\discount: Counting in Large Image Collections with Detector-Based Importance Sampling
Abstract
Many modern applications use computer vision to detect and count objects in massive image collections. However, when the detection task is very difficult or in the presence of domain shifts, the counts may be inaccurate even with significant investments in training data and model development. We propose \discount– a detector-based importance sampling framework for counting in large image collections that integrates an imperfect detector with human-in-the-loop screening to produce unbiased estimates of counts. We propose techniques for solving counting problems over multiple spatial or temporal regions using a small number of screened samples and estimate confidence intervals. This enables end-users to stop screening when estimates are sufficiently accurate, which is often the goal in a scientific study. On the technical side we develop variance reduction techniques based on control variates and prove the (conditional) unbiasedness of the estimators. \discountleads to a 9-12 reduction in the labeling costs over naive screening for tasks we consider, such as counting birds in radar imagery or estimating damaged buildings in satellite imagery, and also surpasses alternative covariate-based screening approaches in efficiency. ††∗equal advising contribution
1 Introduction
Many modern applications use computer vision to detect and count objects in massive image collections. For example, we are interested in applications that involve counting bird roosts in radar images and damaged buildings in satellite images. The image collections are too massive for humans to solve these tasks in the available time. Therefore, a common approach is to train a computer vision detection model and run it exhaustively on the images.
The task is interesting because the goal is not to generalize, but to achieve the scientific counting goal with sufficient accuracy for a fixed image collection. The best use of human effort is unclear: it could be used for model development, labeling training data, or even directly solving the counting task! A particular challenge occurs when the detection task is very difficult, so the accuracy of counts made on the entire collection is questionable even with huge investments in training data and model development. Some works resort to human screening of the detector outputs Norouzzadeh et al. (2018); Nurkarim and Wijayanto (2023); Perez et al. (2022), which saves time compared to manual counting but is still very labor intensive.
These considerations motivate statistical approaches to counting. Instead of screening the detector outputs for all images, a human can “spot-check” some images to estimate accuracy, and, more importantly, use statistical techniques to obtain unbiased estimates of counts across unscreened images. In a related context, Meng et al. (2022) proposed IS-count, which uses importance sampling to estimate total counts across a collection when (satellite) images are expensive to obtain by using spatial covariates to sample a subset of images.
We contribute counting methods for large image collections that build on IS-count in several ways. First, we work in a different model where images are freely available and it is possible to train a detector to run on all images, but the detector is not reliable enough for the final counting task, or its reliability is unknown. We contribute human-in-the-loop methods for count estimation using the detector to construct a proposal distribution, as seen in Fig. 1. Second, we consider solving multiple counting problems—for example, over disjoint or overlapping spatial or temporal regions—simultaneously, which is very common in practice. We contribute a novel sampling approach to obtain simultaneous estimates, prove their (conditional) unbiasedness, and show that the approach allocates samples to regions in a way that approximates the optimal allocation for minimizing variance. Third, we design confidence intervals, which are important practically to know how much human effort is needed. Fourth, we use variance reduction techniques based on control variates.
Our method produces unbiased estimates and confidence intervals with reduced error compared to covariate-based methods. In addition, the labeling effort is further reduced with \discountas we only have to verify detector predictions instead of producing annotations from scratch. On our tasks, \discountleads to a 9-12 reduction in the labeling costs over naive screening and 6-8 reduction over IS-Count. Finally, we show that solving multiple counting problems jointly can be done more efficiently than solving them separately, demonstrating a more efficient use of samples.

(a) (b) (c) (d)
2 Related Work
Computer vision techniques have been deployed for counting in numerous applications where exhaustive human-labeling is expensive due to the sheer volume of imagery involved. This includes areas such as detecting animals in camera trap imagery Norouzzadeh et al. (2018); Tuia et al. (2022), counting buildings, cars, and other structures in satellite images Nurkarim and Wijayanto (2023); Cavender-Bares et al. (2022); Burke et al. (2021); Leitloff et al. (2010), species monitoring in citizen science platforms Tuia et al. (2022); Van Horn et al. (2018), monitoring traffic in videos Won (2020); Coifman et al. (1998), as well as various medicine, science and engineering applications. For many applications the cost associated with training an accurate model is considerably less than that of meticulously labeling the entire dataset. Even with a less accurate model, human-in-the-loop recognition strategies have been proposed to reduce annotation costs by integrating human validation with noisy predictions Branson et al. (2010); Wah et al. (2014).
