Deep Video Prediction for Time Series Forecasting
Abstract.
Time series forecasting is essential for decision making in many domains. In this work, we address the challenge of predicting prices evolution among multiple potentially interacting financial assets. A solution to this problem has obvious importance for governments, banks, and investors. Statistical methods such as Auto Regressive Integrated Moving Average (ARIMA) are widely applied to these problems. In this paper, we propose to approach economic time series forecasting of multiple financial assets in a novel way via video prediction. Given past prices of multiple potentially interacting financial assets, we aim to predict the prices evolution in the future. Instead of treating the snapshot of prices at each time point as a vector, we spatially layout these prices in 2D as an image similar to market change visualization, and we can harness the power of CNNs in learning a latent representation for these financial assets. Thus, the history of these prices becomes a sequence of images, and our goal becomes predicting future images. We build on advances from computer vision for video prediction. Our experiments involve the prediction task of the price evolution of nine financial assets traded in U.S. stock markets. The proposed method outperforms baselines including ARIMA, Prophet and variations of the proposed method, demonstrating the benefits of harnessing the power of CNNs in the problem of economic time series forecasting.
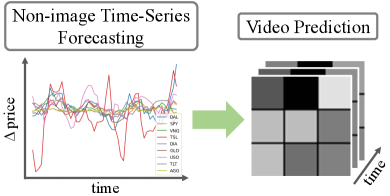
1. Introduction
In many time series forecasting tasks such as predictions on market, sales, and weather, the underlying data is non-image. Common statistical methods such as ARIMA have been widely adopted across these domains for time series forecasting tasks. These methods consider the history of the numerical data and predict the future values of the observed data. On the other hand, given tables or lists of numerical data, humans rely much more on visualizing the underlying numerical data rather than directly eyeing at the numbers themselves to develop a high-level understanding of the data. For example, experienced traders develop intuition for making buy/sell decisions by observing visual market charts (Cohen et al., 2020).
The power of visualizations lies in that they provide spatial structural information (Sharma et al., 2019) when laying out the underlying data in 2D images, which is not available in the original data. When looking at 2D images, human eyes are proficient at capturing spatial structure or patterns to help make better decisions or predictions. Advances in deep learning and computer vision have shown that Convolutional Neural Networks (CNNs) (Krizhevsky et al., 2012) carry the capabilities to extract features of local spatial regions, which enables systems to recognize spatial patterns such as those in object detection and recognition tasks.
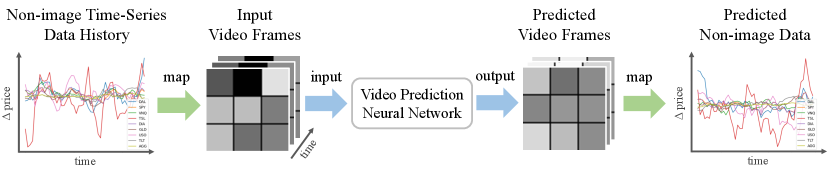
Inspired by how humans benefit from 2D visualizations of numerical data, we propose to spatially layout numerical information in 2D images similarly to market change visualizations. Then we take the advantage of CNNs for time series forecasting tasks, which were originally studied in non-image domains. In this paper, we take a unique perspective in predicting non-image time-series data through the lens of computer vision. To achieve this, we propose to first visualize the multivariate time-series data as a sequence of images, thus forming a video, and then build on video prediction techniques (Franceschi et al., 2020; Babaeizadeh et al., 2017) to predict future image frames, i.e., future visualizations of the underlying non-image data.
Our experiments focus on the task of forecasting market changes over time, where 9 publicly traded assets including 2 stocks and 7 Exchange-Traded Funds (ETFs) are being considered as shown in Figure 1. We demonstrate that our proposed method outperforms other baselines, such as DeepInsight (Sharma et al., 2019), ARIMA and Prophet (on non-image numerical data), as well as variations of our proposed method. Our study shows that our method is able to learn high-level knowledge jointly over multiple assets, and produces better prediction accuracy compared to either learning each asset independently, or learning multiple assets as a vector other than a 2D image.
