NewReferences
Dimension Reduction for Fréchet Regression
Abstract
With the rapid development of data collection techniques, complex data objects that are not in the Euclidean space are frequently encountered in new statistical applications. Fréchet regression model (Peterson & Müller 2019) provides a promising framework for regression analysis with metric space-valued responses. In this paper, we introduce a flexible sufficient dimension reduction (SDR) method for Fréchet regression to achieve two purposes: to mitigate the curse of dimensionality caused by high-dimensional predictors and to provide a visual inspection tool for Fréchet regression. Our approach is flexible enough to turn any existing SDR method for Euclidean into one for Euclidean and metric space-valued . The basic idea is to first map the metric space-valued random object to a real-valued random variable using a class of functions and then perform classical SDR to the transformed data. If the class of functions is sufficiently rich, then we are guaranteed to uncover the Fréchet SDR space. We showed that such a class, which we call an ensemble, can be generated by a universal kernel (cc-universal kernel). We established the consistency and asymptotic convergence rate of the proposed methods. The finite-sample performance of the proposed methods is illustrated through simulation studies for several commonly encountered metric spaces that include Wasserstein space, the space of symmetric positive definite matrices, and the sphere. We illustrated the data visualization aspect of our method by the human mortality distribution data from the United Nations Databases.
Keywords: Ensembled sufficient dimension reduction, Inverse regression, Statistical objects, Universal kernel, Wasserstein space.
1 Introduction
With the rapid development of data collection techniques, complex data objects that are not in the Euclidean space are frequently encountered in new statistical applications, such as the graph Laplacians of networks, the covariance or correlation matrices for the brain functional connectivity in neuroscience Ferreira & Busatto (2013), and probability distributions in CT hematoma density data (Petersen & Müller, 2019). These data objects, also known as random objects, do not obey the operation rules of a vector space with an inner product or a norm but instead reside in a general metric space. In a prescient paper, Fréchet (1948) proposed the Fréchet mean as a natural generalization of the expectation of a random vector. By extending the Fréchet mean to the conditional Fréchet mean, Petersen & Müller (2019) introduced the Fréchet regression model with random objects as the response and Euclidean vectors as predictors, which provides a promising framework for regression analysis with metric space-valued responses. Dubey & Müller (2019) showed the consistency of the sample Fréchet mean using the results of Petersen & Müller (2019), derived a central limit theorem for the sample Fréchet variance that quantifies the variation around the Fréchet mean, and further developed the Fréchet analysis of variance for random objects. Dubey & Müller (2020) designed a method for change-point detection and inference in a sequence of metric-space-valued data objects.
The Fréchet regression of Petersen & Müller (2019) employs the global least squares and the local linear or polynomial regression to fit the conditional Fréchet mean. It is well known that the global least squares are based on a restrictive assumption of the regression relation. Although the local regression is more flexible, it is effective only when the dimension of the predictor is relatively low. As this dimension gets higher, its accuracy drops significantly–a phenomenon known as the curse of dimensionality. To address this issue, it is essential to reduce the dimension of the predictor without losing the information about the response. For classical regression, this task is performed by sufficient dimension reduction (SDR; see Li 1991; Cook & Weisberg 1991; Cook 1996 and Li 2018 among others). SDR works by projecting the high-dimensional predictor onto a low-dimensional subspace that preserves the information about the response through the use of sufficiency.
Besides assisting regression in overcoming the curse of dimensionality, another important function of SDR for classical regression is to provide a data visualization tool to gain insights into how the regression surface looks in high-dimensional space before even fitting a model. By inspecting the sufficient plots of the response objects against the sufficient predictors, we can gain insights into the general trends of the response as the most informative part of the predictor varies, whether there are outlying observations, and whether there are subjects with high leverage that have undue influence on the regression estimates-the usual information a statistician looks for in the exploratory and model checking stages of the regression analysis. This function is also needed in Fréchet regression. In fact, it can be argued that data visualization is even more important for the regression of random objects, as the regression relation may be even more difficult to discern among the complex details of the objects.
To fulfill these demands, in this paper, we systematically develop the theories and methodologies of sufficient dimension reduction for Fréchet regression. To set the stage, we first give an outline of SDR for classical regression. Let be a -dimensional random vector in and a random variable in . The classical SDR aims to find a dimension reduction subspace of such that and are independent conditioning on , that is, where is the projection on to with respect to the usual inner product in . In this way, can be used as the synthetic predictor without loss of regression information about the response . Under mild conditions, the intersection of all such dimension reduction subspaces is also a dimension reduction subspace, and the intersection is called the central subspace denoted by (Cook, 1996; Yin et al., 2008). For the situation where the primary interest is in estimating the regression function, Cook & Li (2002) introduced a weaker form of SDR, the mean dimension reduction subspace. A subspace of is a mean SDR subspace if satisfies , and the intersection of all such spaces if it is still a mean SDR subspace, is the central mean subspace, denoted by . The central mean subspace is always contained in central subspace when they exist. Many estimating methods for the central subspace and the central mean subspace have been developed over the past decades. For example, for the central subspace, we have the sliced inverse regression (SIR; Li 1991), the sliced average variance estimate (SAVE; Cook & Weisberg 1991), the contour regression (CR; Li et al. 2005), and the directional regression (DR; Li & Wang 2007). For the central mean subspace, we have the ordinary least squares (OLS; Li & Duan 1989), the principal Hessian directions (PHD; Li 1992), the iterative Hessian transformation (IHT Cook & Li 2002), the outer product of gradients (OPG) and the minimum average variance estimator (MAVE) of Xia et al. (2002).
SDR has been extended to accommodate some complex data structures in the past, for example, to functional data (Ferré & Yao 2003; Hsing & Ren 2009; Li & Song 2017), to tensorial data (Li et al. 2010; Ding & Cook 2015), and to panel data (Fan et al., 2017; Yu et al., 2020; Luo et al., 2021). Most recently, Ying & Yu (2022) extended SIR to the case where the response takes values in a metric space. Taking a substantial step forward, in this paper, we introduce a comprehensive and flexible method that can adapt any existing SDR estimators to metric space-valued responses.
The basic idea of our method stems from the ensemble SDR for Euclidean and of Yin & Li (2011), which recovers the central subspace by repeatedly estimating the central mean subspace for a family of functions that is rich enough to determine the conditional distribution of . Such a family is called an ensemble and satisfies Using this relation, we can turn any method for estimating the central mean space into one that estimates the central subspace.
While borrowing the idea of the ensemble, our goal is different from Yin & Li (2011): we are not interested in turning an estimator for the central mean subspace into one for the central subspace. Instead, we are interested in turning any existing SDR method for Euclidean into one for Euclidean and metric space-valued . Let be a random vector in and a random object that takes values in a metric space . Still use the symbol to represent the intersection of all subspaces of satisfying . We call the central subspace for Fréchet SDR, or simply the Fréchet central subspace. Let be a family of functions that are measurable with respect to the Borel -field on the metric space. We use two types of ensembles to connect classical SDR with Fréchet SDR:
-
•
Central Mean Space ensemble (CMS-ensemble) is a family that is rich enough so that Note that we know how to estimate the spaces using the existing SDR methods since is a number. We use this ensemble to turn an SDR method that targets the central mean subspace into one that targets the Fréchet central subspace. We will focus on two forward regression methods: OPG and MAVE, and three moment estimators of the CMS.
-
•
Central Space ensemble (CS-ensemble) is a family that is rich enough so that We use this ensemble to turn an SDR method that targets the central subspace for real-valued response into one that targets the Fréchet central subspace. We will focus on three inverse regression methods: SIR, SAVE, and DR.
A key step in implementing both of the above schemes is to construct an ensemble in each case. For this purpose, we assume that the metric space is continuously embeddable into a Hilbert space. Under this assumption, one can construct a universal reproducing kernel, which leads to an that satisfies the required characterizing property.
As with classical SDR, the Fréchet SDR can also be used to assist data visualization. To illustrate this aspect, we consider an application involving factors that influence the mortality distributions of 162 countries (see Section 7 for details). For each country, the response is a histogram with the numbers of deaths for each five-year period from age 0 to age 100, which is smoothed to produce a density estimate, as shown in panel (a) of Figure 1. We considered nine predictors characterizing each country’s demography, economy, labor market, health care, and environment. Using our ensemble method we obtained a set of sufficient predictors. In panel (b) of Figure 1, we show the mortality densities plotted against the first sufficient predictor. A clear pattern is shown in the plot: for countries with low values of the first sufficient predictor, the modes of the mortality distributions are at lower ages, and there are upticks at age 0, indicating high infant mortality rates; for countries with high values of the first sufficient predictor, the modes of the mortality distributions are significantly higher, and there are no upticks at age 0, indicating very low infant mortality rates. The information provided by the plot is clearly useful, and many further insights can be gained about what affects the mortality distribution by taking a careful look at the loadings of the first sufficient predictor, as will be detailed in Section 7.
