Deep-Unfolded Massive Grant-Free Transmission
in Cell-Free Wireless Communication Systems
Abstract
Grant-free transmission and cell-free communication are vital in improving coverage and quality-of-service for massive machine-type communication. This paper proposes a novel framework of joint active user detection, channel estimation, and data detection (JACD) for massive grant-free transmission in cell-free wireless communication systems. We formulate JACD as an optimization problem and solve it approximately using forward-backward splitting. To deal with the discrete symbol constraint, we relax the discrete constellation to its convex hull and propose two approaches that promote solutions from the constellation set. To reduce complexity, we replace costly computations with approximate shrinkage operations and approximate posterior mean estimator computations. To improve active user detection (AUD) performance, we introduce a soft-output AUD module that considers both the data estimates and channel conditions. To jointly optimize all algorithm hyper-parameters and to improve JACD performance, we further deploy deep unfolding together with a momentum strategy, resulting in two algorithms called DU-ABC and DU-POEM. Finally, we demonstrate the efficacy of the proposed JACD algorithms via extensive system simulations.
Index Terms:
Active user detection, cell-free communication, channel estimation, data detection, deep unfolding, grant-free transmission, massive machine-type communication.I Introduction
Massive machine-type communication (mMTC) is an essential scenario of fifth-generation (5G) and beyond-5G wireless communication systems [3, 4, 5, 6, 7, 8], and focuses on supporting a large number of sporadically active user equipments (UEs) transmitting short packets to an infrastructure base station (BS) [9, 10, 11, 12, 13, 14, 15, 16]. On the one hand, grant-free transmission schemes [17, 18, 19, 20] are essential for mMTC scenarios, as they reduce signaling overhead, network congestion and transmission latency compared with traditional grant-based transmission schemes [21, 22, 23]. In grant-free transmission schemes, UEs transmit signals directly to the BS over shared resources, bypassing the need for complex scheduling. On the other hand, to improve coverage in mMTC, cell-free communication offers a promising solution [24, 25, 26, 27, 28]. In cell-free systems, numerous decentralized access points (APs) are connected to a central processing unit (CPU), jointly serving UEs to effectively broaden the coverage, mitigate inter-cell interference and enhance spectral efficiency [29, 30]. The key tasks of the CPU for massive grant-free transmission in cell-free wireless communication systems involve (i) identifying the set of active UEs, (ii) estimating their channels, and (iii) detecting their transmitted data.
I-A Contributions
This paper proposes a novel framework for joint active user detection, channel estimation, and data detection (JACD) in cell-free systems with grant-free access. We start by formulating JACD as an optimization problem that fully exploits the sparsity of the wireless channel and data matrices and then approximately solve it using forward-backward splitting (FBS) [31, 32]. To enable FBS, we relax the discrete constellation constraint to its convex hull and employ JACD methods with the incorporation of either a regularizer or a posterior mean estimator (PME), guiding symbols toward discrete constellation points, resulting in the box-constrained FBS and PME-based JACD algorithms, respectively. To reduce complexity, we replace the exact proximal operators with approximate shrinkage operations and approximate PME computations. To improve convergence and JACD performance, we include per-iteration step sizes and a momentum strategy. To avoid tedious manual parameter tuning, we employ deep unfolding (DU) to jointly tune all of the algorithm hyper-parameters using machine learning tools. To improve active user detection (AUD) performance, we include a novel soft-output AUD module that jointly considers the estimated data and channel matrix. Based on the aforementioned modifications, we have developed the deep unfolding versions of the box-constrained FBS and PME-based JACD algorithms, referred to as DU-ABC and DU-POEM. We use Monte–Carlo simulations to demonstrate the superiority of our framework compared to existing methods.
I-B Prior Work
I-B1 Massive Grant-Free Transmission in Cell-Free Wireless Communication Systems
Recent results have focused on AUD, channel estimation (CE), and data detection (DD) for massive grant-free transmission in cell-free wireless communication systems [1, 2, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46]. Reference [33] proposes two different AUD algorithms based on dominant APs and clustering, respectively. On this basis, a parallel AUD algorithm is developed to reduce complexity. Reference [34] proposes a covariance-based cooperative AUD method in which APs exchange their low-dimensional local information with neighbors. Reference [35] introduces a correlation-based AUD algorithm, accompanied by simulation results and empirical analysis, demonstrating that the cell-free system outperforms the collocated system in AUD performance. Reference [36] proposes centralized and distributed AUD algorithms for asynchronous transmission caused by low-cost oscillators. For near-real-time transmission, reference [37] introduces a deep-learning-based AUD algorithm, in which distributed computing units employ convolutional neural networks for preliminary AUD, and the CPU subsequently refines them through transfer learning. Capitalizing on the a-priori distribution of channel coefficients, reference [38] introduces a modified expectation-maximization approximate message passing (AMP) algorithm for CE, followed by AUD through the posterior support probabilities. Reference [39] proposes a two-stage AUD and CE method, in which AUD is first conducted via adjacent APs utilizing vector AMP, and CE is performed through a linear estimator. Reference [40] performs joint AUD and CE through a single-measurement-vector-based minimum mean square error (MMSE) estimation approach at each AP independently. Considering both centralized and edge computing paradigms, reference [41] presents an AMP-based approach for the joint AUD and CE while addressing quantization accuracy. In millimeter-wave systems, reference [42] introduces two distinct algorithms for joint AUD and CE, leveraging the inherent characteristic that each UE’s channel predominantly comprises a few significant propagation paths. Reference [43] presents a joint AUD and DD (JAD) algorithm, employing an adaptive AP selection method based on local log-likelihood ratios. Reference [44] performs AUD, MMSE-based CE, and successive interference cancellation (SIC)-based data decoding under a probabilistic -repitition scheme. Reference [45] first presents a joint AUD and CE approach for grant-free transmission using orthogonal time frequency space (OTFS) modulation in low Earth orbit (LEO) satellite communication systems. Subsequently, it introduces a least squares-based parallel time domain signal detection method. Reference [46] presents a Gaussian approximation-based Bayesian message passing algorithm for JACD, combined with an advanced low-coherence pilot design. Our previous work in [2] introduced a DU-based JAD algorithm, in which all algorithm hyper-parameters are optimized using machine learning. In addition, our study in [1] presents a box-constrained FBS algorithm designed for JACD. Unlike previous methods, this paper tackles the task of JACD for massive grant-free transmission in cell-free systems. To improve JACD performance, we capture the sporadic UE activity more accurately by representing both the channel matrix and the data matrix as sparse matrices.
I-B2 Joint Active User Detection, Channel Estimation, and Data Detection for Single-Cell Massive Grant-Free Transmission
JACD for single-cell massive grant-free transmission has been extensively investigated in [47, 48, 49, 50, 51, 52, 53]. Considering low-precision data converters, reference [47] utilizes bilinear generalized AMP (Bi-GAMP) with belief propagation algorithms for JACD in single-cell mMTC systems. Reference [48] proposes a bilinear message-scheduling generalized AMP for JACD, in which the channel decoder beliefs are used to refine AUD and DD. Reference [49] develops a Bi-GAMP algorithm for JACD, capturing the row-sparse channel matrix structure stemming from channel correlations. Reference [50] divides the JACD scheme into slot-wise AUD and joint signal and channel estimation, which are addressed using message passing. Reference [51] combines AMP and belief propagation (BP) to perform JACD for asynchronous mMTC systems, in which the UEs transmit different lengths of data packets. Reference [52] introduces a turbo-structured receiver for JACD and data decoding, utilizing the channel decoder’s information to improve CE and DD performance. Reference [53] introduces a JACD algorithm based on message passing and Markov random fields for LEO satellite-enabled mMTC scenarios, which employs OTFS modulation to capitalize on the sparsity in the delay-Doppler-angle domain. In contrast to these message-passing-based JACD methods that have been designed for single-cell systems that primarily focus on UE activity sparsity, we consider the JACD problem in cell-free systems by taking into account two distinct sources of sparsity in the channel matrix: (i) column sparsity, which stems from the sporadic UE activity in mMTC scenarios, and (ii) block sparsity within each non-zero column, which stems from the vast discrepancies in large-scale channel fading between UEs and distributed APs in cell-free systems [54]. Furthermore, we propose our JACD methods within the FBS framework, incorporating efficient strategies to improve the JACD performance and reduce computational complexity.
