DiffCL: A Diffusion-Based Contrastive Learning Framework with Semantic Alignment for Multimodal Recommendations
Abstract
Multimodal recommendation systems integrate diverse multimodal information into the feature representations of both items and users, thereby enabling a more comprehensive modeling of user preferences. However, existing methods are hindered by data sparsity and the inherent noise within multimodal data, which impedes the accurate capture of users’ interest preferences. Additionally, discrepancies in the semantic representations of items across different modalities can adversely impact the prediction accuracy of recommendation models. To address these challenges, we introduce a novel diffusion-based contrastive learning framework (DiffCL) for multimodal recommendation. DiffCL employs a diffusion model to generate contrastive views that effectively mitigate the impact of noise during the contrastive learning phase. Furthermore, it improves semantic consistency across modalities by aligning distinct visual and textual semantic information through stable ID embeddings. Finally, the introduction of the Item-Item Graph enhances multimodal feature representations, thereby alleviating the adverse effects of data sparsity on the overall system performance. We conduct extensive experiments on three public datasets, and the results demonstrate the superiority and effectiveness of the DiffCL.
Index Terms:
Multimodal Recommender Systems, Self-supervised Learning, Diffusion Model, Graph Contrastive Learning.I Introduction
Recommender systems (RSs), widely applied across various online platforms [1, 2, 3], represent a category of information filtering technologies designed to anticipate user preferences for various items and subsequently deliver tailored recommendations. These systems analyze users’ historical behavioral patterns alongside relevant information to identify items or content that may align with their interests. Initially, early RSs predominantly relied on user interaction data, leveraging historical interaction to reflect behavioral similarities among users. However, as user needs become increasingly complex and diverse, these traditional systems have begun to reveal their limitations. In response to this challenge, multimodal recommender systems (MRSs) have emerged, emphasizing the integration of interaction information between users and items while incorporating diverse multimodal features. This approach enables MRSs to capture user preferences in a more comprehensive manner. MRSs have demonstrated considerable success in domains such as e-commerce and short video recommendations, where the richness of multimodal information enhances their ability to deliver personalized recommendations effectively.
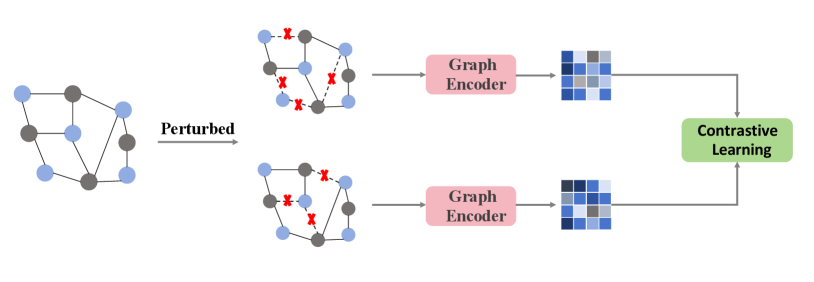
Building upon conventional recommendation methods [4, 5], current MRSs employ diverse strategies to integrate information from multiple modalities. For instance, VBPR, as an extension of matrix factorization techniques [5], introduces visual modal information into the feature representation of items for the first time, thereby effectively addressing the data sparsity challenge in RSs. Nevertheless, early methods primarily concentrated on unimodal data, resulting in models that are incapable of comprehensively modeling user preferences and item representations. As deep learning technology [6, 7, 8] advances and gain widespread application, RSs leveraging deep learning have attracted significant attention from researchers. These methods [9, 10] are capable of learning the underlying features of raw data and complex nonlinear correlations between items and users, thereby effectively modeling users’ complex preferences. ACNE [11] is an deep learning approach and its enhanced version (ACNE-ST) for modeling overlapping communities in network embedding, demonstrating superior performance in vertex classification task. CRL [12] is based on matrix factorization, simultaneously considering the complementarity of global and local information, and collaboratively learning both topics and network embeddings. Simultaneously, deep learning technology can represent different modal features in the same embedding space, which provides conditions for the rapid development of MRSs. To capture higher-order features of user interaction with the items, Graph Neural Networks (GNN) are utilized in RSs [13, 14, 15]. It updates the representation of the current node by accumulating information from adjacent nodes within the graph, thereby integrating modal information through the message-passing process to yield a more comprehensive item representation. Existing GNN-based recommendation methods [16, 17, 18] require a significant amount of high-quality interaction data for modeling user-item relationships. Nonetheless, in practical applications of recommendation systems, interaction data is frequently sparse, which constrains the ability of recommendation models to produce accurate results.
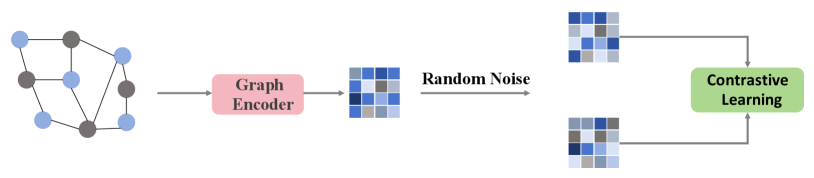
Recently, self-supervised learning (SSL) generates supervision signals from unlabeled data, providing a new method for addressing the data sparsity issue in RSs [19]. For instance, NCL [20] and HCCF [21] combine SSL with collaborative filtering to model user-item interactions, yet they do not adapt them to specific multimodal recommendation scenarios. On the other hand, SGL [22] employs dropout techniques to randomly eliminate interaction edges, subsequently constructing contrastive views to enhance item representations through contrastive learning. However, these methods concentrate exclusively on the enhancement of interactive data, neglecting the importance of considering multimodal information during the data augmentation process, which limits the model’s capacity to representation multimodal information. Recent research has sought to address this gap by proposing the integration of multimodal modeling with self-supervised techniques [23, 24] to enhance the accuracy of RSs. MMGCL [25] and SLMRec [23] construct contrastive views for contrastive learning by perturbing the final modal features with added random noise. MMSSL [26] enriches the multimodal feature embeddings of items based on SSL with interaction information to achieve better recommendation results. Nevertheless, as shown in the Figure 1, these methods are generally based on intuitive cross-view contrastive learning or simple random augmentation techniques, which can introduce noise information irrelevant to the recommendation results to some extent.