2. Related Work
Time series forecasting (Hyndman and Athanasopoulos, 2018) has many applications across diverse domains, e.g. finance, climate, resource allocation, etc. Among a collection of statistical tools, exponential smoothing and ARIMA are two of the most widely adopted approaches for time series forecasting. Exponential smoothing predicts the future value of a random variable by a weighted average of its past values, where the weight associated with each past value decreases exponentially as we go back in time. Several variations of exponential smoothing are proposed to consider trend (Gardner Jr and McKenzie, 1985) and seasonality (Holt, 2004; Winters, 1960) in the data. ARIMA combines autoregressive and moving average models for forecasting and ARIMAs use differencing to help reduce trend and seasonality in the data. However, ARIMA, as well as VAR (vector autoregressive) model for multivariate cases, cannot capture nonlinear patterns in time series, rendering it insufficient for forecasting when nonlinear patterns occur. Our experiments show that a neural network based approach, which is nonlinear, outperforms ARIMA.
Recent works (Zhang, 2003; Pai and Lin, 2005; Safari and Davallou, 2018) focus on combinations of statistical and machine learning methods to improve forecasting accuracy. Yet the data involved in these time series forecasting tasks (Makridakis et al., 2018) is usually non-image.
In this work, we provide a new perspective of the time series forecasting problem, by transforming it into a video prediction problem. We visualize the underlying numerical data as an image at each time stamp, and bring recent advances in video prediction (Oprea et al., 2020) from the field of computer vision for forecasting.
Early works on video prediction directly predict future appearance as a composition of predicted image patches (Ranzato et al., 2014), without explicit modeling of temporal dynamics in the video. Others have attempted to learn explicit transformations (ae.g. per pixel motion (Reda et al., 2018), or affine transformations (Finn et al., 2016)) that synthesize the future frame from the last observed frame. These works learn to infer the transformation parameters from observed video frames. More recently, researchers aim to disentangle motion and visual content (Hsieh et al., 2018; Franceschi et al., 2020) in videos. The prediction task becomes more tractable because prediction can be performed in a latent space modeling the temporal dynamics. Thus, we built on (Franceschi et al., 2020) for video prediction.
Similar to our work, there are recent works that also tackle classification or regression tasks on non-image data from the computer vision perspective. (Cohen et al., 2020; Du and Barucca, 2020) developed image classifiers for stock analysis, e.g. buy/sell, and positive/negative price change. (Sharma et al., 2019) proposed DeepInsight which visualizes non-image data as an image through dimension reduction technique, and trained CNNs for classification on cancer types given visualized gene expressions. Although DeepInsight achieves promising classification accuracy as discussed in (Sharma et al., 2019), our experiment suggests that DeepInsight is not necessarily suitable for prediction tasks. (Li et al., 2020) proposed to transform non-image data into recurrence images, and then use CNNs to extract image features to predict weights for averaging multiple statistical forecasting methods. However, their method is concerned only with univariate time series forecasting. Real-world problems often involve multivariate time series forecasting, and it’s important to understand the relationships between multiple variables. Our work addresses multivariate time series forecasting as discussed in the experiments.
3. Methods
Given a time series of a random variable , where , the goal is to predict the values of the random variable at future time stamps . In this work, for each time , we visualize as an image, i.e., . Then the task of predicting is converted to a video prediction task, i.e., predicting future image frames given an input video clip. We will explain how we spatially layout data in 2D and the video prediction method as following.
3.1. Visualization
The particular visualizations of the underlying data varies across domains. Humans usually rely on domain knowledge to develop visualizations of numerical data, and these visualizations evolve over time as humans continuously improve them. We do not aim to provide an unified way to visualize all numerical data across arbitrary domains. We believe domain knowledge is important (as we will also show in experiments), and aiming to provide an unified way of visualizations poses the risk of throwing away domain knowledge.