I-B3 Deep-Unfolding for Massive Grant-Free Transmission and Cell-Free Systems
DU techniques [55, 56, 57, 58] have increasingly found application in the domain of massive grant-free transmission and cell-free systems [42, 51, 59, 60, 61, 62, 63], which adeptly utilize backpropagation and stochastic gradient descent to automatically learn algorithm hyper-parameters. Reference [42] employs DU to a linearized alternating direction method of multipliers and vector AMP, improving the performance of joint AUD and CE. Reference [51] applies DU to AMP-BP to improve JACD performance, fully exploiting the three-level sparsity inherent in UE activity, transmission delay, and data length diversity. Reference [59] introduces a model-driven sparse recovery algorithm to estimate the sparse channel matrix in mMTC scenarios, effectively utilizing the a-priori knowledge of partially known supports. Reference [60] unfolds AMP, tailored for JAD in mMTC under single-phase non-coherent schemes, wherein the embedded parameters are trained to mitigate the performance degradation caused by the non-ideal i.i.d. model. Reference [61] uses DU together with an iterative shrinkage thresholding algorithm for joint AUD and CE, wherein multiple computable matrices are treated as trainable parameters, thereby providing improving optimization flexibility. Reference [62] proposes a DU-based multi-user beamformer for cell-free systems, improving robustness to imperfect channel state information (CSI), where APs are equipped with fully digital or hybrid analog-digital arrays. Reference [63] unfolds a zero-forcing algorithm to achieve multi-user precoding, reducing complexity and improving the robustness under imperfect CSI. In contrast to these results, we deploy DU to train all hyper-parameters in our proposed algorithms to improve the JACD performance and employ approximations for high-complexity steps to decrease computational complexity. Furthermore, we train the hyper-parameters of our soft-output AUD module that generates information on UE activity probability.
I-C Notation
Matrices, column vectors, and sets are denoted by uppercase boldface letters, lowercase boldface letters, and uppercase calligraphic letters, respectively. stands for the element of matrix at the th row and th column, and stands for the th entry of the vector . The all-ones matrix is and the identity matrix is . The unit vector, which is zero except for the th entry, is , and the zero vector is ; the dimensions of these vectors will be clear from the context. We use hat symbols to refer to the estimated values of a variable, vector, or matrix. The superscripts and represent transpose and conjugate transpose, respectively, and the superscript denotes the th iteration. The Frobenius norm is denoted by . In addition, stands for a diagonal matrix with entries on the main diagonal; stands for the determinant of . The cardinality of a set is . The operators and denote Hadamard product and proportional relationships. For , and represent its real and imaginary part, respectively. and denote probability and expectation, respectively; the indicator function returns for valid conditions and otherwise. The multivariate complex Gaussian probability distribution with mean vector and covariance matrix evaluated at is
| (1) |
and the symbol means “is defined as.” Besides, the shrinkage operation is defined as
| (2) |
and the element-wise clamp function is defined as
| (3) | ||||
I-D Paper Outline
The rest of this paper is organized as follows. Section II presents the necessary prerequisites for the subsequent derivations. Section III introduces the system model and formulates the JACD optimization problem. Section IV introduces two distinct JACD algorithms: (i) box-constrained FBS and (ii) PME-based JACD. Section V deploys DU techniques and details the AUD module. Section VI investigates the efficacy of the proposed algorithms via Monte–Carlo simulations. Section VII concludes the paper. Proofs are relegated to the appendices.
II Prerequisites
In this section, we introduce some background knowledge and mathematical definitions related to the subsequent sections. Specifically, the introduction to FBS will provide insights into the derivation of the JACD algorithms under the FBS framework in Section IV. In addition, Definitions 1 and 3 are primarily used for the derivation of the PME-based JACD algorithm in Section IV-B, and Definition 2 is mainly utilized in the derivation of the DU-POEM algorithm in Section V-B.
II-A A Brief Introduction to FBS
FBS, also known as proximal gradient methods, is widely used for solving a wide variety of convex optimization problems [31, 32]. FBS splits the objective function into two components: a smooth function, denoted as , and another not necessarily smooth function, , and solves the following optimization problem:
| (4) |
FBS iteratively performs a gradient step in the smooth function (denoted as the forward step) and a proximal operation to find a solution in the vicinity of the minimizer of the function (denoted as the backward step). The forward step proceeds as
| (5) |
where the superscript denotes the th iteration, represents the step size at iteration , and is the gradient of . The backward step proceeds as
| (6) |
This process is iterated for until a predefined convergence criterion is met or a maximum number of iterations has been reached.
II-B Some Mathematical Definitions
Here, we introduce Definitions 1 and 2 to specify the probability distributions that the random vector may follow.
Definition 1: For a random vector taken from the discrete set (), we call follows the -mixed discrete uniform distribution on , denoted as , if , where is the probability of being non-zero.
Definition 2: For a random vector in a discrete set (), we call follows a discrete uniform distribution on , denoted as , if .
We also define the PME of a vector under the specific conditions as follows:
Definition 3: Given the observation vector with following the prior distribution and Gaussian estimation error , we call
| (7) |
the PME of under the prior .
III System Model and Problem Formulation
We consider an mMTC scenario in a cell-free wireless communication system as illustrated in Fig. 1. We model the situation using distributed APs with antennas that serve single-antenna sporadically active UEs. We assume that the active UEs are synchronized in time and simultaneously transmit uplink signals to APs over resource elements, assuming frequency-flat and block-fading channels.
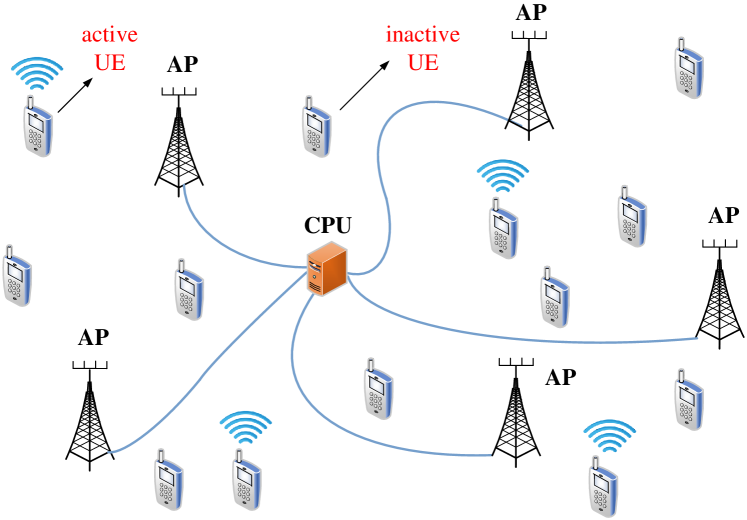
III-A System Model
Following our previous work in [1, 2], we model the input-output relation of this scenario as follows:
| (8) |
Here, the received signal matrix from all APs is denoted by , and is th UE’s activity indicator with indicating the th UE is active and otherwise. We assume that the activity between UEs is independent and all UEs have the same activity probability , i.e., . The channel vector between the th UE and all APs is with being the channel vector between the th UE and the th AP. The th UE’s signal vector consists of the pilot vector and the data vector with data entries independently and uniformly sampled from the constellation set . Entries in the noise matrix are assumed to be i.i.d. circularly-symmetric complex Gaussian variables with variance .
| (14) |
| (16) |
For ease of notation, we rewrite the system model in (8) as
| (9) |
where with and being the received pilot matrix and received data matrix, respectively. The channel matrix is given by . The signal matrix contains the pilot matrix and the data matrix , where with .
