DESI DR1 Ly 1D power spectrum: The Fast Fourier Transform estimator measurement
Abstract
We present the one-dimensional Lyman- forest power spectrum measurement derived from the data release 1 (DR1) of the Dark Energy Spectroscopic Instrument (DESI). The measurement of the Lyman- forest power spectrum along the line of sight from high-redshift quasar spectra provides information on the shape of the linear matter power spectrum, neutrino masses, and the properties of dark matter. In this work, we use a Fast Fourier Transform (FFT)-based estimator, which is validated on synthetic data in a companion paper. Compared to the FFT measurement performed on the DESI early data release, we improve the noise characterization with a cross-exposure estimator and test the robustness of our measurement using various data splits. We also refine the estimation of the uncertainties and now present an estimator for the covariance matrix of the measurement. Furthermore, we compare our results to previous high-resolution and eBOSS measurements. In another companion paper, we present the same DR1 measurement using the Quadratic Maximum Likelihood Estimator (QMLE). These two measurements are consistent with each other and constitute the most precise one-dimensional power spectrum measurement to date, while being in good agreement with results from the DESI early data release.
1 Introduction
The Lyman- (Ly) forest is a set of resonant Ly (Å) absorption features imprinted in the spectra of background objects, such as quasars, caused by intervening neutral hydrogen overdensities in the intergalactic medium (IGM) along their lines-of-sight. From ground-based observations, the Ly forest is measured in the redshift range . At higher redshift, the ionization state of the IGM is such that Ly absorption is near-complete, while the atmospheric UV cutoff constrains lower redshift observations.
Thanks to the redshift effect, the absorption features measured at different but closeby wavelengths probe separate, closeby, IGM regions: for example, at , absorptions seen at Å separation are sourced on average by clouds of IGM separated by Mpc. This property makes the Ly forest a unique probe to study the matter density field on small cosmological scales at [1, 2, 3, 4].
Many summary statistics based on Ly measurements have been used to infer properties of the IGM and the underlying matter field (e.g. [5, 6, 7]). Here, we focus on , the one-dimensional power spectrum of the fluctuations of the Ly transmission field along lines-of-sight. The Ly transmitted flux fraction is the relative IGM Ly absorption as a function of wavelength in the observer’s frame, i.e., the ratio of the measured flux to the background source’s intrinsic flux, in the absence of any contaminants such as absorptions by metals or instrumental effects. The corresponding flux contrast is , and is the one-dimensional power spectrum of the Ly forest signal in . As a decisive advantage, is quite directly connected to the linear matter power spectrum at redshift and near-Mpc scales (e.g. [8, 9]). As a consequence, measurements has been used to test several cosmological scenarios, such as a running of the primordial matter power spectrum, the effect of the sum of neutrino masses [10, 11, 12, 13, 14], and several dark matter models such as warm [15, 16, 17, 18, 13, 19, 14], fuzzy [20, 21], or interacting dark matter [22], or primordial black holes [23].
The Dark Energy Spectroscopic Instrument (DESI) survey [24, 25, 26] provides an unprecedented sample of high-redshift quasar spectra from which Ly forest information can be extracted. A major goal of DESI is to measure the three-dimensional auto-correlation of the Ly forest, as well as its cross-correlation with quasar positions, on large scales, to derive the BAO scale and linear growth of structures at redshift [27, 28, 29, 30, 31, 32]. In this article, we focus on the one-dimensional correlations of the Ly forest, which can be studied down to small scales thanks to DESI spectral resolution ( for wavelength ranging from to Å). In [33, 34], we reported on the first measurements of the related power spectrum based on the DESI Early Data Release (EDR) [35, 36] and its first two months (M2) data sample (noted EDR+M2 hereafter). Two different estimators were used to compute , one based on the Fast-Fourier Transform of individual 1D spectra (FFT [33] and noted R23 hereafter), and one based on a Quadratic Maximum Likelihood Estimator (QMLE, [34]). In this article, as well as companion papers [37, 38] (noted K25 and KR25 hereafter), we update those measurements, using the vastly larger (five times more) Ly sample included in the DESI Data Release 1 (DR1) [39], built from the first year of DESI main survey. In addition to the massive statistical gain, we present a series of analysis improvements and robustness tests.
Given the abundance of quasar spectra collected over the years from different instruments, several measurements of were performed over a range of redshifts and wavenumbers. On the one hand, with high-resolution spectra from, e.g., VLT/UVES [40], VLT/X-shooter [41] or Keck [42, 43], was measured for large values of the wavenumber . On the other hand, was estimated for smaller values of , and with higher statistical precision, thanks to the massive Ly forest samples from the first SDSS spectroscopic survey, the Baryon Oscillation Spectroscopic Survey (BOSS)[44] and follow-up eBOSS[45] surveys. Compared to BOSS and eBOSS data, the Ly spectra from DESI have a better spectral resolution, therefore enabling measurements of up to larger , overlapping with the measurements derived from the high-resolution samples.
The outline of this paper is as follows. After presenting the dataset used in section 2, including the catalogs of contaminants, we describe the current implementation of the FFT method in section 3, and present a new characterization of the impact of instrumental properties, especially the noise in section 4. We then discuss in section 5 a series of data splits and analysis variations that were used to assess the robustness of the measurement. After that, we turn to our estimate of the statistical covariance and systematic uncertainties in section 6. Finally, we present in section 7 our measurement and compare it to high-resolution and eBOSS measurements.
2 Data
2.1 The DESI DR1 data set
The Dark Energy Spectroscopic Instrument (DESI) is a multi-object spectrograph whose purpose is to measure the spectra of more than million galactic (stars) and extra-galactic objects (galaxies and quasars). The main science goal of DESI is to infer the properties of dark energy using Baryon Acoustic Oscillations (BAO) and Redshift Space Distortions (RSD) measured in galaxy, quasars, and Ly correlation functions. Additionally, the significant statistics and variety of observations allows DESI to cover broader scientific objectives, including the one presented in this article. The focal plane of DESI is equipped with robotic fiber positioners [25, 46, 47, 48, 49] to quickly reconfigure the observation pattern and point towards pre-selected targets [50]. A full description of the DESI instrument is given in [26]. We use the first data release noted DESI-DR1 (or DR1 for conciseness), which results from the first year of DESI observation [39].
2.2 Quasar catalog and spectra
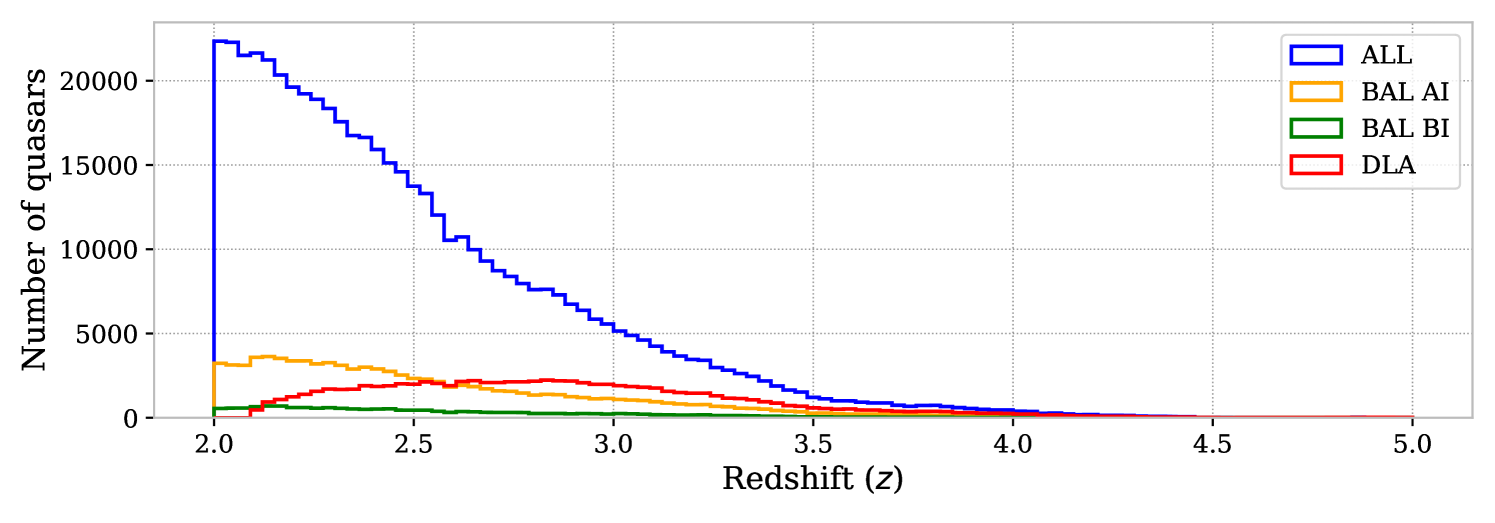
Quasars candidates are pre-selected with a dedicated targeting to obtain a denser sample of high-redshift targets [50, 51, 52]. The DESI-DR1 quasar sample is constructed by automated classifiers. A first template fitting software called redrock \faGithub111https://github.com/desihub/redrock [53] is used to classify quasars, galaxies, and stars, and to provide a robust redshift measurement. A dedicated neural network software called QuasarNet \faGithub222https://github.com/desihub/QuasarNP [54, 55] picks up quasars missed by redrock. As QuasarNet is designed explicitly for classification, the redshift of retrieved quasars is determined by running redrock again with an informed prior. Finally, a Mgii line fitter algorithm catches low-redshift quasars () whose redshifts were correctly measured, but which have been classified as objects of another type. The full description of the pipeline used to generate the quasar catalog is given in [52]. The histogram of the DR1 quasar redshifts is represented in figure 1. It contains quasars with a redshift in the Ly forest range of interest ().
Several modifications are made to this quasar catalog. First, spectra from secondary target programs dedicated to the search for high-redshift quasars are added. A visual inspection campaign of those targets is carried out (see the companion paper K25 for more details). Second, we remove quasars whose measured individual power spectrum appears as an outlier. The full DR1 sample cannot be entirely visually inspected and still contains outliers passing the automated classifier criteria. We carry out a pre-study in which the individual power spectrum of each Ly forest is measured. Taking the full DR1 catalog, we remove quasars for which the average of individual power spectrum over large scales ( Å-1) is more than higher than the average for all quasars, where is the standard deviation over all quasars. This analysis is carried out in the Ly and side-band SB1 ( Å) regions used later in this paper. A visual inspection showed that the removed spectra are indeed quasar spectra but exhibiting spikes caused by instrumental artifacts. A small number of and quasars are removed by conducting this study in the Ly and SB1 region, respectively. This removal eliminates spurious oscillations in the measurement of the one-dimensional power spectrum.
2.3 Other catalogs
The computation of one-dimensional power spectra necessitates accounting for several effects that causes changes in the spectra (absorptions or emissions), and that are not directly related to IGM absorptions. Our choice concerning these contaminants is to remove the spectra from the data sample or mask the impacted spectral region.
First, the Broad Absorption Lines (BAL) quasars present specific blueshifted absorptions caused by the quasar torus, thus directly related to its surroundings. These specific quasars are found using the baltools \faGithub333https://github.com/paulmartini/baltools software [56], which is a minimizer that measures blueshifted Civ or Siiv absorptions compared to an unabsorbed quasar continuum. The baltools software computes for each quasar spectrum the Balnicity Index (BI) and Absorption Index (AI) [56] defined as
| (2.1) |
where is the normalized flux, i.e., the observed quasar flux divided by a model fitted to the quasar without BAL features, is the separation from the Civ line center in velocity units, and is a constant null term unless is greater than zero for more than . The is a stricter criterion to define a BAL quasar, thus all BAL quasars are included in the sample. The measurement is carried out after removing all quasars that satisfies the criterion ( in the total data set).
Specific absorptions called High-Column Density (HCD) systems are present in the spectrum of some quasars. They are caused by the passage of the quasar light in the vicinity of a galaxy, called a circumgalactic medium. HCD objects contaminate the Ly forest by imprinting a saturated absorption that spans a much larger spectral range than the size of the galaxy itself and adds metal absorption lines present in the circumgalactic medium [57]. The HCD objects are detected using the combination of a convolutional neural network (CNN) algorithm desi-dlas \faGithub444https://github.com/cosmodesi/desi-dlas [58] and a Gaussian process (GP) algorithm \faGithub555https://github.com/jibanCat/gpy_dla_detection [59]. The GP algorithm provides a better estimate of the HCD column density , and the CNN a better detection completeness. We only consider the Damped Ly(DLA) objects, defined by . We take the same criteria as R23 to define our sample: valid DLA detection by CNN with a confidence level higher than for quasars continuum-to-noise ratio and a confidence level higher than when . For the GP algorithm, we take a minimal confidence level. The final catalog results from the merging of DLA detected by either algorithm. When both algorithms detect the DLA, the GP column density is used. The core region of a detected DLA, defined by an induced absorption larger than , is masked at the spectrum level. The remaining DLA damping wings are corrected at the spectrum stage using a Voigt profile (see e.g. [27] for details regarding DLA masking). Approximately % of the quasars in the DR1 catalog have at least one detected DLA in their spectrum. The redshift distribution of quasars presenting at least one detected DLA and that of quasars passing the or BAL quasar criteria are shown in figure 1.
Finally, absorption lines caused by passing through the Milky Way and atmospheric emission lines cause spurious spectra modifications even after being corrected by the DESI pipeline. We mask the lines in the line catalog adapted to DESI spectral resolution and developed in R23(\faGithub666https://github.com/corentinravoux/p1desi/tree/main/etc/skylines/list_mask_p1d_DESI_EDR.txt). The transmitted flux fraction of masked pixels (DLA or lines) is fixed to its average value (), which corresponds to a zero flux contrast. This masking induces a bias on that will be corrected in section 7.
3 Method
The one-dimensional power spectrum is computed with the same method as R23. This section aims to summarize the continuum fitting procedure and the FFT estimator used in this paper and to update the studies carried out in R23 with the DR1 dataset employed here.
3.1 Continuum fitting procedure
The continuum fitting procedure estimates the flux contrast , i.e., the normalization of the flux variation caused by all absorptions in the Ly forest, from the measured flux at a specific wavelength :
| (3.1) |
where is the quasar continuum corresponding to the unabsorbed flux emitted by the quasar and expressed at the quasar redshift . The term corresponds to the average fraction of transmitted flux in the IGM. We use the picca \faGithub777https://github.com/igmhub/picca [60] software package to fit for the product using the following parameterization for the continuum:
| (3.2) |
where is the rest-frame wavelength, and are parameters fitted for each quasar individually, accounting for their variability, is a function used to model the common continuum of all quasars. The latter is computed as the average of all the quasar spectra available in the sample. The fitting procedure is done iteratively for the ensemble of all quasars, updating the common continuum and fitting for the and terms at each iteration, by minimizing the following log-likelihood:
| (3.3) |
The noise associated to each flux contrast is directly given by the estimate of the DESI pipeline noise, noted (see [61] and R23), normalized by the product. We then define the mean signal-to-noise ratio of a quasar as
| (3.4) |
Following R23, we only keep quasars with . The fitting procedure is performed for an observed wavelength range of Åand a rest-frame range of Å. The quasar spectra are linearly binned in observed wavelength with Å. We adopt the same rebinning scheme of the common continuum in the rest-frame basis with a bin size equal to Å. Finally, the stack of all flux contrasts is set to zero at the end of the procedure.
