Depth Guided Adaptive Meta-Fusion Network
for Few-shot Video Recognition
Abstract.
Humans can easily recognize actions with only a few examples given, while the existing video recognition models still heavily rely on the large-scale labeled data inputs. This observation has motivated an increasing interest in few-shot video action recognition, which aims at learning new actions with only very few labeled samples. In this paper, we propose a depth guided Adaptive Meta-Fusion Network for few-shot video recognition which is termed as AMeFu-Net. Concretely, we tackle the few-shot recognition problem from three aspects: firstly, we alleviate this extremely data-scarce problem by introducing depth information as a carrier of the scene, which will bring extra visual information to our model; secondly, we fuse the representation of original RGB clips with multiple non-strictly corresponding depth clips sampled by our temporal asynchronization augmentation mechanism, which synthesizes new instances at feature-level; thirdly, a novel Depth Guided Adaptive Instance Normalization (DGAdaIN) fusion module is proposed to fuse the two-stream modalities efficiently. Additionally, to better mimic the few-shot recognition process, our model is trained in the meta-learning way. Extensive experiments on several action recognition benchmarks demonstrate the effectiveness of our model.

ACM Reference Format:
Yuqian Fu, Li Zhang, Junke Wang, Yanwei Fu, Yu-Gang Jiang. 2020. Depth Guided Adaptive Meta-Fusion Network for Few-shot Video Recognition. In Proceedings of the 28th ACM International Conference on Multimedia (MM’20), October 12–16, 2020, Seattle, WA, USA. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3394171.3413502
1. Introduction
The ubiquitous availability and use of mobile devices facilitate capturing and sharing videos on social platforms. Therefore, general video understanding is extremely important to real-world multimedia applications, e.g. robotic interaction (Xu et al., 2019) and auto-driving (Geiger et al., 2012), and thus attracting extensive research attention. Particularly, with the advent of state-of-the-art deep architectures (Simonyan and Zisserman, 2014; Carreira and Zisserman, 2017; Feichtenhofer et al., 2019; Perez-Rua et al., 2020), the performance of video recognition has been dramatically improved in the standard supervised-learning setting. However, a large amount of manually labeled video data are necessary, which is an ideal and yet impractical requirement. In contrast, humans can easily learn a novel concept, even when we have seen only one or extremely few samples. Such a gap inspires the study of few-shot learning in the Multimedia community.
Generally, it still presents significant challenges for the community to enable models to own the ability to recognize novel classes by learning from limited labeled data, i.e., few-shot learning (Koch et al., 2015; Vinyals et al., 2016; Sung et al., 2018), as deep models are prone to overfitting with few training instances. This will worsen the generalization ability of the models. Most few-shot recognition works have been explored for images (Chen et al., 2018; Lake and Salakhutdinov, 2013; Snell et al., 2017a; Sung et al., 2018; Wang et al., 2020a, b), but to a lesser extent for videos (Zhu and Yang, 2018; Zhang et al., 2020). Particularly, learning representations from the temporal sequences of video frames is intrinsically much more difficult and complex than those from images. It is non-trivial to learn good representations for few-shot video recognition. Recent few-shot video recognition efforts have been made on using key-value memory network paradigm (Zhu and Yang, 2018), matching videos via temporal alignment (Cao et al., 2020), learning from web data (Tu et al., 2019), and applying attention mechanism (Zhang et al., 2020).
Different from the aforementioned methods, this paper tackles few-shot action recognition from a fundamentally different perspective. We argue that depth modality is useful for facilitating few-shot video action recognition since it is able to model the geometric relations within the context. Besides, shifting depth of a video can implicitly represent the motion information of the objects in the scene. Based on these two insights, in this paper, we explore the depth information guided few-shot video action recognition. Specifically, the representation bias (Li et al., 2018), e.g., scene representation bias, is inevitably learned by supervised video recognition methods, since human actions often happen in specific scene contexts. Despite the fact that such bias may damage the generalization ability of learned representation (Choi et al., 2019), the co-occurrence of actions and corresponding scenes may help to alleviate the difficulty of lack of labeled instances. To this end, rather than using segmentation methods to directly recognize the scenes, we resort to predicting depth frames to help understand the geometric relations within the scenes as the richer representation of moving persons and their corresponding environments. For example, as shown in Fig. 1, the action of ”Riding Mountain Bike” mostly happens in the scene of the mountain, where the geometric relation from corresponding depth images between the person and scene, would essentially help to recognize the action.
Furthermore, as shown in Fig. 1, we can still recognize the action correctly even if the scene shifts from the mountain (Scene B) to the roadside (Scene C). That is, even though the depth clip is not exactly corresponding to the RGB clip, the model should still be able to recognize the action correctly in principle. Such an asynchronization between depth and RGB clips inspires us to propose a more natural way of augmenting video representations – temporal asynchronization augmentation mechanism by randomly sampling unpaired RGB and depth clips.
Formally, this paper proposes a novel depth guided Adaptive Meta-Fusion Network (AMeFu-Net) for few-shot video recognition. Specifically, the depth frames are predicted by an off-the-shelf depth predictor (Godard et al., 2019) and serve as a carrier in understanding the geometric relations within the scene. Furthermore, we augment our original videos by sampling some non-strictly corresponding RGB and depth pairs as the training data, which helps us to enhance the robustness of our model. Besides, our model includes a key component, depth guided adaptive instance normalization (DGAdaIN) module, which effectively fuses RGB and depth features. We learn the affine parameters from depth feature adaptively, and then apply them to deform the original RGB feature. Therefore, the information of RGB modality and depth modality are integrated more effectively.
Our model is trained via the meta-learning mechanism (Vinyals et al., 2016). Specifically, it automatically learns cross-task knowledge so that the model can quickly acquire task-specific knowledge of new few-shot learning tasks at inference time.
Our contributions are summarized as follows. 1) For the first time, we propose to use depth information to alleviate the data-scarce problem in few-shot video action recognition. 2) We propose a novel temporal asynchronization augmentation mechanism, which randomly samples depth data for RGB data to augment the source video representation. 3) We propose a depth guided adaptive instance normalization module (DGAdaIN) to better fuse the two-stream features. 4) Extensive experiments show that our proposed AMeFu-Net allows us to establish new state-of-the-art on three widely used datasets including Kinetics, UCF101, and HMDB51.