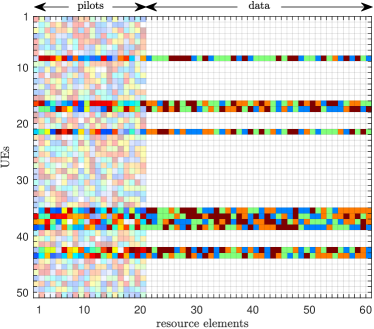
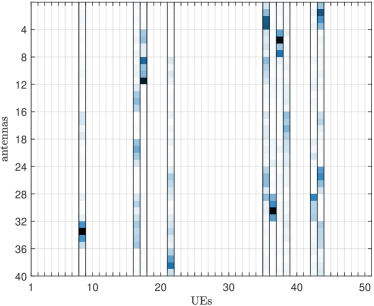
A typical signal matrix is depicted in Fig. 2. Here, the data matrix is a row-sparse matrix due to sporadic UE activity, and the pilot matrix is characterized as a non-sparse matrix, retaining all known pilot information for subsequent optimization. A typical channel matrix is depicted in Fig. 3, where sparsity is due to two reasons: (i) the UEs’ sporadic activity results in column sparsity and (ii) the inherent discrepancies in large-scale fading between UEs and different APs, caused by their varying distances, lead to the block sparsity within each non-zero column.
While row/column sparsity and block sparsity have been widely studied in compressed sensing, the intricate interplay of these sparsities in our setting remains largely unexplored. In our system model (9), the estimation of both and poses a significant challenge, as exhibits both column and row sparsity, while displays row sparsity. In the subsequent problem formulation and algorithm derivation, we will effectively leverage the sparsity of both the channel matrix and the data matrix to enhance JACD performance.
III-B Problem Formulation
Using the system model (9), we formulate the maximum-a-posteriori JACD problem for massive grant-free transmission in cell-free wireless communication systems as [1, 2]
| (10) |
where the channel law is given by
| (11) |
Here, we employ the complex-valued block-Laplace model and Laplace model for block sparsity in and column sparsity in , respectively, as follows [1, 2]
| (12) | |||
| (13) |
with and indicating the sparsity levels of and , respectively.
By inserting (11), (12), and (13) into (10), we can rewrite the JACD problem as problem with , expressed in problem (14) above. This problem aims to estimate the channel matrix and the data matrix using the received signal matrix and the pilot matrix , in which UE activity is indicated by the column sparsity of and row sparsity of .
III-C Problem Relaxation
The discrete set renders a discrete-valued optimization problem for which a naïve exhaustive search is infeasible. To circumvent this limitation, as in [1, 2], we relax the discrete set to its convex hull , thereby transforming into a continuous-valued optimization problem. The set is given by111For quadrature phase shift keying (QPSK), the set can be specified as .
| (15) |
To push the entries in the data matrix towards points in discrete set , two distinct methodologies can be used: Method (i) introduces a regularizer (also called penalty term) into the objective function of [1, 64] and method (ii) leverages the PME to denoise the estimated data matrix [2]. As such, we can transform the original discrete-valued optimization problem into problem in (16) above. The penalty parameter is for method (i) and for method (ii). For the regularizer , many alternatives are possible, such as utilized in [1]. In the next section, we will develop the FBS algorithm based on method (i) and method (ii) respectively to efficiently compute approximate solutions to problem .
IV JACD Algorithms
We develop two JACD algorithms that utilize FBS, each leveraging specific techniques to improve JACD performance. Specifically, the first algorithm based on method (i) is called the box-constrained FBS algorithm [1], which utilizes a regularizer within the objective function to guide the estimated symbols toward the discrete constellation points, thereby improving DD accuracy. The second algorithm based on method (ii) is called the PME-based JACD algorithm, which employs PME to modify estimated data to further improve DD performance.
IV-A Box-Constrained FBS Algorithm for JACD
For this method, we utilize the FBS with the incorporation of the regularizer to approximately solve the non-convex problem . Using the definition in [1, 2, 54], we can split the objective function of into the two functions
| (17) | ||||
| (18) |
where represents the constraint in problem . Following the FBS framework outlined in Section II-A, the corresponding forward and backward steps can be specified as follows.
IV-A1 Forward Step
IV-A2 Backward Step
The proximal operator for can be decomposed into separate proximal operators for and , respectively. The proximal operator for is
| (22) |
with representing the step size at iteration in the forward step (5). The closed-form solution of problem (22) is given by [54, 31, 32]
| (23) |
with the shrinkage operation defined in (2). The proximal operator for can be decomposed as independent proximal operators for as follows
| (24) |
which is a convex optimization problem, and the optimal solution of (24) can be obtained by the KKT conditions outlined in [1]. For completeness, the following proposition details the closed-form solution to (24) and its proof is given in Appendix A.
Proposition 1: The optimal solution of (24) is given by , where is expressed as:
| (25) | ||||
Here, , , and , where . In addition, is the solution of the quartic equation within the interval (0,1], if it exists; otherwise, .
The pseudocode for the proposed box-constrained FBS algorithm is presented in Algorithm 1.
| (27) |
IV-B PME-Based JACD Algorithm
An alternative technique that considers the discrete constellation constraint in uses a PME, which denoises the data matrix ; for this approach, we set . We now only discuss the differences to the box-constrained FBS algorithm from Section IV-A with , which are in the computation of the proximal operator for .
In our paper, the PME assumes that one observes a signal of interest through noisy Gaussian observations (see Definition 3 in Section II-B) and obtains the best estimates in terms of minimizing the mean square error by leveraging the known prior probability of the signal. As in [65, 66], instead of calculating a proximal operator for the data matrix , we simply denoise the output of the forward step using a carefully designed PME. To this end, we model the th UE’s estimated data vector in the th iteration as
| (26) |
Here, is unknown and is the estimation error at iteration , which we assume to be complex Gaussian following the distribution . Here, the vector from (26) follows -mixed discrete uniform distribution on , i.e., (see Definition 1 in Section II-B), where is the UE activity probability. Accordingly, we can employ the PME of under the prior , i.e., (refer to Definition 3 in Section II-B) as the estimate of the data matrix [2], expressed as in (27). Algorithm 2 outlines the pseudocode for the proposed PME-based JACD algorithm.
IV-C Active User Detection and Data Detection
After estimating the channel and data matrices over iterations using box-constrained FBS or PME-based JACD, we proceed with AUD and DD for both algorithms. As in [1], we determine UE activity based on the channel energy. Specifically, if the channel energy of the th UE surpasses a threshold , then the UE is deemed active; otherwise, we consider it inactive. Mathematically, we describe AUD as follows:
| (28) |
The estimated UE activity indicators can now be used to update the estimated data matrix as
| (29) |
where is obtained by mapping the entries in to the nearest symbols in as follows:
| (30) |
In Section V-C, we will introduce a trainable soft-output AUD module that leverages information from both the estimated channel and data matrices to improve AUD performance.
IV-D Complexity Comparison
We assess the computational complexity of our algorithms using the number of complex-valued multiplications, which are expressed in big-O notation. For each iteration, the complexity of the forward steps in these algorithms is . Here, varies depending on the chosen regularizer222For instance, for the regularizer .. The per-iteration complexities of the backward steps in the box-constrained FBS and PME-based JACD algorithms are and , respectively. In addition, the computational complexity of the AUD and DD module is .
The summation terms in the PME expression (27) lead to exponential complexity with the data length serving as the exponent, which results in higher complexity for the PME-based JACD algorithm compared to the box-constrained FBS algorithm. In Section V, we will leverage DU to tune hyper-parameters in these algorithms, improving their effectiveness automatically. Besides that, we introduce approximations to replace the costly computations in (25) and (27) in the backward steps of these algorithms to further reduce complexity.
