Detection Selection Algorithm: A Likelihood based Optimization Method to Perform Post Processing for Object Detection
Abstract
In object detection, post-processing methods like Non-maximum Suppression (NMS) are widely used. NMS can substantially reduce the number of false positive detections but may still keep some detections with low objectness scores. In order to find the exact number of objects and their labels in the image, we propose a post processing method called Detection Selection Algorithm (DSA) which is used after NMS or related methods. DSA greedily selects a subset of detected bounding boxes, together with full object reconstructions that give the interpretation of the whole image with highest likelihood, taking into account object occlusions. The algorithm consists of four components. First, we add an occlusion branch to Faster R-CNN to obtain occlusion relationships between objects. Second, we develop a single reconstruction algorithm which can reconstruct the whole appearance of an object given its visible part, based on the optimization of latent variables of a trained generative network which we call the decoder. Third, we propose a whole reconstruction algorithm which generates the joint reconstruction of all objects in a hypothesized interpretation, taking into account occlusion ordering. Finally we propose a greedy algorithm that incrementally adds or removes detections from a list to maximize the likelihood of the corresponding interpretation. DSA with NMS or Soft-NMS can achieve better results than NMS or Soft-NMS themselves, as is illustrated in our experiments on synthetic images with mutiple 3d objects.
Keywords: Object Detection, Post Processing, Occlusion Relationship Reasoning, Amodal Instance Segmentation.
1 Introduction
Object detection is one of the most important tasks in computer vision. Most object detection algorithms return detections in the form of bounding boxes. They give the center, height and width of each predicted bounding box, and perform classification of the object inside it. Some object detection algorithms, for example Faster R-CNN [1], also provide an objectness score, which quantifies the confidence of having an object in the bounding box.
Usually, object detection algorithms first generate excessive detections and then use post processing methods like Non-maximum Suppression (NMS) to reduce the number of detections. NMS keeps the most promising detections through local comparisons. A NMS-threshold is needed to determine when to suppress the less promising neighboring bounding boxes. After NMS, the remaining bounding boxes do not necessarily have high objectness scores and there are usually more bounding boxes than the real number of objects. In Faster R-CNN [1], the top-N bounding boxes after NMS are declared as the final detections. But people usually don’t know how many objects are in the image, so is still usually larger than the actual number of objects.
Unlike NMS, Soft-NMS [2] does not directly eliminate less promising neighboring bounding boxes. It reduces their objectness scores as a function of the Intersection-over-Union (IoU). After Soft-NMS, we still need to use either a maximal number of boxes, or a lower bound threshold on the objectness socres of detections. The Soft-NMS [2] paper uses top detections per image on MS-COCO.
To find the correct number of objects and labels in the image, one natural idea is to use a threshold on the objectness scores. Bounding boxes above are used as the final detections. The threshold can be determined by a validation set. But what if the validation set has a different distribution than the test set? The result can be very sensitive to the threshold . A distribution shift from the validation set to the test set may cause significant damage to model performance.
Our work proposes a novel post processing method for object detection algorithms building on the work in [3]. The idea is to find the most likely interpretation of an image, where an interpretation is an ordered subset of detections, ordered according to occlusion. Each object class is modeled by a generative model that maps a low dimensional latent space to image space, and the pixel values are assumed to be independent Gaussian conditional on the latent variables. The generative model provides both a reconstruction of the object image and a region of object support. The log-likelihood of the entire image conditional on the objects, their locations and the values of the latent variables is the sum of the log-likelihoods of the individual objects on their visible parts. That is why the occlusion ordering is essential; objects in the back are only visible outside the support of objects in front. Optimizing over ordered subset of detections is prohibitive computationally. We thus use a greedy search, where we take advantage of the objectness scores provided by the Faster R-CNN. Furthermore we add an additional branch to the Faster R-CNN that provides an occlusion score between 0 and 1, we call this Faster R-CNN-OC. And object with higher occlusion score is assumed in front of one with lower occlusion score. These outputs provide important inputs to the greedy search for the most likely interpretation as described below. In short, the Detections Selection Algorithm (DSA) is a greedy search over ordered subsets of detections for the one with highest likelihood, using objectness and occlusion scores provided by the Faster R-CNN.
The first component of DSA is a single reconstruction algorithm that reconstructs the entire object based on its visible parts. Here we use a decoder architecture as in VAE’s, and instead of reconstructing based on latent variables predicted from an encoder, we optimize over the latent variables. This modification is essential because we don’t always see the whole object, and the reconstruction loss - the negative log-likelihood (NLL) is computed only on the visible part. It is not possible to adapt the encoder to different visible inputs. The single reconstruction algorithm takes a bounding box and its associated information, as well as reconstructions of previous objects in the sequence as input, and returns the whole appearance of the hypothesized object for that bounding box. The output is an approximation of the negative marginal log-likelihood of the image data in the visible part. A byproduct of the single reconstruction algorithm is that it performs amodal instance segmentation using the reconstruction. The second component of DSA is the whole reconstruction algorithm. It puts together the results of the single reconstruction algorithm on the current sequence of selected objects to provide the NLL of the entire image data, given this sequence. The final component - greedy search, is a greedy search through the detections provided by the Faster R-CNN-OC, ordered based on their objectness score. At each step we add one detection, reconstruct it from its visible part - computed as the complement within its bounding box of the union of supports of previously reconstructed detections with higher occlusion scores. If the NLL of the whole reconstruction is lower we include the additional object, if not we omit it. We also perform a one step- back search, in case eliminating a previously added object decreases the NLL if the new object is included. We add a fixed penalty term for each added object which is equivalent to an exponential prior on the number of objects. At some point the decrease in NLL of an additional object is cancelled by the object penalty and the search terminates.
