minkowski dimension , which is more general than that considered in Petersen and Voigtlaender (2018); Imaizumi and Fukumizu (2019), see Section 4.3.3 and 4.5.3 for more detailed discussions.
Our paper is organized as follows: In Section 2, we introduce notations and concepts used in this paper. Tree based adaptive approximation and some examples are presented in Section 3. We present our main results, the adaptive approximation and generalization theories of deep neural networks in Section 4, and the proofs are deferred to Section 6. Our theories is validated by numerical experiments in Section 5. This paper is concluded in Section 7.
2 Notation and Preliminaries
In this section, we introduce our notation, some preliminary definitions and ReLU networks.
2.1 Notation
We use normal lower case letters to denote scalars, and bold lower case letters to denote vectors. For a vector , we use to denote the -th entry of . The standard 2-norm of is . For a scalar , denotes the largest integer that is no larger than , denotes the smallest integer that is no smaller than . Let be a set. We use to denote the indicator function on such that if and if . The notation denotes the cardinality of .
Denote the domain . For a function and a multi-index , denotes , where . We denote . Let be a measure on . The norm of with respect to the measure is . We say if . We denote for any .
The notation of means that there exists a constant independent of any variable upon which and depend, such that ; similarly for . means that and .
2.2 Preliminaries
Definition 1 (Hölder functions).
A function belongs to the Hölder space with a Hölder index , if
| (1) |
Definition 2 (Minkowski dimension).
Let . For any , denotes the fewest number of -balls that cover in terms of . The (upper) Minkowski dimension of is defined as
We further define the Minkowski dimension constant of as
Such a constant is an upper bound on the rate of how scales with .
ReLU network. In this paper, we consider the feedforward neural networks defined over in the form of
| (2) |
where ’s are weight matrices, ’s are biases, and denotes the rectified linear unit (ReLU). Define the network class as
| (3) | |||
for any matrix and vector , and denotes the number of nonzero elements of its argument.
3 Adaptive approximation
This section is an introduction to tree-based nonlinear approximation and a function class whose regularity is defined through nonlinear approximation theory. We re-visit tree-based nonlinear approximations and define this function class in Subsection 3.1. Several examples of this function class are given in Subsection 3.2.
3.1 Tree-Based Nonlinear Approximations
In the classical tree-based nonlinear approximations (Binev et al., 2007, 2005; Cohen et al., 2001), piecewise polynomials are used to approximate the target function on an adaptive partition. For simplicity, we focus on the case that the function domain is . Let be a probability measure on and . The multiscale dyadic partitions of give rise to a tree structure. It is natural to consider nonlinear approximations based on this tree structure.
Let be the collection of dyadic subcubes of of sidelength . Here denotes the scale of with a small and denotes the location. A small represents the coarse scale, and a large represents the fine scale. These dyadic cubes are naturally associated with a tree . Each node of this tree corresponds to a cube . The dyadic partition of the 2D cube and its associated tree are illustrated in Figure 1. Every node at scale has children at scale . We denote the set of children of by . When the node is a child of the node , we call the parent of , denoted by . A proper subtree of is a collection of nodes such that: (1) the root node is in ; (2) if is in , then its parent is also in . Given a proper subtree of , the outer leaves of contain all such that but the parent of belongs to : but . The collection of the outer leaves of , denoted by , forms a partition of .
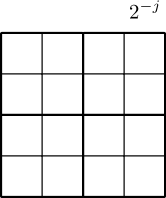
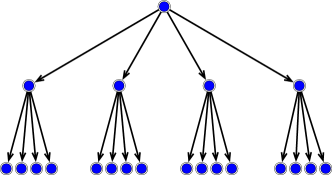
The tree-based nonlinear approximation generates an adaptive partition with a thresholding technique. In certain cases, this thresholding technique boils down to wavelet thresholding. Specifically, one defines a refinement quantity on each node of the tree, and then thresholds the tree to the smallest proper subtree containing all the nodes whose refinement quantity is above certain value. Adaptive partitions are given by the outer leaves of this proper subtree after thresholding.
We consider piecewise polynomial approximations of by polynomials of degree , where is a nonnegative integer. Let be the space of -variable polynomials of degree no more than . For any cube , the best polynomial approximating on is
| (4) |
At a fixed scale , can be approximated by the piecewise polynomial . Denote as the space of -order piecewise polynomial functions on the partition . By definition, is a linear subspace and . We have and is the best approximation of in . Let be the orthogonal complement of in , and then
When the node is refined to its children , the difference of the approximations between these two scales on is defined as
| (5) |
For , we let . Note that and therefore and are orthogonal if .
The refinement quantity on the node is defined as the norm of :
| (6) |
In the case piecewise constant approximations, i.e. , corresponds to the Haar wavelet coefficient of , and is the magnitude of the Haar wavelet coefficient.
The target function can be decomposed as
Due to the orthogonality of the ’s, we have
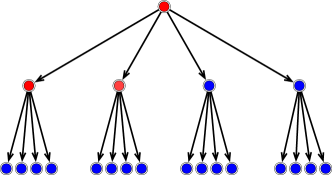
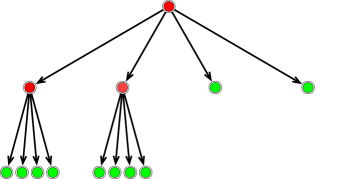

In the tree-based nonlinear approximation, one fixes a threshold value , and truncate to – the smallest subtree that contains all with . The collection of outer leaves of , denoted by , gives rise to an adaptive partition. This truncation procedure is illustrated in Figure 2. In Figure 2, the red nodes have the refinement quantity above , and then the master tree is truncated to the smallest subtree containing the red nodes in (b). The outer leaves of this truncated tree are given by the green nodes in Figure 2 (c), and the corresponding adaptive partition is given in Figure 2 (d).
The piecewise polynomial approximation of on this adaptive partition is
| (7) |
In the adaptive approximation, the regularity of can be defined by the size of the tree .
Definition 3 ((2.19) in Binev et al. (2007)).
For a fixed , a polynomial degree , we let the function class be the collection of all , such that
| (8) |
where is the truncated tree of approximating with piecewise -th order polynomials with threshold .
In Definition 3, the complexity of the adaptive approximation is measured by the cardinality of the truncated tree . In fact, the cardinality of the adaptive partition is related with the cardinality of the truncated tree such that
| (9) |
The lower bound follows from
3.2 Case Study of the Function Class
The class contains a large collection of functions, including Hölder functions, piecewise Hölder functions, functions which are irregular on a set of measure zero, and regular functions with distribution concentrated on a low-dimensional manifold. For some examples to be studied below, we make the following assumption on the measure :
Assumption 1.
There exists a constant such that any subset satisfies
where is the Lebesgue measure of .
3.2.1 Hölder functions
Example 1a (Hölder functions).
Example 1a is proved in Section 6.4.1. At the end of Example 1a, we assume without loss of generality. The same statement holds if is bounded by an absolute constant. Such a constant only changes the bound in (12), i.e. will depends on this constant.
The neural network approximation theory for Hölder functions is given in Example 1b and the generalization theory is given in Example 1c.