V Algorithm Tuning Using Deep-Unfolding
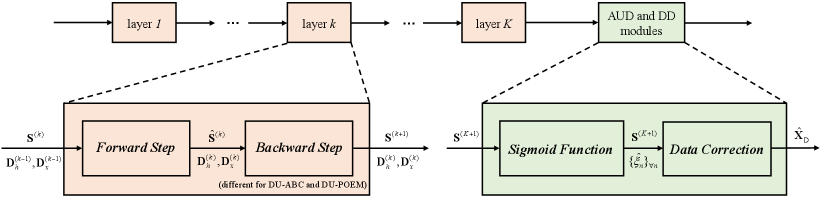
The JACD algorithms introduced in Section IV involve numerous hyper-parameters, making manual parameter tuning challenging. We apply DU to tune all of the involved hyper-parameters automatically. The resulting deep-unfolded algorithms are called the Deep-Unfolding-based Approximate Box-Constrained (DU-ABC) algorithm and the Deep-Unfolding-based aPproximate pOsterior mEan estiMator (DU-POEM) algorithm. Their corresponding deep-unfolded architecture is outlined in Fig. 4.
| (40) |
V-A DU-ABC Algorithm
V-A1 Forward Step
In the forward step of the box-constrained FBS algorithm, the same step size in each iteration is utilized to compute both and . Due to the vast difference in dynamic range of and , for DU-ABC, we introduce separate step sizes and to update and , respectively. To accelerate convergence, we apply a momentum strategy, where the gradient information of all previous iterations is used to compute in each iteration [2, 66]. Furthermore, we allow the penalty coefficient to be iteration-dependent as . In summary, the forward step (5) of the box-constrained FBS algorithm is modified as
| (31) | ||||
| (32) |
where the momentum terms and incorporate the gradient information from the first iterations, and are given by
| (33) | ||||
| (34) |
Here, and are weights for the momentum terms of the quantities and , respectively, and and .
V-A2 Backward Step
Since we introduce separate step sizes and in the forward step of DU-ABC, we accordingly define trainable parameters and for all , to facilitate subsequent computations. Consequently, the proximal operator for in (23) is modified as follows:
| (35) |
As for the proximal operation on , the optimal solution of the problem (24) involves a complicated quartic equation, as mentioned in Proposition 1, thereby preventing the utilization of DU techniques. To solve this problem, we introduce a simpler alternative: first solve problem (24) without considering the constraints to obtain the optimal solution ; then, clamp the result to the convex hull . The procedure is
| (36) |
with the clamp function defined in (3). In addition, and are introduced trainable parameters for the coefficient and bias vector at the th iteration, respectively, to increase the flexibility of optimization.
For DU-ABC, the trainable hyper-parameters in forward and backward steps are and , respectively, where denotes the set of trainable hyper-parameters in the regularizer .
V-B DU-POEM Algorithm
The forward step and the proximal operations on in the backward step of the DU-POEM algorithm align with those of the DU-ABC algorithm with , as detailed in (31)-(35). We now only focus on the proximal operation for in DU-POEM, which is different from that of the DU-ABC.
As for the PME of in the PME-based JACD algorithm, the summation of numerous exponential terms in (27) can result in high computational complexity and lead to numerical stability issues. To mitigate these issues, we show the following proposition that reveals the linear relationship between the PME of under two specific prior distributions: and (refer to Definition 2 in Section II-B).
Proposition 2: Given observation vector with Gaussian estimation error , there is a linear relationship between and , i.e.,
| (37) | ||||
where , and the coefficient is defined as
| (38) |
The proof is given in Appendix B.
According to Proposition 2, we can reformulate the PME of under the prior , , in equation (27) as the product of a coefficient and . The main advantage of this reformulation is that we can further decouple each element in and compute them independently, which is explained by Proposition 3. The proof is given in Appendix C.
Proposition 3: Given observation vector with and Gaussian estimation error , we can express the -th entry of as
| (39) |
where .
According to Proposition 3, we can calculate the th entry of by the expression (40), which only relates to and avoids a summation of a large number of exponential terms, thereby reducing complexity and avoiding numerical stability issues.
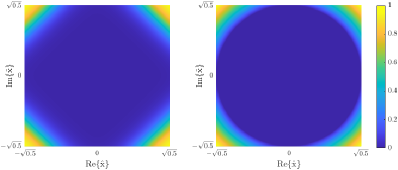
Although in (37) requires low computational complexity and alleviates numerical stability issues, Proposition 2 also introduces as shown in (38), which remains complex due to the summation of numerous exponential terms in the denominator. To address this, we propose the following approximate shrinkage operation as a simplified alternative:
| (41) |
where and are tunable parameters. In Fig. 5, we illustrate with , , and alongside its approximation with and in a simplified one-dimensional complex-value space for ease of visualization. Evidently, the resulting approximation , illustrated on the right of Fig. 5, exhibits sufficient similarity with .
Consequently, we employ an approximate PME at the backward step to replace the exact PME (27) as done in [2]:
| (42) | ||||
Here, the hyper-parameters and the variance of the estimation error at iteration are trainable.
In DU-POEM, the trainable hyper-parameters in the forward and backward steps are and , respectively.
V-C Trainable Soft-Output Active User Detection and Data Detection Modules
Both the sparsity in the channel matrix and in the data matrix indicate UE activity. To obtain accurate soft information for UE activity , we propose the use of a sigmoid function as in [2] to fully extract activity information from both the channel and data matrices as follows:
| (43) |
Here, the parameters , , and are tuned using DU. Utilizing soft information, we can detect the UEs’ active states by comparing them against a threshold , i.e.,
| (44) |
Determining depends on the desired UE miss-detection and false-detection rates333The UE miss-detection rate is the ratio of the number of active UEs mistakenly deemed inactive to the total number of UEs. The UE false-detection rate is the ratio of the number of inactive UEs incorrectly classified as active to the total number of UEs.. Generally, larger might result in more UEs being detected as inactive, subsequently potentially increasing the UE miss-detection rate and reducing the UE false-detection rate. Strictly speaking, as increases, the UE miss-detection rate should not decrease, and the UE false-detection rate should not increase.
V-D Training Procedure
In our previous work [2], we trained the hyper-parameters in the unfolded layers of these algorithms and the AUD module separately. As a result, the AUD module is unable to guide these unfolded layers to estimate more accurate outputs that could potentially improve AUD performance. This one-way interaction limits the effectiveness of the parameter tuning. Furthermore, the performance of these unfolded layers was also not fully optimized in [2] due to the lack of valuable feedback from the AUD module. These separate training processes result in a missed opportunity for more effective hyper-parameter tuning. To achieve better JACD performance, we choose to jointly train the hyper-parameters in the unfolded layers in conjunction with the AUD module utilizing the following loss function:
| (45) |
The above loss function underscores our emphasis on the precision of both AUD and DD performance, aligning seamlessly with the objectives of the practical wireless communication systems. We note that due to the absence of the error term comparing the estimated channel matrix and actual channel matrix in the loss function (45), i.e., we do not explicitly optimize our algorithms for CE accuracy.
Note that the shrinkage operation (2) and approximate shrinkage operation (41) applied in DU-based algorithms have no gradient at . To circumvent this issue, we replace the denominator in these equations with , producing valid gradients and avoiding a denominator of , where is a small value (we use in the simulations).
V-E Complexity Comparison
The computational complexity per iteration for the forward steps in both the DU-ABC and DU-POEM algorithms is . Additionally, for the backward steps, the per-iteration complexity is for the DU-ABC algorithm and for the DU-POEM algorithm. The computational complexity of the trainable AUD and DD module is .
By approximating the PME expression (27) through Propositions 2 and 3, we have significantly reduced the complexity of the backward step in the DU-POEM algorithm to , in contrast to in the PME-based JACD algorithm. This reduction makes the computational complexities of both the DU-ABC and DU-POEM algorithms comparable, improving their efficiency and practicality.
VI Simulation Results
We now demonstrate the efficacy of our proposed JACD algorithms and compare them to existing baseline methods.
VI-A Simulation Setup
Building upon the system settings from [1, 2, 54], we consider a cell-free wireless communication system in an area of 500 m 500 m. Unless stated otherwise, we use the following assumptions. We consider uniformly distributed APs at the height of m, each with antennas, that serve uniformly distributed single-antenna UEs at the height of m. We set the UE activity probability to . Active UEs transmit pilot signals, originating from a complex equiangular tight frame as described in [67], and QPSK data signals over the channel with a bandwidth of MHz and a carrier frequency of MHz. These signals satisfy the energy constraints and , implying that for QPSK. We assume that the UEs’ transmission power is 0.1 W, with power control allowing for a dynamic range of up to 12 dB between the strongest and weakest UE [54]. Moreover, we account for a shadow fading variance of dB, a noise figure of dB, and a noise temperature of K.
