Diffusion-model approach to flavor models: A case study for modular flavor model
Abstract
We propose a numerical method of searching for parameters with experimental constraints in generic flavor models by utilizing diffusion models, which are classified as a type of generative artificial intelligence (generative AI). As a specific example, we consider the modular flavor model and construct a neural network that reproduces quark masses, the CKM matrix, and the Jarlskog invariant by treating free parameters in the flavor model as generating targets. By generating new parameters with the trained network, we find various phenomenologically interesting parameter regions where an analytical evaluation of the model is challenging. Additionally, we confirm that the spontaneous CP violation occurs in the model. The diffusion model enables an inverse problem approach, allowing the machine to provide a series of plausible model parameters from given experimental data. Moreover, it can serve as a versatile analytical tool for extracting new physical predictions from flavor models.
1 Introduction
There are many approaches to elucidate the flavor structure of quarks and leptons. Among them, the flavor symmetry was utilized in understanding the peculiar patterns of fermion masses and mixings through both bottom-up and top-down approaches. A prototypical example of continuous symmetries is a flavor symmetric model using the Froggatt-Nielsen (FN) mechanism Froggatt:1978nt , and non-Abelian discrete symmetries were also broadly employed (see for reviews, Refs. Altarelli:2010gt ; Ishimori:2010au ; Hernandez:2012ra ; King:2013eh ; King:2014nza ; Petcov:2017ggy ; Kobayashi:2022moq ). When Yukawa couplings transform under the modular symmetry, it belongs to a class of modular flavor symmetric models Feruglio:2017spp (see for reviews, Refs. Kobayashi:2023zzc ; Ding:2023htn ).
In most of models with flavor symmetries, there exist free parameters that are not controlled under the flavor symmetries. Although the flavor structure of fermions can be controlled by flavor symmetries, a realization of realistic flavor structure requires a breaking of the symmetries by a vacuum expectation value (VEV) of a scalar field (so-called flavon field), charged under the flavor symmetries. Since the VEV will also be determined by free parameters of the model, these parameters play an important role in evaluating fermion masses and mixing angles quantitatively. So far, we have often adopted a certain optimization method, such as the Monte-Carlo simulation, to address the flavor structure of quarks and leptons. When we search model parameters using the traditional optimization methods, obtained results are sensitive to the initial values of the model parameters, indicating that it will be difficult to find out realistic flavor patterns from a broad theoretical landscape in a short time.
To achieve highly efficient learning, a machine learning approach is essential. For instance, reinforcement learning was used to address the flavor structure of quarks and leptons in the Froggatt-Nielsen model Harvey:2021oue ; Nishimura:2023nre ; Nishimura:2024apb . Recently, a diffusion model known as one of generative artificial intelligence (generative AI), was utilized to explore the unknown flavor structure of neutrinos in the context of the Standard Model with three right-handed neutrinos Nishimura:2025rsk . In particular, the conditional diffusion model was employed to search for model parameters. Although the diffusion model was often applied in generating images where the data of various paintings is collected as input data with a certain associated information , Ref. Nishimura:2025rsk proposed that the input data corresponds to a set of model parameters and the label is specified as neutrino masses and mixing angles. Then, the conditional diffusion model successfully reproduces the neutrino mass-squared differences and mixing angles with current experimental constraints, and exhibits non-trivial distributions of the leptonic CP phases and the sums of neutrino masses.
