DESI 2024 II: Sample Definitions, Characteristics, and Two-point Clustering Statistics
Abstract
We present the samples of galaxies and quasars used for DESI 2024 cosmological analyses, drawn from the DESI Data Release 1 (DR1). We describe the construction of large-scale structure (LSS) catalogs from these samples, which include matched sets of synthetic reference ‘randoms’ and weights that account for variations in the observed density of the samples due to experimental design and varying instrument performance. We detail how we correct for variations in observational completeness, the input ‘target’ densities due to imaging systematics, and the ability to confidently measure redshifts from DESI spectra. We then summarize how remaining uncertainties in the corrections can be translated to systematic uncertainties for particular analyses. We describe the weights added to maximize the signal-to-noise of DESI DR1 2-point clustering measurements. We detail measurement pipelines applied to the LSS catalogs that obtain 2-point clustering measurements in configuration and Fourier space. The resulting 2-point measurements depend on window functions and normalization constraints particular to each sample, and we present the corrections required to match models to the data. We compare the configuration- and Fourier-space 2-point clustering of the data samples to that recovered from simulations of DESI DR1 and find they are, generally, in statistical agreement to within 2% in the inferred real-space over-density field. The LSS catalogs, 2-point measurements, and their covariance matrices will be released publicly with DESI DR1.
1 Introduction
The large-scale structure (LSS) of the Universe, which can be measured by the clustering of galaxy and quasar tracers, provides a means to test cosmological models. Galaxy redshift surveys measure the angular coordinates and redshift distances of many galaxies and thus enable measurement of their clustering in 3D, from which cosmological information can be inferred. The Dark Energy Spectroscopic Instrument (DESI; [1, 2, 3, 4]) is carrying out a Stage-IV redshift survey aiming to significantly improve the cosmological constraints derived from clustering measurements made with samples of galaxies, quasars and the Lyman- forest.
DESI is a robotic, fibre-fed, highly multiplexed spectroscopic instrument that operates on the Nicholas U. Mayall 4-meter telescope at Kitt Peak National Observatory (KPNO) in Arizona. DESI is conducting a five-year survey over square degrees, which will measure the spectra of million galaxies and quasars in the redshift range , covering several different target classes [5]. During bright time of telescope operation, DESI conducts the bright galaxy survey (BGS) at low redshifts, . During dark time, DESI targets luminous red galaxies (LRGs) in the redshift range , emission-line galaxies (ELGs) in , and quasars (QSOs) over . The Lyman- forest spectral absorption in a further population of high-redshift quasars at redshifts is used to trace the distribution of neutral hydrogen, and a sample of stellar objects is also observed in the overlapping Milky Way Survey (MWS; [6]). During the first 13 months of main survey operation, DESI successfully observed spectra of over 18 million unique objects, more than 75% of which are extragalactic. The key cosmological goals of clustering analyses using these data that form DESI Data Release 1 (DR1; [7]) include:
- •
-
•
analysis of the redshift-space distortion (RSD) signature that alters the clustering amplitude as a function of the angle to the line of sight and allows the rate of structure growth to be measured [10],
-
•
and measurement of the scale-dependent ‘bias’ signature imprinted by squeezed primordial non-Gaussianity () on the clustering on the largest scales [11].
These cosmological goals are achieved through measurement of the 2-point clustering signal of the different galaxy and quasar tracers. This signal is captured in the 2-point correlation function (2PCF) or its Fourier-space analogue, the power spectrum. These statistics encode the clustering of cosmological density fluctuations: however, survey operations, target selection effects, instrumental effects and astrophysical foregrounds all produce additional non-cosmological fluctuations in the observed galaxy density, and unless corrected for these contribute spurious correlations to the measured clustering. Accurately characterising the survey selection function is a key requirement for DESI. This is achieved in multiple steps, the first of which is through the creation of random catalogs of unclustered distributions of points covering the observed survey region. Then, the effects of known non-cosmological sources of density fluctuations in the data can be incorporated into this random catalog by adjusting the density or through the additional use of weights. Rather than apply weights to randoms to match data we can alternatively apply inverse weights to the data to remove effects. Our adopted approach depends on the particular nature of each effect and is detailed in this work. In the final catalogs, the ratio of weighted galaxy counts to weighted random counts is intended to produce a density field that is free from non-cosmological fluctuations. These weighted data and random catalogs are used to obtain measurements of the clustering signal that can be accurately modeled, including additional correction terms for observational effects. One purpose of this work is to identify the aspects of the analysis that require these correction terms and how they can be modeled.
This paper describes the selection of the galaxy and quasar catalogs used for the cosmological analyses and released as part of DESI DR1, the creation of the random catalogs and correction of survey-specific effects and foregrounds, and measurement and validation of the 2-point clustering statistics. We summarize here the work of many supporting studies, including a technical overview of the DESI LSS catalog creation [12], the pipeline for simulating DESI fiber assignment [13], the catalog blinding scheme and its validation [14, 15], and the creation and use of a new map of Galactic extinction based on spectra DESI has measured of stars [16]. The impact of imaging survey systematics on target selection is studied by [17] for LRGs and [18] for ELGs, and the impact of this for full-shape clustering measurements is presented in [19], for primordial non-Gaussianity measurements in [11], and for BAO in [18]. Systematic variations in the DESI spectroscopic success rate and our approach to modelling and removing the trends from the DR1 data are described in [20], and the ELG spectroscopic success rate and effects of catastrophic redshift errors are studied in [21]. A general overview of the effects of the DESI fiber assignment algorithm on the DR1 sample and a method to quickly emulate fiber assignment effects in simulations is presented in [22], while the method for mitigating fiber assignment effects in our clustering analyses is described and validated in [23]. [24] presents an overview of all DESI DR1 simulations; all of these are based on measurements [25, 26, 27] of the clustering signal in DESI Early Data Release [28]. Finally, the methods for determining the covariance of the measured 2-point clustering statistics are described in [29, 30] and validated in [31].
| Ref. | Topic | Section |
| [12] | DESI LSS catalogs | Sections 2.3, 4, 5.1 and 8 |
| [14] | Catalog-level blinding | Section 2.4 |
| [15] | Catalog-level blinding method for measurements | Section 2.4 |
| [22] | Incompleteness due to fiber assignment | Section 5 |
| [23] | Removing scales affected by fiber assignment incompleteness | Section 5 |
| [13] | Alternative realizations of DESI fiber assignment | Section 5.2 |
| [16] | Improved Galactic extinction maps from DESI Observations of stars | Section 6 |
| [17] | Forward modelling imaging systematics for DESI LRGs | Section 6 |
| [18] | Correcting for imaging systematics in DESI ELGs | Section 6 |
| [20] | DESI spectroscopic systematics | Section 7 |
| [21] | Correcting for spectroscopic systematics in DESI ELGs | Section 7 |
| [31] | Comparison between analytical and mock-based covariance matrices | Section 10.2 |
| [29] | Analytic covariance matrices for correlation functions | Section 10.2 |
| [30] | Analytic covariance matrices for power spectra | Section 10.2 |
| [24] | Simulations of DESI LSS | Section 11 |
The results presented here are part of a wider series of key papers based on the DESI DR1. These include measurement of BAO in galaxies and quasars [8] and in the Lyman- forest [9], cosmological model constraints derived from BAO [32], analysis of the full-shape of the 2-point clustering power spectrum including redshift-space distortions [10], and cosmological implications of these full-shape measurements [33].
This paper is structured as follows: In Section 2, we summarize the DESI DR1 data and how it is transformed into LSS catalogs. In Section 3, we describe the spectroscopic selection criteria applied to DESI DR1 LSS catalogs and present the resulting redshift distributions and sample sizes. In Section 4, we present the sky geometry of the DESI DR1 LSS catalogs and the various veto masks applied within the area. In Section 5, we summarize the details of fiber assignment incompleteness in DR1 and how its effects are mitigated in both the construction and analysis of the DR1 LSS catalogs. In Section 6, we present how properties of the imaging used to select DESI samples impart spurious density variation into the DR1 LSS catalogs and how we correct for this. In Section 7, we summarize trends in the DESI spectroscopic success rates with DESI observing properties and how we conclude they have a negligible effect on DR1 2-point clustering measurements. In Section 8, we present how weights are applied to the LSS catalogs, drawing on the previous three sections, and the normalizations of the DR1 samples. Section 9 compares DESI DR1 to the Sloan Digital Sky Survey (SDSS) in footprint and redshift coverage and consistency in redshift measurements for the more than 400,000 objects with both SDSS and DESI spectra. Section 10, we described how 2-point statistics are measured from the LSS catalogs in both configuration- and Fourier-space, how window functions are estimated to allow comparison between the 2-point statistics and cosmological models, and how covariance matrices that allow the consistency between the measurements and models are estimated. In Section 11, we describe how simulations of the DR1 data were produced. In Section 12, we present comparisons between the 2-point clustering of the DR1 data and our simulations of it. Finally, we conclude in Section 13.
Throughout this work, for the calculation of the distance-redshift relation and to set the initial conditions of any simulations we use a fiducial flat CDM cosmological model with: (with a single massive neutrino eigenstate). This model matches the mean of the posterior from fitting to the CMB temperature, polarisation and lensing power spectra as measured by Planck [34].
2 Data
The DESI instrument [4] on the Nicholas U. Mayall Telescope at Kitt Peak, Arizona measures the spectra of 5,000 ‘targets’ [35] at once, using robotic positioners to place optical fibers in the 7 square degree field of view of the focal plane [36] at the celestial coordinates of the targets [37, 38]. The fibers are divided into ten ‘petals’ and carry the light to a corresponding ten climate-controlled spectrographs. Each set of targets assigned to a set of 5,000 fibers is represented by a specific central sky position and denoted as a ‘tile’.
The DESI main survey started observations on May 14, 2021, after a period of survey validation [39]. We analyze the main survey data to be released with DESI DR1 [7]; this includes observations through to June 14, 2022. The DESI spectroscopic pipeline [40] first processed these data the morning following observations for immediate quality checks, and then reprocessed them in a homogeneous processing run denoted as ‘iron’.111It was processed with version 23.1 of the DESI software, available on NERSC via source /global/common/software/desi/desi_environment.sh 23.1. We use the redshift catalogs produced with the iron spectroscopic processing, which will be released in DR1. Full details of what we use are presented in Section 2.2.
DESI has two distinct observing programs for large-scale structure observations, referred to as ‘bright’ and ‘dark’ time [41]. The decision on which type of tile to observe is determined prior to every exposure, depending on the observing conditions [41]. As described in [35], dark and bright time each have their own set of target samples, with independent ‘Merged Target Ledgers’ (MTL). Each MTL is used to track the observation history of the targets. The states of the successfully observed targets are updated in the MTL after every tile is observed and validated so that the completed targets will no longer compete with unobserved targets for fibers. The updated MTL is then used as an input to determine which targets are assigned to what fibers on every tile, using DESI’s fiberassign software [42].222https://github.com/desihub/fiberassign DR1 contains 2744 tiles observed in ‘dark’ time and 2275 in ‘bright’ time. Completeness, in terms of the ratio of observed spectra to total targets, is built up by overlapping tiles, nominally up to four times in bright and seven in dark time. The main survey strategy prioritizes observing tiles that overlap at any given area of the sky, after validating the quality of observations of any underlying tile [41], rather than covering new area.
In the following two subsections, we describe the input target samples used for these observations and then the outputs from the analysis of observed spectra.
2.1 Target Samples used for DR1 LSS Catalogs
DESI observes four classes of extra-galactic targets: quasars (QSO; [43]), luminous red galaxies (LRG; [44]), emission line galaxies (ELG; [45]), and a bright galaxy sample (BGS; [46]). All four of these classes of DESI targets were selected based on photometry from Data Release 9 (DR9) of Legacy Survey (LS) [47, 48] imaging. The LS data combines photometric data from multiple sources. DESI targeting in the North Galactic Cap (NGC) at declination uses and band photometry obtained by the Beijing-Arizona Sky Survey (BASS; [49]) and the band photometry obtained by the Mayall z-band Legacy Survey (MzLS). At low declination and in the South Galactic Cap (SGC), all of the , , bands were observed using the Dark Energy Camera (DECam; [50]), as part of the Dark Energy Camera Legacy Survey (DECaLS) and the Dark Energy Survey (DES; [51]). Further details on all of these imaging programs are available in [47]. These regions are denoted, respectively, as the ‘North’ and ‘South’ photometric regions. Infrared photometry in the and bands from the WISE satellite [52, 53] is used over the entire sky.
In this paper, we describe the samples used in the DESI DR1 cosmological analyses. The samples are first defined by their target bits, encoded in the DESI_TARGET column of the target catalogs, which map directly to the priority with which targets are assigned fibers. When science targets compete for fibers, the one with the highest priority receives the assignment. Any given target can pass the selection cuts of multiple target classes and in such cases, the target is always assigned the highest of the potential priority values.
We create DR1 LSS catalogs for three (nearly) distinct target samples observed exclusively in dark time (LRG, ELG, QSO) and one observed exclusively in bright time (BGS). Below, we describe the target properties of the dark time tracers in the order of greatest to least priority, then describe the bright time sample. We finally discuss the associated random samples created to enable clustering measurements. In all cases, we describe any cuts applied at the level of targeting (i.e., without any information from spectroscopic observations) that produce the samples considered for DR1 LSS catalogs.
QSO:
QSO are assigned the highest priority (PRIORITY value 3400 in the target catalogs). They have the lowest sky density at 310 deg-2. They were given a high priority to ensure high completeness. This is important given the low density of the sample, which means that measurements are shot-noise-limited. Further, each target determined to have a redshift is given three additional observations at high priority (PRIORITY value 3350 in the target catalogs). These additional observations are meant to increase the signal-to-noise of spectra with Lyman- forest absorption features. The full details of the QSO target selection are provided in [43]. Imaging in all of the , , , , and bands is used, from which a random forest algorithm selects likely quasars, restricting to data with . This algorithm was trained and applied separately in the BASS/MzLS region, the DES region, and the DECaLS region333See the beginning of Section 2.1 for more details on these regions.. DES and DECaLS used the same instrument, but the DES region typically contains data with greater imaging depth than the DECaLS data. There are thus three distinct photometric selections for QSO applied to three distinct regions on the sky, and we correct for imaging systematics and assign redshifts to the randoms (see Sections 6 and 8.1) for QSO separately in each of these three regions. However, for the results we present, we will typically show the combined DECam (DES + DECaLS) dataset.
LRG:
DESI LRG targets have a sky density of just over 600 deg-2 and are given an intermediate priority (PRIORITY value 3200 in the target catalogs). They are selected as described in [44] using , , , and flux measurements. The specific selection is tuned separately in the BASS/MzLS and DECam regions to obtain a sample of passively evolving galaxies with an approximately constant number density Mpc-3 in the redshift range . Above this redshift the density falls, to less than Mpc-3 by (see Figure 1), due to a -band fiber magnitude threshold (see [44] for full details).
ELG:
The total sky density of DESI ELG targets is 2400 deg-2, but the sample is somewhat complicated as it is split into three groups of different priorities. The targets are initially assigned either lower priority (‘ELG_VLO’: PRIORITY value 3000, 25% of the total) or higher priority (‘ELG_LOP’: PRIORITY value 3100, 75% of the total) based on the photometric cuts described in [45]. The same selection cuts are applied to the photometry in the BASS/MzLS and DECam regions, with a threshold. A random selection of 10% of both priority groups are promoted to the same priority (3200) as LRG targets, and are given an additional targeting bit ‘ELG_HIP’. This boosting of priority increases the chance that pairs of LRG and ELG at small angular separations will be observed. Any ELG_HIP is always also either VLO or LOP. For the DR1 cosmological analyses, we select only ELG_LOP targets for the final sample, 10% of which are also ELG_HIP. For our analyses of DR1 data, the VLO is omitted simply due to the complexity it added to an already complicated analysis, but we plan to include it in analyses of future DESI data releases. Additionally, any of these targets that are classified as QSO by the target selection pipeline, and thus included in the QSO sample, are rejected. This removes duplicates from the DR1 analysis and simplifies the priority masking (see Section 4.2). We refer to this final selected sample simply as ‘ELG’ from here on.
BGS:
Of the targets observed in bright time, we use only the BGS_BRIGHT sample [46] for cosmological analysis. This sample is defined by a simple magnitude threshold of , which provides a target density of 864 deg-2 and is selected via the BGS_TARGET column in the DESI target catalogs. In Section 3 below we describe a further absolute magnitude cut that is later applied to this target sample, with the resultant clustering sample denoted simply as ‘BGS’.
Random samples:
In addition to the DESI target samples, the DESI targeting team provide samples of uniform random sky positions occupying the same area as the DESI targets (covering the full DESI footprint), as described in Section 4.5 of [35]. Conveniently, each entry in these ‘randoms’ includes the most relevant metadata associated with the imaging data, at the given celestial coordinates. These data are processed in a manner that matches the processing of the target samples defined above, and they thus define a reference sample that matches the sky geometry of the observed DESI samples.
The randoms are divided into many distinct files, each with a density of 2500 deg-2. The constant density is convenient for quick calculations of sky area. For DR1 LSS catalogs, we provide up to 18 of them. They can be used independently and the total number used depends on the density needed for a particular analysis. The combination of all 18 provides a sky density that is more than 100 times that of all of the DR1 LSS catalogs.
We use the DESI fiberassign software together with the details on all of the individual observed tiles and positioners to determine all of the targets and randoms that could have been reached by a DESI positioner and were thus a ‘potential assignment’. The collection of all potential assignments of targets or randoms forms the potential assignment galaxy and random catalogs. Since in the fiducial tiling, a given area on the sky is observable up to seven times and much of the focal plane can be reached by two positioners, all targets and randoms are (typically) assigned multiple tile and fiber values, and thus each unique TARGETID is likely to have multiple entries in the potential assignment catalogs. Section 3.1 of [12] describes this process in more detail.
2.2 Adding Spectroscopic Information
We use the ‘cumulative’ tile-based redshift catalogs and associated data products from the iron version of the DESI spectroscopic reduction pipeline Redrock [54, 55], which are released with DR1.444These are pairs of FITS files containing information on the redshift fits for all of the spectra observed on DR1 tiles. Targets observed on multiple tiles get multiple entries and these are matched to the potential target catalogs via the target ID, tile ID, and fiber ID. The metadata associated with the particular coadded spectrum is matched via tile and fiber to the potential target and random catalogs.
An exception to using the iron reductions is for data taken on the night of December 12th, 2021. When investigating trends between the spectroscopic success and the observation date, [20] found this night to have unusually low spectroscopic success. It was found that during the iron processing, a bug caused incorrect calibration data to be used, only for this night’s results. This issue was identified after the iron data was frozen and all the data taken for the night were reprocessed separately. We substitute the reprocessed data for the original data on the affected 8 dark and 9 bright tiles before constructing the LSS catalogs. These data will be released as a supplementary value-added catalog to the DR1 release.
To define the samples ultimately used for clustering analysis, we also use various additional data from the iron spectroscopic reductions that are produced for every tile (and will be released with DR1) but are not included in the redshift catalogs.
For BGS, we use the information obtained from fastspecfit [56] for -corrections, which are used to define the absolute magnitude threshold used for the DR1 cosmology sample described in Section 3. For ELG samples, we use the [OII] emission line flux measurements and uncertainties produced in the emlin files, which are used in defining the ELG spectroscopic success criteria, as detailed in Section 3. We concatenate the information over all tiles and join it to the ELG potential target catalog via a match to the target ID, tile, and fiber.
For the QSO samples, in addition to Redrock redshifts we use the results produced per tile by the machine learning-based classifier QuasarNET and the MgII ‘afterburner’ [43], which are used to define a ‘good’ QSO. The observations of QSO targets that pass the QSO selection are evaluated per tile and are then concatenated into a QSO catalog that is later joined to the QSO potential target catalog via a match to the target ID, tile, and fiber. A similar process concatenates the QSO information that is determined from spectra that are coadded across tiles (when observations on multiple tiles exist) and separated into Healpix [57] pixels. These separate ‘Healpix’ QSO catalogs are used for Lyman- forest analyses [9], but are not used for the LSS analyses except for some comparisons.
Finally, for all samples, we use the information in the ‘zmtl’ files, which include flags that indicate whether the DESI instrument was performing properly in terms of positioning, CCD wavelength coverage, calibrations, etc. The region of data flagged can be as large as a petal or as small as an individual fiber. We concatenate this information across all tiles, match it to the redshift catalog via the tile, fiber, and target ID, and store it in the column ZWARN_MTL. This information is used for the hardware veto described in Section 4.1.
2.3 Transforming Data into LSS Catalogs
The combination of all the data described in the previous two subsections provides information associated with every instance in which a DESI target or random could be reached by a DESI fiber positioner, which is recorded in the ‘combined information’ catalogs described in Section 3 of [12]. We define the DESI footprint555The footprint of DESI DR1 LSS samples can be seen in Figure 2, which is discussed further in Section 5.3 in the context of completeness variations. as the area containing such reachable targets, and subsequently apply a series of veto masks to this, as described below. The area of this footprint, and coverage properties within it, can be matched to a resolution of less than one arcsecond666This accuracy is assessed by comparing the physical position determined by the DESI fiberassign software to the actual physical position on the focal plane that a fiber positioner was instructed to move to at the time of observation. These differ, e.g., due to dynamic changes in the DESI optics. by randoms through the use of the DESI fiberassign software, as described in [12].
To create what we denote as the ‘full’ LSS catalogs, the data and random potential assignment catalogs are reduced to a sample with unique entries for each target ID. This process includes careful sorting to ensure that only the most relevant instance for each target is retained—most importantly, keeping good observations over non-observations—and is vital for obtaining accurate completeness corrections. The process is described fully in Section 4 of [12]. The resulting catalogs are split by target class and include one entry per target. No cuts are applied to these full catalogs based on analysis of the observed spectra, but all of the relevant information is included in order to enable quality cuts as desired. For instance, one can apply simple criteria to the columns provided in the catalogs to obtain a sample with ‘good’ redshifts within some desired redshift range. The fact that we do not apply cuts based on the spectra also means that we can quickly determine completeness statistics, in terms of both assignment and spectroscopic success.
Several additional processing steps are applied to the LSS catalogs to produce the final ‘clustering’ catalogs. First, the DR1 full catalogs are output in three stages: before any veto masks (‘full_noveto’), after fiducial veto masks (‘full’), and after applying vetoes based on imaging properties recorded in Healpix maps (‘full_HPmapcut’). These veto masks are described in Section 4. The full catalogs are used to determine corrections for variations in completeness (Section 5.3), imaging data properties (Section 6), and spectroscopic data properties (Section 7). Cuts on the spectroscopic information are then applied to the full catalogs to produce clustering catalogs, as described in Section 3. We summarize and define new weights included in the clustering catalogs in Section 8. These clustering catalogs are then used as the inputs for all results presented in the sections after Section 8. Versions v1.2 (used in [8, 32]) and v1.5 (used in [10, 33]) will be released publicly with DR1. The differences between the versions are detailed in Appendix B. All of the results presented in this work are based on version v1.5 of the DESI DR1 LSS catalogs unless otherwise noted.
2.4 Catalog Blinding
To protect against confirmation bias in our DESI DR1 cosmological inference, we applied a blinding scheme to obscure the true cosmology during early analyses until the full large-scale structure analysis pipeline was finalised. This blinding scheme was applied at the catalog level, to produce blinded clustering catalogs for further analysis. The blinding was meant to alter three distinct pieces of information that can be extracted from the DESI 2-point measurement: 1) the location of the BAO feature; 2) the anisotropy in the clustering imparted via redshift-space distortions (RSD) due to structure growth; and 3) the large-scale scale-dependent bias that is generated by local primordial non-Gaussianity, . The specific blinding method applied, and its validation using DESI simulations, is presented in [14]. We summarize the procedure here.
The BAO and RSD signatures were blinded by shifting the measured DESI redshifts, following the methods proposed in [58]. The measured redshifts were first altered in a way that would mimic a change in the dark energy equation of state parameters and . To do this, the measured true redshifts were converted to comoving distances using the DESI fiducial cosmology, and then coherently shifted based on the expected difference in redshifts between an object at that same comoving distance from an observer in a cosmological model with hidden values of and , and in the fiducial cosmological model. A further shift was applied to blind the RSD structure growth measurements. To do this, RSD effects present in the measured redshifts were approximately subtracted based on an estimate of the local displacement field and the fiducial growth rate, and then new RSD shifts were applied to match the effect of a blinded growth rate value (full details of the method can be found in [14]). The shift in was implemented by altering the weight column of the LSS catalogs, using the methodology described in [15].
To choose a pair for blinding, we produced a list of 1000 randomly sampled pairs, with the range of possible values bounded to keep the expected shift to the isotropic BAO scale measurement relative to its value in the fiducial cosmology to within 3% over the redshift range . The order of the pairs was randomized and they were written to a file on disk. The first time that the DESI DR1 LSS ‘clustering’ catalogs were generated, a random integer was chosen as the row to select the pair used for DR1 blinding. The value of the integer was stored in a separate file, which was then read every subsequent time the LSS catalog production was run (following iterative improvements to the pipeline while the analysis remained blinded), so that the same blinding was consistently applied.
Rather than being drawn randomly, the relative shift in was automatically calculated, using a linear RSD model as described in [14], in order to approximately compensate for the expected change due to the blinding in the monopole of the redshift-space clustering, but with a maximum allowed shift of up to 10% relative to its fiducial value. The procedure left the expected amplitude of the clustering monopole approximately unchanged by the blinding, which meant that, e.g., the clustering amplitude of the (blinded) data monopole would still be expected to match that of DESI mocks. However, the procedure imparted a shift in the amplitude of the higher-order multipoles determined by the unknown values of the pair, effectively blinding the true structure growth information in the data. The relative shift in was randomly chosen to be between , and the value applied to DR1 blinding was held fixed for all blinded catalogs by generating the value via a random seed determined from the random integer described above.
The application of the blinding scheme took the ‘full’ catalogs described in the previous subsection as inputs. These catalogs contain all of the selection function details that are described in Sections 5.3, 6 and 7, but the blinding procedure itself changed this . The completeness-corrected was determined from the number density in the full catalogs and the redshifts were shifted as described above. The was then re-measured and a weighting was applied to the blinded clustering catalog to make the blinded match the original . The steps of adding radial information to the randoms and adding an ‘FKP’ [59] weight to optimize the expected signal to noise given the number density variations then proceeded as described in Section 8.
Six versions of the blinded DR1 LSS catalogs were produced and their clustering measurements analysed while the LSS pipeline was iteratively improved before the first unblinded version of the catalog was created. Changes to the LSS catalogs that occurred after unblinding are described in Appendix B.
3 Redshift Selection for DR1 LSS Catalogs
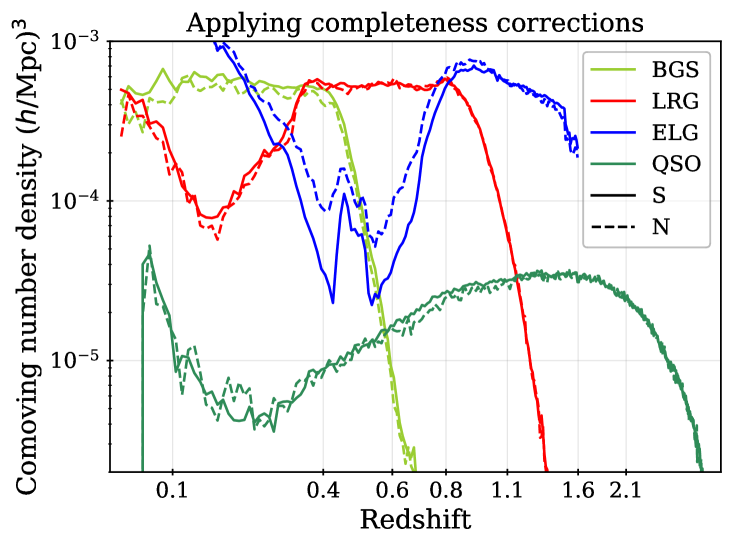
For some fraction of the observed DESI spectra, secure redshifts could not be measured. We thus require spectroscopic success criteria that can be applied to the outputs of the redshift fitting pipeline that recover samples that maximize the sample size while maintaining sufficiently high purity and sufficiently low catastrophic failure rates. For each DR1 sample, we apply the same spectroscopic success criteria as used for the DESI SV3 LSS catalogs [28, 46, 44, 45, 43], and we describe these below, together with the redshift cuts and the redshift binning that is applied within those cuts. For the galaxy samples, the spectral type from the redshift fit (which can be QSO, GALAXY, or STAR) does not enter in the success criteria; e.g., an observed LRG target that is classified by Redrock as a quasar or star but passes the success criteria defined below will be counted as a success, as we believe DESI has properly classified the observation based on the spectrum. Table 2 summarizes the statistics of the final samples, while Table 3 provides the numbers of good redshifts in each of the redshift bins used for clustering measurements, and the redshift distributions are shown in Figure 1.
