DIAL: Distribution-Informed Adaptive Learning of Multi-Task Constraints for Safety-Critical Systems
Abstract
Safe reinforcement learning has traditionally relied on predefined constraint functions to ensure safety in complex real-world tasks, such as autonomous driving. However, defining these functions accurately for varied tasks is a persistent challenge. Recent research highlights the potential of leveraging pre-acquired task-agnostic knowledge to enhance both safety and sample efficiency in related tasks. Building on this insight, we propose a novel method to learn shared constraint distributions across multiple tasks. Our approach identifies the shared constraints through imitation learning and then adapts to new tasks by adjusting risk levels within these learned distributions. This adaptability addresses variations in risk sensitivity stemming from expert-specific biases, ensuring consistent adherence to general safety principles even with imperfect demonstrations. Our method can be applied to control and navigation domains, including multi-task and meta-task scenarios, accommodating constraints such as maintaining safe distances or adhering to speed limits. Experimental results validate the efficacy of our approach, demonstrating superior safety performance and success rates compared to baselines, all without requiring task-specific constraint definitions. These findings underscore the versatility and practicality of our method across a wide range of real-world tasks.
Index Terms:
Deep Learning in Robotics and Automation, Learning from Demonstration, Robot Safety, Robotics in Hazardous Fields.I introduction
Acquiring comprehensive knowledge [1, 2, 3] has been a central focus in the fields of deep reinforcement learning (RL) [4] and imitation learning (IL) [5, 6, 7], as it enables solving complex real-world problems. Recent advances in task-agnostic exploration [8, 9, 10, 11] demonstrate that leveraging shared knowledge across diverse tasks can significantly enhance performance in downstream tasks. However, in safety-critical domains such as autonomous driving, unrestricted exploration is infeasible [12, 13, 14]. Safe RL [15, 16, 17] addresses this by defining safely explorable regions as constraints. Learning a safe exploration policy [18] not only ensures adherence to safety requirements but also promotes effective transferability to novel tasks, enabling the agent to explore states within the boundaries of predefined constraints. Nevertheless, crafting accurate constraint functions across diverse tasks presents a burden. Moreover, relying solely on the acquired policy without constraints during transfer learning (TL) risks losing essential safety information previously learned.
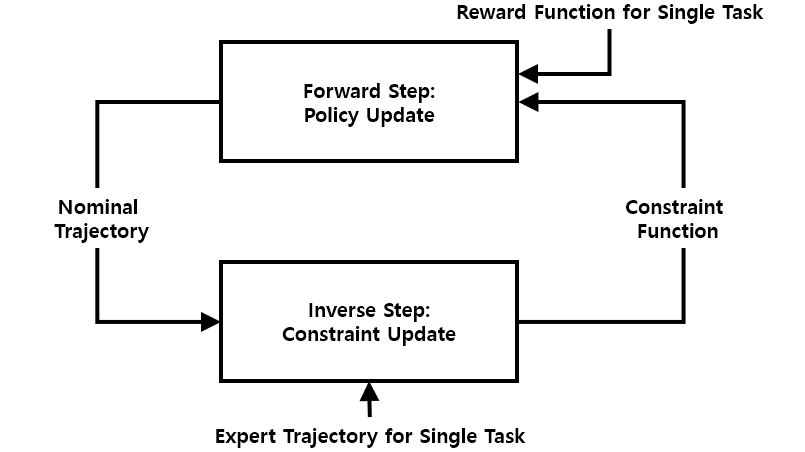
The inverse constraint RL (ICRL) framework [19, 20] offers a solution by alternatively learning constraints to ensure safety while simultaneously developing the policy that achieves goals safely under the defined reward function. However, when these constraints are restored solely from single-task demonstrations, unexplored areas in the policy space are considered unsafe. This can lead to discrepancies between inferred and actual constraints, resulting in conservative policies with large regret bounds. The issue is further exacerbated in downstream tasks, where overly conservative constraints impede finding feasible solutions. To reduce regret bounds, incorporating multi-task demonstrations to learn constraints is preferable [21]. Nonetheless, collecting demonstrations across diverse tasks poses practical challenges because it requires meeting multiple safety requirements and addressing biases that arise from experts’ risk tendencies, which remain significant hurdles in existing ICRL methods.
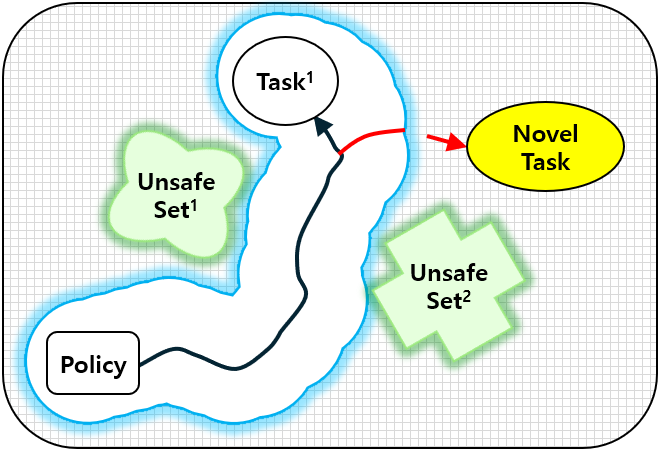
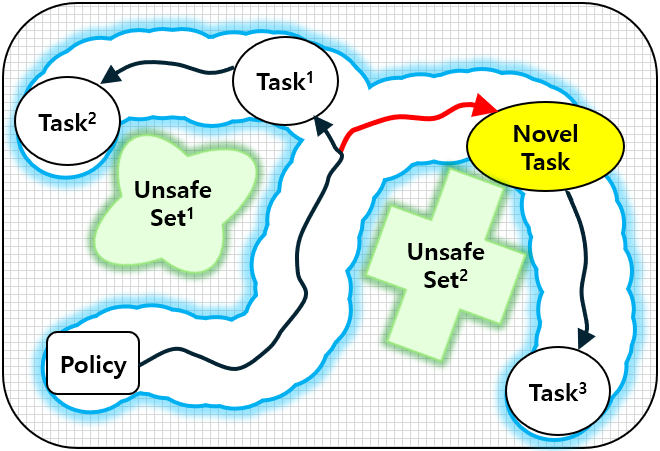
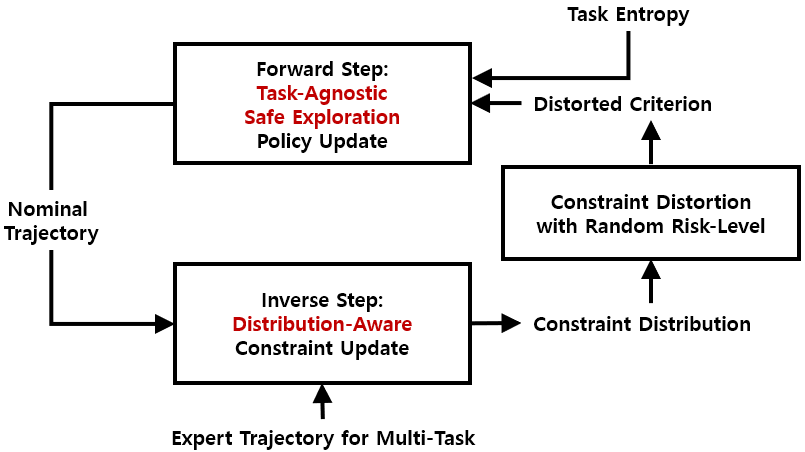
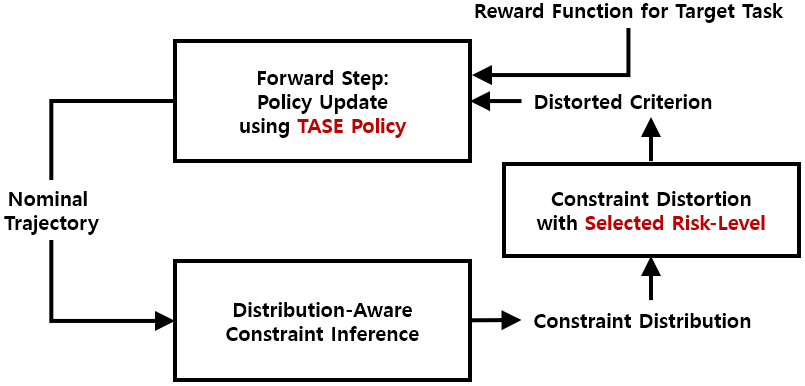
To overcome these limitations, we propose distribution-informed adaptive learning (DIAL), a novel method that leverages shared knowledge across diverse tasks to enable safe and effective adaptation to novel tasks. DIAL extends the ICRL framework by incorporating a distributional understanding of risks inherent in multi-task demonstrations. This risk-awareness is implemented through distorted criteria such as conditional value at risk (CVaR), allowing dynamic adjustment of risk levels to facilitate safe adaptation to changing environments [22, 23, 24]. The core idea of DIAL is to design the constraint function to capture the distribution of risk across tasks while encouraging task-agnostic safe exploration (TASE) by maximizing entropy across diverse risk levels. Fig. 1 describes an overview of DIAL. Similar to standard ICRL, DIAL alternatively learns both the constraint function and the policy from demonstrations. However, DIAL introduces two critical innovations: 1) In the inverse step, DIAL learns the constraint distribution from the multi-task demonstrations, providing rich supervision of safety requirements. 2) In the forward step, DIAL maximizes task entropy within the learned risk bounds, encouraging safe exploration across a broader range of tasks. These innovations bring several benefits. The learned constraint distribution facilitates risk adjustment through distorted criteria, enabling adaptation to changed safety conditions, as illustrated by the green polygons on the left side of Fig. 1b. TASE policy also enables agents to effectively find feasible solutions for TL to meta-task scenarios, as depicted by the red arrow.
Our work offers three main contributions:
-
•
We propose DIAL by incorporating awareness of constraint distributions from multi-task demonstrations and TASE into ICRL. This enables scalable knowledge acquisition that ensures compliance with safety requirements and supports solving multiple tasks.
-
•
We also alleviate the burden of manually designing cost functions by capturing constraint distributions through restored functions that align with actual safety constraints across various tasks.
-
•
Safe adaptation to novel tasks in shifted safety conditions is achieved by applying risk-sensitive constraints to guide TASE policy exploration while correcting biases in demonstrations. This enables DIAL to excel in safety-critical TL benchmarks, showcasing strong real-world potential.
II Related Work
Building on recent advancements in RL and IL, this research is inspired by various methodologies that enhance task adaptability and safety in autonomous systems.
Learning Safe Exploration Policy: Task-agnostic exploration [25, 26, 27] has become essential in RL to build generalized knowledge across diverse tasks without reliance on specific rewards or environmental dynamics. Early efforts [1, 2, 3] established frameworks for learning exploration policy that adapts effectively to new tasks. Most techniques in this area focus on improving exploration efficiency through deep RL or IL [10, 28, 29]. While these methods excel in adaptability, they typically do not address the safety constraints critical to real-world applications. On the contrary, our study aims to address through a safety-focused exploration strategy. Safe exploration policy balances the need for broad state exploration with constraints that maintain system safety. Previous works [30, 31] have proposed state density maximization as a means to enable exploration but often limited its application to discrete state spaces. Some studies [32, 18] on maximizing constrained entropy illustrate how safety constraints can be incorporated into RL frameworks to ensure TASE while enabling TL across different domains. Our study builds upon these ideas by proposing a model that uses IL rather than RL to learn safe exploration policy, reducing the need for precise cost functions and improving sample efficiency.
Learning Reward Function: Traditional IL methods [33, 34, 35], which align policy with expert behaviors through supervised learning, often encounter compounding errors, especially in dynamic settings. Advanced hybrid methods [36, 37, 38] based on maximum entropy IRL (MaxEnt IRL) [39] have mitigated these issues by unifying IL and RL approaches [40, 41]. However, adversarial IRL approaches such as GAIL [36] and AIRL [37] present stability and interpretability issues in reward function learning. To address these issues, assuming that the reward function is known, we modify the ICRL framework [20] that avoids adversarial training and focuses on interpretable constraint learning that can generalize across safety-critical tasks.
