Design and Experimental Evaluation of a Hierarchical Controller for an Autonomous Ground Vehicle with Large Uncertainties
Abstract
Autonomous ground vehicles (AGVs) are receiving increasing attention, and the motion planning and control problem for these vehicles has become a hot research topic. In real applications such as material handling, an AGV is subject to large uncertainties and its motion planning and control become challenging. In this paper, we investigate this problem by proposing a hierarchical control scheme, which is integrated by a model predictive control (MPC) based path planning and trajectory tracking control at the high level, and a reduced-order extended state observer (RESO) based dynamic control at the low level. The control at the high level consists of an MPC-based improved path planner, a velocity planner, and an MPC-based tracking controller. Both the path planning and trajectory tracking control problems are formulated under an MPC framework. The control at the low level employs the idea of active disturbance rejection control (ADRC). The uncertainties are estimated via a RESO and then compensated in the control in real time. We show that, for the first-order uncertain AGV dynamic model, the RESO-based control only needs to know the control direction. Finally, simulations and experiments on an AGV with different payloads are conducted. The results illustrate that the proposed hierarchical control scheme achieves satisfactory motion planning and control performance with large uncertainties.
Index Terms:
Autonomous ground vehicles (AGVs), trajectory planning and tracking, uncertainty, model predictive control (MPC), extended state observer (ESO).I Introduction
Nowadays, autonomous ground vehicles (AGVs) are playing an ever-increasing role in both civilian and military fields. These devices can increase productivity, decrease costs and human faults. However, in real applications (e.g., material handling in warehouses), an AGV is characterized by uncertain and challenging operational conditions, such as different payloads, varying ground conditions, and manufacturing imperfection [2, 3]. In this paper, we aim to solve the motion planning and control problem of AGVs with large uncertainties.
In general, there are three basic phases and modules in the AGV motion planning and control system, i.e., path planning, trajectory tracking control, and dynamic control [4]. The planning phase generates a feasible path for the AGV to follow. In the literature, various kinds of planning algorithms have been developed, such as A∗ algorithm [5], D∗ algorithm [6], and rapidly exploring random trees (RRT) [7]. With a prior map of the environment, an AGV is able to plan a desired trajectory in real-time. The trajectory tracking control attempts to produce the velocity commands to enable the vehicle to track the planned path. So far, many approaches have been applied to AGV trajectory tracking control, such as classical PID control [8], sliding mode control [9], robust control [10], and intelligent control [2]. However, realistic constraints imposed by the AGV model and physical limits cannot be effectively handled in theses methods.
In fact, the AGV path planning and trajectory tracking control with constraints can be naturally formulated into a constrained optimal control problem [11]. Therefore, model predictive control (MPC), which is capable of systematically handling constraints, became a well-known method to solve the AGV path planning and trajectory tracking control problem [12, 13, 14, 15, 16]. In [15], a linear parameter varying MPC (LPV-MPC) strategy was developed for an AGV to follow the trajectory computed by an offline nonlinear model predictive planner (NLMPP). In [16], an MPC-based trajectory tracking controller which is robust against the AGV parameter uncertainties was proposed. The controller in [16] can be obtained by solving a set of linear matrix inequalities which are derived from the minimization of the worst-case infinite horizon quadratic objective function. Note that in [12, 13, 14, 15, 16], the trajectory tracking control is independent from the planning phase. However, a better integration between the path planning and trajectory tracking control would be helpful for enhancing the overall performance of an AGV. These observations motivate us to develop a novel MPC-based path planning and trajectory tracking control scheme for AGVs. The original rough path generated by a global planner is smoothed using MPC. A velocity planner is developed to assign the reference speed along the optimal path. Then an MPC-based trajectory tracking controller is designed to track the resulting trajectory. Since both the path planning and trajectory tracking control problems are solved using MPC-based methods, the AGV is expected to achieve better tracking performance.

The dynamic control, which performs in the AGV dynamic model level, aims to guarantee that the AGV moves according to the commands generated by the trajectory tracking controller. In practice, the AGV dynamic model is largely uncertain due to changing operational conditions. The active disturbance rejection control (ADRC), which is an efficient approach to handle uncertainties, has received an increasing attention in recent years [17, 18, 19]. The basic idea of ADRC is to view the uncertainties as an extended state of the system, and then estimate it using an extended state observer (ESO), and finally compensate it in the control action. In this paper, this idea is employed to design the AGV dynamic controller. A reduced-order ESO (RESO) is leveraged to estimate the uncertainties in the dynamic model of the AGV. On the theoretical side, we find that for general first-order uncertain nonlinear systems, the RESO-based ADRC controller only needs to know the sign of the control gain (i.e., the control direction). This is the weakest condition on the control gain compared with the existing ADRC literature (e.g., [20, 21, 22, 24, 23, 26, 27, 25]). More importantly, this feature of the RESO-based ADRC controller is vital to handle the possibly largely uncertain control gain in the AGV dynamic model.
