mpred \addauthorarblue
Differentially Private Distributed Estimation and Learning
Abstract
We study distributed estimation and learning problems in a networked environment where agents exchange information to estimate unknown statistical properties of random variables from their privately observed samples. The agents can collectively estimate the unknown quantities by exchanging information about their private observations, but they also face privacy risks. Our novel algorithms extend the existing distributed estimation literature and enable the participating agents to estimate a complete sufficient statistic from private signals acquired offline or online over time and to preserve the privacy of their signals and network neighborhoods. This is achieved through linear aggregation schemes with adjusted randomization schemes that add noise to the exchanged estimates subject to differential privacy (DP) constraints, both in an offline and online manner. We provide convergence rate analysis and tight finite-time convergence bounds. We show that the noise that minimizes the convergence time to the best estimates is the Laplace noise, with parameters corresponding to each agent’s sensitivity to their signal and network characteristics. Our algorithms are amenable to dynamic topologies and balancing privacy and accuracy trade-offs. Finally, to supplement and validate our theoretical results, we run experiments on real-world data from the US Power Grid Network and electric consumption data from German Households to estimate the average power consumption of power stations and households under all privacy regimes and show that our method outperforms existing first-order privacy-aware distributed optimization methods.
Keywords: Distributed Learning, Differential Privacy, Estimation
1 Introduction
Differential privacy (DP) is a gold standard in privacy-preserving algorithm design that limits what an adversary (or any observer) can learn about the inputs to an algorithm by observing its outputs (Dwork, , 2011; Dwork and Roth, , 2014), according to a privacy budget that is usually denoted by . It requires that given the output, the probability that any pair of adjacent inputs generate the observed output should be virtually the same. Adding noise to the input data helps enforce this standard in different settings — e.g., for distributed learning — but the added noise can also degrade our performance, e.g., lowering the quality of distributed estimation and collective learning for which agents exchange information.
This paper provides aggregation algorithms that facilitate distributed estimate and learning among networked agents while accommodating their privacy needs (e.g., protecting their private or private signals and network neighborhoods). Each algorithm implies a different tradeoff between its quality of collective learning and how much privacy protection it affords the participating agents (i.e., their privacy budgets). Our performance metrics reflect how distributional features of the private signals and the nature of privacy needs for individual agents determine the learning quality and requisite noise.
Decentralized decision-making and distributed learning problems arise naturally in a variety of applications ranging from sensor and robotic networks in precision agriculture, digital health, and military operations to the Internet of things and social networks (Bullo et al., , 2009; Jackson, , 2008); see Section 1.2 for a detailed literature review. We are particularly interested in distributed estimation problems that arise in smart grids with distributed generation and energy resources. Notably, a recent report from National Academies of Sciences, Engineering, and Medicine, 2023a ; National Academies of Sciences, Engineering, and Medicine, 2023b suggests that net metering practices should be revised to reflect the value of distributed electricity generation, such as rooftop solar panels. Net metering compensates customers for the electricity they provide to the grid through distributed generation. The report notes that net metering has facilitated the embrace of distributed generation in states where it has been put into effect, resulting in levels surpassing 10% in a few states and projected to rise in both these and other states. Additionally, the report emphasizes the need to revisit and evolve net metering policies to support the deployment of distributed generation that adds value in reducing fossil fuel use, enhancing resilience, and improving equity. In this context, each customer faces an individual privacy risk in sharing their estimates since revealing exact measurements can pose security risks that can be leveraged by an adversary (e.g., understanding when someone is at their home, daily habits, family illness, etc.), and, therefore, developing privacy-preserving methods that support decentralized decision making in such setups is critical.
This paper introduces novel algorithms designed for the distributed estimation of the expected value of sufficient statistics in an exponential family distribution. The proposed methods leverage signals received by individual agents, who maintain and update estimates based on both these signals and information from their local neighborhood. Our contributions to the existing literature on distributed optimization include new privacy-aware distributed estimation algorithms that exhibit faster convergence rates compared to established first-order methods (cf. Rizk et al., (2023)). Notably, our algorithms safeguard the information in agents’ signals and local neighborhood estimates, ensuring optimal convergence times to true estimates. Furthermore, in contrast to existing approaches, our algorithms can support privacy-aware estimation within an online learning framework, accommodate dynamic topologies, and balance privacy and accuracy by distributing the privacy budget among agents. Finally, we verify our proposed algorithms on real-world datasets and show that they outperform existing first-order methods.
1.1 Main Results
Summary of main notations. We use barred bold letters to denote vectors (e.g., ) and bold letters to indicate vector components (e.g., is a component of ). We use capital letters to denote matrices (e.g., ) and small letters to represent their entries (e.g., ). We use small letters to denote scalars. We denote the column vector of all ones by .
Summary of the Problem Setup (see Section 2.2). We consider a network of agents indexed by whose interconnections are characterized by a symmetric, doubly-stochastic, adjacency matrix . This adjacency structure, encoded by graph neighborhoods, , may be a consequence of geospatial constraints such as sensing and communication range or geographic proximity; it can also be a reflection of how the network has evolved and other engineering considerations, e.g., which nodes belong to which countries or companies in a multi-party network. The adjacency weights may also result from geoeconomic constraints such as access to local trade and business intelligence (contracts, sales, and filled orders). In the case of social networks, they can also represent the presence of influence and mutual interactions among individuals.
Given the adjacency structure , at every round , each agent receives a private signal that is sampled from an exponential family distribution with the natural sufficient statistic and a common, unknown parameter belonging to a measurable set . The goal of the agents is to collectively estimate the common value of by combining their samples. This is achieved through a consensus algorithm by forming an estimate and exchanging it with their network neighbors in a distributed manner respecting the adjacency structure of . The agents also want to control the information that is leaked about their signals and the estimates of their neighbors . They add noise to their updates. The noise level should be high enough not to violate an differential privacy budget. Briefly, we say that a mechanism is -DP when for any pair of “adjacent” inputs (i.e., private signals or private signals and neighboring estimates), the logarithm of the probability ratio of any output in the range space of being resulted from either of the adjacent inputs is bounded by : , for all adjacent pairs ( and ) in the input domain and any subset of the output range space. Our specific notion of adjacency between the input pairs will be determined by the nature of information leaks, i.e., private signals or private signals and network neighborhoods, against which the exchanged estimates () are being protected (Figure 1).
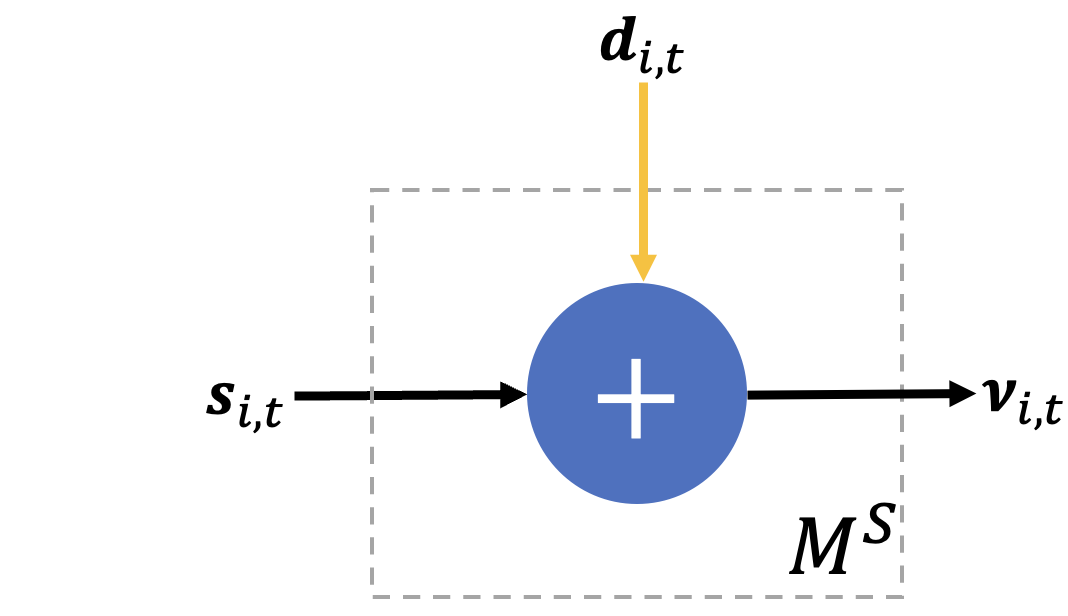
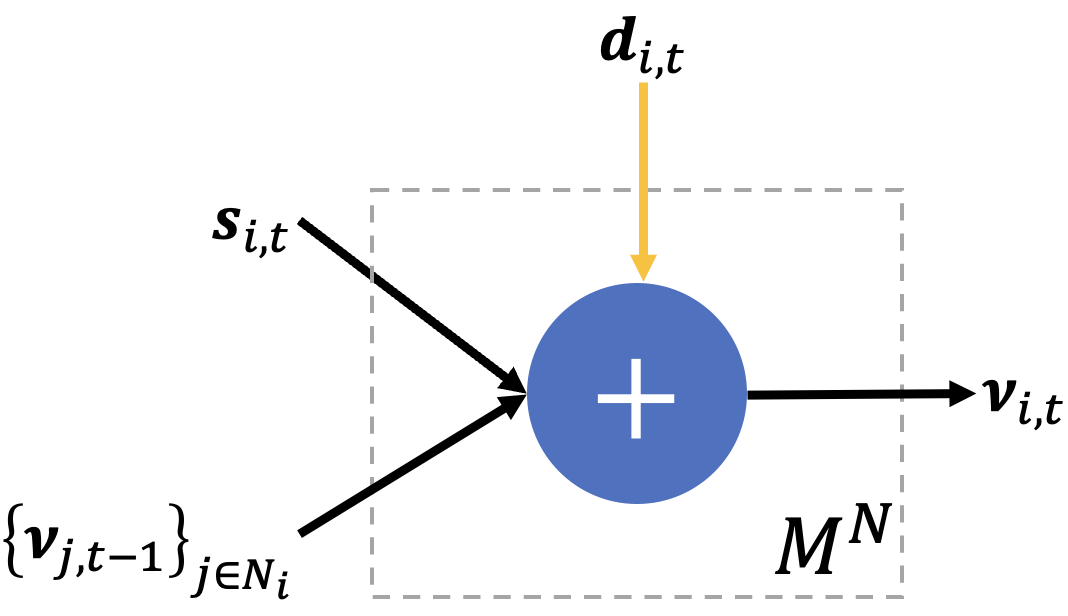
Theoretical Contributions (Sections 3.1 and 4). In this paper, we provide bounds for the convergence of the DP estimates to the desired value , where . We decompose the total error as follows:
Here, corresponds to the vector of non-private estimates. The first term corresponds to the “Cost of Privacy” (CoP), the estimation cost incurred by the -DP noising. The second term corresponds to the expected error from running the non-private distributed learning algorithm and, therefore, measures the “Cost of Decentralization” (CoD). In Section 3, when we consider “offline” estimation of from a fixed collection of initial signals available at the beginning (), we replace by the best possible estimate — the minimum variance unbiased estimate (MVUE) — of an omniscient observer who has centralized access to all the private signals.
Our goal is to find differentially private aggregation mechanisms with fast convergence guarantees that minimize CoP parametrized by noise distributions of the agents and subject to their differential privacy budget constraints, i.e., “s.t. -DP”:
| (1) |
From now on, we will refer to this optimal value as the cost of privacy. In our analysis, the CoP and CoD are proportional to the signal and noise variance. The convergence rate also depends on the number of nodes and the spectral gap of the doubly-stochastic adjacency matrix , which dictates the convergence rate of to its limiting matrix , as .