Regarding the channel model, we assume that the small-scale fading parameters follow the standard complex Gaussian distribution, while the large-scale fading follows a three-slope path-loss model [54, 25, 68]. Specifically, the large-scale fading between the th UE and the th AP, denoted as , is given by [25, Eq. (52)], [54], [68]
| (46) |
Here, [km] is the distance between the th UE and the th AP with breakpoints at km and km [25]. Besides, the shadow fading follows , and [25, Eq. (53)].
VI-B Baseline Methods
To assess the effectiveness of our algorithms444Since the PME-based JACD algorithm involves tuning numerous hyper-parameters and has a high computational complexity, this section only presents performance simulations for its deep-unfolded variant, DU-POEM, alongside the box-constrained FBS algorithm and DU-ABC., we introduce the following baseline methods for comparison:
-
•
Baseline 1: In this baseline, we first employ the FBS method [31] to estimate sparse channels from the system model . Then, active UEs are identified by equation (28) based on the estimated channels , resulting in the active UE set . Subsequently, we perform DD through , where . Finally, we map the result to the nearest constellation symbols using equation (30).
-
•
Baseline 2: In this baseline, we utilize the AMP algorithm [22] to estimate sparse channels, while all other components remain unchanged from Baseline 1.
-
•
Baseline 3: This baseline retains all components of Baseline 1, except that we employ a soft MMSE-based iterative detection method [69] for DD.
-
•
Baseline 4: We adopt a joint AUD-CE-DD method as proposed in [47], which combines Bi-GAMP for CE and DD, alongside sum-product loopy belief propagation (LBP) for AUD.
- •
To accelerate convergence, we take the result of Baseline 1 to initialize Baseline 5, the box-constrained FBS, DU-ABC, and DU-POEM algorithms. In addition, we carry out a maximum number of iterations for Baselines 1-to-5 and box-constrained FBS algorithm, with a stopping tolerance of for FBS. We use layers (equal to the maximum number of iterations) for DU-ABC and DU-POEM. To ensure a fair comparison with DU-ABC and DU-POEM, we also present the results of high-performance Baselines 2, 4, 5 and the box-constrained FBS algorithm with only iterations.
To illustrate the trade-off between JACD performance and computational complexity, we now provide the computational complexities for Baselines 1-5 before we analyze their performance. Specifically, their computational complexities are , , , , and , respectively, where is the iteration number of these baselines.
VI-C Performance Metrics
To evaluate the performance of the proposed algorithms and the baseline methods, we consider the following performance metrics: UE detection error rate (UDER), channel estimation normalized mean square error (NMSE), and average symbol error rate (ASER), which are defined as follows:
| (47) | |||
| (48) | |||
| (49) |
Furthermore, we also consider a receiver operating characteristic (ROC) curve analysis with the goal of exploring the trade-off between true positive rate (TPR) and false positive rate (FPR) for AUD, which are defined as follows:
| FPR | (50) | |||
| TPR | (51) |
The results shown next are from Monte–Carlo trials.
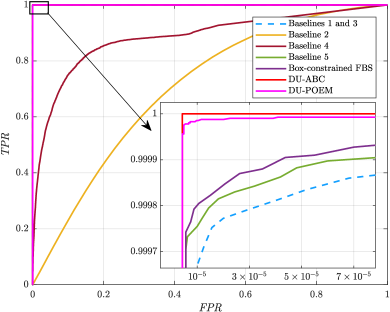
VI-D Simulation Results
VI-D1 Performance Analysis for Different AP Numbers
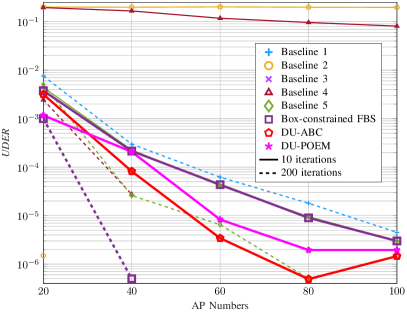
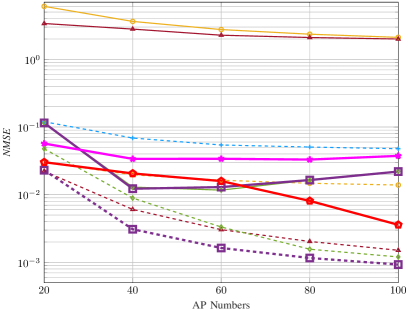
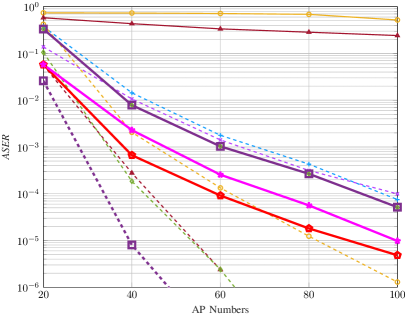
In Fig. 6, we evaluate the JACD performance across various algorithms for different numbers of APs. Figs. 6(a)-6(c) show that, when running iterations, the box-constrained FBS algorithm consistently outperforms all other considered methods in terms of NMSE and ASER across various AP numbers. In addition, the performance of the box-constrained FBS algorithm in UDER surpasses that of most baseline methods. The superior performance of the box-constrained FBS algorithm is primarily due to its effective utilization of the block sparsity in the channel matrix and the row sparsity in the data matrix.
Furthermore, when executing iterations, DU-ABC and DU-POEM surpass all baseline methods in terms of ASER and UDER while maintaining comparable performance with others in NMSE. The superiority of these DU-based algorithms in UDER and ASER can be attributed to the precise tuning of algorithm hyper-parameters through DU. However, their moderate performance in NMSE is due to the fact that their loss function primarily focuses on AUD and DD without accounting for CE accuracy.
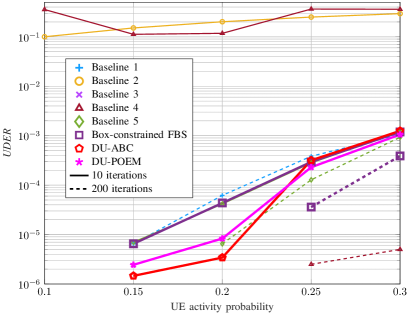
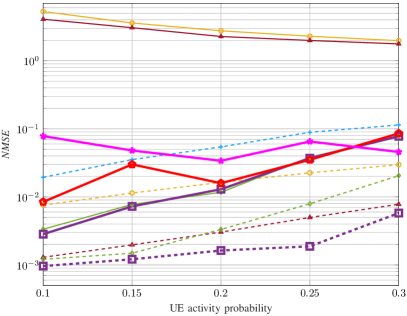
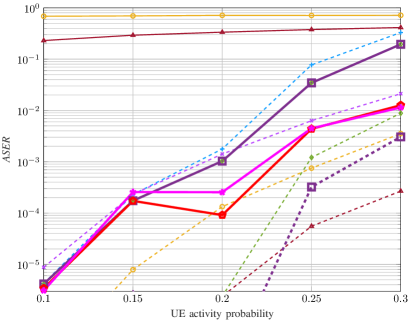
The insufficient iterations for some algorithms to converge result in the following phenomena: (i) The NMSE of Baseline 5 and the box-constrained FBS algorithm with 10 iterations show instability as the number of APs increases, and (ii) AMP-based Baseline 2 and Bi-GAMP-based Baseline 4 experience significant JACD performance degradation when limited to 10 iterations compared to their performance with 200 iterations. In addition, the UDER of DU-ABC at exhibits inferior performance compared to that at , resulting from the optimization objective (45) integrating both AUD and DD performance. In these scenarios, the optimization process might give precedence to the precision of DD and compromise the performance of AUD for a smaller value of the loss function.
