Differentially Private Sliced Wasserstein Distance
Abstract
Developing machine learning methods that are privacy preserving is today a central topic of research, with huge practical impacts. Among the numerous ways to address privacy-preserving learning, we here take the perspective of computing the divergences between distributions under the Differential Privacy (DP) framework — being able to compute divergences between distributions is pivotal for many machine learning problems, such as learning generative models or domain adaptation problems. Instead of resorting to the popular gradient-based sanitization method for DP, we tackle the problem at its roots by focusing on the Sliced Wasserstein Distance and seamlessly making it differentially private. Our main contribution is as follows: we analyze the property of adding a Gaussian perturbation to the intrinsic randomized mechanism of the Sliced Wasserstein Distance, and we establish the sensitivity of the resulting differentially private mechanism. One of our important findings is that this DP mechanism transforms the Sliced Wasserstein distance into another distance, that we call the Smoothed Sliced Wasserstein Distance. This new differentially private distribution distance can be plugged into generative models and domain adaptation algorithms in a transparent way, and we empirically show that it yields highly competitive performance compared with gradient-based DP approaches from the literature, with almost no loss in accuracy for the domain adaptation problems that we consider.
1 Introduction
Healthcare and computational advertising are examples of domains that could find a tremendous benefit from the continous advances made in Machine Learning (ML). However, as ethical and regulatory concerns become prominent in these areas, there is the need to devise privacy preserving mechanisms allowing i) to prevent the access to individual and critical data and ii) to still leave the door open to the use of elaborate ML methods. Differential privacy (DP) offers a sound privacy-preserving framework to tackle both issues and effective DP mechanisms have been designed for, e.g., logistic regression and Support Vector Machines [27, 8].
Here, we address the problem of devising a differentially private distribution distance with, in the hindsight, tasks such as learning generative models and domain adaptation —which both may rely on a relevant distribution distance [20, 10]. In particular, we propose and analyze a mechanism that transforms the sliced Wasserstein distance (SWD) [26] into a differentially private distance while retaining the scalability advantages and metric properties of the base SWD. The key ingredient to our contribution: to take advantage of the combination of the embedded sampling process of SWD and the so-called Gaussian mechanism.
Our contributions are as follows: i) we analyze the effect of a Gaussian mechanism on the sliced Wasserstein distance and we establish the DP-compliance of the resulting mechanism DP-SWD; ii) we show that DP-SWD boils down to what we call Gaussian smoothed SWD, that inherits some of the key properties of a distance, a novel result that has value on its own; iii) extensive empirical analysis on domain adaptation and generative modeling tasks show that the proposed DP-SWD is competitive, as we achieve DP guarantees without almost no loss in accuracy in domain adaptation, while being the first to present a DP generative model on the RGB CelebA dataset.
Outline.
Section 2 states the problem we are interested in and provides background on differential privacy and the sliced Wasserstein distance. In Section 3, we analyze the DP guarantee of random direction projections and we characterize the resulting Gaussian Smoothed Sliced Wasserstein distance. Section 4 discusses how this distance can be plugged into domain adaptation and generative model algorithms. After discussing related works in Section 5, Section 6 presents empirical results, showing our ability to effectively learn under DP constraints.
2 Problem Statement and Background
2.1 Privacy, Gaussian Mechanism and Random Direction Projections
We start by stating the main problem we are interested in: to show the privacy properties of the random mechanism
where is a matrix (a dataset), a random matrix made of uniformly distributed unit-norm vectors of and a matrix of zero-mean Gaussian vectors (also called the Gaussian Mechanism).
We show that is differentially private and that it is the core component of the Sliced Wassertein Distance (SWD) computed thanks to random projection directions (the unit-norm matrix ) and, in turn, SWD inherits111This is a slight abuse of vocabulary as the Sliced Wasserstein Distance takes two inputs and not only one. the differential private property of . In the way, we show that the population version of the resulting differentially private SWD is a distance, that we dub the Gaussian Smoothed SWD.
2.2 Differential Privacy (DP)
DP is a theoretical framework to analyze the privacy guarantees of algorithms. It rests on the following definitions.
Definition 1 (Neighboring datasets).
Let (e.g. ) be a domain and . are neighboring datasets if and they differ from one record.
Definition 2 (Dwork [11]).
Let . Let be a randomized algorithm, where is the image of through . is -differentially private, or -DP, if for all neighboring datasets and for all sets of outputs , the following inequality holds:
where the probability relates to the randomness of .
Remark 1.
Note that given and a randomized algorithm , defines a distribution on (a subspace of) with
where means equality up to a normalizing factor.
The following notion of privacy, proposed by Mironov [22], which is based on Rényi -divergences and its connections to -differential privacy will ease the exposition of our results (see also [2, 3, 32]):
Definition 3 (Mironov [22]).
Proposition 1 (Mironov [22], Prop. 3).
An -RDP mechanism is also -DP, .
Remark 2.
A folk method to make up an (R)DP algorithm based a function is the Gaussian mechanism defined as follows:
where . If has - (or -) sensitivity
then is -RDP.
As we shall see, the role of will be played by the Random Direction Projections operation or the Sliced Wasserstein Distance (SWD), a randomized algorithm itself, and the mechanism to be studied is the composition of two random algorithms, SWD and the Gaussian mechanism. Proving the (R)DP nature of this mechanism will rely on a high probability bound on the sensitivy of the Random Direction Projections/SWD combined with the result of Remark 2.
