Diagnostics for Deep Neural Networks with
Automated Copy/Paste Attacks
Abstract
This paper considers the problem of helping humans exercise scalable oversight over deep neural networks (DNNs). Adversarial examples can be useful by helping to reveal weaknesses in DNNs, but they can be difficult to interpret or draw actionable conclusions from. Some previous works have proposed using human-interpretable adversarial attacks including copy/paste attacks in which one natural image pasted into another causes an unexpected misclassification. We build on these with two contributions. First, we introduce Search for Natural Adversarial Features Using Embeddings (SNAFUE) which offers a fully automated method for finding copy/paste attacks. Second, we use SNAFUE to red team an ImageNet classifier. We reproduce copy/paste attacks from previous works and find hundreds of other easily-describable vulnerabilities, all without a human in the loop. 111https://github.com/thestephencasper/snafue
1 Introduction
It is important to have scalable methods that allow humans to exercise effective oversight over deep neural networks. Adversarial examples are one type of tool which can be used to study weaknesses in DNNs [13, 53, 45]. Typically, adversarial examples are generated by optimizing perturbations to the input of a network. And some previous works offer examples of adversaries being used to develop generalizable interpretations of DNNs [13, 53, 27, 10].
However, there are limitations to what one can learn about flaws in DNNs from synthesized features [5]. First, synthetic adversarial perturbations are often difficult to describe and thus offer limited help with human-centered approaches to interpretability. Second, even when synthetic adversarial features are interpretable, it is unclear without additional testing whether they fool a DNN due to their interpretable features or due to hidden motifs [7, 27]. This makes developing a generalizable understanding from them difficult. Third, there is a gap between research and practice in adversarial robustness [2]. Real-world failures of DNNs are often due to atypical natural features or combinations thereof [22], but synthesized features are off this distribution.
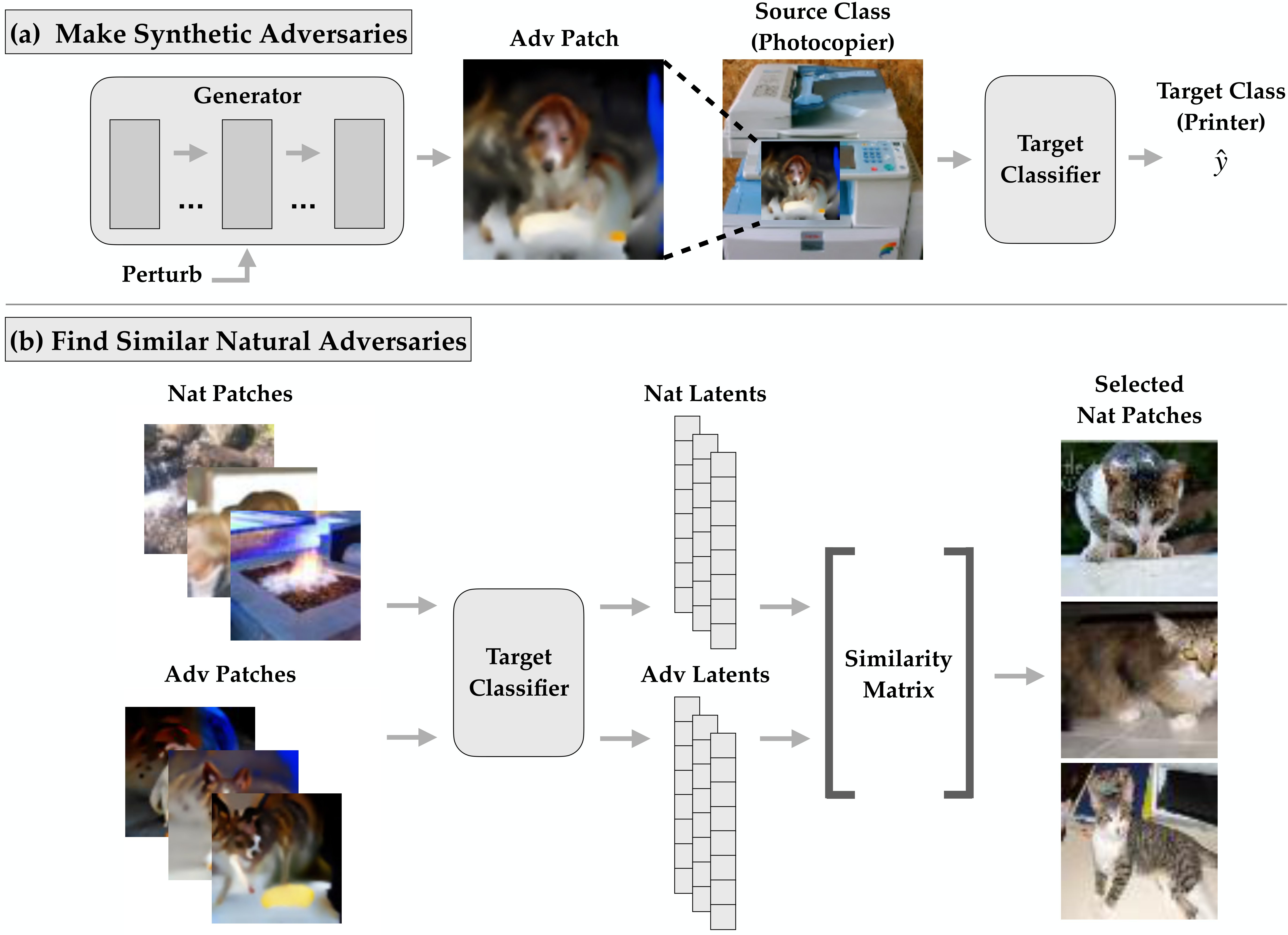

Here, we work to diagnose weaknesses in DNNs using natural, interpretable features. We introduce using a Search for Natural Adversarial Features Using Embeddings (SNAFUE) to find novel adversarial combinations of natural features. We apply SNAFUE to find copy/paste attacks for an image classifier in which one natural image is inserted as a patch into another to induce a targeted misclassification. Figure 1 outlines this approach. First, we use a generator to synthesize robust feature-level adversarial patches [10] which are designed to make any image from a particular source class misclassified as a target. Second, we use the target model’s latent activations to create embeddings of both these synthetic patches and a dataset of natural patches. Finally we select the natural patches that embed most similarly to the synthetic ones.