3.2 Fast Fourier Transform estimator
The one-dimensional Ly power spectrum, noted , is defined as the power spectrum of the Ly absorption contrast along the quasar line-of-sight. Following R23, we include in the definition the cross-correlations between the Ly absorption line and other IGM elements whose rest-frame absorption is very close to the Ly line. In particular, we include absorptions from Siii and Siiii ( and Å, and Å) whose cross-correlation with Ly absorption is modeled at the cosmological interpretation stage. Neglecting the Siii and Siiii auto-correlations as they correspond to minor metal lines, we mathematically define as
| (3.5) |
where is the Dirac function, and are the absorption contrasts associated to the Siii and Siiii lines.
To compute , we first separate the flux contrast from each spectrum into three non-overlapping sub-forests of equal size, Å in the rest frame, with a flux contrast noted . Each of the sub-forests (with the total number of quasars) is referred to with the index in the following equations. This splitting reduces correlations between redshift bins and increases the smallest accessible wavenumber to Å-1. Furthermore, the resulting sub-forest covers at most , and we use this value to define the redshift binning for . The redshift associated with a sub-forest is determined by the center of its observed wavelength range, which assigns it to a redshift bin. Therefore, each redshift bin contains information from adjacent redshift bins, as sub-forests with a central redshift near a bin edge have half their spectrum extending beyond their redshift bin. It implies the existence of an inter-redshift correlation, which is not accounted for in this work but will be in future studies. The sub-forest flux contrasts are then transformed to Fourier space by picca using a multiprocessed Fast Fourier Transform (FFT) algorithm.
The FFT estimator is built under the main assumption that each sub-forest in our dataset provides an independent realization of the IGM Ly absorptions at the redshift at which they occur. In other words, we assume that the average of all sub-forests gives an unbiased estimator of the one-dimensional power spectrum, and we neglect correlations between sub-forests. The FFT estimator is derived from the relation between the observed flux contrast obtained after continuum fitting and the Ly contrast . This relation is derived by considering all the instrumental (noise, resolution) and astrophysical (metals) effects that imprint absorptions in the Ly region. Following the decomposition detailed in R23, the FFT estimator for the wavenumber bin and redshift bin is defined by
| (3.6) |
where is the power spectrum of the flux contrast , is the noise power spectrum, is the metal power spectrum resulting from the combination of metal forests whose emission lines are located redwards of the three Ly, Siii and Siiii absorptions, is a practical term called individual power spectrum of the sub-forest , and is the average of the Fourier transform of the resolution matrix provided by the DESI pipeline. This matrix encodes for each spectrum and each wavelength the complete resolution information, resulting from spectroscopic extraction (see e.g. [62, 61] and R23 for more details). The resolution matrix is symmetric and is averaged for each spectra pixel in the wavelength space before applying the Fourier transform. We call , and power spectra although they correspond to one single sub-forest and only their average over many sub-forest is a measurement of the power spectrum.
The picca software is used to compute this FFT estimator. In agreement with R23, we fix our minimal redshift to to avoid the Å region of the spectra where atmospheric absorptions significantly increase the flux noise. As we apply several masks (DLA, BAL, and atmospheric emission line catalogs), we remove sub-forests shorter than 75 wavelength pixels or with more than 120 masked pixels. We compute the raw power spectrum for each sub-forest directly from the flux contrast as . The noise power spectrum is computed using the DESI pipeline noise. The software generates a large number () of Gaussian signals with standard deviation equal to for each wavelength, and the noise power spectrum is obtained by averaging those signals in Fourier space, i.e. .
The picca software averages the individual power spectra with a weighting scheme. In each bin , we distribute the power spectra of individual sub-forests in bins in the signal-to-noise ratio of the sub-forests . We compute the variance of the power spectra in each bin. We then fit these variances with a simple least-squares minimization as a function of according to:
| (3.7) |
The fitted terms and are used to define the inverse-variance weights of each sub-forest as . By construction, the weights tend to zero when tends to 1, in agreement with the applied cut. Finally, the weighted average in equation 3.6 is explicitly computed as:
| (3.8) |
4 Instrumental characterization of one-dimensional power spectrum
4.1 Updates on DR1 data set
Some methods applied to the analysis of EDR+M2 DESI datasets in R23 are applied in this paper to the DR1 data set without any modifications. We review the new characterization of those instrumental features with the DR1 data set. The updated figures are located in appendix A.
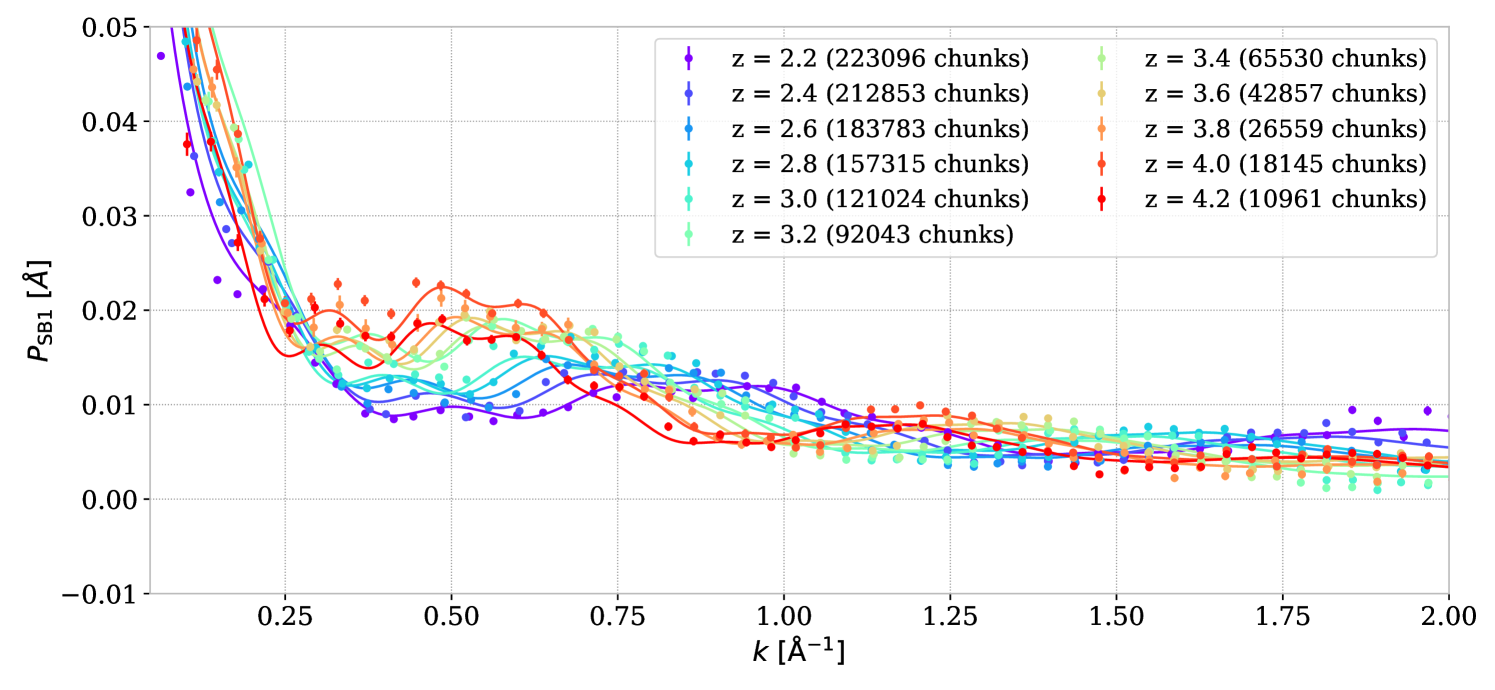
The metal power spectrum, in equation 3.6, is estimated using the side-band region SB1 ( Å). We show the SB1 power spectrum in figure 16, which is measured using the averaging of equation 3.6 in the SB1 rest-frame range. Here, we use a rest-frame range distinct from the Ly forest one, but with the same observed wavelength range. The quasars selected for SB1 are then located at lower redshifts than those selected for Ly. Consequently, our correction assumes that the continuum fitting process can catch the quasar emission variability as a function of redshift. As in R23, we average the side-band power spectrum over redshift bin on a common rest-frame wavenumber binning . This average is fitted with a least-square minimization by a physically motivated model considering Siiv and Civ doublets oscillations:
| (4.1) |
The evolution of the SB1 power spectrum as a function of redshift is accounted for in a second step, by multiplying and fitting a linear function independently for each redshift, . The resulting fitted functions are used as the metal power spectrum correction in equation 3.6. The fitted parameters for SB1 power spectrum are similar to the EDR+M2 ones in R23. The DR1 power spectrum contains a larger number of sub-forests (by at least a factor for all redshifts) and consequently gives lower error bars.
The R23 method is applied to measure the resolution damping with DR1 dataset. The resolution damping term in equation 3.6 is the average of the Fourier transform of the resolution matrix. The average resolution damping is shown in Fig. 15 and is almost identical to the one measured for EDR+M2 data set in R23. Consequently, we choose the same maximal wavenumber value Å-1, corresponding to a factor 5 correction.
4.2 Improving noise assessment
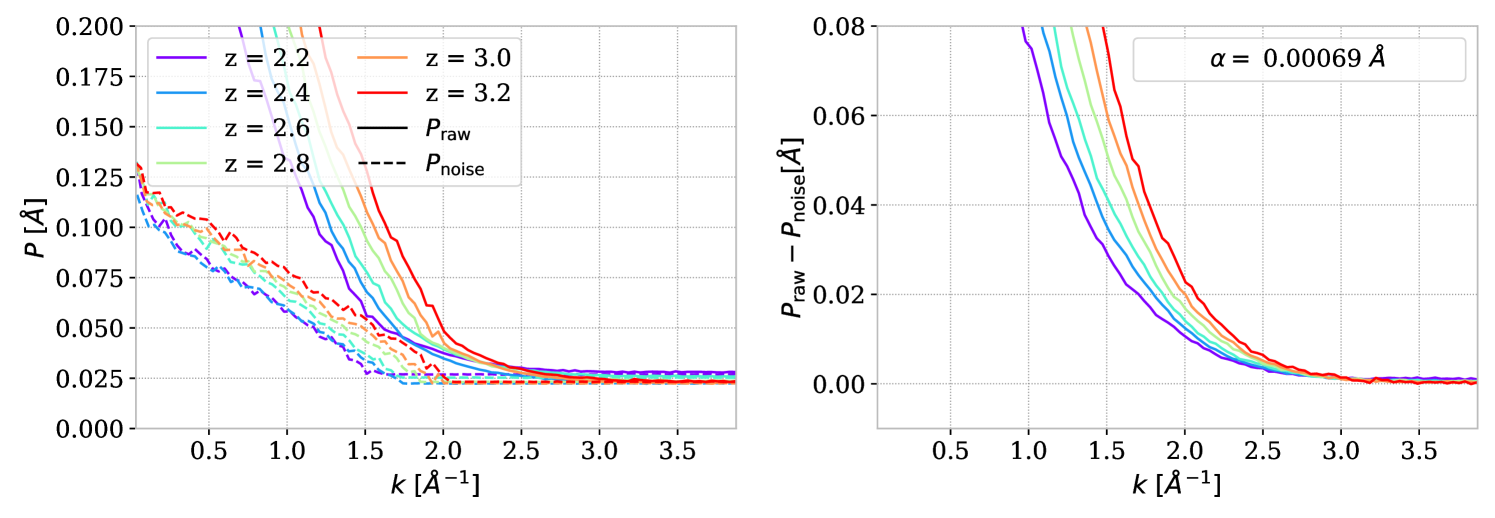
We measure the noise power spectrum with the method detailed in section 3.2 directly from the DESI pipeline output. As highlighted in R23, characterizing the noise sources in DESI is challenging, and the noise level can be underestimated. To have an alternative way to estimate the noise level, we use the smallest scales of , for which the resolution damping completely suppresses the signal, resulting in an expected equality between the raw and noise power spectra. Consequently, the measurement of at the largest wavenumber is a suitable noise level estimator. The noise and raw power spectra are compared in figure 2 for the DR1 dataset.
We derive an additive noise correction by averaging the difference for wavenumber where the resolution damping is higher than 98 % ( Å-1), which gives . The measured Å for DR1 corresponds to a 2.8 % noise power spectrum underestimation. This is lower than the value obtained for DESI-M2 in R23, a dataset with similar properties, which means we have better control over the noise characterization thanks to the dataset quality. In contrast to R23, the noise power spectrum is not flat for Å-1. This is due to the weighting used for DR1 and not for R23. Indeed, the noise power spectrum is flat for all individual power spectra, but since we are considering different weights in the Å-1 range, the weights distribution impacts the averaging of the noise power spectrum in a wavenumber-dependent way.
To control the noise power spectrum even better, we developed an alternative power spectrum estimator called cross-exposure, which does not need to model or measure the noise power spectrum explicitly. The DESI standard pipeline coadds the multiple exposures of a given quasar to create less noisy spectra [61]. In contrast, the cross-exposure estimator computes the one-dimensional individual cross-power spectrum between all distinct exposures of a given quasar. This provides an estimator free from noise influence if the noise realizations are independent between exposures.
Therefore, to minimize the impact of correlated noise sources, we select exposures to get only one per quasar and per night. It removes the noise sources resulting from exposures using the same calibration images, such as bias and flat calibrations, but not necessarily that resulting from dark calibration, which is not performed each night (see e.g. [61] or appendix C of R23 for an extensive description of noise sources).
For a quasar with exposures in DESI, we define the following cross-exposure operator:
| (4.2) |
where and are two contrast sets of size representing the contrast for different exposures. For example, can be a vector of Ly contrasts and a vector of noise contrasts. For this section only, the vector notation refers to a set of contrasts for different exposures.
We replace the simple raw power spectrum coadd estimator given in section 3.2 by the cross-exposure estimator , where is the set of sub-forest flux contrast for the exposures.
Noise correction and resolution damping must be accounted for to build a one-dimensional power spectrum estimator. Following R23, the flux contrast can be decomposed in Fourier space as . Following the demonstration in R23 to build the estimator, the cross-exposure estimator yields:
| (4.3) |
In this decomposition, since the noise contrasts are purely random Gaussian signals, they are all independent from each other and from Ly contrasts. Consequently, the last two terms of the decomposition are null. We numerically verified this assumption on the DR1 data set by assessing that the average of the last two terms is consistent with zero. Consequently, the cross-exposure estimator is given by:
| (4.4) |
We use a new implementation in picca to compute this cross-exposure estimator by performing the continuum fitting on each exposure of all the DR1 quasar catalog. Since distinct exposures of the same quasar have different , we perform the continuum fitting independently, as if each exposure were an independent quasar. We tried alternative continuum fitting methods and concluded that using the continuum fitted on the coadd of all exposures or on the exposure with the highest introduces biases and spurious oscillations in .