The main contribution of this paper is the DSA algorithm consisting of the three components described above. Our main goal is to find the exact number of objects and labels in the image, based on the whole reconstruction with the lowest NLL. There are several byproducts:
-
•
The augmented Faster R-CNN-OC provides an occlusion ordering. In particular we have found that it is sufficient to train the Faster R-CNN-OC only on pairs of objects to get excellent detections on multiple object scenes together with very reliable occlusion scores.
-
•
The single reconstruction algorithm automatically reconstructs the invisible parts of objects and can be easily used for amodal instance segmentation.
-
•
The whole reconstruction algorithm provides a way to generate an image given several hypothesized objects and their locations.
The rest of this article is organized as follows: section 2 introduces some related work about object detection, post processing methods, occlusion relationship reasoning and amodal instance segmentation. The probabilistic framework and three algorithms are explained in section 3. Our dataset is described in section 4 and experiments are shown in section 5. Finally we provide a discussion in section 6.
2 Related Work
The application of neural networks in object detection has attracted much attention. Some object detection algorithms rely on region proposal generation. For example, Fast R-CNN [4] and Faster R-CNN [1]. Some are single-stage methods, including Single Shot MultiBox Detector (SSD) [5] and You Only Look Once (YOLO) [6]. All these object detection methods predict class probabilities and bounding box locations. Faster R-CNN [1] also predicts the objectness score which represent the confidence of a detection.
Post-processing is an important step to remove false positive detections in all object detection algorithms. One type of popular post-processing method is Non-maximum Suppression (NMS) and its variants. The paper Efficient Non-Maximum Suppression [7] proposed several algorithms to accelerate NMS. A recent review paper [8] summarized five NMS techniques: Soft-NMS [2], Softer-NMS [9], IOU-Guided NMS [10], Adaptive NMS [11] and DIoU-NMS [12].
These five methods emphasize local information as opposed to optimizing a global objective function. Among them, Softer-NMS [9], IOU-Guided NMS [10] and Adaptive NMS [11] require modifying the detection model or adding additional modules. Instead of setting a threshold to suppress highly overlapping bounding boxes, in each step Soft-NMS [2] decreases the detection score by a factor that depends on the IoU. Distance-IoU (DIoU) [12] takes into account the distance between the centers of bounding boxes. The idea of DIoU can be used in NMS and in designing IoU-related loss functions.
Another type of post-processing method defines a global objective functions and uses some search procedure to choose the final detections. Examples are a Bayesian model for face detection [13], HS-NMS [14] and probabilistic faster R-CNN [15]. Probabilistic faster R-CNN [15] trains Gaussian Mixture Models (GMM) on heights and widths of region proposals [4] and uses GMM to calculate the likelihood for each region proposal.
The Bayesian model in [13] first uses a kernel smoother on the face hypotheses to estimate the prior distribution, then uses face templates to estimate face likelihood, and use MCMC to get a stable face distribution from the posterior distribution. Our work differs in that we try to find the correct number of objects and take into account the occlusion relationships of objects.
Understanding the occlusion relationship between objects is called Occlusion Relationship Reasoning. MT-ORL [16] can predict object boundary maps and occlusion orientation maps and requires corresponding ground truths in order to train. A recent work [17] performs occlusion relationship reasoning by pixel-level competition for conflict areas in segmentation.
Researchers have payed attention to reconstructing the invisible parts and predicting the entire mask of an object including its invisible parts. The latter is often called amodal instance segmentation. SeGAN [18] jointly predict invisible masks and generate invisible parts of objects under the GAN [19] framework. One work [20] uses Multi-Level Coding to guide invisible mask prediction by multi-branch features.
Our idea to compare likelihoods of the image based on different hypothesis of objects is motivated by POP model [3]. However the POP model uses a deformable template to model objects, as opposed to the more flexible decoder structure, and needs to find the occlusion ordering of the objects as part of the optimization. Here we take advantage of the output of the Faster R-CNN-OC to obtain the occlusion ordering. Furthermore we apply the algorithm to images of 3d objects, whereas the POP model was restricted to 2d objects.
3 Our Method
For simplicity, we assume the image consists of some objects placed on a blank background. We run a detection algorithm like the Faster R-CNN-OC as detailed in Section 3.1 to get detections. The detections are in the form of . For each detection , is the objectness score defined in [1], is the bounding box, is the classification result, and is the occlusion score obtained from the occlusion branch. We denote by the image restricted to the bounding box . If the objects in and overlap, and , the object in is predicted to be occluded in the overlapping area by the object in . Typically there are false positive detections among all detections produced by the Faster R-CNN-OC. In other words, only a subset of is correct. Our goal is to find the ordered subset which yields the best interpretation of the image, namely the lowest NLL. But, trying every possible ordered subset of is computational prohibitive. Our proposed Detections Selection Algorithm (DSA) in Section 3.5 greedily selects the detections when processing them according to their objectness scores from high to low, taking into account the occlusion scores to identify the visible parts of each object.
