[columns=3, title=Alphabetical Index, intoc]
DiRe Committee : Diversity and Representation Constraints in Multiwinner Elections
Abstract
The study of fairness in multiwinner elections focuses on settings where candidates have attributes. However, voters may also be divided into predefined populations under one or more attributes (e.g., “California” and “Illinois” populations under the “state” attribute), which may be same or different from candidate attributes. The models that focus on candidate attributes alone may systematically under-represent smaller voter populations. Hence, we develop a model, DiRe Committee Winner Determination (DRCWD), which delineates candidate and voter attributes to select a committee by specifying diversity and representation constraints and a voting rule. We analyze its computational complexity, inapproximability, and parameterized complexity. We develop a heuristic-based algorithm, which finds the winning DiRe committee in under two minutes on 63% of the instances of synthetic datasets and on 100% of instances of real-world datasets. We present an empirical analysis of the running time, feasibility, and utility traded-off.
Overall, DRCWD motivates that a study of multiwinner elections should consider both its actors, namely candidates and voters, as candidate-specific models can unknowingly harm voter populations, and vice versa. Additionally, even when the attributes of candidates and voters coincide, it is important to treat them separately as diversity does not imply representation and vice versa. This is to say that having a female candidate on the committee, for example, is different from having a candidate on the committee who is preferred by the female voters, and who themselves may or may not be female.
Keywords Fairness Multiwinner Elections Computational Social Choice
1 Introduction
The problem of selecting a committee from a given set of candidates arises in multiple domains; it ranges from political sciences (e.g., selecting the parliament of a country) to recommendation systems (e.g., selecting the movies to show on Netflix). Formally, given a set of candidates (politicians and movies, respectively), a set of voters (citizens and Netflix subscribers, respectively) give their ordered preferences over all candidates to select a committee of size . These preferences can be stated directly in case of parliamentary elections, or they can be derived based on input, such as when Netflix subscribers’ viewing behavior is used to derive their preferences. In this paper, we focus on selecting a -sized (fixed size) committee using direct, ordered, and complete preferences.
Which committee is selected depends on the committee selection rule, also called multiwinner voting rule. Examples of commonly used families of rules when a complete ballot of each voter is given are Condorcet principle-based rules [1], which select a committee that is at least as strong as every other committee in a pairwise majority comparison, approval-based voting rules [1, 2, 3] where each voter submits an approval ballot approving a subset of candidates, and ordinal preference ballot-based voting rules like k-Borda and -Chamberlin-Courant (-CC) [4, 5] that are analogous to single-winner rules. We note that this version of CC rule is different from the Chamberlin–Courant approval voting rule used in the context of approval elections [6, 7]. We refer readers to Section 2.2 of [5] for further details on the commonly used families of multiwinner voting rules. In this paper, we focus on ordinal preference-based rules that are analogous to single-winner rules.
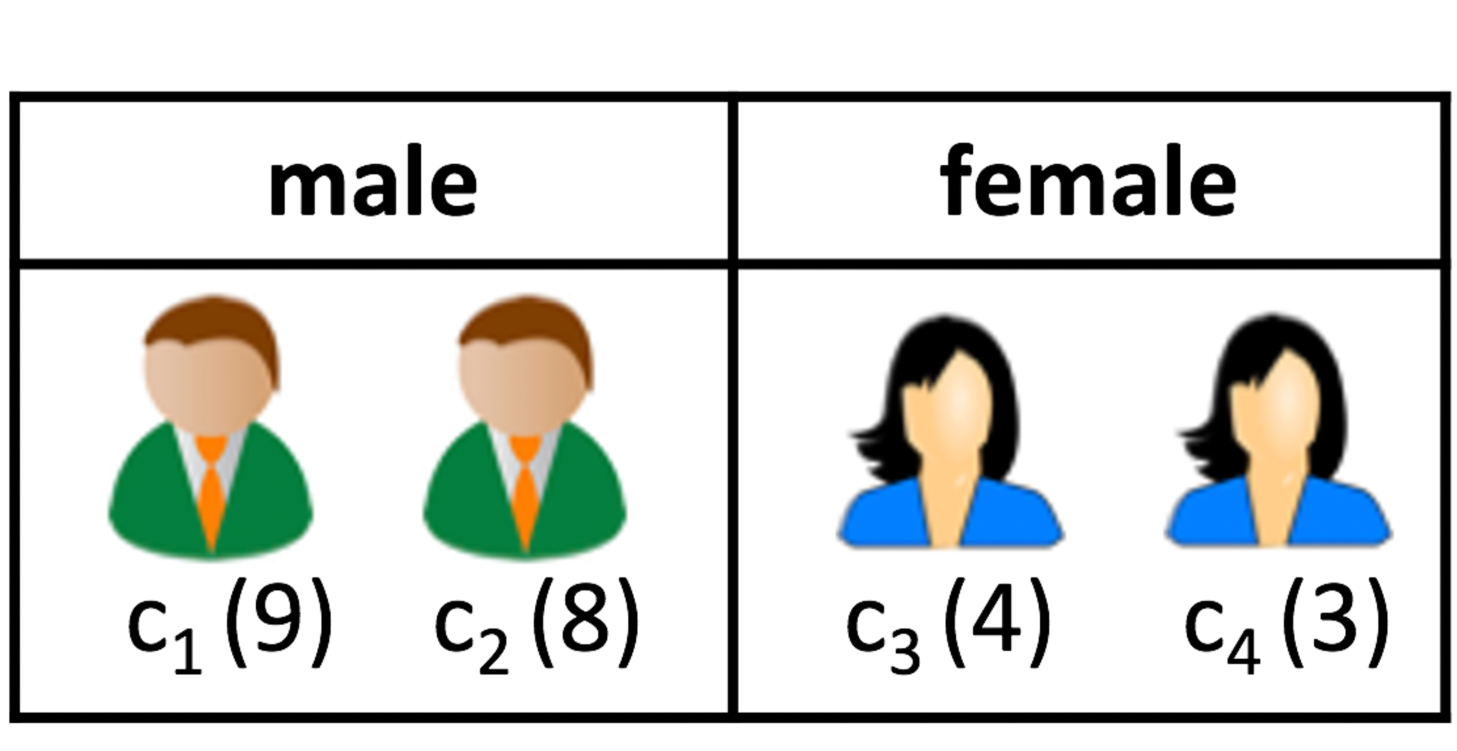
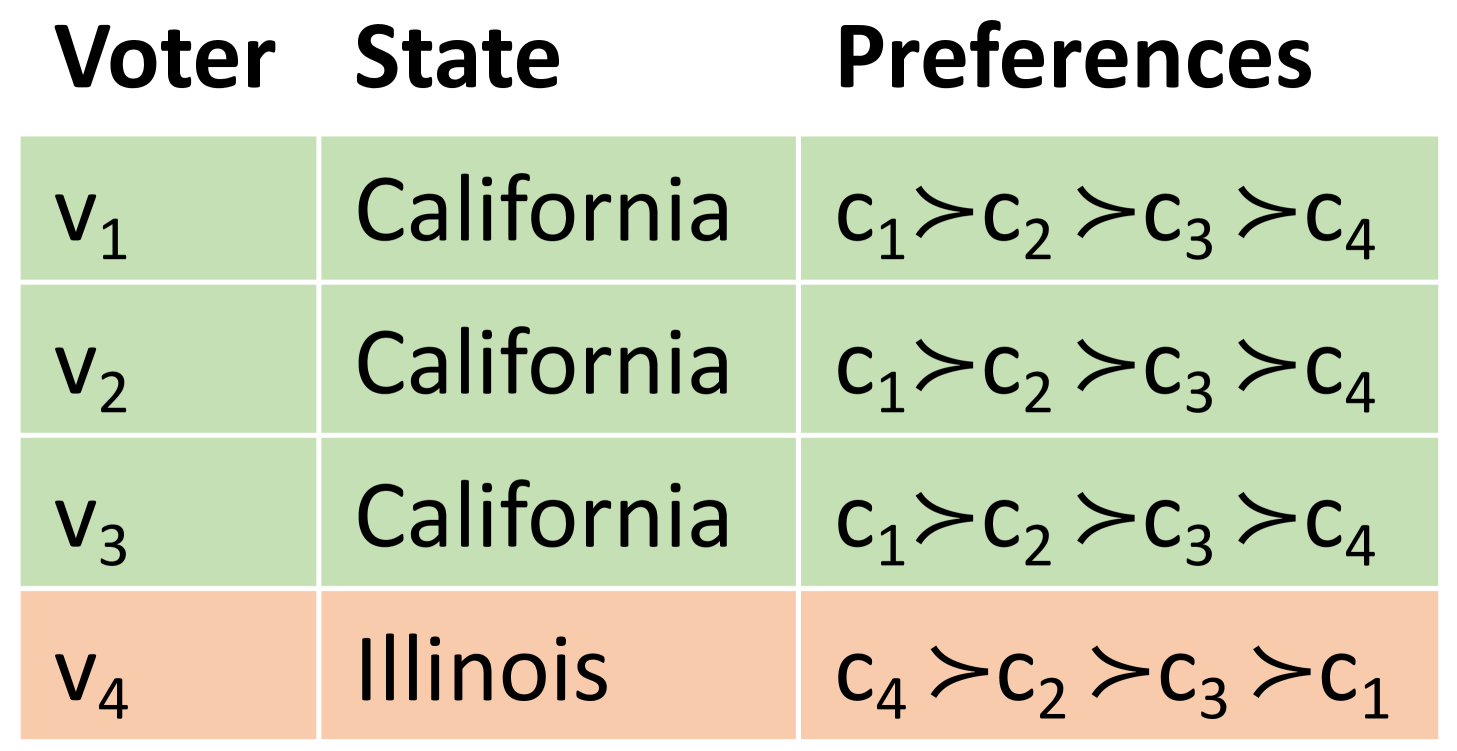
Recent work on fairness in multiwinner elections show that these rules can create or propagate biases by systematically harming candidates coming from historically disadvantaged groups [8, 9]. Hence, diversity constraints on candidate attributes were introduced to overcome this problem. However, voters may be divided into predefined populations under one or more attributes, which may be different from candidate attributes. For example, voters in Figure 1(b) are divided into “California” and “Illinois” populations under the “state” attribute. The models that focus on candidate attributes alone may systematically under-represent smaller voter populations.
Example 1.
Consider an election consisting of = 4 candidates (Figure 1(a)) and = 4 voters giving ordered preference over candidates (Figure 1(b)) to select a committee of size = 2. Candidates and voters have one attribute each, namely gender and state, respectively. The -Borda111The Borda rule associates score with the position, and -Borda selects candidates with the highest Borda score. winning committee computed for each voter population is , for California and , for Illinois.
Suppose that we impose a diversity constraint that requires the committee to have at least one candidate of each gender, and a representation constraint that requires the committee to have at least one candidate from the winning committee of each state. Observe that the highest-scoring committee, which is also representative, consists of , (score = 17), but this committee is not diverse, since both candidates are male. Further, the highest-scoring diverse committee consisting of , (score = 13) is not representative because it does not include any winning candidates from Illinois, the smaller state. The highest-scoring diverse and representative committee is , (score = 12).
This example illustrates the inevitable utility cost due to enforcing of additional constraints.
Note that, in contrast to prior work in computational social choice, we incorporate voter attributes that are separate from candidate attributes. Also, our work is different from the notion of “proportional representation” [3, 10, 11], where the number of candidates selected in the committee from each group is proportional to the number of voters preferring that group, and from its variants such as “fair” representation [12]. All these approaches dynamically divide the voters based on the cohesiveness of their preferences. Another related work, multi-attribute proportional representation [13], couples candidate and voter attributes. An important observation we make here is that, even if the attributes of the candidates and of the voters coincide, it may still be important to treat them separately in committee selection. This is because having a female candidate on the committee, for example, is different from having a candidate on the committee who is preferred by the female voters, and who themselves may or may not be female.
Contributions. In this paper, we define a model that treats candidate and voter attributes separately during committee selection, and thus enables selection of the highest-scoring diverse and representative committee. We show NP-hardness of committee selection under our model for various settings, give results on inapproximability and parameterized complexity, and present a heuristic-based algorithm. Finally, we present an experimental evaluation using real and synthetic datasets, in which we show the efficiency of our algorithm, analyze the feasibility of committee selection and illustrate the utility trade-offs.
2 Related Work
Our work is at an intersection of multiple ideas, and hence, in this section, we briefly summarize the related work spread across different domains, some of which we already discussed in the previous section.
Fairness in Ranking and Set Selection.
There is a growing understanding in the field of theoretical computer science about the possible presence of algorithmic bias in multiple domains [14, 15, 16, 17, 18, 19], especially in variants of set selection problem [20]. The study of fairness in ranking and set selection, closely related to the study of multiwinner elections, use constraints in algorithms to mitigate bias caused against historically disadvantaged groups. Stoyanovich et al. [20] use constraints in streaming set selection problem, and Yang and Stoyanovich [21] and Yang et al. [22] use constraints for ranked outputs. Kuhlman and Rundensteiner [23] focus on fair rank aggregation and Bei et al. [24] use proportional fairness constraints. Our work adds to the research on the use of constraints to mitigate algorithmic bias.
Fairness in Participatory Budgeting.
Multiwinner elections are a special case of participatory budgeting, and fairness in the latter domain has also received particular attention. For example, projects (equivalent to candidates) are divided into groups and for fairness they consider lower and upper bounds on utility achieved and the lower and upper bounds on cost of projects used in every group [25]. Fluschnik et al. [26] aim to achieve fairness among projects using their objective function. Next, Hershkowitz et al. [27] have studied fairness from the utility received by the districts (equivalent to voters), Peters et al. [28] define axioms for proportional representation of voters, and Lackner et al. [29] define fairness in long-term participatory budgeting from voters’ perspective. However, we note that none of these work simultaneously consider fairness from the perspective of both, the projects and the districts.
Two-sided Fairness.
The need for fairness from the perspective of different stakeholders of a system is well-studied. For instance, Patro et al. [30], Chakraborty et al. [31], and Suhr et al. [32] consider two-sided fairness in two-sided platforms222A two-sided platform is an intermediary economic platform having two distinct user groups that provide each other with network benefits such that the decisions of each set of user group affects the outcomes of the other set [33]. For example, credit cards market consists of cardholders and merchants and health maintenance organizations consists of patients and doctors. and Abdollahpouriet al. [34] and Burke et al. [35] shared desirable fairness properties for different categories of multi-sided platforms. However, this line of work focuses on multi-sided fairness in multi-sided platforms, which is technically different from an election. An election, roughly speaking, can be considered a “one-sided platform” consisting of more than one stakeholders as during an election, candidates do not make decisions that affect the voters. Hence, -sided fairness in one-sided platform is also needed where is the number of distinct user-groups on the platform. More generally, -sided fairness in -sided platform warrants an analysis of perspectives of fairness, i.e., the effect of fairness on each of the stakeholders for each of the fairness metrics being used. In elections, (candidates and voters) and (voting). Additionally, Aziz [36] summarized a line of work related to diversity concerns in two-sided matching that focused on diversity with respect to one stakeholder only.
Unconstrained Multiwinner Elections and Proportional Representation.
The study of complexity of unconstrained multiwinner elections has received attention [5]. Selecting a committee using Chamberlin-Courant (CC) [37] rule is NP-hard [38], and approximation algorithms have resulted in the best known ratio of [39, 40]. Yang and Wang [41] studied its parameterized complexity. Another commonly studied rule, Monroe [11], is also NP-hard [42, 4]. Sonar et al. [43] showed that even checking whether a given committee is optimal when using these two rules is hard. Finally, the hardness of problems involving restricted voter preferences and committee selection rule have been studied [44, 45] and so has the proportional representation in dynamic ranking [46].
Constrained Multiwinner Elections.
The study of complexity of using diversity constraints in elections and its complexity has also received particular attention. Goalbase score functions, which specify an arbitrary set of logic constraints and let the score capture the number of constraints satisfied, could be used to ensure diversity [47]. Using diversity constraints over multiple attributes in single-winner elections is NP-hard [13]. Also, using diversity constraints over multiple attributes in multiwinner elections is NP-hard, which has led to approximation algorithms and matching hardness of approximation results by Bredereck et al. [8] and Celis et al. [9]. Finally, due to the hardness of using diversity constraints over multiple attributes in approval-based multiwinner elections [48], these have been formalized as integer linear programs (ILP) [49]. In contrast, Skowron et al. [39] showed that ILP-based algorithms fail in real world when using ranked voting-related proportional representation rules like Chamberlin-Courant and Monroe rules, even when there are no constraints.
Overall, the work by Bredereck et al. [8], Celis et al. [9], and Lang and Skowron [13] is closest to ours. However, we differ as we: (i) consider elections with predefined voter populations under one or more attributes, (ii) delineate voter and candidate attributes even when they coincide, and (iii) consider representation and diversity constraints. No previous work, to the best of our knowledge, has considered fairness from the perspective of voter attributes or has delineated candidate and voter attributes even when they coincide.
3 Preliminaries and Notation
Multiwinner Elections.