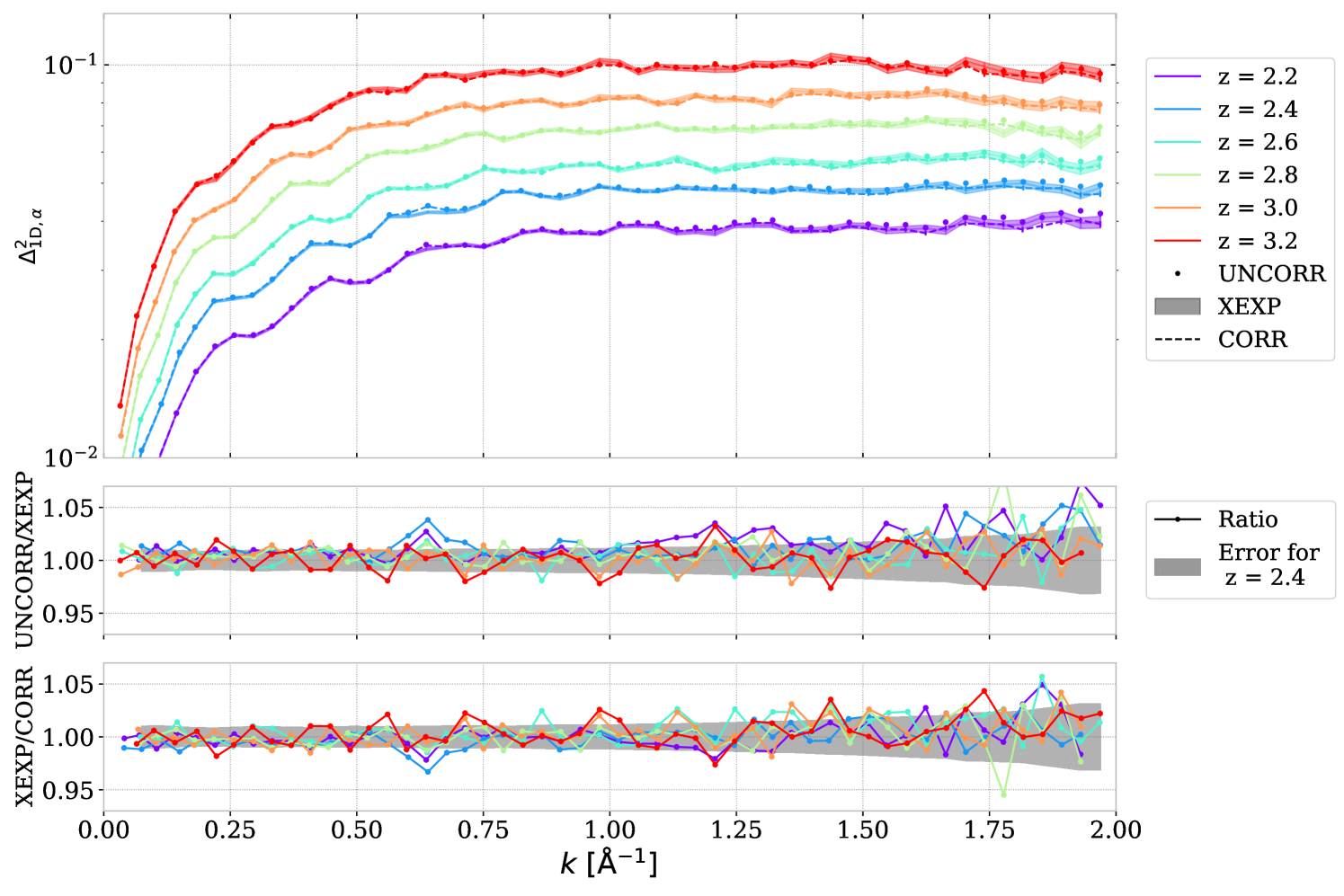
Figure 3 compares the one-dimensional power spectrum measured on DR1 dataset before noise correction with after noise correction, and with the cross-exposure estimation, . The two bottom panels are showing the ratios between those three analysis variations. At large wavenumber ( Å-1), the cross-exposure estimator has the same trend as the noise-corrected measurement, indicating that both noise estimations match. The uncorrected have a discrepancy at small redshifts for those scales, even if the difference is still within the statistical error bar. Near Å-1, both uncorrected and corrected measurements show a slight discrepancy with the cross-exposure estimator. This bump is caused by a pattern in a specific faulty DESI amplifier and is studied in detail in section 5.4. The cross-exposure estimator can remove part of this contamination at low redshifts.
The cross-exposure estimator only uses between and % (depending on the redshift bin) of the quasar catalog because of the need for several exposures and the fact that we select exposures from different nights. Consequently, we do not directly use the cross-exposure estimator for high redshifts, where the statistical errors are large. As discussed in 7, to better control the noise estimate, we use the cross-exposure estimator as the baseline for the redshift bins where we see small-scale and amplifier discrepancies, i.e. , and . For the other bins, we use the noise-corrected measurement as it agrees with the cross-exposure but results in smaller error bars due to the larger number of sub-forests and exposures available. Additionally, considering the extensive studies we performed here and in R23, we assert here that we have sufficient control over the noise level to drop the associated systematic error bar, which was already overly conservative in R23. We assume that the increase in the statistical error at low redshift due to using the cross-exposure estimator makes the systematic error due to noise negligible.
5 Data splits and variations
We aim at improving the robustness of the measurement by testing most of the hypotheses and choices we performed regarding the treatment of quasar spectra, the catalogs used (see section 2), and the methodology itself developed in section 3. As it is now standard with other Ly analyses [29, 31], we vary several analysis options and perform data splitting concerning different types of properties, and compare the resulting to a baseline. This first application of data variations and splits for also aims to set the basis for this measurement. It will be improved in future studies, notably by performing it for the final baseline analysis and covariance matrix and considering additional effects. To improve readability, we explicitly label on the plot the tests that we intuitively expect to fail or pass.
For the sake of simplicity, we take a simple baseline, which uses the same methodology as the EDR+M2 measurement in R23, without any correction. To be more explicit, DLAs and atmospheric emission lines are masked, and the BAL quasars verifying the criterion are removed. We do not apply noise correction, cross-exposure estimator, metal subtraction, or multiplicative correction from synthetic data. Except for cross-exposure, all the corrections that will be applied to our measurement in section 7 are the same for all analysis variations and data splits performed here. Considering that cross-exposure only slightly impacts , we can safely suppose that all the tests performed in this section are also valid for the final measurement for which all corrections are applied.
This section aims to conduct a blind exploration of four data variations (DLA and BAL catalogs, continuum fitting, and averaging parameters) and four data splits (number of exposures, amplifiers, sky regions, and Civ equivalent width).
The ratio between the baseline and the variation or split power spectra is noted . The statistical uncertainty on this ratio depends on the correlation between the two power spectra. In the data split case, we have a sub-sample of the baseline, we can compute the correlation and obtain 888This is coming from and .:
| (5.1) |
where and are the standard deviations of the two measurements, see section 6.1. We then compute a -value given from the cumulative distribution function , and note it hereafter “ -value”:
| (5.2) |
We cannot easily compute the error bars on the ratio for analysis variations; thus, they are not shown in the following. We design other statistical tests to quantify the ratio positioning and the trend as a function of wavenumber. The first test characterizes the distribution of the ratio with respect to unity. We consider the fraction of pixels below and above unity and associate a simple “Distribution -value” equal to twice the lower of the two fractions.
To characterize a potential trend with respect to the wavenumber, we want to compute the Pearson sample correlation coefficient between the wavenumber and the ratio . However, the error on varies with . In order to have a quantity whose error does not depend on , we compute for each redshift the correlation between and , where is given by equation 5.1 without the last covariance term. It is largely overestimating , but only the variation with matters here, and we assume that we should get a fair estimate of this variation. The associated “Correlation -value” to test the existence of a correlation is given by the two-sided Student -distribution:
| (5.3) |
where is the number of data points. This -value is computed for all redshifts independently, and we report the minimal one.
Some of the tests performed in this section are used to see the impact on , and some to compare to a purer sample, which removes specific contaminants but decreases the statistics. We use the criterion to check if the test is passed in the latter case. This study allows us to conduct a data-driven exploration of potential analysis issues and modify our baseline accordingly.
5.1 DLA and BAL catalog variations
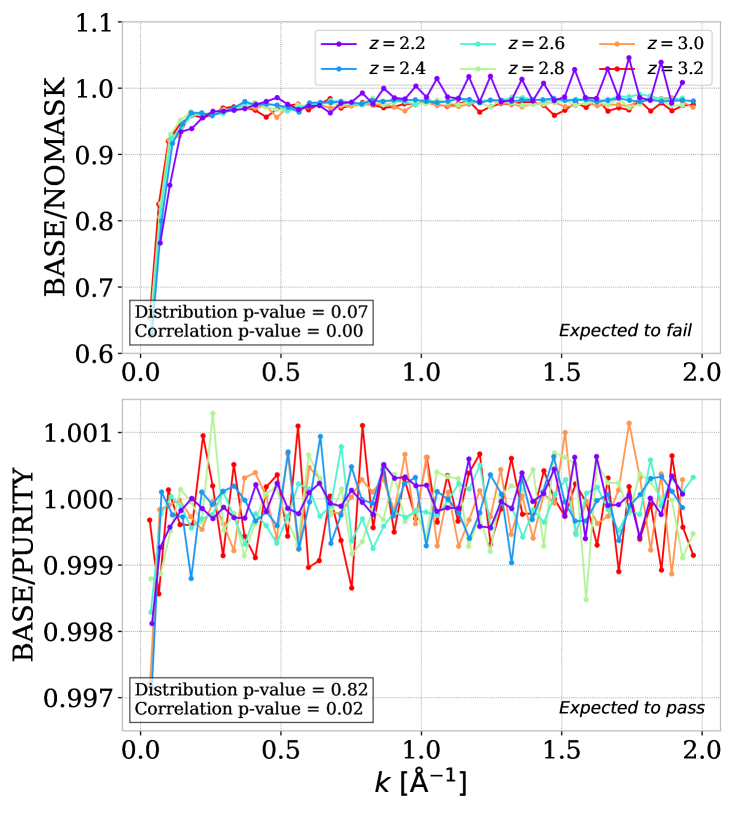
The DLA catalog used for masking was created with the specific CNN and GP confidence cuts in section 3. Variations of those parameters provide insight into DLA completeness. The left panel of figure 4 shows the two variations related to the DLA catalog. We start by not masking DLA (NOMASK) and comparing it to the baseline. In agreement with the previous measurement in R23 or on simulation in [63], not masking DLAs greatly increases the power spectrum at the largest scales considered. This test is used in section 6.2 to derive a systematic uncertainty associated with the DLA completeness.
Conjointly with the companion paper K25, we modify the confidence cut to obtain a higher purity version of the DLA catalog. This alternative cutting uses the same confidence cut () for GP, and a continuum-to-noise ratio ()-dependent cut for the CNN: for , for , and for . The resulting catalog contains approximately % less DLA than the high-completeness version used for the baseline. When using this high-purity catalog, the obtained power spectrum is compared to the baseline in the last panel of Figure 4 (PURITY). The -values reported show a statistically significant correlation with respect to wavenumber, coming from small wavenumbers and small redshifts. We note, however, that this difference is small (around 2) and is well below the level of the systematic uncertainties that we derive in section 6.2 for DLA completeness. Thus, employing a purer or more complete sample of DLA does not largely impact our measurement. Furthermore, even if the two catalogs give different DLA numbers, the impact of masking is not significantly changed. We choose to keep the high-completeness catalog as the baseline.
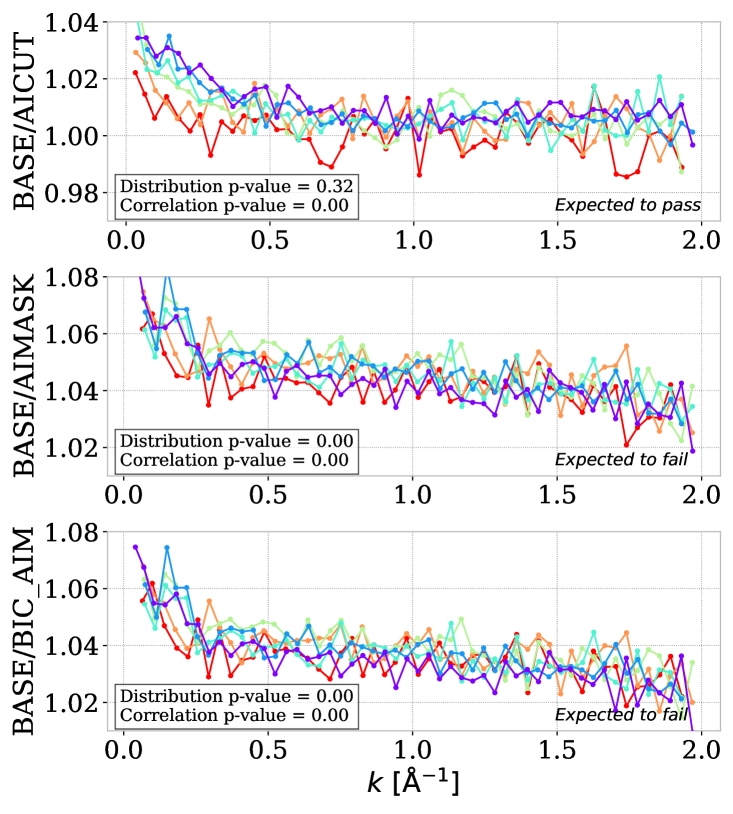
We have a larger number of sub-forests than in R23, sufficient to study the effect of the completeness of BAL catalog, as illustrated in the right panels of figure 4. The baseline measurement (BASE) uses a catalog in which quasars tagged as BAL with the criterion have been removed. The upper panel of the figure compares it to an analysis variation (AICUT) with the cut, which removes % of quasars, including the % of quasars. We observe a near % difference at small scales, well above the level of statistical uncertainties, giving a Correlation -value. However, removing all BAL quasars would induce a large drop in statistics, and we aim to match the power spectrum obtained with this severe cut while keeping most of the quasars.
Two additional variations are then performed: masking at the spectrum level all BAL absorptions while keeping all quasars in the catalog (AIMASK) and masking all BAL pixels while removing BAL quasars from the catalog (BIC_AIM). AIMASK is a drastic change relative to baseline as no quasars are removed from the input catalog, while BIC_AIM can be considered as the baseline while additionally masking for BAL regions that are passing criterion. As shown on the lower two right panels of the same figure, the impact of masking BAL is very similar for AIMASK and BIC_AIM: it decreases the level for all scales due to the effect of pixel masking while accounting for the small scale difference due to the unaccounted BAL that are masked. Since the impact of masking is way more prominent when the BAL quasars are kept (AIMASK), we choose BIC_AIM as our new baseline.