2.3 Sliced Wasserstein Distance
Let be a probability space and the set of all probability measures over . The Wasserstein distance between two measures , is based on the so-called Kantorovitch relaxation of the optimal transport problem, which consists in finding a joint probability distribution such that
| (1) |
where is a metric on , known as the ground cost (which in our case will be the Euclidean distance), and are the marginal projectors of on each of its coordinates. The minimizer of this problem is the optimal transport plan and for , the -Wasserstein distance is
| (2) |
A case of prominent interest for our work is that of one-dimensional measures, for which it was shown by Rabin et al. [26], Bonneel et al. [5] that the Wasserstein distance admits a closed-form solution which is
where is the inverse cumulative distribution function of the related distribution. This combines well with the idea of projecting high-dimensional probability distributions onto random 1-dimensional spaces and then computing the Wasserstein distance, an operation which can be theoretically formalized through the use of the Radon transform [5], leading to the so-called Sliced Wasserstein Distance
where is the Radon transform of a probability distribution so that
| (3) |
with be the -dimensional hypersphere and the uniform distribution on .
In practice, we only have access to and through samples, and the proxy distributions of and to handle are and By plugging those distributions into Equation 3, it is easy to show that the Radon transform depends only the projection of on . Hence, computing the sliced Wasserstein distance amounts to computing the average of 1D Wasserstein distances over a set of random directions , with each 1D probability distribution obtained by projecting a sample (of or ) on by . This gives the following empirical approximation of SWD
| (4) |
given a matrix of of unit-norm column .
3 Private and Smoothed Sliced Wasserstein Distance
We now introduce how we obtain a differentially private approximation of the Sliced Wasserstein Distance. To achieve this goal, we take advantage of the intrinsic randomization process that is embedded in the Sliced Wasserstein distance.
3.1 Sensitivity of Random Direction Projections
In order to uncover its -DP , we analyze the sensitivity of the random direction projection in SWD. Let us consider the matrix representing a dataset composed of examples in dimension organized in row (each sample being randomly drawn from the distribution ). One mechanism of interest is
where is a vector whose entries are drawn from a zero-mean Gaussian distribution. Let and be two matrices in that differ only on one row, say and such that , where and are the -th row of and , respectively. For ease of notation, we will from now on use
Lemma 1.
Assume that is a unit-norm vector and a vector where each entry is drawn independently from . Then
where is the beta distribution of parameters .
Proof.
See appendix. ∎
Instead of considering a randomized mechanism that projects only according to a single random direction, we are interested in the whole set of projected (private) data according to the random directions sampled through the Monte-Carlo approximation of the Sliced Wasserstein distance computation (4). Our key interest is therefore in the mechanism
and in the sensitivity of . Because of its randomness, we are interested in a probabilistic tail-bound of , where the matrix has columns independently drawn from .
Lemma 2.
Let and be two matrices in that differ only in one row, and for that row, say , . Denote and has columns independently drawn from . With probability at least , we have
| (5) | |||
| with | |||
| (6) | |||
Proof.
See appendix. ∎
The above bound on the squared sensitivity has been obtained by first showing that the random variable is the sum of iid Beta-distributed random variables and then by using a Bernstein inequality. This bound, referred to as the Bernstein bound, is very conservative as soon as is very small. By calling the Central Limit Theorem (CLT), assuming that is large enough (), we get under the same hypotheses (proof is in the appendix) that
where and is the cumulative distribution function of a zero-mean unit variance Gaussian distribution. This bound is far tighter but is not rigourous due to the CLT approximation. Figure 1 presents an example of the probability distribution histogram of for two fixed arbitrary , and for random draws of . It shows that the CLT bound is numerically far smaller than the Bernstein bound of Lemma 2. Then, using the -based bounds jointly with the Gaussian mechanism property gives us the following proposition.
Proposition 2.
Let and , given a random direction projection matrix , then the Gaussian mechanism , where is a Gaussian matrix in with entries drawn from is -DP.
Proof.
The claim derives immediately by the relation between RDP and DP and by Lemma 2 with . ∎
The above DP guarantees apply to the full dataset. Hence, when learning through mini-batches, we benefit from the so-called privacy amplification by the “subsampling” principle, which ensures that a differentially private mechanism run on a random subsample of a population leads to higher privacy guarantees than when run on the full population [4]. On the contrary, gradient clipping/sanitization acts individually one each gradient and thus do not fully benefit from the subsampling amplification, as its DP property may still depend on the batch size [9].
This Gaussian mechanism on the random direction projections can be related to the definition of the empirical SWD as each corresponds to one entry of . Hence, by adding a Gaussian noise to each projection, we naturally derive our empirical DP Sliced Wasserstein distance, which inherits the differential property of , owing to the post-processing proposition [12].
3.2 Metric Properties of DP-SWD
We have analyzed the sensitivity of the random direction projection central to SWD and we have proposed a Gaussian mechanism to obtain a differentially private SWD (DP-SWD) which steps are depicted in Algorithm 1. In our use-cases, DP-SWD is used in a context of learning to match two distributions (one of them requiring to be privately protected). Hence, the utility guarantees of our DP-SWD is more related to the ability of the mechanism to distinguish two different distributions rather than on the equivalence between SWD and DP-SWD. Our goal in this section is to investigate the impact of adding Gaussian noise to the source and target distributions in terms of distance property in the population case.