Drawing inspiration from the success of diffusion models in the field of data generation, we propose a novel framework based on diffusion models for MRSs. Specifically, we first utilize graph convolutional networks to process pre-extracted raw multimodal features in order to capture higher-order multimodal feature representations. Subsequently, to construct a contrastive view that distinct from previous methods, we introduce diffusion models into the graph contrastive learning phase, utilizing both the forward and inverse processes of diffusion models to generate contrastive views, as opposed to merely adding random noise or employing dropout techniques. This approach effectively mitigates the impact of noise introduced during self-supervised learning. Finally, an Item-Item graph is introduced to augment the embedding of items, addressing the impact of data sparsity in RSs. Alongside this, we implement an ID-guided semantic alignment task to align semantic information across different modalities, enhancing semantic consistency. This alignment, guided by ID features, leverages their stability and uniqueness to ensure that the semantics of the item remain consistent, irrespective of the modality perspective. The contributions of this paper are briefly summarized as follows:
-
•
We propose a novel Diffusion-Based Contrastive Learning framework (DiffCL) for multi-modal recommendation, which enhances the semantic representation of items by introducing Item-Item graphs to mitigate the effects of data sparsity.
-
•
We introduce diffusion model to generate contrastive views during the graph contrastive learning phase, reducing the impact of noisy information in graph contrastive learning tasks.
-
•
We utilize stable ID embeddings to guide the semantic alignment for enhancing consistency different modalities, thereby enabling effective complementary learning between the visual and textual modalities.
-
•
We conduct extensive experiments on three public datasets to validate the superiority and effectiveness of the DiffCL.
II Related Work
II-A Multimodal Recommendation
The multimodal recommendation system introduces multiple data sources as auxiliary information, extracts the semantic information corresponding to these auxiliary sources, and integrates them through multimodal fusion technology to obtain the user’s multimodal preferences and the item’s multimodal representation, which are used in final recommendation stage to improve recommendation accuracy. Early research focuses on single modality. For example, DUIF [27] builds on this foundation by utilizing additional user information to further enhance the user’s feature representation. ACF [28] utilizes an attention network to adaptively learn the weights of user preferences for items. In realistic scenarios, items exist with multiple modal information; therefore, utilizing different modal information at the same time allows for better modeling of user preferences. CKE [29] is designed to enrich the feature representation of an item by combining image features and text features of item using a knowledge graph based on the matrix factorization technique. Wei et al. [16] use multiple graph convolutional network to process different modal information as a way to extract cues about user’s preference for particular modality. Zhang et al. [30] provide a more comprehensive representation of items by building item semantic graphs to present hidden relationships between items. In this study, we endeavor to comprehensively leverage the multimodal features of items to model user interest preferences. To this end, we enhance item feature representation through the construction of an Item-Item graph, which uncovers latent relationships among items and establishes a more robust foundation for recommendations.
II-B Graph-based Models for Recommendation
Graph Convolutional Networks (GCNs) have unique advantages in processing graph data structures, aggregate information from neighboring nodes, and facilitate the extraction of higher-order features [31, 32]. They are widely used in recommender systems. NGCF [9] fuses the GCN architecture based on matrix factorization, pursuing explicit encoding of higher-order collaborative signals to improve the performance of RSs. Several studies suggest that the nonlinear structures in GCNs are ineffective for extracting collaborative signals between users and items. Based on this, a lightweight GCN recommendation framework, LightGCN is proposed, which removes the original weight matrix and nonlinear activation function in GCN and achieves better recommendation effects. The GCN captures prevalence features other than collaborative signals, and the JMPGCF [33], to match the user’s sensitivity on prevalence, utilizes graph Laplace paradigm to capture prevalence features at multi-grained simultaneously. Recently, some contrastive learning methods are introduced into GCN-based recommender systems. SGL [22] generates different contrast views through various dropout operations to perform contrastive learning based on them. MMSSL [26] introduces an inter-modal contrast learning task to retain semantic commonality across modalities, reducing the impact of noisy information on recommendation results. Building on these approaches, this work leverages graph convolutional networks to model user preferences and item multimodal features effectively. Furthermore, by incorporating a diffusion model into the graph contrastive learning phase, we aim to reduce the influence of multimodal noise, thereby achieving more robust and accurate recommendation outcomes.
II-C Diffusion Models for Recommendation
In recent years, inspired by the diffusion model’s (DM) wide application [34, 35, 36] in the generative domain, some research combines DM with recommender systems to seek better recommendation results. For example, PDRec [37] leverages diffusion-based user preferences to improve the performance of sequential recommendation models. DreamRec [38] introduces DM to explore the latent connections of items in the item space and uses the user’s sequential behavior as a guide to generate the final recommendations. DiffRec [39] uses DM in the denoising process to generate collaborative information that is similar to the global but personalized. Unlike the application of DM in the continuous item embedding space, LD4MRec [40] uses DM on the discrete item index and combines it with multimodal sequential information to guide the prediction of recommendation results. DiffMM [41] enhances the user’s representation by combining cross-modal contrast learning with a modal awareness graph diffusion model to better model collaborative signals as well as align multimodal feature information. In this work, we propose a novel graph contrastive learning component grounded in the diffusion model. Unlike conventional methods that rely on adding random noise to generate contrastive views, our approach harnesses the strong generative capabilities of DM to construct more informative and meaningful contrastive views, thereby enhancing the effectiveness of the learning process.
III Preliminary
In this section, we present some preliminary knowledge related to the paper.
III-A Graph Neural Networks (GNNs)
GNNs [42] used to learn relationships between data from graph data structures. Where nodes denote entities and edges signify the relationships between these entities. The abstract structure of a GNN can be understood in terms of: message passing, aggregation and update functions.
The message passing from neighbor to is represented by Equation 1. Each node collects information from its neighbors. The formula is as follows:
| (1) |
here, is the aggregated message for node at layer , denotes the set of neighbors of , and are the feature vectors of nodes and from the before layer, and denotes the edge features. The accumulation function combines these messages to form a new representation for the node: , where is an update function that can take various forms, such as summation, mean, or a learnable neural network. The foundational structure of Graph Neural Networks (GNNs) centers on the interplay of message passing, aggregation, and updating mechanisms, facilitating effective learning from complex relational data. This framework is highly versatile and can be adapted to address a wide range of tasks.
III-B Multimodal Fusion
Multimodal fusion [43] is a powerful approach that integrates information from various modalities or sources to enhance the performance of machine learning models. By utilizing multiple types of data, multimodal fusion allows the system to offer a more holistic perspective of the underlying information. The process of multimodal fusion is divided into three main phases: feature extraction, alignment, and combination. During the feature extraction stage, pertinent features are identified and retrieved from each modality and converted into a unified representation. Alignment involves matching or correlating features across modalities to ensure that the information is contextually relevant. Finally, in the combination phase, the aligned features are merged using techniques such as early fusion, late fusion, or hybrid methods to generate a final representation that captures the strengths of each modality.
III-C Graph Contrastive Learning
Graph contrastive learning is a self-supervised learning algorithm for graph data that optimizes graph embedding by constructing pairs of positive and negative samples. The core idea is to maximize the similarity between positive samples and the difference between negative samples to enhance the learning of graph representation. The most important part in graph contrastive learning is the graph augmentation strategy, which generates different views by randomly transforming (e.g. node dorpping, edge perturbation, attribute masking and subgraph) the original graph to increase the robustness and generalization ability of the model.