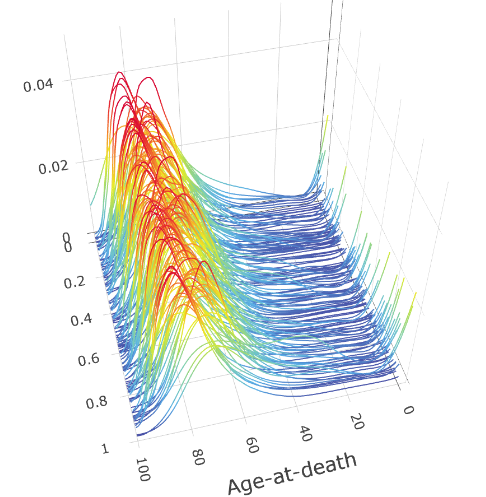
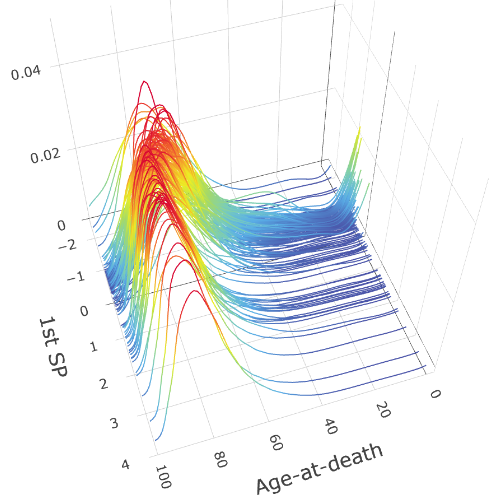
The rest of this paper is organized as follows. Section 2 defines the Fréchet SDR problem and provides sufficient conditions for a family to characterize the central subspace. Section 3 then constructs ensemble for the Wasserstein space of univariate distributions, the space of covariance matrix, and a special Riemannian manifold, the sphere. Section 4 proposes the CMS-ensembles by extending five SDR methods that target the central mean space for real-valued response: OLS, PHD, IHT, OPG and MAVE, and CS-ensembles by extending three SDR methods that target the central space for real-valued response: SIR, SAVE, and DR. Section 5 establishes the convergence rate of the proposed methods. Section 6 uses simulation studies to examine the numerical performances of different ensemble estimators in different settings, including distributional responses and covariance matrix responses. In Section 7, we analyze the mortality distribution data to demonstrate the usefulness of our methods. Section 8 includes a few concluding remarks and discussion. All the proofs and additional simulation studies and real application are presented in the Supplementary Material.
2 Characterization of the Fréchet Central Subspace
Let be a probability space. Let be a metric space with metric and the Borel -field generated by the open sets in . Let be a subset of and the Borel -field generated by the open sets in . Let be a random element mapping from to measurable with respect to the product -field . We denote the marginal distributions of and by and , respectively, and the conditional distributions of and by and , respectively. We formulate the Fréchet SDR problem as finding a subspace of such that and are independent conditioning on :
| (1) |
where is the projection on to with respect to the inner product in . As in the classical SDR, the intersection of all such subspaces still satisfies (1) under mild conditions (Cook & Li, 2002). Indeed, it does not require any structure of the space . A sufficient condition shown in Yin et al. (2008) is that is supported by a matching set. For example, if the support of is convex, then this sufficient condition is satisfied. We call this subspace the Fréchet central subspace and denote it by . Similar to Cook (1996), it can be shown that if the support of X is open and convex, the Fréchet central subspace satisfies (1).
2.1 Two types of ensembles and their sufficient conditions
Let be a family of measurable functions , and for an , let be the central mean subspace of versus . As mentioned in Section 1, we use two types of ensembles to recover the Fréchet central subspace. The first type is any that satisfies
| (2) |
This is the same ensemble as that in Yin & Li (2011), except that, here, the right-hand side is the Fréchet central subspace. Relation (2) allows us to recover the Fréchet central subspace by a collection of classical central mean subspaces. We call a class that satisfies (2) a CMS-ensemble. The second type of ensembles is any family that satisfies
| (3) |
which we call a CS-ensemble. Proposition 1 shows that a CMS ensemble is a CS-ensemble.
PROPOSITION 1.
If is a CMS-ensemble, then it is a CS-ensemble.
We next develop a sufficient condition for an to be a CMS-ensemble and hence also a CS-ensemble. Let be the family of measurable indicator functions on , and let be the linear span of , where . Yin & Li (2011) showed that if is a subset of that is dense in , then (2) holds for the classical . Here, we generalize that result to our setting by requiring only to be dense in .
LEMMA 1.
If is a subset of and is dense in with respect to the -metric, then is a CMS-ensemble and hence also a CS-ensemble.
2.2 Construction of the CMS-ensemble
To construct a CMS-ensemble, we resort to the notion of the universal kernel. Let be the family of continuous real-valued functions on . When is compact, Steinwart (2001) defined a continuous kernel as universal (we refer to it as c-universal) if its associated RKHS is dense in under the uniform norm. To relax the compactness assumption, Micchelli et al. (2006) proposed the following notion of universality, which is referred to cc-univsersal in Sriperumbudur et al. (2011). For any compact set , let be the RKHS generated by . We should note that a member of is supported on , rather than . Let denote the restriction of on , and the class of all continuous functions with respect to the topology in restricted on .
DEFINITION 1.
(Micchelli et al., 2006) We say that is cc-universal if, for any compact set , any member of , and any , there is an such that
When is compact, Sriperumbudur et al. (2011) showed that two notions of universality are equivalent. In the following, we look into the conditions under which a metric space has a cc-universal kernel and how to construct such a kernel when it does.
Micchelli et al. (2006) showed that when , many standard kernels, including Laplacian kernels and Gaussian RBF kernels, are cc-universal. Unfortunately, when is a general metric space, direct extension of these types of kernels, for example, , are no longer guaranteed to be cc-universal. Christmann & Steinwart (2010) showed that for compact , if there exists a separable Hilbert space and a continuous injection , then for any analytic function whose Taylor series at zero has strictly positive coefficients, the function defines a c-universal kernel on . They also provide an analogous definition of the Gaussian-type kernel in the above case. We extend this result to construct cc-universal kernels on non-compact metric space. The proof is given in the Supplementary Material.
PROPOSITION 2.
Suppose is a complete and separable metric space, and there exists a separable Hilbert space and a continuous injection . If is an analytic function of the form then the function defined by is a positive definite kernel. Furthermore, if for all , then is a cc-universal kernel on .
As an example, Corollary 1 shows that the Gaussian-type kernel is cc-universal on .
COROLLARY 1.
Suppose the conditions in Proposition 2 are satisfied, then the Gaussian-type kernel is cc-universal. Furthermore, if the continuous function is isometric, that is, , then Gaussian-type kernel is cc-universal.
The second part of Corollary 1 is straightforward since an isometry is an injection. Similar results can be established for Laplacian-type kernel .
The continuous embedding condition in Proposition 2 covers several metric spaces often encountered in statistical applications. Section 3 employs it to construct cc-universal kernels on the space of univariate distributions endowed with Wasserstein-2 distance, correlation matrices endowed with Frobenius distance, and spheres endowed with geodesic distance.
By using the notion of regular probability measure, we connect the cc-universal kernel on with the CMS-ensemble, which is the theoretical foundation of our method. Recall that a measure on is regular if, for any Borel subset and any , there is a compact set and an open set , such that .
THEOREM 1.
Suppose, on metric space , (1) is a bounded cc-universal kernel and (2) is a regular probability measure. Then the family is a CMS-ensemble.
The proof of Theorem 1 is given in the Supplementary Material. Condition (2), which requires to be regular, is quite mild: it is known that any Borel measure on a complete and separable metric space is regular (see Granirer (1970, Chapter 2: Theorem 1.2, Theorem 3.2)). Thus, a sufficient condition of Condition (2) is being complete and separable, which is satisfied by all the metric spaces we consider. Specifically, note that if is separable and complete, then so is the Wasserstein-2 space (Panaretos & Zemel, 2020, Proposition 2.2.8, Theorem 2.2.7). Therefore, is complete and separable. Similarly, the SPD matrix space endowed with Frobenius distance and the sphere endowed with geodesic distance are both completely separable metric spaces. Furthermore, the Gaussian kernel and Laplacian kernel we considered satisfy Condition (1) in Theorem 1.
