DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
Abstract
We propose a new formulation of temporal action detection (TAD) with denoising diffusion, DiffTAD in short. Taking as input random temporal proposals, it can yield action proposals accurately given an untrimmed long video. This presents a generative modeling perspective, against previous discriminative learning manners. This capability is achieved by first diffusing the ground-truth proposals to random ones (i.e., the forward/noising process) and then learning to reverse the noising process (i.e., the backward/denoising process). Concretely, we establish the denoising process in the Transformer decoder (e.g., DETR) by introducing a temporal location query design with faster convergence in training. We further propose a cross-step selective conditioning algorithm for inference acceleration. Extensive evaluations on ActivityNet and THUMOS show that our DiffTAD achieves top performance compared to previous art alternatives. The code will be made available at https://github.com/sauradip/DiffusionTAD.
1 Introduction
Temporal action detection (TAD) aims to predict the temporal duration (i.e., start and end time) and the class label of each action instance in an untrimmed video [32, 9]. Existing methods rely on proposal prediction by regressing anchor proposals [83, 13, 21, 47] or predicting the start/end times of proposals [41, 8, 42, 87, 49, 84, 85]. These models are all discriminative learning based.
In the generative learning perspective, diffusion model [63] has been recently exploited in image based object detection [15]. This represents a new direction for designing detection models in general. Although conceptually similar to object detection, the TAD problem presents more complexity due to the presence of temporal dynamics. Besides, there are several limitations with the detection diffusion formulation in [15]. First, a two-stage pipeline (e.g., RCNN [13]) is adopted, suffering localization-error propagation from proposal generation to proposal classification [48]. Second, as each proposal is processed individually, their relationship modeling is overlooked, potentially hurting the learning efficacy. To avoid these issues, we adopt the one-stage detection pipelines [72, 77] that have already shown excellent performance with a relatively simpler design, in particular, DETR [11].
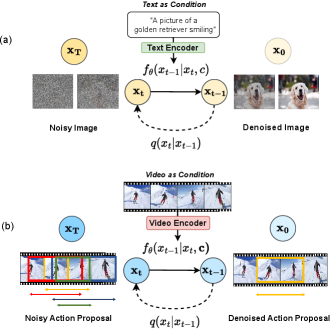
Nonetheless, it is non-trivial to integrate denoising diffusion with existing detection models, due to several reasons. (1) Whilst efficient at handling high-dimension data simultaneously, diffusion models [18, 39] typically work with continuous input data. But temporal locations in TAD are discrete. (2) Denoising diffusion and action detection both suffer low efficiency, and their combination would make it even worse. Both of the problems have not been investigated systematically thus far.
To address the aforementioned challenges, a novel Conditioned Location Diffusion method is proposed for efficiently tackling the TAD task in a diffusion formulation, abbreviated as DiffTAD. It takes a set of random temporal proposals (i.e., the start and end time pairs) following Gaussian distribution, and outputs the action proposals of a given untrimmed video. At training time, Gaussian noises are first added to the ground truth proposals to make noisy proposals. These discrete noisy proposals are then projected into a continuous vector space using sinusoidal projection [44] to form noisy queries in which the decoder (e.g., DETR) will conduct the denoising diffusion process. Our denoising space choice facilitates the adoption of existing diffusion models, as discussed above. As a byproduct, the denoising queries strategy itself can accelerate the training convergence of DETR type models [38]. At inference time, conditioned on a test video, DiffTAD can generate action temporal boundaries by reversing the learned diffusion process from Gaussian random proposals. For improving inference efficiency, we further introduce a cross-timestep selective conditioning mechanism with two key functions: (1) minimizing the redundancy of intermediate predictions at each sampling step by filtering out the proposals far away from the distribution of corrupted proposals generated in training, and (2) conditioning the next sampling step by selected proposals to regulate the diffusion direction for more accurate inference.
Our contributions are summarized as follows. (1) For the first time we formulate the temporal action detection problem through denoising diffusion in the elegant transformer decoder framework. Additionally, integrating denoising diffusion with this decoder design solves the typical slow-convergence limitation. (2) We further enhance the diffusion sampling efficiency and accuracy by introducing a novel selective conditioning mechanism during inference. (3) Extensive experiments on ActivityNet and THUMOS benchmarks show that our DiffTAD achieves favorable performance against prior art alternatives.
2 Related Works
Temporal action detection. Inspired by object detection in static images [55], R-C3D [83] uses anchor proposals by following the design of proposal generation and classification. With a similar model design, TURN [21] aggregates local features to represent snippet-level features for temporal boundary regression and classification. SSN [93] decomposes an action instance into three stages (starting, course, and ending) and employs structured temporal pyramid pooling to generate proposals. BSN [42] predicts the start, end, and actionness at each temporal location and generates proposals with high start and end probabilities. The actionness was further improved in BMN [41] via additionally generating a boundary-matching confidence map for improved proposal generation. GTAN [47] improves the proposal feature pooling procedure with a learnable Gaussian kernel for weighted averaging. G-TAD [87] learns semantic and temporal context via graph convolutional networks for more accurate proposal generation. BSN++ [68] further extends BMN with a complementary boundary generator to capture rich context. CSA [67] enriches the proposal temporal context via attention transfer. VSGN [92] improves short-action localization using a cross-scale multi-level pyramidal architecture. Recently, Actionformer [90] and React [60] proposed a purely DETR based design for temporal action localization at multiple scales. Our DiffTAD is the very first TAD model which proposes action detection as a generative task.
Diffusion models. As a class of deep generative models, diffusion models [28, 64, 66] start from the sample in random distribution and recover the data sample via a gradual denoising process. Diffusion models have recently demonstrated remarkable results in fields including computer vision [5, 54, 58, 51, 26, 20, 57, 61, 27, 91, 29, 89], nature language processing [4, 39, 24], audio processing [52, 88, 82, 37, 70, 31, 35], interdisciplinary applications[33, 30, 3, 86, 73, 81, 59], etc. More applications of diffusion models can be found in recent surveys [89, 10].
Diffusion model for perception tasks. While Diffusion models have achieved great success in image generation [28, 66, 18], their potential for other perception tasks has yet to be fully explored. Some pioneer works tried to adopt the diffusion model for image segmentation tasks [79, 6, 25, 34, 7, 2, 16]. For example, Chen et al. [16] adopted Bit Diffusion model [17] for panoptic segmentation [36] of images and videos. However, despite significant interest in this idea, there is no previous solution that successfully adapts generative diffusion models for object detection, the progress of which remarkably lags behind that of segmentation. This might be because the segmentation task can be processed in an image-to-image style, which is more similar to image generation in formulation [14]. While object detection is a set prediction problem [11] with a need for assigning object candidates [56, 43, 11] to ground truth objects. However, Chen et al. [15] managed to apply a diffusion model to object detection for the first time. Similarly, we make the first attempt at formulating TAD in the diffusion framework by integrating the denoising process with the single-stage DETR architecture.
3 Methodology
3.1 Preliminaries
Temporal action detection. Our DiffTAD model takes as input an untrimmed video with a variable number of frames. Video frames are first pre-processed by a feature encoder (e.g., a Kinetics pre-trained I3D network [12]) into a sequence of localized snippets following the standard practice [41]. To train the model, we collect a set of labeled video training set . Each video is labeled with temporal annotation where / denote the start/end time, is the action category, and is the number of action instances.