Our approach is related to work in active learning Settles (2009) and semi-supervised learning Chapelle et al. (2009), where the goal is to reduce human labeling effort to learn models that generalize on i.i.d. held out data. While these approaches reduce the cost of labels on training data, they often rely on large labeled test sets to estimate the performance of the model, which can be impractical. Active testing Nguyen et al. (2018); Kossen et al. (2021) aims to reduce the cost of model evaluation by providing a statistical estimate of the performance using a small number of labeled examples. Unlike traditional learning where the goal is performance on held out data, the goal of active testing is to estimate performance on a fixed dataset. Similarly, our goal is to estimate the counts on a fixed dataset, but different from active testing we are interested in estimates of the true counts and not the model’s performance. In particular, we want unbiased estimates of counts even when the detector is unreliable. Importantly, since generalization is not the goal, overfitting to the dataset statistics may lead to more accurate estimates.
Statistical estimation has been widely used to conduct surveys (e.g., estimating population demographics, polling, etc.) Cochran (1977). In IS-Count Meng et al. (2022), the authors propose an importance sampling approach to estimate counts in large image collections using humans-in-the-loop. They showed that one can count the number of buildings at the continental scale by sampling a small number of regions based on covariates such as population density and annotating those regions, thereby reducing the cost of obtaining high-resolution satellite imagery and human labels. However, for many applications the dataset is readily available, and running the detector is cost effective, but human screening is expensive. To address this, we propose using the detector to guide the screening process and demonstrate that this significantly reduces error rates in count estimation given a fixed amount of human effort. Furthermore, for some applications, screening the outputs of a detector can be significantly faster than to annotate from scratch, leading to additional savings.
An interesting question is what is the best way to utilize human screening effort to count on a dataset. For example, labels might be used to improve the detector, measure performance on the deployed dataset, or, as is the case in our work, to derive a statistical estimate of the counts. Our work is motivated by problems where improving the detector might require significant effort, but counts from the detector are correlated with true counts and can be used as a proposal distribution for sampling.
3 \discount: Detector-based IS-Count
Consider a counting problem in a discrete domain (usually spatiotemporal) with elements that represent a single unit such as an image, grid cell, or day of year. For each there is a ground truth “count” , which can be any non-negative measurement, such as the number or total size of all objects in an image. A human can label the underlying images for any to obtain .
Define to be the cumulative count for a region . We wish to estimate the total counts for different subsets , or regions, while using human effort as efficiently as possible. The regions represent different geographic divisions or time ranges and may overlap — for example, in the roost detection problem we want to estimate cumulative counts of birds for each day of the year, while disaster-relief planners want to estimate building damage across different geographical units such as towns, counties, and states. Assume without loss of generality that , otherwise the domain can be restricted so this is true.
We will next present our methods; derivations and proofs of all results are found in the appendix.
3.1 Single-Region Estimators
Consider first the problem of estimating the total count for a single region . Meng et al. (2022) studied this problem in the context of satellite imagery, with the goal of minimizing the cost of purchasing satellite images to obtain an accurate estimate.
Simple Monte Carlo Meng et al. (2022)
This is a baseline based on simple Monte Carlo sampling. Write . Then the following estimator, which draws random samples uniformly in to estimate the total, is unbiased:
IS-Count Meng et al. (2022)
Meng et al. then proposed an estimator based on importance sampling Owen (2013). Instead of sampling uniformly, the method samples from a proposal distribution that is cheap to compute for all . For example, to count buildings in US satellite imagery, the proposal distribution could use maps of artificial light intensity, which are freely available. The importance sampling estimator is:
\discount
IS-count assumes images are costly to obtain, which motivates using external covariates for the proposal distribution. However, in many scientific tasks, the images are readily available, and the key cost is that of human supervision. In this case it is possible to train a detection model and run it on all images to produce an approximate count for each . Define to be the approximate detector-based count for region . We propose the detector-based IS-count ("\discount") estimator, which uses the proposal distribution proportional to on region , i.e., with density . The importance-sampling estimator then specializes to:
To interpret \discount, let be the ratio of the true count to the detector-based count for the th sample or (importance) weight. \discountreweights the detector-based total count by the average weight , which can be viewed as a correction factor based on the tendency to over- or under-count, on average, across all of .
is unbiased as long as for all such that . Henceforth, we assume detector counts are pre-processed if needed so that for all relevant units, for example, by adding a small amount to each count.
