11email: {p6bhatta, k2czarne}@uwaterloo.ca
Deformable PV-RCNN: Improving 3D Object Detection with Learned Deformations
Abstract
We present Deformable PV-RCNN, a high-performing point-cloud based 3D object detector. Currently, the proposal refinement methods used by the state-of-the-art two-stage detectors cannot adequately accommodate differing object scales, varying point-cloud density, part-deformation and clutter. We present a proposal refinement module inspired by 2D deformable convolution networks that can adaptively gather instance-specific features from locations where informative content exists. We also propose a simple context gating mechanism which allows the keypoints to select relevant context information for the refinement stage. We show state-of-the-art results on the KITTI dataset.
1 Introduction
3D object detection from point clouds is critical for autonomous driving and robotics. We build on the success of PV-RCNN [7], a state-of-the-art 3D object detector.
Motivation Part of PV-RCNN’s success is due to the randomly sampled keypoints which capture multi-scale features for proposal refinement while retaining fine-grained localization information. However, random sampling is not effective over potentially ambiguous scenes. For example, ‘pedestrians’ and ‘traffic poles’ can be very hard to distinguish in point clouds. In this case, we wish to align the keypoints towards the most discriminative areas, so that principal features for a pedestrian can be highlighted. Similarly, the scales for cars, pedestrians and cyclists are very different. While multi-scale feature aggregation is advantageous for image features, the non-uniform density of point clouds makes it hard to detect them with a single model. We wish to adaptively aggregate and focus on their most salient features at various scales. Lastly to handle clutter and avoid false positives, for example, to avoid detecting all seated individuals as cyclists, we need to pick up on unevenly distributed contextual information.
Contribution We construct Deformable PV-RCNN, a 3D detector that handles sparsity of LIDAR points, is adaptive to non-uniform point cloud density especially at long distances and can address clutter in real-world traffic scenes. We show that we can outperform PV-RCNN across different categories and especially at long-distances on the KITTI 3D object detection dataset.
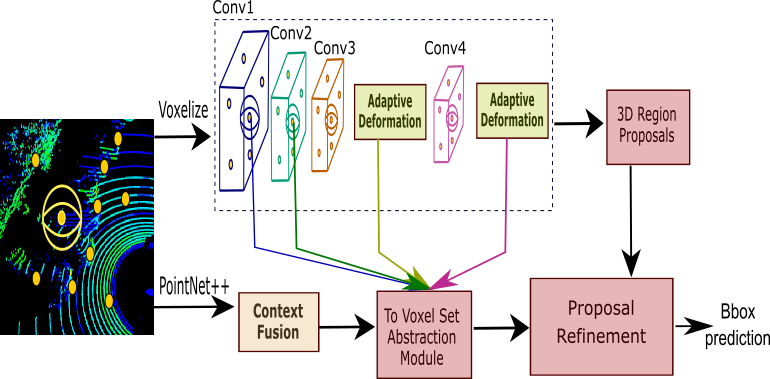
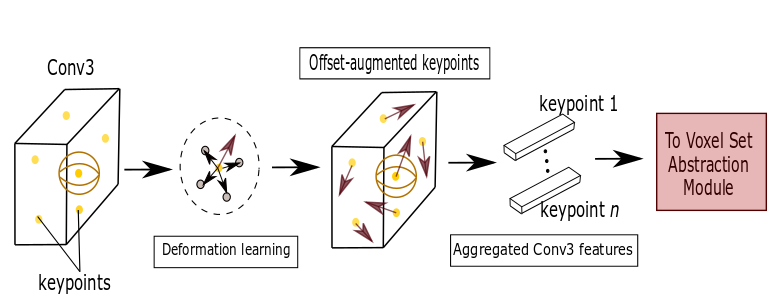
2 Methods
Our 3D detection pipeline is presented in Fig. 1. It consists of an Adaptive Deformation module (Fig. 2) and a Context Fusion module (Fig. 3).

Adaptive Deformation The sampled keypoints (shown in yellow in Fig. 1) have a 3D position and a feature vector corresponding to either of Conv3 or Conv4 layers. Our module computes updated features as follows:
ReLU, where gives the -th keypoint’s neighbors in the point-cloud and is a learned weight matrix. We then obtain the new deformed keypoint positions as tanh, where is a learned weight matrix. This is similar to [4], [6]. We then proceed to compute the features for the deformed keypoints using PointNet++ similar to the PV-RCNN pipeline.
Context Fusion This module uses context gating to dynamically select representative and discriminative features from local evidence, highlighting object features and suppressing clutter. Given a keypoint feature , the modulating feature is obtained as and the context-gated feature is computed as , where , , are learned from data [2].
3 Results
| Model | Car | Cyclist | Pedestrian |
|---|---|---|---|
| SECOND [9] | 78.62 | 67.75 | 52.98 |
| F-PointNet [5] | 70.92 | 56.49 | 61.32 |
| Part-A2 [8] | 79.40 | 69.90 | 60.05 |
| PV-RCNN [7] | 83.69 | 69.47 | 54.84 |
| Ours | 83.30 | 73.46 | 58.33 |
| Deformations | Context-Fusion | Car | Cyclist | Pedestrian |
|---|---|---|---|---|
| 84.20 | 69.65 | 54.49 | ||
| ✓ | 84.24 | 70.21 | 57.31 | |
| ✓ | ✓ | 84.71 | 73.03 | 57.65 |
| Distance | Model | Car | Cyclist | Pedestrian |
|---|---|---|---|---|
| 0-30 m | PV-RCNN | 91.71 | 73.76 | 56.82 |
| Ours | 91.65 | 74.89 | 59.61 | |
| 30-50 m | PV-RCNN | 50.00 | 35.15 | - |
| Ours | 52.02 | 47.00 | - |
The 3D object detection benchmark of KITTI [3] contains 7481 training samples. Following [1], we divide them into 3712 training samples and 3769 validation samples. We report our results on the validation (val) split of KITTI.