Diffusion models [62, 28, 64, 63] are a class of likelihood-based models inspired by nonequilibrium thermodynamics [64, 65]. These models define a Markovian chain of diffusion forward process by gradually adding noises to the sample data. The forward noising process is defined as
| (1) |
which transforms a sample to a latent noisy sample () by adding noises to . and represents the noise variance schedule [28]. During training, a neural network is trained to predict from by minimizing the training objective with loss [28]:
| (2) |
At inference, a sample is reconstructed from noise with the model and an updating rule [28, 63] in an iterative way, i.e., . More details of diffusion models can be found in Supplementary.
3.2 DiffTAD
Diffusion-based TAD formulation.
In this work, we formulate the temporal action detection task in a conditional denoising diffusion framework. In our setting, data samples are a set of action temporal boundaries , where denotes temporal proposals. A neural network is trained to predict from noisy proposals , conditioned on the corresponding video . The corresponding category label is produced accordingly.
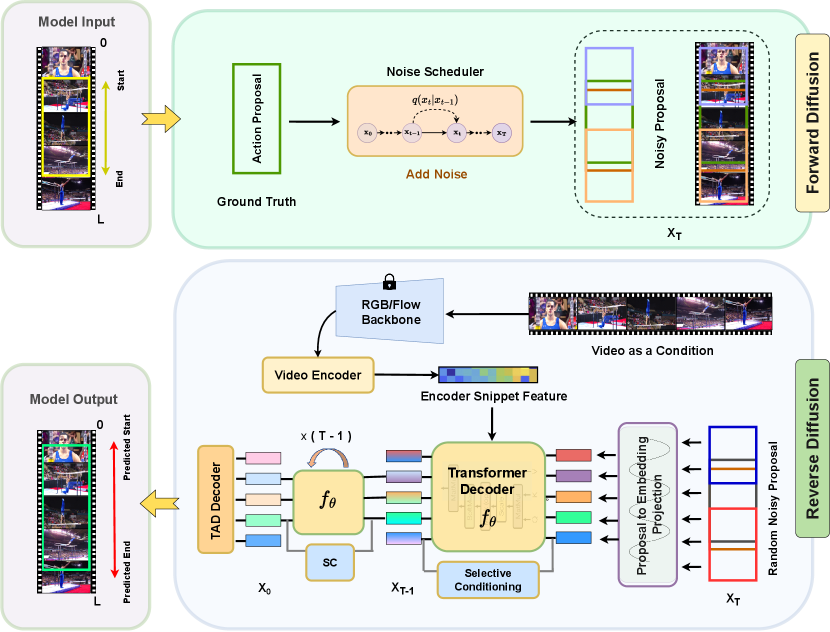
Since the diffusion model generates a data sample iteratively, it needs to run the model multiple times in inference. However, it would be computationally intractable to directly apply on the raw video at every iterative step. For efficiency, we propose to separate the whole model into two parts, video encoder and detection decoder, where the former runs only once to extract a feature representation of the input video , and the latter takes this feature as a condition to progressively refine the noisy proposals .
Video encoder. The video encoder takes as input the pre-extracted video features and extracts high-level features for the following detection decoder. In general, any video encoder can be used. We use a video encoder same as [90]. More specifically, the raw video is first encoded by a convolution encoder to obtain multiscale feature for RGB and optical flow separately. This is followed by a multi-scale temporal transformer [74] that performs global attention across the time dimension to obtain the global feature as:
| (3) |
where query/key/value of the transformer is set to and is the number of scales. We estimate the shared global representations across all the scales and concatenate them as .
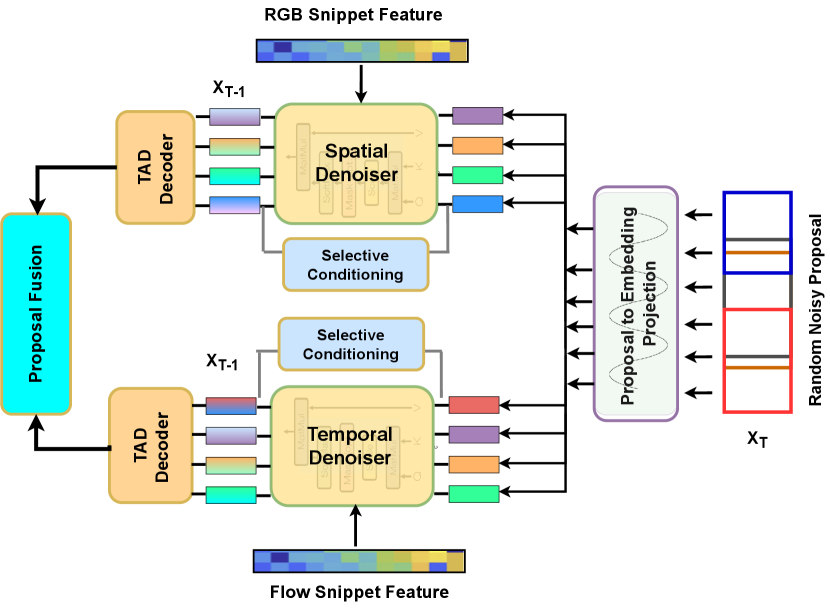
Previous TAD works [41, 87] typically use fused RGB and flow features (i.e., early fusion) for modeling. Considering the feature specificity (RGB for appearance, and optical flow for motion), we instead exploit a late fusion strategy (Fig. 3). Specifically, we extract the video features and for RGB and optical flow separately. The proposal denoising is then conducted in each space individually. The forward/noising process is random (i.e., feature agnostic) and thus shared by both features. We will compare the two fusion strategies empirically (see Table 6).
Detection decoder. Similar to DETR [40], we use a transformer decoder [74] (denoted by ) for detection. Functionally it serves as a denoiser. In traditional DETR, the queries are learnable continuous embeddings with random initialization. In DiffTAD, however, we exploit the queries as the denoising targets.
Specifically, we first project discrete proposals to continuous query embeddings [78]:
| (4) |
where is MLP-based learnable projection. Taking as input, the decoder then predicts outputs:
| (5) |
where is the global encoder feature and the is the final embedding. is finally decoded using three parallel heads namely (1) action classification head, (2) action localization head, and (3) completeness head, respectively. The first estimates the probability of a particular action within the action proposal. The second estimates the start, end and IOU overlap between the proposals. The third estimates the quality of predicted action proposals.
Cross-timestep selective conditioning.
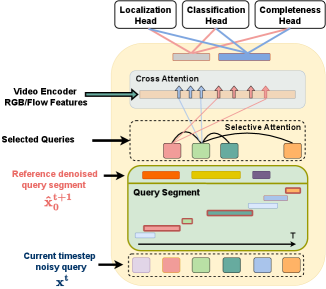
In DiffTAD, the denoising decoder takes action queries and then denoises each of them iteratively. Processing a large number of queries is thus inefficient. An intuitive way for better efficiency is to use static thresholds to suppress unimportant candidates [15], which however is ad-hoc and ineffective.
