Deterministic Equations for Feedback Control of Open Quantum Systems
Abstract
Feedback control in open quantum dynamics is crucial for the advancement of various coherent platforms. For a proper theoretical description, however, most feedback schemes rely on stochastic trajectories, which require significant statistical sampling and lack analytical insight. Currently, only a handful of deterministic feedback master equations exist in the literature. In this letter we derive a set of deterministic equations for describing feedback schemes based on generic causal signals. Our formulation is phrased in terms of sequentially applied quantum instruments, and is therefore extremely general, recovering various known results in the literature as particular cases. We then specialize this result to the case of quantum jumps and derive a new deterministic equation that allows for feedback based on the channel of the last jump, as well as the time since the last jump occurred. The strength of this formalism is illustrated with a detailed study of population inversion of a qubit using coherent drive and feedback, where our formalism allows all calculations to be performed analytically.
Introduction.— Feedback control finds numerous applications across practically all quantum coherent platforms, in tasks such as cooling protocols Hopkins et al. (2003); D’Urso et al. (2003); Steck et al. (2006); Bushev et al. (2006); Jacobs et al. (2015); Frimmer et al. (2016); Guo et al. (2019); Buffoni et al. (2019); Manikandan and Qvarfort (2023); De Sousa et al. (2025), quantum error correction Sarovar et al. (2004); Marcos et al. (2020), entanglement generation Ristè et al. (2013), thermodynamics Pekola (2015); Potts and Samuelsson (2018); Barker et al. (2022), transport van der Wiel et al. (2002), control Vijay et al. (2012); Ristè et al. (2012); Campagne-Ibarcq et al. (2013), and quantum batteries Mitchison et al. (2021). Notably, feedback has been instrumental in the experimental realization of Maxwell’s demon in the quantum regime Vidrighin et al. (2016); Naghiloo et al. (2018); Ribezzi-Crivellari and Ritort (2019), prompting the development of generalized formulations of the second law of thermodynamics to incorporate feedback-based measurement processes Sagawa and Ueda (2010, 2012); Funo et al. (2013). These developments highlight the fundamental importance of quantum feedback in both theory and experiment, motivating further research into its underlying principles and applications.
Broadly speaking, feedback refers to the process of dynamically controlling a system based on previous detection outcomes (see Fig. 1(a)). In continuously monitored open quantum systems this can be readily implemented using stochastic differential equations, both in the quantum jump and the quantum diffusion (e.g. homodyne/heterodyne) unravellings Belavkin (1983, 1992a, 1987, 1992b); Wiseman (1994a); Wiseman and Milburn (1993, 2010); Korotkov (2001); Jacobs (2014); Zhang et al. (2017). However, this approach typically requires computationally expensive statistical sampling and often obscures physical insights, as it does not yield analytical expressions for key system properties, such as the steady state (when it exists). For this reason, deterministic feedback equations have long been sought for Sarovar et al. (2004); Tilloy (2024); Annby-Andersson et al. (2022); Wiseman and Milburn (1993); Wiseman (1994b); Wiseman and Milburn (2010); Kewming et al. (2024).
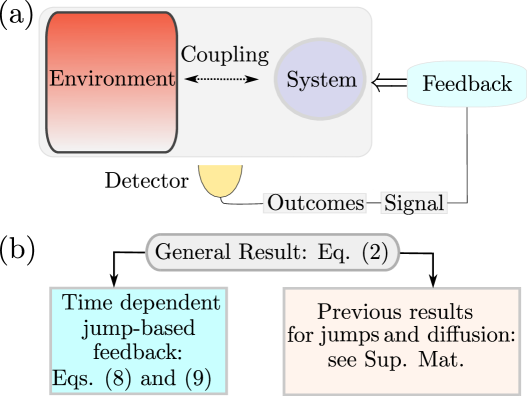
Let denote some stochastic data obtained from an experiment. Typically, feedback schemes do not make use of the entire dataset. Instead, they rely on a compressed representation of the data, which we henceforth refer to as the signal. This signal is defined as a function of the data, . Hence, to classify different types of feedback schemes, it is helpful to clarify (i) what signal is being used and (ii) what the corresponding feedback actions are. For a given choice of signal, one can then construct various types of feedback actions. An illustrative example is homodyne detection-based feedback Wiseman and Milburn (1993): the data is the homodyne current; the signal is the instantaneous outcome (); and the action is a drive in the system Hamiltonian that depends on the magnitude of the signal. Ref. Annby-Andersson et al. (2022) recently extended this to low-pass (LP) filters of the form , for a bandwidth . The particular case in which all detection weights are equal to one corresponds to a signal that depends on the entire history (often called the “integrated charge”), , and was studied in Kewming et al. (2024). In these cases, the authors derive deterministic equations that describe the feedback protocol based on the corresponding signals.
To further illustrate this point, Ref. Wiseman (1994a) derived a famous deterministic jump equation that implements the following protocol: if a quantum jump is observed, then we apply a quantum channel. The channel is now an abrupt action, that instantaneously modifies the system. Extending this to a smooth time-dependent action, such as turning on a Hamiltonian drive, is one of our present goals. Furthermore, for more general jump-based feedback — especially those involving time-dependent actions — no deterministic equations are typically available. For instance, in the case of quantum jumps, the output data at each time step is not a continuous, noisy current, but rather a discrete sequence of “clicks”, being either (no jump) or for a jump in channel . A natural kind of feedback for quantum jumps would be: if a quantum jump is observed, modify the Hamiltonian for some fixed amount of time. This protocol is, in fact, routinely used in quantum dot experiments which monitor the jumps using a quantum point contact Hofmann et al. (2016); Ye et al. (2025). However, this cannot be described using only feedback based on the latest outcome () because most of the time we would have . Consequently, feedback schemes that depend on jump timing generally lack a corresponding deterministic evolution equation.