2. Related work
Few-shot learning. Few-shot learning aims at recognizing unseen concepts with only a few labeled samples. Many works have been done to address this problem in the image domain. Flagship works include metric-learning based methods (Snell et al., 2017b; Vinyals et al., 2016; Liu et al., 2020; Sung et al., 2017; Zhang et al., 2017b), meta-learning methods (Finn et al., 2017; Wang et al., 2017; Wang and Hebert, 2016), and generative models (Lake et al., 2011; Erik G. Miller and Viola, 2000; Wang et al., 2018). Comparatively, the video domain still remains under-explored. (Zhu and Yang, 2018) proposes a compound key-value memory network paradigm. (Fu et al., 2019) learns from virtual actions which are generated by embodied agents. (Cao et al., 2020) uses a temporal alignment method to compare the similarity between videos. (Zhang et al., 2020) handles this problem by introducing an attention mechanism with self-supervised training. In this paper, we mainly explore how to alleviate the problem of extremely limited samples in few-shot learning by fusing extra modality information.
Context for video understanding. Visual context information has been validated to be very useful for video understanding tasks. Many visual concepts have been explored as a supplementary information of videos. Previous works mainly focus on scenes (Li and Fei-Fei, 2007; Marszalek et al., 2009; Wu et al., 2016), objects (Gupta and Davis, 2007; Ikizler-Cinbis and Sclaroff, 2010; Jain et al., 2015; Wu et al., 2007; Wang and Gupta, 2018), poses or skeletons (Jiang et al., 2015; Wang et al., 2013; Yang et al., 2010; Yan et al., 2019, 2018). However, these methods are prohibitively expensive and sensitive to the noise. On the other hand, the middle-level representations, such as objects and the human body skeletons, are too abstract to contain enough information of motion and scenes. Comparatively, the information of depth makes the best of both worlds: it can not only effectively represent the detailed information of objects, scenes, and their potential motion expressed in videos, but also depth information is well robust to noise thanks to recently developed models. To the best of our knowledge, we are the first to introduce depth as the carrier of scene information for video recognition under few-shot learning. Note that (Boukhers et al., [n.d.]) estimates the depth to correct the camera odometry. Most of the multi-modality models simply fuse the features from different streams by averaging (Simonyan and Zisserman, 2014), concatenation (Wang and Gupta, 2018), recurrent neural networks (Zhang et al., 2017a) or with fully connected layers (He et al., 2018), while we adaptively learn how to combine the RGB stream and depth stream by introducing a novel depth guided adaptive instance normalization module.
Instance normalization. The instance normalization (Ulyanov et al., 2017) is first proposed for feed-forward style-transfer (Gatys et al., 2016; Huang and Belongie, 2017) by replacing the widely used Batch Normalization (Ioffe and Szegedy, 2015), resulting in significant improvement to the quality of image stylization. After that, several related methods have been proposed (Huang and Belongie, 2017; Huang et al., 2018; Park et al., 2019; Qian et al., 2020). Among them, AdaIN (Huang and Belongie, 2017), a module for style transfer, proposes to align the mean and variance of the content feature of image , with those of the style feature of image . This inspires us to fuse the RGB stream and depth stream by learning the scale and shift affine parameters from depth, thus deforming RGB information towards depth for few-shot video action recognition.
Temporal shift mechanism. Temporal Shift Module (TSM) (Lin et al., 2019) utilizes a temporal shift mechanism to shift part of the channels along the temporal dimension to model the spatial-temporal representation of videos. LGTSM (Chang et al., 2019) further extends the TSM by shifting temporal kernels for video inpainting. Different from previous works which aim at fusing temporal information by shifting features, in this paper, the temporal shift is used to sample asynchronized depth and RGB clips in the temporal dimension to synthesize new instances in feature space. By doing this, our method essentially samples unpaired data to generate more abundant video representations. It is fundamentally different to previous data augmentation works (Chen et al., 2019a, b; Fu et al., 2019; Zhong et al., 2020; Hariharan and Girshick, 2017; Wang et al., 2018; Schwartz et al., 2018; Gao et al., 2018).
3. Methodology
Problem setup. For few-shot learning setting, there is a base action set and a novel action set . The categories of the base and novel set are disjoint, that is, . All the videos contained in base set , are used as source data to train the model. We denote the th video and its corresponding class label as , , respectively. In few-shot video recognition setting, the goal of our algorithms is to recognize the novel videos contained in novel dataset , the recognition model learned on should generalize to the novel categories contained in , that is, it should be able to recognize given only one or few labeled example videos per class.
Framework overview. Our proposed AMeFu-Net mainly consists of the following components: backbone with depth, temporal asynchronization augmentation module, depth guided adaptive instance normalization fusion (DGAdaIN) module, and the few-shot classifier. The schematic illustration is shown in Fig. 2.
Following (Zhu and Yang, 2018), we use the meta-learning strategy for model training and testing. Meta-learning (Finn et al., 2017) consists of the meta-train and meta-test phases. Generally, meta-learning can efficiently learn cross-task knowledge with in meta-train phase, so that the model can quickly acquire task-specific knowledge of novel few-shot learning tasks in at meta-test time. Specifically, we adopt the episode-based training strategy (Zhu and Yang, 2018; Snell et al., 2017b; Sung et al., 2017) which randomly sample training instances from for each batch in meta-train phase. Each episode consists of a support set and a query set, and the task of our model is to predict the action class of the query video based on the videos in the corresponding support set. In a N-way-K-shot problem, for each episode, a collection of classes each with videos are randomly sampled as the support set, and other videos belong to classes are formed as the query set. Following CMN (Zhu and Yang, 2018), only one video is sampled for the query set in each episode.
During the meta-train phase, we first use the temporal asynchronization augmentation module to sample pairs. The sampled pairs are then fed into the feature extractors to get RGB and depth features, respectively. Then the DGAdaIN adaptive fusion module is adopted to integrate the two-stream information to get the final representations of videos. By virtue of such a way, for the -th training video in the support set and the only query video in the query set, we obtain the corresponding fused feature denoted as , and , respectively. Finally, a few-shot classifier is used to predict the probability by comparing the distance between and . Concretely, We apply a softmax layer on distance similarities to obtain the predicted probabilities. Finally, cross entropy is used to calculate the loss, thus optimizing our network.