We apply SNAFUE at the ImageNet scale. First, we use SNAFUE to replicate all successful known examples of copy/paste attacks from previous works with no human involvement. Second, we demonstrate its scalability by identifying hundreds of vulnerabilities. Figure 2 and Figure 9 show examples which illustrate easily-describable misassociations between features and classes in the network. Overall, this work makes two contributions.
-
1.
Algorithmic: We introduce Search for Natural Adversarial Features Using Embeddings (SNAFUE) as a tool for scalable human oversight.
-
2.
Diagnostic: We apply SNAFUE by red-teaming an image classifier. We demonstrate that it automatedly identifies weaknesses due to natural features that are uniquely human-interpretable.
Meanwhile, in concurrent work [9], we compare SNAFUE to other interpretability tools by using them to help humans rediscover trojans in a network. We find that SNAFUE offers an effective and unique tool for helping humans interpret and debug DNNs. Code is available at https://github.com/thestephencasper/snafue.
2 Related Work
Describable Synthetic Adversarial Attacks: Conventional adversarial attacks are effective but difficult for a human to interpret. They tend to be imperceptible and, when exaggerated, typically appear as random or mildly-textured noise [52, 19]. Thus, from a human-interpretability perspective, they demonstrate little aside from how the network can be vulnerable to this specific class of perturbations. Some works have used perturbations inside the latents of image generators to synthesize more describable synthetic attacks [37, 47, 50, 30, 29, 49, 24, 55]. These works however, have not focused on interpretability and only studied small networks trained on simple datasets (MNIST [34], Fashion MNIST [57], SVHN [42], CelebA [38], BDD [58], INRIA [12], and MPII [1]). In the trojan detection literature, some methods have aimed to reconstruct trojan features using regularization and transformations. Thus far, however, they have been limited to recovering small, few-pixel triggers while failing to reconstruct triggers that take the form of larger objects [54, 20].
Natural Adversarial Features: Several approaches have been used for discovering natural adversarial features. One is to analyze examples in a test set that a DNN mishandles [22, 15, 28], but this limits the search for weaknesses to a fixed dataset and cannot be used for discovering adversarial combinations of features. Another approach is to search for failures over an easily-describable set of perturbations [17, 33, 51], but this requires performing a zero-order search over a fixed set of changes.
Copy Paste Attacks: Copy/paste attacks have been a growing topic of interest and offer another method for studying natural adversarial features. Some interpretability tools have been used to design copy/paste adversarial examples including feature-visualization [8] and methods based on network dissection [3, 41, 23]. Our approach is related to that of [10] who introduce robust feature level adversarial patches and use them for interpreting DNNs and designing copy-paste attacks. However, copy/paste attacks from [8, 41, 23, 10] have been limited to simple proofs of concept with manually-designed copy/paste attacks. They also required a human process of interpretation, trial, and error in the loop. We build off of these with SNAFUE which is the first method that identify adversarial combinations of natural features for vision models in a way that is (1) not restricted to a fixed set of transformations or a limited set of source and target classes and (2) efficiently automatable.
3 Methods
Figure 1 outlines our approach for finding copy/paste adversaries for image classification. For all experiments, we report the success rate defined as the proportion of the time that a patched image was classified as the target class minus the proportion of the time the unpatched natural image was. Additional details are in Appendix A.1.
Synthetic adversarial patches: First, we create synthetic robust feature level adversarial patches as in [10] by perturbing the latent activations of a BigGAN [6] generator. The synthetic adversarial patches were trained to cause any source class image to be misclassified as the target regardless of the insertion location in the source image.
Candidate patches: Patches for SNAFUE can come from any source and do not need labels. Features do not necessarily have to be natural and could, for example, be procedurally generated. Here, we used a total of 265,457 natural images from five sources: the ImageNet validation set [46] (50,000) TinyImageNet [32] (100,000), OpenSurfaces [4] (57,500), the non OpenSurfaces images from Broden [3] (37,953), plus four trojan triggers (4) (see Section 4).

Embeddings: We used the 265,457 natural patches along with adversarial patches, and passed them through the target network to get an -dimensional embedding of each using the post-ReLU latents from the penultimate (avgpooling) layer of the target network. The result was a nonnegative matrix of natural patch embeddings and a matrix of adversarial patch embeddings. A different must be computed for each attack, but only needs to be computed once. This plus the fact that embedding the natural patches does not require insertion into a set of source images makes SNAFUE much more efficient than a brute-force search. We also weighted the values of based on the variance of the success of the synthetic attacks and the variance of the latent features under them. Details are in Appendix A.1.

Selecting natural patches: We then obtained the matrix of cosine similarities between and . We took the patches that had the highest similarity to any of the synthetic images, excluding ones whose classifications from the target network included the target class in the top 10 classes. Finally, we evaluated all natural patches under random insertion locations over all 50 source images from the validation set and subsampled the natural patches that increased the target network’s post-softmax confidence in the target class the most. Screening the natural patches for the best 10 caused only a marginal increase in computational overhead. The method was mainly bottlenecked by the cost of training the synthetic adversarial patches (for 64 batches of 32 insertions each).
