toltxlabel \newcitessecAppendices
Determinantal point processes based on orthogonal polynomials for sampling minibatches in SGD
Abstract
Stochastic gradient descent (SGD) is a cornerstone of machine learning. When the number of data items is large, SGD relies on constructing an unbiased estimator of the gradient of the empirical risk using a small subset of the original dataset, called a minibatch. Default minibatch construction involves uniformly sampling a subset of the desired size, but alternatives have been explored for variance reduction. In particular, experimental evidence suggests drawing minibatches from determinantal point processes (DPPs), tractable distributions over minibatches that favour diversity among selected items. However, like in recent work on DPPs for coresets, providing a systematic and principled understanding of how and why DPPs help has been difficult. In this work, we contribute an orthogonal polynomial-based determinantal point process paradigm for performing minibatch sampling in SGD. Our approach leverages the specific data distribution at hand, which endows it with greater sensitivity and power over existing data-agnostic methods. We substantiate our method via a detailed theoretical analysis of its convergence properties, interweaving between the discrete data set and the underlying continuous domain. In particular, we show how specific DPPs and a string of controlled approximations can lead to gradient estimators with a variance that decays faster with the batchsize than under uniform sampling. Coupled with existing finite-time guarantees for SGD on convex objectives, this entails that, for a large enough batchsize and a fixed budget of item-level gradients to evaluate, DPP minibatches lead to a smaller bound on the mean square approximation error than uniform minibatches. Moreover, our estimators are amenable to a recent algorithm that directly samples linear statistics of DPPs (i.e., the gradient estimator) without sampling the underlying DPP (i.e., the minibatch), thereby reducing computational overhead. We provide detailed synthetic as well as real data experiments to substantiate our theoretical claims.
1 Introduction
Consider minimizing an empirical loss
| (1) |
with some penalty . Many learning tasks, such as regression and classification, are usually framed that way [1]. When , computing the gradient of the objective in (1) becomes a bottleneck, even if individual gradients are cheap to evaluate. For a fixed computational budget, it is thus tempting to replace vanilla gradient descent by more iterations but using an approximate gradient, obtained using only a few data points. Stochastic gradient descent (SGD; [2]) follows this template. In its simplest form, SGD builds an unbiased estimator at each iteration of gradient descent, independently from past iterations, using a minibatch of random samples from the data set. Theory [3] and practice suggest that the variance of the gradient estimators in SGD should be kept as small as possible. It is thus natural that variance reduction for SGD has been a rich area of research; see for instance the detailed references in [4, Section 2].
In a related vein, determinantal point processes (DPPs) are probability distributions over subsets of a (typically large or infinite) ground set that are known to yield samples made of collectively diverse items, while being tractable both in terms of sampling and inference. Originally introduced in electronic optics [5], they have been turned into generic statistical models for repulsion in spatial statistics [6] and machine learning [7, 8]. In ML, DPPs have also been shown to be efficient sampling tools; see Section 2. Importantly for us, there is experimental evidence that minibatches in (1) drawn from DPPs and other repulsive point processes can yield gradient estimators with low variance for advanced learning tasks [4, 9], though a conclusive theoretical result has remained elusive. In particular, it is hard to see the right candidate DPP when, unlike linear regression, the objective function does not necessarily have a geometric interpretation.
Our contributions are as follows. We combine continuous DPPs based on orthogonal polynomials [10] and kernel density estimators built on the data to obtain two gradient estimators; see Section 3. We prove that their variance is , where is the size of the minibatch, is the dimension of data; see Section 4. This provides theoretical backing to the claim that DPPs yield variance reduction [4] over, say, uniformly sampling without replacement. In passing, the combination of analytic tools –orthogonal polynomials–, and an essentially discrete subsampling task –minibatch sampling– sheds light on new ways to build discrete DPPs for subsampling. Finally, we demonstrate our theoretical results on simulated data in Section 5.
A cornerstone of our approach is to utilise orthogonal polynomials to construct our sampling paradigm, interweaving between the discrete set of data points and the continuum in which the orthogonal polynomials reside. A few words are in order regarding the motivation for our choice of techniques. Roughly speaking, we would like to use a DPP that is tailored to the data distribution at hand. Orthogonal Polynomial Ensembles (OPEs) provide a natural way of associating a DPP to a given measure (in this case, the probability distribution of the data points), along with a substantive body of mathematical literature and tools that can be summoned as per necessity. This makes it a natural choice for our purposes.
Notation.
Let data be denoted by , and assume that the ’s are drawn i.i.d. from a distribution on . Assume is compactly supported, with support bounded away from the border of . Assume also that is continuous with respect to the Lebesgue measure, and that its density is bounded away from zero on its support. While our assumptions exclude learning problems with discrete labels, such as classification, we later give experimental support that our estimators yield variance reduction in that case too. We define the empirical measure where is the delta measure at the point . Clearly, in ; under our operating assumption of compact support, this amounts to convergence in .
For simplicity, we assume that no penalty is used in (1), but our results will extend straightforwardly. We denote the gradient of the empirical loss by . A minibatch is a (random) subset of size such that the random variable
| (2) |
for suitable weights , provides a good approximation for .
2 Background and relevant literature
Stochastic gradient descent.