In this paper, we provide a framework for applying the conditional diffusion model to flavor models, where the input data corresponds to model parameters and is specified as physical observables such as fermion masses and mixing angles. By randomly preparing the model parameters, the diffusion model learns to predict noise in a diffusion process and generates new data in an inverse process in the context of the conditional label . As a concrete example, we analyze a specific flavor model, i.e., modular flavor model, to address the flavor structure of quarks. Since the flavor structure of quarks is highly dependent on the value of the symmetry breaking field (modulus ), the usual optimization methods are much more sensitive to initial values in numerical simulations. Hence, a limited region in the parameter space has been explored in e.g., Refs. Novichkov:2020eep ; Abe:2023qmr . By applying the conditional diffusion model to model parameters in the modular flavor model, it turns out that a semi-realistic flavor structure of quarks can be realized at a certain value of the modulus in a short time. Note that the obtained parameter region is different from that in the previous literatures. Furthermore, the CP symmetry will be spontaneously broken by the modulus . Therefore, our proposed diffusion-model approach will be regarded as an alternative numerical method to address the flavor structure of quarks.
This paper is organized as follows. The conditional diffusion model is introduced for flavor models in Sec. 2, and Sec. 3 presents the modular flavor model as a practical application. In that section, we describe the modular symmetry in Sec. 3.1. Based on this symmetry, the quark sector of the modular flavor model is organized in Sec. 3.2, and we construct a concrete diffusion model in Sec. 3.3. We discuss the results generated by the diffusion model in Sec. 4. Finally, Sec. 5 is devoted to the conclusion and future prospects.
2 Diffusion models for flavor physics
In this section, we provide a brief introduction to denoising diffusion probabilistic models (DDPMs) Ho:2020epu with classifier-free guidance (CFG) ho:2022cla . They provide an intuitive definition of conditional diffusion models. For further details regarding the formulation of DDPMs and CFG, see the Appendices of Ref. Nishimura:2025rsk .
The diffusion model consists of two stages: (i) the diffusion process and (ii) the inverse process. In the diffusion process, noise is added to the input data and a machine learns to predict the added noise. In the inverse process, noise is gradually removed from a pure noise to generate meaningful data. In the context of flavor models, let us denote as free parameters in flavor models and as a conditional label specifying physical observables such as masses and mixings. For instance, the lepton sector was analyzed by incorporating the Yukawa couplings into and the neutrino masses and the PMNS matrix into in Ref. Nishimura:2025rsk . In this study, we aim to apply this method to the quark sector.
Based on an initial input data , a series of new data is defined as Markov process that adds noise to the input :
| (2.1) | ||||
| (2.2) |
with . Here, a conditional probability denotes the probability of given the condition . In addition, is a normal distribution with a random variable , an average , and a variance . We will omit for brevity. is defined as , and the parameters decide the variance of . By the definition of and , the series of data close to pure noise that follows a standard normal distribution along with . Based on this property, and are referred to as noise schedules.
For practical purposes, the noised data at any given time is determined as
| (2.3) | ||||
| (2.4) |
with . Here, is a noise obeying a standard normal distribution . Among the various ways to choose , we adopt a linear schedule:
| (2.5) |
We adopt , , and .
Then, in the reverse process, pure noise from is prepared as initial data, and based on is sampled in sequence according to the following Markov process:
| (2.6) | ||||
| (2.7) |
The conditional probability at each step is estimated using a neural network, which is explained later, and characterized by parameters . In practice, sampling from corresponds to determining as follows:
| (2.8) | |||
| (2.9) |
where is a conditional label and is a disturbance following . In addition, the coefficient , which is called the CFG scale, satisfies the condition . A larger CFG scale means that the data are more faithful to the label , but the diversity of generated results tends to be lost. On the other hand, when , it emphasizes the diversity. is adopted in this study.
The predicted noise is determined by a linear combination of the unlabeled noise and the labeled noise. In contrast to the expression of Eq. (2.9), just one mathematical model is required by considering . For practical training, is adopted with a low probability (10-20%), and the learning of CFG proceeds with mixing the cases with and without labels. For , a learned embedding vector or a zero vector is often used. In this study, we dropped out the labels in 10% of the cases, and 0 is used as in our study.