Regardless of domains, the rule of thumb for generating visualizations of time-series data is that correlated data shall be visualized in a way such that they are spatially close to each other in the 2D image. The intuitive reason for this principle is that when looking at visualizations, CNN is good at extracting structural features in local regions represented by its limited receptive field. By visualizing correlated data (i.e. potentially dependent) spatially close in an image, CNN gets the chance to learn the high-level joint features of these correlated data, which can be exploited for prediction tasks. As we later show in our experiments, separating correlated data in visualizations results in a drop of prediction accuracy.
Here we discuss the particular visualization that we use for the market change prediction task in our experiments. Given the time-series market history of 9 assets in terms of relative percentage change of close values, i.e., , the goal is to predict future percentage changes of these assets. Following the same intuition of a commonly adopted market change visualization in industry from Finviz111https://finviz.com/map.ashx?t=sec_all, we visualize the percentage changes of these 9 assets in a 3x3 tile heatmap, as shown in Figure 1. We will discuss how domain knowledge helps arrange these 9 assets and achieve better performance in experiments and discussion. To visualize numerical data into pixels, we convert the percentage change of th asset at time , , into a pixel ,
| (1) | ||||
| (2) |
where is a sigmoid function, thus . For example, if , meaning that th asset has a increase in its close value at time , then the corresponding pixel value will be 243. As such, the higher the percentage increase, the brighter the visualized pixel. And the more the percentage decrease, the darker the visualized pixel.
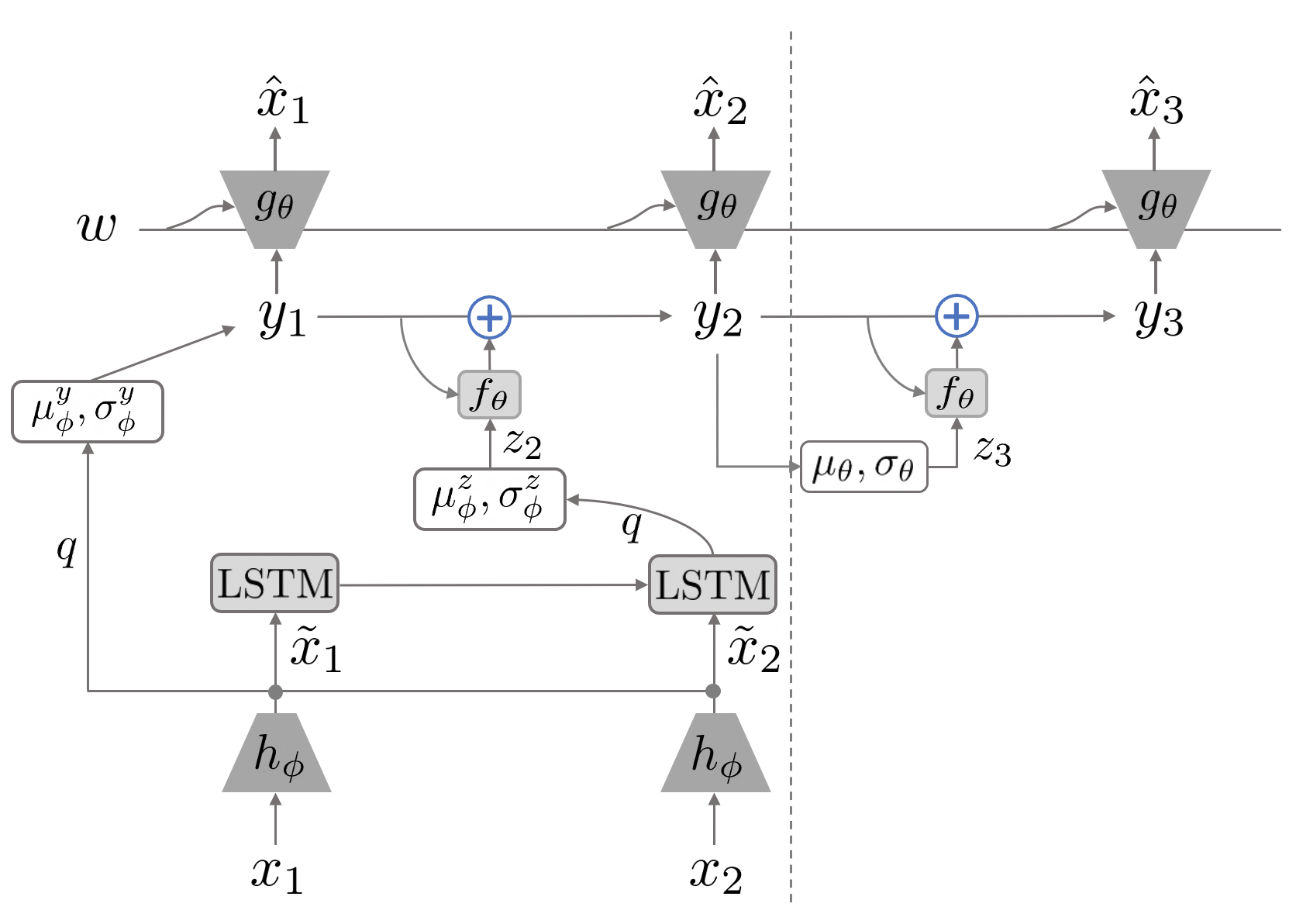
3.2. Video Prediction
In this work, we adapted a video prediction network SRVP (Stochastic Latent Residual Video Prediction) (Franceschi et al., 2020) in computer vision for the economic time series forecasting task. Compared to most works in the literature which rely on image-autoregressive recurrent networks, SRVP decouples frame synthesis and video dynamics estimation. SRVP has shown to outperform prior state-of-the-art methods across a simulated (Denton and Fergus, 2018) dataset, and real-world datasets of human activities (Schuldt et al., 2004; Ionescu et al., 2013) as well as robot actions (Ebert et al., 2017). We adapted the video prediction network from predicting frames in natural video to predicting frames in visualizations.