IV Methodology
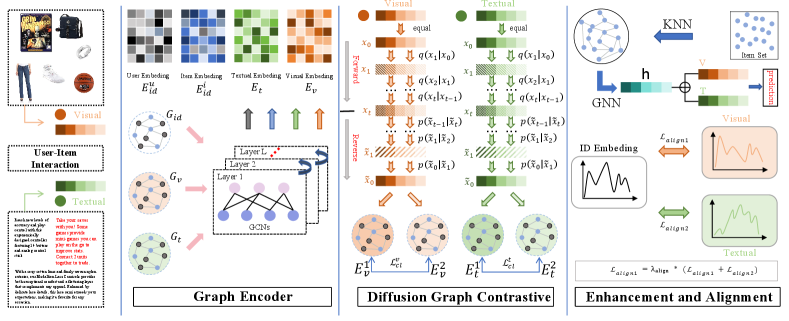
In this section, we take an indepth exploration of the DiffCL framework. It includes what key components the DiffCL consists of and a mathematical description of those components. The detailed workflow of the DiffCL is illustrated in Figure 2.
IV-A Problem Formulation
In the recommendation process, relying solely on user-item interaction data may lead to insufficient information, failing to fully reflect users’ interests and preferences. Multimodal recommendation systems can capture users’ needs more comprehensively by integrating data from different modalities, thus providing more personalized and accurate recommendations.
The process of multimodal recommender system is as follows, given and as the sets of users and items, respectively, the total counts are and . We process the original user-item ID interaction to get the embedded feature of the ID, and then the visual modal features and textual modal features are obtained through different encoders. After a series of enhancement and alignment operations, we obtain the final item embedding and user embedding . And the inner product of the two is calculated to obtain the predicted score of user for the target item , with the following formula:
| (2) |
The multimodal recommender system calculates the user’s predicted scores for different items and orders them from highest to lowest score, taking the top-K items as the final recommended list.
IV-B Graph Encoder
Some research on recommender systems based on GCNs has demonstrated that constructing item-user heterogeneous graphs and processing them with graph neural networks can better capture the user’s preference cues, which in turn improves the recommendation accuracy of the whole system. Inspired by these works, we propose a graph encoder component that consists of three different GCNs to capture higher-order features of different modalities.
First, we use ResNet50 [44] and BERT [27] to extract the image information and text information in the raw data, respectively, and encode the features of these modal information. After that, the graph encoder component is utilized to capture the higher-order features of user-item interactions, image and text features, respectively.
Anchored in the interaction information in the raw data and the multi-model information of the items, we constructed three user-item graphs . We construct the interaction matrix to represent the interaction information, such that if an interaction exists between user and item , otherwise . denotes user-item graph, , represents the set of nodes and represents the set of edges in the graph. The features after the -th layer of convolutional network are denoted as and the final embedded features are denoted as and they are mathematically expressed as follows:
| (3) |
where, is the single-hop neighbor of in graph , is the single-hop neighbor of in graph .
| (4) |
where, is the layer count of the graph convolution, is the original feature after initial feature extraction.
IV-C Diffusion Graph Contrastive Learning
Over the last few years, diffusion model (DM) has excelled in the field of data generation, which can generate data that is highly consistent with the original data. Motivated by the application of DM, we propose a new multimodal recommender system method called DiffCL based on DM. Diffusion Graph Contrastive Learning is the most important component of the DiffCL. We introduce the DM to the graph contrastive learning phase and use it to generate two similar but inconsistent contrasting views to enhance the representation of items and users. Specifically, we gradually add Gaussian noise to the original user-item graph to destroy the original interaction information between the two, and then restore the original interaction by predicting the original state of the data through a probabilistic diffusion process.
IV-C1 Graph Diffusion Forward Process
The higher order feature captured by the Graph Encoder is , which is represented by the following mathematical form:
| (5) |
where, , and denote user embedding and item embedding in a particular modality, respectively.
Our graph diffusion process includes only visual modalities and textual modalities, here we take visual modalities as an example to describe the diffusion process mathematically. We consider the visual modality of the embedding . We initialize the diffusion process with . The forward process is a Markov chain that constructs the final by gradually adding Gaussian noise at each time step . Specifically, the process from to is expressed as follows:
| (6) |
where, represents a Gaussian distribution, and is a noise scale that regulates the increase of Gaussian noise at every time step . As , will converge to a standard Gaussian distribution. Since independent Gaussian noise distributions are additive, it follows that we can get directly from . This process is expressed by the formula:
| (7) |
We utilize two parameters to control the total amount of noise added during the process from to : and . Their mathematical representation is as follows:
| (8) |
| (9) |
Then can be re-parameterized as:
| (10) |
where, . We employ a linear noise scheduler for to control the amount of noise in :
| (11) |
where, , is noise scale and , and represent the maximum and minimum limits of additive noise.
IV-C2 Graph Diffusion Reverse Process
Reverse process’s objective is to eliminate the noise introduced through process from to and to recover . This process generates a pseudo-feature similar to the original visual representation. The transformation associated with the reverse process begins at and gradually recovers through a denoising transformation step. The mathematical expression for the reverse process is as follows:
| (12) |
and denote the predicted values of the mean and variance of the Gaussian distribution in the next state, respectively, and we obtain them by having two learnable parameter neural networks.
IV-C3 Graph Contrastive Learning
Our framework employs a widely used enhancement strategy that utilizes contrast learning to enhance modality-specific feature representations. Specifically, we utilize diffusion model to generate contrasting views. The visual representation of the graph contrastive learning of visual modalities, for example, is after the graph convolution operation. Let , we can get a representation similar to through diffusion model. Repeat the execution of the operation’s to another representation . Then we perform graph contrastive learning based on InfoNCE [45] loss function with the following formula:
| (13) | |||
| (14) |
| (15) |
here, represents the cosine similarity function, and is a hyperparameter that controls the rate of model convergence.
The same reasoning leads to:
| (16) |
The final loss of graph contrastive learning loss is as follows:
| (17) |
where, is a hyperparameter used to control the graph contrastive learning loss.
IV-D Multimodal Feature Enhancement and Alignment
IV-D1 Multimodal Feature Enhancement
To extract the semantic connections among various items, we build the Item-Item graph ( I-I graph), which is implemented by the KNN algorithm. Specifically, we calculate the similarity scores between different item pairs separately based on different modal features to obtain I-I graphs for specific modalities. The similarity score is calculated by the following equation:
| (18) |
where, and denote pairs of items consisting of different items. and denote the original features of the specific modes of items and , respectively. represents the modality.