Since , as defined in Equation (3), is a push-forward operator of probability distributions, the Gaussian mechanism process implies that the Wasserstein distance involved in SWD compares two 1D probability distributions which are respectively the convolution of a Gaussian distribution and and . Hence, we can consider DP-SWD uses as a building block the 1D smoothed Wasserstein distance between and with the smoothing being ensured by and its formal definition being, for ,
While some works have analyzed the theoretical properties of the Smoothed Wasserstein distance [15, 14], as far as we know, no theoretical result is available for the smoothed Sliced Wasserstein distance, and we provide in the sequel some insights that help its understanding. The following property shows that DP-SWD preserves the identity of indiscernibles.
Property 1.
For continuous probability distributions and , we have, for , .
Proof.
Showing that is trivial as the Radon transform and the convolution are two well-defined maps. We essentially would like to show that implies . If then for almost every . As convolution yields to multiplication in the Fourier domain and because, the Fourier transform of a Gaussian is also a Gaussian and thus is always positive, one can show that we have for all equality of the Fourier transforms of and . Then, owing to the continuity of and and by the Fourier inversion theorem, we have . Finally, as for the SWD proof [6, Prop 5.1.2], this implies that , owing to the projection nature of the Radon Transform and because the Fourier transform is injective. ∎
Property 2.
For , is symmetric and satisfies the triangle inequality.
Proof.
The proof easily derives from the metric properties of Smoothed Wasserstein distance [14] and details are in the appendix. ∎
These properties are strongly relevant in the context of our machine learning applications. Indeed, while they do not tell us how the value of DP-SWD compares with SWD, at fixed or when , they show that they can properly act as (for any ) loss functions to minimize if we aim to match distributions (at least in the population case). Naturally, there are still several theoretical properties of that are worth investigating but that are beyond the scope of this work.
4 DP-Distribution Matching Problems
There exists several machine learning problems where distance between distributions is the key part of the loss function to optimize. In domain adaptation, one learns a classifier from public source dataset but looks to adapt it to private target dataset (target domain examples are available only through a privacy-preserving mechanism). In generative modelling, the goal is to generate samples similar to true data which are accessible only through a privacy-preserving mechanism. In the sequel, we describe how our distance can be instantiated into these two learning paradigms for measuring adaptation or for measuring similarity between generated an true samples.
For unsupervised domain adaptation, given source examples and their label and unlabeled private target examples , the goal is to learn a classifier trained on the source examples that generalizes well on the target ones. One usual technique is to learn a representation mapping that leads to invariant latent representations, invariance being measured as some distance between empirical distributions of mapped source and target samples. Formally, this leads to the following learning problem
| (7) |
where can be any loss function of interest and . We solve this problem through stochastic gradient descent, similarly to many approaches that use Sliced Wasserstein Distance as a distribution distance [20], except that in our case, the gradient of involving the target dataset is -DP. Note that in order to compute the , one needs the public dataset and the public generator. In practice, this generator can either be transferred, after each update, from the private client curating or can be duplicated on that client. The resulting algorithm is presented in Algorithm 2.
In the context of generative modeling, we follow the same steps as Deshpande et al. [10] but use our instead of SWD. Assuming that we have some examples of data sampled from a given distribution, the goal of the learning problem is to learn a generator to output samples similar to those of the target distribution, with at its input a given noise vector. This is usually achieved by solving
| (8) |
where is for instance a Gaussian vector. In practice, we solve this problem using a mini-batching stochastic gradient descent strategy, following a similar algorithm than the one for domain adaptation. The main difference is that the private target dataset does not pass through the generator.
Tracking the privacy loss
Given that we consider the privacy mechanism within a stochastic gradient descent framework, we keep track of the privacy loss through the RDP accountant proposed by Wang et al. [32] for composing subsampled private mechanisms. Hence, we used the PyTorch package [33] that they made available for estimating the noise standard deviation given the budget, a number of epoch, a fixed batch size, the number of private samples, the dimension of the distributions to be compared and the number of projections used for . Some examples of Gaussian noise standard deviation are reported in Table 4 in the appendix.
5 Related Works
5.1 DP Generative Models
Most recent approaches [13] that proposed DP generative models considered it from a GAN perspective and applied DP-SGD [1] for training the model. The main idea for introducing privacy is to appropriately clip the gradient and to add calibrated noise into the model’s parameter gradient during training [29, 9, 34]. This added noise make those models even harder to train. Furthermore, since the DP mechanism applies to each single gradient, those approaches do not fully benefit from the amplification induced by subsampling (mini-batching) mechanism [4]. The work of Chen et al. [9] uses gradient sanitization and achieves privacy amplification by training multiple discriminators, as in [18], and sampling on them for adversarial training. While their approach is competitive in term of quality of generated data, it is hardly tractable for large scale dataset, due to the multiple (up to 1000 in their experiments) discriminator trainings.