BGS:
For BGS, we apply the same spectroscopic success criteria as originally suggested in [46]:
-
•
Spectroscopic success: ZWARN==0,
Here is the difference in the fit for the best-fit and second-best fit redshift solutions from the Redrock pipeline [54], and ZWARN != 0 is a Redrock output flag indicating any known problems with the data or the fit. Using this definition, and after applying the vetoes described in the following section, 98.9% of observed BGS_BRIGHT targets are classified as a success. A redshift selection is applied to the BGS sample, and we apply an absolute magnitude cut , which provides a sample with an approximately constant number density, matching the number density of the LRG sample at redshift 0.4. The value is determined using the SDSS -band -corrected absolute magnitude determined using Fastspecfit [60], , and an correction:
| (3.1) |
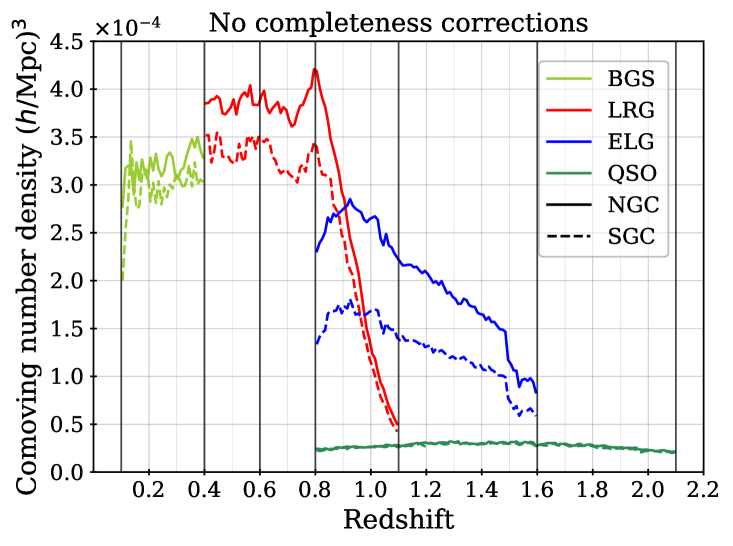
The redshift dependence of the correction matches that applied to the SV3 sample, and the constant 0.095 produces a sample that is a close match to the SV3 characteristics for any given cut. The cut reduces the total number of successful redshifts from 4,036,190 (for the BGS_BRIGHT sample within the area defined in the following section) to 485,331. Although it removes much of the data, the selection produces a sample with an approximately constant number density around 5, after completeness corrections. Applying redshift bounds further reduces the number of redshifts to the 300,043 that we use in the final DESI DR1 cosmological analysis. The upper bound in redshift separates the BGS and LRG samples, while the lower bound of was chosen as the effects of bright limits on the fiber magnitudes becoming increasingly important at lower redshifts, while this cut removes only a small fraction of the available volume. The left-hand panel of Figure 1 shows the comoving number density, , calculated based on the completeness-weighted counts of observed redshifts within redshift shells (the area that enters the volume calculation is described in the following section). One can see that the BGS number density is a close match to that of the LRG sample at the separation redshift , and that it decreases sharply just above this. The right-hand panel of Figure 1 shows the raw density, without completeness corrections, which represents the density one should use to estimate shot-noise contributions. This is just greater than 3 for the BGS sample, which is dense enough to make shot-noise a minor contribution to the BGS statistical uncertainty in the DR1 2-point measurements (as ). Thus, despite removing nearly 90% of the BGS sample, we expect the sample with the cut applied to contain most of the clustering information useful to the cosmological analyses of [8, 10] and to have a nearly constant galaxy population that is simpler to model and simulate. LSS catalogs have been produced for the full DESI BGS_BRIGHT (and BGS_ANY that includes a selection to a fainter flux limit) DR1 samples and will be released publicly with DR1. However, they were not subject to the same scrutiny applied to the sample that we refer to as ‘BGS’ from here on.
| Tracer | # of good z | range | Area [deg2] | z succ. % | |
| BGS () | 300,043 | 7473 | 63.6% | 98.9% | |
| LRG | 2,138,627 | 5740 | 69.3% | 99.1% | |
| ELG | 2,432,072 | 5924 | 35.2% | 72.7% | |
| QSO | 1,223,391 | 7249 | 87.4% | 66.8% | |
| QSO | 856,831 | 7249 | 87.4% | 66.8% |
| Tracer(bin) | # of good z | range |
| BGS | 300,043 | |
| LRG1 | 506,911 | |
| LRG2 | 771,894 | |
| LRG3 | 859,822 | |
| ELG1 | 1,016,365 | |
| ELG2 | 1,415,707 | |
| QSO | 856,831 |
LRG:
For LRGs, we apply the same spectroscopic success criteria as originally suggested in [44]:
-
•
Spectroscopic success: ZWARN==0,
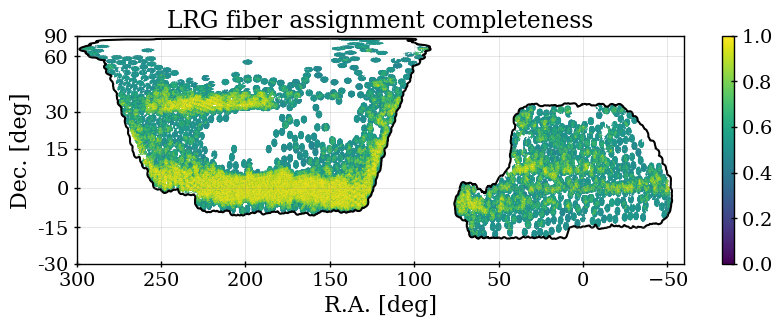
The LRG target selection was optimized for and the BGS sample covers at a higher number density. We therefore apply the redshift cuts for the LRG sample, using three redshift bins of , , and . These provide samples with sufficient signal-to-noise for BAO measurements [8] and match choices applied to previous SDSS studies. The split at was chosen to match the choice of the lower bound on the ELG sample (described next). Figure 1 shows that the LRG number density is nearly constant for and begins to drop for : the redshift upper limit was chosen as the number density falls to less than 1 above it. The redshift efficiency of the LRG sample is the highest of the DESI DR1 targets: 99.1% of observed LRG targets (within the footprint defined in the following section) have a good redshift and 90% are also within . The DR1 LRG sample is the most efficient in terms of the fraction of observed spectra included in the clustering measurements.
ELG:
For ELGs, we apply the same spectroscopic success criteria as originally suggested in [45]:
-
•
spectroscopic success: ,
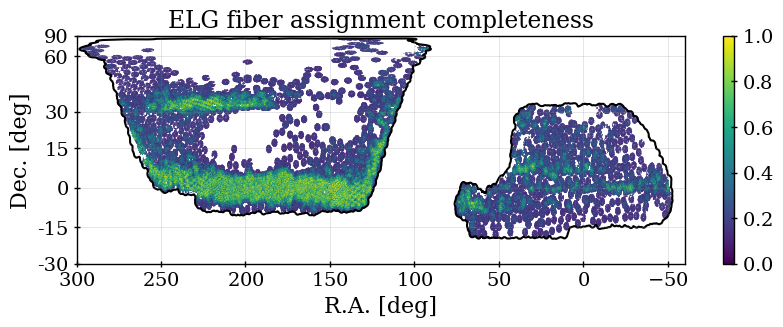
where is the signal-to-noise ratio of the [OII] emission line doublet. We select ELGs in the range . 72.7% of ELG observations yield a successful redshift, 86% of which are also within . Below redshift 0.8, the expected signal-to-noise is dominated by LRGs and target density fluctuations become more severe, including strong variations in the redshift distribution with the imaging depth, detailed in [18]. Above redshift 1.6, the [OII] doublet cannot be observed with the DESI spectrograph; a significant fraction of the redshift failures are presumed to be galaxies. Figure 1 shows that the number density of ELGs decreases sharply for as at these redshifts the [OII] doublet falls at wavelengths that overlap highly with sky lines, increasing the noise entering the determination and thus lowering the success fraction. While this reduces the number density in the range, we are able to account for trends in the success with effective observing time (see Section 7) and any impact of catastrophic redshift failures, e.g., due to misidentified sky lines, is found to be negligible in [21]. One can further observe that the difference between the raw number densities in the NGC and SGC is greater for the ELG sample than for any other. This is due to the difference in completeness between the NGC and SGC and will be discussed further in the following section; the ELG sample is most affected because it has the lowest priority. The ELG sample is split into two redshift bins, and , with the split at motivated by it being the maximum redshift used in the LRG analysis.
QSO:
We apply the same spectroscopic success criteria as originally suggested in [43], and treat all instances where an object has either Redrock, MgII, or QuasarNET spectral identification as a QSO as successes. Thus the criterion is simply:
-
•
Spectroscopic success: Not rejected by the quasar catalog.
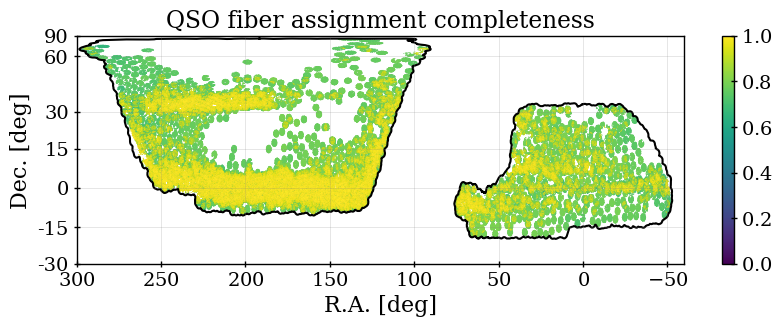
The QSO sample is the only sample in DR1 that uses the spectral type as a factor in the spectroscopic success criteria. This is a complicating factor in the modeling of redshift systematics for the sample, discussed further in [20]. We consider a broad redshift selection for QSOs, although a smaller subset with is used for primary analyses of the quasar clustering. 66.8 % of observed QSO targets (within the region defined in the following section) yield a successful redshift, with 93% of them within and 65% within . For the DR1 LSS catalogs, we use the QSO redshift measurement based on the first tile a QSO is observed on. We find that doing so has a negligible effect on the overall spectroscopic success rate (changes are ) and simplifies the modeling of the spectroscopic success rate.
The QSO sample is significantly less dense than the other DESI tracer samples, as can be seen in Figure 1. In the range, the completeness-corrected number density is no more than 15% of that of ELGs at any redshift, and is typically below 10%. However, since the QSO completeness is approximately that of the ELG sample in DR1, the number of redshifts is just under a factor of 5 smaller (2,432,027 for ELGs and 502,462 for QSO). The 354,190 QSOs with provide the only tracers in that redshift range for DESI DR1. These QSO numbers can be compared to the 454,452 QSOs with used for SDSS DR16 clustering analyses [61].
4 DESI DR1 Geometry and Veto Masks
We define the DESI footprint as the locations on the sky where it was possible to assign a fiber to a target and obtain a ‘good’ DESI observation, which we fully define below. This definition is applied equally to data targets and random points, as described in [12]. The randoms thus trace our footprint definition and, given that the input density of randoms is 2500 deg-2 per random catalog, the area of the footprint can be trivially determined by counting the number of random points and dividing by 2500 deg-2. In what follows, we will present the total covered area in DR1 and then step through the area removed by each type of veto mask. The details for how these veto masks are applied in the LSS pipeline can be found in [12]. Here, we describe the specific choices for the veto masks that are applied to the DR1 LSS catalogs.
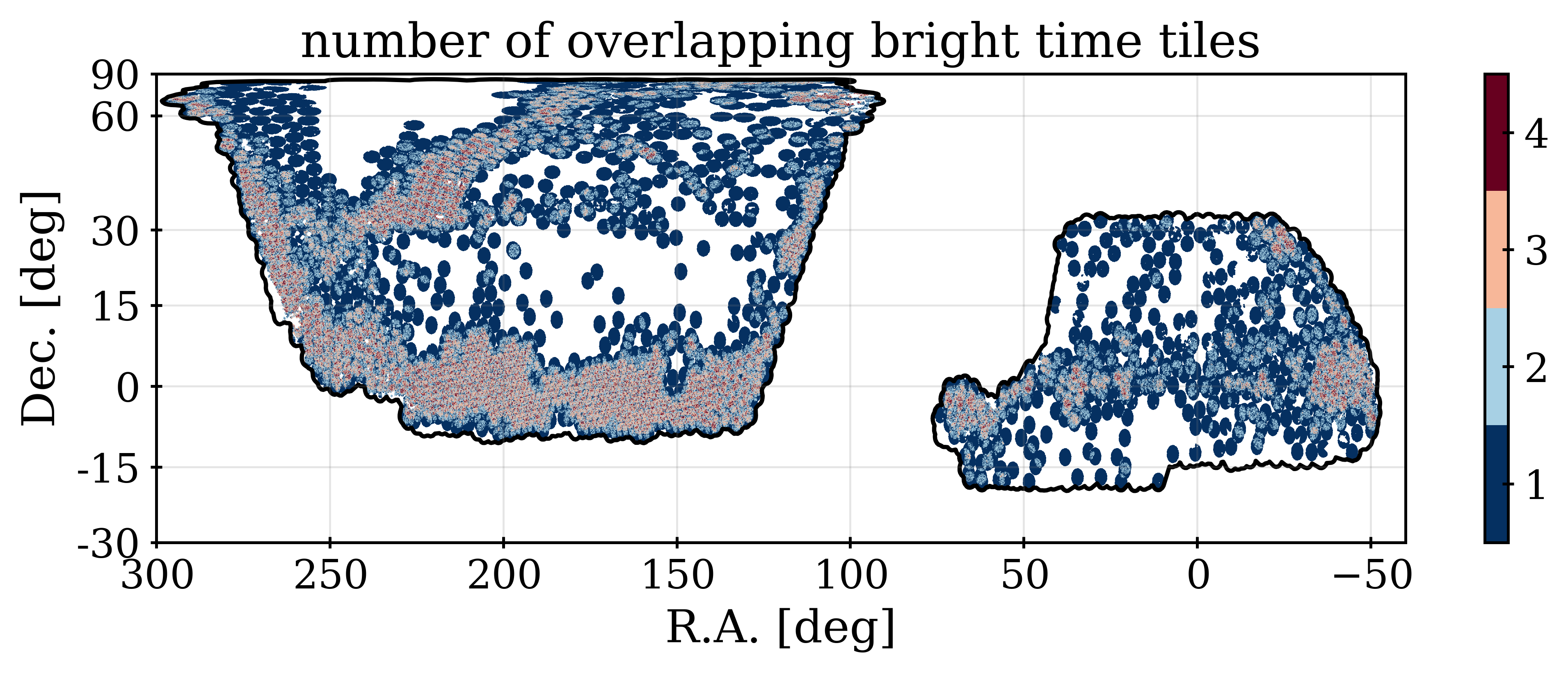
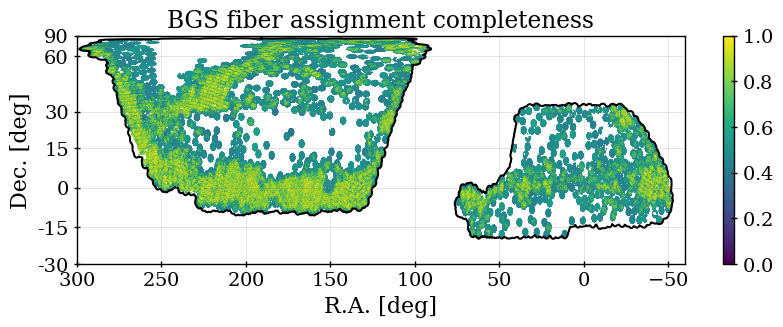
Table 2 includes details of the sky area for each tracer used in the DESI DR1 cosmological analyses. The footprint for these samples is shown in Figure 2. The dark time tracers (LRG, ELG, and QSO) include the same tiles, and thus at a coarse level (at scales larger than an individual tile) their footprints are the same, as can be seen from the distribution of circular tiles in the figure. The differences in area Table 2 are thus only due to the differences in the veto masks at smaller scales, with the biggest effect coming from the priority veto, which is primarily due to QSOs. This veto removes more than 1300 deg2 of the DR1 footprint, as can be seen by comparing the ELG and QSO areas. The LRG footprint is 187 deg2 smaller than that of the ELGs because the bright star mask applied to LRGs removes more area than that applied to ELGs (see Section 4.3). Finally, the BGS sample was observed with a different set of tiles than the dark tracers, and thus has a different footprint (although from Figure 2 one can see that it is similar, by design [41]).
| Mask/region | Area [deg2] | fraction of total |
| Total, dark time | 8,194.8 | 1 |
| Total, bright time | 8,319.9 | 1 |
| Regions (no vetos) | ||
| DECam, dark time | 6574.8 | 0.802 |
| BASS/MzLS, dark time | 1620.0 | 0.198 |
| NGC, dark time | 5213.7 | 0.636 |
| SGC, dark time | 2981.1 | 0.364 |
| DES, dark time | 745.6 | 0.091 |
| DECam, bright time | 5760.5 | 0.692 |
| BASS/MzLS, bright time | 2559.5 | 0.308 |
| NGC, bright time | 5856.5 | 0.704 |
| SGC, bright time | 2463.5 | 0.296 |
| DES, bright time | 601.8 | 0.072 |
| Vetos | ||
| Hardware, dark time | 254.2 | 0.031 |
| Hardware, bright time | 193.3 | 0.023 |
| Priority, LRG & ELG | 1666.7 | 0.203 |
| Priority, QSO | 38.5 | 0.005 |
| Priority, BGS | 25.9 | 0.003 |
| LRG imaging | 631.9 | 0.077 |
| QSO imaging | 488.4 | 0.060 |
| ELG imaging | 362.5 | 0.044 |
| BGS imaging | 373.0 | 0.045 |
4.1 Hardware Veto Masks
All veto masks associated with individual components of the DESI instrument are grouped together to define ‘bad hardware’ regions that are to be masked from the LSS catalogs. When producing the LSS catalogs with a unique entry per target (data and randoms), we prioritize the cases that were reachable by good hardware over the cases that were not, as detailed in [12]. Data and randoms are flagged as bad if they can only be reached by a fiber defined as having bad hardware in the initial compilation. This minimizes the area lost to bad hardware (as such areas are likely to be recovered as good when a tile overlaps the area on a subsequent pass) and also allows us to determine the area lost. One can see in Table 4 that the area lost to bad hardware is only 2.3% in bright time and 3.1% in dark time.
Three distinct sources of information define the DR1 hardware veto:
-
•
The ZWARN_MTL information compiled from the spectroscopic pipeline outputs (see Section 2.2) contains flags that indicate whether an observation passes the cuts to count as observed in the MTL. We apply the same definition as part of the hardware mask.777A difference between what we use and what was used for MTL decisions, however, is that we are using the information as determined during the iron spectroscopic reductions, and the determination for the MTL is based on the ‘daily’ version of the spectroscopic pipeline.
-
•
We require a minimum template signal-to-noise ratio, TSNR2. These values are determined for each tracer type and are proportional to the effective observing time. They are determined per coadded spectrum, but are independent of the target observed to produce the spectrum; they use a fixed template and the estimated noise. Each is defined in [40]. In dark time, we apply a threshold for all samples, while in bright time, we apply a threshold . The spectroscopic success rates for spectra with TSNR2 values below these thresholds decline dramatically and these cuts remove less than 1% of the observed data. All tile and fiber combinations below these thresholds are marked as bad hardware.
-
•
We identify 60 poor-performing fibers, as defined in [20]. All data from those fibers are flagged as bad hardware. Figure 3 shows the LRG and BGS failure rate for each fiber on petal 5, highlighting this petal as it has the largest concentration of bad fibers, largely lying between FIBER 2675 and 2691. We describe the process used to identify bad fibers in [20] and show failure rates for the other petals and tracers there.

4.2 Priority Mask
To account for the areas on the sky where a given target type could not be observed, we apply a priority veto mask. Similar to the hardware veto, the priority veto is applied to the initial compilation of reachable data and random targets and is based on the metadata associated with the potential assignments; i.e., it is determined purely from the fiber assignment information. For both data and randoms, before cutting to unique objects, the priority of every target assigned on the given tile and fiber is known and stored in the catalogs as the column PRIORITY_ASSIGNED. If the PRIORITY_ASSIGNED is greater than that of the sample under consideration, the object’s particular occurrence (associated with the given tile and fiber) is vetoed. Note that the given object can still be included (i.e., not ultimately vetoed) in the final catalog if it was a potential assignment on a different tile or fiber. For our dark time DESI DR1 samples, only QSO and rare high-priority strong lens candidates with priority 4000 cause priority vetoes. We choose not to have LRG targets cause priority vetos on ELGs, as 10% of ELGs have the same priority as LRGs and there is significant overlap between the samples in redshift. For BGS, only white dwarf candidates have a higher priority (2998) than our BGS sample and cause a priority veto.
The priority mask for the LRG and ELG samples is caused by the same QSO and strong lens candidates and it is thus the same area of 1666.7 deg2 for both, which is 20% of the DR1 footprint. In the completed DESI survey, the impact of the priority mask will be much smaller, as the high-priority targets will already have been observed when a given area of the sky is revisited. One can compare coverage areas in Table 6 and observe that the area covered by dark time tracers matches to within 7% in areas covered by more than one tile, e.g., the area of the LRG sample that is covered by two or more tiles is 3390.6 deg2 and for QSO it is 3634.0 deg2. For BGS, the white dwarfs remove 25.9 deg2 and for QSO, the strong lens candidates remove 38.5 deg2. Full details of the implementation of the priority mask in the LSS pipeline can be found in [12].
An implicit assumption in the application of the priority mask is that the higher priority sample is not correlated with the sample being masked. This is not strictly true for QSO and LRG/ELG, as the samples overlap in redshift, though the angular correlations are strongly diluted due to the breadth of the QSO redshift distribution. This makes simulations that include all three tracers and are processed to produce LSS catalogs in the same way as for the real DESI data important. These are described in Section 11.
4.3 Imaging Veto Masks
We apply two types of veto masks that are related to imaging conditions. One set, which we denote ‘bright object’, masks areas around bright stars, galaxies, and defects in the imaging. The bright object masks are different for each tracer type. The other, which we denote as ‘property’, masks data in regions with bad imaging conditions and we use the mask for all tracers. We provide the details for each below.
4.3.1 Bright Object Masks
All tracers had masks defined by the maskbits in the Legacy Survey DR9 imaging888https://www.LegacySurvey.org/dr9/bitmasks/ applied to their targeting. For dark time tracers (QSO, LRG, ELG), these are the bright star mask (bit 1) set for Tycho MagVT or Gaia , the bright galaxy mask (bit 12), and the globular cluster mask (bit 13). For bright time (BGS), we do not apply the bright galaxy mask, as this removes many real low redshift galaxy targets. The redshifts of the galaxies that define the bright galaxy mask are predominately and thus do not share large-scale structure with any of the dark time tracers, which have all have or higher. The presence of the bright galaxies makes the photometry in their vicinity unreliable, and we thus mask the area from the dark time LSS catalogs. Further, the area must have been covered by at least one exposure in all of the bands. These masks are applied to the corresponding randoms (and any DR1 simulations), prior to determining their potential assignments.999They were already applied to the DESI target samples and thus do not need to be reapplied to the data.
We apply additional bright-object veto masks to the DR1 LSS catalogs masks that were not applied to the DESI target samples, with details that depend on the tracer, as follows:
-
•
For all dark-time tracers (QSO, ELG, LRG), we apply the custom mask described at the end of Appendix D in [44] that removes less than 0.01% of the footprint.
-
•
For ELG, we apply an additional custom mask, which eliminates areas at the location of, e.g., Milky Way dwarf satellites and imaging ghosts that result in significant excesses of ELG targets. This custom mask is defined in [62] and removes 0.1% of the ELG footprint.
-
•
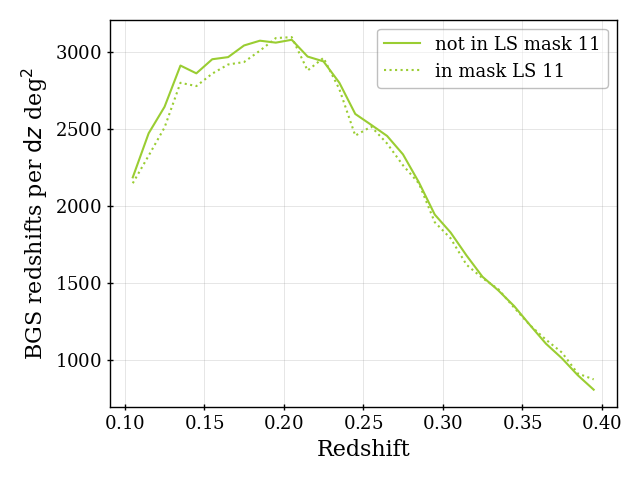
For BGS and ELG, we apply the Legacy Survey MEDIUM star mask (bit 11) that masks area around bright stars based on the Gaia magnitude, up to . The comparison of the for ELG data inside and outside of this masked region is shown in the top left panel of Figure 4. The density of ELG data inside of the mask is 10% to 20% lower depending on the redshift. We make the simple choice to discard the 4.5% of the footprint within the mask, though given the moderate effect, one could imagine modeling the ELG selection function within this region in the future. The bottom left panel of Figure 4 compares the BGS_BRIGHT data inside and outside of the imaging veto mask we apply, where we find only a small () effect; while the effect is small, we still opt for the conservative choice to remove the 5.2% of footprint data within the mask for the Y1 analyses.
-
•
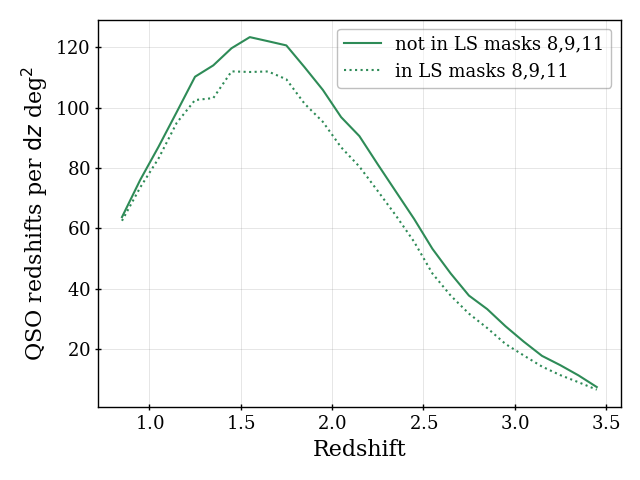
For QSO, we apply three additional maskbits from Legacy Survey, on top of the three applied to targeting. These are the bright star masks for WISE W1 and W2 (bits 8 and 9) and the same MEDIUM star mask applied to the BGS sample. The for the QSO data outside of and inside of this masked region is shown in the bottom right panel of Figure 4; the results are corrected for completeness. One can see that the density is significantly lower, by 10% to 20% depending on redshift, within the masked region. (Splitting the data into the BASS/MzLS and DECam photometric regions does not affect the comparison.) Further, we find that the spectroscopic success is significantly worse for the data within the masked region: 53% compared to 67%. Thus, we apply these masks to the Y1 QSO data, which removes 6.3% of the footprint. However, given the size of the differences, one can imagine that future work properly determines the selection function for these masked data and includes them in future DESI analyses.
-
•
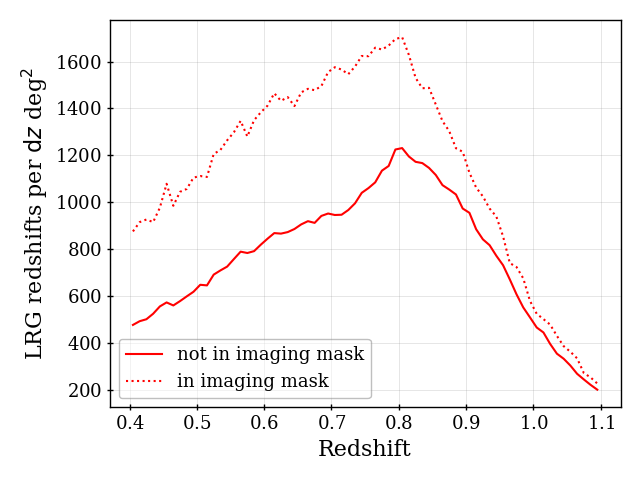
For LRG, we also apply masks for WISE and Gaia bright stars, but they are constructed as described in [44] and remove more area than the Legacy Survey bits 8, 9, and 11. The mask is particularly important for LRG, as considerably more LRG are targeted within these masks, with almost all having good redshifts; i.e., the photometry is affected within these regions in a way that produces a much denser sample than outside of them. This increased sample size can be observed in the upper right panel of Figure 4. The size of the masks determined by [44] keep the area where the LRG selection function can be determined with the methods described throughout the rest of this paper. Given that the data within the LRG mask yields such a surplus of galaxies with good redshifts, one could imagine that in future releases we could determine methods to down-select to the sample of galaxies statistically matching the intended DESI LRG sample.
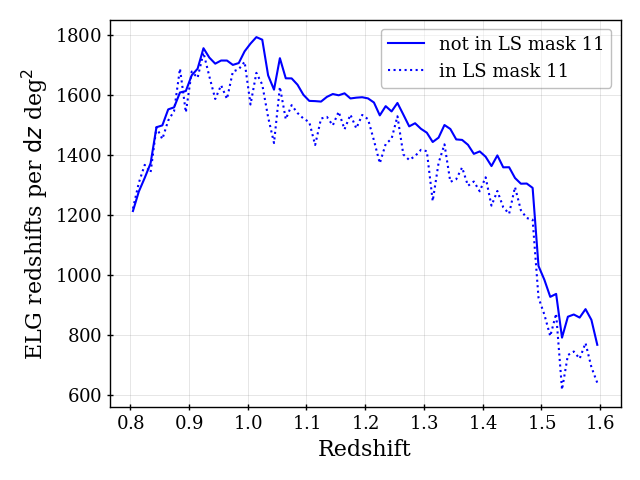
Similar to LRG, ELG targets have an excess density around bright stars, beyond what would be removed by the MEDIUM mask. An extended mask was thus defined and applied in [62]. However, unlike LRGs, the excess targets are not found to have redshifts within the redshift range used for DR1 ELG clustering analyses. That is, after applying completeness weights, the of DESI ELGs within the extended mask region is consistent with the of ELGs in the rest of the footprint. We therefore do not apply the extended mask to the DR1 ELG sample.
4.3.2 Masks for Imaging Properties
We remove portions of the footprint in the tails of the distribution of imaging conditions containing the worst data, as traced by the Healpix maps we use for regressions to correct for imaging systematics (described in Section 6). The full details of the cuts applied to all samples and how much of the QSO footprint they remove are given in Table 5.101010The fractions of the footprint removed are very similar for all tracers, with slight differences due to each tracer having its own set of veto masks. The main purpose of these cuts is to remove the small amount of data that exists as outliers in the image property space that would have the potential to affect the performance of the regressions unduly. The choice of was motivated in part because it matches previous SDSS analysis choices [63, 61]. In total, the Healpix based mask removes 3.4% of both of the QSO and BGS footprints and 3.2% of both of the ELG and LRG footprints.
| Map | cut | frac. removed N | frac. removed S | frac. removed total |
| E(B-V)SFD | mag | 0.003 | 0.019 | 0.016 |
| Gaia star density | 0.006 | 0.005 | ||
| PSFG | 0.018 | 0.004 | ||
| PSFR | 0.009 | 0.002 | ||
| PSFZ | ||||
| GALDEPTHG | nmag | 0.006 | 0.001 | |
| GALDEPTHR | nmag | 0.006 | 0.001 | |
| GALDEPTHZ | nmag | 0.009 | 0.007 | |
| PSFDEPTHW1 | nmag | |||
| all | - | 0.041 | 0.032 | 0.034 |
5 Fiber Assignment Completeness
The fiber assignment completeness for any arbitrary selection of targets is simply the number of those targets assigned to a fiber, divided by the total number of those targets. We denote this as . This, determined over the full DR1 footprint for each tracer, is listed in Table 2. For the dark time tracers, the relative completeness is determined by the relative assignment priorities. Maps of the completeness for each of our DR1 DESI samples are shown in Figure 2. One can see that for the three dark time tracers, the pattern is the same, but is most pronounced for the ELG sample. The SGC region has less of its footprint covered to high completeness than the NGC, which explains the difference in determined without completeness corrections, shown in the right-hand panel of Figure 1.