3.1 Faster R-CNN-OC
Faster R-CNN [1] is a detection framework which uses a Region Proposal Network (RPN) to generate region proposals, and uses the Fast-RCNN [21] module to do bounding box regression and classification for each region proposal. From the RPN we get an objectness score for each bounding box, with a higher score indicating more confident detection.
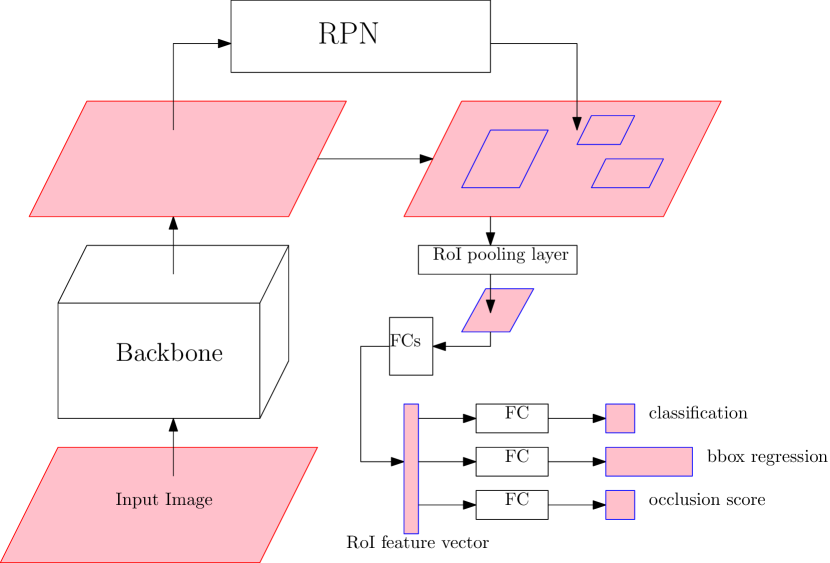
We added an additional branch called the occlusion branch to Faster R-CNN parallel to the regression branch and the classification branch inside the Fast-RCNN module. The Faster R-CNN-OC is shown in Figure 1.
The occlusion branch also consists of a fully-connected layer. The output of the fully-connected layer goes through a sigmoid function so that we get an occlusion score between 0 and 1. As we mentioned earlier, if two objects overlap, the one with higher occlusion score is predicted to be visible in the overlapping area. During inference, we only need to compare the occlusion scores of objects to determine the occlusion sequence. One way to train the occlusion branch is to provide pairs of overlapping objects, and assign the occlusion score of the occluded and occluding object to be 0 and 1 respectively. More details will be explained in Section 5.1.
This occlusion branch has provided reliable results in our experiments. We trained it on two-object images, and found that it generalizes well to images which contain multiple objects. Related experiments can be found in Section 5.2.
3.2 Single Reconstruction Algorithm
Our single reconstruction algorithm is based on a generative model of the form of a decoder in a VAE [22]. During training of a full VAE we maximize the (variational) lower bound on the marginal likelihood
| (1) |
where and are encoder and decoder parameters. For simplicity, assume , and is the density of , where is the output of the decoder if the input is , and is a diagonal matrix
| (2) |
with for .
During inference part of the object may be occluded, and the reconstruction will be based only on the visible part which makes it difficult for the encoder to predict and . Instead, both in training and in inference, we optimize over and while fixing the decoder parameters . Thus we drop the VAE encoder and only train the decoder. After training, we can find and for an incomplete object, then pass to the decoder to reconstruct the whole appearance of the object.
The first half of this section assumes the target bounding box has the same size as the decoder training images. But in reality the target bounding boxes may have different sizes. So we use the parameterised sampling grid idea of Spatial Transformer Networks [23] to deal with this issue as is explained in the second half of this section.
3.2.1 Fixed-size Reconstructions
The decoder is trained using the method of stochastic variational inference (SVI) [24]. Instead of using the encoder to predict , , we update these variables with a fixed number of optimization steps using gradient descent. Then we fix , and update the decoder parameters . We do these updates iteratively until convergence. The training data of our decoder are fixed-size images. Each image only has one object in it and we train a separate model for each class.
During reconstruction, for a target bounding box , where the set of visible pixels is , we optimize , to maximize Equation 1 based on the visible part, while keeping the decoder fixed. To be more specific, Equation 1 becomes
| (3) |
then we can get our reconstruction as
| (4) |
where is set to be . Since the decoder is trained with complete objects, the output will contain complete objects.
