XX \jnumXX \jmonthXXXXX \paper1234567 \doiinfoTAES.2022.Doi Number
Manuscript received October 1, 2022; revised Februrary 24, 2023 and May 26, 2023; accepted July 25, 2023.
This work was a collaboration between the University of Texas at Austin and KBR, and was partially supported by KBR’s office for Internal Research and Development.
(Corresponding author: M. Wilmanski)
Michael C. Wilmanski was previously part of the Computational Sensing and Imaging Lab at the University of Texas at Austin (Austin, TX 78712 USA) and currently works within the Sensors and Analysis directorate (Ann Arbor, MI 48108 USA) of KBR’s National Security Technologies Group (Houston, TX 77005 USA) (e-mail: wilmanski@utexas.edu, michael.wilmanski@us.kbr.com). Jonathan I. Tamir is with the Chandra Family Department of Electrical and Computer Engineering at the University of Texas at Austin (Austin, TX 78712 USA) and serves as faculty advisor of the Computational Sensing and Imaging Lab (e-mail: jtamir@utexas.edu).
Color versions of one or more of the figures in this article are available online at http://ieeexplore.ieee.org.
978-1-5386-5541-2/18/$31.00 ©2018 IEEE
Differentiable Rendering for
Synthetic Aperture Radar Imagery
Abstract
There is rising interest in differentiable rendering, which allows explicitly modeling geometric priors and constraints in optimization pipelines using first-order methods such as backpropagation. Incorporating such domain knowledge can lead to deep neural networks that are trained more robustly and with limited data, as well as the capability to solve ill-posed inverse problems. Existing efforts in differentiable rendering have focused on imagery from electro-optical sensors, particularly conventional RGB-imagery. In this work, we propose an approach for differentiable rendering of Synthetic Aperture Radar (SAR) imagery, which combines methods from 3D computer graphics with neural rendering. We demonstrate the approach on the inverse graphics problem of 3D Object Reconstruction from limited SAR imagery using high-fidelity simulated SAR data.
3D reconstruction, deep neural networks, differentiable rendering, inverse graphics, neural rendering, synthetic aperture radar.
1 INTRODUCTION
Synthetic aperture radar (SAR) is an imaging modality based on pulse-doppler radar. As a radar antenna moves, successive pulses of radio waves are transmitted to illuminate a scene. Echoed pulses from multiple antenna positions can be combined, which forms the synthetic aperture that enables higher resolution images than would otherwise be possible for a physical antenna [1]. In aerial and automotive vehicles, the vehicle’s motion provides the movement needed to form the synthetic aperture.
Recently, there is a rising interest in differentiable rendering for SAR imagery in order to perform downstream imaging tasks such as 3D object reconstruction. Similar to applications in electro-optical (EO) imagery, differentiable rendering is useful within the context of first-order optimization problems that may benefit from pixel-level supervisions flowing to 3D properties, including for training deep neural networks [2]. While there have been successful demonstrations of methods for differentiable rendering of EO-domain imagery in recent years, these methods are not directly applicable to SAR-domain imagery, as SAR and EO images exhibit substantially different geometry and phenomenology. Chief among these differences is the imaging wavelength. As a result, many man-made objects will appear smooth at radar wavelengths and therefore be dominated by specular reflections. For a similar reason, other objects (such as cloud cover) may appear transparent at radar wavelengths despite being opaque at visible light wavelengths.
As SAR is a coherent imaging method and a form of active sensing, many priors about a scene are inherently known and controlled up to sensor and measurement error. Specifically, in this work we assume detailed knowledge about the scene’s illumination as well as positions of the sensor and illuminator relative to the area on the ground being imaged. In addition to control over illumination and prior positional knowledge that can be expected, SAR imagery is invariant to many uncontrollable environmental effects that mar EO-domain imagery. This includes weather and atmospheric effects such as cloud cover, as well as illumination changes due to day/night cycles. Collectively, these differences mean that SAR-domain images have few scene parameters that are uncontrollable or unknown to the user, and thus are especially well-suited for differentiable rendering.
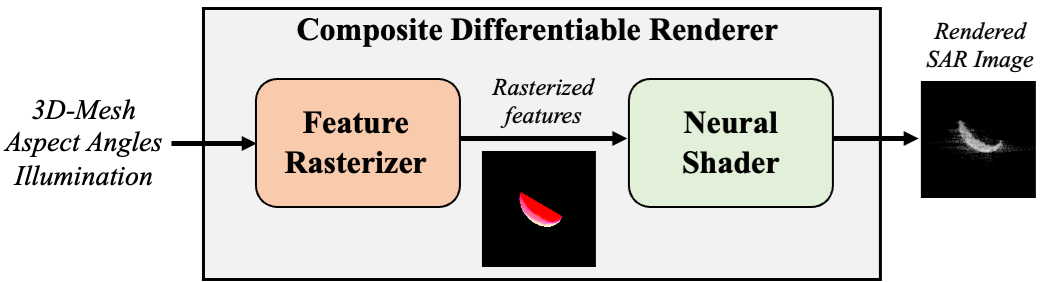
Therefore, in this work we present a proof-of-concept and starting point for differentiable rendering in SAR imagery. Our proposed approach is composed of a Feature Rasterizer followed by a Neural Shader, depicted in the block diagram of Figure 1. The Feature Rasterizer produces image-like feature maps that convey context about the structure and illumination of the scene. These features act as the input condition to the Neural Shader, which is implemented as a conditional generative adversarial network (CGAN) inspired by [3]. The Neural Shader processes the feature maps to produce realistic SAR scattering effects to complete the rendering procedure.
The primary benefit of this approach is its differentiability with respect to 3D scene parameters. Due to its basis in rasterization, the differentiable rendering scheme is also computationally efficient and capable of real-time rendering; this attribute is important given its intended use in optimization problems, which typically involve many thousands of iterations. The principal drawbacks to using rasterization are that the rendering scheme will inherently be limited to a first-order (single-bounce) approximation, as well as being limited to producing non-polarized magnitude imagery.
To demonstrate the utility of our framework, we implement 3D object reconstruction from multiple SAR images as it is a common and highly useful downstream task enabled by differentiable rendering. Consequently, differentiation is with respect to an object’s mesh vertices.
Our primary contributions are the following:
-
1.
We develop a differentiable rendering pipeline for SAR imagery, composed of a Feature Rasterizer and Neural Shader. The former uses softened rasterization to project mesh-based scene representations into 2D feature maps tailored to SAR’s imaging geometry, while the latter uses a CGAN to estimate SAR scattering effects from the feature maps.
-
2.
We show how to train the system end-to-end for SAR shading using high-fidelity simulated SAR data.
-
3.
We demonstrate proof-of-principle use via the inverse graphics problem of 3D object reconstruction.
While our prototype renderer relies on high-fidelity SAR simulation, the framework is general and can be applied to physical SAR systems in the future.
The remainder of this work is organized as follows. In Section 2 we discuss related work from the literature. In Section 3 we describe the generation of a simulated dataset used for the experiments. In Sections 4 and 5 we detail the feature rasterizer and neural shader components of the differentiable renderer, respectively. In Section 6 we describe experiments used to test the effectiveness of the differentiable renderer at solving the inverse problem of 3D object reconstruction. In Section 7 we discuss the methods current limitations, future work, and provide a comparison of imagery from the differentiable renderer to collected data. Lastly, Section 8 provides a conclusion of this work’s findings.
2 RELATED WORK
2.1 SAR Simulators
The survey of SAR simulators in [4] distinguishes two main categories of SAR simulation systems:
-
(a)
SAR image simulators, which directly produce focused SAR images.
-
(b)
SAR raw signal simulators, which simulate raw sensor measurements.
Category (a) simulators include examples such as RaySAR [5], CohRaS® [6], and SARviz [7]. A comparison of these and assessment of their limitations is provided in [8]. Of these, SARviz is the only simulator that uses rasterization, while the others involve a form of ray tracing. RaySAR is the only project that is open source, but also has the most limited shading effects, relying on Phong shading [9].