To reduce the effect of redundant data upon model accuracy, we selectively discard the obtained similarity scores. We keep only the K neighbors whose similarity scores are ranked in the top-K and assign them a value of , which can be expressed as follows:
| (19) |
When is 1, it represents a potential connection between item pairs . Simultaneously, we fix = 10. We normalize utilize the following formula:
| (20) |
Here, represents diagonal matrix of and . It generates a symmetric, normalized matrix that helps eliminate the influence of node degrees on the results, making subsequent aggregation operations more stable. The calculation formula for is as follows:
| (21) |
Then, we aggregate multi-layer neighbor information based on the obtained modality-aware adjacency matrix:
| (22) |
where, is first-order neighbor of , denote the embedding of item in modality , .
To better utilize various modal information to dig user preferences, we enhance the final embedding using the embeddings of the specific modal I-I graph, expressed by the formula:
| (23) |
IV-D2 Multimodal Feature fusion
Different modalities carry distinct modal information, which is both relevant and complementary. To more comprehensively capture user behavior preferences, we implement feature-level fusion for visual and textual features, resulting in the following fused feature representation:
| (24) |
where, and denote the visual features and textual features, respectively, and is a trainable parameter with an initial value of 0.5.
In the phase of feature fusion, we do not fuse the ID modality with other multimodal features. This is because, in multimodal recommendation systems, the ID modality possesses uniqueness and stability. Therefore, we only use it to align multimodal features and calculate the final predicted scores.
IV-D3 Multimodal Semantic Alignment
In multimodal recommendation systems, the feature distributions of different modalities are generally inconsistent, and the fusion process often retains a lot of noise information. Moreover, some existing modal semantic alignment methods disrupt historical interaction information, which adversely affects the final predictions. Therefore, we propose a cross-modal alignment method that uses stable ID features as guidance, effectively leveraging the ID embedding to better align semantic information of different modalities, ensuring semantic consistency among the information from various modalities. Inspired by the article PPMDR [46], we parameterize the final ID modality feature , the visual modality feature , and the textual modality feature using a Gaussian distribution. Then, we calculate the distance between the ID modality and the visual modality, and the textual modality feature distributions as losses, respectively. The formula is as follows:
| (25) |
| (26) |
| (27) |
The final alignment loss is calculated as follows:
| (28) |
where, is hyper-parameter used to balance the alignment loss.
IV-E Model Optimization
In recommendation tasks, Bayesian Personalized Ranking (BPR) is a commonly used optimization method. The basic idea of BPR is to increase the distinction between the expected scores of positive and negative samples, as it supposes users are more likely to prefer the items they have interacted with. We construct a triplet for calculating the BPR loss, represents user, denote the items that have been interacted with by and denote the items that have been interacted with by . The formula is as follows:
| (29) |
where, represents predicted score for by , while denotes the predicted score for by the same user. Additionally, refers to the sigmoid function.
and are calculated by the following equations:
| (30) |
| (31) |
where, and signify the representations of and following modal fusion, respectively. Meanwhile, and refer to the ID embeddings for an .
Finally, we combine BPR loss, diffusion graph contrastive learning loss, and cross-modal alignment loss to calculate the total loss, as shown in the following formula:
| (32) |
is the regularization loss, the calculation formula is as follows:
| (33) |
where, is hyperparameter to regulate the impact of the regularization.
| Dataset | #User | #Item | #Interaction | Spasity |
|---|---|---|---|---|
| Baby | 19,445 | 7,050 | 160,792 | 99.88% |
| Sports | 35,598 | 18,357 | 296,337 | 99.96% |
| Video | 24,303 | 10,672 | 231,780 | 99.91% |
V Experiments
To fairly appraise the performance of the DiffCL, we construct a large number of experiments to assess its performance. First, we compare the DiffCL with other state-of-the-art multimodal recommendation methods, this comparison is based on the same dataset processing. In addition, we construct different variants for the DiffCL to validate the effect of distinct components to ensure that we can effectively improve the final recommendation accuracy for each component. Finally, we set different hyperparameters for the model to search for the optimal hyperparameter settings. This experiment is set up to answer the following three questions:
-
•
RQ1: How does the DiffCL’s performance on different datasets compare to general RSs and MRSs?
-
•
RQ2: How does the different components that make up the DiffCL affect its overall recommended performance?
-
•
RQ3: How does setting different hyperparameters change the performance of the DiffCL?
V-A Experimental Settings
In this paper, the dataset used is the Amazon review dataset, which is extensively used in MRSs. The initial dataset contains information about the user’s interaction with the item, description of the text and images of the items, and the text of comments about the item from interacting users, as well as other information such as the price of the item. For all comparative models, we use the same way of processing the dataset. Specifically, we use 5-core filtering to filter the raw data and optimize the data quality. Prior to model training, we pre-extracted item’s visual and textual features for the following recommendation task by utilizing the pre-trained ResNet50 [44] and BERT [47] with initial dimensions of 4096 and 384 dimensions for the visual and textual features, respectively. The data sets are as follows: (1) Baby, (2) Video, (3) Sports and Outdoors (denoted as Sports). Table I shows the details of the three datasets. The training, validation and test sets are divided in the ratio of 8:1:1.
V-A1 Baselines
In this subsection, we demonstrate the superiority of DiffCL by comparing it with current state-of-the-art recommendation methods. The comparative models used for the experiments include general recommendation model as well as multimodal recommendation model. Our purpose is use comparative experiments to demonstrate that DiffCL has some advantages over other models in the recommendation task. In addition, sufficient support for its application in real world is provided by experiments on real-world datasets.
The general recommendation model and multimodal recommendation model used for the comparative experiments are as follows:
(a) general recommendation methods:
BPR [48] : This is a recommendation algorithm for implicit feedback that uses a Bayesian approach to model user preferences for items and randomly selects negative samples during training to improve model’s generalization.
LightGCN: It removes some unnecessary components from the graph convolutional network and improves the training efficiency of the model.
(b) multimodal recommendation methods:
VBPR: This method is based on an extension of BPR that introduces visual features of items to improve RS’s performance for multimodal recommendation scenarios that include visual data.
MMGCN [16]: This method utilizes a graph structure to capture complicated relationships between users and items. It also designs specialized mechanisms to integrate information from various modalities, ensuring that information from various modalities can effectively complement .
DualGNN [18] : This method models the relationships between users and items simultaneously using GNN, capturing multi-level relational information to improve the accuracy and personalization of recommendations.
SLMRec [49] : This method utilizes self-supervised learning by designing tasks to generate labels and adopts a contrastive learning strategy to optimize the model by constructing positive and negative sample pairs.
BM3 [24] : This method simplifies the self-supervision task in multimodal recommender systems.