Going back to [2], SGD has been a major workhorse for machine learning; see e.g. [1, Chapter 14]. The basic version of the algorithm, applied to the empirical risk minimization (1), is to repeatedly update
| (3) |
where is a (typically decreasing) stepsize, and is a minibatch-based estimator (2) of the gradient of the empirical risk function (1), possibly depending on past iterations. Most theoretical analyses assume that for any , in the -th update (3) is unbiased, conditionally on the history of the Markov chain so far. For simplicity, we henceforth make the assumption that does not depend on the past of the chain. In particular, using such unbiased gradients, one can derive a nonasymptotic bound [3] on the mean square distance of to the minimizer of (1), for strongly convex and smooth loss functions like linear regression and logistic regression with penalization. More precisely, for and , [3, Theorem 1] yields
| (4) |
where are problem-dependent constants, , and is the trace of the covariance matrix of the gradient estimator, evaluated at the optimizer of (1). The initialization bias is thus forgotten subexponentially fast, while the asymptotically leading term is proportional to . Combined with practical insight that variance reduction for gradients is key, theoretical results like (4) have motivated methodological research on efficient gradient estimators [4, Section 2], i.e., constructing minibatches so as to minimize . In particular, repulsive point processes such as determinantal point processes have been empirically demonstrated to yield variance reduction and overall better performance on ML tasks [4, 9]. Our paper is a stab at a theoretical analysis to support these experimental claims.
The Poissonian benchmark.
The default approach to sample a minibatch is to sample data points from uniformly, with or without replacement, and take constant in (2). Both sampling with or without replacement lead to unbiased gradient estimators. A similar third approach is Poissonian random sampling. This simply consists in starting from , and independently adding each element of to the minibatch with probability . The Poisson estimator is then (2), with constant weights again equal to . When , which is the regime of SGD, the cardinality of is tightly concentrated around , and has the same fluctuations as the two default estimators, while being easier to analyze. In particular, and ; see Appendix S1 for details.
DPPs as (sub)sampling algorithms.
As distributions over subsets of a large ground set that favour diversity, DPPs are intuitively good candidates at subsampling tasks, and one of their primary applications in ML has been as summary extractors [7]. Since then, DPPs or mixtures thereof have been used, e.g., to generate experimental designs for linear regression, leading to strong theoretical guarantees [11, 12, 13]; see also [14] for a survey of DPPs in randomized numerical algebra, or [15] for feature selection in linear regression with DPPs.
When the objective function of the task has less structure than linear regression, it has been more difficult to prove that finite DPPs significantly improve over i.i.d. sampling. For coreset construction, for instance, [16] manages to prove that a projection DPP necessarily improves over i.i.d. sampling with the same marginals [16, Corollary 3.7], but the authors stress the disappointing fact that current concentration results for strongly Rayleigh measures (such as DPPs) do not allow yet to prove that DPP coresets need significantly fewer points than their i.i.d. counterparts [16, Section 3.2]. Even closer to our motivation, DPPs for minibatch sampling have shown promising experimental performance [4], but reading between the lines of the proof of [4, Theorem 1], a bad choice of DPP can even yield a larger variance than i.i.d. sampling!
For such unstructured problems (compared to, say, linear regression) as coreset extraction or loss-agnostic minibatch sampling, we propose to draw inspiration from work on continuous DPPs, where faster-than-i.i.d. error decays have been proven in similar contexts. For instance, orthogonal polynomial theory motivated [10] to introduce a particular DPP, called a multivariate orthogonal polynomial ensemble, and prove a faster-than-i.i.d. central limit theorem for Monte Carlo integration of smooth functions. While resorting to continuous tools to study a discrete problem such as minibatch sampling may be unexpected, we shall see that the assumption that the size of the dataset is large compared to the ambient dimension crucially allows to transfer variance reduction arguments.
3 DPPs, and two gradient estimators
Since we shall need both discrete and continuous DPPs, we assume that is either or , and follow [17] in introducing DPPs in an abstract way that encompasses both cases. After that, we propose two gradient estimators for SGD that build on a particular family of continuous DPPs introduced in [10] for Monte Carlo integration, called multivariate orthogonal polynomial ensembles.
3.1 DPPs: The kernel machine of point processes
A point process on is a distribution on finite subsets of ; see [18] for a general reference. Given a reference measure on , a point process is said to be determinantal (DPP) if there exists a function , the kernel of the DPP, such that, for every ,
| (5) |
for every bounded Borel function , where the sum in the LHS of (5) ranges over all pairwise distinct -uplets of the random finite subset . A few remarks are in order. First, satisfying (5) for every is a strong constraint on , so that not every kernel yields a DPP. A set of sufficient conditions on is given by the Macchi-Soshnikov theorem [5, 19]. In words, if , and if further corresponds to an integral operator
that is trace-class with spectrum in , then the corresponding DPP exists. Second, note in (5) that the kernel of a DPP encodes how the points in the random configurations interact. A strong point in favour of DPPs is that, unlike most interacting point processes, sampling and inference are tractable [17, 6]. Third, (5) yields simple formulas for the mean and variance of linear statistics of a DPP.
Since the seminal paper [7], the case has been the most common in machine learning. Taking to be , any kernel is given by its restriction to , usually given as an matrix . Equation (6) with , a subset of size of , and the indicator of yields This is the usual way finite DPPs are introduced [7], except maybe for the factor , which comes from using as the reference measure instead of . In this finite setting, a careful implementation of the general DPP sampler of [17] yields DPP samples of average cardinality in operations [22].
We now go back to a general and fix . A canonical way to construct DPPs generating configurations of points almost surely, i.e. , is the following. Consider orthonormal functions in , and take for kernel
| (8) |
In this setting, the (permutation invariant) random variables with joint distribution
| (9) |
generate a DPP with kernel , called a projection DPP. For further information on determinantal point processes, we refer the reader to [17, 7].
3.2 Multivariate orthogonal polynomial ensembles
This section paraphrases [10] in their definition of a particular projection DPP on , called a multivariate orthogonal polynomial ensemble (OPE). Fix some reference measure on , and assume that it puts positive mass on some open subset of . Now choose an ordering of the monomial functions ; in this work we use the graded lexical order. Then apply the Gram-Schmidt algorithm in to these ordered monomials. This yields a sequence of orthonormal polynomial functions , the multivariate orthonormal polynomials w.r.t. . Finally, plugging the first multivariate orthonormal polynomials into the projection kernel (8), we obtain a projection DPP with kernel denoted as , referred to as the multivariate OPE associated with the measure .
