Deeply Interleaved Two-Stream Encoder for Referring Video Segmentation
Abstract
Referring video segmentation aims to segment the corresponding video object described by the language expression. To address this task, we first design a two-stream encoder to extract CNN-based visual features and transformer-based linguistic features hierarchically, and a vision-language mutual guidance (VLMG) module is inserted into the encoder multiple times to promote the hierarchical and progressive fusion of multi-modal features. Compared with the existing multi-modal fusion methods, this two-stream encoder takes into account the multi-granularity linguistic context, and realizes the deep interleaving between modalities with the help of VLGM. In order to promote the temporal alignment between frames, we further propose a language-guided multi-scale dynamic filtering (LMDF) module to strengthen the temporal coherence, which uses the language-guided spatial-temporal features to generate a set of position-specific dynamic filters to more flexibly and effectively update the feature of current frame. Extensive experiments on four datasets verify the effectiveness of the proposed model.
1 Introduction
This paper aims to address a task called referring video segmentation. Given a video clip and a referring expression, the goal of this task is to segment the corresponding entity (object) in the video sequence according to the description of query language. Traditional semi-supervised video object segmentation uses the ground-truth mask of the first frame (or a few frames) as the guide to segment the corresponding foreground object(s) in the remaining video sequence. Similarly, referring video segmentation considers language expression as interactive information to guide the segmentation of video object. Compared with the ground-truth mask, the language labeling is more flexible and economy. This task can be applied to language-driven video editing, human-robot interaction, etc.
Referring video segmentation contains two crucial issues. They are how to achieve the modality consistency between linguistic and visual information and how to leverage the temporal coherency between frames. For the first issue, the referring image/video segmentation methods that have emerged in recent years adopt straightforward concatenation-convolution [7], recurrent LSTM [16], convolution LSTM [14], dynamic filters [18, 6, 24], cross-modal attention [23, 27, 25, 8, 9, 11, 22, 5, 10, 4] to aggregate linguistic and visual features. According to the position of multi-modal fusion in the network, they can be divided into two categories: decoder fusion (Fig. 1 (a)) and encoder fusion (Fig. 1 (b)). The former uses linguistic feature to separately guide visual features of different levels in the decoder for cross-modal embedding. The latter realizes the progressive guidance of language to the multi-modal features in the encoder [5]. However, during the process of linguistic feature extraction, both of them ignore the semantic hierarchy of language information similar to the multi-level property embodied by visual features, which may weaken the consistency of the multiple-granularity cross-modal alignment.
Regarding the second issue, most of the existing methods [6, 25, 24, 19] directly employ a I3D encoder [1] to extract visual features for each frame, which implicitly characterizes the temporal relevance among different frames. The visual features are then handled the same way as image referring segmentation methods do. These video based methods actually focus on the design of cross-modal fusion while neglecting the inter-frame relationship modeling. Moreover, they do not utilize the language to guidance inter-frame feature interaction. These flaws inevitably weaken the temporal coherence among the features of frames. In [10], the language-guided channel attention is designed to re-weight and combine the features of current frame and reference frame, in which their attention weights are query-specific and are shared across the whole video. This design of temporal modeling does not consider the inter-frame adaptability and the intra-frame inhomogeneity well.
To address the above-mentioned problems, we introduce the vision-language interleaved encoder and the language-guided dynamic filtering mechanism. Firstly, from the perspective of vision-language fusion, we adopt CNN encoder and transformer encoder to extract visual and linguistic features, respectively. Meanwhile, a vision-language mutual guidance (VLMG) module is repeatedly embedded between the two encoding streams to gradually transfer hierarchical cross-modal information to each other. Thus, the cross-modal alignment can be achieved at multiple levels of granularity. Secondly, for the temporal modeling, we propose a language-guided multi-scale dynamic filtering (LMDF) module, which exploits the spatial-temporal features to learn a set of position-specific and frame-specific dynamic filters under the guidance of language, and then utilize these filters to update the multi-level features of current frame. This module can promote the network to steadily and accurately capture the visual clues referred by the language query along the video.
Our main contributions are as follows:
-
•
We propose a vision-language interleaved two-stream encoder, which leverages the vision-language mutual guidance module to effectively realize the multi-level information interaction between vision and language encoding steams. The interleaved encoder can produce a compact multi-modal representation.
-
•
We design a language-guided multi-scale dynamic filtering module, which utilizes the language-guided spatial-temporal context to generate region-aware dynamic filters to update the features of current frame, thereby ensuring the temporal coherence of multi-modal feature learning.