During the meta-test phase, we sample episodes from . Different from the meta-train phase, we do not apply the temporal asynchronization augmentation mechanism, which means only one strictly corresponding pair for each video is sampled. The action class with the highest probability is selected as the predicted class.
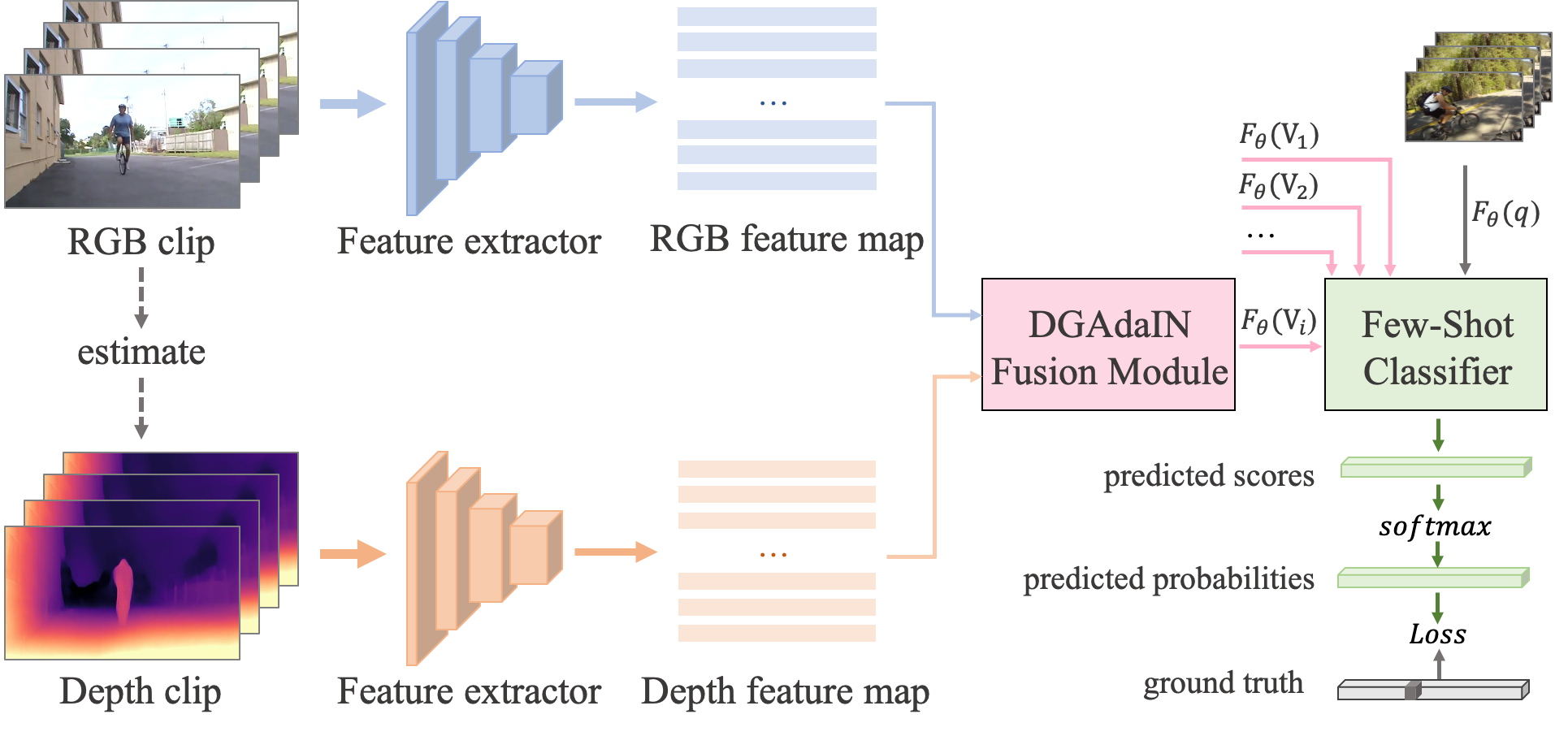
3.1. Backbone with depth
As shown in Fig. 2, the backbone is designed as the two-stream architecture, of which the RGB stream extracts more generic and robust visual information of the input videos, while the depth stream is introduced as supplementary scene information to make up for the lack of data and represent context features. In other words, we address the few-shot problem from a multi-modal perspective. For both streams, we adopt a ResNet-50 (He et al., 2016) network pre-trained on ImageNet (Deng et al., 2009) as the backbone. The output of the last convolution layer is extracted as the representation of videos. We finetune the feature extractor on the source domain to better fit them on the target datasets.
Our depth maps are obtained by utilizing the off-the-shelf depth estimation model – Monodepth2 (Godard et al., 2019). More specifically, it takes a single RGB image as input and predicts its corresponding depth frame. In this work, we take the depth model as an off-the-shelf depth feature extractor, which is pre-trained on KITTI dataset (Geiger et al., 2012). Notably, despite the large domain discrepancy between the video datasets used in our experiments and KITTI, the pre-trained depth model can effectively predict a usable depth image, thus working as a generic depth predictor in our model.
3.2. Depth guided adaptive fusion module
In this section, the RGB information and depth information should be combined to facilitate few-shot video recognition. For this purpose, we propose a depth guided adaptive instance normalization (DGAdaIN) fusion module, inspired by the Instance Normalization (IN), which is defined as,
| (1) |
where denotes the input batch , are the mean and standard deviation of input , while are affine parameters learned from data. , , , denotes the batch size, channel of feature map (i.e.the color channel of an RGB image), the height and width of the image feature map, respectively.
Different from the widely used Batch Normalization, where the mean and standard deviation are calculated for each individual feature channel, IN calculates them for each sample; so the are computed across the spatial dimensions. Formally, let denotes the element of the input ,
| (2) |
| (3) |
In our model, the input batch is denoted as , where denotes the number of frames of a single video and denotes the dimension of feature for each frame.