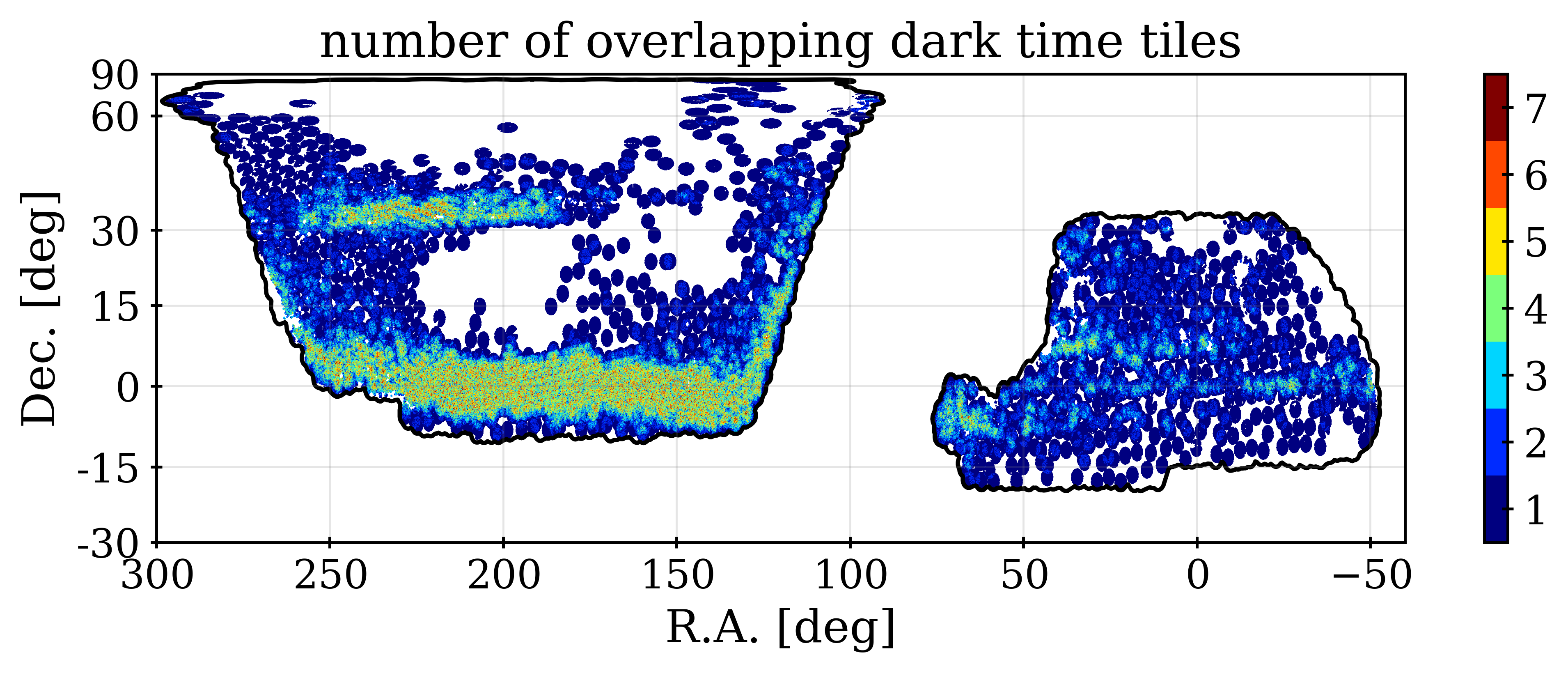
The completeness is almost entirely a function of the number of overlapping tiles, , at any given location. This can be observed by comparing the completeness patterns in Figure 2 to the maps of for dark and bright time in the same figure. We determine for all data and random targets within the DR1 area by counting the number of times the target was reachable, after applying the hardware veto described in Section 4.1. The priority veto is not considered and thus at any given celestial coordinate is the same for all dark time tracers. Full details of the calculation are provided in [12].
Table 6 provides completeness, area, and number of observed redshifts as a function of for each of our four tracers. From the numbers in the table, one can determine that for BGS, over half of the DR1 area is in regions with single tile coverage ( deg2 compared to 3382.5 deg2), and for QSO, it is almost exactly half (3634.0/7249.1 = 0.501). By comparing the QSO and ELG areas, one can see that the QSO priority veto removes more than 1/3 of the footprint in areas covered by only 1 tile but only removes a few percent of the footprint in areas covered by 2 or more tiles. While the completeness statistics improve dramatically as the coverage increases, any minimum cut on removes a large fraction of the data. The effect is smallest for ELGs, but would still remove at least 1/6th of the redshifts from the sample. Thus, our fiducial choice for the DR1 LSS catalogs is not to apply any (or any other completeness) threshold.
| BGS | |||||||
| % | 63.6 | 81.5 | 90.5 | 95.7 | - | - | - |
| Area [deg2] | 7472.7 | 3382.5 | 1268.5 | 233.9 | - | - | - |
| 300,043 | 177,399 | 75,427 | 14,608 | - | - | - | |
| LRG | |||||||
| % | 69.3 | 81.8 | 90.5 | 94.3 | 96.6 | 98.2 | 99.2 |
| Area [deg2] | 5739.7 | 3390.6 | 1908.7 | 1087.7 | 506.3 | 146.0 | 16.7 |
| 2,138,627 | 1,502,311 | 938,237 | 556,506 | 264,730 | 77,483 | 9,040 | |
| ELG | |||||||
| % | 35.2 | 48.0 | 61.6 | 71.5 | 79.5 | 86.6 | 92.2 |
| Area [deg2] | 5924.0 | 3500.3 | 1969.1 | 1120.6 | 520.9 | 150.0 | 17.1 |
| 2,432,072 | 1,985,319 | 1,460,897 | 977,272 | 508,848 | 160,646 | 19,545 | |
| QSO | |||||||
| % | 87.4 | 97.5 | 98.9 | 99.2 | 99.5 | 99.7 | 99.8 |
| Area [deg2] | 7249.1 | 3634.0 | 1980.6 | 1117.7 | 516.7 | 148.5 | 17.0 |
| 1,223,391 | 682,903 | 377,235 | 214,073 | 98,901 | 28,489 | 3,219 |
In the following three subsections, we first discuss completeness calculations determined for different resolutions, we then compare to assignment probabilities determined from repeated realizations of the DR1 fiber assignment, and we finally describe how we use the calculations to determine completeness corrections in the DR1 LSS catalogs.
5.1 Completeness Definitions
For the DESI DR1 cosmological analyses, our fiducial approach to fiber assignment incompleteness is to divide it into two components, in a way that mimics the SDSS approach [63, 61]. The full details of the calculations are provided in [12] and we repeat the basic definitions and concepts here.
The first component is analogous to the SDSS ‘close-pair’ weights. Recall that the full catalogs are split by target type and cut from the potential assignments catalog to unique TARGETID, after a careful sorting (described in [12]) that puts each object at the most relevant combination of tile and fiber. Thus, every target (observed or not) in the full LSS catalog is associated with a single combination of tile and fiber. By definition, the unobserved targets are at combinations of tile and fiber assigned to a different observed target. For unobserved targets, reducing the potential assignments catalogs111111Again, this is fully detailed in [12]. to unique TARGETID prioritizes the instances of tile and fiber assigned to the given type. The result is that most unobserved targets in the full LSS catalogs are at combinations of tile and fiber that were used to observe the given target type. Every observed DESI target in each respective full catalog is given a completeness, , that is simply the inverse of the total number of unique DESI targets within the catalog at the given tile and fiber. This number is essentially the number of targets that were competing for the fiber.
The calculation of does not account for all fiber assignment incompleteness. Some fraction of (unobserved) targets in the full catalogs will be at a tile and fiber that did not observe any target of the given type. These data thus do not influence any calculations. These cases occur due to, e.g., the fiber needing to be assigned to a standard star or sky fiber to meet the minimum threshold. In the case of ELGs, it will also be due to an LRG being assigned to the combination of tile and fiber associated with the given ELG target. In such cases, the target that ultimately received the observation should only depend on randomized processes within the DESI targeting, such as the subpriority value of the target, or—for ELGs competing with LRGs—whether or not it was one of the 10% that were boosted to the LRG priority. We therefore expect such completeness effects to be distributed equally within any given set of overlapping tiles, which we denote . The associated with a given point on the sky is the set of tiles that had a DESI fiber postioner included in the good hardware definition that could have reached the point. It can thus be determined for the data and random catalogs based on set of tiles for each TARGETID that are in the respective potential assignments catalog, after applying the bad hardware veto. We thus determine a completeness, , per that treats the targets that influenced the calculation as if they were observed. The groups of overlapping tiles are analogous to SDSS ‘sectors’ and is thus analogous to . Please see section 4.3 of [12] for the full details.
5.2 Realizations of Fiber Assignment
A separate way to evaluate DESI assignment completeness, and to enable more than point estimates of it, is through the production of alternative realizations of assignment histories. Such realizations are produced by changing the random seed that determines quantities such as the subpriority or whether an ELG is given the same priority as an LRG. Such changing of the random seed happens when creating the initial MTL and the impact on the assignment history can be simulated by running the fiberassign software using the same settings and updating the ‘alternative’ MTL in the same order as for DR1 observations. This process is described and validated in [13]; we denote it as the ‘altmtl’ process. A total of 128 altmtl realizations were produced for DR1 LSS catalogs. We apply the same hardware veto as described in Section 4.1 to the assignments determined for each realization and store the binary True/False information on whether each target was assigned for each realization within a bit array,121212In practice, we store the results from the 128 realizations via two 64 bit arrays. which we store in the column BITWEIGHTS. Counting DR1 observations, we have 129 total realizations and the probability of assignment for any target is simply
| (5.1) |
where is the number of realisations in which the target is assigned.
For observed targets, we expect to be a close match to . Detailed comparisons of the assignment completeness determined from the altmtl realizations and are presented in [22]. We describe the DESI DR1 LSS catalogs that use the altmtl data for completeness corrections in Appendix C. We recommend using the altmtl version of the LSS catalogs for small-scale clustering measurements.
5.3 Weights for Completeness
To correct for the variations in completeness in the DR1 2-point functions, we produce weights based on the completeness definitions described in the previous subsection. For our fiducial LSS catalogs, we simply use
| (5.2) |
This is analogous to the SDSS close pair weight, as described in Section 5.1.
The defined in Eq. 5.2 does not account for the incompleteness that we have tracked via the determination. Given that we identify the same tile groupings in data and random samples, we choose to apply as a weight to the randoms. A small number of tile groupings are present only in randoms, i.e., there were no reachable targets within some tile groupings for a particular tracer. Such tile groupings are typically very small regions with many overlapping tiles. We assigned these areas . The precise implementation is detailed further in Section 8.
Our fiducial method for including completeness weights in the DR1 LSS catalogs does not produce unbiased 2-point clustering statistics, because it does not account for the fact that the number of close pairs observed at small angular scales is highly incomplete, because of the physical limit on the minimum separation of neighbouring fibers in a single tile. To account for this, [23] develop a “-cut” method to remove small angular separations from 2-point measurements in both configuration- and Fourier-space and include the impact of removing such information into a window matrix, to be convolved with the theoretical model. We remove pairs at angular separation scales less than 0.05 degrees, as spectra of targets at separations greater than this scale can be measured simultaneously, given the distance between fiber positioners. The -cut method is the default choice in the DESI DR1 analyses to remove any biases in derived parameters due to fiber assignment incompleteness when using large-scale 2-point clustering measurements. Residual uncertainties related to the process are studied in [10], by comparing results obtained from realistic DR1 simulations (the ‘altmtl’ mocks described in Section 11.2) to the results of simulations without any fiber assignment incompleteness.
Alternatively, one can use the bit arrays determined from the alternative fiber assignment realizations described in the previous subsection to compute ‘pairwise inverse probability’ (PIP) weights which can be used to obtain unbiased 2-point clustering measurements, as described in [64]. This is not our fiducial method in the DR1 analysis for two main reasons. One is simply that the altmtl process required to obtain the bit arrays takes significant computing time131313Currently, it takes several days on a NERSC Perlmutter CPU node with 128 physical cores to obtain 128 realizations, with the time dominated by the I/O feedback loop that must occur in the proper order. and it is not feasible to run this number of realizations on each of a large number of separate simulations. For instance, in the DESI 2024 cosmological analyses, 25 simulations of DESI DR1 were used for validation and 1000 were used to help determine covariance matrices (these are described in Section 11). The other is that PIP weights alone cannot correct for cases where there are 0 probability pairs. There are many such pairs in regions that have been covered by only one tile, which is a significant fraction of the DR1 footprint. For any group of targets that is reachable only to one single combination of tile and fiber, the probability of observing any pairs within the group is 0. The effect of the 0 probability pairs can be corrected via angular upweighting, but the results are no longer strictly unbiased. Any angular upweighting must rely on the angular clustering of the full target sample. The relative amount of area that is covered by only 1 pass will decrease as the DESI survey is completed, and the impact of 0 probability pairs will thus decrease. The fiducial methods to correct for fiber assignment incompleteness will be re-evaluated with each data release. Characterization of fiber assignment incompleteness issues in DR1, for all DESI tracers, is detailed further in [22].
While it is not our fiducial choice for DESI DR1 analysis, the use of PIP weights and angular up-weighting is our only option for accurately measuring small-scale clustering. The PIP weights will account for both the and factors. Thus, we must not weight the randoms by when obtaining PIP-weighted clustering measurements. We discuss this further in Section 8 and Appendix C.
6 Treatment for Imaging Systematics
Our fiducial approach for mitigating the effect of imaging systematics in the clustering of DESI DR1 is to seek the minimal set of image property maps to use, paired with the simplest regression method, that allows us to reduce trends between the density of our LSS catalogs projected onto the celestial sphere (‘projected density’) and the full set of image property maps used for validation to a level consistent with those observed in simulations. The complexity of how mode-removal effects are introduced by this procedure (alternatively understood as over-fitting or noise biases) bias our estimated 2-point functions increases with both the number of maps used and the complexity of the regression method applied.
In early versions of the catalogs, we took a different approach, where we applied the non-linear SYSNet neural net (NN) [65] and Regressis random forest (RF) [66] regressions to all of the maps potentially relevant for a given tracer. When doing so and applying the process to simulations with no systematic contamination, we found that the mode removal effects on the LRG and BGS tracers were greater than the estimated removal of systematic contamination; i.e., the mitigation method imparted more bias in the 2-point functions than it removed. After learning this, we adopted a procedure where we first tested the performance of the linear regression method used for the final eBOSS catalogs [67, 61] (with the code integrated into the DESI framework) and only used one of the non-linear methods if it was determined to be necessary based on the null tests described below.
We perform the regressions for each tracer using the following redshift bins and regression techniques:
-
•
BGS , linear
-
•
LRG , , , linear
-
•
ELG , , SYSNet
-
•
QSO , , Regressis
For all samples but QSO these redshift bins are the same as those used for clustering measurements. In all cases, the regressions determine a model for how the observed density varies with the imaging properties included in the regression model. The maps of imaging properties that we use have Healpix resolution Nside=256. The inverse of the model determined in each Healpix pixel and for the particular redshift bin, is added as a weight to the LSS catalogs and recommended for use in all subsequent calculations.
For all tracers, we performed null tests where we determined the normalized number density versus the value of the imaging property (with the potential to cause systematic variation), in 10 evenly spaced bins of imaging property, both with and without using the determined imaging systematic weight in the calculation. The counts always include completeness weights. To enable comparisons while the ‘clustering’ catalogs (see Section 8) remained blinded, the full catalogs (with all vetos applied) were used. A weight, , similar to the FKP weight added to the clustering catalogs as described in Section 8.2 was calculated and applied to the counts. Instead of allowing the number density to evolve with redshift, for simplicity, we chose a constant number density, for each tracer, with values (/Mpc)3 for BGS and ELG, (/Mpc)3 for LRG, and (/Mpc)3 for QSO. We then used
| (6.1) |
where is the mean completeness at a given (discrete) number of overlapping tiles. Similarly, we refactored the completeness weights to depend on (as done in Section 8.2). In each bin, we then estimated the uncertainty based on the Poisson error determined from the weighted counts141414When doing so, we erroneously divided by the mean completeness weight for the full sample, as determined before the refactoring. This will make the uncertainties under-estimated, but was consistently applied to the data and mocks and thus does not impact the null tests that depended on the comparison of data and mock results.. The approach of using FKP-weighted counts in the uncertainty calculation has been shown to provide approximately correct uncertainties [68]. Since these are only approximately correct, we applied the same methodology to mocks and compared the recovered statistics—where the null expectation is a constant—from the data to the distribution of values from 25 mocks from the DESI DR1 AbacusSummit suite with realistic fiber assignment applied (these are the ‘altmtl’ mocks described in Section 11). In all cases, the regressions have been run on the mocks using the same maps and settings as for the DESI data and obtained and applied to the calculations. However, unlike the data, the mocks have no systematic contamination.
The validation null tests were always performed against the full set of maps that were considered potentially relevant (even those not included in the regression). When blinded, we classified the null tests as passed if the sum of the for the data across all tested maps was less than that from at least one of the 25 mocks and each of the individual maps tested had a less than at least two of the 25 mocks. Figure 5 shows examples of this test for the BGS sample. Cases where these two criteria were not met were investigated further. Statistically, given the number of maps tested, one would expect a small number of cases that do not pass. We investigated the severity of each failure and, e.g., in cases where the map was not originally included to be regressed against, we tested whether adding it significantly improved the results. This determined the final choices of the maps and the regression methods to be applied to the catalogs, which were fixed based on tests on the blinded data and never changed on the unblinded data. The tests on the blinded data were applied to an earlier iteration of the DR1 mocks and the results of the null tests change slightly when the catalog versions are updated. In the subsections that follow, we present the results obtained with the final data and mock versions and pay particular attention to results that are outside of the expectations provided by the mock results and in some cases fail the above criteria.
The following maps are always included in the null tests presented for each tracer in the subsections that follow:
-
•
The stellar density (deg-2) as determined from Gaia stars [69] with ; we label it as STARDENS.
- •
- •
-
•
The imaging depths and PSF sizes in the , , bands (as determined by the DR9 Legacy Survey). We label these as DEPTH_<band> and PSF_<band>.151515See the definitions at https://www.LegacySurvey.org/dr9/files/#randoms-1-fits. We use the galaxy depths for all tracers except the QSO, for which we use the PSF depths.
-
•
The difference between the SFD (applied to DESI targeting) and the determined by [16] using spectra of DESI stars Legacy Survey photometry161616Note that for the derivation of DESI , instead of using different extinction coefficients for the BASS/MzLS and DECam regions as in [16], here we use the DECam coefficients for BASS/MzLS to be consistent with the extinction correction in DESI target selection.. Assuming the map determined from DESI stars is truth, any trend is the result of applying an incorrect Galactic extinction correction to DESI targeting. This produced two separate maps, one based on and the other . Here, we report the results obtained from , which produces the less noisy map, and label it EBV GR.
We describe how these maps are created in Appendix A. For LRGs, we also add the depth in , while for QSO we add the depth in and . When we regress against the imaging depth, we always apply the nominal Galactic extinction corrections to the depth maps, but in the null tests presented throughout this section, we do not. This was an arbitrary choice as we expect to pass the null test either way, assuming systematic trends have been removed. In the following subsections, we describe the regressions performed and the results per tracer.
6.1 BGS
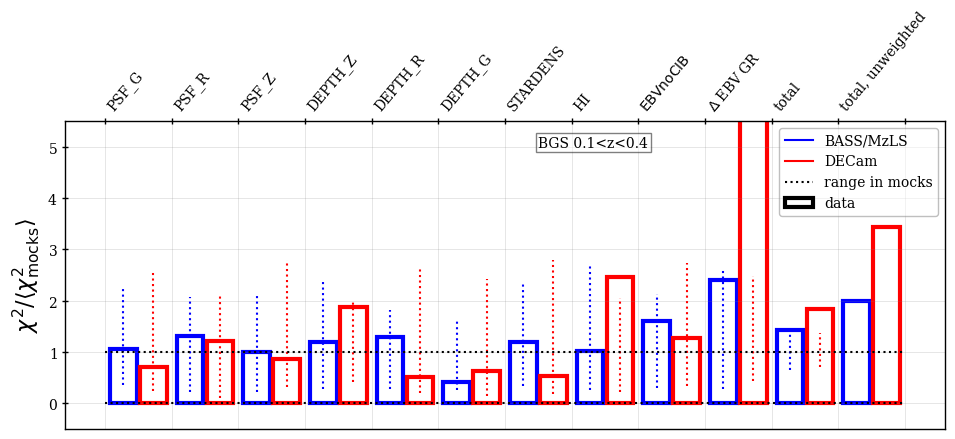
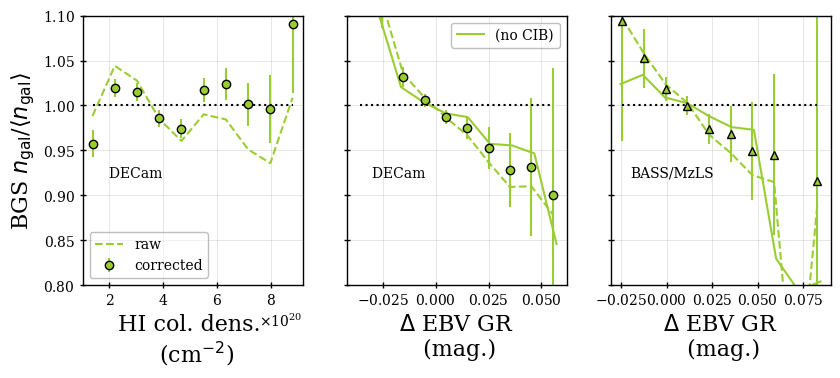
For our BGS sample, we use only three maps and the linear method for the regression to determine the imaging systematic weights. The three maps used are the -band depth, the stellar density, and the HI column density.
The top panel of Figure 5 summarizes the imaging systematic validation tests for the BGS sample. As for Figure 6, we show the obtained from the data relative to the mean of that from the mocks, displaying the results for the data with bars and the range of values obtained from the individual mocks with dotted lines. The results are shown for the individual maps used for the BGS null test, all with the fiducial imaging systematic weights applied. If the three above-listed maps are sufficient, we expect satisfactory results when testing all of the maps. We also show the results summed over all maps without (last column) and with (second to last column) the imaging systematic weights. One can observe that the improvement from using the weights is close to a factor of 2 for DECam and more moderate for BASS/MzLS.
For particular maps, three cases are highlighted. One is the HI column density in the DECam region, which is included as one of the three in the regressions. The trend against HI before and after applying weights can be observed in the bottom left panel of Figure 5: the improves from 51.3 to 26.8. One can observe the result is just outside of the range found in the 25 mocks. The other two cases are similarly strong trends in the BGS density against the EBV GR in both the DECam and BASS/MzLS regions. The result is more significant in the DECam region, as it includes more data. This map was not used in the regressions, as we expect the difference in to include CIB contamination and the BGS density to correlate with CIB contamination. We use a solid curve to display the results for EBV GR when substituting EBVnoCIB for the fiducial SFD . The trend becomes more moderate but remains significant. In terms of the we determine, the fiducial value is 43.0 for the DECam region and reduces to 24.8 when using EBVnoCIB. For the data in the BASS/MzLS region, the corresponding are 17.9 (which is within the range found in the mocks) and 9.7, respectively. This improvement in the in both regions suggests the trends with EBV GR are primarily driven by CIB contamination in SFD and any regression applied that would remove the trends is likely to remove real clustering modes (traced by CIB).
DESI BAO [18] and Full-Shape analysis [19] studies demonstrate that the results using DR1 BGS samples are robust even when not using the imaging systematic weights. For any analysis that instead proves sensitive to the imaging systematic weights, we suggest robustness tests against including the difference when determining the imaging systematic weights.
6.2 LRG


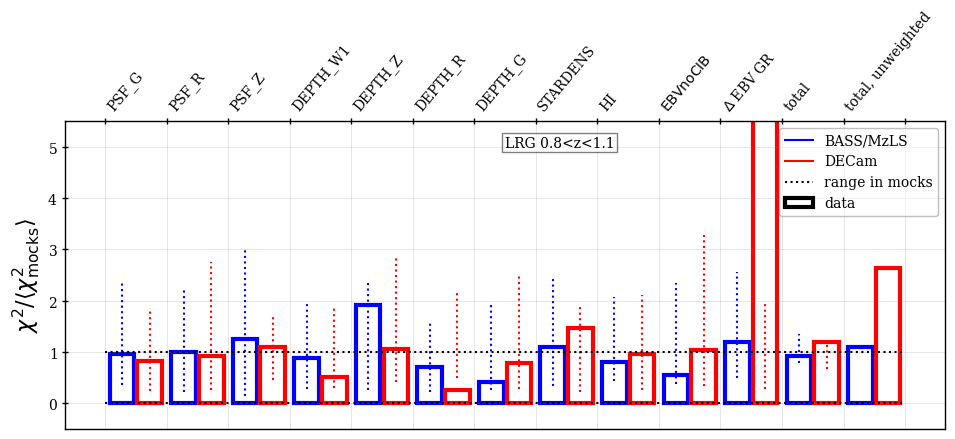
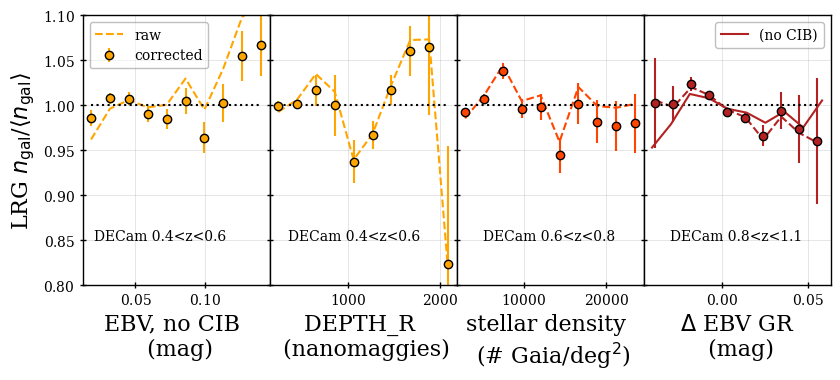
For LRGs, we apply the linear regression method. The regressions are performed separately in each of the three LRG redshift bins. In all three, we regress against maps of stellar density, HI column density, -band galaxy depth, -band PSF size, and PSF depth. These five maps are sufficient to pass all null tests in the BASS/MzLS imaging area, and are motivated by the results of studies by [65] and [17] on the LRG target sample. Based on the null tests in the DECam imaging area, one additional map was needed in each redshift bin, applied only to the regression in the DECam area: -band galaxy depth for , -band galaxy depth for , and the -band PSF size for .
Figure 6 shows the values obtained for each tested map, relative to the mean obtained across the 25 mocks. The results for the data are shown in bars, while the range of values obtained from each of the individual mocks is displayed with dotted lines. In the final two columns, we show the results summing across all of the maps, one when applying the weights and the other without applying weights. One can observe that the use of imaging weights decreases the total by more than a factor of two for all redshift ranges for the data in the DECam region, and for the data in the BASS/MzLS region. However, the weights make little difference for LRG data at in the BASS/MzLS region.
There are four combinations of imaging property map and redshift range where the from the DR1 LRG data is significantly higher than obtained for any mock realization. These are all in the DECam region, which has the majority of the DR1 data and thus the least statistical uncertainty on these tests. We plot the trends for each in Figure 7. Two cases are for the redshift bin. One is the SFD map with CIB removed (EBVnoCIB), which was used for validation but not in the regression. The trend is improved considerably by the imaging weights compared to the case without weights applied (‘raw’, using the dashed curve): the improves from 50.9 to 21.1 when using the weights obtained from the linear regression (‘corrected’, points with error bars). The other case is for a trend with the depth in -band, which we do include in the regression for this redshift bin. One can observe that a downward fluctuation at a depth of 1000 nanomaggies drives the discrepancy with the null expectation. The improves from 30.4 to 20.6 when comparing the unweighted to weighted cases.
For the redshift bin, none of the 25 mocks have a greater than found when testing the DR1 data against Gaia stellar density. The stellar density is included in the regression. One can observe in Figure 7 that the size of the is driven by large fluctuations at particular stellar density values. The improves from 52.1 to 35.8 when comparing the unweighted to weighted cases. Notably, the total sum of the for the DR1 LRG data with is greater than found in any mock. We discuss this at the end of the subsection.
Finally, for the bin, there is a significant trend in the DECam data with the difference in determined using the spectra of DESI stars and the SFD map used in targeting. It can be seen in the right panel of Figure 7. One can observe that there is a clear trend showing an approximately 5% decrease in the DR1 LRG density. One can further observe that the weights make little difference; the is indeed slightly worse with weights, 33.4 compared to 31.6. This map was not considered for use for regressions against the LRG data, as one component of the difference in should be CIB contamination, which we expect to be correlated with the large-scale structure traced by LRGs. We can test this by determining EBV GR using EBVnoCIB instead of the fiducial SFD . When we do so, the result is plotted using a solid curve in Figure 7 and we find the is reduced to 13.2. The dramatic reduction in suggests that the trend is indeed primarily driven by the CIB contamination component of EBV GR and is thus not a trend we wish to regress out of the data, as it would remove real large-scale structure.
The residual trends for LRGs that have been identified as potentially significant are small compared total improvement provided by the systematic weights. DESI studies of the BAO [18] and full-shape [19] fits demonstrate that the cosmology results using our DR1 LRG samples are robust even when not using the imaging systematic weights. However, further study of the residual trends may be necessary to obtain robust results from the DESI DR1 LRG samples, as studied in [11]. For any analysis that proves sensitive to the inclusion of imaging systematic weights, we suggest robustness tests against splitting out the DES region, including the difference when determining the weights, and any residual trends as a function of the -band flux threshold, as motivated by the results of [17]. Many such tests are performed in [11].