In this letter we consider the most general type of continuously monitored open quantum system, formulated in terms of quantum instruments Milz and Modi (2021). We first show (Result 1) that it is possible to derive a deterministic feedback equation for any signal that can be written as , where is an update rule that depends only on the previous signal and the present outcome. To illustrate the generality and power of this result, in the Supplemental Material Sup we use it to derive various other deterministic feedback equations Annby-Andersson et al. (2022); Wiseman and Milburn (1993); Wiseman (1994b); Kewming et al. (2024) in the literature (see Fig. 1(b)). Next, we specialize this to the case of quantum jumps, and derive a deterministic equation (Result 2) that allows for feedback based on: (i) what was the channel of the last jump [Eq. (6)] and (ii) how long has it been since the last jump occurred [Eq. (7)]. The combination of these two features allow for non-trivial feedback strategies that are experimentally relevant Hofmann et al. (2016); Ye et al. (2025). For example, one can turn on coherent drives based on whether a tunneling event into or out of a quantum dot has occurred, or depending on whether a photon has been emitted or absorbed by an atom. More sophisticated strategies are also possible, such as turning on a drive only after a certain time has elapsed since the last detected jump.
Sequential measurements. Continuously measured quantum systems can be described by the sequential application of super-operators , corresponding to trace non-increasing maps such that is a quantum channel Milz and Modi (2021). These maps are called instruments, and they describe the joint transition of the quantum state induced by the dynamical evolution and measurement process, whereas represents a possible measurement outcome.
For instance, one may assume that the measurements are described by the set of Kraus operators applied at regular intervals , where and . In between, the system may evolve from to with some dynamical map . Given an initial state , after steps one obtains a sequence of outcomes , and the corresponding conditional state of the system is denoted by . In this case, the instruments are defined as the maps , and according to the measurement postulate, the probability of the next outcome given the previous dataset is given by , and the post-detection state becomes .
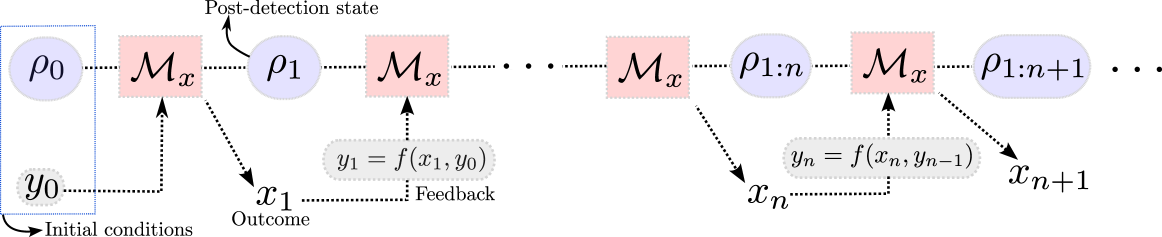
A feedback mechanism is a dynamic adjustment of the instruments at each step, based on prior outcomes. The most general mechanism could depend on the entire detection history, and would therefore give rise to instruments of the form , where the variable in the subscript defines the possible random outcomes and the variable in parenthesis defines the past information that can be used to alter the instrument. In practice, however, one seldom uses the entire data record , but only some summary statistic. Here we implement this by defining a signal which evolves according to the update rule , for some function . This defines a general type of causal signal. But it is worth noting that this is still entirely general. For instance, if we choose an update rule of the form , then the signal becomes the entire dataset. But, of course, in this case the memory required grows with each step. In practice, however, one is often interested in signals with finite memory. Feedback is implemented by assuming that, in each step, the instruments can depend on the signal at that instant (see Fig. 2). The stochastic dynamics therefore reads
| (1) | ||||
Our goal is to develop a deterministic equation for this general feedback protocol. To do that we define the signal-resolved state Kewming et al. (2024); Annby-Andersson et al. (2022) (also called Hybrid Quantum-Classical State Tilloy (2024); Layton et al. (2024); Diósi (2023); Oppenheim et al. (2023)) as , where denotes the average over trajectories, and is the Kronecker delta. The trace of this state, , gives the distribution of the stochastic signal at step , while the marginalization over all possible signals yields the unconditional state of the system, . Notice that is a stochastic (conditional) state, but is deterministic. As our first result, we show in Sup that evolves according to a deterministic equation.
Result 1.
If an instrument depends only on a causal signal , the corresponding signal-resolved state evolves according to the deterministic equation
| (2) |
where the sum runs over all possible outcomes and all possible signal values .
The particular case is treated separately in Sup , section S.V.B. The intuition behind (2) is that because is resolved in , the state at step should be just a sum over all possible trajectories consistent with the constraint . Solving (2) yields not only the unconditional state , but also the probability distribution of the stochastic signal . Moreover, it can be used to study either transients or the steady-state, obtained by setting . To illustrate the generality of this result, in Sup we use it to derive various other deterministic equations in the literature Annby-Andersson et al. (2022); Wiseman and Milburn (1993); Wiseman (1994b); Kewming et al. (2024).
Quantum jumps. We now specialize Result 1 to the case of quantum jumps, for which deterministic feedback equations are much more scarce. We assume the system evolves according to a quantum master equation of the form
| (3) |
with Hamiltonian and jump operators . Our goal is to augment this with the possibility that and both depend on the recorded signal .
Let denote the set of jumps that are assumed to be monitored. At the stochastic level, the outcome at each step is either (no jump) or when there is a jump of type . The corresponding instruments read Landi et al. (2024)
| (4) | ||||
| (5) |
where and .
We consider two types of signals. First, one that records the channel of the last jump. This can be constructed with a filter function of the form
| (6) |
Second, a signal that counts how much time has elapsed since the last jump, which is built using
| (7) |
We refer to them as the jump signal and the counting signal, respectively. The total signal is and we consider feedback mechanisms that may depend on both. In this case, the instruments are defined by Eqs. (4) and (5), and the feedback action corresponds to allowing both the system’s Hamiltonian and the jump operators at step to depend on the last jump and the elapsed time since its detection. Starting from Result 1, we show in Sup the following result:
Result 2.
In this limit the signals become continuous-time stochastic processes and . They specify that, at time , the last jump that happened was in channel , and occurred at time . The quantity is the joint distribution of , and from (7) it follows that . The resolved state is normalized as , and the unconditional state is recovered as
| (10) |
Result 2 cannot, in general, be written as a differential equation. Notwithstanding, it is still amenable to analytical treatment — as detailed in Sup — especially if one is interested in the steady-state. In contrast, let us now consider the special case where the feedback is independent of the counting signal (7), but might still depend on the jump signal (6). We show in Sup that the marginal state will evolve as
| (11) | |||||
This is now simply a system of coupled master equations, one for each possible jump channel . A similar equation was previously derived in Blanchard and Jadczyk (1995) in a different context.