Inspired by the remarkable success of IN in style transfer, we deform the RGB feature towards the depth to fuse multi-modality features. Therefore, we propose a novel depth guided instance normalization method, in which the and are designed to learn from the depth feature map adaptively. More specifically, our DGAdaIN module receives a RGB input batch and a depth input batch , and learns the affine parameters from the depth stream,
| (4) |
where and are both a learnable fully-connected (FC) layer and jointly optimized with the whole network. The outputs are treated as the affine parameters and respectively. They are utilized as ”scale” and ”shift” factors to deform the RGB feature. and are computed along the dimension:
| (5) |
| (6) |
3.3. Temporal asynchronization augmentation
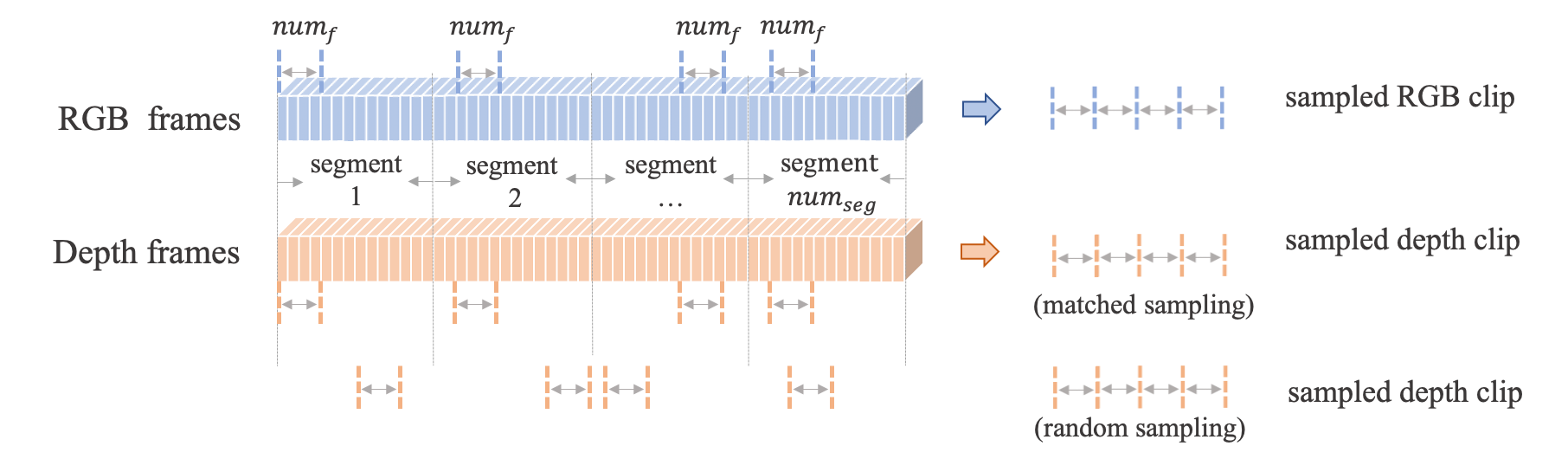
This module introduces the temporal asynchronization augmentation mechanism for data augmentation. Although the context information facilitates to understand a video, a robust model should have the ability to recognize the video action correctly in different contexts. That is even when the depth clip is unmatched with the RGB clip, our model should still recognize the action. Therefore, we propose to shift the position of depth clip with respect to its corresponding RGB clip along the temporal dimension, as illustrated in Fig. 3.
Inspired by TSN (Wang et al., 2016), we propose a basic sampling strategy to handle the video inputs for our few-shot action recognition. Specifically, we first divide the video frames into segments of equal length, then consecutive frames are sampled from each segment to form a sampled clip. As for the temporal asynchronization augmentation mechanism, we not only sample the corresponding pair as most multi-modality methods do, but also sample another pairs by randomly select the consecutive frames from each segment. During the meta-train phase, the pairs are iteratively used to train our model. By virtue of this way, we augment our original datasets by times, which enhances the robustness of our model effectively.
3.4. Few-shot classifier
Our few-shot classifier is derived from ProtoNet (Snell et al., 2017b). Specifically, denotes the set of videos with label . For each action , its prototype is calculated by averaging the feature of videos belongs to as follows,
| (7) |
Then we predict the action of query video by comparing the feature of with the prototypes of different actions. We apply a softmax over the distance similarities to obtain the probabilities of predicted results. Formally, the probability that query video belongs to action , is defined as follows:
| (8) |
where denotes the distance similarity, denotes the predicted label for video . Notably, the original Protonet calculates the Euclidean distances, we find that cosine distances performs better under our setting.
4. Experiments
4.1. Datasets
To verify the effectiveness of our method, we conduct experiments on three widely used detests for video action recognition.
Kinetics The original Kinetics dataset (Kay et al., 2017) contains 400 action classes and 306,245 videos. We follow the splits constructed by CMN (Zhu and Yang, 2018), which contains 100 action classes, each with 100 videos. 64, 12 and 24 non-overlapping classes are used as training set, validation set, and testing set, respectively.
4.2. Implementation details
Pre-processing. As described in section 3.3, for each video, we sample RGB and depth clips of length which are used to extract RGB feature and depth feature. In our experiments, both and are set to 4. During the meta-train phase, the is set to 2, while during the meta-test phase we only sample the strictly matched pair from the middle of all the segments. As for the processing of images, we first resize them to , and then randomly crop a region. In the testing phase, we adopt a center crop to obtain the region.