-
•
Extensive evaluations on four referring video segmentation datasets (A2D, J-HMDB, Ref-DAVIS2017 and Ref-Youtube-VOS) demonstrate that our method surpasses the previous state-of-the-art approaches.
2 Related Work
2.1 Vision-Language Interaction
Early method [7] utilizes concatenation and convolution to fuse linguistic and visual features. Subsequently, Liu et al. [16] and Li et al. [14] adopt recurrent LSTM and convolutional LSTM to gradually combine the concatenated multi-modal features in the decoder, respectively. These methods directly concatenate visual and linguistic features, which dose not explicitly consider the relationship between each pixel and each word.
To solve this problem, some methods exploit attention mechanism to model the cross-modal relationship. For example, Shi et al. [23] use the visual features as a guidance to learn the keywords corresponding to each pixel, which can suppress the noise in the query expression. Ye et al. [27] and Seo et al. [22] employ non-local module to model the relationship between the pixel-word mixed features. Wang et al. [25] propose an asymmetric cross-attention module, which utilizes two affinity matrices to update visual and linguistic features, respectively. Hu et al. [8] build a bidirectional relationship decoder to realize the mutual guidance between language and vision. Hui et al. [11] rely on the dependency parsing tree to re-weight the edges of the word graph, thereby suppressing the useless edges in the initial fully connected graph. Huang et al. [9] first perceive all entities in the image according to the category and appearance information and then employ the relation words to model the relationships among all entities. Ding et al. [4] design a transformer-based query generation module at the decoding end to understand the vision-language context.
Some other methods employ the dynamic filters generated by the sentence to match the visual features, thereby strengthening the response of the language-related visual region. Gavrilyuk et al. [6] directly apply a dynamic filter to weight all channels of feature map and sum them to yield the pixel-wise segmentation map. Similarly, Margffoy-Tuay et al. [18] learn a set of dynamic filters for each word to re-weight the visual features. Wang et al. [24] introduce deformable convolution [2] into the process of dynamic filtering. In addition. McIntosh et al. [19] design a capsule network to perform vision-language coding.
A common feature of all the above methods is that they fuse visual and linguistic features at the decoding end of the network. The interaction between visual feature of each scale and language feature is isolated. Recently, the encoder fusion strategy [20, 5, 10] is applied to referring segmentation task. It achieves the continuous guidance of language to multi-scale visual features. Regardless of the encoder fusion or the decoder fusion, their language encoding processes do not consider the boosting effect of visual information of multiple levels, and ignore the semantic hierarchy of linguistic information. Integrating the same language features with visual features of different levels may weaken the consistency of cross-modal matching. Different from them, we propose a vision-language interleaved two-stream encoder, which can extract hierarchical language information with the help of multi-level visual features and implement the bidirectional cross-modal interaction at different levels.
2.2 Temporal Feature Modeling
Modeling temporal information between frames is important for referring video segmentation. A straightforward idea is to use 3D convolution to capture temporal cues of the video. Therefore, some methods [6, 25, 24, 19] directly employ the I3D network [1] to encode video sequences. In the testing phase, the fixed convolution parameters are not easily generalized to all video clips, which limits the capability of temporal modeling. To solve this problem, Seo et al. [22] design a non-local based memory attention to learn the inter-frame correlation. Hui et al. [10] consider the cross-modal property of referring video segmentation task and utilize language feature to build channel attention, which is applied to the weighted fusion of frames. In this paper, we leverage the language-guided spatial-temporal information to learn a set of position-specific and frame-specific dynamic filters, which can fully exploit the inter-modality and inter-frame information interaction to progressively combine the cross-modal aligned features at multiple scales for current frame.
3 Method
The overall structure of the proposed model is shown in Fig. 2. Firstly, the video features from the CNN-based encoder and language features from the transformer-based encoder are deeply interweaved through the vision-language mutual guidance (VLMG) module. In the pipeline of network, after the initial interweaving, the features flowed into the trailing end of the encoder and the whole decoder are already the multi-modal mixed features. Next, we propose a language-guided multi-scale dynamic filtering (LMDF) module to fuse temporal information across frames. The multiple-scale spatial-temporal features output by LMDF and the visual features from the first two encoder blocks of the visual encoder are fed to the decoder for progressive fusion and upsampling, thereby generating the final segmentation result. Note that, for the reference frame () and the current frame (), their encoder parameters are shared.