3.3 Our first estimator: reweight, restrict, and saturate an OPE kernel
Let and
| (10) |
be a single-bandwidth kernel density estimator of the pdf of the data-generating distribution ; see [23, Section 4.2], In particular, is chosen so that . Note that the approximation kernel is unrelated to any DPP kernel in this paper. Let now be a separable pdf on , where each is Nevai-class111See [10, Section 4] for details. It suffices that each is positive on .. Let be the multivariate OPE kernel defined in Section 3.2, and form a new kernel
The form of is reminiscent of importance sampling [24], which is no accident. Indeed, while the positive semidefinite matrix
| (11) |
is not necessarily the kernel matrix of a DPP on , see Section 3.1, we built it to be close to a projection of rank . More precisely,
If is large compared to and , so that in particular , the term within brackets will be close to , so that is almost a projection in .
Let us actually consider the orthogonal projection matrix with the same eigenvectors as , but with the largest eigenvalues replaced by , and the rest of the spectrum set to . By the Macchi-Soshnikov theorem, is the kernel matrix of a DPP; see Section 3.1. We thus consider a minibatch . Coming from a projection DPP, almost surely, and we define the gradient estimator
| (12) |
In Section 4, we shall prove that is unbiased, and examine under what assumptions its variance decreases faster than .
On the computational cost of .
The bottleneck is computing the largest eigenvalues of matrix (11), along with the corresponding eigenvectors. This can be done once before running SGD, as a preprocessing step. Note that storing the kernel in diagonalized form only requires storage. Each iteration of SGD then only requires sampling a rank- projection DPP with diagonalized kernel, which takes elementary operations [22]. In practice, as the complexity of the model underlying increases, the cost of computing individual gradients shall outweigh this overhead. For instance, learning the parameters of a structured model like a conditional random field leads to arbitrarily costly individual gradients, as the underlying graph gets more dense [25]. Alternately, (12) can be sampled directly, without sampling the underlying DPP. Indeed the Laplace transform of (12) is a Fredholm determinant, and it is shown in [26] that Nyström-type approximations of that determinant, followed by Laplace inversion, yield an accurate inverse CDF sampler.
Finally, we stress the unusual way in which our finite DPP kernel is constructed, through a reweighted continuous OPE kernel, restricted to the actual dataset. This construction is interesting per se, as it is key to leveraging analytic techniques from the continuous case in Section 4.
3.4 Our second estimator: sample the OPE, but smooth the gradient
In Section 3.3, we smoothed the empirical distribution of the data and restricted a continuous kernel to the dataset , to make sure that the drawn minibatch would be a subset of . But one could actually define another gradient estimator, directly from an OPE sample . Note that in that case, the “generalized minibatch” is not necessarily a subset of the dataset . Defining a kernel density estimator of the gradient,
we consider the estimator
On the computational cost of .
Since each evaluation of this estimator is at least as costly as evaluating the actual gradient , its use is mostly theoretical: the analysis of the fluctuations of is easier than that of , while requiring the same key steps. Moreover, the computation of all pairwise distances in could be efficiently approximated, possibly using random projection arguments [27], so that the limited scope of might be overcome in future work. Note also that, like , inverse Laplace sampling [26] applies to .
4 Analysis of determinantal sampling of SGD gradients
We first analyze the bias, and then the fluctuations, of the gradient estimators introduced in Section 3. By Proposition 1 with , it comes
so that we immediatly get the following result.
Proposition 2.
.
Thus, is unbiased, like the classical Poissonian benchmark in Section 2. However, the smoothed estimator from Section 3.4 is slightly biased. Note that while the results of [3], like (4), do not apply to biased estimators, SGD can be analyzed in the small-bias setting [28].
Proposition 3.
Assume that in (10) has compact support and is bounded on . Then .
Proof.
Using the first part of Proposition 1 again, it comes
| (13) |
where, in the last step, we have used the fact that is a probability density. The error term arises because we integrate that pdf on rather than . But since is a compactly supported kernel, for points that are within a distance from the boundary of , we incur an error of . By Proposition 1, the expected number of such points is , where is the -neighbourhood of the boundary of . By a classical asymptotic result of Totik, see [10, Theorem 4.8], is on ; whereas is a bounded density, implying that . Putting together all of these, we obtain the error term in (13). ∎
The rest of this section is devoted to the more involved task of analyzing the fluctuations of and . For the purposes of our analysis, we discuss certain desirable regularity behaviour for our kernels and loss functions in Section 4.1. Then, we tackle the main ideas behind the study of the fluctuations of our estimators in Section 4.2. Details can be found in Appendix S3.
4.1 Some regularity phenomena
Assume that is bounded on the domain uniformly in (note that possibly depends on ). Furthermore, assume that is 1-Lipschitz, with Lipschitz constant and bounded in .
Such properties are natural in the context of various known asymptotic phenomena, in particular asymptotic results on OPE kernels and the convergence of the KDE to the distribution . The detailed discussion is deferred to Appendix S2; we record here in passing that the above asymptotic phenomena imply that
| (14) |
Our desired regularity properties may therefore be understood in terms of closeness to this limit, which itself has similar regularity. At the price of these assumptions, we can use analytic tools to derive fluctuations for by working on the limit in (14). For the fluctuation analysis of the smoothed estimator , we similarly assume that is and 1-Lipschitz with an Lipschitz constant that is bounded in . These are once again motivated by the convergence of to .