As shown in Figure 3, SRVP explicitly models the hidden state as well as the dynamics (the residual gets added to from at each time point) of the video in a latent space. Specifically, denotes the input frame at time , is the latent state variable, is the latent state dynamics variable, and is a content variable that encodes the static content in the video (e.g. static background, constant shape of foreground object, etc).
For each input frame , is an CNN-based encoder that encodes into encoded frame . Given encoded frames of the input video, the initial latent state is obtained through variational inference. We use across our experiments. The latent state then propagates forward with a transition function ,
where is an Multilayer Perception (MLP) that learns the first-order movement of latent state . As part of the input to , the latent dynamics is inferred through an LSTM on the encoded input frames. The content variable is inferred through a permutation-invariant function (Zaheer et al., 2017) given few encoded frames. Lastly, is a decoder network that concatenates the content variable and latent state and decode it back to the original space of , thus producing the estimated . Note that at testing time, we need to predict future when is not available. Instead of inferring through LSTM on s as explained earlier, is inferred from through two MLPs to generate , which are trained to fit .
In our experiments, we used VGG16 (Simonyan and Zisserman, 2014) as the encoder network and decoder network (mirrored VGG16). The image size is 64x64, and we choose to keep this generic choice so that we don’t tailor it towards the specific task in our experiments. We used 50 dimensions for both and . The loss function is negative log-likelihood and we used L2 regularization to prevent overfitting. We used Adam for optimization during training, with learning rate , and .
4. Experiments
The experiments were conducted on a Linux machine with Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz, 19 GB RAM, and NVIDIA T4 GPU. Our experiments focus on the task of forecasting market changes. We consider 9 assets in the market:
-
•
DAL (Delta Air Lines, Inc)
-
•
SPY (SPDR S&P 500 ETF Trust)
-
•
VNQ (Vanguard Real Estate Index Fund ETF Shares)
-
•
TSLA (Tesla, Inc.)
