Defending Regression Learners Against Poisoning Attacks
Abstract
Regression models, which are widely used from engineering applications to financial forecasting, are vulnerable to targeted malicious attacks such as training data poisoning, through which adversaries can manipulate their predictions. Previous works that attempt to address this problem rely on assumptions about the nature of the attack/attacker or overestimate the knowledge of the learner, making them impractical. We introduce a novel Local Intrinsic Dimensionality (LID) based measure called N-LID that measures the local deviation of a given data point’s LID with respect to its neighbors. We then show that N-LID can distinguish poisoned samples from normal samples and propose an N-LID based defense approach that makes no assumptions of the attacker. Through extensive numerical experiments with benchmark datasets, we show that the proposed defense mechanism outperforms the state of the art defenses in terms of prediction accuracy (up to lower MSE compared to an undefended ridge model) and running time.
Index Terms:
poisoning attack, linear regression, local intrinsic dimensionality, supervised learning1 Introduction
Linear regression models are a fundamental class of supervised learning, with applications in healthcare, business, security, and engineering [1, 2, 3, 4]. Recent works in the literature show that the performance of regression models degrades significantly in the presence of poisoned training data [5, 6, 7]. Through such attacks, adversaries attempt to force the learner to end up with a prediction model with impaired prediction capabilities. Any application that relies on regression models for automated decision making could potentially be compromised and make decisions that could have serious consequences.
For example, as demonstrated by Vrablecová et al. [4], regression models can be used for forecasting the power load in a smart electrical grid. In such a setting, if an adversary compromises that forecasting system and forces it to predict a lower power demand than the expected power demand for a particular period, the power supplied during that period would be insufficient and may cause blackouts. Conversely, if the adversary forces the forecasting system to predict a higher power demand than the expected demand, there would be surplus power generated that may overload the power distribution system.
In practice, such attacks can take place in situations where the attacker has an opportunity to introduce poisoned samples to the training process. For example, this can occur when data is collected using crowd-sourcing marketplaces, where organizations build data sets with the help of individuals whose authenticity cannot be guaranteed. Due to the size and complexity of datasets, the sponsoring organization may not be able to extensively validate the quality of all data/labels. Therefore, to address this problem, defense mechanisms that take adversarial perturbations into account need to be embedded into regression models.
Although adversarial manipulations pose a significant threat to critical applications of regression, only a few previous studies have attempted to address this problem. Most works in the literature are related to robust regression, where regression models are trained in the presence of stochastic noise instead of maliciously poisoned data [8, 9]. Recently, however, several works have presented linear regression models that consider the presence of adversarial data samples. Jagielski et al. [5] and Liu et al. [6] present two such defense models that iteratively exclude data samples with the largest residuals from the training process. However, both require the learner to be aware of the number of normal samples in the training dataset, which can be considered as an overestimation of the learner’s knowledge, making them impractical.
Local Intrinsic Dimensionality (LID) is a metric known for its capability to characterize adversarial examples [10, 11]. LID has been applied for detecting adversarial samples in Deep Neural Networks (DNNs) [12] and as a mechanism to reduce the effect of noisy labels for training DNNs [13]. In this paper, we propose a novel LID-based defense mechanism that weights each training sample based on the likelihood of them being normal samples or poisoned samples. The resulting weight vector can then be used in conjunction with any linear regression model that supports a weighted loss function (e.g., weighted linear least squares function). Therefore the proposed defense mechanism can be used to make learners such as ridge regression, LASSO regression, elastic-net regression, and neural network regression (NNR) resilient against poisoning attacks.
We first introduce a novel LID measure called Neighborhood LID ratio (N-LID) that measures the local deviation of a particular sample’s LID with respect to its nearest neighbors. Therefore N-LID can identify regions with similar LID values and samples that have significantly different LID values than their neighbors. We then show that N-LID values of poisoned and normal samples have two distinguishable distributions and introduce a baseline weighting mechanism based on the likelihood ratio of each data sample’s N-LID (i.e., how many times more likely that the N-LID value is from the N-LID distribution of normal samples than the N-LID distribution of poisoned samples). Although the learners’ capabilities are exaggerated, this paves the way for another N-LID based weighting scheme that assumes no knowledge of the attacker or the attacked samples. The latter defense has up to lower mean squared error (MSE) compared to an undefended ridge model, without the increased computational costs associated with prior works.
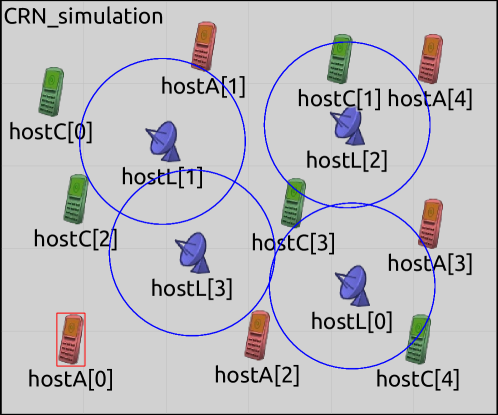
As a real-world application of the proposed defense algorithm, we consider the following security application in the communications domain as a case study. Software-defined radios (SDRs) with considerable computing and networking capabilities can be utilized as an inexpensive scanner array for distributed detection of transmissions (Figure 1). Based on the captured transmission signals, the transmission sources are assigned a risk value , based on the probability of them being malicious transmission sources (i.e., rogue agent). To clarify, background radio traffic (e.g., civilians) would have a value closer to zero, and a transmission source identified as a rogue agent would have a value closer to one. Due to the widespread presence of encryption methods, the risk association for transmission sources has to be inferred based on their statistical characteristics, without considering the transmitted information.
The task of assigning a risk value can be formulated as a regression problem where the learner creates an estimator based on data collected from known transmission sources. However, if the rogue agents deliberately try to mask their activities by altering their transmission patterns during the initial deployment of the SDR network (i.e., when the data is collected for training), they may force the learner to learn an estimator that is compromised (poisoning attack). Therefore, to prevent the estimator from being compromised, the learner uses a defense algorithm during the training phase. In Section 6.1, we present details of the simulation setup followed by empirical results demonstrating the usefulness of our proposed defense.
The main contributions of this work are:
-
1.
A novel LID measure called Neighborhood LID ratio that takes into account the LID values of a sample’s nearest neighbors.
-
2.
An N-LID based defense mechanism that makes no assumptions regarding the attack, yet can be used in conjunction with several existing learners such as ridge, LASSO and NNR.
-
3.
Extensive numerical experiments that show N-LID weighted regression models provide significant resistance against poisoning attacks compared to state of the art alternatives.
The remainder of the paper is organized as follows. Section 2 provides details of previous literature relevant to this work. Section 3 formally defines the problem being addressed followed by Section 4, where we introduce the defense algorithms. We then describe the existing attacks against regression models in Section 5. Section 6 includes a detailed empirical analysis of the attacks and defenses on several real-world datasets followed by the results and discussion. The concluding remarks of Section 7 conclude the paper.
2 Literature review
In this section, we briefly review the relevant previous work in the literature.
2.1 Robust regression
In robust statistics, robust regression is well studied to devise estimators that are not strongly affected by the presence of noise and outliers [14]. Huber [15] uses a modified loss function that optimizes the squared loss for relatively small errors and absolute loss for relatively large ones. As the influence on absolute loss by outliers is less compared to squared loss, this reduces their effect on the optimization problem, thereby resulting in a less distorted estimator. Mangasarian and Musicant [9] solve the Huber M-estimator problem by reducing it to a quadratic program, thereby improving its performance. The Theil–Sen estimator, developed by Thiel [16] and Sen [17] uses the median of pairwise slopes as an estimator of the slope parameter of the regression model. As the median is a robust measure that is not influenced by outliers, the resulting regression model is considered to be robust as well.
Fischler and Bolles [18] introduced random sample consensus (RANSAC), which iteratively trains an estimator using a randomly sampled subset of the training data. At each iteration, the algorithm identifies data samples that do not fit the trained model by a predefined threshold as outliers. The remaining data samples (i.e., inliers) are considered as part of the consensus set. The process is repeated a fixed number of times, replacing the currently accepted model if a refined model with a larger consensus set is found. Huang et al. [8] decomposes the noisy data in to clean data and outliers by formulating an optimization problem. The estimator parameters are then computed using the clean data.
While these methods provide robustness guarantees against noise and outliers, we focus on malicious perturbations by sophisticated attackers that craft adversarial samples that are similar to normal data. Moreover, the aforementioned classical robust regression methods may fail in high dimensional settings as outliers might not be distinctive in that space due to high-dimensional noise [19].
2.2 Adversarial regression
The problem of learning under adversarial conditions has inspired a wide range of research from the machine learning community, see the work of Liu et al. [20] for a survey. Although adversarial learning in classification and anomaly detection has received a lot of attention [21, 22, 23, 24], adversarial regression remains relatively unexplored.