Let be an election consisting of a candidate set and a voter set , where each voter has a preference list over candidates, ranking all of the candidates from the most to the least desired. denotes the position of candidate in the ranking of voter , where the most preferred candidate has position 1 and the least preferred has position .
Given an election and a positive integer (for , we write ), a multiwinner election selects a -sized subset of candidates (or a committee) using a multiwinner voting rule (discussed later) such that the score of the committee is the highest. Formally, given and , outputs the required committee of exactly candidates with the highest score. We assume ties are broken using a pre-decided priority order over all candidates.
Candidate Groups.
The candidates have attributes, , such that and . Each attribute , for all , partitions the candidates into groups, . Formally, , . For example, candidates in Figure 1(a) have one attribute gender ( = 1) with two disjoint groups, male and female ( = 2). Overall, the set of all such arbitrary and potentially non-disjoint groups will be . Note that the number of groups a candidate belongs to is equal to the number of attributes .
Voter Populations.
The voters have attributes, , such that and . The voter attributes may be different from the candidate attributes. Each attribute , for all , partitions the voters into populations, . Formally, , . For example, voters in Figure 1(b) have one attribute state ( = 1), which has two populations California and Illinois ( = 2). Overall, the set of all such predefined and potentially non-disjoint populations will be .
The number of populations a voter belongs to is equal to the number of attributes . Additionally, we are given , the winning committee of each population . We note that a fine-grained accounting of representation is not possible in our model. This is because when a committee selection rule such as Chamberlin-Courant rule is used to determine each population’s winning committee , then a complete-ranking of each population’s collective preferences is not possible. Thus, we have design our model to only consider each population’s winning committee .
Multiwinner Voting Rules.
There are multiple types of multiwinner voting rules, also called committee selection rules. In this paper, we focus on committee selection rules that are based on single-winner positional voting rules, and are monotone and submodular ( and ) [8, 9].
Definition 1.
Chamberlin–Courant (CC) rule: The CC rule [37] associates each voter with a candidate in the committee who is their most preferred candidate in that committee. The score of a committee is the sum of scores given by voters to their associated candidate. Specifically, -CC uses Borda positional voting rule such that it assigns a score of to the ranked candidate who is their highest ranked candidate in the committee.
Definition 2.
Monroe rule: The Monroe rule [11] dynamically divides the voters into populations based on the cohesiveness of their preferences where = (assuming divides ). Then, each subpopulation’s most preferred candidate is selected into the -sized committee. Formally, for each population, say , select the candidate that has the highest score for that subpopulation: . In other words, each candidate in the committee is represented by an equal number of voters.
A special case of submodular functions are separable functions, which calculate the score of committee as follows: score of a committee is the sum of the scores of individual candidates in the committee. Formally, is separable if it is submodular and [8]. Monotone and separable selection rules are natural and are considered good when the goal of an election is to shortlist a set of individually excellent candidates [5]:
Definition 3.
-Borda rule The -Borda rule outputs committees of candidates with the highest Borda scores.
4 DiRe Committee Model
In this section, we formally define a model to select a diverse and representative committee, namely committee, and show its generality.
Definition 4.
Unconstrained Committee Winner Determination (UCWD): We are given a set of candidates, a set of voters such that each voter has a preference list over candidates, a committee selection rule , and a committee size . Let denote the family of all size- committees. The goal of UCWD is to select a committee that maximizes .
We now discuss the diversity and representation constraints. The lowest possible value that these constraints can take is 1, which replicates real-world scenarios. For instance, the United Nations charter guarantees at least one representative to each member country in the United Nations General Assembly, independent of the country’s population. Similarly, each state of the United States of America is guaranteed at least three representatives in the US House of Representatives. Hence, from fairness perspective, each candidate group and voter population deserves at least one candidate in the committee. Theoretically, all results in this paper hold even if the lowest possible value that the constraints can take is 0.
Diversity Constraints,
denoted by for each candidate group , enforces at least candidates from the group to be in the committee . Formally, for all , . We note that we do not propose to use the upper bounds as it induces quota system, which is not desirable from social choice perspective.
Representation Constraints,
denoted by for each voter population , enforces at least candidates from the population ’s committee to be in the committee . Formally, for all , . We again do not propose to use the upper bounds as it induces the undesirable quota system.
Definition 5.
()-DiRe Committee Feasibility ((, )-DRCF): We are given an instance of election , a committee size , a set of candidate groups over attributes and their diversity constraints for all , and a set of voter populations over attributes and their representation constraints and the winning committees for all . Let denote the family of all size- committees. The goal of (, )-DRCF is to select committees that satisfy the diversity and representation constraints such that for all and for all . All such committees that satisfy the constraints are called DiRe committees.
If a committee selection rule is also an input to the feasibility problem, we get the (, , )-DRCWD problem:
Definition 6.
(, )-DiRe Committee Winner Determination ((, , )-DRCWD): Given an instance of (, )-DRCF and a committee selection rule , let denote the family of all size- committees, then the goal of (, , )-DRCWD is to select a committee that maximizes the among all committees.
We note that we denote the possible values that and can take using parenthesis. For example, ‘(, 0, )-DRCWD’ implies that we are specifying a setting . We use the same notation for ‘’ such that ‘(, 0, )-DRCWD’ implies that we are specifying a setting . We use the same notation for .
Observation 1.
(, , )-DRCWD is a generalized version of (, )-DRCF and UCWD. Hence, if (, , )-DRCWD is polynomial time computable, then so are the corresponding UCWD and (, )-DRCF problems. If either UCWD is NP-hard or (, )-DRCF is NP-hard, then (, , )-DRCWD is NP-hard.
4.1 (, , )-DRCWD and Related Models
Our model provides the flexibility to specify the diversity and representation constraints and to select the voting rule. Thus, in this section we define the diverse committee problem [8, 9] and the apportionment problem [10, 50] as special cases of (, , )-DRCWD.
(, 0, )-DRCWD and Diverse Committee Problem.
We define the diverse committee problem in our model [8, 9]: In the diverse committee problem, we are given an instance of UCWD that consists of a set of candidate groups and the corresponding diversity constraints, lower bound and upper bound , for all . Let denote the family of all size- committees. The goal of the diverse committee problem is to select a committee that maximizes the among the committees that satisfy the constraints.
It is clear that (, 0, )-DRCWD, i.e., without the presence of any voter attributes, is equivalent to the diverse committee problem. As we do not use upper bounds, our model is generalizable when the upper bound in the diverse committee model is equal to the size of group for all and the minimum value that the lower bound can take is 1 for all . This is in line with the approach used in Theorem 6 of Celis et al. [9]. Formally, and for all .
(0, 1, )-DRCWD and Apportionment Problem.
We define the apportionment problem in our model [10]: In the apportionment problem, we are given an instance of UCWD that consists of a set of disjoint voter populations over one attribute and winning committees for all . Let denote the family of all size- committees. The goal of the apportionment problem is to select a committee that maximizes the among all the committees that satisfy the lower quota, i.e., , .
It is easy to see that (0, 1, )-DRCWD, which consists of zero candidate attributes and one voter attribute, is same as the apportionment problem if we set the representation constraint of each population to be equal to the lower quota of the apportionment problem. Formally, , = , realistically assuming that .
Finally, we note that our model can be adopted to accept approval votes as an input and thus if each population is completely cohesive within itself, then the representation constraints can be set to formulate known representation methods like proportional justified representation [3] and extended justified representation [6] as (, , )-DRCWD. Though we note that such reformulations may not be as straightforward as the discussed reformulations.
5 Complexity Results
| Instance of (, , )-DRCWD | Computational Complexity |
|---|---|
| (, , separable)-DRCWD | P (Lem. 1) |
| (, 0, separable)-DRCWD | NP-hard (Thm. 3, Thm. 4) |
| (, , separable)-DRCWD | NP-hard (Thm. 5, Cor. 2) |
| (, , submodular)-DRCWD | NP-hard (Thm. 6, Cor. 3) |
In this section, we give a classification of the computational complexity333The hardness, inapproximability, and parameterized complexity results throughout the paper are under the assumption P NP. of the (, , )-DRCWD problem under different settings. Finding a committee using a submodular scoring function like the utilitarian version of Chamberlin-Courant rule is known to be NP-hard [38] and selecting a diverse committee when a candidate belongs to three groups is also known to be NP-hard [8, 9]. However, the proofs of these hardness results are fragmented over several papers and the proofs use reductions from several well-known NP-hard problems. For instance, the proof of hardness for the use of Chamberlin-Courant uses a reduction from exact 3-cover [38] and the proof of hardness for computing a diverse committee uses a reduction from 3-dimensional matching [8] and 3-hypergraph matching [9]. Moreover, we are the first ones to introduce representation constraints and hardness due to its use is unknown. Hence, in this section, we provide a complete classification of the (, , )-DRCWD problem by giving a reduction from a single well-known NP-hard problem, namely, the vertex cover problem, inspired by the similar approach used in [51].
Finally, we note that as the following classification holds for every integer (specifically, every whole number as can not be negative) and every integer , our reductions are designed for the same range of values.
Theorem 1.
Let : and be a committee selection rule, then (, , )-DRCWD is NP-hard.
Corollary 1.
Classification of Complexity of (, , )-DRCWD.
-
1.
If , , and is a monotone, submodular function, then (, , )-DRCWD is NP-hard.
-
2.
If , , , and is a monotone, separable function, then (, , )-DRCWD is in P.
-
3.
If , , and is a monotone, separable function, then (, , )-DRCWD is NP-hard.
-
4.
If , , and is a monotone, separable function, then (, , )-DRCWD is NP-hard.
5.1 Tractable Case
Theorem 2.
[Theorem 21, Corollary 22 in full-version of Celis et al. [9]] The diverse committee feasibility problem can be solved in polynomial time when = 2.
Without loss of generality (W.l.o.g.), the above theorem holds when it is assumed that . Hence, it holds for all : 2. Therefore, based on the relationship between (, 0, )-DRCWD and Diverse Committee Problem (Section 4.1), we prove the following lemma, which in turn proves the statement in Corollary 1(2):
Lemma 1.
If , , , and is a monotone, separable function, then (, , )-DRCWD is in P.
Proof.
When =0, there are no voter attributes or representation constraints, and hence, the (, , )-DRCWD problem is equivalent to the diverse committee problem. Moreover, when is a monotone, separable function, then the complexity of the (, , )-DRCWD is equivalent to the complexity of (, )-DRCF. Thus, the polynomial time result of diverse committee feasibility problem when the number of groups a candidate belongs to is equal to two, which in our model implies that the number of candidate attributes is equal to two (), holds for our setting (Theorem 9 [8], Corollary 22 (full-version) [9]).
More specifically, when , we use the algorithm given in the proof of Theorem 21 by Celis et al. [9] and set the upper bound equal to the group size. Formally, for all .
Next, when , a straight-forward algorithm that selects the top scoring candidates for all results into a DiRe committee, which satisfies the diversity constraints . ∎
5.2 Hardness Results
NP-hard problem used.
As discussed earlier, the NP-hardness of (, , )-DRCWD when using representation constraints is unknown. Moreover, the known hardness results for using submodular but not separable scoring function and diverse committee selection problems were established via reductions from different NP-hard problems. We will establish the NP-hardness of (, , )-DRCWD for various settings of , , and via reductions from a single well known NP-hard problem, namely, the vertex cover problem on 3-regular444A 3-regular graph stipulates that each vertex is connected to exactly three other vertices, each one with an edge, i.e., each vertex has a degree of 3. The VC problem on 3-regular graphs is NP-hard. We use 3-regular graphs to exploit its structure to prove the hardness of (, , )-DRCWD with respect to (w.r.t.) diversity constraints (Theorem 3 and Theorem 4). We note that the reductions used in the proofs of Theorem 5 and Theorem 6 do not need 3-regular graphs and hold for VC problem on arbitrary graphs as well., 2-uniform555The size of hyperedges has implications in the hardness of approximation and parameterized complexity results and hence, we mention it over here. For the complexity results, we use 2-uniform hypergraphs only. hypergraphs [52, 53].
Definition 7.
Vertex Cover (VC) problem: Given a graph consisting of a set of vertices = and a set of edges = where each connects two vertices in such that corresponds to a 2-element subset of , then a vertex cover of is a subset of vertices such that each contains at least one vertex from (i.e. , ). The vertex cover problem is to find the minimum vertex cover of .
5.2.1 (, , )-DRCWD w.r.t. diversity constraints
When , (, , )-DRCWD is related to the diverse committee selection problem. However, the hardness of (, , )-DRCWD when does not follow the hardness of the diverse committee selection problem when the number of groups that a candidate can belong to is greater than or equal 3 [8, 9] as the reductions in these papers are specifically for the case when .
More specifically, Theorem 9 of Bredereck et al. [8] uses a reduction from 3-Dimensional Matching that only holds for instances when the number of groups that a candidate can belong to is exactly 3. Also, they set lower bound and upper bound to 1, which is mathematically different from our setting where we only allow lower bounds. On the other hand, Theorem 6 (“NP-hardness of feasibility: 3”666In Celis et al. [9], denotes “the maximum number of groups in which any candidate can be”.) of Celis et al. [9] uses two reductions: the first reduction from -hypergraph matching is indeed for the case when the number of groups that a candidate can belong to is greater than or equal to 3 but is limited to instances when lower bound is set to 0 and upper bound to 1, which is a trivial case in our setting as we only use lower bounds and do not allow for upper bounds. Moreover, in-principle, the reduction from -hypergraph matching uses a different problem for each as when , the -hypergraph matching and -hypergraph matching are separate problems. The second reduction from 3-regular vertex cover is for instances when the number of groups that a candidate can belong to is exactly 3.
Hence, in this section, we give a reduction from a single known NP-hard problem, namely the vertex cover problem, such that our result holds even when , . Also, the reductions are designed to conform to the real-world stipulations: (i) each candidate attribute , partitions all the candidates into two or more groups and (ii) either no two attributes partition the candidates in the same way or if they do, the lower bounds across groups of the two attributes are not the same. For stipulation (ii), note that if two attributes partition the candidates in the same way and if the lower bounds across groups of the two attributes are also the same, then mathematically they are identical attributes that can be combined into one attribute. The next two theorems help us prove the statement in Corollary 1(3).
Theorem 3.
If and is an odd number, , and is a monotone, separable function, then (, , )-DRCWD is NP-hard, even when , .
Proof.
We reduce an instance of vertex cover (VC) problem to an instance of (, , )-DRCWD. We have one candidate for each vertex , and dummy candidates where corresponds to the number of vertices in the graph and is a positive, odd integer (hint: the number of candidate attributes). Formally, we set = {} and the dummy candidate set = {}. Hence, the candidate set = is of size candidates. We set the target committee size to be .
Next, we have candidate attributes. Each edge that connects vertices and correspond to a candidate group that contains two candidates and . As our reduction proceeds from a 3-regular graph, each vertex is connected to three edges. This corresponds to each candidate having three attributes and thus, belonging to three groups. Next, for each of the candidates , we have blocks of dummy candidates and each block contains dummy candidates . Thus, we have a total of dummy candidates, which equals to dummy candidates. Next, each block of candidates contains 3 sets of candidates: Set contains one candidate and Sets and contain candidates each. Specifically, each of the blocks for each candidate is constructed as follows:
-
•
Set consists of single dummy candidate, .
-
•
Set consists of dummy candidates, for all .
-
•
Set consists of dummy candidates, for all .
Each candidate in the block has attributes and are grouped as follows:
-
•
The dummy candidate is in the same group as candidate . It is also in groups, individually with each of dummy candidates, . Thus, the dummy candidate has attributes and is part of groups.
-
•
For each dummy candidate , it is in the same group as as described in the previous point. It is also in groups, individually with each of dummy candidates, . Thus, each dummy candidate has attributes and is part of groups.
-
•
For each dummy candidate , it is in groups, individually with each of dummy candidates, , as described in the previous point. Next, note that when is an odd number, is an even number, which means Set has an even number of candidates. We randomly divide candidates into two partitions. Then, we create groups over one attribute where each group contains two candidates from Set such that one candidate is selected from each of the two partitions without replacement. Thus, each pair of groups is mutually disjoint. Thus, each dummy candidate is part of exactly one group that is shared with exactly one another dummy candidate where . Overall, this construction results in one attribute and one group for each dummy candidate . Hence, each dummy candidate has attributes and is part of groups.
As a result of the above described grouping of candidates, each candidate also has attributes and is part of groups. Note that each candidate already had three attributes and was part of three groups due to our reduction from vertex cover problem on 3-regular graphs. Additionally, we added blocks of dummy candidates and grouped candidate with candidate from each of the blocks. Hence, each candidate has attributes and is part of groups. We set for all , which corresponds that each vertex in the vertex cover should be covered by some chosen edge.
Finally, we introduce voters. For simplicity, let denote the candidate in set . The first voter ranks the candidates based on their indices.
The second voter improves the rank of each candidate by one position but places the top-ranked candidate to the last position.
Next, the third voter further improves the rank of each candidate by one position but places the top-ranked candidate to the last position.