4.2 Reduced fluctuations for determinantal samplers
For succinctness of presentation, we focus on the theoretical analysis of the smoothed estimator , leaving the analysis of to Appendix S3, while still capturing the main ideas of our approach.
Proposition 4.
Under the assumptions in Section 4.1, .
Proof Sketch.
Invoking (7) in the case of a projection kernel,
| (15) |
where we used the 1-Lipschitzianity of , with the Lipschitz constant.
We control the integral in (15) by invoking the renowned Christoffel-Darboux formula for the OPE kernel [29]. For clarity of presentation, we outline here the main ideas for ; the details for general dimensions are available in Appendix S3. Broadly speaking, since is an orthogonal projection of rank in , we may observe that ; so that without the term in (15), we would have a behaviour in total, which would be similar to the Poissonian estimator. However, it turns out that the leading order contribution to comes from near the diagonal , and this turns out to be neutralised in an extremely precise manner by the factor that vanishes on the diagonal.
This neutralisation is systematically captured by the Christoffel-Darboux formula [29], which implies
where and are two orthonormal functions in . Substituting this into (15), a simple computation shows that . This leads to a variance bound , which is the desired rate for . For general , we use the fact that is a product measure, and apply the Christoffel-Darboux formula for each , leading to a variance bound of , as desired. ∎
The theoretical analysis of follows the broad contours of the argument for as above, with additional difficulties introduced by the spectral truncation from to ; see Section 3. This is addressed by an elaborate spectral approximation analysis in Appendix S3. In combination with the ideas expounded in the proof of Proposition 4, our analysis in Appendix S3 indicates a fluctuation bound of .
5 Experiments
In this section, we compare the empirical performance and the variance decay of our gradient estimator to the default . We do not to include , whose interest is mostly theoretical; see Section 4. Moreover, while we focus on simulated data to illustrate our theoretical analysis, we provide experimental results on a real dataset in Appendix S4. Throughout this section, the pdf introduced in Section 3.2 is taken to be , with tuned to match the first two moments of the th marginal of . All DPPs are sampled using the Python package
PPy } \cite{GBPV19}, which is under MIT licence.
\paragraph{Experimental setup.}
We consider the ERM setting \eqref{e:ERM} for linear regression $\el_{\text{lin}}((x,y),\t)=0.5(\langle x, \theta\rangle-y)^2$ and logistic regression $\el_\text{log}((x,y),\t)=\log[1+\exp(-y\langle x,\theta\rangle )]$, both with an additional $\ell_2$ penalty $\lambda(\theta)=(\lambda_0/2)\|\theta\|_2^2$.
Here the features are $x\in[-1,1]^{d-1}$, and the labels are, respectively, $y\in[-1,1]$ and $y\in \{-1,1\}$.
Note that our proofs currently assume that the law $\gamma$ of $z=(x,y)$ is continuous w.r.t. Lebesgue, which in all rigour excludes logistic regression.
However, we demonstrate below that if we draw a minibatch using our PP but on features only, and then deterministically associate each label to the drawn features, we observe the same gains for logistic regression as for linear regression, where the DPP kernel takes into account both features and labels.
For each experiment, we generate data points with either the uniform distribution or a mixture of well-separated Gaussian distributions on . The variable is generated as , where is given, and is a white Gaussian noise vector. In the linear regression case, we scale by to make sure that . In the logistic regression case, we replace each by its sign. The regularization parameter is manually set to be and the stepsize for the -th iteration is set as , so that (4) applies. In each experiment, performance metrics are averaged over independent runs of each SGD variant.
Performance evaluation of sampling strategies in SGD.
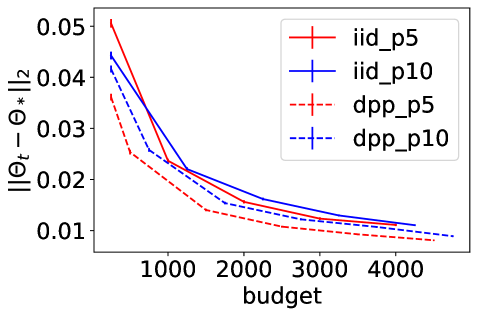
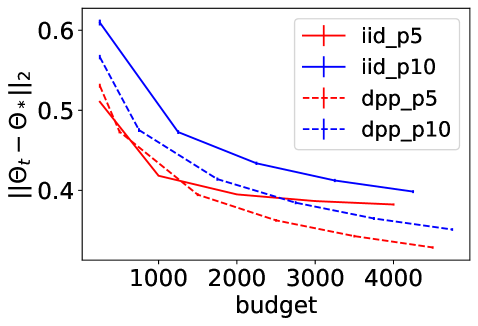
Figure 1 summarizes the experimental results of and , with and . The top row shows how the norm of the complete gradient decreases with the number of individual gradient evaluations , called here budget. The bottom row shows the decrease of . Note that using on all -axes allows comparing different batchsizes. Error bars on the bottom row are one standard deviation of the mean. In all experiments, using a DPP consistently improves the performance of Poisson minibatches of the same size, and the DPP with batchsize sometimes even outperforms Poisson sampling with batchsize , showing that smaller but more diverse batches can be a better way of spending a fixed number of gradient evaluations. This is particularly true for mixture data (middle column), where forcing diversity with our DPP brings the biggest improvement. Maybe less intuitively, the gains for the logistic regression in (last column) are also significant, while the case of discrete labels is not covered yet by our theoretical analysis, and the moderately large dimension makes the improvement in the decay rate of the variance minor. This indicates that there is variance reduction beyond the change of the rate.