Subsequently, the noise distribution can be optimized by minimizing the weighted variances of the noise terms in the upper bounds subject to DP constraints. Our main results are summarized in Table 1. These consist of minimum variance unbiased estimation (Section 3) and online learning (Section 4) of expected values under (i) protection of the private signals (Signal DP), and (ii) protection of the private signals and the local neighborhoods (Network DP). The following Informal Theorem summarizes our theoretical contributions along with Table 1:
Informal Theorem. If is the global sensitivity of at time , and are the weights of the adjacency matrix, then the upper bound in CoP is minimized by the Laplace noise with parameters for the case of Signal DP, and parameters for the case of network DP.
Moreover, whenever the global sensitivity is unbounded, something that happens to a variety of sufficient statistics , we rely on the smooth sensitivity introduced by Nissim et al., (2007) and derive the same algorithms (but with parameters depending on the smooth sensitivity instead of ), which achieve -DP, namely using the smooth sensitivity introduces a compromise in the -DP guarantee by a small information leakage probability , relaxing the DP constraint for a mechanism as follows: , for all adjacent input pairs ( and ) and all subsets of the output range space.
| Minimum Variance Unbiased Estimation | Online Learning of Expected Values | |
|---|---|---|
| Signal DP | Theorem 3.1 | Theorem 4.1 |
| Network DP | Corollary 3.2 | Theorem 4.2 |
Experiments (Section 5). We conduct experiments with two real-world datasets motivated by decentralized decision problems in power grids (see Section 1). The first dataset considers the daily consumption of several German Households over three years (Milojkovic, , 2018), and the second one considers the US Power Grid network from Watts and Strogatz, (1998). Our experiments show that we can achieve -DP while not significantly sacrificing convergence compared to the non-private baselines. The results also indicate the increased challenges in ensuring network DP compared to Signal DP and the importance of distributional features of the signals, in particular, having sufficient statistics with bounded derivatives.
Code and Data. For reproducibility, we supplement the manuscript with our code and data, which can be found at: https://github.com/papachristoumarios/dp-distributed-estimation.
1.2 Related Work
Our results relate to different bodies of literature across the engineering, statistics, and economics disciplines, and in what follows, we shall expand upon these relations.
Decentralized Decision Making and Distributed Learning have attracted a large body of literature over the years, with notable examples of Borkar and Varaiya, (1982); Tsitsiklis and Athans, (1984); Tsitsiklis, (1993); Papachristou and Rahimian, (2024). Recently, there has been a renewed interest in this topic due to its applications to sensor and robotic networks (Chamberland and Veeravalli, , 2003; Olfati-Saber and Shamma, , 2005; Kar et al., , 2012; Atanasov et al., 2014b, ; Atanasov et al., 2014a, ) and emergence of a new literature considering networks of sensor and computational units (Shahrampour et al., , 2015; Nedić et al., , 2015, 2017). Other relevant results investigate the formation and evolution of estimates in social networks and subsequent shaping of the individual and mass behavior through social learning (Krishnamurthy and Poor, , 2013; Wang and Djuric, , 2015; Lalitha et al., , 2014; Rahimian and Jadbabaie, 2016a, ; Rahimian and Jadbabaie, 2016c, ). Obtaining a global consensus by combining noisy and unreliable locally sensed data is a crucial step in many wireless sensor network applications; subsequently, many sensor fusion schemes offer good recipes to address this requirement (Xiao et al., , 2005, 2006). In many such applications, each sensor estimates the field using its local measurements, and then, the sensors initiate distributed optimization to fuse their local forecast. If all the data from every sensor in the network can be collected in a fusion center, then a jointly optimal decision is readily available by solving the global optimization problem given all the data (Alexandru et al., , 2020). However, many practical considerations limit the applicability of such a centralized solution. This gives rise to the distributed sensing problems that include distributed network consensus or agreement (Aumann, , 1976; Geanakoplos and Polemarchakis, , 1982; Borkar and Varaiya, , 1982), and distributed averaging (Dimakis et al., , 2008); with close relations to the consensus and coordination problems that are studied in the distributed control theory (Jadbabaie et al., , 2003; Mesbahi and Egerstedt, , 2010; Bullo et al., , 2009). Our work contributes to this body of work by providing a privacy-aware method for distributed estimation over a network.
The work most importantly connected to our work is the work of Rizk et al., (2023), which introduces a first-order DP method for distributed optimization over a network of agents. While their work presents a general first-order method for DP distributed optimization, which is suitable for a larger family of optimization problems that include MVUE, adapting their method to our task comes with important trade-offs in the quality of the estimation, as running their method results in significantly higher error (up to more; see Figure 7) for the MVUE task due to the repeated inclusion of the signal in the belief updates. Moreover, contrary to ours, their method does not support the online learning regime. Finally, the concept of “graph-homomorphic noise” proposed in their paper is equivalent to the Network DP regime of our paper.
Differential privacy is a modern definition of data privacy encompassing many previous definitions, such as -anonymity. A mechanism is differentially private if it maps similar records to the same value with equal probability. One consequence of the definition is that it guarantees that the outcome of a statistical analysis will be identical whether the individual chooses to participate in the social learning process. Many previously proposed mechanisms can be shown to be differentially private, such as randomized response (Warner, , 1965), the Laplace mechanism, and the Gaussian mechanism. The randomized response algorithm originally proposed by Warner, (1965) consists of randomly perturbing binary responses, and it allows the population means to be recovered while giving individual respondents plausible deniability – an instance of adding noise to data.
Statistical disclosure control of donated data, e.g., submitting recommendations to a public policy agency or submitting online product reviews to an e-commerce platform, requires safeguarding donors’ privacy against adversarial attacks where standard anonymization techniques are shown to be vulnerable to various kinds of identification (Barbaro et al., , 2006), linkage and cross-referencing (Sweeney, , 2015; Narayanan and Shmatikov, , 2008; Sweeney, , 1997), and statistical difference and re-identification attacks (Kumar et al., , 2007). Here, we propose to analyze the efficiency of distributed estimation where agents learn from each other’s actions protected by the gold standard of differential piracy (Dwork, , 2011) to optimize statistical precision against the privacy risks to data donors who engage in social learning.
DP can be implemented using central or local schemes. In centralized DP implementations, individual data are collected, and privacy noise is added to data aggregates, used, e.g., in the U.S. Census Bureau’s Disclosure Avoidance system (US Census, , 2020). In local implementations, DP noising is done as data is being collected. Local methods forego the need for any trusted parties and typically provide more fundamental protection that can withstand a broader range future infiltration, e.g., even a government subpoena for data cannot violate the privacy protection when collected data is itself subject to privacy noising — e.g., Google, LinkedIn, and Apple’s DP noising of their user data (Apple Differential Privacy Team, , 2017; Erlingsson, , 2014; Cardoso and Rogers, , 2022; Rogers et al., , 2020), cf. (Wilson et al., , 2020; Guevara, , 2019).
Regarding privacy and networks, Koufogiannis and Pappas, (2017) present a privacy-preserving mechanism to enable private data to diffuse over social networks, where a user wants to access another user’s data and provide privacy guarantees on the privacy leak, which depends on the shortest path between two users in the network. Alexandru and Pappas, (2021) study the problem of private weighted sum aggregation with secret weights, where a central authority wants to compute the weighted sum of the local data of some agents under multiple privacy regimes. Rahimian et al., 2023a ; Rahimian et al., 2023b study influence maximization using samples of network nodes that are collected in a DP manner.
Our work contributes to the above line of work by introducing a novel DP mechanism for distributed estimation and learning of exponential family distributions. Particularly, to the best of our knowledge, in the online learning regime, our algorithm introduces a novel weighting scheme that can protect both the individual signals and the neighboring beliefs, which can efficiently learn the expected value of the sufficient statistic. Moreover, we also provably derive the optimal distributions that minimize the convergence time of the algorithm and show that they are the Laplace distributions with appropriately chosen parameters.
Cyber-Physical Systems (e.g., energy, transportation systems, healthcare systems, etc.) correspond to the building blocks of modern information and communication technologies, whose privacy and security are crucial for the function of such technologies. There have been multiple methods, such as encryption and -anonymity, to achieve privacy and security in cyber-physical systems (Hassan et al., , 2019; Zhang et al., , 2016; Kontar et al., , 2021). By incorporating differential privacy techniques, such as noise injection or data aggregation, into the design and operation of cyber-physical systems, privacy risks can be mitigated while preserving the utility of the collected data. This ensures that individual privacy is protected, as the data released from these systems cannot be used to infer sensitive information about specific individuals. Moreover, the application of differential privacy to cyber-physical systems enables the collection and analysis of data at scale, allowing for improved system performance, anomaly detection, and predictive maintenance while maintaining the trust of individuals and protecting their privacy in an increasingly connected world (Li et al., , 2010; Gowtham and Ahila, , 2017; Xu et al., , 2017). Our method’s efficiency, e.g., compared to Rizk et al., (2023); see Sections 5 and B, makes it suitable for several large-scale data applications.
Federated Learning (FL) is a collaborative learning paradigm for decentralized optimization without the need to collect all data points in a central server for gradient calculations (McMahan and Thakurta, , 2022; Kontar et al., , 2021), with many applications in mind: distributed training of ML models (Bonawitz et al., , 2021; Shi et al., , 2023; Yue et al., , 2022), healthcare (Kaissis et al., , 2020), wireless communications (Niknam et al., , 2020), etc. While more general than the setup we consider here, it suffers from issues in terms of communication and privacy. Existing privacy-preserving FL methods (cf. Rizk et al., (2023)) usually adopt the instance-level differential privacy (DP), which provides a rigorous privacy guarantee but with several bottlenecks (Truong et al., , 2021). Truex et al., (2019) proposed a privacy-aware FL system that combines DP with secure multiparty computation, which utilizes less noise without sacrificing privacy as the number of federating parties increases and produces models with high accuracy. Other FL methods, such as Zhang et al., (2022), accommodate differentially private updates via incorporating gradient clipping before adding privacy noise to achieve good performance subject to privacy constraints.
Contrary to most of these methods, which are first-order optimization methods that are suitable to a large variety of losses compared to our method, our zero-order belief updates for the MVUE are simple, more efficient, and have significantly lower error than first-order methods (see Figure 7 for comparison with Rizk et al., (2023)). Moreover, our method can learn from data that arrive in an online way, whereas methods such as Rizk et al., (2023); Zhang et al., (2022) are offline. Finally, most of these approaches rely on SGD. In contrast, our method focuses more on the decision-theoretic and statistical problem of estimating the expected value of the sufficient statistics of signals generated by an exponential family distribution.
2 Differential Privacy Protections in a Distributed Information Environment
2.1 The Distributed Information Aggregation Problem Setting
Let be any measurable set, and in particular, not necessarily finite. Consider a network of agents and suppose that each agent observes an i.i.d. samples from a common distribution over a measurable sample space (For simplicity in our proofs, we consider the simple case of 1D signals, i.e., . Extending to multi-dimensional signals (i.e., ) is straightforward and considers the norm of the partial derivatives.). We assume that belongs to a one-parameter exponential family so that it admits a probability density or mass function that can be expressed as
| (2) |
where is a measurable function acting as a complete sufficient statistic for the i.i.d. random samples , and is a mapping from the parameter space to the real line , is a positive weighting function, and is a normalization factor known as the -partition function. In (2), is a complete sufficient statistic for . It is further true that is a complete sufficient statistic given the i.i.d. signals that the agents have received (Bickel and Doksum, , 2015, Section 1.6.1). In particular, any inferences that involve the unknown parameter based on the observed signals can be equivalently performed given . The agents aim to estimate the expected value of : , with as little variance as possible. The Lehmann-Scheffé theory — cf. (Casella and Berger, , 2002, Theorem 7.5.1) — implies that any function of the complete sufficient statistic that is unbiased for is the almost surely unique minimum variance unbiased estimator of . In particular, the minimum variance unbiased estimator of given the initial data sets of all nodes in the network is given by: .