Similarly, all the voters rank the candidates based on this method. Hence, the last voter will have the following ranking:
Finally, there are no voter attributes, and hence, and there are no representation constraints (. This completes our construction for the reduction, which is a polynomial time reduction in the size of and . Note that we assume that the number of candidate attributes is always less than the number of candidates . More specifically, our reduction holds when , which is a realistic assumption as we ideally expect to be very small [9].
We first compute the score of the committee and then show the proof of correctness. When is a monotone, separable scoring function, we know that
Next, given a scoring vector where is the score associated with candidate in the ranking of voter whose and so on, and , the score of each candidate is
but as each candidate occupies each of the positions once, can be rewritten as
Hence, as all candidates have the same score, the score of each -sized committee will be the highest such that is
Note that computing any highest scoring committee using a monotone, separable function takes time polynomial in the size of input.
For clarity w.r.t. to the score of the committee, consider the following example: W.l.o.g., if we assume that is -Borda, then . Hence, all candidates get the same Borda score of
which is the sum of first natural numbers, all the scores in the scoring vector of Borda rule. Therefore, each -sized committee will be the highest scoring committee with a of
Hence, the NP-hardness of the problem is due to finding a feasible committee that satisfies for all , where . Therefore, for the proof of correctness, we show the following:
Claim 1.
We have a vertex cover of size at most that satisfies for all if and only if we have a committee of size at most that satisfies all the diversity constraints, which means that for all , which equals as for all .
() If the instance of the VC problem is a yes instance, then the corresponding instance of (, , )-DRCWD is a yes instance as each and every candidate group will have at least one of their members in the winning committee , i.e., for all . Note that we have set for all .
More specifically, for each block of candidates, we select one dummy candidate from Set and all dummy candidates from Set . This helps to satisfy the condition for all candidate groups that contain at least one dummy candidate . Overall, we select candidates from blocks for each of the candidates that correspond to vertices in the vertex cover. This results in candidates in the committee. Next, for groups that do not contain any dummy candidates, select candidates that correspond to vertices that form the vertex cover. These candidates satisfy the constraints. Specifically, these candidates satisfy for all the candidate groups that do not contain any dummy candidates. Hence, we have a committee of size .
() The instance of the (, , )-DRCWD is a yes instance when we have candidates in the committee. This means that each and every group will have at least one of their members in the winning committee , i.e., for all . Then the corresponding instance of the VC problem is a yes instance as well. This is because the vertices that form the vertex cover correspond to the candidates that satisfy for all the candidate groups that do not contain any dummy candidates. This completes the proof. ∎
Theorem 4.
If and is an even number, , and is a monotone, separable function, then (, , )-DRCWD is NP-hard, even when , .
Proof.
We reduce an instance of vertex cover (VC) problem to an instance of (, , )-DRCWD. We have two candidate and for each vertex , and dummy candidates where corresponds to the number of vertices in the graph and is a positive, even integer (hint: the number of candidate attributes). Formally, we set = {} {} and the dummy candidate set = {}. Hence, the candidate set = is of size candidates. We set the target committee size to be .
Next, we have candidate attributes. Each edge that connects vertices and correspond to two candidate groups such that group contains two candidates and that correspond to vertices and and the group contains two candidates and that also correspond to vertices and . Note that by having candidates in , we are in fact duplicating the graph . As our reduction proceeds from a 3-regular graph, each vertex is connected to three edges. This corresponds to each candidate having three attributes and thus, belonging to three groups. Next, for each candidate , we have blocks of dummy candidates, each block containing dummy candidates . Thus, we have a total of dummy candidates, which equals to dummy candidates. Next, each block of candidates contains 3 sets of candidates: Set contains one candidate and Sets and contain candidates each. Specifically, each of the blocks for each candidate is constructed as follows in line with the construction in the proof for Theorem 3:
-
•
Set consists of single dummy candidate, .
-
•
Set consists of dummy candidates, for all .
-
•
Set consists of dummy candidates, for all .
Each candidate in the block has attributes and are grouped as follows:
-
•
The dummy candidate is in the same group as candidate . It is also in groups, individually with each of dummy candidates, . Thus, the dummy candidate has attributes and is part of groups.
-
•
For each dummy candidate , it is in the same group as as described in the previous point. It is also in groups, individually with each of dummy candidates, . Thus, each dummy candidate has attributes and is part of groups.
Note that the grouping of the candidates in Set differs significantly from the construction in the proof for Theorem 3:
-
•
For each dummy candidate , it is in groups, individually with each of dummy candidates, , as described in the previous point. Next, note that when is an even number, is an odd number, which means Set has an odd number of candidates. We randomly divide candidates into two partitions. Then, we create groups over one attribute where each group contains two candidates from Set such that one candidate is selected from each of the two partitions without replacement. Thus, each pair of groups is mutually disjoint. Hence, each dummy candidate is part of exactly one group that is shared with exactly one another dummy candidate where . Overall, this construction results in one attribute and one group for all but one dummy candidate , which results into a total of attributes and groups for these candidates. This is because groups can hold candidates. Hence, one candidate still has attributes and is part of groups. If this block of dummy candidates is for candidate , then another corresponding block of dummy candidates for candidate will also have one candidate who will have attributes and is part of groups. We group these two candidates from separate blocks. Hence, now that one remaining candidate also has attributes and is part of groups. As there is always an even number of candidates in set (), such cross-block grouping of candidates among a total of blocks, also an even number, is always possible.
As a result of the above described grouping of candidates, each candidate also has attributes and is part of groups. Note that each candidate already had three attributes and was part of three groups due to our reduction from vertex cover problem on 3-regular graphs. Additionally, we added blocks of dummy candidates and grouped candidate with candidate from each of the blocks. Hence, each candidate has attributes and is part of groups. We set for all , which corresponds that each vertex in the vertex cover should be covered by some chosen edge.
Finally, we introduce voters, in line with our reduction in proof of Theorem 3. For simplicity, let denote the candidate in set . The first voter ranks the candidates based on their indices.
The second voter improves the rank of each candidate by one position but places the top-ranked candidate to the last position.
Similarly, all the voters rank the candidates based on this method. Hence, the last voter will have the following ranking:
Finally, there are no voter attributes, and hence, and there are no representation constraints (. This completes our construction for the reduction, which is a polynomial time reduction in the size of and . Note that we assume that the number of candidate attributes is always less than the number of candidates . More specifically, our reduction holds when , which is a realistic assumption as we ideally expect to be very small [9].
We first compute the score of the committee and then show the proof of correctness. When is a monotone, separable scoring function, we know that
Next, given a scoring vector where is the score associated with candidate in the ranking of voter whose and so on, and , the score of each candidate is
but as each candidate occupies each of the positions once, can be rewritten as
Hence, as all candidates have the same score, the score of each -sized committee will be the highest such that is
Note that computing any highest scoring committee using a monotone, separable function takes time polynomial in the size of input.
For clarity w.r.t. to the score of the committee, consider the following example: W.l.o.g., if we assume that is -Borda, then . Hence, all candidates get the same Borda score of
which is the sum of first natural numbers, all the scores in the scoring vector of Borda rule. Therefore, each -sized committee will be the highest scoring committee with a of
Hence, the NP-hardness of the problem is due to finding a feasible committee that satisfies for all , where . Therefore, for the proof of correctness, we show the following:
Claim 2.
We have a vertex cover of size at most that satisfies for all if and only if we have a committee of size at most that satisfies all the diversity constraints, which means that for all , which equals as for all .
() If the instance of the VC problem is a yes instance, then the corresponding instance of (, , )-DRCWD is a yes instance as each and every candidate group will have at least one of their members in the winning committee , i.e., for all . Note that we have set for all .
More specifically, for each block of candidates, we select one dummy candidate from Set and all dummy candidates from Set . This helps to satisfy the condition for all candidate groups that contain at least one dummy candidate . Overall, we select candidates from blocks for each of the candidates that correspond to vertices in the vertex cover. This results in candidates in the committee. Next, for groups that do not contain any dummy candidates, select candidates that correspond to vertices that form the vertex cover. These candidates satisfy the constraints. Specifically, these candidates satisfy for all the candidate groups that do not contain any dummy candidates. Hence, we have a committee of size .
() The instance of the (, , )-DRCWD is a yes instance when we have candidates in the committee. This means that each and every group will have at least one of their members in the winning committee , i.e., for all . Then the corresponding instance of the VC problem is a yes instance as well. This is because the vertices that form the vertex cover correspond to the candidates that satisfy for all the candidate groups that do not contain any dummy candidates. We remind that we had constructed candidates in the instance of (, , )-DRCWD problem that correspond to vertices in the VC problem, which means that we need candidates instead of candidates to satisfy diversity constraints for candidate groups that do not contain any dummy candidates. This completes the proof. ∎
5.2.2 (, , )-DRCWD w.r.t. representation constraints
We now study the computational complexity of (, , )-DRCWD due to the presence of voter attributes. Note that the reduction is designed to conform to the real-world stipulations that are analogous to the stipulations for the candidate attributes. The following theorem helps us prove the statement in Corollary 1(4).
Theorem 5.
If , , and is a monotone, separable function, then (, , )-DRCWD is NP-hard, even when , .
Proof.
We reduce an instance of vertex cover (VC) problem to an instance of (, , )-DRCWD. We have one candidate for each vertex , and dummy candidates where corresponds to the number of edges and corresponds to the number of vertices in the graph . Formally, we set = {} and the dummy candidate set = {}. Hence, the candidate set = consists of candidates. We set the target committee size to be .
We now introduce voters, voters for each edge . More specifically, an edge connects vertices and . Then, the corresponding voters rank the candidates in the following collection of sets , , , such that :
-
•
Set : candidates and that correspond to vertices and are ranked at the top two positions, ordered based on their indices. For voter where , we denote the candidates and as and .
-
•
Set : out of () dummy candidates are ranked in the next positions, again ordered based on their indices. For each voter, these candidates are distinct as shown below. Hence, for all pairs of voters , we know that .
-
•
Set : the next positions are occupied by the remaining candidates in that correspond to the vertices in graph , ordered based on their indices.
-
•
Set : the last positions are occupied by the remaining dummy candidates in , ordered based on their indices.
More specifically, the voters rank the candidates as shown below:
| Voters | Set | Set | Set | Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| , …, | |||||||||||||
| , …, | |||||||||||||
| , …, | |||||||||||||
| ⋮ | |||||||||||||
| , …, | |||||||||||||
Next, there are no candidate attributes, and hence, and there are no diversity constraints (. The voters are divided into disjoint population over one or more attributes when . Specifically, the voters are divided into populations as follows: , , , voter is part of a population such that contains all voters with the same and . Each voter is part of populations. We set the representation constraint to 1. Hence, for all . The winning committee for each population will always consist of the top -ranked candidates in the ranking of the voters in population , which means that , , can not contain candidates from Set and Set . This is because, by construction, (a) the ranking of all voters within a population , for all , is the same and (b) the first candidates of each population will only get selected because either (i) they will indeed be the highest scoring candidates for the population or (ii) in case of a tie, they get precedence because we break ties based on the indices of candidates such that gets precedence over for all .
This completes our reduction, which is a polynomial time reduction in the size of and . For the proof of correctness, we show the following:
Claim 3.
We have a vertex cover of size at most that satisfies for all if and only if we have at least one committee of size at most that satisfies all the representation constraints, which means that for all , which equals as for all .
() If the instance of the VC problem is a yes instance, then the corresponding instance of (, , )-DRCWD is a yes instance as each and every population’s winning committee, for all , will have at least one of their members in the winning committee , i.e., for all . Indeed, even had the winning committee of each population been of size 2 instead of , the instance of (, , )-DRCWD will be a yes instance as the vertex cover corresponds to the winning committee representing each and every population as for all .
() The instance of the (, , )-DRCWD is a yes instance when each and every population’s winning committee, for all , will have at least one of their members in the winning committee , i.e., for all . Then the corresponding instance of the VC problem is a yes instance as well. More specifically, there are two cases when the instance of the (, , )-DRCWD can be a yes instance:
-
•
Case 1 - When only the candidates from Set are in the committee : An instance of (, , )-DRCWD when and is a yes instance when each and every population has at least one representative in the committee, i.e., for all . We note that for all , each population’s winning committee consists of two candidates from Set and top candidates from Set . Hence, when the winning committee consists of only the candidates from Set of the ranking of each and every voter , it implies that it will be a yes instance, which in turn, implies that there is a vertex cover of size at most that covers all the edges because the vertices in vertex cover correspond to the candidates in the winning committee .
-
•
Case 2 - When candidates from Set and Set are in the committee : In Case 1, we showed that if a candidate in the winning committee is from Set , then it corresponds to a vertex in the vertex cover. Additionally, as the population’s winning committee for all is of size , an instance of (, , )-DRCWD can be a yes instance even if a dummy candidate from Set is in the winning committee . More specifically, there are two sub-cases:
-
–
for some population , dummy candidate from Set AND candidate from from Set are in the committee : if a population’s candidate from Set , who is also in , is in , then this sub-case is equivalent to Case 1, and hence, a corresponding vertex in the vertex cover exists. We note that this sub-case does not allow for any of population to have a representative from in only from Set , which is our next sub-case.
-
–
for some population , only dummy candidate from Set is in the committee : if for a given population , a committee represents the population via only the dummy candidate who is in a population’s winning committee , then the representation constraint is satisfied as . However, for all pairs of voters , we know that . Hence, we can replace any such dummy candidate with a candidate as that candidate can not be representing any other population . Formally, a winning committee is always tied777W.l.o.g., we make a subtle assumption that all candidates bring the same utility to the committee . The aim to make this assumption is to show that even under this assumption, the problem remains hard, which is to say that even finding a feasible committee that simply satisfies the constraints is NP-hard even when we have . The assumption does not change the composition of each population’s winning committee for all . to another winning committee where = where for some . This is equivalent to saying that we are replacing candidate from Set with a candidate from Set of the population . Thus, a yes instance of (, , )-DRCWD due to , or due to the equivalent committee , in this sub-case corresponds to a vertex cover that covers all the edges .
-
–
These cases complete the other direction of the proof of correctness.
Finally, we note that for this reduction and the proof of correctness, we assume the ties are broken using a predecided order of candidates. We also note that as we are using a separable committee selection rule, computing scores of candidates takes polynomial time. This completes the overall proof. ∎
Corollary 2.
If , , and is a monotone, separable function, then (, , )-DRCWD is NP-hard, even when , and , .
The reduction in the proof of Theorem 5 holds as each voter in the reduction can belong to more than one population. Next, as focus of this section was to understand the computational complexity with respect to representation constraints, we ease the stipulation that required each candidate attribute to partition all candidates into more than two groups. Hence, for each candidate attribute , , we simply create one group that consists of all the candidates and set for all and the problem still remains NP-hard.
5.2.3 (, , )-DRCWD w.r.t. submodular scoring function
Chamberlin-Courant (CC) rule is a well-known monotone, submodular scoring function [9], which we use for our proof. The novelty of our reduction is that it holds for determining the winning committee using CC rule that uses any positional scoring rule with scoring vector such that , , and : and .
The following theorem and corollary proves the statement in Corollary 1(1).
Theorem 6.
If is a monotone, submodular function, then (, , )-DRCWD is NP-hard even when and .
Proof.
We reduce an instance of vertex cover (VC) problem to an instance of (, , )-DRCWD. Each candidate corresponds to a vertex . For each edge , we have a voter whose complete linear order is as follows: the top two most preferred candidates correspond to the two vertices connected by an edge . These two candidates are ranked based on their indices. The remaining candidates are ranked in the bottom positions, again based on their indices. We set the committee size to . This is a polynomial time reduction in the size of and .
For the proof of correctness, we note that there are no candidate and voter attributes, and thus, no diversity and representation constraints. Hence, we show the following:
Claim 4.
We have a vertex cover of size at most that satisfies for all if and only if we have a committee of size at most with total misrepresentation of zero, which means that at least one of the top 2 ranked candidates of each voter is in the committee .
( If the instance of the VC problem is a yes instance, then the corresponding instance of (, , )-DRCWD is a yes instance as each and every voter will have at least one of their top two candidates in the committee and this will result in a misrepresentation score of zero as and .
() If the instance of (, , )-DRCWD is a yes instance, then the VC is also a yes instance. When a committee does not represent a voter’s one of the top-2 candidates, it implies that the dissatisfaction is greater than zero. Hence, for each voter that is not represented, there exists an edge that is not covered. Hence, we can say that (, , )-DRCWD is NP-hard with respect to , and submodular function. ∎
Corollary 3.
If , , and is a monotone, submodular function, then (, , )-DRCWD is NP-hard, even when , and , .
The proof of Theorem 6 shows that when we use a submodular but not separable committee selection rule , (, , )-DRCWD is NP-hard even when and . Next, as focus of this section was to understand the computational complexity with respect to monotone submodular scoring rule, we ease the stipulation that required each candidate attribute to partition all candidates into more than two groups and required each voter attribute to partition all voters into more than two population. The problem remains hard even when we have candidate attributes and the diversity constraints are set to one and have voter population and the representation constraints set to one. Specifically, for each candidate attribute, create one group that contains all the candidates and for each voter attribute, create one population that contains all the voters. This is analogous to not having any candidate or voter attributes. Hence, even when for all and for all , (, , )-DRCWD is NP-hard if is submodular committee selection rule.