The proposed overall control scheme for an AGV with large uncertainties has a hierarchical structure (see, Fig. 1), i.e., an MPC-based path planning and trajectory tracking control in the high-level to plan the trajectory and steer the vehicle, while the RESO-based dynamic control in the low-level to track the velocity commands and handle the uncertainties. To verify the effectiveness of the developed hierarchical controller, we implement it in an industrial AGV platform with different payloads. The main contributions of this paper are threefold.
-
1.
An MPC-based path planning and trajectory tracking control strategy is developed for industrial AGVs. Compared with the existing results, the developed strategy enables a better integration between the path planning and trajectory tracking control to enhance the overall tracking performance.
-
2.
A RESO-based dynamic controller is designed to handle the large uncertainties. It is proved that for a first-order uncertain nonlinear system, the RESO-based controller only needs to know the control direction. This is a new theoretical contribution, and makes the controller especially suitable for the AGV dynamic control, since in real applications such as material handling, the control gain of the AGV dynamic model is largely uncertain but its sign is fixed.
-
3.
Experiments of an AGV with different payloads are conducted in a warehouse. The maximal payload in the experiments is about double the weight of the AGV itself. This indicates that large uncertainties exist in the AGV dynamics, and it is a very challenging scenario that has been rarely considered in the literature. The experimental results show that the proposed hierarchical control scheme is easy for implementation, satisfactory in motion planning and trajectory tracking control, and effective in handling large uncertainties.
The remainder of this paper is organized as follows. In Section II, the AGV system model and problem statement are presented. In Section III, the proposed MPC-based path planning and trajectory control approach is introduced. Section IV gives the design and analysis of the RESO-based controller. Simulation and experimental results are provided in Section V to demonstrate the effectiveness and superiority of the proposed hierarchical control scheme. Finally, Section VI concludes the paper.
II System Model and Problem Statement

The schematic representation of the AGV is depicted in Fig. 2. The mathematical model of the AGV, including the kinematic equations and the dynamic equations, can be expressed as
| (1) |
where is the position of the AGV, is the orientation, represents the pose of the AGV with respect to the coordinate ; and are the linear and angular velocities, respectively; and are the mass and moment of inertia of the AGV, respectively; and are the distance between the two wheels and the radius of the wheel, respectively; and are the torques of the right and left wheels, respectively; and are the external disturbance force and torque, respectively.
Let and be the velocities of the left and right wheels of the AGV, respectively. Due to physical limitations, the velocities of the wheels are bounded by and , where is the maximal wheel speed. What is more, the linear and angular velocities of the AGV can be formulated as
| (2a) | ||||
| (2b) | ||||
It follows from (2) that
| (3) |
The inequality (3) defines a diamond-shaped domain constraint on and [13]. Besides, the path planning and trajectory tracking control are inherently coupled [11]. Thus the first problem to be solved in this paper is to design an optimal path planning and trajectory tracking control approach, with the motion constraints systematically handled.
On the other hand, it can be observed from (1) that the dynamics of the AGV suffer from the external disturbance force and torque (such as friction force and torque). Most importantly, in some real applications, the mass and moment of inertia of the AGV platform are largely uncertain, due to different payloads and load distributions. For example, in our experiments, the maximal payload of the AGV reaches double of its own weight (i.e., the mass of the AGV platform varies between and , where is the own weight of the AGV). The second problem to be solved in this paper is to design a robust controller which is easy to implement and capable of handling the large uncertainties.
III MPC-based Trajectory Planning and Tracking Control
A global path consists of a sequence of waypoints. Each waypoint can be represented by . If the total number of the waypoints is , the path can be represented by a list . A trajectory is a mapping between the time domain and space domain of the path. It can be represented by a list , where is the reference time for the waypoint . In this paper, we assume a navigation map is prebuilt by simultaneous localization and mapping (SLAM), and a rough original path is obtained by a geometric path planning algorithm (e.g., A* algorithm). First, this original path is assigned with a constant reference velocity to execute an MPC-based optimization process, which is for improving the smoothness of the original path with all the constraints systematically handled. Then, based on the smoothed path, a reference velocity planner is developed to assign the AGV speed. Finally, the MPC-based trajectory tracking controller is designed.