Thus, Proposition 2 and Theorem 1 provide a general mechanism to construct the CMS-ensemble over any separable and complete metric space without a linear structure, provided it can be continuously embedded in a separable Hilbert space. For the case where multiple cc-universal kernels exist, we design a cross-validation framework in Section 6 to choose the kernel type and the bandwidth .
3 Important Metric Spaces and their CMS Ensembles
This section gives the construction of CMS-ensembles for three commonly used metric spaces.
3.1 Wasserstein space
Let be or a closed interval of , the -field of Borel subsets of , and the collection of all probability measures on . The Wasserstein space is defined as the subset of with finite second moment, that is, endowed with the quadratic Wasserstein distance where and are members of and and are the quantile functions of and , which we assume to be well defined. This distance can be equivalently written as The set endowed with is a metric space with a formal Riemannian structure (Ambrosio et al., 2004).
Here, we present some basic results that characterize , whose proofs can be found, for example, in Ambrosio et al. (2004) and Bigot et al. (2017). For , we say that a -measurable map transports to if . This relation is often written as . Let be a reference measure with a continuous . The tangent space at is where, for a set , denotes the -closure of . The exponential map from to , defined by , is surjective. Therefore its inverse, , defined by , is well defined on . It is well known that the exponential map restricted to the image of map, denoted as , is an isometric homeomorphism (Bigot et al., 2017). Therefore, is a continuous injection from to . We can then construct CMS-ensembles using the general constructive method provided by Theorem 1 and Proposition 2. The next proposition gives two such constructions, where the subscripts “G” and “L” for the two kernels refer to “Gaussian” and “Laplacian”, respectively.
PROPOSITION 3.
For , and are both cc-universal kernels on . Consequently, the families and are CMS-ensembles.
3.2 Space of symmetric positive definite matrices
We first introduce some notations. Let be the set of invertible symmetric matrices with real entries and the set of symmetric positive definite (SPD) matrices. For any , the matrix exponential of is defined as the infinite power series . For any , the matrix logarithm of is defined as any matrix such that and denoted by .
Let be the Frobenius metric. Then is a metric space continuously embedded by identity mapping in , which is a Hilbert space with the Frobenius inner product . Also, the identity mapping is obviously isometric. Therefore, by Corollary 1, the two types of radial basis function kernels for Wasserstein space can be similarly extended to . That is, let and then and are CMS-ensembles.
Another widely used metric over is the log-Euclidean distance that is defined as Basically, it pulls the Frobenius metric on back to by the matrix logarithm map. The matrix logarithm is a continuous injection to Hilbert . By Corollary 1, the two types of radial basis function kernels and are cc-universal. Then, and are CMS-ensembles.
3.3 The sphere
Consider the random vector taking values in the sphere . To respect the nonzero curvature of , the geodesic distance , which is derived from its Riemannian geometry, is often used rather than the Euclidean distance. However, the popular Gaussian-type RBF kernel is not positive definite on (Jayasumana et al., 2013). In fact, Feragen et al. (2015) proved that for complete Riemannian manifold with its associated geodesic distance , is positive semidefinite only if is isometric to a Euclidean space. Honeine & Richard (2010) and Jayasumana et al. (2013) proved that the Laplacian-type kernel is positive definite on the sphere . We show in the following proposition that is cc-universal.
PROPOSITION 4.
The Laplacian-type kernel , defined by , where is the geodesic distance on , is a cc-universal kernel for any . Consequently, is a CMS-ensemble.
4 Fréchet Sufficient Dimension Reduction
In this section, we develop the Fréchet SDR estimators based on the CMS-ensembles and CS-ensembles and establish their Fisher consistency.
4.1 Ensembled moment estimators via CMS ensembles
We first develop a general class of Fréchet SDR estimators based on the ensembled moment estimators of the CMS, such as the OLS, PHD, and IHT. Let be the collection of all distributions of , and let be a measurable function to be used as an estimator of the Fréchet central subspace . A function defined on is called statistical functional; see, for example, Chapter 9 of Li (2018). In the SDR literature, such a function is also called a candidate matrix (Ye & Weiss, 2003). Let be a generic member of , the true distribution of , and the empirical distribution of based on an i.i.d. sample . Extending the terminology of classical SDR (see, for example, Li 2018, Chapter 2), we say that the estimate is unbiased if , exhaustive if , and Fisher consistent if . We refer to as the Fréchet candidate matrix.
Suppose we are given a CMS-ensemble . Let be a function to be used as an estimator of for each . This is not a statistical functional in the classical sense, as it involves an additional set . So, we redefine unbiasedness, exhaustiveness, and Fisher consistency for this type of augmented statistical functional.
DEFINITION 2.
We say that is unbiased for estimating if, for each , Exhaustiveness and Fisher consistency of are defined by replacing in the above by and , respectively.
Note that is an estimator of the classical central mean subspace , as is a random number rather than a random object. We refer to as the ensemble candidate matrix or, when confusion is possible, the CMS-ensemble candidate matrix. Our goal is to construct a Fréchet candidate matrix from the ensemble candidate matrix . To do so, we assume is of the form , where is a cc-universal kernel. Given such an and , we define as follows
where is the distribution of derived from .
We now adapt several estimates for the classical central mean subspace to the estimation of Fréchet SDR: the ordinary least squares (OLS; Li & Duan 1989), the principal Hessian directions (PHD; Li 1992), and the Iterative Hessian Transformation (IHT; Cook & Li 2002). These estimates are based on sample moments and require additional conditions on the predictor for their unbiasedness. Specifically, we make the following assumptions :
ASSUMPTION 1.
1.Linear Conditional Mean (LCM): is a linear function of , where is a basis matrix of the Fréchet central subspace ;
2. Constant Conditional Variance (CCV): is a nonrandom matrix.
Under the first assumption, the ensemble OLS and IHT are unbiased for estimating the Fréchet central subspace; under both assumptions, the ensemble PHD is unbiased for estimating . More detailed discussions on the unbiasedness and fisher consistency of ensemble estimators are presented in Section 4.4. In practice, the two assumptions above cannot be checked directly since we do not know . However, as was shown by Eaton (1986), if Assumption 1 holds for all , then the distribution of is elliptical, and vice versa. If further is multivariate normal, then Assumption 2 is satisfied. Currently, the scatter plot matrix is the most commonly used empirical method to check the elliptical distribution assumption. If non-elliptical features are observed, one can use marginal transformations of the predictors, such as the Box-Cox transformation, to mitigate the non-ellipticity problem. Furthermore, in practice, the SDR methods that require ellipticity usually still work reasonably well even when the elliptical distribution assumption is violated. This occurs particularly when the dimension of is high. See Hall & Li (1993) and Li & Yin (2007) for the theoretical supports. Our simulation results in Section 6 support this phenomenon.
It is most convenient to construct these ensemble estimators using standardized predictors. The theoretical basis for doing so is an equivariant property of the Fréchet central subspace, as stated in the next proposition.
PROPOSITION 5.
If is the Fréchet central subspace, is a non-singular matrix, and is a vector in , then
The proof is essentially the same as that for the classical central subspace (see, for example, Li, 2018, page 24), and is omitted. Using this property, we first transform to , estimate the Fréchet central subspace , and then transform it by , which is the same as . The candidate matrices and for ensemble OLS, PHD, and IHT are formulated in Remark 1. Detailed motivation for each can be found in Li (2018, Chapter 8). The sample estimates can then be constructed by replacing the expectations in and with sample moments whenever possible. Algorithm 1 summarize the steps to implement an ensembled moment estimator, where stands for the centered kernel .
REMARK 1.
The candidate matrix for Fréchet OLS, PHD, and IHT are
-
(1)
(Fréchet OLS) , where ;
-
(2)
(Fréchet PHD) ;
-
(3)
(Fréchet IHT) , where .
4.2 Ensembled forward regression estimators via CMS ensembles
In this subsection, we adapt the OPG (Xia et al. 2002), a popular method for estimating the classical CMS based on nonparametric forward regression, to the estimation of the Fréchet central subspace, which do not require LCM and CCV conditions. The adaption of another forward regression method MAVE is similar and presented in Section S.3.2 of the Supplementary Material. The framework of the statistical functional is no longer sufficient to cover this case because we now have a tuning parameter here. So, we adopt the notion of tuned statistical functional in Section 11.2 of Li (2018) to accommodate a tuning parameter.
Let , , and be as defined in Section 4.1. For simplicity, we assume the tuning parameter to be a scalar, but it could also be a vector. Given a CMS-ensemble , let be a tuned functional to be used as an estimator of for each . We refer to as the ensemble-tuned candidate matrix. The unbiasedness, exhaustiveness, and Fisher consistency of are defined as follows.