3.2 -\discount
We now return to the multiple region counting problem. A naive approach would be to run \discountseparately for each region. However, this is suboptimal. First, it allocates samples equally to each region, regardless of their size or predicted count. Intuitively, we want to allocate more effort to regions with higher predicted counts. Second, if regions overlap it is wasteful to repeatedly draw samples from each one to solve the estimation problems separately.
-\discount
We propose estimators based on samples drawn from all of with probability proportional to . Then, we can estimate for any region using only the samples from . Specifically, the -\discountestimator is
where is the number of samples in region and is the average importance weight for region .
Claim 1.
The -\discountestimator is conditionally unbiased given at least one sample in region . That is, .
The unconditional bias can also be analyzed (see Appendix). Overall, bias has negligible practical impact. It occurs only when the sample size is zero, which is an event that is both observable and has probability that decays exponentially in , where .
In terms of variance, -\discountbehaves similarly to \discountrun on each region with sample size equal to . To first order, both approaches have variance where is the importance-weight variance. In the case of disjoint regions, running \discounton each region is the same as stratified importance sampling across the regions, and the allocation of samples to region is optimal in the following sense:
Claim 2.
Suppose partition and the importance weight variance is constant across regions. Assume \discountis run on each region with samples. Given a total budget of samples, the sample sizes that minimize are given by .
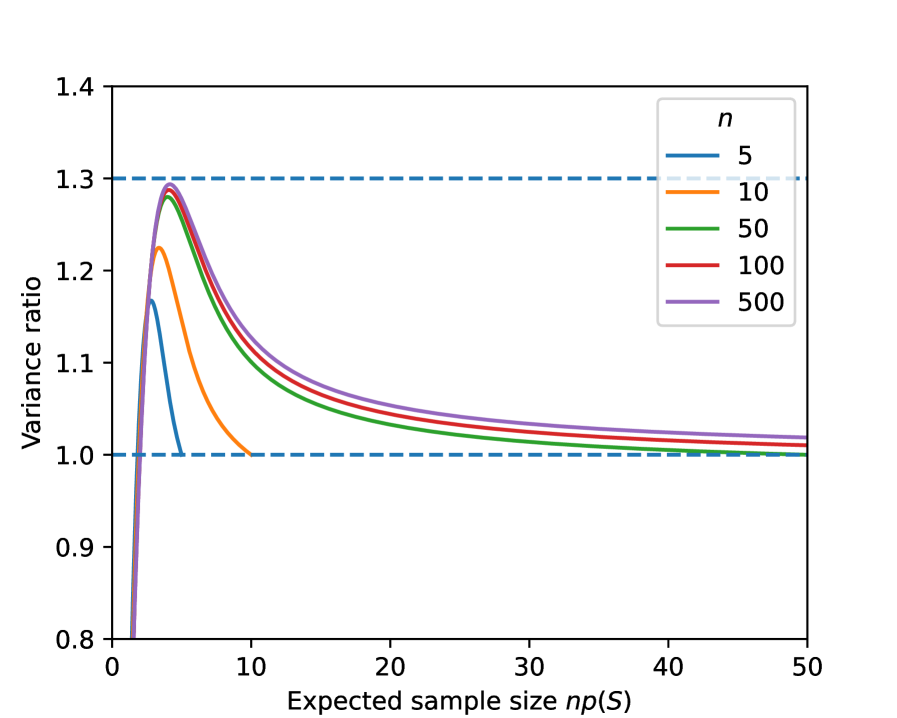
The analysis uses reasoning similar to the Neyman allocation for stratified sampling Cochran (1977), and shows that -\discountapproximates the optimal allocation of samples to (disjoint) regions under the stated assumptions. One key difference is that -\discountdraws samples from all of and then assigns them to regions, which is called “post-stratification” in the sampling literature Cochran (1977). An exact variance analysis in the Appendix reveals that, if the expected sample size for a region is very small, -\discountmay have up to 30% “excess” variance compared to stratification due to the random sample size, but the excess variance disappears quickly and both approaches have the same asymptotic variance. A second key difference to stratification is that regions can overlap; -\discount’s approach of sampling from all of and then assigning samples to regions extends cleanly to this setting.
3.3 Control Variates
Control variates are functions whose integrals are known and can be combined with importance sampling using the following estimator:
where and . It is clear that has the same expectation as , but might have a lower variance under certain conditions (if and are sufficiently correlated Owen (2013)). For bird counting, estimated counts from previous years could be used as control variates as migration is periodic to improve count estimates (see experiments in § 4 for details).