Automation of interpretations: Unlike previous proofs of concept, SNAFUE does not rely on a human in the loop. However, we still rely on a human after the loop for analyzing the final results and making a final interpretation by default. To test how easily this may be automatable, we test a method for turning many images into a single caption in Appendix A.3.
4 Experiments
Replicating previous ImageNet copy/paste attacks without human involvement. First, we set out to replicate all known successful ImageNet copy/paste attacks from previous works without any human involvement. To our knowledge, there are 9 such attacks, 3 each from [8], [23]222The attacks presented in [23] were not universal within a source class and were only developed for a single source image each. When replicating their results, we use the same single sources. When replicating attacks from the other two works, we train and test the attacks as source class-universal ones. and [10].333[10] test a fourth attack involving patches making traffic lights appear as flies, the examples they identified were not successful at causing targeted misclassification.444[41] also test copy paste attacks, but not on ImageNet networks We used SNAFUE to find 10 natural patches for all 9 attacks. Figure 3 shows the results. In all cases, we are able to find successful natural adversarial patches. We also find in most cases that we find similar adversarial features to the ones identified in the prior works. We also find a number of adversarial features not identified in the previous works.

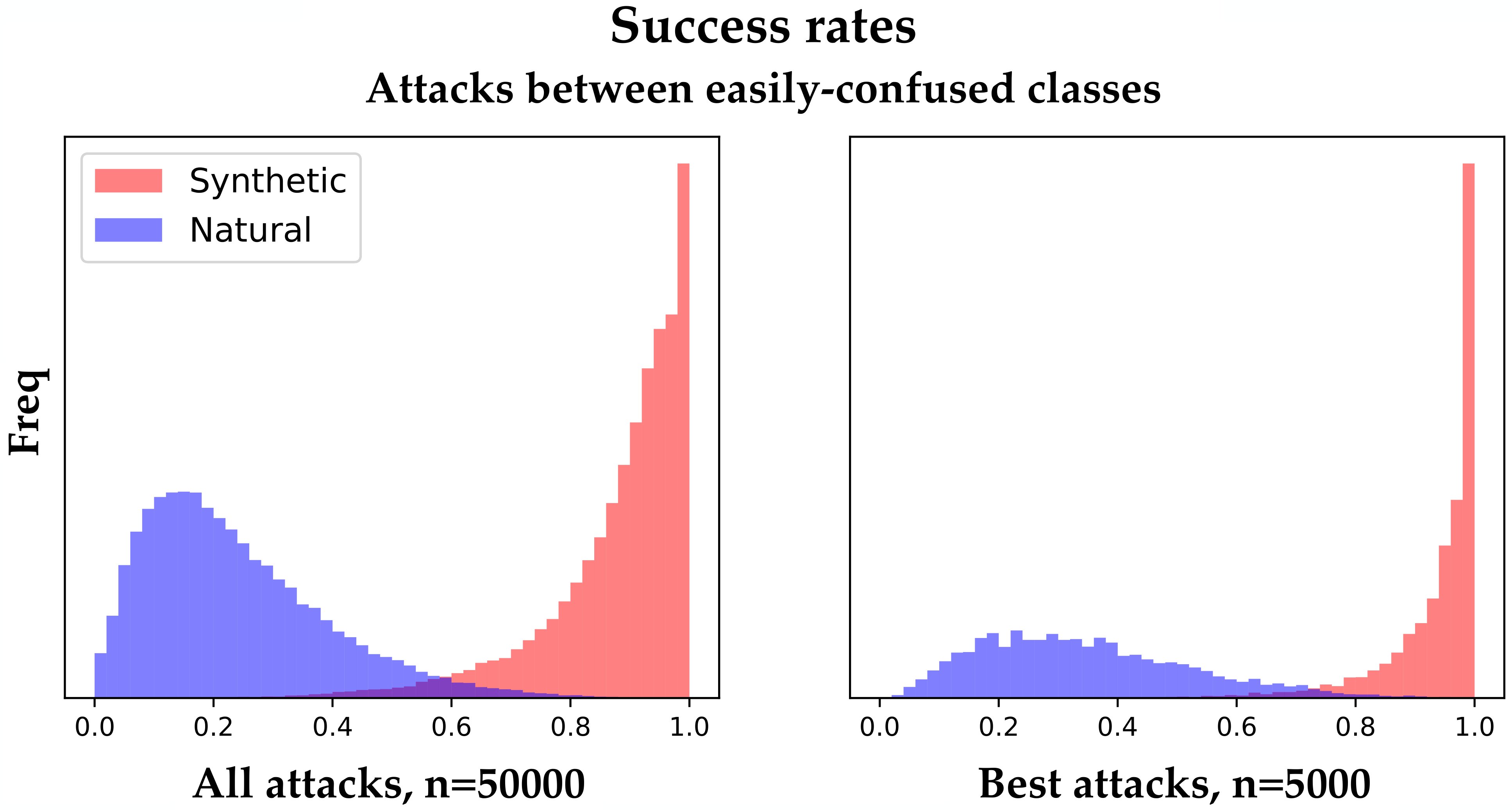
SNAFUE is scalable and effective between similar classes. There are many natural visual features that image classifiers may encounter and many more possible combinations thereof, so it is important that tools for interpretability and diagnostics with natural features are scalable. Here, we test the scalability and effectiveness of SNAFUE with a broad search for vulnerabilities. Based on prior proofs of concept [8, 41, 23, 10] copy/paste attacks tend to be much easier to create when the source and target class are related (see Figure 3). To choose similar source/target pairs, we computed the confusion matrix for the target network with giving the mean post-softmax confidence on class that the network assigned to validation images of label . Then for each of the 1,000 ImageNet classes, we conducted 5 attacks using that class as the source and each of its most confused 5 classes as targets. For each attack, we produced synthetic adversarial patches and natural adversarial patches. Figure 2 and Figure 4 show examples from these attacks with many additional examples in Appendix Figure 9. Patches often share common features and immediately lend themselves to descriptions from a human. In Appendix A.3, we find that these patches also often lend themselves to common descriptions from neural captioning models.