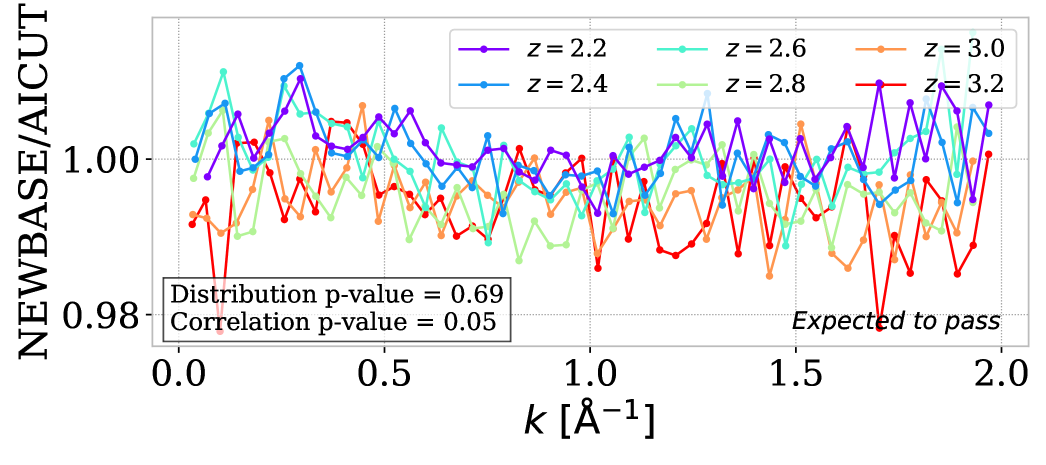
To verify that the impact of BAL quasars is correctly accounted for, we compare our new baseline to the case where all BAL quasars are removed from the catalog (AICUT). The new baseline is corrected for the impact of BAL masking using the correction derived in KR25. The number of BAL quasars is larger in the DR1 data than in the mocks used in KR25. We normalize the absolute level of the BAL masking correction to account for the larger fraction of BAL in the data. The resulting new baseline (BIC_AIM with corrections) is compared to the cutting case in figure 5. Compared to the first left panel of figure 4, the new baseline properly accounts for the BAL, as shown by the value. This p-value is the lower value for six bins in redshift, so indicates that the test is passed for all redshift bins. We will use this study of the impact of BAL to derive systematic uncertainties linked to BAL completeness and the BAL masking correction.
5.2 FFT method parameters variation
We vary some parameters chosen as fixed in section 3 to blindly search for potential sources of analysis systematic error. First, the parameters used for continuum fitting in section 3.1 are varied, and the ratio with baseline is shown in the left panels of figure 6. We carry out the continuum fitting while allowing noise-dependent weights in the likelihood used for fitting (VARW). In equation 3.3, the weights in the likelihood are replaced by:
| (5.4) |
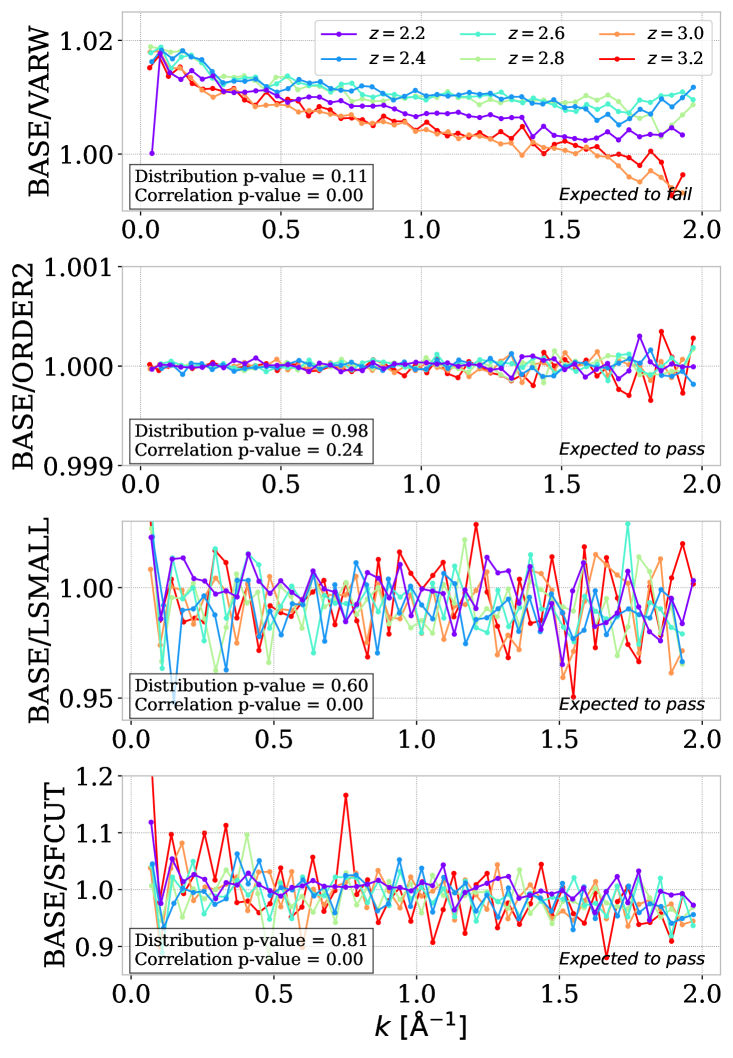
with additional wavelength-dependent parameters , and , as it is the case for BAO analysis. In a second variation, we added a term to compute individual quasar continuum in equation 3.2 (ORDER2). In a third variation we modify the minimum and maximum wavelength considered in the computation of flux contrast from Å to the reduced range Å (LSMALL). Finally, we perform the sub-forest cut before the continuum fitting and fit the continuum independently for each sub-forest (SFCUT). For the latter variation, in comparison to baseline, we also remove the in equation 3.2 as this term would generate a broken linear continuum fitting when separated in sub-forests and would suppress small-wavenumber modes. Note that the SFCUT variation corresponds to how continuum fitting was performed for eBOSS [45].
The four variations considered do not induce a significant decrease in the number of sub-forests: only a nearly % decrease for LSMALL due to the creation of shorter sub-forests that do not pass the size cuts. The second test (ORDER2) has a very small effect on as indicated by the reported -values. All the three other tests (VARW, LSMALL, SFCUT) shows some statistically significant correlation between the ratio and the wavenumber. The VARW test has a small but significant effect on the power spectrum. However, including in the weights is biasing the evaluation of the power spectrum, so this effect is not surprising. The LSMALL and SFCUT variations show more significant fluctuations. We interpret those spikes as caused by adding smaller sub-forests that appear as outliers in the averaging, and that are potentially not accounted by the outlier finder detailed in section 2. Those two variations should be considered in a cosmological interpretation study as they could potentially yield different results.
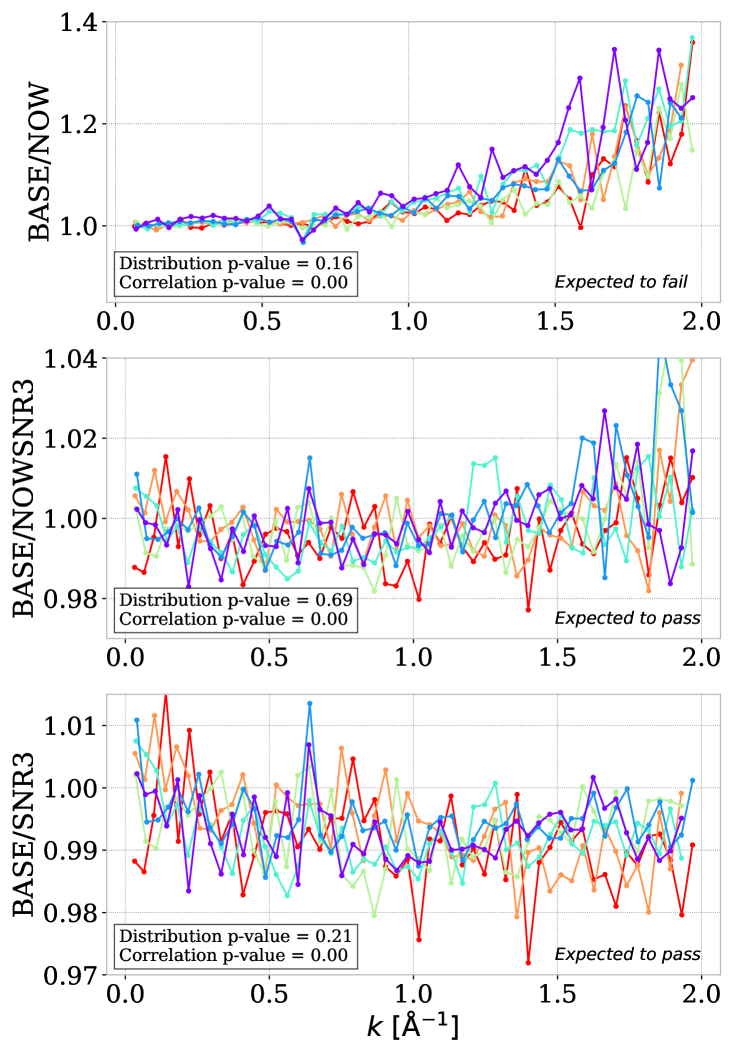
In a separate study, we test the average computation by varying the cut and the weighting scheme. The right panels of figure 6 show the variation performed here: using a constant weighting scheme with the same cut (NOW), with a cut (NOWSNR3) which is close to what was done in eBOSS [45], or using the same weighting scheme as baseline with the cut (SNR3). The cut implies keeping only between to % of the DR1 sub-forests depending on the redshift bin. It corresponds to a drastic cut in statistics, but can be considered a robust sample for small scales, for which noisy sub-forests can significantly impact the measurement. Indeed, noisy sub-forests have a large noise power spectrum and a slight noise misestimation causes a large small-scale variation. The upper plot exhibits a large discrepancy between the baseline and the case without weighting.
For the second plot when a cut is applied to the unweighted analysis, the ”Distribution” p-value is improved, but there still exists a wavenumber correlation. However, we note that the ratio is very close to unity with a maximal value near %. The NOW discrepancy can therefore be ascribed to noisy spectra with , and probably mostly to spectra with . These spectra have a very small weight and a negligible contribution to the baseline power spectrum, which, therefore, is hardly affected by removing spectra, as illustrated by the lower plot, which shows a small (near %) difference, which is well below the level of small-scale systematics (e.g., resolution) associated to the final measurement in section 6.2. Even if the impact of biasing caused by low sub-forest is mostly accounted for by our -weighting, the can be considered a potential variation for cosmological interpretations.
5.3 Comparison of exposure numbers
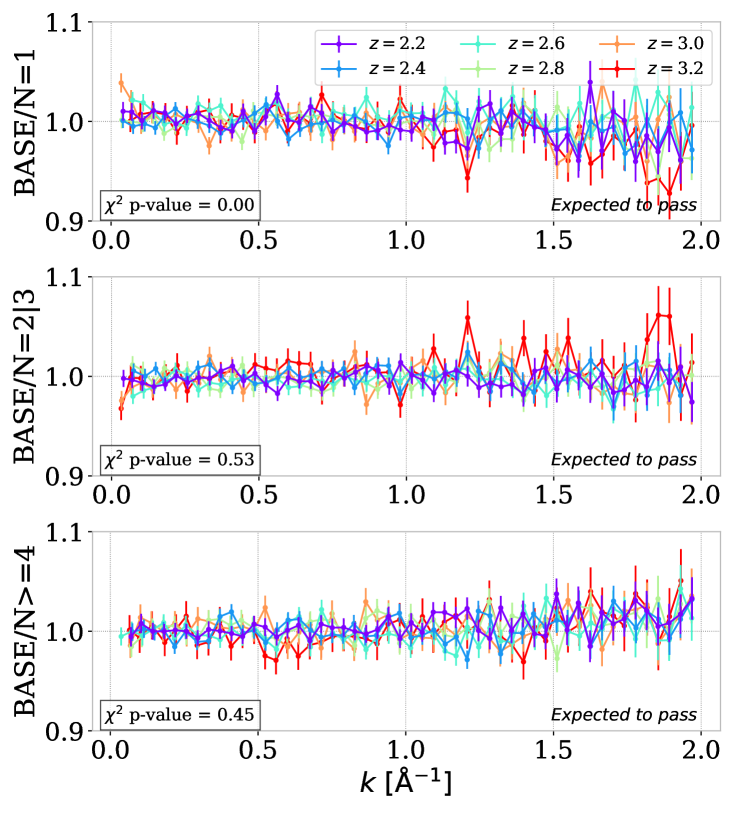
Each quasar is planned to be observed several times by the DESI instrument, and since DR1 is an intermediate data set, it contains spectra observed with very different numbers of exposures. The coadding of exposures can potentially introduce a bias, especially when it involves a large number of exposures with very different integration times and observing conditions. A data split involving quasars observed over only one (N=1), two or three (N=23), or four or more (N=4) exposures is shown in the left panels of figure 7. The data splits contain, on average over redshift bins, %, %, and % of the total number of sub-forests, respectively, thus resulting in larger error bars. The ratios do not show strong variations from unity; however, only the (N=2 3) and (N =4) are passing the test. The low number of exposures (N=1) can potentially bias our measurement, especially at small scales, because a quasar with a low number of exposures tends to be noisier, thus giving different weights when averaging. Removing this sample implies a too-large decrease in statistics, but this variation should be considered for cosmological interpretation and future measurement with larger data sets and a larger number of exposures.
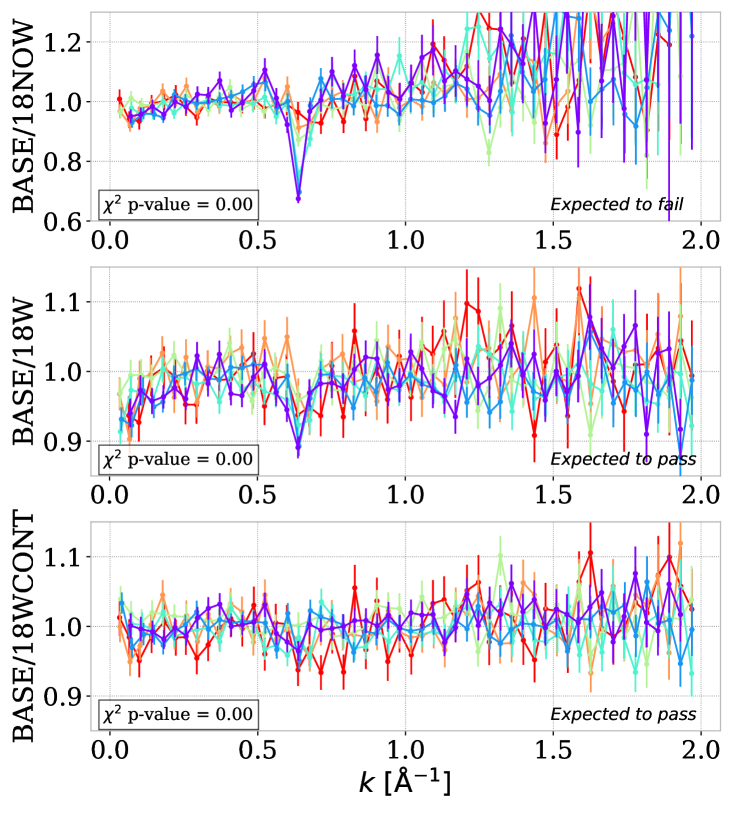
5.4 Measurement with different amplifier sets
The focal plane of the DESI instrument is composed of ten modules called petals, each containing 500 robotic fiber positioners. The light measured by those positioners is linked to ten spectrographs by optical fibers. Each spectrograph receives the fiber associated with one petal and scatters the received light using volume phase holographic gratings. Three CCD cameras per spectrograph read the spectra, covering different wavelength ranges. Finally, four amplifiers per CCD are positioned in squares to perform the readout. In the direction, a CCD image contains different spectra chunks, while is the direction of wavelengths. A given quasar spectrum is then measured over six amplifiers (2 per CCD camera). For one spectrograph, the fibers directed to the left and right parts of the CCD cameras constitute two sets, measured with completely distinct amplifiers. At the spectrum level, the data can be split between 20 amplifier sets, according to the left and right parts of the ten spectrographs.