3.2.2 Piecewise Hölder functions in 1D
Example 2a (Piecewise Hölder functions in 1D).
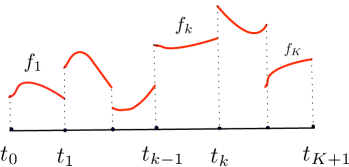
Let , and be a positive integer. Under Assumption 1, all bounded piecewise -Hölder functions with discontinuity points belong to . Specifically, let be a piecewise -Hölder function such that , where . Each function is -Hölder in , and is discontinuous at . Assume is bounded such that . In this case, we have . See Figure 3 (a) for an illustration of a piecewise Hölder function in 1D. Furthermore, if then
for some constant depending on and in Assumption 1, and does not depend on specific ’s.
Example 2a is proved in Section 6.4.2. Example 2a demonstrates that, for 1D bounded piecewise -Hölder functions with a finite number of discontinuities, the overall regularity index is under Definition 3. In comparison with Example 1a, we prove that, a finite number of discontinuities in 1D does not affect the regularity index in Definition 3.
3.2.3 Piecewise Hölder functions in multi-dimensions
In the next example, we will see that, for piecewise -Hölder functions in multi-dimensions, the overall approximation error is dominated either by the approximation error in the interior of each piece or by the error along the discontinuity. The overall regularity index depends on and .
Example 3a (Piecewise Hölder functions in multi-dimensions).
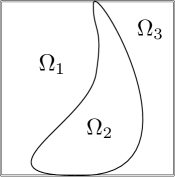
Let , and be subsets of such that and the ’s only overlap at their boundaries. Each is a connected subset of and the union of their boundaries has upper Minkowski dimension . See Figure 3 (b) for an illustration of the ’s. When satisfies Assumption 1, all piecewise -Hölder functions with discontinuity on belong to
| (13) |
Specifically, let be a piecewise -Hölder function such that where is the indicator function on . Each function is -Hölder in the interior of : where denotes the interior of , and is discontinuous at . Assume is bounded such that . In this case, with the given in (13). Furthermore, if , then
for some depending on (the Minkowski dimension constant of defined in Definition 2) and in Assumption 1.
Example 3a is proved in Section 6.4.3. Example 3a demonstrates that, for piecewise -Hölder functions with discontinuity on a subset with upper Minkowski dimension , the overall regularity index has a phase transition. When , the approximation error is dominated by that in the interior of the ’s. When , the approximation error is dominated by that around the boundary of the ’s. As the result, the overall regularity index is the minimum of and .
3.2.4 Functions irregular on a set of measure zero
The definition of is dependent on the measure , since the refinement quantity is the norm with respect to . This measure-dependent definition is not only adaptive to the regularity of , but also adaptive to the distribution . In the following example, we show that, the definition of allows the function to be irregular on a set of measure zero. For , denotes the set within distance to such that .
Example 4a (Functions irregular on a set of measure zero).
Let , be a subset of and . If is an -Hölder function on and , then . Furthermore, if , then
for some constant depending on and in Assumption 1.
Example 4a is proved in Section 6.4.4. In Example 4a, is -Hölder on , and can be irregular on a measure zero set. In comparison with Example 1a, such irregularity on a set of measure zero does not affect the smoothness parameter in Definition 3. In this example, we set to be a larger set than , in order to avoid the discontinuity effect at the boundary of .
3.2.5 Hölder functions with distribution concentrated on a low-dimensional manifold
Since the definition of is dependent on the probability measure , this definition is also adaptive to lower-dimensional sets in . We next consider a probability measure concentrated on a -dimensional manifold isometrically embedded in .
Example 5a (Hölder functions with distribution concentrated on a low-dimensional manifold).
Let . Suppose can be decomposed to and , i.e. where is a compact -dimensional Riemannian manifold isometrically embedded in . Assume that , and conditioned on is the uniform distribution on . If , then . Furthermore, if , then
with depending on and , where is the reach (Federer, 1959) of and is the surface area of .
4 Adaptive approximation and generalization theory of deep neural networks
This section contains our main results: approximation and generalization theories of deep ReLU networks for the function class. We present some preliminaries in Subsection 4.1, the approximation theory in Subsection 4.2, case studies of the approximation error in Subsection 4.3, the generalization theory in Subsection 4.4, and case studies of the generalization error in Subsection 4.5.
4.1 Preliminaries
Each is a hypercube in the form of , where is a scalar and
| (14) |
is a hypercube with edge length in .
The collection of polynomials form a basis for the space of -variable polynomials of degree no more than . Let be a measure on and . The piecewise polynomial approximator for can be written as
| (15) |
where .
In this paper, we focus on the set of functions with bounded coefficients in the piecewise polynomial approximation.
Assumption 2.
Let , be a nonnegative integer, and be a probability measure on . We assume and
-
(i)
,
-
(ii)
,
-
(iii)
On every , the polynomial approximator for in the form of (15) satisfies for all with .
By Assumption 2 (i) and (ii), has a bounded quantity and norm, which is a common assumption in nonparametric estimation theory (Györfi et al., 2002). Assumption 2 (iii) requires the polynomial coefficients in the best polynomial approximating on every to be uniformly bounded by . The following lemma shows that Assumption 2 (iii) can be implied from Assumption 2 (ii) when is the Lebesgue measure on .
Lemma 1.
4.2 Approximation Theory
Our approximation theory shows that deep neural networks give rise to universal approximations for functions in the class under Assumption 2 if the network architecture is properly chosen.
Theorem 1 (Approximation).
Let and be a nonnegative integer. For any , there is a ReLU network class with parameters
| (16) |
such that, for any satisfying Assumption 1 and any satisfying Assumption 2, if the weight parameters of the network are properly chosen, the network yields a function such that
| (17) |
The constants hidden in depends on (the dimension of the domain for ), (in Assumption 1), (the polynomial order), , , and (in Assumption 2).
Theorem 1 is proved in Section 6.2. Theorem 1 demonstrates the universal approximation power of deep neural networks for the function class. The parameters in (16) specifies the network architecture. To approximate a specific function , there exist some proper weight parameters which give rise to a network function to approximate .
4.3 Case Studies of the Approximation Error
In this subsection, we apply Theorem 1 to the examples in Subsection 3.2, and derive the approximation theory for each example. In the following case studies, we need Assumptions 1, 2 (iii) and 3, but not Assumption 2 (i) - (ii). In each case, we have shown in Subsection 3.2 that Assumption 2 (i) holds: with a proper and the regularity index depends on each specific case.
4.3.1 Hölder functions
Consider Hölder functions in Example 1a such that . Applying Theorem 1 gives rise to the following neural network approximation theory for Hölder functions.
Example 1b (Hölder functions).
4.3.2 Piecewise Hölder functions in 1D
Considering 1D piecewise Hölder functions in Example 2a, we have the following approximation theory:
Example 2b (Piecewise Hölder functions in 1D).
Let . For any , there is a ReLU network class with parameters
| (18) |
such that for any satisfing Assumption 1, and any piecewise -Hölder function in the form of in Example 2a satisfying , and Assumption 2(iii), if the weight parameters of the network are properly chosen, the network yields a function such that
The constant hidden in depends on .