-
•
DIA (SPDR Dow Jones Industrial Average ETF Trust)
-
•
GLD (SPDR Gold Shares)
-
•
USO (United States Oil Fund, LP)
-
•
TLT (iShares 20+ Year Treasury Bond ETF)
-
•
AGG (iShares Core U.S. Aggregate Bond ETF)
We deliberately selected a diverse group of assets. There exists interdependencies between these assets. For instance, the airline stock DAL will usually go up in price when the oil ETF USO goes down in price. This is because fuel derived from oil is one of the primary operating costs for airlines, and a decrease in fuel prices can be predictive of future profits. Similarly, SPY which represents large U.S. company stocks is typically inversely related to the movement of TLT which represents long term bonds. Other assets in the mix share other correlations or anti-correlations that reflect the structure of the U.S. economy. We show that our method is able to learn and exploit these hidden interdependencies to make joint predictions.
In our experiments, we used the closing prices of these assets from June 29th, 2010 to Dec 31rd, 2019 (source: Yahoo!-Finance222https://finance.yahoo.com/). We pre-processed the collected data by calculating the percentage change of each asset’s closing price on each day with respect to its closing price 5 days ago. The task is that given the percentage changes of assets over 5 consecutive days, we need to predict the future percentage changes of assets for the next 10 days. We split the historical data from June 29th, 2010 to Dec 31rd, 2018 for training and validation (we did 95% split for training and validation), and Jan 1st, 2019 to Dec 31rd, 2019 for testing. We benchmarked the prediction performance of our proposed video prediction base method (referred as Video-Full below), against baseline methods including ARIMA and Prophet on original non-image data, as well as variations of the proposed method. Specifically,
-
•
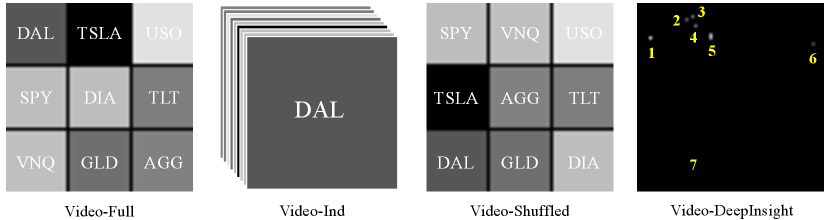
Video-Full: We turn the numerical data of market percentage change into visualizations of 3x3 tile heatmap as explained in section 3.1. Then 5 frames are given as input to the SRVP neural network, which outputs predicted 10 future frames. Thus, the learned SRVP neural network predicts all 9 assets market change jointly. Note that the 3x3 tile arrangements of the 9 assets are based on domain knowledge, such that known to be correlated assets are placed close to each other.
-
•
Video-Ind: Instead of visualizing all 9 assets in a 3x3 tile heatmap and learn to predict jointly as in Video-Full, here we turn each asset market percentage change into a single tile heatmap, thus producing one video clip for each asset. For each asset, we independently train a SRVP neural network to predict its future percentage change.
-
•
Video-Shuffled: This baseline method is the same as Video-Full, except that 3x3 tile arrangements of the 9 assets are shuffled such that it goes against the domain knowledge, meaning that known to be correlated assets are placed apart from each other.
-
•
Video-DeepInsight: As discussed in section 2, DeepInsight (Sharma et al., 2019) takes a similar perspective of converting non-image data to image data, and adopt computer vision techniques on the image data. Here we use their proposed method to visualize the non-image data, by corresponding each dimension of the non-image data with a 2D pixel coordinate on the image plane through PCA. We then apply SRVP on the resulting visualizations.
-
•
Vector: Instead of turning numerical data into 2D heatmaps as in the proposed method, here we directly use the original numerical data (normalized to ) as a 9x1 vector. In order to use the same SRVP network architecture as in other baselines for fair comparison, we repeat the 9x1 vectors to match the same size of input used in other baselines. Note that this method can be perceived as a neural network based nonlinear vector autoregressive model.
-
•
ARIMA: For each asset, we directly apply ARIMA to the non-image numerical data to predict its future percentage changes. We used auto ARIMA333https://alkaline-ml.com/pmdarima/index.html to search for a proper set of parameters for each asset and fit the data.
-
•
Prophet: For each asset, we use Prophet444https://facebook.github.io/prophet/ library from Facebook designated for time series forecasting. We applied Prophet on the original numerical data to predict its future percentage changes.