To predict the added noise, we utilize a neural network model in which a -th layer with dimensional vector transforms into a dimensional vector by following relation:
| (2.10) |
where respectively denote the activation function, the weight and the bias. In general, the neural network realizes multiple nonlinear transformations through . In our architecture, a fully-connected network is adopted, and the network is trained by minimizing the mean squared error (MSE) loss representing the difference between the actual added noise and the predicted noise , as shown in Fig. 1. In the end, a well-trained network can accurately estimate the noise component in .
When we complete training a neural network once using initial data, the inverse process with that network can provide various new data including free parameters in flavor models. If the network does not reach the desired level of accuracy, many types of strategies are possible to tackle this problem. To enhance learning efficiency and accuracy, transfer learning is often applied by reusing a neural network that has already been learned. In a more narrowly defined method called fine-tuning, the parameters of the learned neural network are used as the initial values of a new neural network, and all parameters are updated based on other training data. This study also implements this method and evaluates its effectiveness. The details of transfer learning and fine-tuning are provided in Ref. Nishimura:2025rsk .

3 modular flavor model as a case study
In this section, we apply the conditional diffusion model to a particular flavor model, namely the modular flavor model. By introducing the modular symmetry in Sec. 3.1, we present the modular flavor model in Sec. 3.2. The formulation of the conditional diffusion model is discussed in Sec. 3.3.
3.1 Modular symmetry
In this section, we review the modular symmetry and introduce the modular flavor model. A principal congruence subgroup of is defined as follows:
| (3.1) |
This group acts on the complex variable called modulus () in the following way:
| (3.2) |
with . In addition, is generated by the three generators:
| (3.3) |
These generators satisfy the following algebraic relations:
| (3.4) |
Using the definition of , various finite modular groups are defined as follows:
| (3.5) | ||||
| (3.6) | ||||
| (3.7) |
Note that with are isomorphic to , respectively. Similarly, with are isomorphic to , which are double covering groups of , respectively. In these groups, the generator satisfies , so it generates a symmetry.
In this paper, we focus on , having ten irreducible representations:
| (3.8) |
The non-hatted and hatted representations respectively transform under trivially and non-trivially. In other words, and are satisfied for any representation and . In this work, we choose representation matrices in which is diagonal and is real. For the doublet and the triplet , the representation matrices is chosen as follows Novichkov:2020eep :
| (3.9) | ||||
| (3.10) |
Then, the primed/hatted representations obey following relations for any representation and :
| (3.11) | ||||
| (3.12) | ||||
| (3.13) |
In the upper half-plane in the complex plane of , a modular form of representation with a weight is defined as a holomorphic function which transforms in the following rule under the modular symmetry:
| (3.14) |
with a representation matrix . In addition, a matter field is assumed to obey the same rule as follows:
| (3.15) |
with representation and weight .
To present an explicit expression of the modular form under the modular symmetry, let us introduce the Dedekind eta function :
| (3.16) |
Using this, two functions and are defined as follows:
| (3.17) | ||||
where we show their -expansions with . Under the modular symmetry, there is a representation with , which is referred to in Ref. Novichkov:2020eep :
| (3.18) |
Modular forms with higher weight are calculated by tensor products given in Ref. Novichkov:2020eep . In the following, we list relevant modular forms utilized in this work:
| (3.19) | ||||
3.2 Quark sector
Then, we consider a specific example of modular flavor model with an emphasis on the quark sector. Following Ref. Abe:2023qmr , we suppose that is a triplet representation of , are trivial singlets of , and are the non-trivial singlets of , i.e.,
| (3.20) |
In addition, Higgs doublets and are considered trivial singlets . These assignments are summarized in Table 1. In the previous study, it was investigated that the CKM matrix has diagonal textures by this configuration.
| Weight | 0 | 0 |
|---|
Under this setup, the superpotential in the quark sector is given by
| (3.21) |
In each term, is a trivial singlet among the results of the tensor product in the parentheses. The products of the triplet representations are given by
| (3.22) | ||||
| (3.23) |
Then, mass terms of the up-type quarks are derived as follows:
| (3.24) |
i.e.,
| (3.25) |
In the same way, mass terms of the down-type quarks are derived as follows:
| (3.26) |
i.e.,
| (3.27) |
The Kähler potential of the chiral superfield is written as follows:
| (3.28) |
where is a weight of the superfield. Thus, each component of the mass matrices is modified by the canonical normalization as
| (3.29) |
with and .