3.4 Confidence intervals
Confidence intervals for -\discountcan be constructed in a way similar to standard importance sampling. For a region , first estimate the importance weight variance as:
An approximate confidence interval is then given by , where is the quantile of the standard normal distribution, e.g., for a 95% confidence interval. The theoretical justification is subtle due to scaling by the random sample size . It is based on the following asymptotic result, proved in the Appendix.
Claim 3.
The -\discountestimator with scaling factor is asymptotically normal, that is, the distribution of converges to as .
In preliminary experiments we observed that for small expected sample sizes the importance weight variance can be underestimated leading to intervals that are too small — as an alternative, we propose a practical heuristic for smaller sample sizes where is used instead of ; that is, all samples are used to estimate variability of importance weights for each region .
4 Experimental Setup
In this section we describe the counting tasks and detection models (§ 4.1–4.2) and the evaluation metrics (§ 4.3) we will use to evaluate different counting methods. We focus on two applications: counting roosting birds in weather radar images and counting damaged buildings in satellite images of a region struck by a natural disaster.
4.1 Counting Roosting Birds from Weather Radar
Many species of birds and bats congregate in large numbers at nighttime or daytime roosting locations. Their departures from these “roosts” are often visible in weather radar, from which it’s possible to estimate their numbers Winkler (2006); Buler et al. (2012); Horn and Kunz (2008). The US “NEXRAD” weather radar network nex (2023) has collected data for 30 years from 143+ stations and provides an unprecedented opportunity to study long-term and wide-scale biological phenomenon such as roosts Rosenberg et al. (2019); Sánchez-Bayo and Wyckhuys (2019). However, the sheer volume of radar scans (250M) prevents manual analysis and motivates computer vision approaches Chilson et al. (2018); Lin et al. (2019); Cheng et al. (2020); Perez et al. (2022). Unfortunately, the best computer vision models Perez et al. (2022); Cheng et al. (2020) for detecting roosts have average precision only around 50% and are not accurate enough for fully automated scientific analysis, despite using state-of-the-art methods such as Faster R-CNNs Ren et al. (2015) and training on thousands of human annotations — the complexity of the task suggests substantial labeling and model development efforts would be needed to improve accuracy, and may be impractical.
Previous work Belotti et al. (2023); Deng et al. (2023) used a roost detector combined with manual screening of the detections to analyze more than 600,000 radar scans spanning a dozen stations in the Great Lakes region of the US to reveal patterns of bird migration over two decades. The vetting of nearly 64,000 detections was orders of magnitude faster than manual labeling, yet still required a substantial 184 hours of manual effort. Scaling to the entire US network would require at least an order of magnitude more effort, thus motivating a statistical approach.
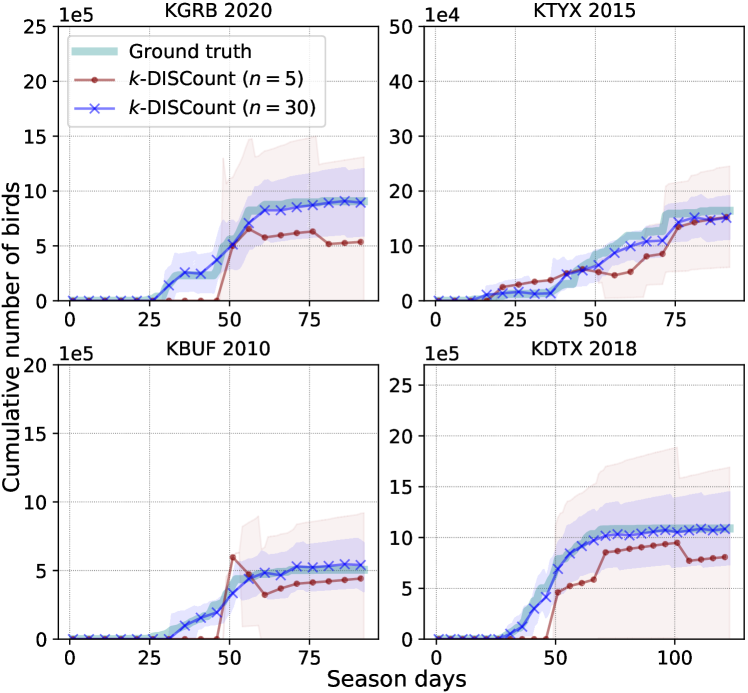
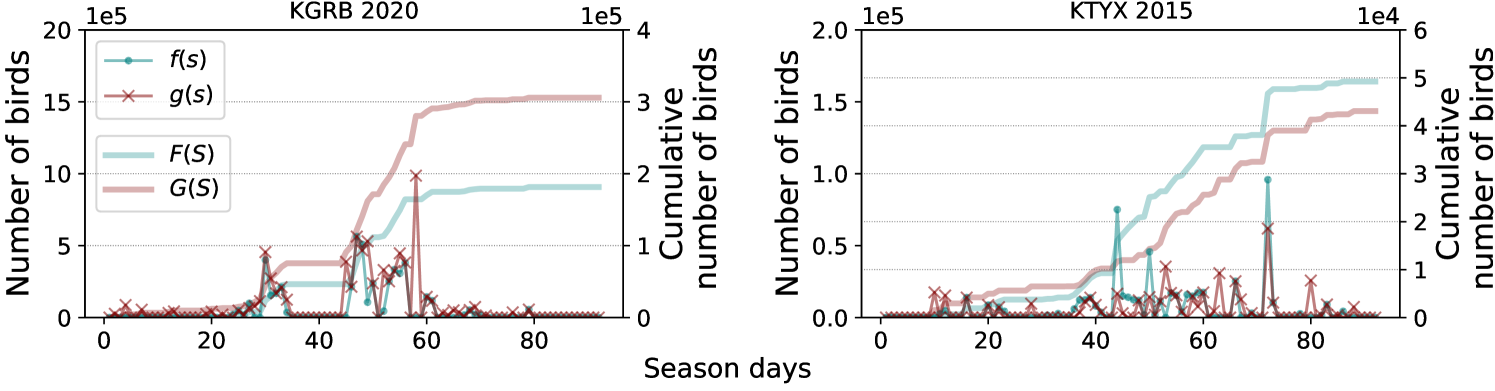