3.2.2 Arbitrary-size Reconstructions
Our target image is the visible part of everything inside the bounding box. But the bounding box size is usually not the same as the size of VAE training images. To deal with this issue, we turn to the parameterized sampling grid idea of the Spatial Transformer Network [23]. A similar idea also appears in [25]. If our target image box is , we assume an affine transformation between and the decoder output. For any coordinate in our reconstruction, after the affine transformation we get
| (5) |
and for each channel, the coordinate in our reconstruction should have the same image value as coordinate in the decoder output. As shown in Figure 2, if our reconstruction is and the decoder output is , and or is the pixel value at coordinate and channel in image or , then
| (6) |
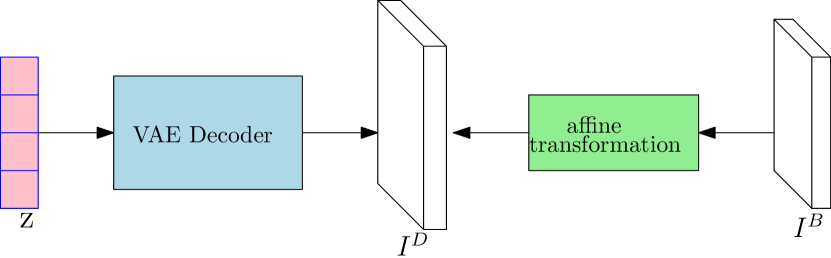
For simplicity, and to avoid too much flexibility, we do not consider rotation in the affine transformation. The shearing parameters represent scaling in the and axis. We assume an isotropic scaling and fix , where is the VAE training image size and is the maximum between the height and width of the target image box . The translation parameters are kept free. The coordinate can be any integer coordinate in our reconstruction. However, after the transformation, we get the corresponding , which may not be integers. We utilize the bilinear sampling kernel to interpolate for coordinate . The bilinear sampling kernel is formulated as
| (7) |
In this case, our reconstruction is an image, so we need to crop a region at the center of the image to get our reconstruction for the target bounding box.
With the affine transformation and bilinear sampling kernel, gradients can still back-propagate from the target image to the latent code. In this way, we compare the difference between the target image and our reconstruction for the target bounding box, and obtain the latent codes as well as , using gradient descent.
In summary, for target image box , we fix but optimize , and , where and are parameters in the posterior distribution . Given , , and , we sample from , pass it to the decoder to get a decoder output, and use the affine transformation and bilinear sampling kernel to get a reconstruction called . This procedure from , and to is called Decoder(, , ) in Algorithm 1.
Besides , Algorithm 1 also returns , an bounding box which centers at the center of the target bounding box . Because has size , if we place on the whole image, we should place it inside the bounding box , not .
Our single reconstruction is an object on a blank background, and the support of the object is assumed to be all the pixels whose magnitude is larger than some pre-determined threshold called the "occlusion threshold". Since Algorithm 1 aims at reconstructing the single object based on a single bounding box, we call it the single reconstruction algorithm.
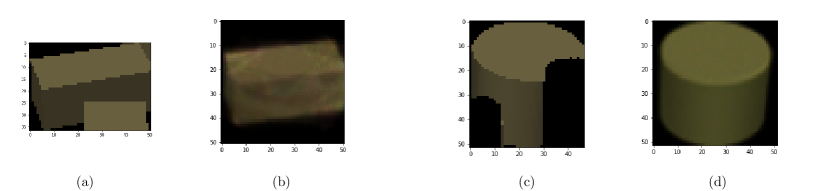
An example of the single reconstruction algorithm can be found in Figure 3, where . Image is the cropped target image where clutter is present. Image is the single reconstruction for target , where . Similarly, image is the single reconstruction for target , except that is now an incomplete image.
3.3 Whole Reconstruction Algorithm
The whole reconstruction algorithm, see Algorithm 2, is used to put together single reconstructions of an ordered subset of detections on a blank background the same size as the image, according to their occlusion scores. As we mentioned earlier, if the supports of two objects overlap, the visible object in the overlapping area is the one with higher occlusion score.
In Algorithm 2, we loop through the ordered set of detections, if the single reconstruction of the current detection has not been computed we implement the single reconstruction algorithm. This requires computing which pixels within the current bounding box are visible, so we consider all pre-computed single reconstructions which have a higher occlusion score. We put those objects with higher occlusion scores on the background. After that, the blank part on the background is assumed to be still visible.
As mentioned in the single reconstruction algorithm, a pre-determined threshold is used to determine which pixels constitute the support of the object in its single reconstruction. Only those pixels which are within the support acquire the values of the reconstruction, the others remain blank.
Figure 4 provides an example of Algorithm 2. The original image with objects are shown in . In there are detected bounding boxes labeled at their lower right corners from to according to their objectness scores from high to low. Image are the whole reconstruction canvases when we select detections , and respectively. Single reconstructions from Figure 3 are used here. From to the cylinder in bounding box is occluded by two cuboids in bounding boxes . Image in Figure 3 is an incomplete cylinder because we only keep the visible part.

It is worth noting that the single reconstruction has size and is usually larger than the size of the target bounding box. However, we don’t restrict the single reconstruction inside the region of the target bounding box. In other words, if the support of the object is outside the target bounding box, we still add those pixels to the canvas in the whole reconstruction algorithm. Our reason for doing this is that if the reconstructed object indeed exists, its part outside its target bounding box should exist as well.
3.4 Probabilistic Framework
In our approach a good interpretation of the image should achieve two goals. First, we want to get a good reconstruction of the whole image based on our selected detections. Second, we need to avoid selecting redundant detections. These two goals motivate the following probabilistic framework.
Suppose a detection algorithm yields detection results , and is a subset used to interpret the image. For the number of detections in the subset, we assume a prior for . For every detection , its latent code has the same prior . We assume non-informative prior on each , so the prior for is equivalent to the prior , i.e. .
Given and , we assume the distribution of the hypothesized image is Gaussian with the same variance on each pixel, and the pixels are independent conditioned on the mean. The mean of this Gaussian distribution is assumed to be the reconstruction produced by the whole reconstruction algorithm.
Therefore, if the image is , the log marginal likelihood of the interpretation is
| (8) |
which is intractable in terms of computation. Using the well known variational approximation
| (9) |
and
| (10) |
we drop the last Kullback–Leibler divergence term and use
| (11) |
to approximate .
