Detecting DeFi Securities Violations from Token Smart Contract Code
Abstract
Decentralized Finance (DeFi) is a system of financial products and services built and delivered through smart contracts on various blockchains. In the past year, DeFi has gained popularity and market capitalization. However, it has also been connected to crime, in particular, various types of securities violations. The lack of Know Your Customer requirements in DeFi poses challenges to governments trying to mitigate potential offending in this space. This study aims to uncover whether this problem is suited to a machine learning approach, namely, whether we can identify DeFi projects potentially engaging in securities violations based on their tokens’ smart contract code. We adapt prior work on detecting specific types of securities violations across Ethereum, building classifiers based on features extracted from DeFi projects’ tokens’ smart contract code (specifically, opcode-based features). Our final model is a random forest model that achieves an 80% F-1 score against a baseline of 50%. Notably, we further explore the code-based features that are most important to our model’s performance in more detail, analyzing tokens’ Solidity code and conducting cosine similarity analyses. We find that one element of the code our opcode-based features may be capturing is the implementation of the SafeMath library, though this does not account for the entirety of our features. Another contribution of our study is a new data set, comprised of (a) a verified ground truth data set for tokens involved in securities violations and (b) a set of legitimate tokens from a reputable DeFi aggregator. This paper further discusses the potential use of a model like ours by prosecutors in enforcement efforts and connects it to the wider legal context.
keywords:
Research
Introduction
Decentralized Finance (DeFi) refers to a suite of financial products and services delivered in a decentralized and permissionless manner through smart contracts111Smart contracts are programs stored on a blockchain which automatically carry out specified actions when certain conditions are met [1]. on a blockchain222A blockchain is a secure, decentralized database comprised of entries called blocks, which are cryptographically connected to one another through a hash of the previous block, thereby ensuring its security and resistance to fraud. In the case of cryptocurrencies, blockchains serve as a decentralized, distributed public ledger that records all transactions [2, 3]. In this sense, blockchains underpin the “decentralized” nature of “decentralized finance”, as they allow users to transact with one another in a trustless manner, without the need for an intermediary financial institution., most commonly Ethereum. Its promoters have proclaimed it to be the future of finance [4], an assertion supported by the increase in its market capitalization by more than 8,000% between May 2020 and May 2021 [5]. Unfortunately, criminal activity in the DeFi ecosystem has also grown in parallel with its value. As of August 2021, 54% of cryptocurrency fraud was DeFi-related, compared to only 3% the previous year [6]. Furthermore, vast numbers of new DeFi projects are created every day and anyone is permitted to create one. Taken together, these present a challenge for law enforcement. The volume of projects, coupled with the magnitude of criminal offending, makes the development of an automated fraud detection method to guide investigative efforts particularly critical.
Securities violations are one category of crime affecting the cryptocurrency space [7, 8, 9]. Securities violations refer to offenses relating to the registration of securities and misrepresentations in connection with the purchase or sale of securities, including pyramid schemes and foreign exchange scams [10, 11]. Preliminary empirical research on decentralized exchanges (one of DeFi’s core product offerings) points to the prevalence of specific types of securities violations (such as exit scams333Exit scams, also referred to as “rug pulls”, involve developers of a project stealing all funds paid into or invested in their project [12]., advance fee fraud444Advance fee fraud refers to a scammer convincing a victim to send them an amount of money in exchange for returning the original amount plus a premium. The fraudster simply takes the original funds [13]., and market manipulation) on these platforms [14], while others have chronicled securities violations like Ponzi schemes on decentralized applications (dApps) [15].555DApps are the user interfaces of DeFi-based products and services. This limited empirical work suggests possible approaches for identifying general scam tokens and certain types of securities violations like Ponzi schemes in the wider cryptocurrency universe. While we acknowledge the realm of work using opcode-based features to identify malicious activity (see, for example, [16]), research has not yet explored automated detection a) of securities violations overall (rather than specific types of securities violations like scam tokens or Ponzi schemes, b) across a broader subspace of the DeFi ecosystem (i.e., ERC-20 tokens on all DeFi platforms, instead of a single decentralized exchange); or c) alongside detailed analyses of the ERC-20 tokens’ smart contract code. We consider an automated approach to be preferable because of the sheer volume of DeFi projects that exist and are being created.
Against this background, we seek to answer the following research questions: (1) is a machine learning approach appropriate for identifying DeFi projects likely to be engaging in violations of U.S. securities laws?666Developers write smart contracts in a high-level programming language called Solidity [17]. Smart contracts are responsible for DeFi’s application infrastructure, as well as for creating cryptocurrency tokens themselves. and (2) what are the reasons, at feature level, such a model is or is not successful for this classification problem? This study presents and critically evaluates the first method for automated detection of various types of securities violations in the DeFi ecosystem on the basis of their token’s smart contract code, providing a tool which may identify starting points for further investigation. The contributions of this study are as follows:
-
•
We build a classifier to detect DeFi projects committing various types of securities violations. Our work is the first to expand existing machine learning-based classification models to encompass multiple types of securities violations.
-
•
We use and make available a new data set of violations verified by court actions.
-
•
Our work is the first to prioritize the explainability of classification decisions in terms of opcode-based features.
Finally, the results of this study contribute to the theory and practice of financial markets. Forecasting, detecting, and deterring financial fraud is critical to maintaining overall financial stability [18]. In particular, “frauds harm the integrity of financial markets and disrupt the mechanism of efficient allocation of financial resources” [18]. This is particularly pertinent in the cryptocurrency space [18], especially as these markets become more entwined with traditional ones [19].
Decentralized Finance (DeFi)
DeFi refers to a collection of financial products and services made possible by smart contracts built on various blockchains, most commonly the Ethereum blockchain. DeFi offers traditional financial products and services, such as loans, derivatives, and currency exchange, in a decentralized manner through smart contracts. DeFi is an open source, permissionless system, that is not operated by a central authority. Rather than transacting with one another through an intermediary like a centralized exchange, users’ interactions occur through dApps, created by smart contracts, on a blockchain [20]. In this section we describe our DeFi system model for this research and briefly outline its main components. As it is the subject of our research, we focus our explanation on the Ethereum-based DeFi space, though DeFi, of course, exists on various blockchains.
Ethereum-based DeFi System Model
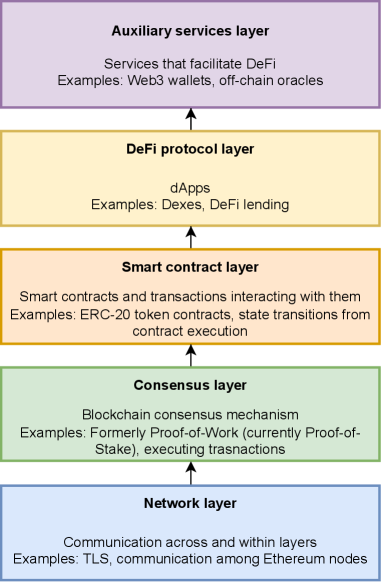
Before we explain DeFi in more detail, we define our system model. The Ethereum-based DeFi system model can be conceptualized as a five-layer system, consisting of a network layer, a blockchain consensus layer, a smart contract layer, the DeFi protocol layer, and an auxiliary services layer [21]. The network layer is concerned with communicating data across and within the various layers. It involves several elements, including network communication protocols and the Ethereum network; in particular, it includes communication among Ethereum peers/nodes. The consensus layer refers to the Ethereum blockchain’s consensus mechanism [21]. At the time of our research, this was still Proof-of-Work [22]. The consensus layer also encompasses nodes’ actions which rely on the consensus mechanism such as “data propagation”, “data verification”, executing transactions, and mining blocks. While the first two layers are implied in our research, this study primarily focuses on the smart contract layer. This includes the smart contract code that creates the ERC-20 tokens from which we derive our data set, and that creates the dApps that use them. The smart contract layer also includes transactions executed by smart contracts, the Ethereum Virtual Machine (EVM) state, and the state transition upon execution of DeFi transactions. The DeFi protocol layer refers to decentralized applications with which users interact, and the auxiliary service layer involves services that facilitate DeFi’s functioning, such as wallets and off-chain oracles. We describe these elements in more detail below and provide a visual representation thereof in Figure 1.
Ethereum
Ethereum functions as a distributed virtual machine and is the platform on which much of the DeFi ecosystem currently runs. This paper focuses on explaining the features of Ethereum which are most relevant to DeFi’s functioning.777For further details on Ethereum, see the Ethereum Yellow Paper [22].
In addition to holding balances, Ethereum accounts can store smart contract code and other information. A smart contract is a computer program that automatically carries out certain actions when specified conditions—such as payments—are met [3]. The smart contract code is immutable and publicly available on the blockchain. Smart contracts allow parties who do not trust one another to enter into contracts—rather than trusting each other or a third party to execute the contract, smart contracts ensure the terms will be executed as coded into the contract [1].
Before smart contracts are executed, they must be compiled into bytecode to be deployed and understood by the Ethereum Virtual Machine (EVM). Once compiled, Ethereum smart contracts take the form of a string of numbers (bytecode). The EVM is a stack-based environment888In stack-based programming, “all functions receive arguments from a numerical stack and return their result by pushing it on the stack.” These specific functions come from a set of pre-defined functions [23]., with a 256-bit stack size. It reads the bytecode as operational codes (opcodes) which are, essentially, a set of instructions (from a set of 144 possible instructions). The opcodes include actions like retrieving the address of the individual interacting with the contract, various mathematical operations, and storing information [24, 22].
Tokens
Many DeFi projects also have associated tokens created by smart contracts, which either entitle holders to something within the dApp (analogous to a video game’s in-game currency) or serve as “governance tokens”. For example, UNI is the Uniswap decentralized exchange’s governance token [25]. Another example is the SCRT token which, in addition to being a governance token, is required to pay transaction fees on the Secret network [26]. Holders of governance tokens can vote on the future of projects; their voting power is proportional to the amount of governance tokens they hold. Most non-NFT DeFi tokens on Ethereum follow the ERC-20 (Ethereum Request for Comment) standard, which facilitates interoperability among projects. The ERC-20 standard allows for token capabilities like transferring among accounts, maintaining balances, and the supply of tokens, among others [27]. In this paper, we focus on ERC-20 tokens.
dApps
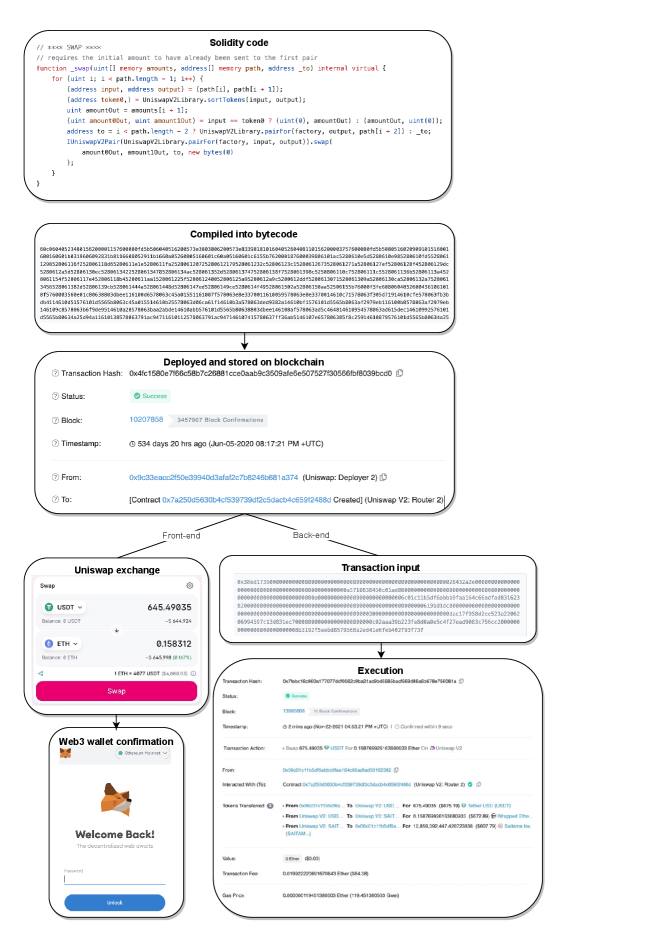
Developers create dApps which serve as the interfaces to execute these smart contracts. DeFi’s current core product offerings—including decentralized exchanges (dexes), lending products, prediction markets, insurance, and other financial products and services—are delivered through dApps [28]. Table 1 describes the primary products that make up the DeFi ecosystem.