We use the exhaustively screened detections from the Great Lakes analysis in Belotti et al. (2023); Deng et al. (2023) to systematically analyze the efficiency of sampling based counting. The data is organized into domains corresponding to 12 stations and 20 years (see Fig. 7 in Appendix B). Thus the domains are disjoint and treated separately. Counts are collected for each day by running the detector using all radar scans for that day to detect and track roost signatures and then mapping detections to bird counts using the measured radar “reflectivity” within the tracks. For the approximate count we use the automatically detected tracks, while for the true count we use the manually screened and corrected tracks. For a single domain, i.e., each station-year, we divide a complete roosting season into temporal regions in three different scenarios: (1) estimating bird counts up to each day in the roosting season (i.e., regions are nested prefixes of days in the entire season), (2) the end of each quarter of (i.e., regions are nested prefixes of quarters in the entire season), and (3) estimating each quarter’s count (each region is one quarter). We measure error using the fully-screened data and average errors across all domains and regions. Fig. 2 shows the counts and confidence intervals estimated using -\discountfor the first scenario on four station-years.
4.2 Counting Damaged Buildings from Satellite Images
Building damage assessment from satellite images Kim and Yoon (2018); Deng and Wang (2022) is often used to plan humanitarian response after a natural disaster strikes. However, the performance of computer vision models degrades when applied to new regions and disaster types. Our approach can be used to quickly vet the data produced by the detector to correctly estimate counts in these scenarios.
We use the building damage detection model by DIUx-xView , the winner of the xView2 challenge xvi . The model is based on U-Net Ronneberger et al. (2015) to detect buildings in the pre-disaster image, followed by a “siamese network" that incorporates at pre- and post-disaster images to estimate damage. The model is trained on the xBD dataset Gupta et al. (2019) that contains building and damage annotations spanning multiple geographical regions and disaster types (e.g., earthquake, hurricane, tsunami, etc.). While the dataset contains four levels of damage (i.e., 0: no-damage, 1: minor-damage, 2: major-damage, and 3: destroyed), in this work we combine all damage levels (i.e., classes 1-3) into a single “damage” class.
We consider the Palu Tsunami from 2018; the data consists of 113 high-resolution satellite images labeled with 31,394 buildings and their damage levels. We run the model on each tile to estimate the number of damaged buildings , while the ground-truth number of damaged buildings is used as . Our goal is to estimate the cumulative damaged building count in sub-regions expanding from the area with the most damaged buildings as shown in Fig. 9 in the Appendix C. To define the sub-regions, we sort all images by their distance from the epicenter (defined as the image tile with the most damaged buildings) and then divide into chunks or “annuli” of size . The task is to estimate the cumulative counts of the first chunks for from 1 to 7.