The mass matrices are diagonalized by unitary matrices as follows:
| (3.30) | ||||
| (3.31) |
Moreover, the flavor mixing is defined as the difference between mass eigenstates and flavor eigenstates:
| (3.32) |
with and . Moreover, the Jarlskog invariant is defined as follows:
| (3.33) |
which is a measure of CP violation.
At and the SUSY breaking scale , we show values of masses and mixings in Table 2, which is calculated from Ref. Antusch:2013jca . In addition, from mixing angles in that data, absolute values of the CKM matrix is derived as follows:
| (3.37) |
From an analytical point of view, and when . This makes the hierarchical structure of mass matrices Eq. (3.25) and Eq. (3.27), so it is easy to realize semi-realistic flavor structure. It is non-trivial how small is allowed to reproduce the flavor structure, and was found as one of the optimal values in Ref. Abe:2023qmr .
3.3 Conditional diffusion model
In this section, we present the detailed design of the conditional diffusion model adopted for the modular flavor model as a case study. The diffusion process, the inverse process, and the transfer learning will be described in this order.
Diffusion process
We adopt . In preparing the initial data, we deal with the following values ***In our analysis, the modulus field (symmetry breaking field) is regarded as a parameter, but the VEV of will be determined by its stabilization mechanism proposed in e.g., Ishiguro:2020tmo ; Novichkov:2022wvg ; Ishiguro:2022pde .:
| (3.38) | ||||
| (3.39) |
with . For , we introduce trivial labels to represent and . These dummy labels allow the dimensions of to be matched to a number of independent physical quantities, which is beneficial for developing a generic architecture of the neural network. However, it remains uncertain whether these dummy labels enhance learning accuracy. The necessity of these dummy labels will be reported elsewhere. In addition, we avoid exponential differences in the input values to the neural network by applying the logarithm to the mass ratio and the Jarlskog invariant.
Now, has 10 components and has 16 components. Each element of was generated as uniform random numbers satisfying the following ranges:
| (3.40) | ||||
| (3.41) | ||||
| (3.42) |
Eq. (3.40) and Eq. (3.41) mean that the ratios of coefficients satisfy . In addition, data processing techniques such as normalization and standardization are important for achieving efficient learning of neural networks. In this respect, the ratio in the component of is divided by ten to realize the proper normalization .
Then, is computed from a randomly generated based on Eq. (3.25) and Eq. (3.27), and a neural network is trained using pairs of the input and the label . In actual learning process, we prepare pairs of as initial data. Of these data, 90% are used as training data and 10% as validation data. When the integer is randomly selected from , the noisy data is determined according to Eq. (2.4). When an input layer of the neural network receives as input, it performs nonlinear transformations according to Eq. (2.10).
The detailed architecture of our neural network is presented in Table 3. There are 646,836 parameters that are adjusted during training. The activation function in Eq. (2.10) is selected as the SELU function for hidden layers and an identity function for an output layer. The batch size is set to 64, and the parameter updates are performed times. In addition, we employ the ADAM optimizer in PyTorch to update the weight and bias described in Eq. (2.10). The learning rate is automatically adjusted using the scheduler “OneCycleLR” provided by PyTorch, and we adopted as the maximum rate.
| Layer | Dimension | Activation | Layer | Dimension | Activation |
|---|---|---|---|---|---|
| Input | - | Hidden 6 | SELU | ||
| Hidden 1 | SELU | Hidden 7 | SELU | ||
| Hidden 2 | SELU | Hidden 8 | SELU | ||
| Hidden 3 | SELU | Hidden 9 | SELU | ||
| Hidden 4 | SELU | Hidden 10 | SELU | ||
| Hidden 5 | SELU | Output | Identity |
Reverse process
In the reverse process, the generation is performed with labels that reflect real observables. In particular, is designated as follows based on Table 2 and Eq. (3.37):
| (3.43) | ||||
Then, is recalculated using the generated , and the data that falls within a specified error range is extracted. As a result, the data corresponding to the experimental values has been derived solely from the experimental label.