Learning Constraint Function: The shift from reward learning to constraint learning arises from the need to ensure safety rather than merely replicating expert behaviors. Approaches [42, 20] that use maximum likelihood inference, a variant of IRL, aim to learn constraint conditions from expert demonstrations without predefined functions. However, these methods can be sensitive to data quality and may struggle to generalize constraint conditions across multiple tasks. Other approaches [19, 43, 44] use grid-based or probabilistic parameters to define safety boundaries, guiding robots to avoid dangerous areas through model-based exploration. These methods show potential for maintaining constraint conditions across various tasks and enabling real-world robotic applications. However, high-resolution grid representations come with increased computational costs, which limit scalability. To address this, efforts have focused on developing flexible models capable of applying constraint functions to new environments. For instance, some studies [45, 46, 47] incorporate uncertainty into constraint inference from a distributional perspective, allowing learned constraints to adapt reliably to changed dynamics. Meanwhile, a reward-decomposition approach [48] facilitates the safe transfer of constraints to new reward structures. While these studies improve the generalizability of learned constraint functions, they often remain limited to specific tasks. Prior works [21, 26] address this limitation by exploring multi-task learning, but they still fail to account for distributional shifts. In contrast, our proposed approach learns an adaptive policy and constraint function that adjusts risk to ensure safety without strict assumptions tied to any specific task, providing a more flexible and broadly applicable solution.
Previous studies highlight the need for constraint learning that can be flexibly applied across diverse tasks. Our proposed approach, DIAL, emphasizes the derivation of a risk-sensitive constraint function and an adaptive policy from multi-task demonstrations, allowing for safety without being bound to specific tasks. DIAL effectively adjusts risk bias and supports policy adaptation across various scenarios. This design ensures scalability and safety, positioning it as a promising solution for applications such as autonomous driving and other safety-critical fields.
III Preliminaries
III-A Maximum Entropy Constrained Reinforcement Learning
The CRL approach considers the environment as a constrained Markov decision process (CMDP) [49] to learn an optimal policy that maximizes the discounted cumulative rewards while ensuring the agent adheres to a set of safety constraints. To maintain consistency in notation, we redefine the CMDP from a distribution perspective as a following tuple . Here and are state and action space, respectively, where are the elements for each space. indicates the state transition dynamics. represents the set of all reward functions, where is a reward function. Let denote the initial state distribution, the discount factor, and the set of constraints. For the -th constraint, gives the probability of incurring cost in state and action , and is a budget, which is an upper bound on expected cumulative costs. A cost function is represented as an indicator function for unsafe conditions, where is the set of all cost functions. We denote a policy as , which maps states to probability distributions over actions, where is the set of all policies. Let us refer to the -discounted cumulative sum over an infinite time horizon as the return. To be specific, we denote reward-return as and cost-return as , respectively. Here is a trajectory of state-action pair and a set of trajectories is . When is defined as the probability that policy yield trajectory with , , and for , we can represent the expected reward-return as and a constraint with expected cost-return as , respectively. Note that this type of constraint is typically referred to as ”soft”, meaning that it allows some trajectories to exceed the cost-return threshold , as long as the expected cost-return stays within . In contrast, a ”hard” constraint demands that each trajectory individually remains within the cost bound of . To enforce a hard constraint, one could set to ensure all costs remain non-negative. In this context, the objective of maximum entropy (MaxEnt) CRL is to determine an optimal policy that maximizes the expected entropy-regularized reward-return while satisfying the given constraints. This is represented by the following formulation [15]:
| (1) | ||||
where augmented term with coefficient promotes randomness in action selection, supporting a certain level of exploration to prevent getting stuck in local optima while satisfying constraints.
III-B Inverse Constraint Reinforcement Learning
In practical applications, it is challenging to manually specify all constraints to obtain an optimal policy in CRL. Nevertheless, it may be feasible to obtain expert demonstrations that satisfy safety requirements. ICRL effectively recovers the constraints from expert trajectories, assuming that the reward is available separately. To formalize this, previous studies [42, 20] that build on our starting point extend the MaxEnt model [39]. This model represents the probability of a trajectory under the policy and is adapted to CMDP as follows:
| (2) | ||||
Here serves as a feasibility indicator, representing whether a trajectory meets all constraints. Since checking this indicator becomes intractable when the state and action spaces are continuous, it is replaced by a binary classifier , which approximates the indicator using a differentiable neural network with sigmoid activation. This leads to the following maximum likelihood problem [20]:
| (3) | ||||
| where |
can be decomposed into a product of feasibility factors for each state-action pair. The feasibility that each state-action pair for all constraints is denoted as . Note that due to the properties of the sigmoid output. From here, we set with and interpret as an estimate of the probability that will be feasible, similar to the case of soft constraints. In this context, the value is usually set just above zero, allowing it to operate like a hard constraint. When calculating the gradient of the constraint model to optimize the log-likelihood in Eq. 3, the reward term can be ignored. The partition function can also be estimated through a sample-based approximation using nominal policy learned in the forward step. Thus, the update of the constraint function is derived by matching the expected gradient of for each expert and nominal trajectories as follows [20]:
| (4) |
where represents importance sampling weights, defined as the ratio relative to computed in earlier iterations. Additionally, the subscript E indicates elements associated with the expert. Assuming that the expert policy is known, we have access to expert trajectories sampled from . The standard ICRL method uses an iterative approach that alternates between updating the policy and the constraint function based on Eq. 1 and Eq. 4, as illustrated on the right side of Fig. 1a. In practice, the constraint function is approximated using the complement of obtained from the inverse step, treating it as to establish the constraints. The nominal policy is then updated using the PPO Lagrange algorithm [50].
IV Distribution-Informed Adaptive Learning
In this paper, we aim to enable agents to safely adapt to diverse environments in navigation and control domains, particularly in safety-critical systems. To achieve this objective, we propose the DIAL method, a two-stage approach designed for environments represented by a CMDP. This method first performs safe IL and then shifts its focus to safe TL. The core idea of DIAL is to simultaneously learn a constraint function that is aware of the risk distribution across various tasks and a policy encouraging safe exploration of new tasks. These components are then used to facilitate safe adaptation. In the first stage, safe IL, we use multi-task demonstrations, as illustrated on the right side of Fig. 1b, to learn both the constraint distribution and a TASE policy. Since the true constraints of the environment are unknown in this stage, we rely on expert demonstrations that accomplish multiple tasks. We assume that while these demonstrations meet all safety requirements in the original environment, they may be sub-optimal in adapted environments due to inherent biases in the expert’s risk preference. In the second stage, safe TL, as shown in Fig. 2, we utilize the distorted criterion and TASE policy. Both are flexibly adjusted based on the risk level to enable safe and efficient adaptation to meta-tasks. To illustrate the benefits of DIAL in this stage, we configure a changed environment with the same safety requirements but a new target task. The underlying hypothesis of DIAL is that the TASE strategy with awareness of the constraint distribution is crucial for managing potential risks arising from limited data while facilitating adaptation to new tasks. Notably, DIAL can also be effectively coupled with a stable linear model-based controller [51] for autonomous driving, enabling structured exploration while maintaining lane alignment. The remainder of this section provides a detailed explanation of the design of DIAL. We begin by introducing methods to infer the constraint distribution from multi-task demonstrations that allow for flexible adjustment of the risk level. We also explain how to derive a policy that supports TASE. We then describe the process of carefully adjusting the learned constraint distribution by selecting an appropriate risk level to ensure safety in the changed environment and utilizing the TASE policy to facilitate meta-task resolution.
IV-A Constraint Inference with Risk-Sensitive Criterion
When designing the distribution-aware constraint in Fig. 1b, we aim to capture the diverse risk preferences in expert demonstrations that meet safety requirements, even for randomly assigned tasks. To achieve this, we employ a learning approach that infers distorted constraint distributions with properly selected risk levels. Instead of maximum likelihood estimation for , Bayesian methods [52, 45, 46] can estimate a posterior distribution by combining a prior with the trajectory likelihood , as specified in Eq. 2. Previous methods calculate the constraint to ensure the mean of the estimated distribution remains below the threshold. However, this approach is vulnerable to long or heavy-tailed distributions, rendering it insufficiently stringent for handling rare but extreme situations. The mean constraint ultimately lacks the flexibility to adjust risk levels for changes in the unsafe set, shown as the green polygon in Fig. 1b. This limitation becomes even more pronounced in multi-task settings, where the attraction region, marked by the blue boundary, expands to cover more tasks. Although a previous study [46] addresses this issue by employing a risk-sensitive criterion like CVaR, it focuses solely on optimizing the policy for a single task during the forward step. In contrast, we emphasize using CVaR in the inverse step to learn constraints capable of handling scalable novel tasks.
When estimating statistical metrics like the mean or CVaR of a posterior distribution, it is often challenging because arbitrary distributions lack a precise closed form. Therefore, it is necessary to approximate them with more manageable distributions. In our case, we would like to model the probability that a trajectory is safe as a random variable that falls within a finite interval between 0 and 1. Consequently, we choose an ideal Beta distribution as the posterior distribution and set . The Beta distribution is particularly useful as it can represent asymmetric or heavy-tailed distributions. This distribution reflects the ratio of binary outcomes, such as successes and failures, of safe paths and is characterized by two parameters, . For simplicity in notation, we omit and assume a single constraint case. To handle multiple constraints, we can factorize , expressing it as a product of independent components.
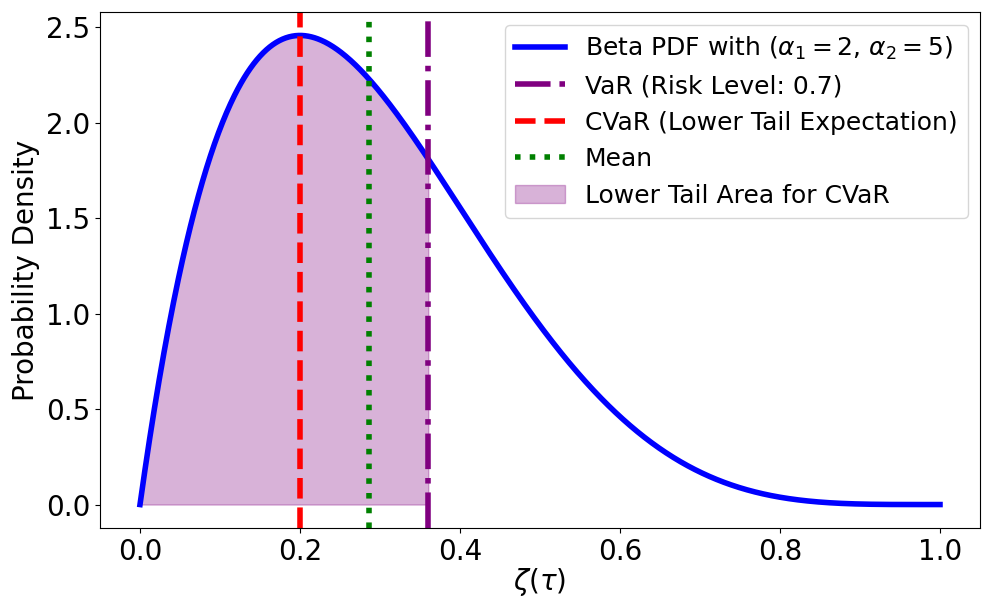
We use CVaR to measure distorted risk, taking into account the probability of a path being safe at a specified risk level within the Beta distribution. Fig. 3 illustrates how CVaR is calculated in contrast to the mean. First, we determine the value at risk (VaR), which represents the threshold probability of safety at a given risk level . This value is the -percentile , with defined as the lower -quantile of the distribution:
| (5) |
where represents the cumulative distribution function (CDF) of the distribution. Next, CVaR is obtained by calculating the expected value over the region below as follows:
| (6) |
This represents the average of extreme values at a given risk level. Note that if , CVaR is equal to the mean. We employ a neural network , which takes a trajectory as input and outputs the parameter of a Beta distribution. This approach facilitates constraint learning by capturing the risk distribution and incorporating CVaR. Since the two parameters of the Beta distribution are positive, the final layer is implemented with a softplus activation. We interpret the network’s output as variables sampled from two Gamma distributions, treating the approximated network as a prior model for the Beta distribution. This approach allows the shape of the Beta distribution to be determined by random variables generated by the Gamma distributions, rather than fixed parameters, thereby capturing uncertainty in the data. This flexibility makes probabilistic modeling more adaptable and relevant to the context. Therefore, we update the constraint model by applying the risk-sensitive criterion in place of in Eq. 4. Consequently, the gradient of the loss is formulated as:
| (7) |
In addition, considering diverse risk levels is known to be beneficial for acquiring risk-sensitive knowledge [53]. For this reason, we update the network using risk level sampled from the uniform distribution in the safe IL stage where multi-task learning is conducted. In the later safe TL stage, where achieving high performance on the target task is crucial, fine-tuning is performed using grid search to determine . Following this, we include a regularization term when optimizing the evidence lower bound (ELBO) for the approximate posterior as follows:
| (8) |
Given that both distributions and are Beta distributions, the Kullback-Leibler (KL) divergence can be computed in closed form, as shown in [54].