Instead of considering adversarial training, some DP generative model works have investigated the use of distance on distributions. Harder et al. [17] proposed random feature based maximum-mean embedding distance for computing distance between empirical distributions. Cao et al. [7] considered the Sinkhorn divergence for computing distance between true and generated data and used gradient clipping and noise addition for privacy preservation. Their approach is then very similar to DP-SGD in the privacy mechanism. Instead, we perturb the Sliced Wasserstein distance by smoothing the distributions to compare. This yields a privacy mechanism that benefits subsampling amplification, as its sensitivity does not depend on the number of samples, and that preserves its utility as the smoothed Sliced Wasserstein distance is still a distance.
5.2 Differential Privacy with Random Projections
Sliced Wasserstein Distance leverages on Radon transform for mapping high-dimensional distributions into 1D distributions. This is related to projection on random directions and the sensitivity analysis of those projections on unit-norm random vector is key. The first use of random projection for differential privacy has been introduced by Kenthapadi et al. [19]. Their approach was linked to the distance preserving property of random projections induced by the Johnson-Lindenstrauss Lemma. As a natural extension, LeTien et al. [21] and Gondara & Wang [16] have applied this idea in the context of optimal transport and classification. The fact that we project on unit-norm random vector, instead of any random vector as in Kenthapadi et al. [19], requires a novel sensitivity analysis and we show that this sensitivity scales gracefully with ratio of the number of projections and dimension of the distributions.
6 Numerical Experiments
In this section, we provide some numerical results showing how our differentially private Sliced Wasserstein Distance works in practice. The code for reproducing some of the results is available in https://github.com/arakotom/dp_swd.
6.1 Toy Experiment
The goal of this experiment is to illustrate the behaviour of the DP-SWD compared with the SWD in controlled situations. We consider the source and target distributions as isotropic Normal distributions of unit variance with added privacy-inducing Gaussian noise of different variances. Both distributions are Gaussian of dimension and the means of the source and target are respectively and with . Figure 2 presents the evolution of the distances averaged over random draws of the Gaussian and noise. When source and target distributions are different, this experiment shows that DP-SWD follows the same increasing trend as SWD. This suggests that the order relation between distributions as evaluated using SWD is preserved by DP-SWD, and that the distance DP-SWD is minimized when , which are important features when using DP-SWD as a loss.


6.2 Domain Adaptation

We conduct experiments for evaluating our DP-SWD distance in the context of classical unsupervised domain adaptation (UDA) problems such as handwritten digit recognitions (MNIST/USPS), synthetic to real object data (VisDA 2017) and Office 31 datasets. Our goal is to analyze how DP-SWD performs compared with its public counterpart SWD [20], with one DP deep domain adaptation algorithm DP-DANN that is based on gradient clipping [31] and with the classical non-private DANN algorithm. Note that we need not compare with [21] as their algorithm does not learn representation and does not handle large-scale problems, as the OT transport matrix coupling need be computed on the full dataset. For all methods and for each dataset, we used the same neural network architecture for representation mapping and for classification. Approaches differ only on how distance between distributions have been computed. Details of problem configurations as well as model architecture and training procedure can be found in the appendix. Sensitivity has been computed using the Bernstein bound of Lemma 2.
Table 1 presents the accuracy on the target domain for all methods averaged over iterations. We remark that our private model outperforms the DP-DANN approach on all problems except on two difficult ones. Interestingly, our method does not incur a loss of performance despite the private mechanism. This finding is confirmed in Figure 3 where we plot the performance of the model with respect to the noise level (and thus the privacy parameter ). Our model is able to keep accuracy almost constant for .
| Methods | ||||
|---|---|---|---|---|
| Data | DANN | SWD | DP-DANN | DP-SWD |
| M-U | 93.9 0 | 95.5 1 | 87.1 2 | 94.0 0 |
| U-M | 86.2 2 | 84.82 | 73.5 2 | 83.4 2 |
| VisDA | 57.4 1 | 53.81 | 49.0 1 | 47.0 1 |
| D - W | 90.9 1 | 90.7 1 | 88.0 1 | 90.9 1 |
| D - A | 58.6 1 | 59.4 1 | 56.5 1 | 55.2 2 |
| A - W | 70.4 3 | 74.5 1 | 68.7 1 | 72.6 1 |
| A - D | 78.6 2 | 78.5 1 | 73.7 1 | 79.8 1 |
| W - A | 54.7 3 | 59.1 0 | 56.0 1 | 59.0 1 |
| W - D | 91.1 0 | 95.7 1 | 63.4 3 | 92.6 1 |






6.3 Generative Models
| MNIST | FashionMNIST | |||
|---|---|---|---|---|
| Method | MLP | LogReg | MLP | LogReg |
| SWD | 87 | 82 | 77 | 76 |
| GS-WGAN | 79 | 79 | 65 | 68 |
| DP-CGAN | 60 | 60 | 50 | 51 |
| DP-MERF | 76 | 75 | 72 | 71 |
| DP-SWD-c | 77 | 78 | 67 | 66 |
| DP-SWD-b | 76 | 77 | 67 | 66 |
In the context of generative models, our first task is to generate synthetic samples for MNIST and Fashion MNIST dataset that will be afterwards used for learning a classifier. We compare with different gradient-sanitization strategies like DP-CGAN [29], and GS-WGAN [9] and a model MERF [17] that uses MMD as distribution distance. We report results for our DP-SWD using two ways for computing the sensitivity, by using the CLT bound and the Bernstein bound, respectively noted as DP-SWD-c and DP-SWD-b. All models are compared with the same fixed budget of privacy . Our implementation is based on the one of MERF [17], in which we just plugged our DP-SWD loss in place of the MMD loss. The architecture of ours and MERF’s generative model is composed of few layers of convolutional neural networks and upsampling layers with approximately 180K parameters while the one of GS-WGAN is based on a ResNet with about 4M parameters. MERF’s and our models have been trained over epochs with an Adam optimizer and batch size of . For our DP-SWD we have used random projections and the output dimension is the classical .