For concreteness, we can consider a group of suppliers whose private signals consist of their contracts, sales orders, and fulfillment data. These suppliers would benefit from aggregating their private information to better estimate market conditions captured by the unknown parameter , e.g., to predict future demand. However, sharing their private signals would violate the privacy of their customers and clients. In Section 2.2, we explain how the agents can compute the best (minimum variance) unbiased estimator of using average consensus algorithms Olshevsky, (2014) that guarantee convergence to the average of the initial values without direct access to each other’s private signals.
2.2 The Information Exchange Model
We consider an undirected network graph and let the undirected network which corresponds to a Markov chain with a doubly-stochastic symmetric adjacency/transition matrix with the uniform stationary distribution. For instance, such an adjacency matrix can defined according to the Metropolis-Hastings weights (Boyd et al., , 2004): if , and otherwise for ; furthermore, . This choice of weights leads to a Markov chain where the stationary distribution is the uniform distribution (Boyd et al., , 2004), and the agents can set these weights locally based on their own and neighboring degrees without the global knowledge of the network structure. For choices of that yield the fastest mixing Markov chain (but may not be locally adjustable), see Boyd et al., (2004).
ALGORITHM 1 Non-Private Distributed Minimum Variance Unbiased Estimation The agents initialize with: , and in any future time period the agents communicate their values and update them according to the following rule: (3)
The mechanisms for convergence, in this case, rely on the product of stochastic matrices, similar to the mixing of Markov chains (cf. Levin et al., (2009); Shahrampour et al., (2015)); hence, many available results on mixing rates of Markov chains can be employed to provide finite time grantees after iteration of the average consensus algorithm for fixed . Such results often rely on the eigenstructure (eigenvalues/eigenvectors) of the communication matrix , and the facts that it is a primitive matrix and its ordered eigenvalues satisfy , as a consequence of the Perron-Frobenius theory (Seneta, , 2006, Theorems 1.5 and 1.7).
Moreover, another mechanism considers learning the expected values in an online way where agents receive signals at every round and then update their estimate by averaging the estimates of their neighbors, their own estimate, and the new signals (see Algorithm 2).
ALGORITHM 2 Non-Private Online Learning of Expected Values Initializing arbitrarily, in any future time period the agents observe a signal , communicate their current values , and update their beliefs to , according to the following rule: (4)
The discounting provided in the above algorithm enables learning the expected values asymptotically almost surely with a variance that scales as ; i.e., linearly in time. As shown in Rahimian and Jadbabaie, 2016b , the variance upper bound comprises two terms. The former term considers the rate at which the Markov chain with transition matrix is mixing and is governed by the spectral gap, i.e., the second largest magnitude of the eigenvalues of . The latter term captures the diminishing variance of the estimates with the increasing number of samples gathered by all the agents in the network.
Now that we have the necessary background in distributed estimation, we present the two DP protection mechanisms that our paper considers: the Signal DP and the Network DP.
2.3 Differential Privacy Protections
2.3.1 Definitions and Mechanisms
In this paper, we consider two methods for differential privacy and refer to them as Signal Differential Privacy (Signal DP) and Network Differential Privacy (Network DP). Both algorithms are local in principle; the agents simply add noise to their estimates to achieve a desired privacy guarantee. Roughly, Signal DP adds noise to protect the signal of each agent, and Network DP adds noise to protect the signal of each agent, as well as the estimates of her neighbors from round . We assume that the non-private network dynamics evolve as
| (5) |
for each agent , and , where , , and are functions determined by the learning algorithm, and correspond to the information from the agent’s own estimate, the information from the neighboring estimates, and the information from the agent’s private signal respectively. To achieve differential privacy, each agent adds some amount of noise drawn from a distribution to their estimate and reports the noisy estimate to their neighbors. The agent can either aim to protect only their private signal – which we call Signal DP and denote by –, or protect their network connections and their private signal – which we call Network DP and denote by . The noisy dynamics are:
| (6) |
In Equations 6 and 1, we have outlined the dynamics of the two types of privacy protections. Formally, the two types of mechanisms can also be written as
| () | ||||
| () |
and the -DP requirement is denoted as
for all .
Central vs. Local Privacy. In a local privacy scheme, the DP noise of the measurements can occur at the agent level by adding noise to the collected signals. Noise may be added to the signals after measurement to protect them against the revelations of belief exchange. The central scheme assumes a trusted environment where signal measurements can be collected without privacy concerns, but to the extent that protecting signals from the revelations of beliefs exchange is concerned, these methods would be equivalent.
3 Minimum Variance Unbiased Estimation
3.1 Minimum Variance Unbiased Estimation with Signal DP
We present our first algorithm, which considers Minimum Variance Unbiased Estimation (MVUE). In this task, we aim to learn the MVUE of , i.e., to construct the estimate through local information exchange. The non-private version of this algorithm is presented in Algorithm 1 according to which, the agents start with some private signals , calculate the sufficient statistics and then exchange these initial estimates with their local neighbors. Algorithm 1 converges to in steps to -accuracy, which depends on the number of nodes , the maximum absolute value of the sufficient statistics, and the spectral gap of the transition matrix .
In its DP version, the algorithm proceeds similarly to the non-DP case, except each agent adds noise to their sufficient statistic . As we show later, to respect -DP, the noise depends on the agent’s realized signal , the sufficient statistics , and the privacy budget . We provide the algorithm for the differentially private in Algorithm 3:
ALGORITHM 3 Minimum Variance Unbiased Estimation with Signal/Network DP The agents initialize with where ( is an appropriately chosen noise distribution), and in any future time period the agents communicate their values and update them according to the following rule: (7)
Regarding convergence, in Theorem 3.1, we prove that the convergence error is incurred due to two sources. The first source of error is the error due to the omniscient observer, which is the same as in the non-DP case, and the second source of error is incurred due to the privacy noise. Briefly, the latter term can be roughly decomposed to correspond to two terms: the former term is due to estimating the minimum variance unbiased estimator due to the noise, i.e. and is vanishing with a rate proportional to , and an additional non-vanishing term which is due to the mean squared error of which corresponds to the sum of the variances of the signals.
To minimize the convergence error, it suffices to minimize each variance subject to -DP constraints. By following recent results on the DP literature (cf. Koufogiannis et al., (2015)) we deduce that the variance minimizing distribution under -DP constraints are the Laplace distributions with parameters , where corresponds to the signal sensitivity (see below) and is the privacy budget. We present our Theorem (proved in Section A.1):
Theorem 3.1 (Minimum Variance Unbiased Estimation with Signal DP).
The following hold for Algorithm 3:
-
1.
For all and any zero-mean zero-mean distributions
(8) where and .
-
2.
The optimal distributions that minimize the MSE for each agent are the Laplace distribution with parameters where is the global sensitivity of Subsequently, .
Proof Sketch. We do an eigendecomposition on and prove that since the noise is independent among agents, we can show that . By using Jensen’s inequality, we can show that . To minimize the convergence time, it suffices to minimize the variance of subject to privacy constraints for all , resulting in an optimization problem which we resolve by applying the main result of Koufogiannis et al., (2015). ∎
Finally, we note that similarly, in the multi-dimensional case, the sensitivity would be .
A Note about Global Sensitivity of . In the above Theorem, it is tempting to think that the local sensitivity of each agent, i.e., can be used to calibrate the noise distribution that preserves differential privacy and has the minimum variance. However, as it has been shown in Nissim et al., (2007), releasing noise that depends on the local sensitivity can compromise the signal. However, there are cases where global sensitivity is unsuitable for the learning task. For instance, in many distributions, such as the log-normal distribution, the global sensitivity may be unbounded (e.g., for the log-normal and the sensitivity is in this case). A possible solution for this situation and many exponential family distributions is to use another sensitivity instead of the global sensitivity. (Nissim et al., , 2007, Definition 2.2) proposes the use of the -smooth sensitivity. The way of constructing the -smooth sensitivity is to calculate
Using the Laplace mechanism with parameters for would guarantee -DP; see (Nissim et al., , 2007, Corollary 2.4).
For example, we will consider the case of mean estimation in a log-normal distribution with known variance, a common task in many sensor networks, as we argue in Section 5. The sufficient statistic in this case is , and the local sensitivity at distance can be computed to be . Therefore, the smooth sensitivity is (note the global sensitivity in this case is unbounded):
| (9) |
If agents have access to several signals, and the exact formula of is not known, the sensitivity can still be approximated via samples as shown in Wood and Zhang, (1996).
Remark for Network DP. Note that to achieve Network DP, one natural algorithm is to add noise at each round of Algorithm 3 at a high enough level to protect both the network neighborhoods and the private signals. The issue with this algorithm is that it is divergent, i.e., , because the estimate at time is , and its mean squared error, i.e., , grows linearly with and . To avoid the accumulation of the DP noise, we should limit the DP noising to the initial step, which will achieve a bounded error because the mixing matrix, , is doubly stochastic. To this end, we choose the noise level to satisfy -DP with the aim of protecting both signals and network connections — and run Algorithm 3 at the new noise level. The error of this algorithm will be identical to the error bound of Theorem 3.1. However, the sensitivity of the noise should be set to accommodate both network and signal dependencies as follows: , and the optimal distributions will be ; see Corollary 3.2. In the case that is unbounded, we can replace with the smooth sensitivity accounting for the network effects, i.e., for each signal and get an -DP algorithm. Note that private signals will remain DP-protected by the post-processing immunity of the Laplace mechanism. In Section A.2, we use induction to show that Network DP is preserved at the level for all times when the mixing matrix is non-singular. The following corollary summarizes our results:
Corollary 3.2 (Total Error of Minimum Variance Unbiased Estimation with Network DP).
Assume the mixing matrix is non-singular, let be the global sensitivity of , and . The Total Error of Algorithm 3 with Network DP satisfies
Tightness of Analysis. We note that the above analysis is tight because there exists an instance for which the upper bound is precisely achieved (for any noise distribution). To show this, consider the complete graph , which corresponds to weights for all with a spectral gap of zero, and . The network dynamics on the complete graph converge in one iteration, and it is straightforward to show that the total error (TE) converges to as for any noise distributions subject to -DP constraints (by the central limit theorem), i.e., Equation A.1 in the Supplementary Materials holds with equality.
4 Online Learning of Expected Values
4.1 Privacy Frameworks
We consider the online learning framework where the agents aim to learn the common expected value of the sufficient statistics of their signal distributions. In this regime, the agents observe signals at every time and update their estimates by weighing the information content of their most recent private signals, , their previous estimates, , and the estimates of their neighbors, . The mechanisms that we analyze in this section will accommodate two types of privacy needs with convergence and -DP guarantees for the agents:
-
:
Signal DP (Algorithm 4). Here the agent adds noise to privatize their belief with respect to their signal. To assert the consistency of the estimator, the agent averages her previous estimate and the estimates of her neighbors with weight and her signal with weight , similarly to Algorithm 2. Therefore, the local sensitivity of this mechanism is the sensitivity of the sufficient statistic weighted by and equals .