DEFINITION 3.
We say that is unbiased for estimating if, for each , Exhaustiveness and Fisher consistency of are defined by replacing in the above by and , respectively.
Given and , we define the tuned Fréchet candidate matrix as We say that the estimate is unbiased if , exhaustive if , and Fisher consistent if .
For a function , we use to denote evaluated at . The OPG aims to estimate central mean subspace by where the gradient is estimated by local linear approximation as follows. Let be a kernel function as used in kernel estimation. For any and bandwidth , let . At the population level, for fixed and , we minimize the objective function
| (4) |
over all and . The minimizer depends on and we write it as , . The ensemble tuned candidate matrix for estimating the central mean subspace is and the tuned Fréchet candidate matrix is .
At the sample level, we minimize, for each , the empirical objective function
| (5) |
over and , where Following Xia et al. (2002), we take the bandwidth to be where and , which is slightly larger than the optimal in terms of the mean integrated squared errors. As proposed in Li (2018, Lemma 11.6), instead of solving from (5) times, we solve multivariate weighted least squares to obtain simultaneously. Computation details are given in Section S.3 of the Supplementary Material.
We can further enhance the performance of FOPG by projecting the original predictors onto the directions produced by the FOPG to re-estimate . Specifically, after the first round of FOPG, we form the matrix and replace the kernel by with an updated bandwidth , and complete the next round of iteration, which leads to an updated . We then iterate this process until convergence. In this way, we reduce the dimension of the kernel from to and mitigate the “curse of dimensionality”. To avoid confusion, We call this refined version of Fréchet OPG as FOPG in the following. The algorithms for FOPG are summarized as Algorithm 2.
4.3 Ensembled inverse regression estimators via CS ensembles
In this subsection, we adapt several well-known estimators for the classical central subspace to Fréchet SDR, which include SIR (Li, 1991), SAVE (Cook & Weisberg, 1991), and DR (Li & Wang, 2007). We use the CS-ensemble to combine these classical estimates through (3). Let be a CS ensemble, where is a cc-universal kernel. Let be a CS-ensemble candidate matrix. Let be the Fréchet candidate matrix.
Again, we work with the standard predictor . The candidate matrices for ensemble SIR, SAVE, and DR are formulated in Remark 2. Detailed motivation for each can be found in Li (2018, Chapter 3,5,6). At the sample level, we replace any unconditional moment by the sample average , and replace any conditional moment, such as , by the slice mean. The algorithms are also included in Algorithm 1. A more detailed algorithm is given by Algorithm 5 in the Supplementary Material.
REMARK 2.
The candidate matrices for Fréchet SIR, SAVE, and DR are , , and , respectively.
REMARK 3.
Regarding the time complexity of the Frechet SDR methods, by construction, the ensemble estimator requires times the computing time of the original estimator because it needs to reapply the original estimator for each , . For example, if SAVE is used as the original estimator, then the largest matrix multiplication is which requires basic computation units; the largest matrix to invert or eigen decomposition to perform is a matrix, which requires basic computation units. So the net computation complexity is .
4.4 Fisher consistency
In this subsection, we establish the unbiasedness and Fisher consistency of the tuned Fréchet candidate matrix. As a special case, the Fréchet candidate matrix constructed by any moment-based methods in Section 4.1 can be considered as tuned Fréchet candidate matrix with the tuning parameter taken to be . The next theorem shows that if is unbiased (or Fisher consistent), then is unbiased (or Fisher consistent). In the following, we say that a measure on is strictly positive if and only if for any nonempty open set , . For a matrix , represents the operator norm.
THEOREM 2.
Suppose is a CMS-ensemble, where is a cc-universal kernel. We have the following results regarding unbiasedness and Fisher consistency for .
-
1.
If is unbiased for and , where is a real-valued function with , then is unbiased for ;
-
2.
If (a) is Fisher consistent for , (b) is positive semidefinite for each , and , (c) with , (d) is strictly positive on , and (e) the mapping is continuous, then is Fisher consistent for .
We similarly develop Fisher consistency for Fréchet SDR based on the CS-ensemble, including methods in Section 4.3. The next corollary says that if is Fréchet consistent for , then is Fréchet consistent for . The proof is similar to that of Theorem 2 and is omitted.
COROLLARY 2.
Suppose is a CS-ensemble, where is a cc-universal kernel. We have the following results regarding unbiasedness and Fisher consistency for .
-
1.
If is unbiased for , then is unbiased for ;
-
2.
If is Fisher consistent for , is positive semidefinite for each and , is strictly positive, and the mapping is continuous, then is Fisher consistent for .
Unbiasedness and Fisher consistency of or are satisfied by different sets of sufficient conditions for the moment-based or forward-regression-based estimators. We outline these conditions below.
-
1.
For ensembled moment estimators in Section 4.1 and ensembled inverse regression estimators in Section 4.3, most of them are unbiased under either the LCM assumption or both the LCM and CCV assumption. For example, the unbiasedness of SIR, OLS, and IHT requires the LCM assumption, whereas the unbiasedness of SAVE, DR, and PHD requires both the LCM and the CCV assumptions. The estimators SIR, OLS, IHT, and PHD are generally not exhaustive (recall that unbiased along with exhaustiveness is equivalent to Fisher consistency). But sufficient conditions for SAVE, DR to be exhaustive are reasonably mild (see Li & Wang (2007) and Li (2018, Chapter 6)).
-
2.
Sufficient conditions for Fisher consistency for OPG are given in Li (2018, Section 11.2). Specifically, it requires: (a) the smooth kernel function is a spherically-contoured p.d.f. with finite fourth moments; (b) the p.d.f. of is supported on and has continuous bounded second derivatives. Note that neither LCM nor CCV assumption is needed for the OPG estimator.
5 Convergence Rates of the Ensemble Estimates
In this section, we develop the convergence rates of the ensemble estimates for Fréchet SDR. To save space, we will only consider the CMS-ensemble; the results for the CS-ensemble are largely parallel. To simplify the asymptotic development, we make a slight modification of the ensemble estimator, which does not result in any significant numerical difference from the original ensembles developed in the previous sections. For each , let be the empirical distribution based on the sample with th subject removed: . Our modified ensemble estimate is of the form
The purpose of this modification is to break the dependence between the ensemble member and the CMS estimate, which substantially simplifies the asymptotic argument. Here, we let the tuning parameter depend on . Again, the Fréceht candidate matrix constructed by moment-based methods can be considered as a special case with .
Rather than deriving the convergence rate of each individual ensemble estimate case by case, we will show that, under some mild conditions, the ensemble convergence rate is the same as the corresponding CMS-estimate’s rate. Since the convergence rates of many CMS-estimates are well established, including all the forward regression and sample moment-based estimates mentioned earlier, our general result covers all the CMS-ensemble estimates.
In this following, for a matrix , represents the operator norm and the Frobenius norm. If and are sequences of positive numbers, we write if ; we write if is a bounded sequence. We write (or ) if (or ). We write if and . Let and .
THEOREM 3.
Let and be a positive sequence of numbers satisfying and . Suppose the entries of have finite variances. If , then .
The above theorem says that, under some conditions, the convergence rate of an ensemble Fréchet SDR estimator is the same as the corresponding CMS estimator. This covers all the estimators developed in Section 4. Specifically:
-
1.
For all moment-based ensemble methods, such as OLS, PHD, IHT, SIR, SAVE, DR, the ensemble candidate matrices can be written in the form , where is a matrix possessing the second order von Mises expansion, implying . See, for example, Li (2018)
-
2.
For nonparametric forward regression ensemble methods, OPG and MAVE, the convergence rate of was reported in Xia (2007) as where . Although the convergence was established in terms of convergence in probability, under mild conditions such as uniformly integrability, we can obtain the same rate for .
6 Simulations
We evaluate the performance of the proposed Fréchet SDR methods with distributions and symmetric positive definite matrices as responses. For space consideration, the additional simulation for spherical data is presented in the Supplementary Material.