Returning to the general Result 2, the situation simplifies when the feedback is applied only on the no-jump part of the dynamics (e.g. in the Hamiltonian). In this case and Eqs. (8)- (10) imply that
| (12) |
The signal-resolved state can hence be written in terms of the unconditional state which, in turn, satisfies the closed integral equation
| (13) |
The steady-state, if it exists, is obtained by setting and will therefore be the solution of the algebraic equation
| (14) |
Combining this with Eq. (12) yields the steady-state signal-resolved state. In turn, this can be used to calculate various time-related properties, such as waiting-time distributions, the average time between jumps, etc.
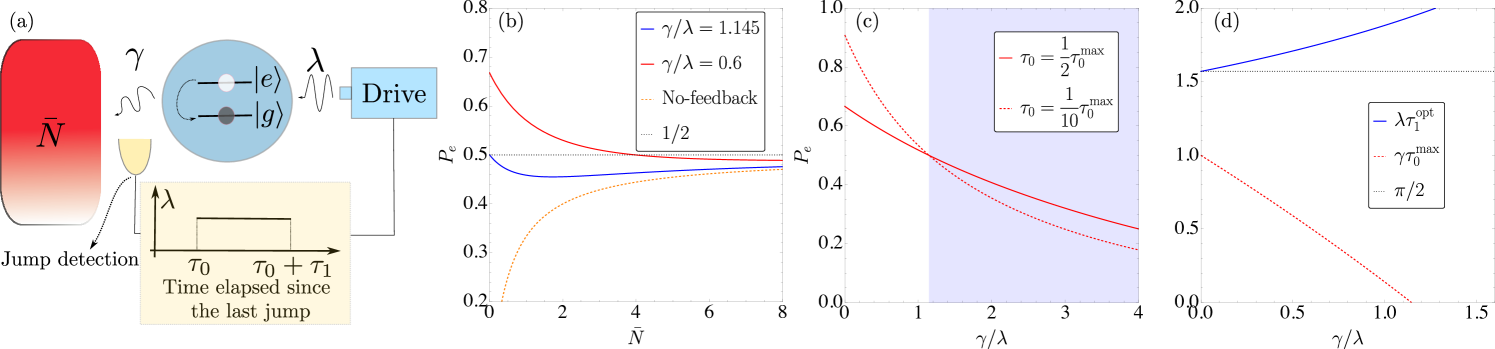
Example.– To illustrate our results, consider a coherently driven qubit coupled to a thermal reservoir with temperature and energy under the action of feedback. Let (excited) and (ground) denote the computational basis. We assume a master equation of the form (3) with jump operators and describing, respectively, the emission and absorption of a quanta. Here is the Bose-Einstein distribution and is the coupling strength. The 3 possible outcomes, at each , are therefore (emission, absorption, no-jump). We consider a drive with intensity and frequency , working in a frame rotating at and under the rotating wave approximation. The Hamiltonian when the driving is turned off/on are, respectively, and , where . Our goal is to invert the populations of and (achieving ) using the quantum jump detection record and feedback.
The protocol is defined as follows: If (thermal absorption) the system’s Hamiltonian is set to . If (thermal emission), and a time elapses without any subsequent absorption, we turn the external drive () for a duration . The idea is that, upon detecting an emission and observing no absorption for a time , the external drive acts on the system for a time , inducing Rabi oscillations that transfer the population from to (see Fig. 3(a)). Whenever the drive is active and an absorption event is detected, the drive is subsequently turned off.
This feedback protocol affects only the system’s Hamiltonian; hence, the steady state can be obtained from Eq. (14). The analytical formula for the population of the excited state, , is provided Sup for the case , as a function of the bath parameters and , as well as the feedback parameters , , and . By maximizing with respect to , one obtains the optimal duration for which the external drive should remain on. We find that
| (15) |
where and is the Heaviside function. This is only finite for , and diverges otherwise. It is noteworthy that is independent of both the feedback delay and the bath occupation ; it depends only the ratio between the coupling rate to the bath and the external drive. Fig. 3(b) shows vs. for . We find that for (determined numerically), there exists a critical value such that for all . This therefore establishes the population inversion threshold. For the drive is so weak that a pi pulse takes a time that is longer than the time-scale over which the bath exchanges energy with the qubit.
Next we consider a more realistic scenario where we have a time delay between the last detected jump and the moment the external drive is turned on. Even in this more general case, the optimal drive duration that maximizes the population of the excited state remains given by Eq. (15) Sup . In the low-temperature limit , the expression for , evaluated at the optimal drive duration, simplifies to
| (16) |
The time delay appear as an additive term in the denominator. The largest delay that still provides a population inversion () in the low-temperature limit () is
| (17) |
In Fig. 3(c), we illustrate how is affected by varying the delay . We consider , for which occurs precisely at . The plots show how increasing deteriorates the population inversion. Fig. 3(d) plots Eqs. (15) and (17) vs. , again for . In the strong-drive regime (), we find that , indicating that the maximum delay is on the order of the system’s natural timescale . Conversely, for , reflecting that population inversion is no longer possible in this regime, regardless of the feedback delay. Additionally, we observe that increases with , implying that as the drive strength decreases relative to , the drive must remain on for a longer duration to optimize .
As a final comment, it is worth mentioning that this protocol can be adapted to increase the population of the ground state: by turning on the drive when an absorption is detected, the drive will move the system toward the ground state through Rabi oscillations. In this case, the protocol effectively operates as a cooling protocol based on quantum jump detections.
Conclusion.—We derived a deterministic equation that describes a general feedback protocol, encompassing both discrete and continuous feedback. It encompass previous results as particular cases, and allows for the derivation of novel feedback schemes, as we have shown here in the context of quantum jumps. The method is based on a signal-resolved state, which provides access not only to the quantum dynamics, but also to the full statistics of the detection signal. Furthermore, it is a deterministic approach, which introduces new analytical tools that offer deeper physical insight into the interplay between feedback and quantum dynamics. Its applications span a wide range of fields, with particular relevance to quantum control, thermodynamics, and quantum information theory. We illustrated this with a detailed account of the use quantum jump detections and feedback for population inversion of a two-level system.