Simulators of category (b) are usually based on physical optics approximations [10] and enhanced further with the shooting and bouncing rays (SBR) method pioneered in [11]. Instead of producing images directly, these physics-based simulators simulate raw sensor measurements, which the user must process themselves to coherently form images. These methods are the most realistic, but also computationally intensive. Examples in this category include Xpatch [12, 13], CASpatch [14], FACETS [15], SigmaHat [16], FEKO [17], POFACETS [18], and SARCASTIC [19]. Most simulators in this category are closed-source commercial products and do not explicitly support differentiable optimization. Of these, POFACETS and SARCASTIC are the only projects that are open source, but lack some advanced features such as SBR.
Our proposed differentiable rendering approach can be categorized as a SAR image simulator, though the data used to evaluate it was produced by a SAR raw signal simulator. Importantly, the simulators above are not suitable for solving inverse problems as they are not easily differentiable, and are therefore limited to black-box optimization.

2.2 Neural and Differentiable Rendering
Neural rendering is an umbrella term referring to a broad field of methods that fuse machine learning models with techniques or domain-knowledge from computer-graphics. A beneficial property of techniques in this family is that they are inherently differentiable; as they are composed of neural network building blocks, the resulting models can be easily backpropagated through. While they have been successful, it is worth noting that most neural rendering methods aim to manipulate existing images, rather than create images from raw scene representations [20]. Such techniques are thus more akin to sophisticated pixel shaders, and not renderers in the formal sense. The survey in [21] describes these collectively as “2D Neural Rendering” methods, and distinguishes them from an emerging paradigm it calls “3D Neural Rendering.”
Methods of this new paradigm, such as [22], learn to represent a scene in 3D, using a differentiable rendering algorithm to facilitate training a neural network to represent the scene. Methods of this branch of neural rendering are consequently best described as neural scene representations, and are yet another application of differentiable rendering. Cases such as [22] use volume rendering techniques, which are naturally differentiable while also memory inefficient.
Besides volumetric techniques, most differentiable rendering work in the literature has focused on rasterization-based methods from computer graphics [2]. Rasterization is computationally-efficient, but not naturally differentiable. However, smoothed variants have emerged [23, 24, 25], which have made rasterization-based methods viable. Physics-based differentiable rendering methods which model global light transport effects exist as well [26, 27], but are substantially slower. These methods are the most accurate, but the hypothetical improvements in rendering accuracy may not be worth the increased computational cost.
Use of neural and differentiable rendering methods in the context of SAR has so far been limited. Several works have proposed using CGANs for image-to-image translation from SAR to EO imagery [28, 29, 30]. A more related example is [31], which attempts to improve the realism of the RaySAR SAR image simulator [5] by training a deep neural network to estimate realistic SAR scattering effects. This falls under the “2D Neural Rendering” paradigm and is similar in principal to our use of a CGAN for the Neural Shader.
Other instances of differentiable rendering for SAR include [32], which is an academic report of an earlier iteration of this work, and very recently [33], which proposes a scheme for 3D object reconstruction from SAR images using differentiably-rendered silhouettes. Although the latter’s proposed scheme is capable of outputting simulated SAR images in tandem with the silhouettes, the simulated SAR images do not support differentiation, and thus the scheme is not well-suited for inverse problems such as 3D object reconstruction.
3 DATA GENERATION
Computer-aided design models for a total of seven object shapes were created, pictured in Figure 2. The objects were created in Blender [34] and exported as triangulated meshes. The ground plane gridded lines are spaced in units of one meter, making these objects similar in size to medium or large vehicles.
The first five objects were used to generate training data for the Neural Shader. The Long Cuboid was used to generate validation data to inform hyperparameter tuning for both the Feature Rasterizer and Neural Shader. The Elliptic Cone was reserved for generating test-only data and used only after all aspects of the end-to-end rendering process were frozen.
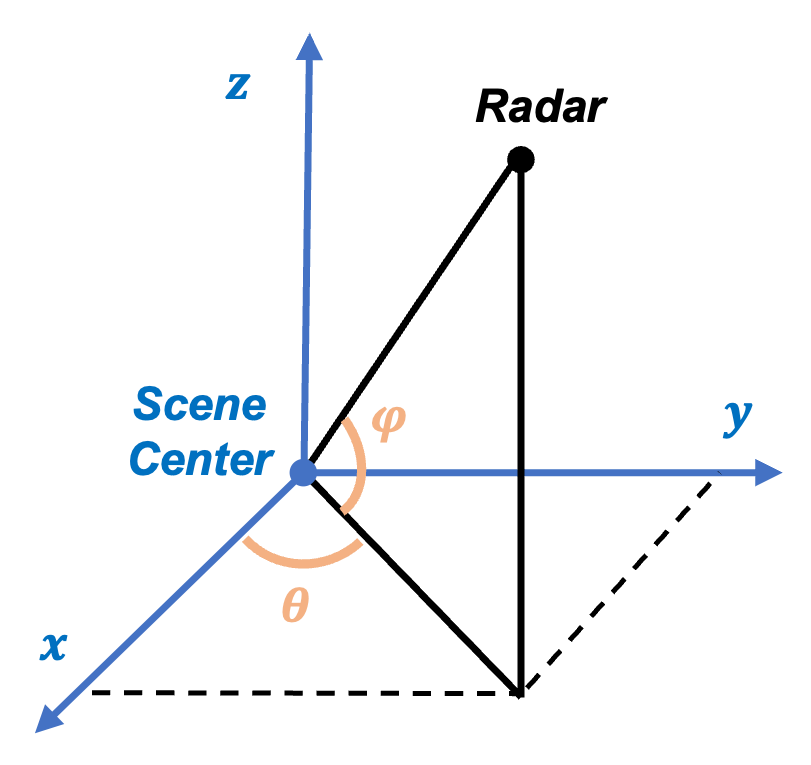
The data generated for this study consist of six distinct elevation angles, evenly spaced between [10°, 60°], and 36 distinct azimuth angles, evenly spaced between [0°, 350°]. This gives a total of 216 distinct aspect-angle combinations per object. A geometric representation of the aspect angles is illustrated in Figure 3. Data are assumed to be monostatic, meaning transmitter and receiver are co-located, which is the most common scenario for SAR.
Every object is assumed to be made of perfect electric conducting material. This simplifies the simulations and is a reasonable assumption for most metallic objects, though it is straightforward to simulate other materials at a modest increase in data generation time. The texture of the surfaces of each object are assumed to be of moderate roughness (0.5cm RMS of surface variability). Each simulation uses nominally 256 pulses at X-band frequencies, spanning 11° of synthetic aperture and having 2GHz of total bandwidth. The resulting SAR collections have a very fine spatial resolution of approximately 0.075m in both range and cross-range directions prior to tapering.
The raw Fourier data (known as “phase history” in the SAR community) acquired from the simulations are first Taylor-weighted as described in [35]. Adding such a taper to the data is used primarily to decrease the prevalence of sidelobes in the formed images, albeit at the expense of slight degradation in spatial resolution. Next, images are formed via Backprojection, based on [36]. This implementation also projects the SAR images into the ground-plane.
Following image formation, the complex-valued images may optionally be augmented with one of two types of noise for additional training data diversity. The first type of noise is additive and follows a complex-normal distribution. The absolute value of a zero-mean complex-normal random variable will be Rayleigh-distributed. For this reason, the Rayleigh distribution has traditionally been used to model random clutter in magnitude-detected SAR imagery [37]. Consequently, pixels that had an original magnitude of zero will follow a Rayleigh distribution after augmentation and magnitude-detection. As the original magnitude of a pixel increases, its distribution after augmentation and magnitude-detection will shift toward being normally-distributed, centered around the original magnitude. The second type of noise is multiplicative and follows a uniform distribution. This type of noise is typically used to model SAR speckle [38]. Equations for applying both types of noise augmentation are given as:
| (1) | ||||
| (2) |
where and represent the original and augmented signals, respectively. represents zero-mean complex-normal noise, represents zero-mean uniform noise, and subscripts and specify a pixel. During optimization, images are augmented at random, with either equation 1 (25%), equation 2 (25%), or neither (50%).