3.1 Vision-Language Interleaved Encoder
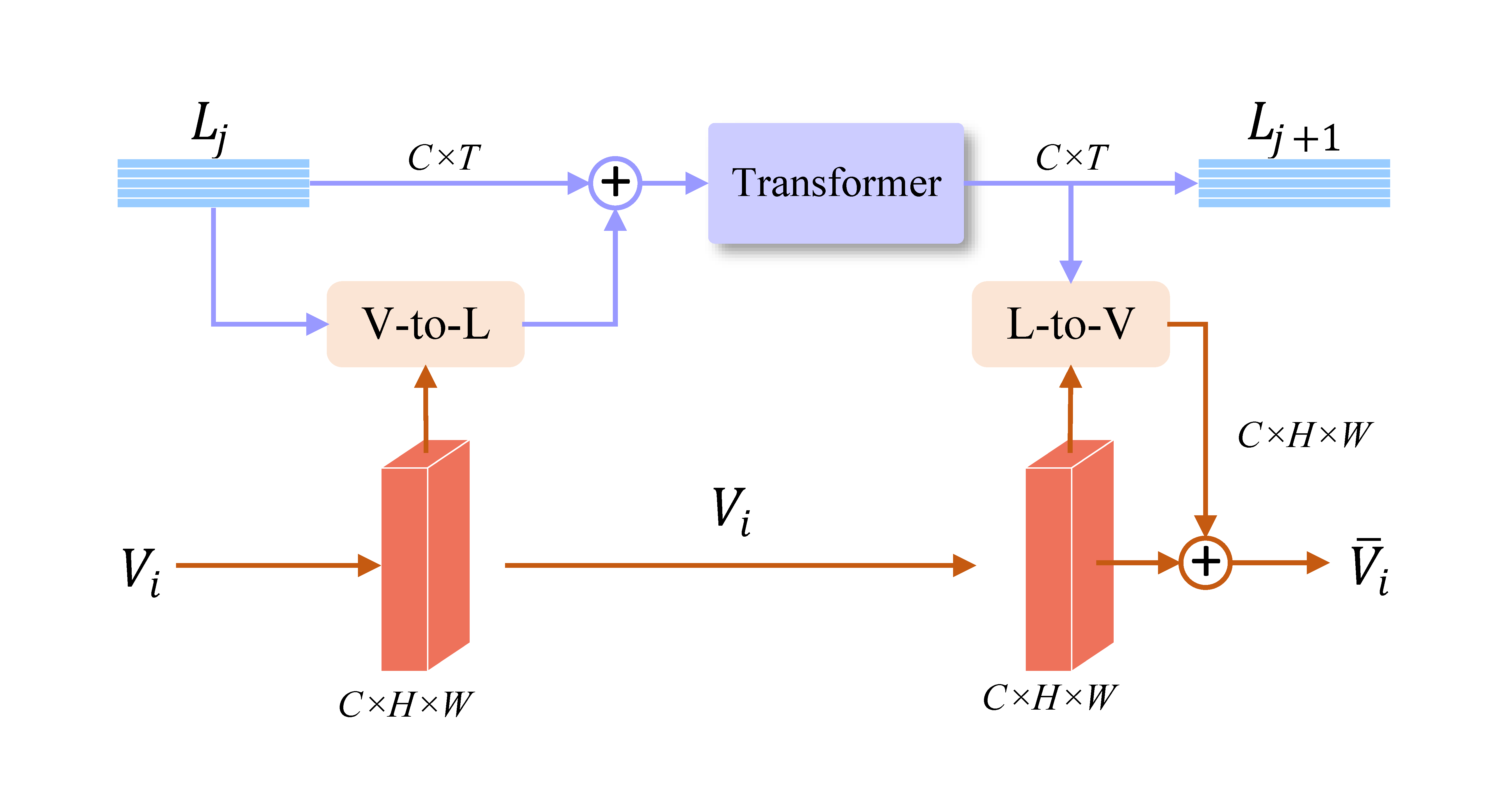
We design a deeply interleaved two-stream encoder to achieve the mutual guidance and embedding between visual and linguistic features. It can not only encode the hierarchical semantic context of the sentence, but also gradually realize the mixing of multi-modal information from the feature extractors at different levels.
Specifically, we take ResNeSt [30] as the visual encoder. It contains five feature blocks, and their features are defined as . The query expression is denoted as , where indicates the -th word and is the total number of words. We utilize the Bert-embedding [3] to obtain the initial representation of . is fed into three cascaded transformer blocks to encode the linguistic context .