Example 2b is a corollary of Theorem 1 with . Assumption 2 (i) is not explicitly enforced in Example 2b , but is implied from the condition of by Example 2a. Example 2b shows that, to achieve an approximation error for 1D functions with a finite number of discontinuities, the network size is comparable to that for 1D Hölder functions in Example 1b.
4.3.3 Piecewise Hölder function in multi-dimensions
Considering piecewise Hölder functions in multi-dimensions in Example 3a, we have the following approximation theory:
Example 3b (Piecewise Hölder functions in multi-dimensions).
Let , and be subsets of such that and the ’s only overlap at their boundaries. Each is a connected subset of and the union of their boundaries has upper Minkowski dimension . Denote the Minkowski dimension constant of by . For any , there is a ReLU network class with parameters
such that for any satisfying Assumption 1, and any piecewise -Hölder function in the form of in Example 3a satisfying , and Assumption 2(iii), if the weight parameters of the network are properly chosen, the network yields a function such that
The constant hidden in depends on .
Example 3b is a corollary of Theorem 1 with for the given in (13). Assumption 2 (i) is not explicitly enforced in Example 3b , but is implied from the condition of by Example 3a. Example 3b implies that to approximate a piecewise Hölder function in Example 3a, the number of nonzero weight parameters is in the order of . The discontinuity set in Example 3b has upper Minkowski dimension , which is a weak assumption without additional regularity assumption or low-dimensional structures.
Neural network approximation theory for piecewise smooth functions has been considered in Petersen and Voigtlaender (2018). The setting in Petersen and Voigtlaender (2018) is similar but different from that of Example 3b. In Petersen and Voigtlaender (2018), the authors considered piecewise functions , where the different “smooth regions” of are separated by hypersurfaces. If is a piecewise -Hölder function and the Hölder norm of on each piece is bounded, it is shown in Petersen and Voigtlaender (2018, Corollary 3.7) that such can be universally approximated by a ReLU network with at most weight parameters to guarantee an approximation error . It is further shown in Petersen and Voigtlaender (2018, Theorem 4.2) that, to achieve an approximation error , the optimal required number of weight parameters is lower bounded in the order of . Our result in Example 3b is comparable to that of Petersen and Voigtlaender (2018) when and . When the discontinuity hypersurface has higher order regularity, i.e. , the network size in Petersen and Voigtlaender (2018) is smaller/better than that in Example 3b since the higher order smoothness of the discontinuity hypersurface is exploited in the approximation theory. However, Example 3b imposes a weaker assumption on the discontinuity hypersurface. Example 3b requires the discontinuity hypersurface to have upper Minkowski dimension , while the the discontinuity hypersurface in Petersen and Voigtlaender (2018, Definition 3.3) is the graph of a function on coordinates. In this sense, Example 3b can be applied to a wider class of piecewise Hölder functions.
4.3.4 Functions irregular on a set of measure zero
Functions in the class can be irregular on a set of measure zero, as in Example 4a. The approximation theory for functions in Example 4a is given below:
Example 4b (Functions irregular on a set of measure zero).
Let and be a subset of . For any , there is a ReLU network class with parameters
For any satisfying Assumption 1 and , and for any satisfying and Assumption 2(iii), if the weight parameters of the network are properly chosen, the network class yields a function such that
The constant hidden in depends on .
4.3.5 Hölder functions with distribution concentrated on a low-dimensional manifold
Theorem 1 cannot be directly applied to Example 5a, since Assumption 1 is violated when is supported on a low-dimensional manifold. In literature, neural network approximation theory has been established in Chen et al. (2019a) for functions on a low-dimensional manifold, and in Nakada and Imaizumi (2020) for Hölder functions in while the support of measure has a low Minkowski dimension. See Section 4.5.5 for a detailed discussion about the generalization error.
4.4 Generalization Error
Theorem 1 proves the existence of a neural network to approximate with an arbitrary accuracy , but it does not give an explicit method to find the weight parameters of . In practice, the weight parameters are learned from data through the empirical risk minimization. The generalization error of the empirical risk minimizer is analyzed in this subsection.
Suppose the training data set is where the ’s are i.i.d. samples from , and the ’s have the form
| (19) |
where the ’s are i.i.d. noise, independently of the ’s. In practice, one estimates the function by minimizing the empirical mean squared risk
| (20) |
for some network class . The squared generalization error of is
where the expectation is taken over the joint the distribution of training data .
To establish an upper bound of the squared generalization error, we make the following assumption of noise.
Assumption 3.
Suppose the noise is a sub-Gaussian random variable with mean and variance proxy .
Our second main theorem in this paper gives a generalization error bound of .
Theorem 2 (Generalization error).
Let and be a nonnegative integer. Suppose satisfies Assumption 1, satisfies Assumption 2, and Assumption 3 holds for noise. The training data are sampled according to (19). If the network class is set with parameters
then the minimizer of (20) satisfies
The constant and the constant hidden in depend on (the variance proxy of noise in Assumption 3), (the dimension of the domain for ), (in Assumption 1), (the polynomial order), , , and (in Assumption 2).
4.5 Case Study of the Generalization Error
In this subsection, we apply Theorem 2 to the examples in Subsection 3.2, and derive the squared generalization error for each example. In the following case studies, we assume Assumptions 1, 2 (iii) and 3, but not Assumption 2 (i) and (ii). In each case, we have shown in Subsection 3.2 that Assumption 2 (i) holds: with a proper and the regularity index depends on each specific case.
4.5.1 Hölder functions
Consider Hölder functions in Example 1a such that . Applying Theorem 2 gives rise to the following generalization error bound for Hölder functions.
Example 1c (Hölder functions).
4.5.2 Piecewise Hölder functions in 1D
Considering 1D piecewise Hölder functions in Example 2a, we have the following generalization error bound:
Example 2c (Piecewise Hölder functions in 1D).
Let . Suppose satisfies Assumption 1. Let be an 1D piecewise -Hölder function in the form of in Example 2a satisfying , and Assumption 2(iii). Suppose Assumption 3 holds and the training data are sampled according to (19). Set the network class as
| (21) |
Then the empirical minimizer of (20) satisfies
| (22) |
The constant and the constant hidden in depend on .
Example 2c shows that a finite number of discontinuities in 1D does not affect the rate of convergence of the generalization error.
4.5.3 Piecewise Hölder functions in multi-dimensions
Considering piecewise Hölder functions in multi-dimensions in Example 3a, we have the following generalization error bound:
Example 3c (Piecewise Hölder functions in multi-dimensions).
Let . Let be subsets of such that and the ’s only overlap at their boundaries. Each is a connected subset of and the union of their boundaries has upper Minkowski dimension . Denote the Minkowski dimension constant of by . Suppose satisfies Assumption 1. Let be a piecewise -Hölder function in the form of in Example 3a satisfying , and Assumption 2(iii). Suppose Assumption 3 holds and the training data are sampled according to (19). Set the network class as
| (23) |
Then the empirical minimizer of (20) satisfies
| (24) |
The constant and the constant hidden in depend on .