Figure 2 depicts the process of dApp creation and execution through smart contracts, using Uniswap (a popular dex) as an example. As depicted in Figure 2, DeFi users must have a Web3 software wallet to hold DeFi tokens and interact with dApps. These wallets can be thought of as akin to a mobile banking application and exhibit similar features (sending transactions, showing balances, etc.). The difference is that, unlike with a banking application, users retain custody of their funds and can send transactions and execute other functions directly, rather than through an intermediary institution [29]. Using cryptographic digital signatures, users approve connections to their Web3 wallets, “sign in” to dApps, and approve interactions with the smart contracts on these platforms through their wallet.
| Decentralized exchanges | These services allow users to exchange cryptocurrencies using liquidity provided by other users, generally through Automated Market Makers, which algorithmically set prices [30]. Participants can provide liquidity to liquidity pools for certain pairs of cryptocurrencies and receive a Liquidity Provider token for doing so. They can “stake” this token (i.e., lock it into the system and agree not to withdraw it for a certain period) and earn interest on it, usually paid in the decentralized exchange’s governance token (referred to as “yield farming”). The return on investment for these yield farms may be in the hundreds or even thousands of percent. Participants can stake governance tokens in “pools” and earn further rewards. This incentivizes users to provide liquidity to keep the exchanges running.999For a more detailed discussion of decentralized exchanges, see [14]. |
|---|---|
| DeFi lending | Loans are issued through smart contracts rather than intermediaries and use cryptocurrencies as collateral [31]. Loans are often issued in stablecoins—cryptoassets whose value is pegged to government-issued fiat currencies—and interest rates tend to be set algorithmically [32]. Users can earn interest for providing liquidity for loans and earn fees from loans. One primary DeFi lending innovation is flash loans, which are loans issued and repaid in a single transaction. Because they are issued and repaid in one transaction, they do not require collateral [12]. |
| Prediction markets | These allow users to bet on real-world outcomes—such as sporting events or elections—through smart contracts [33]. Prediction markets rely on blockchain oracles, which are external sources of information that determine the outcome of the prediction market [12]. Based on this information about the outcome, the smart contract releases the appropriate funds to the winners [33]. |
| DeFi insurance | DeFi insurance community members serve as underwriters and share in premiums paid to the protocol. Holders of the project’s governance token vote on claims payouts. DeFi insurance remains a nascent industry, but some companies are attempting to handle claims directly through smart contracts. So far, DeFi insurance tends to insure only other DeFi protocols [34]. |
| Other financial products | A range of other financial products, including those not usually available to retail investors, can be implemented within DeFi. These include derivatives trading, margin trading, and other securities [35]. |
U.S. Securities Laws
An understanding of U.S. securities law is necessary prior to defining our DeFi threat model. DeFi has raised alarm in regulatory circles due to concerns over DeFi tokens’ potential conflict with existing U.S. securities laws [36]. U.S. securities are primarily governed at the federal level by the Securities Act and the Exchange Act, though the Sarbanes-Oxley Act, Trust Indenture Act, Investment Advisors Act, and Investment Company Act are also relevant. Enforcement of these laws is the responsibility of the Securities and Exchange Commission (SEC) and the Financial Industry Regulatory Authority (FINRA) [11].
The Securities Act relates to the offer and sale of securities. One of the key provisions which has been charged in cryptocurrency cases is Section 5, which requires the registration of the offer and sale of securities and stipulates specific provisions thereof [11].101010For cryptocurrency case law involving the Securities Act, see [37, 38, 39]. Other sections detail the required registration information111111Sections 7 and 10. and exemptions121212Section 3, Section 4, Regulation S, Rule 144A, Regulation D, Rule 144, Rule 701, Section 28. [11]. Various SEC enforcement actions have successfully argued that ERC-20 tokens are securities (see, for example, [40]), arguing that they constitute investment contracts [41]. For further details on the application of the Howey Test (the SEC’s criteria for determining whether something is a security), as it relates to digital assets, see [41].
The Exchange Act specifies public companies’ reporting requirements and regulates securities trading through securities exchanges. It also handles securities fraud; under section 10(b) and 10b-5, fraud and manipulation in relation to buying or selling securities is illegal. One cannot make false or misleading statements (including by omission) in relation to the sale or purchase of securities, including those exempt from registration under the Securities Act. The registration of securities, securities exchanges, brokers, dealers, and analysts is covered in Sections 12 and 15 of the Exchange Act [11]. Section 12 regulates registration of initial public offerings, which is relevant for cryptocurrency initial coin offerings (ICOs).131313For cryptocurrency case law involving the Exchange Act, see [37, 38, 39]. Finally, Section 13 relates to companies’ reporting obligations under the Exchange Act [11].
In practice, in addition to various registration and reporting violations, securities laws in the U.S. tend to cover the following fraudulent conduct: high yield investment programs, Ponzi schemes, pyramid schemes, advance fee fraud, foreign exchange scams, and embezzlement by brokers, among others [10].141414For definitions of these offenses, see [13]. Financial frauds have been shown to impact financial stability, market integrity, and resource allocation and, in the case of cryptocurrency frauds, to have an impact on markets in traditional finance [18, 42].
Threat Model
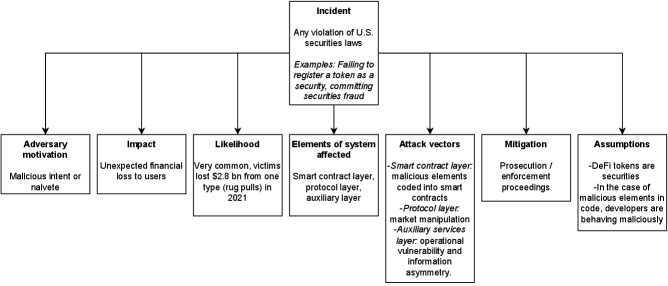
We define our threat model in line with the U.S. securities laws described above. With that in mind, an “incident” is any activity that is in violation of these laws, such as failing to register a token as a security or an ICO or committing securities fraud. These actions may be the result of intentionally malicious behavior or naivete. Both cases “result in an unexpected financial loss” to users [21]. While we do not have an estimate of all of the losses individuals incurred as a result of DeFi securities violations, we know, for example that the Finiko ponzi scheme took $1.1 billion from victims in 2021 and rug pulls stole $2.8 billion worth of funds from victims in 2021 [43]. These incidents occur at the smart contract layer, the protocol layer, and the auxiliary layer of the DeFi system. In terms of the smart contract layer, this includes both the creation of the ERC-20 token itself (in the case of registration violations), as well as any malicious elements coded into the smart contracts such as Ponzi schemes, advance feed fraud, or certain types of exit scams. At the protocol level, the primary attack vector would be market manipulation [21]. Finally, at the auxiliary layer, we see both “operational vulnerability” (such as price oracle manipulation) and “information asymmetry” (such as smart contract honeypots) [21]. Information asymmetry is primarily at play in the case of securities fraud. Users are often unable to (or do not take the time to) analyze DeFi protocol smart contracts (and related security risks) prior to allowing them to utilize their assets. Users’ “understanding of a contract operation” is more likely to come from projects’ marketing materials than the contract source code itself [21].
The above threat model involves various assumptions. First, we assume that, based on the classification of the tokens used to construct our data set by the SEC, the DeFi tokens in question are securities under U.S. law. As discussed above, precedent has been established in this regard. Notably, this also means that many otherwise legitimate projects may be operating contrary to U.S. securities laws by virtue of the fact that they are not appropriately registered. The second assumption we make is that, in the case of frauds coded into the smart contract code, the developers of the DeFi tokens violating securities laws are behaving maliciously, rather than their violations being the result of errors. For this reason, patching or fixing smart contract code (as discussed in [44] and [45]) would not be a suitable way to allay this threat. Registration violations may result from either malicious intent or naivete.
Finally, we assume that prevention measures have failed in these instances and, therefore, the primary course of justice is detection and prosecution. While prevention is certainly preferable, it is not possible to prevent all crimes and, therefore, detection and prosecution remain an important way to remedy the threats discussed above. Figure 3 offers a visual representation of our threat model.
Related Work on Detecting Fraud on Ethereum
Previous studies have used machine learning to detect certain specific types of securities violations and fraud on Ethereum. The most common type of securities violation examined in the literature is smart contract Ponzi schemes [46, 47, 48, 49, 50, 15, 51, 52, 53, 54]. The various machine learning algorithms these studies employ to identify such Ponzi schemes—and their relative performance—can be found in Table 2. We acknowledge the existence of various sequential machine learning studies in other contexts (many of which feature more sophisticated classification models). However, in this article, we limit our review to studies which apply sequential machine learning techniques to detect fraud on Ethereum, as the classification problems they seek to solve are most similar to ours.
| Study | Method | Features | Performance |
|---|---|---|---|
| [46] | Semantically-aware classifier that includes “a heuristic-guided symbolic execution technique” | Code-based |
Precision: 100%
Recall: 100% F1: 100% |
| [49] | “Anti-leakage” model based on ordered boosting | Code-based |
Precision: 95%
Recall: 96% F1: 96% |
| [50] | Deep learning model | Code-based |
Precision: 96.3%
Recall: 97.8% F1: 97.1% |
| [15] | Long-term short-term memory neural network | Transaction-based |
Precision: Between 88.2% and 96.9% for different types of contracts
Recall: Between 81.6% and 97.7% for different types of contracts F1: Between 85% and 96.7% for different types of contracts |
| [53] | Long-term short-term memory neural network | Code- and transaction-based |
Precision: 97%
Recall: 96% F1: 96% |
| [52] | Heterogeneous Graph Transformer Networks | Code- and transaction-based | F1: Between 78% and 82% for fraudulent smart contracts and 87% and 89% for normal smart contracts for different classification tasks |
| [54] | LightGBM | Code- and transaction-based |
Precision: 96.7%
Recall: 96.7% F1: 96.7% |
| [48] | XGBoost | Code- and transaction-based |
Precision: 94%
Recall: 81% F1: 86% |
| [51] | Decision trees, random forest, stochastic gradient descent | Code- and transaction-based |
Precision: Between 90% and 98% for different models
Recall: Between 80% and 96% for different models F1: Between 84% and 96% for different models |
| [55] | Random forest | Code- and transaction-based |
Precision: Between 64% and 95% for different features
Recall: Between 20% and 73% for different features F1: Between 30% and 82% for different features |
Previous work on smart contract Ponzi schemes has examined code-based features [46, 50, 49]; transaction-based features [15]; or both [53, 52, 51, 54, 48, 55]. Code-based features include the frequency with which each opcode appears in a smart contract and the length of the smart contract bytecode [51]. Transaction- and account-based features refer to the number of unique addresses interacting with the smart contract, and the volume of funds transferred into and out of the smart contract, among others [51]. Notably, one study [46] identifies four specific Ponzi scheme typologies based on bytecode sequences.