Table 2 reports some quantitative results on the task. We note that MERF and our DP-SWD perform on par on these problems (with a slight advantage for MERF on FashionMNIST and for DP-SWD on MNIST). Note that our results on MERF are better than those reported in [9]. We also remark that GS-WGAN performs the best at the expense of a model with -fold more parameters and a very expensive training time (few hours just for training the discriminators, while our model and MERF’s take less than 10min). Figure 4 and 5 present some examples of generated samples for MNIST and FashionMNIST. We can note that the samples generated by DP-SWD present some diversity and are visually more relevant than those of MERF, although they do not lead to better performance in the classification task. Our samples are a bit blurry compared to the ones generated by the non-private SWD: this is an expected effect of smoothing.
We also evaluate our DP-SWD distance for training generative models on large RGB datasets such as the CelebA dataset. To the best of our knowledge, no DP generative approaches have been experimented on such a dataset. For instance, the GS-WGAN of [9] has been evaluated only on grayscale MNIST-like problems. For training the model, we followed the same approach (architecture and optimizer) as the one described in Nguyen et al. [23]. In that work, in order to reduce the dimension of the problems, distributions are compared in a latent space of dimension . We have used projections which leads to a ratio . Noise variance and privacy loss over iterations have been evaluated using the PyTorch package of [32] and have been calibrated for and , since the number of training samples is of the order of K. Details are in the appendix. Figure 6 presents some examples of samples generated from our DP-SWD and SWD. We note that in this high-dimensional context, the sensitivity bound plays a key role, as we get a FID score of 97 vs 158 respectively using CLT bound and Bernstein bound, the former being smaller than the latter.



7 Conclusion
This paper presents a differentially private distance on distributions based on the sliced Wasserstein distance. We applied a Gaussian mechanism on the random projection inherent to SWD and analyzed its properties. We proved that a bound (à la Bernstein) on sensitivity of the mechanism as an inverse dependence on the problem dimension and that a Central limit theorem bound, although approximate, gives a tighter bound. One of our key findings is that the privacy-inducing mechanism we proposed turns the SWD into a smoothed sliced Wasserstein distance, which inherits all the properties of a distance. Hence, our privacy-preserving distance can be plugged seamlessly into domain adaptation or generative model algorithms to give effective privacy-preserving learning procedures.
References
- Abadi et al. [2016] Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., and Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 308–318, 2016.
- Asoodeh et al. [2020] Asoodeh, S., Liao, J., Calmon, F. P., Kosut, O., and Sankar, L. Three variants of differential privacy: Lossless conversion and applications. arXiv preprint arXiv:2008.06529, 2020.
- Balle & Wang [2018] Balle, B. and Wang, Y.-X. Improving the Gaussian mechanism for differential privacy: Analytical calibration and optimal denoising. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 394–403, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR. URL http://proceedings.mlr.press/v80/balle18a.html.
- Balle et al. [2018] Balle, B., Barthe, G., and Gaboardi, M. Privacy amplification by subsampling: Tight analyses via couplings and divergences. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 31, pp. 6277–6287. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper/2018/file/3b5020bb891119b9f5130f1fea9bd773-Paper.pdf.
- Bonneel et al. [2015] Bonneel, N., Rabin, J., Peyré, G., and Pfister, H. Sliced and radon wasserstein barycenters of measures. Journal of Mathematical Imaging and Vision, 51(1):22–45, 2015.
- Bonnotte [2013] Bonnotte, N. Unidimensional and evolution methods for optimal transportation. PhD thesis, Paris 11, 2013.
- Cao et al. [2021] Cao, T., Bie, A., Kreis, K., and Fidler, S. Differentially private generative models through optimal transport, 2021. URL https://openreview.net/forum?id=zgMPc_48Zb.
- Chaudhuri et al. [2011] Chaudhuri, K., Monteleoni, C., and Sarwate, A. D. Differentially private empirical risk minimization. Journal of Machine Learning Research, 12(3), 2011.
- Chen et al. [2020] Chen, D., Orekondy, T., and Fritz, M. Gs-wgan: A gradient-sanitized approach for learning differentially private generators. In Neural Information Processing Systems (NeurIPS), 2020.
- Deshpande et al. [2018] Deshpande, I., Zhang, Z., and Schwing, A. G. Generative modeling using the sliced wasserstein distance. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3483–3491, 2018.
- Dwork [2008] Dwork, C. Differential privacy: A survey of results. In International conference on theory and applications of models of computation, pp. 1–19. Springer, 2008.
- Dwork et al. [2014] Dwork, C., Roth, A., et al. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3-4):211–407, 2014.
- Fan [2020] Fan, L. A survey of differentially private generative adversarial networks. In The AAAI Workshop on Privacy-Preserving Artificial Intelligence, 2020.