Transfer learning
After the diffusion model generates the data , the physical values corresponding to can be calculated. The accuracy of in comparison to the target experimental label is quantitatively evaluated by the value defined as follows:
| (3.44) |
where respectively denote prediction for physical observable, central value and deviations. In this work, the function is calculated for following 8 observables:
| (3.45) |
so the CP violation is considered in .
Now, we refer to the first neural network as a pre-network. The data generated by the pre-network are collected for transfer learning, and the pre-network is retrained based on this new data. All parameters of the pre-network are updated, which is why the second training phase is referred to as fine-tuning. In our training process, the hyperparameters during the second phase are the same as those used in the first phase. The second network constructed through fine-tuning is referred to as a tuned-network in the following discussion.
4 Results
Our calculations are performed using Google Colaboratory with a CPU (not a GPU), so this method accessible to everyone. The diffusion process takes approximately 1 hour, and the reverse process requires approximately 4.6 hours per generating data in a single session. First, we generate data using a pre-network. The total number of data generated by the network is , of which 103,663 satisfy the condition . Therefore, in the diffusion model without fine-tuning, the ratio of data satisfying condition is 2.59%. Second, we perform fine-tuning on the 103,663 data generated by the pre-network that satisfy condition . When we generate a total of data using the tuned-network, there are 17 solutions that satisfy the condition . Here, in the diffusion model with fine-tuning, the ratio of data satisfying condition is 5.95%. Finally, we extract 11 solutions such that the CP phase is positive.
Based on these results, the accuracy of the data has improved through fine-tuning. In other words, fine-tuning enables the diffusion model to reproduce experimental values with greater precision. Furthermore, since the architectures of both the pre-network and the tuned-network are identical, the enhancement in accuracy can be achieved simply by repeating the learning process. Consequently, this method of improvement can be applied irrespective of the specific details of the flavor model. It is also anticipated that fine-tuning can be repeated to achieve the desired level of accuracy.
To show the progress of the generation process, Fig. 2 presents three graphs depicting the distribution of modulus as the amount of generated data increases. We observed a growing number of candidates that reproduce the flavor structure of the quarks with . In fact, phenomenologically promising candidates of appear in various locations, particularly concentrated around . The values of the data corresponding to the solution with the lowest value are as follows:
| (4.1) | ||||
These parameters lead to the following observables within .
| (4.2) | ||||
As mentioned above, this study confirmed that the accuracy of the generated results can be enhanced by performing the transfer learning only once. In order to reproduce the experimental values with even greater precision, it may be beneficial not only to conduct transfer learning multiple times but also to combine conventional methods, such as the Monte-Carlo method, with the parameters proposed by the diffusion model. The superiority of either approach remains to be investigated, and a comparison of their effectiveness taking into account computational resources should be reserved for future research.
As described in Sec. 3.2, the flavor structure in the modular flavor model strongly depends on . When is large, it is easy to reproduce the semi-realistic flavor structure. On the other hand, in regions where is small, estimating the appropriate becomes challenging, as even a slight variation can lead to a significantly different flavor structure. As a result, analytic evaluation with small is a difficult issue. The diffusion model that we developed does not impose strict restrictions on the parameter regions to be explored and generates a variety of candidates across a broad search range. Because of this property, there is no need for human beings to adjust the search region of parameters. Under these circumstances, the fact that the solutions have smaller than those in previous studies indicates that the diffusion model can find out characteristics of flavor models that are difficult to capture using conventional methods.