To establish the connection between the two encoders, we propose a vision-language mutual guidance (VLMG) module to interlacedly guide their feature extraction. For the convenience of description, we define the sizes of and as and , respectively. , and denote the height, width and channel number, respectively. The feature is first reshaped into a matrix representation with size . The vision-to-language affinity matrix between and can be calculated as follows:
| (1) |
where , are the learnable parameters. describes the similarity between each pixel of and each word of . The softmax function is used to normalize the affinity matrix along the first dimension. We utilize to project the visual feature to the language space as follows:
| (2) |
Next, the features and are fed into the standard transformer structure to learn their co-embedding:
| (3) |
where denotes the multi-head self-attention module. represents the LayerNorm layer. FFN is the feed forward network. We further use and to learn the affinity matrix of language-to-vision:
| (4) |
where , are the learned parameters. Similarly, the column-wise normalized affinity matrix is utilized to map the mixed multi-modal feature to the vision space:
| (5) |
Finally, we adopt concatenation and convolution to incorporate the feature into the visual encoder:
| (6) |
where the represents the L2-normalize, and its purpose is to normalize the feature maps to the same order of magnitude to avoid preference bias. The updated multi-modal feature is fed to the next convolution block of the visual encoder for further feature extraction. Fig. 3 illustrates the detailed structure of VLMG. By embedding VLMG between the visual CNN encoder and the linguistic transformer encoder, the multi-modal interaction process runs through the entire network. And most of the previous global attention methods [25, 8] need to calculate an affinity matrix with the size of , so increasing the size of the input image will lead to a sharp increase in computational cost. The size of the affinity matrix calculated in VLMG is much smaller than (e.g. in Eq. 1 and Eq. 4, in Eq. 3). This also makes our encoder more suitable for real applications.
3.2 Language-Guided Multi-Scale Dynamic Filtering
For referring video segmentation, the language expression contains important spatial-temporal information related to the video. Therefore, we can use it to guide the cross-frame feature fusion. Let and indicate the features of the reference frame and the current frame, respectively. They are generated by Eq. 6. To capture useful spatial-temporal information from the reference frame and the current frame through the guidance of linguistic features, we firstly calculate the affinity matrix between and , as:
| (7) |
The column-wise normalized similarity matrix is used to map the reference feature to the language space, as:
| (8) |
We further adopt the transformer block to mix and and obtain the reference-frame modulated language feature :
| (9) |
Then, we superpose the current frame to further compute a multi-frame modulated language feature as follows:
| (10) |
Thus, under the guidance of language, the feature successively fuses the language related spatial-temporal information from the reference frame and the current frame.
In order to generate the position-specific dynamic filters to accurately calibrate the current-frame feature based on the inter-frame and inter-modality information, we in advance learn the position-adaptive guidance feature based on the feature :
| (11) |
where . and represent the vectors of position in and , respectively. Then is used to generate a set of dynamic kernels to filter the features of the neighborhood around :
| (12) |
where is the learnable parameter. denotes the element-wise multiplication. Actually, Eq.12 can be understood as a 33 depth-wise convolution with dilated rate . During the process of filtering, the multi-scale neighborhood is adopted. We then concatenate and multiple of different dilated rates and follow a convolution layer to combine them. Finally, the resulted cross-frame multi-modal features from stage3stage5 and the visual features from stage1stage2 are feed into the decoder (feature pyramid network) to predict the final segmentation result.
Comparison with Other Temporal Models. Our LMDF is different from other temporal modeling methods, e.g. CMDy [24] and LGFS [10]. 1) They exploit the global guidance features of language after max or average pooling to generate the filters. The pooling operation causes all spatial positions of visual feature to share the same language guidance. While the LMDF combines the inter-modality and inter-frame information to yield the position-adaptive language guidance for dynamic filtering, which is more flexible and adaptive to appearance changes. 2) The LMDF learns the frame-specific filters, and implements the cross-modal and cross-frame interaction twice. The pre-interaction process before dynamic kernel generation sequentially mixes the language features with the multi-modal features of reference frame and current frame, which can effectively obtain spatial-temporal guidance information. Next, the re-interaction process of dynamic filtering further guarantees the temporal coherence of features for segmentation prediction. While LGFS [10] uses the global language features to generate query-specific filters, which are shared along the whole video. And, it achieves the cross-modal and cross-frame interaction once. The CMDy [24] uses 3D convolution to obtain the multi-frame mixed feature for each frame. The mixed temporal information without language guidance may confuse spatial features of the current frame.