MGCN [17] : This method is based on the GCN, which utilizes item information to purify modal features. A behavior-aware fuser is also designed that can adaptively learn different modal features.
DiffMM [41] :This method is based on diffusion model, which enhances the user’s representation by combining cross-modal contrastive learning and modality-aware graph diffusion models for more accurate recommendation results.
Freedom [50] : This method is based on freezing the U-I graph and the I-I graph, and a degree-sensitive edge pruning method is designed to delete possible noisy edges.
V-A2 Evaluation protocols
In this subsection, we introduce the evaluation metrics used in the experiments. The evaluation metrics employ in this experiment are Recall@ (R@) and NDCG@ (N@). Recall represents the recall rate, while NDCG stands for Normalized Discounted Cumulative Gain. We set , indicating number of items in final recommendation list.
V-A3 Details
This subsection provides a detailed description of the hyperparameter settings of the DiffCL on different datasets. To ensure the fairness of the evaluation, we use MMRec [51] to implement all the comparative baselines and also execute a grid search for hyperparameters of these models to determine the optimal hyperparameter settings. In addition, Adam optimizer is employed to make superior the DiffCL and other models.
We install learning rate of the DiffCL to 0.001, dropout rate to 0.5, and in graph contrastive learning to 0.4. Besides, the values of , and are not the same for different datasets. Specifically, we set three different sets of loss weights for the baby, video, and sports datasets, respectively. They are as follows: , and .
| Datasets | Baby | Video | Sports | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | R@10 | R@20 | N@10 | N@20 | R@10 | R@20 | N@10 | N@20 | R@10 | R@20 | N@10 | N@20 |
| BPR | 0.0268 | 0.0441 | 0.0144 | 0.0188 | 0.0722 | 0.1106 | 0.0386 | 0.0486 | 0.0306 | 0.0465 | 0.0169 | 0.0210 |
| LightGCN | 0.0402 | 0.0644 | 0.0274 | 0.0375 | 0.0873 | 0.1351 | 0.0475 | 0.0599 | 0.0423 | 0.0642 | 0.0229 | 0.0285 |
| DiffCL | 0.0641 | 0.0987 | 0.0343 | 0.0433 | 0.1421 | 0.2069 | 0.0804 | 0.0974 | 0.0754 | 0.1095 | 0.0421 | 0.0509 |
| Improv. | 32.50% | 42.70% | 14.23% | 5.60% | 59.45% | 50.55% | 62.11% | 56.43% | 64.78% | 60.59% | 65.06% | 64.91% |
| VBPR | 0.0397 | 0.0665 | 0.0210 | 0.0279 | 0.1198 | 0.1796 | 0.0647 | 0.0802 | 0.0509 | 0.0765 | 0.0274 | 0.0340 |
| MMGCN | 0.0397 | 0.0641 | 0.0206 | 0.0269 | 0.0843 | 0.1323 | 0.0440 | 0.0565 | 0.0380 | 0.0610 | 0.0206 | 0.0266 |
| DualGNN | 0.0518 | 0.0820 | 0.0273 | 0.0350 | 0.1200 | 0.1807 | 0.0656 | 0.0814 | 0.0583 | 0.0865 | 0.0320 | 0.0393 |
| SLMRec | 0.0529 | 0.0775 | 0.0290 | 0.0353 | 0.1187 | 0.1767 | 0.0642 | 0.0792 | 0.0663 | 0.0990 | 0.0365 | 0.0450 |
| BM3 | 0.0539 | 0.0848 | 0.0283 | 0.0362 | 0.1166 | 0.1772 | 0.0636 | 0.0793 | 0.0632 | 0.0940 | 0.0346 | 0.0426 |
| MGCN | 0.0608 | 0.0927 | 0.0333 | 0.0415 | 0.1345 | 0.1997 | 0.0740 | 0.0910 | 0.0713 | 0.1060 | 0.0392 | 0.0489 |
| Freedom | 0.0622 | 0.0948 | 0.0330 | 0.0414 | 0.1226 | 0.1858 | 0.0662 | 0.0827 | 0.0722 | 0.1062 | 0.0394 | 0.0484 |
| DiffMM | 0.0619 | 0.0947 | 0.0326 | 0.0394 | — | — | — | — | 0.0683 | 0.1019 | 0.0374 | 0.0455 |
| DiffCL | 0.0641 | 0.0987 | 0.0343 | 0.0433 | 0.1421 | 0.2069 | 0.0804 | 0.0974 | 0.0754 | 0.1095 | 0.0421 | 0.0509 |
| Improv. | 3.05% | 4.11% | 3.93% | 4.58% | 5.65% | 3.60% | 8.64% | 7.03% | 4.43% | 3.11% | 6.85% | 5.16% |
| Variants | Metrics | Datasets | ||
|---|---|---|---|---|
| Baby | Video | Sports | ||
| DiffCLbaseline | R@20 | 0.0854 | 0.1907 | 0.0956 |
| N@20 | 0.0364 | 0.0856 | 0.0428 | |
| DiffCLdiff | R@20 | 0.0925 | 0.1978 | 0.1095 |
| N@20 | 0.0396 | 0.0895 | 0.0509 | |
| DiffCLalign | R@20 | 0.0907 | 0.1965 | 0.0960 |
| N@20 | 0.0392 | 0.0893 | 0.0428 | |
| DiffCLh | R@20 | 0.0986 | 0.1921 | 0.1099 |
| N@20 | 0.0430 | 0.0872 | 0.0494 | |
| DiffCLdiff+align | R@20 | 0.0911 | 0.1904 | 0.1093 |
| N@20 | 0.0403 | 0.0866 | 0.0506 | |
| DiffCLdiff+h | R@20 | 0.0986 | 0.1940 | 0.1102 |
| N@20 | 0.0430 | 0.0885 | 0.0495 | |
| DiffCLalign+h | R@20 | 0.0993 | 0.1968 | 0.1114 |
| N@20 | 0.0432 | 0.0896 | 0.0496 | |
| DiffCL | R@20 | 0.0987 | 0.2069 | 0.1095 |
| N@20 | 0.0433 | 0.0974 | 0.0509 | |
V-B Comparative Experiments (RQ1)
The experimental results are comprehensively summarized in Table II. This table presents the specific performance of DiffCL alongside all comparative models. Bold numbers represent the results for DiffCL, underlined numbers denote the results for the best comparative model, and Improv. denotes the percentage improvement of DiffCL over the best comparative model.