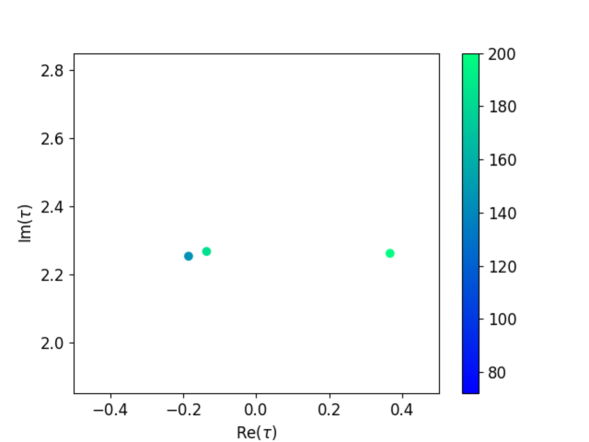
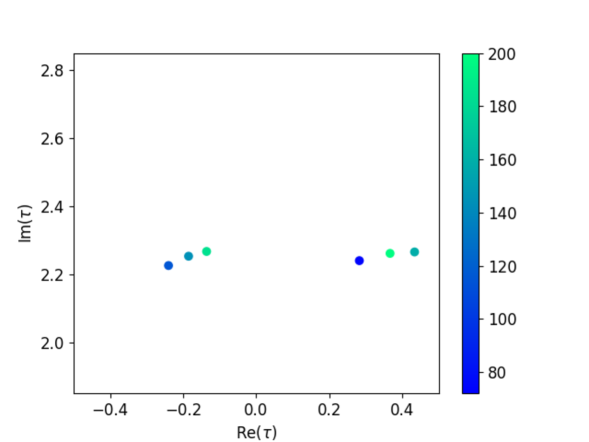
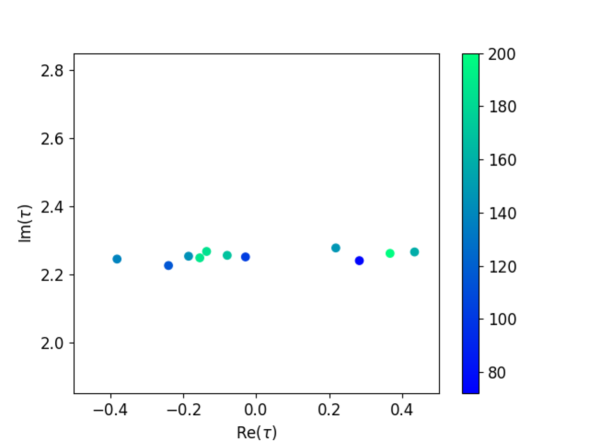
We now discuss the physical implications of the 11 results generated by the diffusion model. Table 4 summarizes the values of and the Jarlskog invariant for each result. In particular, the median value of the Jarlskog invariant is , which is comparable in magnitude to the experimental value . Various previous studies addressing the modular flavor models often introduce the coefficients as complex numbers to reproduce a Jarlskog invariant of reasonable size. In contrast, this study treats the parameters as real numbers, and the Jarlskog invariant is reproduced from only . Thus, the spontaneous CP violation can be realized in the modular flavor model. By broadly exploring the parameter space, the diffusion model can reveal new properties of the model that are difficult to discover through human experience alone.