| Method | Precision | mAP | IoU | |||||
| prec@0.5 | prec@0.6 | prec@0.7 | prec@0.8 | prec@0.9 | 0.5:0.95 | Overall | Mean | |
| Hu et al.16 [7] | 34.8 | 23.6 | 13.3 | 3.3 | 0.1 | 13.2 | 47.4 | 35.0 |
| Li et al.17 [15] | 38.7 | 29.0 | 17.5 | 6.6 | 0.1 | 16.3 | 51.5 | 35.4 |
| Gavrilyuk et al.18 [6] | 47.5 | 34.7 | 21.1 | 8.0 | 0.2 | 19.8 | 53.6 | 42.1 |
| Gavrilyuk et al.18 [6]∗ | 50.0 | 37.6 | 23.1 | 9.4 | 0.4 | 21.5 | 55.1 | 42.6 |
| ACGA19 [25] | 55.7 | 45.9 | 31.9 | 16.0 | 2.0 | 27.4 | 60.1 | 49.0 |
| VT-Capsule20 [19] | 52.6 | 45.0 | 34.5 | 20.7 | 3.6 | 30.3 | 56.8 | 46.0 |
| CMDy20 [24] | 60.7 | 52.5 | 40.5 | 23.5 | 4.5 | 33.3 | 62.3 | 53.1 |
| PRPE20 [20] | 63.4 | 57.9 | 48.3 | 32.2 | 8.3 | 38.8 | 66.1 | 52.9 |
| CMSA-V21 [28] | 48.7 | 43.1 | 35.8 | 23.1 | 5.2 | - | 61.8 | 43.2 |
| LGFS21 [10] | 65.4 | 58.9 | 49.7 | 33.3 | 9.1 | 39.9 | 66.2 | 56.1 |
| CMPC-V21 [17] | 65.5 | 59.2 | 50.6 | 34.2 | 9.8 | 40.4 | 65.3 | 57.3 |
| Ours | 70.2 | 66.3 | 58.5 | 42.8 | 15.1 | 46.9 | 71.4 | 59.8 |
| Method | Precision | mAP | IoU | |||||
| prec@0.5 | prec@0.6 | prec@0.7 | prec@0.8 | prec@0.9 | 0.5:0.95 | Overall | Mean | |
| Hu et al.16 [7] | 63.3 | 35.0 | 8.5 | 0.2 | 0.0 | 17.8 | 54.6 | 52.8 |
| Li et al.17 [15] | 57.8 | 33.5 | 10.3 | 0.6 | 0.0 | 17.3 | 52.9 | 49.1 |
| Gavrilyuk et al.18 [6] | 69.9 | 46.0 | 17.3 | 1.4 | 0.0 | 23.3 | 54.1 | 54.2 |
| ACGA19 [25] | 75.6 | 56.4 | 28.7 | 3.4 | 0.0 | 28.9 | 57.6 | 58.4 |
| VT-Capsule20 [19] | 67.7 | 51.3 | 28.3 | 5.1 | 0.0 | 26.1 | 53.5 | 55.0 |
| CMDy20 [24] | 74.2 | 58.7 | 31.6 | 4.7 | 0.0 | 30.1 | 55.4 | 57.6 |
| PRPE20 [20] | 69.1 | 57.2 | 31.9 | 6.0 | 0.1 | 29.4 | - | - |
| CMSA-V21 [28] | 76.4 | 62.5 | 38.9 | 9.0 | 0.1 | - | 62.8 | 58.1 |
| LGFS21 [10] | 78.3 | 63.9 | 37.8 | 7.6 | 0.0 | 33.5 | 59.8 | 60.4 |
| CMPC-V21 [17] | 81.3 | 65.7 | 37.1 | 7.0 | 0.0 | 34.2 | 61.6 | 61.7 |
| Ours | 87.4 | 79.1 | 58.6 | 18.2 | 0.3 | 44.1 | 68.0 | 66.6 |
4 Experimental Comparison
4.1 Datasets
In order to illustrate the effectiveness of the proposed method, we conduct extensive experiments on four referring video segmentation datasets, which are A2D Sentences [6], J-HMDB Sentences [6], Refer-DAVIS2017 [13], and Refer-Youtube-VOS [22]. Gavrilyuk et al. [6] extended the original Actor-Action Dataset (A2D) [26] and J-HMDB [12] datasets to the referring video segmentation task by adding additional natural language descriptions. A2D Sentences is composed of 3,782 videos with 6,655 referring expressions. And this videos contain 8 different actions that are preformed by 7 actor classes. Following the previous setting [25, 10], we split A2D into two parts, 3,017 of which are used for training and 737 for testing. Each video contains 3 to 5 frame pixel-level segmentation masks. For J-HMDB Sentences, it consists of 928 videos with 21 different action classes. Each video contains a corresponding language expression. And the main purpose of this dataset is to evaluate the generalization ability of the model. Generally, previous methods directly use the model trained on the A2D dataset to test all the videos in this dataset. Similarly, Refer-DAVIS2017 is based on DAVIS2017 [21]. It contains 90 videos, 60 for training and 30 for testing. Refer-Youtube-VOS is by far the largest dataset, it contains a total of 3,978 videos and about 15,000 language expressions.