Comparison with state-of-the-art methods Table 1 shows the performance of Deformable PV-RCNN on the KITTI val split. We run the officially released checkpoints for SECOND, Part-A2 and PV-RCNN.111https://github.com/open-mmlab/OpenPCDet Our method outperforms the state-of-the-art on the cyclist class. Compared to PV-RCNN, it performs better on pedestrian and cyclist class by 3.5 % and 4%, respectively, and on par for the car class.
Ablation Studies Table 2 validates the effectiveness of learning deformable offsets and context gating by comparing with a retrained PV-RCNN baseline. We find that deformation prediction contributes to the performance increase over all classes, but especially for the pedestrian class, which is probably due to being able to focus on representative features like arms and legs. Context fusion also increases performance over all classes, indicating that contextual information is important for refinement.
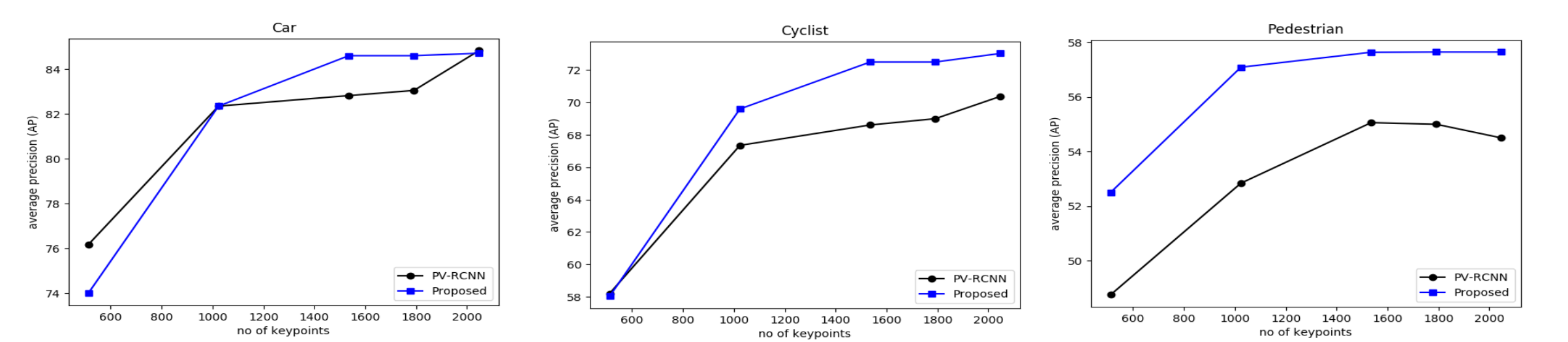
Comparison with PV-RCNN Table 3 shows that our model outperforms the baseline at different distances for the pedestrian and cyclist class. We also find a 2% increase in AP for the car class at long distances where the scans are sparse and context information becomes important. Fig. 4 shows that similar AP performance can be obtained with fewer keypoints as compared to the baseline across all classes, which is probably due to their deformability to cover representative locations. Fig. 5 shows qualitative 3D detection results.
4 Conclusion
We present Deformable PV-RCNN, a 3D object detector for detecting 3D objects from raw point cloud. Our proposed deformation prediction method adaptively aligns the keypoints encoding the scene towards the most discriminative and representative features. The proposed context gating network adaptively highlights relevant context features thereby favouring more accurate proposal refinement. Our experiments show that Deformable PV-RCNN outperforms PV-RCNN in various challenging cases on the 3D detection benchmark of KITTI dataset, especially benefiting smaller objects and complex scenes more.

References
- [1] Chen, X., Ma, H., Wan, J., Li, B., Xia, T.: Multi-view 3d object detection network for autonomous driving. CoRR abs/1611.07759 (2016), http://arxiv.org/abs/1611.07759
- [2] Dauphin, Y.N., Fan, A., Auli, M., Grangier, D.: Language modeling with gated convolutional networks. CoRR abs/1612.08083 (2016), http://arxiv.org/abs/1612.08083
- [3] Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: the KITTI dataset. The International Journal of Robotics Research 32, 1231–1237 (09 2013). https://doi.org/10.1177/0278364913491297
- [4] Gkioxari, G., Malik, J., Johnson, J.: Mesh R-CNN. CoRR abs/1906.02739 (2019), http://arxiv.org/abs/1906.02739
- [5] Qi, C.R., Liu, W., Wu, C., Su, H., Guibas, L.J.: Frustum pointnets for 3d object detection from RGB-D data. CoRR abs/1711.08488 (2017), http://arxiv.org/abs/1711.08488
- [6] Qin, C., You, H., Wang, L., Kuo, C.C.J., Fu, Y.: Pointdan: A multi-scale 3d domain adaption network for point cloud representation (2019)
- [7] Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., Li, H.: PV-RCNN: Point-voxel feature set abstraction for 3d object detection. ArXiv abs/1912.13192 (2019)
- [8] Shi, S., Wang, Z., Wang, X., Li, H.: Part-A net: 3d part-aware and aggregation neural network for object detection from point cloud. CoRR abs/1907.03670 (2019), http://arxiv.org/abs/1907.03670
- [9] Yan, Y., Mao, Y., Li, B.: SECOND: Sparsely embedded convolutional detection. Sensors 18, 3337 (10 2018). https://doi.org/10.3390/s18103337