In addition to smart contract Ponzi schemes, other studies examining smart contracts use machine learning to detect general fraud and scams [56, 57, 58, 59, 14, 60]; advance fee fraud [61]; smart contract honeypots [50, 62]; ICO scams [63, 64]; and “abnormal contracts” causing financial losses [65] . Notably, one study [65] also uses contract source code-based features, as well as opcode and transaction-based ones.
Most existing work in this field examines Ethereum smart contracts in general, but some specifically refer to dApps and DeFi in their work [49, 15, 53, 59, 14], though they do so to varying degrees and, at times, conflate DeFi with Ethereum more broadly. Notably, one study [15] uses machine learning to classify different types of dApp smart contracts into their various categories, including those for gaming, gambling, and finance, among others.
Gaps and Issues
While the results of the studies described in Table 2 suggest that approaches of this nature can perform well for this task, a number of points of caution have also been raised. Literature concerning smart contract Ponzi scheme detection points to issues of overfitting, due to the imbalance of classifications in many data sets [49]. Studies have addressed this using the over- and under-sampling techniques [46, 49, 53, 54]. Other scholars [46] criticize the interpretability of results based on opcode features, i.e., why the presence of certain opcodes would point to criminality. Perhaps most fundamentally, however, these studies have given little consideration to whether machine learning techniques are actually necessary for this task; or, at least, superior to other, possibly simpler, approaches. While the methods applied undoubtedly show high performance, it remains possible that similar metrics could be achieved without recourse to these kinds of techniques.
Another issue with previous work is the repeated use of two particular data sets [48, 66]. Of the studies cited above, four use the Bartoletti et al. [66] data set [46, 50, 52, 51] and two use the Chen et al. [48] one [53, 54], while one study combined both data sets and added additional data [49]. While using the same data sets may be useful for comparing performance, it may be less useful in practice for combating fraud, with any shortcomings of these data sets having a polluting effect on the literature. Indeed, when manually inspecting the Bartoletti et al. [66] data set, one study [46] identified issues involving duplication and bias. Finally, though used to classify general fraud rather than Ponzi schemes, one article uses proprietary company data [59], which hinders reproducibility and evaluations of results.
The majority of existing related work uses smart contracts in general as opposed to ERC-20 token smart contracts (as [14] and we do). The only other work that specifically examines DeFi token smart contracts using machine learning is [14]. However, their work focuses on scam tokens in general (rather than securities violations) and on a single dApp (the dex Uniswap).
Aims of this Paper
This paper seeks to fill these gaps by a) evaluating whether a machine learning approach is appropriate for identifying DeFi projects likely to be engaging in securities violations; b) examining securities violations more comprehensively (rather than just scam tokens or Ponzi schemes); c) investigating these violations across Ethereum-based DeFi, rather than specific sub-spaces, like decentralized exchanges; and d) examining the code-based features identified by our model in order to better explain its performance. We also develop an entirely new data set of violating and legitimate tokens.
Method
This paper adapts its methods from prior research on the detection of Ethereum smart contract Ponzi schemes, adapting an approach that performed well in that context [51] and applying it to DeFi projects engaging in securities violations. We build various classification models based on features extracted from DeFi tokens’ smart contract code to classify the tokens into two categories: securities violations and legitimate tokens. Figure 4 provides a summary of our methods.

Data Collection
To answer our question of whether it can be determined if a project may be engaging in securities violations from its token’s smart contract code using machine learning, we first required ground truth sets of both securities violations and legitimate tokens. One source of such information is provided by token lists compiled by DeFi projects or companies around particular themes. One function of token lists is to help combat token impersonation and scams; reputable token lists provide users with some assurance that the tokens that appear are not fraudulent. Uniswap posts lists which are contributed by projects in the community; users generally follow lists from projects they trust [67]. The lists contain information like project websites (important for avoiding phishing attempts), symbols, and their smart contract addresses.
Securities Violations
The Blockchain Association (BA), a lawyer-led blockchain lobbying organization, has created one such list of ERC-20 tokens which have been subject to U.S. SEC enforcement actions.151515https://tokenlists.org/token-list?url=https://raw.githubusercontent.com/The-Blockchain-Association/sec-notice-list/master/ba-sec-list.json At the time of our study, this list contained 47 tokens and these represent our ground truth for projects engaging in securities violations. Many of these actions involve Initial Coin Offerings (ICOs), primarily in the context of companies or individuals failing to register their token as a security when it was required and/or making fraudulent misrepresentations in connection with said token (for example, Coinseed Token, Tierion, ShipChain SHIP, SALT, UnikoinGold, Boon Tech, and others) [68]. Other violations include Ponzi schemes (RGL, for example) and market manipulation (Veritaseum, for example) [69, 70]. The defendants in these cases are distinct, thereby supporting the independence of the tokens in our violations data set. We acknowledge the limitations of using such a small set, but this comprises all SEC actions involving DeFi tokens to date. Therefore, it makes for a more credible ground truth data set than attempting to find individual investment scams and securities violations on blockchain forums (as other data sets do, including [66]) in that it is more systematic and does not involve any subjective judgment of wrongdoing. It is worth noting that the nature of the list itself highlights the need for a systematic detection method: most of the actions either derived from the U.S. government whistleblower program, or were well-publicized scams, suggesting that enforcement is currently reliant on these sources. [71].
Legitimate Projects
The nature of the DeFi industry means that a substantial proportion of tokens in general may be of questionable validity—even if they have not been formally identified as violations—which poses a challenge when building a data set of legitimate tokens. Were we to simply take a random sample of all projects, for example, it is likely that this would contain problematic tokens, compromising our analysis. For this reason, we took an alternative approach, including only tokens for which we had some evidence of credibility. To do this we use the token list maintained by the DeFi platform Zapper.161616https://tokenlists.org/token-list?url=https://zapper.fi/api/token-list Zapper serves as a DeFi project aggregator which allows users to monitor their liquidity provision, staking, yield farming, and assets across different DeFi protocols. As of November 2021, Zapper had over a million total users, $11 billion worth of transaction volume, and raised $15 million in venture funding [72]. While they do not claim to provide financial advice to users, they make an effort to internally vet projects they list, opting for those with audited contracts and reputable teams [73]. To be clear, inclusion in this list does not provide any indication of the “quality” of a token—it is not analogous to a list of “blue chip” stocks—but simply an indication of authenticity. The Zapper list contains 2,146 ERC-20 tokens, and we used this as our ground truth of legitimate tokens. We acknowledge that this may not be as representative of DeFi tokens in general as a random sample, but this is the best available source of tokens which have some marker of credibility.
Final Data set
We extracted the smart contract addresses for the ERC-20 tokens on both of these lists and combined them into a single data set, with a binary indicator added to flag violations. This gave us an initial data set of 2,193 smart contract addresses. Seven tokens were present on both lists. These likely represent tokens which are otherwise legitimate, but violated U.S. securities laws by failing to register as securities. Since the Blockchain Association list is verified by court actions, we remove these from our “legitimate” token set. This also shows that our data set captures projects that occupy the “middle ground” with respect to legitimacy, rather than only at extremes of offending and non-offending. The final data set thus consisted of 2,186 tokens (47 of which were the subject of an SEC case in the U.S., i.e., where the individuals/company that created/marketed that token broke securities laws). Our final data set (including our features as described below), can be found here: https://osf.io/xcdz6/?view_only=5a61a06ae9154493b67b24fa4979eddb.
Features
Next, we used the Web3 Python package [74] to extract the bytecode for each of the tokens in our data set. We used an Infura node, which allows users to interface with the Ethereum blockchain through nodes the company runs, using their API171717https://www.infura.io/. Our classification features come from the token smart contract bytecode we collected. We opted to use only code-based features (rather than transaction-based features, for example), following other recent studies which have achieved high levels of performance (including 100% precision and recall in [46]) in classifying Ethereum-based smart contract Ponzi schemes [46, 49, 15]. Furthermore, using only code-based features allows for classification as soon as smart contracts are deployed [51]—rather than waiting to examine the characteristics of associated transactions—and permits analysis of smart contracts with few transactions [46].
For this initial analysis, our aim was to keep the classifier as simple and as computationally inexpensive as possible. It is also the first classifier for Ethereum-based DeFi securities violations more broadly, so our aim was to obtain a baseline for this novel classification problem in order to determine if it is, in fact, suited to machine learning, rather than improving on the state of the art for previously addressed problems (as [49, 46] and others have done for smart contract Ponzi scheme classification).
EVM bytecode can be computationally “disassembled” into its corresponding opcodes. This process is illustrated in Figure 4. Following [51], we included a feature in our classifier for each opcode that appeared in our smart contracts, representing the frequency with which that opcode appeared in any given smart contract. We used the Pyevmasm Python package [75] to disassemble each contract’s bytecode into its equivalent opcodes and then used a counter to determine the number of times each opcode appeared in the contract.
Feature Exploration
Prior to building any classification models, we used elastic net regression (with alpha=0.001, and with the data mean-centered and normalised using scikit-learn’s StandardScaler)181818Elastic Net regression combines the ridge penalty (which reduces coefficients of correlated variables) and the lasso penalty (which chooses one of the correlated variables and eliminates the others). The alpha value sets this penalty, with alpha=0 for full ridge regression and alpha=1 for lasso [76]. We chose alpha=0.001 and used the scikit-learn StandardScaler to pre-process our data to enable convergence of our model. The StandardScaler pre-processes the features in a data set by “removing the mean and scaling to unit variance” [77]. to explore the importance of our features. Table 3 shows the top 10 non-zero coefficients of the model.
| Feature | Coefficient |
|---|---|
| SWAP2 | 0.015 |
| DUP2 | 0.014 |
| SHL | 0.013 |
| PUSH30 | 0.012 |
| PUSH21 | 0.012 |
| PUSH9 | 0.011 |
| LOG4 | 0.010 |
| MLOAD | 0.008 |
| SLT | 0.007 |
| RETURN | 0.007 |
Overall, 55 of the features had non-zero coefficients in our elastic net regression model. However, we note that none of these coefficients were particularly large. This is to be expected because each line of Solidity code ultimately is translated into several opcodes, which means that multiple opcodes could capture the same behavior/action. Table 4 describes the opcodes included in Table 3.
| Opcode | Description |
|---|---|
| SWAPn | Exchange first and nth stack item |
| DUPn | Duplicate nth stack item |
| SHL | “Shift left” |
| PUSHn | Put n-byte item on the stack |
| LOGn | Append log record with n topics |
| MLOAD | Load a word previously saved to memory |
| SLT | “Signed less-than comparison” |
| RETURN | Stop code execution and return output data |
Classification
We first used a random forest classifier to attempt to determine if a project was potentially engaging in securities violations. We chose a random forest classifier for the following reasons:
-
1.
Research involving data similar to ours achieved the best classification results with a random forest, compared with other classifiers ([14]; precision: 96.45%, recall: 96.79%, F1-score: 96.62%).
-
2.
While initial work on smart contract Ponzi schemes [51] has been optimized in later studies (for example, [49]), our goal is to achieve a baseline of performance for classifying Ethereum-based DeFi securities violations. Previous work [51] found the random forest algorithm performed the best on their data set, when compared with other standard classification algorithms (J48 decision tree and stochastic gradient descent).
-
3.
Given our primary goal of determining if machine learning methods are suitable for developing a classifier useful for law enforcement investigations, using a model with greater transparency and traceability is most informative.