6 Inapproximability and Parameterized Complexity
| Result | Parameter | (,0) | (0,) | (,) |
|---|---|---|---|---|
| inapproximability | - | (Thm. 7) | (Thm. 9)888For Theorem 9, we assume that the Unique Games Conjecture (UGC) [54] holds, specifically as the result that showed pseudorandom sets in the Grassmann graph have near-perfect expansion completed the proof of 2-to-2 Games Conjecture [55], which is considered to be a significant evidence towards proving the UGC. Moreover, GapUG(, ) is found to be NP-hard, i.e., a weaker version of the UGC holds with completeness (See [56] and “Evidence towards the Unique Games Conjecture” in [55] for more details). Without the assumption on UGC, the result for our problem when and will change and for arbitrarily small constant , the problem is inapproximable within a factor of for every integer [57] and within a factor of when [55, 58]. | () (Thm. 8) |
| parameterized | is constant | (Obs. 3) | ||
| complexity | W[2]-hard (Cor. 4) | (Thm. 11) | W[2]-hard (Cor. 5) | |
The hardness of (, , )-DRCWD is mainly due to the hardness of (, )-DRCF, which is to say that satisfying the diversity and representation constraints is computationally hard, even when all constraints are set to 1. Formally, the hardness remains even when for all and for all . Hence, in this section, we focus on the hardness of approximation to understand the limits of how well we can approximate (, )-DRCF and focus on parameterized complexity of (, )-DRCF.
It is natural to try to reformulate representation constraints as diversity constraints. However, in our model, it is not possible to do so as each candidate attribute partitions all candidates into groups and the lower bound is set such that for all . However, for representation constraints, , for all , contains only candidates and the remainder candidates consisting of , for all , may never be selected. Hence, representation constraints can not be easily reformulated to diversity constraints. Moreover, even if we relax the lower bound of the diversity constraint to instead of , for all , to allow for such a reformulation, the following settings of (, )-DRCF and (, , )-DRCWD are technically different and we may not carry out any reformulations amongst each other:
-
•
Using only diversity constraints
-
•
Using only representation constraints
-
•
Using both, diversity and representation, constraints
The above listed settings are technically different from each other as the sizes of candidate groups and the size of the winning committees of populations have implications on our approach to solve a problem. For instance, using both, diversity and representation, constraints and using only representation constraints are mathematically as different as the vertex cover problem on hypergraphs and the vertex cover problem on -uniform hypergraphs, respectively. The differences between the hardness of approximation for the latter two problems is well-known. Overall, while reformulations such as converting representation constraints to diversity constraints do not impact the computational complexity of the problem, it affects the approximation and parameterized complexity results. Hence, we study the hardness of approximation and the parameterized complexity of the above listed settings of (, )-DRCF in detail without carrying out any reformulations between the different settings of the constraints.
Observation 2.
and , the following settings of the (, )-DRCF problem are not equivalent: (i) =0 and , (ii) and , and (iii) and .
6.1 Inapproximability
In this subsection, we focus on allowing size violation as deciding on which constraints to violate is not straightforward, especially as constraints are linked to human groups. Hence, we define the size optimization version of (, )-DRCF and study its inapproximability:
Definition 8.
(, )-DRCF-size-optimization: In the (, )-DRCF-size-optimization problem, given a set of candidates, a set of voters such that each voter has a preference list over candidates, a committee size , a set of candidate groups and the corresponding diversity constraints for all , and a set of voter populations and the corresponding representation constraints and the winning committees for all , find a minimum-size committee such that satisfies all the diversity and representation constraints, i.e., for all and for all , respectively.
Theorem 7.
For , : , and , (, )-DRCF-size-optimization problem is inapproximable within , even when = 1 .
Proof.
We reduce from the set multi-cover problem with sets of bounded size, a known NP-hard problem [52], to (, )-DRCF-size-optimization problem.
More specifically, given a set = , and a collection of sets such that , the goal is to choose some sets of minimum cardinality covering each element .
Then, we construct a (, )-DRCF-size-optimization instance. To do so, we have a corresponding candidate for each set , and a corresponding group which is equal to for each element . Hence there are candidates and candidate groups such that each candidate belongs to at most groups. The diversity constraints are set to be equal to 1, which corresponds to the requirement that each element is covered.
This is an approximation-preserving reduction for all and . Hence, the minimum cardinality of the constrained set cover problem is at most if and only if an at most -sized feasible committee exists. Given that set multi-cover problem is inapproximable within [59], so is our (, )-DRCF-size-optimization problem. We note that this result holds for (, )-DRCF-size-optimization problem for all and . ∎
While the above proof is similar in flavor to the one given in Theorem 7 (Hardness of feasibility with committee violations) of Celis et al. [9], we note that our inapproximability ratio differs from their inapproximability ratio of (). This is because our ratio exploits the candidate structure where each candidate is bounded by the number of attributes , which bounds the number of groups they can be a part of. Hence, our reduction is from set cover problem where each set is of bounded size.
For our next result, we first give a reduction from regular hitting set (HS) to (, )-DRCF. Next, as the regular HS problem is equivalent to the minimum set cover problem [60], the latter’s inapproximability [61] holds for our problem.
Theorem 8.
For , : , and : , (, )-DRCF-size-optimization problem is inapproximable within a factor of (), even when = 1 and = 1 .
Proof.
We reduce from regular hitting set (HS), a known NP-hard problem [52], to (1, 1)-DRCF-size-optimization problem.
An instance of HS consists of a universe = and a collection of subsets of , each of size . The objective is to find a subset of size at most that ensures for all , .
We construct the (, )-DRCF-size-optimization instance as follows. For each element in the universe , we have the candidate in the candidate set . For each subset in collection , we either have candidate group or winning committee of population . Note that we have . We set for all and for all , which means 1 and 1, respectively. This corresponds to the requirement that .
Hence, we have a subset of size at most that satisfies if and only if we have a committee of size at most that satisfies 1 for all and 1 for all .
We note that this is also an approximation-preserving reduction for all and . Given that minimum set cover problem, which is equivalent to the hitting set problem, is inapproximable within () [61], so is our (, )-DRCF-size-optimization problem. We note that this result holds for (, )-DRCF-size-optimization problem and . ∎
Assuming the Unique Games Conjecture [54], Bansal and Khot [62] showed that vertex cover problem on -uniform hypergraphs, for any integer , is inapproximable within , even when the -uniform hypergraph is almost -partite. We use this result for our next theorem.
Theorem 9.
For , , and : , (, )-DRCF-size-optimization problem, assuming the Unique Games Conjecture [54], is inapproximable within , even when .
Proof.
We give a reduction from vertex cover problem on -uniform hypergraphs to (0, )-DRCF.
An instance of vertex cover problem on -uniform hypergraphs consists of a set of vertices = and a set of hyperedges , each connecting exactly vertices from . A vertex cover is a subset of vertices such that each edge contains at least one vertex from (i.e. for each edge ). The vertex cover problem on -uniform hypergraphs is to find a vertex cover of size at most .
We construct the (, )-DRCF instance as follows. For each vertex , we have the candidate . For each edge , we have a population’s winning committee of size for all . Note that we have . We set for all , which means 1. This corresponds to the requirement that .
Hence, we have a vertex cover of size at most if and only if we have a committee of size at most that satisfies 1 for all .
This is an approximation-preserving reduction for and for all . Given that the vertex cover problem on -uniform hypergraphs is inapproximable within [62] assuming the Unique Games Conjecture, so is our (, )-DRCF-size-optimization problem. We note that this result holds for (, )-DRCF-size-optimization problem for all and . ∎
In addition to this general inapproximability result, we informally conjecture that improve upon the ratio of .
Conjecture 1.
[Informal] If and , then (, )-DRCF-size-optimization problem can be approximated to at most using a polynomial time algorithm.
A proof of above conjecture implies that there exists a polynomial time approximation algorithm for the (, )-DRCF-size-optimization problem ( and ) with approximation ratio at most where is a function that maps the cohesiveness of the preferences to the maximum number of winning committees that a candidate can belong to. Specifically, if such a exists and if , then the stated approximation ratio exists directly due to Halperin [63].
6.2 Parameterized Complexity
In most real-world elections, the committee size is constant. Hence, our first result here is inspired by the parameterized complexity results in this field [38, 41].
Observation 3.
The (, )-DRCF problem can be solved in . If is a constant, then it is a polynomial time algorithm.
We select a set of committees , each of size , and then check for the satisfiability of the constraints for each committee . It is easy to see that has committees, that is, . Checking whether a committee satisfies all the constraints takes , which is the total number of constraints to be checked. Hence, we can solve (, )-DRCF in time polynomial in and , given is constant.
Next, when the committee size () is not a constant, the rate of growth of the number of candidates to be elected may be much slower than the number of candidates ().
Theorem 10.
Corollary 4.
If : and , then (, )-DRCF problem is W[2]-hard w.r.t. and the hardness holds even when = 1 .
Proof.
In the proof for Theorem 7, we gave a reduction from minimum set cover problem to (, )-DRCF problem w.r.t. and for all : and . Additionally, we know that the minimum set cover problem has a well-known one to one relationship with the hitting set problem with no restriction on the subset size [60, 65, 66]. Hence, as regular HS with unbounded size of subsets is W[2]-hard [60], our results here follow due to the one to one relationship between the regular HS problem and the minimum set cover problem. ∎
Corollary 5.
If : and : , then (, )-DRCF problem is W[2]-hard w.r.t. and the hardness holds even when = 1 and = 1 .
When , our problem is equivalent to regular HS (Theorem 8).
Theorem 11.
If , : , and , then (, )-DRCF problem can be solved using an time algorithm where and . If , then it is a polynomial time algorithm.
Proof.
Proof of Theorem 9 shows that our problem is equivalent to -HS when and . Hence, our algorithm here is motivated from bounded tree search algorithm in Section 6 of [60] where they showed that when is small, a -hitting set problem, which upper bounds the cardinality of every element in the subsets to be hit to , can be solved using an time algorithm with . In our case, . We have modified our algorithm from [60] to return all committees that satisfy the representation constraints.
Input: , , and and for all
Output: : for all
In the above algorithm, steps 3 and 4 creates branches in total. Hence, if the number of leaves in a branching tree is , then the first branch has at most leaves. Next, let be the number of leaves in a branching tree where there is at least one set of size or smaller. For each , there is some committee in the given collection such that , but . Therefore, the size of is at most after excluding from and including in the committee . Altogether we get .
If there is already a set with at most elements, we can repeat the above steps and get . The branching number of this recursion is from above, and note that it is always smaller than . ∎
As a conclusion of our theoretical analyses, we make an interesting observation: When , (, )-DRCF becomes NP-hard when . On the other hand, when , (, )-DRCF becomes NP-hard even when . This means that introducing representation constraints makes the problem hard “faster” than introducing diversity constraints. In contrast, with respect to the parameter , the former case is W[2]-hard and the latter is fixed parameter tractable for all . This reinforces our claim that even if it may seem natural to try and reformulate representation constraints as diversity constraints, we should not do so as the size of candidate groups and the size of winning committee of voter populations has implications on how one may try to solve the problem efficiently.
7 Heuristic Algorithm
In the previous sections, we saw that our model, which is useful from the social choice theory perspective to have more “fairer” elections, is computationally hard and it is hard even when we parameterize the problem on the size of the committee. Hence, we take a pragmatic approach to evaluate if our model is efficient in practice. We do so by developing a two-stage heuristic-based algorithm, in part motivated from the literature on distributed constraint satisfaction [67], which allow us to efficiently compute DiRe committees in practice.
We develop a heuristic-based algorithm as the use of integer linear program formulation in multiwinner elections is not efficient [39], especially when using the Monroe rule. Moreover, in addition to the known temporal efficiency of using a heuristic approach as compared to a linear programming approach, our empirical evaluation shows that the algorithm returns an optimal solution (discussed later in Section 8.3.1), thus overcoming one of the biggest disadvantages of using a heuristic approach.
7.1 DiReGraphs
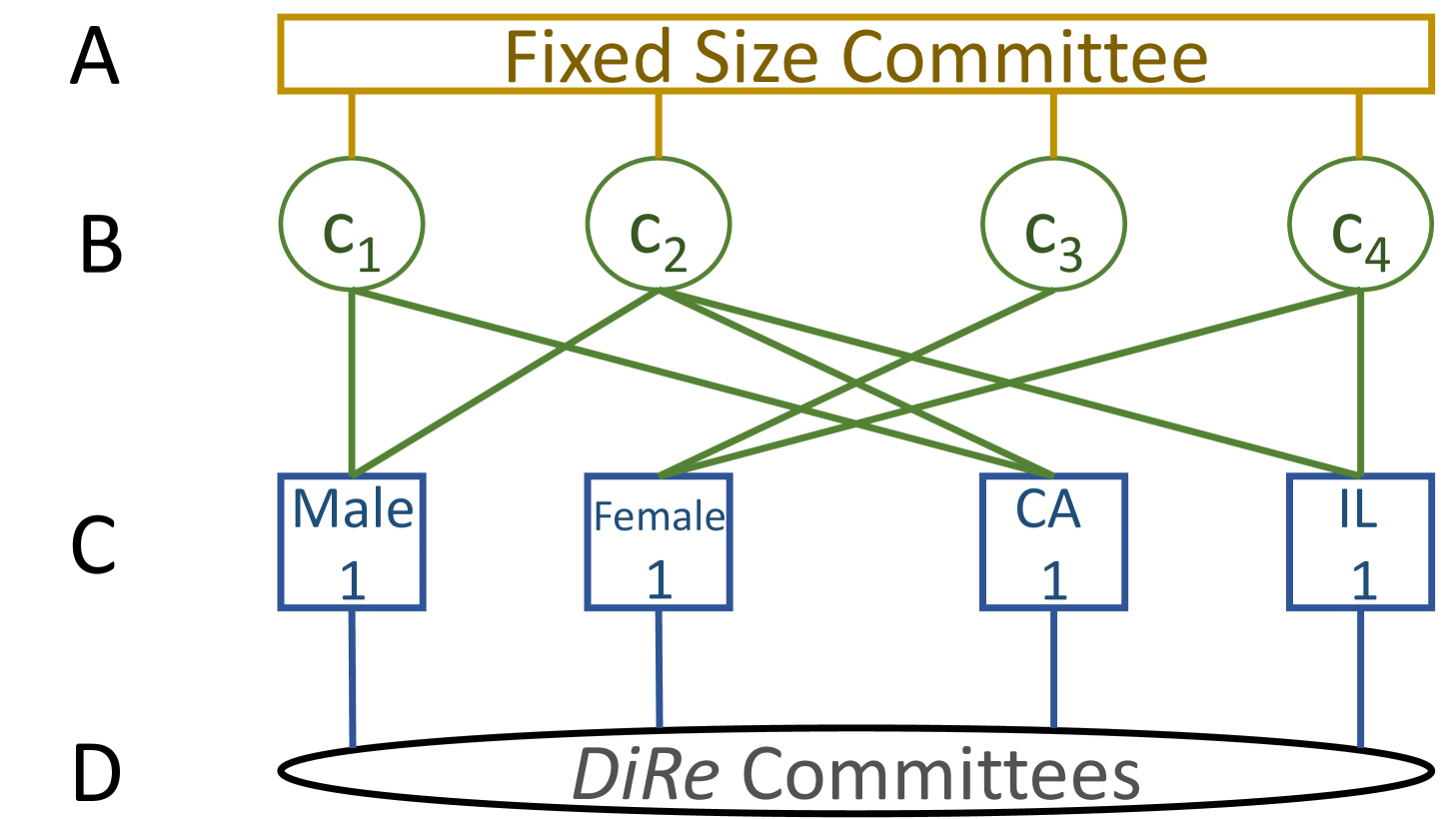
We represent an instance of the (, , )-DRCWD problem from Figure 1 as a DiReGraph (Figure 2). The constraints are represented by quadrilaterals and candidates by ellipses. More specifically, there are candidates (Level B) and the DiRe committee (Level D). Next, there is a global committee size constraint (Level A) and unary constraints that lower bound the number of candidates required from each candidate group or voter population (Level C). Edges connecting candidates (Level B) to unary constraints (Level C) depends on the candidate’s membership in a candidate group or a population’s winning committee. The idea behind DiReGraph is to have a “network flow” from A to D such that all nodes on level C are visited. More specifically, the aim is to select candidates (Level A) from candidates (Level B) such that the in-flow at the unary constraint nodes (Level C) is equal to the specified diversity or representation constraint. A node is said to have an in-flow of when candidates in the committee are part of the group/winning population. Formally, for each candidate group and for each population . When the last condition is fulfilled, there will be a DiRe committee (Level D).
Example 2.
Creating DiReGraph: Consider the election setup shown in Figure 1. The candidate (Figure 1) is a male who is in winning committees of both the states, namely California and Illinois. Hence, in DiReGraph (Figure 2) is connected with the three sets of constraints, one each for male and the two states, namely CA (California) and IL (Illinois).