After image formation and optional augmentation, the complex-valued images are magnitude-detected and remapped via the Piecewise Extended Density Format (PEDF), as implemented in the SarPy library [39]. PEDF remaps pixel magnitudes to a log-like scale, to account for SAR’s naturally high dynamic range and improve interpretability. Figure 2 shows examples of resulting images after this remapping.
4 SAR FEATURE RASTERIZER
In this section we describe the SAR Feature Rasterizer, which projects mesh-based scene representations into 2D feature maps that convey context about the structure and illumination of the scene. The Feature Rasterizer consists of three stages: Coordinate Transformations, Rasterization, and Shading. Standard computer graphics rendering follows analogous stages; however, each stage requires alterations either to accommodate backpropagation, account for SAR’s unique imaging geometry, or for the features we want to produce for the Neural Shader. The implementation of this Feature Rasterizer extends and is based on the PyTorch3D API [40].
4.1 SAR Imaging Geometry and Coordinate Transformations
| Transform Name | Input Coordinates | Output Coordinates | Description |
|---|---|---|---|
| View Transform |
World
Space |
View
Space |
Coordinates relative to camera’s point of view |
| Range Transform |
View
Space |
Range
Space |
z-coordinates (depth, or distance from camera) become new y-coordinates |
| Ground-plane Projection |
Range
Space |
Ground
Space |
Stretches perceived y-dimension s.t. each pixel maps to a consistent-sized cell on ground |
| Orthographic Projection |
Ground
Space |
NDC
Space |
Normalizes coordinate values into range natively interpretable by graphics processor (skips perspective projection, as distance from camera does not affect perceived size) |

SAR’s unique imaging geometry makes adapting methods in differentiable rendering designed for EO imagery non-trivial. For rasterization-based methods, imaging geometry is controlled primarily through the coordinate transformation sequence. Consequently, understanding the geometry differences between these imaging modalities is necessary to design a coordinate transformation sequence.
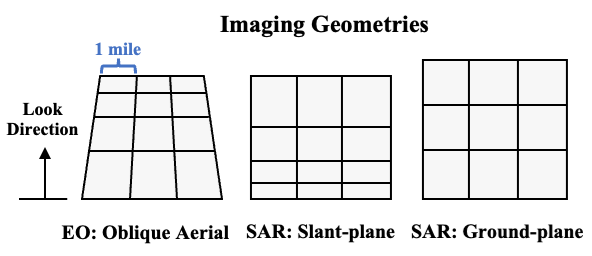
In EO imagery, distance from the sensor affects an object’s perceived size. This results in the “oblique aerial” imaging geometry, seen in Figure 4. In computer graphics, this effect is known as “perspective,” and is typically accounted for via a “perspective projection” during the conversion to Normalized Device Coordinates (NDC) [41]. However in SAR imagery, distance from the sensor determines which range-bin reflected energy funnels into, and thus affects an object’s perceived position in range.
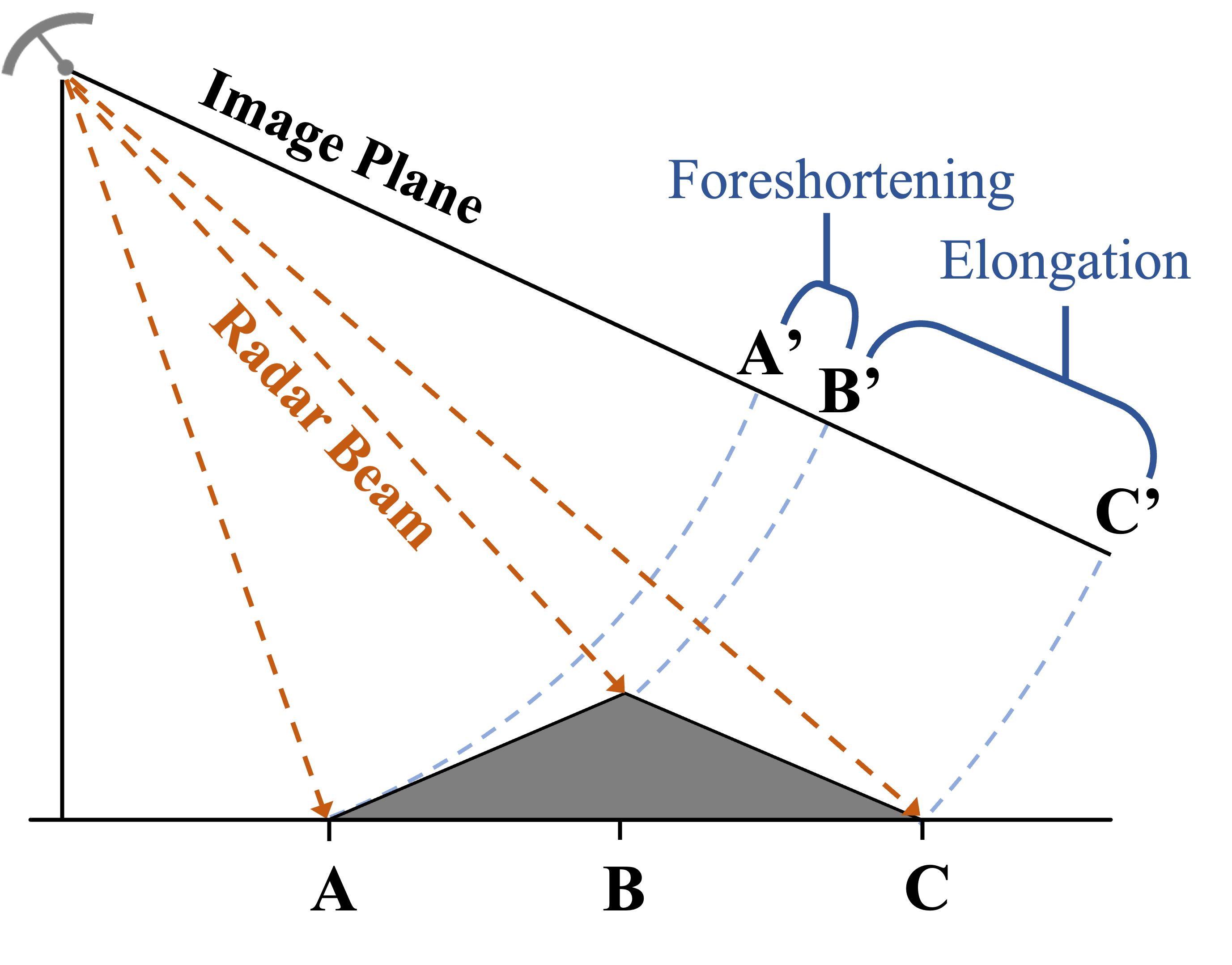
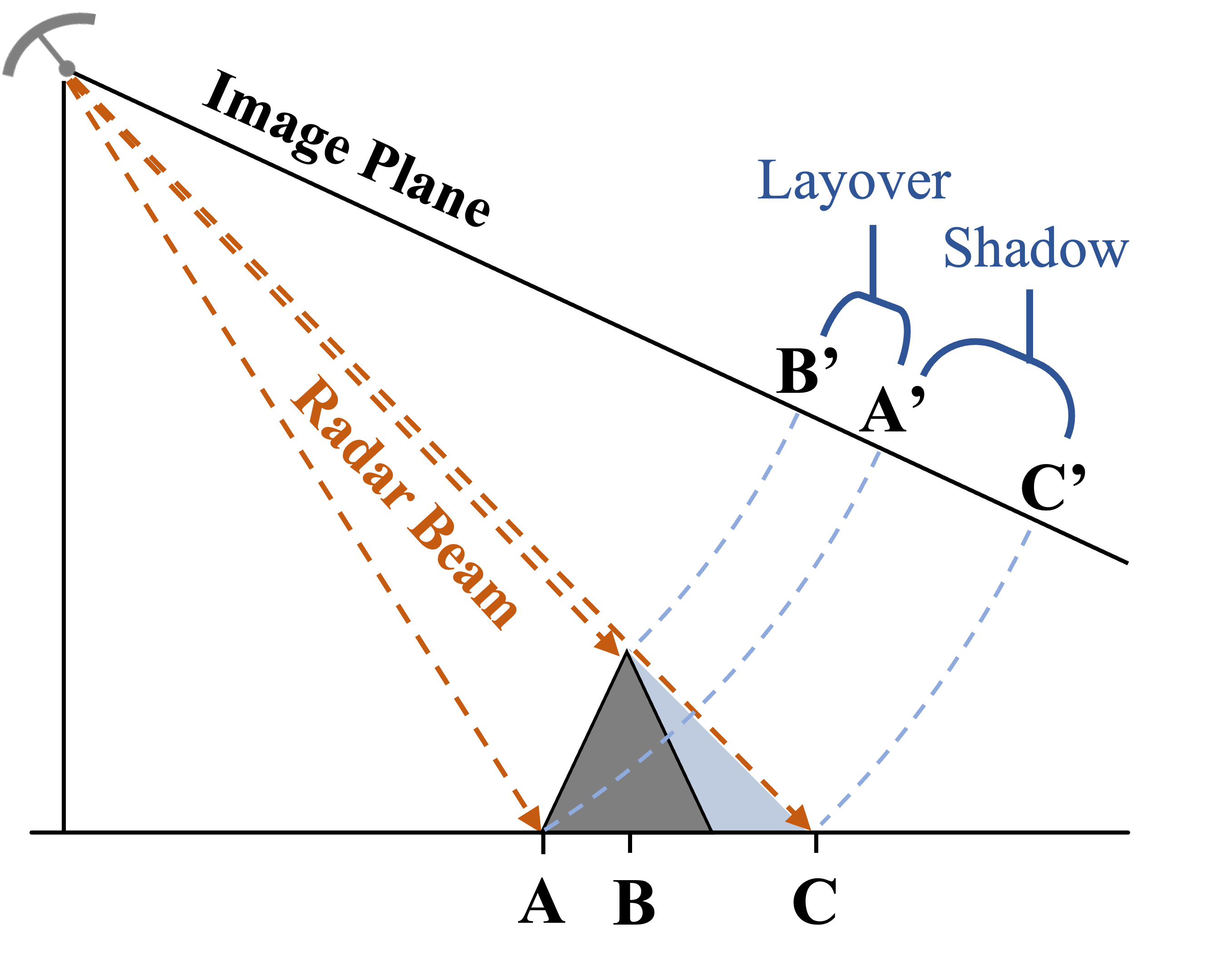
This leads to a natural “slant-plane” imaging geometry for points on the ground. SAR images may be projected into the “ground-plane” as part of image formation, nominally mapping image pixels to equally spaced points along the ground. Distance to the sensor is also influenced by an object’s height. Consequently, imaging objects of variable height will yield sampling distortions known as “foreshortening,” “elongation,” and “layover,” as well as SAR’s signature self-shadowing effect. These phenomena are described in detail by [35, 42] and graphically depicted in Figure 5.