6.1 Computational Details
Choice of tuning parameters and kernel types. We first implement a unified cross-validation procedure to select the kernel type and bandwidth in the kernel. For both distributional response and symmetric positive definite matrix response, we consider Gaussian radial basis kernel and Laplacian radial basis kernel as candidates to construct the ensembles. For the bandwidth , we set the default value as
| (6) |
in the Gaussian radial basis kernel, and
in the Laplacian radial basis kernel. The same choices were used in Lee et al. (2013) and Li & Song (2017). We then fine-tune and kernel types together via the -fold cross-validation as follows. Randomly split the whole sample into subsets of roughly equal sizes, say . For each , use as the test set and its complement as the training set. We first use the training set to implement the Fréchet SDR with an initial dimension , say . This choice of a relatively large dimension helps to guarantee the unbiasedness of the estimated Fréchet central subspace. We then substitute the estimated into the testing set to produce the sufficient predictor and then fit a global Fréchet regression model (Petersen & Müller, 2019) to predict the response in the testing set. Compute the prediction error for each and aggregate the error for all rotations , which yields an overall cross-validation error. This overall error depends on the tuning parameter and kernel type and is then minimized over a grid to obtain the optimal combinations.
Estimation of the dimensions. For the ensemble estimators that possess a candidate matrix (such as the ensemble moment estimators in Section 4.1), the recently developed order-determination methods, such as the ladle estimate (Luo & Li, 2016), and predictor augmentation estimator (Luo & Li, 2021) can be directly applied to estimate . In addition, the BIC-criterion introduced by Zhu et al. (2006) can also be used for this purpose.
In this paper, we adapted the predictor augmentation estimator to the current setting. A detailed introduction of the predictor augmentation method and more simulation results are included in the Supplementary Material. For the predictor augmentation estimator, we take the times of augmentations and the dimension of augmented predictors , where is the original dimension of predictors.
Estimation error assessment. We used the error measurement for subspace estimation as in Li et al. (2005): if and are two subspaces of of the same dimension, then their distance is defined as where is the projection on to , and is the Frobenius matrix norm. If and are two matrices whose columns form bases of and respectively, this distance can be equivalently written as This distance is coordinate-free, as it is invariant to the basis matrices involved.
To facilitate the comparison, we also include the benchmark error, which is set as the expectation of the above distance when is taken as any basis matrix of the true central subspace, and entries of are generated randomly from i.i.d. . This expectation is computed by Monte Carlo with 1000 repeats.
6.2 Scenario I: Fréchet SDR for distributions
Let be the metric space of univariate distributions endowed with Wasserstein metric , as described in Section 3. The construction of the ensembles requires computing the Wasserstein distances for . However, the distributions are usually not fully observed in practice, which means we need to estimate them in the implementation of the proposed methods. There are multiple ways to do so, such as by estimating the c.d.f.’s, the quantile functions (Parzen, 1979), or the p.d.f’s (Petersen & Müller, 2016; Chen et al., 2021). For computation simplicity, we use the Wasserstein distances between the empirical measures. Specifically, suppose we observe , where are independent samples from the distribution . Let be the empirical measure , where is the Dirac measure at , then we estimate by . For the theoretical justification, see Fournier & Guillin (2015) and Lei (2020). For simplicity, we assume the sample sizes to be the same and denote the common sample size by . Then the distance between empirical measures and is a simple function of the order statistics: where is the -th order statistics of the sample .
Let , , and . To generate univariate distributional response , we let , where and are random variables dependent on , and almost surely, defined by the following models:
-
I-1
: and .
-
I-2
: and where .
-
I-3
: and with truncated range and .
-
I-4
: and with truncated range and .
To generate the predictor , we consider both the scenarios where Assumption 1 is satisfied and violated. Specifically, for Model I-1 and I-2, is generated by the following two scenarios:
-
(a)
; in this case both LCM and CCV in Assumption 1 are satisfied;
-
(b)
we first generate from the model with mean 0 and covariance matrix , and then generate by . For this model, both LCM and CCS are violated.
For Model I-3 and I-4, we generate , where is the multivariate c.d.f. of and is generated as in (b). For this model, both LCM and CCS are violated.
Ying & Yu (2022) considered similar models to Model I-1 and Model I-2. In Model I-3 and Model I-4, the error depends on , which means the Fréchet central subspace contains direction out of the conditional Fréchet mean function. For Model I-1, and ; for Model I-2, and ; and for Models I-3, I-4, and . In the simulation, we first generate , then generate . For each , we then generate independently from . We take and .
We compare performances of the CMS ensemble methods and CS ensemble methods described in Section 4, including FOLS, FPHD, FIHT, FSIR, FSAVE, FDR, and FOPG (with refinement). We first implement the predictor augmentation (PA) method to estimate the dimension of the Fréchet central subspace. Then with estimated , we evaluate the estimation error. For FOPG, the number of iterations is set as 5, which is large enough to guarantee numerical convergence. For FSIR, FSAVE, the number of slices is chosen as ; for FDR, the number of slices is chosen as . We also implement the weighted inverse regression ensemble (WIRE) method proposed by Ying & Yu (2022) for comparison. We repeat the experiments 100 times and summarize the proportion of correct identification of order and the mean and standard deviation of estimation error in Table 1 and Table 2. A smaller distance indicates a more accurate estimate, and the estimate with the smallest distance is shown in boldface. The benchmark distances are shown at the bottom of the table.
| Model | FOLS | FPHD | FIHT | FSIR | FSAVE | FDR | FOPG | WIRE | |
|---|---|---|---|---|---|---|---|---|---|
| I-1-(a) | 100% | 87% | 100% | 98% | 75% | 87% | 100% | 100% | |
| (10,200) | 0.343 | 0.667 | 0.349 | 0.271 | 0.561 | 0.407 | 0.167 | 0.235 | |
| (0.088) | (0.229) | (0.089) | (0.128) | (0.316) | (0.261) | (0.057) | (0.054) | ||
| 100% | 84% | 100% | 100% | 83% | 90% | 100% | 100% | ||
| (20,400) | 0.359 | 0.705 | 0.365 | 0.262 | 0.511 | 0.393 | 0.220 | 0.249 | |
| (0.073) | (0.214) | (0.073) | (0.044) | (0.27) | (0.225) | (0.052) | (0.041) | ||
| I-1-(b) | 94% | 95% | 93% | 86% | 75% | 91% | 100% | 86% | |
| (10,200) | 0.415 | 0.663 | 0.437 | 0.33 | 0.504 | 0.338 | 0.135 | 0.3 | |
| (0.18) | (0.155) | (0.187) | (0.283) | (0.341) | (0.228) | (0.036) | (0.294) | ||
| 95% | 95% | 96% | 89% | 73% | 95% | 99% | 84% | ||
| (20,400) | 0.402 | 0.667 | 0.415 | 0.303 | 0.511 | 0.297 | 0.196 | 0.314 | |
| (0.156) | (0.141) | (0.142) | (0.254) | (0.329) | (0.176) | (0.089) | (0.309) | ||
| I-2-(a) | 100% | 57% | 100% | 99% | 97% | 100% | 100% | 100% | |
| (10,200) | 0.413 | 1.048 | 0.416 | 0.387 | 0.537 | 0.418 | 0.253 | 0.316 | |
| (0.092) | (0.206) | (0.092) | (0.101) | (0.161) | (0.099) | (0.054) | (0.056) | ||
| 100% | 48% | 100% | 100% | 99% | 100% | 100% | 100% | ||
| (20,400) | 0.419 | 1.131 | 0.423 | 0.367 | 0.552 | 0.433 | 0.290 | 0.318 | |
| (0.072) | (0.175) | (0.073) | (0.05) | (0.1) | (0.062) | (0.051) | (0.039) | ||
| I-2-(b) | 100% | 56% | 100% | 97% | 98% | 100% | 99% | 99% | |
| (10,200) | 0.552 | 1.135 | 0.558 | 0.477 | 0.627 | 0.504 | 0.288 | 0.379 | |
| (0.111) | (0.143) | (0.109) | (0.147) | (0.139) | (0.107) | (0.097) | (0.11) | ||
| 100% | 56% | 100% | 100% | 100% | 100% | 100% | 100% | ||
| (20,400) | 0.570 | 1.161 | 0.576 | 0.469 | 0.658 | 0.534 | 0.337 | 0.391 | |
| (0.072) | (0.121) | (0.072) | (0.066) | (0.089) | (0.07) | (0.049) | (0.054) |
| Model | FOLS | FPHD | FIHT | FSIR | FSAVE | FDR | FOPG | WIRE | |
|---|---|---|---|---|---|---|---|---|---|
| I-3 | 100% | 13% | 100% | 100% | 75% | 99% | 100% | 93% | |
| (10,200) | 0.269 | 1.150 | 0.269 | 0.342 | 0.741 | 0.408 | 0.242 | 0.311 | |
| (0.05) | (0.11) | (0.051) | (0.067) | (0.303) | (0.117) | (0.047) | (0.199) | ||
| 100% | 11% | 100% | 100% | 96% | 100% | 100% | 100% | ||
| (20,400) | 0.279 | 1.165 | 0.279 | 0.333 | 0.674 | 0.407 | 0.259 | 0.273 | |
| (0.046) | (0.092) | (0.046) | (0.061) | (0.177) | (0.071) | (0.042) | (0.045) | ||
| I-4 | 100% | 39% | 100% | 100% | 69% | 99% | 99% | 67% | |
| (10,200) | 0.383 | 1.303 | 0.384 | 0.431 | 0.897 | 0.535 | 0.311 | 0.583 | |
| (0.08) | (0.172) | (0.08) | (0.104) | (0.248) | (0.136) | (0.104) | (0.322) | ||
| 100% | 47% | 100% | 100% | 86% | 99% | 100% | 95% | ||
| (20,400) | 0.408 | 1.349 | 0.409 | 0.443 | 0.843 | 0.536 | 0.328 | 0.419 | |
| (0.072) | (0.152) | (0.072) | (0.078) | (0.234) | (0.106) | (0.048) | (0.156) |
For Model I-1 and Model I-2, the best performer FOPG achieves 100% correct order determination percentage and enjoys the smallest estimation error. The moment-based ensemble methods are slightly less accurate than FOPG. Compared with the benchmark, all methods can successfully estimate the true central subspace except FPHD. Compared to the results from predictor settings (a) and (b), we see that most moment-based methods and inverse-regression-based methods have larger estimation error and less percentage of correct order determination under setting (b), but FOPG, which is free from the elliptical assumption of predictors, still give the most precise estimation. Overall, the correlation between predictors and non-ellipticity does not affect the results much compared with the benchmark error. In Model I-3 and Model I-4, there exist directions in the central subspace but not contained in the conditional Fréchet mean. In these cases, the best performer is still FOPG.