4.2 Implementation Details
Experiment setting. We exploit the pytorch platform to implement our network, and adopt a Nvidia RTX 3090 GPU to train and test it. During training, we use the SGD optimizer to optimize the whole network. And we set the initial learning rate, momentum and weight decay to 1e-3, 0.9 and 5e-4, respectively. The batch size is set to 16 and the input frame is resized to 320320. The maximum length of the referring expression is limited to 20. The dilated rates of LMDS are set . For Refer-DAVIS2017 and Refer-Youtube-VOS, we use the referring image segmentation dataset RefCOCO [29] to assist their training. And random affine transformation is used to for data augmentation. The maximum number of iterations for A2D Sentences, Refer-DAVIS2017, and Refer-Youtube-VOS are set to 75,000, 150,000, and 300,000, respectively. And after 50,000, 80,000, and 200,000 iterations, the learning rate is reduced by 5 times. J-HMDB Sentences is only used to verify the generalization ability of the model.
4.3 Comparison with State-of-the-arts
| Mtehod | |||
| Khoreva et al.18 [13] | 37.3 | 41.3 | 39.3 |
| URVOS20 [22] | 41.23 | 47.01 | 44.12 |
| Ours | 47.71 | 52.33 | 50.02 |
We compare the performance of our method and the previous state-of-the-art methods on four different datasets. First of all, for the A2D Sentences dataset, we can find that the proposed method is significantly better than the previous methods. This also reflects the effectiveness of the two-stream encoder and language-guided dynamic filtering. For all the evaluation metrics in Tab. 1, our model achieves an average absolute gain of more than 5.5%. Especially on Prec@0.6, Prec@0.7 and Prec@0.8, our method obtains absolute enhancement of 7.1%, 7.9% and 8.6% compared with the second-best method. For the metric Prec@0.9, our method improves it from 9.8% to 15.1%, which is 1.5 times the previous performance. This also proves that our network can more accurately perceive the boundary of the object.
| Mtehod | |||
| URVOS20 [22] | 45.27 | 49.19 | 47.23 |
| CMPC-V21 [17] | 45.64 | 49.32 | 47.48 |
| Ours | 48.44 | 50.67 | 49.56 |
Following the previous methods [10, 17], we further use the J-HMDB Sentences dataset to verify the generalization ability of the model trained on the A2D Sentences dataset. As shown in Tab. 2, we can find that the proposed model achieves the best performance under all evaluation metrics. Particularly, our network shows a very significant improvement of 19.7% on Prec@0.7. For the Refer-DAVIS2017, it only contains 60 training videos, so the previous methods [13, 22] usually take advantage of RefCOCO [29] for data augmentation. Our model achieves the gain of 6.5% and 5.3% in terms of and . Finally, Tab. 4 illustrates the accuracy on the large-scale dataset Refer-Youtube-VOS. Our model surpasses other methods in all evaluation metrics. We also present some visual cases in Fig. 4. It can be seen that our method can produce accurate segmentation masks, even when the language expression does not contain location information or the length of query is various.
| EFN | EFN∗ | Dual | LMDF | prec@0.5 | prec@0.6 | prec@0.7 | prec@0.8 | prec@0.9 | ||||
| ✓ | 43.83 | 38.45 | 32.05 | 23.46 | 10.20 | 40.33 | 45.67 | 43.00 | ||||
| ✓ | 44.42 | 38.62 | 31.63 | 23.67 | 9.45 | 41.68 | 47.22 | 44.45 | ||||
| ✓ | 50.38 | 44.65 | 37.11 | 26.83 | 10.40 | 45.20 | 50.19 | 47.70 | ||||
| ✓ | ✓ | 53.93 | 47.57 | 40.44 | 30.06 | 10.81 | 47.71 | 52.33 | 50.02 |
| Query: “a black colored” | Query: “a big man on the right in a black jacket” | ||||
 |
 |
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Image | Result | GT | Image | Result | GT |
| Metrics | MaxPool | w/o pre-interaction | w/ weight-sharing | ||
| 47.71 | 46.62 | 46.41 | 45.73 | 46.50 | |
| 52.33 | 51.26 | 51.68 | 50.23 | 51.05 | |
| 50.02 | 48.94 | 49.05 | 47.98 | 48.78 |
| Query: “a black swan” | ||||||
 |
 |
 |
 |
 |
 |
|
| Query: “a girl on the left holding two cell phones” | ||||||
 |
 |
 |
 |
 |
 |
|
| Query: “a blonde haired girl dancing in a blue dress” | ||||||
 |
 |
 |
 |
 |
 |
|
| Image | EFN | EFN∗ | Dual | Dual+LMDF | GT | |
4.4 Ablation Study
We carefully evaluate the proposed components on the Refer-DAVIS2017 dataset. The quantitative results are shown in Tab. 5 and Tab. 6.