At the bottom of Figure 4, are histograms for the mean attack success rate for all patches and for the best patches (out of 10) for each attack. The synthetic feature-level adversaries were generally highly successful, and the the natural patches were also successful a significant proportion of the time. In this experiment, 3,451 (6.9%) out of the 50,000 total natural images from all attacks were at least 50% successful at being targeted adversarial patches under random insertion locations into random image of the source class. This compares to a 10.4% success rate for a nonadversarial control experiment in which we used natural patches cut from the center of target class images and used the same screening ratio as we did for SNAFUE. Meanwhile, 963 (19.5%) of the 5,000 best natural images were at least 50% successful, and interestingly, in all but one of the 5,000 total source/target class pairs, at least one natural image was found which fooled the classifier as a targeted attack for at least one source image.
Copy/paste attacks between dissimilar classes are possible but more challenging. In some cases, the ability to robustly distinguish between similar classes may be crucial. For example, it is important for autonomous vehicles to effectively tell red and yellow traffic lights apart. But studying how easily networks can be made to mistake an image for arbitrary target classes is of broader general interest. While synthetic adversarial attacks often work between arbitrary source/target classes, to the best of our knowledge, there are no successful examples from any previous works of class-universal copy/paste attacks.
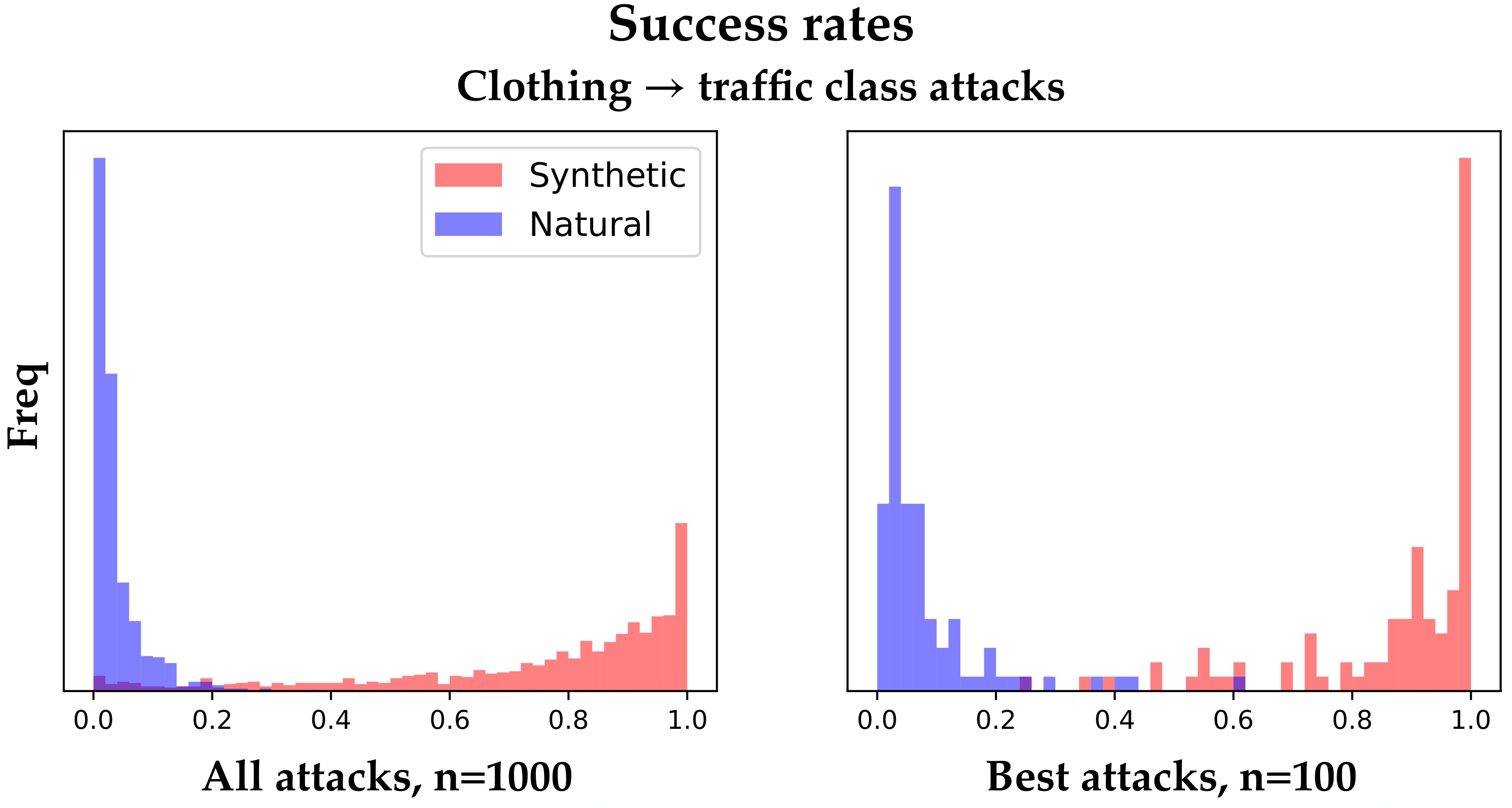
We chose to examine the practical problem of understanding how vision systems in vehicles may fail to detect pedestrians [43] because it provides an example where failures due to novel combinations of natural features could realistically pose safety hazards. To test attacks between dissimilar classes, we chose 10 ImageNet classes of clothing items (which frequently co-occur with humans) and 10 of traffic-related objects.555{academic gown, apron, bikini, cardigan, jean, jersey, maillot, suit, sweatshirt, trenchcoat} {fire engine, garbage truck, racer, sports car, streetcar, tow truck, trailer truck, trolleybus, street sign, traffic light} We conducted 100 total attacks with SNAFUE using each clothing source and traffic target. Figure 5 shows these results. Outcomes were mixed.