Example 3c shows that the convergence rate of the generalization error has a phase transition. When , the generalization error is dominated by that in the interior of the ’s, so that the squared generalization error converges in the order of . When , the generalization error is dominated by that around the boundary of the ’s, so that the squared generalization error converges in the order of . As a result, the overall rate of convergence is up to log factors.
Under the setting of Petersen and Voigtlaender (2018) (discussed in Section 4.3.3 where different “smooth regions” of are separated by hypersurfaces), the generalization error for estimating piecewise -Hölder function by ReLU network is proved in the order of in Imaizumi and Fukumizu (2019). When , our rate matches the result in Imaizumi and Fukumizu (2019). When , the smoothness of boundaries is utilized in Imaizumi and Fukumizu (2019), leading to a better result than ours. Nevertheless, the setting considered in this paper assumes a weaker assumption on the discontinuous boundaries, which are not required to be hypersurfaces.
4.5.4 Functions irregular on a set of measure zero
Functions in the class can be irregular on a set of measure zero, as in Example 4a. The generalization error for functions in Example 4a is given below:
Example 4c (Functions irregular on a set of measure zero).
Example 4c shows that function irregularity on a set of measure zero does not affect the rate of convergence of the generalization error. Deep neural networks are adaptive to data distributions as well.
4.5.5 Hölder functions with distribution concentrated on a low-dimensional manifold
When the measure is concentrated on a low-dimensional manifold as considered in Example 5a, Theorem 2 cannot be directly applied since Assumption 1 is not satisfied. Instead, a more dedicated network structure can be designed to develop approximation and generalization error analysis. The setting of Example 5a has been studied in Nakada and Imaizumi (2020), which assumes that the ’s are sampled from a measure supported on a set with an upper Minkowski dimension . If the target function is an Hölder function on and if the network structure is properly set, the generalization error is in the order of up to a logarithmic factor (Nakada and Imaizumi, 2020). The result in Nakada and Imaizumi (2020) can be applied to the setting of Example 5a, since a dimensional Riemannian manifold has the Minkowski dimension .
Another related setting is that is a -Hölder function on a dimensional Riemannian manifold embedded in . This setting has been studied in Chen et al. (2019a) for approximation theory and in Chen et al. (2019b) for generalization theory by ReLU networks. In this setting, the squared generalization error converges in the order of up to a logarithmic factor.
5 Numerical experiments
In this section, we perform numerical experiments on 1D piecewise smooth functions, which fit in Example 2a. The following functions are included in our experiments:
-
•
Function with 1 discontinuity point,
-
•
Function with 3 discontinuity points,
-
•
Function with 5 discontinuity points,
-
•
Function with 7 discontinuity points,
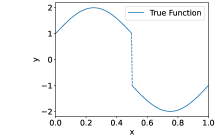
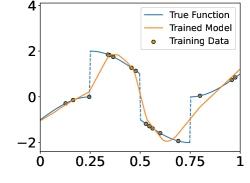
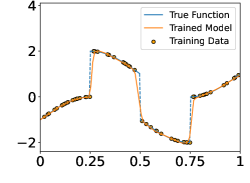
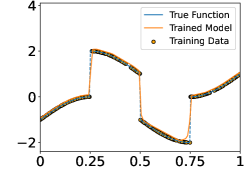
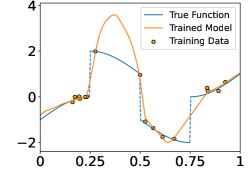
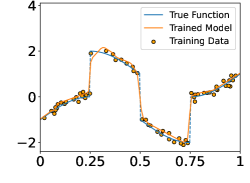
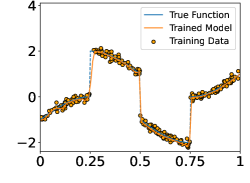
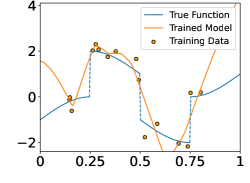
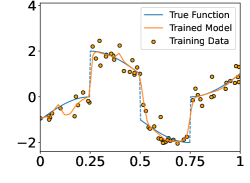
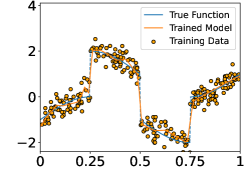
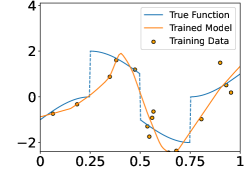
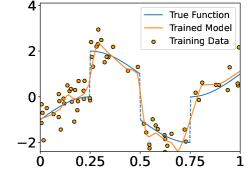
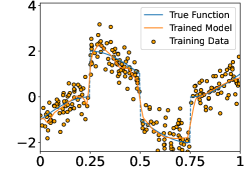
These functions are shown in the Figure 4. In each experiment, we sample i.i.d. training samples according to the model in (19). Specifically, the ’s are independently and uniformly sampled in , and with being a normal random variable with zero mean and standard deviation . Given the training data, we train a neural network through
| (25) |
where the ReLU neural network class comprises four fully connected layer (64, 128, 64 neurons in each hidden layer). All weight and bias parameters are initialized with a uniform distribution, and we use Adam optimizer with learning rate for training.
Figure 5 shows the ground-truth, training data, and the trained model with different number of training data and noise levels. When is fixed, the trained model approaches the ground-truth function when increases, which is consistent with Theorem 2.
The test mean squared error (MSE) is evaluated on the test samples
with . We use a large in order to reduced the variance in the evaluation of the test MSE.
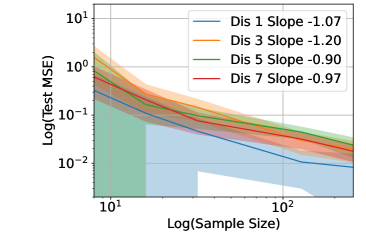
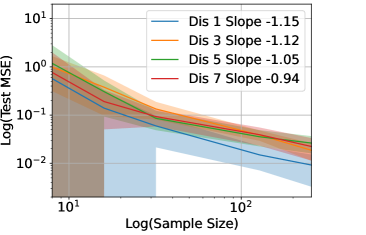
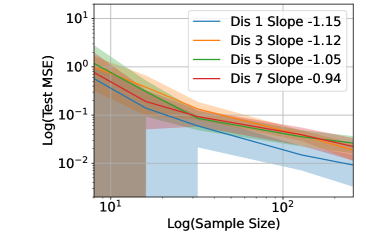
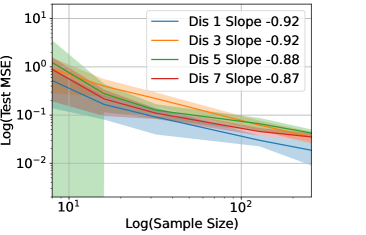
Figure 6 shows the Test MSE versus in - scale for the regression of functions with different number of discontinuity points shown in Figure 4, when in (a), in (b), in (c) and in (d), respectively. We repeat 20 experiments for each setting. The curve represents the average test MSE in 20 experiments and the shade represents the standard deviation. A least-square fit of the curve gives rise to the slope in the legend. These functions fit in Example 2c, which follows for a large since the functions are smooth except at the discontinuity points. Our Example 2c predicts the slope about in the - plot of test MSE versus , and the slope is not sensitive to the number of (finite) discontinuity points. The numerical slopes in Figure 6 are consistent with our theory.