- Goldfeld & Greenewald [2020] Goldfeld, Z. and Greenewald, K. Gaussian-smoothed optimal transport: Metric structure and statistical efficiency. In International Conference on Artificial Intelligence and Statistics, pp. 3327–3337. PMLR, 2020.
- Goldfeld et al. [2020] Goldfeld, Z., Greenewald, K., and Kato, K. Asymptotic guarantees for generative modeling based on the smooth wasserstein distance. Advances in Neural Information Processing Systems, 33, 2020.
- Gondara & Wang [2020] Gondara, L. and Wang, K. Differentially private small dataset release using random projections. In Conference on Uncertainty in Artificial Intelligence, pp. 639–648. PMLR, 2020.
- Harder et al. [2020] Harder, F., Adamczewski, K., and Park, M. Differentially private mean embeddings with random features (dp-merf) for simple & practical synthetic data generation. arXiv preprint arXiv:2002.11603, 2020.
- Jordon et al. [2018] Jordon, J., Yoon, J., and Van Der Schaar, M. Pate-gan: Generating synthetic data with differential privacy guarantees. In International Conference on Learning Representations, 2018.
- Kenthapadi et al. [2013] Kenthapadi, K., Korolova, A., Mironov, I., and Mishra, N. Privacy via the johnson-lindenstrauss transform. Journal of Privacy and Confidentiality, 5(1), 2013.
- Lee et al. [2019] Lee, C.-Y., Batra, T., Baig, M. H., and Ulbricht, D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10285–10295, 2019.
- LeTien et al. [2019] LeTien, N., Habrard, A., and Sebban, M. Differentially private optimal transport: Application to domain adaptation. In IJCAI, pp. 2852–2858, 2019.
- Mironov [2017] Mironov, I. Rényi differential privacy. In 2017 IEEE 30th Computer Security Foundations Symposium (CSF), pp. 263–275, 2017. doi: 10.1109/CSF.2017.11.
- Nguyen et al. [2020] Nguyen, K., Ho, N., Pham, T., and Bui, H. Distributional sliced-wasserstein and applications to generative modeling. arXiv preprint arXiv:2002.07367, 2020.
- Nguyen et al. [2021] Nguyen, K., Ho, N., Pham, T., and Bui, H. Distributional sliced-wasserstein and applications to generative modeling. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=QYjO70ACDK.
- Nietert et al. [2021] Nietert, S., Goldfeld, Z., and Kato, K. From smooth wasserstein distance to dual sobolev norm: Empirical approximation and statistical applications. arXiv preprint arXiv:2101.04039, 2021.
- Rabin et al. [2011] Rabin, J., Peyré, G., Delon, J., and Bernot, M. Wasserstein barycenter and its application to texture mixing. In International Conference on Scale Space and Variational Methods in Computer Vision, pp. 435–446. Springer, 2011.
- Rubinstein et al. [2009] Rubinstein, B. I., Bartlett, P. L., Huang, L., and Taft, N. Learning in a large function space: Privacy-preserving mechanisms for svm learning. arXiv preprint arXiv:0911.5708, 2009.
- Rényi [1961] Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, pp. 547–561, Berkeley, Calif., 1961. University of California Press. URL https://projecteuclid.org/euclid.bsmsp/1200512181.
- Torkzadehmahani et al. [2019] Torkzadehmahani, R., Kairouz, P., and Paten, B. Dp-cgan: Differentially private synthetic data and label generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 0–0, 2019.
- [30] Tu, S. Differentially private random projections.
- Wang et al. [2020] Wang, Q., Li, Z., Zou, Q., Zhao, L., and Wang, S. Deep domain adaptation with differential privacy. IEEE Transactions on Information Forensics and Security, 15:3093–3106, 2020. doi: 10.1109/TIFS.2020.2983254.
- Wang et al. [2019] Wang, Y.-X., Balle, B., and Kasiviswanathan, S. P. Subsampled rényi differential privacy and analytical moments accountant. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 1226–1235. PMLR, 2019.
- Xiang [2020] Xiang, Y. Autodp : Automating differential privacy computation, 2020. URL https://github.com/yuxiangw/autodp.
- Xie et al. [2018] Xie, L., Lin, K., Wang, S., Wang, F., and Zhou, J. Differentially private generative adversarial network. arXiv preprint arXiv:1802.06739, 2018.
Supplementary material
Differentially Private Sliced Wasserstein Distance
8 Appendix
8.1 Lemma 1 and its proof
Lemma 1.
Assume that is a unit-norm vector and a vector where each entry is drawn independently from . Then
where is the beta distribution of parameters .
Proof.