Here, we propose a more principled cross-timestep selective conditioning mechanism (Fig. 4). More specifically, we calculate a similarity matrix between the queries of current timestep and queries of conditioned/previous timestep . Each element of represents the similarity of the same queries across two successive timesteps. We select a set of queries according to:
| (6) |
where is a preset similarity threshold. We consider higher IoU with the desired (approximated by the estimate of the last step) proposals, more effective for the queries to be denoised. Thus, we construct an IoU based matrix between two successive timesteps:
| (7) |
where / indexes the queries. This allows for the most useful queries to be selected (see Fig. 1 in Supplementary).
We obtain the final query set as with denotes the set divide operation. For a selected query , its key and value features can be obtained by fusion as . Each query feature is then updated as
| (8) |
These selected queries will be passed through the cross-attention with video embeddings for denoising. This selective conditioning is applied on a random proportion (e.g., 70%) of proposals per mini-batch during training, and on all the proposals during inference.
Our selective conditioning strategy shares the spirit of self-conditioning [17] in the sense that the output of the last step is used for accelerating the subsequent denoising. However, our design and problem setup both are different. For example, self-conditioning can be simply realized by per-sample feature concatenation, whilst our objective is to select a subset of queries based on the pairwise similarity and IoU measurement in an attention manner. We validate the conditioning design in the experiments (Table 2).
3.3 Training
During training, we first construct the diffusion process that corrupts the ground-truth proposals to noisy proposals. We then train the model to reverse this noising process. Please refer to Algorithm 1 for more details.
alpha_cumprod(t): cumulative product of , i.e.,
Proposal corruption.
We add Gaussian noises to the ground truth action proposals. The noise scale is controlled by (in Eq. (1)), which adopts the monotonically decreasing cosine schedule in different timestep , following [50]. Notably, the ground truth proposal coordinates need to be scaled as well since the signal-to-noise ratio has a significant effect on the performance of diffusion model [16]. We observe that TAD favors a relatively lower signal scaling value than object detection [15] (see Table 4). More discussions are given in Supplementary.
Training losses.
The detection detector takes as input corrupted proposals and predicts predictions each including the category classification, proposal coordinates, and IOU regression. We apply the set prediction loss [11, 69, 94] on the set of predictions. We assign multiple predictions to each ground truth by selecting the top predictions with the least cost by an optimal transport assignment method [22, 23, 80, 19].
3.4 Inference
In inference, starting from noisy proposals sampled in Gaussian distribution, the model progressively refines the predictions as illustrated in Algorithm 2.
linespace: generate evenly spaced values
Sampling step.
At each sampling step, the random or estimated proposals from the last sampling step are first projected into the continuous query embeddings and sent into the detection decoder to predict the category, proposal IOU and proposal coordinates. After obtaining the proposals of the current step, DDIM [63] is adopted to estimate the proposals for the next step.
Proposal prediction.
DiffTAD has a simple proposal generation pipeline without post-processing (e.g., non-maximum suppression). To make a reliable confidence estimation for each proposal, we fuse the action classification score and completeness score for each proposal with a simple average to obtain the final proposal score .
3.5 Remarks
One model multiple trade-offs.
Once trained, DiffTAD works under multiple settings with a varying number of proposals and sampling steps during inference (Fig. 5(b)). In general, better accuracy can be obtained using more proposals and more steps. Thus, a single DiffTAD can realize a number of trade-off needs between speed and accuracy.
Faster convergence.
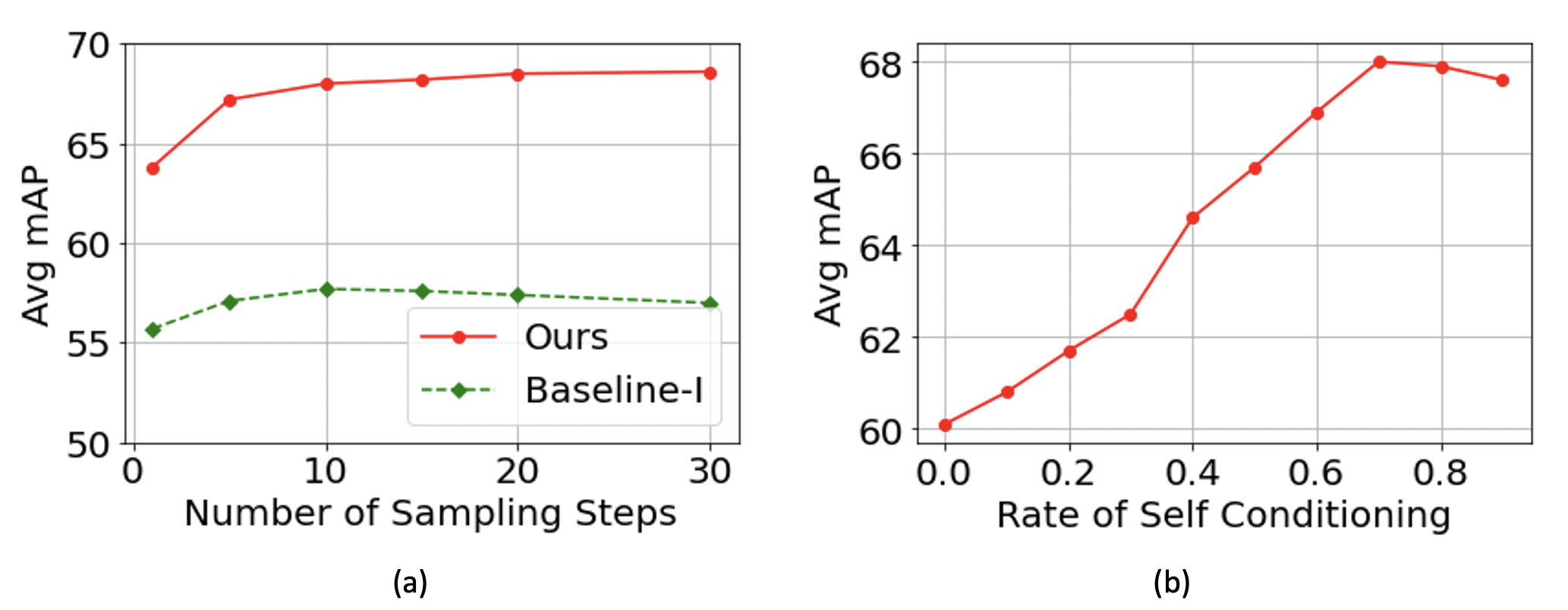
DETR variants suffer generally slow convergence [45] due to two reasons. First, inconsistent updates of the anchors, the objective for the object queries to learn, would make the optimization of target boundaries difficult. Second, the ground truth assignment using a dynamic process (e.g., Hungarian matching) is unstable due to both the nature of discrete bipartite matching and the stochastic training process. For instance, a small perturbation with the cost matrix might cause enormous matching and inconsistent optimization. Our DiffTAD takes a denoising strategy that makes learning easier. More specifically, each query is designed as a proposal proxy, a noised query, that can be regarded as a good anchor due to being close to a ground truth. With the ground truth proposal as a definite optimization objective, the ambiguity brought by Hungarian matching can be well suppressed. We validate that our query denoising based DiffTAD converges more stably than DiffusionDet [15] based Baseline-I (Fig. 5(a)), whilst achieving superior performance (Table 1).