Given the classification imbalance in our data, we used down-sampling of the majority class to balance it with the minority class. Specifically, we randomly sampled 47 smart contracts from the majority class (i.e., from the n=2,139 legitimate contracts) and ran a random forest classifier on the resulting balanced data set (i.e., 47 violations vs. 47 legitimate tokens). This procedure was repeated 100 times with different random samples, and we report the average performance of these 100 iterations.191919Under-sampling, combined with properly executed cross-validation, performs well on highly imbalanced data sets [78]. While other, related work to ours [49] has used the Synthetic Minority Over-Sampling Technique (SMOTE) to train imbalanced data, we chose the more conservative under-sampling method. SMOTE combines majority class under-sampling and minority class over-sampling and synthesizes additional data for the minority class [79].
For each iteration, we used 70% of our data to train our model and 30% for our test set, following previous work in classifying smart contract Ponzi schemes [53]. We calculated accuracy, and weighted precision, recall, and F1-score to evaluate our model [80]. We calculated the means of these metrics across our 100 iterations to arrive at our final performance scores. We analyzed the average feature importance across the 100 iterations of our model and then built several subsequent models based on this information.
While, for the aforementioned reasons, we focused on random forest classification, in order to more comprehensively answer our first research question as to machine learning’s suitability for this classification task, we needed to build multiple kinds of models, including a simpler approach. For this reason, we also built logistic regression models from our data. As with our random forest classifier, we used down-sampling across 100 iterations, a 70%-30% train-test split, and calculated accuracy and weighted precision, recall, and F-1 score metrics. After analyzing feature importance, we constructed further models using different sets of features.202020We did not build any more complex machine learning models, like neural networks, to answer our first research question because our data set is much smaller than those traditionally used to train deep learning models. Neural networks are much less interpretable than simpler machine learning models [81] and would therefore be less suitable for our purposes (where results could potentially be involved in legal proceedings) in any case.
Results
Classification
Random Forest
While we used the results of our elastic net-based feature exploration as input for some of our models, because none of the coefficients were particularly large, we also performed further feature exploration with random forest models. We built our initial classification model using the frequency of all opcodes contained in our data set (a total of 142 features), employing bootstrapped under-sampling to evenly balance the classes in our data set over 100 iterations. As can be seen from the evaluation metrics shown in the top row of Table LABEL:tab5, we achieved satisfactory performance with this model compared to our baseline (50%). We then calculated the relative importance of the features included in the model, the results of which are reported in Table 6.
| Accuracy | Precision | Recall | F1-score | |
|---|---|---|---|---|
| RF1: Full-feature model | 0.759 | 0.757 | 0.759 | 0.757 |
| RF2: Top 10 features of model RF1 | 0.801 | 0.800 | 0.800 | 0.800 |
| RF3: Top 3 features of RF1 | 0.780 | 0.780 | 0.780 | 0.780 |
| RF4: Top feature of RF1 (CALLDATASIZE) | 0.777 | 0.774 | 0.777 | 0.774 |
| RF5: Non-zero coefficients of EN regression model | 0.731 | 0.731 | 0.731 | 0.731 |
| RF6: Top 10 features of RF5 | 0.743 | 0.742 | 0.743 | 0.742 |
| RF7: Top 3 features of RF5 | 0.741 | 0.741 | 0.741 | 0.741 |
| RF8: Top feature of RF5 (LT) | 0.747 | 0.747 | 0.747 | 0.747 |
| RF9: Top 10 features of EN regression model | 0.690 | 0.689 | 0.690 | 0.689 |
| RF1 | RF2 | RF3 | RF5 | RF6 | RF7 | RF9 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. |
| CALLDATASIZE | 0.062 | CALLDATASIZE | 0.203 | CALLDATASIZE | 0.340 | LT | 0.077 | LT | 0.165 | LT | 0.357 | SWAP2 | 0.206 |
| LT | 0.034 | LT | 0.125 | CALLVALUE | 0.334 | CALLVALUE | 0.075 | CALLVALUE | 0.158 | CALLVALUE | 0.340 | DUP2 | 0.192 |
| CALLVALUE | 0.032 | CALLVALUE | 0.123 | LT | 0.326 | CALLER | 0.046 | CALLER | 0.111 | CALLER | 0.303 | MLOAD | 0.180 |
| SHR | 0.029 | SWAP3 | 0.118 | DUP2 | 0.043 | SWAP2 | 0.094 | RETURN | 0.152 | ||||
| EXP | 0.026 | EXP | 0.110 | SWAP2 | 0.043 | DUP2 | 0.094 | SHL | 0.122 | ||||
| SWAP3 | 0.026 | CALLER | 0.089 | MLOAD | 0.039 | MLOAD | 0.088 | PUSH21 | 0.061 | ||||
| NUMBER | 0.023 | SHR | 0.072 | DUP7 | 0.039 | DUP7 | 0.084 | SLT | 0.031 | ||||
| PUSH5 | 0.021 | NUMBER | 0.063 | DUP5 | 0.033 | DUP5 | 0.074 | LOG4 | 0.020 | ||||
| CALLER | 0.018 | PUSH5 | 0.055 | GT | 0.033 | GT | 0.071 | PUSH30 | 0.019 | ||||
| ADDRESS | 0.018 | ADDRESS | 0.041 | DUP11 | 0.032 | DUP11 | 0.061 | PUSH9 | 0.018 | ||||
Next, we built models using only the 10 features with the highest importance in our original model, the three most important features, and, finally, the single most important feature (CALLDATASIZE). The weighted precision, recall, and F1-score and accuracy are reported in Table LABEL:tab5. We also built models with all the non-zero coefficients of our elastic net regression model (a total of 55 features), calculated the feature importances for this model, then used this information to build models with the 10 features with the highest importance in this 55-feature model, the top three features, and one with the top feature (LT) of this model. Finally, we built a model using the top 10 non-zero coefficients in our elastic net regression model as our features. We assessed the feature importance for all our further models, and this is reported in Table 6. Table 7 describes the opcodes whose frequency in the smart contracts was determined to be of high importance to the models, which were not previously described.
| Opcode | Description |
|---|---|
| CALLDATASIZE | Retrieve size of “input data in current environment” |
| LT | “Less-than comparison” |
| CALLVALUE | Amount deposited by current transaction/instruction |
| EXP | “Exponential operation” |
| CALLER | Get address of caller |
| SHR | “Logical shift right” |
| NUMBER | Retrieve block number |
| ADDRESS | Retrieve address of account executing transaction |
| GT | “Greater-than comparison” |
Using the F1-score as our primary metric, we achieved the best performance with RF2, our 10-feature model built with the top 10 features from our full-feature model (RF1). This model performed relatively well (F-1 score of 80%) compared to our baseline of 50%. Three features—the frequencies of CALLDATASIZE, LT, and CALLVALUE—were the most important features across all our random forest models.
Logistic Regression
In order to more fulsomely answer our research question about whether machine learning is appropriate for identifying DeFi projects likely to be engaging in violations of U.S. securities laws, we next built a logistic regression model to see if a simpler model could correctly classify our data. We used the same bootstrapped under-sampling as we did in constructing our random forest models, subsequently calculated feature importance, and built further models accordingly. We report the accuracy, weighted precision, recall, and F-1 scores for these models in Table 8 and the feature importance for the top 10 features in Table 9. Table 10 describes the opcodes present among the features reported in Table 9 which were not previously described.
| Accuracy | Precision | Recall | F1-score | |
|---|---|---|---|---|
| LR1: Full-feature model (using standard scaler) | 0.739 | 0.738 | 0.739 | 0.738 |
| LR2: Top 10 features of LR1 | 0.638 | 0.634 | 0.638 | 0.634 |
| LR3: Top 8 features of LR1 | 0.639 | 0.634 | 0.639 | 0.634 |
| LR4: All non-zero coefficients of EN regression (using standard scaler) | 0.725 | 0.724 | 0.725 | 0.724 |
| LR5: Top 10 features of LR4 | 0.606 | 0.601 | 0.606 | 0.601 |
| LR6: Top 9 features of LR4 | 0.602 | 0.596 | 0.602 | 0.596 |
| LR7: Top 10 features of EN regression model | 0.648 | 0.646 | 0.648 | 0.646 |
| LR1 | LR2 | LR3 | LR4 | LR5 | LR6 | LR7 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. | Feature | Imp. |
| SWAP15 | 0.396 | PUSH30 | 0.637 | CALLVALUE | 0.043 | SWAP7 | 0.515 | BALANCE | 0.260 | PUSH30 | 0.701 | PUSH30 | 0.671 |
| RETURN | 0.340 | SWAP15 | 0.514 | CODESIZE | 0.484 | CALLVALUE | 0.514 | CALLER | 0.023 | SWAP15 | 0.389 | LOG4 | 0.215 |
| PUSH30 | 0.299 | CODESIZE | 0.443 | EXP | 0.020 | PUSH9 | 0.430 | CALLVALUE | 0.058 | BALANCE | 0.215 | PUSH21 | 0.168 |
| CALLVALUE | 0.287 | PUSH31 | 0.146 | LOG1 | 0.070 | RETURN | 0.427 | LOG1 | 0.145 | LOG1 | 0.165 | RETURN | 0.140 |
| LOG1 | 0.253 | LOG1 | 0.102 | PUSH30 | 0.592 | SWAP15 | 0.382 | PUSH30 | 0.706 | PUSH31 | 0.088 | SLT | 0.118 |
| PUSH9 | 0.248 | PUSH9 | 0.091 | PUSH31 | 0.184 | PUSH31 | 0.377 | PUSH31 | 0.124 | SWAP7 | 0.064 | PUSH9 | 0.083 |
| PUSH31 | 0.233 | CALLVALUE | 0.050 | PUSH9 | 0.025 | PUSH30 | 0.328 | PUSH9 | 0.038 | CALLVALUE | 0.061 | DUP2 | 0.022 |
| EXP | 0.230 | EXP | 0.022 | SWAP15 | 0.590 | LOG1 | 0.271 | RETURN | -0.022 | CALLER | 0.012 | MLOAD | 0.007 |
| SWAP7 | 0.197 | RETURN | -0.030 | CALLER | 0.266 | SWAP15 | 0.450 | PUSH9 | 0.003 | SHL | -0.031 | ||
| Opcode | Description |
|---|---|
| CODESIZE | “Size of code running in current environment” |
| BALANCE | Retrieve account balance |
Overall, our logistic regression models performed worse than our random forest models. Our best performing logistic regression models, using the weighted F-1 score as our primary metric, were the models with the most features, namely our 142-feature model (LR1, with an F-1 score of 73.8%) and our 55-feature model (LR4, with an F-1 score of 72.4%). Our other logistic regression models performed closer to our baseline performance (50%).
There is not much overlap in the most important features of our logistic regression and random forest models (besides, of course, in the models built with the top 10 features of our elastic net regression model). EXP was one of the most important features in a handful of both random forest and logistic regression models (RF1, RF2, LR1, LR2, LR3). CALLVALUE was among the top 10 most important features for all our models aside from those built using the top 10 non-zero coefficients of our elastic net regression model. CALLER, which was among the top 10 most important features for five of our random forest models, also had high levels of feature importance in logistic regression models LR4, LR5, LR6.
Using the weighted F-1 score as our primary metric, we achieved the best performance (an F-1 score of 80%) with RF2, a 10-feature random forest model. This is, therefore, our final model.