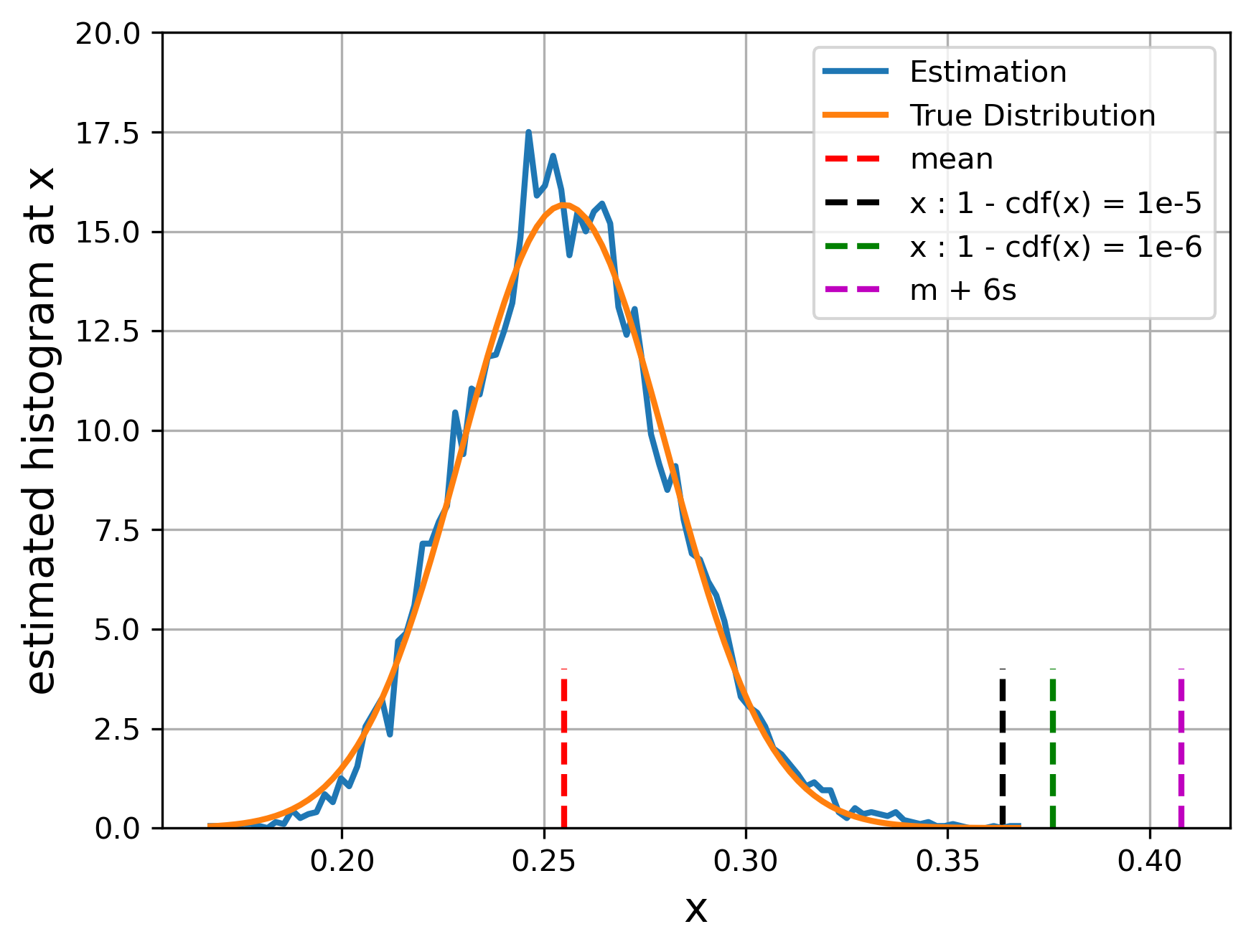
At first, consider a vector of unit-length in , say , that can be completed to an orthogonal basis. A change of basis from the canonical one does not change the length of a vector as the transformation is orthogonal. Thus the distribution of
does not depend on . can be either the vector in or (as is an unit-norm vector). However, for simplicity, let us consider as , we thus have
where the are iid from a normal distribution of standard deviation . Hence, because and the are independent, the above distribution is equal to the one of
where (and is a chi-square distribution) ) and and thus follows a beta distribution . And the fact that is also a unit-norm vector concludes the proof.
∎
A simulation of the random and resulting histogram is depicted in Figure 7.
Remark 3.
From the properties of the beta distribution, expectation and variances are given by
Remark 4.
Note that if is not of unit-length then follows

8.2 Lemma 2 and its proof
Lemma 2.
Suppose again that is unit norm. With probability at least , we have
| (9) | |||
| with | |||
| (10) | |||
Proof.
First observe that:
Therefore, is the sum of iid -distributed random variables.
It is thus possible to use any inequality bounding from its mean to state a highly probable interval for . We here use inequality, that is tighter than Hoeffding inequality, whenever some knowledge is provided on the variance of the random variables considered. Recall that it states that if and zero-mean independent RV with such that a.s:
For , we have
and Bernstein’s inequality gives
where
is the variance of each beta distributed variable. Making the right hand side be equal to , solving the second-order equation for give that, with probability at least
The proof follows directly from Lemma 1 and the fact ∎
From the above lemma, we have a probabilistic bound on the sensitivity of the random direction projection and SWD . The lower this bound is the better it is, as less noise needed for achieving a certain -DP. Interestingly, the first and last terms in this bound have an inverse dependency on the dimension. Hence, if the dimension of space in which the DP-SWD has to be chosen, for instance, when considering latent representation, a practical compromise has to be performed between a smaller bound and a better estimation. Also remark that if , the bound is mostly dominated by the term . Compared to other random-projection bounds [30] which have a linear dependency in . For our bound, dimension also help in mitigating this dependency.
8.3 Proof of the Central Limit Theorem based bound
Proof.