6 Proof of main results
In this section, we present the proof of our main results. Some preliminaries for the proof are introduced in Subsection 6.1. Theorem 1 is proved in Subsection 6.2 and Theorem 2 is proved in Subsection 6.3.
6.1 Proof preliminaries
We first introduce some preliminaries to be used in the proof.
6.1.1 Trapezoidal function and its neural network representation
Given an interval and , the function defined as
| (26) |
is piecewise linear and supported on (or or ). In the rest of the proof, for simplicity, we only discuss the case for . The case for or can be derived similarly. Function can be realized by the following ReLU network with 1 layer and width 4:
6.1.2 Multiplication operation and neural network approximation
The following lemma from Yarotsky (2017) shows that the product operation can be well approximated by a ReLU network.
Lemma 2 (Proposition 3 in Yarotsky (2017)).
For any and . If , there is a ReLU network, denoted by , such that
Such a network has layers and parameters, where the constants hidden in depends on . The width of each layer is bounded by 6 and all parameters are bounded by , where the constant hidden in is an absolute constant.
Furthermore, the following lemma shows that composition of products can be well approximated by a ReLU network (see a proof in Appendix C)
Lemma 3.
Let be a set of real numbers satisfying for any . For any , there exists a neural network such that
The network has
| (27) |
where the constant hidden in of and depends on , and is some absolute constant.
6.2 Proof of Theorem 1
Proof of Theorem 1.
To prove Theorem 1, we first decompose the approximation error into two parts by applying the triangle inequality with the piecewise polynomial on the adaptive partition defined in (7). The first part is the approximation error of by , which can be bounded by (10). The second part is the network approximation error of . Then we show that can be approximated by the given neural network with an arbitrary accuracy. Lastly, we estimate the total approximation error and quantify the network size. In the following we present the details of each step.
Decomposition of the approximation error. For any given by the network in (17), we decompose the error as
| (28) |
where is to be determined later. The first term in (28) can be bounded by (10) such that
| (29) |
Bounding the second term in (28). We next derive an upper bound for the second term in (28) by showing that can be well approximated by a network . This part contains four steps:
- Step 1
-
Estimate the finest scale of the truncated tree.
- Step 2
-
Construct a partition of unity of with respect to the truncated tree. Each element of the partition of unity is a network.
- Step 3
-
Based on the partition of unity, construct a network to approximate on each cube.
- Step 4
-
Estimate the approximation error.
In the following we disucss details of each step.
— Step 1: Estimate the finest scale. Denote the truncated tree and its outer leaves of by and respectively for simplicity. Each is a hypercube in the form of , where are scalars and
is a hypercube with edge length in .
We estimate the finest scale in . Let be the largest integer such that for some . In other words, is the finest scale of the cubes in . Let so that
with the given in (8), which implies
| (30) |
For any and its parent , we have . Meanwhile, we have
This implies
| (31) |
Substituting (30) into (31) gives rise to
| (32) |
where is a constant depending on and . Since (32) holds for any , we have
| (33) |
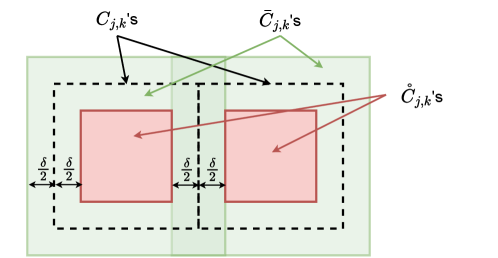
— Step 2: Construct a partition of unity. Let . For each , we define two sets:
| (34) |
The set is in the interior of , with distance to the boundary of . The set contains the boundary of . The relations of and are illustrated in Figure 7.
For each , we define the function
where , and the function is defined in (26). The function has the following properties:
-
1.
is piecewise linear.
-
2.
is supported on , and when .
-
3.
The ’s form a partition of unity of : when .
In this paper, we approximate by
where the network with inputs is defined in Lemma 3 with accuracy . We have with
By Lemma 3, we have
| (35) |
— Step 3: Approximate on each cube. According to (15), for each , is a polynomial of degree and is in the form of
| (36) |
where .
By Assumption 2(ii), there exists so that is uniformly bounded by for any for any . By Lemma 3, we have
| (37) |
for some dpending on , and with
— Step 4: Estimate the network approximation error for . We approximate
by
| (38) |
where is the product network with accuracy , according to Lemma 2.
Denote . The error is estimated as
| (39) |
For the first term in (39), we have
| (40) | ||||
| (41) |
In the derivation above, we used when . Additionally, (35) is used in the second inequality, (37) is used in the third inequality.
We next derive an upper bound for the second term in (39) by bounding the volume of . We define the common boundaries of a set of cubes being the outer leaves of a truncated tree as the set of points that belong to at least two cubes. We will use the following lemma to estimate the surface area for the common boundaries of (see a proof in Appendix D).
Lemma 4.
Given a truncated tree and its outer leaves , we denote the set of common boundaries of the subcubes in by . The surface area of in , denoted by , satisfies
| (42) |
Putting all terms together. Set , and substitute (44) and (29) into (28) gives rise to
| (45) |
We then quantify the network size of .
-
: The product network has depth , width , number of nonzero parameters , and all parameters are bounded by .
-
: Each has depth , width , number of parameters , and all parameters are bounded by .
-
: Each has depth , width , number of parameters , and all parameters are bounded by .
Substituting the value of and , we get with
| (46) |
Note that by (33) we have
| (47) |
We have .
Setting
finishes the proof. ∎
6.3 Proof of Theorem 2
Proof of Theorem 2.
Let be the minimizer of (20). We decompose the squared generalization error as
| (48) | ||||
| (49) |
Bounding . We bound as
| (50) |
In (50), the first term is the network approximation error. The second term is a stochastic error arising from noise. By Theorem 1, we have an upper bound for the first term. Let . By Theorem 1, there exists a network architecture with
| (51) |
so that there is a network function with this architecture satisfying
| (52) |
where the constant hidden in depends on .
We thus have
| (53) |
Let be the covering number of under the metric. Denote . The following lemma gives an upper bound for the second term in (50) (see a proof in Appendix E)
Lemma 5.
Under the conditions of Theorem 2, for any , we have
| (54) |
Substituting (53) and (54) into (50) gives rise to
| (55) |
Let
Relation (55) can be written as
which implies
Thus we have
| (56) |
Bounding .
The following lemma gives an upper bound of (see a proof in Appendix F):
Lemma 6.
Under the condition of Theorem 2, we have
| (57) |
Putting both terms together. Substituting (56) and (57) into (49) gives rise to
| (58) | ||||
| (59) |
The covering number of can be bounded using network parameters, which is summarized in the following lemma:
Lemma 7 (Lemma 6 of Chen et al. (2019b)).
Let be a class of networks: . For any , the -covering number of is bounded by
| (60) |
Substituting the network parameters in (51) into Lemma 7 gives
| (61) |
where is some constant depending on and .
The resulting network has parameters
| (64) |
∎
6.4 Proof of the Examples in Section 3.2
6.4.1 Proof of Example 1a
Proof of Example 1a.