4.3 Evaluation
We measure the fractional error between the true and the estimated counts averaged over all regions in a domain as:
For the bird counting task, for any given definition of regions within one station-year (i.e., cumulative days or quarters defined in § 4.1) we report the error averaged across all station-years corresponding to 12 stations and years. For the damaged building counting problem there is only a single domain corresponding to the Palu Tsunami region. In addition, we calculate the average confidence interval width normalized by . We run 1000 trials and plot average metrics over the trials. We also evaluate confidence interval coverage, which is the fraction of confidence intervals that contain the true count over all domains, regions, and trials.
5 Results
In this section, we present the results comparing detector-based to covariate-based sampling. Also, we show reductions in labeling effort and demonstrate the advantages of estimating multiple counts jointly. Finally, we show confidence intervals and control variates results.
Detector-based sampling reduces error
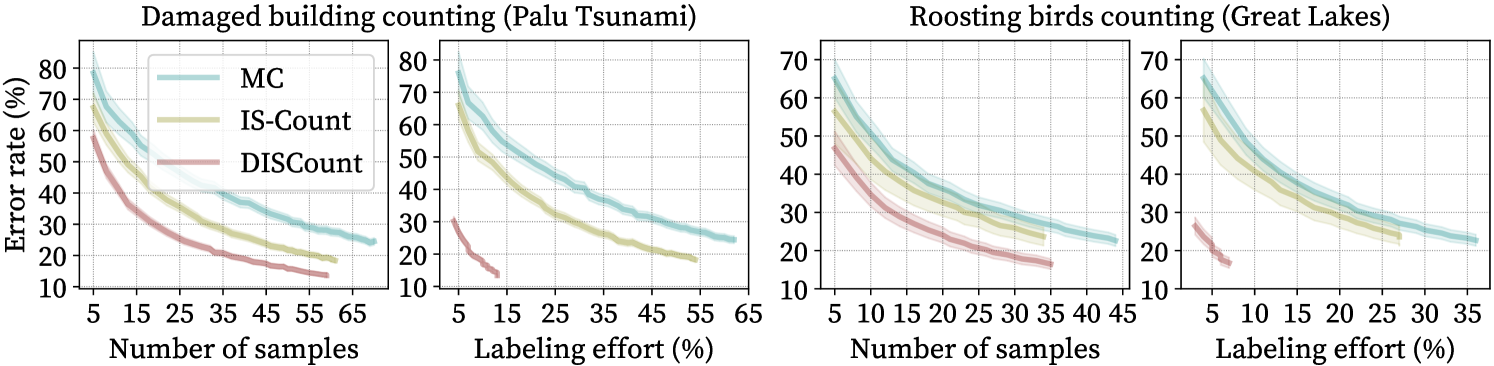
We first compare \discount(detector-based sampling) to IS-Count and simple Monte Carlo sampling for estimating , that is, the total counts of birds in a complete roosting season for a given station year, or damaged buildings in the entire disaster region. Fig. 3 shows the error rate as a function of number of labeled samples (i.e., the number of distinct sampled, since each is labeled at most once). In the buildings application, a sample refers to an image tile of size pixels, while for the birds a sample refers to a single day.
Using the detector directly without any screening results in high error rates — roughly 136% and 149% for estimating the total count for the damaged buildings and bird counting tasks respectively. Meng et al. (2022) show the advantages of using importance sampling with screening to produce count estimates with base covariates as opposed to simple Monte Carlo sampling (MC vs. IS-Count). For the bird counting task, we construct a non-detector covariate by fitting a spline to with 10% of the days from an arbitrarily selected station-year pair (station KBUF in 2001). For the damaged building counting task, the covariate is the true count of all buildings (independent of the damage) obtained using the labels provided with the xBD dataset.
Covariate-based sampling (IS-Count) leads to significant savings over simple Monte Carlo sampling (MC), but \discountprovides further improvements. In particular, to obtain an error rate of 20% \discountrequires fewer samples than IS-Count and fewer samples than MC for both counting problems.