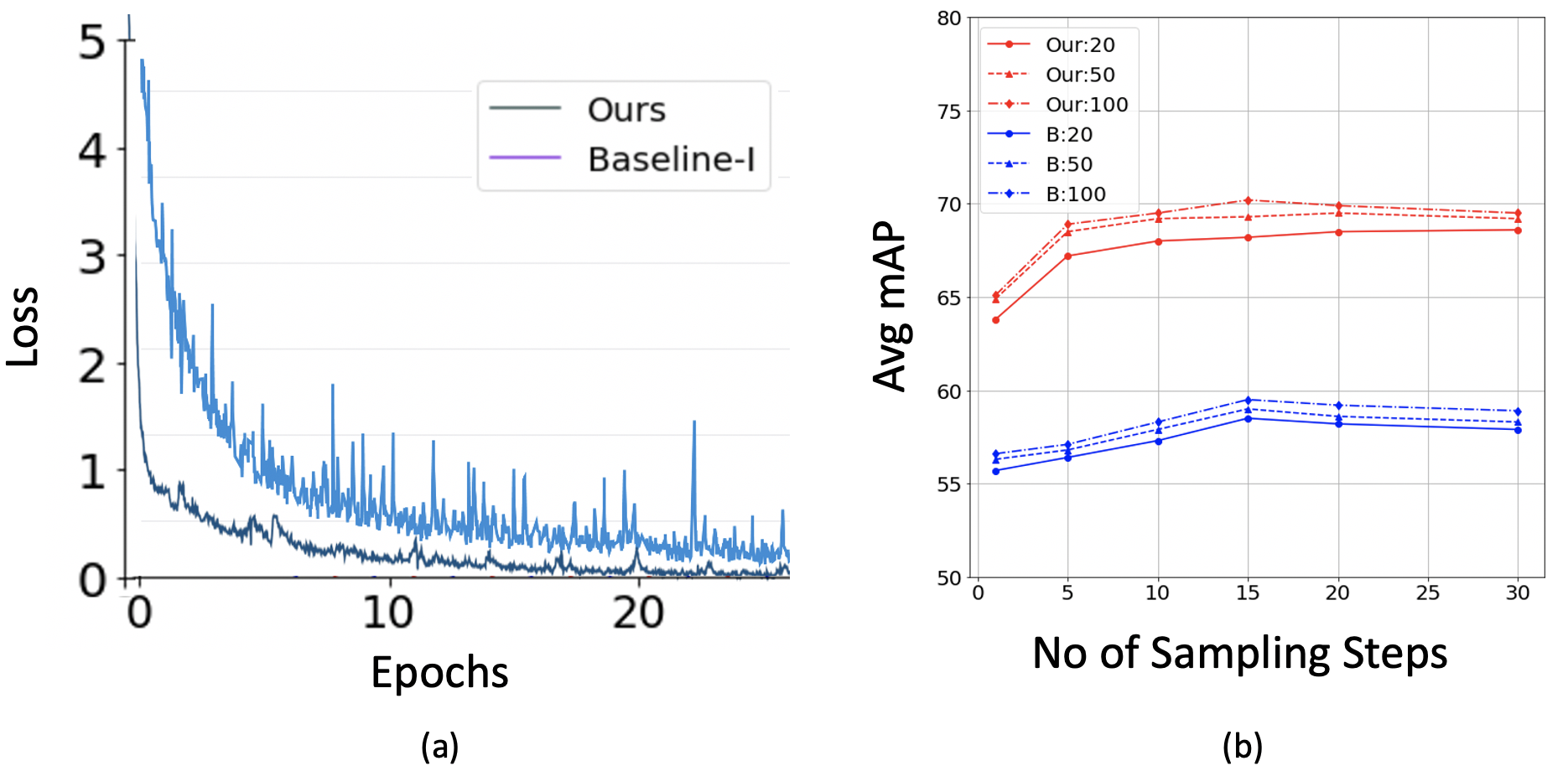
Better sampling.
We evaluate DiffTAD under a varying number of (10/50/100) random proposals by increasing the sampling steps from 1 to 30. As shown in Table 1, under all three settings, DiffTAD yields steady performance gains from more steps consumed. In particular, in the case of fewer random proposals, often DiffTAD can achieve larger gains than DiffusionDet [15]. For example, in the case of 50 proposals, the mAP of DiffTAD boosts the avg mAP from 64.9% (1 step) to 68.5% (5 steps), i.e., an absolute gain of 3.6% avg mAP. Unlike object detection, we find TAD benefits little from increasing the number of proposals. One intuitive reason is that positive samples are less in TAD than in object detection. Compared to the previous two-stage refinement of discriminative learning based TAD models [71], our gain is also more decent (0.8% vs. 4.2% (10 steps)). This is because it lacks a principled iterative inference ability as in diffusion models.
| THUMOS | ActivityNet | |||||||||||
| Models | Design | Feature | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | Avg | 0.5 | 0.75 | 0.95 | Avg |
| Discriminative learning based models | ||||||||||||
| TAL-Net [13] | 2-stage | I3D | 53.2 | 48.5 | 42.8 | 33.8 | 20.8 | - | 38.2 | 18.3 | 1.3 | 20.2 |
| BMN [41] | 2-stage | TSN | 56.0 | 47.4 | 38.8 | 29.7 | 20.5 | 38.5 | 50.1 | 34.8 | 8.3 | 33.9 |
| GTAD [87] | 2-stage | TSN | 54.5 | 47.6 | 40.3 | 30.8 | 23.4 | 39.3 | 50.4 | 34.6 | 9.0 | 34.1 |
| RTD-Net [71] | 2-stage | I3D | 68.3 | 62.3 | 51.9 | 38.8 | 23.7 | - | 47.2 | 30.7 | 8.6 | 30.8 |
| TCANet [53] | 2-stage | I3D | 60.6 | 53.2 | 44.6 | 36.8 | 26.7 | 44.3 | 52.3 | 36.7 | 6.9 | 35.5 |
| MUSES [46] | 2-stage | I3D | 68.9 | 64.0 | 56.9 | 46.3 | 31.0 | — | 50.0 | 35.0 | 6.6 | 34.0 |
| ContextLoc [95] | 2-stage | I3D | 68.3 | 63.8 | 54.3 | 41.8 | 26.2 | 50.9 | 56.0 | 35.2 | 3.6 | 34.2 |
| RCL [76] | 2-stage | I3D | 70.1 | 62.3 | 52.9 | 42.7 | 30.7 | 57.1 | 51.7 | 35.2 | 8.0 | 34.4 |
| React [60] | 1-stage | I3D | 69.2 | 65.0 | 57.1 | 47.8 | 35.6 | 55.0 | 49.6 | 33.0 | 8.6 | 32.6 |
| TAGS [48] | 1-stage | I3D | 68.6 | 63.8 | 57.0 | 46.3 | 31.8 | 52.8 | 56.3 | 36.8 | 9.6 | 36.5 |
| ActionFormer [90] | 1-stage | I3D | 82.1 | 77.8 | 71.0 | 59.4 | 43.9 | 66.8 | 53.5 | 36.2 | 8.2 | 35.6 |
| Generative learning based models | ||||||||||||
| Baseline(1-step) | 2-stage | I3D | 65.2 | 61.3 | 55.4 | 44.6 | 35.5 | 52.4 | 48.5 | 31.4 | 8.6 | 31.5 |
| Baseline(5-step) | 2-stage | I3D | 69.1 | 65.7 | 60.2 | 47.1 | 36.4 | 55.7 | 50.2 | 32.3 | 8.9 | 32.2 |
| Baseline(10-step) | 2-stage | I3D | 70.0 | 66.5 | 60.6 | 47.5 | 36.9 | 56.3 | 51.0 | 32.9 | 9.0 | 32.4 |
| \cellcolor[HTML]CBCEFB DiffTAD(1-step) | \cellcolor[HTML]CBCEFB 1-stage | \cellcolor[HTML]CBCEFBI3D | \cellcolor[HTML]CBCEFB68.7 | \cellcolor[HTML]CBCEFB66.8 | \cellcolor[HTML]CBCEFB64.7 | \cellcolor[HTML]CBCEFB61.2 | \cellcolor[HTML]CBCEFB57.3 | \cellcolor[HTML]CBCEFB63.8 | \cellcolor[HTML]CBCEFB52.4 | \cellcolor[HTML]CBCEFB35.6 | \cellcolor[HTML]CBCEFB8.8 | \cellcolor[HTML]CBCEFB34.8 |
| \cellcolor[HTML]CBCEFBDiffTAD(5-step) | \cellcolor[HTML]CBCEFB 1-stage | \cellcolor[HTML]CBCEFBI3D | \cellcolor[HTML]CBCEFB73.4 | \cellcolor[HTML]CBCEFB71.5 | \cellcolor[HTML]CBCEFB69.9 | \cellcolor[HTML]CBCEFB62.8 | \cellcolor[HTML]CBCEFB58.4 | \cellcolor[HTML]CBCEFB67.2 | \cellcolor[HTML]CBCEFB55.2 | \cellcolor[HTML]CBCEFB36.8 | \cellcolor[HTML]CBCEFB8.9 | \cellcolor[HTML]CBCEFB36.0 |
| \cellcolor[HTML]CBCEFBDiffTAD(10-step) | \cellcolor[HTML]CBCEFB 1-stage | \cellcolor[HTML]CBCEFBI3D | \cellcolor[HTML]CBCEFB74.9 | \cellcolor[HTML]CBCEFB72.8 | \cellcolor[HTML]CBCEFB71.2 | \cellcolor[HTML]CBCEFB62.9 | \cellcolor[HTML]CBCEFB58.5 | \cellcolor[HTML]CBCEFB68.0 | \cellcolor[HTML]CBCEFB56.1 | \cellcolor[HTML]CBCEFB36.9 | \cellcolor[HTML]CBCEFB9.0 | \cellcolor[HTML]CBCEFB36.1 |
4 Experiments
Datasets. We conduct extensive experiments on two popular TAD benchmarks. (1) ActivityNet-v1.3 [9] has 19,994 videos from 200 action classes. We follow the standard setting to split all videos into training, validation and testing subsets in ratio of 2:1:1. (2) THUMOS14 [32] has 200 validation videos and 213 testing videos from 20 categories with labeled temporal boundary and action class.
4.1 Implementation details
Training schedule. For video feature extraction, we use Kinetics pre-trained I3D model [12, 90] with a downsampling ratio of 4 and R(2+1)D model [1, 90] with a downsampling ratio of 2. Our model is trained for 50 epochs using Adam optimizer with a learning rate of for AcitivityNet/THUMOS respectively. The batch size is set to 40 for ActivityNet and 32 for THUMOS. For selective conditioning, we apply the rate of 70% during training. All models are trained with 4 NVIDIA-V100 GPUs.