The results of this experiment show that most multimodal recommendation models perform significantly better than general recommendation models. This is due to the ability of multimodal recommendation methods to integrate multimodal information about items, thus enabling better capture of user preference cues. From the experimental results, the DiffCL performs best on the sports dataset compared to the general recommendation model. It improves 64.78%, 60.59%, 65.06% and 64.91% on the four evaluation metrics R@, R@, N@ and N@ respectively. In contrast, the DiffCL has a smaller boost on the baby dataset, improving only 32.50%, 42.70%, 14.23%, and 5.60% under each of the four metrics mentioned above. This result shows that on the baby dataset, the multimodal information of the items has little effect on the user’s preference, and users may be more concerned about other factors such as the quality and price of the items.
Compared to other multimodal recommendation models, DiffCL consistently outperforms the leading models across all scenarios. According to the experimental results, DiffCL demonstrates superior performance on the video dataset, with improvements of 5.65%, 3.60%, 8.64%, and 7.03% across the four evaluation metrics: R@, R@, N@, and N@, respectively. These results validate the effectiveness of DiffCL in improving recommendation accuracy. Overall, the findings indicate that DiffCL enhances recommendation performance by constructing contrastive views for graph-based contrastive learning through the diffusion model, utilizing the Item-Item (I-I) graph for data augmentation, and employing ID modality-guided inter-modal alignment.
V-C Ablation Study (RQ2)
In this section, a large number of ablation experiments are performed in order to verify the effectiveness of the various components that make up DiffCL. Specifically, our ablation experiments included the following variants:
-
•
DiffCLbaseline: Remove all components.
-
•
DiffCLdiff: Retain only the diffusion graph contrastive learning task.
-
•
DiffCLalign: Retain only the ID modal guidance intra-modal semantic alignment task.
-
•
DiffCLh: Retain only the feature enhancement task.
-
•
DiffCLdiff+align: Retain both the diffusion graph contrastive learning task and the ID modal guidance intra-modal semantic alignment task.
-
•
DiffCLdiff+h: Retain both the diffusion graph contrastive learning task and the feature enhancement task.
-
•
DiffCLalign+h: Retain both the ID modal guidance intra-modal semantic alignment task and the feature enhancement task.
Table III shows the results of the final ablation experiments. Bold numbers denote best result and underlined numbers denote sub-optimal results. According to the final results, all components of the DiffCL are valid in improving the performance of the whole system respectively. In addition, the models consisting of the combination of any two components also get better recommendation results compared to the models with a single component.
V-D Hyperparameter Effects (RQ3)
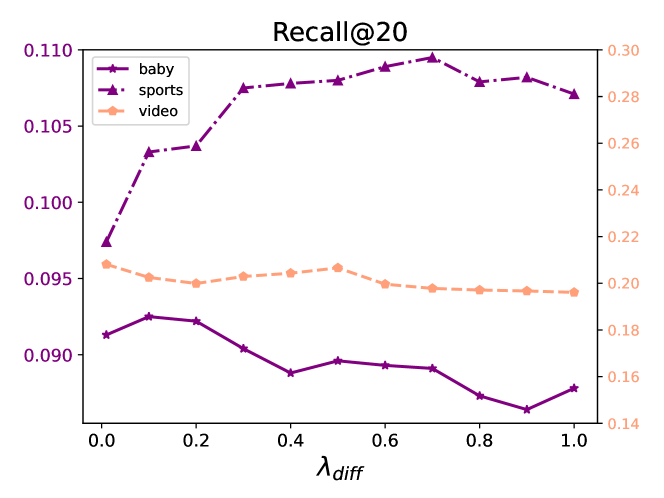
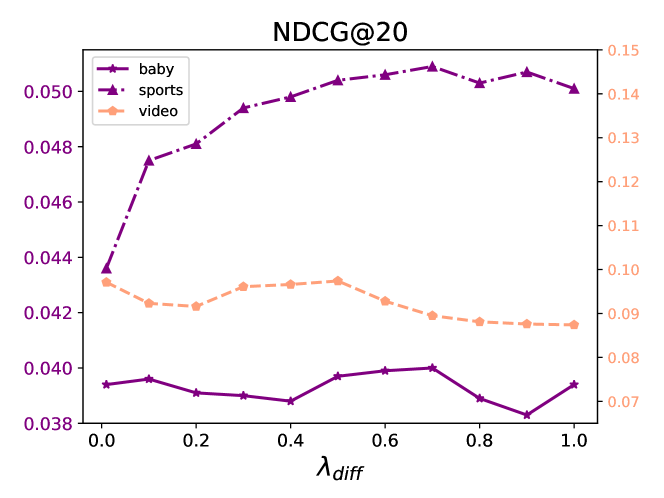
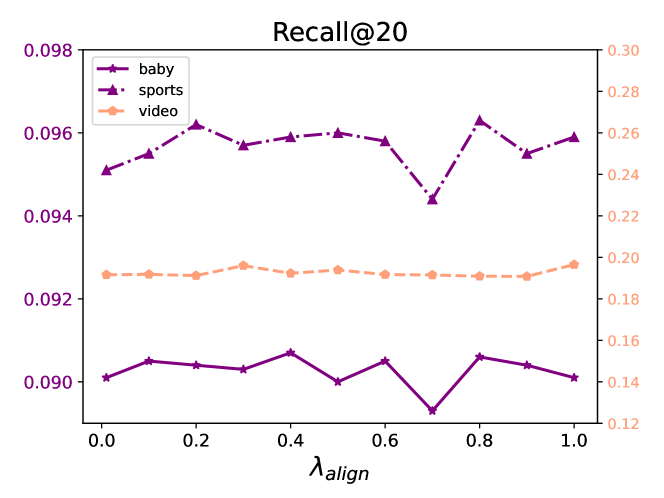
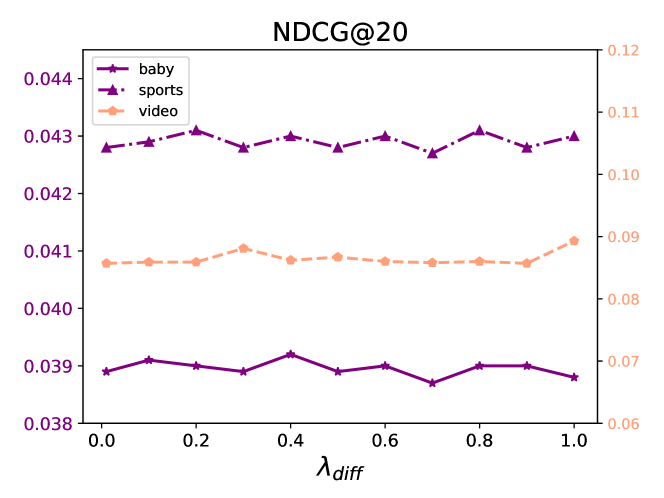
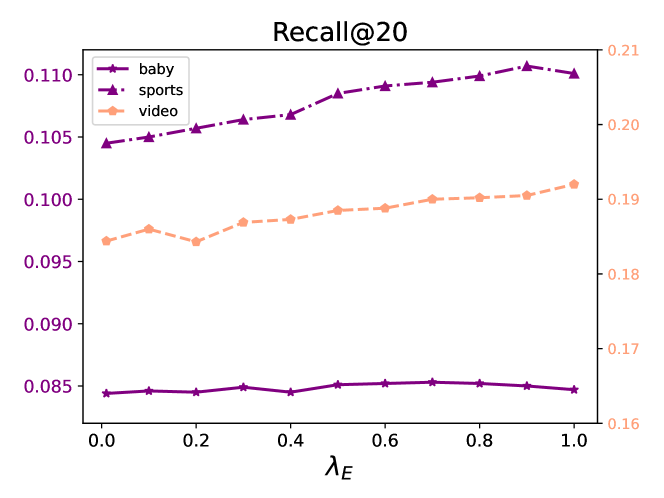
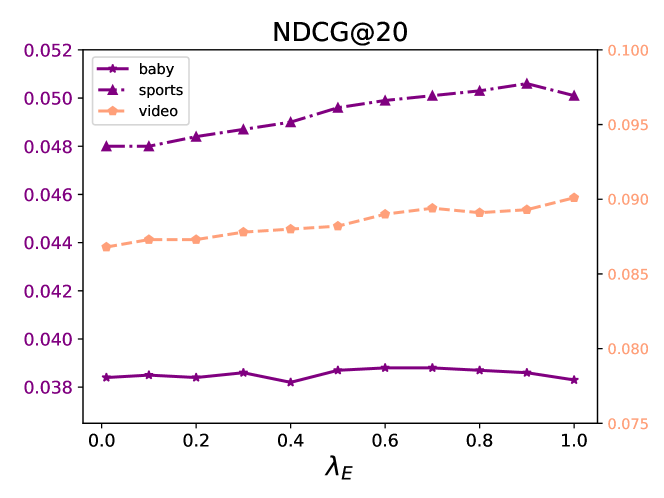
In this section, we investigate the effect of varying loss weights on the performance of diffusion map contrastive learning and multimodal indirect alignment. Specifically, we conduct a series of hyperparameter experiments to analyze how the values of these weights impact model performance. The loss weights for both the diffusion map contrastive learning task and the multimodal indirect alignment task are set to: . The experimental results across three datasets are presented in Figures 3, 4, and 5.The results reveal that the values of the loss weights significantly influence the model’s performance. Although the loss weights for the three parameters, , , and , are set to the same range, the optimal values for each weight vary depending on the dataset and task. Tuning these weights appropriately is crucial for achieving the best performance. The findings emphasize the importance of hyperparameter selection in optimizing the robustness and accuracy of the Diffcl across different task.
VI Conclusion