Acknowledgments.— The authors acknowledge fruitful discussions with Mark Mitchison, Guilherme Fiusa, Abhaya Hegde.
References
- Hopkins et al. (2003) A. Hopkins, K. Jacobs, S. Habib, and K. Schwab, Phys. Rev. B 68, 235328 (2003).
- D’Urso et al. (2003) B. D’Urso, B. Odom, and G. Gabrielse, Phys. Rev. Lett. 90, 043001 (2003).
- Steck et al. (2006) D. A. Steck, K. Jacobs, H. Mabuchi, S. Habib, and T. Bhattacharya, Phys. Rev. A 74, 012322 (2006).
- Bushev et al. (2006) P. Bushev, D. Rotter, A. Wilson, F. m. c. Dubin, C. Becher, J. Eschner, R. Blatt, V. Steixner, P. Rabl, and P. Zoller, Phys. Rev. Lett. 96, 043003 (2006).
- Jacobs et al. (2015) K. Jacobs, H. I. Nurdin, F. W. Strauch, and M. James, Phys. Rev. A 91, 043812 (2015).
- Frimmer et al. (2016) M. Frimmer, J. Gieseler, and L. Novotny, Phys. Rev. Lett. 117, 163601 (2016).
- Guo et al. (2019) J. Guo, R. Norte, and S. Gröblacher, Phys. Rev. Lett. 123, 223602 (2019).
- Buffoni et al. (2019) L. Buffoni, A. Solfanelli, P. Verrucchi, A. Cuccoli, and M. Campisi, Phys. Rev. Lett. 122, 070603 (2019).
- Manikandan and Qvarfort (2023) S. K. Manikandan and S. Qvarfort, Phys. Rev. A 107, 023516 (2023).
- De Sousa et al. (2025) G. De Sousa, P. Bakhshinezhad, B. Annby-Andersson, P. Samuelsson, P. P. Potts, and C. Jarzynski, Phys. Rev. E 111, 014152 (2025).
- Sarovar et al. (2004) M. Sarovar, C. Ahn, K. Jacobs, and G. J. Milburn, Phys. Rev. A 69, 052324 (2004).
- Marcos et al. (2020) D. Marcos, A. Smith, A. Bednorz, and N. Yunger Halpern, Phys. Rev. X 10, 041013 (2020).
- Ristè et al. (2013) D. Ristè, M. Dukalski, C. A. Watson, G. de Lange, M. J. Tiggelman, Y. M. Blanter, K. W. Lehnert, R. N. Schouten, and L. DiCarlo, Nature 502, 350 (2013).
- Pekola (2015) J. P. Pekola, Nature Physics 11, 118 (2015).
- Potts and Samuelsson (2018) P. P. Potts and P. Samuelsson, Phys. Rev. Lett. 121, 210603 (2018).
- Barker et al. (2022) D. Barker, M. Scandi, S. Lehmann, C. Thelander, K. A. Dick, M. Perarnau-Llobet, and V. F. Maisi, Phys. Rev. Lett. 128, 040602 (2022).
- van der Wiel et al. (2002) W. G. van der Wiel, S. De Franceschi, J. M. Elzerman, T. Fujisawa, S. Tarucha, and L. P. Kouwenhoven, Rev. Mod. Phys. 75, 1 (2002).
- Vijay et al. (2012) R. Vijay, C. Macklin, D. H. Slichter, S. J. Weber, K. W. Murch, R. Naik, A. N. Korotkov, and I. Siddiqi, Nature 490, 77 (2012).
- Ristè et al. (2012) D. Ristè, C. C. Bultink, K. W. Lehnert, and L. DiCarlo, Phys. Rev. Lett. 109, 240502 (2012).
- Campagne-Ibarcq et al. (2013) P. Campagne-Ibarcq, E. Flurin, N. Roch, D. Darson, P. Morfin, M. Mirrahimi, M. H. Devoret, F. Mallet, and B. Huard, Phys. Rev. X 3, 021008 (2013).
- Mitchison et al. (2021) M. T. Mitchison, J. Goold, and J. Prior, Quantum 5, 500 (2021).
- Vidrighin et al. (2016) M. D. Vidrighin, O. Dahlsten, M. Barbieri, M. S. Kim, V. Vedral, and I. A. Walmsley, Phys. Rev. Lett. 116, 050401 (2016).
- Naghiloo et al. (2018) M. Naghiloo, J. J. Alonso, A. Romito, E. Lutz, and K. W. Murch, Phys. Rev. Lett. 121, 030604 (2018).
- Ribezzi-Crivellari and Ritort (2019) M. Ribezzi-Crivellari and F. Ritort, Nature Physics 15, 660 (2019).
- Sagawa and Ueda (2010) T. Sagawa and M. Ueda, Phys. Rev. Lett. 104, 090602 (2010).
- Sagawa and Ueda (2012) T. Sagawa and M. Ueda, Phys. Rev. Lett. 109, 180602 (2012).
- Funo et al. (2013) K. Funo, Y. Watanabe, and M. Ueda, Phys. Rev. E 88, 052121 (2013).
- Belavkin (1983) V. P. Belavkin, Autom. Remote Control 44, 178 (1983).
- Belavkin (1992a) V. P. Belavkin, J. Multivar. Anal. 42, 171 (1992a).
- Belavkin (1987) V. P. Belavkin, in Information Complexity and Control in Quantum Physics, edited by A. Blaquiere, S. Diner, and G. Lochak (Springer Vienna, Vienna, 1987) pp. 311–329.
- Belavkin (1992b) V. P. Belavkin, Commun. Math. Phys. 146, 611 (1992b).
- Wiseman (1994a) H. M. Wiseman, Phys. Rev. A 49, 2133 (1994a).
- Wiseman and Milburn (1993) H. M. Wiseman and G. J. Milburn, Phys. Rev. Lett. 70, 548 (1993).
- Wiseman and Milburn (2010) H. M. Wiseman and G. J. Milburn, Quantum Measurement and Control (Cambridge University Press, 2010).