We measured over those 20 amplifier set splits independently, which constitutes a significant drop in terms of statistics. The right panels of figure 7 show the ratio between baseline and the power spectrum using only spectra from the amplifier set number 18 with constant-weight averaging (18NOW), with -weight averaging (18W), and with the -weight averaging but using the continuum from the complete DR1 data set (18WCONT). The 18th amplifier set was chosen because it shows a considerable difference for low redshift near wavenumber Å-1. Among the 20 splits of the amplifier set, only two exhibit this behavior, with the 16th data split showing a smaller spike amplitude. Those spikes originate from oscillatory patterns of period Å(corresponding to Å-1) present on DR1 calibrations images used for bias corrections.
The source of those patterns was not identified and was highly complicated to correct due to their partial coverage of the amplifier and sporadic occurrence. In contrast to the companion paper K25, the impact of this feature drastically decreases when using the weighting scheme. Furthermore, comparing 18W and 18WCONT indicates that a subsequent part of the spike is caused by the continuum fitting procedure itself when using only the 18th amplifier set. The spike is more prominent at small redshifts. As pointed out in section 4.2, the cross-exposure estimator accounts for this spike because it uses the individual cross-power spectrum between different fibers and, consequently, different amplifier sets. As we use the cross-exposure estimator for the lower redshift () where the Å-1 spike is the largest ( for and for and dropping to or below for larger redshifts), we consider that this feature does not impact our measurement, and we choose not to add a dedicated systematic uncertainty. We interpret the low -value for the last panel to be mostly caused by fluctuations and not by the Å-1 spike itself.
5.5 Galactic hemisphere split
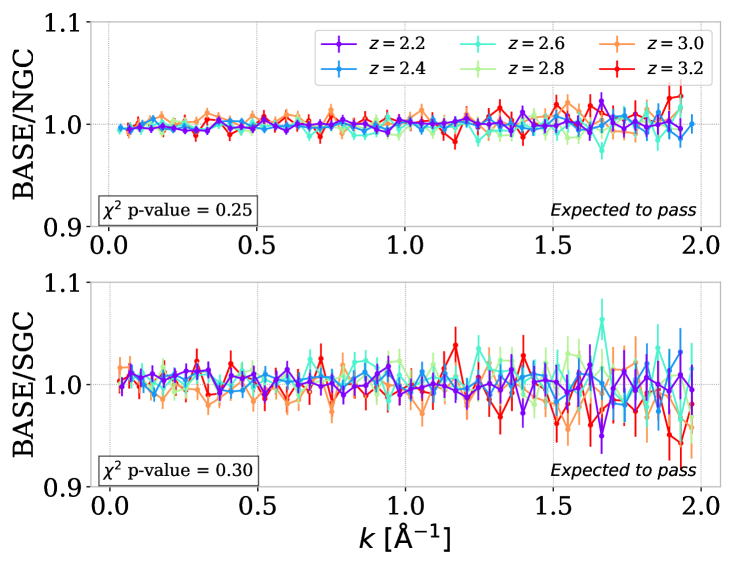
Different imaging surveys are used for the quasar target selection of the DESI survey [50, 51, 52]. Inhomogeneities in the photometric target pre-selection can significantly impact galaxy clustering studies, since they affect the target density and subsequently the estimation of the matter density. We do not expect an impact on the measurement of since each spectrum pixel is a proxy for the IGM density independently of the quasar density. However, as a sanity check, we still perform a data split between the North Galactic Cap (NGC) and the South Galactic Cap (SGC), as shown on the left panels of figure 8. The NGC dataset contains % of the sub-forests, and the SGC %. As expected, the measured on both data splits show no visible difference with the baseline, as also indicated by the reported -values.
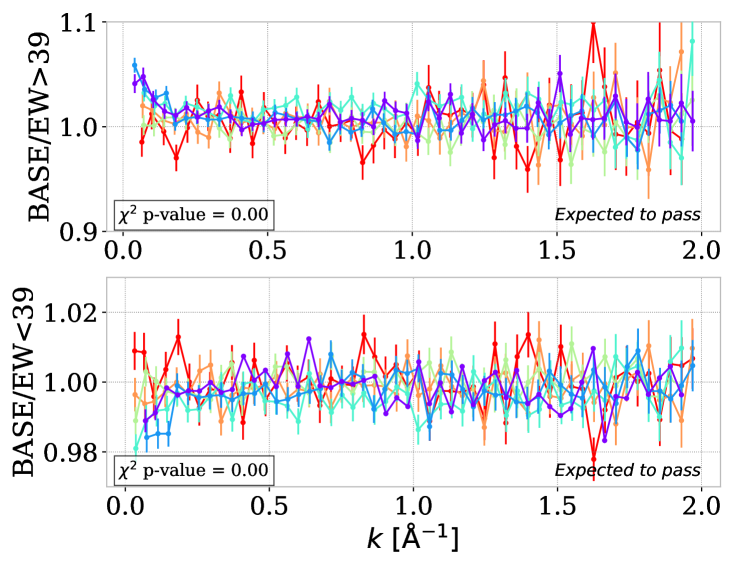
5.6 CIV equivalent width
The last data split performed follows the BAO analysis [29, 31] and is related to the Civ equivalent width (EW) in angstrom, i.e. the spectral area associated with the quasar Civ emission line. The EW variable is a good quasar population discriminant because of the Baldwin effect, which causes EW to be anti-correlated to the quasar continuum luminosity [64]. Consequently, the high EW quasars will tend to be noisier. We use the EW measurement performed with fastspecfit\faGithub999https://github.com/desihub/fastspecfit in [29, 31] to create two populations equal in terms of quasar number: EW39 and EW39. The result of computations for those two EW populations is shown in the right panels of figure 8. Since we apply a quality cut, the noisier EW39 measurement contains only % of the total sub-forests. The EW39 data set shows a % discrepancy for small redshift and Å-1. This discrepancy can be interpreted as a proximity effect impacting the larger scales of the quasar spectra. The EW39 sample is also showing a discrepancy, shown by the -value, but with a smaller level (near % at large scales). Removing the EW39 sample would imply a statistical drop that is too large. For this analysis, we keep the two populations of quasars in the baseline measurement. However, the EW39 data sample should also be considered as a variation for cosmological analysis, and this EW test should be investigated more in future studies. For now, the level of the induced bias compared to EW39 is well below the level of large-scale systematics such as DLA completeness detailed in section 6.2.
5.7 Analysis variation and data split conclusion
We performed an extensive data split study to find potential biases in our measurement. Those data splits allow us to validate our measurement and improve the characterization of systematic uncertainties. Notably, this study indicates that the impact of BAL on the measurement cannot be ignored, and we changed the baseline measurement to mask the associated absorptions. This analysis shows that some effects are slightly changing the global trend of , and some imprint fluctuations sufficient not to pass our statistical tests. We can also note that the ”Correlation -value” test is especially severe. Removing the sub-samples that do not pass the tests would imply a significant statistical drop; we then keep them for this paper. First, those effects (continuum fitting variations, number of exposures, amplifier splits, and Civ EW quasar population) should be considered as baseline variations for any cosmological interpretation. Secondly, those sub-samples should potentially be removed for future DESI releases with even larger data sets available.
6 Power spectrum uncertainties
6.1 Statistical uncertainties and covariance matrix
As the aim of this DR1 measurement is to be interpreted in terms of cosmological parameters, we estimate the covariance matrix associated with . Furthermore, we improve the study conducted in R23 concerning the estimation of statistical and systematic uncertainties. The full derivation of the variance and covariance estimators used here is presented in Appendix B.
The expression of the power spectrum involves a weighted average of (Eq. 3.6). In Appendix B, we derive an estimator for the variance of a weighted average and for the covariance between two such weighted averages. However, this derivation requires that the be uncorrelated. When a sub-forest has several wavenumbers in a given bin, these wavenumbers are correlated, so we cannot use our variance estimator for the weighted average .
We therefore introduce as the ensemble of wavenumbers associated with sub-forest that fall into bin , the number of wavenumbers in , and the average of individual power spectra in bin . We can neglect the correlation between different sub-forests as accounting for them would give a three-dimensional estimator. Therefore, we use our variance estimator for the . We introduce the weights to rewrite as a weighted average of the :
| (6.1) |
We can then use our estimator for the variance
| (6.2) |
and the covariance
| (6.3) |
We note that our estimator fluctuates significantly and can even result in a negative variance for a small dataset size (at high redshift in our case). This issue is solved by smoothing the variance with a Savitzky-Golay filter implemented in scipy [65]. Similarly, the covariance matrix is smoothed along its two dimensions using a Savitzky-Golay filter implemented in sgolay2 \faGithub101010https://github.com/espdev/sgolay2. The covariance and variance estimators have been validated in the companion KR25 paper by comparing the variation between DR1-like uncontaminated mocks with the average of those mocks. This validation showed that our estimator slightly overestimates the covariance by %. We correct our covariance matrix by renormalizing by this factor, independently of redshift.
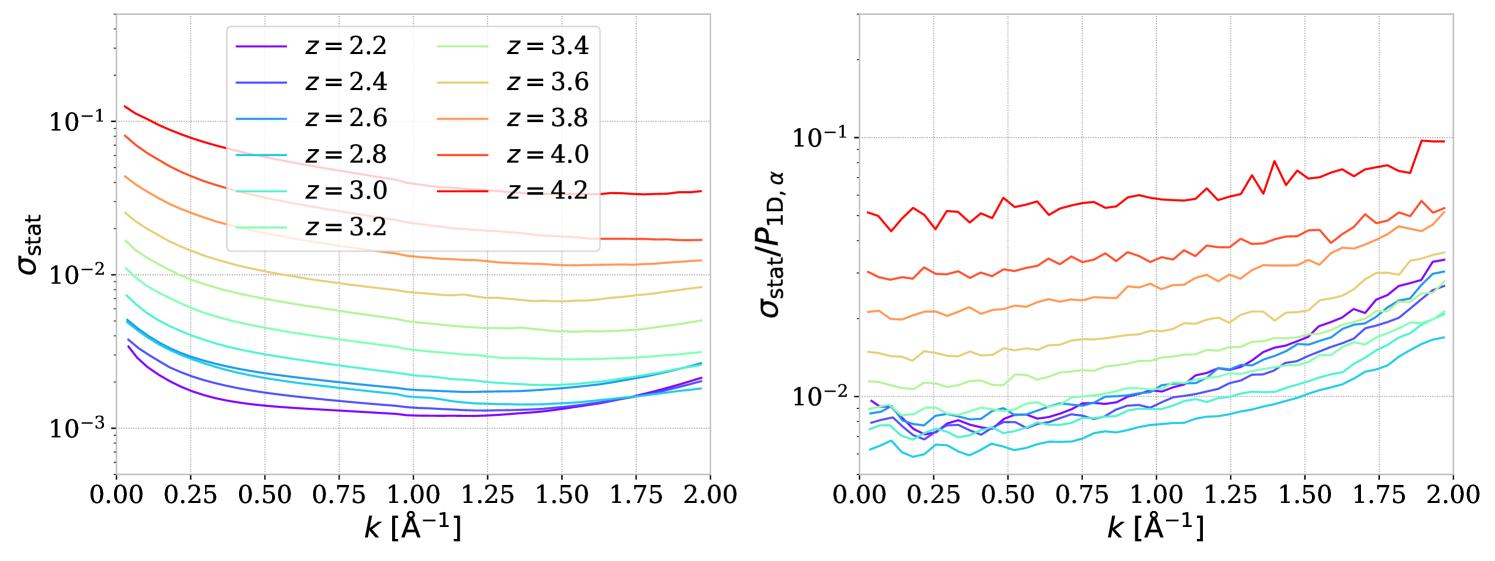
Figure 9 shows the standard deviation calculated with equation 6.2 for the DR1 power spectrum. The three smallest redshift bins (, , and ) have a different profile because the cross-exposure estimator (see section 4.2) is used for these bins. Due to the reduced number of sub-forests available for the cross-exposure estimator, the error bars increase, especially at large wavenumber. Compared to R23 results, the uncertainties are smoother due to the applied smoothing but have a similar profile. The level of uncertainties is much lower than for R23: between and times decrease depending on redshift. This improvement is even higher than the five times increase in quasar statistics, which should decrease the error bar only by times. Considering that weighting is used in both measurements, we interpret this significant improvement as caused by decreasing noise in the input data set.
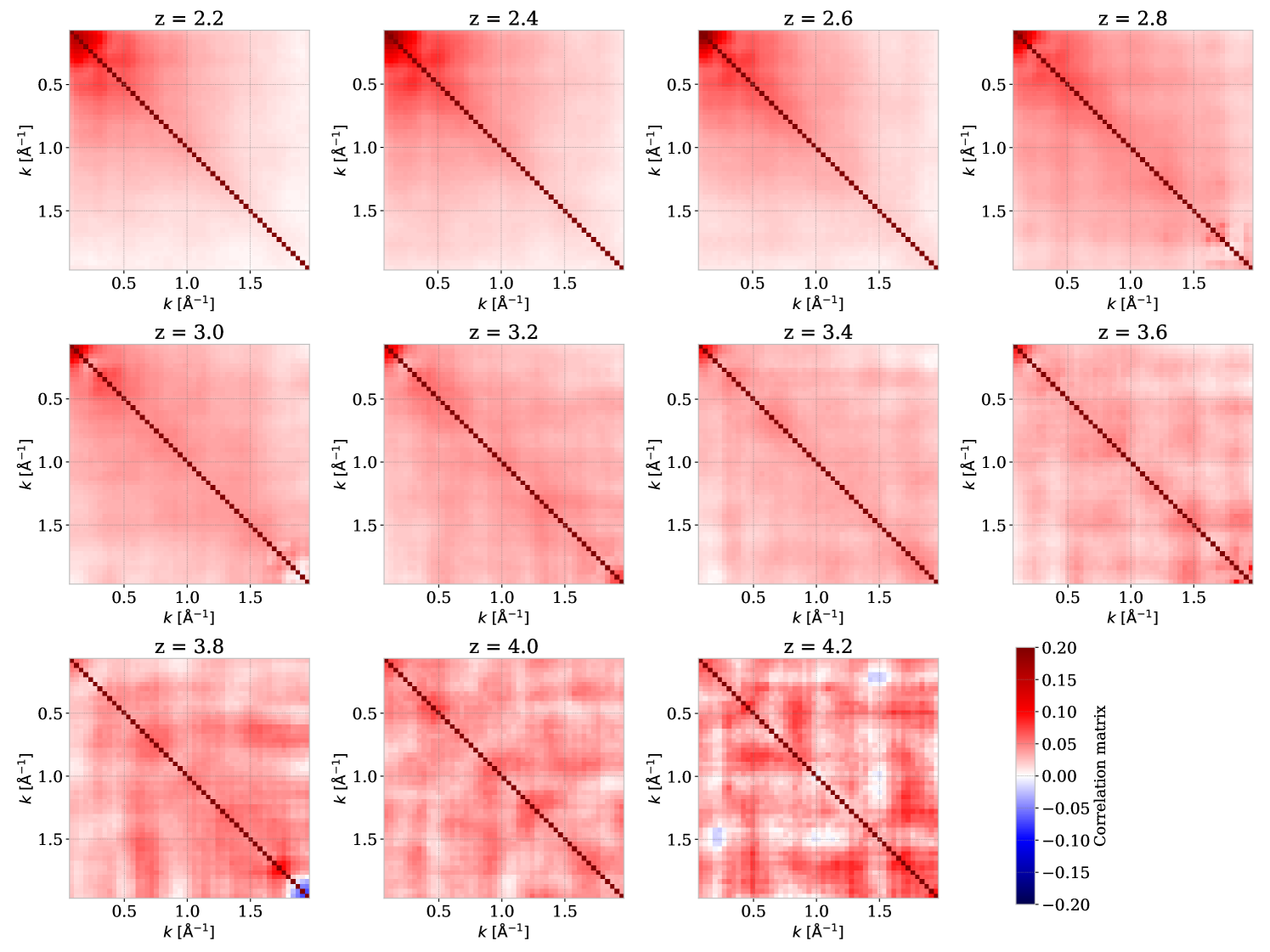
Figure 10 shows the correlation matrix for the DR1 data set. The correlation profile is very similar to the one obtained for eBOSS in [45], with a significant correlation (near %) at small wavenumber and decreasing as a function of redshift. There are some instabilities for high redshift caused by the low number of available sub-forests. The cosmological interpretation of this measurement should account for those instabilities.