6.3 QSO

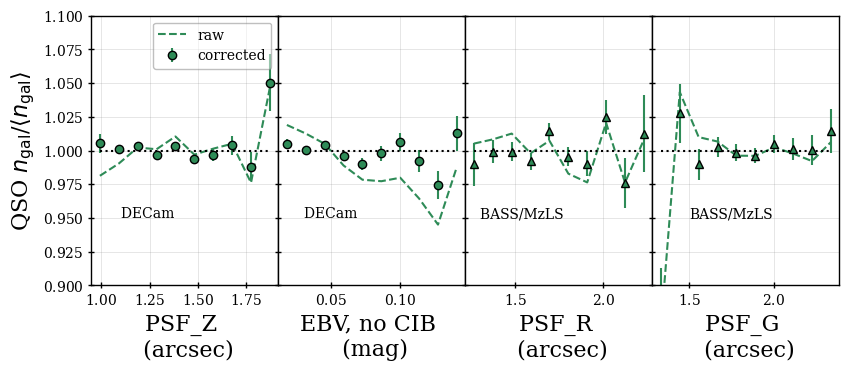
For QSO, we apply the RF regression, using all the maps that we include for validation, except for the EBVnoCIB map. The RF regression method was developed with DESI QSO in mind [66]. Another unique aspect of the QSO regressions is that the DES and DECaLS regions are fit independently. In the validation plots, we still combine the two regions into the full DECam region.
The top panel of Figure 8 summarizes the imaging systematic validation tests for the QSO sample, in the same manner as already shown for LRG and BGS in the previous two subsections. One can observe that the overall improvement of the across all of the maps is greater than a factor of five for the DECam region and a factor of two for the BASS/MzLS region. In the DECam region, the total after applying weights is still right at the maximum edge of the mock distribution, which motivates careful study of potential systematic effects on the clustering of the sample. The importance of any residual uncertainty on 2-point measurements is studied in the context of in [11], structure growth measurements in [19], and BAO measurements in [18].
In terms of specific maps, the bottom panel of Figure 8 presents the four cases where the data result is most extreme compared to the mock distribution. In all cases, one can observe that the trends are significantly improved compared to the unweighted (‘raw’) case. In the DECam region, for the -band PSF size the improves from 38.5 to 15.3, and for EBVnoCIB it goes from 166 to 19.8. In the BASS/MzLS region, for the -band PSF size the improves from 22.2 to 14.5, and for the -band PSF size, it goes from from 15.9 to 13.1. Given the improvement in the trends and the fact that all of these high values are not far from the maximum found in the mocks, we do not find any maps to point to particular concerns with the DESI DR1 QSO sample.
6.4 ELG
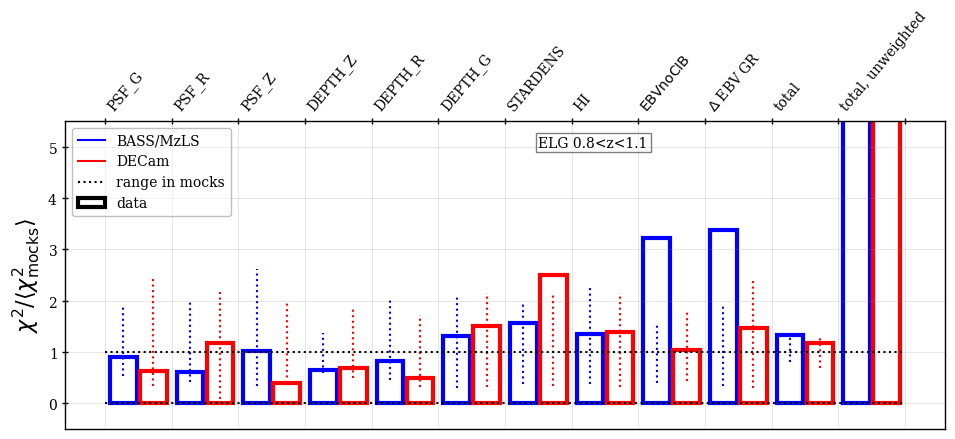

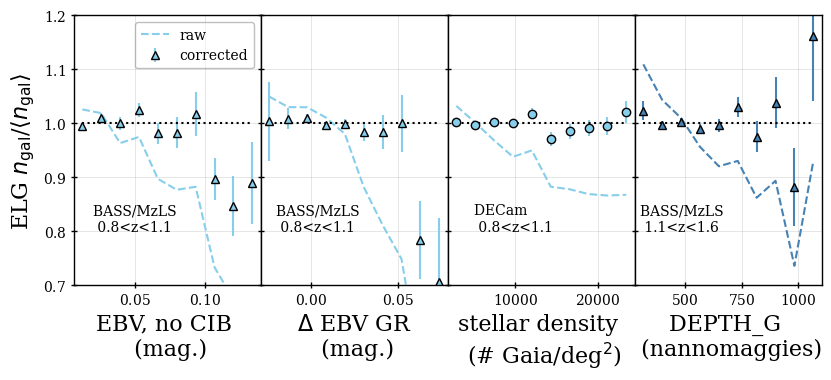
For DESI ELGs, we use the SYSNet NN regression to obtain weights to correct for the trends with imaging properties. All of the maps used for validation are used for training, due to severe trends with imaging properties for this tracer, except for EBVnoCIB (which is expected to be redundant with HI). The full details on the settings used are provided in [18]
Figure 9 shows the results of imaging validation tests performed on the DR1 ELG sample, in a similar manner as presented in the previous three subsections. In the top panel, the data results are compared to the distribution of results recovered from our 25 mock samples. In the top two panels, one can see that for both the and redshift ranges, the total results for the data are consistent with those from the mocks, and that there is more than a factor of five improvement in the total comparing the weighted and unweighted cases.
The results when testing against four individual maps show values that are outside of the bounds recovered from the 25 mock realizations. The trends in these cases are displayed in the bottom panel of Figure 9. In all cases, there is a large improvement in the trends when comparing before (‘raw’) and after (‘corrected’) applying the weights for imaging systematics. For the case of the EBVnoCIB map tested against the data with in the BASS/MzLS region, the is 23.8 with weights and 189.3 without. Similarly, for EBV GR in the same redshift range and region, the is 18.2 with weights and 182.6 without. For both, one can observe deviations at the high end of the map quantity; only 2.7% of the BASS/MzLS region has a EBVnoCIB value greater than 0.1 and only 0.5% of the region has a EBV GR greater than 0.05. For the stellar density, in the DECam region and is 13.4 after weighting and 654.2 before. Finally for the DR1 data with in the BASS/MzLS region, the weighted is 12.5 and the unweighted is 204.6.
While the imaging systematic mitigation can produce results that are consistent with our mock tests, the impact of imaging systematics on the DESI ELG sample is by far the most severe of any of the DESI tracers. Further details on the ELG density variations, including how well they are predicted by image simulations, changes in the expected redshift distribution, and the relative impact on clustering measurements can be found in [18]. There, it is also demonstrated that despite the severity of the trends, there is negligible impact on BAO measurements. The potential impact on studies of the full shape of ELG clustering statistics is investigated in [19], where a method to account for systematic uncertainty related to imaging systematic is validated and applied to obtain DR1 results. We recommend similar testing and rigor be adopted for any LSS studies of the DR1 ELG sample.
7 Treatment for Spectroscopic Systematics
When observed, some DESI targets spuriously receive the wrong redshift estimate, or are unable to receive a reliable redshift estimate because they are too faint or were not observed with sufficient effective exposure time. The latter effect can cause spatially dependent variations in the density of confirmed DESI targets, tracing structure in the focal plane or variations related to spectroscopic observing conditions on larger scales. We therefore correct for these variations with a set of weights, described in Section 7.1. We do not correct for the former effect of incorrect redshift estimates, but in Sec. 7.2 we characterize the precision and accuracy of redshifts by tracer, and also estimate the rates of catastrophic redshift failures, where the measured redshift has a large offset from the truth.
7.1 Redshift Failure Weights
The elimination of spurious fluctuations in the observed tracer density correlated with properties relating to how DESI spectra were observed, and the impact of this elimination, are detailed in [20, 21]. Significant trends were found and investigated for numerous properties, including the effective observing time, the survey speed, number of exposures or nights required to fully observe a target, the date of observation, and the focal plane position. One outcome of the investigation was the identification of issues with the DR1 processing of data taken on the night of Dec. 12th, 2021, and the ultimate replacement of that data in our DR1 LSS catalogs, as described in Section 2.2. Despite finding many significant trends, both studies show that the impacts of these trends on the two-point clustering statistics, even when uncorrected, are negligible.
For the corrections we ultimately apply to the DR1 LSS catalogs, for all tracers we model the success rate, , as a function of the template signal-to-noise ratio, TSNR2. These TSNR2 values are determined for each tracer type and per coadded spectrum, but are independent of the specific properties of the target (e.g., its brightness) observed to produce the spectrum; they use a fixed template (different for each tracer type) for the signal and the estimated noise and the result is thus proportional to an estimated effective observing time. Each is defined in [40] and we use the TSNR2 associated with the particular tracer (i.e., TSNR2_ELG for ELGs). For the BGS, LRG, and QSO samples, we use the fiberflux of the observed target as a secondary variable in the modeling [20]. For ELGs, depends strongly on the precise redshift of the galaxy, due to noise from sky lines interfering with the ability to detect the [OII] doublet. The success rate is thus modeled as a function of TSNR2_ELG and the galaxy redshift, as described in [21].
In all cases, to apply weights we find the relative success at the given redshift or FIBERFLUX, . For BGS, LRG, and QSO, the success model is asymptotic and the weight can thus be defined as
| (7.1) |
where is the TSNR2 value and is a function modelling the success rate as a function of FIBERFLUX and TSNR2. As TSNR2 goes to infinity, must asymptote to a constant value at fixed FIBERFLUX; we use an error function to achieve this behavior, fit it to the observed redshift failure rates, and evaluate it in the limit of to determine the numberator of Eq. 7.1. For the ELGs, a linear relationship is determined for the expected success rate as a function of TSNR2_ELG at each redshift. These linear relationships are normalized to have a mean of one, weighting by the effective observing time.
For all tracers, the modeling approach described above means that we do not over-correct for samples that have an overall poor spectroscopic success rate (i.e., when is much less than 1); e.g., in the most extreme case, QSO at low fiberflux have a success rate and rather than upweight them all by a factor of 3, we only correct for the 10% variation in the success rate of the subsample as a function of effective observing time. The weighted observed density for any selection in fiberflux will have a null trend with TSNR2, and thus any impact of the DESI observing pattern is expected to be nulled, under the assumption that the fiberflux dependence captures any trends with redshift171717This not being the case for ELGs necessitated the specific redshift dependence of their weights. and TSNR2 captures the DESI observing pattern.
7.2 Accuracy and Precision of Redshift Estimation
Uncertainties in the estimation of the DESI redshift impact the measured clustering, but are not accounted for in the LSS catalogs. These uncertainties include the random scatter from standard measurement noise, systematic biases in the redshifts, and also catastrophic errors that are due to, e.g., mis-identification of emission lines or confusion with sky lines.
For LRG, redshift accuracy can be assessed using repeated observations and is estimated at a standard deviation of 40–60 km s-1 [74, 75] (note that different statistics are used, with [74] quoting the standard deviation and [75] quoting the normalized median absolute deviation). Its dependence on magnitude is measured in [75] and on redshift in [74], who show that the distribution of redshift errors is best fit by a Lorentzian distribution. Comparison to BOSS redshifts in Section 9 shows that only 0.3% of the LRG targets in common differ by more than 0.002 in redshift (250 km s-1 at typical LRG redshifts), with a mean difference of 4 km s-1 (very similar to the mean difference of 3.3 km s-1 found in [75] from comparison to DEEP2).
Since BGS is brighter than LRG, its redshifts are more accurate: the standard deviation is 10 km s-1 with little dependence on [75], with a mean difference of 6.5 km s-1 compared to DEEP2 or 2 km s-1 compared to BOSS, and a 0.2% outlier fraction.
While ELGs are faint, their redshifts are measured more accurately than LRGs due to their strong emission lines. Their redshift errors are 8–10 km s-1 and best fit with a Lorentzian [75, 74, 76], again from repeat observations. The impact of ELG catastrophic errors are extensively studied in [21], who find 0.27% of ELG redshifts have catastrophic redshift errors km s-1. [21] characterize the origins of these catastrophic errors, and their impact on the galaxy clustering two-point statistics.
Quasar redshifts are more challenging, both due to the difficulty of centroiding the broad emission lines and due to systemic shifts in the high-ionization CIV line, which is observable by DESI at . The more reliable MgII line redshifts out of the DESI wavelength range at , making particularly problematic. The Redrock quasar templates were updated from the Early Data Release [77], improving the redshift accuracy and bias compared to early studies in [74, 78, 79], which used the old BOSS quasar templates. The LSS catalogs use the updated templates presented and validated in [77], whereas the Ly analysis additionally applied a correction for the evolution of the Ly mean flux, which further improves the quasar redshifts at [80]. Redshift precision is assessed by comparing redshifts in the SV Repeat Exposures, with an overall normalized median absolute deviation (NMAD) of 57 km s-1, which rises with redshift from a low of 20 km s-1 at to a peak at km s-1 at , and declines thereafter [77]. Redshift precision as a function of redshift is shown in Fig. 7 of [77]. The distribution of redshift errors has very heavy, non-Gaussian tails, and are better fit by a Lorentzian [74] or a combination of three Gaussians [78]. Quasar redshift accuracy is assessed via small-scale cross-correlations with LRG, ELG, and the Ly forest [77]: biases in quasar redshift measurements will lead to a radial shift in the peak of the cross-correlation from zero. These biases are shown in Table 6 of [77] and are 30—60 km s-1 at . Finally, catastrophic redshift errors are assessed from the comparison of DESI automated and VI redshifts in [79] (using the old quasar templates), with 0.7% (4.5%) of quasars having offsets (1000) km s-1 at and 1.8% (12.2%) at . This paper uses the old BOSS quasar templates, but [77] finds that the catastrophic rate is very similar between the old and the new templates.
Random redshift errors have a similar impact on the two-point functions as the small-scale Finger of God velocity dispersion, though smaller because the redshift errors are much smaller than the virial velocities. For the BAO analysis of the clustering of BGS, LRG, ELG and QSO tracers, the small-scale velocity dispersion is modelled by a Lorentzian multiplying the broad-band power spectrum with free parameter which is taken to have a Gaussian prior [8]. The redshift error can be absorbed by and the BAO damping parameter at the level of 1-2 Mpc for quasars (and smaller for other tracers); as shown in [81], the BAO results are insensitive to this level of change in and . Likewise, the impact of redshift errors on the Ly BAO analysis is presented in [82] and the impact on the BAO peak position is found to be negligible. For the analysis of the full shape of clustering statistics for discrete tracers, modifications to the simple Lorentzian Finger of God form (e.g. due to the heavy tails in the redshift error distribution) are effectively encapsulated by additional EFT counterterms [83]. The impact of ELG catastrophic errors on the power spectrum and correlation function is extensively studied in [21], who find shifts of in the two-point functions, at a level that does not affect the derived parameters.
8 Summary of Weights and Normalization of Randoms
The completeness weights (defined in Section 5.3), redshift failure weights (defined in Section 7, and imaging systematic weights (defined in Section 6) are combined to a total weight to correct for how the DESI selection function changes as a function of position,
| (8.1) |
In this section, we first describe how redshift and weight information are added to the DESI DR1 LSS random catalogs. We then describe how the weights that optimally balance number density variations are determined for both data and randoms, and how this requires a refactoring of .
8.1 Randoms
To assign redshifts to the random catalogs introduced in Section 2.1 while matching their redshift distribution to that of the data, we assign them redshifts and all associated weights from randomly chosen galaxies in the data catalogs. The random catalogs will thus have all of the same weights as the galaxies, but , , and are present purely to make sure that their weighted (normalized) redshift distribution matches the data. For ELG, LRG, and BGS, the assignment of these quantities to the randoms is done separately in the BASS/MzLS and DECam photometric regions. For QSO, the DECam region is further split into the DES region and DECaLS regions as the photometric selection of QSO is different in each region. We then multiply the sampled value by (Section 5.1). Finally, we normalize the weights181818The weights described in the following subsection do not affect the normalization, as they are applied equally to data and randoms. on the randoms such that the ratio of weighted data to weighted random counts is the same in each photometric region191919The regions are the North and South for all tracers except QSO, which further divide the South region into DES and not DES.. Further details on the process are given in Section 7.2 of [12].
Assigning redshifts to the random points as described above is often described as ‘shuffled’ randoms and matches the approach applied to SDSS [63, 61] Out of the available options, it was determined to be the least biased method for BOSS CMASS galaxies [84]. However, given the radial distribution of the randoms exactly matches the data by construction, this method nulls purely radial clustering modes and introduces a radial integral constraint bias [85], whose effects must be modeled. We summarize the method and present details on all window effects accounted for in the DESI DR1 analyses in Section 10.1.2.
8.2 Weights to Optimally Balance Sampling Rate
Based on the principles first presented in [59], to increase the expected signal-to-noise of our clustering measurements, we apply weights to data and randoms based on the observed number density as a function of redshift and , which we denote . The completeness variations in DESI DR1 are large (see Figure 2). We thus incorporate the mean completeness (see Section 5.3) as a function of into our calculation. The process is fully detailed in section 7.3 of [12] and we repeat some details below. In order to do so while accounting for the completeness weights202020They are all greater than 1 and thus otherwise up-weight incomplete regions., we first divide the total data weight column , for both data and random by the mean completeness weight as a function of , . Thus, the final , included for both data and randoms and meant to account for selection function variations, becomes
| (8.2) |
This is the column WEIGHT in the DR1 ‘clustering’ catalogs. In this way, the total data counts are normalized such that they sum to approximately the number of observed objects, but still fully account for the impact of variations due to fiber assignment incompleteness, imaging systematics, and redshift systematics.
The factoring of the weights applied above allows us to determine , taking the variation in observed number density as a function of redshift and survey coverage into account. First, we define
| (8.3) |
where assignment completeness values are determined in the same way as in Table 6 (selecting the particular discrete rather than applying a threshold)212121The values of and vary with for the same reason, the fiber. In this manner, is the expected number density at the location of any galaxy or random point. We then define following the standard convention
| (8.4) |
The value of is chosen separately for each tracer, given an approximate nominal value of the power spectrum monopole . The values used in the DR1 analysis are , , and . These values are only roughly consistent with the actual clustering amplitude of the respective DESI samples and it is likely that slightly more optimal choices can be adopted in future DESI analyses. These are meant to improve the expected signal-to-noise of 2-point function measurements at the scales used for BAO analyses. For such calculations, one can simply multiply by to obtain the total weight to apply to each data/random point. Analyses that use different scales or clustering estimates might wish to derive their own, more optimal, weighting to apply. Indeed, the primordial non-Gaussianity analysis presented in [11] derives alternative weights.
9 Comparison with SDSS
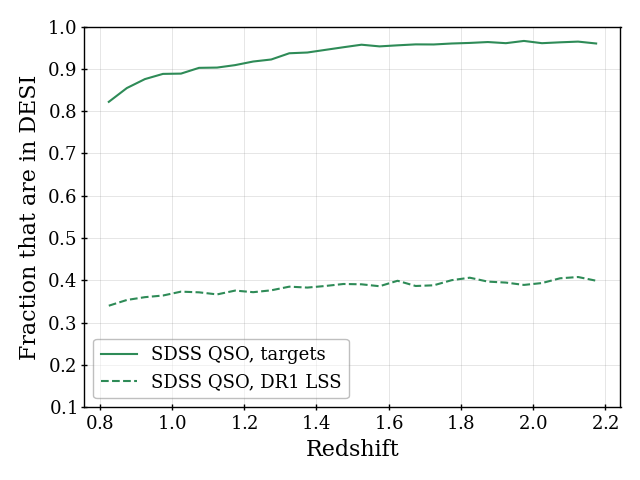
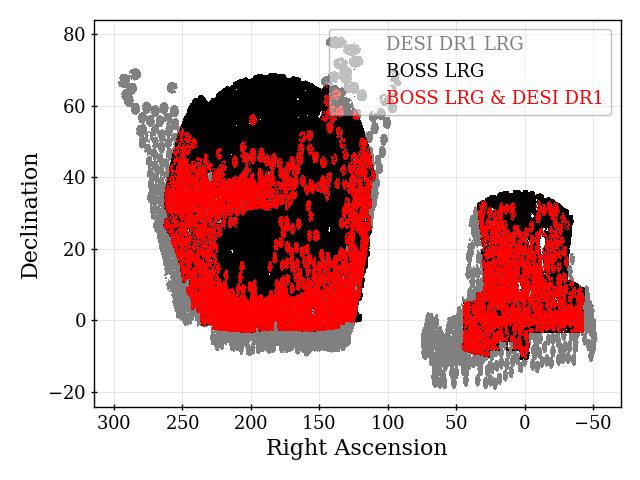
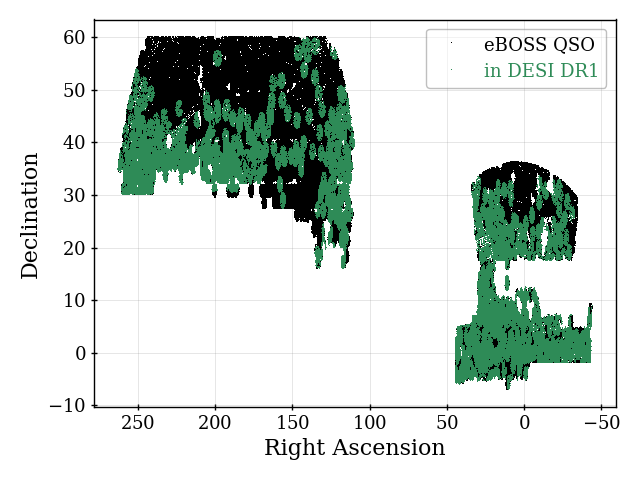
The area on the sky covered by the SDSS (e)BOSS LSS catalogs [63, 61] is a subset of that covered by DESI. DESI targeting does not take into account whether or not SDSS has already observed any potential target. Thus, a large fraction of the (e)BOSS galaxies and quasars are DESI targets. This is quantified in Figure 10, where we match between (e)BOSS LSS catalogs and DESI data by treating any targets within 1 arcsecond of each other as a match. The fractions that are matched to DESI targets are shown with solid curves. For BOSS, we match to the combination of BGS and LRG targets. The matched fraction is greater than 0.95 at low redshift, as almost all BOSS data at such redshifts have -band magnitudes brighter than 19.5. For redshifts , the DESI LRG sample dominates the matches. For both BOSS and eBOSS, the matched fraction increases with redshift. Despite the DESI number density being greater by 25%, only 65% of BOSS galaxies are targeted as DESI LRGs at . Within the eBOSS QSO LSS catalog redshift range of , the fraction that are DESI targets is always greater than 0.8 and is greater than 0.95 for .
The dashed curves in Figure 10 show the fractions of the galaxies and quasars in the (e)BOSS LSS catalogs that are matched to galaxies and quasars in the DESI DR1 LSS catalogs. Due to the redshift bounds of the DESI LSS catalogs, all SDSS LRGs with redshifts are matched to BGS galaxies, and those with are matched to DESI LRGs. The matched fraction is consistently just greater than 0.2 for LRGs and close to 0.4 for quasars. Given the overall fraction of SDSS QSOs that are DESI targets is nearly 1, and that the completeness of the DESI DR1 QSO sample is 0.87, one can infer that DESI DR1 overlaps with just less than half of the eBOSS quasar LSS sample. A similar calculation for BOSS yields a result closer to 2/5th. The overlap can be seen in Figure 11, by comparing the colored points to the black ones. Based on the gray points, one can also see that a considerable amount of the DR1 area is outside the SDSS footprint.
| Tracer and Redshift bin | DESI | SDSS |
| BGS | 300,043 | 82,398 |
| LRG | 506,911 | 138,405 |
| LRG | 771,894 | 70,979 |
| LRG | 859,822 | 10,474 |
| QSO | 856,831 | 124,726 |
We next compare the fraction of DESI DR1 galaxies that are repeats of SDSS LSS data. The numbers are found in Table 7. For BGS, 27% of the sample was already observed by BOSS (. For the LRGs, in the redshift bin we again find that 27% of the sample was already observed by BOSS. For , 9% of the sample was already observed by BOSS and eBOSS (51,175 in BOSS and 19,804 in eBOSS), while for , just 1% of the sample was already observed by BOSS and eBOSS (550 in BOSS and 9924 in eBOSS). Finally, the fraction for DESI QSO in the range the fraction is 15%.
In total, 190,277 BOSS galaxies are matched to DR1 DESI LRGs. Of these, only 602 (0.3%) have a redshift that differs by more than 0.001. For those that differ by less than 0.001, the mean is 1.4 and the standard deviation is 1.7. Comparing the DESI DR1 BGS and BOSS redshifts, the differences are all smaller: the outlier rate is 0.2%, and after rejecting outliers the mean difference is 4, and standard deviation 1.3. We expect that this level of difference will be negligible for most uses of the DESI LSS catalogs.
The measurement of quasar redshifts is much more uncertain than for galaxies, as discussed in Section 7. Thus, for comparing the DESI and SDSS quasar redshifts, we increase the outlier cut to and find that 0.5% of the DESI sample is an outlier. After removing outliers, the standard deviation of is and the mean difference, (with no scaling factor) is . These differences are consistent with the DESI quasar redshift results discussed in Section 7.
10 2-point Functions
For the DR1 clustering analysis, the information from the DESI galaxy and quasar samples is condensed into redshift-space 2-point measurements. To this end, angular positions and redshifts are converted into Cartesian coordinates using the fiducial cosmology model (see Section 1). We apply estimators in both configuration- and Fourier-space, to measure the correlation function and power spectrum respectively. These binned measurements of the 2-point functions are compared to physical models in the cosmology analyses; doing so requires both a covariance matrix of the binned measurements and knowledge of the window function that converts a smooth analytic model to the expectation of the binned measurement and accounts for the effects of the survey window and estimator bias. Each of these pieces is detailed in the following subsections.
10.1 Clustering Estimators
We describe separately below the methods for estimating the correlation function and the power spectrum.
10.1.1 Correlation Function
The anisotropic 2-point correlation function is a measure of the excess probability of finding two galaxies (at positions , ) at a separation distance and with cosine angle between their separation vector and the line-of-sight from the observer, . We use the so-called Landy-Szalay estimator [86], with the mid-point line-of-sight convention:
| (10.1) |
where the notation corresponds to the weighted number of pairs of objects and in a bin, divided by the total weighted number of pairs. Specifically, is the weighted number of data (galaxy and quasar) pairs and is the weighted number of pairs of objects in the random catalog which samples the selection function. For the autocorrelation (single-tracer) measurements performed in our analysis, by symmetry . For standard estimates, pair weights are the product of the total individual weights and of the two objects in the pair, themselves obtained as the product of systematic correction weights and FKP weights. When BAO reconstruction is applied, both data and randoms are shifted to (partially) undo non-linear structure formation and redshift-space distortions. In notation introduced in [87], the shifted data is denoted as and the shifted randoms are denoted as , and the Landy-Szalay estimator is modified to be
| (10.2) |
that is, the convention is to use the counts from the unshifted randoms as the normalization.
We use -bins up to (subsequently regrouped in bins) and bins in . The anisotropic correlation function is further projected onto the basis of Legendre polynomials to estimate the monopole (), quadrupole () and hexadecapole () moments of the correlation function:
| (10.3) |
where is the Legendre polynomial of order . In practice, the above integral is turned into a finite sum over -bins, weighted by the integral of over the bin (ensuring that multipoles of a purely isotropic signal are ).
To optimize computing time we use the technique of [88], which consists of summing , , and pair counts obtained using several random catalogs each of a size approximately matching that of the data catalog. In practice, for each tracer, there are up to 18 random catalogs available, each with a density of 2500 deg-2. We thus vary the number used for pair-counts for each tracer, choosing the number that provides at least 50x the number of data points for each case. This comes to 1, 8, 10, and 4 of the LSS catalog random files for BGS, LRG, ELG, and QSO respectively. Correlation function estimates are obtained for each galactic cap and redshift range within minutes on a NERSC Perlmutter 4 A100 GPU node. NGC and SGC measurements are then combined by summing the pair counts computed within each region.
As explained in [23], to mitigate the effect of fiber collisions, specifically the loss of galaxy pairs at small separations, so-called -cut 2-point correlation function multipoles are estimated by removing pairs at small angular separation from all terms of Eq. 10.1. This -cut, and to a lesser extent pair count binning, make the relation between the average of the measured correlation function and the theory non-trivial, such that , with a window matrix that is computed as detailed in [23].
Correlation function measurements are performed with pycorr222222https://github.com/cosmodesi/pycorr which wraps a version of the Corrfunc package [89] modified to also run on GPU and support alternative lines-of-sight (first-point, end-point) and weight definitions (PIP and angular up-weights, see Appendix C) and the -cut, along with jackknife utilities.
We use the methods described above to produce the following three types of measurements of the multipoles of the 2-point correlation function from the DESI DR1 LSS catalogs, split into the redshift bins listed in Table 3 and weighting by :
-
•
‘raw’: These are obtained directly from the catalogs, using all weighted pair-counts.
-
•
‘-cut’: These are obtained when removing all pair-counts with an angular separation .
-
•
‘reconstructed’: These are obtained using the catalogs produced after applying BAO reconstruction. The -cut is not applied.
In Section 12, we compare the raw clustering measurements from the data to those obtained from simulations of DESI DR1. The reconstructed measurements are presented in [8], where they are used to measure the BAO scale and compared to the raw pre-reconstruction results. All of these measurements will be released publicly with DR1.
10.1.2 Power Spectrum
The power spectrum estimator [90] is based on the FKP field [59]:
| (10.4) |
where and are the weighted number of galaxies and randoms painted on a grid, and is the ratio of the total weight of galaxies to that of randoms. The power spectrum multipoles can then be estimated as:
| (10.5) |
where the sum should be interpreted as an average over the Fourier-space grid within a given bin of , and , as sums over the configuration space grid. The normalization term is given by the sum over grid cells with fixed cell size of (which in practice approximates the norm of the window matrix in the middle of the -range of interest). The shot noise term is non-zero only for the monopole:
| (10.6) |
We choose the direction to the first galaxy as the ‘first-point’ line-of-sight , such that the above double integral can be split into:
| (10.7) |
with:
| (10.8) |
is then recast as a sum of Fast Fourier Transforms (FFT) following [91]. As a default, we use the TSC (triangular shaped cloud) scheme to paint galaxies onto the grid and obtain , . The Fourier-space grid is therefore compensated for by the kernel with , see [92], with the Nyquist frequency of the grid. We also implement the interlacing method to mitigate aliasing. The interlacing at order consists in painting the density field shifted by mesh cell size in , and directions, average the FFT multiplied by the appropriate phase terms, and (if required) FFT back to configuration-space, see [93]. Given the TSC assignment kernel, we found interlacing of order to be sufficient to achieve percent precision up to the Nyquist frequency.