IV-B Policy Improvement with Task-Agnostic Safe Exploration
We introduce a novel policy improvement method within the ICRL framework that ensures safety by allowing limited exploration at an acceptable risk level, enabling effective learning across diverse tasks. Through this proposed approach, we obtain a TASE policy that helps in learning shared knowledge across various tasks. This enables the recovery of a more flexible constraint function that supports robust inference by accounting for varying risk levels and task-specific environmental changes. Our approach builds on the observation that using data spanning a wider range of tasks improves the accuracy of generalizable constraint learning [21]. Unlike prior approaches that either set constraints tailored to specific tasks [47] or apply the same constraints across all tasks [26], our method provides improved generalization and adaptability to new situations.
Learning a policy in IL involves aligning it to frequently visit the state-action spaces observed in the demonstrations. Effective training requires the nominal policy to aim for an even coverage of a wide range of states. This approach enables divergence in the probability density of state-action coverage from the expert policy, thereby facilitating learning. In practice, this approach involves increasing the entropy of the probability density over the state-action pairs that the agent visits. To achieve this, Eq. 1 includes an entropy regularizer term that directly measures the probability distribution of the nominal policy, thereby enhancing exploration. However, this naive method has limitations as it focuses solely on the probability distribution of the policy without capturing the correlations between states. In addition, simply relying on random actions for exploration can be inefficient, particularly in high-dimensional spaces or complex tasks. When the policy repeatedly selects high-reward actions early in training, confidence in these actions increases, resulting in lower entropy and reduced exploration. This can eventually hinder learning or prevent the achievement of goals.
To address these limitations, we promote structured exploration by incorporating correlations between states into our entropy estimation. This approach is implemented under constraints that ensure safety. By focusing on task-relevant states, we interpret the increase in entropy as an exploration bonus in the policy update process, effectively enhancing task entropy. To extend to complex domains, we can indirectly model the state density function using particle groups [55]. Using these particle groups, we represent the average state density visited by the policy as for time horizon , where . The entropy of the state density is computed as . In practice, we approximate this entropy using the particle groups, yielding , where represents the interval width around each particle . The approximated density for these particles is determined by estimating the volume of a hypersphere formed by the radius . This calculation uses the -NN method for each particle, where represents the position of the -th nearest neighbor (-NN) particle to . This density gives the -NN entropy estimator [56] as follows:
| (9) | ||||
Here, represents the gamma function, and is the digamma function, which is the logarithmic derivative of the gamma function. The last two terms correct the average bias introduced to address entropy underestimation for small values. To integrate this entropy estimator into RL, we use samples from the old policy to approximate the state entropy of the current policy . The policy is parameterized by a neural network with parameters . For simplicity, we denote as , omitting in the notation. Subsequently, to handle the discrepancy between the sampling policy and the target policy , we apply an importance-weighted (IW) -NN estimator [57] as follows:
| (10) | ||||
Here, is the set of indices of -NN of . In this context, when and a uniform weight is applied, we obtain . Notably, in the IW -NN estimation approach, trajectories are sampled independently, while the states within each trajectory account for the correlations among neighboring particles. Furthermore, to stabilize the convergence, we utilize a KL estimator [18]. This is computed as the difference between the IW -NN estimator in Eq. 10 and the estimator in Eq. 9, with the bias correction term canceling out. As long as the updated policy satisfies , we can optimize the policy multiple times, serving as a trust-region constraint.
Eventually, we can replace the constraint with the risk-sensitive criterion and the entropy regularizer term with the IW k-NN estimator in Eq. 1. We then solve an unconstrained min-max optimization problem by applying the Lagrangian method to the objective function [58]. This approach allows us to handle the original constrained problem as an equivalent unconstrained problem, which we define as follows:
| (11) |
where encourages the maximization of expected reward-return. Moreover, is an entropy-based term, scaled by to control the degree of entropy regularization, thereby encouraging exploration in the policy. Lastly, is a constraint term that ensures the policy remains within the constraint threshold with an expected risk . In this setup, , also referred to as the safety weight, is a Lagrange multiplier associated with the constraint term . By optimizing this Lagrangian formulation, we effectively balance maximizing rewards and entropy while minimizing the constraint violation. Algo. 1 and 2 summarize our training procedure for the safe IL and safe TL stages in DIAL, respectively.
V Experiments
We organize the experimental analysis using the following two aspects to evaluate our proposed method. First, we demonstrate our method that encourages safe exploration at varying risk levels by using multi-task demonstrations instead of explicit constraints in safe IL. Second, we reveal that leveraging our recovered risk-sensitive constraints and safe exploration policy can accelerate learning of the target task and show benefit safety assurance in safe TL.
V-A Benchmarks
Safe IL and TL are evaluated within the navigation and control domain, encompassing scenarios with risky situations involving static or dynamic obstacles across state spaces ranging from low to high dimensions. In safe IL, the aim is to perform exploration that navigates through as many safe states as feasible for arbitrarily given tasks. In safe TL, the objective is to conduct safe exploitation that effectively tackles a given target task while ensuring it remains within the constraints. To demonstrate the advantages of these two components, we have composed urban driving tasks that address real-world navigation and robot control tasks to validate performance across diverse environments, further details are described in the following paragraphs.
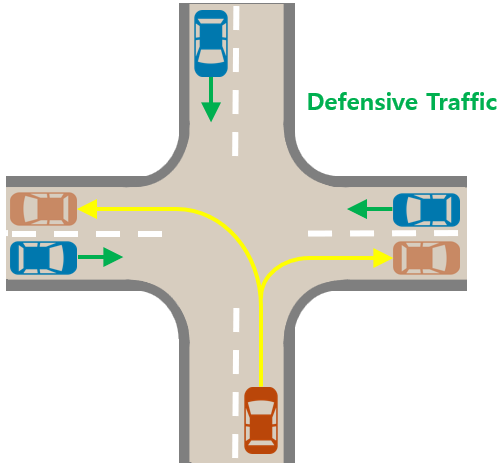
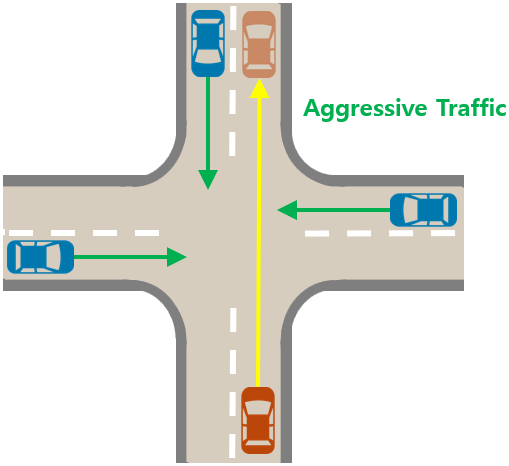
Urban Driving: To compare environments characterized by dynamic risks in high-dimensional states, we use a modified version of the intersection environment provided by HighwayEnv [59], referring [26]. Fig. 4 illustrates safe IL, where the agent learns shared constraints (4b) from demonstrations in the multi-task scenario (4a), and safe TL, where the agent applies this learned knowledge to adapt in the meta-task scenario (4c). The observation space includes 7 types of kinematic information, such as position and speed, for the agent and 15 surrounding vehicles. To achieve a permutation-invariant representation of the input independently of the order of surrounding vehicles, we use an attention-based encoder as the backbone network for the constraint model . This encoder captures the relative importance of each surrounding vehicle and calculates a weighted sum to represent the input as a latent variable in . We adopt the same controllers, reward function, and constraints as specified in [26] to ensure fair comparisons with the baselines. Each vehicle follows a fixed path by adjusting acceleration and steering angle through a linearized controller parameterized in [51]. Surrounding vehicles maintain fixed parameters, while the agent’s parameters are optimized using a constrained cross-entropy method (CEM) [32] rather than the PPO Lagrangian in Eq.11. This approach addresses multiple constraints by first ranking parameters according to the number of constraint violations, then assessing them based on violation magnitude and reward. The reward function is designed as a linear combination of random variables and features to reflect various driving preferences, including reaching the target, driving speed, and lane changes:
| (12) |
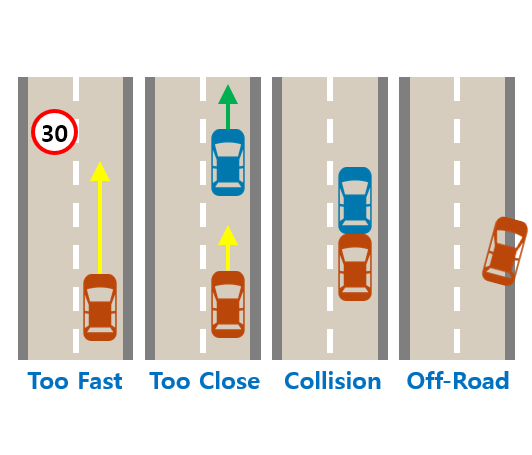
where represents the vehicle’s speed, indicates the difference angle between the heading of the vehicle and the target lane, and and are random variables. The target lane is the path extending to the given target location along the road network provided by the environment. The constraint function limits dangerous events by defining features composed of four metrics, . These features include cases where the speed exceeds 15, the distance to the vehicle ahead is less than 10, a collision occurs, and the vehicle departs from the road. A safe situation is defined as one where the probability of each event occurring in an episode remains below the ground truth constraint thresholds . In this problem, we consider as the feasibility function and learn to infer thresholds for the four defined features.