-
:
Network DP (Algorithm 5). Here we consider the protection of the agent’s signals together with their local neighborhood, namely the neighboring beliefs . We note that when deciding the noise level at time , we do not need to include the agent’s own belief from time in the DP protection; including all the private signals up to and including at time remain protected by the property of the post-processing immunity. If we were to use Algorithm 4 for Network DP the sensitivity of the mechanism would be which approaches 1 as and violates the consistency of the estimator . For this reason, we need to adapt the weighting scheme of Algorithm 4 to be consistent and respect Network DP. We give more details of the altered algorithm (Algorithm 5) in Section 4.3.
ALGORITHM 4 Online Learning of Expected Values with Signal DP In any time period the agents observe a signal , and update their estimates according to the following rule: (10) where is appropriately chosen noise.
4.2 Online Learning of Expected Values with Signal DP
Here we will analyze the performance of Algorithm 4 where agents only protect their signals and present the corresponding error analysis. The error of the estimates compared to the expected value , again consists of two terms; one due to decentralization and the statistics of the signals themselves (CoD), and another due to the variances of the added DP noise variables (CoP). Each of these two terms decays at a rate of . They, in turn, can be bounded by the sum of two terms: a constant that is due to the principal eigenvalue of and represents the convergence of the sample average to , and terms due to for which dictate the convergence of the estimates to their sample average. The latter depends on the number of nodes and the spectral gap of matrix . We formalize our results as follows (proved in Section A.3):
Theorem 4.1 (Online Learning of Expected Values with Signal DP).
The following hold for Algorithm 4 and mechanism :
-
1.
For every time , and all distributions we have that
-
2.
The optimal distributions are , where is the global sensitivity. Moreover, we have: .
Proof Sketch. We note that . We decompose as where is the eigenvalue matrix and is the orthonormal eigenvector matrix, and upper bound as a weighted sum of powers of the eigenvalues of and the sum of the variances of , i.e., . We apply the Cauchy-Schwarz inequality again and bound this term with the sum of all variances across all agents and all the rounds , plus the sum of the powers of the eigenvalues of , i.e., . The latter term is decomposed into a term that depends on the principal eigenvalue and terms that are dominated by the spectral gap . We do the same analysis for , and we finally apply Jensen’s inequality and the triangle inequality to get the final bound. To optimize the bound, it suffices to minimize the variances for all and subject to -DP constraints. The optimal noise distributions are derived by solving the same optimization problems as in Theorem 3.1 for all and all . Calculating the bound for Laplace noise with parameters gives the upper bound on . ∎
4.3 Online Learning of Expected Values with Network DP
Above, we briefly discussed why a learning algorithm that puts weights on the network predictions and on the private signal would not work (and in fact, the dynamics become divergent in that case). In Algorithm 5, we present a different learning scheme that uses weights for the private signals and neighboring observations and for the previous beliefs of the agent. The motivation behind this learning scheme is that the sensitivity is now going to be which goes to zero, instead of which approaches 1. The drawback is that the added self-weight on one’s own beliefs at every time step will slow down the mixing time and convergence. In the sequel, we present Algorithm 5 and analyze its performance.
ALGORITHM 5 Online Learning of Expected Values with Network DP In any time period the agents observe a signal and update their estimates according to the following rule: (11) where is appropriately chosen noise.
We can write the above system in matrix notation as where and for all . First, we study the convergence of Algorithm 5 when no noise is added, i.e., . Note that similarly to Algorithm 4, the error term is comprised of two terms, one owing to the principal eigenvalues of , i.e., which controls the convergence of the sample average of the estimates to , and terms due to which control the convergence of the estimates to their sample average.
Theorem 4.2 (Online Learning of Expected Values with Network DP).
For Algorithm 5, the following hold:
-
1.
For all and all distributions , we have that
-
2.
The optimal distributions that minimize the MSE bound subject to -DP are the Laplace Distributions with parameters . Moreover, if is the global sensitivity and , then
Proof Sketch. Our proof (Section A.4) follows a similar analysis to Theorem 4.1. We first note that can be written as , and therefore shares the same eigenvectors with and has eigenvalues . We define , and show that . Moreover, . By using the bound on the eigenvalues of for and by applying the same analysis as in Theorem 4.1, we decompose and get that the sum of the powers of the eigenvalues consists of a term due to the principal eigenvalues, which decays with the rate and terms that decay as . We finally deduce that . The same bound holds for , and by applying Jensen’s inequality and the triangle inequality, we get the error bound. The optimization of the noise variables follows similar logic to Theorem 4.1, with a different sensitivity. ∎
Tightness of analysis. We note that the analysis is tight, and the tight example is precisely the same as the example we provided for MVUE.

5 Real-World Experiments
Datasets and Real-World Scenarios. To showcase the effectiveness of our algorithms, i.e., convergence to the actual estimates subject to -DP, we conduct two experiments that correspond to the estimation of power consumption in the electric grid.
The first case considers estimating power consumption via electricity measurements of individual households. Consumption behavior is considered highly sensitive. It can reveal compromising information about daily habits and family illnesses or pose a security threat if exploited by an adversary, e.g., to coordinate attack time. Here, we assume that each household faces a privacy risk in sharing their measurements, and they may decide to mitigate the privacy risks by adding noise to their estimates. The ability to estimate average consumption in a distributed manner is useful for distributed load balancing and deciding generation plans.
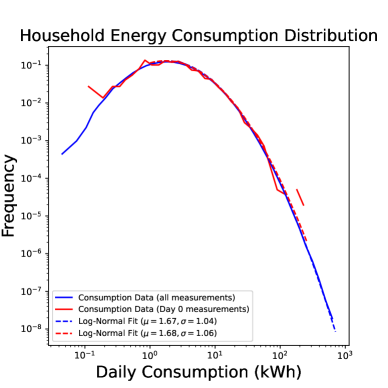
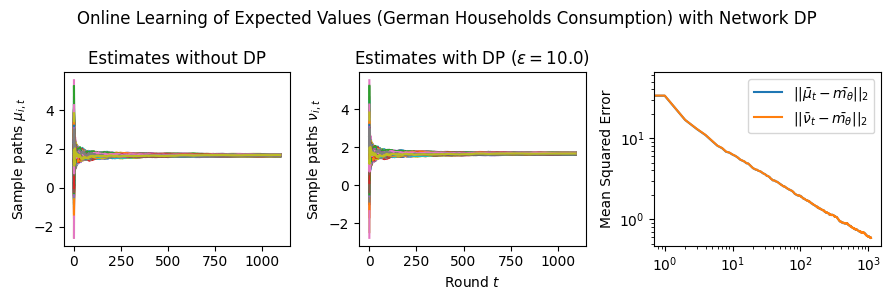
For this scenario, we consider the GEM House openData dataset Milojkovic, (2018), which contains power consumption measurements of individual households over days (i.e., three years). The dataset contains cumulative power consumption measurements for each particular day. To extract the actual measurements (in kWh) we take the differences between consecutive days and divide by (see Section 3.2.1 of Milojkovic, (2018)), i.e., . We observe that follows a log-normal distribution with mean and standard deviation , as shown in Figure 2. Moreover, in this dataset, the network structure is absent. For this reason, we generate a random geometric graph, i.e., we generate nodes randomly distributed in and connect nodes with a distance at most . Random geometric graphs have been used to model sensor networks Kenniche and Ravelomananana, (2010) and correspond to a straightforward criterion for determining links since they connect nearby households. For a fixed random seed (seed = 0), the network contains edges and is visualized in Figure 2.
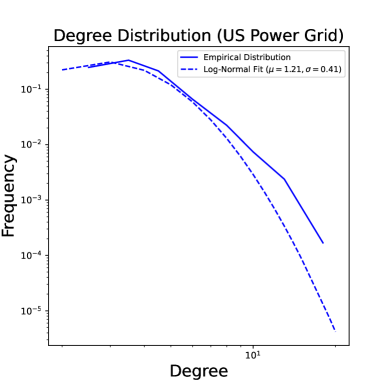
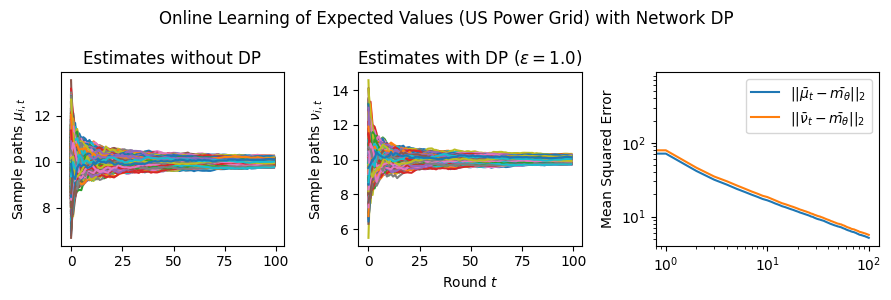
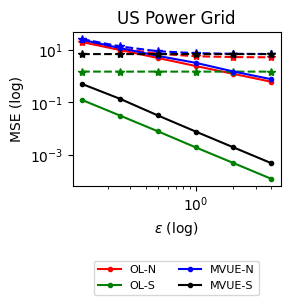
The second dataset examines estimating power consumption in the US Power Grid Network from Watts and Strogatz, (1998). In this case, we hypothesize that each power station faces a privacy risk – for example, vulnerability to a cyber attack – in sharing their measurements and decides to reduce its privacy risk by adding noise. The network contains nodes and edges. Figure 2 shows the power network and its degree distribution. Here we artificially generate i.i.d. signals for as .