III-A MPC-based Improved Path Planning
The main idea of the MPC-based improved path planning is generating an optimal path by simulating a tracking process using MPC along the original path. The new path is smoother than the original path, and is kinematically feasible for the AGV to follow.
Since only the spatial information is considered in the global path planning stage, a trajectory with a constant velocity is first generated based on the global path . In our study, the resolution of the environment map is assumed to be high enough, so the distance between adjacent reference waypoints and is small. The time interval can be approximated by
| (4) |
where the reference velocity of the robot at position is set to be a constant value . Based on the time interval , the corresponding reference time of each waypoint can be expressed as
| (5) |
Then, an MPC-based tracking process is executed on the trajectory to generate a new path. The optimal trajectory tracking control problem at time is formulated as
| (6a) | ||||
| s.t. | (6b) | |||
| (6c) | ||||
| (6d) | ||||
where is the cost within the finite horizon and is the terminal cost. Here is the pose of the AGV, and is the control input which consists of the linear and angular velocities. This optimization problem is solved under several constraints. Eq. (6b) represents the initial state constraint. The initial state is given by current state . Eq. (6c) represents the kinematic constraint which is used to predict the motion of the AGV. According to the kinematic equation in (1) and the reference trajectory, the kinematic constraint (6c) can be specified by
| (7) |
Note that in (7), the time interval should be small enough to reduce the discretization error. According to (4), it means that the trajectory should be adequately dense. Since the MPC predicts the AGV’s future trajectory within a fixed horizon, a denser trajectory will lead to a higher computational complexity. Therefore, in practice, there exists a tradeoff between the model discretization accuracy and the computational complexity. Besides, Eq. (6d) represents the state and control input constraints, where and are the feasible sets for and , respectively.
In the MPC framework, the cost function needs to be carefully defined to achieve satisfactory performance. For the path smoothing task, both tracking accuracy and smoothness of the control should be considered. Therefore, the complete cost function is designed as
| (8) |
where
| (9a) | |||
| (9b) | |||
| (9c) | |||
and , , and are positive definite weighting matrices. The cost function consists of three parts. represents the distance between the state and the corresponding reference waypoint at time step , so the first part of the cost function penalizes the distance between the smoothed path and original path within the time horizon . represents the difference between the control input and the reference velocity at time step . Since a constant velocity is used to generate the trajectory, here . represents the variation between two successive control inputs. The third part of the cost function penalizes the fluctuation of the control signal and makes the robot motion smoother.
Note that the optimization problem (6) is non-convex due to the inclusion of the non-convex constraint (6c). In this study, we use the interior point method [28] to solve the non-convex optimization problem (6). This method implements an interior point line search filter to find a local optimal solution. Since our objective is to find an optimal path close to the original path, the original path is leveraged to initialize the optimization problem, which makes it very likely to converge to the global optimal solution. The optimal predicted states and control inputs are denoted by
| (10) |
The predicted states can be regarded as a new path which consists of waypoints. In the optimization problem, the tracking error and control input fluctuation have been penalized, so the new path should be both close to the original path and smooth enough. What is more, since the kinematic model and the velocity limits are considered during the optimization process, the new path is kinematically and physically feasible for the AGV.
If the prediction horizon is selected as the length of the original path , the new optimal path can be directly obtained by . We denote this global optimal path as . However, in this case, the dimension (number of the decision variables) of the optimization problem is quite large and the computation will become time-consuming. Here, to solve this problem, we propose a piecewise path generation approach to achieve an efficient planning.
To begin with, a straightforward method is given. The MPC problem (6) within a proper time horizion is solved. Then, based on the optimization result, is extracted to the new path, and the final predicted state is used to update the initial constraint (6b) which generates the next MPC problem. This process is repeated until the whole original path is replaced by the optimal predicted states. However, the path generated in this way maybe not smooth at the piecewise points. To overcome this limitation, we overlap the time horizon of the successive optimization process. Specifically, in each optimization step, only the first elements of is extracted to generate the new path and the initial state of the next MPC problem is set as , where denotes the update horizon which satisfies . In this way, the obtained path is smoother than the original path and close to the global optimal path . The proposed MPC-based improved path planning is summarized in Algorithm 1.
III-B Reference Velocity Planning
In our approach, the trajectory generation is decomposed into spatial path generation and reference velocity (speed profile) planning. A reasonable and efficient reference velocity planning is necessary to obtain safe and comfortable navigation behavior. Based on the MPC-improved path, a velocity planner is developed in this subsection to assign the reference speed along the path, which completes the trajectory planning phase.