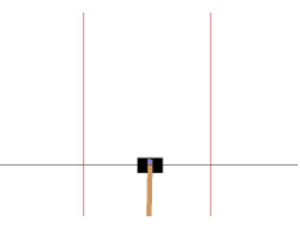
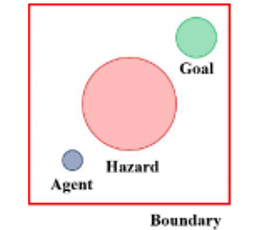

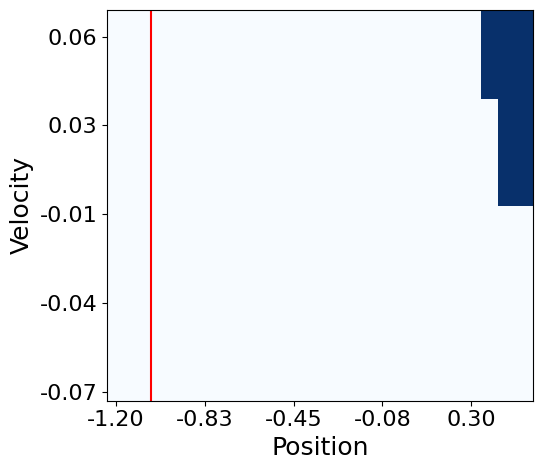
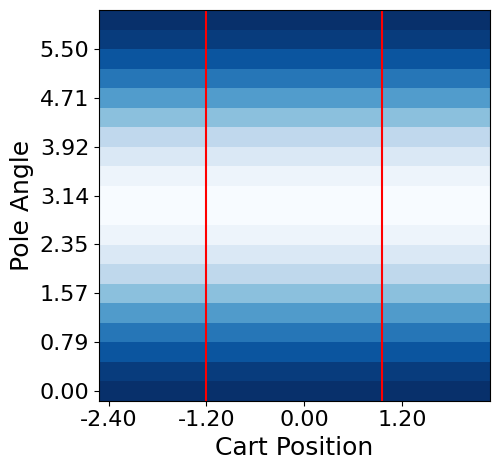
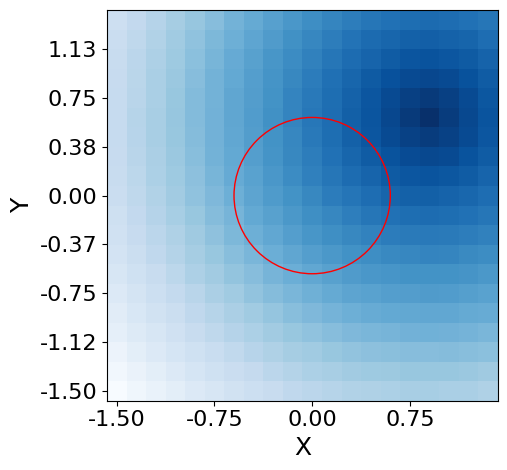
Robot Control: To compare environments with static risks in low-dimensional states, we use a modified version of OpenAI Gym [60], shown in Fig. 5a-c. Each environment has a safety area marked with a red line. For MountainCar, the goal is to reach the point where the right flag is located without the car going to the left of the red line. However, the agent is penalized so that a large action is not performed. For CartPole, the goal is to raise the pole angle vertically while keeping the cart inside both red lines. For BasicNav, the goal is to reduce the goal distance while avoiding the circular hazard region in the center. For evaluating responses to risks involving randomness in high-dimensional states, we use Safety Gym [50], illustrated in Fig. 5d. For PointGoal, we aim to control the point robot to reach a random goal described as a green cylinder. In this environment, the agent is restricted from entering the blue circles depicted on the ground or pushing the vase marked with a cyan block. A vase moving upon contact and stationary blue circles are randomly generated within a certain range around the target point.
The rewards and costs used to train the RL agent are given the prefix ”extrinsic” for those provided by the environment and ”intrinsic” for those recovered through IL. Each environment provides an extrinsic cost whenever unsafe interactions occur, but this is used only for performance evaluation and not for training. However, the extrinsic rewards from the environment and the recovered intrinsic costs are both used for training. Further details on each environment are provided in the Appendix. A.
V-B Baselines
Our approach, DIAL, is an algorithm designed to learn constraints that ensure safety when addressing new meta-tasks. These tasks are set in similar but slightly different environments from those demonstrated in multi-task settings. Several approaches based on IRL or ICL serve as natural starting points to address our constraint learning problem. This makes them suitable for comparison with our proposed method. We adopt the following three methods as baselines: MERL [39], MECL [20], and COCL [26]. MERL and MECL both belong to the MaxEnt-based IL family. They can derive the optimal policy that imitates the expert from single-task demonstrations. The key difference between these methods lies that MERL recovers rewards, while MECL focuses on recovering constraints under the assumption that rewards are known. In MERL, the average of the inferred individual rewards for each task demonstration, , can be added as a penalty term to the reward for a new meta-task. In MECL, the average of the inferred individual constraints across multi-task demonstrations, , is incorporated as a constraint term. This term is considered separately from the reward , under the assumption that the rewards for multi-task demonstrations are already known. COCL does not belong to the IL family that cannot obtain the policy. However, it can recover a shared constraint even without knowing the individual rewards for each task. This is achieved by constructing the convex hull of the safety set based on feature expectations from the demonstration data. Subsequently, if and are known, a policy can be obtained by optimizing Eq. 1. In the robot control environment illustrated in Fig. 5, COCL is excluded as a baseline because it cannot be applied due to the lack of directly defined feature vectors for the state. We highlight that our approach, like COCL, learns constraints across multi-task demonstrations. However, DIAL can derive the TASE policy and considers the distribution of constraints. These aspects distinguish our method and provide notable advantages, particularly in helping to safely adapt to changed environments when addressing new tasks.

V-C Implementation Details
DIAL trains two learnable models: the constraint function and the policy. Both models have a two-layer neural network architecture with 256 hidden units and ReLU activation across all methods. The policy handles continuous action spaces by outputting the mean and variance of a Gaussian distribution. The mean is constrained to a specific range using a tanh output, while the variance ensures positive values using a softplus output. In our approach, the constraint function approximates the parameters of a Beta distribution, which is why we use a softplus output instead of softmax. All neural network parameters are updated using the Adam [61] optimizer. As an exception, in the Urban driving environment, we employ an encoder that embeds inputs into permutation-invariant representations as the backbone model for the constraint function in all methods. Additionally, in this environment, the policy is represented by a linearized controller instead of neural network and is optimized using CEM [32]. The hyperparameters used in the experiments were tuned through a coarse grid search. Appendix. B provides detailed descriptions of the expert demonstration collection method, hyperparameter selection, and stabilization techniques for training to facilitate experiment reproduction. We observed experimentally that DIAL achieves asymptotic performance within approximately 150K environmental steps in urban driving of Fig. 4 and within 20K, 300K, 300K, and 1M environmental steps in robot control of Fig. 5. We believe these results are due to the use of a distribution-aware constraint function, which allows for flexible adjustment of risk levels and cautious exploration of new tasks. All experiments were conducted on a PC with an Intel Xeon Gold 6248R CPU (3.00GHz, 48 cores), an NVIDIA GeForce RTX 3090 GPU, and 256GB of memory.
V-D Metrics
We use the following metrics to evaluate performance: reward-return (RR), cost-return (CR), constraint violation rate (CV), and state entropy (SE). RR and CR represent the average of the total explicit rewards and costs obtained by the agent during an episode, averaged across multiple episodes. RR reflects task performance, while CR evaluates safety performance. CV indicates the proportion of episodes where the value of CR divided by exceeds the specified constraint budget , representing the likelihood of violating constraints in a single episode. When handling multiple constraints, the sum of all CVs is used. SE is calculated by discretizing two primary states in each environment and measuring the frequency with which the policy visits each state during all episodes. This metric is used to compare the exploration level of different policies. In particular, the map that assigns visit frequencies or inferred constraints to each discretized state is useful for qualitative comparisons. The two primary states are empirically selected for each environment to clearly highlight differences. For more details, please refer to Tab. LABEL:table:environmental_settings in Appendix. A. All metrics are presented as the average values measured over 20 episodes for 5 seeds. The shaded areas in the plots represent the standard deviation.
V-E Results for Safe Imitation Learning
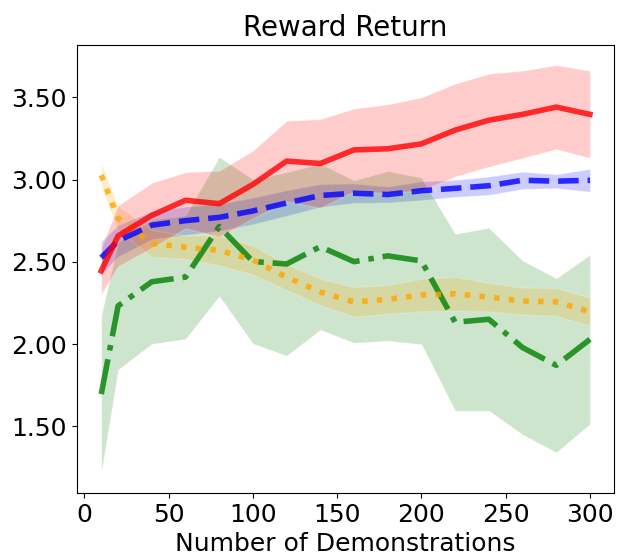
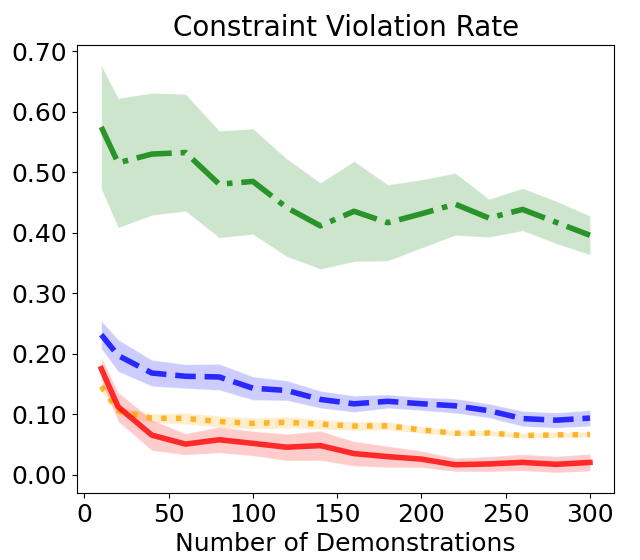
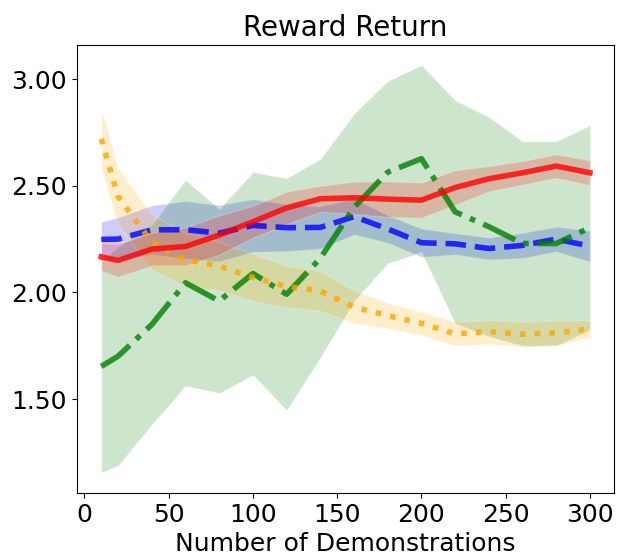
This section evaluates the constraint function related to safety requirements and the policy associated with task success through safe imitation learning (IL) from demonstrations collected while safely performing multi-task. Fig. 6a shows the RR measured according to the number of expert demonstrations used for training, as well as the sum of the four CVs presented in Fig. 4b. Our proposed DIAL method achieves both higher task performance and lower CV as more demonstrations are used, demonstrating the best results among the compared baselines. While there is a slight increase in the variance of RR in the last segment of the plot, the values show a gradually stable increase. This can be interpreted as a natural phenomenon due to the differences in scale among the various tasks. COCL maintains relatively stable performance but is not as efficient as DIAL. MERL shows little improvement in RR even when many demonstrations are used, and it decreases at the end due to overfitting. Additionally, CV remains high. Although MECL effectively reduces CV, RR decreases as more demonstrations are added due to excessive conservatism.