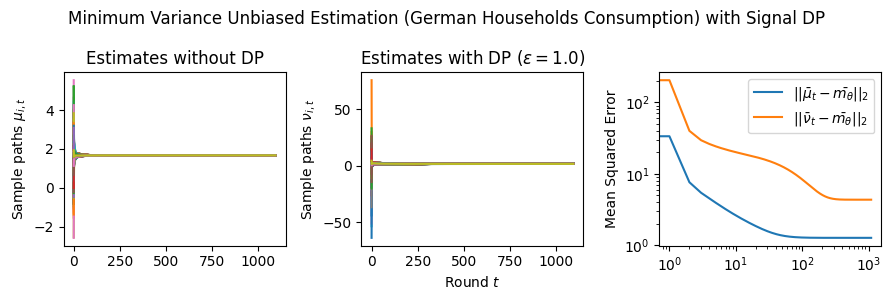
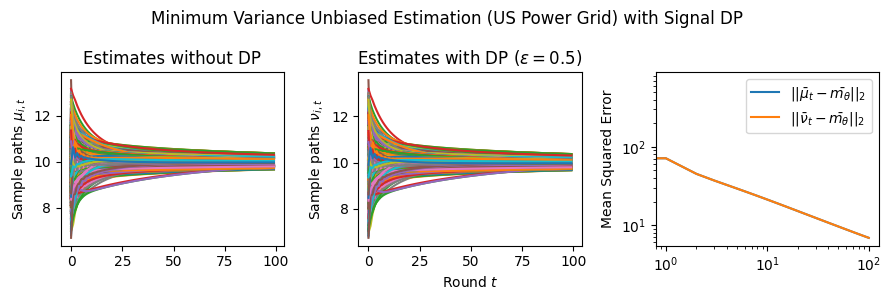
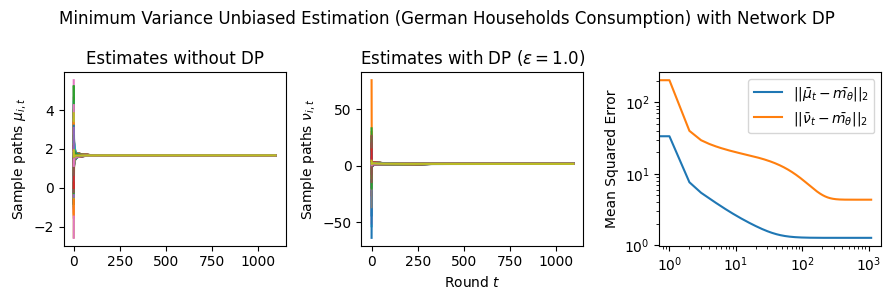
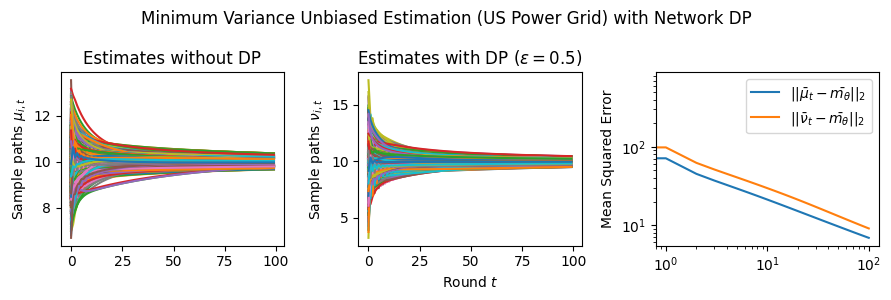
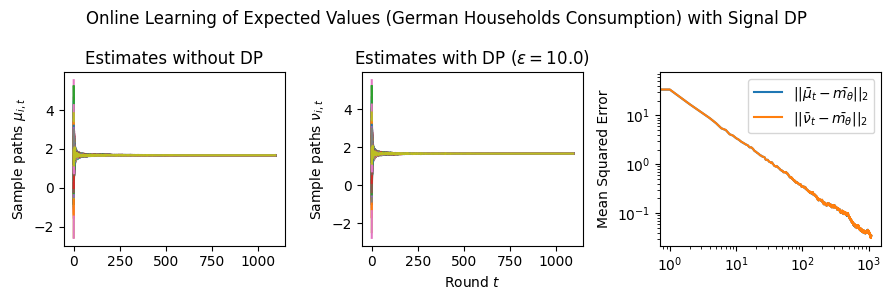
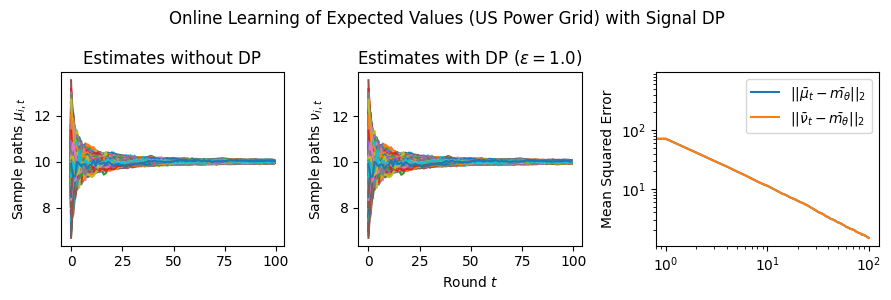
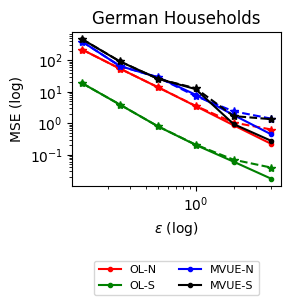
Estimation Tasks. In both cases, the task is to estimate each log-normal distribution’s mean in two scenarios. In the first scenario, we estimate the mean only from the initial measurements, i.e., estimate . Figure 3 presents some sample paths for this task as the horizon varies, and Figure 7 presents the final MSE after for various values of the privacy budget . In the second scenario, we estimate the mean with online learning (OL) to estimate . We run simulations in both regimes where we want to protect the signal and the network connections. Because in this case the global sensitivity is unbounded, we use the smooth signal sensitivities for each signal with . The resulting algorithms are -DP (see Section 3.1).
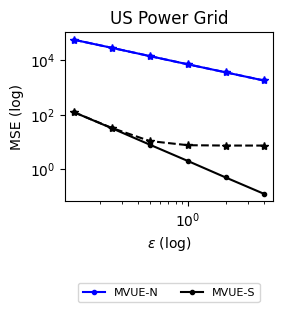
Comparison with Rizk et al., (2023). Finally, in Appendix B we explain the adaptation of Rizk et al., (2023) first-order DP consensus algorithm to both MVUE and OL tasks. Figure 7 shows the comparison of MSE performances between our algorithms and Rizk et al., (2023) given the same privacy budget per agent. Compared to Rizk et al., (2023), our method is able to achieve significantly smaller MSE under the same total privacy budget; smaller for both datasets. While Rizk et al., (2023)’s algorithm are applicable to a broader set of tasks than the MVUE and OL estimation setups presented here, their inclusion of private signals at every iteration entails DP noising at every step of the iteration and comes at a higher cost to accuracy.
6 Discussion and Conclusion
Results and Insights. In all cases of signal DP with the US power grid network, the DP noise did not affect the convergence rate in practice for this choice of signals, privacy budget , and information leakage probability . Also, we observe that Algorithm 4 converges faster than Algorithm 5 (even in the absence of DP noise) because of the underlying mixing matrices, which are , and respectively. Moreover, both of these algorithms converge faster (with and without DP noise) than Algorithm 3. This is expected since Algorithm 3 has access to samples in total, while Algorithms 4 and 5 have access to signals and can bring the estimation error down by a factor. Comparison of Signal DP (Figures 3 and 5) with Network DP (Figures 4 and 6) for MVUE and online learning tasks points to the increased difficulty of ensuring network DP: network privacy protections are harder to achieve and they imply signal protections automatically. On the other hand, when the local sensitivities can grow large — as with the German household dataset — maintaining privacy for households with low consumption comes at a huge cost to accuracy (see, e.g., Figure 5). This is because for the log-normal distribution, grows unbounded as .
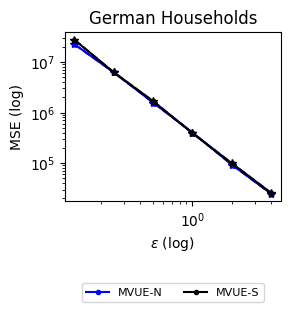
Extensions. We extend our algorithms to address additional forms of heterogeneity. Specifically, in Appendix C, we show how our algorithms can provably converge under minimal assumptions when the network topology is changing dynamically (Section C.1) and when the corresponding topology is directed (Section C.2). These scenarios are pertinent to real-world sensor networks since sensors and communications can fail, corresponding to dynamically changing networks with asymmetries (cf. Touri and Nédic, (2009)). Moreover, to balance the trade-offs between accuracy and privacy, the agents can resort to heterogeneous privacy budgets and improve their collective estimation performance while maintaining a minimum privacy protection (capping the individual privacy budgets at ). The possibility to accommodate heterogeneous budgets in the local DP setting leads to interesting design choices for improving the collective learning performance, e.g., using personalized DP methods Acharya et al., (2024); Jorgensen et al., (2015). In Section C.3, we provide both centralized and decentralized schemes to allocate privacy budgets to optimize their collective accuracy subject to individual privacy budget caps and test their performance on the German Households dataset (cf. Supplementary Figure 3).
Conclusion. Our paper focuses on distributed estimation and learning in a networked environment subject to privacy constraints. The aim is to estimate the statistical properties of unknown random variables based on observed data. Our aggregation methods aim to combine the observed data efficiently without requiring explicit coordination beyond the local neighborhood of each agent. This allows for estimating a complete sufficient statistic using either offline or online signals provided to the agents. To preserve privacy, agents add noise to their estimates, adhering to a differential privacy budget (-DP) to safeguard the privacy of either their signals (signal DP) or their signals and network neighborhoods (Network DP). Our algorithms employ linear aggregation schemes that combine the observations of all agents while incorporating the added noise, either online or offline. We prove that the estimation error bounds depend on two terms: the first term corresponds to the error incurred due to the aggregation scheme (which we call Cost of Decentralization) and can be controlled by the mixing rate of the doubly-stochastic adjacency weights, and the second term corresponds to the error due to the DP noising (which we call Cost of Privacy). We prove that under all cases (see also Section 1.1), the noise distributions that minimize the convergence rate correspond to the Laplace distributions with parameters that depend on the (local or global) signal sensitivities, the network structure, and the differential privacy budget . Finally, we test our algorithms and validate our theory in numerical experiments.
When sensitivities are locally bounded, signal DP can be achieved efficiently with a graceful accuracy loss over a decreasing privacy budget. This is facilitated by the post-processing immunity of DP (Dwork and Roth, , 2014, Proposition 2.1) that no future leaks are possible after adequate noising of the private signals and indicates the resilience of linear aggregation schemes to DP noising. However, achieving network DP with noising of estimates is significantly more challenging, and while individual noisy estimates are protected against a one-time attack, network information can still leak over time across multiple estimates. The composition property (Dwork and Roth, , 2014, Chapter 3) implies that we can protect the network neighborhoods at -DP level against an adversary who eavesdrops times by protecting individual estimates at -DP level. Such protection can be challenging if an adversary can eavesdrop on the estimates for a long time or has simultaneous access to estimates of multiple agents. In such cases, a fast convergence rate (using the fastest mixing weights) can limit communications and help agents maintain privacy without completely sacrificing the accuracy of their estimates.
References
- Acharya et al., (2024) Acharya, K., Boenisch, F., Naidu, R., and Ziani, J. (2024). Personalized differential privacy for ridge regression. arXiv preprint arXiv:2401.17127.
- Alexandru and Pappas, (2021) Alexandru, A. B. and Pappas, G. J. (2021). Private Weighted Sum Aggregation. IEEE Transactions on Control of Network Systems, 9(1):219–230.
- Alexandru et al., (2020) Alexandru, A. B., Tsiamis, A., and Pappas, G. J. (2020). Towards Private Data-driven Control. In IEEE Conference on Decision and Control (CDC 2020), pages 5449–5456. IEEE.
- Apple Differential Privacy Team, (2017) Apple Differential Privacy Team (2017). Learning with privacy at scale. https://machinelearning.apple.com/research/learning-with-privacy-at-scale. Accessed: 2023-05-18.
- (5) Atanasov, N., Tron, R., Preciado, V. M., and Pappas, G. J. (2014a). Joint Estimation and Localization in Sensor Networks. IEEE Conference on Decision and Control (CDC 2014), pages 6875–6882.
- (6) Atanasov, N. A., Le Ny, J., and Pappas, G. J. (2014b). Distributed Algorithms for Stochastic Source Seeking with Mobile Robot Networks. Journal of Dynamic Systems, Measurement, and Control.
- Aumann, (1976) Aumann, R. J. (1976). Agreeing to Disagree. The Annals of Statistics, pages 1236–1239.
- Barbaro et al., (2006) Barbaro, M., Zeller, T., and Hansell, S. (2006). A face is exposed for AOL searcher no. 4417749. New York Times, 9(2008):8.
- Bickel and Doksum, (2015) Bickel, P. J. and Doksum, K. A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics, volume I. CRC Press.
- Bonawitz et al., (2021) Bonawitz, K., Kairouz, P., McMahan, B., and Ramage, D. (2021). Federated Learning and Privacy: Building Privacy-preserving Systems for Machine Learning and Data Science on Decentralized Data. Queue, 19(5):87–114.