As in previous sections, denotes the cropped image from at bounding box . Without loss of generality, we can assume is sorted by occlusion scores from high to low. Then we use the following approximation
| (12) |
where denotes the visible pixels in the bounding box of object taking into account the union of supports of reconstructions , where (see Algorithm 2), and is the posterior distribution of given cropped image , and detection . Using , equation 11 can be approximated by
| (13) |
In this way, we approximate the log marginal likelihood as
| (14) |
where is sampled from . In the single reconstruction algorithm, minimizing the loss gives us , and , so we can sample from . If the whole reconstruction using and is , then
| (15) |
It is important to emphasize that (15) always provides a log-likelihood for the entire image. The output of the whole reconstruction algorithm provides the union of the supports of the different objects in the image as the set of all non-zero pixels. The complement of this set is considered background and the hypothesized distribution at each background pixel based on the equations above is simply in each channel.
3.5 Detection Selection Algorithm - Greedy Search
Note that for . Based on our probabilistic framework, if are the indices of the selected detections, which are used as an interpretation of the image, we have
| (16) |
where is the whole reconstruction given by and , is the cardinality of image . Dropping some constants in Equation 16, our loss function is defined as
| (17) |
where can be regarded as a penalty on the number of selected boxes .
If there are detections in total, it is impossible to enumerate and evaluate all possible ordered subsets . So we propose a greedy search, see Algorithm 3, to find a good subset in polynomial time.
In Algorithm 2 we processed selected detections by their occlusion scores because we want to find the visible pixels for each bounding box. However, some very low quality detections may have high occlusion score. Because higher objectness scores indicate more confident detections, and more confident detections are more likely to appear in our final selection, in Algorithm 3 we process the detections according to their objectness scores from high to low. At each step, given a subset of detections, we pass it to Algorithm 2 where the detections are reordered according to occlusion score to provide the whole reconstruction and provide the NLL.
We use to represent the currently selected detections, which is in the beginning. If selecting yields smaller loss than with , we prefer interpretation to . But we also consider the case when there is a , , which has significant overlap with . It is possible that is the correct detection and isn’t. So we select the detection with highest overlap with , and consider the interpretation . Thus, we compare , and , the one which has the smallest loss is used as the new . Then we move on to the next detection in the objectness score ordering.
In Algorithm 3, is chosen as the previously selected detection which has the highest IoU with . If there is no previous selected detection, or if all previously selected detections have zero IoU with , then doesn’t exist and we don’t need to consider . In this case we set for that in Algorithm 3.
Our Detections Selection Algorithm (DSA) greedily selects detection subsets to minimize Equation 17. The first term in Equation 17 encourages DSA to select the interpretation which has better reconstruction performance. At times, selecting duplicated detections can give us almost the same reconstruction loss. The penalty on the number of boxes is needed to help DSA avoid such situations.
After all the detections have been processed, we choose the final selected detections in Algorithm 3 as our interpretation for the image.

In Figure 5, we show the original image with five actual objects and detections indexed from to , ordered according to their objectness score, same as in Figure 4. and the last bounding box is redundant. As stated in Algorithm 3, we start from . In the first step, we only consider detection , which has highest objectness score. The loss is , so we have , as shown in . Next we move on to bounding box as the next highest objectness score. Because no bounding box has an intersection with bounding box , in the second step we only consider the ordered set , (there is no possible detection to omit). The loss is , which is better than , so . Its canvas is shown in . In the third step bounding box has the largest IoU with bounding box , so we compare both and and select in . Its loss is . Similarly we compare and and select in which gives us loss . In step , and are compared and with loss is selected. Finally, since bounding box has the largest IoU with bounding box , we process and , which gives us losses and respectively, and their canvases are shown in . But neither or has a smaller loss than , so . Therefore, ultimately we interpret the image by bounding boxes , which means there are objects and our predicted labels are the corresponding labels of the bounding boxes . Some more experiments about DSA are shown in Section 5.3.
4 Data
Our synthesized datasets have classes of objects labeled from class through class . The classes are shown in Figure 6: sphere, ellipsoid, torus, regular cube, lying thin cuboid, standing thin cuboid, regular cylinder, standing thin cylinder, lying thin cylinder and cone. Regardless of the object classes, each image has a random color on all of its objects, where are uniformly chosen conditioned on . We set the objects to have the same color to make the detection more difficult.

In all our datasets, the objects are placed onto a black background by randomly choosing their locations. We use the Python package ’pyvista’ to generate the images. In each image, there are three lights with fixed directions and fixed intensities as . The camera position and focus are fixed as well, but the objects can rotate from to degrees horizontally. It can be seen from Figure 6 that classes are rotational invariant, others are not.
4.1 Training sets
In order to train the Faster R-CNN model or Faster R-CNN-OC model in section 3.1, we generate paired occluded objects on a black background as our training set. These objects are placed on an invisible floor. Rejection sampling is applied to ensure that although they are occluded, the two objects won’t be too close to each other and each object has at least visible pixels. The classes of the two paired objects are chosen from the classes we have to make each class appears exactly times in the dataset. So we have images in total for Faster R-CNN.