- Korotkov (2001) A. N. Korotkov, Phys. Rev. B 63, 115403 (2001).
- Jacobs (2014) K. Jacobs, Quantum Measurement Theory and Its Applications (Cambridge University Press, 2014).
- Zhang et al. (2017) J. Zhang, Y.-X. Liu, R.-B. Wu, K. Jacobs, and F. Nori, Phys. Rep. 679, 1 (2017).
- Tilloy (2024) A. Tilloy, SciPost Phys. 17, 083 (2024).
- Annby-Andersson et al. (2022) B. Annby-Andersson, F. Bakhshinezhad, D. Bhattacharyya, G. De Sousa, C. Jarzynski, P. Samuelsson, and P. P. Potts, Phys. Rev. Lett. 129, 050401 (2022).
- Wiseman (1994b) H. M. Wiseman, Phys. Rev. A 49, 2133 (1994b).
- Kewming et al. (2024) M. J. Kewming, A. Kiely, S. Campbell, and G. T. Landi, Phys. Rev. A 109, L050202 (2024).
- (42) See the Supplemental Material at [URL will be inserted by publisher] for details.
- Hofmann et al. (2016) A. Hofmann, V. F. Maisi, C. Gold, T. Krähenmann, C. Rössler, J. Basset, P. Märki, C. Reichl, W. Wegscheider, K. Ensslin, and T. Ihn, Phys. Rev. Lett. 117, 206803 (2016).
- Ye et al. (2025) F. Ye, A. Ellaboudy, and J. M. Nichol, Phys. Rev. Appl. 23, 044063 (2025).
- Milz and Modi (2021) S. Milz and K. Modi, PRX Quantum 2, 030201 (2021).
- Layton et al. (2024) I. Layton, J. Oppenheim, and Z. Weller-Davies, Quantum 8, 1565 (2024).
- Diósi (2023) L. Diósi, Phys. Rev. A 107, 062206 (2023).
- Oppenheim et al. (2023) J. Oppenheim, C. Sparaciari, B. Šoda, and Z. Weller-Davies, Quantum 7, 891 (2023).
- Landi et al. (2024) G. T. Landi, M. J. Kewming, M. T. Mitchison, and P. P. Potts, PRX Quantum 5, 020201 (2024).
- Blanchard and Jadczyk (1995) P. Blanchard and A. Jadczyk, Annalen der Physik 507, 583 (1995).
- Oppenheim (2023) J. Oppenheim, Phys. Rev. X 13, 041040 (2023).
- Jacobs and Steck (2006) K. Jacobs and D. A. Steck, Contemporary Physics 47, 279 (2006).
- Bednorz et al. (2012) A. Bednorz, W. Belzig, and A. Nitzan, New Journal of Physics 14, 013009 (2012).
Appendix A Supplementary Material
We begin by introducing the language of instruments in Section B, defining the concepts that were used throughout this work. Next, we provide a detailed proof of the central results presented in the main text – namely, Results 1 and 2 – in Section C. Furthermore, we present a formulation in terms of matrix equations for the main results in Section D, where we also include a discussion about the steady state and generator of the feedback dynamics. In Section E, we present the details of the example used in the main text, namely the inversion protocol, and finally in Section F we show how some previous results can be recovered starting from Eq. (18).
| (18) |
| Protocol | Signal | Instrument | Equation |
| Combined Jump time dependent feedback | Result 2 | ||
| Quantum Fokker-Planck Master Equation | Eq. (86) | ||
| Single Jump feedback | Eq. (95) | ||
| Diffusion feedback | Eq. (105) | ||
| Charge-based feedback | Eq. (116) |
Appendix B Instruments and Quantum Measurements
Let us consider a collection of trace non-increasing maps – for any density operator – where is an arbitrary set. If the sum is a completely positive trace-preserving (CPTP) map, then the maps are called instruments. Instruments can describe both transitions induced by measurement processes and those arising from dynamical evolutions. First, let us show that any measurement can be written in terms of instruments, and subsequently consider a dynamical evolution combined with detection.
Given a observable that can assume any value in the set , a measurement of is defined by a set such that
| (19) |
where the set corresponds to the Kraus operators associated with the measurement of . Also, the probability distribution of the outcomes in a state is given by
| (20) |
and the post-detection state when we measure result is
| (21) |
For instance, if one considers a projective measurement of , then , where is the eigenvector of with eigenvalue .
Now, we can define the new maps for any , hence the probability distribution and the post-detection state can be written as
| (22) | |||||
| (23) |
Let us remember that a set satisfying the completeness relation defines a quantum channel (CPTP map) by
| (24) |
where Eq. (24) is called the Kraus decomposition of the channel . Thus, we can conclude that is a CPTP map. Furthermore, since it follows that , hence for any quantum state . Therefore, is an instrument that describes the detection of the outcome . We can generalize the measurement postulates using the concept of instruments, where a quantum measurement is described by a collection of trace non-increasing super-operators such that the sum corresponds to a CPTP map, where is the set of possible outcomes , the probability distribution of is given by , and the system state updates to after a measurement of the result .
With the language of instruments, we can also address the dynamical evolution between two detections. For example, let us consider a sequential measurement, where a quantum measurement described by a set of Kraus operators is applied at any time , and let us suppose that the system evolves dynamically from to according to the a master equation , where is (for simplicity) time independent. In this case, the instrument that describes joint measurement-dynamics transitions between two detection is given by
| (25) |
where describes the measurement, and describes the dynamical evolution of the system. Therefore, when we are dealing with sequential measurements, the instruments are also including the possibility of dynamical evolution between two detections.
Appendix C Proof of the main results
C.1 Proof of the Result 1
Suppose a sequential quantum detection described by the instruments , as defined in the main text, where denotes a stochastic signal. Let us consider a causal signal governed by the recursive relation
| (26) |
where is a given function. This signal is causal in the sense that it depends on the previous signal and the measurement outcome at time . After measurements, we have the data set , and the conditional state is denoted by . The signal-resolved state is defined as
| (27) |
where represents the ensemble average over all possible trajectories with outcomes in the data set. By using the conditional update rule for the post-measurement state, , we obtain
Let us denote as the conditional average over given the previous outcomes . Using the identity , we find
To isolate the definition of , we introduce a dummy summation over and a Kronecker delta as follows
where we have inserted a Kronecker delta along with a sum over , then replaced in the expression with via . Notably, this also allows us to substitute inside with the deterministic value , giving
Finally, we identify the definition of the signal-resolved state as , and we arrive at
| (28) |
as described in Result 1.