Testing schedule. At the inference stage, the detection decoder iteratively refines the predictions from Gaussian random proposals. By default, we set the total sampling time steps as 10.
4.2 Main results
Competitors.
Results on THUMOS.
We make several observations from Table 1: (1) Our DiffTAD achieves the best result, surpassing strong discriminative learning based competitors like TCANet [75] and ActionFormer [90] by a clear margin. This suggests the overall performance advantage of our model design and generative formulation idea. (2) Importantly, DiffTAD excels on the alternative generative learning design (i.e., Baseline), validating the superiority of our diffusion-based detection formulation. For both generative models, more sampling steps lead to higher performance. This concurs with the general property of diffusion models. (3) In particular, our model achieves significantly stronger results in stricter IOU metrics (e.g., IOU@0.5/0.6/0.7), as compared to all the other alternatives. This demonstrates the potential of generative learning in tackling the action boundary often with high ambiguity, and the significance of proper diffusion design.
Results on ActivityNet.
Similar observations can be drawn in general on ActivityNet from Table 1. We further highlight several differences: (1) Indeed, overall our DiffTAD is not the best performer, with a slight edge underneath TAGS [48]. However, we note that all other DETR style methods (e.g., RTD-Net) are significantly inferior. This means that our method has already successfully filled up the most performance disadvantage of the DETR family. We attribute this result to our design choice of denoising in the query space and cross-timestep selective conditioning. That being said, our formulation in exploiting the DETR architecture for TAD is superior than all prior attempts. (2) Compared to the generative competitor (i.e., Baseline), our model is not only more stable to converge (Fig. 5(a)), but also yields a margin of 3.7% (smaller than that on THUMOS as this is a more challenging test for the DETR family in general).
4.3 Ablation study
We conduct ablation experiments on THUMOS to study DiffTAD in detail. In all experiments, we use 30 proposals for training and inference, unless specified otherwise.
Cross-timestep selective conditioning.
We examine the effect of the proposed selective conditioning for proposal refinement (Section 3.2). To that end, we vary the rate/portion of proposals per batch at which selective conditioning is applied during training. The case of 0% training rate means no conditioning. Note, during inference selective conditioning is always applied to all the proposals (i.e., 100% test rate). As demonstrated in Fig. 6(b), we observe a clear correlation between conditioning rate and sampling quality (i.e., mAP), validating the importance of our selective conditioning in refining proposals for enhanced denoising.
Sampling decomposition.
We decompose the sampling strategy with DiffTAD by testing four variants: (1) No denoising: No DDIM [63] is applied, which means the output prediction of the current step is used directly as the input of the next step (i.e., a naive baseline). (2) Vanilla denoising: DDIM is applied in the original form. (3) Selective conditioning: Only selective conditioning is used but no vanilla denoising. (4) Both vanilla denoising and selective conditioning: Our full model. We observe from Table 3 that (1) Without proper denoising, applying more steps will cause more degradation, as expected, because there is no optimized Markovian chain. (2) Applying vanilla denoising can address the above problem and improve the performance from multiple sampling accordingly. However, the performance increase saturates quickly. (3) Interestingly, our proposed selective conditioning even turns out to be more effective than vanilla denoising. (4) When both vanilla denoising and selective conditioning are applied (i.e., our full model), the best performances can be achieved, with a clear gain over the either and even improved saturation phenomenon. This suggests that the two ingredients are largely complementary, which is not surprising given their distinctive design nature.
| ID | SC | step 1 | step 5 | step 10 |
| ✗ | ✗ | 62.7 | 62.9 | 61.3 |
| ✓ | ✗ | 62.7 | 65.0 | 64.9 |
| ✗ | ✓ | 62.7 | 65.7 | 65.6 |
| \rowcolor[HTML]EFEFEF ✓ | ✓ | 62.7 | 67.2 | 68.0 |
Signal scaling.