Most works in adversarial regression provide performance guarantees given several assumptions regarding the training data and noise distribution hold. The resilient algorithm by Chen et al. [25] assumes that the training data before adversarial perturbations, as well as the additive noise, are sub-Gaussian and that training features are independent. Feng et al. [26] provides a resilient algorithm for logistic regression under similar assumptions.
Xiao et al. [7] examined how the parameters of the hyperplane in a linear regression model change under adversarial perturbations. The authors also introduced a novel threat model against linear regression models. Liu et al. [6] use robust PCA to transform the training data to a lower-dimensional subspace and follow an iterative trimmed optimization procedure where only the samples with the lowest residuals are used to train the model. Note that here is the number of normal samples in the training data set. Jagielski et al. [5] use a similar approach for the algorithm “TRIM”, where trimmed optimization is performed in the input space itself. Therefore they do not assume a low-rank feature matrix as done in [6]. Both approaches, however, assume that the learner is aware of (or at least an upper bound for ), thereby reducing the practicality of the algorithms.
Tong et al. [27] consider an attacker that perturbs data samples during the test phase to induce incorrect predictions. The authors use a single attacker, multiple learner framework modeled as a multi-learner Stackelberg game. Alfeld et al. [28] propose an optimal attack algorithm against auto-regressive models for time series forecasting. In our work, we consider poisoning attacks against models that are used for interpolating instead of extrapolating. Nelson et al. [29] originally introduced RONI (Reject On Negative Impact) as a defense for adversarial attacks against classification models. In RONI, the impact of each data sample on training is measured, and samples with notable negative impacts are excluded from the training process.
In summary, to the best of our knowledge, no linear regression algorithm has been proposed that reduces the effects of adversarial perturbations in training data through the use of LID. Most existing works on adversarial regression make strong assumptions regarding the attacker/attack, making them impractical, whereas, we propose a novel defense that makes no such assumptions.
3 Problem statement
We consider a linear regression learning problem in the presence of a malicious adversary. Define the labeled pristine training data (i.e., prior to adversarial perturbations) as , where is the feature matrix and the corresponding response variable vector. We let denote the training sample, associated with a corresponding response variable from . Note that each for unlike in classification problems where the labels take discrete categorical values.
A linear regression model can be described by a linear function of the form that predicts the response variable for each . The function is parameterized by the vector consisting of the feature weights and the bias of the hyperplane . The parameter vector is obtained by applying a learning algorithm, such as ridge regression (shown below), on :
| (1) |
Note that is a regularization parameter.
The adversary’s goal is to maximize the regression model’s prediction error for unseen data samples (i.e., testing phase). To succeed in this, the adversary introduces a set of poisoned data samples and labels into the pristine training set , resulting in a contaminated training dataset where and . Applying a learning algorithm on the contaminated training data would result in a compromised regression model as follows,
| (2) |
where and . Through and , the adversary forces the learner to obtain a parameter vector that is significantly different from , which it would have obtained had the training data been unaltered.
To address this problem, we propose an LID based weighting scheme that can be incorporated into learning algorithms that optimize quadratic loss functions such as the Mean Squared Error in Equation (2). In weighted least squares (WLS), a weight is assigned for each sample in order to discriminate and vary their influence on the optimization problem. A small value would allow for a large residual value, and the effect of the sample would be de-emphasized. Conversely, a large value would emphasize that particular sample’s effect. The weighted regression learning problem is formulated as the following convex optimization problem:
| (3) |
By carefully selecting a weight vector , the learner can minimize the effects of the adversarial perturbations and recover the correct estimator .
4 Defense algorithms
First, we briefly introduce the theory of LID for assessing the dimensionality of data subspaces, then, we present our novel LID based mechanism to obtain the weight vector and show how it can easily be incorporated into existing regression algorithms.
Expansion models of dimensionality have previously been successfully employed in a wide range of applications, such as manifold learning, dimension reduction, similarity search, and anomaly detection [10, 30]. In this paper, we use LID to characterize the intrinsic dimensionality of regions where attacked samples lie, and create a weighting mechanism that de-emphasizes the effect of samples that have a high likelihood of being adversarial examples.
4.1 Theory of Local Intrinsic Dimensionality.
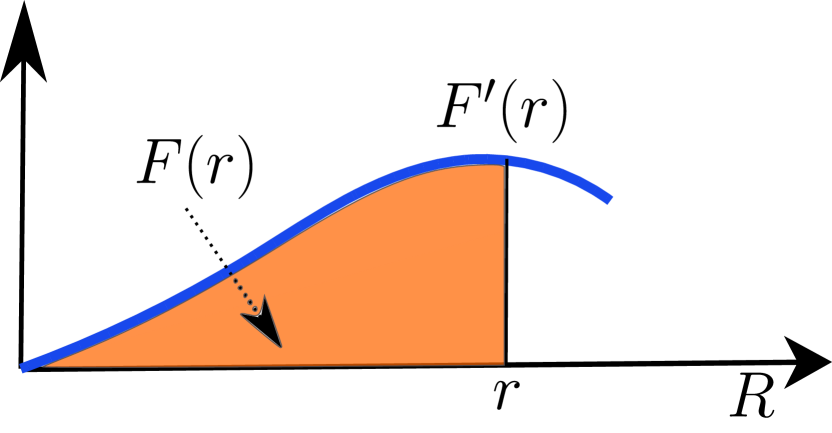
In the theory of intrinsic dimensionality, classical expansion models measure the rate of growth in the number of data samples encountered as the distance from the sample of interest increases [10]. As an example, in Euclidean space, the volume of an m-dimensional ball grows proportionally to , when its size is scaled by a factor of . From this rate of change of volume w.r.t distance, the expansion dimension can be deduced as:
| (4) |
Transferring the concept of expansion dimension to the statistical setting of continuous distance distributions leads to the formal definition of LID. By substituting the cumulative distance for volume, LID provides measures of the intrinsic dimensionality of the underlying data subspace. Refer to the work of Houle [10] for more details concerning the theory of LID. The formal definition of LID is given below [10].
Definition 1 (Local Intrinsic Dimensionality).
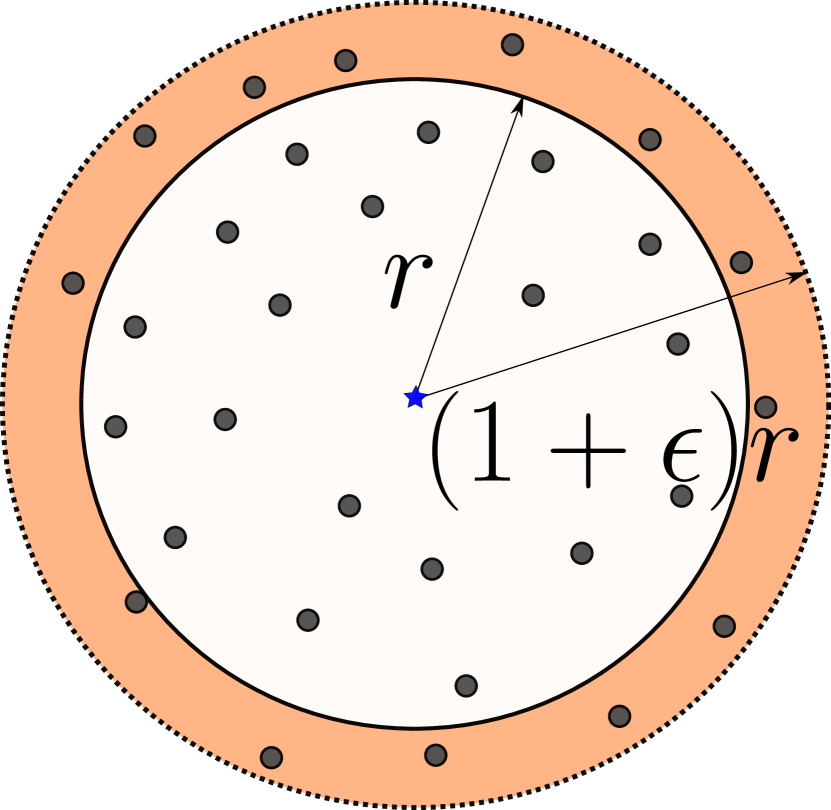
Given a data sample , let be a random variable denoting the distance from to other data samples. If the cumulative distribution function of is positive and continuously differentiable at distance , the LID of at distance is given by:
| (5) |
whenever the limit exists.
The last equality of Equation (5) follows by applying L’Hôpital’s rule to the limits [10]. The local intrinsic dimension at is in turn defined as the limit when the radius tends to zero:
| (6) |
describes the relative rate at which its cumulative distribution function increases as the distance increases from (Figure 2). In the ideal case where the data in the vicinity of is distributed uniformly within a subspace, equals the dimension of the subspace; however, in practice these distributions are not ideal, the manifold model of data does not perfectly apply, and is not an integer [12]. Nevertheless, the local intrinsic dimensionality is an indicator of the dimension of the subspace containing that would best fit the data distribution in the vicinity of .