When BAO reconstruction is applied, we use the shifted data and randoms to compute the FKP field in Eq. 10.4, while, similarly to the case of the correlation function, we estimate the normalization factor and the window matrix with the standard (unshifted) random catalogs.
In computing the gridded densities, we use physical box sizes of , , , for BGS, LRG, ELG, QSO respectively, and a grid cell size of , resulting in a Nyquist frequency of . Since the computing cost is to first order independent of the number density of points, for these measurements we use the maximum number of random catalogs available (18), which corresponds to more than 100 the data density for all tracer types.
Power spectrum estimates are obtained for each galactic cap and redshift bin with MPI within minutes (including -cut, as described below) on a Perlmutter CPU node. NGC and SGC measurements are then combined by averaging the two power spectra (with weights corresponding to the normalization amplitude in each cap). In the following, the power spectrum estimates thus obtained are called raw power spectrum measurements.
As for the correlation function, the ensemble average of power spectrum multipoles are related to the theory as . We estimate the window matrix from the 2-point selection function which we compute by concatenating the power spectra of the random catalogs obtained with box sizes , and the nominal box size used for the data power spectrum measurements. Following [94], and as detailed in [23], this window matrix also includes first-order wide-angle effects. As for the correlation function and as explained in [23], we also provide so-called -cut power spectrum estimates by removing from the standard estimator above the power spectrum of galaxy pairs at angular separation . The window matrix calculation is modified accordingly by removing such pairs from the calculation of the 2-point selection function.
In practice, to estimate power spectra we use pypower,232323https://github.com/cosmodesi/pypower which is a modified version of the nbodykit implementation [95] to account for our new definition of the normalization , and implements cross-power spectra estimation, -cut, and utilities to estimate the window matrix.
The veto masks described in Section 4—and more importantly, the implementation of the -cut—mix small and large scale modes, such that the window matrix is very non-diagonal. Convolution of this non-diagonal window with the theory power would therefore naively require specifying to scales that cannot be described by perturbation theories. Although [23] show that in practice this is not a problem for DESI, in principle it is preferable not to have a window matrix which produces sensitivity to details of the theory model above the maximum where the theory is reliable. Therefore, following [23], we rotate the data vector (composed of the binned estimated power spectrum multipoles with bins), the window matrix and the covariance matrix to the corresponding transformed quantities
| (10.9) | ||||
| (10.10) | ||||
| (10.11) |
where (of shape ) , (each of shape , with running over multipoles) and (each also of shape ) are chosen as explained in [23] by an optimisation procedure in order to make the rotated window as compact as possible and the rotated covariance as close to diagonal as possible.
The amplitude vector (of size ) is a free parameter, to be marginalized in the fit assuming a given prior. To specify this prior, we fit to minimize the difference (within scales ) between the rotated power spectrum multipoles from the AbacusSummit ‘complete’ cutsky mocks (described in Section 11.2 below) measured with the -cut, contained in , and the power spectrum multipoles of the corresponding cubic box mocks multiplied by the rotated window . The agreement between and is illustrated for the high LRG redshift bin in Figure 12, and is smaller than th of the measurement uncertainties for DR1 data: i.e., given the number of mocks used in this test we are unable to detect any systematic bias produced by this method. We then assume a Gaussian prior on with both mean and standard deviation given by the previously obtained best-fit value. In practice, is directly marginalized over at the power spectrum level, by providing as rotated power spectrum measurement and adding to the rotated covariance matrix the contribution .
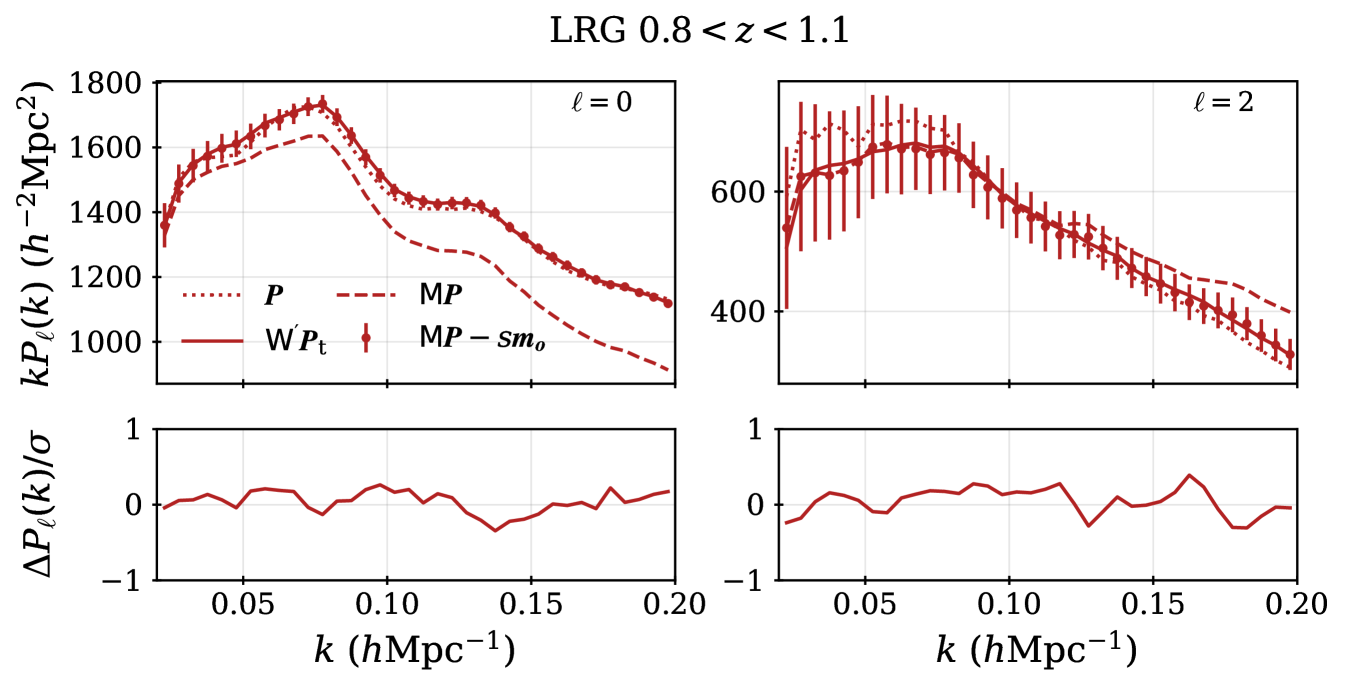
.
Finally, we implement two further systematic corrections to the measured power spectrum. First, as discussed in Section 8.1, since the redshift distribution of randoms is constructed to exactly to match that of data, radial modes in the measured power spectrum or correlation function are nulled, known as the radial integral constraint (RIC) [85]. To model this, we produce EZmock realisations of the measurements with and without the RIC effect, by creating random catalogs in which redshifts are taken from the corresponding mock data realization using the shuffle method in the former case and by sampling random redshifts from the smooth redshift selection applied in creating the mocks in the latter case. We then measure the difference in the mean of the power spectra over 50 EZmocks with and without the RIC, fit this difference with a polynomial of the form to obtain a template, and subtract this fitted template from the rotated power spectrum measured from the data. The results of this procedure are illustrated in the left panel of Figure 13 for the BGS sample. The dashed lines in the plot show the measured power difference and the solid lines show the polynomial fits. The RIC removes power for radial modes, i.e. at , where the Legendre polynomials of order are both positive, resulting in damped monopole and quadrupole power on large scales. We note that the polynomial model is a good fit to the observed RIC effect relative to the measurement uncertainties in the DR1 data indicated by the shaded bands.
The second correction is for the effect of an angular integral constraint (AIC) introduced by the use of the imaging systematic weights discussed in Section 6. These are determined by regressing the observed galaxy density with a set of maps encoding imaging properties. Depending on the exact regression method (linear, SYSNet, or Regressis), this may result in added noise and the removal of large scale angular modes. To estimate this, we use 25 AbacusSummit ‘altmtl’ cutsky mocks without imaging contamination (see Section 11.2) and as for the RIC correction, we use the difference in the mean power spectrum measurements obtained with and without the imaging weights to create a template model that is subtracted from the rotated power spectrum measured from the DR1 data. An example of this correction is shown in the right panel of Figure 13 for the ELG sample (which applied SYSNet). The AIC removes power for angular modes, i.e. at , where the Legendre polynomials of order and are positive and negative respectively. Thus on large scales it damps power in the monopole and enhances it in the quadrupole. Again the polynomial model is seen to be a good description of the observed mode-removal effect from the AIC given the measurement precision of DESI DR1.
This correction for the AIC is applied only for imaging weights derived from the SYSNet and Regressis methods for the ELG and QSO samples, as for linear regression the mode removal effect is much smaller and is barely detectable even in the mean power spectrum over 25 mocks.
For both the AIC and RIC, the correction to be applied depends on the geometry and the large-scale clustering of the given sample. This implies that the accuracy of the correction depends on how closely the mocks match the data. We expect any residual uncertainty from this dependence to be negligible for most analyses, given that the estimated size of the effect is already sub-dominant compared to the uncertainty of the DR1 measurements (as can be seen in Figure 13).
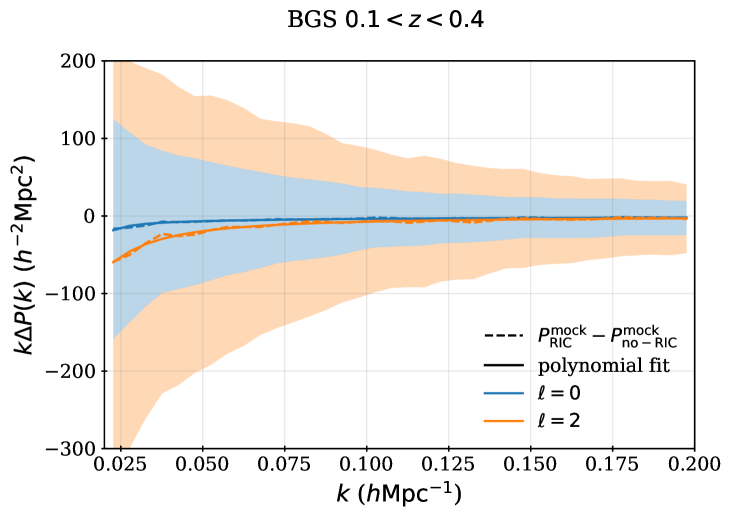
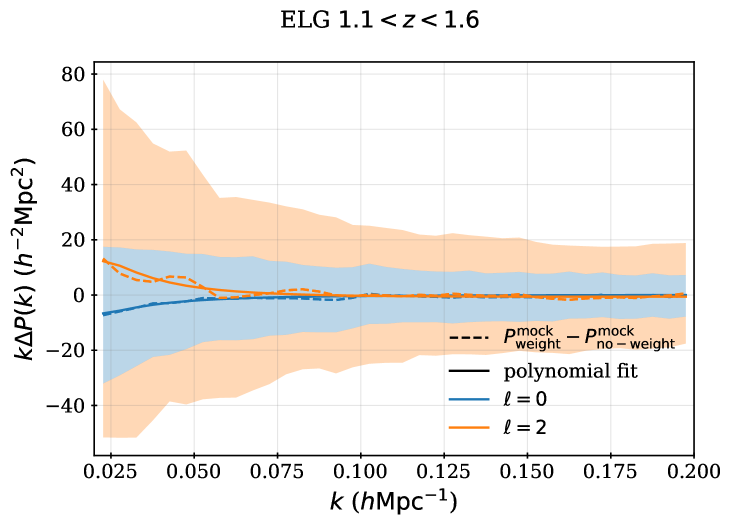
To summarise the contents of this section: we use the methods described above to produce the following four types of measurements of the multipoles of the power spectrum from the DESI DR1 LSS catalogs, split into the redshift bins listed in Table 3 and weighting by :
-
•
‘raw’: These are obtained from the direct application of the standard estimator Eq. 10.5 to the data, without further corrections.
-
•
‘-cut’: These are obtained after removing the impact of all pair-counts with an angular separation .
-
•
‘-cut+rotation+RIC+AIC’: These results are obtained from applying the window rotation and corrections for the radial integral constraint and angular integral constraint to the ‘-cut’ measurements.
-
•
‘reconstructed’: These are obtained from the DR1 catalogs after applying BAO reconstruction shifts, but without using the -cut, rotation, or RIC and AIC corrections.
In Section 12, we compare the raw clustering measurements obtained from the data and from simulations of DESI DR1. The reconstructed measurements are presented in [8], where they are used to measure the BAO scale and compared to the raw pre-reconstruction results. The -cut+rotation+RIC+AIC measurements are presented in [10] and used for the cosmological constraints obtained from the full-shape of the power spectrum [33]. All flavours of the measurements will be released publicly with DR1.
10.2 Covariances
Analytic or semi-empirical models of the covariance of DESI DR1 2-point function measurements are produced in configuration-space [29] and Fourier-space [30]. These models are validated in [31] via comparison to the clustering statistics measured from 1000 mock realizations (the EZmocks) of the DR1 data described in Section 11. There, it is found that configuration-space RascalC semi-empirical covariance matrices constructed to fit to the EZmocks match the covariance matrices constructed from the EZmocks themselves to within the expected statistical scatter. However, the RascalC covariance matrices tuned to fit the DESI DR1 data predict higher variance than is seen in the DR1 EZmocks. We interpret this as the result of the failure of the EZmocks to precisely match all aspects of the DR1 data—in particular, as described in Section 11.2 below, they only approximately reproduce the true effects of fiber assignment in the data. Since the RascalC covariance matrices are flexible enough to allow recalibration from the DR1 data, we use them for all configuration-space analysis and recommend all reanalyses of the DR1 2-point clustering results do the same.
The efforts to model the covariance in Fourier-space were less successful in reproducing the numerical covariance obtained from the EZmocks, even when tuned to these mocks. For the Fourier-space covariance matrices, we therefore use the mock-based numerical covariance, but rescale it in order to account for the mismatch between the EZmocks and the DR1 covariances seen in configuration space. The rescaling applied is determined through comparison of the configuration-space mock-based covariance and the RascalC version determined for the DR1 data: we use what [29] refer to as the ‘reduced ’ for the comparison of these covariance matrices:
| (10.12) |
and multiply the mock-based Fourier-space EZmock covariance by to account for the enhanced total variance observed in the DR1 data in configuration-space. To determine for all tracers, we use the covariance elements corresponding to the monopole and quadrupole moments in the range Mpc (without BAO reconstruction) in the expression above. We find that the obtained value of varies only at the percent level when restricting to only the monopole elements or when reducing the range of scales. The enhancement factor applied to each tracer and redshift bin is given in Table 8.
| Tracer | BGS | LRG1 | LRG2 | LRG3 | ELG1 | ELG2 | QSO |
| 1.39 | 1.15 | 1.15 | 1.22 | 1.25 | 1.29 | 1.11 |
The covariance matrices used to test cosmological models against DESI DR1 power spectra measurements in [10, 33] include additional terms that account for observational and theoretical systematic uncertainties. The full details are provided in [10]. Notably, the method to account for residual imaging systematic uncertainty, validated in [19], is included as a component of the covariance matrix.
11 DESI DR1 Simulated Data
A full description of the simulations used and the process applied to them to obtain mock DESI DR1 LSS catalogs (mocks) is provided in [24]. The mocks are produced in two sets: one based on 25 realisations of the (2Gpc)3 AbacusSummit N-body simulations [96, 97] tiled to cover the DESI DR1 volume, and the other based on (6Gpc)3 EZmocks simulations [98] that provide 1000 realizations of DESI DR1 without requiring any replication. Each type of mock is used for different applications, depending on the level of survey realism we need and the scales of analysis. Abacus mocks, coming from an N-body simulation, will reproduce the small-scale clustering with much more accuracy than EZmocks, but the computing cost to generate them limits us to 25 realizations that require some replication to simulate DESI DR1. On the other hand, the EZmocks were fast to produce, such that the computing cost for each input realization was sub-dominant compared to the post-processing steps of LSS catalog generation and analysis, but they are less precise at small scales.
In what follows, we detail the general steps that are applied to all mocks to turn them into mock DESI DR1 LSS catalogs. We divide the discussion into two subsections. The first describes how the target samples are simulated. The second describes the different ways in which the fiber assignment process is applied to the target samples, and how the LSS catalog pipeline is applied.
11.1 Simulating Target Samples
To properly simulate the DR1 data sample, we must simulate the dark- and bright-time target samples. First, we calibrate the halo occupation distributions separately for each target type (BGS, LRG, ELG, and QSOs) based on the EDR clustering signal for dark time tracers [25, 26, 27] and using early versions of the full DR1 BGS sample (without any absolute magnitude cut) for BGS, using the methods described in [99]. We use simulation boxes at different redshift snapshots. These include for BGS, for LRGs, for ELGs, and for QSO. We convert the box coordinates into angular sky coordinates and ‘real-space’ redshifts—converted directly from radial comoving distances—with respect to a chosen observer position using the fiducial DESI DR1 cosmology. To this end, for each Galactic hemisphere, we place an observer at one corner of the (6Gpc)3 box (in the case of AbacusSummit, obtained by tiling multiple copies of the smaller simulated box) and specify a line-of-sight such that the boxes cover the full DR1 comoving volume (see [19]).
To simulate the effect of redshift space distortions, we further adjust the redshift coordinate of each tracer to obtain the ‘apparent’ redshift as follows,
| (11.1) |
where denotes the ‘real-space’ redshift, indicates the peculiar velocity of the tracer, and is the unit line-of-sight vector in comoving space.
For LRGs, the box is used for simulation data with and the box is used for . For ELGs, we use the snapshot for and for . These redshift splits allow some of the evolution in the samples determined by [25, 26] to be included in our DR1 mocks.242424Including evolution at a better resolution in redshift is a goal for future DESI analyses.
We then subsample these catalogs to match the distribution estimated for a complete sample divided by the spectroscopic success rate; i.e., for dark time, we take the curves in the left-hand panel of Figure 1 and divide them by the spectroscopic success fraction reported in Table 2. For the ELGs, we use the estimated separately in the DECam and BASS/MzLS regions, but for the rest of the tracers we use the same over the entire footprint. All dark-time tracers are combined into a single target file and formatted to match the data model required to properly run DESI fiber assignment. For bright-time, the AbacusSummit mocks simulate all BGS targets and assign them absolute magnitudes. However, for the EZmocks, only a sample matching the sample we analyze is simulated. This has some consequences for the fiber assignment on the mocks, which we describe in the following subsection.
11.2 Fiber Assignment and LSS Pipeline
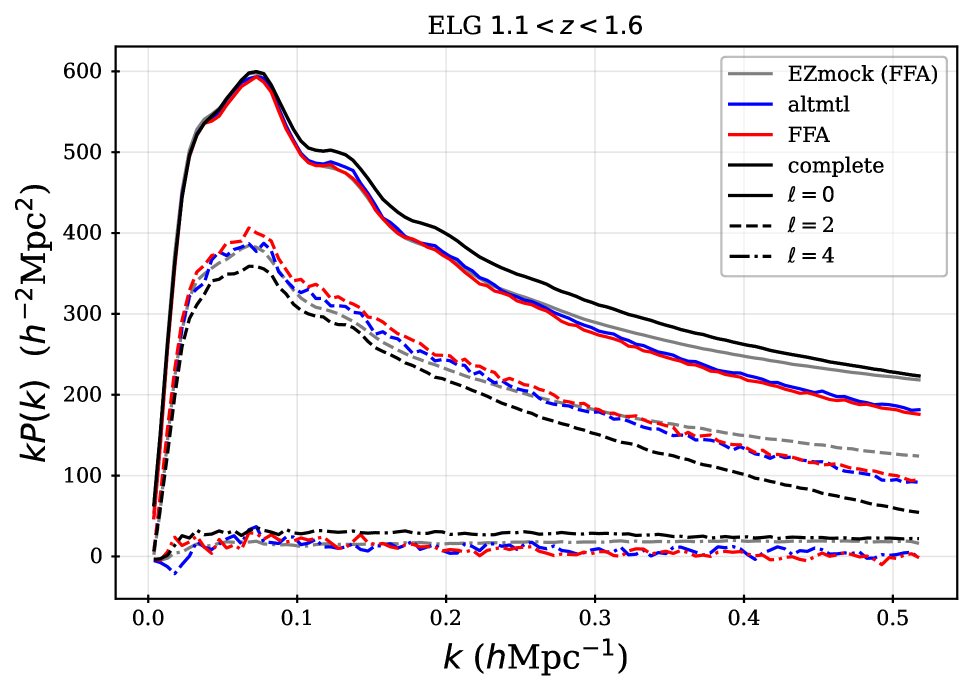
For DESI DR1, we have developed and applied three separate treatments to account for DESI fiber assignment in the mock catalogs, which we label as mock “flavors”. In all cases, we obtain the potential assignments using the same methods as applied to obtain the DR1 random samples. We are thus able to utilize the same random angular coordinates as used for the real data full_noveto samples (see Section 2.3), and with the only difference in the veto masks being the realization specific priority veto (see Section 4.2). The footprint of all of the mock flavors and the real data are thus identical and use the same hardware and imaging veto masks as the DR1 data. The only variation concerns the priority veto mask, which we describe below.
The three flavors are:
-
•
complete: For the ‘complete’ mocks, all potential assignments are treated as observed. All completeness weights are thus 1 and there is no priority veto mask to apply.
-
•
altmtl: For the ‘altmtl’ mocks, we follow the method [13] described in Section 5.2 to run the mock data through the same fiber assignment loop as the real data, considering the same hardware status and tile ordering as the DR1 processing and observing. This method allows us to run the LSS catalog pipeline in the same way as applied to the DR1 data. We expect all completeness statistics to match those of the DESI data up to the level that the underlying simulations match the DR1 data target samples252525One example of the simulations being imperfect is they are not full lightcones and thus, e.g., the ‘redshift’ at which QSO and ELG targets overlap do not correspond to the redshift output of the simulations..
-
•
FFA: The large computation time needed for the altmtl method makes running it on all 1000 EZmocks impractical. Therefore we developed a “fast-fiberassign” (FFA) [22] method to simulate DESI fiber assignment. The method uses a shallow learning algorithm to produce a fiber assignment emulator that takes the local angular density, determined via friends-of-friends with a linking length that is tuned per tracer, and as input variables. The training and assignment are applied individually to each tracer type. This means that the priority veto mask does not get applied; instead, the average effect of, e.g., QSO on LRG targets as a function of is learned, and then the FFA assignments are based on the local density of the given tracer type and . Similarly, each “assigned” target is given a probability of assignment, , and for FFA is simply its inverse. There is no decomposition into and .
We produce AbacusSummit mocks in all three flavors. For the EZmocks, we only apply FFA. For altmtl and FFA mocks, to simulate redshift failures, we simply select a random fraction of the “observed” redshifts to be failures, using a rate that provides a match to the number of good redshifts observed in each DR1 sample, to better than 99%. All flavors produce ‘full_HPmapcut’ catalogs for data and randoms that are then passed to the LSS catalog pipeline in the same way to apply redshift cuts and the steps described in Section 8. The results are catalogs with the same datamodel as the real DR1 LSS catalogs, that are closely matched in the number of redshifts and the footprint they occupy. This allows the same clustering analysis pipeline to be applied consistently to all of them. For altmtl and FFA, we expect a close match between the signal-to-noise of the resulting mock clustering measurements and real DR1 data.
Figure 14 shows the mean multipole moments of the power spectrum obtained for ELG mocks with . The results averaged across 1000 EZmocks are shown in gray; they were only generated using FFA. The complete mocks, with curves shown in black, have all targets given redshifts. One can see clear offsets between the complete mocks and all other versions, for all multipoles. This shows how much fiber assignment biases the power spectrum estimation. It is shown in [23] that when removing small-scale angular pairs via the -cut method the power spectra obtained for complete and altmtl mocks are in good agreement. One can observe a close match between the results that apply FFA (red) and those that apply the full realism of the altmtl (blue). Their agreement is further studied, including for all tracers, in [22]. The EZmocks do not approximate small-scale clustering accurately, but one can see that they produce power spectra that are a good match to those from AbacusSummit out to Mpc-1. However, despite the match in clustering amplitude, we find that the FFA mocks return clustering measurements with less variance than the altmtl mocks, see Section 10.2. Further details on the EZmocks, for all tracers, can be found in [24] and [31]. In the following section, we will compare the clustering measurement of the DR1 data to the mean obtained from altmtl mocks, for all tracers.
12 DESI DR1 raw 2-point Clustering Measurements
In this section, we present the ‘raw’ multipoles of 2-point clustering of DESI tracers in Fourier- and configuration-space and compare to the same measurements obtained from DESI DR1 mock LSS catalogs. As discussed in Section 10, these ‘raw’ measurements refer to the results obtained without applying any -cut or rotation and without BAO reconstruction. We always apply the weighting to data and random points. The 2-point functions displayed throughout this section are not those used for the BAO measurements of [8] (they used BAO reconstruction) and are not those used by [10] to constrain cosmological models (they applied the -cut, RIC and AIC corrections, and rotations). However, [10] obtain their 2-point measurements from the same LSS catalogs and redshift bins as we use in this section and we thus expect any comparison with similarly treated simulated data would yield consistent results.262626Ref. [8] used an earlier version of the catalogs, v1.2 compared to v1.5, and recovered nearly identical BAO scale measurements from the two versions.
We compare the results of the DESI DR1 2-point clustering to the mean measured on the 25 ‘altmtl’ mocks; these have had fiber assignment and an LSS pipeline applied that is fully consistent with the DR1 LSS pipeline. We thus expect the results to match to the DESI data, statistically, if the underlying input mocks are properly matched, as all window functions and integral constraints that could bias the clustering measurements are the same. We expect that any modeling framework that can obtain unbiased results on these mocks would also obtain unbiased results on the data.272727Here, we are assuming the modeling framework has been demonstrated to already perform well on mocks without such observational complexity. Specifically, we obtain values via
| (12.1) |
where represents a given multipole of a 2-point measurement and is a scaling parameter that we use to test for the level of consistency in the clustering amplitude of the mocks and DESI data. The covariance matrix is obtained as described in Section 10.2 and we do not apply any corrections to the Fourier-space results based on biases due to the use of 1000 mock realizations (given at most 80 measurement bins, any corrections are less than 10%).
We present the results of each tracer within the subsections that follow, going in order of redshift. We make comparisons over a range of scales— and in configuration and Fourier space respectively—that is is larger than the ranges used in [8] and [10] for cosmological fits, and we also present comparisons for the hexadecapole, which is not used in those papers. In cases where the clustering results from the mocks disagree with the data, we test whether a rescaling factor, for the monopole and for the quadrupole, significantly improves the agreement. When significant disagreement remains after the rescaling test, we test restricting the range of scales used for comparison. The results are summarized in Table 9. In all cases, we use the covariance matrices described in Section 10.2. In general, if we are able to find good agreement between the simulations and data with only moderate bias factors, this serves as a validation of the approach to produce the simulations, which relied on fits to the EDR clustering measurements [27, 25, 26]. Alternatively, assuming the inputs to the simulations were determined properly, finding good agreement implies that the fiber assignment and LSS catalog pipeline applied to the simulations indeed matches the process applied to the data and we are thus able to simulate these important effects.
12.1 BGS
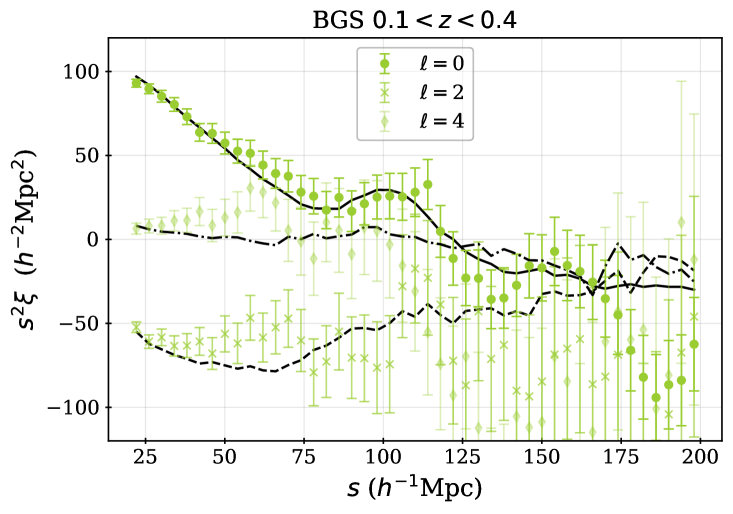
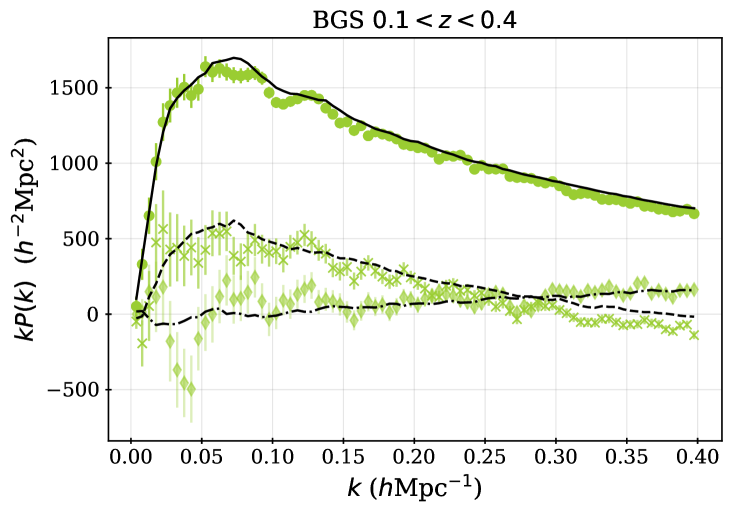
Figure 15 displays the 2-point clustering measurements for our DR1 BGS sample (points with error-bars), compared to the mean of the 25 ‘altmtl’ mocks (curves). In configuration space, we find excellent statistical agreement, given that in the range no multipole has a per degrees of freedom (dof) that is greater than 1.1, as can be seen in the first row of Table 9. In Fourier-space, the dof is greater than 1.5 for both the monopole and quadrupole. For the monopole, it can be reduced to282828There are 80 measurement bins and we remove 1 dof based on the bias parameter fit. 102.8/79 by scaling the mean of the mocks by a factor 0.9832, and improved further to292929We did not re-fit, but used the bias parameter fit to the full range and thus quote the value for 39 dof from 40 measurement bins. 37.8/39 when restricting to . This implies good agreement in the shape of the monopole of power spectrum measurements, especially at larger scales, and that the bias of the mocks is 1.5% higher than the data.