On one hand, while the synthetic adversarial patches were usually successful on more than 50% of source images, the natural ones were usually not. Only one out of the 1,000 total natural patches (the leftmost natural patch in Figure 5) succeeded for at least 50% of source class images. This suggests a limitation of either SNAFUE or of copy/paste attacks in general for targeted attacks between unrelated source and target classes. On the other hand, 54% of the natural adversarial patches were successful for at least one source image, and such a natural patch was identified for 87 of all 100 source/target class pairs.
SNAFUE is unique and relatively effective compared to other interpretability/diagnostic tools: Finally, we test how SNAFUE compares to related tools meant to help humans better understand and diagnose bugs in models. In concurrent work [9], we evaluate interpretability tools for DNNs based on how effective they are at helping humans identify trojans that have been implanted into DNNs. We test SNAFUE against 8 other interpretability tools for DNNs based on feature synthesis/search. We find that SNAFUE and robust feature level adversaries [10] are the most successful overall and that combinations of methods are more helpful than individual ones.
5 Discussion and Broader Impact
Implications for scalable human oversight. Having effective diagnostic tools to identify problems with models is important for trustworthy AI. The most common way to evaluate a model is with a test set. But good testing performance does not imply that a system will generalize safely in deployment. Test sets do not typically reveal failures such as spurious features, out of distribution inputs, and adversarial vulnerabilities. Thus, it is important to have scalable tools that allow humans to exercise effective oversight over deep neural networks.
Interpretability tools are useful for building more trustworthy AI because of the role they can play in helping humans exercise oversight. But many techniques from the literature suffer from limitations including a lack of scalability and usefulness for identifying novel flaws. This has led to criticism, with a number of works noting that few interpretability tools are used by practitioners in real applications [14, 36, 40, 31, 45]. Toward practical methods to find weaknesses in DNNs, we introduce SNAFUE as an automated method for finding natural adversarial features.
SNAFUE identifies distinct types of problems. In some cases, networks may learn flawed solutions because they are given the wrong learning objective while in other cases, they may fail to converge to a desirable solution even with the correct objective [26]. SNAFUE can discover both types of issues. In some cases, it discovers failures that result from dataset biases. Examples include when it identifies that cats make envelopes misclassified as cartons or that young children make bicycles-built-for-two misclassified as tricycles (Figure 2 rows 1-2). In other cases, SNAFUE identifies failures that result from the particular representations a model learns, presumably due to equivalence classes in the DNN’s representations. Examples include equating black and white birds with killer whales, parallel lines with spatulas, and red/orange cars with fiddler crabs (Figure 2 rows 3-5).
Limitations. We find that it scales well and can easily identify hundreds of sets of copy/paste vulnerabilities that are very easy for a human to interpret and describe. However, we also find limitations including how SNAFUE is less effective for dissimilar source and target classes. In Appendix A.4, we catrogize and discuss different types of failures with SNAFUE.
Three directions for future work.
-
1.
Diagnostics in the wild: Vision datasets are full of biases, including harmful ones involving human demographic groups [16]. A compelling use of SNAFUE and similar techniques could be for discovering these in deployed systems. This could be valuable for exploring the practical relevance of diagnostic tools.
-
2.
Debugging: In addition to is use for interpretability, SNAFUE also produces adversarial data which can be used for adversarial training or probing the network to guide targeted procedural edits. Correcting vulnerabilities to copy/paste attacks could be useful applications or tests for model editing tools (e.g. [18, 11, 56, 39]). In the real world, vision systems often fail due to distractor features, atypical contexts, and occlusion [22]. Debugging with copy/paste attacks may be well-equipped to address these failures.
-
3.
NLP: Using a version of SNAFUE in natural language processing could be helpful for identifying natural phrases that could cause language models to fail. This could be valuable for language models because the discrete nature of their inputs makes it difficult to use gradient based methods to construct adversarial perturbations in input space. However, SNAFUE could be used to produce interpretable adversaries from synthetic adversarial insertions to the latents. Other recent works have aimed to generate adversarial triggers for language models that appear as natural language phrases. However, these often depend on either using reinforcement learning to train language generators which can be unstable and computationally expensive [44] or on using humans in the loop [59]. Because SNAFUE is automated and can work flexibly with any dataset of candidate features, it may offer a competitive alternative to existing tools.
All of the proposals for building safe AI outlined in [25] explicitly call for adversarial robustness and/or oversight via interpretability tools. Finding and fixing bugs in advanced AI systems will hinge on interpretability, adversaries, and adversarial training. Consequently, continued work toward scalable techniques for interpretability and diagnostics will be important for safer AI.
Acknowledgments
We thank Rui-Jie Yew and Phillip Christoffersen for feedback and Evan Hernandez for discussing how to best replicate results from [23]. Stephen Casper’s work was supported by the Future of Life Institute and Kaivalya Hariharan’s work was supported by the Open Philanthropy Project.