Definition 2 (Estimation of LID).
Given a reference sample , where represents the data distribution, the Maximum Likelihood Estimator of the LID at is defined as follows [30]:
| (7) |
Here, denotes the distance between and its -th nearest neighbor within a sample of points drawn from , and is the maximum of the neighbor distances.
The above estimation assumes that samples are drawn from a tight neighborhood, in line with its development from Extreme Value Theory. In practice, the sample set is drawn uniformly from the available training data (omitting itself), which itself is presumed to have been randomly drawn from . Note that the LID defined in Equation (6) is the theoretical calculation, and that defined in Equation (7) is its estimate.
4.2 Neighborhood LID Ratio.
We now introduce a novel LID based measure called neighborhood LID ratio (N-LID) and discuss the intuition behind using N-LID to identify adversarial samples during training. By perturbing the feature vector, the adversary moves a training sample away from the distribution of normal samples. Computing LID estimates with respect to its neighborhood would then reveal an anomalous distribution of the local distance to these neighbors. Furthermore, as is an indicator of the dimension of the subspace that contains , by comparing the LID estimate of a data sample to the LID estimates of its nearest neighbors, we can identify regions that have a similar lower-dimensional subspace. More importantly, any samples that have a substantially different lower-dimensional subspace compared to its neighbors can be identified as poisoned samples.
Considering this aspect of poisoning attacks, we propose a novel LID ratio measure that has similar properties as the local outlier factor (LOF) algorithm introduced by Breunig et al. [31] as follows:
Definition 3 (Neighborhood LID ratio).
Given a data sample , the neighborhood LID ratio of is defined as:
| (8) |
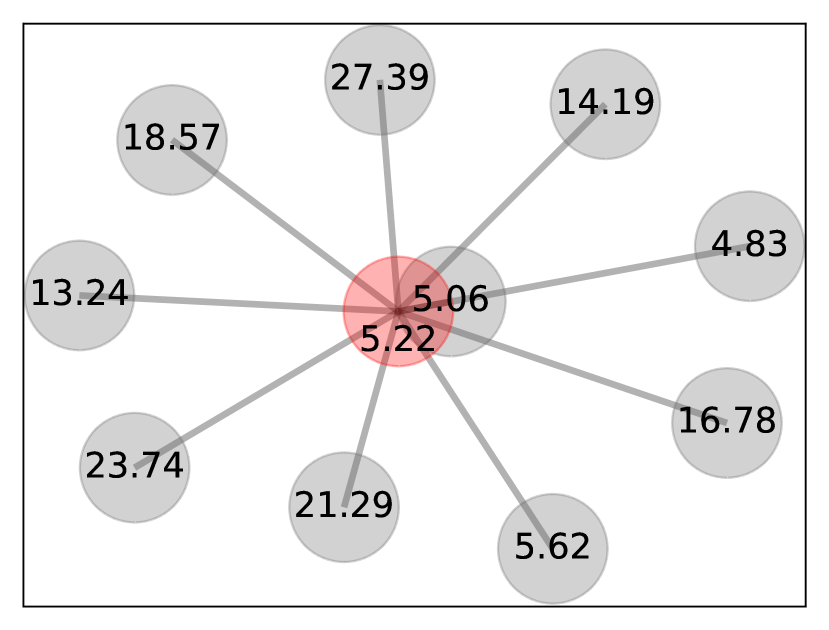
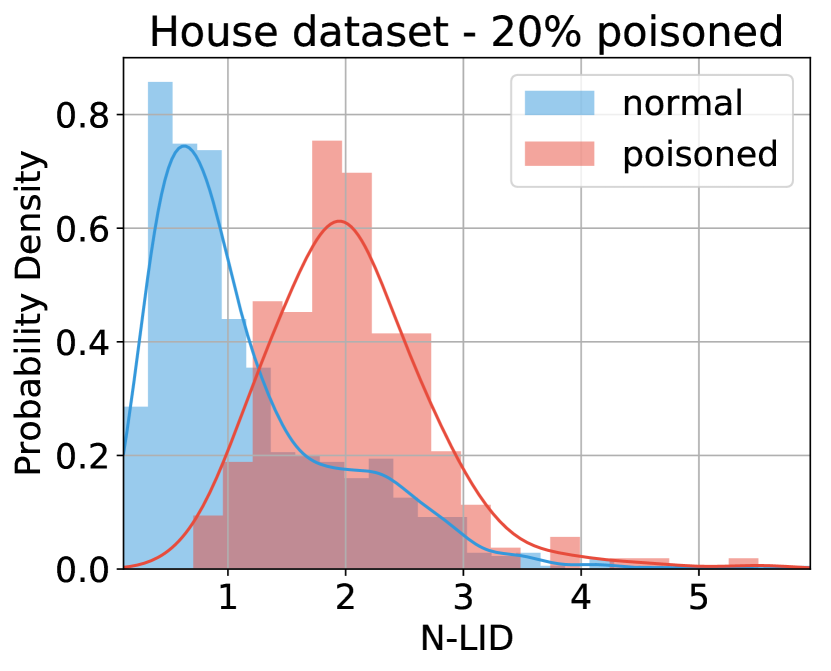
Here, denotes the LID estimate of the -th nearest neighbor from the nearest neighbors of . Figure 3(a) shows the LID estimates of a poisoned sample and its nearest neighbors. As the poisoned sample’s LID estimate is substantially different from its neighbors, the N-LID value calculated using Equation(8) highlights it as an outlier. As Figure 3(b) shows, N-LID is a powerful metric that can give two distinguishable distributions for poisoned and normal samples. Although ideally, we like to see no overlap between the two distributions, in real-world datasets, we see some degree of overlap.
4.3 Baseline Defense.
We now describe a baseline weighting scheme calculated using the N-LID distributions of poisoned and normal samples. Define and as the probability density functions of the N-LID values of normal samples and poisoned samples. For a given data sample with the N-LID estimate , we define two possible hypotheses, and as
| (9) | ||||
where the notation “” denotes the condition “ is from the distribution ”. To clarify, is the hypothesis that is from the N-LID distribution of normal samples and is the hypothesis that is from the N-LID distribution of poisoned samples.
The likelihood ratio (LR) is usually used in statistics to compare the goodness of fit of two statistical models. We define the likelihood ratio of a data sample with the N-LID estimate as
| (10) |
where denotes the probability of the N-LID of sample w.r.t the probability distribution . To clarify, expresses how many times more likely it is that is under the N-LID distribution of normal samples than the N-LID distribution of poisoned samples.
As there is a high possibility for and to have an overlapping region (Figure 3(b)), there is a risk of emphasizing the importance of (giving a higher weight to) poisoned samples. To mitigate that risk, we only de-emphasize samples that are suspected to be poisoned (i.e., low LR values). Therefore, we transform the LR values such that . The upper bound is set to to prevent overemphasizing samples.
Subsequently, we fit a hyperbolic tangent function to the transformed LR values () in the form of and obtain suitable values for the parameters and . The scalar value of maintains the scale and vertical position of the function between and . By fitting a smooth function to the LR values, we remove the effect of noise and enable the calculation of weights for future training samples. Finally, we use the N-LID value of each and use Equation (11) to obtain its corresponding weight .
| (11) |
4.4 Attack Unaware Defense.
The LR based weighting scheme described above assigns weights to training samples based on the probabilities of their N-LID values. This approach requires the learner to be aware of the probability density functions (PDFs) of normal and poisoned samples. The two distributions can be obtained by simulating an attack and deliberately altering a subset of data during training, by assuming the distributions based on domain knowledge or prior experience or by having an expert identify attacked and non-attacked samples in a subset of the dataset. However, we see that the N-LID measure in Equation (8) results in larger values for poisoned samples compared to normal samples (Figure 3(b)). In general, therefore, it seems that a weighting scheme that assigns small weights to large N-LID values and large weights to small N-LID values would lead to an estimator that is less affected by the poisoned samples present in training data.