Input:
variables = {}
domain = () : each is or
unary constraints = {} : each is for each or for each
Output:
set of committees : ,
7.2 DiRe Committee Feasibility Algorithm
Algorithm 2 has two stages: (i) preprocessing reduces the search space used to satisfy the constraints and efficiently finds infeasible instances, and (ii) heuristic-based search of candidates decreases the number of steps needed either to find a feasible committee, or return infeasibility.
7.2.1 Create DiReGraph
The first step of the algorithm is to create the DiReGraph based on the variables that are given as the input. We have the following input: variables = {} are represented by the nodes on Level C. The domain = () of these variables are represented by edges that connect the node on Level C to the nodes (candidates) on Level B. Formally, for each where is or , we have an edge that connect node on Level B with node on Level C. The constraints = {} correspond to the diversity and representation constraints. Formally, for each , is for each or for each .
Example 3.
Input Variables: = {Male, Female, CA, IL}
= ({}, {}, {}, {})
= {1, 1, 1, 1}
function (, , ) returns false if an inconsistency is found, or true
function (, , , , ) returns true iff the domain of is reduced
function (, , , , ) returns a solution or infeasibility
function (, , , )
function (, , , , , )
7.2.2 Preprocessing
Find the strongly connected components of a graph in time linear in the size of and , equivalent to and in real-world settings. The next step is find inter- and intra-component pairwise feasibility. We note that we only do a pairwise feasibility test as previous work has shown that doing a three-way, a four-way or greater feasibility tests increase the computational time significantly without improving the scope of finding a group of variables whose combination guarantees an infeasible instance [67].
Inter-component pairwise feasibility:
Select two variables , corresponding to constraints , on level C of DiReGraph, one each from different components of . Do a pairwise feasibility check for each pair and return infeasibility if any one pair of variables can not return a valid committee. The correctness and completeness of this step is easy. If there are more constraints than the available candidates, it is impossible to find a feasible solution. Also, if a pair of constraints are pairwise infeasible, then it is clear that they will remain infeasible overall.
Intra-component pairwise feasibility:
Repeat the above procedure but now, within a component. This step also helps in returning infeasibililty efficiently.
Reducing domain:
Based on empirical evidence of the previous work that used a setting similar to ours, pairwise infeasibility causes a majority of overall infeasible instances [67]. Hence, if a committee did exist, the domain of each variable is reduced by removing candidates that explicitly do not help to find feasible committees.
Now do a restricted version of intra-component pairwise feasibility. If algorithm reaches this stage, we know that all of the constraints are pairwise feasible due to presence of at least one solution. Hence, reduce the domain by removing a candidate who, when included in the solution, always returns pairwise infeasible solution with another constraint. Specifically, fix a candidate from the domain of a variable and do a pairwise feasibility check with other domain across all possible solutions that contains the candidate . If all solutions that contain result in infeasibility, then remove candidate from the domain of .
7.2.3 Heuristic Backtracking.
Use depth-first search for backtracking. Specifically, choose one variable at a time, and backtrack when has no legal values left to satisfy the constraint. This technique repeatedly chooses an unassigned variable, and then tries all values in its domain, trying to find a solution. If an infeasibility is returned, traverse back by one step and move forward by trying another value.
Select unsatisfied variable:
Use the “minimum-remaining-values (MRV)” heuristic to choose the variable having the fewest legal values. This heuristic picks a variable that is most likely to cause a failure soon, thereby pruning the search tree. For example, if some variable has no legal values left, the MRV heuristic will select and infeasibility will be returned, in turn, avoiding additional searches.
Sort most favorite candidates:
Use the “most-favorite-candidates (MFC)” heuristic to sort the candidates in domain such that a candidate on level B of DiReGraph who is most connected to level C (out-degree) is ranked the highest. This heuristic tries to reduce the branching factor on future choices by selecting the candidate that is involved in the largest number of constraints.
Overall, the aim is to select the most favorite candidates into the committee as they help satisfy the highest proportion of constraints. For completeness and to get multiple DiRe committees, after sorting step, use a “shift-left” approach where the second candidate becomes the first, the first becomes the last, and so on. This allows us to get multiple DiRe committees.
Example 4.
Sorting candidates: In Figure 2, the ordering of candidates will be , , , and as has out-degree of 3, and has 2, and has 1. Ties are broken randomly.
We now give an example to explain the entire algorithm.
Example 5.
Implementation of Algorithm: Consider the election setup shown in Figure 1, which consists of four candidates and four voters, each having one attribute.
The input to the algorithm is (i) a set of variables (candidate group names and voter population names) = {Male, Female, CA, IL}. (ii) a collection of sets of domain for each variable (candidates part of the candidate groups and winning committee of each population) = ({}, {}, {}, {}). (iii) a collection of constraints for each variable = (1, 1, 1, 1).
The first step of the algorithm is to create a DiReGraph as shown in Figure 2. Level A is set to 2 as . Level B consists of four nodes, each representing one candidate. Level C consists of four nodes, which is equal to , the number of candidate groups and voter populations in the election. Level D consists of the final output. Each node on Level B is connected with Level A and each node on Level C is connected to Level D. The candidate is a male who is in winning committees of California. Hence, in DiReGraph is connected with the two sets of constraints, one each for male and CA (California).
Next, a subgraph consisting of eight nodes from Levels B and C and the corresponding edges that connect these eight nodes is created.
As there is only one strongly connected components in the SG, we directly check for the intra-component pairwise feasibility. For each pair of domains, there is always a feasible committee that exists. Hence, the algorithm continues to execute. Moreover, none of the domains get reduced as the constraints are set to one.
Before reaching the final step of the algorithm, the algorithm would have terminated if no feasible committee existed that satisfied all the pairwise constraints.
In the final step, the function selects a candidate at random as all the variables have the same ratio of 2 for as =2 and =1 for all and . Next, for each variable that remains, we check whether adding that variable violates the global constraint (committee size on Level A of DiReGraph) or not. We keep on backtracking till we either find a committee or exhaustively navigate through our pruned search space. To get more than one committee, rerun the function by applying an additional “left-shift” operation on the result of the function each time the function is implemented. We note that this increases the time complexity of the algorithm linearly in the size of and .
8 Empirical Analysis
We now empirically assess the efficiency of our heuristic-based algorithm using real and synthetic datasets. We also assess the effect of enforcing diversity and representation constraints on the feasibility and utility of the winning committee selected using different scoring rules.
8.1 Datasets
8.1.1 Real Datasets
RealData 1:
The Eurovision dataset [68] consists of 26 countries ranking the songs performed by each of the 10 finalist countries. We aim to select a 5-sized DiRe committee. Each candidate, a song performed by a country, has two attributes, the European region and the language of the song performed. Each voter has one attribute, the voter’s European region. Specifically for the European region attribute, Australia and Israel were labeled as “Others” as they are not a part of Europe.
RealData 2:
The United Nations Resolutions dataset [69] consists of 193 UN member countries voting for 81 resolutions presented in the UN General Assembly in 2014. We aim to select a 12-sized DiRe committee. Each candidate has two attributes, the topic of the resolution and whether a resolution was a significant vote or not. Each voter has one attribute, the continent.
8.1.2 Synthetic Datasets
SynData 1:
We set committee size () to 6 for 100 voters and 50 candidates. We generate complete preferences using RSM by setting selection probability to replicate Mallows’ [70] model (, randomly chosen reference ranking of size ) (Theorem 3, [71]) and preference probability , .
Dividing Candidates into Groups and Voters into Populations: To assess the impact of enforcing constraints, we generate datasets with varying number of candidate and voter attributes by iteratively choose a combination of , such that and . For each candidate attribute, we choose a number of non-empty partitions , , uniformly at random. Then to partition , we randomly sort the candidates and select positions from , , uniformly at random without replacement, with each position corresponding to the start of a new partition. The partition a candidate is in is the attribute group it belongs to. For each voter attribute, we repeat the above procedure, replacing with , and choosing positions from the set , . For each combination of , we generate five datasets. We limit the number of candidate groups and number of voter populations per attribute to to simulate a real-world division of candidates and voters.
SynData 2:
We use the same setting as SynData 1, except we fix and each to 2 and vary the cohesiveness of voters by setting selection probability to replicate Mallows’ [70] model’s , , with increments of 0.1. We divide the candidates into groups and voters into populations in line with SynData 1.
8.2 Setup
System.
We note that all our experiments were run on a personal machine without requiring the use of any commercial or paid tools. More specifically, we used a controlled virtual environment using Docker(R) on a 2.2 GHz 6-Core Intel(R) Core i7 Macbook Pro(R) @ 2.2GHz with 16 GB of RAM running MacOS Big Sur (v11.1). We used Python 3.7.
Constraints.
For each , we choose , uniformly at random. For each , we choose , uniformly at random.
Voting Rules.
We use previously defined -Borda, -CC, and Monroe rules. More specifically, we have two rules from from submodular, monotone class of committee selection rule due to inherent difference in their method of computing committees and one rule from separable, monotone class of functions. We deem these to be sufficient due to our focus on the study of (, )-DRCF as discussed later.
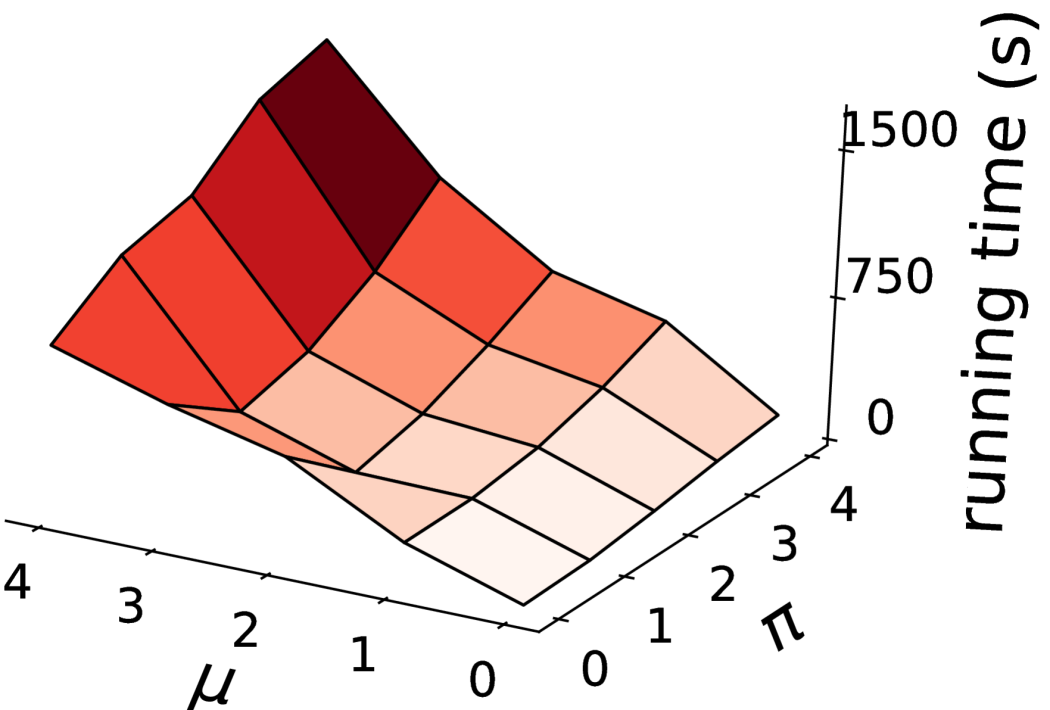
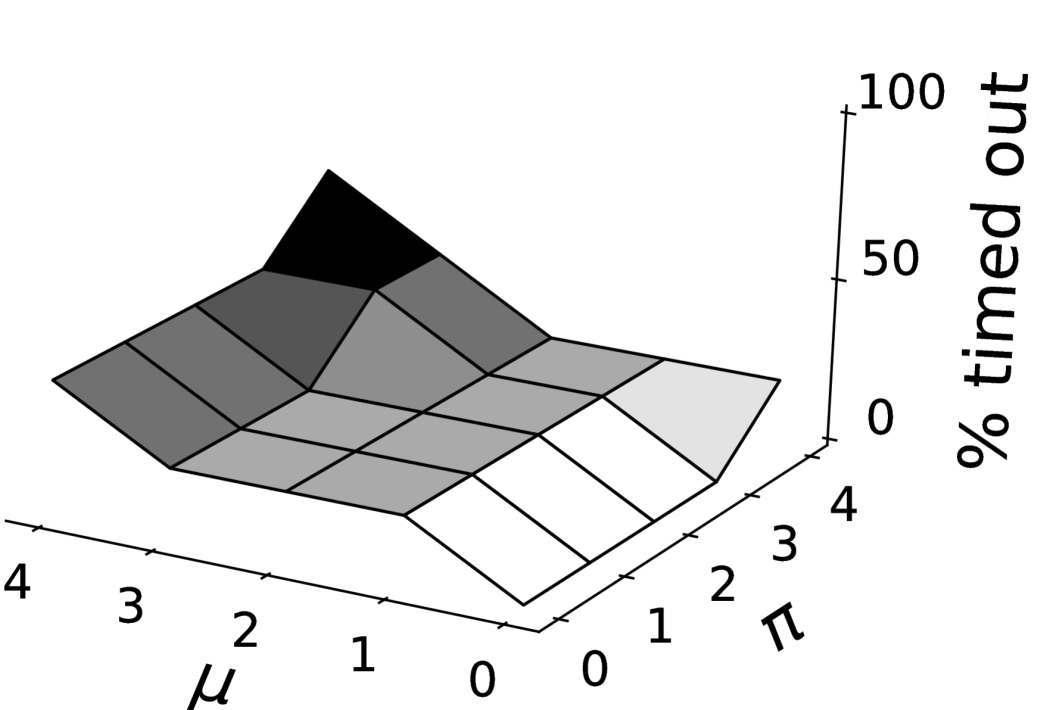
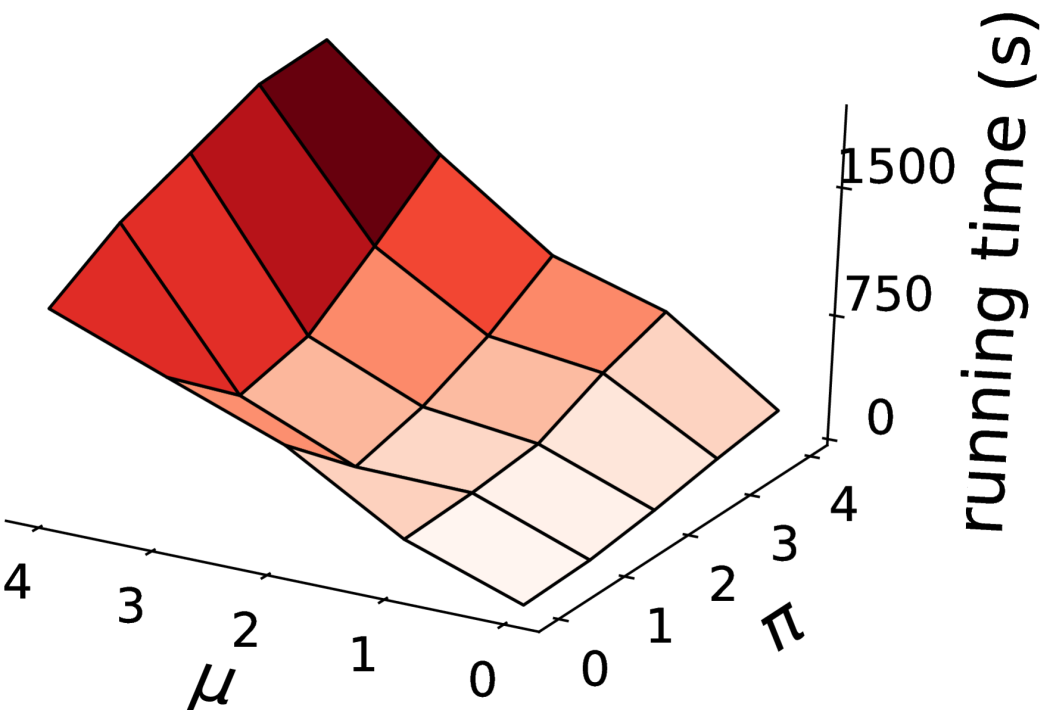
8.3 Results
We now present results of empirical analyses of the efficiency of the heuristic algorithm and of the feasibility of DiRe committees and the cost of fairness.
8.3.1 Efficiency of Heuristic Algorithm
All experiments in this section combine instances of -Borda and -CC as there was no pairwise significant difference in the running time between the sets of instances of these two scoring rules (Student’s t-test, 0.05). We present the result for Monroe rule separately.
Algorithm is efficient:
Our heuristic-based algorithm is efficient on tested data sets (Figure 3, Figure 4, and Figure 5). Only 18.90% of 525 instances timed out at 2000 sec. Among the instances that did not time out, the average running time was 566.48 sec (standard deviation (sd) = 466.66) for -Borda and -CC, and 724.39 sec (sd = 575.31) for Monroe. In contrast, 93.71% of 525 instances timed out at 2000 sec when using brute-force algorithm.