In real applications, the need for safe robot motion (e.g., to prevent rollover) should be considered. It is dangerous for an AGV to turn sharply at a high forward speed. However, the velocity constraint (3) cannot provide the guarantee of the safety. To solve this problem, we introduce a new parameter into the constraint (3), that is
| (11) |
By adjusting the parameter , the velocity constraint (11) can satisfy different requirements of the safety level. The linear constraint (11) is utilized to generate the reference velocity (speed profile). Firstly, we approximate based on the path . Note that now each waypoint in the path is represented by , where denotes the reference position, and denotes the reference heading angle of the AGV. Denote the distance between adjacent waypoints and as , and the arc length from the origin to the waypoint as . It can be computed that
| (12) |
Since the time interval and the distance are small, the reference velocity and time derivative of the heading angle can be approximated by
| (13) |
| (14) |
According to (13) and (14), we obtain
| (15) |
It can be observed from the AGV kinematic equations in (1) that the term represents in the planning phase. However, if is approximated by the discrete difference equation (14), it may perform a discontinuous phenomenon and leads to an uncomfortable speed profile. To solve this problem, the polynomial curve fitting approach is leveraged to obtain a smooth reference velocity profile. The path can be parameterized using the arc length along the path , e.g., . Similarly, the heading angle can be also parameterized by . A cubic polynomial curve fitting of heading angle with respect to is given by
| (16) |
where to are coefficients determined by minimizing the fit error [29]. Generally, a single polynomial function cannot represent a long path precisely. Therefore, a piecewise polynomial curve fitting is implemented. Note that
| (17) |
As a result, the constraint (11) can be rewritten as
| (18) |
For differential wheeled AGVs, it is assumed that , which means the AGV can only move forward. Consider the time-efficiency of the planned trajectory, the reference velocity is likely to be selected as large as possible. Therefore, the smoothed reference velocity at waypoint is specificed by
| (19) |
This together with the MPC-improved path yields the new trajectory , where the timing information is calculated by
| (20) |
Note that in this paper, the spatial and temporal planning of the trajectory are separated. More specifically, the path is first smoothed by optimization using a constant velocity , and then the smoothed path is leveraged for the velocity planning. Our simulation and experimental experiences indicate that such a simple two-stage procedure suffices to achieve a satisfactory performance. In some cases, an iterative procedure between the path smoothing and velocity planning could further improve the performance, but with longer computation time.
III-C MPC-based Kinematic Controller
In the online kinematic control stage, due to some practical issues such as localization error, the control sequences generated in the trajectory planning stage cannot be directly applied. A trajectory tracking controller is needed to make the vehicle track the planned trajectory. What is more, those unnecessary aggressive maneuvers should also be avoided. Due to these considerations, the MPC-based trajectory tracking problem is formulated as
| (21a) | ||||
| (21b) | ||||
| (21c) | ||||
| (21d) | ||||
| (21e) | ||||
where , and . The optimal control problem needs to be solved at each sampling time. At time , the localization system gives the estimated state of the robot , which is used to update the initial constraint (21b). The index in the kinematic constraint (21c) and (21d) satisfies . By solving (21), the optimal predicted states and inputs are obtained, then only the first element of is applied to the AGV as the kinematic control input. At the next sampling time, the optimization problem (21) is rebuilt and solved again. The whole process is repeated until the goal position is reached.
IV RESO-based Dynamic Controller
The kinematic controller generates the commands of the linear and angular velocities (denoted by and , respectively) for the AGV to track the planned trajectory. The objective of the dynamic controller is to make the actual AGV velocities and follow and , respectively. What is more, the large uncertainties (maybe introduced by friction, payloads, etc) in the dynamic equations of the AGV need to be properly handled. To accomplish this goal, we first design a RESO-based tracking controller for a class of general first-order uncertain nonlinear systems. Rigorous theoretical analysis is given to show that, the tracking error can be made arbitrary small under large uncertainties. This approach is then applied to design the dynamic controller for the AGV.
IV-A RESO-based Tracking Control for First-Order Uncertain Nonlinear Systems
Consider the following first-order uncertain nonlinear system
| (22) |
where is the state, is the external disturbance, are uncertain continuously differentiable functions. The objective of the control is to guarantee that the state of the system (22), , tracks a given reference signal .
Assumption A1: The external disturbance and its first derivative are bounded.
Assumption A2: The reference signal and its first two derivatives are bounded.