Vision-Language Interleaved Encoder. We first remove the vision-language mutual guidance module (VLMG) and language-guided multi-scale dynamic filtering module (LMDF) from the overall network to construct the basic encoder fusion network (EFN). In EFN, the initial vector representation () of the language is directly inserted into the visual encoder three times by tile and convolution to achieve the fusion of language and vision (as used in [5]). In Tab 5, EFN∗ indicates that the transformer structure is used to extract the multi-granularity language context of . By comparing EFN∗ and EFN, we can find that the hierarchical language information in EFN∗ can be better integrated with the multi-level visual information, thereby improving the performance of the network. Next, we introduce VLMG to realize the mutual interweaving of vision and language (marked as Dual in Tab. 5). The experimental results show that the dual interleaved encoding strategy can further bring 3.5%, 3.0%, and 3.3% gains in terms of , , and .
Language-Guided Multi-Scale Dynamic Filtering.
By comparing the third and fourth rows in Tab 5, we can find that the LMDF achieves the performance improvement by 2.5%, 2.1%, and 2.3% in terms of , , and , respectively. This indicates that this module can accurately capture the temporal coherence between frames.
Different Settings of LMDF.
We evaluate the design options about LMDF, and the results are shown in Tab. 6.
By comparing the second (full LMDF) and third columns, it can be seen that learn multi-scale semantic context can produce more accurate segmentation mask.
The LMDF uses Eq. 11 to compute the position-adaptive guidance feature for dynamic filtering. While CMDy [24] and LGFS [10] use max or average pooling to obtain the global guidance feature. Because their source codes are not available, we adjust the setting of LMDF to imitate the global language guidance for experimental comparison.
Specifically, we firstly use max pooling to deal with the multi-modal spatial-temporal feature (generated by Eq. 10). And then, the pooled vector is used to weight the feature of current frame by element-wise multiplication. Thus, the global guidance information for each position is obtained. Lastly, we generate dynamic kernels and filter the current frame by Eq. 12. The results (marked as MaxPool) show that the pooling operation indeed weakens the local perception required by the segmentation task.
In addition, LMDF interacts linguistic features with visual features in advance (Eq. 7Eq. 10), which makes the dynamic filters better align spatial-temporal grouping cues. The comparison between the second column and w/o pre-interaction also confirms this statement.
Unlike LGFS [10], which shares weight parameters across all spatial positions, LMDF learns the position-adaptive dynamic kernels. For comparison, we utilize to generate the position-independent dynamic kernels.
Specifically, we conduct max pooling on to obtain the global guidance vector, based on which the dynamic filters are generated the same way as in [10].
The results of the rightmost column in Tab. 6 show that the position-independent strategy leads to performance degradation.
Qualitative cases. Fig. 5 gives some representative examples to illustrate the benefits of our proposed module. We can find that the dual interleaved encoder can help the network accurately locate the referred object region, and the LMDF can utilize the temporal coherence to optimize the local details of the object. Thus, our model obtains a prediction mask that is closer to the ground-truth.
5 Conclusion
In this paper, we propose a vision-language interleaved dual encoder and a language-guided multi-scale dynamic filtering mechanism to address the referring video segmentation. Specifically, our method utilizes a language encoder, a visual encoder and a vision-language mutual guidance (VLMG) module to complete the progressive interweaving of different levels of multi-modal features between the two encoders. In addition, in order to fully depict the temporal coherence in the video, we further propose a language-guided multi-scale dynamic filtering (LMDF) module, which can learn adaptive spatial-temporal information with the guidance of language to promote the feature update of current frame. Extensive experiments on four referring video segmentation datasets demonstrate that the proposed model significantly outperforms the state-of-the-art methods. The ablation study also verifies the effectiveness of the proposed modules.
References
- [1] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- [2] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision, pages 764–773, 2017.
- [3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [4] Henghui Ding, Chang Liu, Suchen Wang, and Xudong Jiang. Vision-language transformer and query generation for referring segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16321–16330, 2021.
- [5] Guang Feng, Zhiwei Hu, Lihe Zhang, and Huchuan Lu. Encoder fusion network with co-attention embedding for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15506–15515, 2021.