When consistently (to leading order) scaling the quadrupole by , the slightly decreases to303030The bias parameter was fit only to the monopole, so the dof are the same as the number of measurement bins, 80. 127.2/80. This implies that how the Fourer-space quadrupole changes as a function of is inconsistent with the data. However, we find that for , the dof is 31.46/40 for the quadrupole. Thus, despite the substantial scatter around the mean that can be observed in quadrupole for , the results are statistically consistent with our DR1 mocks. A similar scatter is observed for the hexadecapole, but results in acceptable in all cases.
12.2 LRG
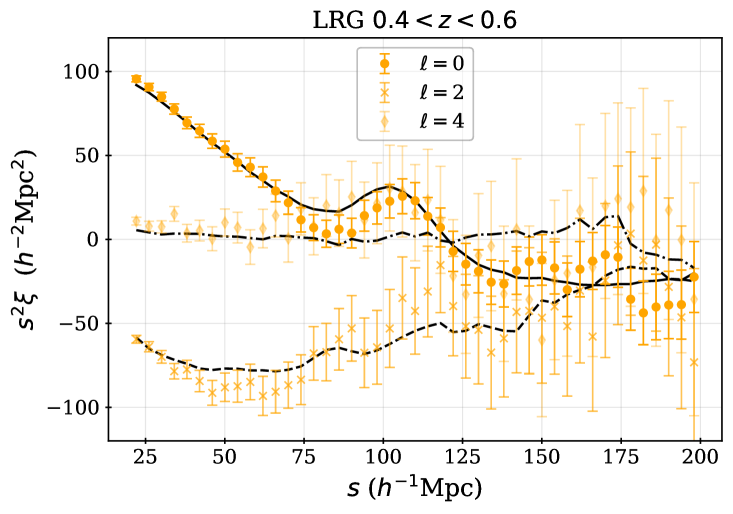
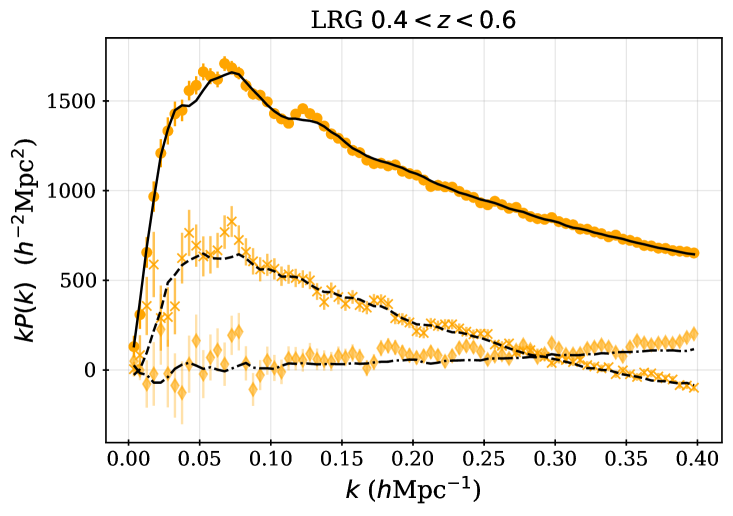
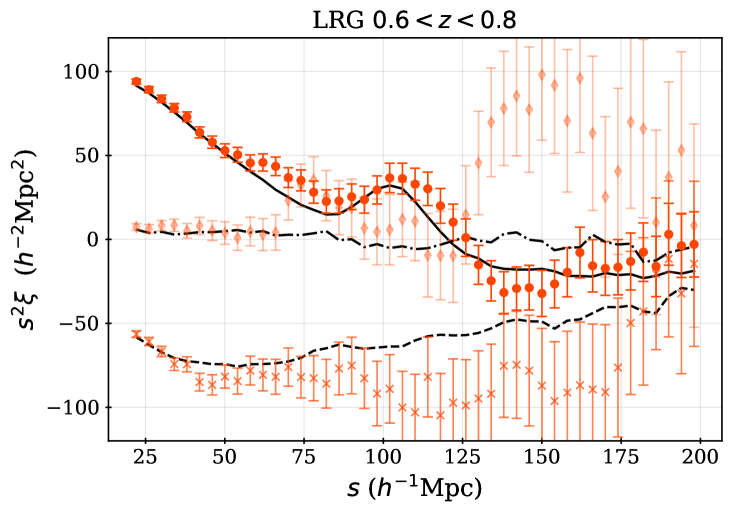
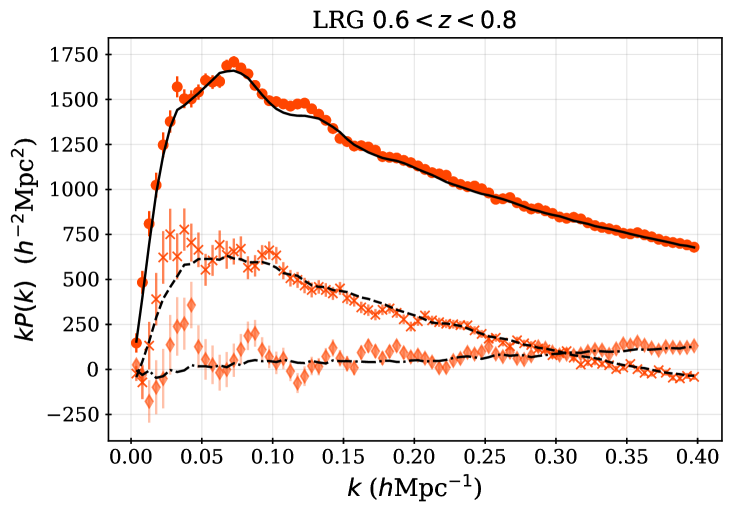
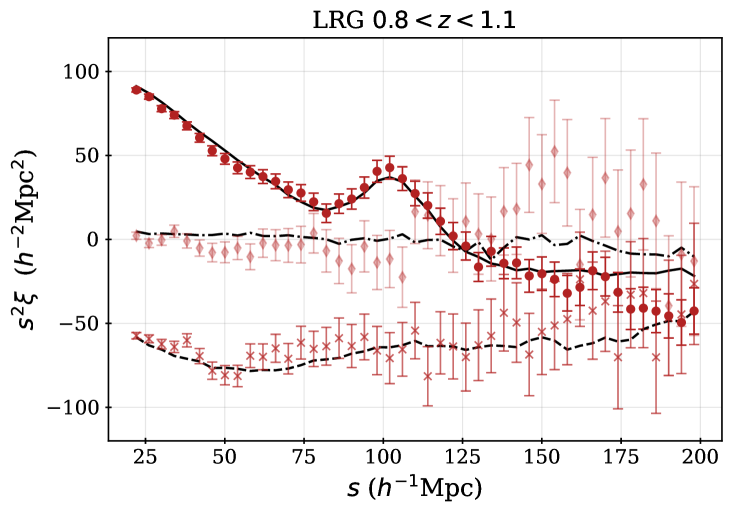
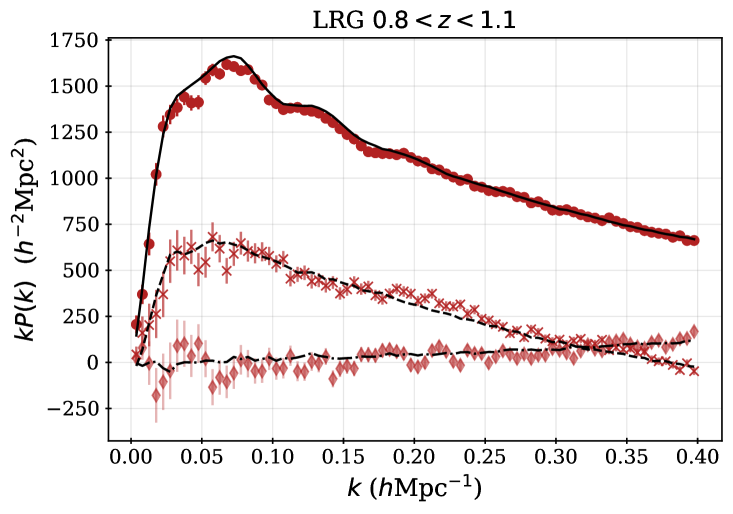
Figure 16 displays the 2-point clustering measurements for our DR1 LRG sample, split into three redshift bins, , , and . The left-hand panels display the results in configuration space, and we observe excellent statistical agreement between the mean of the mocks and the DR1 LRG data. The greatest dof found in Table 9 is 54.6/45 for the monopole of the sample. One can observe, however, that the BAO peak appears at greater Mpc values in the data compared to the mocks. This corresponds to a smaller distance to these galaxies than expected in our fiducial DESI cosmology and is fully quantified (and enhanced using BAO reconstruction) in [8].
The configuration space measurements have a strong correlation between bins. The impact of this is illustrated by the fact that all of the hexadecapole measured for the redshift bin appears greater than the mock expectation for all , yet the /dof is only 49.2/45. Similarly, the quadrupole in the same redshift bin appears coherently lower at all scales , yet the dof is only 40.6/45.
The statistical agreement between the DR1 LRGs and the altmtl mocks is somewhat worse for Fourier space, but the dof is less than or equal to 89.1/80 for 6 of the 9 cases considered. In the redshift bin, the monopole reduces from 103.8 to 97.0 when the mean of the mocks is multiplied by 1.0062; i.e., the results are thus simply consistent with a 0.6% difference between the bias of the data and mock LRG.
The dof values are greatest for LRGs in the redshift bin. Scaling the mean of the mocks can only improve the of the monopole to 122.1 and consistently scaling the quadrupole makes its slightly worse. The results in this bin thus are not consistent with a small difference in the linear galaxy bias. However, the dof are considerably improved when one considers only the range. In this case, and when assuming a linear bias factor of 0.99 (fit to the monopole), the results are 47.7/39, 51.6/40, and 44.9/40 for the dof for the monopole, quadrupole, and hexadecapole, respectively.
12.3 ELG
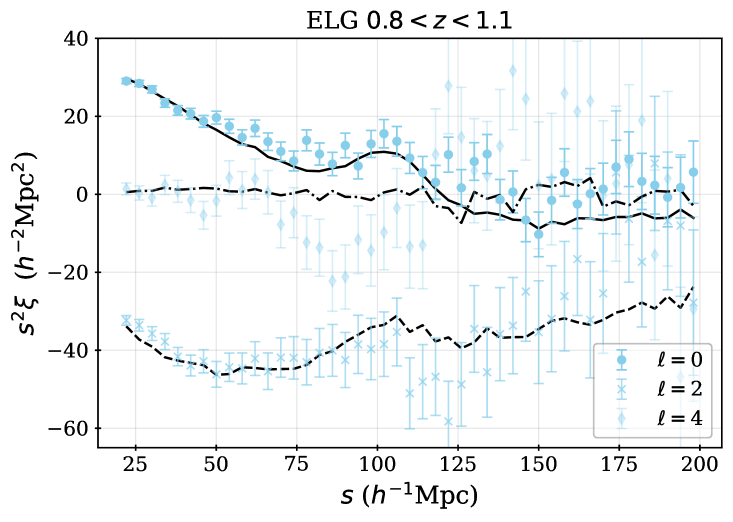
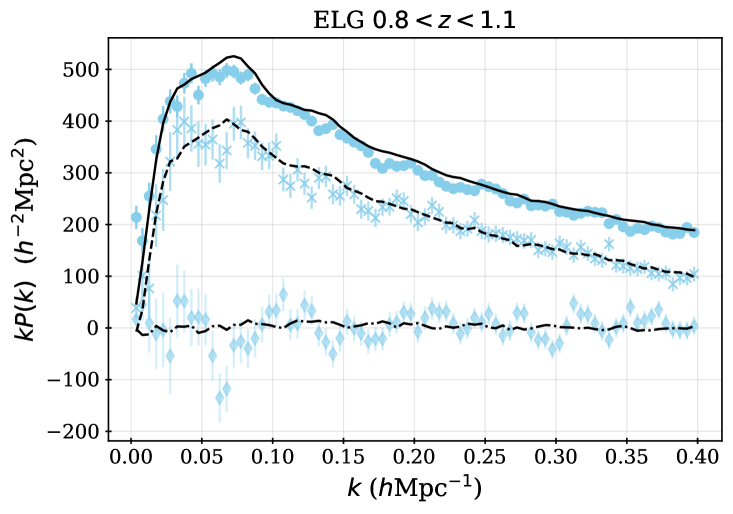
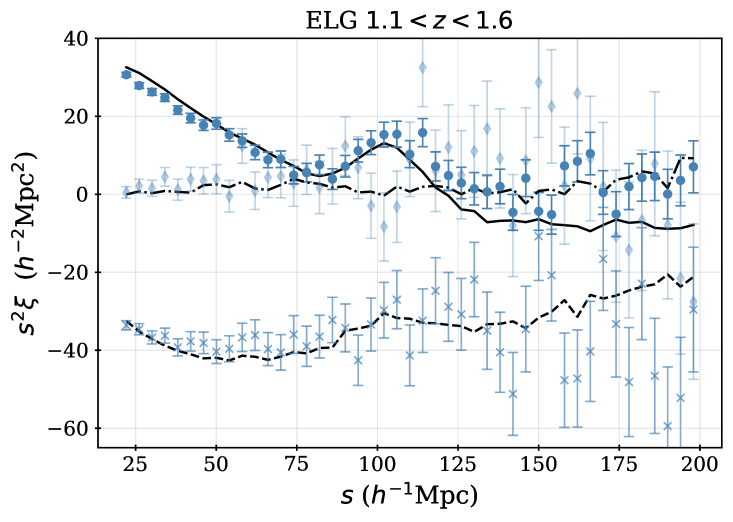
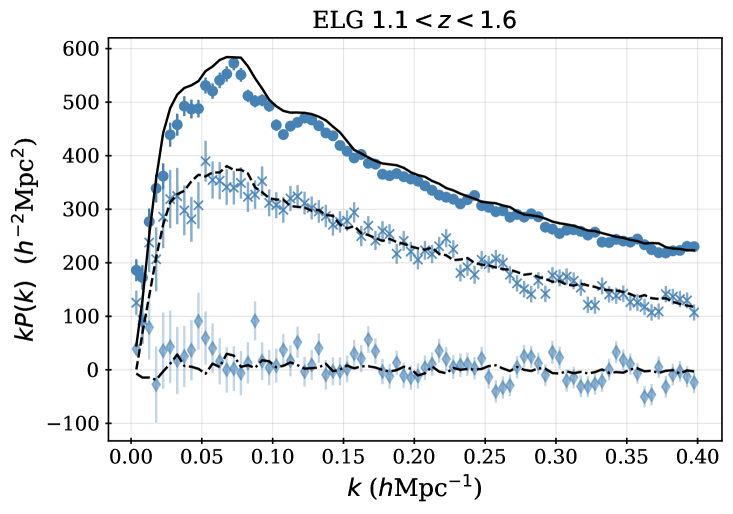
Figure 17 displays the 2-point clustering measurements for our DR1 ELG sample, split into two redshift bins, and . In configuration space, the dof (again found in Table 9) is somewhat high for the monopole in both redshift bins. In the bin, the /dof = 68.2/45 has a probability to exceed (PTE) value of 0.014, but we do not find significant improvement when rescaling the mean of the mocks. However, in the bin, the improves from 78.7 to 56.5, when the mocks are rescaled by 0.962. Consistently scaling the quadrupole by the 0.96 factor yields a slight increase in the from 59.1 to 59.8. The configuration space results are thus roughly statistically consistent with the mocks (the PTE values are 0.03 for + and 0.05 for ++, ignoring covariance between multiples), except for a 4% mismatch in the linear bias.
In Fourier space, the disagreement between the monopoles of the data and the mean of the mocks is greater than in configuration space. For the monopole, the dof is nearly 3 in both redshift bins. In both redshift bins, we find that the combination of a small re-scaling of the mock clustering and restricting to yields greatly improved values. In the bin, rescaling the monopole by 0.9762 improves the from 220.9 to 151.6. Applying the same factor in configuration space produces a negligible change, as the decreases from 68.2 to 69.0; the Fourier-space results are clearly much more sensitive to the overall clustering amplitude. When further cutting the four measurement bins with and applying the same 0.976 factor, the for the 76 measurement bins are 87.8, 69.7, and 93.1 for the Fourier-space monopole, quadrupole, and hexadecapole of the ELGs with . The results in the bin are similar. Rescaling the mock monopole can only reduce the to 154.4 using a factor 0.9792. Consistently scaling the quadrupole by 0.979 only reduces its to 133.7. However, restricting to yields values of 92.0, 79.8, and 87.6 for the 76 measurement bins for the monopole, quadrupole, and hexadecapole. The results suggest that the effective galaxy bias used for DR1 ELG simulations is just over 2% too high and that residual imaging systematics impact the measurements at the largest scales (lowest ), as we detail further below.
Excess clustering at large scales is often due to observational systematics. The ELG clustering is affected strongly by imaging systematics, which is detailed in [18]. It is likely that the excess power at observed in comparison to the mocks is due to residual observational systematics that are present even after the imaging corrections described in previous sections. The strongest source of systematic variation is from the systematic change in Galactic extinction, which can be observed in the trends displayed in Figure 9. The differences between the clustering measured without accounting for this systematic variation and that with it is are greater than 2500 in both redshift bins [18]. Despite this enormous difference, the BAO results are nearly identical, suggesting that the changes in the clustering are fully absorbed by the broadband terms in the BAO modeling. However, any studies that use broadband information must be more careful. In order to obtain structure growth measurements and account for residual systematic uncertainties, [19] develop a method that allows an additional systematic component to be added to the modeling. The systematic component is based on a smooth fit to the difference between the weighted and unweighted data in Fourier space. We recommend a similar treatment (and validation) for any study that uses the broadband information of the DESI DR1 ELG 2-point clustering measurements.
12.4 QSO
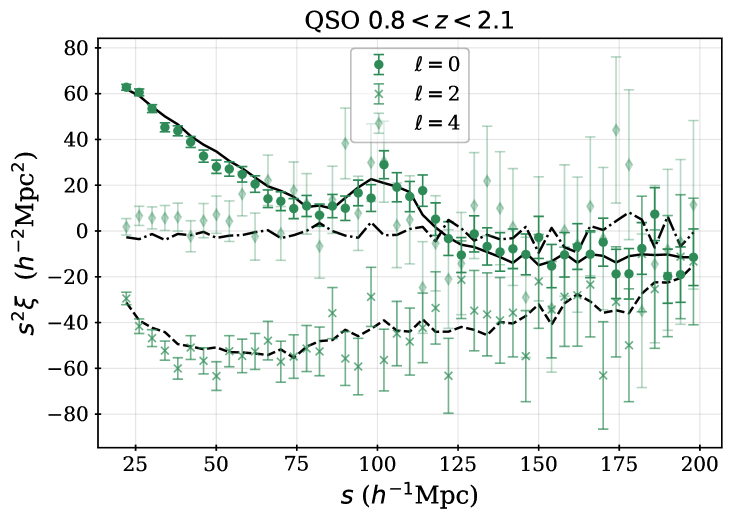
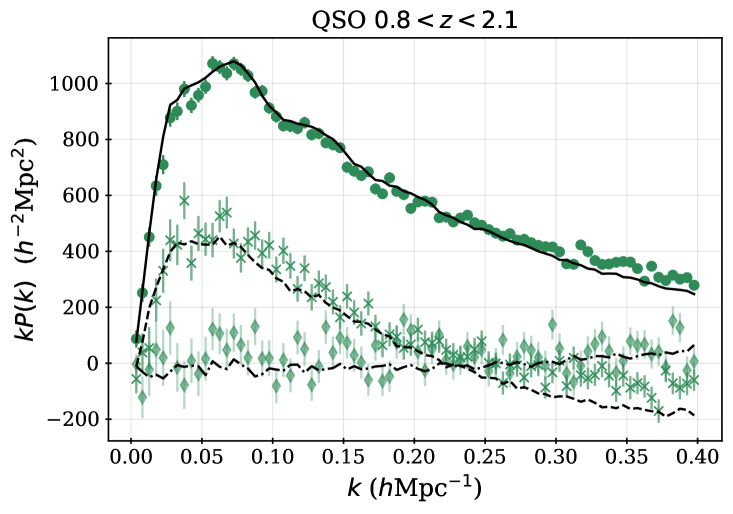
Figure 18 displays the 2-point clustering measurements for our DR1 QSO sample (points with error-bars), compared to the mean of the 25 ‘altmtl’ mocks (curves). In configuration-space, the multipoles are statistically consistent, with only the hexadecapole having a dof (once more found in Table 9) that is greater than 1.
In Fourier space, the quadrupole is most inconsistent. One can observe the amplitude in the mocks is lower and that it crosses 0 at a lower value. A linear rescaling thus does not provide significant improvement. Cutting to does provide significant improvement for the monopole and quadrupole, as the dof become 65.6/40 and 47.7/40, while the hexadecapole becomes 58.1/40. The monopole can be reduced to 49.3 when applying scaling factor 0.9882, which slightly increases the quadrupole to 49.6. Further restricting to Mpc-1 (and applying no amplitude factor) yields dof 35.0/30, 40.1/30, and 36.5/30.
The mismatch between the DESI DR1 QSO clustering in data and simulations is clearly strongly scale dependent. The amplitude of the mock becomes increasingly too small going to high , and the effect is most prominent in the quadrupole. A significant factor in the QSO clustering is the redshift uncertainty. The characteristics of the mismatch are consistent with the expected results if slightly too large of a redshift uncertainty was included in the mocks. Otherwise, the results are in reasonable agreement.
| Tracer | statistic | range | /dof mono. | /dof quad. | /dof hexadeca. | |
| BGS | 20-200 | 1 | 49.6/45 | 50.5/45 | 41.0/45 | |
| BGS | 0-0.4 | 1 | 126.5/80 | 127.7/80 | 69.8/80 | |
| BGS | 0-0.4 | 0.983 | 102.8/79 | 127.2/80 | 69.8/80 | |
| BGS | 0-0.2 | 0.983 | 37.8/39 | 31.6/40 | 29/40 | |
| LRG1 | 20-200 | 1 | 42.1/45 | 35.5/45 | 54.1/45 | |
| LRG1 | 0-0.4 | 1 | 88.7/80 | 79.7/80 | 87.9/80 | |
| LRG2 | 20-200 | 1 | 54.6/45 | 40.6/45 | 49.2/45 | |
| LRG2 | 0-0.4 | 1 | 103.8/80 | 81.7/80 | 79.0/80 | |
| LRG2 | 0-0.4 | 1.006 | 97.0/79 | 82.0/80 | 79.0/80 | |
| LRG3 | 20-200 | 1 | 42.1/45 | 51.2/45 | 47.8/45 | |
| LRG3 | 0-0.4 | 1 | 105.5/80 | 121.1/80 | 89.1/80 | |
| LRG3 | 0-0.4 | 0.993 | 95.0/79 | 121.5/80 | 89.1/80 | |
| LRG3 | 0-0.2 | 0.99 | 37.7/39 | 43.5/40 | 40.9/40 | |
| ELG1 | 20-200 | 1 | 68.2/45 | 41.2/45 | 58.8/45 | |
| ELG1 | 0-0.4 | 1 | 220.9/80 | 86.4/80 | 104.8/80 | |
| ELG1 | 0-0.4 | 0.976 | 151.6/79 | 83.6/80 | 104.8/80 | |
| ELG1 | 0.02-0.4 | 0.976 | 87.8/79 | 69.7/80 | 93.1/80 | |
| ELG2 | 20-200 | 1 | 78.7/45 | 59.1/45 | 46.5/45 | |
| ELG2 | 20-200 | 0.96 | 56.5/44 | 59.8/45 | 46.5/45 | |
| ELG2 | 0-0.4 | 1 | 234.3/80 | 135.7/80 | 107.5/80 | |
| ELG2 | 0-0.4 | 1 | 234.3/80 | 135.7/80 | 107.5/80 | |
| ELG2 | 0-0.4 | 0.979 | 154.4/79 | 133.7/80 | 107.5/80 | |
| ELG2 | 0.02-0.4 | 0.979 | 92.0/75 | 79.8/80 | 87.6/80 | |
| QSO | 20-200 | 1 | 35.7/45 | 31.5/45 | 49.7/45 | |
| QSO | 0-0.4 | 1 | 145.3/80 | 163.0/80 | 115.9/80 | |
| QSO | 0-0.2 | 1 | 65.6/40 | 47.7/40 | 58.1/40 | |
| QSO | 0-0.2 | 0.988 | 49.3/39 | 49.6/40 | 58.1/40 | |
| QSO | 0-0.15 | 1 | 35.0/30 | 40.1/30 | 36.5/40 | |
| QSO | 0-0.15 | 0.988 | 26.2/29 | 41.8/30 | 36.5/40 |
13 Conclusions
We have presented the details of LSS catalogs obtained from the DESI DR1 data, and their validation for use in DESI 2024 cosmological analyses. The catalogs contain over 5.7 million unique tracers and will be made publicly available with DESI DR1.
We have presented the methodology for the measurement of the multipoles of 2-point functions used in DESI 2024 cosmological analyses in Section 10. The raw clustering measurements obtained from these LSS catalogs are biased compared to naive theoretical expectations, due to a combination of effects from fiber assignment incompleteness, survey geometry, and integral constraint effects. Where necessary, corrections for these effects, through the combination of the application of window functions to models and correction terms to the 2-point clustering are detailed in Section 10. Specifically:
-
•
The raw clustering measurements of post-reconstruction configuration-space 2-point functions were demonstrated to provide unbiased BAO measurements [8].
-
•
Fiber assignment incompleteness biases both the total and relative amplitudes of the measured 2-point multipoles. When fitting the full-shape of DESI 2-point functions in [8], this effect is mitigated by the removal of clustering information from angular scales less than 0.05 degrees, directly in the estimator for the measurements and in the window function for the model, with full details presented in [23].
-
•
The survey geometry is accounted for using a standard window function application in Fourier-space.
-
•
The LSS catalog randoms sample the data to obtain radial information. This induces a radial integral constraint (RIC) and nulls purely radial modes in the clustering measurements. The corrections applied for imaging systematics induce stronger angular integral constraints (AIC) than would otherwise be present. We describe how an empirical correction based on the results of simulations is applied to the measured power spectra used for cosmological constraints in companion papers. Any clustering analyses that use DESI DR1 LSS catalogs may have to derive their own corrections, specific to their own clustering measurements.
We have summarized how the selection functions and corrections for systematic sources of number density variation are determined for each tracer and provided recommendations for addressing the remaining systematic uncertainties and known biases. These include:
-
•
Observational systematic uncertainties remain in the data both due to DESI spectroscopic observations and issues in the imaging data used to obtain DESI targets.
-
•
Imaging systematics have a significant impact on DESI clustering measurements, especially at low-. This is quantified in [18], where the fiducial measurements are compared to those without the imaging systematic weights derived in Section 6 are presented. No impact was found on BAO measurements. However, [19] find a significant impact for ELG and QSO full-shape measurements and derive a method to marginalize over the residual uncertainty from imaging systematics.
-
•
We recommend any clustering analysis that uses DESI DR1 LSS catalogs perform similar studies of its sensitivity to imaging systematics.
-
•
As summarized in Section 7, significant trends in the DESI spectroscopic success with observing conditions and with instrumental properties are found and documented in [20, 21]. However, the impact on 2-point clustering measurements was shown to be negligible, as was the effect of catastrophic redshift errors. We recommend similar tests to be performed on the impact on any higher-order or alternative kind of clustering statistic.
In Section 11, we have summarized the simulations of the DESI DR1 data that have been produced. In Section 12, we compared the 2-point clustering measurements of the simulations that include realistic application of DESI fiber assignment (the ‘altmtl’ mocks) to the DESI DR1 data measurements. The 2-point clustering of DESI DR1 data in configuration- and Fourier-space is generally consistent with that of simulations of DESI DR1, within a 2% factor of galaxy bias. In Fourier-space, reducing the scale range to Mpc-1 is necessary for reasonable agreement for BGS, LRG , and QSO. The combination of galaxy bias factors and small-scale disagreement indicates that improvements can be made by updating the precise manner in which galaxies occupy dark matter halos in the simulations. For ELGs, reasonable agreement requires removing scales Mpc-1, suggesting residual observational systematic contamination.
The catalogs we have presented are intended for cosmological analysis of 2-point functions on large-scales (Mpc, Mpc-1). For higher-order and alternative clustering measurements that use similarly large scales that are significantly greater than those affected by fiber collisions (0.05 degrees), we recommend using the same catalogs and using the information outlined above to account for any biases and/or systematic uncertainties in the measurements. To probe smaller scales, the effects of fiber assignment incompleteness must be corrected statistically, e.g., with PIP weights (see Section 5). DESI DR1 LSS catalogs that support PIP weights will be released as a separate version of the catalogs and are described in Appendix C.
Despite the issues described above, observational systematic uncertainties are sub-dominant to the statistical uncertainties in the DESI 2024 cosmological analyses [8, 10]. While this study is being finalized, analysis of the nearly three years of data that will be released with Data Release 2 (DR2) has begun, which contains more than 20 million good extra-Galactic redshifts. For DR2 and beyond, DESI will continue to improve the LSS catalogs, with the aim of keeping observational systematic uncertainty sub-dominant while maximizing the signal-to-noise accessible for cosmological constraints.
Acknowledgements
This material is based upon work supported by the U.S. Department of Energy (DOE), Office of Science, Office of High-Energy Physics, under Contract No. DE–AC02–05CH11231, and by the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility under the same contract. Additional support for DESI was provided by the U.S. National Science Foundation (NSF), Division of Astronomical Sciences under Contract No. AST-0950945 to the NSF’s National Optical-Infrared Astronomy Research Laboratory; the Science and Technology Facilities Council of the United Kingdom; the Gordon and Betty Moore Foundation; the Heising-Simons Foundation; the French Alternative Energies and Atomic Energy Commission (CEA); the National Council of Humanities, Science and Technology of Mexico (CONAHCYT); the Ministry of Science, Innovation and Universities of Spain (MICIU/AEI/10.13039/501100011033), and by the DESI Member Institutions: https://www.desi.lbl.gov/collaborating-institutions.