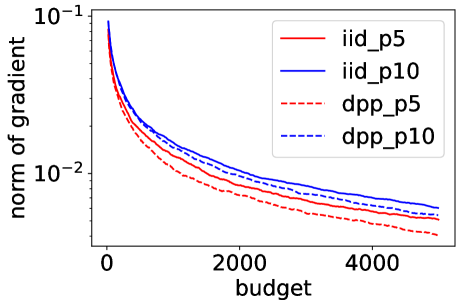
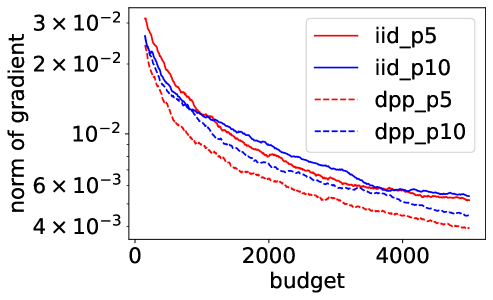
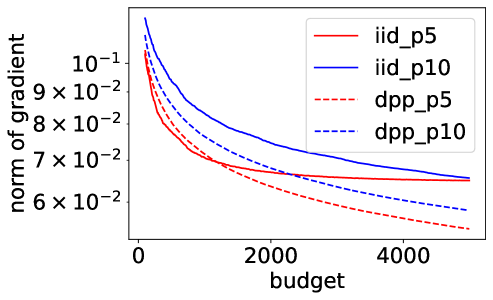
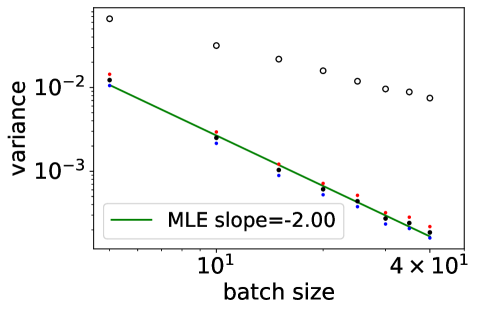
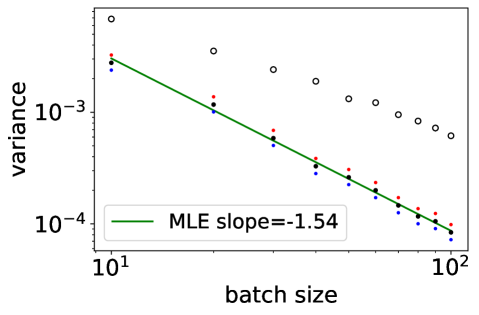
Variance decay.
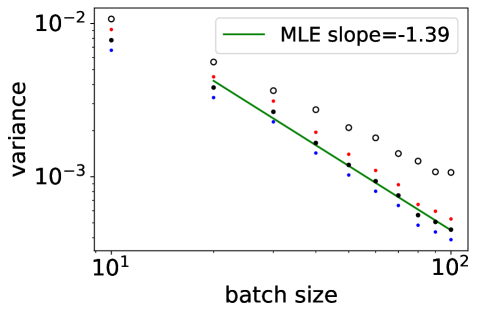
For a given dimension , we want to infer the rate of decay of the variance , to confirm the rate discussed in Section 4. We take as an example, with i.i.d. samples from the uniform distribution on . For , we show in Figure 2 the sample variance of realizations of the variance of (white dots) and (black dots), conditionally on . Blue and red dots indicate standard marginal confidence intervals, for indication only. The slope found by maximum likelihood in a linear regression in the log-log scale is indicated as legend. The experiment confirms that is smaller for the DPP, decays as , and that this decay starts at a batchsize that increases with dimension.
6 Discussion
In this work, we introduced an orthogonal polynomial-based DPP paradigm for sampling minibatches in SGD that entails variance reduction in the resulting gradient estimator. We substantiated our proposal by detailed theoretical analysis and numerical experiments. Our work raises natural questions and leaves avenues for improvement in several directions. These include the smoothed estimator , which calls for further investigation in order to be deployed as a computationally attractive procedure; improvement in the dimension dependence of the fluctuation exponent when the gradients are smooth enough, like [31, 32] did for [10]; sharpening of the regularity hypotheses for our theoretical investigations to obtain a more streamlined analysis. While our estimators were motivated by a continuous underlying data distribution, our experiments suggest notably good performance in situations like logistic regression, where the data is at least partially discrete. Extensions to account for discrete settings in a principled manner, via discrete OPEs or otherwise, would be a natural topic for future research. Another natural problem is to compare our approach with other, non-i.i.d., approaches for minibatch sampling. A case in point is the method of importance sampling, where the independence across data points suggests that the variance should still be as in uniform sampling. More generally, incorporating ingredients from other sampling paradigms to further enhance the variance reducing capacity of our approach would be of considerable interest. Finally, while our results already partly apply to more sophisticated gradient estimators like Polyak-Rupert averaged gradients [3, Section 4.2], it would be interesting to introduce repulsiveness across consecutive SGD iterations to further minimize the variance of averaged estimators. In summary, we believe that the ideas put forward in the present work will motivate a new perspective on improved minibatch sampling for SGD, more generally on estimators based on linear statistics (e.g. in coreset sampling), and beyond.
Acknowledgements
RB acknowledges support from ERC grant Blackjack (ERC-2019-STG-851866) and ANR AI chair Baccarat (ANR-20-CHIA-0002). S.G. was supported in part by the MOE grants R-146-000-250-133 and R-146-000-312-114.
Appendices
For ease of reference, sections, propositions and equations that belong to this supplementary material are prefixed with an ‘S’.
Appendix S1 The Poissonian Benchmark
Our benchmark for comparing the efficacy of our estimator would be a subset obtained via Poissonian random sampling, which is characterised by independent random choices of the elements of from the ground set , with each element of being selected independently with probability . The estimator for Poissonian sampling is simply an analogue of the empirical average; in the context of (2) this is simply the choice for all . While the true empirical average may be realised with ; we exploit here the fact that, for large , the empirical cardinality is tightly concentrated around its expectation .