Examples of visualizations based on these discussed methods are as shown in Figure 4. We present only visualizations for methods that do involve a visualization step and learn in image domain, thus excluding Vector, ARIMA and Prophet.
Our goal of predicting asset price changes is not to automate the process of trading, but to augment practitioners during decision making. When looking at asset price history, practitioners can benefit from predictions of whether the price will go up or down (reflected by the sign of the relative percentage changes). Thus, in order to measure the prediction performance, we evaluate the accuracy of the predicted sign of asset relative percentage change, defined as
| (3) | ||||
| (4) |
where is 1 if share the same sign, otherwise 0.
| Video-Full | Video-Ind | Video-Shuffled | Video-DeepInsight | Vector | ARIMA | Prophet | |
|---|---|---|---|---|---|---|---|
For each asset, we convert the predicted pixel values averaged within the corresponding tile in the heatmap back to numerical data using the inverse of Eq. 1. Note that we use the exponentially decaying weight to weight the prediction accuracy. indicates the 1st day into the future following the given days in the input. This is to reflect that it is more important to achieve a better prediction in the near future compared to far into the future.
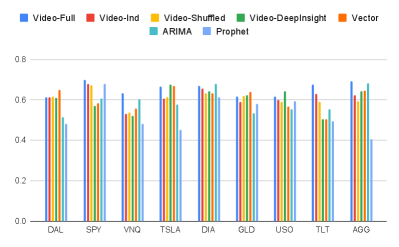
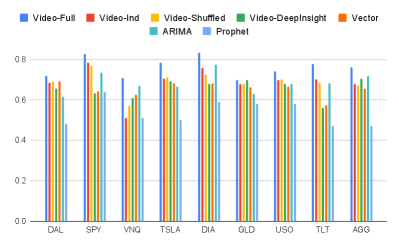
We show the prediction performance for each asset in Figure 5, 6, and Table 1. In Figure 5, (Equation 4), thus the weights of prediction accuracy at each future time stamp are , , which indicates that the prediction accuracy starting on the 5th day into the future do not matter as much. In Figure 6, (Equation 4), thus the weights of prediction accuracy at each future time stamp are , indicating that we focus on the prediction performance for the very next future day. Table 1 summarizes the prediction accuracy averaged over all 9 assets for each method.
As we can see, for either value, Video-Full outperforms other baseline methods across all 9 assets. More importantly, we show that when learning to predict the market changes jointly, we achieve better prediction performance in Video-Full compared to Video-Ind, which learns to predict the change of each asset independently. This is because Video-Full allows the network to learn and exploit the joint dynamics of these assets, where the interdependencies between these assets play an important role.
We also show that Video-Full outperforms Video-DeepInsight (Sharma et al., 2019). DeepInsight was originally proposed for classification tasks, and it corresponds each asset to a single pixel during visualization, resulting in a sparse set of points in the image (as shown in Figure 4). A key issue is that this method can lead to different assets being visualized at the same pixel locations, thus pixel location conflicts, and one has to retain one of the assets information and discard the others at such conflicted pixel locations. Although (Sharma et al., 2019) showed DeepInsight to be suitable for classification tasks, we have shown that it is not necessarily suitable for prediction tasks, due to the sparse visualization and especially pixel location conflicts. We will discuss the comparison between Video-Full and Video-Shuffled in detail in the later section 5.
Without the 2D structural information from visualized images, we can see that Vector, ARIMA and Prophet lead to less prediction accuracy than Video-Full in general. This suggests that by turning non-image time-series forecasting into a video prediction problem, we have introduced informative 2D spatial structure in the visualized images, which can be leveraged by CNNs in Video-Full for forecasting.
5. Discussion
When comparing Video-Shuffled against Video-Full, we can clearly see a drop in prediction performance in Video-Shuffled. This is because Video-Shuffled suffers from the poor 3x3 tile arrangements of those 9 assets, where correlated assets are placed apart from each other in the visualization. On the contrary, Video-Full uses domain knowledge in finance to guide the 3x3 tile arrangements of those 9 assets. For instance, we place SPY and DIA, which represent the similar S&P 500 stock index and the Dow Jones Industrial index respectively, next to one another. TLT and AGG, which represent large bond indexes are also placed adjacently.