References
- [1] Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, pages 3686–3693, 2014.
- [2] Giovanni Apruzzese, Hyrum S Anderson, Savino Dambra, David Freeman, Fabio Pierazzi, and Kevin A Roundy. " real attackers don’t compute gradients": Bridging the gap between adversarial ml research and practice. arXiv preprint arXiv:2212.14315, 2022.
- [3] David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations, 2017.
- [4] Sean Bell, Paul Upchurch, Noah Snavely, and Kavita Bala. OpenSurfaces: A richly annotated catalog of surface appearance. ACM Trans. on Graphics (SIGGRAPH), 32(4), 2013.
- [5] Judy Borowski, Roland S Zimmermann, Judith Schepers, Robert Geirhos, Thomas SA Wallis, Matthias Bethge, and Wieland Brendel. Exemplary natural images explain cnn activations better than state-of-the-art feature visualization. arXiv preprint arXiv:2010.12606, 2020.
- [6] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
- [7] Tom B Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer. Adversarial patch. arXiv preprint arXiv:1712.09665, 2017.
- [8] Shan Carter, Zan Armstrong, Ludwig Schubert, Ian Johnson, and Chris Olah. Activation atlas. Distill, 4(3):e15, 2019.
- [9] Stephen Casper, Yuxiao Li, Jiawei Li, Tong Bu, Kevin Zhang, and Dylan Hadfield-Menell. Benchmarking interpretability tools for deep neural networks. arXiv preprint arXiv:2302.10894, 2023.
- [10] Stephen Casper, Max Nadeau, and Gabriel Kreiman. Robust feature-level adversaries are interpretability tools. CoRR, abs/2110.03605, 2021.
- [11] Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, and Furu Wei. Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08696, 2021.
- [12] Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), volume 1, pages 886–893. Ieee, 2005.
- [13] Yinpeng Dong, Hang Su, Jun Zhu, and Fan Bao. Towards interpretable deep neural networks by leveraging adversarial examples. arXiv preprint arXiv:1708.05493, 2017.
- [14] Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning, 2017.
- [15] Sabri Eyuboglu, Maya Varma, Khaled Saab, Jean-Benoit Delbrouck, Christopher Lee-Messer, Jared Dunnmon, James Zou, and Christopher Ré. Domino: Discovering systematic errors with cross-modal embeddings. arXiv preprint arXiv:2203.14960, 2022.
- [16] Simone Fabbrizzi, Symeon Papadopoulos, Eirini Ntoutsi, and Ioannis Kompatsiaris. A survey on bias in visual datasets. Computer Vision and Image Understanding, 223:103552, 2022.
- [17] Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv preprint arXiv:1811.12231, 2018.
- [18] Amirata Ghorbani and James Zou. Neuron shapley: Discovering the responsible neurons, 2020.
- [19] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- [20] Wenbo Guo, Lun Wang, Xinyu Xing, Min Du, and Dawn Song. Tabor: A highly accurate approach to inspecting and restoring trojan backdoors in ai systems. arXiv preprint arXiv:1908.01763, 2019.
- [21] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [22] Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15262–15271, 2021.
- [23] Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Jacob Andreas. Natural language descriptions of deep visual features. arXiv preprint arXiv:2201.11114, 2022.
- [24] Yu-Chih-Tuan Hu, Bo-Han Kung, Daniel Stanley Tan, Jun-Cheng Chen, Kai-Lung Hua, and Wen-Huang Cheng. Naturalistic physical adversarial patch for object detectors. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7848–7857, 2021.
- [25] Evan Hubinger. An overview of 11 proposals for building safe advanced ai. arXiv preprint arXiv:2012.07532, 2020.
- [26] Evan Hubinger, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. Risks from learned optimization in advanced machine learning systems. arXiv preprint arXiv:1906.01820, 2019.
- [27] Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Adversarial examples are not bugs, they are features. Advances in neural information processing systems, 32, 2019.
- [28] Saachi Jain, Hannah Lawrence, Ankur Moitra, and Aleksander Madry. Distilling model failures as directions in latent space, 2022.
- [29] Ameya Joshi, Amitangshu Mukherjee, Soumik Sarkar, and Chinmay Hegde. Semantic adversarial attacks: Parametric transformations that fool deep classifiers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4773–4783, 2019.
- [30] Shalmali Joshi, Oluwasanmi Koyejo, Been Kim, and Joydeep Ghosh. xgems: Generating examplars to explain black-box models. arXiv preprint arXiv:1806.08867, 2018.
- [31] Maya Krishnan. Against interpretability: a critical examination of the interpretability problem in machine learning. Philosophy & Technology, 33(3):487–502, 2020.
- [32] Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge. CS 231N, 7(7):3, 2015.
- [33] Guillaume Leclerc, Hadi Salman, Andrew Ilyas, Sai Vemprala, Logan Engstrom, Vibhav Vineet, Kai Xiao, Pengchuan Zhang, Shibani Santurkar, Greg Yang, et al. 3db: A framework for debugging computer vision models. arXiv preprint arXiv:2106.03805, 2021.
- [34] Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database. ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010.
- [35] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
- [36] Zachary C Lipton. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue, 16(3):31–57, 2018.
- [37] Hsueh-Ti Derek Liu, Michael Tao, Chun-Liang Li, Derek Nowrouzezahrai, and Alec Jacobson. Beyond pixel norm-balls: Parametric adversaries using an analytically differentiable renderer. arXiv preprint arXiv:1808.02651, 2018.
- [38] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of International Conference on Computer Vision (ICCV), December 2015.
- [39] Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. arXiv preprint arXiv:2202.05262, 2022.
- [40] Tim Miller. Explanation in artificial intelligence: Insights from the social sciences. Artificial intelligence, 267:1–38, 2019.