The signal scaling factor (Eq. (1)) controls the signal-to-noise ratio (SNR) of the denoising process. We study the influence of this facet in DiffTAD. As shown in Table 4, the scaling factor of 0.5 achieves the optimal performance. This means this setting is task-specific at large (e.g., the best choice is 2.0 for object detection [15]).
| mAP | ||||
| Scale | 0.3 | 0.5 | 0.7 | Avg |
| 0.1 | 70.5 | 67.5 | 57.2 | 66.6 |
| \rowcolor[HTML]EFEFEF 0.5 | 74.9 | 71.2 | \cellcolor[HTML]EFEFEF58.5 | 68.0 |
| 1.0 | 73.2 | 70.6 | 58.0 | 67.3 |
| 2.0 | 69.9 | 67.3 | 56.8 | 64.2 |
Accuracy vs. speed.
We evaluate the trade-off between the accuracy and memory cost with DiffTAD. In this test, we experiment with three choices in the number of proposals. For each choice, the same is applied to both model training and evaluation consistently. We observe in Table 5 that: (1) Increasing the number of proposals/queries from 30 to 50 brings about 0.5% in mAP with extra 0.46 GFLOPs, thanks to the proposed selective conditioning. (2) However, further increasing the proposals is detrimental to the model performance. This is because the number of action instances per video is much fewer than that of objects per image on average. (3) With 50 proposals, increasing the sampling steps from 1 to 5 provides an mAP gain of with an additional cost of 1.9 GFLOPs. A similar observation is with the case of 100 proposals.
| mAP | ||||||
| Proposals | Step | 0.3 | 0.5 | 0.7 | Avg | GFLOPs |
| \cellcolor[HTML]EFEFEF30 | \cellcolor[HTML]EFEFEF5 | \cellcolor[HTML]EFEFEF74.9 | \cellcolor[HTML]EFEFEF71.2 | \cellcolor[HTML]EFEFEF58.5 | \cellcolor[HTML]EFEFEF68.0 | \cellcolor[HTML]EFEFEF0.81 |
| 50 | 1 | 69.2 | 65.2 | 53.0 | 64.9 | 1.27 |
| 50 | 5 | 77.2 | 73.5 | 59.1 | 68.5 | 3.17 |
| 100 | 1 | 70.4 | 66.1 | 53.8 | 65.1 | 2.18 |
| 100 | 5 | 77.1 | 73.8 | 58.7 | 68.4 | 6.32 |
Decoupled diffusion strategy.
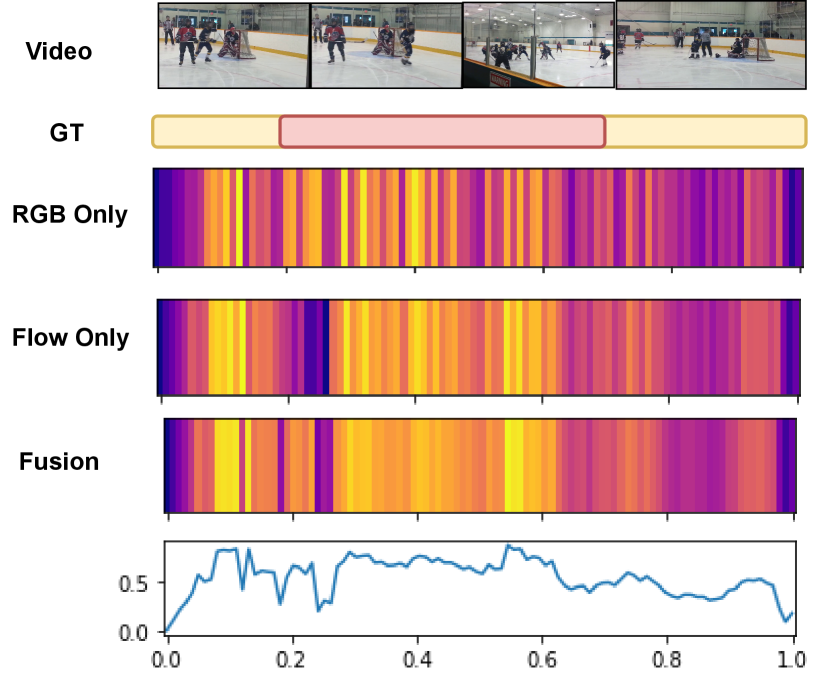
We evaluate the impact of feature decoupling (video encoder in Sec. 3.2). Typically, existing TAD methods [87, 41] use fused RGB and optical flow video features (i.e., early fusion). However, we take a late fusion strategy where the RGB and flow features are processed separately before their proposals are fused (Fig. 3). We contrast the two fusion strategies. It is evident in Table 6 that with the typical early fusion (i.e., passing early fused features as a condition to our detection decoder), a drop of in average mAP is resulted. This indicates that due to modal specificity there is a need for specific conditional inference, validating our design consideration. For visual understanding, an example is given in Fig. 7 to show how the two features can contribute to TAD in a cooperative manner.
| Decoupling | 0.5 | 0.75 | 0.95 | Avg |
| ✗ | 71.8 | 67.4 | 57.1 | 66.0 |
| \rowcolor[HTML]C0C0C0 ✓ | 74.9 | 71.2 | 58.5 | 68.0 |
NMS-free design.
As shown in Table 7, when comparing DiffTAD with and without non-maximum suppression (NMS), we observe similar results. NMS is not necessary in DiffTAD because the predictions are relatively sparse and minor overlapped with our cross-step conditional strategy (Sec. 3.2). In contrast, existing non-generative TAD works like BMN [41] and GTAD [87] generate highly overlapped proposals with similar confidence. Thus, NMS becomes necessary to suppress redundant proposals.
Ablation of denoising strategy.
Due to the inherent query based design with the detection decoder, (1) we can corrupt discrete action proposals and project them as queries, and (2) we can also corrupt the action label and project it as label queries. Both can be taken as the input to the decoder. For corrupting the label queries, we use random shuffle as the noise in the forward diffusion step. To validate this design choice experimentally, we test three variants: (1) only labels are corrupted, (2) only proposals are corrupted, and (3) both proposals and labels are corrupted. For the non-corrupted quantity, we add noise to the randomly initialized embedding. For the last variant, we stack all the corrupted proposals and labels and pass them into the decoder. It can be observed in Table 4.3 that corrupting labels alone observes the most drop in performance, and corrupting both labels and proposals is inferior to only corrupting the proposals.
| Denoising Strategy | mAP | ||||||
| Proposal | Label | 0.3 | 0.5 | 0.7 | Avg | ||
| ✗ | ✓ | 70.1 | 65.9 | 52.7 | 62.4 | ||
| \rowcolor[HTML]EFEFEF \cellcolor[HTML]EFEFEF✓ | ✗ | 74.9 | 71.2 | \cellcolor[HTML]EFEFEF58.5 | 68.0 | ||
| ✓ | ✓ | 73.8 | 70.4 | 58.0 | 67.3 | ||

5 Visualization of proposal denoising
We visualize our sampling step of DiffTAD in Fig 8. The model is initialized with 30 proposals for better visualization. This experiment is performed on a random testing video from ActivityNet dataset.
(a) Initial action proposals are randomly sampled from the Gaussian distribution () and then projected as queries into the detection decoder .
(b) The detection decoder predicts the action proposals (start/end point) along with the action class. The noise is calculated and then the action proposals are denoised using DDIM based denoising diffusion strategy.