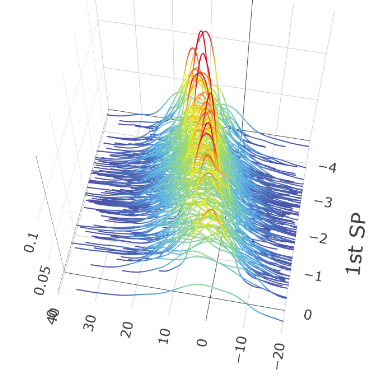
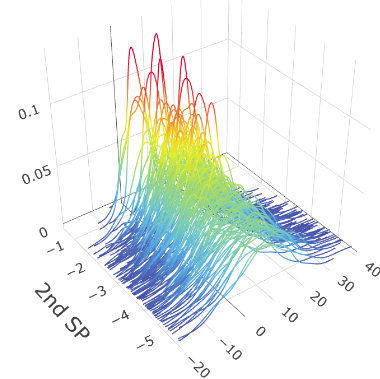
We also show the plots of versus the sufficient predictors obtained by FOPG for Model I-3. From Figure 2, we see a strong relation between and the first two estimated sufficient predictors and , compared with versus individual predictor . We also observe that the first sufficient predictor captures the location variation and the second sufficient predictor captures the scale variation.
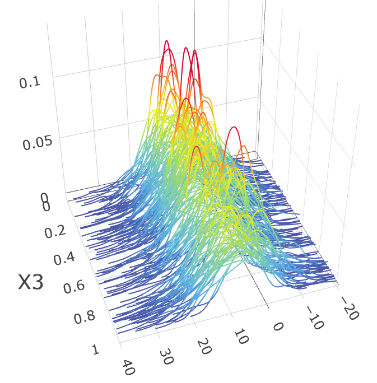

6.3 Scenario II: Fréchet SDR for positive definite matrices
Let be the space endowed with Frobenius distance . To accommodate the anatomical intersubject variability, Schwartzman (2006) introduced the symmetric matrix variate Normal distributions. We adopt this distribution to construct the regression model with correlation matrix response. We say that has the standard symmetric matrix variate Normal distribution if it has density with respect to Lebesgue measure on . As pointed out in Schwartzman (2006), this definition is equivalent to a symmetric matrix with independent diagonal elements and off-diagonal elements. We say has symmetric matrix variate Normal distribution if where , is a non-singular matrix, and . As a special case, we say if .
We generate predictors as in settings (a) and (b) in of Scenario II. We generate following , where is the matrix logarithm defined in Section 3, and is specified by the following models:
-
II-1:, where .
-
II-2: , where and .
In Model II-1, and ; in Model II-2, and . We note that is not necessarily the Fréchet conditional mean of given , but it still measures the central tendency of the conditional distribution . We also compare performances of the CMS ensemble methods and CS ensemble methods, with . The experiments are repeated 100 times. The proportion of correct identification of order and the means and standard deviations of estimation errors are summarized in Table 3.
| Model | FOLS | FPHD | FIHT | FSIR | FSAVE | FDR | FOPG | WIRE | |
|---|---|---|---|---|---|---|---|---|---|
| II-1-(a) | 100% | 68% | 100% | 100% | 91% | 99% | 100% | 100% | |
| (10,200) | 0.153 | 0.836 | 0.153 | 0.158 | 0.264 | 0.159 | 0.150 | 0.150 | |
| (0.043) | (0.296) | (0.043) | (0.037) | (0.245) | (0.095) | (0.04) | (0.041) | ||
| 100% | 69% | 100% | 100% | 89% | 99% | 100% | 100% | ||
| (20,400) | 0.160 | 0.905 | 0.160 | 0.169 | 0.283 | 0.165 | 0.151 | 0.158 | |
| (0.029) | (0.267) | (0.029) | (0.026) | (0.262) | (0.088) | (0.026) | (0.028) | ||
| II-1-(b) | 97% | 64% | 97% | 95% | 53% | 64% | 93% | 98% | |
| (10,200) | 0.248 | 1.017 | 0.249 | 0.276 | 0.726 | 0.525 | 0.251 | 0.218 | |
| (0.154) | (0.276) | (0.155) | (0.186) | (0.342) | (0.387) | (0.219) | (0.133) | ||
| 100% | 54% | 100% | 97% | 43% | 63% | 98% | 100% | ||
| (20,400) | 0.233 | 1.117 | 0.233 | 0.252 | 0.779 | 0.533 | 0.216 | 0.213 | |
| (0.049) | (0.247) | (0.049) | (0.144) | (0.349) | (0.388) | (0.121) | (0.045) | ||
| II-2-(a) | 100% | 19% | 100% | 99% | 78% | 99% | 100% | 100% | |
| (10,200) | 0.295 | 1.185 | 0.295 | 0.310 | 0.619 | 0.371 | 0.149 | 0.293 | |
| (0.085) | (0.139) | (0.085) | (0.113) | (0.293) | (0.133) | (0.034) | (0.084) | ||
| 100% | 24% | 100% | 100% | 81% | 100% | 100% | 100% | ||
| (20,400) | 0.312 | 1.231 | 0.312 | 0.325 | 0.626 | 0.382 | 0.181 | 0.311 | |
| (0.065) | (0.155) | (0.065) | (0.064) | (0.233) | (0.084) | (0.032) | (0.065) | ||
| II-2-(b) | 100% | 32% | 100% | 100% | 60% | 76% | 100% | 100% | |
| (10,200) | 0.675 | 1.461 | 0.675 | 0.697 | 1.193 | 0.920 | 0.245 | 0.671 | |
| (0.183) | (0.195) | (0.183) | (0.186) | (0.246) | (0.249) | (0.071) | (0.182) | ||
| 100% | 43% | 100% | 100% | 57% | 90% | 100% | 100% | ||
| (20,400) | 0.697 | 1.492 | 0.697 | 0.714 | 1.253 | 0.936 | 0.331 | 0.694 | |
| (0.136) | (0.182) | (0.136) | (0.13) | (0.206) | (0.208) | (0.075) | (0.137) |
We conclude that all ensemble methods give reasonable estimation except FPHD. FOPG performs best in all settings except Model II-1-(b). To illustrate the relation between the response and estimated sufficient predictor , we adopt the ellipsoidal representation of SPD matrices. Each can be associated with an ellipsoid centered at the origin . Figure 3 plots the responses ellipsoid versus the estimated sufficient predictor in panel (a), compared with the responses versus predictor for Model II-1-(a). We can tell a clear pattern of change in shape and rotation of response ellipsoids versus .