For the single reconstruction algorithm, we train a VAE decoder. When we generate the pairs of objects for the Faster R-CNN training images, we keep the same individual objects as our decoder training data, but they are isolated and centered in a images. Another difference is that, the isolated objects are re-scaled to make them as large as possible in the images. This is implemented using the parameterized sampling grid technique mentioned in section 3.2.2. In Figure 7, image is a training image for Faster R-CNN and two images in are the corresponding training data for the decoder. We have images for decoder.

4.2 Validation and test sets
To test the performance of our post processing methods, we have a validation set and a test set. These datasets still contain images, but in each image we have to objects. The difficulty of post processing usually increases as the number of objects increases.
Both our validation set and test set for post processing have images. We ensure that every object has at least visible pixels and objects are not too close to each other. For the validation set, we have images with objects and images with objects in them. An example of a validation image can be found in image of Figure 7. For the test set, we have images with objects respectively. Image in Figure 7 is a test set example which contains objects.
5 Experiments
5.1 Implementation Details
As explained in section 4, we train the Faster R-CNN and our Faster R-CNN-OC model with paired occluded objects. We further divide them into training images and validation images. Both models are trained with and the default Faster R-CNN parameters without any pre-training. The training stops when we observe continuous epochs of no improvement on the validation loss. The Faster R-CNN and Faster R-CNN-OC model stopped at epoch and respectively. For the occlusion branch, during training the "occlusion scores" of the upper object and the lower object are set to be and respectively.
We train a separate decoder for each class. The latent dimension is . There is one hidden layer with hidden units fully connected to a layer with 7500 units corresponding to the 50x50x3 output. We use a ReLU nonlinearity after the hidden layer and a sigmoid nonlinearity after the final layer. The first images are used in training the decoder and the remaining images are used for testing. Our decoder is trained for epochs and we update the decoder parameters once after optimization iterations of the latent code. We fix and . Adam optimizers are used and the learning rates for updating decoder parameters and latent code are and .
For the full detection selection algorithm (DSA), we drop detections with objectness score less than , such detections would anyhow be rejected by the greedy search but at an unnecessary computational cost.
5.2 Experiments on Occlusion Scores
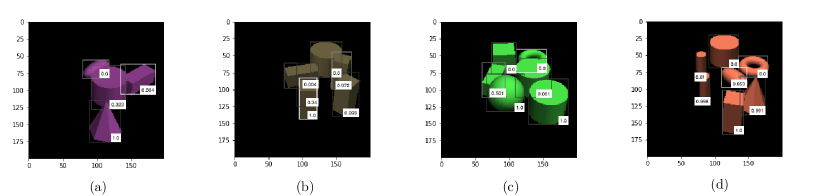
The Faster R-CNN-OC model is trained on pairs of objects, but it generalizes well when we test on three or more overlapping objects. Since occlusion relationship reasoning is not our main focus, we only display some results in Figure 8, where the predicted occlusion score is displayed at the lower right corner for each bounding box. Note that for clarity we only display the top several bounding boxes after NMS by Faster R-CNN.
5.3 Experiments on DSA
People often use mAP (mean Average Precision) to evaluate the quality of detections. However, in order to determine the correct number of objects, the precision when matters the most. In this work we use two types of accuracies as our evaluation metrics:
-
•
The precent of images where the correct number of boxes is chosen.
-
•
The percent of images with the correct number of boxes and correct predicted labels.
For example, if there are one class-1 object and two class-2 objects in the image, and our prediction is two class-1 objects plus one class-2 object, then we are correct under the first evaluation metric and wrong under the second evaluation metric. Clearly, the second evaluation metric is more strict.
5.3.1 NMS, Soft-NMS and DIoU-NMS
In Table 1 we compare three post processing methods for the Faster R-CNN: NMS, Soft-NMS and DIoU-NMS. The parameters and are both thresholds mentioned in section 1. In the first half of the table, we determined the optimal threshold using a grid search over the range as threshold on the validation set. Detections above the chosen threshold for each method are used as final detections. Similarly, tries to maximize the accuracy of labels in the validation set. It seems that the chosen and are pretty close to each other. The thresholds for Soft-NMS are lower because Soft-NMS decreases objectness scores. For comparison, in the second half of Table 1, we just fix the thresholds to be . Due to these lower thresholds, the accuracies of NMS decrease drastically.
| Methods | Accuracy for Boxes | Accuracy for Labels | ||
|---|---|---|---|---|
| NMS | 0.91 | 0.91 | 0.962 (0.0086) | 0.962 (0.0086) |
| Soft-NMS | 0.69 | 0.69 | 0.950 (0.0097) | 0.950 (0.0097) |
| DIoU-NMS | 0.91 | 0.91 | 0.940 (0.0106) | 0.940 (0.0106) |
| NMS | 0.5 | 0.5 | 0.772 (0.0188) | 0.772 (0.0188) |
| Soft-NMS | 0.5 | 0.5 | 0.946 (0.0101) | 0.946 (0.0101) |
| DIoU-NMS | 0.5 | 0.5 | 0.934 (0.0111) | 0.934 (0.0111) |
The accuracies in Table 1 are calculated on the test set based on the thresholds obtained by the validation set. Because the validation set and test set have different distributions, the thresholds may not be optimal. The numbers in the parenthesis are the estimated standard deviations using , where is the average accuracy and is the number of test samples. Accuracy for boxes and accuracy for labels are the first and second evaluation metrics mentioned earlier. We can see that for every method, the accuracy for boxes and labels are the same.