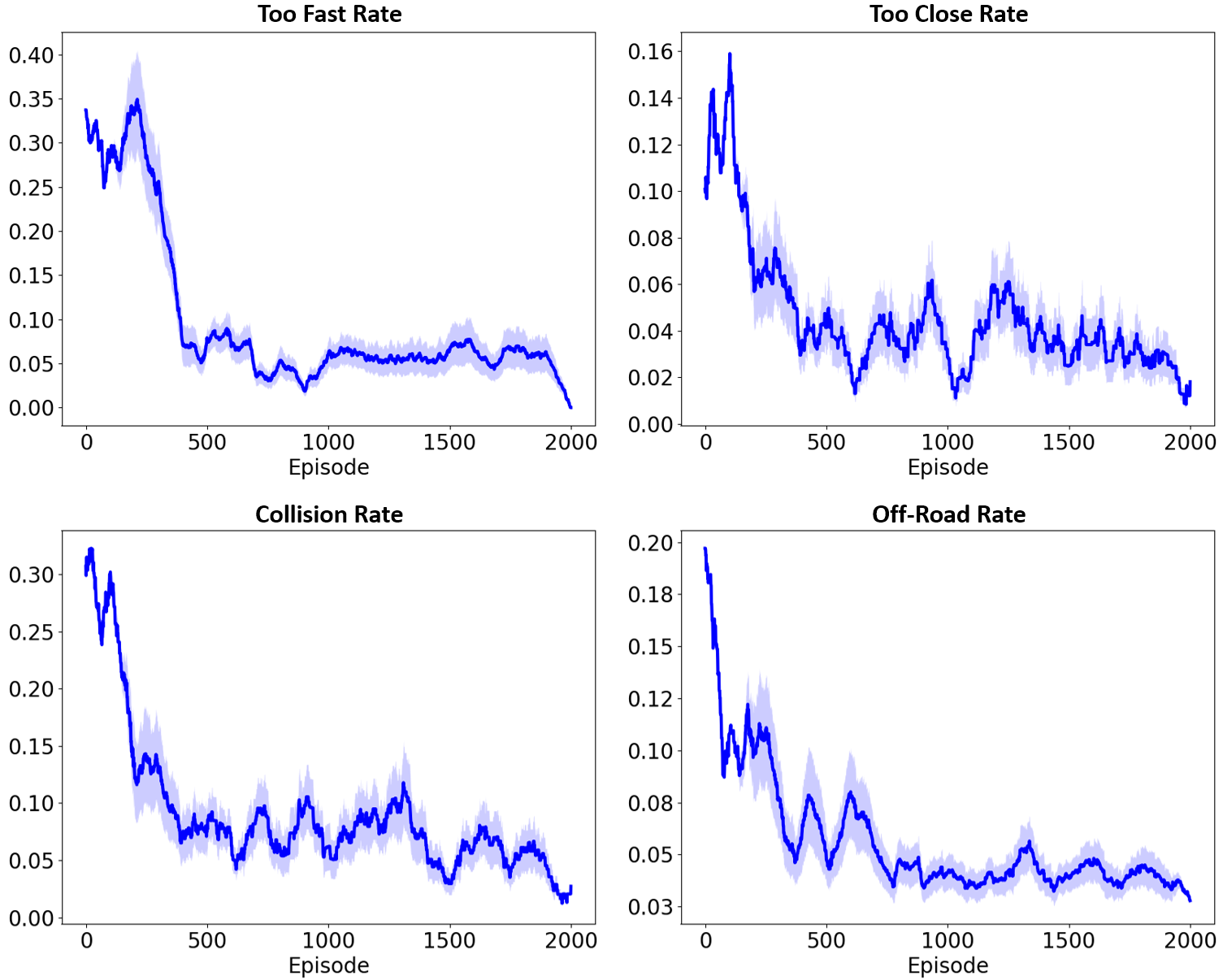
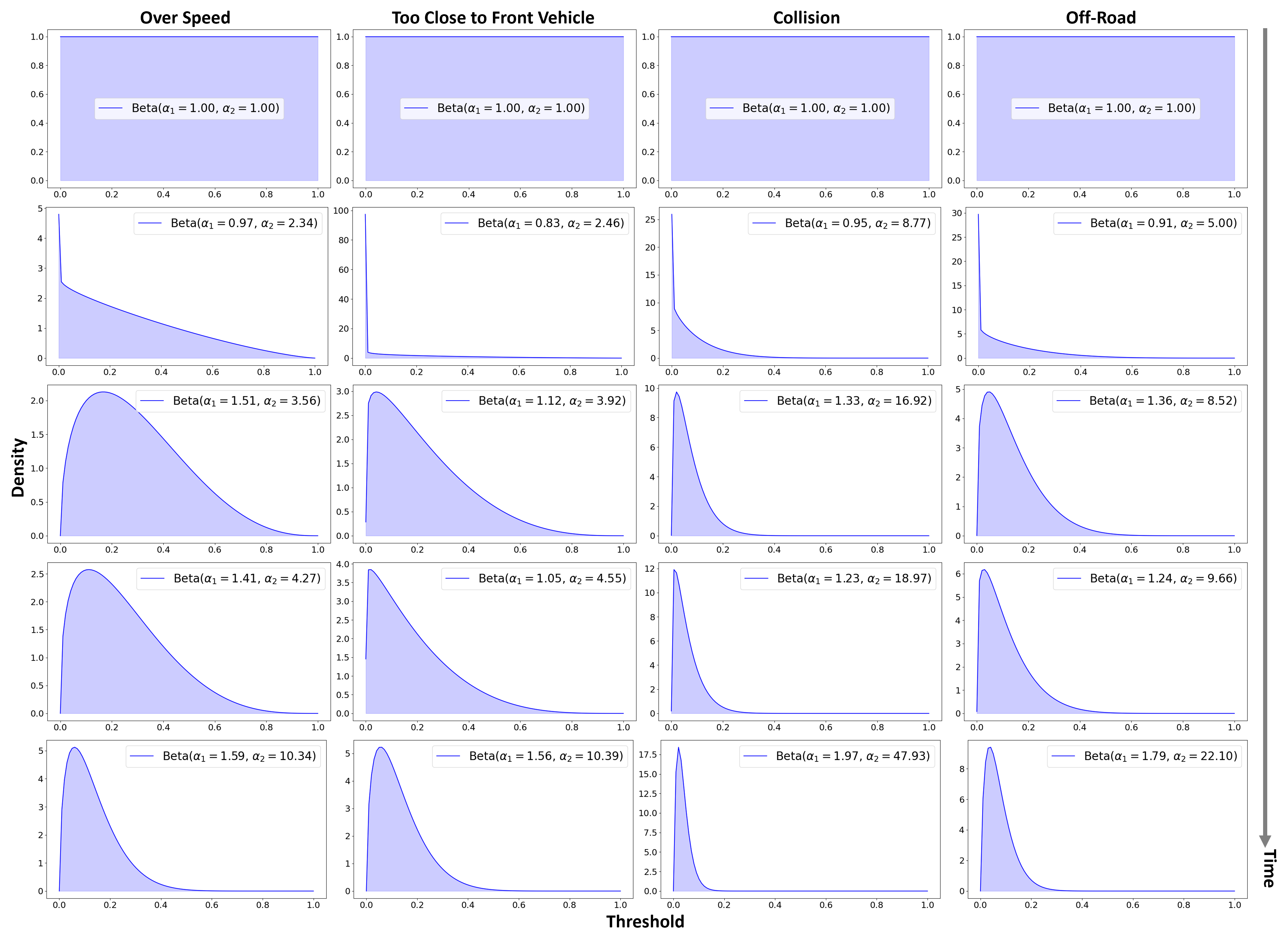
To confirm whether DIAL has successfully learned all the designed constraints when trained with 300 expert trajectories, Fig. 7 presents learning curves showing the violation rates for each condition. As training progresses, the violation rates for all constraints gradually decrease and ultimately stabilize at low levels, demonstrating the stability and reliability of the proposed method. Furthermore, to examine the proposed method that approximates each constraint budget as variables of a Beta distribution, Fig. 8 shows how the density function of this distribution evolves for training. These results indicate that DIAL can learn to adhere to the constraints more effectively. At the beginning of training, all conditions start with low parameter values, resulting in a distribution that is evenly spread across the entire threshold range. As training progresses and the value increases rapidly, the distribution becomes concentrated in the lower threshold region. This rapid increase can cause the agent to become overly conservative, potentially limiting task performance. To prevent this, the proposed method distorts the distribution based on randomly sampled risk levels, encouraging flexible exploration for specific conditions. Additionally, the term in Eq. 8 prevents overfitting of the distribution by incorporating a given prior probability. Due to this design, soft constraints like speeding or maintaining distance from the vehicle ahead can allow some violations during the middle stages of training, enabling finer adjustments. Towards the later stages of training, there is a noticeable tendency for the density to increase at specific thresholds and for the distribution to narrow. This implies that the model has gradually achieved stable performance.
| Environments | MountainCar | CartPole | BasicNav | |||||||||||||||
| Trajectories | 1 | 10 | 50 | 1 | 10 | 50 | 1 | 10 | 50 | |||||||||
| Metrics | SE | CR | SE | CR | SE | CR | SE | CR | SE | CR | SE | CR | SE | CR | SE | CR | SE | CR |
| MERL | 4.17 | 4.03 | 4.21 | 0.34 | 4.30 | 0.18 | 4.41 | 7.25 | 4.48 | 1.97 | 4.49 | 1.41 | 2.61 | 85.3 | 2.89 | 47.2 | 2.97 | 17.9 |
| MECL | 3.45 | 0.03 | 4.08 | 0.12 | 4.10 | 0.61 | 4.35 | 1.21 | 4.46 | 1.81 | 4.47 | 2.02 | 1.61 | 0.38 | 1.96 | 1.01 | 2.02 | 1.75 |
| DIAL | 4.04 | 0.01 | 4.29 | 0.02 | 4.34 | 0.05 | 4.45 | 0.03 | 4.48 | 0.26 | 4.49 | 1.37 | 2.73 | 0.35 | 2.84 | 0.71 | 2.94 | 1.10 |

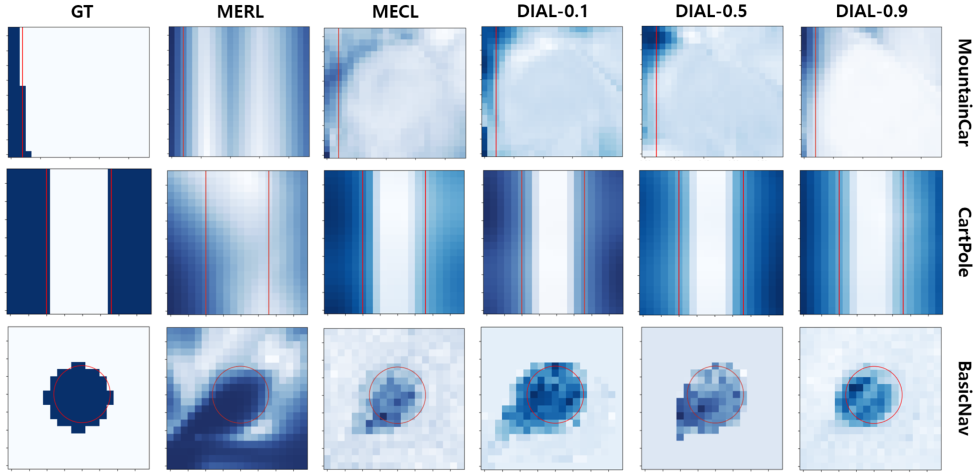
In the robot control environments, we evaluate the degree of safe exploration of policy by comparing the SE and CR based on the number of expert trajectories used, as shown in Tab. I. DIAL demonstrates higher SE and simultaneously lower CR compared to other methods, even when using a relatively small number of trajectories in all environments. MERL exhibits high exploration performance in terms of SE but has a high CR, leading to reduced safety. MECL maintains a relatively low CR but has low SE, indicating insufficient exploration performance. Although DIAL’s SE is slightly lower than MERL’s, the difference is minimal as shown by the underlined numbers and there is a significant difference in CR. These results demonstrate that our method successfully balances diverse state exploration and safety.