In this paper, a diffusion-based contrastive learning (DiffCL) framework is proposed for multimodal recommendation. This method generates high-quality contrastive views by introducing a diffusion model during the graph contrastive learning stage, effectively addressing the issue of reduced recommendation accuracy caused by noise in self-supervised tasks. Furthermore, it employs stable ID embeddings to guide semantic alignment across different modalities, significantly enhancing the semantic consistency of items. To comprehensively evaluate the performance of the DiffCL , we conduct a series of experiments on multiple real-world datasets and compare it with various recommendation models. The experimental results demonstrate the effectiveness of each component of the DiffCL and its superiority in recommendation performance.
In future research, we aim to optimize the integration of diffusion models within recommender systems, extending their application beyond specific stages of the recommendation process. By leveraging the powerful generative capabilities of the diffusion model, we intend to perform data augmentation from multiple perspectives to achieve superior recommendation outcomes.
References
- [1] D. Wang, X. Zhang, D. Yu, G. Xu, and S. Deng, “Came: Content- and context-aware music embedding for recommendation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 3, pp. 1375–1388, 2021.
- [2] Y. Zheng, J. Qin, P. Wei, Z. Chen, and L. Lin, “Cipl: Counterfactual interactive policy learning to eliminate popularity bias for online recommendation,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–14, 2023.
- [3] J. Chen, G. Zou, P. Zhou, W. Yirui, Z. Chen, H. Su, H. Wang, and Z. Gong, “Sparse enhanced network: An adversarial generation method for robust augmentation in sequential recommendation,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 8, pp. 8283–8291, 2024.
- [4] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T.-S. Chua, “Neural collaborative filtering,” in Proceedings of the 26th international conference on world wide web, 2017, pp. 173–182.
- [5] S. Rendle, “Factorization machines,” in 2010 IEEE International conference on data mining. IEEE, 2010, pp. 995–1000.
- [6] Q. Song, R. Dian, B. Sun, J. Xie, and S. Li, “Multi-scale conformer fusion network for multi-participant behavior analysis,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 9472–9476.
- [7] Q. Song, B. Sun, and S. Li, “Multimodal sparse transformer network for audio-visual speech recognition,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 12, pp. 10 028–10 038, 2023.
- [8] J. Han, L. Zheng, Y. Xu, B. Zhang, F. Zhuang, P. S. Yu, and W. Zuo, “Adaptive deep modeling of users and items using side information for recommendation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 3, pp. 737–748, 2020.
- [9] X. Wang, X. He, M. Wang, F. Feng, and T.-S. Chua, “Neural graph collaborative filtering,” in Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval, 2019, pp. 165–174.
- [10] Y. Lei, Z. Wang, W. Li, H. Pei, and Q. Dai, “Social attentive deep q-networks for recommender systems,” IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 5, pp. 2443–2457, 2020.
- [11] J. Chen, Z. Gong, J. Mo, W. Wang, W. Wang, C. Wang, X. Dong, W. Liu, and K. Wu, “Self-training enhanced: Network embedding and overlapping community detection with adversarial learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 11, pp. 6737–6748, 2022.
- [12] J. Chen, Z. Gong, W. Wang, W. Liu, and X. Dong, “Crl: Collaborative representation learning by coordinating topic modeling and network embeddings,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 8, pp. 3765–3777, 2022.
- [13] P. Qiao, Z. Zhang, Z. Li, Y. Zhang, K. Bian, Y. Li, and G. Wang, “Tag: Joint triple-hierarchical attention and gcn for review-based social recommender system,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 10, pp. 9904–9919, 2022.
- [14] J. Yu, H. Yin, J. Li, M. Gao, Z. Huang, and L. Cui, “Enhancing social recommendation with adversarial graph convolutional networks,” IEEE Transactions on knowledge and data engineering, vol. 34, no. 8, pp. 3727–3739, 2020.
- [15] J. Yu, X. Xia, T. Chen, L. Cui, N. Q. V. Hung, and H. Yin, “Xsimgcl: Towards extremely simple graph contrastive learning for recommendation,” IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 2, pp. 913–926, 2023.