Screening leads to a further reduction in labeling effort
alleviates the need for users to annotate an image from scratch, such as identifying an object and drawing a bounding box around it. Instead, users only need to verify the detector’s output, which tends to be a quicker process. In a study by Su et al. (2012) on the ImageNet dataset Deng et al. (2009), the median time to draw a bounding-box was found to be 25.5 seconds, whereas verification took only 9.0 seconds (this matches the screening time of 10s per bounding-box in Deng et al. (2023); Belotti et al. (2023)). The right side of Fig. 3 presents earlier plots with the x-axis scaled based on labeling effort, computed as , where denotes the number of screened samples and represents the fraction of time relative to labeling from scratch. For instance, the labeling effort is 100% when all elements must be labeled from scratch ( and ). For \discount, we estimate , since annotating from scratch requires both drawing and verification, while screening requires only verification. To achieve the same 20% error rate, \discountrequires less effort than IS-Count and less effort than MC for the bird counting task, and less effort than IS-Count and less effort than MC for building counting.
Multiple counts can be estimated efficiently (-\discount)
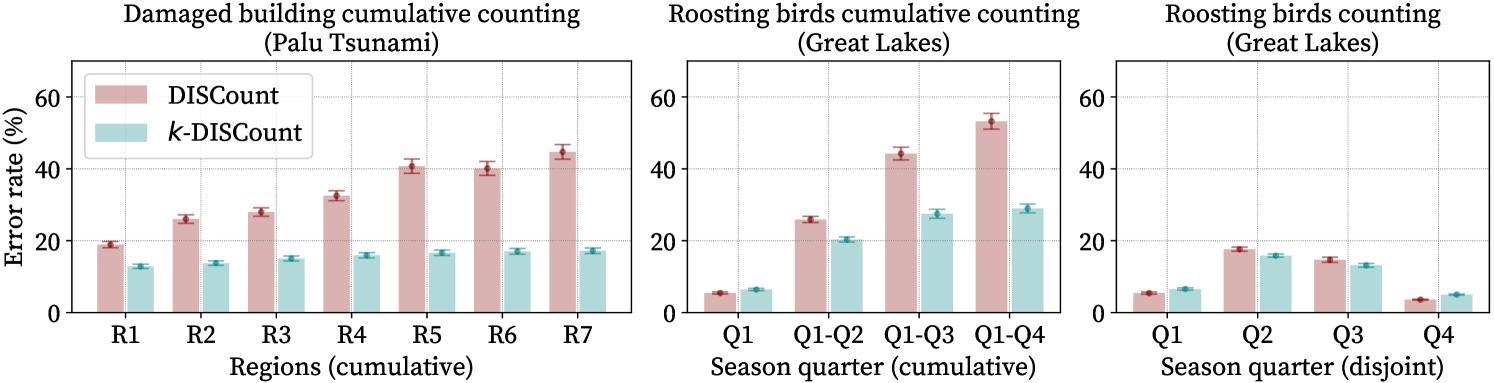
To solve multiple counting problems, we compared -\discountto using \discountseparately on each region. For bird counting, the task was to estimate four quarterly counts (cumulative or individual) as described in § 4.1. For -\discount, we sampled days from the complete season to estimate the counts simultaneously. For , we solved each of the four problems separately using samples per region for the same total number of samples. For building damage counting, the task was to estimate seven cumulative counts as described in § 4.2. For -\discount, we used images sampled from the entire domain, while for \discountwe used sampled images per region.
Fig. 4 shows that solving multiple counting problems jointly (-\discount) is better than solving them separately (\discount). For the cumulative tasks, -\discountmakes much more effective use of samples from overlapping regions. For single-quarter bird counts, -\discounthas slightly higher error in Q1 and Q4 and lower errors in Q2 and Q3. This can be understood in terms of sample allocation: -\discountallocates in proportion to predicted counts, which provides more samples and better accuracy in Q2-Q3, when many more roosts appear, and approximates the optimal allocation of Claim 2. \discountallocates samples equally, so has slightly lower error for the smaller Q1 and Q4 counts. In contrast, for building counting, -\discounthas lower error even for the smallest region R1, since this has the most damaged buildings and thus gets more samples than \discount. Fig. 5 (left) shows -\discountoutperforms simple Monte Carlo (adapted to multiple regions similarly to -\discount) for estimating cumulative daily bird counts as in Fig. 2.