5.3.2 NMS+DSA and Soft-NMS+DSA using Faster R-CNN-OC
Given a set of detections by an object detection algorithm, DSA as described has no ability of reducing False Negatives, but can be used to reduce False Positives. We use DSA after NMS or DSA after Soft-NMS, to post-process the detections of the Faster R-CNN-OC. The threshold for NMS is set at .5. In Table 2, DSA after NMS is called "NMS+DSA" and DSA after Soft-NMS is called "Soft-NMS+DSA".
The penalties and are also chosen by the validation set to maximize the two evaluation metrics respectively. We tried the values . If there are ties, we choose the median.
| Methods | Accuracy for Boxes | Accuracy for Labels | ||
|---|---|---|---|---|
| NMS+DSA | 15 | 15 | 0.980 (0.0063) | 0.980 (0.0063) |
| Soft-NMS+DSA | 20 | 20 | 0.982 (0.0059) | 0.980 (0.0063) |
5.3.3 Recovering False Negatives
We conducted a simple experiment to see how DSA might be extended to recover missed detections of NMS or soft-NMS. We rotated each test image by 10 degrees. This minor perturbation significantly reduces the accuracy of the detection algorithms. For example soft-NMS yields 0.90 for number of boxes and 0.652 for proportion of images with correct labels. Just observing the results it is clear that the small rotation leads the faster R-CNN to label many instances of class 8 - the upright cylinder as class 9. So we added a minor hack in the code, where any time a box is labeled 9, we also run the whole reconstruction algorithm on exactly the same input except that the new box is labeled 8 instead of 9 and then compare the NLL’s. Furthermore, we introduce a new variable in the decoder for rotation in addition to the translation variable so that the decoder optimization is over . This yielded a significant improvement of 0.906 proportion of images with correct number of detected boxes and 0.856 proportion of images with all labels correct. In Figure 9 we show the different whole reconstructions produced without and with the likelihood comparison between class 9 and class 8. This experiment points to the possibility of recovering from distribution shifts by extending the free parameters of the decoder as well as entertaining more than one class label for each detected box.
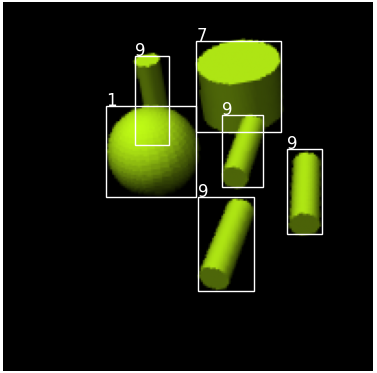


5.3.4 Enlarged Objects
Another experiment of interest is rescaling all objects by the same proportion in the test set, and keeping the training and validation sets the same. This is implemented by cropping a region which contains all the objects and enlarging it to become a image.
| Methods | Accuracy for Boxes | Accuracy for Labels | ||
|---|---|---|---|---|
| NMS | 0.91 | 0.91 | 0.886 (0.0142) | 0.880 (0.0145) |
| Soft-NMS | 0.69 | 0.69 | 0.916 (0.0124) | 0.908 (0.0129) |
| DIoU-NMS | 0.91 | 0.91 | 0.886 (0.0142) | 0.874 (0.0148) |
| Methods | Accuracy for Boxes | Accuracy for Labels | ||
|---|---|---|---|---|
| NMS+DSA | 15 | 15 | 0.988 (0.0049) | 0.982 (0.0059) |
| Soft-NMS+DSA | 20 | 20 | 0.964 (0.0083) | 0.960 (0.0088) |
The results are summarized in Table 3 and Table 4. From the results we can see that DSA leads to highly significant improvements. NMS+DSA again performs especially well. From ordinary objects to the enlarged objects, the accuracies of NMS drop from to , while the accuracies of NMS+DSA don’t drop.
Because the sizes of objects in the new images are new to Faster R-CNN, the objectness scores become less reliable. That’s why NMS, Soft-NMS and DIoU-NMS exhibit worse performance. Our single reconstruction algorithm is capable of handling bounding boxes of various scales, so our DSA still works on enlarged objects.
Figure 10 illustrates why we need to compare with and in the detection selection algorithm. In Figure 10, an object of class 5 is predicted in two different bounding boxes by Faster R-CNN as class 4 and class 5 with objectness scores and respectively. Thus, the class 4 object is processed before the class 5 object in the DSA. The whole reconstruction by the top 5 detections in terms of objectness scores yields loss . It selects the wrong bounding box of class 4. In the next step, DSA considers dropping the bounding box of class 4 and adding the bounding box of class 5. The loss decreases to , and it gives us the right interpretation.
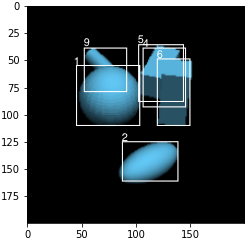
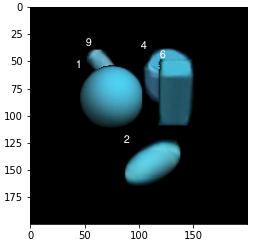
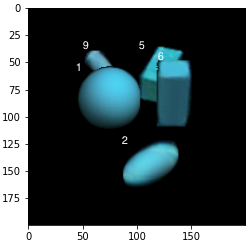
6 Discussion
In this work, we have proposed the Detection Selection Algorithm (DSA) and several supportive algorithms, which can be used to determine the exact number of objects and their labels in the image. DSA is used after NMS or related methods. The framework is likelihood based where comparisons are made between image interpretations - ordered sequences of instantiated objects. The probabilistic framework offers a global evaluation of any interpretation and takes into account the relationships between the different objects. Some byproducts of DSA include finding the occlusion sequence of objects, reconstructing the invisible parts of objects, and generating images on a given set of hypothesized objects.