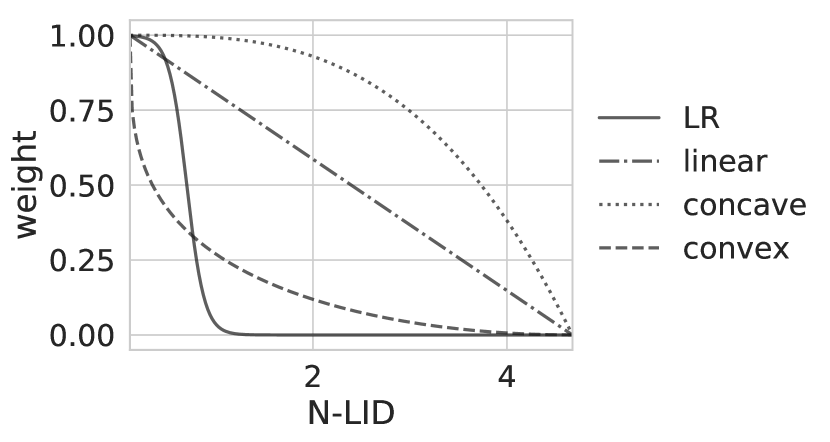
Considering this aspect of N-LID, we choose three weighting mechanisms that assign for the sample with the smallest N-LID and for the sample with the largest N-LID as shown in Figure 4. Note that there is a trade-off between preserving normal samples, and preventing poisoned samples from influencing the learner. The concave weight function attempts to preserve normal samples, which causes poisoned samples to affect the learner as well. In contrast, the convex weight function reduces the impact of poisoned samples while reducing the influence of many normal samples in the process. The linear weight function assigns weights for intermediate N-LID values linearly without considering the trade-off.
We obtain the weight functions by first scaling the N-LID values of the training samples to . Take as the scaled N-LID value of sample . Then, for the linear weight function, we take as the weight. For the concave weight function we use and for the convex weight function we use . We choose these two arbitrary functions as they possess the trade-off mentioned in the paragraph above. Any other functions that have similar characteristics can also be used to obtain the weights.
The main advantage of our proposed defense is that it is decoupled from the learner; it can be used in conjunction with any learner that allows the loss function to be weighted. In Section 6, we demonstrate the effectiveness of our proposed defense by incorporating it into a ridge regression model and an NNR model.
The high level procedures used to obtain uninfluenced ridge regression models under adversarial conditions are formalized in Algorithms 1 and 2 for the baseline defense (N-LID LR) and the convex weight function based defense (N-LID CVX).
5 Threat models
In this work, we assume a learner that does not have access to a collection of pristine data samples. The training data it uses may or may not be manipulated by an adversary. The learner chooses its defense algorithm and regression model, without knowing details of the attack employed by the adversary.
The attacks being considered are white-box attacks, with the attacker knowing the pristine training data and any hyper-parameters of the learning algorithm. While these assumptions exaggerate the capabilities of a real-world attacker, it allows us to test the performance of defense algorithms under a worst-case scenario. Moreover, relying on secrecy for security is considered as a poor practice when designing defense algorithms [32].
We employ the attack algorithm introduced by Jagielski et al. [5] against linear regression models, which is an adaptation of the attack algorithm by Xiao et al. [7]. The latter attack algorithm is used in prior works on adversarial regression as the threat model [6]. While giving a brief description of the attack algorithm, we refer the readers to [5] for more details.
The underlying idea is to move selected data samples along the direction that maximally increases the MSE of the estimator on a pristine validation set. Unlike in classification problems, the attacker can alter the response variable as well. We use similar values used by Jagielski et al. [5] for the hyper-parameters that control the gradient step and convergence of the iterative search procedure of the attack algorithm. The line search learning rate (), which controls the step size taken in the direction of the gradient, is selected from a set of predefined values by evaluating the MSE values on a validation set.
The amount of poisoning is controlled by the poisoning rate, defined as , where is the number of pristine samples, and is the number of poisoned samples. The attacker is allowed to poison up to of the training data in line with prior works in the literature [5, 7].
The Opt attack algorithm selects the initial set of data points to poison randomly from the training set. The corresponding response variables are initialized in one of two methods: (i) and (ii) . The first approach, known as Inverse Flipping (IFlip), results in a less intense attack compared to the latter, known as Boundary Flipping (BFlip), which pushes the response values to the extreme edges. In our experiments, we test against attacks that use both initialization techniques.
We also considered the optimization based attack by Tong et al. [27], but it was unable to exact a noticeable increase in MSE even at a poisoning rate of . Therefore we do not present experimental results for it.
6 Experimental results and discussion
In this section, we describe the datasets used and other procedures of the experimental setup. We extensively investigate how the performance of N-LID weighted regression models holds against an increasing fraction of poisoned training data. Our code and datasets are available at https://github.com/sandamal/lid-regression.
6.1 Case study: risk assignment to suspicious transmissions
We provide here a brief description of the simulations that were conducted to obtain the data for the case study that we are considering in this paper. Refer to the work of Weerasinghe et al. [33] for additional information regarding the security application in SDR networks.
Network simulation and data collection: We use the INET framework for OMNeT++ [34] as the network simulator, considering signal attenuation, signal interference, background noise, and limited radio ranges in order to conduct realistic simulations. We place the nodes (civilians, rogue agents, and listeners) randomly within the given confined area. The simulator allows control of the frequencies and bit rates of the transmitter radios, their communication ranges, message sending intervals, message lengths, the sensitivity of the receivers, minimum energy detection of receivers, among other parameters. It is assumed that all the communications are encrypted; therefore, the listeners are unable to access the content of the captured transmissions. We obtain the duration of the reception, message length, inter-arrival time (IAT), carrier frequency, bandwidth, and bitrate as features using the data captured by the listeners.
Considering the data received by the three closest listeners (using the power of the received signal) of each transmission source, the duration, message length, and IAT of the messages received by each listener are averaged every five minutes, which results in () features in total. Adding the latter three parameters (fixed for each transmission source) gives the full feature vector of features. The response variables (i.e., the risk of being a rogue agent) are assigned based on the positions of the data samples in the feature space.
6.2 Benchmark datasets.
We use the following combination of relatively high dimensional and low dimensional regression datasets in our experimental analysis. In particular, The House and Loan datasets are used as benchmark datasets in the literature [5]. Table I provides the training and test set sizes, the regularization parameter of the ridge regression model, and the line search learning rates of the attacks considered for each of the datasets.
House dataset: The dataset uses features such as year built, floor area, number of rooms, and neighborhood to predict the sale prices of houses. There are features in total, including the response variable. All features are normalized into . We fix the training set size to , and the test set size to .
Loan dataset: The dataset contains information regarding loans made on LendingClub. Each data sample contains features, including loan amount, term, the purpose of the loan, and borrower’s attributes with the interest rate as the response variable. We normalize the features into and fix the training set and test set size as above.
Grid dataset: Arzamasov et al. [35] simulated a four-node star electrical grid with centralized production to predict its stability, w.r.t the behavior of participants of the grid (i.e., generator and consumers). The system is described with differential equations, with their variables given as features of the dataset. In our work, we use the real component of the characteristic equation root as the response variable for the regression problem.
Machine dataset: The dataset by Kibler et al. [36] is used to estimate the relative performance of computer hardware based on attributes such as machine cycle time, memory, cache size, and the number of channels.
| Dataset | # of features | Training size | Test size | of BFlip | of IFlip | |
| House | 274 | 840 | 280 | 0.0373 | 0.01 | 0.01 |
| Loan | 88 | 840 | 280 | 0.0273 | 0.05 | 0.05 |
| OMNeT | 111 | 502 | 125 | 0.0002 | 0.01 | 0.01 |
| Grid | 12 | 840 | 280 | 0.0173 | 0.01 | 0.30 |
| Machine | 6 | 125 | 42 | 0.0223 | 0.03 | 0.03 |
6.3 Experimental setup.
For each learning algorithm, we find its hyperparameters using five-fold cross-validation on a pristine dataset. For LID calculations we tune over as previously done by Ma et al. [12]. Kernel density estimation for LR calculation was performed using a Gaussian kernel with the bandwidth found using a cross-validation approach to avoid overfitting. The effects of kernel density estimation are neutralized by the smooth function fitting (Equation (11)); therefore, the algorithm is robust to these choices.
For each dataset, we create five cross-validation sets. We present the average MSE of the cross-validation sets for each learner when the poisoning rate increases from to . While increasing the poisoning rate over is feasible, it is unrealistic to expect a learner to withstand such amounts of poisoned data, and it also assumes a powerful attacker with significant influence over the training data. As the existence of such an attacker is unlikely, we limit the poisoning rate to , similar to prior works in the literature.
6.4 Results and discussion.
6.4.1 Attacker unaware defense
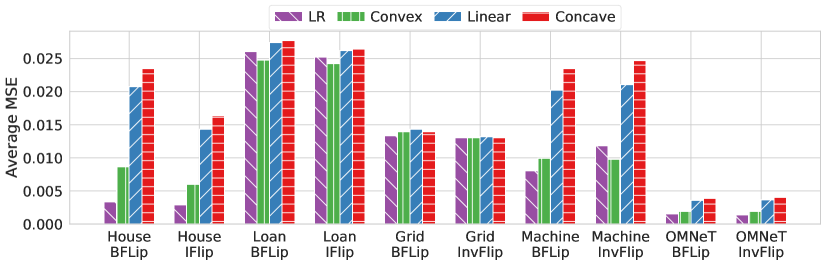
Figure 5 compares the average MSE for the three attacker unaware weighting schemes and the LR based weighting scheme that we introduced in Section 4.4. Of the three attacker unaware weighting schemes, we see that the convex weight function has lower average MSE in House, in Loan, in Machine, and in OMNeT. This is not surprising as the convex weight function is the closest to the ideal LR based weight function. The result suggests that it is favorable to the learner to reduce the weights of suspected adversarial samples even if there is an increased risk of de-emphasizing normal samples as well. This is to be expected with linear regression data where there is high redundancy; losing a portion of normal data from training would not significantly impact the performance of the estimator. In future studies, it might be possible to investigate the performance of the three weighting functions in situations where data redundancy is low, such as non-linear regression problems. In the following sections, the term N-LID CVX refers to a ridge regression model with the convex weight function based defense.