6.2 Systematic uncertainties
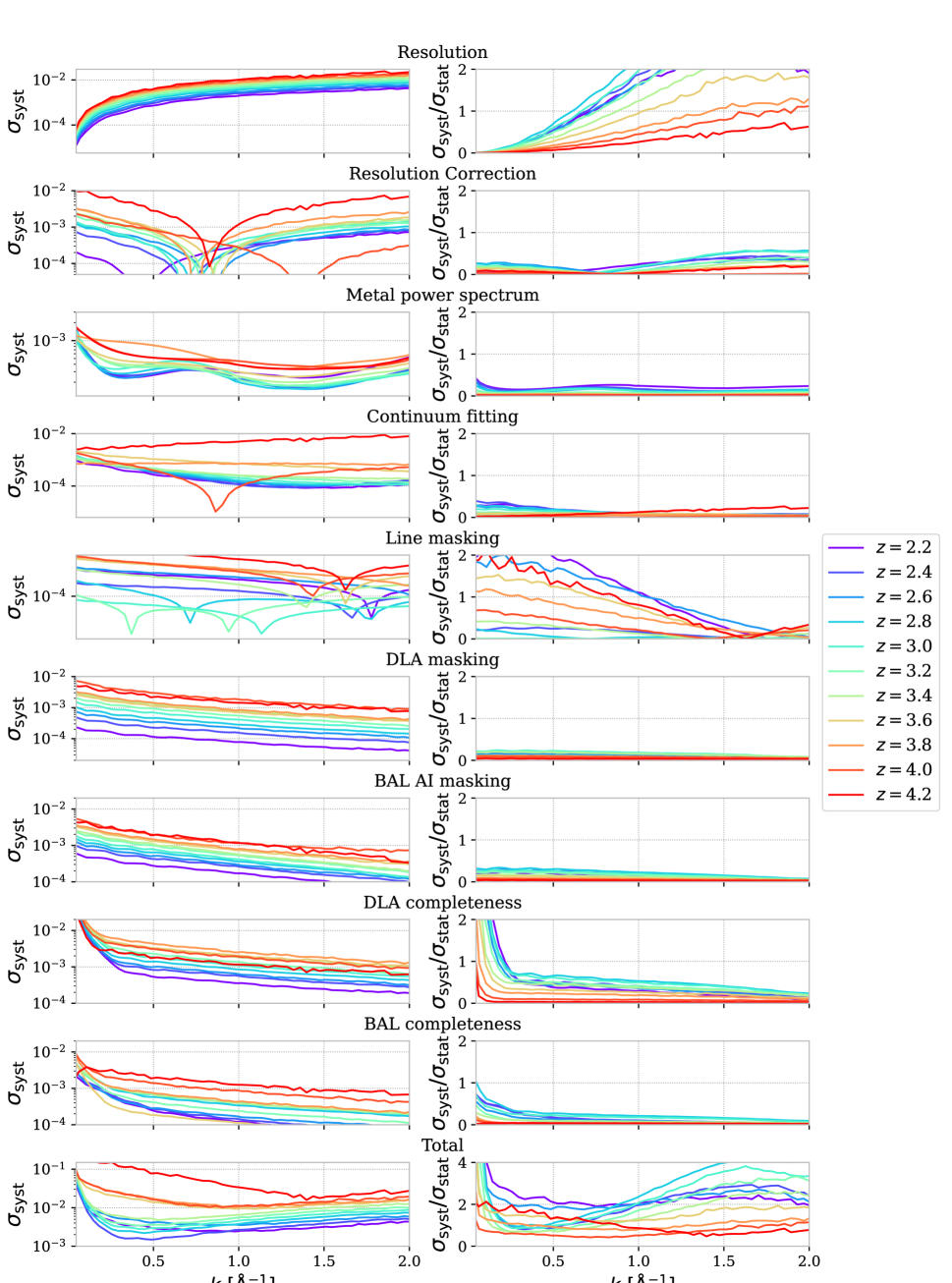
We re-evaluated the systematic uncertainty budget of R23 to account for new sources of systematics and improvements developed in this article and in the validation companion paper KR25. More specifically, pixel masking and resolution corrections were reevaluated to match DR1 statistics. The continuum fitting correction, see below, was also derived in the same paper.
All systematic uncertainties included in the total error budget are shown in figure 11. As mentioned in section 4.2, with the development of a cross-exposure estimator that measures the noise in a fully data-driven way, we consider that the systematic error associated with the noise level estimation is negligible and can safely be removed from the systematic error budget. Other systematic uncertainties associated to a bin and noted , are defined similarly to R23 in the following way:
-
•
Resolution damping: We ascribe an uncertainty to the stability of the Point Spread Function (PSF) and its impact on the DESI resolution matrix. Following R23, the average resolution damping in figure 15 is fitted with a simplified resolution damping model to measure the effective spectral resolution in Å. The uncertainty is given by , where is the error on for which we take a conservative absolute error of following the PSF stability measurement in [61].
-
•
Resolution correction: A correction for the resolution modeling is derived in the companion paper KR25. We apply this multiplicative correction to the main measurement and ascribe a systematic error that is % of the correction, i.e., .
-
•
Metal power spectrum: The metal power spectrum is measured in section 4.1 in the SB1 side-band wavelength range and shown in figure 16. The measurement is directly corrected by a physically motivated fit . We add a systematic uncertainty equal to the statistical error bar of the side-band power spectrum.
-
•
Continuum fitting: A multiplicative correction accounting for the bias introduced by the continuum fitting is derived from DR1-like mocks in KR25. This correction, noted , directly multiplies the power spectrum measurement, and a % relative systematic uncertainty is added to the total budget.
-
•
Pixel masking corrections: At the continuum fitting stage, some spectrum pixels are masked due to DLA, BAL passing the criterion, and atmospheric emission lines, as discussed in sections 2 and 5.1. Multiplicative corrections, respectively noted , , and are computed in KR25. As for the previous multiplicative corrections, we correct the power spectrum measurement and associate a % relative systematic uncertainty. For the special case of BAL masking, a dedicated study in KR25 shows that a 30 value is over-estimating the systematic uncertainty, and we take a 6 value.
-
•
Catalog completeness: The DLA and BAL finding algorithms detailed in section 2 result in incomplete detections, especially for the low spectra. The data splits presented in section 5.1 provide insight into the impact of undetected DLA and BAL. In contrast with R23, we derive the impact of DLA and BAL from the data splits instead of mocks, making this analysis independent of the distribution of DLA and BAL in mocks. For DLA, we compare the power spectrum obtained when DLA are masked and the power spectrum corrected by to the case where no DLA are masked. The resulting ratio corresponds to the top left panel of figure 4 with the additional DLA masking correction. We fit this ratio with a power-law function provided by [63]. Following R23 which uses the same DLA finding algorithms, we ascribe a conservative % incompleteness to the DLA finders. The associated systematic uncertainty is obtained by multiplying this incompleteness factor by the product of the fitted function times . In a very similar way, we estimate the impact of unmasked BAL absorptions by comparing our new baseline for which we masked BAL, corrected by , to the previous baseline measurement where those absortions where left unmasked. We use the same fitting function and associate a systematic uncertainty considering a % incompleteness for the finder, following [56].
For multiplicative correction, the % relative systematic uncertainty is motivated by considering a random shift of the correction between and %. Considering a uniform distribution for this shift gives a % standard deviation. It is a straightforward but very conservative way of generating an error bar associated with the multiplicative corrections because it gives overestimated error bars related to larger corrections, such as atmospheric lines. In contrast, taking the standard deviation of the correction for different mock realizations gives too small and non-conservative error bars. We chose not to use this method based on mocks for systematic uncertainties.
All systematic uncertainties are added in quadrature to compute the total systematic error, which is shown in the last panels of figure 11. The correlations between wavenumber bins induced by these systematics are complex to model, and their contribution to the covariance matrix will be discussed in the upcoming inference of this work. Given the improvement in statistics compared to R23, the statistical error bars have decreased by between 260 to 300 % depending on redshift, and now the measurement is dominated by systematic errors for most redshifts and wavenumbers.
7 Measurement
The measurement is obtained from running the entire pipeline given in 3, correcting for underestimated noise for high redshifts (), using the cross-exposure estimator for low redshift (), applying pixel masking, continuum fitting and resolution corrections, and subtracting the estimated metal power spectrum . The final estimator is defined as
| (7.1) | ||||
where the individual power spectra definition is redshift dependent:
| (7.2) |
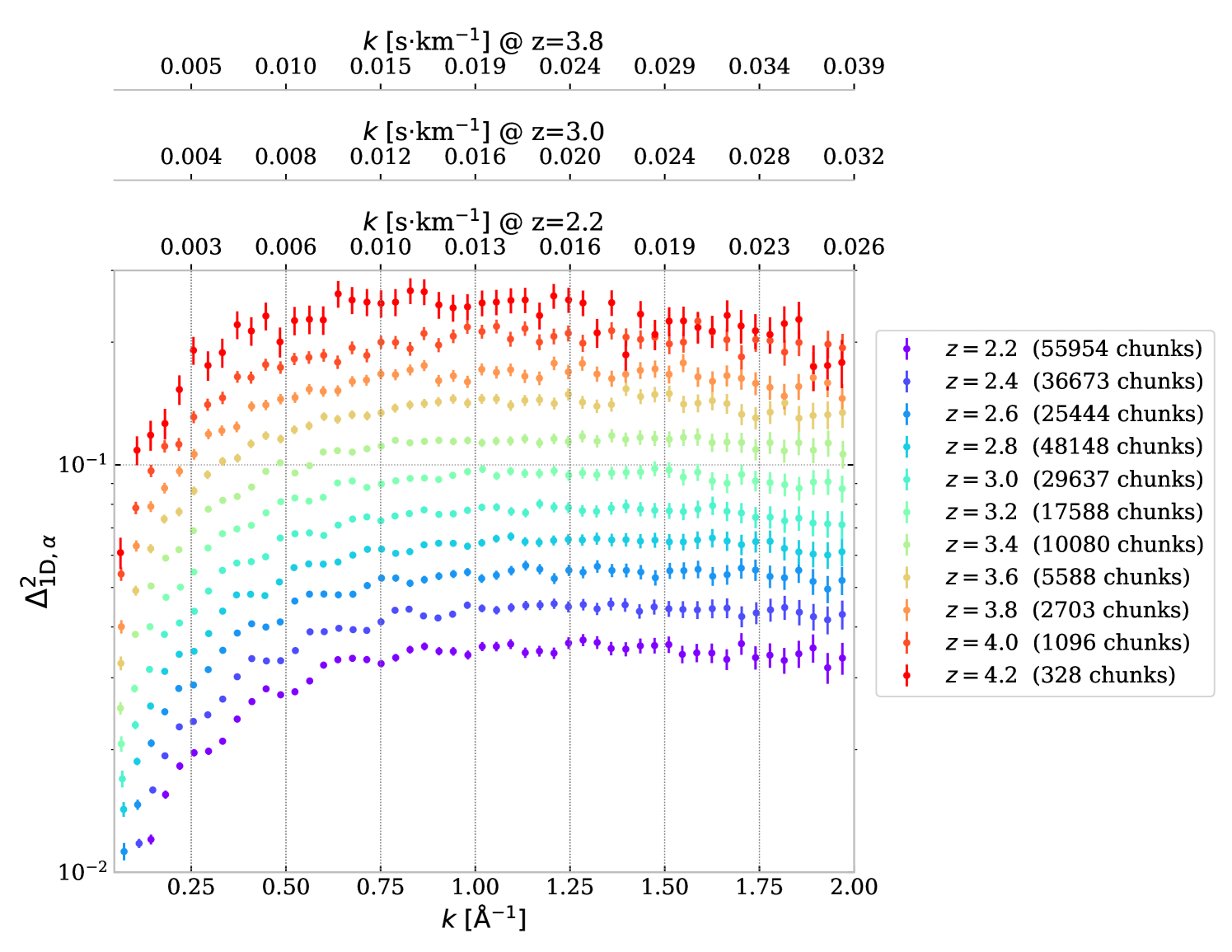
Figure 12 shows the one-dimensional power spectrum measurement obtained from DESI-DR1 data set with this full FFT estimator. The error bars are the quadratic sum of the statistical and total systematic uncertainties detailed in previous sections. The increase in statistics is visible by eye compared to the previous EDR+M2 measurement in R23. We did not compute the for redshift higher than because of the too-low number of sub-forests and the significant variation of .
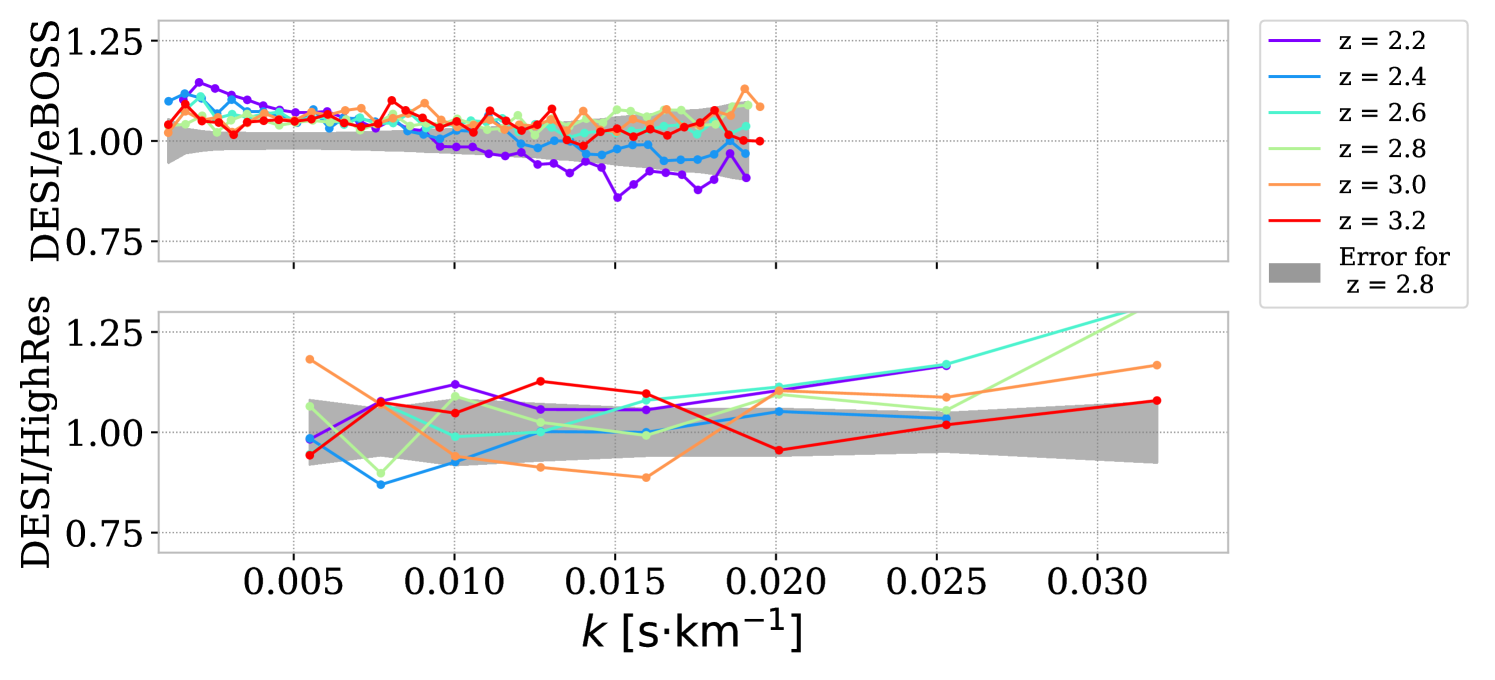
We compare the resulting measurement with the previous eBOSS [45] and high-resolution measurements from the combination of KODIAQ, SQUAD, and XQ-100 surveys [66] in figure 13. As those studies expressed in velocity units (), the DR1 power spectrum is converted using before the averaging stage using the redshift of individual sub-forests. We reproduce all aforementioned corrections with the velocity unit measurements on DR1 data and synthetic data in KR25.