We note that most network models used today in image processing are fully feed-forward. The input passes through the network and produces the output. This works well when there is ample training data and when the distribution of the test data is the same as that of the training data, i.e. no distributional shift. However such methods are quite sensitive to distributional shifts as demonstrated in the experiments above, and it appears to us that in certain settings adjusting to such shifts without retraining necessitates an online optimization procedure that can accommodate the modified distribution, and in particular using global likelihood based reasoning. A full probabilistic model is the most principled way to achieve this, albeit at a significant computational cost. Our greedy algorithm implements only one step back search, only inspecting the detection with highest overlap. More extensive searches could be implemented exploring a wider range of ordered subsets of the detections, again, at a higher computational cost.
Further research is needed to extend the DSA to real-world images with colored background and clutter. A possible way to do this is to extract features from real-world images in such a way that reduce the task to dealing with images on black background.
References
- [1] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” in Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1, ser. NIPS’15. Cambridge, MA, USA: MIT Press, 2015, p. 91–99.
- [2] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis, “Soft-nms–improving object detection with one line of code,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 5561–5569.
- [3] Y. Amit and A. Trouvé, “Pop: Patchwork of parts models for object recognition,” International Journal of Computer Vision, vol. 75, no. 2, pp. 267–282, 2007.
- [4] R. B. Girshick, “Fast R-CNN,” CoRR, vol. abs/1504.08083, 2015. [Online]. Available: http://arxiv.org/abs/1504.08083
- [5] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg, “SSD: single shot multibox detector,” CoRR, vol. abs/1512.02325, 2015. [Online]. Available: http://arxiv.org/abs/1512.02325
- [6] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” CoRR, vol. abs/1506.02640, 2015. [Online]. Available: http://arxiv.org/abs/1506.02640
- [7] A. Neubeck and L. Van Gool, “Efficient non-maximum suppression,” in 18th International Conference on Pattern Recognition (ICPR’06), vol. 3. IEEE, 2006, pp. 850–855.
- [8] M. Gong, D. Wang, X. Zhao, H. Guo, D. Luo, and M. Song, “A review of non-maximum suppression algorithms for deep learning target detection,” in Seventh Symposium on Novel Photoelectronic Detection Technology and Applications, vol. 11763. SPIE, 2021, pp. 821–828.
- [9] Y. He, X. Zhang, M. Savvides, and K. Kitani, “Softer-nms: Rethinking bounding box regression for accurate object detection,” arXiv preprint arXiv:1809.08545, vol. 2, no. 3, pp. 69–80, 2018.
- [10] B. Jiang, R. Luo, J. Mao, T. Xiao, and Y. Jiang, “Acquisition of localization confidence for accurate object detection,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 784–799.
- [11] S. Liu, D. Huang, and Y. Wang, “Adaptive nms: Refining pedestrian detection in a crowd,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6459–6468.
- [12] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, “Distance-iou loss: Faster and better learning for bounding box regression,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 993–13 000.
- [13] E. Zaytseva and J. Vitrià, “A search based approach to non maximum suppression in face detection,” in 2012 19th IEEE International Conference on Image Processing. IEEE, 2012, pp. 1469–1472.
- [14] Y. Song, Q.-K. Pan, L. Gao, and B. Zhang, “Improved non-maximum suppression for object detection using harmony search algorithm,” Applied Soft Computing, vol. 81, p. 105478, 2019.
- [15] D. Yi, J. Su, and W.-H. Chen, “Probabilistic faster r-cnn with stochastic region proposing: Towards object detection and recognition in remote sensing imagery,” Neurocomputing, vol. 459, pp. 290–301, 2021.
- [16] P. Feng, Q. She, L. Zhu, J. Li, L. Zhang, Z. Feng, C. Wang, C. Li, X. Kang, and A. Ming, “Mt-orl: Multi-task occlusion relationship learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9364–9373.
- [17] X. Yuan, A. Kortylewski, Y. Sun, and A. Yuille, “Robust instance segmentation through reasoning about multi-object occlusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 141–11 150.
- [18] K. Ehsani, R. Mottaghi, and A. Farhadi, “Segan: Segmenting and generating the invisible,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6144–6153.
- [19] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” 2014. [Online]. Available: https://arxiv.org/abs/1406.2661
- [20] L. Qi, L. Jiang, S. Liu, X. Shen, and J. Jia, “Amodal instance segmentation with kins dataset,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3014–3023.
- [21] R. Girshick, “Fast r-cnn,” 2015.
- [22] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [23] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spatial transformer networks,” in Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, ser. NIPS’15. Cambridge, MA, USA: MIT Press, 2015, p. 2017–2025.
- [24] M. D. Hoffman, D. M. Blei, C. Wang, and J. Paisley, “Stochastic variational inference,” Journal of Machine Learning Research, 2013.
- [25] K. Gregor, I. Danihelka, A. Graves, D. Rezende, and D. Wierstra, “Draw: A recurrent neural network for image generation,” in International conference on machine learning. PMLR, 2015, pp. 1462–1471.