Furthermore, Fig. 9 visually demonstrates the effectiveness of DIAL’s design in finely adjusting the deviation in risk levels by carefully selecting with limited data. Even when using the same expert data shown on the far left in Fig. 9a, the exploratory tendencies of the learned policy vary depending on the choice of . Policy tend to avoid risks when is low and take risks when is high. This result suggests that setting a low is advantageous for balancing when expert states are near the safety boundary. Conversely, when the data is far from the boundary, setting a high is more appropriate. Fig. 9b shows that we can infer a constraint that most closely resembles the ground truth (GT) located on the far left by finely tuning in DIAL. In contrast, MERL fails to properly capture the constraint distribution, and MECL can have its distribution’s center and shape distorted differently from the GT due to reliance on the characteristics of the data used for training.
| Environments | MountainCar | CartPole | BasicNav | PointGoal | ||||
| Metrics | RR | CR (0.5) | RR | CR (5) | RR | CR (10) | RR | CR (25) |
| MERL | 74.2 12.6 | 4.26 1.63 | 695 1.34 | 99.4 26.7 | 215 0.64 | 98.7 0.17 | 13.3 0.09 | 34.3 0.85 |
| MECL | 36.2 15.2 | 0.64 0.28 | 694 1.45 | 86.1 19.4 | 210 0.83 | 74.7 12.6 | 7.08 0.23 | 27.5 1.94 |
| DIAL | 92.9 0.23 | 0.41 0.11 | 693 2.25 | 3.66 2.01 | 213 0.54 | 4.32 2.88 | 10.55 0.39 | 20.3 1.19 |
V-F Results for Safe Transfer Learning
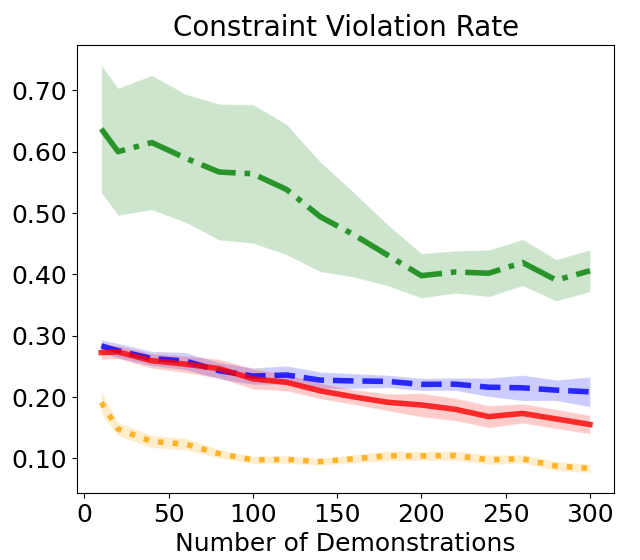
In this section, we address safe TL in environments where the safety requirements are the same as safe IL, but the explicit reward functions for the target task are given. In safe TL, the key concern is whether the agent can maintain compliance with the constraints without forgetting them despite changes in the objective function for solving the target task. To demonstrate that using the function recovered through safe IL reduces the burden of cost design, we use the extrinsic cost only to evaluate safety and do not use it in safe TL. Details of the hyperparameters used for training the agent are provided in Tab. LABEL:table:safeTL_hyperparameters in Appendix. B. Fig. 6b compares the performance of meta-task learning in the urban driving environment illustrated in Fig. 4c. For DIAL, as the number of demonstrations increases, RR steadily improves while CV decreases. In the case of COCL, although it has slightly better performance than DIAL when the number of demonstrations is small, it shows only a marginal reduction in CV and almost no improvement in RR, even with an increased number of demonstrations. MERL has significant limitations in terms of safety, while MECL suffers from degraded performance due to overly conservative behavior. Overall, DIAL effectively balances performance and safety, utilizing the available demonstrations to achieve the best overall results.
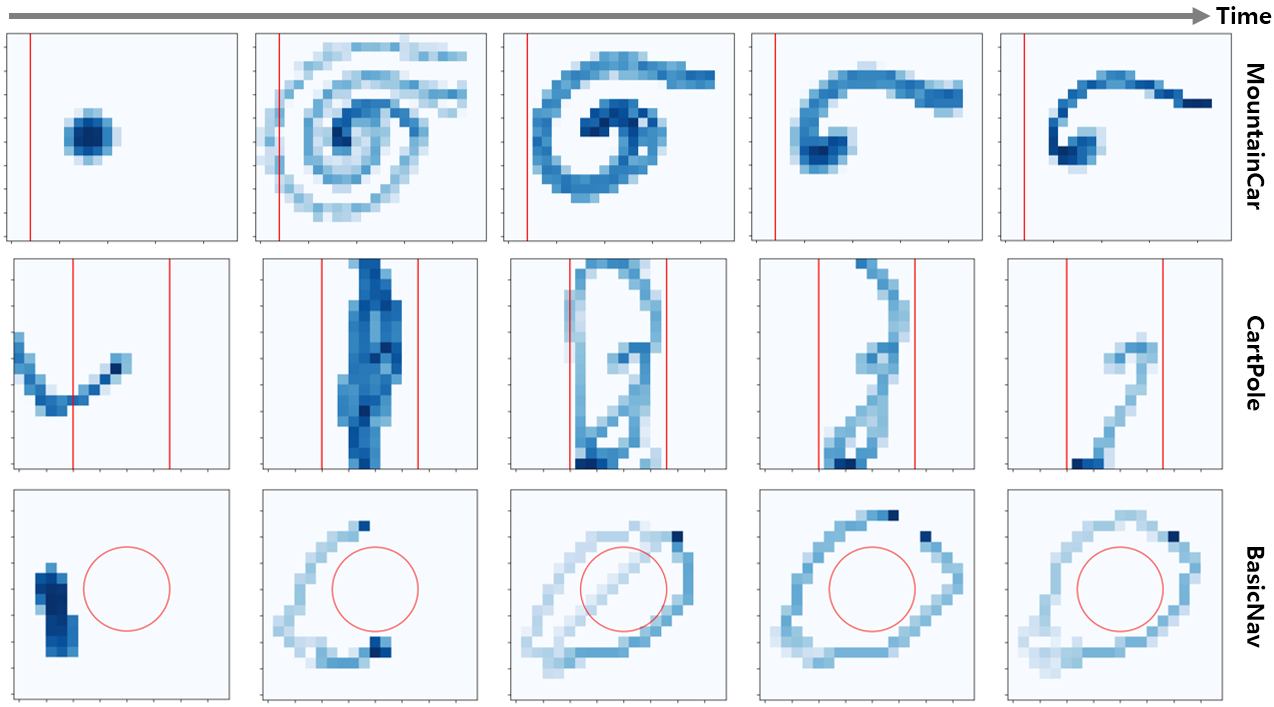
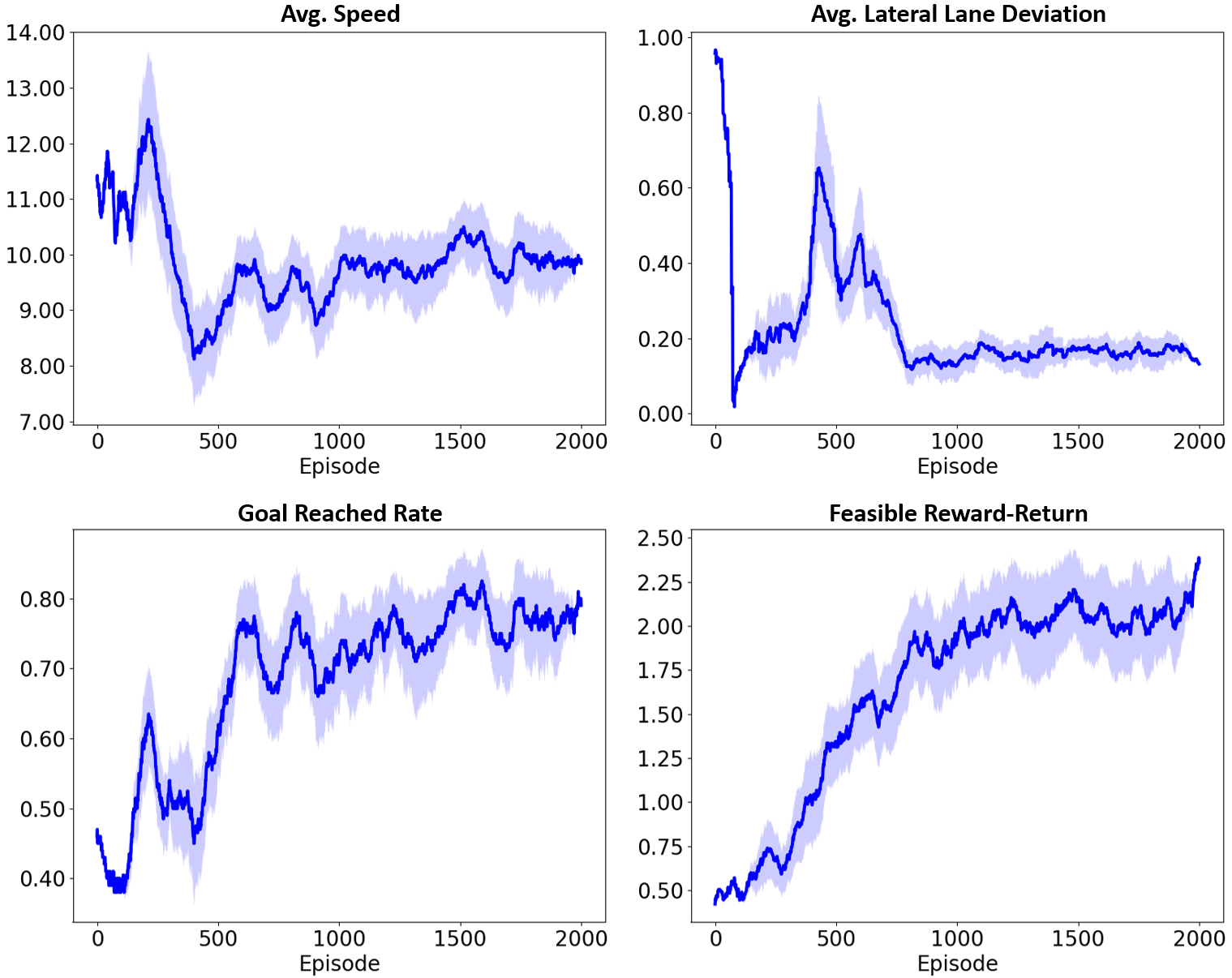
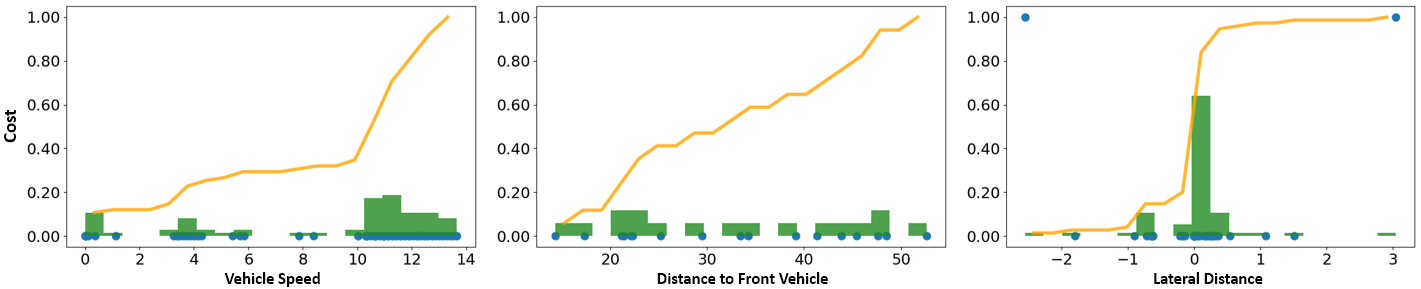
Fig. 10 illustrates how the DIAL agent gradually acquires the ability to perform tasks safely and efficiently during the learning process. The average speed fluctuates significantly in the early stages, However, it gradually stabilizes between approximately 11 and 12 as the episodes progress. The vehicle’s deviation from the lane center also reaches a stable level below 0.2. The goal achievement rate and feasible rewards steadily increase and converge to certain values, where feasible rewards are the sum of rewards the agent obtains only when all safety requirements are met. In the % of cases where the goal is not achieved, timeouts occur due to deadlocks caused by congestion or collisions in the surrounding traffic. To verify how the agent trained with DIAL performs the meta-task safely, we visualize the distribution of environmental data obtained by the agent while executing tasks in a single episode, as shown in Fig. 11. The vehicle’s speed remains mostly concentrated near the threshold without exceeding the speed limit of 15. The distance to the vehicle ahead is evenly distributed over values greater than the threshold of 10. The lateral distance from the center of the lane is concentrated within the range of -1 to 1 to prevent lane departure, where the deviations in values are due to reaching the destination. These results show that the agent learns and retains behaviors such as maintaining speed limits, safe distances, and staying centered in the lane, even when performing novel tasks.