Promisingly, using DiReGraph made the algorithm more efficient on instances that were sparsely connected as the average running time for all when was 281.47 sec (sd = 208.65) for -Borda and -CC, and 358.87 sec (sd = 265.82) for Monroe. Higher led to denser DiReGraphs.
Performance when compared to ILP:
The real-world application of an ILP-based algorithm is very limited when using Chamberlin-Courant and Monroe rules [39]. More specifically, some instances of the ILP-algorithm that implemented the Monroe rule for =9, =30, and =100 timed out after one hour. The running time increased exponentially with increase in the number of voters as all instances of the ILP-algorithm that implemented the Monroe rule for =9, =30, and =200 did not terminate even after one day [39]. Hence, our algorithm, which (i) handles constraints and any committee selection rule and (ii) terminated in (avg) 724 sec, has a clear edge. Promisingly, the first committee returned by the algorithm (in 120 sec) was the winning DiRe committee among 63% of all instances. Moreover, our algorithm scales linearly with an increase in the number of voters.
Efficiency and cohesiveness:
Our algorithm was the most efficient when the voters were either less cohesive ( 0.3) or more cohesive ( 0.8) (Figure 5). Among these two efficient sets of instances, the time taken (mean = 105.40 sec (sd = 4.16) for -Borda and -CC, and mean = 141.06 sec (sd = 8.08) for Monroe) by the preprocessing stage to return infeasibility for low was less and the time taken (mean = 156.80 sec (sd = 2.86) for -Borda and -CC, and mean = 203.98 sec (sd = 12.66) for Monroe) by the heuristic-based search stage to return a DiRe committee for higher was less. This shows the efficiency of our algorithm in opposing scenarios: the preprocessing step was efficient when was low as it was easy to find a pair of constraints that are pairwise infeasible, and the heuristic-based backtracking was efficient when was high as it was easy to find a DiRe committee.
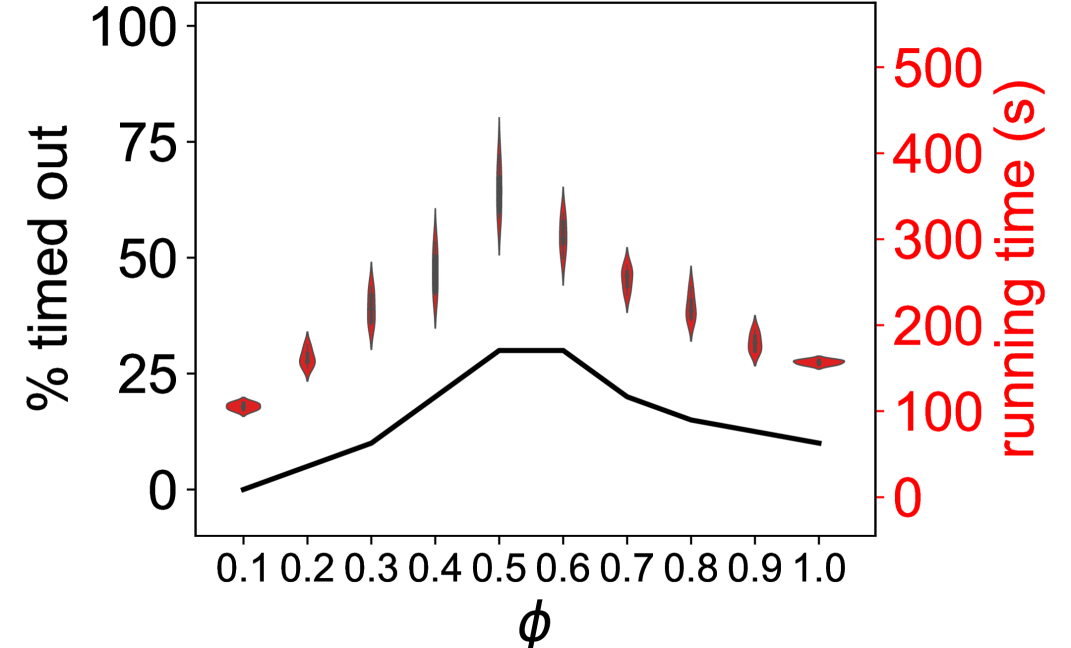
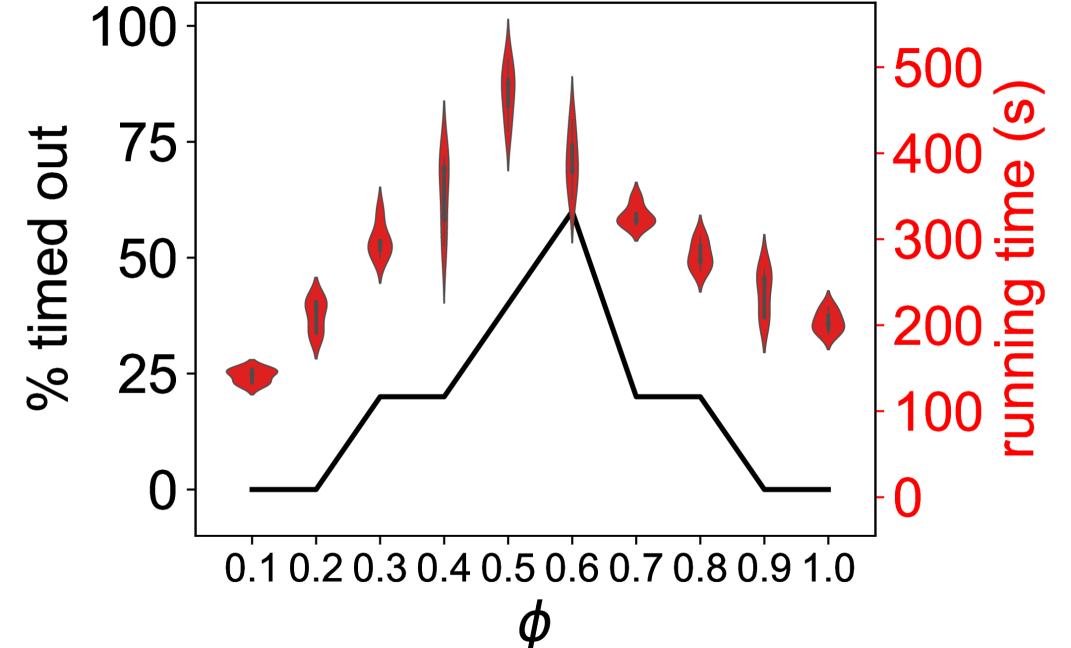
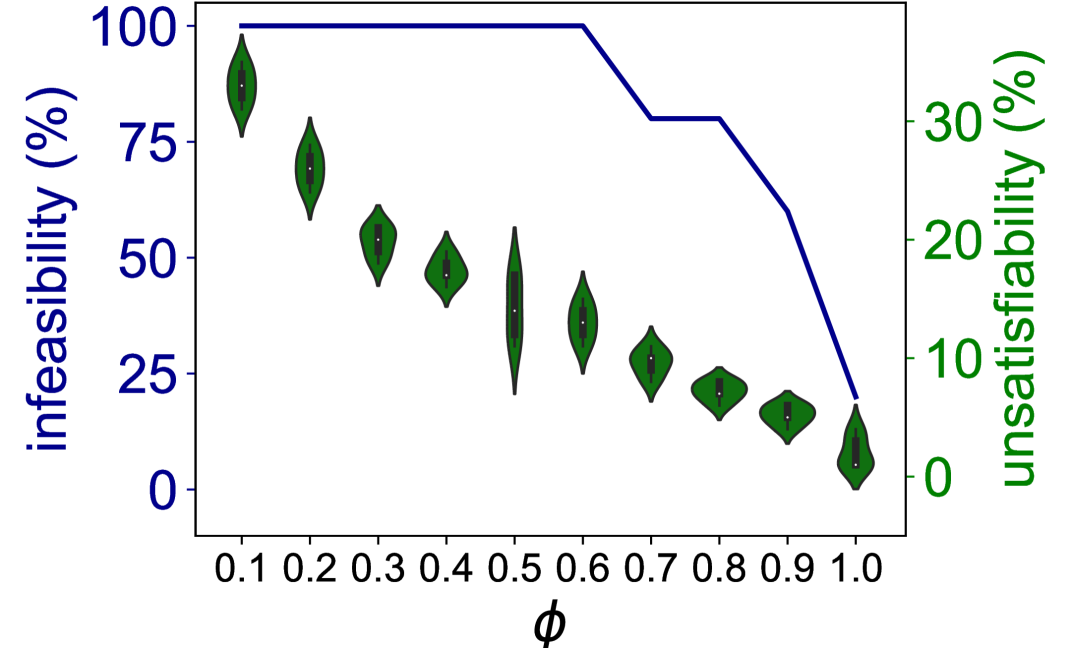
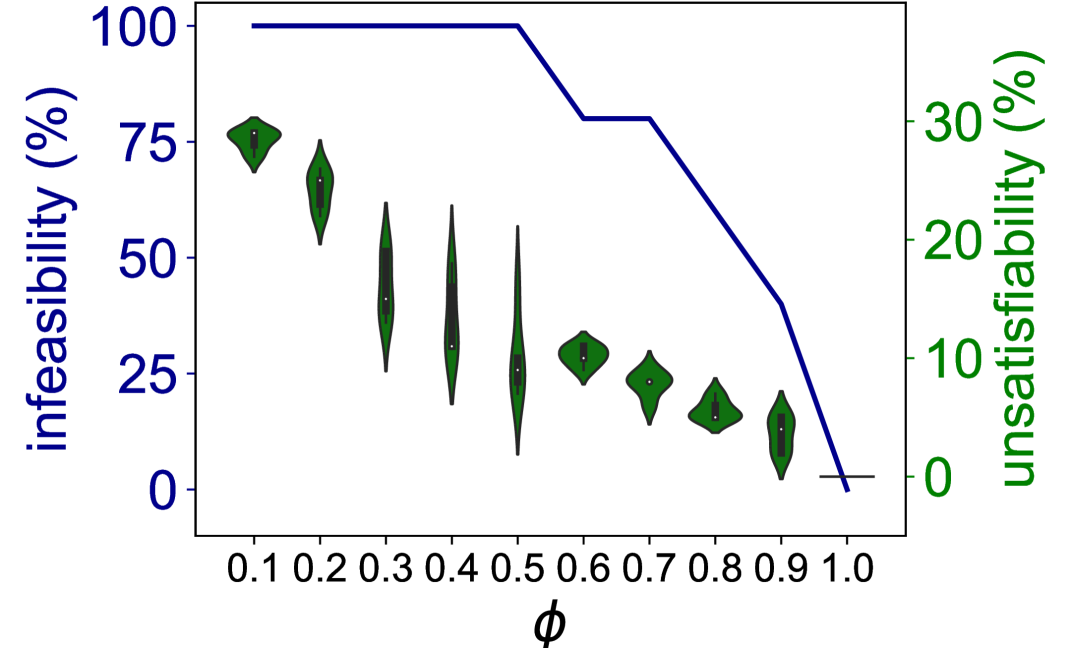
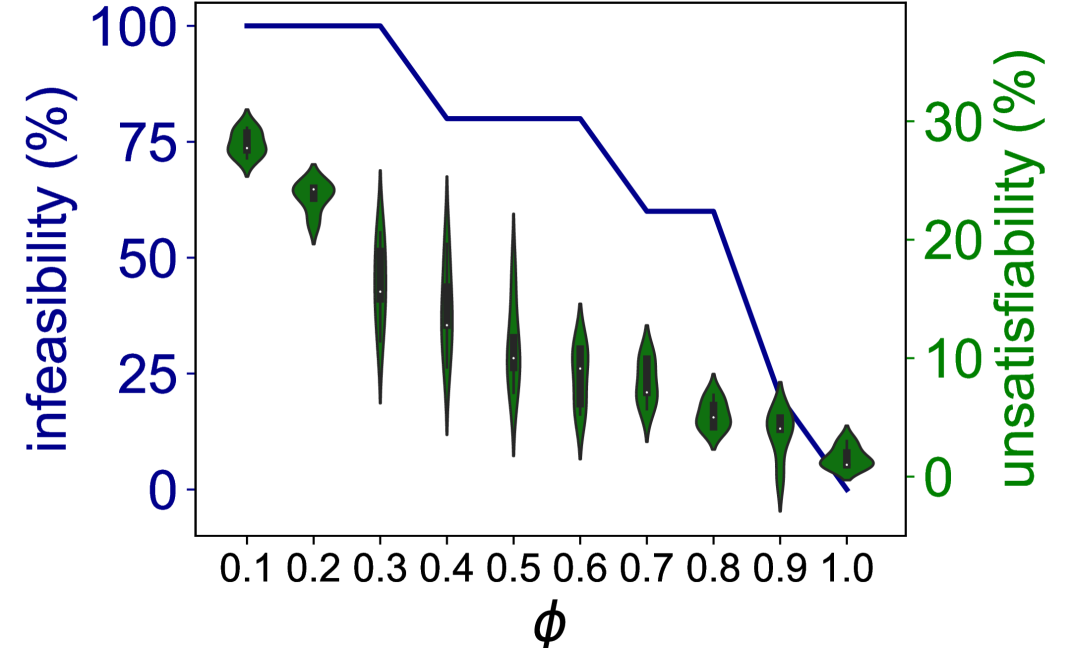
8.3.2 Feasibility and Cost of Fairness
All experiments in this section consider instances of -Borda and -CC separately as there was a difference in the unsatisfiability between the two (Student’s t-test, 0.05). We continue to an analyze Monroe separately.
Higher number of attributes result in infeasible committee:
Figure 7 shows the proportion of feasible instances for each combination of and . As the number of attributes increases, the proportion of feasible instances decreases. However, Figure 8 shows that the mean proportion of constraints satisfied for each instance is (sd [0, 5]). Hence, from the computational perspective, these results show the real-world utility of breaking down (, , )-DRCWD problem into two-steps: (i) (, )-DRCF problem solved using our algorithm followed by (ii) utility maximization problem. As we expect a constant number of committees to be feasible in real-world, we can overcome the intractability of using submodular scoring function, notwithstanding the worst case when all committees are feasible.
On the other hand, more promisingly: (i) When the sum of all the constraints was less than (), then, indeed, a feasible committee did exist on 85% of instances. (ii) More specifically, when the sum of the constraints was less than for all groups under each candidate attribute individually, then, indeed, a feasible committee did exist on all but one instance.
Infeasibility and unsatisfiability is dependent on cohesiveness:
There was a negative correlation between the maximum proportion of unsatisfied constraints and , for all the three scoring rules (mean Pearson’s = -0.95, 0.05) It was to easier to satisfy the constraints when the cohesiveness () was high, which led to lower infeasibility for higher (Figure 6).
Note that the correlation is stated keeping the candidate groups and voter populations constant. Only the preferences vary and hence, do the winning committee for each population . This is to say that higher cohesiveness of voters leads to higher cohesiveness among all s and in turn easier to satisfy the constraints and in turn higher proportion of feasible committees.
-CC and Monroe satisfies higher proportion of representation constraints:
-CC and Monroe rules are better at satisfying representation constraints as compared to -Borda (Figure 7) as they are designed to maximize the voter representation, and in turn, the population satisfaction. However, we note that even when we use a committee selection rule that guarantees proportional representation, our analysis found that it was indeed the smaller population whose the representation constraints were violated disproportionately more than that of the larger population. Hence, the price of diversity was paid more by smaller population as compared to larger population, which quantitatively reaffirms the need for DiRe committees.