Assumption A3: For all , the control gain , and its sign is fixed and known.
Note that large uncertainties exist in system (22), since the drift dynamics is totally unknown, and only the sign of the control gain is known. Let be a nominal function of the control gain . In this paper, we only require the signs of and are the same. By Assumption A3 and without loss of generality, it is assumed that . For system (22), the total uncertainty is defined as
| (23) |
According to (22) and (23), a first-order RESO is designed as
| (24) |
where is the observer state, is a small positive constant, and is the observer gain. The output of the RESO (24) is
| (25) |
which, is the estimate of the total uncertainty .
Based on the output of the RESO (24), the control is designed as
| (26) |
where . Furthermore, inherited from the previous high-gain observer results [23, 24, 20, 21], to protect the system from the peaking caused by the initial error and high-gain, the control to be injected into the system is modified as
| (27) |
where is the bound selected such that the saturation will not be invoked under state feedback [23, 24], i.e.,
| (28) |
The function is odd and defined by [24]
It can be observed that is nondecreasing, continuously differentiable with locally Lipschitz derivative, and satisfies and , , where is the standard unity saturation function denoted by .
Theorem 1: Consider the closed-loop system formed of (22), (24), (25), and (27). Suppose Assumptions A1 to A3 are satisfied, and the initial conditions and are bounded. Then for any , there exists such that for any ,
| (29) |
and
| (30) |
Proof: See the Appendix. ∎
Remark 1: It is now well-realized that the ESO-based control (or ADRC) needs a good prior estimate of the control gain [20, 21, 24, 23, 26, 27, 25]. In other words, the nominal control gain should be “close” to the actual control gain . However, the results in Theorem 1 show that for the first-order uncertain nonlinear system (22), the RESO-based controller only relies on the knowledge of the control direction (i.e., the sign of ). This result is very meaningful, since in practice it is much easier to obtain the knowledge of the control direction than an accurate prior estimate of the control gain. In [30], a similar conclusion was achieved via frequency-domain analysis for first-order linear uncertain systems. As far as the author’s knowledge goes, this paper is the first work that conducts rigorous time-domain analysis for RESO-based control for first-order uncertain nonlinear systems.
IV-B Dynamic Controller for an AGV with Large Uncertainties
For the AGV dynamic controller design, we first consider the following transformation:
| (31) |
Then the AGV dynamic model can be rewritten as
| (32) |
Note that in (32), the control gains for the AGV linear and angular velocities (i.e., and ) are largely uncertain due to different payloads, but their signs are fixed and known to the designer. Therefore, the developed RESO-based controller is capable of handling the large uncertainties in the AGV dynamic model.
By Theorem 1, the observers and controllers are designed as
| (33) |
| (34) |
| (35) |
| (36) |
where and are the nominal values of and , respectively; and are the estimates of the uncertainties and , respectively; , ; and are the saturation bounds.
Finally, by (31), the actual control commands are obtained by
| (37) |







V Simulation and Experimental Evaluation
This section presents the simulation and experimental results of the proposed hierarchical control scheme. The MPC-based trajectory planning and tracking control algorithm is first implemented on Robot Operating System (ROS) to tune the parameters, and to verify its superiority. The effectiveness of the RESO-based dynamic controller in handling large uncertainties is then tested in Matlab/Simulink. Finally, experiments are conducted on an AGV in a warehouse environment with different payloads.
V-A Simulation Results
The stage simulator is used to build the simulation environment in ROS. An efficient optimization solver named Interior Point OPTimizer (IPOPT) [28] is employed to solve the MPC problem. The parameters in the MPC-based trajectory planning and tracking control algorithm are selected as , , , , , , and . The linear and angular velocities of the AGV are limited by and , respectively. We consider the scenario depicted in Fig. 3. The task of the AGV is to move from point A to point B, and then come back to point C. The original path generated by A* and the MPC-improved path are plotted in Fig. 4. It can be observed that the MPC-improved path enhances the smoothness of the original path. Fig. 5 shows the planned velocity profile. According to the colorbar, one can see that at the turning phase, the velocity is planned to be slow; along the straight lines, the velocity is planned close to the maximum speed.