The goal of the coordinate transformation stage is to transform mesh coordinates appropriately to get the desired SAR ground-plane imaging geometry, including foreshortening/elongation/layover effects. Coordinate Transformation sequences must start in world space coordinates and end in NDC. The primary sequence is described in Table 1 and illustrated in Figure 6. If the ground-plane projection were to be omitted, the result would be a SAR slant-plane imaging geometry instead. An equivalent EO “oblique aerial” imaging geometry would require omitting both the range transform and ground-plane projection, as well as changing the orthographic projection to a perspective projection.
4.2 Rasterizing and Shading Feature Maps
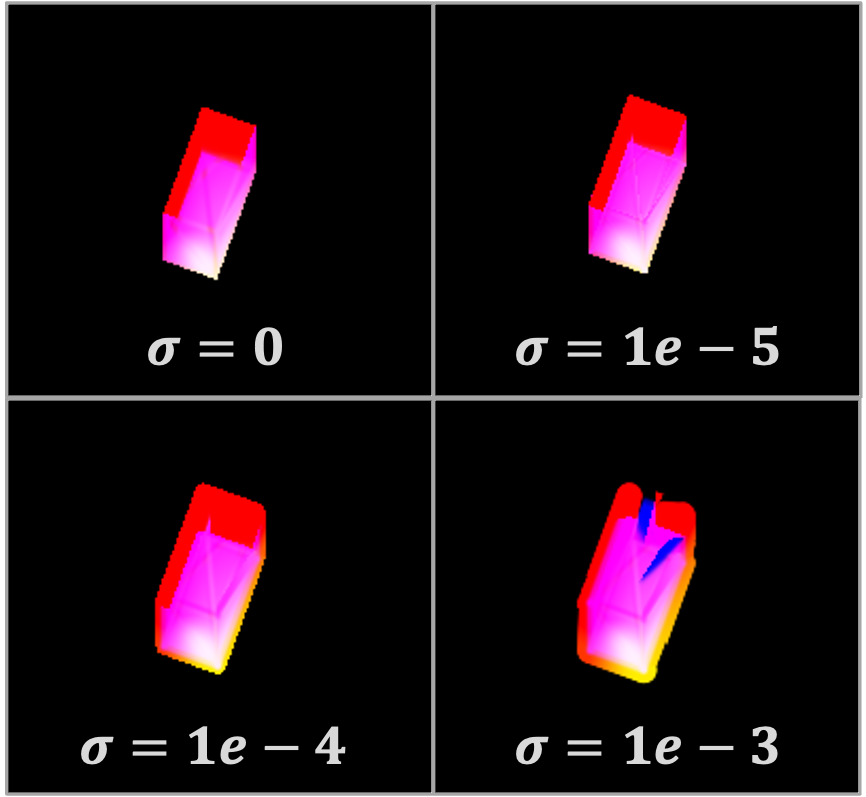
The rasterization method is based on the soft rasterizer of [25]. The method in [25] blends facet contributions for pixels near edges to mitigate the discontinuities that would arise if trying to backpropagate through a standard rasterization operator. Soft rasterization will yield slightly distorted images but allows backpropagating more useful gradients. Examples of artifacts from soft rasterization are shown in Figure 7.
Rasterizing with our custom coordinate transform sequence produces the fragments necessary to shade the first two feature maps. The first feature map is a basic silhouette of the object. This can be produced by making a mask out of fragments that have no corresponding facets. The second feature we want is pixel-wise surface-normal information, relative to the direction of the sensor and illumination. For monostatic imagery, this is given as:
| (3) |
where is the direction of the illumination, is the per-pixel surface-normal of the object, and denotes the inner-product.
The last feature map to shade is an alpha channel. Deriving the alpha channel is complicated by SAR’s self-shadowing effect. To address this, we rasterize a reference view from the perspective of the radar, which is used to determine which facets should be visible in its main beam. Any facet that is not visible from this reference viewpoint is masked out from contributing in the main view when calculating the alpha channel feature map. An example of all three shaded feature maps is shown in Figure 8.

5 NEURAL SHADER
The Neural Shader is trained to predict realistic SAR shading/scattering effects conditioned on the features output by the Feature Rasterizer. Given this is effectively a paired image-to-image translation problem, we choose a model based on Pix2Pix [3]. While some newer approaches have outperformed Pix2Pix, we choose it as a basis for its simplicity in this proof of principle work. The most noteworthy deviation made is to use batch renormalization [43] instead of instance normalization. Batch renormalization addresses the original issues that motivated the authors to use instance normalization, while improving consistency and accuracy.
5.1 Training
The feature map inputs used in training involve minor data augmentation via differing values for blending radius (0, 1e-5, 1e-4, 1e-3), like those seen in Figure 7. This adds diversity to the training data and should help the CGAN be more robust to distortions caused by soft rasterization. As described in Section 3, the SAR images are augmented via additive (clutter-like) and multiplicative (speckle-like) types of noise.
The CGAN is trained for 200 epochs with early stopping based on performance with the validation subset. Both the generator and discriminator are trained with the AdamW optimizer [44]. AdamW is a slight improvement over the original Adam optimizer [45] by making a correction to the implementation of weight decay. Learning rates start at 2e-4 and decay linearly every epoch to reach 2e-5 by the end of training.