- [41] Jesse Mu and Jacob Andreas. Compositional explanations of neurons. Advances in Neural Information Processing Systems, 33:17153–17163, 2020.
- [42] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning, 2011.
- [43] National Transportation Safety Board NTSB. Collision between vehicle controlled by developmental automated driving system and pedestrian, 2018.
- [44] Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. arXiv preprint arXiv:2202.03286, 2022.
- [45] Tilman Räukur, Anson Ho, Stephen Casper, and Dylan Hadfield-Menell. Toward transparent ai: A survey on interpreting the inner structures of deep neural networks. arXiv preprint arXiv:2207.13243, 2022.
- [46] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [47] Pouya Samangouei, Ardavan Saeedi, Liam Nakagawa, and Nathan Silberman. Explaingan: Model explanation via decision boundary crossing transformations. In Proceedings of the European Conference on Computer Vision (ECCV), pages 666–681, 2018.
- [48] J Schulman, B Zoph, C Kim, J Hilton, J Menick, J Weng, JFC Uribe, L Fedus, L Metz, M Pokorny, et al. Chatgpt: Optimizing language models for dialogue, 2022.
- [49] Sumedha Singla, Brian Pollack, Junxiang Chen, and Kayhan Batmanghelich. Explanation by progressive exaggeration. arXiv preprint arXiv:1911.00483, 2019.
- [50] Yang Song, Rui Shu, Nate Kushman, and Stefano Ermon. Constructing unrestricted adversarial examples with generative models. arXiv preprint arXiv:1805.07894, 2018.
- [51] Florian Stimberg, Ayan Chakrabarti, Chun-Ta Lu, Hussein Hazimeh, Otilia Stretcu, Wei Qiao, Yintao Liu, Merve Kaya, Cyrus Rashtchian, Ariel Fuxman, Mehmet Tek, and Sven Gowal. Benchmarking robustness to adversarial image obfuscations, 2023.
- [52] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- [53] Richard Tomsett, Amy Widdicombe, Tianwei Xing, Supriyo Chakraborty, Simon Julier, Prudhvi Gurram, Raghuveer Rao, and Mani Srivastava. Why the failure? how adversarial examples can provide insights for interpretable machine learning. In 2018 21st International Conference on Information Fusion (FUSION), pages 838–845. IEEE, 2018.
- [54] Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y Zhao. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In 2019 IEEE Symposium on Security and Privacy (SP), pages 707–723. IEEE, 2019.
- [55] Shuo Wang, Shangyu Chen, Tianle Chen, Surya Nepal, Carsten Rudolph, and Marthie Grobler. Generating semantic adversarial examples via feature manipulation. arXiv preprint arXiv:2001.02297, 2020.
- [56] Eric Wong, Shibani Santurkar, and Aleksander Madry. Leveraging sparse linear layers for debuggable deep networks. In International Conference on Machine Learning, pages 11205–11216. PMLR, 2021.
- [57] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
- [58] Fisher Yu, Wenqi Xian, Yingying Chen, Fangchen Liu, Mike Liao, Vashisht Madhavan, and Trevor Darrell. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv preprint arXiv:1805.04687, 2(5):6, 2018.
- [59] Daniel M Ziegler, Seraphina Nix, Lawrence Chan, Tim Bauman, Peter Schmidt-Nielsen, Tao Lin, Adam Scherlis, Noa Nabeshima, Ben Weinstein-Raun, Daniel de Haas, et al. Adversarial training for high-stakes reliability. arXiv preprint arXiv:2205.01663, 2022.
Appendix A Appendix
A.1 Additional Methodological Details
Details on synthetic patches: As in [10], we optimized these patches under transformation using an auxiliary classifier to regularize them to not appear like the target class. Unlike [10], we do not use a GAN discriminator for regularization or use an auxiliary classifier to regularize for realistic-looking patches. Also in contrast with [10], we perturbed the inputs to the generator in addition to its internal activations in a certain layer because we found that it produced improved adversarial patches.
Image and patch scaling: All synthetic patches were parameterized as images. Each was trained under transformations including random resizing. Similarly, all natural patches were a uniform resolution of pixels. All adversarial patches were tested by resizing them to and inserting them into source images at random locations.
Weighting: To reduce the influence of embedding features that vary widely across the adversarial patches, we apply an -dimensional elementwise mask to the embedding in each row of with weights
where is the coefficient of variation over the ’th column of , with and for some small positive .
To increase the influence of successful synthetic adversarial patches and reduce the influence of poorly-performing ones, we also apply a -dimensional elementwise mask to each column of with weights
where is the mean fooling confidence increase of the post-softmax value of the target output neuron under the patch insertions for the synthetic adversary. If any is negative, we replace it with zero, and if the denominator is zero, we set to zero.
Finally, we multiplied elementwise with each row of and elementwise with every column of to obtain the masked embeddings .