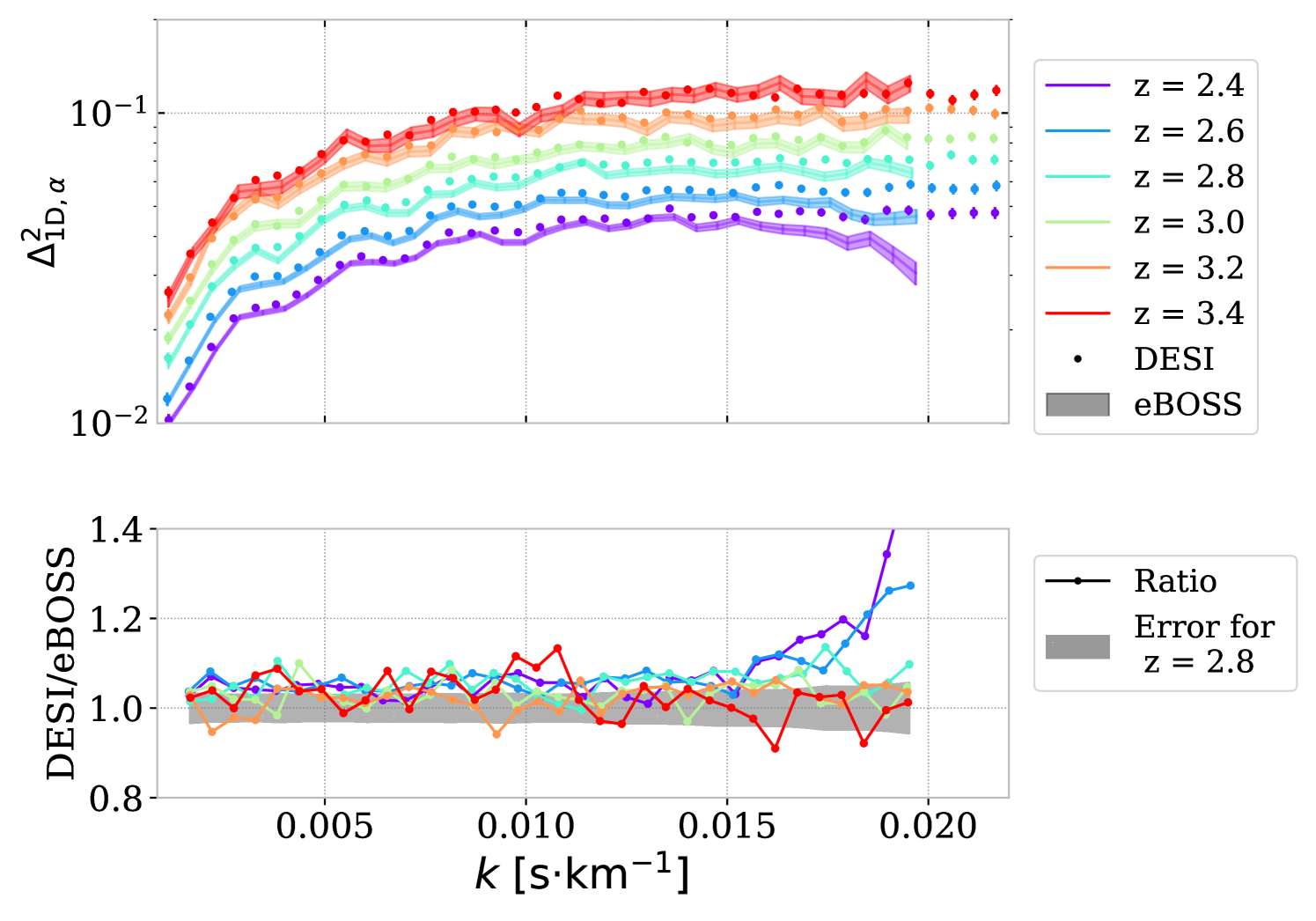
We observe a discrepancy with eBOSS, especially at large scales () and for the first two redshift bins (). This is primarily due to the different DLA catalogs. Indeed, analyzing eBOSS data with our DLA catalog and using procedures close to the DESI analysis results in a DESI to eBOSS ratio independent of and for s/km, as illustrated in figure 14. The origin of this 1.05 ratio is unknown and will be further studied in future publications. We ascribe the differences at higher in figure 14 to the noise characterization, which is much less controlled for eBOSS than for DESI data set. This is confirmed by the fact that DESI data appear in agreement with high-resolution experiments up to s/km in figure 13.
The difference between our DR1 measurement and previous non-DESI ones is smaller than for EDR+M2 measurement in R23. In particular, our measurement is in better agreement with the high-resolution measurement at the smallest scales, implying an improved control of small-scale systematics in our study. However, we note that there still exists a disagreement larger than the error bar at which will need to be explored in future work before using both measurements for a cosmological interpretation. Since the DESI spectroscopic pipeline is built on a more robust methodology (e.g., ”spectroperfectionism” algorithm detailed in [62]) than the eBOSS one, and considering the extended data split analysis performed in our study, we are confident that our DR1 measurement is more robust than eBOSS for cosmological interpretation.
8 Conclusion and prospects
Using a Fast Fourier Transform estimator, we measured the one-dimensional Ly power spectrum with the DESI-DR1 data set. Following the work performed in the previous DESI study R23 [33], we extended the instrumental characterization to the entire DR1 data set. The noise control was improved by introducing a new estimator, which uses the individual cross-power spectrum between different DESI exposures of the same quasar. This cross-exposure estimator, used for the low redshift sample of the DR1 measurement, does not require explicit modeling of the noise power spectrum and allows in addition for the reduction of fiber-related instrumental effects.
An extended analysis of potential sources of systematics was performed by computing for various data splits and method variations. Those studies notably concluded that the broad absorption line quasars detected with the absorption index should be accounted for by masking the associated absorptions. All the other data splits and method variations highlighted the robustness of our measurement. We conducted a detailed investigation of the statistical and systematic uncertainty budget. Notably, the variance estimator had to be modified to take into account spectrum weighting, and the impact of broad absorption line quasars was added to the systematic budget. A covariance estimator that accounts for weighting was developed and used to compute the covariance matrix, which will be used for cosmological interpretation of the measurement.
The resulting measured on the DR1 data set constitutes the best intermediate-resolution power spectrum measurement in terms of resolution and statistics. In particular, our measurement represent a drastic statistical improvement ( times increase in number of quasars, and around times decrease in statistical uncertainty) compared to the previous DESI measurement [33, 34]. We compared the DR1 measurement to eBOSS [45] and high-resolution [66] measurements. Relative to R23, we observe a global improvement in the agreement with previous measurements, although we still have large and small-scale discrepancies.
The FFT measurement is associated with a companion paper [37] presenting the measurement of with a quadratic maximum likelihood estimator. Both measurements agree in a comparison made in [37]. They will be cosmologically interpreted in another paper in preparation. High-resolution hydrodynamic simulations will be used in hand with state-of-the-art Gaussian process emulators [67, 68, 69] to interpret those measurements. They will put strong constraints on the amplitude and slope of the matter power spectrum, the sum of neutrino masses, and exotic dark matter models.
The uncertainty budgeting conducted in this article showed that systematic uncertainties now dominate the one-dimensional power spectrum measurement for most scales. Future measurements should aim to enhance the characterization of the different systematic sources to lower their contribution, as done for the noise systematic in this study. The increase in statistics with the next data release of DESI will provide the opportunity to measure data from sub-samples less contaminated by systematics. For example, the systematics related to pixel masking can be suppressed using masking window methods as in [70]. We note that other surveys such as 4MOST Cosmology Redshift Survey [71] or WEAVE-QSO [72] will also provide clean Ly forest data sets that can be used to measure .
Appendix A Updated figures for DR1 data set
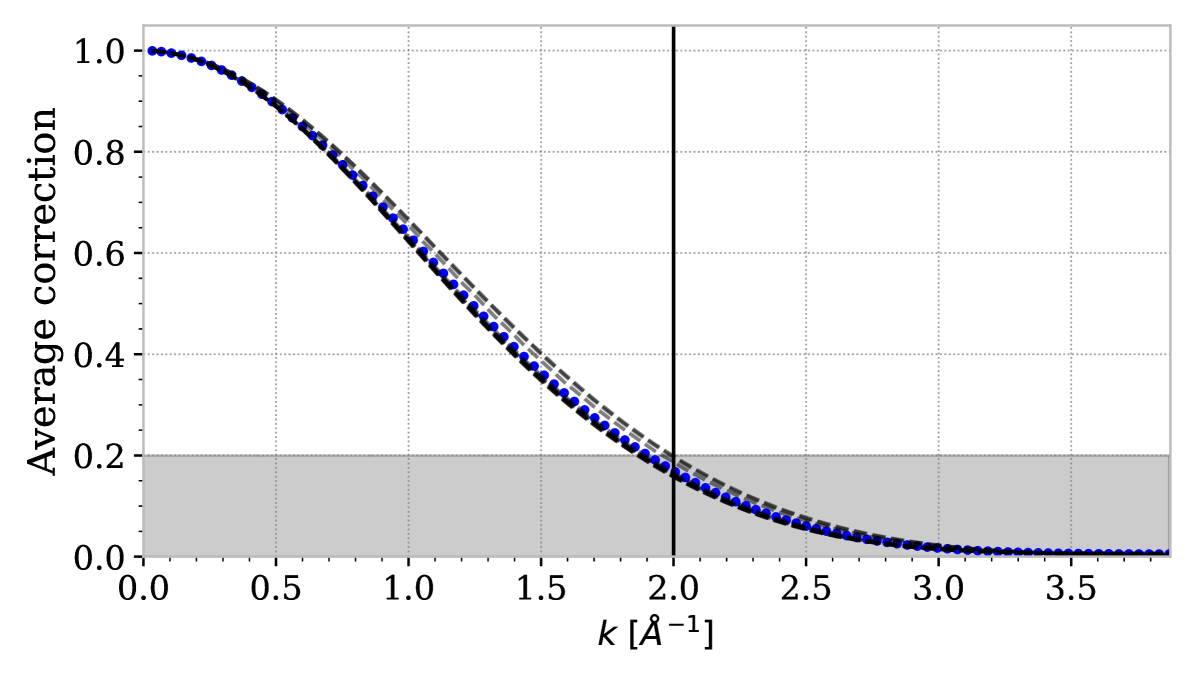
This appendix contains the figures for which we used in this paper the same methods as were used for EDR+M2 data set in R23. We provide those figures to show an update using the new DESI-DR1 data set. Figure 15 shows the resolution damping computed as from the average of the Fourier transform of the DESI pipeline resolution matrix. This resolution damping determines both the maximal wavenumber considered and the systematic uncertainty from PSF stability.
Figure 16 shows the power spectrum measured in the side-band SB1 ( Å) and used to estimate the metal power spectrum .
Appendix B Covariance and variance estimators
Let us consider we have pairs of measurements of two physics quantities and and the weighted means and . We note , and , which means we assume when and in particular . We have
| (B.1) |
We want to extract this covariance from the dispersions of the and . In order to get the term, we should include in the estimator and normalize it by . But this will produce a term in that we should try to cancel out, let’s try the following quantity:
| (B.2) |
We have
| (B.3) |
and
| (B.4) | |||||
| (B.5) |
We can now compute where the terms do cancel out and get
| (B.6) |
So we just have to divide by the above parenthesis to get an unbiased estimator of the covariance:
| (B.7) |
which gives for the variance:
| (B.8) |
We can set , , and to get our estimators of the variance and covariance of .
An alternative estimator of the variance of a weighted average is sometimes proposed [73], where is replaced by . However, the same kind of algebra as above shows that this estimator fails if the weights are not proportional to the inverse variance. In our case, this proportionality is only approximate, which makes this estimator inappropriate. In addition, this estimator cannot be generalized to a covariance estimator. These analytic findings were confirmed by a small Monte Carlo simulation that showed that our estimator for the variance is unbiased and that the estimator fails in the general case.
Acknowledgments
This material is based upon work supported by the U.S. Department of Energy (DOE), Office of Science, Office of High-Energy Physics, under Contract No. DE–AC02–05CH11231, and by the National Energy Research Scientific Computing Center, a DOE Office of Science User Facility under the same contract. Additional support for DESI was provided by the U.S. National Science Foundation (NSF), Division of Astronomical Sciences under Contract No. AST-0950945 to the NSF’s National Optical-Infrared Astronomy Research Laboratory; the Science and Technology Facilities Council of the United Kingdom; the Gordon and Betty Moore Foundation; the Heising-Simons Foundation; the French Alternative Energies and Atomic Energy Commission (CEA); the National Council of Humanities, Science and Technology of Mexico (CONAHCYT); the Ministry of Science, Innovation and Universities of Spain (MICIU/AEI/10.13039/501100011033), and by the DESI Member Institutions: https://www.desi.lbl.gov/collaborating-institutions. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the U. S. National Science Foundation, the U. S. Department of Energy, or any of the listed funding agencies.
The authors are honored to be permitted to conduct scientific research on I’oligam Du’ag (Kitt Peak), a mountain with particular significance to the Tohono O’odham Nation.
The project leading to this publication has received funding from Excellence Initiative of Aix-Marseille University - A*MIDEX, a French “Investissements d’Avenir” program (AMX-20-CE-02 - DARKUNI).
Data availability
The DESI spectra and associated catalogs from DESI-DR1 are publicly available111111https://data.desi.lbl.gov/doc/releases/dr1/. All the plots of this article are generated with picca (9.12.3) and p1desi \faGithub121212https://github.com/corentinravoux/p1desi (2.0.1). All the data points of the figures in this article will be made available upon publication according to the data management policy of DESI.