- [6] Kirill Gavrilyuk, Amir Ghodrati, Zhenyang Li, and Cees GM Snoek. Actor and action video segmentation from a sentence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5958–5966, 2018.
- [7] Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. In European Conference on Computer Vision, pages 108–124. Springer, 2016.
- [8] Zhiwei Hu, Guang Feng, Jiayu Sun, Lihe Zhang, and Huchuan Lu. Bi-directional relationship inferring network for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4424–4433, 2020.
- [9] Shaofei Huang, Tianrui Hui, Si Liu, Guanbin Li, Yunchao Wei, Jizhong Han, Luoqi Liu, and Bo Li. Referring image segmentation via cross-modal progressive comprehension. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10488–10497, 2020.
- [10] Tianrui Hui, Shaofei Huang, Si Liu, Zihan Ding, Guanbin Li, Wenguan Wang, Jizhong Han, and Fei Wang. Collaborative spatial-temporal modeling for language-queried video actor segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4187–4196, 2021.
- [11] Tianrui Hui, Si Liu, Shaofei Huang, Guanbin Li, Sansi Yu, Faxi Zhang, and Jizhong Han. Linguistic structure guided context modeling for referring image segmentation. In European Conference on Computer Vision, pages 59–75. Springer, 2020.
- [12] Hueihan Jhuang, Juergen Gall, Silvia Zuffi, Cordelia Schmid, and Michael J Black. Towards understanding action recognition. In Proceedings of the IEEE international conference on computer vision, pages 3192–3199, 2013.
- [13] Anna Khoreva, Anna Rohrbach, and Bernt Schiele. Video object segmentation with language referring expressions. In Asian Conference on Computer Vision, pages 123–141. Springer, 2018.
- [14] Ruiyu Li, Kaican Li, Yi-Chun Kuo, Michelle Shu, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia. Referring image segmentation via recurrent refinement networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5745–5753, 2018.
- [15] Zhenyang Li, Ran Tao, Efstratios Gavves, Cees GM Snoek, and Arnold WM Smeulders. Tracking by natural language specification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6495–6503, 2017.
- [16] Chenxi Liu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, and Alan Yuille. Recurrent multimodal interaction for referring image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1271–1280, 2017.
- [17] Si Liu, Tianrui Hui, Shaofei Huang, Yunchao Wei, Bo Li, and Guanbin Li. Cross-modal progressive comprehension for referring segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [18] Edgar Margffoy-Tuay, Juan C Pérez, Emilio Botero, and Pablo Arbeláez. Dynamic multimodal instance segmentation guided by natural language queries. In ECCV, pages 630–645, 2018.
- [19] Bruce McIntosh, Kevin Duarte, Yogesh S Rawat, and Mubarak Shah. Visual-textual capsule routing for text-based video segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9942–9951, 2020.
- [20] Ke Ning, Lingxi Xie, Fei Wu, and Qi Tian. Polar relative positional encoding for video-language segmentation. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 948–954, 2020.
- [21] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 724–732, 2016.
- [22] Seonguk Seo, Joon-Young Lee, and Bohyung Han. Urvos: Unified referring video object segmentation network with a large-scale benchmark. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
- [23] Hengcan Shi, Hongliang Li, Fanman Meng, and Qingbo Wu. Key-word-aware network for referring expression image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 38–54, 2018.
- [24] Hao Wang, Cheng Deng, Fan Ma, and Yi Yang. Context modulated dynamic networks for actor and action video segmentation with language queries. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12152–12159, 2020.
- [25] Hao Wang, Cheng Deng, Junchi Yan, and Dacheng Tao. Asymmetric cross-guided attention network for actor and action video segmentation from natural language query. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3939–3948, 2019.
- [26] Chenliang Xu, Shao-Hang Hsieh, Caiming Xiong, and Jason J Corso. Can humans fly? action understanding with multiple classes of actors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2264–2273, 2015.
- [27] Linwei Ye, Mrigank Rochan, Zhi Liu, and Yang Wang. Cross-modal self-attention network for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10502–10511, 2019.
- [28] Linwei Ye, Mrigank Rochan, Zhi Liu, Xiaoqin Zhang, and Yang Wang. Referring segmentation in images and videos with cross-modal self-attention network. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [29] Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In ECCV, pages 69–85. Springer, 2016.
- [30] Hang Zhang, Chongruo Wu, Zhongyue Zhang, Yi Zhu, Haibin Lin, Zhi Zhang, Yue Sun, Tong He, Jonas Mueller, R Manmatha, et al. Resnest: Split-attention networks. arXiv preprint arXiv:2004.08955, 2020.