We first estimate for every . Let and be the center of the cube (each coordinate of is the midpoint of the corresponding side of ). Denote be the th order Taylor polynomial of centered at . By analyzing the tail of the Taylor polynomial, we obtain that, for every ,
| (65) |
The proof of (65) is standard and can be found in Györfi et al. (2002, Lemma 11.1) and Liu and Liao (2024, Lemma 11). The point-wise error above implies the following approximation error of the in (4):
| (66) |
As a result, the refinement quantity satisfies
| (67) |
Notice that depends on and . For any , the nodes of with satisfy . The cardinality of satisfies
Therefore, for any , so that . Furthermore, since depends on and , if , then for some depending on and .
∎
6.4.2 Proof of Example 2a
Proof of Example 2a.
We first estimate the for every interval (1D cube) . There are two types of intervals: the first type does not intersect with the discontinuities and the second type has intersection with .
The first type (Type I): When , we have
according to (67).
The second type (Type II): When , is irregular on .
We have
| (68) |
where .
For any , the master tree is truncated to . Consider the leaf node . The type-I leaf nodes satisfy . There are at most leaf nodes of Type I where is the largest integer with . The type-II leaf nodes in the truncated tree satisfy . Since there are at most discontinuity points, there are at most leaf nodes of Type II at scale , where is the largest integer with , implying . The cardinality of the outer leaf nodes of can be estimated as
when is sufficiently small, where is a constant depending on and . Notice that
because of (9). Therefore, and we have .
Furthermore, if , we have for some depending on .
∎
6.4.3 Proof of Example 3a
Proof of Example 3a.
We first estimate for every cube . There are two types of cubes: the first type belongs to the interior of some and the second type has intersection with some (the boundary of ).
The first type (Type I): When for some , we have
according to (67).
The second type (Type II): When for some , is irregular on . Similar to (68), we have
where .
For any , the master tree is truncated to . Consider the leaf node . The type-I leaf nodes satisfy . There are at most leaf nodes of Type I where is the largest integer with .
We next estimate the number of type-II leaf nodes. The type-II leaf nodes satisfy . Let be the largest integer satisfying , which implies . We next count the number of dyadic cubes needed to cover , considering has an upper Minkowski dimension . Let be the Minkowski dimension constant of . According to Definition 2, for each , there exists a collection of cubes of edge length covering and . Each at most intersects with dyadic cubes in the master tree at scale . Therefore, there are at most type-II nodes at scale . In total, the number of type-II leaf node is no more than
| (69) |
for some depending on and .
Finally, we count the outer leaf nodes of . The cardinality of the outer leaf nodes of can be estimated as
for some depending on and . Notice that
We have . Thus with .
Furthermore, if , then
for some depending on and . ∎
6.4.4 Proof of Example 4a
Proof of Example 4a.
We first estimate for every cube . There are two types of cubes: the first type belongs to and the second type has intersection with .
The first type (Type I): When , we have
with the given in (67).
The second type (Type II): When , may be irregular on but since , when is sufficiently large.
For sufficiently small , the master tree is truncated to . The size of the tree is dominated by the nodes within . Therefore, and . Furthermore, since depends on and , if , then for some depending on and .
∎
6.4.5 Proof of Example 5a
Proof of Example 5a.
We first estimate for every cube . There are two types of cubes: the first type intersects with and the second type has no intersection with .
The first type: When , thanks to (65), we have
where We next estimate . Since is a compact -dimensional Riemannian manifold isometrically embedded in , has a positive reach (Thäle, 2008, Proposition 14). Each is a -dimensional cube of side length , and therefore is contained in an Euclidean ball of diameter We denote as the conditional measure of on . According to Maggioni et al. (2016, Lemma 19), when is sufficiently small such that ,
| (70) |
where denotes the Euclidean ball of radius centered at origin in , is the surface area of , and is a constant depending on and . (70) implies that
The second type: When , and then
For any , the master tree is truncated to . The size of the tree is dominated by the nodes intersecting . The Type-I leaf nodes with satisfy . At scale , there are at most Type-I leaf nodes. The cardinality of satisfies
Therefore, , so that . Furthermore, if , we have with depending on and .
∎
7 Conclusion
In this paper, we establish approximation and generalization theories for a large function class which is defined by nonlinear tree-based approximation theory. Such a function class allows the regularity of the function to vary at different locations and scales. It covers common function classes, such as Hölder functions and discontinuous functions, such as piecewise Hölder functions. Our theory shows that deep neural networks are adaptive to nonuniform regularity of functions and data distributions at different locations and scales.
When deep learning is used for regression, different network architectures can give rise to very different results. The success of deep learning relies on the optimization algorithm, initialization and a proper choice of network architecture. We will leave the computational study as our future research.
Appendix
Appendix A Proof of the approximation error in (10)
Appendix B Proof of Lemma 1
Proof of Lemma 1.
Let , and be the cardinality of . Denote . We first index the elements in according to in the non-decreasing order. One can obtain a set of orthonormal polynomials on from by the Gram–Schmidt process. This set of polynomials forms an orthonormal basis for polynomials on with degree no more than . Denote this orthonormal set of polynomials by . Each can be written as
| (71) |
for some . There exists a constant only depending on and so that
| (72) |
For the simplicity of notation, we denote with and . The idea of this proof is to obtain a set of orthonormal basis on from (71), where each basis is a linear combination of monomials of . Then the coefficients of can be expressed as inner product between and each basis. Let
| (73) |
The ’s form a set of orthonormal polynomials on , since
Thus form an orthonormal basis for polynomials with degree no more than on . The in (4) has the form
| (74) |
Using Hölder’s inequality, we have
| (75) |
Substituting (73) and (71) into (74) gives rise to
implying that
Putting (72) and (75) together, we have
| (76) |
where , as defined in (72), is a constant depending on .
Furthermore, since , we have
∎
Appendix C Proof of Lemma 3
Appendix D Proof of Lemma 4
Proof of Lemma 4.
Let be the smallest integer so that . Based on , we first construct a so that and for any by the following procedure.
Note that if there exists with , there must be a with . Otherwise, we must have , contradicting to the definition of . Let be a subcube in the finest scale of , and be a subcube in the coarsest scale of . Suppose . We have . Denote the set of children and the parent of by and , respectively. Since is at the finest scale, we have . By replacing by and by , we obtain a new tree with . Note that the subcubes in have side length , has side length . Since , we have
| (79) |
implying that . Replace by and repeat the above procedure, we can generate a set of trees for some until for all . We have
All leaf nodes of are at scale no larger than . For any leaf node of with , we partition it into its children. Repeat this process until all leaf nodes of the tree is at scale , and denote the tree by . Note that doing so only creates additional common boundaries, thus , and we have
We next compute . Note that can be generated sequentially by slicing each cube at scale for . When is sliced to get cubes at scale , hyper-surfaces with area are created as common boundaries. There are in total cubes at scale . Thus we compute as:
| (80) |
where we used in the second inequality according to the definition of . ∎
Appendix E Proof of Lemma 5
Proof of Lemma 5.
Let be a cover of . There exists satisfying .