Denoting by the indicator function for inclusion in the set , the variables are, under Poissonian sampling, i.i.d. Bernoulli random variables with parameter . It may then be easily verified that, , whereas
| (S1) |
Now, by a uniform central limit theorem [33], we obtain
| (S2) |
Thus, the conditional variance
| (S3) |
where , the space of probability measures on , is the (compactly supported) distribution of the data ; see the paragraph on notation in Section 1. Equation (S3) provides us with the theoretical benchmark against which to compare any new approach to minibatch sampling for stochastic gradient descent.
Appendix S2 Regularity Phenomena
For the purposes of our analysis, we envisage certain regularity behaviour for our kernels and loss functions, and discuss the natural basis for such assumptions. The discussion here complements the discussion on this topic undertaken in Section 4 of the main text.
S2.1 Regularity phenomena and uniform CLTs
In addition to the OPE asymptotics discussed in the main text, another relevant class of asymptotic results is furnished by Glivenko-Cantelli type convergence phenomena for empirical measures and kernel density estimators. These results are naturally motivated by convergence issues arising from the law of large numbers. To elaborate, if is a sequence of i.i.d. random variables following the same distribution as the random variable , and is a function such that , then the law of large numbers tells us that the empirical average converges almost surely to . As is also well-known, the classical central limit theorem provides the distributional order of the difference as .
But the classical central limit theorem provides only distributional information, and is not sufficient for tracing the order of such approximations as along a sequence of data , as grows. Such results are rather obtained from uniform central limit theorems, which provide bounds on this error as that hold uniformly over large classes of functions under very mild assumptions. We refer the interested reader to the extensive literature on uniform CLTs [33].
On a related note, we would also be interested in the approximation of a measure with density by a kernel smoothing obtained on the basis of a dataset [23]. Analogues of the uniform CLT for such kernel density approximations are available, also according an approximation [34].
In our context, the uniform CLT is applicable to situations where the measure is approximated by the empirical measure , as well as which is a kernel smoothing of .
Appendix S3 Fluctuation analysis for determinantal samplers
In this section, we provide the detailed proof of Proposition 4 in the main text on the fluctuations of the estimator , and a theoretical analysis for the fluctuations of the estimator . Sections S3.1.1 and S3.1.2 elaborate one of the central OPE-based ideas that enable us to obtain reduced fluctuations.
S3.1 Detailed proof of Proposition 4
To begin with, we recall the fundamental integral expression controlling the variance of , exploiting (7) in the case of a projection kernel:
| (S4) |
where we used the 1-Lipschitzianity of , with the Lipschitz constant.
We control the integral in (S4) by invoking the renowned Christoffel-Darboux formula for the OPE kernel [29]. As outlined in the main text, a fundamental idea which enables us to obtain reduced fluctuations in our determinantal samplers is that, in the context of (S4), the term crucially suppresses fluctuations near the diagonal ; whereas far from the diagonal, the fluctuations are suppressed by the decay of the OPE kernel .
In Sections S3.1.1 and S3.1.2 below, we provide the details of how this idea is implemented by exploiting the Christoffel-Darboux formula; first detailing the simpler 1D case, and subsequently examining the case of general dimensions. In (S6), we will finally demonstrate the desired order of the fluctuations of given the dataset , thereby completing the proof.
S3.1.1 Reduced fluctuations in one dimension
We first demonstrate how to control (S4) for . The Christoffel-Darboux formula reads
| (S5) |
where is the so-called first recurrence coefficient of ; see [29, Section 1 to 3]. But we assumed in Section 3.3 that is Nevai-class, which actually implies by definition; see [10, Section 4]. This implies that, in , we have
S3.1.2 Reduced fluctuations in general dimension
For , following the main text we consider that the measure splits as a product measure of Nevai-class s, i.e. . Assume that for some for simplicity; we discuss at the end of the section how to treat the case .
Because of the graded lexicographic ordering that we chose for multivariate monomials, writes as a tensor product of coordinate-wise OPE kernels of degree , namely . Now, observe that for any ,
As a result, for , setting and , it comes
leading to
| (S6) |
where we have used our earlier analyses of Section S3.1.1.
When , the kernel does not necessarily decompose as a product of one-dimensional OPE kernels. However, the graded lexicographic order that we borrowed from [10] ensures that departs from such a product only up to additional terms, whose influence on the variance can be controlled by a counting argument; see e.g. [10, Lemma 5.3].
S3.2 Fluctuation analysis for
Again using the formula (7) for the variance of linear statistics of DPPs, and remembering that is a projection matrix, we may write
| (S7) |
At this point, we set to be the exponent in the order of spectral approximation obtained in Section S3.2.1 (our analysis in Section S3.2.1 indicates a choice of ; nonetheless we present the analysis here in terms of the parameter , so as to leave open the possibility of simple updates to our bound based on more improved analysis of the spectral approximation). We use the integral and spectral approximations (S15) and (S11), and the inequality to continue from (S7) as
| (S8) |
We may combine (S7) and (S8) to obtain
| (S9) |
This is where we need more assumptions. We recall our assumption that is uniformly bounded in . This assumption is justified, for the kernel part, by OPE asymptotics for Nevai-class measures; see Totik’s classical result [10, Theorem 4.8]. For the gradient part, it is enough to assume that is uniformly bounded in and (with being bounded away from 0 and ). Coupled with the hypothesis that and the density of are uniformly bounded away from 0 and on , and the uniform CLT for the convergence , we may deduce that
| (S10) |
We now demonstrate how the spectral approximations lead to approximations for integrals appearing in the above fluctuation analysis for . To give the general structure of the argument, to be invoked multiple times in the following, we note that
| (S11) |
using the fact that via the Cauchy-Schwarz inequality, and that is by OPE asymptotics.