To evaluate the advantage of the proposed design, three different planning and tracking control schemes are considered: 1) MPC-based trajectory planning + PID tracking control, 2) global planner (A*) + MPC-based tracking control, and 3) the proposed MPC-based trajectory planning and tracking control. To make a fair comparison, these three schemes use the same A* algorithm and their MPC parameters are also the same. The gains for the PID controllers in scheme 1) for the AGV linear and angular velocities are given by the triples (0.065, 0, 0.13) and (0.1, 0.05, 0.2), respectively. Simulation results of the three schemes on the kinematic model of the AGV are depicted in Figs. 6 and 7. The tracking error comparison is summarized in Table I. It can be observed that the proposed approach outperforms the other two approaches in terms of the maximum error , mean error and root mean square error (RMSE) .
| Planning + Tracking | (m) | (m) | (m) |
| MPC + PID | 0.047 | 0.015 | 0.020 |
| A* + MPC | 0.044 | 0.010 | 0.013 |
| MPC + MPC | 0.028 | 0.008 | 0.011 |
The parameters of the RESO-based dynamic controller are selected as , , , , and . The linear and angular velocity commands and are generated from the MPC-based kinematic controller in Fig. 6c. For comparison, we also simulate a PID controller whose transfer function is given by , where is the filter coefficient, and , , and stand for the proportional, integral, and derivative gains, respectively. The gains of this PID controller are selected as , , , and , which are tuned by the PID Tuner function in Matlab/Simulink with an overshoot of zero and a rise time of 0.2 seconds. Consider two simulation cases: case 1) without payload and external disturbance; case 2) with payload (triple the weight of the AGV itself) and external disturbance ( and ). Simulation results of the two cases are shown in Fig. 8. From this figure, one can see that in case 1) the RESO-based controller and PID controller achieve comparable performance; but in case 2) with large uncertainties, the RESO-based controller performs much better than the PID controller. The main reason for this improvement is that in the proposed RESO-based controller, the total uncertainties are estimated by the observer, and compensated for in the control action in real time. Fig. 9 depicts the performance of the RESO. It can be observed that the total uncertainties and are both well-estimated by the RESO in the two cases.






V-B Experimental Results
In the experiment, the AGV (see Fig. 10) is mainly equipped with 1) a 2D LiDAR for localization; 2) a mini PC Intel® NUC to run the MPC-based trajectory planning and tracking control algorithm; 3) an ARM® STM32F103RC MCU to execute the RESO-based dynamic control algorithm; 4) a dual DC motor drive module WSDC2412D to drive the motors. The Adaptive Monte-Carlo Localization (AMCL) algorithm [31] is implemented to localize the AGV. The control frequencies of the high-level kinematic control and low-level dynamic control are 20Hz and 100Hz, respectively.
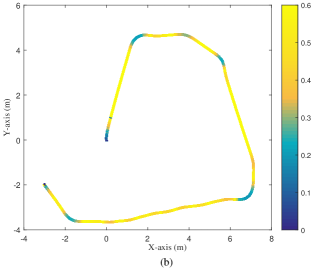
Experiments are conducted in a warehouse environment. Parameters of the proposed hierarchical controller are inherited from the simulation. Note that in our experiment setting, the actual input of the AGV dynamic model is the motor voltage rather than the torque. The dynamics of the DC motor can be approximated by a first-order inertial system with a small time constant [2]. Since the RESO-based controller is capable of handling large uncertainties and only relies on the sign of the control gain, in the implementation stage, the commands of the voltage of the DC motors are also given by (37). Fig. 11a illustrates the map of the environment and the original path generated by the A∗ algorithm. Fig. 11b shows the MPC-improved path and the reference velocity. The maximal velocity of the AGV in the experiments is set as 0.6m/s. Figs. 12 and 13 depict the experimental results with 0 payload and 60kg payload, respectively. Note that 60kg payload is about double the weight of the AGV itself, which indicates large uncertainty corresponding to the AGV dynamics. Such uncertainty will increase the burden of the controller, and has stubborn effects on the overall control performance. However, from Figs. 12 and 13, one can observe that the AGV moves along the planned trajectory accurately, the commands generated by the MPC-based kinematic controller are well-tracked by the RESO-based dynamic controller, and the voltages of the two motors are also acceptable. Fig. 14 depicts the trajectory tracking error with 0 payload and 60kg payload. With 0 payload, the maximal tracking error is 0.071m, the average tracking error is 0.019m; with 60kg payload, the maximal tracking error is 0.105m, the average tracking error is 0.029m. The experimental video is available at https://youtu.be/SxdO9YXbiZs.