We have
| (81) |
In (81), the first inequality follows from Cauchy-Schwarz inequality, the second inequality holds by Jensen’s inequality and
| (82) |
the last inequality holds since
| (83) |
Denote . The first term in (81) can be bounded as
| (84) |
where the second inequality comes from Jensen’s inequality and Cauchy-Schwarz inequality.
For given , is a sub-Gaussian variable with variance proxy .
For any , we have
| (85) |
Appendix F Proof of Lemma 6
Proof of Lemma 6.
Denote . We have . The term can be written as
| (88) |
A lower bound of is derived as
| (89) |
Substituting (89) into (88) gives rise to
| (90) |
Define the set
| (91) |
Denote be an independent copy of . We have
| (92) |
Let be a -cover of . For any , there exists such that .
We bound (92) using . The first term in (92) can be bounded as
| (93) |
We then lower bound as
| (94) |
Substituting (93) and (94) into (92) gives rise to
| (95) |
Denote . We have
Thus is bounded as
| (96) |
Note that . We next study the moment generating function of . For any , we have
| (97) |
where the last inequality comes from for .
For , we have
| (98) |
where the first inequality follows from Jesen’s inequality, the third inequality uses (97).
We then derive a relation between the covering number of and . For any , we have
for some . We have
As a result, we have
and the lemma is proved. ∎
References
- Alipanahi et al. (2015) Alipanahi, B., Delong, A., Weirauch, M. T. and Frey, B. J. (2015). Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nature Biotechnology, 33 831–838.
- Barron (1993) Barron, A. R. (1993). Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information theory, 39 930–945.
- Binev et al. (2007) Binev, P., Cohen, A., Dahmen, W. and DeVore, R. (2007). Universal algorithms for learning theory part II: Piecewise polynomial functions. Constructive Approximation, 26 127–152.
- Binev et al. (2005) Binev, P., Cohen, A., Dahmen, W., DeVore, R., Temlyakov, V. and Bartlett, P. (2005). Universal algorithms for learning theory part I: Piecewise constant functions. Journal of Machine Learning Research, 6.
- Cai (2012) Cai, T. T. (2012). Minimax and adaptive inference in nonparametric function estimation. Statistical Science, 27 31–50.
- Chen et al. (2019a) Chen, M., Jiang, H., Liao, W. and Zhao, T. (2019a). Efficient approximation of deep ReLU networks for functions on low dimensional manifolds. In Advances in Neural Information Processing Systems.
- Chen et al. (2019b) Chen, M., Jiang, H., Liao, W. and Zhao, T. (2019b). Nonparametric regression on low-dimensional manifolds using deep ReLU networks: Function approximation and statistical recovery. arXiv preprint arXiv:1908.01842.
- Chui and Li (1992) Chui, C. K. and Li, X. (1992). Approximation by ridge functions and neural networks with one hidden layer. Journal of Approximation Theory, 70 131–141.
- Chung et al. (2016) Chung, J., Ahn, S. and Bengio, Y. (2016). Hierarchical multiscale recurrent neural networks. arXiv preprint arXiv:1609.01704.
- Cloninger and Klock (2020) Cloninger, A. and Klock, T. (2020). ReLU nets adapt to intrinsic dimensionality beyond the target domain. arXiv preprint arXiv:2008.02545.
- Cohen et al. (2001) Cohen, A., Dahmen, W., Daubechies, I. and DeVore, R. (2001). Tree approximation and optimal encoding. Applied and Computational Harmonic Analysis, 11 192–226.
- Cybenko (1989) Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2 303–314.
- Daubechies (1992) Daubechies, I. (1992). Ten Lectures on Wavelets. SIAM.
- Daubechies et al. (2022) Daubechies, I., DeVore, R., Foucart, S., Hanin, B. and Petrova, G. (2022). Nonlinear approximation and (deep) ReLU networks. Constructive Approximation, 55 127–172.
- Denison et al. (1998) Denison, D., Mallick, B. and Smith, A. (1998). Automatic bayesian curve fitting. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 60 333–350.
- DeVore et al. (2021) DeVore, R., Hanin, B. and Petrova, G. (2021). Neural network approximation. Acta Numerica, 30 327–444.
- DeVore (1998) DeVore, R. A. (1998). Nonlinear approximation. Acta Numerica, 7 51–150.
- Donoho and Johnstone (1994) Donoho, D. L. and Johnstone, I. M. (1994). Ideal spatial adaptation by wavelet shrinkage. Biometrika, 81 425–455.
- Donoho and Johnstone (1995) Donoho, D. L. and Johnstone, I. M. (1995). Adapting to unknown smoothness via wavelet shrinkage. Journal of the American Statistical Association, 90 1200–1224.
- Donoho and Johnstone (1998) Donoho, D. L. and Johnstone, I. M. (1998). Minimax estimation via wavelet shrinkage. The Annals of Statistics, 26 879–921.
- Donoho et al. (1995) Donoho, D. L., Johnstone, I. M., Kerkyacharian, G. and Picard, D. (1995). Wavelet shrinkage: asymptopia? Journal of the Royal Statistical Society: Series B (Methodological), 57 301–337.
- Fan and Gijbels (1996) Fan, J. and Gijbels, I. (1996). Local Polynomial Modelling and Its Applications: Monographs on Statistics and Applied Probability 66, vol. 66. CRC Press.
- Federer (1959) Federer, H. (1959). Curvature measures. Transactions of the American Mathematical Society, 93 418–491.
- Fridedman (1991) Fridedman, J. (1991). Multivariate adaptive regression splines (with discussion). Ann Stat, 19 79–141.
- Funahashi (1989) Funahashi, K.-I. (1989). On the approximate realization of continuous mappings by neural networks. Neural Networks, 2 183–192.
- Graves et al. (2013) Graves, A., Mohamed, A.-r. and Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE.
- Gühring et al. (2020) Gühring, I., Kutyniok, G. and Petersen, P. (2020). Error bounds for approximations with deep ReLU neural networks in norms. Analysis and Applications, 18 803–859.
- Györfi et al. (2002) Györfi, L., Kohler, M., Krzyzak, A., Walk, H. et al. (2002). A Distribution-free Theory of Nonparametric Regression, vol. 1. Springer.
- Haber et al. (2018) Haber, E., Ruthotto, L., Holtham, E. and Jun, S.-H. (2018). Learning across scales—multiscale methods for convolution neural networks. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Hanin (2017) Hanin, B. (2017). Universal function approximation by deep neural nets with bounded width and ReLU activations. arXiv preprint arXiv:1708.02691.
- Hon and Yang (2021) Hon, S. and Yang, H. (2021). Simultaneous neural network approximations in Sobolev spaces. arXiv preprint arXiv:2109.00161.
- Hornik (1991) Hornik, K. (1991). Approximation capabilities of multilayer feedforward networks. Neural Networks, 4 251–257.
- Imaizumi and Fukumizu (2019) Imaizumi, M. and Fukumizu, K. (2019). Deep neural networks learn non-smooth functions effectively. In The 22nd International Conference on Artificial Intelligence and Statistics. PMLR.
- Irie and Miyake (1988) Irie, B. and Miyake, S. (1988). Capabilities of three-layered perceptrons. In IEEE International Conference on Neural Networks, vol. 1.