We now proceed as from (S12) as follows:
| (S13) |
where, in the last two steps, we have used the assumption that and are , and used the rate of convergence of to to pass from the sum to the integral respect to , and from there to the integral with respect to using the rate estimates for kernel density estimation, incurring an additive cost of in each step.
Using the hypothesis that is 1-Lipschitz with a Lipschitz constant that is , we may proceed from (S13) as
| (S14) |
where is the Lipschitz constant that is . We are back to analyzing the same variance term as in Section S3.1, and the rest of the proof follows the very same lines.
S3.2.1 Spectral approximations
We analyse in this section the approximation error when we replace by in Equation (S8). To this end, we study the difference between the entries of and those of when restricted to the data set . We recall the fact that is viewed as a kernel on the space .
The idea is that, since is large, the kernel acting on , which is obtained by spectrally rounding off the kernel acting on , is well approximated by the kernel acting on . By definition, , we may deduce that . Now, the kernel is a projection on . As such, the spectrum of is also close to a projection. Since is obtained by rounding off the spectrum of to , the quantities will be ultimately by controlled by how close the kernel is from a true projection.
To analyse this, we consider the operator on , which is an integral operator given by the convolution kernel
where we have used the convergence of the kernel density estimator as well as the empirical measure to the underlying measure , at the rate described e.g. by the uniform CLT.
We may summarize the above by observing that on is a projection up to an error of , which indicates an approximation of .
To understand the estimator , we also need to understand , which we will deduce from the above discussion. To this end, we observe that
| (S15) |
In drawing the above conclusion, we require that stays bounded away from 0, which we justity as follows. We recall that . We recall from OPE asymptotics that is of the order ; whereas from kernel density approximation and uniform CLT asymptotics. We recall our hypothesis that the densities are bounded away from and on . Putting together all of the above, we deduce that is of order ; in particular it is bounded away from 0 as desired.
S3.3 Order of vs and future work
In this section, we discuss the relative order of and , especially in the context of the estimator . In order to do this for , we undertake a classic bias-variance trade-off argument. To this end, we recall that while the bias is (with being the window size for kernel smoothing), the variance is . Further, we substitute one of the canonical choices for the window size , which is to set for dimension and data size . Setting the bias and the standard deviation to be roughly of the same order, we obtain a choice of as . For the estimator , a similar analysis may be undertaken. However, while the finite sample bias is 0, the variance term is more complicated, particularly with the contributions from the spectral approximation . We believe that the present analysis of the spectral approximation can be further tightened and rigorised to yield more optimal values of that more closely mimic experimental performance. Further avenues of improvement include better ways to handle the boundary effects (to control the asymptotic intensity of the OPE kernels that behave in a complicated manner at the boundary of the background measure); methods to bypass the spectral round-off step in constructing the estimator ; hands-on analysis of the errors caused by switching between discrete measures and continuous densities that is tailored to our setting (and therefore raising the possibility of sharper error bounds), among others.
Appendix S4 Experiments on a real dataset
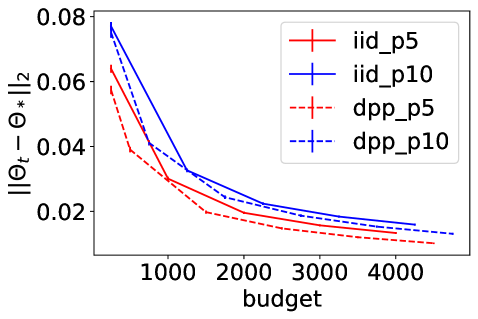
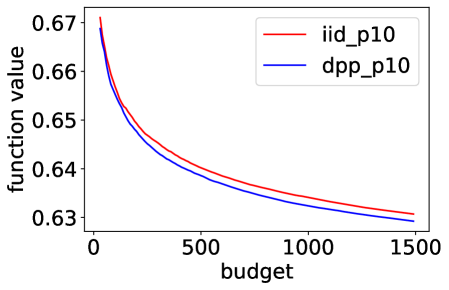
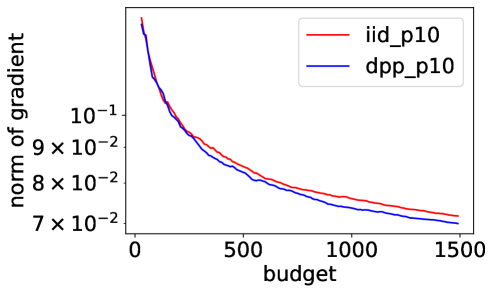
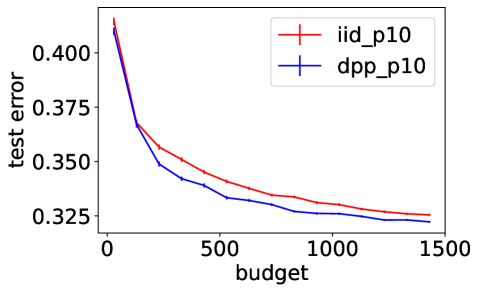
To extensively compare the performance of our gradient estimator to the default , we run the same experiment as in Section 5 of the main paper, but on a benchmark dataset from LIBSVM222https://www.csie.ntu.edu.tw/ cjlin/libsvmtools/datasets/. We download the letter dataset, which consists of training samples and testing samples, where each sample contains features. We modify the -class classification problem into a binary classification problem where the goal is to separate the classes - from the other classes. Denote the preprocessed dataset as letter.binary. We consider , and . Figure 3 summarizes the experimental results on letter.binary, where the performance metrics are averaged over independent runs of each SGD variant. The left figure shows the decrease of the objective function value, the middle figure shows how the norm of the complete gradient decreases with the budget, and the right figure shows the value of the test error. Error bars in the last figure are one standard deviation of the mean. In the experiment, we can see that using a DPP improves over Poisson minibatches of the same size both in terms of minimizing the empirical loss, and of reaching a small test error with a given budget. Compared to the experimental results on the simulated data in the main paper, we can see that although the rate discussed in Section 4 becomes slower as grows, our DPP-based minibatches still gives better performance on this real dataset with compared to Poisson minibatches of the same size, which again demonstrates the significance of variance reduction in SGD.