C.2 Proof of the Result 2
C.2.1 Jump time dependent feedback
Suppose that we are applying a sequential measurement of quantum jumps described by the Kraus operators for , and , where is the effective Hamiltonian, and is the set of all possible jumps. Hence, the correspondent instrument is defined by . Consider a feedback scheme conditioned on the last detected quantum jump and the time interval since its occurrence. The stochastic signal that records the last jump is given by
| (29) |
where is the Kronecker delta, and represents the outcome of the quantum jump detection at time . In this context, corresponds to a no-jump detection, while indicates that a quantum jump occurred in channel . Furthermore, the signal that tracks the time elapsed since the last detected jump is given by
| (30) |
We are considering generic initial condition for both signals, where is fixed and . It is equivalent to say that the system is prepared such that we have a jump at time . Hence, the feedback action is implemented in the quantum jump detections at time by considering the Kraus operators .
By construction, both signals defined in Eq. (29) and Eq. (30) satisfy the causality condition , as required in Result 1. Hence, applying the Result 1 (Eq. (18)) to those signals, we obtain
| (31) | |||||
| (32) | |||||
| (33) |
The first equality follows directly from Result 1 [Eq. (18)]. In the second equality, we decompose the sum over into the two possible cases: (no-jump detection) and (jump detection). The transition from the second to the third line is obtained by using the Kronecker delta to evaluate the first sum over and the last sum over . Finally, in Eq. (33), we make the summation ranges explicit: and with .
Note that Eq. (33) can be separated into two cases: and . When , only the second term survives, yielding
| (34) |
where represents the channel . On the other hand, for , namely where , only the first term of Eq. (33) survives, and we have
| (35) |
where we used the Kronecker delta to perform the sum over , and for quantum jumps. Note that ensures . Then, by applying the last equation recursively, we obtain
| (36) |
By taking the continuous measurement limit and such that remains fixed (and similarly ), and that , Eq. (36) becomes
| (37) |
Finally, by applying this same limit in Eq. (34), we have
| (38) |
and by using Eq. (36) we finally have
| (39) |
Note that Eq. (39) represents a sum over all possible previous trajectories: a jump of type can occur at time if it was preceded by a jump of type at time , followed by no jumps in the interval . The sum over and the integral over account for all such possibilities. This completes the proof of Eq. (37) and Eq. (39) of Result 2.
In the next section, let us analyses the particularly interesting case where the feedback depends only on the quantum jumps part, disregarding the time elapsed since the last detected jump.
C.2.2 Jump feedback
Let us consider that the feedback depends solely on the last detected jump, hence the instruments can be replaced as . The signal-resolved for this feedback dependence is related with the previous one by , that corresponds to a marginalization over the time entry of . Therefore, by applying this marginalization on both sides of Eq. (33), we have
| (40) | |||||
| (41) |
where in the second equality we have used the instruments related with quantum jump detections. For the first term, we have
| (42) |
then we have
| (43) |
By taking the continuous measurement limit , where and , we finally obtain
| (44) |
Therefore, the master equation given by Eq. (44) provides the feedback dynamics when only the last jump is considered. We can recover the unconditional state of the system by marginalizing the signal-resolved state over , , and the probability of detecting a jump at time is given by .
Appendix D Matrix equations: generators and steady state of feedback dynamics
We can rewrite our results in terms of matrix equations as follows. Let us define the propagator , so that Eq. (18) takes the form , where is completely positive and trace-preserving (CPTP) for any , ensuring consistency with the general evolution of a hybrid quantum state Oppenheim (2023). This new representation of Eq. (18) resembles a matrix product. To make this structure explicit, let us define the column vector , whose components correspond to the signal-resolved states , with ranging over the possible values of the stochastic signal at time . We also introduce the double-indexed object , which represents a matrix whose components are the superoperators . With this notation, and using the standard matrix product, Eq. (18) takes the compact form
| (45) |
Moreover, within this matrix representation, we can define the generator of the feedback dynamics. Note that , where represents the identity. Hence, if is well defined, we can introduce the generator , then . Finally, the signal-resolved stead state is defined as , or equivalently , and the unconditional steady state is recovered by marginalizing over , . By considering Eq. (45), we have
| (46) |
where . Hence, one find that the signal-resolved steady state can be seen as the eigenvector of with unit eigenvalue.
One can find the steady state of the system by considering the limit in Result 2. Since is a no-jump Liouvillian, it has negative eigenvalues Landi et al. (2024). Hence, decays to zero for large . Thus, in the limit , we can take out of the integral over in Eq. (39), yielding
| (47) |
Following the same way as in Eq. (45), we can rewrite Eq. (47) in a matrix form as follows. Let us define
| (48) |
and represents a column vector whose the components are for . Then, Eq. (47) becomes , where the steady state is the eigenvector of corresponding to the eigenvalue 1, as discussed in Eq. (46). Therefore, the eigenvector of provides us . On the other hand, Eq. (37) gives , where we have
| (49) |
Now, let us find the steady state for the jump feedback, namely when the feedback is based only on the most recent jump. In this case, the feedback dynamics is described by Eq. (44). Note that we can rewrite this equation as
| (50) |
where
| (51) |
The term couples different values of in the differential equation for and describes the contribution of various jump channels due to the feedback action.
Let us define a column vector whose components are the elements for each jump . Hence, the previous equation can be compactly expressed as
| (52) |
where is a diagonal matrix whose diagonal elements are given by the super-operators , i.e., with , and is a matrix whose entries are the super-operators , i.e., . Defining , we finally obtain
| (53) |
Therefore, Eq. (53) provides a compact, vectorial formulation of Result 2 for the signal-resolved state when the feedback is based solely on the last detected jump. In the steady state, where , the solution satisfies the eigenvalue equation
| (54) |
providing the signal-resolved stead state for each jump . Consequently, the unconditional steady state is given by
| (55) |
Appendix E Example and details
E.1 Rotating frame and Rotating Wave Approximation
In the example presented in the main text, we used a rotating frame together with the rotating wave approximation. In this section, we briefly review these concepts. Consider a two-level system with transition frequency , driven by an external field with frequency and coupling strength . The Hamiltonian in the Schrodinger picture is given by ()
| (56) |
where are the Pauli matrices. In this convention, the ground state has energy . The Hamiltonian in the rotating frame is defined as
| (57) |
where we used that , , , and .