- Borkar and Varaiya, (1982) Borkar, V. and Varaiya, P. (1982). Asymptotic Agreement in Distributed Estimation. IEEE Transactions on Automatic Control, 27(3):650–655.
- Boyd et al., (2004) Boyd, S., Diaconis, P., and Xiao, L. (2004). Fastest Mixing Markov Chain on a Graph. SIAM Review, 46(4):667–689.
- Boyd et al., (2005) Boyd, S., Ghosh, A., Prabhakar, B., and Shah, D. (2005). Gossip Algorithms: Design, Analysis and Applications. In IEEE Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM 2005), volume 3, pages 1653–1664. IEEE.
- Bullo et al., (2009) Bullo, F., Cortés, J., and Martinez, S. (2009). Distributed control of robotic networks: a mathematical approach to motion coordination algorithms, volume 27. Princeton University Press.
- Cardoso and Rogers, (2022) Cardoso, A. R. and Rogers, R. (2022). Differentially Private Histograms under Continual Observation: Streaming Selection into the Unknown. In International Conference on Artificial Intelligence and Statistics (AISTATS 2022), pages 2397–2419. PMLR.
- Casella and Berger, (2002) Casella, G. and Berger, R. L. (2002). Statistical Inference, volume 2. Duxbury Pacific Grove, CA.
- Chamberland and Veeravalli, (2003) Chamberland, J.-F. and Veeravalli, V. V. (2003). Decentralized Detection in Sensor Networks. IEEE Transactions on Signal Processing, 51(2):407–416.
- Chatterjee, (2023) Chatterjee, S. (2023). Spectral Gap of Nonreversible Markov Chains. arXiv preprint arXiv:2310.10876.
- Chazelle, (2011) Chazelle, B. (2011). The Total -energy of a Multiagent System. SIAM Journal on Control and Optimization, 49(4):1680–1706.
- Dimakis et al., (2008) Dimakis, A. D., Sarwate, A. D., and Wainwright, M. J. (2008). Geographic Gossip: Efficient Averaging for Sensor Networks. IEEE Transactions on Signal Processing, 56(3):1205–1216.
- Dwork, (2011) Dwork, C. (2011). A Firm Foundation for Private Data Analysis. Communications of the ACM, 54(1):86–95.
- Dwork and Roth, (2014) Dwork, C. and Roth, A. (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407.
- Erlingsson, (2014) Erlingsson, U. (2014). Learning statistics with privacy, aided by the flip of a coin. https://ai.googleblog.com/2014/10/learning-statistics-with-privacy-aided.html. Accessed: 2023-05-18.
- Geanakoplos and Polemarchakis, (1982) Geanakoplos, J. D. and Polemarchakis, H. M. (1982). We can’t Disagree Forever. Journal of Economic Theory, 28(1):192–200.
- Gowtham and Ahila, (2017) Gowtham, M. and Ahila, S. S. (2017). Privacy Enhanced Data Communication Protocol for Wireless Body Area Network. In International Conference on Advanced Computing and Communication Systems (ICACCS 2017), pages 1–5. IEEE.
- Guevara, (2019) Guevara, M. (2019). Enabling developers and organizations to use differential privacy. https://developers.googleblog.com/2019/09/enabling-developers-and-organizations.html. Accessed: 2023-05-18.
- Hassan et al., (2019) Hassan, M. U., Rehmani, M. H., and Chen, J. (2019). Differential Privacy Techniques for Cyber Physical Systems: a Survey. IEEE Communications Surveys & Tutorials, 22(1):746–789.
- Jackson, (2008) Jackson, M. O. (2008). Social and Economic Networks. Princeton University Press, Princeton, NJ.
- Jadbabaie et al., (2003) Jadbabaie, A., Lin, J., and Morse, A. S. (2003). Coordination of Groups of Mobile Autonomous Agents using Nearest Neighbor Rules. IEEE Transactions on Automatic Control, 48(6):988–1001.
- Jorgensen et al., (2015) Jorgensen, Z., Yu, T., and Cormode, G. (2015). Conservative or Liberal? personalized Differential Privacy. In IEEE International Conference on Data Engineering (ICDE 2015), pages 1023–1034. IEEE.
- Kaissis et al., (2020) Kaissis, G. A., Makowski, M. R., Rückert, D., and Braren, R. F. (2020). Secure, Privacy-preserving and Federated Machine Learning in Medical Imaging. Nature Machine Intelligence, 2(6):305–311.
- Kar et al., (2012) Kar, S., Moura, J., and Ramanan, K. (2012). Distributed parameter estimation in sensor networks: Nonlinear observation models and imperfect communication. IEEE Transactions on Information Theory, 58, no. 6, pp. 3575–3605.
- Kenniche and Ravelomananana, (2010) Kenniche, H. and Ravelomananana, V. (2010). Random Geometric Graphs as Model of Wireless Sensor Networks. In International Conference on Computer and Automation Engineering (ICCAE 2010), volume 4, pages 103–107. IEEE.
- Kontar et al., (2021) Kontar, R., Shi, N., Yue, X., Chung, S., Byon, E., Chowdhury, M., Jin, J., Kontar, W., Masoud, N., Nouiehed, M., et al. (2021). The internet of federated things (IoFT). IEEE Access, 9:156071–156113.
- Koufogiannis et al., (2015) Koufogiannis, F., Han, S., and Pappas, G. J. (2015). Optimality of the laplace mechanism in differential privacy. arXiv preprint arXiv:1504.00065.
- Koufogiannis and Pappas, (2017) Koufogiannis, F. and Pappas, G. J. (2017). Diffusing Private Data over Networks. IEEE Transactions on Control of Network Systems, 5(3):1027–1037.
- Krishnamurthy and Poor, (2013) Krishnamurthy, V. and Poor, H. V. (2013). Social learning and bayesian games in multiagent signal processing: How do local and global decision makers interact? IEEE Signal Processing Magazine,, 30(3):43–57.
- Kumar et al., (2007) Kumar, R., Novak, J., Pang, B., and Tomkins, A. (2007). On Anonymizing Query Logs via Token-based Hashing. In International conference on World Wide Web (WWW 2017), pages 629–638.
- Lalitha et al., (2014) Lalitha, A., Sarwate, A., and Javidi, T. (2014). Social Learning and Distributed Hypothesis Testing. IEEE International Symposium on Information Theory (ISIT 2014), pages 551–555.
- Levin et al., (2009) Levin, D. A., Peres, Y., and Wilmer, E. L. (2009). Markov Chains and Mixing Times. American Mathematical Society.
- Li et al., (2010) Li, M., Lou, W., and Ren, K. (2010). Data Security and Privacy in Wireless Body Area Networks. IEEE Wireless communications, 17(1):51–58.
- McMahan and Thakurta, (2022) McMahan, B. and Thakurta, A. (2022). Federated learning with formal differential privacy guarantees. https://blog.research.google/2022/02/federated-learning-with-formal.html. Accessed: 2024-03-26.
- Mesbahi and Egerstedt, (2010) Mesbahi, M. and Egerstedt, M. (2010). Graph Theoretic Methods in Multiagent Networks. Princeton University Press.
- Milojkovic, (2018) Milojkovic, F. (2018). GEM House Opendata: German Electricity Consumption in Many Households over Three Years 2018–2020 (Fresh Energy).
- Narayanan and Shmatikov, (2008) Narayanan, A. and Shmatikov, V. (2008). Robust De-anonymization of Large Sparse Datasets. In IEEE Symposium on Security and Privacy (SP 2008), pages 111–125.
- (46) National Academies of Sciences, Engineering, and Medicine (2023a). Net metering practices should be revised to better reflect the value of integrating distributed electricity generation into the nation’s power grid. https://www.nationalacademies.org/news/2023/05/net-metering-practices-should-be-revised-to-better-reflect-the-value-of-integrating-distributed-electricity-generation-into-the-nations-power-grid. Accessed: 2023-05-20.
- (47) National Academies of Sciences, Engineering, and Medicine (2023b). The Role of Net Metering in the Evolving Electricity System. https://www.nationalacademies.org/our-work/the-role-of-net-metering-in-the-evolving-electricity-system. Accessed: 2023-05-20.
- Nedić et al., (2015) Nedić, A., Olshevsky, A., and Uribe, C. A. (2015). Nonasymptotic Convergence Rates for Cooperative Learning over Time-varying Directed Graphs. In American Control Conference (ACC 2015), pages 5884–5889. IEEE.
- Nedić et al., (2017) Nedić, A., Olshevsky, A., and Uribe, C. A. (2017). Fast Convergence Rates for Distributed non-Bayesian Learning. IEEE Transactions on Automatic Control, 62(11):5538–5553.
- Niknam et al., (2020) Niknam, S., Dhillon, H. S., and Reed, J. H. (2020). Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges. IEEE Communications Magazine, 58(6):46–51.
- Nissim et al., (2007) Nissim, K., Raskhodnikova, S., and Smith, A. (2007). Smooth Sensitivity and Sampling in Private Data Analysis. In ACM Symposium on Theory of Computing (STOC 2007), pages 75–84.
- Olfati-Saber and Shamma, (2005) Olfati-Saber, R. and Shamma, J. (2005). Consensus Filters for Sensor Networks and Distributed Sensor Fusion. IEEE Conference on Decision and Control (CDC 2005), pages 6698 – 6703.
- Olshevsky, (2014) Olshevsky, A. (2014). Linear Time Average Consensus on Fixed Graphs and Implications for Decentralized Optimization and Multi-agent Control. arXiv preprint arXiv:1411.4186.
- Papachristou and Rahimian, (2024) Papachristou, M. and Rahimian, M. A. (2024). Group Decision-Making among Privacy-Aware Agents. AAAI Workshop on Privacy-preserving Artificial Intelligence (PPAI).
- (55) Rahimian, M. A. and Jadbabaie, A. (2016a). Bayesian learning without recall. IEEE Transactions on Signal and Information Processing over Networks, 3(3):592–606.
- (56) Rahimian, M. A. and Jadbabaie, A. (2016b). Distributed Estimation and Learning over Heterogeneous Networks. In Communication, Control, and Computing (Allerton 2016), pages 1314–1321. IEEE.
- (57) Rahimian, M. A. and Jadbabaie, A. (2016c). Group decision making and social learning. In Decision and Control (CDC), 2016 IEEE 55th Conference on, pages 6783–6794. IEEE.
- (58) Rahimian, M. A., Yu, F.-Y., and Hurtado, C. (2023a). Differentially private network data collection for influence maximization. In Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems, pages 2795–2797.
- (59) Rahimian, M. A., Yu, F.-Y., and Hurtado, C. (2023b). Seeding with differentially private network information. arXiv preprint arXiv:2305.16590.
- Rizk et al., (2023) Rizk, E., Vlaskiy, S., and Sayed, A. H. (2023). Enforcing Privacy in Distributed Learning with Performance Guarantees. IEEE Transactions on Signal Processing.
- Rogers et al., (2020) Rogers, R., Subramaniam, S., Peng, S., Durfee, D., Lee, S., Kancha, S. K., Sahay, S., and Ahammad, P. (2020). LinkedIn’s Audience Engagements API: A Privacy Preserving Data Analytics System at Scale. arXiv preprint arXiv:2002.05839.
- Sayed et al., (2014) Sayed, A. H. et al. (2014). Adaptation, Learning, and Optimization over Networks. Foundations and Trends® in Machine Learning, 7(4-5):311–801.
- Seneta, (2006) Seneta, E. (2006). Non-negative Matrices and Markov Chains. Springer.