Opcodes
To better understand the performance of our final model, we compared the frequencies with which the 10 opcodes from our final model occurred in each of our classes (violations and legitimate tokens). We conducted a t-test to assess whether the average frequencies were significantly different.
| Securities violations | Legitimate tokens | |||||||
|---|---|---|---|---|---|---|---|---|
| Opcode | Mean | St. dev | Mean | St. dev | t-value | p-value |
Effect size
(Cohen’s d) |
CI(95%) |
| CALLDATASIZE | 2.745 | 4.245 | 11.387 | 8.192 | -7.210 | 0.001 | -1.063 | [-1.354, -0.772] |
| LT | 9.404 | 9.124 | 18.676 | 14.799 | -4.277 | 0.001 | -0.631 | [-0.920, -0.341] |
| CALLVALUE | 17.957 | 10.449 | 10.497 | 13.658 | 3.720 | 0.001 | 0.549 | [0.259, 0.838] |
| SWAP3 | 24.723 | 17.501 | 37.273 | 25.214 | -3.394 | 0.001 | -0.500 | [-0.790, -0.211] |
| EXP | 36 | 34.075 | 17.751 | 25.187 | 4.871 | 0.001 | 0.718 | [0.428, 1.008] |
| CALLER | 16.851 | 9.648 | 11.768 | 11.244 | 3.074 | 0.002 | 0.453 | [0.164, 0.743] |
| SHR | 0.085 | 0.282 | 0.818 | 1.361 | -3.688 | 0.001 | -0.544 | [-0.833, -0.254] |
| NUMBER | 0.063 | 0.323 | 1.712 | 2.196 | -5.14 | 0.001 | -0.758 | [-1.048, -0.468] |
| PUSH5 | 0.362 | 1.206 | 2.198 | 2.908 | -4.321 | 0.001 | -0.637 | [-0.927, -0.348] |
| ADDRESS | 1.255 | 2.982 | 2.529 | 3.255 | -2.658 | 0.008 | -0.392 | [-0.681, -0.103] |
The findings from these comparisons are reported in Table 11, and support the analysis of feature importance in our final model. The mean frequencies of each of the features in our final model (reported in Table 11) were significantly different between the securities violations and legitimate token sets, with a much larger effect size for the most important feature (CALLDATASIZE) than for other features.
Analyzing Solidity Code
With the aim of better understanding our final model’s top three features, we randomly selected five contracts from our set of securities violations and five contracts from our set of legitimate tokens and analyzed their Solidity code. The contracts, the frequencies with which our model’s top three features occurred in their code, and the version of Solidity in which their code is written, can be found in Table 12.
| Frequency of opcodes | Solidity version | |||
| CALLDATASIZE | CALLVALUE | LT | ||
| Violating tokens | ||||
| Gladius | 5 | 17 | 11 | 0.4.15 |
| Tierion Network Token | 1 | 15 | 3 | 0.4.13 |
| Dropil | 1 | 16 | 6 | 0.4.18 |
| OpportyToken | 1 | 12 | 3 | 0.4.15 |
| Boon Tech | 3 | 25 | 18 | 0.4.19 |
| Legitimate tokens | ||||
| Sparkle Loyalty | 1 | 19 | 7 | 0.4.25 |
| Prometeus | 8 | 12 | 6 | 0.4.23 |
| ARC Governance Token | 11 | 1 | 18 | 0.5.0 |
| Social Finance | 9 | 22 | 5 | 0.4.23 |
| OST | 1 | 26 | 6 | 0.4.17 |
We used Etherscan,212121https://etherscan.io/ the Ethereum blockchain explorer, to obtain the Solidity code for each of these tokens. Next, we used Remix222222https://remix.ethereum.org/—an Ethereum Integrated Development Environment that allows users to write, compile, deploy, and debug Ethereum-based smart contracts, including in virtual environments—to analyze the code. We compiled and deployed each smart contract on the Remix virtual machine.
We used Remix’s “debugger” tool to analyze the transactions deploying each section of the compiled contracts. The debugger tool allows a user to examine the opcodes for each transaction chronologically and highlights the corresponding line of Solidity code for each opcode (each line of Solidity code is compiled as several opcodes). It also gives information on the functions that the transaction is interacting with, the local Solidity variables, the Solidity state variables, and other information [82, 83]. However, given our goal of better understanding the features of our final classification model, our analysis focused on the opcode tool.
We examined all elements of the smart contracts involved in their deployment transactions. For each, each time one of our target opcodes appeared, we noted the specific aspect of the token smart contract and the corresponding line of Solidity code.
Though it is difficult to ascertain patterns which may be picked up by our classifier from visual examination of our code, we noticed that four of our five violating contracts (Dropil, Tierion Network Token, OpportyToken, and Boon Tech) had the same line of code which was resolved to the CALLVALUE opcode in the SafeMath portion of the smart contract: library SafeMath {. In our legitimate token smart contracts, the CALLVALUE opcode was only present in one of the five token contracts (the OST contract) in the SafeMath part of the contract. SafeMath is part of the OpenZeppelin smart contract development library, which allows developers to import standard, vetted, and audited Solidity code for, for example, ERC-20 tokens [84]. The SafeMath library, in particular, provides overflow checks for arithmetic operations in Solidity; arithmetic operations in Solidity “wrap” on overflow, which can lead to bugs [85]. SafeMath solves this issue by reverting transactions that result in operation overflows [85].232323Notably, the SafeMath library was rendered superfluous by Solidity releases 0.8.0 and above (0.8.0 was released in December 2020 [86]) [87]. We initially hypothesized that violating tokens could utilize older versions of Solidity than legitimate ones due to the lengthy nature of the U.S. justice process. However, upon further inspection of the Solidity code for each token in our sample, they all rely on Solidity versions between 0.4.13 and 0.5.0 (as shown in Table 12), and all but Gladius include it in their code.
Additionally, when subsequently specifying the implementation of SafeMath for various arithmetic operations, the violating tokens use the “constant” function modifier, as opposed to the “pure” modifier used in the legitimate token smart contracts.242424In later versions of Solidity, the “constant” modifier was changed to “view” [88]. These modifiers dictate whether or not a given function affects the Ethereum global state. The use of “constant” indicates that no data from the function is saved or modified, while “pure” adds the attribute that the function also does not read blockchain data [89]. Essentially, while both attributes specify that the function will not write to the Ethereum state, in the case of “pure”, the function also does not read state variables [90]. The “pure” attribute, being stricter about state modification, provides stronger assurance that arithmetic operations resulting in overflow will not (incorrectly) modify the contract’s state. It makes sense that the legitimate token contracts would provide this additional security and specificity.
We previously noted that each line of Solidity code in a smart contract resolves to multiple opcodes. Our smart contract analysis highlights this. In a previous iteration of our model, JUMPDEST was among the top most important features of our model. Various lines of the Solidity code, such as Contract BasicToken is ERC20Basic } involved both this opcode as well as CALLVALUE. However, we did not notice any distinctions in such lines of code between our violating and legitimate token classes.
CALLVALUE and LT were present numerous times in the aspects of the smart contracts we analyzed with the Remix debugger tool, though, based on our disassembly of these tokens’ bytecode, the full frequencies were not present in the portions of the smart contracts we analyzed. The CALLDATASIZE opcode was absent altogether. However, we were unable to execute other transactions in the Remix virtual environment in order to analyze the entirety of the smart contracts (though, we certainly explored a significant portion thereof for each). Furthermore, given our aim in using code-based features to develop a classifier which could be used immediately upon a token contract’s deployment, these are the aspects most relevant for our purposes.
Comparing Smart Contracts
Given our conclusions about the implementation of a particular library in the code being one distinguishing factor between our violating and legitimate token contracts, we sought to delve further into potential code reuse as a reason for our classifier’s performance. Prior studies have found that 96% of Ethereum smart contracts contain duplicative elements (though it is unclear if this is the case in the Ethereum-based DeFi ecosystem specifically)[91]. In that sense, if legitimate projects borrow code from other legitimate projects and projects violating securities laws borrow from other violating projects, smart contracts within each class would have a high degree of internal consistency.
Cosine Similarity for Solidity Code
We used cosine similarities to analyze code reuse among the Solidity code of the smart contracts we analyzed individually. To do this, we tokenized252525“Token” is used here in the sense of natural language processing, to refer to a portion of text (i.e., a word). It differs from the use of “token” in the rest of this article. the Solidity code using FastText [92] and then calculated the cosine similarities between the vectors for each possible combination of the 10 contracts. Cosine similarity measures the level of similarity between two vectors. Cosine similarity is bound to the range -1 to 1; a cosine similarity of -1 means the two vectors are perfectly opposite, 1 means they are identical, and 0 means the two vectors are orthogonal to one another [93]. If code reuse were indeed a possible explanation, we would expect the difference between the cosine similarities within each class and the cosine similarities comparing the violating and legitimate contracts to be more pronounced for violating smart contracts than for legitimate smart contracts. We then compared the means of the cosine similarities each of our token classes. Our results are reported in Table 13.
| Cosine similarity | Comparison with inter-class similarity | |||||
| Class | Mean | St. dev | t-value | p-value | Cohen’s d | CI(95%) |
| Securities violations | 0.934 | 0.053 | -0.906 | 0.3711 | -0.337 | [-1.067, 0.392] |
| Legitimate | 0.962 | 0.0283 | 0.652 | 0.519 | 0.252 | [-0.506, 1.010] |
| Comparison of violations and legitimate | ||||||
| similarities | ||||||
| Inter-class | 0.951 | 0.048 | 1.361 | 0.191 | 0.625 | [-0.275, 1.523] |
The Solidity code was not significantly different among our classes (at least as per the cosine similarity). We note the high levels of similarity in general among the smart contracts; because of the existence of token standards this is as expected. Based on these results it is unlikely that, in the case of these 10 contracts, code reuse explains our classifier’s performance.
Cosine similarity of feature-based vectors
We next compared the opcode frequencies for the smart contracts to one another using cosine similarity to see if the opcodes to which the token Solidity code compiled suggested code reuse could be impacting our classifier’s performance. In this experiment, we used the cosine similarity of the vectors of the features rather than the Solidity code itself, as we did in our first cosine similarity experiment, which revealed significant similarities among ERC-20 token smart contracts due to code and token standards. In doing this, we hypothesized that using the opcode frequencies would better capture nuances in the code. We converted the frequencies of the opcodes in each smart contract into a vector and compared them. We calculated the cosine similarity for each possible combination of a) violating smart contracts, b) legitimate smart contracts, and c) violating and legitimate smart contracts (“inter-class”). For each set, we took the average of the calculated cosine similarities, the results of which can be found in Table 14. We also compared the cosine similarities for the set of violating contracts and for the set of legitimate tokens with the inter-class cosine similarities using t-tests; these results are also reported in Table 14.
| Cosine similarity | Comparison with inter-class similarity | |||||
| Class | Mean | St. dev | t-value | p-value | Cohen’s d | CI(95%) |
| Securities violations | 0.040 | 0.024 | -8.561 | 0.001 | -0.262 | [-0.322, -0.202] |
| Legitimate | 0.054 | 0.062 | 7.719 | 0.001 | 0.025 | [0.019, 0.031] |
| Comparison of violations and legitimate | ||||||
| similarities | ||||||
| Inter-class | 0.052 | 0.048 | 7.381 | 0.001 | 0.225 | [0.165, 0.284] |
Our results show that the legitimate smart contracts’ opcodes are slightly more similar to each other than the violating contracts are (0.054 and 0.040, respectively). The violating contracts’ opcodes are less similar to each other than they are to the legitimate contracts’ (at least per the cosine similarities, which are 0.052 for inter-class cosine similarity and 0.040 for the violating class). This suggests that there may be slightly more code reuse among legitimate contracts than violating ones. However, the cosine similarity for both groups is rather small, as are the effect sizes, which suggests that code reuse overall is unlikely to be the primary reason for our classifier’s performance (though this does not preclude the possibility of certain elements of the code—such as the use of the SafeMath library—being at least partially responsible).