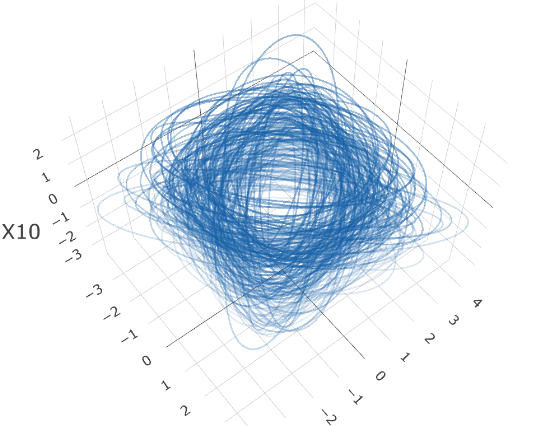
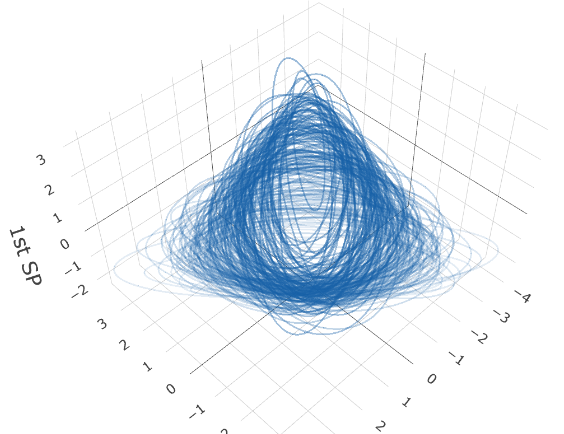
7 Application to the Human Mortality Data
This section presents an application concerning human life spans. Another application concerning intracerebral hemorrhage is presented in Section S.6 of the Supplementary Material.
Compared with summary statistics such as the crude death rate, viewing the entire age-at-death distributions as data objects gives us a more comprehensive understanding of human longevity and health conditions. Mortality distributions are affected by many factors, such as economics, the health care system, as well as social and environmental factors. To investigate the potential factors that are related to the mortality distributions across different countries, we collect nine predictors listed below, covering demography, economics, labor market, nutrition, health, and environmental factors in 2015: (1) Population Density: population per square Kilometer; (2) Sex Ratio: number of males per 100 females in the population; (3) Mean Childbearing Age: the average age of mothers at the birth of their children; (4) Gross Domestic Product (GDP) per Capita; (5) Gross Value Added (GVA) by Agriculture: the percentage of agriculture, hunting, forestry, and fishing activities of gross value added, (6) Consumer price index: treat 2010 as the base year; (7) Unemployment Rate; (8) Expenditure on Health (percentage of GDP); (9) Arable Land (percentage of total land area). The data are collected from United Nation Databases (http://data.un.org/) and UN World Population Prospects 2019 Databases (https://population.un.org/wpp/Download). For each country and age, the life table contains the number of deaths aggregated every 5 years. We treat these data as histograms of the number of deaths at age, with bin widths equal to 5 years. We smooth the histograms for the 162 countries in 2015 using the ‘frechet’ package available at (https://cran.r-project.org/web/packages/frechet/index.html) to obtain smoothed probability density functions. We then calculate the Wasserstein distances between them.
We use Gaussian kernel , where is taken according to (6) in Section 6.1. We standardize all covariates separately, then use the predictor augmentation method combined with FOPG to estimate the dimension of the Fréchet central subspace. The estimated dimension of the Fréchet central subspace is . The first three directions obtained by FOPG are
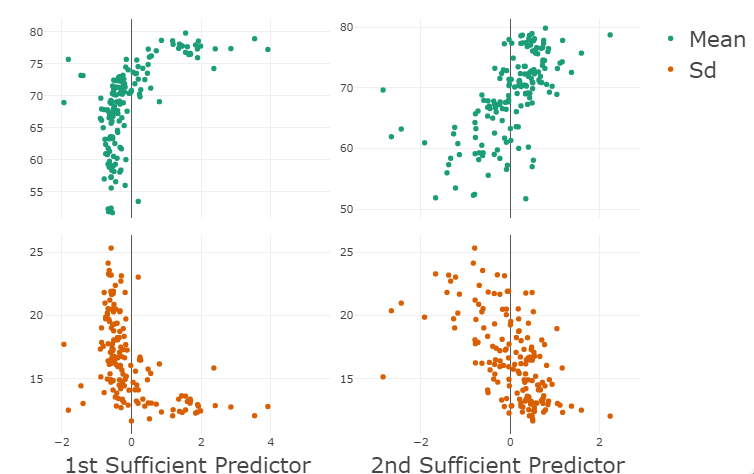
A plot of mortality densities versus the first sufficient predictor is shown in Figure 4(a). Clear and useful patterns emerge from Figure 4(a): the mode of the mortality distribution shifts from right to left (with left indicating a longer life span) as the value of the first sufficient predictor increases. Moreover, there is a significant uptick at the right-most end as the first sufficient predictor decreases, indicating high infant mortality. Meanwhile, the loadings of the first sufficient predictor are strongly positive for the GDP per capita, which indicates the levels of economic development and health care of a country, with larger values associated with more developed countries and smaller values associated with less developed countries. From Figure 4(b), we see that the mean of the mortality distribution increases and the standard deviation decreases with the value of the first sufficient predictor. This also makes sense: the mean life span increases with the level of development, consistent with Figure 4(a). The standard deviation decreases with the first predictor because, as the development level increases, the life span is increasingly concentrated on the high values. Moreover, the high mortality in the lower region of the first sufficient predictor also contributes to the larger standard deviation in this region. The plots of mean and standard deviation versus the second sufficient predictor in Figure 4(b) also indicate an increase in mean and a decrease in standard deviation as the value of the second sufficient predictor increases.
8 Discussion
In the classical regression setting, sufficient dimension reduction has been used as a tool for exploratory data analysis, regression diagnostics, and a mechanism to overcome the curse of dimensionality in regression. As a regression tool, it can help us to effectively treat collinearity in the predictor, detect heteroscedasticity in the response, find the most important linear combinations of predictors, and understand the general shape of the regression surface without fitting an elaborate regression model. All the above items can be revealed by the sufficient plot, where the response is plotted against the sufficient predictors obtained by SDR. Also, because the direction of a vector is an easier target to estimate than the vector itself, it helps us to mitigate the effect of the curse of dimensionality usually accompanying high-dimensional regression. In the same vein, it is easier to estimate a subspace than a specific set of vectors that span the subspace.
Although regression with a metric-space valued random object is a new problem, as a regression problem, it shares the same set of issues, such as the need for exploratory analysis before regression, for model diagnostics after the regression, and for mitigating the curse of dimensionality. As shown in Figure 1 in the paper, the first sufficient predictor clearly reveals useful information about a general trend of mortality distributions among countries. At the lower end of the sufficient predictor, the mortality distribution shifts towards higher longevity, whereas at the high end of the sufficient predictor, the mortality distribution shifts towards low longevity, with a visible uptick near age 0, which is caused by infant mortality.
The proposed methodology is very flexible and versatile: it can be used to turn any existing SDR method into one that can deal with the metric-space-valued response variable. Furthermore, it applies to any separable and complete metric space of negative type with an explicit CMS ensemble. It significantly broadens the current field of sufficient dimension reduction and provides a useful set of tools for Fréchet regression.
References
- (1)
- Ambrosio et al. (2004) Ambrosio, L., Gigli, N. & Savaré, G. (2004), ‘Gradient flows with metric and differentiable structures, and applications to the wasserstein space’, Atti Accad. Naz. Lincei Cl. Sci. Fis. Mat. Natur. Rend. Lincei (9) Mat. Appl 15(3-4), 327–343.
- Bigot et al. (2017) Bigot, J., Gouet, R., Klein, T. & López, A. (2017), ‘Geodesic pca in the wasserstein space by convex pca’, Annales de l’Institut Henri Poincaré, Probabilités et Statistiques 53, 1–26.
- Chen et al. (2021) Chen, Y., Lin, Z. & Müller, H.-G. (2021), ‘Wasserstein regression’, J. Amer. Statist. Assoc. .
- Christmann & Steinwart (2010) Christmann, A. & Steinwart, I. (2010), Universal kernels on non-standard input spaces, in ‘in Advances in Neural Information Processing Systems’, pp. 406–414.
- Cook (1996) Cook, R. D. (1996), ‘Graphics for regressions with a binary response’, J. Amer. Statist. Assoc 91, 983–992.
- Cook & Li (2002) Cook, R. D. & Li, B. (2002), ‘Dimension reduction for conditional mean in regression’, The Annals of Statistics 30(2), 455–474.
- Cook & Weisberg (1991) Cook, R. D. & Weisberg, S. (1991), ‘Sliced inverse regression for dimension reduction: Comment’, Journal of the American Statistical Association 86(414), 328–332.
- Ding & Cook (2015) Ding, S. & Cook, R. D. (2015), ‘Tensor sliced inverse regression’, J. Multivar. Anal. 133, 216–231.