Taking the advantage of domain knowledge, Video-Full places correlated assets close to each other during visualization, and achieves a better prediction performance because CNNs are able to extract high-level structural feature from local regions. As we scale up, one interesting future direction is to learn to spatially layout multivariate non-image data in 2D, with inductive bias from domain knowledge if available.
Although during the experimented period (2010-2019) the overall market goes up as the long-term trend, for the short-term day-to-day price of each asset, the price is not always going up. In particular, across our test dataset, the percentage of time when price goes up is [0.54, 0.70, 0.62, 0.56, 0.63, 0.61, 0.61, 0.55, 0.62], corresponding respectively to assets DAL, SPY, VNQ, TSLA, DIA, GLD, USO, TLT, AGG. That means, if we take a naive predictor that always predicts the prices to go up for the next day for all assets, then the prediction accuracy will be [0.54, 0.70, 0.62, 0.56, 0.63, 0.61, 0.61, 0.55, 0.62]. As shown in Figure 6, the prediction accuracy is [0.72, 0.83, 0.71, 0.78, 0.83, 0.70, 0.74, 0.78, 0.76], which does provide a significant percentage improvement of [0.33, 0.19, 0.15, 0.39, 0.32, 0.15, 0.21, 0.42, 0.22] over the naive predictor for each asset respectively.
6. Conclusion
In this paper, we demonstrate the benefit of learning to predict multivariate non-image time-series data in the 2D image domain. By spatially laying out original non-image data in 2D images, we convert the problem of time series forecasting into a video prediction problem. We then adapt recent state-of-the-art video prediction technique from computer vision to the domain of economic time series forecasting. In our experiments, we show that the proposed method is able to learn spatial structural information from the visualizations and outperforms other baseline methods in predicting future market changes. We provide a proof of concept that, by spatially laying out non-image data in 2D, we can harness the power of CNNs and the proposed method outperforms other methods that either treat each dimension of the multivariate data independently, or treat the multivariate data as a vector. This motivates an interesting future direction of learning to spatially layout non-image data in 2D for multivariate time-series forecasting problems.
Disclaimer:
This paper was prepared for information purposes by the Artificial Intelligence Research group of J. P. Morgan Chase & Co. and its affiliates (“J. P. Morgan”), and is not a product of the Research Department of J. P. Morgan. J. P. Morgan makes no representation and warranty whatsoever and disclaims all liability, for the completeness, accuracy or reliability of the information contained herein. This document is not intended as investment research or investment advice, or a recommendation, offer or solicitation for the purchase or sale of any security, financial instrument, financial product or service, or to be used in any way for evaluating the merits of participating in any transaction, and shall not constitute a solicitation under any jurisdiction or to any person, if such solicitation under such jurisdiction or to such person would be unlawful.
References
- (1)
- Babaeizadeh et al. (2017) Mohammad Babaeizadeh, Chelsea Finn, Dumitru Erhan, Roy H Campbell, and Sergey Levine. 2017. Stochastic variational video prediction. arXiv preprint arXiv:1710.11252 (2017).
- Cohen et al. (2020) Naftali Cohen, Tucker Balch, and Manuela Veloso. 2020. Trading via image classification. In Proceedings of the First ACM International Conference on AI in Finance. 1–6.
- Denton and Fergus (2018) Emily Denton and Rob Fergus. 2018. Stochastic video generation with a learned prior. arXiv preprint arXiv:1802.07687 (2018).
- Du and Barucca (2020) Bairui Du and Paolo Barucca. 2020. Image Processing Tools for Financial Time Series Classification. arXiv preprint arXiv:2008.06042 (2020).
- Ebert et al. (2017) Frederik Ebert, Chelsea Finn, Alex X Lee, and Sergey Levine. 2017. Self-supervised visual planning with temporal skip connections. arXiv preprint arXiv:1710.05268 (2017).
- Finn et al. (2016) Chelsea Finn, Ian Goodfellow, and Sergey Levine. 2016. Unsupervised learning for physical interaction through video prediction. In Advances in neural information processing systems. 64–72.