Tab. II presents a comparison of RR and CR measured using the fully trained policies on robot control tasks. DIAL consistently exhibits the lowest CR across all environments, satisfying the condition that the average is less than the threshold for each environment, as indicated in parentheses. In terms of RR, DIAL shows the highest performance in MountainCar, and while MERL has the highest RR in the other environments, DIAL achieves performance that is nearly comparable to MERL, as seen in the underlined numbers. For MERL, although the RR is relatively high, the CR is extremely large, which limits its ability to address safety issues. In the case of MECL, the RR is generally low, and the CR is higher than that of DIAL, exceeding the threshold for each environment.
Fig. 12 visually depicts the improvement process of the policy learned through DIAL in safe TL. In the early stages of training, the agent visits as many safe states as possible. During the middle of training, unsafe interactions occur at the boundaries of the safe area. However, The agent gradually converges to maximize the reward for the given target task while satisfying safety constraints. For detailed information on the rewards for each environment, please refer to Figure 13 in Appendix A. These results demonstrate that even when the objective function is altered to maximize the reward of a new target task, the proposed method does not lose the safety information previously learned.
VI Conclusion
This paper proposes a novel approach called DIAL for safe RL in autonomous driving. DIAL leverages multi-task demonstrations to reconstruct the distribution of shared safety constraints and flexibly adjusts the required risk levels to address new tasks, demonstrating superior safety and efficiency compared to existing methods in experimental results. This approach offers a promising solution for safe exploration in safety-critical autonomous systems by enabling safe adaptation to new environments without relying on explicitly defined constraints. However, DIAL requires sufficient demonstrations to learn scalable constraints across multiple tasks, which can be challenging and costly in complex environments. Additionally, the two-stage learning structure, in which constraints are first learned from data and then used to safely adapt based on the given reward functions, can reduce learning efficiency. Moreover, selecting inappropriate risk levels during the distortion of constraint distributions may lead to overly conservative or overly optimistic behaviors, potentially hindering task performance or compromising safety. To overcome these limitations, it is necessary to develop methods that effectively utilize suboptimal demonstrations. Furthermore, integrating the two-stage learning structure into a single stage can enhance learning efficiency. Additionally, incorporating techniques that automatically optimize or dynamically adjust risk levels could achieve a more effective balance between safety and performance, presenting a promising research direction. Extending these approaches to other safety-critical domains, such as healthcare, would also allow for the validation of their scalability and broad applicability. These research directions are expected to overcome the limitations of DIAL and contribute to the development of more robust and efficient safe RL methods.
Configurations Intersection MountainCar CartPole BasicNav PointGoal State Dimension [15, 7] 2 4 2 36 Action Dimension 5 1 1 2 2 Constraint Budget () [0.2, 0.2, 0.05, 0.1] 0.005 0.05 0.1 0.25 Maximum Episode Length () 75 400 400 1200 500 Discretized States - [Position, Velocity] [Cart Position, Pole Angle] [Position X, Position Y] - Size for Discretization () - [24, 22] [20, 20] [20, 20] - Reward Function
Appendix A Environmental Settings
Tab. LABEL:table:environmental_settings provides details about each environment used in the experiments. Although we assume infinite-horizon settings, the experimental environment is finite-horizon, which requires calculating the discounted approximation of in a finite horizon as . The parameter represents the threshold for the cost-return. The value ranges between 0 and 1. It indicates the probability that the agent violates the constraint in a single episode. For the robot control tasks shown in Fig. 5(a-d), is set to 0.5, 5, 10, and 25, respectively. These values are consistent with the configurations in [18]. In high-dimensional environments such as Intersection and PointGoal, the states are not discretized for visualization because selecting two main dimensions that clearly represent the state space is difficult. To aid understanding, Fig. 13 presents the visualization map of the reward function based on discretized states for each environment depicted in Fig. 5(a-c). In the main text, the axis information for these visualization maps is consistent with that in the figure and is omitted for simplicity. To implement the PointGoal environment using the SafetyGym engine, the configuration dictionary is as follows:
Appendix B Implementation Details
Expert Demonstrations: To collect the expert trajectories for urban driving tasks, the agent is trained to maximize true rewards while satisfying multiple constraints defined by the designed features in Fig. 4b and the ground-truth budgets. The trained agent from [32] is then deployed in the environment shown in Fig. 4a, targeting randomly selected goal positions that require either a left or right turn. For robot control tasks, we deploy a trained agent based on [18] in an environment with known true costs but no assigned target task.
Hyperparameters: This section briefly describes the hyperparameters required to reproduce our experiments. As shown in Tab. LABEL:table:unified_hyperparameters, several hyperparameters are unified across all methods to ensure a fair comparison. The parameters , , and correspond to the hyperparameters of CEM. While these are not explicitly mentioned in the main text, the pseudocode for CEM is provided in Algo. 4 of [26]. Tab. LABEL:table:safeIL_hyperparameters and LABEL:table:safeTL_hyperparameters present the hyperparameters used for each environment during the safe IL and safe TL stages, respectively.
| Hyperparameters | Value | Notation |
| Number of in Rollout Buffer | ||
| Discount Factor | 0.99 | |
| Learning Rate for Constraint | ||
| Learning Rate for Constraint Prior | ||
| Learning Rate for Safety Weight | ||
| Learning Rate for Reward | ||
| Initial Safety Weight | 1.0 | |
| Number of Neighbors | 4 | |
| Damp Scaling Factor | 10 | |
| Beta Prior | [0.1, 0.9] | |
| Number of Samples for CEM | 80 | |
| Number of Elites for CEM | 20 | |
| Number of Iterations for CEM | 5 |
| Hyperparameters | Intersection | MountainCar | CartPole | BasicNav | PointGoal | Notation |
| Environmental Steps | - | |||||
| Entropy Coefficient | 0.01 | 0.01 | 0.01 | 1.0 | 0.1 | |
| Trust-Region Threshold |
Hyperparameters Intersection MountainCar CartPole BasicNav PointGoal Notation Environmental Steps - Number of in Expert Buffer 100 50 50 50 500 Risk Level 0.5 0.5 0.5 0.5 0.1 Entropy Coefficient 0.01
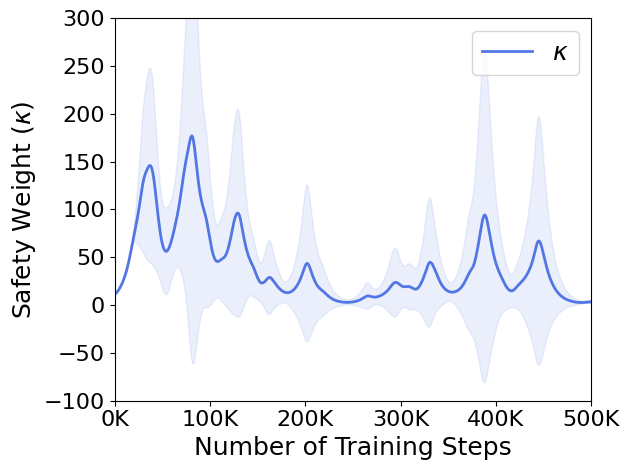
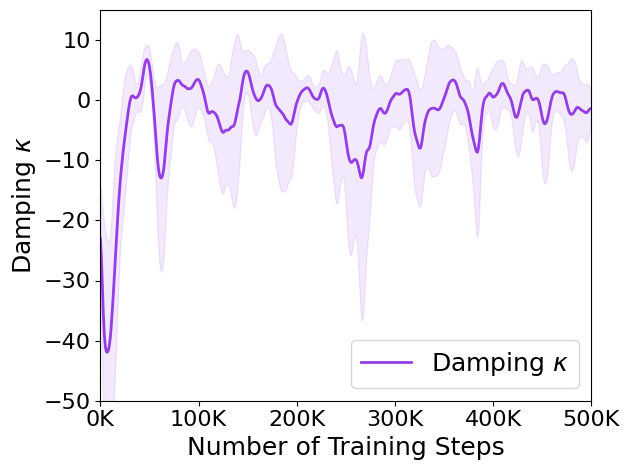
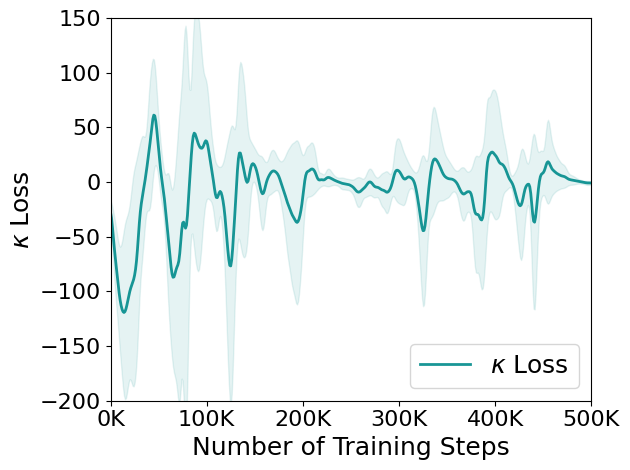
Technique for Learning Stability: In general, the learning rate of is set to a small value. At this point, the following issues arise. When the policy is unsafe, cannot quickly adjust to a larger value needed to ensure safety. Conversely, when the policy is safe, does not swiftly revert to a smaller value. This fact destabilizes the learning process. To address the instability, we introduce a damping weight in place of in Eq. 11. This adjustment directly tackles the issue by allowing the algorithm to dynamically respond to safety considerations while stabilizing the learning process. The damping weight is defined as based on methods [62, 63], where is a damp scaling factor. This formulation adjusts based on the difference between the safety threshold and the expected safety risk , providing a more nuanced response to environmental conditions. Fig. 14 illustrates how the original safety weight and the damping weight operate during environmental interactions, as measured in the CartPole environment. The loss value, which becomes negative when the expected risk exceeds the safety limit and positive when it falls below the limit, directly influences these weights. When the loss value is negative, the safety weight increases, but the damping weight prevents a sharp rise. Conversely, when the loss value is positive, the safety weight decreases, and the damping weight mitigates a rapid decline. Over time, the loss value and damping weight stabilize around zero, while the safety weight fluctuates before eventually converging to a stable value. This approach ensures a more stable learning process by dynamically adjusting based on safety requirements at each iteration.
References
- [1] M. Laskin, H. Liu, X. B. Peng, D. Yarats, A. Rajeswaran, and P. Abbeel, “Cic: Contrastive intrinsic control for unsupervised skill discovery,” in Deep RL Workshop NeurIPS 2021, 2021.
- [2] M. Laskin, D. Yarats, H. Liu, K. Lee, A. Zhan, K. Lu, C. Cang, L. Pinto, and P. Abbeel, “Urlb: Unsupervised reinforcement learning benchmark,” in 35th Conference on Neural Information Processing Systems (NeurIPS). Neural Information Processing Systems Foundation, 2021.
- [3] M. Mutti, M. Mancassola, and M. Restelli, “Unsupervised reinforcement learning in multiple environments,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 7850–7858.
- [4] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [5] D. A. Pomerleau, “Efficient training of artificial neural networks for autonomous navigation,” Neural computation, vol. 3, no. 1, pp. 88–97, 1991.
- [6] S. Schaal, “Learning from demonstration,” Advances in neural information processing systems, vol. 9, 1996.