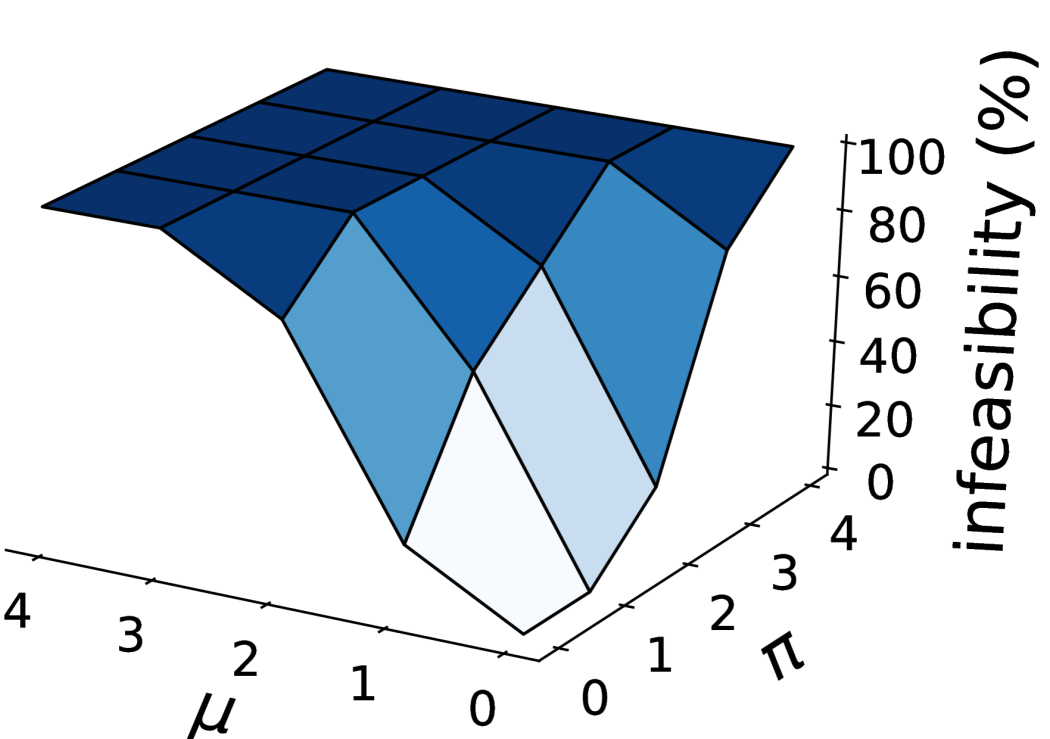
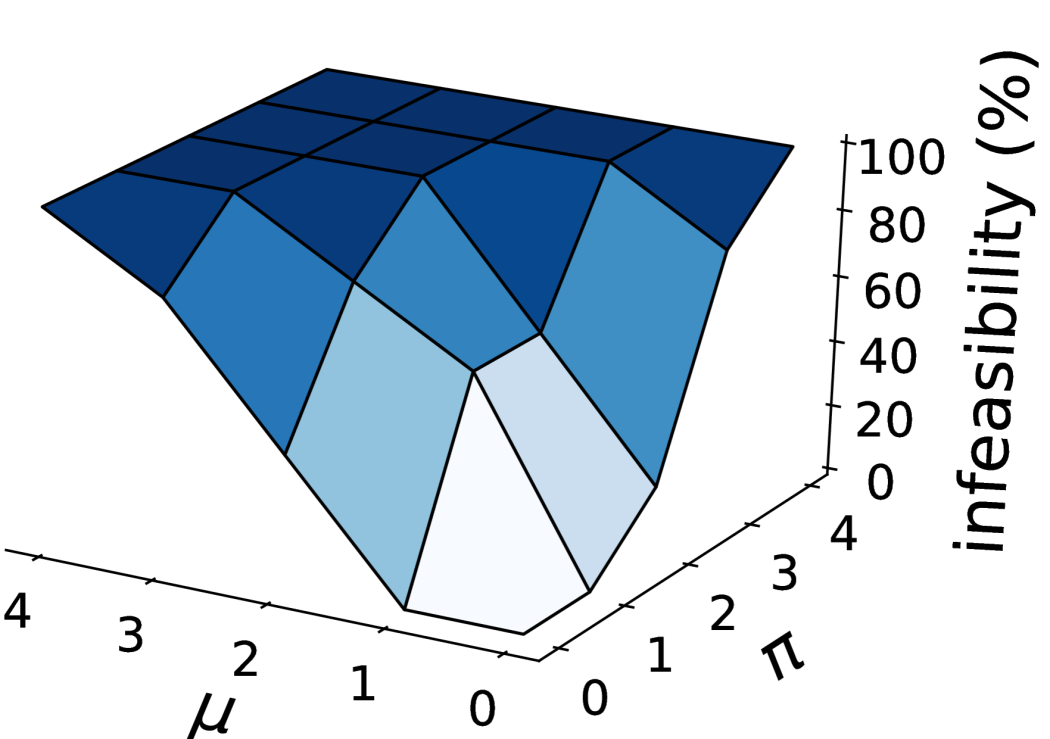
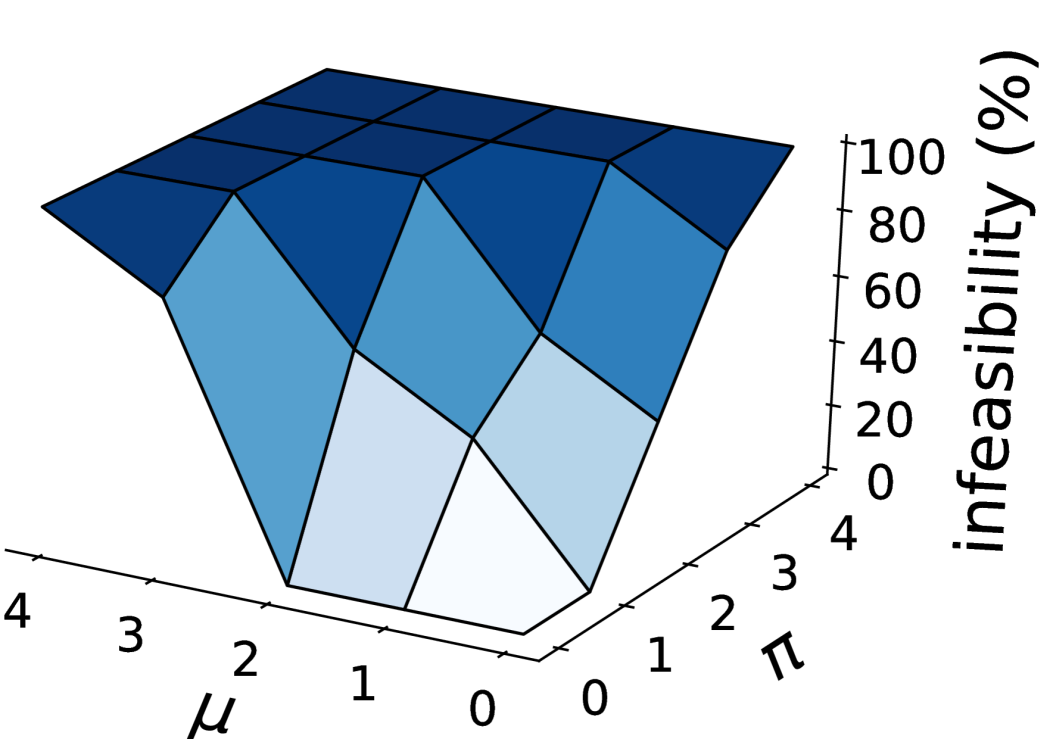
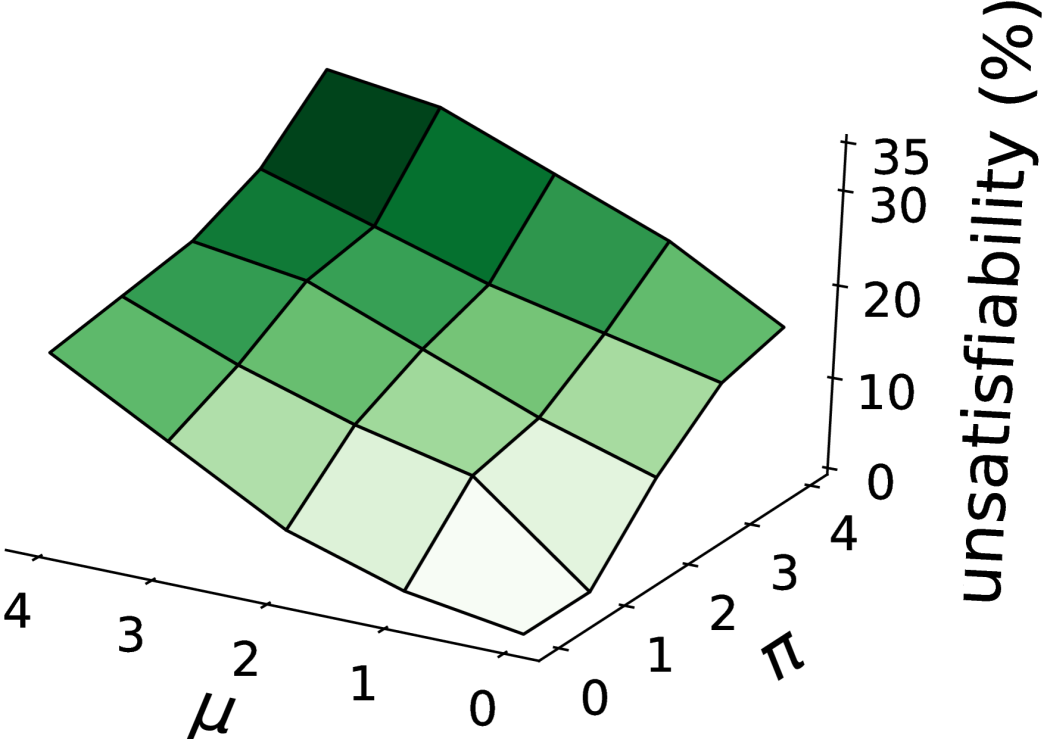
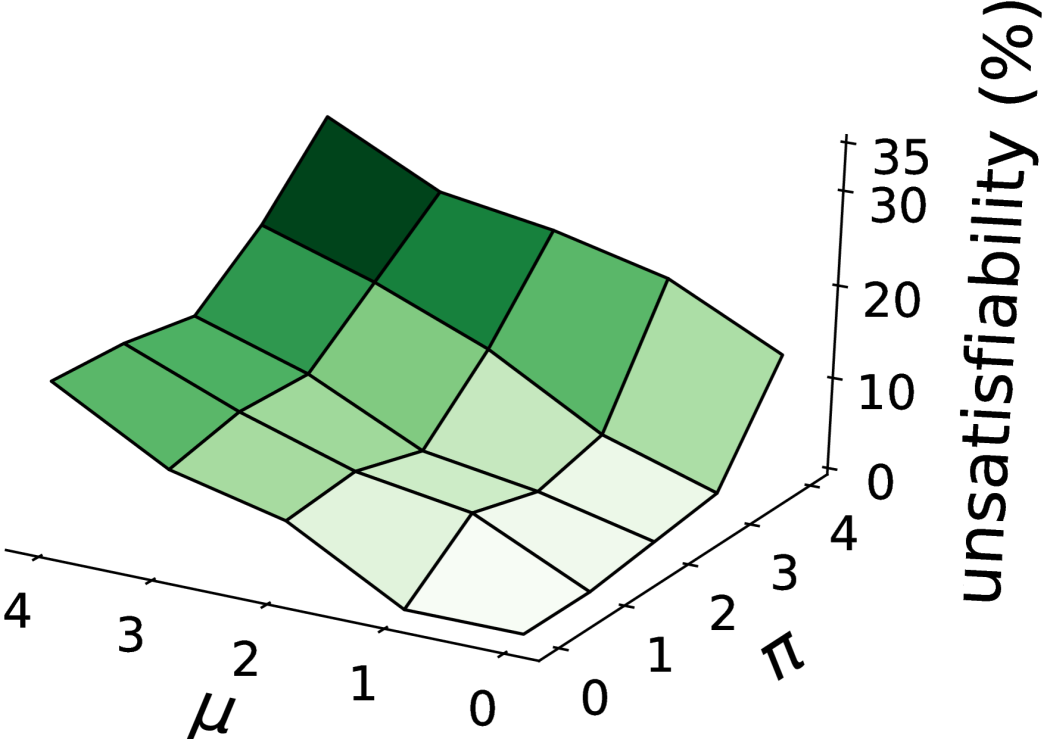
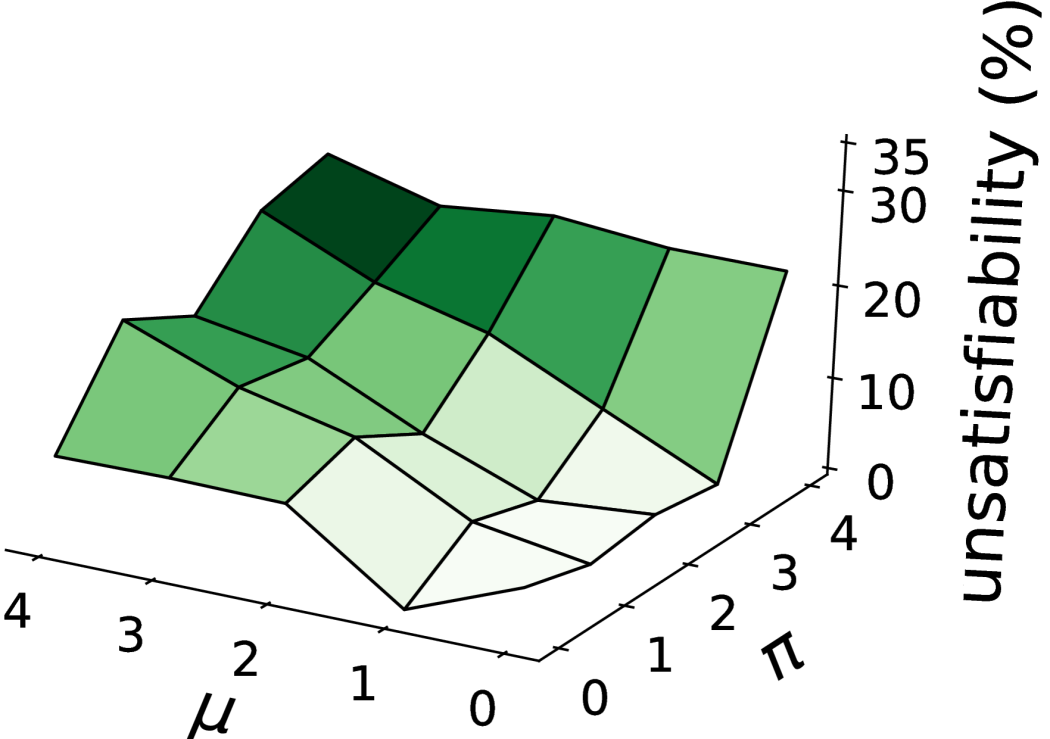
Easier to satisfy constraints when ratio is higher:
The proportion of constraints that are satisfied per instance changed from 100% to 49% (mean=82%, sd=12%) as the ratio changed from 1.00 to 0.25. This analysis basically captures the committee size to number of constraints ratio. Overall, it is easier to have a feasible instance with a larger the committee size () or a smaller the number of constraints ().
Loss in utility is proportional to the number of attributes:
Among all feasible instances, the mean ratio of utilities of constrained to unconstrained committee ranged from 0.99 (sd=0.01; for =1, =0) to 0.43 (sd=0.22; for =2, =1, the highest number of attributes with feasible committee) for -Borda, from 1.00 (sd=0.01; for =0, =1) to 0.49 (sd=0.18; for =1, =2) for -CC, and from 1.00 (sd=0.01; for =0, =1) to 0.48 (sd=0.15; for =2, =2) for the Monroe rule.
Higher group size to lower constraint ratios are easier to satisfy:
An important step of our heuristic algorithm was the use of the “minimum-remaining-value” heuristic, which helped in the selection of unsatisfied variable. We quantified the need for this heuristic by systematically varying the ratio of group (and population) size to lower constraint (equivalent to ), and found that the utility ratio is the highest when the average of the said ratio across all groups and population is the highest. Also, feasibility of an instance increases with an increase in this ratio. Hence, our heuristic, which prioritizes the lower ratio is efficient as it makes sense to first satisfy the groups or populations that are the hardest to satisfy.
8.3.3 Real Datasets
For each dataset, we implemented our model using 3 sets of constraints: constraint 1 only, constraint 2 only, and constraints 1 & 2. For Eurovision, these were at least one from each “region”, at least one from each “language”, and both combined. The ratios of utilities of constrained to unconstrained committees were 0.97, 0.88, and 0.82, respectively. For the UN resolutions, the constraints were at least two from each “topic”, at least six from “significant vote”, and both combined. The ratio of utilities was 0.99 for each of the individual constraints. No feasible committee was found when the constraints were combined. Importantly, our algorithm always terminated in under 102 sec across all instances.
9 Conclusion and Future Work
Conclusion:
There is an understanding in social sciences that organizations that answer the call for diversity to avoid legal troubles or to avoid being labeled as “racists” may actually create animosity towards racial minorities due to their imposing nature [72, 73, 74]. Similarly, when voters feel that diversity is mandatory and if it comes at the cost of their representation, it can do more harm than good. Hence, it is important to consider all actors of an election, namely candidates and voters, when designing fair algorithms. Doing so in this paper, we first motivated the need for diversity and representation constraints in multiwinner elections, and developed a model, (, , )-DRCWD. (, , )-DRCWD, which gives DiRe committees, is also needed because the call for diversity is becoming ubiquitous. However, in the context of elections, only diversity can do more harm than good as the price of diversity may disproportionately be paid more by historically disadvantaged population. Finally, we show the importance to delineate the candidate and voter attributes as we observed that diversity does not imply representation and vice versa, which contrasts the common understanding, and hence, requires further investigation. This is to say that having a female candidate on the committee is different from having a candidate on the committee who is preferred by the female voters, and who themselves may or may not be female. These two are separate but equally important aims that need to be achieved simultaneously.
We note that (, , )-DRCWD can satisfy many properties of multiwinner voting rules (e.g., monotonicity) [4] and it can be used as a common framework to solve other problems. As our model was computationally hard (Tables 1 and 2), we developed a heuristic-based algorithm, which was efficient on tested datasets. Finally, we did an empirical analyses of feasibility, utility traded-off, and efficiency.