- Shahrampour et al., (2015) Shahrampour, S., Rakhlin, A., and Jadbabaie, A. (2015). Distributed detection: Finite-time analysis and impact of network topology. IEEE Transactions on Automatic Control, 61(11):3256–3268.
- Shi et al., (2023) Shi, N., Lai, F., Al Kontar, R., and Chowdhury, M. (2023). Ensemble Models in Federated Learning for Improved Generalization and Uncertainty Quantification. IEEE Transactions on Automation Science and Engineering.
- Sweeney, (1997) Sweeney, L. (1997). Weaving Technology and Policy Together to Maintain Confidentiality. The Journal of Law, Medicine & Ethics, 25(2-3):98–110.
- Sweeney, (2015) Sweeney, L. (2015). Only you, your Doctor, and many others may know. Technology Science, 2015092903(9):29.
- Touri and Nédic, (2009) Touri, B. and Nédic, A. (2009). Distributed consensus over Network with Noisy Links. In International Conference on Information Fusion (FUSION 2009), pages 146–154. IEEE.
- Truex et al., (2019) Truex, S., Baracaldo, N., Anwar, A., Steinke, T., Ludwig, H., Zhang, R., and Zhou, Y. (2019). A Hybrid Approach to Privacy-preserving Federated Learning. In ACM Workshop on Artificial Intelligence and Security, pages 1–11.
- Truong et al., (2021) Truong, N., Sun, K., Wang, S., Guitton, F., and Guo, Y. (2021). Privacy preservation in Federated Learning: An insightful Survey from the GDPR Perspective. Computers & Security, 110:102402.
- Tsitsiklis, (1993) Tsitsiklis, J. N. (1993). Decentralized Detection. Advances in Statistical Signal Processing, 2(2):297–344.
- Tsitsiklis and Athans, (1984) Tsitsiklis, J. N. and Athans, M. (1984). Convergence and asymptotic agreement in distributed decision problems. Automatic Control, IEEE Transactions on, 29(1):42–50.
- US Census, (2020) US Census (2020). 2020 decennial census: Processing the count: Disclosure avoidance modernization. https://www.census.gov/programs-surveys/decennial-census/decade/2020/planning-management/process/disclosure-avoidance.html. Accessed: 2023-05-18.
- Wang and Djuric, (2015) Wang, Y. and Djuric, P. M. (2015). Social Learning with Bayesian Agents and Random Decision Making. IEEE Transactions on Signal Processing, 63(12):3241–3250.
- Warner, (1965) Warner, S. L. (1965). Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias. Journal of the American Statistical Association, 60(309):63–69.
- Watts and Strogatz, (1998) Watts, D. J. and Strogatz, S. H. (1998). Collective Dynamics of “Small-world” Networks. Nature, 393(6684):440–442.
- Wilson et al., (2020) Wilson, R. J., Zhang, C. Y., Lam, W., Desfontaines, D., Simmons-Marengo, D., and Gipson, B. (2020). Differentially Private SQL with Bounded User Contribution. Proceedings on privacy enhancing technologies, 2020(2):230–250.
- Wood and Zhang, (1996) Wood, G. and Zhang, B. (1996). Estimation of the lipschitz constant of a function. Journal of Global Optimization, 8:91–103.
- Xiao et al., (2005) Xiao, L., Boyd, S., and Lall, S. (2005). A Scheme for Robust Distributed Sensor Fusion based on Average Consensus. In International Symposium on Information Processing in Sensor Networks (IPSN 2005), pages 63–70.
- Xiao et al., (2006) Xiao, L., Boyd, S., and Lall, S. (2006). A Space-time Diffusion Scheme for Peer-to-peer Least-squares Estimation. In International Conference on Information Processing in Sensor Networks (IPSN 2006), pages 168–176.
- Xu et al., (2017) Xu, Q., Ren, P., Song, H., and Du, Q. (2017). Security-aware Waveforms for Enhancing Wireless Communications Privacy in Cyber-physical systems via Multipath Receptions. IEEE Internet of Things Journal, 4(6):1924–1933.
- Yue et al., (2022) Yue, X., Kontar, R. A., and Gómez, A. M. E. (2022). Federated Data Analytics: A Study on Linear Models. IISE Transactions, pages 1–25. in-press.
- Zhang et al., (2016) Zhang, H., Shu, Y., Cheng, P., and Chen, J. (2016). Privacy and Performance Trade-off in Cyber-physical Systems. IEEE Network, 30(2):62–66.
- Zhang et al., (2022) Zhang, X., Chen, X., Hong, M., Wu, Z. S., and Yi, J. (2022). Understanding Clipping for Federated Learning: Convergence and Client-level Differential Privacy. In International Conference on Machine Learning (ICML 2022).
Acknowledgements
M.P. was partially supported by a LinkedIn Ph.D. Fellowship, an Onassis Fellowship (ID: F ZT 056-1/2023-2024), and grants from the A.G. Leventis Foundation and the Gerondelis Foundation. M.A.R. was partially supported by NSF SaTC-2318844. The authors would like to thank the seminar participants at Rutgers Business School, Jalaj Upadhyay, Saeed Sharifi-Malvajerdi, Jon Kleinberg, Kate Donahue, and Vasilis Charisopoulos for their valuable discussions and feedback.
Data Availability Statement
The data that support the findings of this study are openly available in the following repositories:
-
1.
GEM House openData. URL: https://dx.doi.org/10.21227/4821-vf03 (Accessed at 1-6-2023), Reference: Milojkovic, (2018).
-
2.
US Power Grid Network. URL: https://toreopsahl.com/datasets/#uspowergrid (Accessed at 1-6-2023), Reference: Watts and Strogatz, (1998).
Our code and data can be found at: https://github.com/papachristoumarios/dp-distributed-estimation.
Biographical Sketches
Marios Papachristou. Marios Papachristou is a 4th year PhD student at the Department of Computer Science at Cornell University and is advised by Jon Kleinberg. His research interests span the theoretical and applied aspects of social and information networks, exploring their roles within large-scale social and information systems and understanding their wider societal implications. His research is supported by the Onassis Scholarship and has been supported in the past by a LinkedIn Ph.D. Fellowship, a grant from the A.G. Leventis Foundation, a grant from the Gerondelis Foundation, and a Cornell University Fellowship.
M. Amin Rahimian. Amin Rahimian has been an assistant professor of industrial engineering at the University of Pittsburgh since 2020, where he leads the sociotechnical systems research lab. Prior to that, he was a postdoc with joint appointments at MIT Institute for Data, Systems, and Society (IDSS) and MIT Sloan School of Management. He received his PhD in Electrical and Systems Engineering from the University of Pennsylvania, and Master’s in Statistics from Wharton School. Broadly speaking his works are at the intersection of networks, data, and decision sciences, and have been published in the Proceedings of the National Academy of Sciences, Nature Human Behaviour, Nature Communications, and the Operations Research journal among others. His research interests are in applied probability, applied statistics, algorithms, decision and game theory, with applications ranging from online social networks, public health, and e-commerce to modern civilian cyberinfrastructure and future warfare. His research is currently supported by NSF, CDC, and the Department of the Army.
Supplementary Material
Appendix A Proofs
A.1 Proof of Theorem 3.1
Proof.
Since is real and symmetric, we can do an eigen decomposition of as where is an orthonormal eigenvector matrix, and is the diagonal eigenvalue matrix. We have that . Note that . Therefore . Since for all we have that , and by using Jensen’s inequality we get that
To minimize the upper bound on the MSE for each agent , it suffices to minimize the variance of , subject to differential privacy constraints. We assume that the PDF of – denoted by – is differentiable everywhere in . The differential privacy constraint is equivalent to
for all and . Letting we get that, in order to satisfy -DP,
where is the global sensitivity of . We have that
| s.t. | ||||
From Theorem 6 of Koufogiannis et al., (2015) we get that the optimal solution to the above problem is the Laplace distribution with scale ,
To derive the upper bound on the error note that by Theorem 3 of Rahimian and Jadbabaie, 2016b we have that , and also . Applying the triangle inequality yields the final result, i.e.,
| (A.1) |
Using the optimal distributions in (8) gives the claimed upper bound on . ∎
A.2 Proof of Corollary 3.2 (DP preservation across time)
To derive the DP guarantee for the MVUE for round , we will do an induction. Specifically, we want to prove that for all we have for all ,
for all adjacent pairs of signals and beliefs, i.e., . We proceed with the induction as follows:
-
•
For , the result is held by the construction of the noise and the definition of DP.
-
•
For time , we assume that for all .
-
•
For time , we have that for all ,
which holds by applying the definition of the MVUE update, the fact that is non-singular, and the inductive hypothesis for .
A.3 Proof of Theorem 4.1
Proof.
Similarly to Theorem 3.1, we decompose as and get that
We take expectations and apply Cauchy-Schwarz to get
| (A.2) | ||||
By Jensen’s inequality, we get that
Also note that the dynamics of obey
By following the same analysis as Equation A.2 we get that
and then, the triangle inequality yields
To optimize the upper bound of Equation A.2, for every index and agent we need to find the zero mean distribution with minimum variance subject to differential privacy constraints. We follow the same methodology as Theorem 3.1 and arrive at the optimization problem
| s.t. | ||||
The optimal distribution is derived identically to Theorem 3.1, and equals for all and .
∎
A.4 Proof of Theorem 4.2
Proof.
Let , and let . Note that can be written as , and we can infer that the eigenvalues of satisfy , and that and have the same eigenvectors. Therefore,
Similarly to Theorem 4.1 we have that
Applying Jensen’s inequality, we get that
Similarly, by considering the dynamics of we get that
The triangle inequality yields the final error bound.
To derive the optimal distributions, note that at each round , the optimal action for agent is to minimize subject to DP constraints. By following the analysis similar to Theorem 3.1, we deduce that the optimal noise to add is Laplace with parameter .
∎
Appendix B Algorithm of Rizk et al., (2023)
We adapt the framework of Rizk et al., (2023) to our problem, for which the identification of the MVUE can be formulated as
The private dynamics for updating the beliefs can be found by simplifying the consensus algorithm given in Equations (24)-(26) of Rizk et al., (2023):
Here, is the learning rate, is noise used to protect the private signal, and , are noise terms used to protect own and the neighboring beliefs. As a first difference, we observe that Rizk et al., (2023) uses noise variables, whereas our method uses just noise variables, which makes our method easier to implement for the MVUE task. It is easy to observe that these dynamics converge slower than our dynamics for two reasons: (i) the privacy protections are added separately for the signal and each neighboring belief, and (ii) the beliefs are always using information from the signals since the method is first-order, thus requiring noise to be added at each iteration.
For this reason, the authors consider graph-homomorphic noise, i.e., noise of the form for all and where are noise variables. Rewriting the dynamics in this form, we get the following update:
Given a privacy budget , in order to make a fair comparison with our algorithm, the noise variable should be chosen as for Signal DP, and for Network DP. Here, since the per-agent privacy budget is , and the noise is added times at each iteration, the initial budget needs to be divided by .
Appendix C Extensions to Dynamic and Directed Networks and Heterogeneous Privacy Budgets
C.1 Dynamic Networks
In this problem, the agents observe a sequence of dynamic networks , for example, due to corrupted links, noisy communications, other agents choosing not to share their measurements, power failures etc. These dynamic networks correspond to a sequence of doubly stochastic matrices . A choice for the weights are the modified Metropolis-Hastings (MH) weights:
| (C.3) |
This is a natural choice of weights since they can be easily and efficiently computed by the agents in a distributed manner (e.g., in a sensor network) from the knowledge of own and neighboring degrees, thus requiring minimal memory to be stored for each agent. Below we will show that the MVUE and the OL algorithms converge under minimal assumptions for the time-varying MH weights.