References
- [1] S. Shalev-Shwartz and S. Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.
- [2] H. Robbins and S. Monro. A stochastic approximation method. The Annals of Mathematical Statistics, pages 400–407, 1951.
- [3] É. Moulines and F. Bach. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In Advances in Neural Information Processing Systems (NeurIPS), volume 24, pages 451–459, 2011.
- [4] C. Zhang, H. Kjellstrom, and S. Mandt. Determinantal point processes for mini-batch diversification. In Uncertainty in Artificial Intelligence (UAI), 2017.
- [5] O. Macchi. The coincidence approach to stochastic point processes. Advances in Applied Probability, 7:83–122, 1975.
- [6] F. Lavancier, J. Møller, and E. Rubak. Determinantal point process models and statistical inference. Journal of the Royal Statistical Society, Series B, 2014.
- [7] A. Kulesza and B. Taskar. Determinantal Point Processes for Machine Learning, volume 5 of Foundations and Trends in Machine Learning. Now Publishers Inc., 2012.
- [8] Subhroshekhar Ghosh and Philippe Rigollet. Gaussian determinantal processes: A new model for directionality in data. Proceedings of the National Academy of Sciences, 117(24):13207–13213, 2020.
- [9] C. Zhang, H. Kjellstrom, and S. Mandt. Active mini-batch sampling using repulsive point processes. In Proceedings of the AAAI conference on Artificial Intelligence, 2019.
- [10] R. Bardenet and A. Hardy. Monte Carlo with determinantal point processes. Annals of Applied Probability, 2020.
- [11] A. Nikolov, M. Singh, and U. T. Tantipongpipat. Proportional volume sampling and approximation algorithms for a-optimal design. arXiv:1802.08318, 2018.
- [12] M. Derezinski and M. K. Warmuth. Unbiased estimates for linear regression via volume sampling. In Advances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., 2017.
- [13] A. Poinas and R. Bardenet. On proportional volume sampling for experimental design in general spaces. arXiv preprint arXiv:2011.04562, 2020.
- [14] M. Derezinski and M. W. Mahoney. Determinantal point processes in randomized numerical linear algebra. Notices of the American Mathematical Society, 68(1), 2021.
- [15] A. Belhadji, R. Bardenet, and P. Chainais. A determinantal point process for column subset selection. Journal of Machine Learning Research (JMLR), 2020.
- [16] N. Tremblay, S. Barthelmé, and P.-O. Amblard. Determinantal point processes for coresets. Journal of Machine Learning Research, 20(168):1–70, 2019.
- [17] J. B. Hough, M. Krishnapur, Y. Peres, and B. Virág. Determinantal processes and independence. Probability surveys, 2006.
- [18] D. J. Daley and D. Vere-Jones. An Introduction to the Theory of Point Processes, volume 1. Springer, 2nd edition, 2003.
- [19] A. Soshnikov. Determinantal random point fields. Russian Mathematical Surveys, 55:923–975, 2000.
- [20] A. Soshnikov. Gaussian limit for determinantal random point fields. Annals of Probability, 30(1):171–187, 2002.
- [21] S. Ghosh. Determinantal processes and completeness of random exponentials: the critical case. Probability Theory and Related Fields, 163(3):643–665, 2015.
- [22] J. A. Gillenwater. Approximate inference for determinantal point processes. PhD thesis, University of Pennsylvania, 2014.
- [23] M. P. Wand and M. C. Jones. Kernel smoothing. CRC press, 1994.
- [24] C. P. Robert and G. Casella. Monte Carlo statistical methods. Springer, 2004.
- [25] S. V. N. Vishwanathan, N. N. Schraudolph, M. W. Schmidt, and K. P. Murphy. Accelerated training of conditional random fields with stochastic gradient methods. In Proceedings of the international conference on machine learning (ICML), pages 969–976, 2006.
- [26] R. Bardenet and S. Ghosh. Learning from DPPs via Sampling: Beyond HKPV and symmetry. arXiv preprint arXiv:2007.04287, 2020.
- [27] S. S. Vempala. The random projection method, volume 65. American Mathematical Society, 2005.
- [28] A. Benveniste, M. Métivier, and P. Priouret. Adaptive algorithms and stochastic approximations. Springer Science & Business Media, 1990.
- [29] B. Simon. The christoffel–darboux kernel. In Perspectives in PDE, Harmonic Analysis and Applications, volume 79 of Proceedings of Symposia in Pure Mathematics, pages 295–335, 2008.
- [30] G. Gautier, R. Bardenet, G. Polito, and M. Valko. DPPy: Sampling determinantal point processes with Python. Journal of Machine Learning Research; Open Source Software (JMLR MLOSS), 2019.
- [31] A. Belhadji, R. Bardenet, and P. Chainais. Kernel quadrature with determinantal point processes. In Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [32] A. Belhadji, R. Bardenet, and P. Chainais. Kernel interpolation with continuous volume sampling. In International Conference on Machine Learning (ICML), 2020.
- [33] R. M. Dudley. Uniform central limit theorems, volume 142. Cambridge university press, 2014.
- [34] E. Giné and R. Nickl. Uniform central limit theorems for kernel density estimators. Probability Theory and Related Fields, 141(3):333–387, 2008.