6.4.2 In the absence of an attack
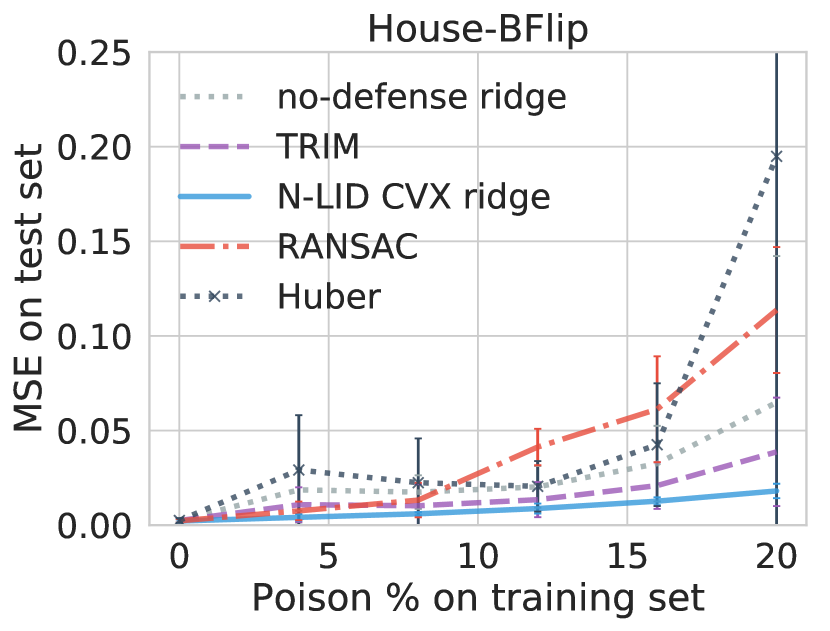
As stated in Section 5, we assume that the learner is unaware of the attacker; therefore the training data may or may not be manipulated by the adversary. Hence it is possible to have a scenario where the learner utilizes a defense algorithm when an attack is not present.
It is common for adversarial learning algorithms to sacrifice performance in the absence of an attack to improve their attack resilience in the presence of attacks. Improving attack resilience often results in decreased performance in the absence of an attack and vice versa. However, as Figure 6 shows, all the adversarial/robust learners considered in the experiments perform similarly to a learner with no built-in defense when the poisoning rate is zero. This result may be explained by the fact that there is a high level of redundancy in the linear regression datasets. Therefore even if a learner removes/de-emphasizes a subset of samples during training even when there is no attack, the remaining data samples are sufficient to obtain an accurate estimator.
| House | Loan | OMNeT | Grid | Machine | ||||||
| BFlip | IFlip | BFlip | IFlip | BFlip | IFlip | BFlip | IFlip | BFlip | IFlip | |
| N-LID LR ridge | -87.27% | -84.24% | -7.53% | -4.78% | -20.53% | -29.36% | -4.29% | -0.86% | -80.64% | -71.63% |
| N-LID CVX ridge | -66.83% | -67.74% | -12.16% | -8.55% | 0.30% | -3.52% | -2.84% | -0.13% | -76.12% | -76.63% |
| TRIM | -38.13% | -70.43% | -1.59% | -0.72% | 31.76% | 6.83% | -6.74% | -0.97% | -86.24% | -61.96% |
| RANSAC | 53.26% | 61.83% | 33.36% | 22.63% | 20.36% | 61.64% | -5.92% | -1.05% | -70.24% | -83.37% |
| Huber | 99.81% | 46.97% | 22.22% | 23.93% | 28.61% | 7.24% | -7.18% | -2.14% | -35.55% | -39.60% |
| House | Loan | OMNeT | Grid | Machine | ||||||
| BFlip | IFlip | BFlip | IFlip | BFlip | IFlip | BFlip | IFlip | BFlip | IFlip | |
| N-LID LR ridge | 14.85 | 17.31 | 47.36 | 42.21 | 30.46 | 28.08 | 127.13 | 88.98 | 199.11 | 198.27 |
| N-LID CVX ridge | 11.30 | 12.88 | 33.83 | 30.04 | 22.91 | 19.52 | 86.43 | 60.85 | 9.89 | 9.78 |
| TRIM | 19.55 | 23.32 | 39.74 | 41.87 | 33.87 | 31.47 | 83.83 | 90.47 | 15.49 | 11.04 |
| RANSAC | 35.65 | 40.31 | 74.62 | 68.32 | 41.48 | 39.28 | 124.35 | 73.19 | 128.26 | 95.18 |
| Huber | 122.18 | 149.28 | 182.52 | 167.81 | 207.86 | 169.31 | 23.24 | 11.96 | 19.50 | 15.08 |
6.4.3 In the presence of an attack
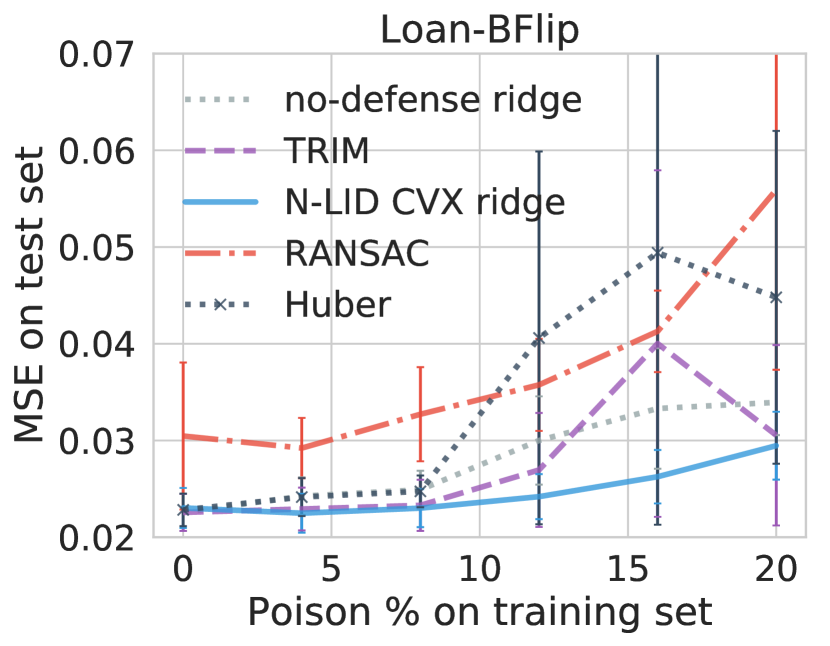
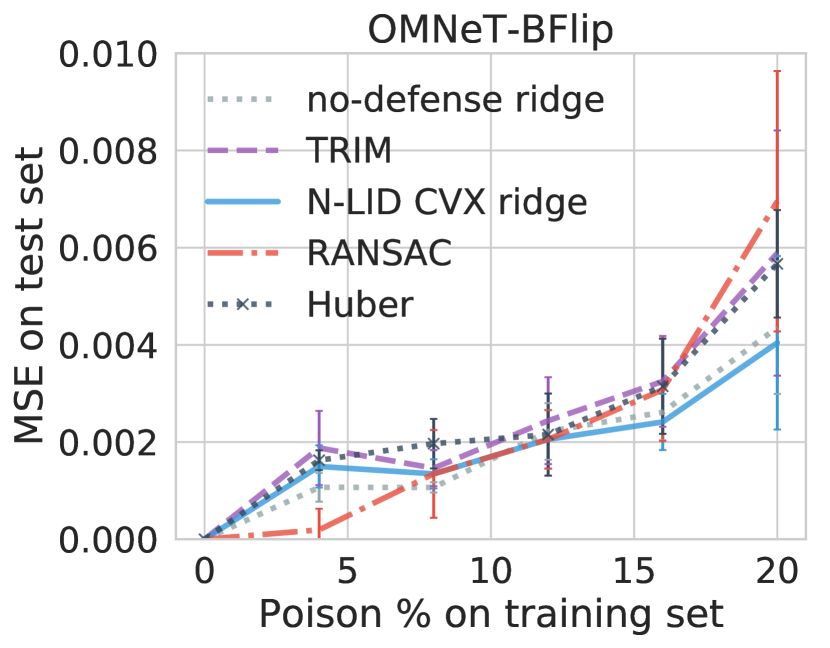
First, we consider the performance of the undefended ridge learner, as shown in Figure 6. We observe that the MSE values increase by and on the House dataset, and on the Loan dataset, and on the Grid dataset, and and on the Machine dataset under BFlip and IFLip Opt attacks respectively. We observe a similar trend in the OMNeT dataset, as well. These results suggest that (i) undefended regression learners can be severely affected by poisoning attacks, and (ii) among the two attack configurations considered, BFlip is more potent than IFlip as the initial movement of the response variable is more aggressive compared to IFlip.