Discussion
This article sought to determine if it is useful to build a machine learning classifier to detect DeFi projects engaging in various types of securities violations from their tokens’ smart contract code. Governments are currently struggling with how to manage fraud in the DeFi ecosystem, particularly because these platforms do not require KYC; a classifier could serve as a triage measure. In addition, we make available a new data set with a verified ground truth. Our research is also novel in its use of ERC-20 token smart contract code to attempt to detect fraud across the Ethereum-based DeFi ecosystem and deeper analysis of the features of our final model. Finally, our research contributes to the existing body of work on financial markets, as well as its practical applications, in that predicting and detecting fraud is crucial for financial stability, market integrity, and market efficiency, particularly in the cryptocurrency space [18].
Ultimately, we found that DeFi securities violations are a detectable problem. We developed a suitable starting point for this classification problem that performed much better than the baseline (80% F-1 score against a baseline of 50%). Our performance was not as high as others’ models for similar classification problems, however, as we describe below, some of this may be due to over-fitting and the data sets used in other work. Previously developed baseline models for related classification problems exhibited performance more in line with ours.
With regard to our second research question, further analysis at the feature level indicated that the success of our model may, in part, be related to the state-based attributes of functions in the SafeMath library.
Comparisons with prior research
Since ours is the first study to attempt to classify DeFi securities violations more broadly, we are unable to compare our model’s performance with previous studies. We do note that other studies which successfully built high performance classifiers for a related classification problem used more complex methods, which improved upon several previous studies addressing the same classification problem [46]. In addition, many previous studies, like ours, also used data with quite imbalanced classes, but they did not always account for this in building their models. Fan et al. [49], in particular, criticize previous work, including [51], on this basis. This may make the high performance metrics reported by some other studies slightly misleading. For example, only 3.6% of the smart contracts in the Chen et al. [48] data set are Ponzi schemes.
In contrast to previous studies, ours considers whether machine learning classification is necessary or whether a simpler model may suffice to solve the same problem. Previous studies have found that models built with, for example, logistic regression, have been much less effective than more complex ones [14]. We also found this to be the case.
Chen et al. [46] note the overall lack of interpretability of the results of classifiers with code-based features. The opcodes themselves have no obvious interpretation with respect to illegal activity, but, equally, there are not any opcodes which would offer a straightforward interpretation—i.e., there is no “STEAL” opcode or similar. The opcodes whose frequencies were among the most important features in our model were CALLDATASIZE, LT, CALLVALUE, SWAP3, EXP, CALLER, SHR, NUMBER, PUSH5, and ADDRESS. The only way to draw definitive conclusions from opcode-based features is to dissect the Solidity code from which they were compiled. Though it would have been impractical to dissect all 2,186 of the smart contracts in our data set, we gleaned some insight about our three most important features from a selection thereof, namely that developers of violating tokens may implement the SafeMath library differently in their code. In particular, they appear to use the “constant” modifier when describing how arithmetic operation overflows should be handled, which offers weaker assurances about the lack of state modification by these functions. It is, therefore, intuitive, for these reasons, that the use of the “pure” function would be associated with the legitimate tokens in this case. However, we note that, our analysis of transactions deploying the compiled Solidity code for certain contracts does not capture all of the opcodes whose frequencies were among the top 10 most important features in our model. Future research could also utilize other frameworks for analyzing token transfer behavior from token bytecode, such as TokenAware [94]. This would be particularly useful as well in instances where the contract Solidity code is not publicly available.
The use of code-based features
Like previous work [51, 46], we emphasize the usefulness of our classifier immediately upon deployment of the smart contract to the Ethereum blockchain and regardless of how many wallets interact with it. This is one of the key advantages of using code-only features for classification rather than transaction- or account-based features. This makes such a model not only useful as a retroactive tool for investigators, but also to prevent future fraud. It also enables investigators to monitor projects which may engage in securities violations in the future. Since investigations and prosecutions take such a long time (upwards of several years for complex cases), it is important for prosecutors to be able to begin gathering evidence as early as possible. However, we acknowledge that code-based analysis is merely one technique among many; future research could explore alternatives.
Potential applications of our model
Our results point to the value of exploring the use of computational triage systems in the enforcement process. This is particularly important given that U.S. enforcement agencies seem to be relying heavily on submissions to their whistleblower programs [95]; a computational model could reduce reliance on whistleblowers and also avoid the government needing to pay out a portion of funds successfully recovered to whistleblowers (which can be millions of dollars [96]).
A classifier of the type we examine here would be more useful as a triage measure rather than a source of evidence due to issues surrounding the admissibility of machine learning-generated evidence in U.S. courts and also the risk for mis-classification. There may be questions about its admissibility under the Fifth Amendment, the Sixth Amendment, and the Federal Rules of Evidence, however legal scholars do not, ultimately, consider them impediments to its admission [97].262626Though a complete discussion of the admissibility of machine learning evidence is outside of the scope of this paper, we provide a brief introduction here. The Fifth Amendment relates to an individual’s right to due process (this could arise in the context of the “black box” of machine learning calculations) and the Sixth Amendment includes the Confrontation Clause. This “black box” not only refers to inexplicable machine learning algorithms but also lay people’s likely lack of understanding about how these algorithms work. The Confrontation Clause requires experts to testify in person and submit to cross-examination. However, this is unlikely to be an issue, as the testimony of a machine learning expert should be satisfactory. The Federal Rules of Evidence around relevance, prejudice, and authenticity may be pertinent as well. Lawyers must further prove the accuracy of the evidence [98]. Some argue that under Rule 702 and Daubert v. Merrell Dow Pharmaceuticals, machine learning evidence would be admissible as expert testimony. Through Daubert, the court developed a set of four considerations for evaluating expert testimony [97]. Even if it is admissible, however, questions about its weight in court remain. In particular, explaining such evidence to a judge and jury (especially the “black box” calculations involved in developing machine learning models) may lead it being discounted. There is variation in levels of trust among jurors in machines in general and jurors must further trust the expert testimony which explains the machine learning tool [97]. This is exacerbated by the need for prosecutors to already explain complex concepts related to cryptocurrency in these cases. A machine learning-based tool would likely lead investigators to more compelling transaction-based evidence or qualitative evidence (for example, marketing material) which can be more easily understood by a judge and jury and which has been effective in prosecuting cryptocurrency-based financial criminal offenses in the past (See [99, 100]).
Considering the ambiguity around the Hinman standard272727The “Hinman standard” refers to William Hinman’s 2018 speech which considered the level of decentralization of a project critical to determining whether it should be classed as a security [36]. in determining whether a project is sufficiently decentralized to avoid being classed as a security, a machine learning model could also serve as an additional tool in developers’ arsenal for determination thereof. Finally, we also perceive a machine learning model as potentially useful for people who are interested in participating in the DeFi ecosystem, as a way for them to research the validity of new projects to help protect themselves from fraud.
Limitations and future research
Our research may suffer from various limitations. The first is the potential for overfitting our model, particularly in the face of imbalanced data [49]. However, since we do not have a separate data set with known labels on which to test our model, overfitting could remain an issue despite our mitigation efforts. Ultimately, we chose a verified ground truth data set that was much smaller than our set of legitimate tokens. We do note that our data set may be making this classification problem simpler than it is in reality. We chose a list of generally reputable projects for our legitimate token set and those which are subject to government enforcement action for our securities violations. In this sense, we believe that, given the experimental nature of DeFi (and the high risk appetite of its participants), and the initial inclusion of a few violating tokens in the legitimate set, this set captures projects that exist in the middle, rather than at only extremes of offending and non-offending, which may be harder to classify. However, it would still be useful for future research to develop more data sets of DeFi securities violations to further test and refine our models, as necessary, using more advanced sequential machine learning techniques. As the number of verified violations increases, future research could also explore DeFi securities violations using more granular classes. These classes would show the different security patterns of the various types of securities violations and could further aid in prevention and detection efforts. It would also be useful for future research to compare the use of code-based features with models using account-based features or a combination thereof.
We note that, given the seeming importance of the implementation of the SafeMath library, in part, to our classifier’s performance, it may be the case that this classifier is less effective in classifying tokens created with Solidity versions 0.8.0 or later. However, this code did not account for all of our most important features. Future research could examine this, again, using an expanded data set.
We accept that there are some limitations around the use of a classifier like this in practice. Our future research will specifically explore how we could use a classifier like this to conduct an investigation and build a viable legal case. This will involve performing manual, in-depth analysis on tokens flagged when applying our classifier to other data sets and interactions with their smart contracts (similarly to Xia et al.’s [14] work on Uniswap scam tokens).
Chen et al. [46] raise the issue of bad actors using adversarial obfuscation methods to trick classifiers like the one we propose. We did not explicitly account for this possibility in building or model, nor did we test our model against known obfuscation techniques. However, this may be a useful avenue for future research to explore.
Further analysis of violating contracts, for example, using methods for analyzing token operational behavior from bytecode (such as TokenAware, which has successfully been applied to discrete instances of fraud [94]) would be fruitful. We encourage other scholars to pursue this line of research using our publicly available data set.
Finally, the jurisdictional focus of our research was limited in scope due to the nature of our data set. Legislation relating to cryptocurrencies is frequently changing; in particular, the European Union recently passed the Regulation on Markets in Cryptoassets (MiCA)[101]282828Currently, the only implemented EU regulations that apply to cryptocurrencies relate to money laundering. The EU’s securities and investment regulations do not currently apply [102].. More generally, a global approach, incorporating legislation from multiple jurisdictions, would be a potential future goal. This would, of course, bring challenges, however, since the legality of particular applications—equivalent to the labels of training data, in technical terms—may vary across jurisdictions and change over time. Overcoming this challenge may require the adaptation of approaches from other domains.
One further prospect is that the output of a classification system such as this may be useful in detecting flaws or risks in novel DeFi functions. While the model would be trained on violations that had previously been detected, it is possible that cases may be identified as being risky even if they do not correspond to known flaws, but rather because they have underlying similarities to existing cases. In such a situation, manual inspection of cases identified as potentially fraudulent may offer insight into new forms of offending. This type of work would usefully contribute to the goal of preventing DeFi frauds and associated losses to individuals. Research on the prevention of such offenses is a crucial complement to the detection work presented in this paper.
Conclusions
Our final model achieves good performance (80% F-1 score against a baseline of 50%) in classifying DeFi-based securities violations based on ten features from the projects’ tokens’ smart contract code: the frequencies with which the CALLDATASIZE, LT, CALLVALUE, SWAP3, EXP, CALLER, SHR, NUMBER, PUSH5, and ADDRESS opcodes occurred in the contract. We achieved higher performance with this random forest model than with logistic regression models, leading us to conclude that this classification problem is, indeed, well-suited to machine learning. Our research is novel in its deeper analysis of the opcode-based features responsible for the performance of our classifier. Though this does not account for all features, the implementation of the SafeMath library in the token smart contracts appears to play a role. Despite the seeming influence of this aspect of the token smart contract code on our classifier, cosine similarity analyses did not suggest code reuse overall was the primary reason for its performance. Overall, a computational model like ours would be highly useful for investigators as a triage tool but could be circumvented by nefarious developers in the future. It is important, therefore, to augment any model as further DeFi projects engaging in securities violations are revealed. This work constitutes the first classifier of securities violations overall in the emerging and fast-growing Ethereum-based DeFi ecosystem and is a useful first step in tackling the documented problem of DeFi fraud. Our work also contributes a novel data set of DeFi securities violations with a verified ground truth and connects the use of such a classifier with the wider legal context, including how law enforcement can use it from the investigative to prosecution stages of a case.
Declarations
Availability of data and materials
The datasets generated and analysed during the current study are available in the OSF repository, Detecting Defi Securities Violations.
Competing interests
The authors declare that they have no competing interests.
Funding
This work was funded by the [redacted for blind review].