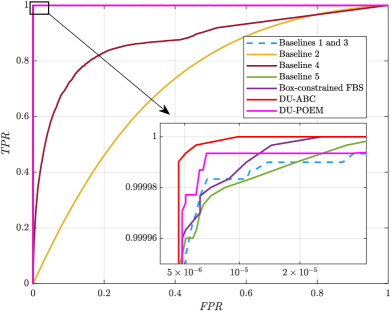
In Fig. 6(d), the ROC of various algorithms is depicted at , where Baseline 1 and 3 run iterations while the remaining algorithms use only iterations. Notably, the AMP-based Baseline 2 and Bi-GAMP-based Baseline 4 perform the worst for iterations. In contrast, the DU-ABC and DU-POEM algorithms manifest superior AUD performance, as evidenced by their elevated TPR at the same FPR. For ROC, an increase in TPR often corresponds to a higher (or identical) FPR, which highlights that the selection of thresholds and embodies a balance between TPR and FPR, contingent upon the targeted metrics for each.
In summary, when running iterations, the proposed box-constrained FBS algorithm generally achieves the best AUD, CE, and DD performance across various numbers of APs. When limited to only iterations, the proposed DU-ABC and DU-POEM algorithms respectively demonstrate the best and second-best performance in AUD and DD in most considered scenarios, respectively, while their CE performance is comparable to that of baseline algorithms.
VI-D2 Performance Analysis for Different UE Activity Probabilities
In Fig. 7, we present a comparative analysis of JACD performance across various UE activity probability scenarios, where the zero value of the UDER for Baseline 2, running 200 iterations under considered activity probabilities, is not shown on the logarithmic axis in Fig. 7(a). Firstly, Figs. 7(a)-7(c) illustrate a significant inverse relationship between UE activity probability and the JACD performance of different algorithms. Typically, with iterations, the proposed box-constrained FBS algorithm exhibits the best CE performance and achieves superior performance in AUD and DD. Conversely, with a reduced iteration count of , the DU-ABC and DU-POEM algorithms generally outperform other benchmarks in AUD and DD despite their subpar CE performance, which is due to the exclusion of a metric assessing the channel estimation accuracy from the loss function.
Analogous to the observations in Fig. 6, the DD of both DU-ABC and DU-POEM algorithms marginally decline at relative to . This is because the loss function of our DU-based algorithms considers both AUD and DD performance, which might lead to the prioritization of one aspect over the other for a lower overall loss function value. Figs. 7(a) and 7(c) demonstrate the DU-based algorithms prioritize DD performance at higher probabilities () and AUD accuracy at lower probabilities ().
In Fig. 7(d), we present the ROC comparison of various algorithms under . Baselines 1 and 3 undergo iterations, while all other algorithms complete iterations each. The AMP-based Baseline 2 and Bi-GAMP-based Baseline 4 demonstrate the worst AUD performance. Moreover, our proposed DU-ABC and DU-POEM algorithms exhibit superior AUD performance, which attains the highest TPR for a given FPR.
To sum up, when running iterations, the proposed box-constrained FBS algorithm typically achieves the best performance in AUD, CE, and DD. Conversely, the proposed DU-based algorithms generally surpass other baseline methods in AUD and DD performance with only iterations.
VII Conclusions
We have proposed a novel framework of joint active user detection, channel estimation, and data detection (JACD) for massive grant-free transmission in cell-free wireless communication systems. From this framework, we have developed several computationally efficient JACD algorithms, denoted as box-constrained FBS and PME-based JACD algorithms, accompanied by their deep-unfolded versions, DU-ABC and DU-POEM. When running algorithm iterations, the box-constrained FBS algorithm often exhibits superior JACD performance. When running only iterations, the proposed DU-ABC and DU-POEM algorithms usually significantly outperform all considered baseline methods regarding active user and data detection performance. The findings of this paper are expected to establish a solid foundation for the development of algorithms for massive machine-type communication.
Appendix A Proof of Proposition 1
As delineated in [1], we recast the complex-valued optimization problem (24) into a real-valued problem:
| (52) | ||||
where and . With the Lagrangian function , the KKT conditions of optimization problem (52) are as follows [1]:
| (53a) | |||
| (53b) | |||
| (53c) | |||
| (53d) | |||
| (53e) | |||
where . The solution of equation (53a) is given by
| (54) |
with . Here, the expression (54) implies that the influence of vectors and serves to diminish the values of some entries in , thereby confining the elements of to the interval and, consequently, guaranteeing that meets the KKT conditions.
To identify the set of elements in that potentially fall outside the interval , an initial resolution of equation (52) without constraints is conducted, i.e., , thereby we can obtain the sets and , which indicates the index of non-zero elements in and , respectively. There are three cases as follows:
-
1)
If , then we should set and to reduce the proximal coefficient and ensure the corresponding value of optimal vector .
-
2)
If , then we should set and to reduce the proximal coefficient and ensure the corresponding value of optimal vector .
-
3)
If , then we should set and because non-negativity of and ensures that the proximal coefficient does not exceed , causing . Consequently, would still satisfy the conditions.
Given the index sets and corresponding to non-zero entries in vectors and , we precisely determine the values of these non-zero entries. We now introduce the notation , and for brevity. Since , then and we have , i.e., . Accordingly, can be rewritten as , where and . This can be substituted into to obtain a quartic equation with respect to as:
where . Among the four solutions, the desired one lies within the range .
If the aforementioned quartic equation has no solution in the range , it means the case has no solution for problem (52), then we can only consider and .
This completes the proof.
Appendix B Proof of Proposition 2
Given observation vector with and Gaussian estimation error , we can express as
| (55) |
Meanwhile, for , we can express the PME of under as
| (56) | ||||
where
| (57) |
This completes the proof.
Appendix C Proof of Proposition 3
If , we can rewrite as
| (58) |
which indicates entries of are independent with each other. Based on this, given observation vector with and Gaussian estimation error , the th entry of can be given by
| (59) | ||||
where is replaced by in equation . This completes the proof.
Acknowledgements
The authors thank Victoria Palhares and Haochuan Song for their help in cell-free channel modeling and Gian Marti for his suggestions on deriving the FBS algorithm. We acknowledge Sueda Taner and Oscar Castañeda for their advice on training deep-unfolded algorithms. We are grateful to Mengyuan Feng for her suggestions on improving the figures in this paper.
References
- [1] G. Sun, M. Cao, W. Wang, W. Xu, and C. Studer, “Joint active user detection, channel estimation, and data detection for massive grant-free transmission in cell-free systems,” in Proc. IEEE Int. Workshop Signal Process. Adv. Wireless Commun. (SPAWC), Sept. 2023, pp. 406–410.
- [2] G. Sun, W. Wang, W. Xu, and C. Studer, “Deep-unfolded joint activity and data detection for grant-free transmission in cell-free systems,” in Proc. Int. Symp. Wireless Commun. Syst. (ISWCS), Jul. 2024, pp. 1–5.
- [3] ITU-R, “Framework and overall objectives of the future development of IMT for 2030 and beyond,” Jun. 2023.
- [4] G. Sun, H. Hou, Y. Wang, W. Wang, W. Xu, and S. Jin, “Beam-sweeping design for mmWave massive grant-free transmission,” IEEE J. Sel. Topics Signal Process., vol. 18, no. 7, pp. 1249–1264, Oct. 2024.
- [5] Z. Gao, M. Ke, L. Qiao, and Y. Mei, “Grant-free massive access in cell-free massive MIMO systems,” in Massive IoT Access for 6G. Springer, 2022, pp. 39–75.
- [6] Y. Mei, Z. Gao, Y. Wu, W. Chen, J. Zhang, D. W. K. Ng, and M. Di Renzo, “Compressive sensing-based joint activity and data detection for grant-free massive IoT access,” IEEE Trans. Wireless Commun., vol. 21, no. 3, pp. 1851–1869, Mar. 2022.
- [7] G. Sun, X. Yi, W. Wang, W. Xu, and S. Jin, “Hybrid beamforming for millimeter-wave massive grant-free transmission,” IEEE Trans. Commun., pp. 1–1, Early Access, Sep. 2024.