5 Conclusions
In order to understand the flavor structure of elementary particles, it is important to deepen our understanding of flavor models. Specifically, if we can find parameters that not only reproduce known observables but also reveal undiscovered properties, we can analyze the underlying structure of flavor models. In this study, we focused on the modular flavor model as a specific application of the diffusion model, a type of generative AI, and searched free parameters that reproduce experimental results. Conventional numerical methods typically require optimization by repeating the process to find out the desirable experimental values around fixed parameters as in the Monte-Carlo method. In contrast to those traditional approaches, the diffusion model provides a framework that is independent of the specific details of flavor models. Furthermore, it enables an inverse problem approach in which the machine provides a series of plausible model parameters from given experimental data. The diffusion models can serve as a versatile analytical tool for extracting new physical predictions from flavor models.
In this paper, we constructed a diffusion model with CFG to analyze the flavor structure of the quarks in the modular flavor model. Sec. 2 introduced the diffusion models and transfer learning in order to apply it to some flavor models. In Sec. 3, the modular flavor model was used as a concrete example, and the diffusion model was applied to search for its free parameters. Following a brief review of the modular symmetry in Sec. 3.1, we organized the description of the quark sector of the model in Sec. 3.2. Specific representations and weights are selected based on the previous study to reproduce the semi-realistic flavor structure, so observables can be calculated by determining the free parameters. To optimize these parameters, the setup of our diffusion model is introduced in Sec. 3.3, and physical implications derived from the data obtained by the diffusion model are discussed in Sec. 4.
Specifically, we confirmed that the accuracy of the data generated by the diffusion model is indeed improved through the transfer learning, and exhibited how various parameter solutions are found as the number of data is increased. The generated results indicated that was concentrated in a smaller region than in the previous study. Furthermore, it was found that the spontaneous CP violation appeared in the modular flavor model from . These findings demonstrate that the diffusion model can find semi-realistic parameters via experimental observables. In conclusion, the diffusion model has significant potential for analyzing flavor models independently of the specific details of the models.
Before closing our paper, we will mention possible future works:
-
•
Although our analysis considers only the quark sector, the lepton sector can also be analyzed by the same procedure. Even within a framework that addresses both quarks and leptons simultaneously, there is no significant difference except that the inputs and outputs of the neural network have approximately double the dimensions. Due to this characteristic, a search for free parameters in other modular flavor models can also be anticipated as a direct extension.
-
•
The representation and modular weights of the fields used in this study were determined from an analytical perspective to achieve semi-realistic flavor structure and were fixed at specific values. In the future, the application of machine learning could automate the selection of the expressions and weights themselves. In fact, reinforcement learning, which is a type of machine learning, was utilized to search for charges to assign to the fields in Refs. Harvey:2021oue ; Nishimura:2023nre ; Nishimura:2024apb . By combining such techniques with diffusion models, it is possible to find out predictions of flavor models that have not been identified in previous empirical studies.
-
•
In light of the two aforementioned prospects, it is expected that various flavor models will be exhaustively explored by parameter searches based on the diffusion models, and one can compare the predictions of each model. While this study involves 10 free parameters, an increase in the number of parameters is inevitable during dealing with many flavor models simultaneously. On the other hand, state-of-the-art generative AIs can effectively manage vast parameter spaces, such as a pixel image of high quality†††One of these technologies is SDXL by Stability AI Podell:2023sdxl , which is improved version of Stable Diffusion.. These technologies utilize large neural networks of course, but they also incorporate various efforts such as Variational Autoencoders (VAEs) and Transformers, which are also applied in particle physics. By perceiving the set of free parameters as an image, a wide range of applications of the diffusion models in flavor physics becomes feasible.
Acknowledgements.
This work was supported in part by Kyushu University’s Innovator Fellowship Program (S. N.), JSPS KAKENHI Grant Numbers JP23H04512 (H.O).References
- (1) C.D. Froggatt and H.B. Nielsen, Hierarchy of Quark Masses, Cabibbo Angles and CP Violation, Nucl. Phys. B 147 (1979) 277.
- (2) G. Altarelli and F. Feruglio, Discrete Flavor Symmetries and Models of Neutrino Mixing, Rev. Mod. Phys. 82 (2010) 2701 [1002.0211].