- [7] B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A survey of robot learning from demonstration,” Robotics and autonomous systems, vol. 57, no. 5, pp. 469–483, 2009.
- [8] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International conference on machine learning. PMLR, 2017, pp. 1126–1135.
- [9] A. P. Badia, P. Sprechmann, A. Vitvitskyi, D. Guo, B. Piot, S. Kapturowski, O. Tieleman, M. Arjovsky, A. Pritzel, A. Bolt et al., “Never give up: Learning directed exploration strategies,” in International Conference on Learning Representations, 2019.
- [10] R. Y. Tao, V. François-Lavet, and J. Pineau, “Novelty search in representational space for sample efficient exploration,” Advances in Neural Information Processing Systems, vol. 33, pp. 8114–8126, 2020.
- [11] Y. Seo, L. Chen, J. Shin, H. Lee, P. Abbeel, and K. Lee, “State entropy maximization with random encoders for efficient exploration,” in International Conference on Machine Learning. PMLR, 2021, pp. 9443–9454.
- [12] J. Garcıa and F. Fernández, “A comprehensive survey on safe reinforcement learning,” Journal of Machine Learning Research, vol. 16, no. 1, pp. 1437–1480, 2015.
- [13] A. Marot, B. Donnot, C. Romero, B. Donon, M. Lerousseau, L. Veyrin-Forrer, and I. Guyon, “Learning to run a power network challenge for training topology controllers,” Electric Power Systems Research, vol. 189, p. 106635, 2020.
- [14] G. Dulac-Arnold, N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester, “Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,” Machine Learning, vol. 110, no. 9, pp. 2419–2468, 2021.
- [15] J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” in International conference on machine learning. PMLR, 2017, pp. 22–31.
- [16] A. Wachi and Y. Sui, “Safe reinforcement learning in constrained markov decision processes,” in International Conference on Machine Learning. PMLR, 2020, pp. 9797–9806.
- [17] Z. Qin, Y. Chen, and C. Fan, “Density constrained reinforcement learning,” in International Conference on Machine Learning. PMLR, 2021, pp. 8682–8692.
- [18] Q. Yang and M. T. Spaan, “Cem: Constrained entropy maximization for task-agnostic safe exploration,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 10 798–10 806.
- [19] G. Chou, D. Berenson, and N. Ozay, “Learning constraints from demonstrations,” in Algorithmic Foundations of Robotics XIII: Proceedings of the 13th Workshop on the Algorithmic Foundations of Robotics 13. Springer, 2020, pp. 228–245.
- [20] S. Malik, U. Anwar, A. Aghasi, and A. Ahmed, “Inverse constrained reinforcement learning,” in International conference on machine learning. PMLR, 2021, pp. 7390–7399.
- [21] K. Kim, G. Swamy, Z. Liu, D. Zhao, S. Choudhury, and S. Z. Wu, “Learning shared safety constraints from multi-task demonstrations,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [22] V. Khokhlov, “Conditional value-at-risk for elliptical distributions,” Evropskỳ časopis ekonomiky a managementu, vol. 2, no. 6, pp. 70–79, 2016.
- [23] Y. C. Tang, J. Zhang, and R. Salakhutdinov, “Worst cases policy gradients,” in Proceedings of the Conference on Robot Learning, ser. Proceedings of Machine Learning Research, L. P. Kaelbling, D. Kragic, and K. Sugiura, Eds., vol. 100. PMLR, 30 Oct–01 Nov 2020, pp. 1078–1093. [Online]. Available: https://proceedings.mlr.press/v100/tang20a.html
- [24] Q. Yang, T. D. Simão, S. H. Tindemans, and M. T. Spaan, “Wcsac: Worst-case soft actor critic for safety-constrained reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 10 639–10 646.
- [25] X. Zhang, Y. Ma, and A. Singla, “Task-agnostic exploration in reinforcement learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 11 734–11 743, 2020.
- [26] D. Lindner, X. Chen, S. Tschiatschek, K. Hofmann, and A. Krause, “Learning safety constraints from demonstrations with unknown rewards,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2024, pp. 2386–2394.
- [27] I. Greenberg, S. Mannor, G. Chechik, and E. Meirom, “Train hard, fight easy: Robust meta reinforcement learning,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [28] B. C. Stadie, S. Levine, and P. Abbeel, “Incentivizing exploration in reinforcement learning with deep predictive models,” arXiv preprint arXiv:1507.00814, 2015.
- [29] C. Jin, A. Krishnamurthy, M. Simchowitz, and T. Yu, “Reward-free exploration for reinforcement learning,” in International Conference on Machine Learning. PMLR, 2020, pp. 4870–4879.
- [30] E. Hazan, S. Kakade, K. Singh, and A. Van Soest, “Provably efficient maximum entropy exploration,” in International Conference on Machine Learning. PMLR, 2019, pp. 2681–2691.
- [31] L. Lee, B. Eysenbach, E. Parisotto, E. Xing, S. Levine, and R. Salakhutdinov, “Efficient exploration via state marginal matching,” arXiv preprint arXiv:1906.05274, 2019.
- [32] M. Wen and U. Topcu, “Constrained cross-entropy method for safe reinforcement learning,” Advances in Neural Information Processing Systems, vol. 31, 2018.
- [33] C. Sammut, S. Hurst, D. Kedzier, and D. Michie, “Learning to fly,” in Machine Learning Proceedings 1992. Elsevier, 1992, pp. 385–393.
- [34] G. M. Hayes and J. Demiris, A robot controller using learning by imitation. University of Edinburgh, Department of Artificial Intelligence Edinburgh, UK, 1994.
- [35] P. Abbeel and A. Y. Ng, “Apprenticeship learning via inverse reinforcement learning,” in Proceedings of the twenty-first international conference on Machine learning, 2004, p. 1.
- [36] J. Ho and S. Ermon, “Generative adversarial imitation learning,” Advances in neural information processing systems, vol. 29, 2016.
- [37] J. Fu, K. Luo, and S. Levine, “Learning robust rewards with adverserial inverse reinforcement learning,” in International Conference on Learning Representations, 2018.
- [38] D. Garg, S. Chakraborty, C. Cundy, J. Song, and S. Ermon, “Iq-learn: Inverse soft-q learning for imitation,” Advances in Neural Information Processing Systems, vol. 34, pp. 4028–4039, 2021.
- [39] B. D. Ziebart, A. L. Maas, J. A. Bagnell, A. K. Dey et al., “Maximum entropy inverse reinforcement learning.” in Aaai, vol. 8. Chicago, IL, USA, 2008, pp. 1433–1438.
- [40] B. Piot, M. Geist, and O. Pietquin, “Bridging the gap between imitation learning and inverse reinforcement learning,” IEEE transactions on neural networks and learning systems, vol. 28, no. 8, pp. 1814–1826, 2016.
- [41] C. Finn, P. Christiano, P. Abbeel, and S. Levine, “A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models,” arXiv preprint arXiv:1611.03852, 2016.
- [42] D. R. Scobee and S. S. Sastry, “Maximum likelihood constraint inference for inverse reinforcement learning,” arXiv preprint arXiv:1909.05477, 2019.
- [43] G. Chou, D. Berenson, and N. Ozay, “Learning constraints from demonstrations with grid and parametric representations,” The International Journal of Robotics Research, vol. 40, no. 10-11, pp. 1255–1283, 2021.
- [44] G. Chou, H. Wang, and D. Berenson, “Gaussian process constraint learning for scalable chance-constrained motion planning from demonstrations,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3827–3834, 2022.
- [45] A. Gaurav, K. Rezaee, G. Liu, and P. Poupart, “Learning soft constraints from constrained expert demonstrations,” in The Eleventh International Conference on Learning Representations, 2023.
- [46] S. Xu and G. Liu, “Uncertainty-aware constraint inference in inverse constrained reinforcement learning,” in The Twelfth International Conference on Learning Representations, 2023.
- [47] S. G. Subramanian, G. Liu, M. Elmahgiubi, K. Rezaee, and P. Poupart, “Confidence aware inverse constrained reinforcement learning,” arXiv preprint arXiv:2406.16782, 2024.
- [48] J. Jang, M. Song, and D. Park, “Inverse constraint learning and generalization by transferable reward decomposition,” IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 279–286, 2023.
- [49] E. Altman, Constrained Markov decision processes. Routledge, 2021.
- [50] A. Ray, J. Achiam, and D. Amodei, “Benchmarking safe exploration in deep reinforcement learning,” arXiv preprint arXiv:1910.01708, vol. 7, no. 1, p. 2, 2019.
- [51] E. Leurent, Y. Blanco, D. Efimov, and O.-A. Maillard, “Approximate robust control of uncertain dynamical systems,” arXiv preprint arXiv:1903.00220, 2019.
- [52] D. Papadimitriou, U. Anwar, and D. S. Brown, “Bayesian methods for constraint inference in reinforcement learning,” Transactions on Machine Learning Research, 2024.
- [53] A. Majumdar, S. Singh, A. Mandlekar, and M. Pavone, “Risk-sensitive inverse reinforcement learning via coherent risk models.” in Robotics: science and systems, vol. 16, 2017, p. 117.
- [54] G. Liu, Y. Luo, A. Gaurav, K. Rezaee, and P. Poupart, “Benchmarking constraint inference in inverse reinforcement learning,” in The Eleventh International Conference on Learning Representations, 2023.
- [55] H. Singh, N. Misra, V. Hnizdo, A. Fedorowicz, and E. Demchuk, “Nearest neighbor estimates of entropy,” American journal of mathematical and management sciences, vol. 23, no. 3-4, pp. 301–321, 2003.
- [56] J. Ajgl and M. Šimandl, “Particle based probability density fusion with differential shannon entropy criterion,” in 14th International Conference on Information Fusion. IEEE, 2011, pp. 1–8.
- [57] M. Mutti, L. Pratissoli, and M. Restelli, “Task-agnostic exploration via policy gradient of a non-parametric state entropy estimate,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 10, 2021, pp. 9028–9036.
- [58] C. Tessler, D. J. Mankowitz, and S. Mannor, “Reward constrained policy optimization,” arXiv preprint arXiv:1805.11074, 2018.
- [59] E. Leurent et al., “An environment for autonomous driving decision-making,” 2018.
- [60] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “Openai gym,” arXiv preprint arXiv:1606.01540, 2016.
- [61] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [62] J. Platt and A. Barr, “Constrained differential optimization,” in Neural Information Processing Systems, 1987.
- [63] S. Kumar, E. Malmi, A. Severyn, and Y. Tsvetkov, “Controlled text generation as continuous optimization with multiple constraints,” Advances in Neural Information Processing Systems, vol. 34, pp. 14 542–14 554, 2021.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/51caeade-2ba0-4630-bf15-56b9aaf7085a/sewook_yoo__.jpg) |
Se-Wook Yoo (Member, IEEE) received the B.S. degree in electrical and electronic engineering from Hongik University, Seoul, South Korea, in 2018. He is currently pursuing the Ph.D. degree in electrical and computer engineering from Seoul National University, Seoul, South Korea. His research interests include reinforcement learning, imitation learning, and autonomous driving. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/51caeade-2ba0-4630-bf15-56b9aaf7085a/prof_vi.jpg) |
Seung-Woo Seo (Member, IEEE) received the B.S. and M.S. degrees in electrical engineering from Seoul National University, Seoul, South Korea, and the Ph.D. degree in electrical engineering from The Pennsylvania State University, University Park, PA, USA. In 1996, he joined as a Faculty Member with the School of Electrical Engineering, Institute of New Media and Communications and the Automation and Systems Research Institute, Seoul National University. He was a Faculty Member at the Department of Computer Science and Engineering, The Pennsylvania State University. He also worked as a member of the Research Staff at the Department of Electrical Engineering, Princeton University, Princeton, NJ, USA. He is currently working as a Professor of electrical engineering with Seoul National University and the Director of the Intelligent Vehicle IT (IVIT) Research Center funded by Korean Government and Automotive Industries. |