Future Work:
It remains open to determine how the diversity and representation constraints are set to have a “fair” outcome. The way these constraints are set can lead to unfairness and hence, newer approaches are needed to ensure fairer outcomes. For instance, existing methods that guarantee representation fail when voters are divided into predefined population over one or more attributes. The apportionment method is one way to set the representation constraints, however, it does not account for the cohesiveness of the preferences within a population. Furthermore, this work can also give mathematical guarantees about the existence of DiRe committees. Additionally, just like correlation does not imply causation, diversity does not imply representation and vice versa. Hence, a mathematical framework is needed that can answer the following question: when does diversity imply representation, or when does representation imply diversity? The implications of such a formal framework range from hiring to clinical trials.
Another open question is determining what candidates are used to satisfy the constraints. Assuming that the given constraints are acceptable by everyone, the candidates chosen to satisfy the constraints can lead to unfair outcomes, especially for historically disadvantaged groups. For example, consider a -sized committee election (). The accepted constraints are that the committee should have two male and two female candidates. Next, consider two cases: (Case 1) top two scoring male candidates are selected in the committee and the bottom two scoring female candidates are selected and (Case 2) the top and the bottom scoring male candidates are selected in the committee and the top and bottom scoring female candidates are selected. While both the cases satisfy the given constraints, Case 1 is unfair for female candidates as their top-scoring candidate does not get a seat on the committee while male candidates do get their top two scoring candidates in the committee. This inequality is distributed in Case 2 and it seems naturally “fairer”.
Next open question pertains to the classification of the complexity of (, , )-DRCWD w.r.t. the committee selection rule . In this paper, could take only two values: it can either be a monotone, submodular but not separable function or a monotone, separable function. We established that determining the winning committee using the former is NP-hard, which was done via establishing hardness of using Chamberlin-Courant rule that uses a positional scoring rule whose first two values of the scoring vector are same (Theorem 6). However, the classification of complexity of determining the winning committee using Chamberlin-Courant rule, Monroe rule, and other submodular but not separable scoring functions w.r.t. different families of positional scoring rules remains open.
Continuing on the mathematical front, another future direction pertains to the relaxations made to group the candidates and the voters for Corollaries 2 and 3. More specifically, we showed the hardness persists even when a candidate attribute groups all candidates into one group and a voter attribute groups all voters into one population. These are unrealistic instances as real-world stipulation will require that each candidate attribute partitions the candidates into two or more groups and each voter attribute partitions the voters into two or more populations. Mathematically, Corollaries 2 and 3 will not hold under this stipulation and new proofs are required such that they conform to the stated stipulations.
Finally, the restrictions on voter preferences is another direction for future research. The reduction used to prove Theorem 5 shows that finding a committee using our model is NP-hard even when each population has one voter. This can be generalized to say that the hardness persists even when each population is completely cohesive within itself, which is a very natural assumption to make. For example, all male voters may have the same preferences and all female voters may have the same preferences and one population’s preferences are different from the other’s. However, given a set of constraints, one can explore as to how does the cohesiveness of voter preferences across populations affect the complexity of our model? In addition, it remains open whether the structure of voter preferences across population affects the complexity? Finally, the winning committees of populations can also be cohesive or structured, independent of the structure and cohesiveness of the voter preferences. Hence, even when voters’ preferences are not cohesive or structured, the cohesiveness or structure among the population’s winning committees may make our model tractable. An immediate consequence of a positive result on this front may be the narrowing of the gap between the intractability of finding a proportionally representative committee (e.g., using Chamberlin-Courant rule) and its tractable instance due to structured preferences. If finding a winning committee is tractable under the assumption of cohesiveness and/or structure of winning committees of the voter populations, then there is hope that finding a proportionally representative committee may also be tractable even under a weaker assumption on the structure of the voter preferences. On the other hand, if we know that the preferences of the voters is cohesive by a factor of : , then we conjecture that there exists a polynomial time approximation algorithm for the (, )-DRCF problem ( and ) with approximation ratio at most where is a function that maps the cohesiveness of the preferences to the maximum number of winning committees of each population that a candidate can belong to. This approximation ratio improves on the general inapproximability ratio of (Theorem 9) for (, )-DRCF when is not known.
Acknowledgement
I am grateful to Julia Stoyanovich for her insights that made me think about DiRe committees. I am thankful to Phokion G. Kolaitis for many helpful discussions that led to the classification of complexity of (, , )-DRCWD. I acknowledge the efforts of high-school students Raisa Bhuiyan and Rachel Rose in collecting the real-world datasets, and of Théo Delemazure for comments on empirical analysis. Finally, I thank anonymous reviewers for their comments on an earlier version of this paper.
References
- [1] Piotr Faliszewski, Piotr Skowron, Arkadii Slinko, and Nimrod Talmon. Committee scoring rules: Axiomatic classification and hierarchy. In IJCAI, pages 250–256, 2016.
- [2] D Marc Kilgour. Approval balloting for multi-winner elections. In Handbook on approval voting, pages 105–124. Springer, 2010.
- [3] Luis Sánchez-Fernández, Edith Elkind, Martin Lackner, Norberto Fernández, Jesús A Fisteus, Pablo Basanta Val, and Piotr Skowron. Proportional justified representation. In AAAI, 2017.
- [4] Edith Elkind, Piotr Faliszewski, Piotr Skowron, and Arkadii Slinko. Properties of multiwinner voting rules. Social Choice and Welfare, 48(3):599–632, 2017.
- [5] Piotr Faliszewski, Piotr Skowron, Arkadii Slinko, and Nimrod Talmon. Multiwinner voting: A new challenge for social choice theory. Trends in computational social choice, 74:27–47, 2017.
- [6] Haris Aziz, Markus Brill, Vincent Conitzer, Edith Elkind, Rupert Freeman, and Toby Walsh. Justified representation in approval-based committee voting. Social Choice and Welfare, 48(2):461–485, 2017.
- [7] Martin Lackner and Piotr Skowron. Consistent approval-based multi-winner rules. Journal of Economic Theory, 192:105173, 2021.
- [8] Robert Bredereck, Piotr Faliszewski, Ayumi Igarashi, Martin Lackner, and Piotr Skowron. Multiwinner elections with diversity constraints. In AAAI, 2018.
- [9] L Elisa Celis, Lingxiao Huang, and Nisheeth K Vishnoi. Multiwinner voting with fairness constraints. In IJCAI, 2018.
- [10] Markus Brill, Jean-François Laslier, and Piotr Skowron. Multiwinner approval rules as apportionment methods. Journal of Theoretical Politics, 30(3):358–382, 2018.
- [11] Burt L Monroe. Fully proportional representation. American Political Science Review, 89(4):925–940, 1995.
- [12] Yukio Koriyama, Antonin Macé, Rafael Treibich, and Jean-François Laslier. Optimal apportionment. Journal of Political Economy, 121(3):584–608, 2013.
- [13] Jérôme Lang and Piotr Skowron. Multi-attribute proportional representation. Artificial Intelligence, 263:74–106, 2018.
- [14] Ricardo Baeza-Yates. Data and algorithmic bias in the web. In Proceedings of the 8th ACM Conference on Web Science, pages 1–1. ACM, 2016.
- [15] Rachel KE Bellamy, Kuntal Dey, Michael Hind, Samuel C Hoffman, Stephanie Houde, Kalapriya Kannan, Pranay Lohia, Jacquelyn Martino, Sameep Mehta, Aleksandra Mojsilovic, et al. Ai fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias. arXiv preprint arXiv:1810.01943, 2018.
- [16] L Elisa Celis, Damian Straszak, and Nisheeth K Vishnoi. Ranking with fairness constraints. 45th International Colloquium on Automata, Languages, and Programming, ICALP, 2018.
- [17] David Danks and Alex John London. Algorithmic bias in autonomous systems. In IJCAI, pages 4691–4697, 2017.
- [18] Sara Hajian, Francesco Bonchi, and Carlos Castillo. Algorithmic bias: From discrimination discovery to fairness-aware data mining. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 2125–2126. ACM, 2016.
- [19] Anja Lambrecht and Catherine Tucker. Algorithmic bias? an empirical study of apparent gender-based discrimination in the display of stem career ads. Management Science, 2019.
- [20] Julia Stoyanovich, Ke Yang, and HV Jagadish. Online set selection with fairness and diversity constraints. In Proceedings of the EDBT Conference, 2018.
- [21] Ke Yang and Julia Stoyanovich. Measuring fairness in ranked outputs. In Proceedings of the 29th International Conference on Scientific and Statistical Database Management, page 22. ACM, 2017.
- [22] Ke Yang, Vasilis Gkatzelis, and Julia Stoyanovich. Balanced ranking with diversity constraints. In IJCAI, 2019.
- [23] Caitlin Kuhlman and Elke Rundensteiner. Rank aggregation algorithms for fair consensus. Proceedings of the VLDB Endowment, 13(11):2706–2719, 2020.
- [24] Xiaohui Bei, Shengxin Liu, Chung Keung Poon, and Hongao Wang. Candidate selections with proportional fairness constraints. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pages 150–158, 2020.
- [25] Deval Patel, Arindam Khan, and Anand Louis. Group fairness for knapsack problems. arXiv preprint arXiv:2006.07832, 2020.
- [26] Till Fluschnik, Piotr Skowron, Mervin Triphaus, and Kai Wilker. Fair knapsack. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 1941–1948, 2019.
- [27] D Ellis Hershkowitz, Anson Kahng, Dominik Peters, and Ariel D Procaccia. District-fair participatory budgeting. Proceedings of AAAI’21, 2021.
- [28] Dominik Peters, Grzegorz Pierczyński, and Piotr Skowron. Proportional participatory budgeting with cardinal utilities. arXiv preprint arXiv:2008.13276, 2020.
- [29] Martin Lackner, Jan Maly, and Simon Rey. Fairness in long-term participatory budgeting. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, pages 1566–1568, 2021.
- [30] Gourab K Patro, Arpita Biswas, Niloy Ganguly, Krishna P Gummadi, and Abhijnan Chakraborty. Fairrec: Two-sided fairness for personalized recommendations in two-sided platforms. In Proceedings of The Web Conference 2020, pages 1194–1204, 2020.
- [31] Abhijnan Chakraborty, Aniko Hannak, Asia J Biega, and Krishna Gummadi. Fair sharing for sharing economy platforms. In Fairness, Accountability and Transparency in Recommender Systems-Workshop on Responsible Recommendation, 2017.
- [32] Tom Sühr, Asia J Biega, Meike Zehlike, Krishna P Gummadi, and Abhijnan Chakraborty. Two-sided fairness for repeated matchings in two-sided markets: A case study of a ride-hailing platform. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3082–3092, 2019.
- [33] Marc Rysman. The economics of two-sided markets. Journal of economic perspectives, 23(3):125–43, 2009.
- [34] Himan Abdollahpouri and Robin Burke. Multi-stakeholder recommendation and its connection to multi-sided fairness. arXiv preprint arXiv:1907.13158, 2019.
- [35] Robin Burke. Multisided fairness for recommendation. arXiv preprint arXiv:1707.00093, 2017.
- [36] Haris Aziz. Two-sided matching with diversity concerns: an annotated reading list. ACM SIGecom Exchanges, 19(1):15–17, 2021.
- [37] John R Chamberlin and Paul N Courant. Representative deliberations and representative decisions: Proportional representation and the borda rule. American Political Science Review, 77(3):718–733, 1983.
- [38] Ariel D Procaccia, Jeffrey S Rosenschein, and Aviv Zohar. On the complexity of achieving proportional representation. Social Choice and Welfare, 30(3):353–362, 2008.
- [39] Piotr Skowron, Piotr Faliszewski, and Arkadii Slinko. Achieving fully proportional representation: Approximability results. Artificial Intelligence, 222:67–103, 2015.
- [40] Tyler Lu and Craig Boutilier. Budgeted social choice: From consensus to personalized decision making. In IJCAI, 2011.
- [41] Yongjie Yang and Jianxin Wang. Parameterized complexity of multi-winner determination: More effort towards fixed-parameter tractability. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, pages 2142–2144, 2018.
- [42] Nadja Betzler, Arkadii Slinko, and Johannes Uhlmann. On the computation of fully proportional representation. JAIR, 47:475–519, 2013.
- [43] Chinmay Sonar, Palash Dey, and Neeldhara Misra. On the complexity of winner verification and candidate winner for multiwinner voting rules. arXiv preprint arXiv:2004.13933, 2020.
- [44] Edith Elkind and Martin Lackner. Structure in dichotomous preferences. In IJCAI, 2015.
- [45] Dominik Peters and Martin Lackner. Preferences single-peaked on a circle. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [46] Jonas Israel and Markus Brill. Dynamic proportional rankings. arXiv preprint arXiv:2105.08043, 2021.
- [47] Joel Uckelman, Yann Chevaleyre, Ulle Endriss, and Jérôme Lang. Representing utility functions via weighted goals. Mathematical Logic Quarterly, 55(4):341–361, 2009.
- [48] Steven J Brams. Constrained approval voting: A voting system to elect a governing board. Interfaces, 20(5):67–80, 1990.
- [49] R Potthoff. Use of linear programming for constrained approval voting. Interfaces, 20(5):79–80, 1990.
- [50] Jonathan K Hodge and Richard E Klima. The mathematics of voting and elections: a hands-on approach, volume 30. American Mathematical Soc., 2018.
- [51] Vishal Chakraborty and Phokion G Kolaitis. Classifying the complexity of the possible winner problem on partial chains. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, pages 297–305, 2021.
- [52] Michael R Garey and David S Johnson. Computers and intractability, volume 174. Freeman San Francisco, 1979.
- [53] Paola Alimonti and Viggo Kann. Hardness of approximating problems on cubic graphs. In Italian Conference on Algorithms and Complexity, pages 288–298. Springer, 1997.
- [54] Subhash Khot. On the power of unique 2-prover 1-round games. In STOC, pages 767–775, 2002.
- [55] Khot Subhash, Dor Minzer, and Muli Safra. Pseudorandom sets in grassmann graph have near-perfect expansion. In FOCS, pages 592–601. IEEE, 2018.
- [56] Irit Dinur, Subhash Khot, Guy Kindler, Dor Minzer, and Muli Safra. Towards a proof of the 2-to-1 games conjecture? In STOC, pages 376–389, 2018.
- [57] Irit Dinur, Venkatesan Guruswami, Subhash Khot, and Oded Regev. A new multilayered pcp and the hardness of hypergraph vertex cover. SIAM Journal on Computing, 34(5):1129–1146, 2005.
- [58] Subhash Khot, Dor Minzer, and Muli Safra. On independent sets, 2-to-2 games, and grassmann graphs. In STOC, pages 576–589, 2017.
- [59] Luca Trevisan. Non-approximability results for optimization problems on bounded degree instances. In Proceedings of the thirty-third annual ACM symposium on Theory of computing, pages 453–461, 2001.
- [60] Rolf Niedermeier and Peter Rossmanith. An efficient fixed-parameter algorithm for 3-hitting set. Journal of Discrete Algorithms, 1(1):89–102, 2003.
- [61] Irit Dinur and David Steurer. Analytical approach to parallel repetition. In STOC, pages 624–633, 2014.
- [62] Nikhil Bansal and Subhash Khot. Inapproximability of hypergraph vertex cover and applications to scheduling problems. In International Colloquium on Automata, Languages, and Programming, pages 250–261. Springer, 2010.
- [63] Eran Halperin. Improved approximation algorithms for the vertex cover problem in graphs and hypergraphs. SIAM Journal on Computing, 31(5):1608–1623, 2002.
- [64] Rodney G Downey and Michael Ralph Fellows. Parameterized complexity. Springer Science & Business Media, 2012.
- [65] Giorgio Ausiello, Alessandro D’Atri, and Marco Protasi. Structure preserving reductions among convex optimization problems. Journal of Computer and System Sciences, 21(1):136–153, 1980.
- [66] Pierluigi Crescenzi, Viggo Kann, and M Halldórsson. A compendium of np optimization problems, 1995.
- [67] Stuart Russell and Peter Norvig. Artificial intelligence: A modern approach. Pearson Education Limited, 2002.
- [68] Kaggle. Eurovision Song Contest 1975-2019, (accessed July 22, 2020), 2019.
- [69] Erik Voeten. UN General Assembly Votes, 1946-2015, (accessed July 22, 2020), 2014.
- [70] C. L. Mallows. Non-null ranking models. i. Biometrika, 44(1-2):114–130, June 1957.
- [71] Vishal Chakraborty, Theo Delemazure, Benny Kimelfeld, Phokion G Kolaitis, Kunal Relia, and Julia Stoyanovich. Algorithmic techniques for necessary and possible winners. ACM/IMS Transactions on Data Science, 2(3):1–23, 2021.
- [72] Frank Dobbin and Alexandra Kalev. Diversity why diversity programs fail and what works better. Harvard Business Review, 94(7-8):52–60, 2016.
- [73] Eduardo Bonilla-Silva. Racism without racists: Color-blind racism and the persistence of racial inequality in the United States. Rowman & Littlefield Publishers, 2006.
- [74] Victor Ray. A theory of racialized organizations. American Sociological Review, 84(1):26–53, 2019.