- [16] Y. Wei, X. Wang, L. Nie, X. He, R. Hong, and T.-S. Chua, “Mmgcn: Multi-modal graph convolution network for personalized recommendation of micro-video,” in Proceedings of the 27th ACM international conference on multimedia, 2019, pp. 1437–1445.
- [17] P. Yu, Z. Tan, G. Lu, and B.-K. Bao, “Multi-view graph convolutional network for multimedia recommendation,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 6576–6585.
- [18] Q. Wang, Y. Wei, J. Yin, J. Wu, X. Song, and L. Nie, “Dualgnn: Dual graph neural network for multimedia recommendation,” IEEE Transactions on Multimedia, vol. 25, pp. 1074–1084, 2021.
- [19] J. Yu, H. Yin, X. Xia, T. Chen, J. Li, and Z. Huang, “Self-supervised learning for recommender systems: A survey,” IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 1, pp. 335–355, 2023.
- [20] Z. Lin, C. Tian, Y. Hou, and W. X. Zhao, “Improving graph collaborative filtering with neighborhood-enriched contrastive learning,” in Proceedings of the ACM web conference, 2022, pp. 2320–2329.
- [21] L. Xia, C. Huang, Y. Xu, J. Zhao, D. Yin, and J. Huang, “Hypergraph contrastive collaborative filtering,” in Proceedings of the 45th International ACM SIGIR conference on research and development in information retrieval, 2022, pp. 70–79.
- [22] J. Wu, X. Wang, F. Feng, X. He, L. Chen, J. Lian, and X. Xie, “Self-supervised graph learning for recommendation,” in Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, 2021, pp. 726–735.
- [23] J. Yu, H. Yin, J. Li, Q. Wang, N. Q. V. Hung, and X. Zhang, “Self-supervised multi-channel hypergraph convolutional network for social recommendation,” in Proceedings of the web conference 2021, 2021, pp. 413–424.
- [24] X. Zhou, H. Zhou, Y. Liu, Z. Zeng, C. Miao, P. Wang, Y. You, and F. Jiang, “Bootstrap latent representations for multi-modal recommendation,” in Proceedings of the ACM Web Conference 2023, 2023, pp. 845–854.
- [25] Z. Yi, X. Wang, I. Ounis, and C. Macdonald, “Multi-modal graph contrastive learning for micro-video recommendation,” in Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2022, pp. 1807–1811.
- [26] W. Wei, C. Huang, L. Xia, and C. Zhang, “Multi-modal self-supervised learning for recommendation,” in Proceedings of the ACM Web Conference, 2023, pp. 790–800.
- [27] X. Geng, H. Zhang, J. Bian, and T.-S. Chua, “Learning image and user features for recommendation in social networks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 4274–4282.
- [28] J. Chen, H. Zhang, X. He, L. Nie, W. Liu, and T.-S. Chua, “Attentive collaborative filtering: Multimedia recommendation with item-and component-level attention,” in Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, 2017, pp. 335–344.
- [29] F. Zhang, N. J. Yuan, D. Lian, X. Xie, and W.-Y. Ma, “Collaborative knowledge base embedding for recommender systems,” in Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016, pp. 353–362.
- [30] J. Zhang, Y. Zhu, Q. Liu, S. Wu, S. Wang, and L. Wang, “Mining latent structures for multimedia recommendation,” in Proceedings of the 29th ACM international conference on multimedia, 2021, pp. 3872–3880.
- [31] Y. Fang, H. Wu, Y. Zhao, L. Zhang, S. Qin, and X. Wang, “Diversifying collaborative filtering via graph spreading network and selective sampling,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 10, pp. 13 860–13 873, 2024.
- [32] B. Wu, X. He, Q. Zhang, M. Wang, and Y. Ye, “Gcrec: Graph-augmented capsule network for next-item recommendation,” IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 12, pp. 10 164–10 177, 2023.
- [33] K. Liu, F. Xue, X. He, D. Guo, and R. Hong, “Joint multi-grained popularity-aware graph convolution collaborative filtering for recommendation,” IEEE Transactions on Computational Social Systems, vol. 10, no. 1, pp. 72–83, 2022.
- [34] F.-A. Croitoru, V. Hondru, R. T. Ionescu, and M. Shah, “Diffusion models in vision: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 9, pp. 10 850–10 869, 2023.
- [35] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [36] M. W. Lam, J. Wang, R. Huang, D. Su, and D. Yu, “Bilateral denoising diffusion models,” arXiv preprint arXiv:2108.11514, 2021.
- [37] H. Ma, R. Xie, L. Meng, X. Chen, X. Zhang, L. Lin, and Z. Kang, “Plug-in diffusion model for sequential recommendation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 8, 2024, pp. 8886–8894.
- [38] Z. Yang, J. Wu, Z. Wang, X. Wang, Y. Yuan, and X. He, “Generate what you prefer: Reshaping sequential recommendation via guided diffusion,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [39] W. Wang, Y. Xu, F. Feng, X. Lin, X. He, and T.-S. Chua, “Diffusion recommender model,” in Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023, pp. 832–841.
- [40] P. Yu, Z. Tan, G. Lu, and B.-K. Bao, “Ld4mrec: Simplifying and powering diffusion model for multimedia recommendation,” arXiv preprint arXiv:2309.15363, 2023.
- [41] Y. Jiang, L. Xia, W. Wei, D. Luo, K. Lin, and C. Huang, “Diffmm: Multi-modal diffusion model for recommendation,” arXiv preprint arXiv:2406.11781, 2024.
- [42] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [43] T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018.
- [44] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [45] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9729–9738.
- [46] W. Liu, C. Chen, X. Liao, M. Hu, J. Yin, Y. Tan, and L. Zheng, “Federated probabilistic preference distribution modelling with compactness co-clustering for privacy-preserving multi-domain recommendation.” in IJCAI, 2023, pp. 2206–2214.
- [47] J. Devlin, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [48] S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme, “Bpr: Bayesian personalized ranking from implicit feedback,” arXiv preprint arXiv:1205.2618, 2012.
- [49] Z. Tao, X. Liu, Y. Xia, X. Wang, L. Yang, X. Huang, and T.-S. Chua, “Self-supervised learning for multimedia recommendation,” IEEE Transactions on Multimedia, 2022.
- [50] X. Zhou and Z. Shen, “A tale of two graphs: Freezing and denoising graph structures for multimodal recommendation,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 935–943.
- [51] H. Zhou, X. Zhou, Z. Zeng, L. Zhang, and Z. Shen, “A comprehensive survey on multimodal recommender systems: Taxonomy, evaluation, and future directions,” arXiv preprint arXiv:2302.04473, 2023.