- [8] Z. Gao, M. Ke, L. Qiao, and Y. Mei, “Joint activity and data detection for grant-free massive access,” in Massive IoT Access for 6G. Springer, 2022, pp. 127–161.
- [9] J. G. Andrews, S. Buzzi, W. Choi, S. V. Hanly, A. Lozano, A. C. K. Soong, and J. C. Zhang, “What will 5G be?” IEEE J. Sel. Areas Commun., vol. 32, no. 6, pp. 1065–1082, Jun. 2014.
- [10] J. Fang, G. Sun, W. Wang, L. You, and R. Ding, “OFDMA-based unsourced random access in LEO satellite Internet of Things,” China Commun., vol. 21, no. 1, pp. 13–23, Jan. 2024.
- [11] X. Chen, D. W. K. Ng, W. Yu, E. G. Larsson, N. Al-Dhahir, and R. Schober, “Massive access for 5G and beyond,” IEEE J. Sel. Areas Commun., vol. 39, no. 3, pp. 615–637, Mar. 2021.
- [12] G. Sun, X. Yi, W. Wang, and W. Xu, “Hybrid beamforming for ergodic rate maximization of mmWave massive grant-free systems,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Dec. 2022, pp. 1612–1617.
- [13] G. Sun, W. Wang, W. Xu, and C. Studer, “Low-coherence sequence design under PAPR constraints,” IEEE Wireless Commun. Lett., vol. 13, no. 12, pp. 3663–3667, Dec. 2024.
- [14] E. Björnson, E. de Carvalho, J. H. Sørensen, E. G. Larsson, and P. Popovski, “A random access protocol for pilot allocation in crowded massive MIMO systems,” IEEE Trans. Wireless Commun., vol. 16, no. 4, pp. 2220–2234, Apr. 2017.
- [15] W. Xu, Y. Huang, W. Wang, F. Zhu, and X. Ji, “Toward ubiquitous and intelligent 6G networks: From architecture to technology,” Sci. China Inf. Sci., vol. 66, no. 3, p. 130300, Feb. 2023.
- [16] G. Sun, Y. Li, X. Yi, W. Wang, X. Gao, L. Wang, F. Wei, and Y. Chen, “Massive grant-free OFDMA with timing and frequency offsets,” IEEE Trans. Wireless Commun., vol. 21, no. 5, pp. 3365–3380, May 2022.
- [17] L. Liu, E. G. Larsson, W. Yu, P. Popovski, C. Stefanovic, and E. de Carvalho, “Sparse signal processing for grant-free massive connectivity: A future paradigm for random access protocols in the Internet of Things,” IEEE Signal Process. Mag., vol. 35, no. 5, pp. 88–99, Sept. 2018.
- [18] Z. Zhang, X. Wang, Y. Zhang, and Y. Chen, “Grant-free rateless multiple access: A novel massive access scheme for Internet of Things,” IEEE Commun. Lett., vol. 20, no. 10, pp. 2019–2022, Oct. 2016.
- [19] G. Sun, Y. Li, X. Yi, W. Wang, X. Gao, and L. Wang, “OFDMA based massive grant-free transmission in the presence of timing offset,” in Proc. 13th Int. Conf. Wireless Commun. Signal Process. (WCSP), Oct. 2021, pp. 1–6.
- [20] Y. Zhu, G. Sun, W. Wang, L. You, F. Wei, L. Wang, and Y. Chen, “Massive grant-free receiver design for OFDM-based transmission over frequency-selective fading channels,” in Proc. IEEE Int. Conf. Commun. (ICC), May 2022, pp. 2405–2410.
- [21] L. Liu and W. Yu, “Massive connectivity with massive MIMO—Part I: Device activity detection and channel estimation,” IEEE Trans. Signal Process., vol. 66, no. 11, pp. 2933–2946, Jun. 2018.
- [22] Z. Chen, F. Sohrabi, and W. Yu, “Sparse activity detection for massive connectivity,” IEEE Trans. Signal Process., vol. 66, no. 7, pp. 1890–1904, Apr. 2018.
- [23] Y. Zhu, G. Sun, W. Wang, L. You, F. Wei, L. Wang, and Y. Chen, “OFDM-based massive grant-free transmission over frequency-selective fading channels,” IEEE Trans. Commun., vol. 70, no. 7, pp. 4543–4558, Jul. 2022.
- [24] E. Björnson and L. Sanguinetti, “Scalable cell-free massive MIMO systems,” IEEE Trans. Commun., vol. 68, no. 7, pp. 4247–4261, Jul. 2020.
- [25] H. Q. Ngo, A. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta, “Cell-free massive MIMO versus small cells,” IEEE Trans. Wireless Commun., vol. 16, no. 3, pp. 1834–1850, Mar. 2017.
- [26] A. Mishra, Y. Mao, L. Sanguinetti, and B. Clerckx, “Rate-splitting assisted massive machine-type communications in cell-free massive MIMO,” IEEE Commun. Lett., vol. 26, no. 6, pp. 1358–1362, Jun. 2022.
- [27] H. Q. Ngo, A. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta, “Cell-free massive MIMO: Uniformly great service for everyone,” in Proc. IEEE Int. Workshop Signal Process. Adv. Wireless Commun. (SPAWC), Jun. 2015, pp. 201–205.
- [28] Z. Gao, M. Ke, Y. Mei, L. Qiao, S. Chen, D. W. K. Ng, and H. V. Poor, “Compressive-sensing-based grant-free massive access for 6G massive communication,” IEEE Internet Things J., vol. 11, no. 5, pp. 7411–7435, Mar. 2024.
- [29] S. Elhoushy, M. Ibrahim, and W. Hamouda, “Cell-free massive MIMO: A survey,” IEEE Commun. Surveys Tuts., vol. 24, no. 1, pp. 492–523, 1st Quart. 2021.
- [30] J. Zhang, S. Chen, Y. Lin, J. Zheng, B. Ai, and L. Hanzo, “Cell-free massive MIMO: A new next-generation paradigm,” IEEE Access, vol. 7, pp. 99 878–99 888, Jun. 2019.
- [31] T. Goldstein, C. Studer, and R. Baraniuk, “A field guide to forward-backward splitting with a FASTA implementation,” arXiv preprint: 1411.3406, Nov. 2014.
- [32] A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imag. Sci., vol. 2, no. 1, pp. 183–202, 2009.
- [33] U. K. Ganesan, E. Björnson, and E. G. Larsson, “Clustering-based activity detection algorithms for grant-free random access in cell-free massive MIMO,” IEEE Trans. Commun., vol. 69, no. 11, pp. 7520–7530, Nov. 2021.
- [34] X. Shao, X. Chen, D. W. K. Ng, C. Zhong, and Z. Zhang, “Covariance-based cooperative activity detection for massive grant-free random access,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Dec. 2020, pp. 1–6.
- [35] H. Wang, J. Wang, and J. Fang, “Grant-free massive connectivity in massive MIMO systems: Collocated versus cell-free,” IEEE Wireless Commun. Lett., vol. 10, no. 3, pp. 634–638, Mar. 2021.
- [36] Y. Li, Q. Lin, Y.-F. Liu, B. Ai, and Y.-C. Wu, “Asynchronous activity detection for cell-free massive MIMO: From centralized to distributed algorithms,” IEEE Trans. Wireless Commun., vol. 22, no. 4, pp. 2477–2492, Apr. 2023.
- [37] L. Diao, H. Wang, J. Li, P. Zhu, D. Wang, and X. You, “A scalable deep-learning-based active user detection approach for SEU-assisted cell-free massive MIMO systems,” IEEE Internet Things J., vol. 10, no. 22, pp. 19 666–19 680, Nov. 2023.
- [38] S. Jiang, J. Dang, Z. Zhang, L. Wu, B. Zhu, and L. Wang, “EM-AMP-based joint active user detection and channel estimation in cell-free system,” IEEE Syst. J., vol. 17, no. 3, pp. 4026–4037, Sept. 2023.
- [39] X. Wang, A. Ashikhmin, Z. Dong, and C. Zhai, “Two-stage channel estimation approach for cell-free IoT with massive random access,” IEEE J. Sel. Areas Commun., vol. 40, no. 5, pp. 1428–1440, May 2022.