5.2 Results
Figure 9 shows example images generated by the fully trained CGAN. Although the most important results are those for the test object, we include predictions from objects in the validation and training sets for additional comparison. Empirically, the predicted and truth images appear very similar, with the most apparent difference being in the sidelobe/glint effects.
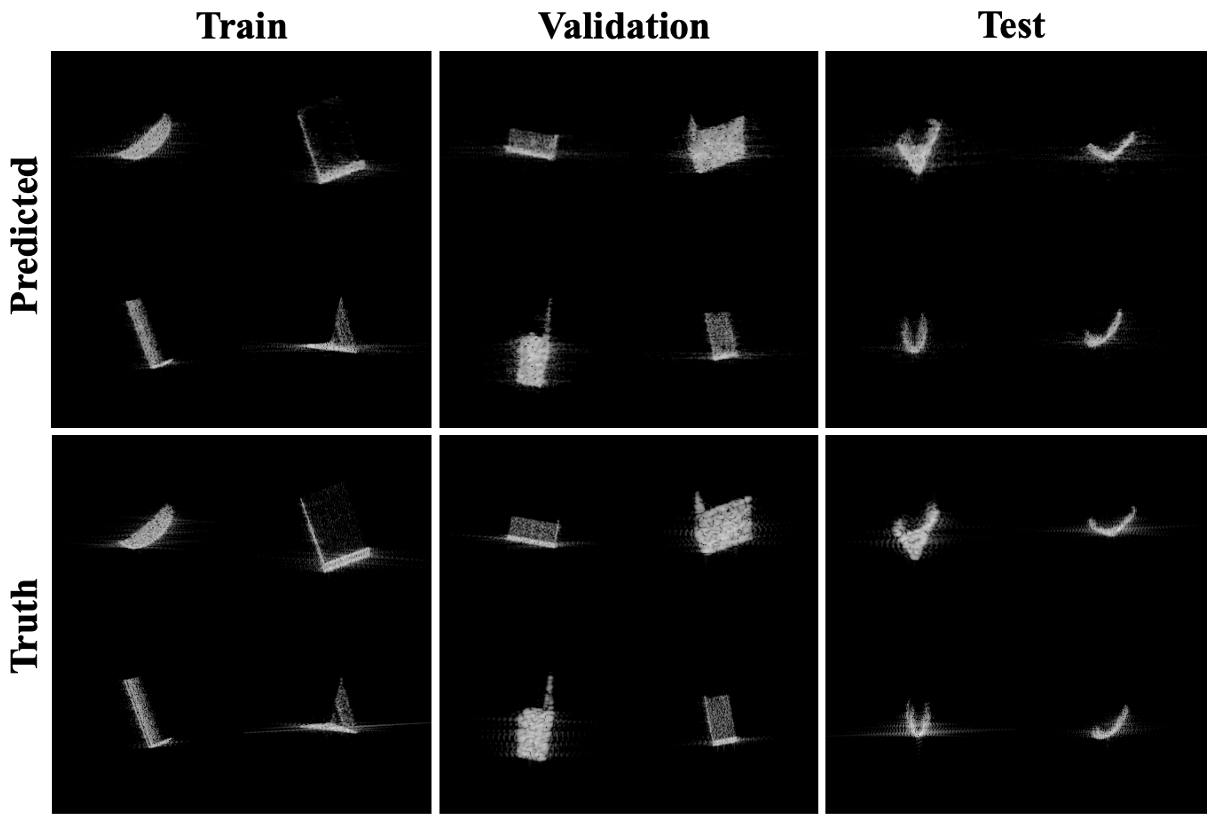
The train, validation and test object sets are compared in terms of the loss produced when generating images of each with the CGAN, in Table 2. The and losses in Table 2 are similar to those found in [3], except that the weighting for is decreased from 1 to 0.5. is a measure of how well the generator fools the discriminator, while is the scaled L1 distance between predicted and truth images.
We also include an energy-normalized metric, , to account for bias due to varying object sizes. The sum-squared-error of the residual is normalized by the energy of the label image, and this ratio is converted to a dB scale. The metric is defined in equation 4, where norms are over pixels.
| (4) |
| Data Set | ||||
|---|---|---|---|---|
| Train | 0.46 | 1.45 | 1.91 | -8.93 |
| Validation | 0.47 | 1.44 | 1.91 | -8.45 |
| Test | 0.49 | 0.94 | 1.43 | -6.38 |
When using the energy-normalized metric , we can see that loss is lowest on the training set as expected, with an increase of +0.48 dB loss on the validation set, and an additional +2.07 dB loss on the test set. This is the pattern of losses we would expect, which suggests the CGAN suffers slightly from both overfitting to the training data and over-tuning to the validation data.
6 3D RECONSTRUCTION EXPERIMENT
In this section we evaluate the proposed differentiable renderer in the task of object reconstruction. Specifically, we use the renderer to reconstruct a mesh of a new object, given only SAR images of the object at various known aspect angles.
6.1 Losses
This subsection details losses used for the 3D reconstruction experiments. The total loss is aggregated from five sources, with weights that were tuned based on reconstruction performance using the validation object, and is given as:
| (5) |
The first term uses pixel-wise mean-squared-error to compare the high-fidelity simulated SAR images (at known aspect angles) to output predictions of the differentiable SAR renderer (at the same aspect angles). Despite the notorious fickleness of SAR speckles, we found this loss still works reasonably well for demonstration purposes and is simple. The other loss terms are for regularization of the mesh shape and are described next. The regularization terms are primarily intended to prevent the mesh from becoming tangled or trapped in a poor local minima while fitting.
6.1.1 Laplacian
6.1.2 Normal Consistency
We use normal consistency mesh regularization as implemented in [40], which encourages adjacent faces to have similar surface-normal directions. If and are surface normal vectors of faces sharing the th edge, then the normal consistency regularization loss is given as:
| (7) |
6.1.3 Edge Length
Edge length regularization is meant to encourage mesh edges to be of similar length. This has the effect of encouraging vertices to be uniformly distributed along the mesh’s surface. If is the set of the mesh’s edge lengths, the edge length regularization loss can be written as:
| (8) |
6.1.4 Floor-Plane
Since only overhead views are realizable, vertices on the underside of the mesh will be occluded from every view, and thus will not receive guiding gradient information from the Primary loss. However, it is known as a prior that such vertices are likely to reside on the scene’s floor plane, as opposed to being suspended in air.
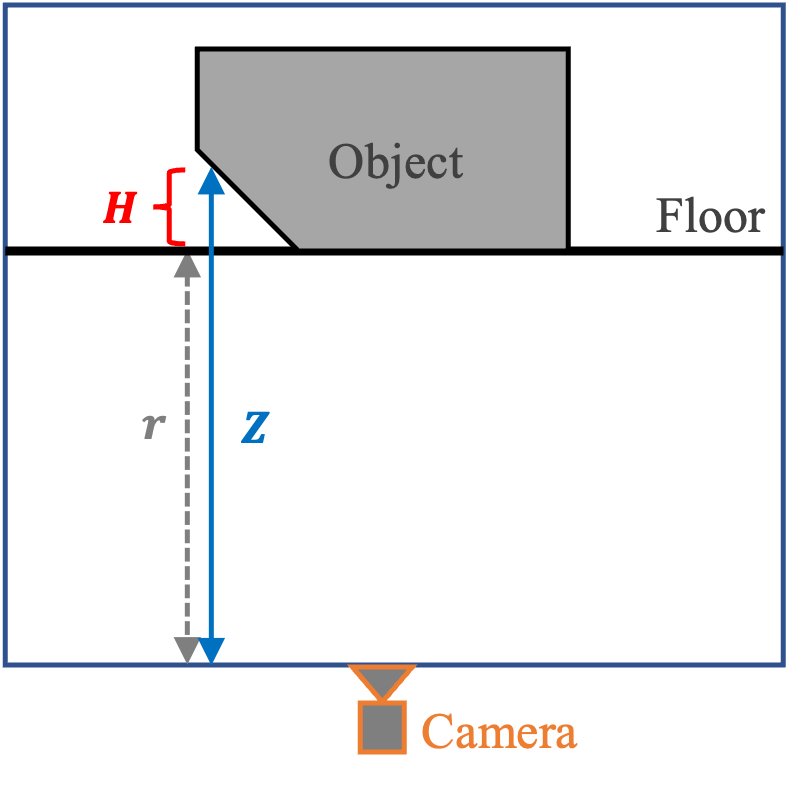
We created the ‘floor-plane’ regularizer to encourage this by first rasterizing the object from a bottom-up view. The depth buffer () from the raster fragments can be used to derive a 2D height map () of the underside of the mesh. We penalize the heights as:
| (9) | ||||
| (10) |
where is the distance between the camera and the scene’s floor-plane. It is assumed that the floor-plane has a height of zero. Figure 10 provides a geometric interpretation of the quantities in equation 9.