Author’s contributions
AT: conceptualization, data collection, analysis, interpretation, and drafting the final manuscript. BT, TD: conceptualization, study design, and feedback on the manuscript. All authors have reviewed the final manuscript.
Acknowledgements
The authors also thank Antonis Papasavva and Antoine Vendeville for their contributions to our code.
List of abbreviations
-
•
DeFi: Decentralized finance
-
•
dApps: Decentralized applications
-
•
Opcode: Operational code
-
•
EVM: Ethereum Virtual Machine
-
•
Dexes: Decentralized exchanges
-
•
KYC: Know Your Client
-
•
SEC: Securities and Exchange Commission
-
•
FINRA: Financial Industry Regulatory Authority
-
•
ICO: Initial Coin Offering
-
•
ERC-20: Ethereum Request for Comment
-
•
BA: Blockchain Association
-
•
SMOTE: Synthetic Minority Over-Sampling Technique
References
- [1] Bartoletti, M., Carta, S., Cimoli, T., Saia, S.: Dissecting ponzi schemes on ethereum: Identification, analysis, and impact. Future Generation Computer System 102, 259–277 (2020). doi:10.1016/j.future.2019.08.014
- [2] Binance Academy: Blockchain. https://academy.binance.com/en/glossary/blockchain Accessed 25 November 2021
- [3] Narayanan, A., Bonneau, J., Felten, E., Miller, A., Goldfeder, S.: Bitcoin and Cryptocurrency Technologies (2016)
- [4] Gapusan, J.: DeFi: Who Will Build The Future Of Finance? (2 November 2021). https://www.forbes.com/sites/jeffgapusan/2021/11/02/defi-who-will-build-the-future-of-finance/ Accessed 18 November 2021
- [5] Wintermeyer, L.: After Growing 88x In A Year, Where Does DeFi Go From Here? (2 November 2021). https://www.forbes.com/sites/lawrencewintermeyer/2021/05/20/after-growing-88x-in-a-year-where-does-defi-go-from-here/ Accessed 18 November 2021
- [6] CipherTrace: Cryptocurrency Crime and Anti-Money Laundering Report, August 2021 (August 2021). https://ciphertrace.com/cryptocurrency-crime-and-anti-money-laundering-report-august-2021/
- [7] Eversheds Sutherland Ltd.: Navigating the issues securities enforcement global update. Report (2018). https://us.eversheds-sutherland.com/mobile/portalresource/lookup/poid/Z1tOl9NPluKPtDNIqLMRV56Pab6TfzcRXncKbDtRr9tObDdEpW3CmS3!/fileUpload.name=/Securities-Enforcement-Global-Update_Fall-2018.pdf
- [8] Musiala, R.A.J., Goody, T.M., Reynolds, V., Tenery, L., McGrath, M., Rowland, C., Sekhri, S.: Cryptocurrencies: Forensic techniques to meet the challenge of new fraud and corruption risks — FVS Eye on Fraud. Report, AICPA (Winter 2020). https://future.aicpa.org/resources/download/cryptocurrencies-forensic-techniques-to-face-new-fraud-and-corruption-risks
- [9] Podgor, E.S.: Cryptocurrencies and securities fraud: In need of legal guidance. Available at SSRN 3413384 (2019)
- [10] FBI: Securities Fraud Awareness & Prevention Tips. https://www.fbi.gov/stats-services/publications/securities-fraud Accessed 18 November 2021
- [11] Practical Law Corporate & Securities: US Securities Laws: Overview. Practice Note 3-383-6798, Thomson Reuters
- [12] Kamps, J., Trozze, A., Kleinberg, B.: forthcoming. In: Wood, S., Hanoch, Y. (eds.) Cryptocurrency Fraud. A Fresh look at Fraud: Theoretical and Applied Approaches. Routledge, forthcoming (2022)
- [13] Trozze, A., Kamps, J., Akartuna, E.A., Hetzel, F., Kleinberg, B., Davies, T., Johnson, S.: Cryptocurrencies and future financial crime. Crime Science (2022)
- [14] Xia, P., wang, H., Gao, B., Su, W., Yu, Z., Luo, X., Zhang, C., Xiao, X., Xu, G.: Demystifying scam tokens on uniswap decentralized exchange. arXiv:2109.00229 [cs] (2021)
- [15] Hu, T., Liu, X., Chen, T., Zhang, X., Huang, X., Niu, W., Lu, J., Zhou, K., Liu, Y.: Transaction-based classification and detection approach for ethereum smart contract. Information Processing & Management 58(2), 102462 (2021). doi:10.1016/j.ipm.2020.102462
- [16] Santos, I., Brezo, F., Ugarte-Pedrero, X., Bringas, P.G.: Opcode sequences as representation of executables for data-mining-based unknown malware detection. Information Sciences: an International Journal 231, 64–82 (2013). doi:10.1016/j.ins.2011.08.020. Accessed 2022-11-21
- [17] Cai, W., Wang, Z., Ernst, J.B., Hong, Z., Feng, C., Leung, V.C.M.: Decentralized applications: The blockchain-empowered software system 6, 53019–53033. doi:10.1109/ACCESS.2018.2870644. Conference Name: IEEE Access
- [18] Shams, S.M.R., Sobhan, A., Vrontis, D.: Detection of financial fraud risk: implications for financial stability. Journal of Operational Risk (2021). Accessed 2022-08-22
- [19] Wang, L., Sarker, P.K., Bouri, E.: Short- and Long-Term Interactions Between Bitcoin and Economic Variables: Evidence from the US. Computational Economics (2022). doi:10.1007/s10614-022-10247-5. Accessed 2022-08-22
- [20] Schär, F.: Decentralized finance: On blockchain- and smart contract-based financial markets. doi:10.20955/r.103.153-74. Accessed 2022-03-22
- [21] Zhou, L., Xiong, X., Ernstberger, J., Chaliasos, S., Wang, Z., Wang, Y., Qin, K., Wattenhofer, R., Song, D., Gervais, A.: SoK: Decentralized Finance (DeFi) Attacks (2023). 2208.13035
- [22] Wood, G.: Ethereum: A Secure Decentralised Generalised Transaction Ledger. Ethereum (2 November 2021). https://ethereum.github.io/yellowpaper/paper.pdf
- [23] Perkis, T.: Stack-based genetic programming. In: Proceedings of the First IEEE Conference on Evolutionary Computation. IEEE World Congress on Computational Intelligence, pp. 148–1531. doi:10.1109/ICEC.1994.350025
- [24] Crytic: Ethereum VM (EVM) Opcodes and Instruction Reference (2021). https://github.com/crytic/evm-opcodes Accessed 17 November 2021
- [25] Uniswap: Uniswap Governance (2021). https://gov.uniswap.org/ Accessed 22 November 2021
- [26] Secret Network: About Secret (SCRT) (2021). https://scrt.network/ Accessed 22 November 2021
- [27] BitcoinWiki: ERC20 Token Standard – Ethereum Smart Contracts – BitcoinWiki (3 February 2021). https://en.bitcoinwiki.org/wiki/ERC20 Accessed 18 November 2021
- [28] Hertig, A.: What Is DeFi? (18 September 2020). https://www.coindesk.com/learn/what-is-defi/ Accessed 25 October 2021
- [29] Ethereum: Ethereum Wallets (23 October 2021). https://ethereum.org/en/wallets/ Accessed 25 October 2021
- [30] Xu, J., Paruch, K., Cousaert, S., Feng, Y.: SoK: Decentralized exchanges (DEX) with automated market maker (AMM) protocols. 2103.12732. Accessed 2022-03-22
- [31] Bartoletti, M., Chiang, J.H.-y., Lluch-Lafuente, A.: SoK: Lending pools in decentralized finance. 2012.13230. Accessed 2022-03-22
- [32] Jagati, S.: DeFi lending and borrowing, explained (18 January 2021). https://cointelegraph.com/explained/defi-lending-and-borrowing-explained Accessed 25 October 2021
- [33] Binance Academy: Blockchain Use Cases: Prediction Markets (29 April 2021). https://academy.binance.com/en/articles/blockchain-use-cases-prediction-markets Accessed 25 October 2021
- [34] Coinbase: Around the Block #14: DeFi insurance (13 May 2021). https://blog.coinbase.com/around-the-block-14-defi-insurance-ebf8e278da13 Accessed 25 October 2021
- [35] DeFi Prime: DeFi and Open Finance. https://defiprime.com/ Accessed 25 October 2021
- [36] Blockchain Association: Understanding the SEC’s Guidance on Digital Tokens: The Hinman Token Standard (2019). https://blockchainassoc.medium.com/understanding-the-secs-guidance-on-digital-tokens-the-hinman-token-standard-dd51c6105e2a Accessed 10 January 2019
- [37] Securities and Exchange Commission V. AriseBank, Jared Rice Sr., and Stanley Ford. N.D. Tex. (23 January 2020). No. 3-18-cv-0186-M
- [38] Securities and Exchange Commission V. PlexCorps, Dominic LaCroix, and Sabrina Paradis-Royer. E.D.N.Y. (2 October 2019). No. 17-cv-7007 (CBA) (RML)
- [39] Securities and Exchange Commission V. REcoin Group Foundation, LLC, DRC World INC. A/k/a Diamond Reserve Club, and Maksim Zaslavskiy. E.D.N.Y (14 May 2018). Civil Action No. 17-cv-05725
- [40] Securities and Exchange Commission V. LBRY. D.N.H. (November 7, 2022). No. 21-CV-260-PB
- [41] U.S. Securities and Exchange Commission: Framework for “Investment Contract” Analysis of Digital Assets (2019). https://www.sec.gov/corpfin/framework-investment-contract-analysis-digital-assets Accessed 2023-02-20
- [42] Xin, Q., Zhou, J., Hu, F.: The economic consequences of financial fraud: evidence from the product market in China. China Journal of Accounting Studies 6(1), 1–23 (2018). doi:10.1080/21697213.2018.1480005. Publisher: Routledge _eprint: https://doi.org/10.1080/21697213.2018.1480005. Accessed 2022-08-22
- [43] Chainalysis: The 2022 Crypto Crime Report. Technical report (February 2022)
- [44] Rodler, M., Li, W., Karame, G.O., Davi, L.: EVMPatch: Timely and automated patching of ethereum smart contracts. In: 30th USENIX Security Symposium (USENIX Security 21), pp. 1289–1306. USENIX Association, ??? (2021). https://www.usenix.org/conference/usenixsecurity21/presentation/rodler
- [45] Ferreira Torres, C., Jonker, H., State, R.: Elysium: Context-Aware Bytecode-Level Patching to Automatically Heal Vulnerable Smart Contracts. In: 25th International Symposium on Research in Attacks, Intrusions And Defenses, pp. 115–128. ACM, Limassol Cyprus (2022). doi:10.1145/3545948.3545975. https://dl.acm.org/doi/10.1145/3545948.3545975 Accessed 2022-11-21
- [46] Chen, W., Li, X., Sui, Y., He, N., Wang, H., Wu, L., Luo, X.: Sadponzi: Detecting and characterizing ponzi schemes in ethereum smart contracts. Proceedings of the ACM on Measurement and Analysis of Computing Systems 5(2), 26–12630 (2021). doi:10.1145/3460093
- [47] Cai, W., Wang, Z., Ernst, J.B., Hong, Z., Feng, C., Leung, V.C.M.: Decentralized applications: The blockchain-empowered software system. IEEE Access 6, 53019–53033 (2018). doi:10.1109/ACCESS.2018.2870644