VI Conclusion
A hierarchical control scheme is proposed for AGVs with large uncertainties. The MPC-based trajectory planning and tracking control at the high level provides satisfactory trajectory and accurate kinematic tracking performance, while the RESO-based dynamic control at the low level handles the large uncertainties. The proposed hierarchical control scheme needs little information of the AGV dynamics, and is simple for implementation. Experimental results for an AGV with different payloads verified the effectiveness of the proposed approach in handling large uncertainties. In future studies, the focus will be on the extension of the hierarchical scheme to multiple-AGVs in complex manufacturing environment. The uncertainties caused by the environment and communication will be considered.







We need a lemma before giving the proof of Theorem 1. Define the tracking error , and a Lyapunov function candidate . Denote , and define two compact sets:
Note that and is an internal point of . The following lemma shows that for sufficiently small , , .
Lemma 1: Consider the closed-loop system formed of (22), (24), (25), and (27). Suppose Assumptions A1 to A3 are satisfied, and the initial conditions and are bounded. Then there exists such that for any , , .
Proof of Lemma 1: Since is an internal point of , and the control is bounded, there exits an -independent such that , . Lemma 1 will be proved by contradiction. Suppose Lemma 1 is false, then there exist such that
| (38) |
Consider the RESO estimation error . By (23)-(25), the dynamics of can be formulated as111For notation simplicity, we omit the time symbol occasionally.
| (39) |
The differentiation of the extended state can be computed as
| (40) |
where
By (25) and (26), the control can be expressed as
It follows that can be computed as
| (41) |
| (42) |
By Assumptions A1, A2, and the boundedness of in the time interval , one can conclude from (VI) that there exist -independent positive constants and such that
| (43) |
where
Consider the Lyapunov function candidate . It follows from (VI) and (43) that
| (44) |
Note that the term satisfies
| (45) |
Since and have the same sign, and , (VI) guarantees that . It then follows from (VI) that there exists sufficiently small such that for any and , .
Next, we show that the function in (27) is out of saturation in the time interval . By the convergence of the RESO, one has
| (46) |
Therefore, up to an error, satisfies the equation
| (47) |
This equation has a unique solution since . Note that the saturation bound satisfies (28). It can be obtained by direct substitution that the unique solution is
| (48) |
Since the saturation bound is selected to satisfy (28), one can conclude that for sufficiently small , will be in the linear region of the saturation function in the time interval . It follows that the time derivative of can be computed as
| (49) |
By (38), in the time interval , . This together with the relation yields
| (50) |
which, contradicts (38). Thus there exists such that for any , , . This completes the proof of Lemma 1. ∎
Based on Lemma 1, we are ready to state the proof of Theorem 1.
References
- [1]
- [2] C. L. Hwang, C. C. Yang, and J. Y. Hung, “Path tracking of an autonomous ground vehicle with different payloads by hierarchical improved fuzzy dynamic sliding-mode control,” IEEE Transactions on Fuzzy Systems, vol. 26, no. 2, pp. 899-914, 2018.
- [3] V. Digani, L. Sabattini, C. Secchi, and C. Fantuzzi, “Ensemble coordination approach in multi-AGV systems applied to industrial warehouses,” IEEE Transactions on Automation Science and Engineering, vol. 12, no. 3, pp. 922-934, 2015.
- [4] N. H. Amer, H. Zamzuri, K. Hudha, and Z. A. Kadir, “Modelling and control strategies in path tracking control for autonomous ground vehicles: a review of state of the art and challenges,” Journal of Intelligent and Robotic Systems, vol. 86, no. 2, pp. 225-254, 2017.
- [5] P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,” IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100-107, 1968.
- [6] A. Stentz, “The focussed D∗ algorithm for real-time replanning,” in Proceedings of the International Joint Conference on Artificial Intelligence, 1995, pp. 1652-1659.
- [7] S. M. LaValle and J. J. Kuffner Jr, “Randomized kinodynamic planning,” The International Journal of Robotics Research, vol. 20, no. 5, pp. 378-400, 2001.
- [8] J. Villagra and D. Herrero-P´erez, “A comparison of control techniques for robust docking maneuvers of an AGV,” IEEE Transactions on Control Systems Technology, vol. 20, no. 4, pp. 1116-1123, 2012.
- [9] Y. Wu, L. Wang, J. Zhang, and L. Li, “Path following control of autonomous ground vehicle based on nonsingular terminal sliding mode and active disturbance rejection control,” IEEE Transactions on Vehicular Technology, vol. 68, no. 7, pp. 6379-6390. 2019
- [10] R. Wang, H. Jing, C. Hu, F. Yan, and N. Chen, “Robust path following control for autonomous ground vehicles with delay and data dropout,” IEEE Transactions on Intelligent Transportation Systems, vol. 17, no. 7, pp. 2042-2050, 2016.