| Model | 1-shot | 2-shot | 3-shot | 4-shot | 5-shot | |
| Baselines | RGB Basenet | 65.1 | 74.9 | 78.9 | 81.2 | 81.9 |
| RGB Basenet++ | 66.5 | 77.2 | 80.7 | 82.9 | 83.7 | |
| Competitors | CMN (Zhu and Yang, 2018) | 60.5 | 70.0 | 75.6 | 77.3 | 78.9 |
| ARN (Zhang et al., 2020) | 63.7 | - | - | - | 82.4 | |
| TRAN (Bishay et al., 2019) | 66.6 | 74.6 | 77.3 | 78.9 | 80.7 | |
| CFA (Hu et al., 2019) | 69.9 | - | 80.5 | - | 83.1 | |
| Embodied Learning (Fu et al., 2019) | 67.8 | 77.8 | 81.1 | 82.6 | 85.0 | |
| TAM (Cao et al., 2020) | 73.0 | - | - | - | 85.8 | |
| Ours | RGB + Depth + DGAdaIN | 73.6 | 80.7 | 84.0 | 85.4 | 86.6 |
| AMeFu-Net | 74.1 | 81.1 | 84.3 | 85.6 | 86.8 |
Training details. Due to the large difference between RGB modality and depth modality, we employ a two-stage training procedure. We first train the RGB sub-model and the depth sub-model, the feature extractors described in section 3.1, with the classical training method under the supervised learning setting separately. Concretely, we replace the last fully connected layer in the original ResNet-50 with our own fully connected layer as a classifier to construct the RGB and depth sub-models. For the RGB sub-model, we finetune it on the source data for 6 epochs, the learning rate of the Resnet-50 is set to 0.0001, and the learning rate of our fully connected layer for classification is set to 0.001. For the depth sub-model, since the feature of the depth frames is hard to extract, we finetune it for 60 epochs. The learning rates and are both set to 0.0001, and we reduce it by 0.1 after 30 epochs. These pre-trained sub-models are further used as the feature extractors which extract the 2048-dimension features for RGB and depth, respectively.
We then use the depth guided adaptive fusion module (DGAdaIN) to fuse the features from these two streams. The DGAdaIN is finetuned in the meta-learning way for another 6 epochs, and the episodes is set to 2000 every epoch. What is worth mentioning is that we train the DGAdaIN module under the 5-way-1-shot setting. The learning rate of DGAdaIN module is set to 0.00002 and the parameters of two sub-models are not updated.
In addition, for all the experiments, we set the batch size to 6. Stochastic Gradient Descent (SGD) with momentum=0.9 is selected as our optimizer. For UCF101 and HMDB51, we train the RGB sub-model and depth sub-model under the same setting with Kinetics. However, considering the scale of the datasets is relatively small, we set to 0.00001, to 1000, and reduce the by 0.1 after 3 epochs.
Evaluation. During the meta-test phase, we randomly sample 10,000 episodes and the average accuracy is reported. Notably, We implement normalization on the fused features before they are fed into our few-shot classifier.
4.3. Results on Kinetics
Baselines and competitors. We compare our method with several baselines to show the effectiveness of our model. We conduct the experiments under setting, and we report 1-shot, 2-shot, 3-shot, 4-shot and 5-shot results in Tab. 1. (1) For the first baseline ”RGB Basenet”, we follow the setting of ”Basenet + test” reported in Embodied Learning (Fu et al., 2019), which adopts an ImageNet pre-trained ResNet-50 as RGB feature extractor directly and uses the Protonet as the few-shot classifier. (2) For the second baseline ”RGB Basenet++”, we also directly use the Imagenet pre-trained ResNet-50 as our RGB feature extractor. The differences between these two baselines lie in two aspects: a) ”RGB Basenet” samples 16 consecutive frames, while ”RGB Basenet++” samples frames as stated above. b) ”RGB Basenet” uses the original Protonet, while we change Euclidean distance to cosine similarity. Besides, these baselines are all conducted without the temporal asynchronization augmentation mechanism.
We also compare our method with several state-of-the-art works. (1) CMN (Zhu and Yang, 2018) mainly proposes a memory network structure. (2) TRAN (Bishay et al., 2019) learns to compare the representation of variable temporal sequence, and calculates the relation scores between the query video and support videos. (3) CFA (Hu et al., 2019) mainly emphasizes the importance of compositionality in visual concept representation and proposes the compositional feature aggregation (CFA) module. (4) Embodied Learning (Fu et al., 2019) learns from virtual videos generated by embodied agents and further proposes a video segment augmentation method. (5) TAM (Cao et al., 2020) proposes a temporal alignment algorithm to measure the similarities between query video and support videos. All the competitors conduct experiments with the same splits of Kinetics.
For ours, the results of ”RGB + depth + DGAdaIN” and ”AMeFu-Net” are reported. The only difference between these two models is whether the temporal asynchronization mechanism is applied. More specifically, for ”RGB + depth + DGAdaIN”, we adopt the DGAdaIN module to fuse the RGB feature and depth feature, however, we just use the matched RGB and depth pair to train our model. While ”AMeFu-Net” means the full model.
Results. From the results shown in Tab. 1, we make the following observations: (1) Our method outperforms all the baselines and competitors, establishing new state-of-the-art with 74.1%, 84.3% and 86.8% on 1-shot, 3-shot and 5-shot settings, respectively. (2) We notice that the strong baseline ”RGB Basenet++” is superior to ”RGB Basenet”, which is mainly contributed by our basic sampling strategy (section 3.3). It quite makes sense, since the clips of length sampled by our method capture more temporal information, especially in the case of long-term videos. We also observe that replacing the Euclidean to cosine distance in the Protonet classifier contributes a little to the performance. (3) The effect of our temporal asynchronization augmentation mechanism is shown by comparing the result of ”RGB + depth + DGAdaIN” with ”AMeFu-Net”. The performance is improved consistently for all shots which verifies that our model is more robust with the augmented video feature representation. (4) Generally, the performance of all the models is getting better as the number of labeled samples increases. However, the improvement brought by our method is getting smaller. This phenomenon shows that our method is most effective when data are extremely scarce.
Visualization. We visualize the Class Activation Map (CAM) (Zhou et al., 2016) of some examples sampled from the validation and testing sets of Kinetics dataset using Grad-CAM (Selvaraju et al., 2017). As shown in Fig. 4, the third and fourth columns show the class activation maps computed from the RGB frames (first column) and depth frames (second column) individually. The fifth column shows the CAM of our AMeFu-Net, in which both the RGB clip and depth clip are fed into our model. In particular, the gradients of the action with the highest probability are back-propagated to highlight its map of interest.
We see that the RGB sub-model outperforms the depth sub-model, which is consistent with the fact that the RGB modality contains most of the visual information. The most important regions are recognized by the RGB sub-model, such as the person and the hula hoop in the example of ”Hula Hoop”, and the ”kids” in the example of ”Dancing Ballet”. Although the CAM of depth sub-model does not seem as good as that of the RGB sub-model, the performance of RGB sub-model is improved by introducing the depth modality, which is demonstrated in the fifth column. Comparing the result of the “RGB sub-model” with ”AMeFu-Net”, we note that AMeFu-Net not only recognizes the important regions correctly but also eliminates the noises brought by irrelevant background to a large extent.