Proof with the Central Limit Theorem According to the Central Limit Theorem — whenever is the accepted rule of thumb — we may consider that
i.e.
and thus
Setting gives , and thus with probability at least
∎
8.4 Proof of Property 2.
Property 2.
is symmetric and satisfies the triangle inequality for .
Proof.
The symmetry trivially comes from the definition of that is
and the fact the Wasserstein distance is itself symmetric.
Regarding the triangle inequality for , our result is based on a very recent result showing that the smoothed Wasserstein for is also a metric [25] (Our proof is indeed valid for , as this recent result generalizes the one of [14] ). Hence, we have
where the first inequality comes from the fact that the smoothed Wassertein distance is a metric and satisfies the triangle inequality and the second one follows from the application of the Minkowski inequality.
∎
8.5 Experimental set-up
8.5.1 Dataset details
We have considered families of domain adaptation problems based on Digits, VisDA, Office-31. For all these datasets, we have considered the natural train/test number of examples.
For the digits problem, we have used the MNIST and the USPS datasets. For MNIST-USPS and USPS-MNIST, we have respectively used 60000-7438, 7438-10000 samples. The VisDA 2017 problem is a -class classification problem with source and target domains being simulated and real images. The Office-31 is an object categorization problem involving classes with a total of 4652 samples. There exists domains in the problem based on the source of the images : Amazon (A), DSLR (D) and WebCam (W). We have considered all possible pairwise source-target domains.
For the VisDA and Office datasets, we have considered Imagenet pre-trained ResNet-50 features and our feature extractor (which is a fully-connected feedforword networks) aims at adapting those features. We have used pre-trained features freely available at https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md.
8.5.2 Architecture details for domain adaptations
Digits
For the MNIST-USPS problem, the architecture of our feature extractor is composed of the two CNN layers with 32 and 20 filters of size . The feature extractor uses a ReLU activation function a max pooling at the first layer and a sigmoid activation function at the second one. For the classification head, we have used a 2-layer fully connected networks as a classifier with and units.
VisDA
For the VisDA dataset, we have considered pre-trained 2048 features obtained from a ResNet-50 followed by fully connected networks with units and ReLU activations. The latent space is thus of dimension . Discriminators and classifiers are also a layer fully connected networks with and respectively 1 and “number of class” units.
Office 31
For the Office dataset, we have considered pre-trained 2048 features obtained from a ResNet-50 followed by two fully connected networks with output of and units and ReLU activations. The latent space is thus of dimension . Discriminators and classifiers are also a layer fully connected networks with and respectively 1 and “number of class” units.
For Digits, VisDA and Office 31 problems, all models have been trained using Adam with learning rate validated on the non-private model.
8.5.3 Architecture details for generative modelling.
For the MNIST, FashionMNIST generative modelling problems, we have used the implementation of MERF available at https://github.com/frhrdr/dp-merf and plugged in our distance. The generator architecture we used is the same as theirs and detailed in Table 3. The optimizer is an Adam optimizer with the default learning rate. The code dimension is and is concatenated with the one-hot encoding of the class label, leading to an overall input distribution of .
For the CelebA generative modelling, we used the implementation of Nguyen et al. [24] available at https://github.com/VinAIResearch/DSW. The generator mixes transpose convolution and batch normalization as described in Table 5. The optimizer is an Adam optimizer with a learning rate of . Again, we have just plugged in our distance.
| Module | Parameters |
|---|---|
| FC | 20 - 200 |
| BatchNorm | , momentum=0.1 |
| FC | 200 - 784 |
| BatchNorm | , momentum=0.1 |
| Reshape | 28 x 28 |
| upsampling | factor = 2 |
| Convolution | 5 x 5 + ReLU |
| Upsampling | factor = 2 |
| Convolution | 5 x 5 + Sigmoid |
| data | N | #epoch | batch size | ||||
| U-M | 784 | 200 | 10000 | 100 | 128 | 4.74 | |
| M-U | 784 | 200 | 7438 | 100 | 128 | 5.34 | |
| VisDA | 100 | 1000 | 55387 | 50 | 128 | 6.40 | |
| Office | 50 | 100 | 497 | 50 | 32 | 8.05 | |
| MNIST (b) | 784 | 1000 | 60000 | 100 | 100 | 2.94 | |
| MNIST (c) | 784 | 1000 | 60000 | 100 | 100 | 0.84 | |
| CelebA (b) | 8192 | 2000 | 162K | 100 | 256 | 2.392 | |
| CelebA (c) | 8192 | 2000 | 162K | 100 | 256 | 0.37 |
| Module | Parameters |
|---|---|
| Transpose Convolution | 32 - 512, kernel = 4x4, stride = 1 |
| BatchNorm | , momentum=0.1 |
| ReLU | |
| Transpose Convolution | 512 - 256, kernel = 4x4, stride = 1 |
| BatchNorm | , momentum=0.1 |
| ReLU | |
| Transpose Convolution | 256 - 128, kernel = 4x4, stride = 1 |
| BatchNorm | , momentum=0.1 |
| ReLU | |
| Transpose Convolution | 128 - 64, kernel = 4x4, stride = 1 |
| BatchNorm | , momentum=0.1 |
| ReLU | |
| Transpose Convolution | 64 - 3, kernel = 4x4, stride = 1 |
| BatchNorm | , momentum=0.1 |
| Tanh |