The rotating wave approximation consists of neglecting the rapidly oscillating terms in the Hamiltonian, which average out over time and have negligible effect on the system’s dynamics. Hence, taking , the Hamiltonian becomes
| (58) |
where , and . To return to the Schrodinger picture, we need to apply the inverse transformation, where
| (59) |
E.2 Inversion protocol
In the main text, we considered a two-level system of energy coupled to a thermal bath under the action of feedback. By employing a time-dependent, jump-based feedback protocol described by Result 2, we demonstrated that it is possible not only to increase the excited state population compared to the thermal case without feedback, but also to achieve population inversion, with . In this section, we provide a step-by-step derivation of the equations governing the populations under feedback. We consider continuous monitoring of quantum jumps, described by the jump operators
| (60) |
which correspond to the emission () and absorption () of a quantum, respectively. The outcome represents a no-jump detection.
The feedback action is defined as follows: if an emission is detected, we turn on an external drive with frequency for a total duration , after a time delay without absorption. During this feedback window, and working in a rotating frame under the rotating wave approximation, the Hamiltonian becomes
| (61) |
where , otherwise we remove the drive (), and we obtain the thermal qubit with Hamiltonian
| (62) |
Since this feedback protocol affects only the system’s Hamiltonian, then the unconditional state evolves according to
| (63) |
and the steady-state, if it exists, is the solution of the algebraic equation
| (64) |
In order to verify whether a steady state exists, it is sufficient to show that the no-jump Liouvillian has only eigenvalues with negative real parts. The reasoning is as follows: if has only negative eigenvalues, then the term vanishes as . Therefore, in the steady-state limit of Eq. (63), when , only contributions with finite survive in , and we can replace inside the integral. For this feedback protocol, the no-jump Liouvillian are given by
| (65) |
where and are the no-jump Liouvillian related with and , respectively. By applying the vectorization technic Landi et al. (2024), the density states become a column vector of entries, and the Liouvillians become a matrix that act on these vectors. By considering a resonant external drive (), the no-jumps Liouvillians are given by
| (66) | ||||
| (67) |
and we can verify that both of them have eigenvalues with negative real part. Hence, the steady state exists and it is given by Eq. (64). We can compute directly from the definition by using Eq. (65), and one finds
| (68) |
Finally, since we have the operator , the steady state of the system is its eigenvector with eigenvalue 1, and the population of the ground and excited state are the diagonal elements of . Furthermore, the steady state found as a eigenvector of belongs to the rotating frame picture. To return to the Schrodinger picture, we can use Eq. (59).
The population of the excited state in the Schrodinger picture is then given by , and one finds that
| (69) |
where
| (70) |
and
| (71) | |||||
| (72) | |||||
| (73) |
Note that when , then , and the exponential terms become hyperbolic functions. On the other hand, when , then is a pure imaginary number, and these terms become a sine and cosine.
Now, let us outline the derivation of the main results for the example presented in the main text. First, we compute the optimal time during which the external drive should remain on to maximize . Maximizing is equivalent to minimizing . Note that the only term in that depends on is proportional to . Therefore, by solving the equation , we obtain the optimal duration as a function of , , , and . Once is determined, we set in all subsequent steps. Surprisingly, we found that the optimal duration of the drive depends only on the ratio , and remains the same regardless of the temperature or the feedback time delay.
We can also determine the population inversion points by solving the equation , which corresponds to the condition . The solution of this equation yields the critical value (or, equivalently, the critical temperature) for a given ratio , such that for any . We show numerically that in the ideal case with zero delay (), the equation admits a solution with only when .
Finally, to analyze the effect of feedback time delay on , we consider the low-temperature limit , effectively removing thermal effects. We then compute the maximum time delay by solving the equation for , given , , and . This yields the maximum delay for which . Consequently, for any , we have provided .
Appendix F Deriving previous results as particular cases of the Result 1
In this section, we will show how the previous results Annby-Andersson et al. (2022); Wiseman and Milburn (1993); Wiseman (1994b); Kewming et al. (2024) can be seen as particular cases of the Result 1, given by the deterministic equation
| (74) |
for a given stochastic signal that satisfies the causality equation for some function , where is the outcome of the detection at time . In each case, the feedback-measurement protocol is fixed by defining the instruments and the adequate stochastic signal, as described in Table 1.
F.1 Low-pass signal and weak Gaussian measurements: Fokker-Planck master equation
Let us consider a sequential measurement described by the instruments , as described in the main text. We will introduce the low-pass signal given by
| (75) |
where and are arbitrary parameters, and is the outcome of the measurement at time . From this definition, we can see that
| (76) |
then the low-pass signal satisfies the causality condition , where . From the Result 1, the corresponding deterministic equation of the signal-resolved state is given by
| (77) |
For , we can solve the sum over by using the Kronecker delta, and the deterministic equation becomes
| (78) |
It is worth to mention that the case , where the signal corresponds to the actual detection, will be considered soon. Therefore, Eq. (78) describes a general feedback-measurement protocol where the stochastic signal is given by Eq. (75).
From now on, let us consider a sequential measurement described by the set of Kraus operators , where
| (79) |
is a given observable of the system, and is the measurement strength Jacobs and Steck (2006); Bednorz et al. (2012). These operators describe a weak Gaussian measurement of , and the corresponding instrument is defined as . Now, let us consider that the system will evolve dynamically according to a Liouvillian between two detections. Hence, the total instrument that describes this scenario is defined as
| (80) |
where the feedback encoded in the stochastic signal can affect the dynamic of the system through . Therefore, from Eq. (78), we have
| (81) |
where the sum is transformed into an integral because the outcomes are real numbers.