MVUE. We can prove that if contain no isolated nodes, the beliefs would converge to as a direct consequence of (Chazelle, , 2011, Theorem 1.4), i.e.
Proposition C.1.
If contains no isolated nodes for all , for accuracy , the dynamics with the modified MH weights of Equation C.3 will converge to the MVUE, , in
steps.
Proof.
The proof follows from applying Theorem 1.4 of Chazelle, (2011), since , the graph is undirected, and the diameter of the points is at most . ∎
Note that the above convergence rate is exponentially worse than the
convergence time that we obtain for static networks.
Online Learning. For the online learning regime, we can follow the approach presented in Touri and Nédic, (2009). For this, we consider the following update rule:
| (C.4) |
We show that under reasonable assumptions on the graph sequence, the above algorithm converges to almost surely.
Proposition C.2.
If contains no isolated nodes for all , and there exists an integer such that is strongly connected for every , then the dynamics of Equation C.4 with the modified MH weights of Equation C.3 converge to almost surely.
Proof.
The dynamics have the form of the dynamics of Touri and Nédic, (2009). We will show the result by showing that the assumptions of Touri and Nédic, (2009) hold. Specifically, all non-zero elements of have value at least , for all by our hypothesis, there exists an integer such that is strongly connected for every by our hypothesis, , and . Thus, by Proposition 2 of Touri and Nédic, (2009), the beliefs converge almost surely to as . Furthermore, we can show that the dependence on becomes slower, i.e., from when the network is static to when the network is dynamic.
∎
C.2 Directed Networks
We can also consider extensions of our results to directed graphs, i.e., when in general. Such asymmetries can arise due to systemic heterogeneities, e.g., varying accuracy and reliability of sensors in a sensor network or imbalances caused by influence dynamics in a social network. The adjacency weights in such cases are no longer doubly stochastic, making the MVUE dynamics in Equations 3 and 7 to converge to where is the stationary distribution of the Markov chain with transition matrix , satisfying and . Unlike the doubly stochastic case, the stationary distribution is not necessarily uniform, in which case the aggregate converges to a weighted average of that is no longer minimum variance. To analyze the convergence rate of the algorithms with asymmetric adjacency weights, we cannot use tools from the theory of doubly-stochastic matrices anymore, and we need to rely on different tools from the analysis of convergence of non-reversible Markov chains. The results of Chatterjee, (2023) extend the notion of spectral gap and can make this analysis possible. However, these results come with significant technicalities, using substantially different analytical steps that are beyond the scope of our present work. More limited conclusions about the asymptotic rates and finite-time convergence can be asserted in special cases by applying existing results such as Touri and Nédic, (2009).
C.3 Heterogeneous Privacy Budgets
Our algorithms extend easily to the case where each agent has their own privacy budget , e.g., due to their differing energy consumption levels. In this case, it is easy to show that all of the results can be updated to accommodate heterogeneous and the smooth sensitivities , as shown in Table 2 below.
| Minimum Variance Unbiased Estimation | Online Learning of Expected Values |
|---|---|
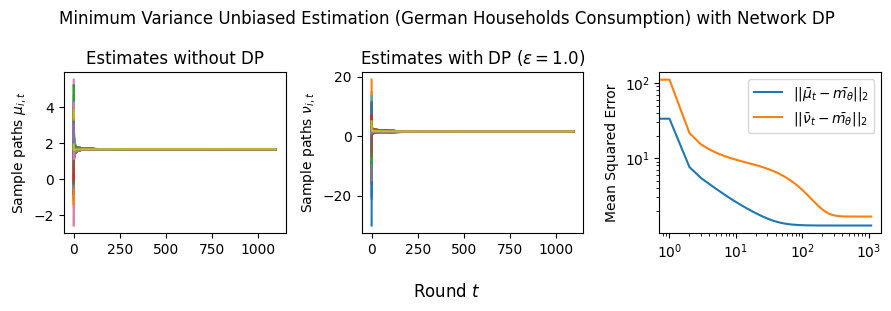
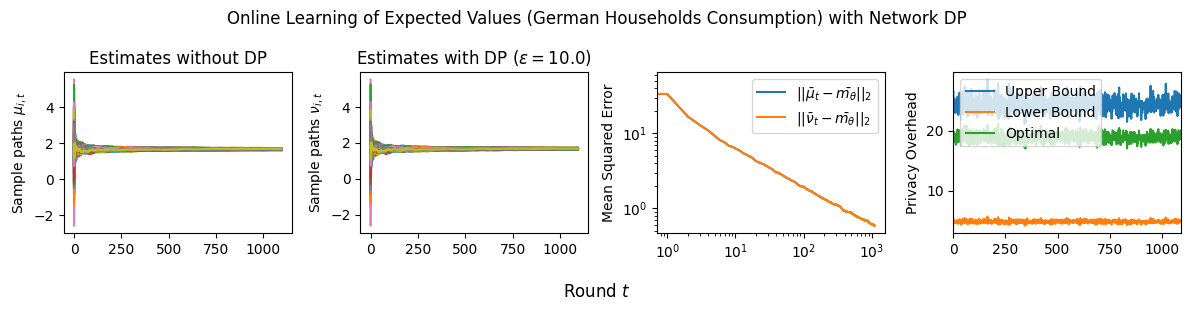
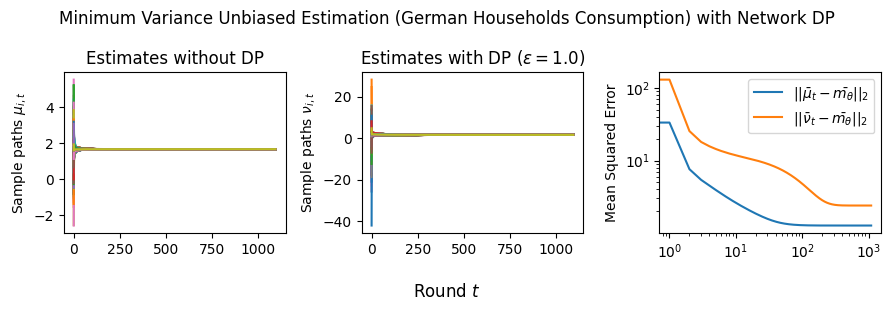
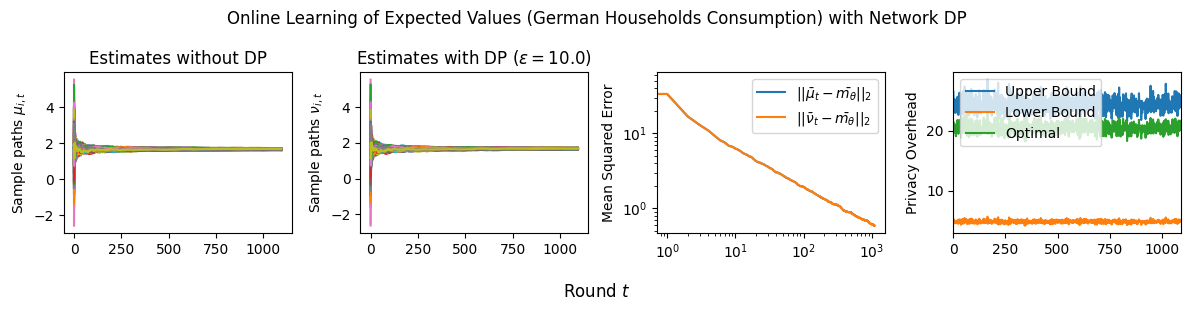
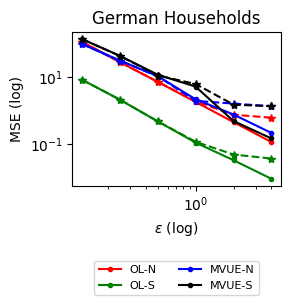
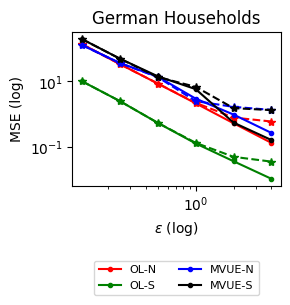
The possibility of heterogeneous privacy budgets opens new avenues to explore the allocation of an overall privacy budget () while respecting individual budgets . Such a situation may arise, e.g., to limit overall information leakage against an adversary that can eavesdrop on some or all of the communications. Suppose that each agent wants to maintain -DP and suppose that there is an adversary that eavesdrops on all of the beliefs (this also covers the cases where the adversary has access to a subset of the , such as in the case of a targeted attack to a large part of the network). Note that all of the results presented so far protect against information leakage about a single agent’s signals (or their network neighborhoods) when their reports are compromised. However, if the goal is to protect the private signals against an adversary that can eavesdrop simultaneously on all or a subset of agents, then each individual agent’s report can be regarded as a data release about the vector of all signals that needs to be protected at the -DP level, in addition to the individual-level -DP protections required by each agent. If the adversary can eavesdrop on all of the signals, then the resulting mechanism that protects the joint distribution of the signals can be thought of as a mechanism which adds -dimensional noise to the sufficient statistics and each dimension of the noise corresponds to , i.e.,
Then, if is the sensitivity for each agent , the noise has PDF:
Now, consider a pair of sets of signals such that
Then, we have that for all :
| (C.5) |
Now suppose we want to protect the vector of all beliefs against the eavesdropper at the -DP level (assuming an average privacy budget of per agent for the overall protection of the vector of all private signals). The noise that is added to individual estimates also works to protect the entire vector of all estimates against the eavesdropper and to achieve the latter at the level, Equation C.5 indicates that it is sufficient to ensure that . On the other hand, given privacy level at every agent , we also want to minimize the accuracy loss by reducing while ensuring that individual privacy budgets do not exceed a preset maximum: for all . The subsequent optimization problem to allocate individual privacy budgets can be formulated as follows:
| (C.6) | ||||
| s.t. | ||||
Following KKT conditions Boyd et al., (2005), Equation C.6 admits a closed-form solution. The solution indicates that by allowing heterogeneous privacy budgets and taking into account individual smooth sensitivities in the optimal allocation, we can improve the total error. These observations are summarized below:
Proposition C.3.
The following hold:
-
1.
If , then the optimal solution to Equation C.6 is
for all . Moreover, the improvement over satisfies .
-
2.
If then the optimal solution is for all .
In a large network making individual nodes aware of their allocated budgets based on their smooth sensitivities is difficult to achieve in a central manner. The following formulation of the allocation problem arrives at a sub-optimal solution that satisfies the global privacy budget constraint by imposing additional constraints in the local neighborhoods: . The advantage of these constraints is that they can be verified locally, and satisfying them implies the global budget constraint in Equation C.6. The subsequent optimization problem is given in Equation C.7. It allows individuals to learn their allocated budgets in a distributed manner by running distributed gradient descent, which is guaranteed to converge since the problem is convex (Sayed et al., , 2014, Chapter 7).
| (C.7) | ||||
| s.t. | ||||
Numerical Experiment. We test our method with the German Households dataset. Specifically, we set a per-agent average budget of for MVUE and for OL. We put a maximum individual budget cap of in both cases. We report the sample paths in Supplementary Figures 1 and 2, and observe that the dynamics converge faster compared to the homogeneous case (cf. Figure 4). In Supplementary Figure 3, we present an MSE plot where the MSE is plotted as a function of , and observe that the algorithm with the heterogeneous thresholds has smaller MSE compared to the homogeneous thresholds. These results confirm our theoretical observations in Proposition C.3.