6.2 Mesh Optimization Loop and Settings
The 3D object reconstruction is done in two levels, to reconstruct the mesh in a coarse-to-fine manner. Both levels use the stochastic gradient descent optimizer with a learning rate of 1.0, momentum of 0.9, and dampening of 0.9. Each level updates the mesh iteratively as follows:
-
1.
A label SAR image of the target object and its aspect angles are chosen.
-
2.
The estimated mesh is rendered via our renderer at the same aspect angles.
-
3.
The total (regularized) loss is computed by equation 5, using the prediction rendered by the model and the chosen label SAR image.
-
4.
The mesh is updated based on backpropagated gradients from the loss.
During the first level of mesh-fitting, the estimated mesh is initialized with a large dome shape of 42 vertices and 80 triangle faces, as seen in Figure 11. We choose a low vertex count to help the optimization loop avoid local minima early on. The soft rasterizer blending radius is =1e-3. The mesh at this level is updated for 1080 iterations using a batch size of two.
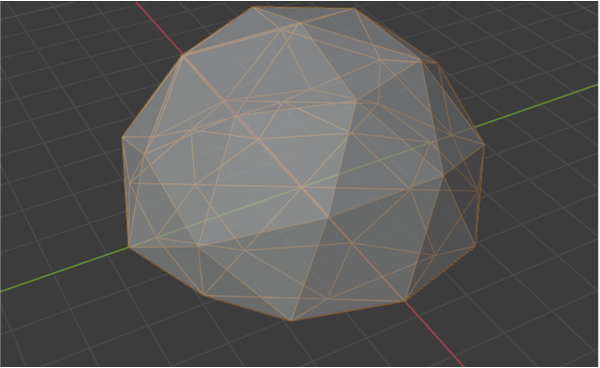
After the first level of mesh-fitting, the mesh estimate is up-sampled by inserting new vertices in the middle of each edge, resulting in a mesh with 162 vertices and 320 triangle faces. This up-sampled mesh initializes the second level. The soft rasterizer blending radius is also lowered to =2.5e-4. The mesh is updated for 540 iterations using a batch size of four. The larger batch size of the second level reduces variance of the gradients, helping the mesh fine-tune.
6.3 Metrics for 3D Reconstruction
For quantitative evaluation, we consider two main metrics, as well as translation-invariant versions of each. The first metric is voxelized intersection over union (IoU), while the second is voxelized cosine similarity (CS). CS is a common comparison metric across many domains, although IoU is more common specifically for comparing 3D volumes. The metrics can be defined as:
| (11) | ||||
| (12) |
where and are voxelized volume representations of the reconstructed and ground-truth meshes, respectively. Norms and summations are over voxels, and each voxel is boolean-valued to indicate whether it lies inside or outside the mesh. Note that since voxels are boolean-valued, the numerators of equations 11 and 12 will be equal. The boolean-valued voxels also mean that the denominator in equation 12 is equivalent to the geometric-mean of the two volume sizes, while the denominator in equation 11 is instead the size of the union between the two volumes. Although both metrics yield values between [0,1], the difference in denominators makes IoU less-forgiving of small deviations between the compared volumes.
Translation-invariant versions of these metrics may also be useful. This removes the influence of potential translational misalignment, so the scores reflect only how well the 3D volumes match in terms of shape. The translation-invariant versions of these metrics take the max score over a sliding window, defined as:
| (13) | ||||
| (14) |
where subscripts , , and represent translations of in each of the three spatial dimensions, bounded by .
6.4 Results
The experiment is performed on three objects: Large Ramp, Long Cuboid, and Elliptic Cone. The primary object of interest to test is the Elliptic Cone because it was reserved exclusively for testing. Results on the Long Cuboid (validation object) and Large Ramp (training object) serve as points of reference to understand how much the mesh-fitting performance may be impacted by hyperparameter over-tuning and Neural Shader overfitting, respectively. The experiment is run five times for each object at different random seeds. The reconstructed meshes for each object shown in Figure 12 are sourced from the median-scoring trial, while Table 3 provides the mean across all trials for each reconstruction metric.

The reconstruction scores from Table 3 trend similarly to what was observed with the metric that compared rendering accuracy in Table 2. When comparing Tables 2 and 3, it is worth noting that the score for the Large Ramp by itself was -10.15 dB, which is better than the average amongst all training objects (-8.93 dB). The most noteworthy difference is that the issue of hyperparameter over-tuning appears to be slightly more prominent in the reconstruction results than it is in the rendering accuracy results. This change may be attributable to the hyperparameters introduced by the 3D reconstruction optimization process, which presents additional opportunities for over-tuning. Similar to the conclusion from subsection 5.5.2, the reconstruction results suggest that the issues of overfitting and over-tuning exist but are both relatively minor.
| Object | ||||
|---|---|---|---|---|
| Large Ramp | 0.862 | 0.869 | 0.927 | 0.932 |
| Long Cuboid | 0.902 | 0.902 | 0.949 | 0.949 |
| Elliptic Cone | 0.853 | 0.853 | 0.921 | 0.921 |
7 DISCUSSION
The method proposed in this work has been successful as a proof of principle. However, there are areas for improvement that should be addressed in the future to help this become a more pragmatic tool for real-world use. This includes support for multiple materials and object segments, support for multistatic modalities, and additional validation on real world data. There are also open research problems related to differentiable rendering for SAR that should be the subject of future work. These include additional applications and an alternative approach based on SAR raw signal simulators.
7.1 Future Improvements
In the method’s current form, objects are assumed to be of a uniform material, and changing the assumed material requires new corresponding weights for the Neural Shader. Support for multiple material types, as well as backpropagation to material properties, would broaden the tool’s utility to other differentiable SAR rendering applications. This could manifest itself as additional feature maps output by the Feature Rasterizer to convey material property context to the Neural Shader.
The current method also only supports one object segment (i.e., one mesh) at a time. Support for multiple segments would allow handling of background clutter, which is typically present in real SAR images, and may make support for multiple materials easier to implement.
This work also only considered monostatic SAR collections. Generalizing the approach to accommodate multistatic SAR modalities (where transmitter and receiver are not co-located) would expand the coverage of SAR collection modes.
Additionally, since this differentiable rendering method is based on rasterization, it is limited to modeling first-order (single-bounce) effects. Depending on object geometry and material, SAR images may have pronounced multi-path effects as well, which cannot be fully captured as-is. In our internal experiments, there were not significant differences between versions of the data simulated with single vs. double-bounce effects, but other settings could differ. A differentiable rendering scheme based on raytracing may be able to capture such multi-path effects, but is outside the scope of this current work.
In real-world SAR systems, contributions from facets that are equidistant from the sensor are coherently summed, causing the effect known as layover. However, in the differentiable renderer’s current form, contributions from facets that get mixed due to layover are combined (non-coherently) via a weighted mean. This is a limitation shared with [7], which utilizes alpha blending. This may partially explain why the peaks are not as sharp on images produced by the differentiable renderer where layover is known to occur, like in Figure 13.
Lastly, the SAR data used to train and evaluate our method was synthetically generated. The cost of collecting large quantities of measured data make it prohibitively expensive to use for training. However, future experiments should at least use measured data for validation and test objects.