- [40] M. Guo and M. C. Gursoy, “Joint activity detection and channel estimation in cell-free massive MIMO networks with massive connectivity,” IEEE Trans. Commun., vol. 70, no. 1, pp. 317–331, Jan. 2022.
- [41] M. Ke, Z. Gao, Y. Wu, X. Gao, and K.-K. Wong, “Massive access in cell-free massive MIMO-based Internet of Things: Cloud computing and edge computing paradigms,” IEEE J. Sel. Areas Commun., vol. 39, no. 3, pp. 756–772, Mar. 2021.
- [42] J. Johnston and X. Wang, “Model-based deep learning for joint activity detection and channel estimation in massive and sporadic connectivity,” IEEE Trans. Wireless Commun., vol. 21, no. 11, pp. 9806–9817, Nov. 2022.
- [43] R. B. Di Renna and R. C. de Lamare, “Adaptive LLR-based APs selection for grant-free random access in cell-free massive MIMO,” in Proc. IEEE Global Commun. Conf. Workshops (GLOBECOM Workshops), Dec. 2022, pp. 196–201.
- [44] G. Femenias and F. Riera-Palou, “K-repetition for grant-free random access in cell-free massive MIMO networks,” IEEE Trans. Veh. Technol., vol. 73, no. 3, pp. 3623–3638, Mar. 2024.
- [45] X. Zhou, K. Ying, Z. Gao, Y. Wu, Z. Xiao, S. Chatzinotas, J. Yuan, and B. Ottersten, “Active terminal identification, channel estimation, and signal detection for grant-free NOMA-OTFS in LEO satellite Internet-of-Things,” IEEE Trans. Wireless Commun., vol. 22, no. 4, pp. 2847–2866, Apr. 2023.
- [46] H. Iimori, T. Takahashi, K. Ishibashi, G. T. F. de Abreu, and W. Yu, “Grant-free access via bilinear inference for cell-free MIMO with low-coherence pilots,” IEEE Trans. Wireless Commun., vol. 20, no. 11, pp. 7694–7710, Nov. 2021.
- [47] Q. Zou, H. Zhang, D. Cai, and H. Yang, “A low-complexity joint user activity, channel and data estimation for grant-free massive MIMO systems,” IEEE Signal Process. Lett., vol. 27, pp. 1290–1294, Jul. 2020.
- [48] R. B. Di Renna and R. C. de Lamare, “Joint channel estimation, activity detection and data decoding based on dynamic message-scheduling strategies for mMTC,” IEEE Trans. Commun., vol. 70, no. 4, pp. 2464–2479, Apr. 2022.
- [49] S. Zhang, Y. Cui, and W. Chen, “Joint device activity detection, channel estimation and signal detection for massive grant-free access via BiGAMP,” IEEE Trans. Signal Process., vol. 71, pp. 1200–1215, Apr. 2023.
- [50] S. Jiang, X. Yuan, X. Wang, C. Xu, and W. Yu, “Joint user identification, channel estimation, and signal detection for grant-free NOMA,” IEEE Trans. Wireless Commun., vol. 19, no. 10, pp. 6960–6976, Oct. 2020.
- [51] Y. Bai, W. Chen, B. Ai, and P. Popovski, “Deep learning for asynchronous massive access with data frame length diversity,” IEEE Trans. Wireless Commun., vol. 23, no. 6, pp. 5529–5540, Jun. 2024.
- [52] X. Bian, Y. Mao, and J. Zhang, “Joint activity detection, channel estimation, and data decoding for grant-free massive random access,” IEEE Internet Things J., vol. 10, no. 16, pp. 14 042–14 057, Aug. 2023.
- [53] B. Shen, Y. Wu, W. Zhang, S. Chatzinotas, and B. Ottersten, “Joint device identification, channel estimation, and signal detection for LEO satellite-enabled random access,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), 2023, pp. 679–684.
- [54] H. Song, T. Goldstein, X. You, C. Zhang, O. Tirkkonen, and C. Studer, “Joint channel estimation and data detection in cell-free massive MU-MIMO systems,” IEEE Trans. Wireless Commun., vol. 21, no. 6, pp. 4068–4084, Jun. 2022.
- [55] A. Balatsoukas-Stimming and C. Studer, “Deep unfolding for communications systems: A survey and some new directions,” in Proc. IEEE Int. Workshop Signal Process. Syst. (SiPS), Oct. 2019, pp. 266–271.
- [56] J. R. Hershey, J. L. Roux, and F. Weninger, “Deep unfolding: Model-based inspiration of novel deep architectures,” arXiv preprint: 1409.2574, 2014.
- [57] A. Jagannath, J. Jagannath, and T. Melodia, “Redefining wireless communication for 6G: Signal processing meets deep learning with deep unfolding,” IEEE Trans. Artif. Intell., vol. 2, no. 6, pp. 528–536, Dec. 2021.
- [58] N. Ye, J. An, and J. Yu, “Deep-learning-enhanced NOMA transceiver design for massive MTC: Challenges, state of the art, and future directions,” IEEE Wireless Commun., vol. 28, no. 4, pp. 66–73, Aug. 2021.
- [59] Y. Bai, W. Chen, B. Ai, Z. Zhong, and I. J. Wassell, “Prior information aided deep learning method for grant-free NOMA in mMTC,” IEEE J. Sel. Areas Commun., vol. 40, no. 1, pp. 112–126, Jan. 2022.
- [60] Z. Ma, W. Wu, F. Gao, and X. Shen, “Model-driven deep learning for non-coherent massive machine-type communications,” IEEE Trans. Wireless Commun., vol. 23, no. 3, pp. 2197–2211, Mar. 2024.
- [61] Y. Shi, S. Xia, Y. Zhou, and Y. Shi, “Sparse signal processing for massive device connectivity via deep learning,” in Proc. IEEE Int. Conf. Commun. Workshops (ICC Workshops), Jun. 2020, pp. 1–6.
- [62] Z. Gao, S. Liu, Y. Su, Z. Li, and D. Zheng, “Hybrid knowledge-data driven channel semantic acquisition and beamforming for cell-free massive MIMO,” IEEE J. Sel. Topics Signal Process., vol. 17, no. 5, pp. 964–979, Sept. 2023.
- [63] S. Liu, Z. Gao, C. Hu, S. Tan, L. Fang, and L. Qiao, “Model-driven deep learning based precoding for FDD cell-free massive MIMO with imperfect CSI,” in Proc. Int. Wireless Commun. Mobile Comput. (IWCMC), May 2022, pp. 696–701.
- [64] O. Castañeda, S. Jacobsson, G. Durisi, M. Coldrey, T. Goldstein, and C. Studer, “1-bit massive MU-MIMO precoding in VLSI,” IEEE J. Emerg. Sel. Topics Circuits Syst., vol. 7, no. 4, pp. 508–522, Dec. 2017.
- [65] H. Song, X. You, C. Zhang, and C. Studer, “Soft-output joint channel estimation and data detection using deep unfolding,” in Proc. IEEE Inf. Theory Workshop (ITW), 2021, pp. 1–5.
- [66] G. Marti, T. Kölle, and C. Studer, “Mitigating smart jammers in multi-user MIMO,” IEEE Trans. Signal Process., vol. 71, pp. 756–771, Feb. 2023.
- [67] J. Tropp, I. Dhillon, R. Heath, and T. Strohmer, “Designing structured tight frames via an alternating projection method,” IEEE Trans. Inf. Theory, vol. 51, no. 1, pp. 188–209, Jan. 2005.
- [68] A. Tang, J. Sun, and K. Gong, “Mobile propagation loss with a low base station antenna for NLOS street microcells in urban area,” in Proc. IEEE Veh. Technol. Conf. Spring (VTC-Spring), vol. 1, May 2001, pp. 333–336.
- [69] M. Zhang and S. Kim, “Evaluation of MMSE-based iterative soft detection schemes for coded massive MIMO system,” IEEE Access, vol. 7, pp. 10 166–10 175, 2019.