(c) Our proposed cross-step selection strategy estimates the best candidate proposals based on the denoised reference proposal from the last step. The proposals with low temporal overlap with the reference proposals are dropped from the denoising step thus accelerating the inference.
(d) After multiple steps of refinement, final denoised action proposal predictions are obtained.
6 Conclusion
In this work, we propose a novel temporal action detection (TAD) paradigm, DiffTAD, by considering it as a denoising diffusion process from noisy proposals to action proposals. This proposed generative model is conceptually distinctive from all previous TAD methods based on discriminative learning. Our model is designed by properly tailoring the diffusion and denoising process in a single-stage DETR framework, with appealing properties such as more stable convergence, flexible proposal sizes, and superior proposal refinement. Experiments on standard benchmarks show that DiffTAD achieves favorable performance compared to both generative and non-generative alternatives.
References
- [1] Humam Alwassel, Silvio Giancola, and Bernard Ghanem. Tsp: Temporally-sensitive pretraining of video encoders for localization tasks. arXiv, 2020.
- [2] Tomer Amit, Eliya Nachmani, Tal Shaharbany, and Lior Wolf. Segdiff: Image segmentation with diffusion probabilistic models. arXiv preprint arXiv:2112.00390, 2021.
- [3] Namrata Anand and Tudor Achim. Protein structure and sequence generation with equivariant denoising diffusion probabilistic models. arXiv preprint arXiv:2205.15019, 2022.
- [4] Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. Advances in Neural Information Processing Systems, 34:17981–17993, 2021.
- [5] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- [6] Dmitry Baranchuk, Andrey Voynov, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Label-efficient semantic segmentation with diffusion models. In International Conference on Learning Representations, 2022.
- [7] Emmanuel Asiedu Brempong, Simon Kornblith, Ting Chen, Niki Parmar, Matthias Minderer, and Mohammad Norouzi. Denoising pretraining for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4175–4186, 2022.
- [8] Shyamal Buch, Victor Escorcia, Chuanqi Shen, Bernard Ghanem, and Juan Carlos Niebles. Sst: Single-stream temporal action proposals. In CVPR, 2017.
- [9] Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In CVPR, pages 961–970, 2015.
- [10] Hanqun Cao, Cheng Tan, Zhangyang Gao, Guangyong Chen, Pheng-Ann Heng, and Stan Z Li. A survey on generative diffusion model. arXiv preprint arXiv:2209.02646, 2022.
- [11] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, pages 213–229. Springer, 2020.
- [12] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- [13] Yu-Wei Chao, Sudheendra Vijayanarasimhan, Bryan Seybold, David A Ross, Jia Deng, and Rahul Sukthankar. Rethinking the faster r-cnn architecture for temporal action localization. In CVPR, 2018.
- [14] Jiaqi Chen, Jiachen Lu, Xiatian Zhu, and Li Zhang. Generative semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2023.
- [15] Shoufa Chen, Peize Sun, Yibing Song, and Ping Luo. Diffusiondet: Diffusion model for object detection. arXiv preprint arXiv:2211.09788, 2022.
- [16] Ting Chen, Lala Li, Saurabh Saxena, Geoffrey Hinton, and David J Fleet. A generalist framework for panoptic segmentation of images and videos. arXiv preprint arXiv:2210.06366, 2022.
- [17] Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning. arXiv preprint arXiv:2208.04202, 2022.
- [18] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- [19] Yuming Du, Wen Guo, Yang Xiao, and Vincent Lepetit. 1st place solution for the uvo challenge on image-based open-world segmentation 2021. arXiv preprint arXiv:2110.10239, 2021.
- [20] Wanshu Fan, Yen-Chun Chen, Dongdong Chen, Yu Cheng, Lu Yuan, and Yu-Chiang Frank Wang. Frido: Feature pyramid diffusion for complex scene image synthesis. ArXiv, abs/2208.13753, 2022.
- [21] Jiyang Gao, Zhenheng Yang, Kan Chen, Chen Sun, and Ram Nevatia. Turn tap: Temporal unit regression network for temporal action proposals. In ICCV, 2017.
- [22] Zheng Ge, Songtao Liu, Zeming Li, Osamu Yoshie, and Jian Sun. Ota: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 303–312, 2021.
- [23] Z Ge, S Liu, F Wang, Z Li, and J Sun. Yolox: Exceeding yolo series in 2021. arxiv. arXiv preprint arXiv:2107.08430, 2021.
- [24] Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Sequence to sequence text generation with diffusion models. arXiv preprint arXiv:2210.08933, 2022.
- [25] Alexandros Graikos, Nikolay Malkin, Nebojsa Jojic, and Dimitris Samaras. Diffusion models as plug-and-play priors. arXiv preprint arXiv:2206.09012, 2022.
- [26] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10696–10706, 2022.
- [27] William Harvey, Saeid Naderiparizi, Vaden Masrani, Christian Weilbach, and Frank Wood. Flexible diffusion modeling of long videos. arXiv preprint arXiv:2205.11495, 2022.
- [28] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- [29] Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. arXiv preprint arXiv:2204.03458, 2022.
- [30] Emiel Hoogeboom, Victor Garcia Satorras, Clement Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. arXiv e-prints, pages arXiv–2203, 2022.
- [31] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. Prodiff: Progressive fast diffusion model for high-quality text-to-speech. arXiv preprint arXiv:2207.06389, 2022.
- [32] Haroon Idrees, Amir R Zamir, Yu-Gang Jiang, Alex Gorban, Ivan Laptev, Rahul Sukthankar, and Mubarak Shah. The thumos challenge on action recognition for videos “in the wild”. Computer Vision and Image Understanding, 155:1–23, 2017.
- [33] Bowen Jing, Gabriele Corso, Regina Barzilay, and Tommi S Jaakkola. Torsional diffusion for molecular conformer generation. In ICLR2022 Machine Learning for Drug Discovery, 2022.
- [34] Boah Kim, Yujin Oh, and Jong Chul Ye. Diffusion adversarial representation learning for self-supervised vessel segmentation. arXiv preprint arXiv:2209.14566, 2022.
- [35] Sungwon Kim, Heeseung Kim, and Sungroh Yoon. Guided-tts 2: A diffusion model for high-quality adaptive text-to-speech with untranscribed data. arXiv preprint arXiv:2205.15370, 2022.
- [36] Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Dollár. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9404–9413, 2019.
- [37] Alon Levkovitch, Eliya Nachmani, and Lior Wolf. Zero-shot voice conditioning for denoising diffusion tts models. arXiv preprint arXiv:2206.02246, 2022.
- [38] Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13619–13627, 2022.
- [39] Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B Hashimoto. Diffusion-lm improves controllable text generation. arXiv preprint arXiv:2205.14217, 2022.
- [40] Matthieu Lin, Chuming Li, Xingyuan Bu, Ming Sun, Chen Lin, Junjie Yan, Wanli Ouyang, and Zhidong Deng. Detr for crowd pedestrian detection, 2021.
- [41] Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, and Shilei Wen. Bmn: Boundary-matching network for temporal action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3889–3898, 2019.
- [42] Tianwei Lin, Xu Zhao, Haisheng Su, Chongjing Wang, and Ming Yang. BSN: Boundary sensitive network for temporal action proposal generation. In ECCV, 2018.
- [43] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- [44] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv preprint arXiv:2201.12329, 2022.