The DESI Legacy Imaging Surveys consist of three individual and complementary projects: the Dark Energy Camera Legacy Survey (DECaLS), the Beijing-Arizona Sky Survey (BASS), and the Mayall z-band Legacy Survey (MzLS). DECaLS, BASS and MzLS together include data obtained, respectively, at the Blanco telescope, Cerro Tololo Inter-American Observatory, NSF’s NOIRLab; the Bok telescope, Steward Observatory, University of Arizona; and the Mayall telescope, Kitt Peak National Observatory, NOIRLab. NOIRLab is operated by the Association of Universities for Research in Astronomy (AURA) under a cooperative agreement with the National Science Foundation. Pipeline processing and analyses of the data were supported by NOIRLab and the Lawrence Berkeley National Laboratory. Legacy Surveys also uses data products from the Near-Earth Object Wide-field Infrared Survey Explorer (NEOWISE), a project of the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration. Legacy Surveys was supported by: the Director, Office of Science, Office of High Energy Physics of the U.S. Department of Energy; the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility; the U.S. National Science Foundation, Division of Astronomical Sciences; the National Astronomical Observatories of China, the Chinese Academy of Sciences and the Chinese National Natural Science Foundation. LBNL is managed by the Regents of the University of California under contract to the U.S. Department of Energy. The complete acknowledgments can be found at https://www.legacysurvey.org/.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the U. S. National Science Foundation, the U. S. Department of Energy, or any of the listed funding agencies.
The authors are honored to be permitted to conduct scientific research on Iolkam Du’ag (Kitt Peak), a mountain with particular significance to the Tohono O’odham Nation.
Data Availability
Data from the plots in this paper will be available on Zenodo as part of DESI’s Data Management Plan.
References
- [1] M. Levi, C. Bebek, T. Beers, R. Blum, R. Cahn, D. Eisenstein et al., The DESI Experiment, a whitepaper for Snowmass 2013, arXiv e-prints (2013) arXiv:1308.0847 [1308.0847].
- [2] DESI Collaboration, A. Aghamousa, J. Aguilar, S. Ahlen, S. Alam, L.E. Allen et al., The DESI Experiment Part I: Science,Targeting, and Survey Design, arXiv e-prints (2016) arXiv:1611.00036 [1611.00036].
- [3] DESI Collaboration, A. Aghamousa, J. Aguilar, S. Ahlen, S. Alam, L.E. Allen et al., The DESI Experiment Part II: Instrument Design, arXiv e-prints (2016) arXiv:1611.00037 [1611.00037].
- [4] DESI Collaboration, B. Abareshi, J. Aguilar, S. Ahlen, S. Alam, D.M. Alexander et al., Overview of the Instrumentation for the Dark Energy Spectroscopic Instrument, AJ 164 (2022) 207 [2205.10939].
- [5] A.D. Myers, J. Moustakas, S. Bailey, B.A. Weaver, A.P. Cooper, J.E. Forero-Romero et al., The Target-selection Pipeline for the Dark Energy Spectroscopic Instrument, AJ 165 (2023) 50 [2208.08518].
- [6] A.P. Cooper, S.E. Koposov, C. Allende Prieto, C.J. Manser, N. Kizhuprakkat, A.D. Myers et al., Overview of the DESI Milky Way Survey, ApJ 947 (2023) 37 [2208.08514].
- [7] DESI Collaboration, DESI 2024 I: Data Release 1 of the Dark Energy Spectroscopic Instrument, in preparation (2025) .
- [8] DESI Collaboration, A.G. Adame, J. Aguilar, S. Ahlen, S. Alam, D.M. Alexander et al., DESI 2024 III: Baryon Acoustic Oscillations from Galaxies and Quasars, arXiv e-prints (2024) arXiv:2404.03000 [2404.03000].
- [9] DESI Collaboration, A.G. Adame, J. Aguilar, S. Ahlen, S. Alam, D.M. Alexander et al., DESI 2024 IV: Baryon Acoustic Oscillations from the Lyman Alpha Forest, arXiv e-prints (2024) arXiv:2404.03001 [2404.03001].
- [10] DESI Collaboration, DESI 2024 V: Analysis of the full shape of two-point clustering statistics from galaxies and quasars, in preparation (2024) .
- [11] E. Chaussidon et al., Constraining the local primordial non-gaussianity via the large scale-dependent bias with the DESI DR1 LRG and QSO, in preparation (2024) .
- [12] A.J. Ross, J. Aguilar, S. Ahlen, S. Alam, A. Anand, S. Bailey et al., The Construction of Large-scale Structure Catalogs for the Dark Energy Spectroscopic Instrument, arXiv e-prints (2024) arXiv:2405.16593 [2405.16593].
- [13] J. Lasker, A.C. Rosell, A.D. Myers, A.J. Ross, D. Bianchi, M.M.S. Hanif et al., Production of Alternate Realizations of DESI Fiber Assignment for Unbiased Clustering Measurement in Data and Simulations, arXiv e-prints (2024) arXiv:2404.03006 [2404.03006].
- [14] U. Andrade, J. Mena-Fernández, H. Awan, A.J. Ross, S. Brieden, J. Pan et al., Validating the Galaxy and Quasar Catalog-Level Blinding Scheme for the DESI 2024 analysis, arXiv e-prints (2024) arXiv:2404.07282 [2404.07282].
- [15] E. Chaussidon, A. de Mattia, C. Yèche, J. Aguilar, S. Ahlen, D. Brooks et al., Blinding scheme for the scale-dependence bias signature of local primordial non-Gaussianity for DESI 2024, arXiv e-prints (2024) arXiv:2406.00191 [2406.00191].
- [16] R. Zhou et al., Stellar reddening map from DESI imaging and spectroscopy, 2409.05140.
- [17] H. Kong, A.J. Ross, K. Honscheid, D. Lang, A. Porredon, A. de Mattia et al., Forward modeling fluctuations in the DESI LRGs target sample using image simulations, arXiv e-prints (2024) arXiv:2405.16299 [2405.16299].
- [18] A. Rosado-Marin et al., Mitigating Imaging Systematics for DESI DR1 Emission Line Galaxies and Beyond, in preparation (2024) .
- [19] R. Zhao et al., Impact and mitigation of imaging systematics for DESI 2024 full shape analysis, in preparation (2024) .
- [20] A. Krolewski, J. Yu, A.J. Ross, S. Penmetsa, W.J. Percival, R. Zhou et al., Impact and mitigation of spectroscopic systematics on DESI DR1 clustering measurements, arXiv e-prints (2024) arXiv:2405.17208 [2405.17208].
- [21] J. Yu, A.J. Ross, A. Rocher, O. Alves, A. de Mattia, D. Forero-Sánchez et al., ELG Spectroscopic Systematics Analysis of the DESI Data Release 1, arXiv e-prints (2024) arXiv:2405.16657 [2405.16657].
- [22] D. Bianchi et al., Characterization of DESI fiber assignment incompleteness effect on 2-point clustering and mitigation methods for 2024 analysis, in preparation (2024) .
- [23] M. Pinon, A. de Mattia, P. McDonald, E. Burtin, V. Ruhlmann-Kleider, M. White et al., Mitigation of DESI fiber assignment incompleteness effect on two-point clustering with small angular scale truncated estimators, arXiv e-prints (2024) arXiv:2406.04804 [2406.04804].
- [24] C. Zhao et al., Mock catalogues with survey realism for the DESI DR1, in preparation (2024) .
- [25] S. Yuan, H. Zhang, A.J. Ross et al., The DESI One-Percent Survey: Exploring the Halo Occupation Distribution of Luminous Red Galaxies and Quasi-Stellar Objects with AbacusSummit, arXiv e-prints (2023) arXiv:2306.06314 [2306.06314].
- [26] A. Rocher, V. Ruhlmann-Kleider, E. Burtin et al., The desi one-percent survey: exploring the halo occupation distribution of emission line galaxies with abacussummit simulations, Journal of Cosmology and Astroparticle Physics 2023 (2023) 016.
- [27] A. Smith, C. Grove, S. Cole, P. Norberg, P. Zarrouk, S. Yuan et al., Generating mock galaxy catalogues for flux-limited samples like the DESI Bright Galaxy Survey, arXiv e-prints (2023) arXiv:2312.08792 [2312.08792].
- [28] DESI Collaboration, A.G. Adame, J. Aguilar, S. Ahlen, S. Alam, G. Aldering et al., The Early Data Release of the Dark Energy Spectroscopic Instrument, AJ 168 (2024) 58 [2306.06308].
- [29] M. Rashkovetskyi, D. Forero-Sánchez, A. de Mattia, D.J. Eisenstein, N. Padmanabhan, H. Seo et al., Semi-analytical covariance matrices for two-point correlation function for DESI 2024 data, arXiv e-prints (2024) arXiv:2404.03007 [2404.03007].
- [30] O. Alves et al., Analytical covariance matrices of DESI galaxy power spectra, in preparation (2024) .
- [31] D. Forero-Sanchez et al., Analytical and EZmock covariance validation for the DESI 2024 results, in preparation (2024) .
- [32] DESI Collaboration, A.G. Adame, J. Aguilar, S. Ahlen, S. Alam, D.M. Alexander et al., DESI 2024 VI: Cosmological Constraints from the Measurements of Baryon Acoustic Oscillations, arXiv e-prints (2024) arXiv:2404.03002 [2404.03002].
- [33] DESI Collaboration, DESI 2024 VII: Cosmological constraints from full-shape analyses of the two-point clustering statistics measurements, in preparation (2024) .
- [34] Planck Collaboration, N. Aghanim, Y. Akrami, M. Ashdown, J. Aumont, C. Baccigalupi et al., Planck 2018 results. VI. Cosmological parameters, A&A 641 (2020) A6 [1807.06209].
- [35] A.D. Myers, J. Moustakas, S. Bailey, B.A. Weaver, A.P. Cooper, J.E. Forero-Romero et al., The Target-selection Pipeline for the Dark Energy Spectroscopic Instrument, AJ 165 (2023) 50 [2208.08518].
- [36] T.N. Miller, P. Doel, G. Gutierrez, R. Besuner, D. Brooks, G. Gallo et al., The Optical Corrector for the Dark Energy Spectroscopic Instrument, AJ 168 (2024) 95 [2306.06310].
- [37] J.H. Silber, P. Fagrelius, K. Fanning, M. Schubnell, J.N. Aguilar, S. Ahlen et al., The robotic multiobject focal plane system of the dark energy spectroscopic instrument (DESI), The Astronomical Journal 165 (2022) 9.
- [38] Raichoor et al. in, Dark Energy Spectroscopic Instrument Fiber Assignment, xxxx.xxxxx.
- [39] DESI Collaboration, A.G. Adame, J. Aguilar, S. Ahlen, S. Alam, G. Aldering et al., Validation of the Scientific Program for the Dark Energy Spectroscopic Instrument, arXiv e-prints (2023) arXiv:2306.06307 [2306.06307].
- [40] J. Guy, S. Bailey, A. Kremin, S. Alam, D.M. Alexander, C. Allende Prieto et al., The Spectroscopic Data Processing Pipeline for the Dark Energy Spectroscopic Instrument, AJ 165 (2023) 144 [2209.14482].
- [41] E.F. Schlafly, D. Kirkby, D.J. Schlegel, A.D. Myers, A. Raichoor, K. Dawson et al., Survey Operations for the Dark Energy Spectroscopic Instrument, arXiv e-prints (2023) arXiv:2306.06309 [2306.06309].
- [42] Raichoor et al., in preparation (2024) .
- [43] E. Chaussidon, C. Yèche, N. Palanque-Delabrouille, D.M. Alexander, J. Yang, S. Ahlen et al., Target Selection and Validation of DESI Quasars, ApJ 944 (2023) 107 [2208.08511].
- [44] R. Zhou, B. Dey, J.A. Newman, D.J. Eisenstein, K. Dawson, S. Bailey et al., Target Selection and Validation of DESI Luminous Red Galaxies, AJ 165 (2023) 58 [2208.08515].
- [45] A. Raichoor, J. Moustakas, J.A. Newman, T. Karim, S. Ahlen, S. Alam et al., Target Selection and Validation of DESI Emission Line Galaxies, AJ 165 (2023) 126 [2208.08513].
- [46] C. Hahn, M.J. Wilson, O. Ruiz-Macias, S. Cole, D.H. Weinberg, J. Moustakas et al., The DESI Bright Galaxy Survey: Final Target Selection, Design, and Validation, AJ 165 (2023) 253 [2208.08512].
- [47] A. Dey, D.J. Schlegel, D. Lang, R. Blum, K. Burleigh, X. Fan et al., Overview of the DESI Legacy Imaging Surveys, AJ 157 (2019) 168 [1804.08657].
- [48] Schlegel et al., in preparation (2024) .
- [49] H. Zou, X. Zhou, X. Fan, T. Zhang, Z. Zhou, J. Nie et al., Project Overview of the Beijing-Arizona Sky Survey, PASP 129 (2017) 064101 [1702.03653].
- [50] B. Flaugher, H.T. Diehl, K. Honscheid, T.M.C. Abbott, O. Alvarez, R. Angstadt et al., The Dark Energy Camera, AJ 150 (2015) 150 [1504.02900].
- [51] DES collaboration, The Dark Energy Survey, astro-ph/0510346.
- [52] E.L. Wright, P.R. Eisenhardt, A.K. Mainzer, M.E. Ressler, R.M. Cutri, T. Jarrett et al., The wide-field infrared survey explorer (wise): mission description and initial on-orbit performance, The Astronomical Journal 140 (2010) 1868.
- [53] D. Lang, unwise: unblurred coadds of the wise imaging, The Astronomical Journal 147 (2014) 108.
- [54] Bailey et al., in preparation (2024) .
- [55] DESI collaboration, Archetype-based Redshift Estimation for the Dark Energy Spectroscopic Instrument Survey, Astron. J. 168 (2024) 124 [2405.19288].
- [56] J. Moustakas et al., FastSpecFit: Fast spectral synthesis and emission-line fitting of DESI spectra, in prep. (2024) [xxxx.xxxxx].
- [57] K.M. Górski, E. Hivon, A.J. Banday, B.D. Wandelt, F.K. Hansen, M. Reinecke et al., HEALPix: A Framework for High-Resolution Discretization and Fast Analysis of Data Distributed on the Sphere, ApJ 622 (2005) 759 [astro-ph/0409513].
- [58] S. Brieden, H. Gil-Marín, L. Verde and J.L. Bernal, Blind Observers of the Sky, J. Cosmology Astropart. Phys 2020 (2020) 052 [2006.10857].
- [59] H.A. Feldman, N. Kaiser and J.A. Peacock, Power spectrum analysis of three-dimensional redshift surveys, Astrophys. J. 426 (1994) 23 [astro-ph/9304022].
- [60] J. Moustakas, D. Scholte, B. Dey and A. Khederlarian, “FastSpecFit: Fast spectral synthesis and emission-line fitting of DESI spectra.” Astrophysics Source Code Library, record ascl:2308.005, Aug., 2023.
- [61] A.J. Ross et al., The Completed SDSS-IV extended Baryon Oscillation Spectroscopic Survey: Large-scale structure catalogues for cosmological analysis, Mon. Not. Roy. Astron. Soc. 498 (2020) 2354 [2007.09000].
- [62] T. Karim, S. Singh, M. Rezaie, D. Eisenstein, B. Hadzhiyska, J.S. Speagle et al., Measuring using DESI Legacy Imaging Surveys Emission-Line Galaxies and Planck CMB Lensing and the Impact of Dust on Parameter Inferenc, arXiv e-prints (2024) arXiv:2408.15909 [2408.15909].
- [63] B. Reid et al., SDSS-III Baryon Oscillation Spectroscopic Survey Data Release 12: galaxy target selection and large scale structure catalogues, Mon. Not. Roy. Astron. Soc. 455 (2016) 1553 [1509.06529].
- [64] D. Bianchi and W.J. Percival, Unbiased clustering estimation in the presence of missing observations, MNRAS 472 (2017) 1106 [1703.02070].
- [65] M. Rezaie et al., Local primordial non-Gaussianity from the large-scale clustering of photometric DESI luminous red galaxies, 2307.01753.
- [66] E. Chaussidon et al., Angular clustering properties of the DESI QSO target selection using DR9 Legacy Imaging Surveys, Mon. Not. Roy. Astron. Soc. 509 (2021) 3904 [2108.03640].
- [67] J.E. Bautista et al., The SDSS-IV extended Baryon Oscillation Spectroscopic Survey: Baryon Acoustic Oscillations at redshift of 0.72 with the DR14 Luminous Red Galaxy Sample, Astrophys. J. 863 (2018) 110 [1712.08064].
- [68] BOSS collaboration, The clustering of galaxies in the completed SDSS-III Baryon Oscillation Spectroscopic Survey: Observational systematics and baryon acoustic oscillations in the correlation function, Mon. Not. Roy. Astron. Soc. 464 (2017) 1168 [1607.03145].
- [69] Gaia Collaboration, A.G.A. Brown, A. Vallenari, T. Prusti, J.H.J. de Bruijne, C. Babusiaux et al., Gaia Data Release 2. Summary of the contents and survey properties, A&A 616 (2018) A1 [1804.09365].
- [70] Y.-K. Chiang, Corrected SFD: A More Accurate Galactic Dust Map with Minimal Extragalactic Contamination, ApJ 958 (2023) 118 [2306.03926].
- [71] D.J. Schlegel, D.P. Finkbeiner and M. Davis, Maps of dust infrared emission for use in estimation of reddening and cosmic microwave background radiation foregrounds, The Astrophysical Journal 500 (1998) 525.
- [72] HI4PI Collaboration, N. Ben Bekhti, L. Flöer, R. Keller, J. Kerp, D. Lenz et al., HI4PI: A full-sky H I survey based on EBHIS and GASS, A&A 594 (2016) A116 [1610.06175].
- [73] D. Lenz, B.S. Hensley and O. Doré, A new, large-scale map of interstellar reddening derived from h i emission, The Astrophysical Journal 846 (2017) 38.
- [74] J. Yu, C. Zhao, V. Gonzalez-Perez, C.-H. Chuang, A. Brodzeller, A. de Mattia et al., The DESI One-Percent Survey: exploring a generalized SHAM for multiple tracers with the UNIT simulation, MNRAS 527 (2024) 6950 [2306.06313].
- [75] T.-W. Lan, R. Tojeiro, E. Armengaud, J.X. Prochaska, T.M. Davis, D.M. Alexander et al., The DESI Survey Validation: Results from Visual Inspection of Bright Galaxies, Luminous Red Galaxies, and Emission-line Galaxies, ApJ 943 (2023) 68 [2208.08516].
- [76] A. Raichoor, J. Moustakas, J.A. Newman, T. Karim, S. Ahlen, S. Alam et al., Target Selection and Validation of DESI Emission Line Galaxies, AJ 165 (2023) 126 [2208.08513].
- [77] A. Brodzeller, K. Dawson, S. Bailey, J. Yu, A.J. Ross, A. Bault et al., Performance of the Quasar Spectral Templates for the Dark Energy Spectroscopic Instrument, AJ 166 (2023) 66 [2305.10426].
- [78] E. Chaussidon, C. Yèche, N. Palanque-Delabrouille, D.M. Alexander, J. Yang, S. Ahlen et al., Target Selection and Validation of DESI Quasars, ApJ 944 (2023) 107 [2208.08511].
- [79] D.M. Alexander, T.M. Davis, E. Chaussidon, V.A. Fawcett, A. X. Gonzalez-Morales, T.-W. Lan et al., The DESI Survey Validation: Results from Visual Inspection of the Quasar Survey Spectra, AJ 165 (2023) 124 [2208.08517].
- [80] A. Bault, D. Kirkby, J. Guy, A. Brodzeller, J. Aguilar, S. Ahlen et al., Impact of Systematic Redshift Errors on the Cross-correlation of the Lyman- Forest with Quasars at Small Scales Using DESI Early Data, arXiv e-prints (2024) arXiv:2402.18009 [2402.18009].
- [81] S.-F. Chen, C. Howlett, M. White, P. McDonald, A.J. Ross, H.-J. Seo et al., Baryon Acoustic Oscillation Theory and Modelling Systematics for the DESI 2024 results, arXiv e-prints (2024) arXiv:2402.14070 [2402.14070].
- [82] S. Youles, J.E. Bautista, A. Font-Ribera, D. Bacon, J. Rich, D. Brooks et al., The effect of quasar redshift errors on Lyman- forest correlation functions, MNRAS 516 (2022) 421 [2205.06648].
- [83] M. Maus, Y. Lai, H.E. Noriega, S. Ramirez-Solano, A. Aviles, S. Chen et al., A comparison of effective field theory models of redshift space galaxy power spectra for desi 2024 and future surveys, arXiv e-prints (2024) arXiv:2404.07272 [2404.07272].
- [84] BOSS collaboration, The clustering of galaxies in the SDSS-III Baryon Oscillation Spectroscopic Survey: Analysis of potential systematics, Mon. Not. Roy. Astron. Soc. 424 (2012) 564 [1203.6499].
- [85] A. de Mattia and V. Ruhlmann-Kleider, Integral constraints in spectroscopic surveys, JCAP 08 (2019) 036 [1904.08851].
- [86] S.D. Landy and A.S. Szalay, Bias and Variance of Angular Correlation Functions, ApJ 412 (1993) 64.
- [87] N. Padmanabhan, X. Xu, D.J. Eisenstein, R. Scalzo, A.J. Cuesta, K.T. Mehta et al., A 2 per cent distance to =0.35 by reconstructing baryon acoustic oscillations - I. Methods and application to the Sloan Digital Sky Survey, Mon. Not. Roy. Astron. Soc. 427 (2012) 2132 [1202.0090].
- [88] E. Keihänen, H. Kurki-Suonio, V. Lindholm, A. Viitanen, A.S. Suur-Uski, V. Allevato et al., Estimating the galaxy two-point correlation function using a split random catalog, A&A 631 (2019) A73 [1905.01133].
- [89] M. Sinha and L.H. Garrison, CORRFUNC - a suite of blazing fast correlation functions on the CPU, MNRAS 491 (2020) 3022 [1911.03545].
- [90] K. Yamamoto, M. Nakamichi, A. Kamino, B.A. Bassett and H. Nishioka, A Measurement of the Quadrupole Power Spectrum in the Clustering of the 2dF QSO Survey, Publications of the Astronomical Society of Japan 58 (2006) 93.
- [91] N. Hand, Y. Li, Z. Slepian and U. Seljak, An optimal FFT-based anisotropic power spectrum estimator, J. Cosmology Astropart. Phys 2017 (2017) 002 [1704.02357].
- [92] Y.P. Jing, Correcting for the Alias Effect When Measuring the Power Spectrum Using a Fast Fourier Transform, ApJ 620 (2005) 559 [astro-ph/0409240].
- [93] E. Sefusatti, M. Crocce, R. Scoccimarro and H.M.P. Couchman, Accurate estimators of correlation functions in Fourier space, MNRAS 460 (2016) 3624 [1512.07295].
- [94] F. Beutler and P. McDonald, Unified galaxy power spectrum measurements from 6dFGS, BOSS, and eBOSS, J. Cosmology Astropart. Phys 2021 (2021) 031 [2106.06324].
- [95] N. Hand, Y. Feng, F. Beutler, Y. Li, C. Modi, U. Seljak et al., nbodykit: An Open-source, Massively Parallel Toolkit for Large-scale Structure, AJ 156 (2018) 160 [1712.05834].
- [96] N.A. Maksimova, L.H. Garrison, D.J. Eisenstein et al., AbacusSummit: a massive set of high-accuracy, high-resolution N-body simulations, Monthly Notices of the Royal Astronomical Society 508 (2021) 4017 [https://academic.oup.com/mnras/article-pdf/508/3/4017/40811763/stab2484.pdf].
- [97] L.H. Garrison, D.J. Eisenstein, D. Ferrer et al., The abacus cosmological N-body code, Monthly Notices of the Royal Astronomical Society 508 (2021) 575 [https://academic.oup.com/mnras/article-pdf/508/1/575/40458823/stab2482.pdf].
- [98] C.-H. Chuang, F.-S. Kitaura, F. Prada, C. Zhao and G. Yepes, EZmocks: extending the Zel’dovich approximation to generate mock galaxy catalogues with accurate clustering statistics, MNRAS 446 (2015) 2621 [1409.1124].
- [99] A. Smith, C. Grove, S. Cole, P. Norberg, P. Zarrouk, S. Yuan et al., Generating mock galaxy catalogues for flux-limited samples like the DESI Bright Galaxy Survey, arXiv e-prints (2023) arXiv:2312.08792 [2312.08792].
- [100] D.P. Finkbeiner, A Full-Sky H Template for Microwave Foreground Prediction, ApJS 146 (2003) 407 [astro-ph/0301558].
- [101] K.C. Chambers, E.A. Magnier, N. Metcalfe, H.A. Flewelling, M.E. Huber, C.Z. Waters et al., The Pan-STARRS1 Surveys, arXiv e-prints (2016) arXiv:1612.05560 [1612.05560].
- [102] M.F. Skrutskie, R.M. Cutri, R. Stiening, M.D. Weinberg, S. Schneider, J.M. Carpenter et al., The Two Micron All Sky Survey (2MASS), AJ 131 (2006) 1163.
- [103] Gaia Collaboration, A.G.A. Brown, A. Vallenari, T. Prusti, J.H.J. de Bruijne, C. Babusiaux et al., Gaia Early Data Release 3. Summary of the contents and survey properties, A&A 649 (2021) A1 [2012.01533].
- [104] G.M. Green, E. Schlafly, C. Zucker, J.S. Speagle and D. Finkbeiner, A 3D Dust Map Based on Gaia, Pan-STARRS 1, and 2MASS, ApJ 887 (2019) 93 [1905.02734].
- [105] N. Mudur, C.F. Park and D.P. Finkbeiner, Stellar-reddening-based Extinction Maps for Cosmological Applications, ApJ 949 (2023) 47 [2212.04514].
- [106] E.F. Schlafly, G. Green, D.P. Finkbeiner, M. Jurić, H.W. Rix, N.F. Martin et al., A Map of Dust Reddening to 4.5 kpc from Pan-STARRS1, ApJ 789 (2014) 15 [1405.2922].
- [107] Planck Collaboration, R. Adam, P.A.R. Ade, N. Aghanim, M.I.R. Alves, M. Arnaud et al., Planck 2015 results. X. Diffuse component separation: Foreground maps, A&A 594 (2016) A10 [1502.01588].
- [108] Planck Collaboration, N. Aghanim, Y. Akrami, M. Ashdown, J. Aumont, C. Baccigalupi et al., Planck 2018 results. VIII. Gravitational lensing, A&A 641 (2020) A8 [1807.06210].
Appendix A Image Property Maps
The DESI LSS catalogs utilize property maps from a range of different sources to characterize systematics associated with the imaging used for DESI target selection, and to aid science analyses. These maps exist in HEALPixel [57] format which can be used directly for regression tests. But, for some analyses, the maps are also incorporated by determining the value of each map at the locations of points in the random catalogs described in Section 4.5 of [5] (see also Section 2.1). In Table 10, we list the full set of map names included with the LSS imaging properties product.313131e.g. https://github.com/desihub/LSS/blob/v1.2-DR1/py/LSS/imaging/sky_maps.py#L64-L96 These map names sometimes propagate into files associated with LSS analyses as column names.
Each map is associated with a particular file, and we now detail each map based on its associated filename, including how the maps were derived and the nature of the file’s content. Each file is associated with a number listed in the “File” column of Table 10, and that table also summarizes some of the features of the maps.
| Map/Column name (fig. label) | Map type | File | Resolution | Nested | Galactic |
| HALPHA | Halpha | (1) | 512 | True | True |
| HALPHA_ERROR | Halpha | (2) | 512 | True | True |
| HALPHA_MASK | Halpha | (3) | 512 | True | True |
| CALIB_G | calibration | (4) | 128 | False | False |
| CALIB_R | calibration | (5) | 128 | False | False |
| CALIB_Z | calibration | (6) | 128 | False | False |
| CALIB_G_MASK | calibration | (4) | 128 | False | False |
| CALIB_R_MASK | calibration | (5) | 128 | False | False |
| CALIB_Z_MASK | calibration | (6) | 128 | False | False |
| EBV_CHIANG_SFDcorr (‘EBVnoCIB’) | EBV | (7) | 2048 | True | True |
| EBV_CHIANG_LSS_MASK | EBV | (8) | 2048 | True | True |
| EBV_MPF_Mean_FW15 | EBV | (9) | 2048 | False | True |
| EBV_MPF_Mean_ZptCorr_FW15 | EBV | (9) | 2048 | False | True |
| EBV_MPF_Var_FW15 | EBV | (9) | 2048 | False | True |
| EBV_MPF_VarCorr_FW15 | EBV | (9) | 2048 | False | True |
| EBV_MPF_Mean_FW6P1 | EBV | (9) | 2048 | False | True |
| EBV_MPF_Mean_ZptCorr_FW6P1 | EBV | (9) | 2048 | False | True |
| EBV_MPF_Var_FW6P1 | EBV | (9) | 2048 | False | True |
| EBV_MPF_VarCorr_FW6P1 | EBV | (9) | 2048 | False | True |
| EBV_SGF14 | EBV | (10) | 512 | False | True |
| EBV_SGF14_MASK | EBV | (10) | 512 | False | True |
| BETA_ML | EBV | (11) | 256 | True | True |
| BETA_MEAN | EBV | (11) | 256 | True | True |
| BETA_RMS | EBV | (11) | 256 | True | True |
| HI | NHI | (12) | 1024 | False | True |
| KAPPA_PLANCK | kappa | (13) | 2048 | False | True |
| KAPPA_PLANCK_MASK | kappa | (14) | 2048 | False | True |
| FRACAREA | pixweight-dark | (15) | 256 | True | False |
| STARDENS | stardens | (16) | 512 | True | False |
| ELG | pixweight-dark | (15) | 256 | True | False |
| LRG | pixweight-dark | (15) | 256 | True | False |
| QSO | pixweight-dark | (15) | 256 | True | False |
| BGS_ANY | pixweight-bright | (17) | 256 | True | False |
-
•
(1) Halpha_fwhm06_0512.fits; (2) Halpha_error_fwhm06_0512.fits; (3) Halpha_mask_fwhm06_0512.fits: Maps of the intensity of H emission at (FWHM) resolution, as originally compiled by [100],323232See, e.g., the Legacy Archive for Microwave Background Data Analysis at https://lambda.gsfc.nasa.gov/product/foreground/fg_halpha_get.html together with the associated error, and a mask indicating bad pixels.