We now compare the performance of an N-LID LR weighted ridge model and N-LID CVX weighted ridge model against TRIM [5], RANSAC [18] and Huber [15] under poisoning attacks. Table II compares their average MSE values with the average MSE of a ridge regression model with no defense (shown as the percentage increase or decrease).
First, we consider the performance of the defenses on the three datasets with a relatively large number of dimensions (i.e., House, Loan, and OMNeT). Considering the experimental evidence on the performance of the robust learners (i.e., Huber and RANSAC), we see that they are not effective at defending against poisoning attacks when the dimensionality of the data is high. In fact, their performance is significantly worse than an undefended ridge regression model. The average MSE of RANSAC is up to higher on the House dataset, up to higher on the Loan dataset and up to higher on the OMNeT dataset when compared with an undefended ridge model. Huber also increases the average MSE by , , and , respectively, for the three datasets. This finding is consistent with that of Jagielski et al. [5] who reported similar performance for robust learners when used with high-dimensional datasets.
This behavior of Huber and RANSAC may be due to high dimensional noise. In high dimensional spaces, poisoned data might not stand out due to the presence of high dimensional noise [19], thereby impairing their performance. Moreover, it should be noted that these defenses are designed against stochastic noise/outliers, not adversarially poisoned data. In an adversarial setting, a sophisticated adversary may poison the data such that the poisoned samples have a similar distribution to normal data, thereby, reducing the possibility of being detected.
In contrast, TRIM, a defense that is designed against poisoning attacks, has up to and lower MSE values compared to an undefended ridge model on the House and Loan datasets. Interestingly, on the OMNeT dataset, we observe and higher MSE values for TRIM. Readers may also notice that the prediction performance of TRIM shown in [5] is different from what we have obtained. Analyzing the provided code revealed that in their experiments the poisoned training dataset is created by appending the poisoned samples to the matrix containing the pristine samples (resulting in ). During the first iteration of TRIM, the first rows are selected to train the regression model, which happens to be the pristine data in this case. To avoid this issue, in our experiments, we randomly permute the rows of before training with TRIM.
The N-LID based defense mechanisms consistently outperformed the other defenses against all the attack configurations on the three datasets with a large number of dimensions. On the House dataset, N-LID LR weighted ridge model has the best prediction performance ( lower MSE) with the N-LID CVX weighted ridge model being closely behind ( lower MSE). A similar trend is present on the OMNeT dataset, where the N-LID LR weighted ridge model has a lower average MSE. On the Loan dataset, we observe that N-LID CVX weighted ridge model has the best performance with a lower average MSE. It is interesting to note that the performance of the N-LID CVX weighting mechanism, which makes no assumptions of the attack, is on par with the N-LID LR baseline weighting scheme in the majority of the test cases considered.
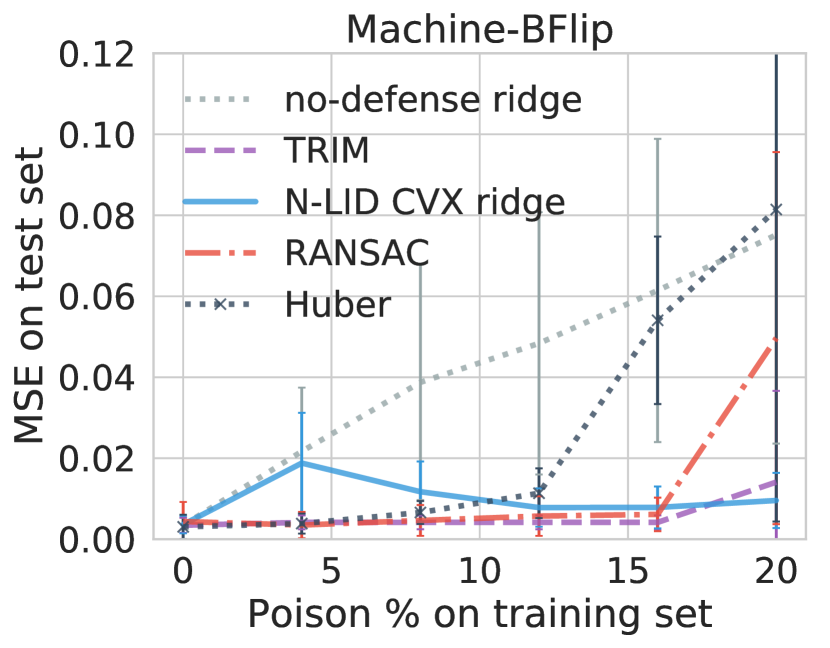
Turning now to the experimental evidence on the performance of the defenses on the two datasets with a small number of dimensions (i.e., Grid and Machine), we see that all the defenses considered can outperform the ridge regression learner without a defense. What stands out in Table II is that the robust regression learners (Huber and RANSAC) that performed worse than an undefended ridge regression model on the three datasets with a large number of dimensions, have significantly lower MSE values on the two datasets with the smaller number of dimensions. Huber has the best prediction performance on the Grid dataset even exceeding the N-LID based defenses. It has up to and lower MSE values, respectively, for the two datasets. The average MSE value of RANSAC is lower on the Grid dataset while having an lower MSE on the Machine dataset.
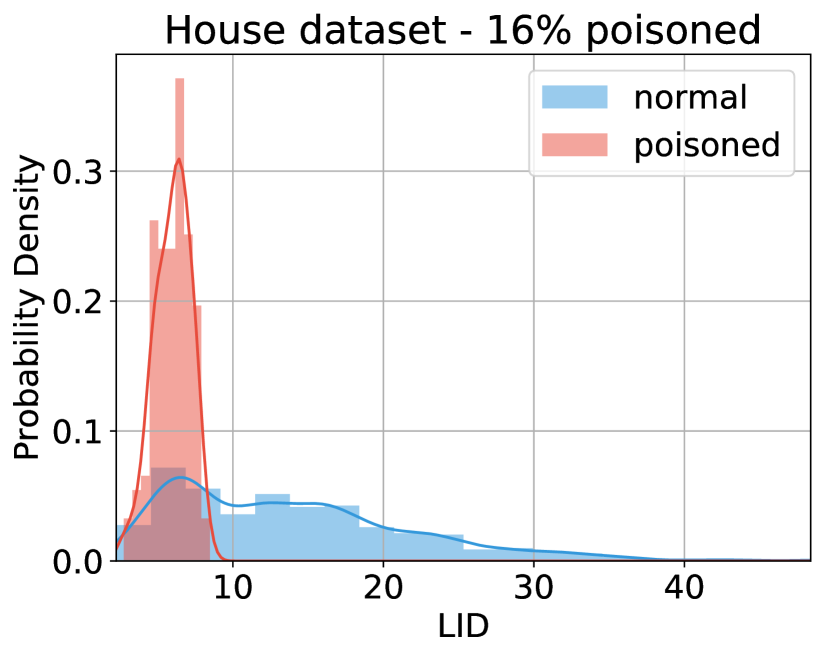
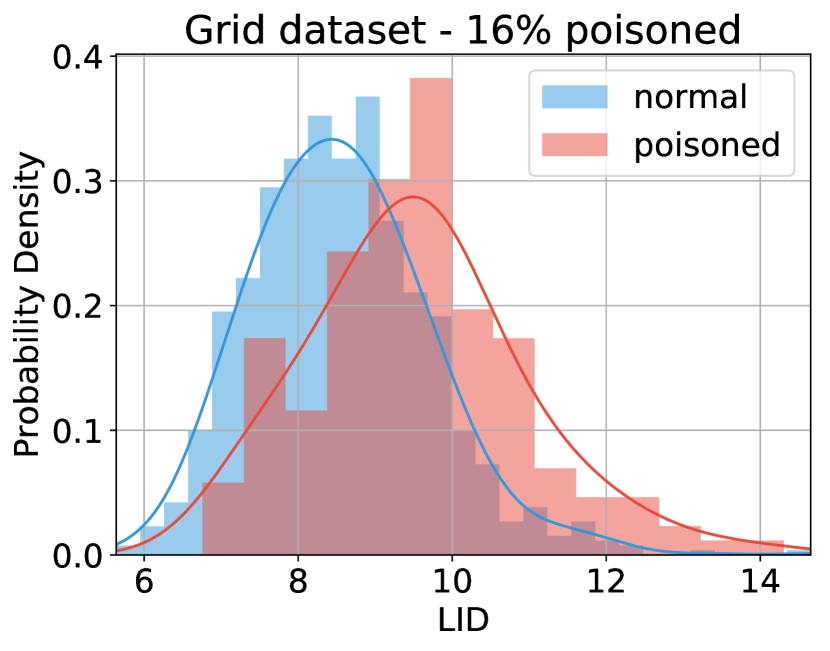
N-LID based defenses perform consistently across all the datasets considered when compared against an undefended ridge regression model. However, their performance improvement is relatively smaller on Grid and Machine. The lack of performance on the two datasets with a small number of dimensions may be explained by Figure 7, which shows the LID (not N-LID) distributions of normal and poisoned samples in two datasets with different dimensions. The LID estimate of a sample is the dimension of the true low-dimensional subspace (at least approximately) in which the particular sample lies (Section 4.1). In other words, it describes the optimal number of features needed to explain the salient features of the dataset. For datasets that have a small number of features, the range of values LID could take is also narrow (as LID is less than the actual number of dimensions). Therefore, if the majority of the features of a particular dataset are salient features, the resulting LID distributions of normal and poisoned samples would have a large overlap (Figure 7(b)). Overlapping LID distributions lead to overlapping N-LID distributions, thereby impairing the performance of LID based defenses on such datasets.