4.4. Results on UCF101 and HMDB51
Baselines and Competitors. We also conduct experiments on UCF101 and HMDB51. We report the 1-shot, 3-shot, 5-shot results on both datasets. As for baselines, the ”RGB Basenet”, ”RGB Basenet++” are reported. The baselines and their settings are the same as those on Kinetics.
| UCF101 | HMDB51 | ||||||
|---|---|---|---|---|---|---|---|
| Model | 1-shot | 3-shot | 5-shot | 1-shot | 3-shot | 5-shot | |
| Baselines | RGB Basenet | 76.4 | 88.7 | 92.1 | 48.8 | 62.4 | 67.8 |
| RGB Basenet++ | 78.5 | 90.0 | 92.9 | 49.3 | 63.0 | 68.2 | |
| Competitors | ARN (Zhang et al., 2020) | 66.3 | - | 83.1 | 45.5 | - | 60.6 |
| Ours | AmeFu-Net | 85.1 | 93.1 | 95.5 | 60.2 | 71.5 | 75.5 |
Results. Our results are shown in Tab. 2. Our method achieves state-of-the-art performance on all settings. For UCF101, we achieve 85.1% on 1-shot and 95.5% on 5-shot, outperforming the ARN (Zhang et al., 2020) by 18.8% and 12.4%, respectively. For HMDB51, our method achieves 60.2% on 1-shot, 71.5% on 3-shot and 75.5% on 5-shot, outperforming the ARN (Zhang et al., 2020) by 14.7% on 1-shot setting. We also want to highlight some other results. First, we notice the performance improvement by comparing ”RGB Basenet++” against ”RGB Basenet”. It keeps consistent with the results on the Kinetics dataset. Second, the results on UCF101 are much better than those on HMDB51. Take the 1-shot as an example, our model achieves 85.1% on UCF101 while HMDB51 only reaches 60.2%. Notably, the action classes of UCF101 are much easier to recognize, such as ”Apply Eye Makeup”, ”Baby Crawling” and ”Sky Diving”. These actions are not difficult to be distinguished. In some extreme cases, we can recognize the actions even with only one keyframe. In comparison, HMDB51 is much more challenging, considering some facial actions are contained, such as ”smile”, ”laugh”, ”chew” and ”talk”. Such actions increase the difficulty of video recognition a lot.
4.5. Ablation study
To verify the effectiveness of components contained in our model, we implement experiments to evaluate them on the Kinetics dataset. Generally, we conduct experiments on the 5-way setting and report the result of 1-shot to 5-shot. The results are reported in Tab. 3.
| Setting | 1-shot | 2-shot | 3-shot | 4-shot | 5-shot |
|---|---|---|---|---|---|
| fusion strategies | |||||
| RGB + Depth + Concat | 67.5 | 76.9 | 81.1 | 82.0 | 83.3 |
| RGB + Depth + DGAdaIN | 73.6 | 80.7 | 84.0 | 85.4 | 86.6 |
| fusion modules | |||||
| RGB guide Depth | 50.6 | 58.7 | 64.3 | 64.1 | 66.1 |
| DGAdaIN | 73.6 | 80.7 | 84.0 | 85.4 | 86.6 |
| two-way guidance | 66.5 | 74.8 | 78.3 | 79.4 | 82.8 |
| temporal shifting times | |||||
| 73.0 | 80.6 | 84.5 | 85.5 | 86.0 | |
| 74.1 | 81.1 | 84.3 | 85.6 | 86.8 | |
| 72.1 | 80.5 | 84.4 | 85.4 | 86.0 | |
How to fuse RGB stream and depth stream? The most natural way to fuse multi-modality features is to concatenate different features directly. We implement this naive method which termed as ”RGB + Depth + Concat”. Specifically, we first concatenate the RGB feature extracted by the ”RGB sub-model” and the depth feature extracted by the ”depth sub-model”, and then the concatenated feature is fed into a fully connected layer. The training procedure is the same with ours ”RGB + Depth + DGAdaIN” which is not equipped with the temporal asynchronization augmentation mechanism. The results in Tab. 3 show that our method achieves superior performance.
How to design the adaptive fusion module? DGAdaIN deforms the RGB feature towards depth feature. We also explore other strategies. For ”RGB guide Depth”, we learn the affine parameters from the RGB feature and use them to deform depth feature. For ”two-way guidance”, we average the output feature of ”RGB guide depth” and ”depth guide RGB” and then feed it to the classifier. We fine-tune the different modules with the same setting. Results in Tab. 3 show that our DGAdaIN achieves the best performance, outperforming the worst ”RGB guide depth” by a large margin. As analyzed above, the most important visual context such as main objects can still be extracted from the RGB frames, so we have to keep the ”context” unchanged while use the depth as the ”style” to guide the original RGB features.
How many times should we shift depth? We explore three different settings of the . Results in Tab. 3 show that as the increases, the performance of our model will finally converge. In most cases, our model achieves the best performance when the is set to 2. That is because when the is set to 1, which means we only shift once, the performance of augmentation is limited. When we set the 2, training on un-matched RGB and depth pairs may bring too much misleading information. In such cases, the depth clips may cause undesired noises. We set to 2 in our final model.
5. Conclusion
In this paper, we have explored and exploited the depth information to alleviate the extremely data-scarce problem in few-shot video action recognition. Technically, we have proposed a novel temporal asynchronization augmentation strategy to augment source video representation. In addition, we have proposed a depth guided adaptive instance normalization module (DGAdaIN) to fuse the features from two different streams adaptively. Extensive experiments show that our proposed method established new state-of-the-art on three widely used datasets including Kinetics, UCF101, and HMDB51.
References
- (1)
- Bishay et al. (2019) Mina Bishay, Georgios Zoumpourlis, and Ioannis Patras. 2019. TARN: Temporal Attentive Relation Network for Few-Shot and Zero-Shot Action Recognition. arXiv preprint (2019).
- Boukhers et al. ([n.d.]) Zeyd Boukhers, Kimiaki Shirahama, and Marcin Grzegorzek. [n.d.]. Example-based 3d trajectory extraction of objects from 2d videos. TCSVT ([n. d.]).