In the next step we will take the limit in the Eq. (81). Let us consider the change of variables defined as , and then . Also, we will define and . Then . Therefore, the deterministic evolution becomes
| (82) |
Now, we can define
| (83) |
and then
| (84) |
As shown in Annby-Andersson et al. (2022) (see supplemental material, Eq. (S7)), we can expand the propagator in first order of , resulting in the following expression
| (85) |
where is the Lindblad dissipator, and . Furthermore, and denote the first and second derivatives of the Dirac distribution , respectively. Therefore, applying this first order expansion of the propagator in Eq. (84) and taking the limit , we finally have
| (86) |
corresponding to the Fokker-Plank master equation of the signal-resolved state Annby-Andersson et al. (2022). Note that, in the limit , Eq. (75) becomes
| (87) |
where is the outcome of the weak Gaussian measurement at time . Therefore, we showed that Eq. (86) can be derived from Result 1 considering a sequential weak Gaussian measurement and a feedback-measurement protocol based on the low-pass signal.
F.2 Feedback based on the most recent detection
In the context of sequential detection, suppose the feedback depends solely on the most recent detection. This is equivalent to assuming that the stochastic signal is given by the current detection, . It may be interpreted as a particular case of the low-pass signal with . Since this feedback protocol does not rely on the prior history of the experiment, it can be regarded as a memory-less feedback scheme. In this scenario, we have with . According to Result 1, the deterministic equation governing the signal-resolved state is then given by
| (88) |
and by performing the sum over , we obtain
| (89) |
where denotes a possible detection outcome at time , and the sum over accounts for all possible outcomes at time . Equation (89) therefore describes a general feedback-measurement protocol based solely on the most recent detection. In what follows, we will explore how this equation applies to specific measurement schemes, thereby recovering earlier results.
F.2.1 Quantum Jumps
Let us consider the application of a quantum channel to the system’s state conditioned on quantum jump detection. The conditional stroboscopic evolution in this feedback-measurement scenario is described by
| (90) |
where the Kraus operators describe the quantum jump detection process, and the quantum channel , referred to as the feedback super-operator, defines the feedback protocol based on the most recent quantum jump Wiseman (1994a). The corresponding instrument for this sequential feedback-measurement protocol is given by , where represents a no-jump detection, and corresponds to a quantum jump. Then, using Eq. (89), we obtain the deterministic equation for the signal-resolved state:
| (91) |
where we have used the identity . Summing this equation over , we finally obtain
| (92) |
Now, let us consider the following feedback super-operator
| (93) |
where is an arbitrary Liouvillian super-operator. With this definition, we can write the evolution of the uncoditional state as
| (94) |
Finally, using the definition of the Kraus operators from the unraveling of the quantum master equation, and taking the limit , we obtain the following master equation
| (95) |
which corresponds to the well-known master equation for feedback based on the most recent jump, as developed in Wiseman (1994a).
F.2.2 Diffusion
Let us consider another scenario where the feedback is based solely on the most recent measurement outcome, but now with diffusion. Considering a weak continuous Gaussian measurement of an hermitian observable described by the Kraus operators defined in Eq. (79), the outcome of the measurements follows a stochastic equation given by
| (96) |
where , is a Wiener increment, and is the conditional state at time . The stochastic master equation for is given by Jacobs and Steck (2006)
| (97) |
In this case, the feedback protocol is defined as follows: the system evolves dynamically from to , and we apply a weak Gaussian measurement of at this point, resulting in the outcome . Hence, the feedback will be based on the most recent outcome of the detection through the feedback super-operator . For simplicity, we will consider a unitary evolution.
The total instrument that describes this discrete evolution is given by , where represents the unitary evolution between and , represents the measurement process, and is the feedback super-operator based on the measurement outcome. Following a similar approach as we developed for quantum jumps in Eq. (92), the deterministic equation for the unconditional state in this case is given by
| (98) |
where the sum was replaced by a integral since the outcomes of the Gaussian measurements are continuous real numbers.
Now, let us consider a particular feedback super-operator. Following the reference Wiseman (1994a), let us define
| (99) |
where is a super-operator that represents a reversible transformation for a given hermitian operator . Hence, the deterministic equation becomes
| (100) |
The next step corresponds to expand the deterministic equation on first order of . For the feedback super-operator, we have Wiseman (1994a)
| (101) |
and the unitary evolutions yields
| (102) |
Also, we can show that
| (103) |
and keeping only terms of order in the instrument , the deterministic equation becomes
| (104) |
Finally, taking the limit and writing , one finds
| (105) |
Eq. (105) coincides with the feedback master equation found in Wiseman and Milburn (1993) for ideal homodyne detection. In that case, one must make the identification , where is a (generally non-Hermitian) jump operator. In homodyne detection, the diffusion arises from continuous measurements of the quadrature operator . Therefore, our result recovers the feedback master equation of Wiseman and Milburn (1993), corresponding to diffusion induced by weak Gaussian measurements of a Hermitian operator .
F.3 Charge-based feedback
Let us consider a continuous monitoring of quantum jumps, as defined in the main text. In this case, represents the outcome of the quantum jump detection at time , where is a no-jump detection, and is a jump in the channel . Let us introduce the following random variable
| (106) |
where is the Kronecker delta. It implies that if we have a jump in the channel at time , and otherwise. Furthermore, the total stochastic number of jumps in the channel until the time is
| (107) |
Hence, we can define the stochastic charge as
| (108) |
corresponding to a linear combination of the total number of jumps in each channel . In the limit , we have
| (109) |
where denotes the Dirac delta. In this way, we have defined the stochastic charge in terms of the measurement outcomes of the continuous monitoring of the quantum jumps. Note that this stochastic signal is causal, and it satisfies
| (110) |
Now, let us consider a feedback protocol where the detections are based on the continuous monitoring of the quantum jumps, and the stochastic signal is the stochastic charge (108). In this case, the instruments are given by Landi et al. (2024)
| (111) | ||||
| (112) |
where and . By applying Eq. (18) and (110), one finds
| (113) | |||||
| (114) | |||||
| (115) |
Finally, using the definition of and , and taking the limit of , we have
| (116) |
Eq. (116) was previously derived in Kewming et al. (2024), encompassing any feedback protocol based on charge detection, and we showed that this result follows directly from Eq. (18).