In contrast, datasets with a large number of dimensions may allow for a wider range of LID values. In such high-dimensional spaces poisoned and normal samples would exhibit distinguishable LID distributions as shown in Figure 7(a) (unless a majority of the features are salient features as explained above). Moreover, in such spaces where most data points seem equidistant, the N-LID based defenses have good performance because they characterize poisoned samples from normal samples using the true low-dimensional manifold of the data. However, the issue of obtaining distinguishable LID distributions for poisoned and normal samples for datasets with a high percentage of salient features is an intriguing one that could be usefully explored in further research.
6.4.4 Practical implications of poisoning attacks
We now turn to the practical implications of the poisoning attacks on the case study considered in this paper. In a security application such as the one discussed, having the decision variable change by even a small amount could have dire consequences. We observe that the BFlip attack changes the assigned risks of of the transmission sources by when a ridge regression model without a defense is used (at poisoning rate). This means a transmission source that should ideally be assigned a high-risk probability may be assigned a significantly lower risk value or vice versa. Nearly half of all the transmission sources () have their assigned risks altered by at least . However, the N-LID LR defense model resulted in none of the transmission sources having their assigned risk increased by over .
6.4.5 Computational complexity
Table III compares the average training time (in seconds) for the learners considered in the experiments. Because ridge regression with no defense has the lowest training time, we report the training times of the other algorithms as a factor of its training time. It is apparent from this table that N-LID CVX ridge has the lowest training time in eight of the ten experiments considered. Its training times are only times higher on the House dataset, times higher on the Loan dataset, times higher on the Grid dataset, times higher on the Machine dataset, and times higher on the OMNeT dataset. TRIM, being an iterative method, has higher training times compared to N-LID CVX ridge in the majority of the test cases. But its computational complexity is significantly lower compared to RANSAC, which is another iterative method.
Of the learners considered, Huber has the most variation in average training time. We observe that on the three datasets with a large number of dimensions, its training times are up to times higher compared to an undefended ridge model. But on the two datasets with a small number of dimensions, its training times are significantly less (with being the lowest among all the defenses on the Grid dataset).
The main advantage of the N-LID based methods is that they are not iterative; the N-LID calculation, albeit expensive, is only done once. Therefore they exhibit significant savings in computation time while incurring little or no loss in prediction accuracy. Given the results of the datasets with a small number of dimensions (i.e., machine and grid), the N-LID based methods also appear to be invariant to the number of dimensions of the data, unlike the robust regression methods we have considered.
Note that the computational complexity of N-LID would scale poorly to the number of training data samples due to its -nearest neighbor based calculation. However, the N-LID calculation can be made efficient by estimating the LID of a particular data sample within a randomly selected sample of the entire dataset. We refer the readers to the work of Ma et al. [12] for further information about this process known as minibatch sampling. Furthermore, calculating the LIDs within each minibatch can be parallelized for improved performance.
6.4.6 Transferability of the defense
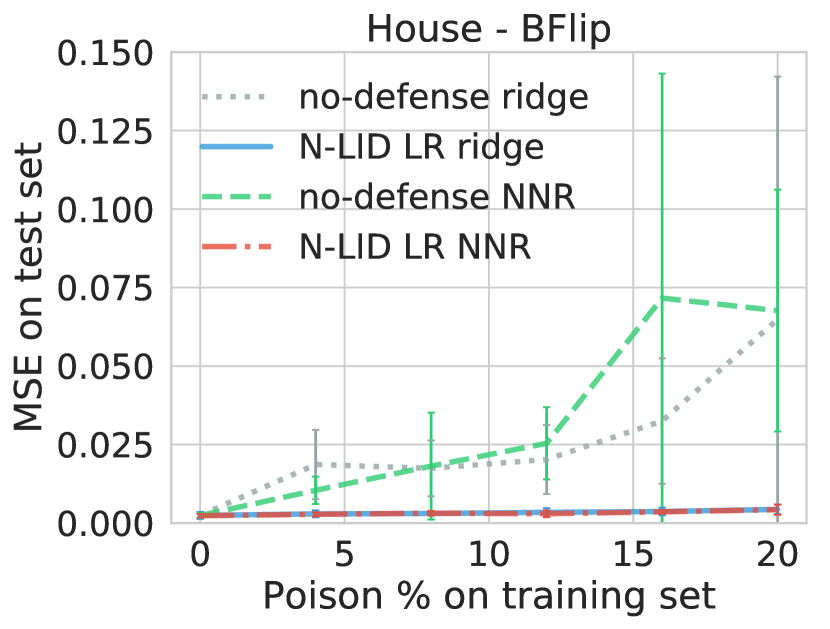
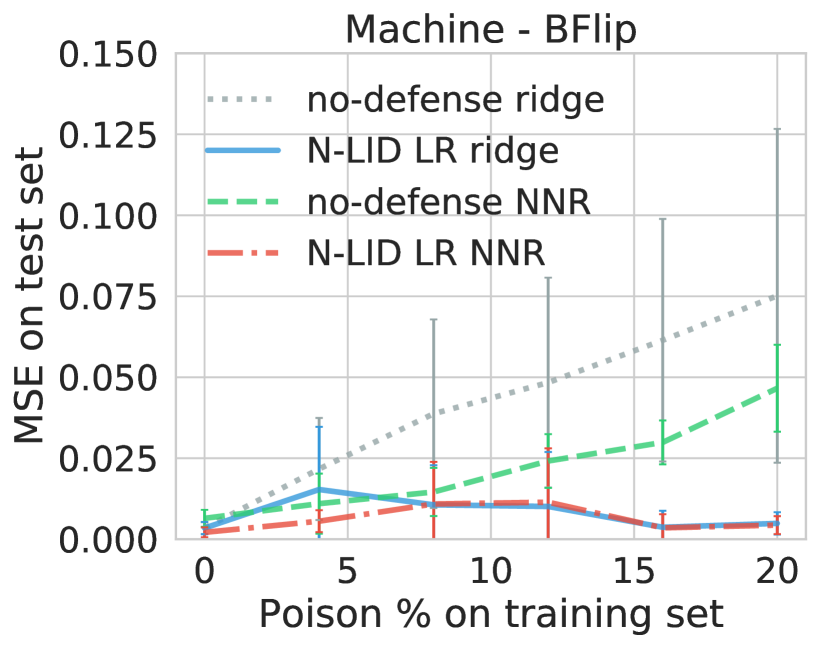
We now investigate the transferability of the proposed defense by applying it to a fundamentally different learner, neural network regression (NNR). Neural network based regression models follow a gradient-based optimization algorithm similar to Ridge regression that minimizes the MSE between the model prediction and the correct response variable [37]. The algorithm uses a linear activation function for the output layer with a single neuron and backpropagation to compute the gradients. The sample weight-based defense can be used with NNR models by multiplying the loss of each sample by its corresponding weight to increase or decrease its importance in the optimization process.
First, we run the Opt attack against ridge regression and obtain a poisoned dataset. Then we train an NNR model on the poisoned data. The average MSE of the NNR model with no defense is higher on the House dataset, higher on the Loan dataset, higher on the OMNeT dataset, higher on the Grid dataset, and lower on the Machine dataset compared to a ridge regression model with no defense. This result may be explained by the fact that an NNR model (which is a nonlinear estimator) is too complex for a linear regression problem; therefore, it overfits the perturbed training data, resulting in poor prediction performance on an unperturbed test set.
However, our aim is to demonstrate that our proposed defense can be applied to different learning algorithms, not to compare the linear ridge regression model with a NNR model. To that end, we observe that if the loss function of the NNR is weighted using the N-LID LR weighting scheme we introduce, it can maintain a near increase in MSE when the poisoning rate is increased to . These findings demonstrate the flexibility of our defense mechanism.