References
- [1] J.E. Gunn and B.A. Peterson, On the Density of Neutral Hydrogen in Intergalactic Space., The Astrophysical Journal 142 (1965) 1633.
- [2] R. Lynds, The Absorption-Line Spectrum of 4c 05.34, The Astrophysical Journal 164 (1971) L73.
- [3] A.A. Meiksin, The Physics of the Intergalactic Medium, Reviews of Modern Physics 81 (2009) 1405.
- [4] M. McQuinn, The Evolution of the Intergalactic Medium, Annual Review of Astronomy and Astrophysics 54 (2016) 313.
- [5] A. Meiksin, Spectral analysis of the lyman-alpha forest using wavelets, Mon. Not. Roy. Astron. Soc. 314 (2000) 566 [astro-ph/0002148].
- [6] R. de la Cruz, G. Niz, V. Iršič, C. Ravoux, C. Ramírez-Pérez and H.K. Herrera-Alcantar, First Ly 1D Bispectrum Measurement in eBOSS, 2410.09150.
- [7] K.-G. Lee et al., IGM Constraints from the SDSS-III/BOSS DR9 Ly Forest Flux Probability Distribution Function, Astrophys. J. 799 (2015) 196 [1405.1072].
- [8] R.A.C. Croft, D.H. Weinberg, N. Katz and L. Hernquist, Recovery of the power spectrum of mass fluctuations from observations of the Lyman alpha forest, Astrophys. J. 495 (1998) 44 [astro-ph/9708018].
- [9] SDSS collaboration, The Linear theory power spectrum from the Lyman-alpha forest in the Sloan Digital Sky Survey, Astrophys. J. 635 (2005) 761 [astro-ph/0407377].
- [10] R.A.C. Croft, W. Hu and R. Dave, Cosmological Limits on the Neutrino Mass from the Lya Forest, Phys. Rev. Lett. 83 (1999) 1092 [astro-ph/9903335].
- [11] U. Seljak, A. Slosar and P. McDonald, Cosmological parameters from combining the Lyman-alpha forest with CMB, galaxy clustering and SN constraints, Journal of Cosmology and Astroparticle Physics 2006 (2006) 014.
- [12] N. Palanque-Delabrouille, C. Yèche, J. Baur, C. Magneville, G. Rossi, J. Lesgourgues et al., Neutrino masses and cosmology with Lyman-alpha forest power spectrum, Journal of Cosmology and Astroparticle Physics 2015 (2015) 011.
- [13] C. Yèche, N. Palanque-Delabrouille, J. Baur and H.d.M.d. BourBoux, Constraints on neutrino masses from Lyman-alpha forest power spectrum with BOSS and XQ-100, Journal of Cosmology and Astroparticle Physics 2017 (2017) 047.
- [14] N. Palanque-Delabrouille, C. Yèche, N. Schöneberg, J. Lesgourgues, M. Walther, S. Chabanier et al., Hints, neutrino bounds and WDM constraints from SDSS DR14 Lyman- and Planck full-survey data, Journal of Cosmology and Astroparticle Physics 2020 (2020) 038.
- [15] M. Viel, J. Lesgourgues, M.G. Haehnelt, S. Matarrese and A. Riotto, Constraining Warm Dark Matter candidates including sterile neutrinos and light gravitinos with WMAP and the Lyman-alpha forest, Physical Review D 71 (2005) 063534.
- [16] M. Viel, G.D. Becker, J.S. Bolton, M.G. Haehnelt, M. Rauch and W.L.W. Sargent, How cold is cold dark matter? Small scales constraints from the flux power spectrum of the high-redshift Lyman-alpha forest, Physical Review Letters 100 (2008) 041304.
- [17] M. Viel, G.D. Becker, J.S. Bolton and M.G. Haehnelt, Warm Dark Matter as a solution to the small scale crisis: new constraints from high redshift Lyman-alpha forest data, Physical Review D 88 (2013) 043502.
- [18] J. Baur, N. Palanque-Delabrouille, C. Yèche, C. Magneville and M. Viel, Lyman-alpha Forests cool Warm Dark Matter, Journal of Cosmology and Astroparticle Physics 2016 (2016) 012.
- [19] J. Baur, N. Palanque-Delabrouille, C. Yèche, A. Boyarsky, O. Ruchayskiy, É. Armengaud et al., Constraints from Ly- forests on non-thermal dark matter including resonantly-produced sterile neutrinos, Journal of Cosmology and Astroparticle Physics 2017 (2017) 013.
- [20] V. Iršič, M. Viel, M.G. Haehnelt, J.S. Bolton and G.D. Becker, First constraints on fuzzy dark matter from Lyman- forest data and hydrodynamical simulations, Physical Review Letters 119 (2017) 031302.
- [21] E. Armengaud, N. Palanque-Delabrouille, C. Yèche, D.J.E. Marsh and J. Baur, Constraining the mass of light bosonic dark matter using SDSS Lyman- forest, Monthly Notices of the Royal Astronomical Society 471 (2017) 4606.
- [22] D.C. Hooper, N. Schöneberg, R. Murgia, M. Archidiacono, J. Lesgourgues and M. Viel, One likelihood to bind them all: Lyman- constraints on non-standard dark matter, JCAP 10 (2022) 032 [2206.08188].
- [23] R. Murgia, G. Scelfo, M. Viel and A. Raccanelli, Lyman- Forest Constraints on Primordial Black Holes as Dark Matter, Phys. Rev. Lett. 123 (2019) 071102 [1903.10509].
- [24] DESI collaboration, The DESI Experiment Part I: Science,Targeting, and Survey Design, 1611.00036.
- [25] DESI collaboration, The DESI Experiment Part II: Instrument Design, 1611.00037.
- [26] DESI collaboration, Overview of the Instrumentation for the Dark Energy Spectroscopic Instrument, The Astronomical Journal 164 (2022) 207 [2205.10939].
- [27] H. du Mas des Bourboux, J. Rich, A. Font-Ribera, V.d.S. Agathe, J. Farr, T. Etourneau et al., The Completed SDSS-IV extended Baryon Oscillation Spectroscopic Survey: Baryon acoustic oscillations with Lyman- forests, The Astrophysical Journal 901 (2020) 153.
- [28] C. Gordon et al., 3D Correlations in the Lyman- Forest from Early DESI Data, JCAP 11 (2023) 045 [2308.10950].
- [29] DESI collaboration, DESI 2024 IV: Baryon Acoustic Oscillations from the Lyman alpha forest, JCAP 01 (2025) 124 [2404.03001].
- [30] DESI collaboration, DESI 2024 VII: Cosmological Constraints from the Full-Shape Modeling of Clustering Measurements, 2411.12022.
- [31] DESI collaboration, DESI DR2 Results I: Baryon Acoustic Oscillations from the Lyman Alpha Forest, 2503.14739.
- [32] DESI collaboration, DESI DR2 Results II: Measurements of Baryon Acoustic Oscillations and Cosmological Constraints, 2503.14738.
- [33] C. Ravoux et al., The Dark Energy Spectroscopic Instrument: one-dimensional power spectrum from first Ly forest samples with Fast Fourier Transform, Mon. Not. Roy. Astron. Soc. 526 (2023) 5118 [2306.06311].
- [34] N.G. Karaçaylı et al., Optimal 1D Ly Forest Power Spectrum Estimation – III. DESI early data, Mon. Not. Roy. Astron. Soc. 528 (2024) 3941 [2306.06316].
- [35] DESI collaboration, Validation of the Scientific Program for the Dark Energy Spectroscopic Instrument, The Astronomical Journal 167 (2024) 62 [2306.06307].
- [36] DESI collaboration, The Early Data Release of the Dark Energy Spectroscopic Instrument, The Astronomical Journal 168 (2024) 58 [2306.06308].
- [37] N.G. Karaçaylı et al., Desi dr1 ly 1d power spectrum: The optimal estimator measurement, in preparation (2025) .
- [38] N.G. Karaçaylı, C. Ravoux et al., Desi dr1 ly 1d power spectrum: Validation of estimators, in preparation (2025) .
- [39] DESI collaboration, Data Release 1 of the Dark Energy Spectroscopic Instrument, 2503.14745.
- [40] M.T. Murphy, G.G. Kacprzak, G.A.D. Savorgnan and R.F. Carswell, The UVES Spectral Quasar Absorption Database (SQUAD) Data Release 1: The first 10 million seconds, arXiv:1810.06136 [astro-ph] (2018) .
- [41] S. Lopez, V. D’Odorico, S.L. Ellison, G.D. Becker, L. Christensen, G. Cupani et al., XQ-100: A legacy survey of one hundred 3.5 < z < 4.5 quasars observed with VLT/XSHOOTER, Astronomy & Astrophysics 594 (2016) A91.
- [42] J.M. O’Meara, N. Lehner, J.C. Howk, J.X. Prochaska, A.J. Fox, M.A. Swain et al., THE FIRST DATA RELEASE OF THE KODIAQ SURVEY, The Astronomical Journal 150 (2015) 111.
- [43] J.M. O’Meara, The Second Data Release of the KODIAQ Survey, The Astronomical Journal (2017) 5.
- [44] N. Palanque-Delabrouille, C. Yèche, A. Borde, J.-M.L. Goff, G. Rossi, M. Viel et al., The one-dimensional Ly-alpha forest power spectrum from BOSS, Astronomy & Astrophysics 559 (2013) A85.
- [45] S. Chabanier, N. Palanque-Delabrouille, C. Yèche, J.-M.L. Goff, E. Armengaud, J. Bautista et al., The one-dimensional power spectrum from the SDSS DR14 Ly forests, Journal of Cosmology and Astroparticle Physics 2019 (2019) 017.
- [46] DESI collaboration, The Robotic Multiobject Focal Plane System of the Dark Energy Spectroscopic Instrument (DESI), Astron. J. 165 (2023) 9 [2205.09014].
- [47] DESI collaboration, The Optical Corrector for the Dark Energy Spectroscopic Instrument, Astron. J. 168 (2024) 95 [2306.06310].
- [48] DESI collaboration, Survey Operations for the Dark Energy Spectroscopic Instrument, Astron. J. 166 (2023) 259 [2306.06309].
- [49] C. Poppett, L. Tyas, J. Aguilar, C. Bebek, D. Bramall, T. Claybaugh et al., Overview of the Fiber System for the Dark Energy Spectroscopic Instrument, The Astronomical Journal 168 (2024) 245.
- [50] A. Dey, D.J. Schlegel, D. Lang, R. Blum, K. Burleigh, X. Fan et al., Overview of the DESI Legacy Imaging Surveys, The Astronomical Journal 157 (2019) 168.
- [51] C. Yèche et al., Preliminary Target Selection for the DESI Quasar (QSO) Sample, Res. Notes AAS 4 (2020) 179 [2010.11280].
- [52] E. Chaussidon et al., Target Selection and Validation of DESI Quasars, Astrophys. J. 944 (2023) 107 [2208.08511].
- [53] DESI collaboration, Performance of the Quasar Spectral Templates for the Dark Energy Spectroscopic Instrument, Astron. J. 166 (2023) 66 [2305.10426].
- [54] N. Busca and C. Balland, QuasarNET: Human-level spectral classification and redshifting with Deep Neural Networks, 1808.09955.
- [55] J. Farr, A. Font-Ribera and A. Pontzen, Optimal strategies for identifying quasars in DESI, JCAP 11 (2020) 015 [2007.10348].
- [56] S. Filbert et al., Broad absorption line quasars in the Dark Energy Spectroscopic Instrument Early Data Release, Mon. Not. Roy. Astron. Soc. 532 (2024) 3669 [2309.03434].
- [57] P. McDonald, U. Seljak, R. Cen, P. Bode and J.P. Ostriker, Physical effects on the Lyman-alpha forest flux power spectrum: damping wings, ionizing radiation fluctuations, and galactic winds, Monthly Notices of the Royal Astronomical Society 360 (2005) 1471.
- [58] D. Parks, J.X. Prochaska, S. Dong and Z. Cai, Deep learning of quasar spectra to discover and characterize damped Ly systems, MNRAS 476 (2018) 1151 [1709.04962].
- [59] M.-F. Ho, S. Bird and R. Garnett, Damped Lyman-alpha Absorbers from Sloan Digital Sky Survey DR16Q with Gaussian processes, Monthly Notices of the Royal Astronomical Society 507 (2021) 704.
- [60] H. du Mas des Bourboux, J. Rich, A. Font-Ribera, V. de Sainte Agathe, J. Farr, T. Etourneau et al., picca: Package for Igm Cosmological-Correlations Analyses, Astrophysics Source Code Library (2021) ascl:2106.018.
- [61] DESI collaboration, The Spectroscopic Data Processing Pipeline for the Dark Energy Spectroscopic Instrument, Astron. J. 165 (2023) 144 [2209.14482].
- [62] A.S. Bolton and D.J. Schlegel, Spectro-Perfectionism: An Algorithmic Framework for Photon Noise-Limited Extraction of Optical Fiber Spectroscopy, Publications of the Astronomical Society of the Pacific (2010) 100119133735095.
- [63] K.K. Rogers, S. Bird, H.V. Peiris, A. Pontzen, A. Font-Ribera and B. Leistedt, Simulating the effect of high column density absorbers on the one-dimensional Lyman forest flux power spectrum, Mon. Not. Roy. Astron. Soc. 474 (2018) 3032 [1706.08532].
- [64] J.A. Baldwin, Luminosity Indicators in the Spectra of Quasi-Stellar Objects, Astrophysical Journal 214 (1977) 679.
- [65] P. Virtanen, R. Gommers, T.E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau et al., SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nature Methods 17 (2020) 261.
- [66] N.G. Karaçaylı, N. Padmanabhan, A. Font-Ribera, V. Iršič, M. Walther, D. Brooks et al., Optimal 1D Ly forest power spectrum estimation – II. KODIAQ, SQUAD, and XQ-100, Monthly Notices of the Royal Astronomical Society 509 (2022) 2842.
- [67] C. Pedersen, A. Font-Ribera, K.K. Rogers, P. McDonald, H.V. Peiris, A. Pontzen et al., An emulator for the Lyman- forest in beyond-CDM cosmologies, JCAP 05 (2021) 033 [2011.15127].
- [68] M. Walther, E. Armengaud, C. Ravoux, N. Palanque-Delabrouille, C. Yèche and Z. Lukić, Simulating intergalactic gas for DESI-like small scale Lyman forest observations, Journal of Cosmology and Astroparticle Physics 2021 (2021) 059.
- [69] M. Walther et al., Emulating the Lyman-Alpha forest 1D power spectrum from cosmological simulations: New models and constraints from the eBOSS measurement, 2412.05372.
- [70] M. Lokken, A. Font-Ribera and P. McDonald, Weighted FFT estimators for 1D and 3D correlations of the Lyman- forest, 2505.02904.
- [71] J. Richard et al., 4MOST Consortium Survey 8: Cosmology Redshift Survey (CRS), The Messenger 175 (2019) 50 [1903.02474].
- [72] WEAVE collaboration, WEAVE-QSO: A Massive Intergalactic Medium Survey for the William Herschel Telescope, in Week of French Astrophysics : Semaine de l’Astrophysique Francaise, 11, 2016 [1611.09388].
- [73] P.R. Bevington and D.K. Robinson, Data reduction and error analysis for the physical sciences, McGraw-Hill Education (2003).