- Cao et al. (2020) Kaidi Cao, Jingwei Ji, Zhangjie Cao, Chien-Yi Chang, and Juan Carlos Niebles. 2020. Few-shot video classification via temporal alignment. In CVPR.
- Carreira and Zisserman (2017) Joao Carreira and Andrew Zisserman. 2017. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR.
- Chang et al. (2019) Ya-Liang Chang, Zhe Yu Liu, Kuan-Ying Lee, and Winston Hsu. 2019. Learnable gated temporal shift module for deep video inpainting. arXiv preprint (2019).
- Chen et al. (2019a) Zitian Chen, Yanwei Fu, Kaiyu Chen, and Yu-Gang Jiang. 2019a. Image block augmentation for one-shot learning. In AAAI.
- Chen et al. (2018) Zitian Chen, Yanwei Fu, Yu-Xiong Wang, Lin Ma, Wei Liu, and Martial Hebert. 2018. Image deformation meta-network for one-shot learning. In CVPR.
- Chen et al. (2019b) Zitian Chen, Yanwei Fu, Yu-Xiong Wang, Lin Ma, Wei Liu, and Martial Hebert. 2019b. Image deformation meta-networks for one-shot learning. In CVPR.
- Choi et al. (2019) Jinwoo Choi, Chen Gao, Joseph Messou, and Jia-Bin Huang. 2019. Why Can’t I Dance in the Mall? Learning to Mitigate Scene Bias in Action Recognition. In NeurIPS.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In CVPR.
- Erik G. Miller and Viola (2000) Nicholas E. Matsakis Erik G. Miller and Paul A. Viola. 2000. Learning from one example through shared densities on transforms. In CVPR.
- Feichtenhofer et al. (2019) Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slowfast networks for video recognition. In CVPR.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML.
- Fu et al. (2019) Yuqian Fu, Chengrong Wang, Yanwei Fu, Yu-Xiong Wang, Cong Bai, Xiangyang Xue, and Yu-Gang Jiang. 2019. Embodied One-Shot Video Recognition: Learning from Actions of a Virtual Embodied Agent. In ACM MM.
- Gao et al. (2018) Hang Gao, Zheng Shou, Alireza Zareian, Hanwang Zhang, and Shih-Fu Chang. 2018. Low-shot learning via covariance-preserving adversarial augmentation networks. In NeurIPS.
- Gatys et al. (2016) Leon A Gatys, Alexander S Ecker, and Matthias Bethge. 2016. Image style transfer using convolutional neural networks. In CVPR.
- Geiger et al. (2012) Andreas Geiger, Philip Lenz, and Raquel Urtasun. 2012. Are we ready for autonomous driving? the kitti vision benchmark suite. In CVPR.
- Godard et al. (2019) Clément Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. 2019. Digging into self-supervised monocular depth estimation. In ICCV.
- Gupta and Davis (2007) Abhinav Gupta and Larry S Davis. 2007. Objects in action: An approach for combining action understanding and object perception. In CVPR.
- Hariharan and Girshick (2017) Bharath Hariharan and Ross Girshick. 2017. Low-shot visual recognition by shrinking and hallucinating features. In ICCV.
- He et al. (2018) K. He, Y. Fu, W. Zhang, C. Wang, Y.-G. Jiang, F. Huang, and X. Xue. 2018. Harnessing Synthesized Abstraction Images to Improve Facial Attribute Recognition.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In CVPR.
- Hu et al. (2019) Ping Hu, Ximeng Sun, Kate Saenko, and Stan Sclaroff. 2019. Weakly-supervised compositional featureaggregation for few-shot recognition. arXiv preprint (2019).
- Huang and Belongie (2017) Xun Huang and Serge Belongie. 2017. Arbitrary style transfer in real-time with adaptive instance normalization. In ICCV.
- Huang et al. (2018) Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. 2018. Multimodal Unsupervised Image-to-image Translation. In ECCV.
- Ikizler-Cinbis and Sclaroff (2010) Nazli Ikizler-Cinbis and Stan Sclaroff. 2010. Object, scene and actions: Combining multiple features for human action recognition. In ECCV.
- Ioffe and Szegedy (2015) Sergey Ioffe and Christian Szegedy. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML.
- Jain et al. (2015) Mihir Jain, Jan C Van Gemert, and Cees GM Snoek. 2015. What do 15,000 object categories tell us about classifying and localizing actions?. In CVPR.
- Jiang et al. (2015) Min Jiang, Jun Kong, George Bebis, and Hongtao Huo. 2015. Informative joints based human action recognition using skeleton contexts. Signal Processing: Image Communication (2015).
- Kay et al. (2017) Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset. arXiv preprint (2017).
- Koch et al. (2015) Gregory Koch, Richard Zemel, and Ruslan Salakhutdinov. 2015. Siamese neural networks for one-shot image recognition. In ICML workshops.
- Kuehne et al. (2011) Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio, and Thomas Serre. 2011. HMDB: a large video database for human motion recognition. In ICCV.
- Lake and Salakhutdinov (2013) Brenden M. Lake and Ruslan Salakhutdinov. 2013. One-shot learning by inverting a compositional causal process. In NeurIPS.
- Lake et al. (2011) Brenden M. Lake, Ruslan Salakhutdinov, Jason Gross, and Joshua B. Tenenbaum. 2011. One shot learning of simple visual concepts. In CogSci.
- Li and Fei-Fei (2007) Li-Jia Li and Li Fei-Fei. 2007. What, where and who? classifying events by scene and object recognition. In ICCV.
- Li et al. (2018) Yingwei Li, Yi Li, and Nuno Vasconcelos. 2018. Resound: Towards action recognition without representation. In ECCV.
- Lin et al. (2019) Ji Lin, Chuang Gan, and Song Han. 2019. Tsm: Temporal shift module for efficient video understanding. In ICCV.
- Liu et al. (2020) Chen Liu, Chengming Xu, Yikai Wang, Li Zhang, and Yanwei Fu. 2020. An Embarrassingly Simple Baseline to One-Shot Learning. In CVPR workshops.
- Marszalek et al. (2009) Marcin Marszalek, Ivan Laptev, and Cordelia Schmid. 2009. Actions in context. In CVPR.