- (3) H. Ishimori, T. Kobayashi, H. Ohki, Y. Shimizu, H. Okada and M. Tanimoto, Non-Abelian Discrete Symmetries in Particle Physics, Prog. Theor. Phys. Suppl. 183 (2010) 1 [1003.3552].
- (4) D. Hernandez and A.Y. Smirnov, Lepton mixing and discrete symmetries, Phys. Rev. D 86 (2012) 053014 [1204.0445].
- (5) S.F. King and C. Luhn, Neutrino Mass and Mixing with Discrete Symmetry, Rept. Prog. Phys. 76 (2013) 056201 [1301.1340].
- (6) S.F. King, A. Merle, S. Morisi, Y. Shimizu and M. Tanimoto, Neutrino Mass and Mixing: from Theory to Experiment, New J. Phys. 16 (2014) 045018 [1402.4271].
- (7) S.T. Petcov, Discrete Flavour Symmetries, Neutrino Mixing and Leptonic CP Violation, Eur. Phys. J. C 78 (2018) 709 [1711.10806].
- (8) T. Kobayashi, H. Ohki, H. Okada, Y. Shimizu and M. Tanimoto, An Introduction to Non-Abelian Discrete Symmetries for Particle Physicists (1, 2022), 10.1007/978-3-662-64679-3.
- (9) F. Feruglio, Are neutrino masses modular forms?, in From My Vast Repertoire …: Guido Altarelli’s Legacy, A. Levy, S. Forte and G. Ridolfi, eds., pp. 227–266 (2019), DOI [1706.08749].
- (10) T. Kobayashi and M. Tanimoto, Modular flavor symmetric models, 7, 2023 [2307.03384].
- (11) G.-J. Ding and S.F. King, Neutrino mass and mixing with modular symmetry, Rept. Prog. Phys. 87 (2024) 084201 [2311.09282].
- (12) T.R. Harvey and A. Lukas, Quark Mass Models and Reinforcement Learning, JHEP 08 (2021) 161 [2103.04759].
- (13) S. Nishimura, C. Miyao and H. Otsuka, Exploring the flavor structure of quarks and leptons with reinforcement learning, JHEP 12 (2023) 021 [2304.14176].
- (14) S. Nishimura, C. Miyao and H. Otsuka, Reinforcement learning-based statistical search strategy for an axion model from flavor, 2409.10023.
- (15) S. Nishimura, H. Otsuka and H. Uchiyama, Exploring the flavor structure of leptons via diffusion models, 2503.21432.
- (16) P.P. Novichkov, J.T. Penedo and S.T. Petcov, Double cover of modular for flavour model building, Nucl. Phys. B 963 (2021) 115301 [2006.03058].
- (17) Y. Abe, T. Higaki, J. Kawamura and T. Kobayashi, Quark and lepton hierarchies from S4’ modular flavor symmetry, Phys. Lett. B 842 (2023) 137977 [2302.11183].
- (18) J. Ho, A. Jain and P. Abbeel, Denoising Diffusion Probabilistic Models, 2006.11239.
- (19) J. Ho and T. Salimans, Classifier-free diffusion guidance, 2207.12598.
- (20) S. Antusch and V. Maurer, Running quark and lepton parameters at various scales, JHEP 11 (2013) 115 [1306.6879].
- (21) K. Ishiguro, T. Kobayashi and H. Otsuka, Landscape of Modular Symmetric Flavor Models, JHEP 03 (2021) 161 [2011.09154].
- (22) P.P. Novichkov, J.T. Penedo and S.T. Petcov, Modular flavour symmetries and modulus stabilisation, JHEP 03 (2022) 149 [2201.02020].
- (23) K. Ishiguro, H. Okada and H. Otsuka, Residual flavor symmetry breaking in the landscape of modular flavor models, JHEP 09 (2022) 072 [2206.04313].
- (24) D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller et al., Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2307.01952.