- Franceschi et al. (2020) Jean-Yves Franceschi, Edouard Delasalles, Mickaël Chen, Sylvain Lamprier, and Patrick Gallinari. 2020. Stochastic Latent Residual Video Prediction. arXiv preprint arXiv:2002.09219 (2020).
- Gardner Jr and McKenzie (1985) Everette S Gardner Jr and ED McKenzie. 1985. Forecasting trends in time series. Management Science 31, 10 (1985), 1237–1246.
- Holt (2004) Charles C Holt. 2004. Forecasting seasonals and trends by exponentially weighted moving averages. International journal of forecasting 20, 1 (2004), 5–10.
- Hsieh et al. (2018) Jun-Ting Hsieh, Bingbin Liu, De-An Huang, Li F Fei-Fei, and Juan Carlos Niebles. 2018. Learning to decompose and disentangle representations for video prediction. In Advances in Neural Information Processing Systems. 517–526.
- Hyndman and Athanasopoulos (2018) Rob J Hyndman and George Athanasopoulos. 2018. Forecasting: principles and practice. OTexts.
- Ionescu et al. (2013) Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. 2013. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence 36, 7 (2013), 1325–1339.
- Krizhevsky et al. (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25, F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger (Eds.). Curran Associates, Inc., 1097–1105. http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- Li et al. (2020) Xixi Li, Yanfei Kang, and Feng Li. 2020. Forecasting with time series imaging. Expert Systems with Applications 160 (2020), 113680.
- Makridakis et al. (2018) Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. 2018. The M4 Competition: Results, findings, conclusion and way forward. International Journal of Forecasting 34, 4 (2018), 802–808.
- Oprea et al. (2020) Sergiu Oprea, Pablo Martinez-Gonzalez, Alberto Garcia-Garcia, John Alejandro Castro-Vargas, Sergio Orts-Escolano, Jose Garcia-Rodriguez, and Antonis Argyros. 2020. A Review on Deep Learning Techniques for Video Prediction. arXiv preprint arXiv:2004.05214 (2020).
- Pai and Lin (2005) Ping-Feng Pai and Chih-Sheng Lin. 2005. A hybrid ARIMA and support vector machines model in stock price forecasting. Omega 33, 6 (2005), 497–505.
- Ranzato et al. (2014) MarcAurelio Ranzato, Arthur Szlam, Joan Bruna, Michael Mathieu, Ronan Collobert, and Sumit Chopra. 2014. Video (language) modeling: a baseline for generative models of natural videos. arXiv preprint arXiv:1412.6604 (2014).
- Reda et al. (2018) Fitsum A Reda, Guilin Liu, Kevin J Shih, Robert Kirby, Jon Barker, David Tarjan, Andrew Tao, and Bryan Catanzaro. 2018. Sdc-net: Video prediction using spatially-displaced convolution. In Proceedings of the European Conference on Computer Vision (ECCV). 718–733.
- Safari and Davallou (2018) Ali Safari and Maryam Davallou. 2018. Oil price forecasting using a hybrid model. Energy 148 (2018), 49–58.
- Schuldt et al. (2004) Christian Schuldt, Ivan Laptev, and Barbara Caputo. 2004. Recognizing human actions: a local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004., Vol. 3. IEEE, 32–36.
- Sharma et al. (2019) Alok Sharma, Edwin Vans, Daichi Shigemizu, Keith A Boroevich, and Tatsuhiko Tsunoda. 2019. DeepInsight: A methodology to transform a non-image data to an image for convolution neural network architecture. Scientific reports 9, 1 (2019), 1–7.
- Simonyan and Zisserman (2014) Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
- Winters (1960) Peter R Winters. 1960. Forecasting sales by exponentially weighted moving averages. Management science 6, 3 (1960), 324–342.
- Zaheer et al. (2017) Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander J Smola. 2017. Deep sets. In Advances in neural information processing systems. 3391–3401.
- Zhang (2003) G Peter Zhang. 2003. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 50 (2003), 159–175.