- Park et al. (2019) Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. 2019. Semantic Image Synthesis With Spatially-Adaptive Normalization. In CVPR.
- Perez-Rua et al. (2020) Juan-Manuel Perez-Rua, Antoine Toisoul, Brais Martinez, Victor Escorcia, Li Zhang, Xiatian Zhu, and Tao Xiang. 2020. Egocentric Action Recognition by Video Attention and Temporal Context. arXiv preprint (2020).
- Qian et al. (2020) Xuelin Qian, Wenxuan Wang, Li Zhang, Fangrui Zhu, Yanwei Fu, Tao Xiang, Yu-Gang Jiang, and Xiangyang Xue. 2020. Long-Term Cloth-Changing Person Re-identification. arXiv preprint arXiv:2005.12633 (2020).
- Schwartz et al. (2018) Eli Schwartz, Leonid Karlinsky, Joseph Shtok, Sivan Harary, Mattias Marder, Abhishek Kumar, Rogerio Feris, Raja Giryes, and Alex Bronstein. 2018. Delta-encoder: an effective sample synthesis method for few-shot object recognition. In NeurIPS.
- Selvaraju et al. (2017) Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. In ICCV.
- Simonyan and Zisserman (2014) Karen Simonyan and Andrew Zisserman. 2014. Two-stream convolutional networks for action recognition in videos. In NeurIPS.
- Snell et al. (2017b) Jake Snell, Kevin Swersky, and Richard Zemel. 2017b. Prototypical networks for few-shot learning. In NeurIPS.
- Snell et al. (2017a) Jake Snell, Kevin Swersky, and Richard S. Zemeln. 2017a. Prototypical networks for few-shot learning. In NeurIPS.
- Soomro et al. (2012) Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. 2012. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint (2012).
- Sung et al. (2018) Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip H.S. Torr, and Timothy M. Hospedales. 2018. Learning to Compare: Relation Network for Few-Shot Learning. In CVPR.
- Sung et al. (2017) Flood Sung, Li Zhang, Tao Xiang, Timothy Hospedales, and Yongxin Yang. 2017. Learning to learn: Meta-critic networks for sample efficient learning. arXiv preprint (2017).
- Tu et al. (2019) Yi Tu, Li Niu, Junjie Chen, Dawei Cheng, and Liqing Zhang. 2019. Learning from Web Data with Memory Module. arXiv preprint (2019).
- Ulyanov et al. (2017) Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. 2017. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In CVPR.
- Vinyals et al. (2016) Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. 2016. Matching networks for one shot learning. In NeurIPS.
- Wang et al. (2013) Chunyu Wang, Yizhou Wang, and Alan L Yuille. 2013. An approach to pose-based action recognition. In CVPR.
- Wang et al. (2016) Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. 2016. Temporal segment networks: Towards good practices for deep action recognition. In ECCV.
- Wang and Gupta (2018) Xiaolong Wang and Abhinav Gupta. 2018. Videos as space-time region graphs. In ECCV.
- Wang et al. (2020a) Yikai Wang, Chengming Xu, Chen Liu, Li Zhang, and Yanwei Fu. 2020a. Instance Credibility Inference for Few-Shot Learning. In CVPR.
- Wang et al. (2020b) Yikai Wang, Li Zhang, Yuan Yao, and Yanwei Fu. 2020b. How to trust unlabeled data? Instance Credibility Inference for Few-Shot Learning. arXiv preprint (2020).
- Wang et al. (2018) Yu-Xiong Wang, Ross Girshick, Martial Hebert, and Bharath Hariharan. 2018. Low-shot learning from imaginary data. In CVPR.
- Wang and Hebert (2016) Yu-Xiong Wang and Martial Hebert. 2016. Learning to learn: Model regression networks for easy small sample learning. In ECCV.
- Wang et al. (2017) Yu-Xiong Wang, Deva Ramanan, and Martial Hebert. 2017. Learning to model the tail. In NeurIPS.
- Wu et al. (2007) Jianxin Wu, Adebola Osuntogun, Tanzeem Choudhury, Matthai Philipose, and James M Rehg. 2007. A scalable approach to activity recognition based on object use. In ICCV.
- Wu et al. (2016) Z. Wu, Y. Fu, Y.-G. Jiang, and L. Sigal. 2016. Harnessing Object and Scene Semantics for Large-Scale Video Understanding. In CVPR.
- Xu et al. (2019) Yang Xu, Cheng Ding, Xiaokang Shu, Kai Gui, Yulia Bezsudnova, Xinjun Sheng, and Dingguo Zhang. 2019. Shared control of a robotic arm using non-invasive brain–computer interface and computer vision guidance. Robotics and Autonomous Systems (2019).
- Yan et al. (2019) An Yan, Yali Wang, Zhifeng Li, and Yu Qiao. 2019. PA3D: Pose-action 3D machine for video recognition. In CVPR.
- Yan et al. (2018) Sijie Yan, Yuanjun Xiong, and Dahua Lin. 2018. Spatial temporal graph convolutional networks for skeleton-based action recognition. In AAAI.
- Yang et al. (2010) Weilong Yang, Yang Wang, and Greg Mori. 2010. Recognizing human actions from still images with latent poses. In CVPR.
- Zhang et al. (2020) Hongguang Zhang, Li Zhang, Xiaojuan Qi, Hongdong Li, Philip HS Torr, and Piotr Koniusz. 2020. Few-shot Action Recognition with Permutation-invariant Attention. In ECCV.
- Zhang et al. (2017a) Li Zhang, Flood Sung, Feng Liu, Tao Xiang, Shaogang Gong, Yongxin Yang, and Timothy M Hospedales. 2017a. Actor-critic sequence training for image captioning. In NeurIPS workshops.
- Zhang et al. (2017b) Li Zhang, Tao Xiang, and Shaogang Gong. 2017b. Learning a deep embedding model for zero-shot learning. In CVPR.
- Zhong et al. (2020) Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. 2020. Random erasing data augmentation. In AAAI.
- Zhou et al. (2016) Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. 2016. Learning deep features for discriminative localization. In CVPR.
- Zhu and Yang (2018) Linchao Zhu and Yi Yang. 2018. Compound memory networks for few-shot video classification. In ECCV.