7.2 Future Directions
We chose the task of 3D object reconstruction for demonstration purposes, but future work should investigate other applications enabled by differentiable rendering. Particularly, we would like to see this applied to the task of generating adversarial examples subject to 3D shape or material constraints. This task may be useful on its own for assisting in vehicle design or augmentation, but also enables the downstream tasks of geometrically-constrained data augmentation and adversarial training for deep neural networks.
An approach based on SAR raw signal simulation would be fully coherent and could capture effects from transmitter and receiver polarizations. It would also allow the user to employ an image formation algorithm of choice. Additionally, it would eliminate the need to train a CGAN for shading, which is cumbersome because of the large number of high-fidelity SAR images needed to train it. However, such an approach would likely be computationally more costly than the one proposed in this paper, which may hinder its utility in optimization problems.
7.3 Comparison to Collected Data
This subsection provides a visual comparison of imagery produced by the differentiable SAR renderer to collected imagery at comparable geometries. Although the differentiable renderer is not intended for use as a general SAR simulator, comparison to additional data sources is helpful for understanding its capabilities and limitations.
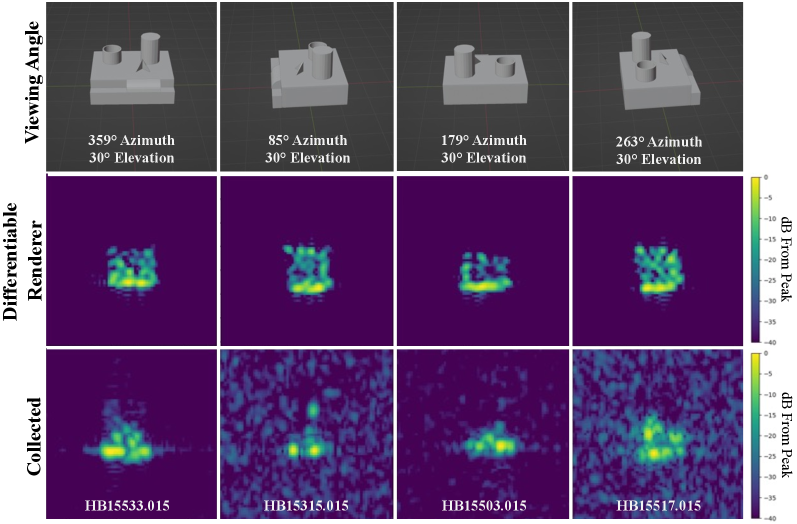
Publicly available SAR data with corresponding scene representation ground-truth information (i.e., detailed CAD models) is difficult to come by, and prohibitively expensive to collect. Fortunately, the Moving and Stationary Target Acquisition and Recognition (MSTAR) public dataset [48] includes a synthetic calibration target known as SLICY (Sandia Laboratory Implementation of Cylinders). While detailed CAD models are not directly available for SLICY, information about the size and shape of the components that compose it is known [49, 50], as well as general information about its material (i.e., smooth metal). We manually constructed a CAD model that is nominally matched to the geometry of SLICY, seen in Figure 13.
The SLICY data was collected at X-band, but at a resolution about 4x as coarse as what was used in our main experiments, and image-formation was done in the slant-plane. We resampled the SLICY imagery to project it into the ground-plane and change its pixel-spacing to 0.15m in both range and cross-range.
To make images from our differentiable renderer comparable, we down-sampled the images it produced to match the resampled SLICY data described above. Also, since the differentiable renderer directly produces images with a PEDF-remapping, we (approximately) reverse-processed the remap to estimate what the raw pixel magnitudes would be. Since the PEDF-remap is lossy, the reverse-processing is imperfect; most notably, only roughly 30dB of dynamic range is retained due to clipping that occurs as part of PEDF-remapping.
Lastly, because scaling differs between image sources, we must normalize each image in order to compare them on a common scale. We normalize each image by its peak magnitude, and display the images on a decibel scale with 40dB of dynamic range. The resulting images are displayed in Figure 13.
Despite a number of mismatches impacting the comparison in Figure 13, the images maintain good structural similarity. The most prevalent difference seems to stem from the differing material types, which explains why a greater proportion of the object’s body appears illuminated in the rendered images compared to the collected counterparts. The SLICY object was also explicitly designed to demonstrate certain multi-path effects, which the differentiable renderer does not emulate. The hollow short cylinder is one such example, and it seems to be the source of the top-right scatterer in collected image HB15315.015. The delayed return from the cavity is what causes the scatterer to appear displaced in range.
8 CONCLUSION
In this work, we described an approach for differentiable rendering of SAR imagery which is a composition of techniques from computer graphics and neural rendering. We presented proof-of-concept results on the task of 3D object reconstruction and discussed the approach’s current limitations. To the best of our knowledge, this is the first successful demonstration of differentiable rendering for SAR-domain imagery, which we hope will serve as a useful starting point for others seeking to use differentiable SAR rendering in their research.
ACKNOWLEDGMENT
The authors would like to thank the editors and anonymous reviewers for their helpful feedback during the review process, along with KBR inc. for partial support of the project. The authors would also like to thank Emeritus Professor Hao Ling for his helpful advice at the project’s onset, as well as Nonie Arora for her help in reviewing the manuscript.
References
- [1] G. W. Stimson, Introduction to Airborne Radar, 2nd ed. SciTech Publishing, 1998, ch. 1: Overview, p. 13.
- [2] H. Kato, D. Beker, M. Morariu, T. Ando, T. Matsuoka, W. Kehl, and A. Gaidon, “Differentiable rendering: A survey,” CoRR, vol. abs/2006.12057, 2020.
- [3] P. Isola, J.-Y. Zhu, T. Zhou, and A. Efros, “Image-to-image translation with condational adversarial networks,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- [4] G. Franceschetti, M. Migliaccio, and D. Riccio, “The sar simulation: an overview,” in 1995 International Geoscience and Remote Sensing Symposium, IGARSS ’95. Quantitative Remote Sensing for Science and Applications, vol. 3, 1995, pp. 2283–2285 vol.3.
- [5] S. Auer, R. Bamler, and P. Reinartz, “Raysar - 3d sar simulator: Now open source,” in Proceedings of IEEE International GeoScience and Remote Sensing Symposium, 2016.
- [6] H. Hammer, S. Kuny, and K. Schulz, “Amazing sar imaging effects - explained by sar simulation,” in Proceedings of 10th European Conference on Synthetic Aperture Radar, 2014.
- [7] T. Balz, “Real-time sar simulation of complex scenes using programmable graphics processing units,” in Proceedings of International Society for Photogrammetry and Remote Sensing, 2006.
- [8] T. Balz, H. Hammer, and S. Auer, “Potentials and limitations of sar image simulators – a comparative study of three simulation approaches,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 101, pp. 102–109, 2015.
- [9] B. T. Phong, “Illumination for computer generated pictures,” Communications of the ACM, vol. 18, pp. 311–317, 1975.
- [10] F. T. Ulaby, R. K. Moore, and A. K. Fung, Microwave Remote Sensing: Active and Passive, vol. Volume III: From Theory to Applications, ser. Microwave Remote Sensing: Active and Passive. Artech House, 1986, vol. III: From Theory to Applications.
- [11] L. Hao, R.-C. Chou, and S.-W. Lee, “Shooting and bouncing rays: Calculating the rcs of an arbitrarily shaped cavity,” IEEE Transactions on Antennas and Propagation, vol. 37, no. 2, pp. 194–205, 1989.
- [12] M. Hazlett, D. J. Andersh, S. W. Lee, H. Ling, and C. L. Yu, “XPATCH: a high-frequency electromagnetic scattering prediction code using shooting and bouncing rays,” in Targets and Backgrounds: Characterization and Representation, W. R. Watkins and D. Clement, Eds., vol. 2469, International Society for Optics and Photonics. SPIE, 1995, pp. 266 – 275.
- [13] D. J. Andersh, “Xpatch 4: the next generation in high frequency electromagnetic modeling and simulation software,” in Proceedings from IEEE International Radar Conference, 2000.