- Jeong and Rockova (2023) Jeong, S. and Rockova, V. (2023). The art of BART: Minimax optimality over nonhomogeneous smoothness in high dimension. Journal of Machine Learning Research, 24 1–65.
- Jiang et al. (2017) Jiang, F., Jiang, Y., Zhi, H., Dong, Y., Li, H., Ma, S., Wang, Y., Dong, Q., Shen, H. and Wang, Y. (2017). Artificial intelligence in healthcare: past, present and future. Stroke and vascular neurology, 2 230–243.
- Jupp (1978) Jupp, D. L. (1978). Approximation to data by splines with free knots. SIAM Journal on Numerical Analysis, 15 328–343.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I. and Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems.
- Leshno et al. (1993) Leshno, M., Lin, V. Y., Pinkus, A. and Schocken, S. (1993). Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Networks, 6 861–867.
- Liu et al. (2022a) Liu, H., Chen, M., Er, S., Liao, W., Zhang, T. and Zhao, T. (2022a). Benefits of overparameterized convolutional residual networks: Function approximation under smoothness constraint. In International Conference on Machine Learning. PMLR.
- Liu et al. (2021) Liu, H., Chen, M., Zhao, T. and Liao, W. (2021). Besov function approximation and binary classification on low-dimensional manifolds using convolutional residual networks. In International Conference on Machine Learning. PMLR.
- Liu and Liao (2024) Liu, H. and Liao, W. (2024). Learning functions varying along a central subspace. SIAM Journal on Mathematics of Data Science, 6 343–371.
- Liu et al. (2022b) Liu, M., Cai, Z. and Chen, J. (2022b). Adaptive two-layer ReLU neural network: I. Best least-squares approximation. Computers & Mathematics with Applications, 113 34–44.
- Liu and Guo (2010) Liu, Z. and Guo, W. (2010). Data driven adaptive spline smoothing. Statistica Sinica 1143–1163.
- Lu et al. (2017) Lu, Z., Pu, H., Wang, F., Hu, Z. and Wang, L. (2017). The expressive power of neural networks: A view from the width. In Advances in Neural Information Processing Systems.
- Luo and Wahba (1997) Luo, Z. and Wahba, G. (1997). Hybrid adaptive splines. Journal of the American Statistical Association, 92 107–116.
- Maggioni et al. (2016) Maggioni, M., Minsker, S. and Strawn, N. (2016). Multiscale dictionary learning: non-asymptotic bounds and robustness. The Journal of Machine Learning Research, 17 43–93.
- Mallat (1999) Mallat, S. (1999). A Wavelet Tour of Signal Processing. Elsevier.
- Mhaskar (1996) Mhaskar, H. N. (1996). Neural networks for optimal approximation of smooth and analytic functions. Neural Computation, 8 164–177.
- Miotto et al. (2018) Miotto, R., Wang, F., Wang, S., Jiang, X. and Dudley, J. T. (2018). Deep learning for healthcare: review, opportunities and challenges. Briefings in Bioinformatics, 19 1236–1246.
- Muller and Stadtmuller (1987) Muller, H.-G. and Stadtmuller, U. (1987). Variable bandwidth kernel estimators of regression curves. The Annals of Statistics 182–201.
- Nakada and Imaizumi (2020) Nakada, R. and Imaizumi, M. (2020). Adaptive approximation and generalization of deep neural network with intrinsic dimensionality. J. Mach. Learn. Res., 21 1–38.
- Oono and Suzuki (2019) Oono, K. and Suzuki, T. (2019). Approximation and non-parametric estimation of ResNet-type convolutional neural networks. In International Conference on Machine Learning.
- Petersen and Voigtlaender (2018) Petersen, P. and Voigtlaender, F. (2018). Optimal approximation of piecewise smooth functions using deep ReLU neural networks. Neural Networks, 108 296–330.
- Petersen and Voigtlaender (2020) Petersen, P. and Voigtlaender, F. (2020). Equivalence of approximation by convolutional neural networks and fully-connected networks. Proceedings of the American Mathematical Society, 148 1567–1581.
- Pintore et al. (2006) Pintore, A., Speckman, P. and Holmes, C. C. (2006). Spatially adaptive smoothing splines. Biometrika, 93 113–125.
- Ruppert and Carroll (2000) Ruppert, D. and Carroll, R. J. (2000). Theory & methods: Spatially-adaptive penalties for spline fitting. Australian & New Zealand Journal of Statistics, 42 205–223.
- Schmidt-Hieber (2017) Schmidt-Hieber, J. (2017). Nonparametric regression using deep neural networks with ReLU activation function. arXiv preprint arXiv:1708.06633.
- Schmidt-Hieber (2019) Schmidt-Hieber, J. (2019). Deep ReLU network approximation of functions on a manifold. arXiv preprint arXiv:1908.00695.
- Smith and Kohn (1996) Smith, M. and Kohn, R. (1996). Nonparametric regression using bayesian variable selection. Journal of Econometrics, 75 317–343.
- Suzuki (2018) Suzuki, T. (2018). Adaptivity of deep ReLU network for learning in Besov and mixed smooth Besov spaces: optimal rate and curse of dimensionality. arXiv preprint arXiv:1810.08033.
- Thäle (2008) Thäle, C. (2008). 50 years sets with positive reach–a survey. Surveys in Mathematics and its Applications, 3 123–165.
- Tibshirani (2014) Tibshirani, R. J. (2014). Adaptive piecewise polynomial estimation via trend filtering1. The Annals of Statistics, 42 285–323.
- Wahba (1995) Wahba, G. (1995). In Discussion of ‘Wavelet shrinkage: asymptopia?’ by D. L. Donoho, I. M. Johnstone, G. Kerkyacharian & D. Picard. J. R. Statist. Soc. B, 57 360–361.
- Wang et al. (2013) Wang, X., Du, P. and Shen, J. (2013). Smoothing splines with varying smoothing parameter. Biometrika, 100 955–970.
- Wood et al. (2002) Wood, S. A., Jiang, W. and Tanner, M. (2002). Bayesian mixture of splines for spatially adaptive nonparametric regression. Biometrika, 89 513–528.
- Yarotsky (2017) Yarotsky, D. (2017). Error bounds for approximations with deep ReLU networks. Neural Networks, 94 103–114.
- Young et al. (2018) Young, T., Hazarika, D., Poria, S. and Cambria, E. (2018). Recent trends in deep learning based natural language processing. IEEE Computational Intelligence Magazine, 13 55–75.
- Zhang et al. (2023) Zhang, Z., Chen, M., Wang, M., Liao, W. and Zhao, T. (2023). Effective Minkowski dimension of deep nonparametric regression: function approximation and statistical theories. In International Conference on Machine Learning. PMLR.
- Zhou (2020) Zhou, D.-X. (2020). Universality of deep convolutional neural networks. Applied and Computational Harmonic Analysis, 48 787–794.
- Zhou and Troyanskaya (2015) Zhou, J. and Troyanskaya, O. G. (2015). Predicting effects of noncoding variants with deep learning–based sequence model. Nature Methods, 12 931–934.