- [48] Chen, W., Zheng, Z., Cui, J., Ngai, E., Zheng, P., Zhou, Y.: Detecting ponzi schemes on ethereum: Towards healthier blockchain technology. In: Proceedings of the 2018 World Wide Web Conference on World Wide Web - WWW ’18, pp. 1409–1418. doi:10.1145/3178876.3186046
- [49] Fan, S., Fu, S., Xu, H., Cheng, X.: Al-spsd: Anti-leakage smart ponzi schemes detection in blockchain. Information Processing & Management 58(4), 102587 (2021). doi:10.1016/j.ipm.2021.102587
- [50] Hu, H., Xu, Y.: Scsguard: Deep scam detection for ethereum smart contracts. arXiv:2105.10426 [cs] (2021)
- [51] Jung, E., Le Tilly, M., Gehani, A., Ge, Y.: Data mining-based ethereum fraud detection, pp. 266–273. IEEE
- [52] Liu, L., Tsai, W.-T., Bhuiyan, M.Z.A., Peng, H., Liu, M.: Blockchain-enabled fraud discovery through abnormal smart contract detection on ethereum. Future Generation Computer Systems 128, 158–166 (2022). doi:10.1016/j.future.2021.08.023
- [53] Wang, L., Cheng, H., Zheng, Z., Yang, A., Zhu, X.: Ponzi scheme detection via oversampling-based long short-term memory for smart contracts. Knowledge-Based Systems 228, 107312 (2021). doi:10.1016/j.knosys.2021.107312
- [54] Zhang, Y., Yu, W., Li, Z., Raza, S., Cao, H.: Detecting ethereum ponzi schemes based on improved lightgbm algorithm. IEEE Transactions on Computational Social Systems, 1–14 (2021). doi:10.1109/TCSS.2021.3088145
- [55] Chen, W., Zheng, Z., Ngai, E., C.-H., Zheng, P., Zhou, Y.: Exploiting blockchain data to detect smart ponzi schemes on ethereum. IEEE Access 7, 37575–37586 (2019)
- [56] Chen, L., Fan, Y., Ye, Y.: Adversarial reprogramming of pretrained neural networks for fraud detection. CIKM ’21, pp. 2935–2939. Association for Computing Machinery, New York, NY, USA. doi:10.1145/3459637.3482053
- [57] Ibrahim, R.F., Mohammad Elian, A., Ababneh, M.: Illicit account detection in the ethereum blockchain using machine learning. In: 2021 International Conference on Information Technology (ICIT), pp. 488–493. doi:10.1109/ICIT52682.2021.9491653
- [58] Lašas, K., Kasputytė, G., Užupytė, R., Krilavičius, T.: Fraudulent behaviour identification in ethereum blockchain
- [59] Li, J., Baldimtsi, F., Brandao, J.P., Kugler, M., Hulays, R., Showers, E., Ali, Z., Chang, J.: Measuring illicit activity in defi: The case of ethereum. Lecture Notes in Computer Science, pp. 197–203. Springer, Berlin, Heidelberg. doi:10.1007/978-3-662-63958-0_18
- [60] Fan, S., Fu, S., Luo, Y., Xu, H., Zhang, X., Xu, M.: Smart Contract Scams Detection with Topological Data Analysis on Account Interaction. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management. CIKM ’22, pp. 468–477. Association for Computing Machinery, New York, NY, USA (2022). doi:10.1145/3511808.3557454. https://doi.org/10.1145/3511808.3557454 Accessed 2022-11-21
- [61] Wilder, R.P., Heidi: Tracing cryptocurrency scams: Clustering replicated advance-fee and phishing websites. arXiv preprint arXiv:2005.14440 (2020)
- [62] Chen, W., Guo, X., Chen, Z., Zheng, Z., Lu, Y., Li, Y.: Honeypot contract risk warning on ethereum smart contracts, pp. 1–8. IEEE
- [63] Karimov, B., Wójcik, P.: Identification of scams in initial coin offerings with machine learning. Frontiers in Artificial Intelligence 4, 718450 (2021). doi:10.3389/frai.2021.718450
- [64] Wu, J., Lin, D., Zheng, Z., Yuan, Q.: T-edge: Temporal weighted multidigraph embedding for ethereum transaction network analysis. Frontiers in Physics 8, 204 (2020). doi:10.3389/fphy.2020.00204
- [65] Aljofey, A., Rasool, A., Jiang, Q., Qu, Q.: A Feature-Based Robust Method for Abnormal Contracts Detection in Ethereum Blockchain. Electronics 11(18), 2937 (2022). doi:10.3390/electronics11182937. Number: 18 Publisher: Multidisciplinary Digital Publishing Institute. Accessed 2022-11-21
- [66] Bartoletti, M., Carta, S., Cimoli, T., Saia, S.: Dissecting Ponzi schemes on Ethereum (2019)
- [67] Uniswap: Introducing Token Lists (26 August 2020). https://uniswap.org/blog/token-lists Accessed 18 November 2021
- [68] Commission, U.S.S.a.E.: Cyber Enforcement Actions (19 January 2022). https://www.sec.gov/spotlight/cybersecurity-enforcement-actions Accessed 10 February 2022
- [69] Securities and Exchange Commission V. Natural Diamonds Investment Co., Eagle Financial Diamond Group Inc A/k/a Diamante Atelier, Argyle Coin, LLC, Jose Angel Aman, Harold Seigel, and Jonathan H. Seigel. S.D. Fla. (11 December 2019). 19-cv-80633
- [70] Securities and Exchange Commission V. Reginald Middleton, et Al. E.D.N.Y. (1 November 2019). 19-cv-4625
- [71] U.S. Securities and Exchange Commission: 2021 Annual Report to Congress Whistleblower Program. https://www.sec.gov/files/2021_OW_AR_508.pdf Accessed 2022-04-04
- [72] Zapper: Your Homepage to DeFi (2021). https://zapper.fi/ Accessed 18 November 2021
- [73] zes: Is it safe to Zap into all liquidity pools on Zapper? (2020). https://zapper.crunch.help/zapper-fi-faq/is-it-safe-to-zap-into-all-liquidity-pools-on-zapper Accessed 18 November 2021
- [74] web3.py. ethereum. original-date: 2016-04-14T15:59:35Z (2023). https://github.com/ethereum/web3.py/blob/acd5b24474dd5b13548dffa33e1d2872c3dccad9/docs/index.rst Accessed 2023-04-28
- [75] Crytic: Pyevmasm. Crytic (2020)
- [76] Hastie, T., Qian, J., Tay, K.: An Introduction to glmnet (2023). https://glmnet.stanford.edu/articles/glmnet.html#introduction Accessed 2023-05-10
- [77] scikit-learn developers: sklearn.preprocessing.StandardScaler (2023). https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html Accessed 2023-05-10
- [78] Blagus, R., Lusa, L.: Joint use of over- and under-sampling techniques and cross-validation for the development and assessment of prediction models. BMC Bioinformatics 16(1), 363 (2015). doi:10.1186/s12859-015-0784-9
- [79] Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: Smote: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research 16, 321–357 (2002). doi:10.1613/jair.953
- [80] Prellberg, J., Kramer, O.: Acute lymphoblastic leukemia classification from microscopic images using convolutional neural networks. arXiv:1906.09020 [cs] (2020)
- [81] Choi, R.Y., Coyner, A.S., Kalpathy-Cramer, J., Chiang, M.F., Campbell, J.P.: Introduction to Machine Learning, Neural Networks, and Deep Learning. Translational Vision Science & Technology 9(2), 14. doi:10.1167/tvst.9.2.14. Accessed 2022-08-22
- [82] Remix: Debugger (2022). https://remix-ide.readthedocs.io/en/latest/debugger.html Accessed 2023-05-15
- [83] Remix: Debugging Transactions (2022). https://remix-ide.readthedocs.io/en/latest/tutorial_debug.html Accessed 2023-05-15
- [84] OpenZeppelin: Contracts (2023). https://docs.openzeppelin.com/contracts/2.x/ Accessed 2023-05-09
- [85] OpenZeppelin: Math (2023). https://docs.openzeppelin.com/contracts/2.x/api/math Accessed 2023-05-15
- [86] Solidity Team: Solidity 0.8.0 Release Announcement (2020). https://blog.soliditylang.org/2020/12/16/solidity-v0.8.0-release-announcement/ Accessed 2023-05-09
- [87] Solidity Dev Studio: Exploring the new Solidity 0.8 Release (2020). https://soliditydeveloper.com/solidity-0.8 Accessed 2023-05-09
- [88] The Solidity Authors: Contracts (2023). https://docs.soliditylang.org/en/v0.8.19/contracts.html#view-functions Accessed 2023-05-09
- [89] Nabi, T.: Pure vs view in solidity (2022). https://hashnode.com/post/pure-vs-view-in-solidity-cl04tbzlh07kaudnv1ial1gio Accessed 2023-05-09
- [90] Modi, R.: Solidity Programming Essentials. Packt, ??? (2018). https://subscription.packtpub.com/book/application-development/9781788831383/7/ch07lvl1sec81/the-view-constant-and-pure-functions Accessed 2023-05-09
- [91] He, N., Wu, L., Wang, H., Guo, Y., Jiang, X.: Characterizing code clones in the ethereum smart contract ecosystem. arXiv:1905.00272 [cs] (2019)
- [92] Meta Research: fastText. original-date: 2016-07-16T13:38:42Z (2023). https://github.com/facebookresearch/fastText Accessed 2023-04-28
- [93] Han, J., Kamber, M., Pei, J.: Getting to know your data. In: Han, J., Kamber, M., Pei, J. (eds.) Data Mining (Third Edition). The Morgan Kaufmann Series in Data Management Systems, pp. 39–82. Morgan Kaufmann. doi:10.1016/B978-0-12-381479-1.00002-2. https://www.sciencedirect.com/science/article/pii/B9780123814791000022 Accessed 2022-04-19
- [94] He, Z., Song, S., Bai, Y., Luo, X., Chen, T., Zhang, W., He, P., Li, H., Lin, X., Zhang, X.: Tokenaware: Accurate and efficient bookkeeping recognition for token smart contracts. ACM Trans. Softw. Eng. Methodol. 32(1) (2023). doi:10.1145/3560263
- [95] Commodity Futures Trading Commission: CFTC Whistleblower Alert: Be on the Lookout for Virtual Currency Fraud (May 2019). https://www.whistleblower.gov/whistleblower-alerts/Virtual_Currency_WBO_Alert.htm Accessed 22 November 2021
- [96] U.S. Securities and Exchange Commission: SEC Awards $22 Million to Two Whistleblowers (2021). https://www.sec.gov/news/press-release/2021-81 Accessed 22 November 2021
- [97] Nutter, P.W.: Machine learning evidence: Admissibility and weight comments. University of Pennsylvania Journal of Constitutional Law 21(3), 919–958 (2018)
- [98] Grossman, P.G., Maura: Artificial intelligence as evidence. In: Maryland State Bar Association Young Lawyer’s Section (25 August 2021)
- [99] United States V. Costanzo. United States District Court, D. Arizona (10 August 2018). No. 2:17-cr-00585-GMS
- [100] United States V. Murgio. United States District Court for the Southern District of New York (19 September 2016). 15-cr-769 (AJN)
- [101] Scicluna, M.C., Debono, J.: MiCA - Landmark crypto regulation approved by EU Parliament (2023). https://www.lexology.com/library/detail.aspx?g=152d8020-bc6e-47b9-b236-5b1f8c6b2b88 Accessed 2023-05-15
- [102] Kolinska, D.: Cryptocurrencies in the EU: new rules to boost benefits and curb threats (2022). https://www.europarl.europa.eu/news/en/press-room/20220309IPR25162/cryptocurrencies-in-the-eu-new-rules-to-boost-benefits-and-curb-threats Accessed 2022-08-22