- [14] R. Zhang, J. Hong, and F. Ming, “Caspatch: A sar image simulation code to support atr applications,” in 2009 2nd Asian-Pacific Conference on Synthetic Aperture Radar, 2009, pp. 502–505.
- [15] A. Pritchard, R. Ringrose, and M. Clare, “Prediction of sar images of ships,” in IEE Colloquium on Radar System Modelling (Ref. No. 1998/459), 1998, pp. 2/1–2/5.
- [16] J. C. Smit, “Sigmahat: A toolkit for rcs signature studies of electrically large complex objects,” in 2015 IEEE Radar Conference, 2015, pp. 446–451.
- [17] M. Bingle, A. Garcia-Aguilar, F. Illenseer, U. Jakobus, E. Lezar, M. Longtin, and J. van Tonder, “Overview of the latest electromagnetic solver features in feko suite 7.0,” in 2015 31st International Review of Progress in Applied Computational Electromagnetics (ACES), 2015, pp. 1–2.
- [18] E. E. Garrido and D. C. Jenn, “A matlab physical optics rcs prediction code,” ACES Newsletter, vol. 15, no. 3, 2000.
- [19] D. Muff, D. Andre, B. Corbett, M. Finnis, D. Blacknell, M. Nottingham, C. Stevenson, and H. Griffiths, “Comparison of vibration and multipath signatures from simulated and real sar images,” in International Conference on Radar Systems (Radar 2017), 2017, pp. 1–6.
- [20] A. Tewari, O. Fried, J. Thies, V. Sitzmann, S. Lombardi, K. Sunkavalli, R. Martin-Brualla, T. Simon, J. M. Saragih, M. Nießner, R. Pandey, S. R. Fanello, G. Wetzstein, J. Zhu, C. Theobalt, M. Agrawala, E. Shechtman, D. B. Goldman, and M. Zollhöfer, “State of the art on neural rendering,” Computer Graphics Forum, vol. 39, pp. 701–727, 2020.
- [21] A. Tewari, J. Thies, B. Mildenhall, P. P. Srinivasan, E. Tretschk, Y. Wang, C. Lassner, V. Sitzmann, R. Martin-Brualla, S. Lombardi, T. Simon, C. Theobalt, M. Nießner, J. T. Barron, G. Wetzstein, M. Zollhöfer, and V. Golyanik, “Advances in neural rendering,” CoRR, vol. abs/2111.05849, 2021. [Online]. Available: https://arxiv.org/abs/2111.05849
- [22] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” in Computer Vision – ECCV 2020, A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds. Cham: Springer International Publishing, 2020, pp. 405–421.
- [23] H. Kato, Y. Ushiku, and T. Harada, “Neural 3d mesh renderer,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [24] F. Petersen, A. H. Bermano, O. Deussen, and D. Cohen-Or, “Pix2vex: Image-to-geometry reconstruction using a smooth differentiable renderer,” CoRR, vol. abs/1903.11149, 2019.
- [25] S. Liu, W. Chen, T. Li, and H. Li, “Soft rasterizer: A differentiable renderer for image-based 3d reasoning,” in Proceedings of IEEE/CVF International Conference on Computer Vision, 2019.
- [26] T.-M. Li, M. Aittala, F. Durand, and J. Lehtinen, “Differentiable monte carlo ray tracing through edge sampling,” ACM Transations on Graphics, vol. 37, no. 6, pp. 1–11, 2018.
- [27] M. Nimier-David, D. Vicini, T. Zeltner, and W. Jakob, “Mitsuba 2: A retargetable forward and inverse renderer,” ACM Transations on Graphics, vol. 38, no. 6, pp. 1–17, 2019.
- [28] L. Wang, X. Xu, Y. Yu, R. Yang, R. Gui, Z. Xu, and F. Pu, “Sar-to-optical image translation using supervised cycle-consistent adversarial networks,” IEEE Access, vol. 7, pp. 129 136–129 149, 2019.
- [29] Y. Li, R. Fu, X. Meng, W. Jin, and F. Shao, “A sar-to-optical image translation method based on conditional generation adversarial network (cgan),” IEEE Access, vol. 8, pp. 60 338–60 343, 2020.
- [30] X. Yang, J. Zhao, Z. Wei, N. Wang, and X. Gao, “Sar-to-optical image translation based on improved cgan,” Pattern Recognition, vol. 121, p. 108208, 2022.
- [31] S. Niu, X. Qiu, B. Lei, and K. Fu, “A sar target image simulation method with dnn embedded to calculate electromagnetic reflection,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 2593–2610, 2021.
- [32] M. Wilmanski, “Differentiable rendering for synthetic aperture radar imagery,” University of Texas at Austin, Tech. Rep., 2021.
- [33] S. Fu and F. Xu, “Differentiable sar renderer and image-based target reconstruction,” arXiv, 2022. [Online]. Available: https://arxiv.org/abs/2205.07099v1
- [34] B. O. Community, Blender - a 3D modelling and rendering package, Blender Foundation, Stichting Blender Foundation, Amsterdam, 2021. [Online]. Available: http://www.blender.org
- [35] R. Goodman, W. Carrara, and R. Majewski, Spotlight Aperture Radar: Signal Processing Algorithms. Artech House, 1995.
- [36] L. A. Gorham and L. J. Moore, “Sar image formation toolbox for matlab,” in Proceedings of SPIE Defense, Security, and Sensing: Algorithms for Synthetic Aperture Radar Imagery XVII, 2010.
- [37] E. E. Kuruoglu and J. Zerubia, “Modeling sar images with a generalization of the rayleigh distribution,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 527–533, April 2004.
- [38] P. Singh and R. Shree, “Analysis and effects of speckle noise in sar images,” in 2016 2nd International Conference on Advances in Computing, Communication, and Automation (ICACCA) (Fall), 2016, pp. 1–5.
- [39] N. G.-I. Agency, SarPy, 1st ed., National Geospatial-Intelligence Agency, Springfield, VA, 2021. [Online]. Available: https://github.com/ngageoint/sarpy
- [40] J. Johnson, N. Ravi, J. Reizenstein, D. Novotny, S. Tulsiani, C. Lassner, and S. Branson, “Accelerating 3d deep learning with pytorch3d,” in SIGGRAPH Asia 2020 Courses, ser. SA ’20. New York, NY, USA: Association for Computing Machinery, 2020. [Online]. Available: https://doi.org/10.1145/3415263.3419160
- [41] J. de Vries, Learn OpenGL: Learn modern OpenGL graphics programming in a step-by-step fashion. Kendall & Welling, June 2020. [Online]. Available: https://learnopengl.com/
- [42] R. Goodman and W. Carrara, Handbook of Image and Video Processing, 1st ed. Academic Press, 2000, ch. 10.1: Synthetic Aperture Radar Algorithms, pp. 749–769.
- [43] S. Ioffe, “Batch renormalization: Towards reducing minibatch dependence in batch-normalized models,” in Proceedings of 31st International Conference on Neural Information Processing Systems, 2017.
- [44] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
- [45] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proceedings of 3rd International Conference on Learning Representations, 2015.
- [46] P. S. M. Desbrun, M. Meyer and A. H. Barr, “Implicit fairing of irregular meshes using diffusion and curvature flow,” in 26th International Conference on Computer Graphics and Interactive Techniques, 1999.
- [47] A. Nealen, T. Igarashi, O. Sorkine, and M. Alexa, “Laplacian mesh optimization,” in International Conference on Computer Graphics and Interactive Techniques in Australasia and South East Asia, 2006.
- [48] T. D. Ross, S. W. Worrell, V. J. Velten, J. C. Mossing, and M. L. Bryant, “Standard SAR ATR evaluation experiments using the MSTAR public release data set,” in Algorithms for Synthetic Aperture Radar Imagery V, E. G. Zelnio, Ed., vol. 3370, International Society for Optics and Photonics. SPIE, 1998, pp. 566 – 573.
- [49] S. K. Wong, “High fidelity synthetic sar image generation of a canonical target,” Defense Research and Development Canada, Tech. Rep., 2010.
- [50] J. Richards, “Target model generation from multiple synthetic aperture radar images,” Ph.D. dissertation, Massachusetts Institute of Technology, 2001.