In summary, these results show that (i) robust learners are unable to withstand carefully crafted adversarial attacks on datasets where the number of dimensions is large, whereas adversarial learners can, (ii) N-LID based defenses that de-emphasize the effects of suspected samples consistently perform better in terms of lower MSE values and running times compared to other defenses, (iii) although N-LID CVX makes no assumptions of the attack, its performance is comparable to the baseline N-LID LR defense, and (iv) the N-LID based defenses can successfully be used in conjunction with different algorithms such as NNR models.
7 Conclusions
This paper addresses the problem of increasing the attack resistance of linear regression models against data poisoning attacks. We observed that carefully crafted attacks could significantly degrade the prediction performance of regression models, and robust regression models are unable to withstand targeted adversarial attacks on datasets with a large number of dimensions. We introduced a novel LID measure that took into account the LID values of a data sample’s neighbors and introduced several weighting schemes that alter each sample’s influence on the learned model. Experimental results suggest that the proposed defense mechanisms are quite effective and significantly outperform prior art in terms of accuracy and computational costs. Further research should be undertaken to investigate the effects of poisoning attacks on non-linear regression models and how N-LID would perform in such scenarios.
References
- [1] H. C. Koh and G. Tan, “Data mining applications in healthcare,” Journal of Healthcare Information Management, vol. 19, no. 2, p. 65, 2011.
- [2] I. Bose and R. K. Mahapatra, “Business data mining - a machine learning perspective,” Information & Management, vol. 39, no. 3, pp. 211–225, 2001.
- [3] I. Naseem, R. Togneri, and M. Bennamoun, “Linear regression for face recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 11, pp. 2106–2112, 2010.
- [4] P. Vrablecová, A. B. Ezzeddine, V. Rozinajová, S. Šárik, and A. K. Sangaiah, “Smart grid load forecasting using online support vector regression,” Computers & Electrical Engineering, vol. 65, pp. 102–117, 2018.
- [5] M. Jagielski, A. Oprea, B. Biggio, C. Liu, C. Nita-Rotaru, and B. Li, “Manipulating machine learning: Poisoning attacks and countermeasures for regression learning,” in 2018 IEEE Symposium on Security and Privacy (SP). IEEE, 2018, pp. 19–35.
- [6] C. Liu, B. Li, Y. Vorobeychik, and A. Oprea, “Robust linear regression against training data poisoning,” in 10th ACM Workshop on Artificial Intelligence and Security. ACM, 2017, pp. 91–102.
- [7] H. Xiao, B. Biggio, G. Brown, G. Fumera, C. Eckert, and F. Roli, “Is feature selection secure against training data poisoning?” in International Conference on Machine Learning, 2015, pp. 1689–1698.
- [8] D. Huang, R. Cabral, and F. D. l. Torre, “Robust regression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 363–375, 2016.
- [9] O. L. Mangasarian and D. R. Musicant, “Robust linear and support vector regression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 22, no. 9, pp. 950–955, 2000.
- [10] M. E. Houle, “Local intrinsic dimensionality I: an extreme-value-theoretic foundation for similarity applications,” in Similarity Search and Applications, C. Beecks, F. Borutta, P. Kröger, and T. Seidl, Eds., 2017, pp. 64–79.
- [11] M. E. Houle, “Local intrinsic dimensionality II: multivariate analysis and distributional support,” in International Conference on Similarity Search and Applications, 2017, pp. 80–95.
- [12] X. Ma, B. Li, Y. Wang, S. M. Erfani, S. N. R. Wijewickrema, G. Schoenebeck, D. Song, M. E. Houle, and J. Bailey, “Characterizing adversarial subspaces using local intrinsic dimensionality,” in 6th International Conference on Learning Representations, ICLR 2018, 2018.
- [13] X. Ma, Y. Wang, M. E. Houle, S. Zhou, S. Erfani, S. Xia, S. Wijewickrema, and J. Bailey, “Dimensionality-driven learning with noisy labels,” in 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 80, 2018, pp. 3355–3364.
- [14] P. J. Rousseeuw and A. M. Leroy, Robust regression and outlier detection. John Wiley & Sons, 2005, vol. 589.
- [15] P. J. Huber, “Robust estimation of a location parameter,” in Breakthroughs in Statistics. Springer, 1992, pp. 492–518.
- [16] H. Thiel, “A rank-invariant method of linear and polynomial regression analysis, Part 3,” in Proceedings of Koninalijke Nederlandse Akademie van Weinenschatpen A, vol. 53, 1950, pp. 1397–1412.
- [17] P. K. Sen, “Estimates of the regression coefficient based on Kendall’s tau,” Journal of the American Statistical Association, vol. 63, no. 324, pp. 1379–1389, 1968.
- [18] M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,” Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981.
- [19] H. Xu, C. Caramanis, and S. Mannor, “Outlier-robust PCA: The high-dimensional case,” IEEE Transactions on Information Theory, vol. 59, no. 1, pp. 546–572, 2012.
- [20] Q. Liu, P. Li, W. Zhao, W. Cai, S. Yu, and V. C. M. Leung, “A survey on security threats and defensive techniques of machine learning: A data driven view,” IEEE Access, vol. 6, pp. 12 103–12 117, 2018.
- [21] S. Tang, X. Huang, M. Chen, C. Sun, and J. Yang, “Adversarial attack type I: Cheat classifiers by significant changes,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2019.
- [22] B. Biggio and F. Roli, “Wild patterns: Ten years after the rise of adversarial machine learning,” Pattern Recognition, vol. 84, pp. 317–331, 2018.
- [23] S. Weerasinghe, S. M. Erfani, T. Alpcan, and C. Leckie, “Support vector machines resilient against training data integrity attacks,” Pattern Recognition, vol. 96, p. 106985, 2019.
- [24] F. Karim, S. Majumdar, and H. Darabi, “Adversarial attacks on time series,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2020.
- [25] Y. Chen, C. Caramanis, and S. Mannor, “Robust sparse regression under adversarial corruption,” in International Conference on Machine Learning, 2013, pp. 774–782.
- [26] J. Feng, H. Xu, S. Mannor, and S. Yan, “Robust logistic regression and classification,” in Advances in Neural Information Processing Systems, 2014, pp. 253–261.
- [27] L. Tong, S. Yu, S. Alfeld, and Y. Vorobeychik, “Adversarial regression with multiple learners,” arXiv preprint arXiv:1806.02256, 2018.
- [28] S. Alfeld, X. Zhu, and P. Barford, “Data poisoning attacks against autoregressive models,” in 30th AAAI Conference on Artificial Intelligence, 2016.
- [29] B. Nelson, M. Barreno, F. J. Chi, A. D. Joseph, B. I. P. Rubinstein, U. Saini, C. Sutton, J. D. Tygar, and K. Xia, “Exploiting machine learning to subvert your spam filter,” 1st Usenix Workshop on Large-Scale Exploits and Emergent Threats, pp. 1–9, 2008.
- [30] L. Amsaleg, O. Chelly, T. Furon, S. Girard, M. E. Houle, K.-I. Kawarabayashi, and M. Nett, “Estimating local intrinsic dimensionality,” in 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2015, pp. 29–38.
- [31] M. M. Breunig, H.-P. Kriegel, R. T. Ng, and J. Sander, “LOF: identifying density-based local outliers,” in ACM Sigmod Record, vol. 29, no. 2. ACM, 2000, pp. 93–104.
- [32] B. Biggio, G. Fumera, and F. Roli, “Security evaluation of pattern classifiers under attack,” IEEE Transactions On Knowledge And Data Engineering, vol. 26, no. 4, pp. 984–996, 2014.
- [33] S. Weerasinghe, S. M. Erfani, T. Alpcan, C. Leckie, and J. Riddle, “Detection of anomalous communications with SDRs and unsupervised adversarial learning,” in 2018 IEEE 43rd Conference on Local Computer Networks (LCN). IEEE, 2018, pp. 469–472.
- [34] A. Varga and R. Hornig, “An Overview of the OMNeT++ Simulation Environment,” in 1st International Conference on Simulation Tools and Techniques for Communications, Networks and Systems & Workshops, 2008, p. 60:1–60:10.
- [35] V. Arzamasov, K. Böhm, and P. Jochem, “Towards concise models of grid stability,” in 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm). IEEE, 2018, pp. 1–6.
- [36] D. Kibler, D. W. Aha, and M. K. Albert, “Instance-based prediction of real-valued attributes,” Computational Intelligence, vol. 5, no. 2, pp. 51–57, 1989.
- [37] J. Rocca. (2018) A gentle journey from linear regression to neural networks. [Online]. Available: https://towardsdatascience.com/a-gentle-journey-from-linear-regression-to-neural-networks-68881590760e