- [45] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. In International Conference on Learning Representations, 2022.
- [46] Xiaolong Liu, Yao Hu, Song Bai, Fei Ding, Xiang Bai, and Philip HS Torr. Multi-shot temporal event localization: a benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12596–12606, 2021.
- [47] Fuchen Long, Ting Yao, Zhaofan Qiu, Xinmei Tian, Jiebo Luo, and Tao Mei. Gaussian temporal awareness networks for action localization. In CVPR, 2019.
- [48] Sauradip Nag, Xiatian Zhu, Yi-zhe Song, and Tao Xiang. Proposal-free temporal action detection via global segmentation mask learning. In ECCV, 2022.
- [49] Sauradip Nag, Xiatian Zhu, and Tao Xiang. Few-shot temporal action localization with query adaptive transformer. arXiv preprint arXiv:2110.10552, 2021.
- [50] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- [51] Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 16784–16804. PMLR, 17–23 Jul 2022.
- [52] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. Grad-tts: A diffusion probabilistic model for text-to-speech. In ICML, 2021.
- [53] Zhiwu Qing, Haisheng Su, Weihao Gan, Dongliang Wang, Wei Wu, Xiang Wang, Yu Qiao, Junjie Yan, Changxin Gao, and Nong Sang. Temporal context aggregation network for temporal action proposal refinement. In CVPR, pages 485–494, 2021.
- [54] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. ArXiv, abs/2204.06125, 2022.
- [55] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: towards real-time object detection with region proposal networks. TPAMI, 39(6):1137–1149, 2016.
- [56] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell., 39(6):1137–1149, 2017.
- [57] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. ArXiv, abs/2208.12242, 2022.
- [58] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022.
- [59] Arne Schneuing, Yuanqi Du, Charles Harris, Arian Jamasb, Ilia Igashov, Weitao Du, Tom Blundell, Pietro Lió, Carla Gomes, Max Welling, Michael Bronstein, and Bruno Correia. Structure-based drug design with equivariant diffusion models. arXiv preprint arXiv:2210.13695, 2022.
- [60] Dingfeng Shi, Yujie Zhong, Qiong Cao, Jing Zhang, Lin Ma, Jia Li, and Dacheng Tao. React: Temporal action detection with relational queries. In European conference on computer vision, 2022.
- [61] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792, 2022.
- [62] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- [63] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- [64] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in Neural Information Processing Systems, 32, 2019.
- [65] Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. Advances in neural information processing systems, 33:12438–12448, 2020.
- [66] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021.
- [67] Deepak Sridhar, Niamul Quader, Srikanth Muralidharan, Yaoxin Li, Peng Dai, and Juwei Lu. Class semantics-based attention for action detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13739–13748, 2021.
- [68] Haisheng Su, Weihao Gan, Wei Wu, Yu Qiao, and Junjie Yan. Bsn++: Complementary boundary regressor with scale-balanced relation modeling for temporal action proposal generation. arXiv preprint arXiv:2009.07641, 2020.
- [69] Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14454–14463, 2021.
- [70] Jaesung Tae, Hyeongju Kim, and Taesu Kim. Editts: Score-based editing for controllable text-to-speech. arXiv preprint arXiv:2110.02584, 2021.
- [71] Jing Tan, Jiaqi Tang, Limin Wang, and Gangshan Wu. Relaxed transformer decoders for direct action proposal generation. In ICCV, 2021.
- [72] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9627–9636, 2019.
- [73] Brian L Trippe, Jason Yim, Doug Tischer, Tamara Broderick, David Baker, Regina Barzilay, and Tommi Jaakkola. Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem. arXiv preprint arXiv:2206.04119, 2022.
- [74] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [75] Lining Wang, Haosen Yang, Wenhao Wu, Hongxun Yao, and Hujie Huang. Temporal action proposal generation with transformers. arXiv preprint arXiv:2105.12043, 2021.
- [76] Qiang Wang, Yanhao Zhang, Yun Zheng, and Pan Pan. Rcl: Recurrent continuous localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13566–13575, 2022.
- [77] Xinlong Wang, Tao Kong, Chunhua Shen, Yuning Jiang, and Lei Li. Solo: Segmenting objects by locations. In ECCV, 2020.
- [78] Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun. Anchor detr: Query design for transformer-based object detection. arXiv preprint arXiv:2109.07107, 3(6), 2021.
- [79] Julia Wolleb, Robin Sandkühler, Florentin Bieder, Philippe Valmaggia, and Philippe C Cattin. Diffusion models for implicit image segmentation ensembles. arXiv preprint arXiv:2112.03145, 2021.
- [80] Junfeng Wu, Qihao Liu, Yi Jiang, Song Bai, Alan Yuille, and Xiang Bai. In defense of online models for video instance segmentation. arXiv preprint arXiv:2207.10661, 2022.
- [81] Lemeng Wu, Chengyue Gong, Xingchao Liu, Mao Ye, and Qiang Liu. Diffusion-based molecule generation with informative prior bridges. arXiv preprint arXiv:2209.00865, 2022.
- [82] Shoule Wu and Ziqiang Shi. Itôtts and itôwave: Linear stochastic differential equation is all you need for audio generation. arXiv e-prints, pages arXiv–2105, 2021.
- [83] Huijuan Xu, Abir Das, and Kate Saenko. R-c3d: Region convolutional 3d network for temporal activity detection. In ICCV, 2017.
- [84] Mengmeng Xu, Juan-Manuel Pérez-Rúa, Victor Escorcia, Brais Martinez, Xiatian Zhu, Li Zhang, Bernard Ghanem, and Tao Xiang. Boundary-sensitive pre-training for temporal localization in videos. In ICCV, pages 7220–7230, 2021.
- [85] Mengmeng Xu, Juan-Manuel Perez-Rua, Xiatian Zhu, Bernard Ghanem, and Brais Martinez. Low-fidelity end-to-end video encoder pre-training for temporal action localization. In NeurIPS, 2021.
- [86] Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. Geodiff: A geometric diffusion model for molecular conformation generation. In International Conference on Learning Representations, 2021.
- [87] Mengmeng Xu, Chen Zhao, David S Rojas, Ali Thabet, and Bernard Ghanem. G-tad: Sub-graph localization for temporal action detection. In CVPR, 2020.
- [88] Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete diffusion model for text-to-sound generation. arXiv preprint arXiv:2207.09983, 2022.
- [89] Ruihan Yang, Prakhar Srivastava, and Stephan Mandt. Diffusion probabilistic modeling for video generation. arXiv preprint arXiv:2203.09481, 2022.
- [90] Chen-Lin Zhang, Jianxin Wu, and Yin Li. Actionformer: Localizing moments of actions with transformers. In European Conference on Computer Vision, pages 492–510. Springer, 2022.
- [91] Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondiffuse: Text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001, 2022.
- [92] Chen Zhao, Ali K Thabet, and Bernard Ghanem. Video self-stitching graph network for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13658–13667, 2021.
- [93] Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xiaoou Tang, and Dahua Lin. Temporal action detection with structured segment networks. In ICCV, 2017.
- [94] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable {detr}: Deformable transformers for end-to-end object detection. In International Conference on Learning Representations, 2021.
- [95] Zixin Zhu, Wei Tang, Le Wang, Nanning Zheng, and Gang Hua. Enriching local and global contexts for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13516–13525, 2021.