-
•
(4) decam-ps1-0128-g.fits; (5) decam-ps1-0128-r.fits; decam-ps1-0128-z.fits: , and band systematic calibration residuals, in magnitudes, constructed by comparing LS stars to stars from Pan-STARRS1 (PS1) [101], in magnitudes. The sense of the residuals is LS minus PS1.
-
•
(7) Chiang23_SFD_corrected_hp2048_nest.fits; and
(8) Chiang23_mask_hp2048_nest.fits: Dust map from [70], and the associated mask of bad pixels. -
•
(9) recon_fw15_final_mult.fits: Dust maps generated from a combination of stellar reddenings derived from PS1 and 2MASS [102] photometry and Gaia EDR3 parallaxes [103], using the Bayestar stellar inference pipeline [104]. The stars are filtered so as to remove objects that are too nearby, and those that are possible extragalactic sources. Mean and variance maps are then generated for the part of the sky at Galactic Latitude that is within the PS1 footprint. Maps are generated both with a FWHM of and with a FWHM of . See [105] for more details.
-
•
(10) ps1-ebv-4.5kpc.fits: Dust map from [106], and the associated mask of bad pixels.
-
•
(11) COM_CompMap_dust-commander_0256_R2.00.fits: Thermal dust map information from [107] as served by the NASA/IPAC Infrared Science Archive.333333https://irsa.ipac.caltech.edu/data/Planck/release_2/all-sky-maps/foregrounds.html The included maps correspond to the dust emissivity index posterior maximum, mean and root mean square.
-
•
(12) NHI_HPX.fits.gz: All-sky H I column densities assembled by combining the Effelsberg-Bonn H I Survey and the third revision of the Galactic All-Sky Survey, as detailed in [72].343434See cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/594/A116#/browse
-
•
(13) dat_klm.fits; (14) mask.fits.gz: Map of lensing convergence () from Planck [108], and the associated mask indicating bad pixels. The map values are, specifically, the mean-field-subtracted minimum-variance estimate from temperature and polarization.353535See also https://wiki.cosmos.esa.int/planck-legacy-archive/index.php/Lensing The map was cut to modes of before being converted to the Healpix scheme.
-
•
(15) pixweight-1-dark.fits; (17) pixweight-1-bright.fits: Maps of values of systematics and of the density () of targets in the dark- and bright-time portions of the DESI Main Survey. Derived from the desitarget random catalog code.363636See https://github.com/desihub/desitarget/blob/1.1.1/py/desitarget/randoms.py#L1076-L1127
-
•
(16) stardens.fits: Map of the density () of stars from Gaia DR2 [69], calculated using the desitarget randoms.stellar_density() function.373737See https://github.com/desihub/desitarget/blob/1.1.1/py/desitarget/randoms.py#L942 Limited to point-like sources in the range .
To produce the Healpix maps used for DESI DR1 regression analysis, the values of the maps listed above are queried at each position in the random catalogs. These random catalogs already contained information from the Legacy Survey DR9 imaging data, including the PSF size and depth in each band.383838As detailed here https://www.LegacySurvey.org/dr9/files/#randoms-1-fits. Columns that we use to build Healpix maps include
-
•
PSFSIZE_<band>
-
•
PSFDEPTH_<band>
-
•
GALDEPTH_<band> .
After all of the desired information is matched to each random point, we create a set of maps at Healpix resolution Nside=256 in Nested format by averaging the values associated with each random point within each pixel. In this way, we can obtain the mean value in each pixel in a manner that is fully consistent with the footprint of the LSS sample. The random catalogs have small differences in their footprints due to differences in the applied veto masks. Thus, the maps used for regression analysis differ slightly for each tracer (even when the map type is the same). The only exception is for how we use the maps determined based on DESI stars in [16]. When using these maps, we simply take the original Nside=256 maps and convert them from Ring to Nested format.
Appendix B Catalog Version Changes after Unblinding
The LSS catalogs that were first used for unblinded DR1 BAO measurements are version ‘v1’. Afterward, small bugs were found and fixed that produced subsequent versions of the LSS catalogs. The first was that initially, groups of overlapping tiles found in the randoms but not the data were given zero completeness for the parameter , defined in Section 5.1. Such groups of tiles tend to be small areas with a large number of overlapping tiles, which would thus likely have a completeness of 1 if any targets existed in the area. Versions ‘v1.2’ and higher have set to 1 in these regions. The effect was greatest on the QSO sample, as it is the most sparse and thus the most likely to have targets absent from any group of overlapping tiles. After fixing the issue, we confirmed that the large-scale clustering of the (blinded) QSO sample was consistent whether we applied to the randoms or 1/ to the data. In ‘v1’, before the fix, the large-scale power of the QSO sample is significantly higher for the (fiducial) case where we apply to the randoms. Version v1.2 of the LSS catalogs for the DESI cosmology results in [8, 32].
A second issue was discovered where the ‘template signal-to-noise ratio’ TSNR2 threshold cut (defined in Section 4.1) was applied only when making the clustering catalogs. This was not a logically consistent choice, as applying such a threshold is equivalent to including the threshold in the ‘good hardware’ definition (and is part of this definition in the final catalogs). This logical inconsistency propagated to small differences in the angular distribution of data and randoms. It falsely increased the determination of the number of overlapping tiles (as all good hardware instances contribute to the number of overlapping tiles). This was fixed in version v1.3 (and all subsequent versions) by applying the TSNR2 threshold as part of the good hardware definition.
Before any Full-Shape analyses were unblinded, one further issue was found. A correlation was induced between different subsets of randoms due to the same random seed being used for the assignment of radial information to the random catalogs. This was fixed by explicitly setting a different random seed. Therefore, a version v1.4 was created, using a new stream-lined pipeline script. After v1.4 was frozen, it was noticed that the updated pipeline script had not included the application of the custom mask for the ELG sample (but it had been applied to v1.2). Thus, a v1.5 was created, which is used for the Full-Shape analysis [10]. We publicly release both versions v1.2 and v1.5.
Appendix C Catalogs for small-scale clustering measurements (PIP weighted)
As discussed in Section 5.3, the fiducial approach to mitigating fiber assignment incompleteness in the DESI 2024 cosmological analysis is to remove the angular scales within a DESI fiber patrol radius, degrees [23]. The fiducial DR1 LSS catalogs described throughout are built to be optimal for this application. Alternatively, one can correct for the effects of fiber assignment incompleteness at any scale via the combination of PIP weights and angular upweights [64]. The LSS catalogs that support such measurements must be constructed differently and are released as v1.5pip. We detail what is different about them below.
As described in Section 5.2, we obtain a total of 129 realizations of the fiber assignment of the DESI DR1 data; one for the real data and 128 using the altmtl method described in [13]. Each target in the full catalogs has information on whether it was assigned or not in each of the 128 altmtl realizations stored in a bit array, and the total probability of assignment stored as , with the number of 1 bits in , i.e. the number of realisations in which the target is assigned. Using these data, the completeness weights for the data, are determined as 1/; this is the individual inverse probability (IIP). The process outlined in Section 8.2 is then followed to obtain and , except the weights for the randoms are not multiplied by , as the IIP weights account for any source of fiber assignment incompleteness.
The process described above provides the LSS catalogs with the needed data to measure PIP-weighted 2-point clustering measurements. Then, each pair weight, is obtained as
| (C.1) |
where (defined fully in [22]) represents the expectation value of in the limit of independent probabilities and . As described in detail in [22], this expression is more robust to scale-dependent artifacts induced by the combination of low probabilities and low number of realisations of the targeting. The randoms are still weighted by .
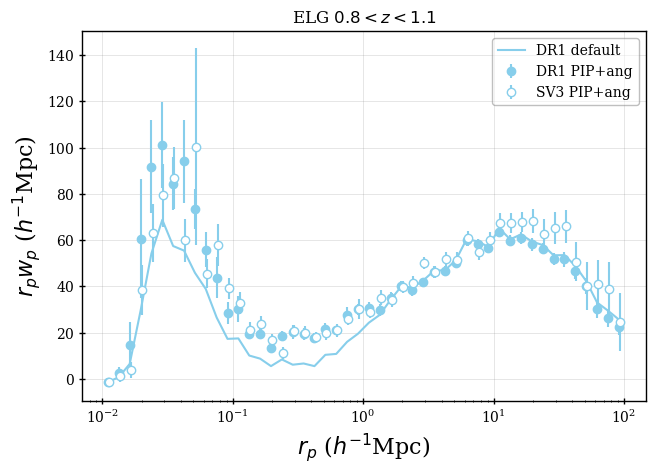
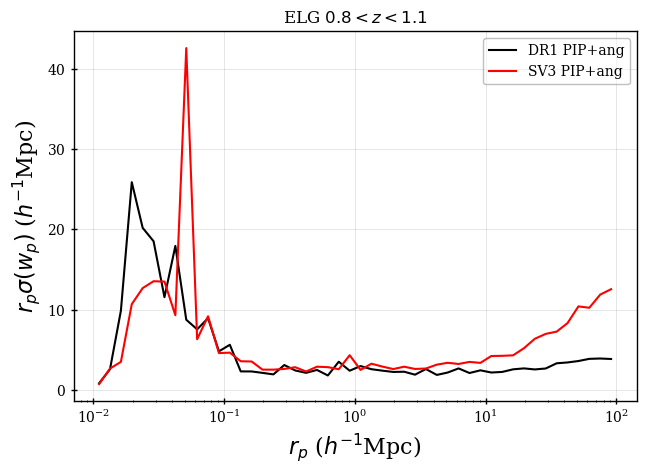
For DESI DR1 LSS catalogs, angular up-weighting is additionally necessary. This is due to much of the area being covered by only 1 or 2 tiles, which leads to a large number of pairs that have 0 probability and thus will not be included in the PIP weights. The angular up-weighting uses the angular separation of pairs in the ‘full’ LSS catalog, using all of the data (‘parent’ in [64]), and also the selection of the data that was assigned a fiber and observed (‘fibered’ in [64]). To do so consistently, we must include weights that account for the variation of and with . The mean value of these quantities in the data catalog is determined as a function of and is added as two new columns to the full LSS catalog.393939They are WEIGHT_NTILE and WEIGHT_FKP_NTILE. These weights are then applied when obtaining the pair counts used for the angular up-weighting. In practice, angular up-weights and are pre-computed as a function of angular separation with a logarithmic binning (40 bins from to ). When running pair counts with angular up-weights, these weights are interpolated linearly at the cosine separation between the galaxies of each pair.
To illustrate the impact of PIP and angular up-weighting on the measured clustering signal, we present the measured projected clustering applying PIP and angular up-weights to the DR1 v1.5pip catalogs for ELGs with in Figure 19. We compare the results to those obtained from the same weighting of EDR (SV3) [26] and those obtained from the default catalogs (v1.5) and default weighting. The projected clustering is defined by
| (C.2) |
where is the line of sight separation (with and defined in Section 10.1.1) and is the projected separation . One can observe that the PIP and angular up-weights are required to obtain small-scale clustering that is in rough agreement with the SV3 results. The sky area covered in SV3 was covered up to 13 times to minimize fiber assignment incompleteness, making it ideal for measuring small-scale clustering without major systematic concerns stemming from fiber assignment. The SV3 clustering at large scales is systematically greater than the DR1 clustering, which is likely due to some combination of correlated noise, uncorrected imaging systematics affecting the SV3 measurements, and variations in the intrinsic DESI ELG galaxy population with sky location. In the right-hand panel, we compare the uncertainty obtained from 128 jackknife realizations of the DR1 and SV3 clustering. One can observe that the uncertainty at small scales is similar for DR1 and SV3, but the improvement on large-scales is dramatic for DR1 compared to SV3. As DESI improves its coverage so that median number of overlapping tiles is greater than 4, the small-scale uncertainty will be dramatically improved.
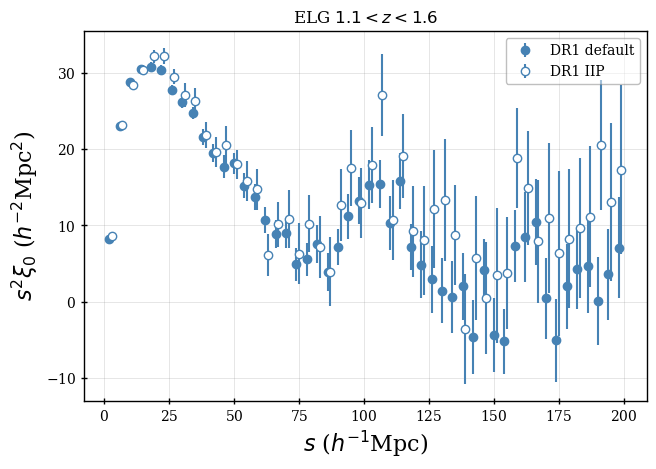

We expect that the application of PIP and angular up-weighting to the v1.5pip LSS catalogs should provide clustering measurements that are unbiased by fiber assignment incompleteness. Based on comparisons of jackknife error estimates, we find that they are noisier on large scales than the results from the fiducial catalogs (v1.5). The effect is most extreme for the ELG sample, which we show in Figure 20. In that figure, we compare the results obtained from the v1.5 catalogs with our default weighting ( on both data and randoms) to that obtained from v1.5pip with the same weighting. The difference is therefore that the IIP weight is used for v1.5pip and there is no weighting applied to the randoms. The uncertainty estimated from 60 jackknife samples is approximately 60% higher for v1.5pip. When applying PIP and angular up-weighting, the results (not shown) at large scales are nearly identical. The primary difference is in how is obtained. There is more variance in the obtained from the IIP than from . Further study of the treatment of fiber assignment incompleteness and the clustering estimators that can be applied can be found in [22].
Appendix D Color Scheme for Figures
For the DESI 2024 cosmological analyses, we consistently applied a common color scheme associated with each tracer and redshift bin. This enabled easy comparisons of the results. Here, we describe the color scheme and some of the motivation behind the choices.
Certain choices were obvious: LRGs are red and ELGs are blue. The QSO sample was given green because SDSS [61] did so for a reason not remembered; the particular shade404040All colors in ‘’ refer to named colors from https://matplotlib.org/stable/gallery/color/named_colors.html. of ‘seagreen’ was determined to be distinguishable when applying color-blindness filters using https://colororacle.org/. The Lyman forest is observed at the lowest wavelengths of DESI spectra, so they were awarded purple.
The LRG redshift bins were given the progression orange, ‘orangered’, and ‘firebrick’.For the ELGs, we used ‘skyblue’ and ‘steelblue’ for and , respectively. They make a handsome and distinguishable pair. The combination of LRG and ELG in the redshift range was given the color ‘slateblue’, which is a quite lovely shade of purple that is distinguishable from any color used by the Lyman- forest group. For BGS, chose ‘yellowgreen’ to make sure it was especially distinguishable from the lowest LRG bin. Figure 21 shows the colors of all tracers and redshift bins used in the DESI DR1 analyses.
Appendix E Glossary
A glossary of DESI quantities and jargon is available at https://data.desi.lbl.gov/doc/glossary/ and [12]. Below, we repeat some of the entries that are most relevant for this work and provide additional entries.
• assignment completeness (): The fiber assignment completeness for any arbitrary selection of targets is the number of those targets assigned to a fiber, divided by the total number of those targets.
• BGS: ‘Bright Galaxy Sample’; Galaxies targeted during bright time (see below); the sample is primarily flux-limited [46].
• bright time: DESI observations taken during ‘bright’ conditions, as defined in [41]. BGS are the only LSS targets during bright time.
• dark time: DESI observations taken during ‘dark’ conditions, as defined in [41]. ELG, LRG, QSO are observed during dark time.
• desitarget: The code package used to select targets for DESI spectroscopic observation and change their status based on their observation history; [35] https://github.com/desihub/desitarget.
• ELG: ‘Emission Line Galaxy’; a class of DESI targets (see below) selected with the expectation they will yield a detection of OII flux with redshift between 0.6 and 1.6. The selection is defined in [45].
• fiber: An individual fiber optic from a positioner on the focal plane to a spectrograph. Fibers are numbered sequentially from 0 to 4999, corresponding to value of FIBER in the catalogs.
• fiber positioner: A two-arm moveable robot holding a DESI fiber on the focal plane.
• fiberassign: The code package used to determine which targets can be assigned to which fiber on the DESI focal plane; [42], https://github.com/desihub/fiberassign.
• Legacy Surveys (LS): The program that delivered the photometric information used to select targets for DESI spectroscopy, via their Data Release 9 (DR9); [47, 48], https://www.LegacySurvey.org/dr9/.
• LOCATION: The identifier corresponding to a particular fiber positioner. Each LOCATION value has a one-to-one mapping to each FIBER value.
• LRG: ‘Luminous Red Galaxy’; a class of DESI targets distinguished by their red colours, resulting from a strong 4000 angstrom break.
• MTL: The ‘Merged Target Ledger’ contains all of the information on how the state of a target has changed. It is updated through desitarget (see above) and controls its priority in fiberassign (see above). Primarily, a target will go from unobserved (and thus high PRIORITY; see below) to observed (and thus low PRIORITY).
• PRIORITY: The quantity given to targets to determine the relative preference for assigning a fiber. The initial PRIORITY are determined based on the target type and the values are reduced after a successful observation.
• QSO: Technically ‘Quasi-Stellar Object’, but we use it synonymously with ‘quasar’; a class of DESI targets likely to be quasars [43]. Those with redshifts 2.1 are ’Lyman-’ quasars, which are at high enough redshift to allow measurement of ’Lyman-’ forest absorption.
• random: Object with celestial coordinates randomly selected at a uniform density from a specified region on the sky.
• target: Object selected via photometry for DESI spectroscopic followup by desitarget (see above), but not necessarily observed (yet) by DESI. Each has a unique TARGETID. Similarly, randoms (see above) that only occupy sky locations where there was Legacy Survey (see above) DR9 imaging were produced by desitarget and have unique TARGETID.
• tile: A single DESI pointing on the sky with assignments of which fibers should observe which targets; each has a unique TILEID.
• TILES: A string listing the tiles that the target appeared on, using the TILEIDs sorted in ascending order and separated by ‘-’. Each unique TILES represents a unique group of overlapping tiles.
• TILELOCID: The identifier we use to match to information associated with a particular tile and fiber, defined as 10000TILEID+LOCATION.
• TSNR2: Template Signal-to-Noise Squared. A signal-to-noise metric weighted by what wavelengths matter most for determining the redshift of DESI targets, given their magnitude and redshift distributions. This depends upon target class, e.g. Lyman-alpha QSO TSNR2 more heavily weights blue wavelengths, while ELG TSNR2 more heavily weights redder wavelengths which cover the emission lines for the DESI redshifts of interest. TSNR2 depends upon the noise properties of individual spectra, but not the signal properties of the target. It is fully defined in [40].
Appendix F Author Affiliations
1Instituto de Física Teórica (IFT) UAM/CSIC, Universidad Autónoma de Madrid, Cantoblanco, E-28049, Madrid, Spain
2Lawrence Berkeley National Laboratory, 1 Cyclotron Road, Berkeley, CA 94720, USA
3Physics Dept., Boston University, 590 Commonwealth Avenue, Boston, MA 02215, USA
4Tata Institute of Fundamental Research, Homi Bhabha Road, Mumbai 400005, India
5Centre for Extragalactic Astronomy, Department of Physics, Durham University, South Road, Durham, DH1 3LE, UK
6Institute for Computational Cosmology, Department of Physics, Durham University, South Road, Durham DH1 3LE, UK
7Department of Physics, University of Michigan, Ann Arbor, MI 48109, USA
8Leinweber Center for Theoretical Physics, University of Michigan, 450 Church Street, Ann Arbor, Michigan 48109-1040, USA
9IRFU, CEA, Université Paris-Saclay, F-91191 Gif-sur-Yvette, France
10Institut de Física d’Altes Energies (IFAE), The Barcelona Institute of Science and Technology, Campus UAB, 08193 Bellaterra Barcelona, Spain
11Instituto de Ciencias Físicas, Universidad Autónoma de México, Cuernavaca, Morelos, 62210, (México)
12Instituto Avanzado de Cosmología A. C., San Marcos 11 - Atenas 202. Magdalena Contreras, 10720. Ciudad de México, México
13Physics Department, Yale University, P.O. Box 208120, New Haven, CT 06511, USA
14Department of Physics and Astronomy, University of California, Irvine, 92697, USA
15Department of Physics, Kansas State University, 116 Cardwell Hall, Manhattan, KS 66506, USA
16Department of Physics & Astronomy, University of Rochester, 206 Bausch and Lomb Hall, P.O. Box 270171, Rochester, NY 14627-0171, USA
17Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
18Dipartimento di Fisica “Aldo Pontremoli”, Università degli Studi di Milano, Via Celoria 16, I-20133 Milano, Italy
19Centre for Astrophysics & Supercomputing, Swinburne University of Technology, P.O. Box 218, Hawthorn, VIC 3122, Australia
20NSF NOIRLab, 950 N. Cherry Ave., Tucson, AZ 85719, USA
21Department of Physics & Astronomy, University College London, Gower Street, London, WC1E 6BT, UK
22Department of Astronomy and Astrophysics, University of Chicago, 5640 South Ellis Avenue, Chicago, IL 60637, USA
23Fermi National Accelerator Laboratory, PO Box 500, Batavia, IL 60510, USA
24Korea Astronomy and Space Science Institute, 776, Daedeokdae-ro, Yuseong-gu, Daejeon 34055, Republic of Korea
25Institute of Cosmology and Gravitation, University of Portsmouth, Dennis Sciama Building, Portsmouth, PO1 3FX, UK
26Departamento de Astrofísica, Universidad de La Laguna (ULL), E-38206, La Laguna, Tenerife, Spain
27Instituto de Astrofísica de Canarias, C/ Vía Láctea, s/n, E-38205 La Laguna, Tenerife, Spain
28Department of Physics and Astronomy, University of Sussex, Brighton BN1 9QH, U.K
29Departamento de Física, Instituto Nacional de Investigaciones Nucleares, Carreterra México-Toluca S/N, La Marquesa, Ocoyoacac, Edo. de México C.P. 52750, México
30Institute for Advanced Study, 1 Einstein Drive, Princeton, NJ 08540, USA
31Center for Cosmology and AstroParticle Physics, The Ohio State University, 191 West Woodruff Avenue, Columbus, OH 43210, USA
32NASA Einstein Fellow
33School of Mathematics and Physics, University of Queensland, 4072, Australia
34Department of Physics and Astronomy, The University of Utah, 115 South 1400 East, Salt Lake City, UT 84112, USA
35Instituto de Física, Universidad Nacional Autónoma de México, Cd. de México C.P. 04510, México
36CIEMAT, Avenida Complutense 40, E-28040 Madrid, Spain
37Department of Physics & Astronomy and Pittsburgh Particle Physics, Astrophysics, and Cosmology Center (PITT PACC), University of Pittsburgh, 3941 O’Hara Street, Pittsburgh, PA 15260, USA
38Department of Astronomy, School of Physics and Astronomy, Shanghai Jiao Tong University, Shanghai 200240, China
39Space Sciences Laboratory, University of California, Berkeley, 7 Gauss Way, Berkeley, CA 94720, USA
40University of California, Berkeley, 110 Sproul Hall #5800 Berkeley, CA 94720, USA
41Universities Space Research Association, NASA Ames Research Centre
42Center for Astrophysics Harvard & Smithsonian, 60 Garden Street, Cambridge, MA 02138, USA
43Department of Physics, The Ohio State University, 191 West Woodruff Avenue, Columbus, OH 43210, USA
44The Ohio State University, Columbus, 43210 OH, USA
45Kavli Institute for Particle Astrophysics and Cosmology, Stanford University, Menlo Park, CA 94305, USA
46SLAC National Accelerator Laboratory, Menlo Park, CA 94305, USA
47Instituto de Astrofísica de Andalucía (CSIC), Glorieta de la Astronomía, s/n, E-18008 Granada, Spain
48Institute of Physics, Laboratory of Astrophysics, École Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, Chemin Pegasi 51, CH-1290 Versoix, Switzerland
49Departamento de Física, Universidad de los Andes, Cra. 1 No. 18A-10, Edificio Ip, CP 111711, Bogotá, Colombia
50Observatorio Astronómico, Universidad de los Andes, Cra. 1 No. 18A-10, Edificio H, CP 111711 Bogotá, Colombia
51Department of Physics, The University of Texas at Dallas, Richardson, TX 75080, USA
52Institut d’Estudis Espacials de Catalunya (IEEC), 08034 Barcelona, Spain
53Institute of Space Sciences, ICE-CSIC, Campus UAB, Carrer de Can Magrans s/n, 08913 Bellaterra, Barcelona, Spain
54Departament de Física Quàntica i Astrofísica, Universitat de Barcelona, Martí i Franquès 1, E08028 Barcelona, Spain
55Institut de Ciències del Cosmos (ICCUB), Universitat de Barcelona (UB), c. Martí i Franquès, 1, 08028 Barcelona, Spain.
56Consejo Nacional de Ciencia y Tecnología, Av. Insurgentes Sur 1582. Colonia Crédito Constructor, Del. Benito Juárez C.P. 03940, México D.F. México
57Departamento de Física, Universidad de Guanajuato - DCI, C.P. 37150, Leon, Guanajuato, México
58Centro de Investigación Avanzada en Física Fundamental (CIAFF), Facultad de Ciencias, Universidad Autónoma de Madrid, ES-28049 Madrid, Spain
59Excellence Cluster ORIGINS, Boltzmannstrasse 2, D-85748 Garching, Germany
60University Observatory, Faculty of Physics, Ludwig-Maximilians-Universität, Scheinerstr. 1, 81677 München, Germany
61Department of Astrophysical Sciences, Princeton University, Princeton NJ 08544, USA
62Institut d’Astrophysique de Paris. 98 bis boulevard Arago. 75014 Paris, France
63Department of Astronomy, University of Florida, 211 Bryant Space Science Center, Gainesville, FL 32611, USA
64Institute for Fundamental Physics of the Universe, via Beirut 2, 34151 Trieste, Italy
65International School for Advanced Studies, Via Bonomea 265, 34136 Trieste, Italy
66Kavli Institute for Cosmology, University of Cambridge, Madingley Road, Cambridge CB3 0HA, UK
67Department of Astronomy, The Ohio State University, 4055 McPherson Laboratory, 140 W 18th Avenue, Columbus, OH 43210, USA
68Department of Physics, Southern Methodist University, 3215 Daniel Avenue, Dallas, TX 75275, USA
69The Ohio State University, Columbus, 43210 OH, USA”
70Department of Physics and Astronomy, University of Waterloo, 200 University Ave W, Waterloo, ON N2L 3G1, Canada
71Perimeter Institute for Theoretical Physics, 31 Caroline St. North, Waterloo, ON N2L 2Y5, Canada
72Waterloo Centre for Astrophysics, University of Waterloo, 200 University Ave W, Waterloo, ON N2L 3G1, Canada
73Graduate Institute of Astrophysics and Department of Physics, National Taiwan University, No. 1, Sec. 4, Roosevelt Rd., Taipei 10617, Taiwan
74Schmidt Sciences, 155 W 23rd St, New York, NY 10011, USA
75Sorbonne Université, CNRS/IN2P3, Laboratoire de Physique Nucléaire et de Hautes Energies (LPNHE), FR-75005 Paris, France
76Department of Astronomy and Astrophysics, UCO/Lick Observatory, University of California, 1156 High Street, Santa Cruz, CA 95064, USA
77Department of Astronomy and Astrophysics, University of California, Santa Cruz, 1156 High Street, Santa Cruz, CA 95065, USA
78Department of Astronomy & Astrophysics, University of Toronto, Toronto, ON M5S 3H4, Canada
79University of Science and Technology, 217 Gajeong-ro, Yuseong-gu, Daejeon 34113, Republic of Korea
80Departament de Física, Serra Húnter, Universitat Autònoma de Barcelona, 08193 Bellaterra (Barcelona), Spain
81Laboratoire de Physique Subatomique et de Cosmologie, 53 Avenue des Martyrs, 38000 Grenoble, France
82Institució Catalana de Recerca i Estudis Avançats, Passeig de Lluís Companys, 23, 08010 Barcelona, Spain
83Max Planck Institute for Extraterrestrial Physics, Gießenbachstraße 1, 85748 Garching, Germany
84Department of Physics and Astronomy, Siena College, 515 Loudon Road, Loudonville, NY 12211, USA
85Department of Physics & Astronomy, University of Wyoming, 1000 E. University, Dept. 3905, Laramie, WY 82071, USA
86National Astronomical Observatories, Chinese Academy of Sciences, A20 Datun Rd., Chaoyang District, Beijing, 100012, P.R. China
87Steward Observatory, University of Arizona, 933 N, Cherry Ave, Tucson, AZ 85721, USA
88Aix Marseille Univ, CNRS, CNES, LAM, Marseille, France
89Departament de Física, EEBE, Universitat Politècnica de Catalunya, c/Eduard Maristany 10, 08930 Barcelona, Spain
90Aix Marseille Univ, CNRS/IN2P3, CPPM, Marseille, France
91University of California Observatories, 1156 High Street, Sana Cruz, CA 95065, USA
92Department of Physics & Astronomy, Ohio University, Athens, OH 45701, USA
93Department of Physics and Astronomy, Sejong University, Seoul, 143-747, Korea
94Abastumani Astrophysical Observatory, Tbilisi, GE-0179, Georgia
95Faculty of Natural Sciences and Medicine, Ilia State University, 0194 Tbilisi, Georgia
96Space Telescope Science Institute, 3700 San Martin Drive, Baltimore, MD 21218, USA
97Centre for Advanced Instrumentation, Department of Physics, Durham University, South Road, Durham DH1 3LE, UK
98Physics Department, Brookhaven National Laboratory, Upton, NY 11973, USA
99Beihang University, Beijing 100191, China
100Department of Astronomy, Tsinghua University, 30 Shuangqing Road, Haidian District, Beijing, China, 100190
101Physics Department, Stanford University, Stanford, CA 93405, USA
102Department of Physics, University of California, Berkeley, 366 LeConte Hall MC 7300, Berkeley, CA 94720-7300, USA
103Institute of Physics, Laboratory of Astrophysics, École Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, CH-1290 Versoix, Switzerland