- Dubey & Müller (2019) Dubey, P. & Müller, H.-G. (2019), ‘Fréchet analysis of variance for random objects’, Biometrika 106(4), 803–821.
- Dubey & Müller (2020) Dubey, P. & Müller, H.-G. (2020), ‘Fréchet change-point detection’, Ann. Stat. 48(6), 3312–3335.
- Eaton (1986) Eaton, M. L. (1986), ‘A characterization of spherical distributions’, J. Multivar. Anal. 20(2), 272–276.
- Fan et al. (2017) Fan, J., Xue, L. & Yao, J. (2017), ‘Sufficient forecasting using factor models’, Journal of Econometrics 201(2), 292–306.
- Feragen et al. (2015) Feragen, A., Lauze, F. & Hauberg, S. (2015), Geodesic exponential kernels: when curvature and linearity conflict, in ‘Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition’, pp. 3032–3042.
- Ferré & Yao (2003) Ferré, L. & Yao, A.-F. (2003), ‘Functional sliced inverse regression analysis’, Statistics 37(6), 475–488.
- Ferreira & Busatto (2013) Ferreira, L. K. & Busatto, G. F. (2013), ‘Resting-state functional connectivity in normal brain aging’, Neuroscience & Biobehavioral Reviews 37(3), 384–400.
- Fournier & Guillin (2015) Fournier, N. & Guillin, A. (2015), ‘On the rate of convergence in wasserstein distance of the empirical measure’, Probability Theory and Related Fields 162(3-4), 707–738.
- Fréchet (1948) Fréchet, M. (1948), ‘Les éléments aléatoires de nature quelconque dans un espace distancié’, Annales de l’Institut Henri Poincaré p. 215–310.
- Granirer (1970) Granirer, E. E. (1970), ‘Probability measures on metric spaces. by k. r. parthasarathy. academic press, new york and london (1967). x 276 pp.’, Canadian Mathematical Bulletin 13(2), 290–291.
- Hall & Li (1993) Hall, P. & Li, K.-C. (1993), ‘On almost linearity of low dimensional projections from high dimensional data’, The Annals of Statistics pp. 867–889.
- Honeine & Richard (2010) Honeine, P. & Richard, C. (2010), The angular kernel in machine learning for hyperspectral data classification, in ‘2010 2nd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing’, IEEE, pp. 1–4.
- Hsing & Ren (2009) Hsing, T. & Ren, H. (2009), ‘An rkhs formulation of the inverse regression dimension-reduction problem’, The Annals of Statistics 37(2), 726–755.
- Jayasumana et al. (2013) Jayasumana, S., Hartley, R., Salzmann, M., Li, H. & Harandi, M. (2013), Combining multiple manifold-valued descriptors for improved object recognition, in ‘2013 International Conference on Digital Image Computing: Techniques and Applications (DICTA)’, IEEE, pp. 1–6.
- Lee et al. (2013) Lee, K.-Y., Li, B. & Chiaromonte, F. (2013), ‘A general theory for nonlinear sufficient dimension reduction: Formulation and estimation’, The Annals of Statistics 41(1), 221–249.
- Lei (2020) Lei, J. (2020), ‘Convergence and concentration of empirical measures under wasserstein distance in unbounded functional spaces’, Bernoulli 26(1), 767–798.
- Li (2018) Li, B. (2018), Sufficient Dimension Reduction: Methods and Applications with R, CRC Press.
- Li et al. (2010) Li, B., Kim, M. K. & Altman, N. (2010), ‘On dimension folding of matrix-or array-valued statistical objects’, The Annals of Statistics 38(2), 1094–1121.
- Li & Song (2017) Li, B. & Song, J. (2017), ‘Nonlinear sufficient dimension reduction for functional data’, The Annals of Statistics 45(3), 1059–1095.
- Li & Wang (2007) Li, B. & Wang, S. (2007), ‘On directional regression for dimension reduction’, Journal of the American Statistical Association 102(479), 997–1008.
- Li & Yin (2007) Li, B. & Yin, X. (2007), ‘On surrogate dimension reduction for measurement error regression: an invariance law’, The Annals of Statistics 35(5), 2143–2172.
- Li et al. (2005) Li, B., Zha, H. & Chiaromonte, F. (2005), ‘Contour regression: a general approach to dimension reduction’, The Annals of Statistics 33(4), 1580–1616.
- Li (1991) Li, K.-C. (1991), ‘Sliced inverse regression for dimension reduction’, J. Amer. Statist. Assoc 86, 316–327.
- Li (1992) Li, K.-C. (1992), ‘On principal hessian directions for data visualization and dimension reduction: Another application of stein’s lemma’, Journal of the American Statistical Association 87(420), 1025–1039.
- Li & Duan (1989) Li, K.-C. & Duan, N. (1989), ‘Regression analysis under link violation’, Ann. Stat. 17(3), 1009–1052.
- Luo & Li (2016) Luo, W. & Li, B. (2016), ‘Combining eigenvalues and variation of eigenvectors for order determination’, Biometrika 103(4), 875–887.
- Luo & Li (2021) Luo, W. & Li, B. (2021), ‘On order determination by predictor augmentation’, Biometrika 108(3), 557–574.
- Luo et al. (2021) Luo, W., Xue, L., Yao, J. & Yu, X. (2021), ‘Inverse moment methods for sufficient forecasting using high-dimensional predictors’, Biometrika 109(2), 473––487.
- Micchelli et al. (2006) Micchelli, C. A., Xu, Y. & Zhang, H. (2006), ‘Universal kernels.’, J. Mach. Learn. Res. 7(12), 2651–2667.
- Panaretos & Zemel (2020) Panaretos, V. M. & Zemel, Y. (2020), An Invitation to Statistics in Wasserstein Space, Springer Nature.
- Parzen (1979) Parzen, E. (1979), ‘Nonparametric statistical data modeling’, J. Amer. Statist. Assoc. 74(365), 105–121.
- Petersen & Müller (2016) Petersen, A. & Müller, H.-G. (2016), ‘Functional data analysis for density functions by transformation to a hilbert space’, The Annals of Statistics 44(1), 183–218.
- Petersen & Müller (2019) Petersen, A. & Müller, H.-G. (2019), ‘Fréchet regression for random objects with euclidean predictors’, The Annals of Statistics 47(2), 691–719.
- Schwartzman (2006) Schwartzman, A. (2006), Random ellipsoids and false discovery rates: Statistics for diffusion tensor imaging data, PhD thesis, Stanford University.
- Sriperumbudur et al. (2011) Sriperumbudur, B. K., Fukumizu, K. & Lanckriet, G. R. (2011), ‘Universality, characteristic kernels and rkhs embedding of measures.’, Journal of Machine Learning Research 12(7), 2389–2410.
- Steinwart (2001) Steinwart, I. (2001), ‘On the influence of the kernel on the consistency of support vector machines’, Journal of Machine Learning Research 2(Nov), 67–93.
- Xia (2007) Xia, Y. (2007), ‘A constructive approach to the estimation of dimension reduction directions’, The Annals of Statistics 35(6), 2654–2690.
- Xia et al. (2002) Xia, Y., Tong, H., Li, W. K. & Zhu, L.-X. (2002), ‘An adaptive estimation of dimension reduction space (with discussion)’, Journal of the Royal Statistical Society. Series B 64(3), 363–410.
- Ye & Weiss (2003) Ye, Z. & Weiss, R. E. (2003), ‘Using the bootstrap to select one of a new class of dimension reduction methods’, Journal of the American Statistical Association 98(464), 968–979.
- Yin & Li (2011) Yin, X. & Li, B. (2011), ‘Sufficient dimension reduction based on an ensemble of minimum average variance estimators’, The Annals of Statistics 39(6), 3392–3416.
- Yin et al. (2008) Yin, X., Li, B. & Cook, R. D. (2008), ‘Successive direction extraction for estimating the central subspace in a multiple-index regression’, Journal of Multivariate Analysis 99(8), 1733–1757.
- Ying & Yu (2022) Ying, C. & Yu, Z. (2022), ‘Fréchet sufficient dimension reduction for random objects’, Biometrika, in press .
- Yu et al. (2020) Yu, X., Yao, J. & Xue, L. (2020), ‘Nonparametric estimation and conformal inference of the sufficient forecasting with a diverging number of factors’, J. Bus. Econ. Stat. 40(1), 342–354.
- Zhu et al. (2006) Zhu, L., Miao, B. & Peng, H. (2006), ‘On sliced inverse regression with high-dimensional covariates’, Journal of the American Statistical Association 101(474), 630–643.