- [11] X. Li, Z. Sun, D. Cao, D. Liu, and H. He, “Development of a new integrated local trajectory planning and tracking control framework for autonomous ground vehicles,” Mechanical Systems and Signal Processing, vol. 87, pp. 118-137, 2017.
- [12] H. Zheng, R. R. Negenborn, and G. Lodewijks, “Fast ADMM for distributed model predictive control of cooperative waterborne AGVs,” IEEE Transactions on Control Systems Technology, vol. 25, no. 4, pp. 1406-1413, 2016.
- [13] Z. Sun and Y. Xia, “Receding horizon tracking control of unicycle type robots based on virtual structure,” International Journal of Robust and Nonlinear Control, vol. 26, no. 17, pp. 3900-3918, 2016.
- [14] J. Ji, A. Khajepour, W. W. Melek, and Y. Huang, “Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints,” IEEE Transactions on Vehicular Technology, vol. 66, no. 2, pp. 952-964, 2016.
- [15] E. Alcalá, V. Puig, J. Quevedo, and U. Rosolia, “Autonomous racing using linear parameter varying-model predictive control (LPV-MPC),” Control Engineering Practice, vol. 95, p.104270, 2020.
- [16] S. Cheng, L. Li, X. Chen, J. Wu, and H. Wang, “Model-predictive-control-based path tracking controller of autonomous vehicle considering parametric uncertainties and velocity-varying,” IEEE Transactions on Industrial Electronics, published online, DOI: 10.1109/TIE.2020.3009585.
- [17] J. Han, “From PID to active disturbance rejection control,” IEEE Transactions on Industrial Electronics, vol. 56, no. 3, pp. 900-906, 2009.
- [18] Y. Huang and W. Xue, “Active disturbance rejection control: methodology and theoretical analysis,” ISA Transactions, vol. 53, no. 4, pp. 963-976, 2014.
- [19] E. Sariyildiz, R. Oboe, and K. Ohnishi, “Disturbance observer-based robust control and its applications: 35th anniversary overview,” IEEE Transactions on Industrial Electronics, published online, doi: 10.1109/TIE.2019.2903752.
- [20] M. Ran, Q. Wang, and C. Dong, “Active disturbance rejection control for uncertain nonaffine-in-control nonliner systems,” IEEE Transactions on Automatic Control, vol. 62, no. 11, pp. 5830-5836, 2017.
- [21] M. Ran, Q. Wang, and C. Dong, “Stabilization of a class of nonlinear systems with actuator saturation via active disturbance rejection control,” Automatica, vol. 63, pp. 302-310, 2016.
- [22] M. Ran, Q. Wang, C. Dong, and L. Xie, “Active disturbance rejection control for uncertain time-delay nonlinear systems,” Automatica, vol. 112, 108692.
- [23] J. Lee, R. Mukherjee, and H. K. Khalil, “Output feedback stabilization of inverted pendulum on a cart in the presence of uncertainties,” Automatica, vol. 54, pp. 146-157, 2015.
- [24] L. B. Freidovich and H. K. Khalil, “Performance recovery of feedback-linearization-based designs,” IEEE Transactions on Automatic Control, vol. 53, no. 10, pp. 2324-2334, 2008.
- [25] T. Jiang, C. Huang, and L. Guo, “Control of uncertain nonlinear systems based on observers and estimators,” Automatica, vol. 59, pp. 35-47, 2015.
- [26] B. Z. Guo and Z. L. Zhao, “On convergence of the nonlinear active disturbance rejection control for MIMO systems,” SIAM Journal on Control and Optimization, vol. 51, no. 2, pp. 1727-1757, 2013.
- [27] D. Wu and K. Chen, “Design and analysis of precision active disturbance rejection control for noncircular turning process,” IEEE Transactions on Industrial Electronics, vol. 56, no. 7, pp. 2746-2753, 2009
- [28] A. Wachter, “An interior point algorithm for large-scale nonlinear optimization with applications in process engineering,” Ph.D. dissertation, Carnegie Mellon University, 2003.
- [29] G. W. Recktenwald, Numerical methods with MATLAB: implementations and applications, New Jersey: Prentice Hall, 2000.
- [30] W. Xue and Y. Huang, “On frequency-domain analysis of ADRC for uncertain system,” in American Control Conference, 2013, pp. 6637-6642.
- [31] D. Fox, “KLD-sampling: Adaptive particle filters and mobile robot localization,” in Advances in Neural Information Processing Systems, pp. 26–32, 2001.
- [32]