A.2 Screening
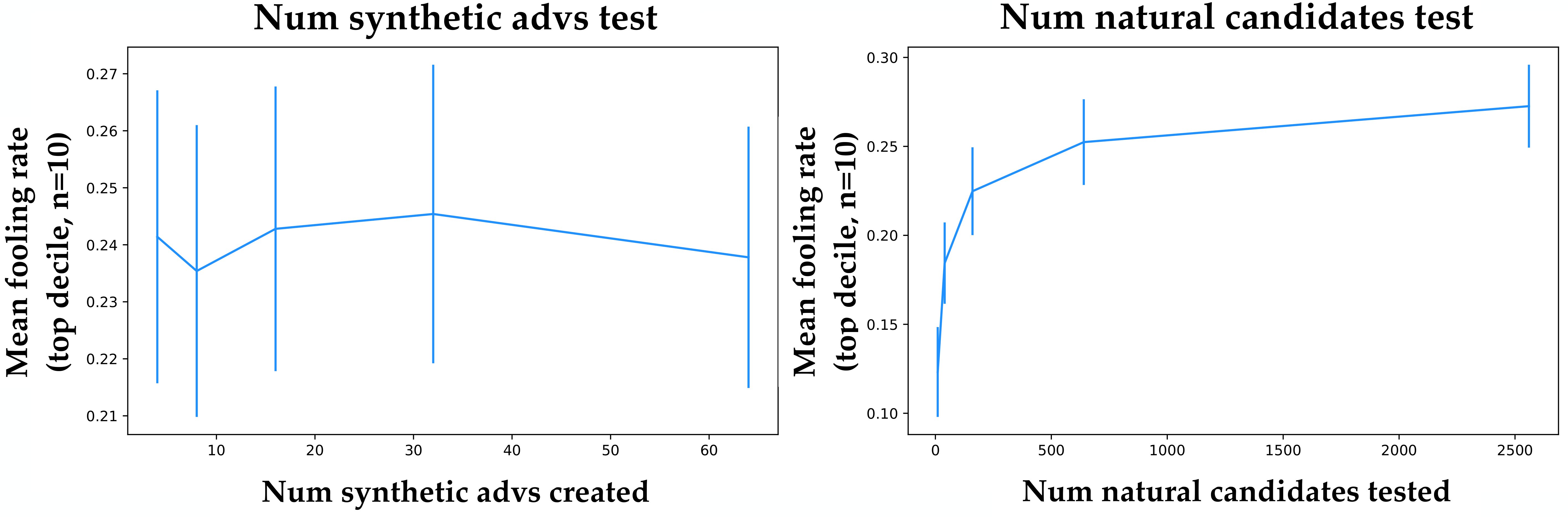
By default, for all experiments in this paper, we train 30 synthetic adversarial patches, select the most adversarial 10, then screen over 300 natural patches, and select the most adversarial 10. These numbers were arbitrary, and because it is fully-automated, SNAFUE allows for flexibility in how many synthetic adversaries to create and how many natural adversaries to screen. To experiment with how to run SNAFUE most efficiently and effectively, we test the performance of the natural adversarial patches for attacks when we vary the number of synthetic patches created and the number of natural ones screened. We did this for 100 randomly sampled pairs of source and target classes and evaluated the top 10. Figure 6 shows the results.
As expected, when the number of natural patches that are screened increases, the performance of the selected ones increases. However, we find that creating more synthetic patches does not strongly influence the performance of the final natural ones. All of our choices of numbers of synthetic patches from 4 to 64 performed comparably well, likely due to redundancy. One positive implication of this is that SNAFUE can be done efficiently with few synthetic adversaries. These were the main bottleneck in our runtime, so this has useful implications for speeding up runtimes. However, a negative implication of this is that redundant synthetic adversaries may fail to identify all possible weaknesses between a source and target class. Future work experimenting with the synthesis of diverse adversarial patches will likely be valuable.
A.3 Are humans needed at all?
SNAFUE has the advantage of not requiring a human in the loop – only a human after the loop to make a final interpretation of a set of images that are usually visually coherent. But can this step be automated too? To test this, we provide a proof of concept in which we use BLIP [35] and ChatGPT [48] to caption the sets of images from the attacks in Figure 2.
First, we caption a set of 10 natural patches with BLIP [35], and second, we give them to ChatGPT (v3.5) following the prompt “The following is a set of captions for images. Please read these captions and provide a simple "summary" caption which describes what thing that all (or most) of the images have in common.”
Results are shown with the images in Figure 7. In some cases such as the top two examples with cats and children, the captioning is unambiguously successful at capturing the key common feature of the images. In other cases such as with the black and white objects or the red cars, the captioning is mostly unsuccessful, identifying the objects but not the all of the key qualities about them. Notably, in the case of the images with stripe/bar features, ChatGPT honestly reports that it finds no common theme. Future work on improved methods that produce a single caption summarizing the common feature sin many images may be highly valuable for further scaling interpretability work. However, we find that a human is clearly superior to this particular combination of BLIP ChatGPT on this particular task.

A.4 Failure Modes for SNAFUE

Here we discuss various non-mutually exclusive ways in which SNAFUE can fail to find informative, interpretable attacks.
-
1.
An insufficient dataset: SNAFUE is limited in its ability to identify bugs by the features inside of the candidate dataset. If the dataset does not have a feature, SNAFUE simply cannot find it.
-
2.
Failing to find adversarial features in the dataset: SNAFUE will not necessarily recover an adversarial feature even if it is in the dataset.
-
3.
Target class features: Instead of finding novel fooling features, SNAFUE sometimes identifies features that simply resemble the target class yet evade filtering. Figure 8 (top) gives an example of this in which hippopotamuses are made to look like Indian elephants via the insertion of patches that evade filtering because they depict African elephants.
-
4.
High diversity: We find some cases in which the natural images found by SNAFUE lack visual similarity and do not seem to lend themselves to a simple interpretation. One example of this is the set of images for damselfly to dragonfly attacks in Figure 8 (middle).
-
5.
Ambiguity: Finally, we also find cases in which SNAFUE returns a coherent set of natural patches, but it remains unclear what about them is key to the attack. Figure 8 (bottom) shows images for a redbone to vizsla attack, and it seems unclear from inspection alone the role that brown animals, eyes, noses, blue backgrounds, and green grass have in the attack because multiple images share each of these qualities in common.
A.5 Examples of Natural Adversarial Patches
See Figure 9.