Confidence intervals
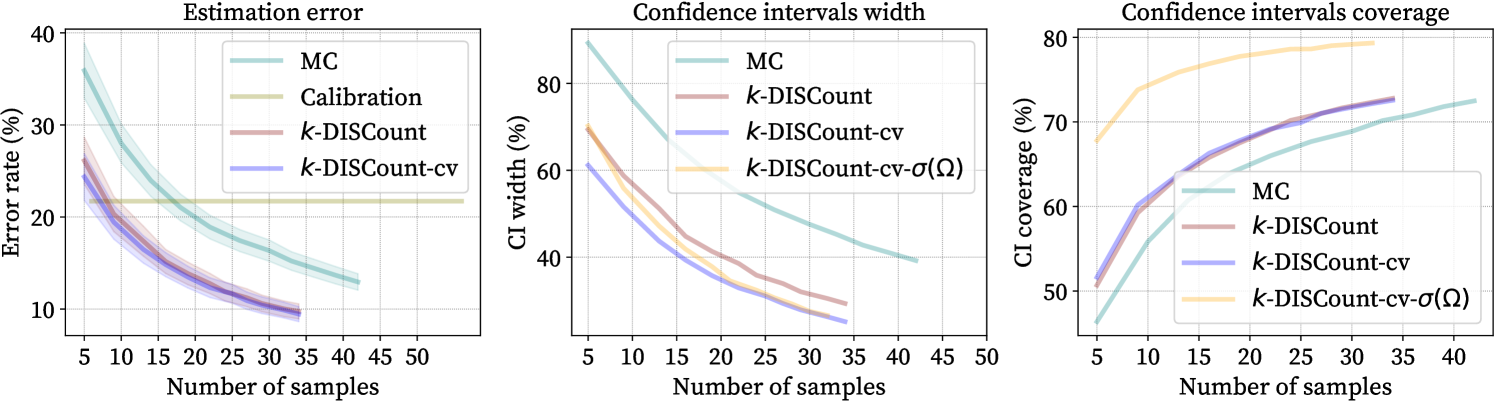
We measure the width and coverage of the estimated confidence intervals (CIs) per number of samples for cumulative daily bird counting; see examples in Fig. 2. We compare the CIs of -\discount, -\discount-cv (control variates), -\discount-cv- (using all samples to estimate variance), and simple Monte Carlo sampling in Fig. 5. When using control variates, the error rate and the CI width are slightly reduced while keeping the same coverage. CI coverage is lower than the nominal coverage (95%) for all methods, but increasing with sample size and substantially improved by -\discount-cv-, which achieves up to coverage. Importance weight distributions can be heavily right-skewed and the variance easily underestimated Hesterberg (1996).
\discountimproves over a calibration baseline
We implement a calibration baseline where the counts are estimated as where we learn an isotonic regression model between the predicted and true counts trained for each station using 15 uniformly selected samples from one year from that station. Results are shown as the straight line in Fig. 5 (left). \discountoutperforms calibration with less than 10 samples per station suggesting the difficulties in generalization across years using a simple calibration approach.
Control variates (-\discount-cv)
We perform experiments adding control variates to -\discountin the roosting birds counting problem. We use the calibrated detector counts defined above as the control variate for each station year. Fig. 5 shows that control variates reduce the confidence interval width (middle: -\discountvs. -\discount-cv) without hurting coverage (right). In addition, the error of the estimate is reduced slightly, as shown in Fig. 5 (left). Note that this is achieved with a marginal increase in the labeling effort.
6 Discussion and Conclusion
We contribute methods for counting in large image collections with a detection model. When the task is complex and the detector is imperfect, allocating human effort to estimate the scientific result directly might be more efficient than improving the detector. For instance, performance gains from adding more training data may be marginal for a mature model. Our proposed solution produces accurate and unbiased estimates with a significant reduction in labeling costs from naive and covariate-based screening approaches. We demonstrate this in two real-world open problems where data screening is still necessary despite large investments in model development. Our approach is limited by the availability of a good detector, and confidence interval coverage is slightly low; possible improvements are to use bootstrapping or corrections based on importance-sampling diagnostics Hesterberg (1996).
7 Acknowledgements
We thank Wenlong Zhao for the deployment of the roost detector, Maria Belotti, Yuting Deng, and our Colorado State University AeroEco Lab collaborators for providing the screened data of the Great Lakes radar stations, and Yunfei Luo for facilitating the building detections on the Palu Tsunami region. This work was supported by the National Science Foundation award #2017756.
References
- Norouzzadeh et al. [2018] Mohammad Sadegh Norouzzadeh, Anh Nguyen, Margaret Kosmala, Alexandra Swanson, Meredith S Palmer, Craig Packer, and Jeff Clune. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proceedings of the National Academy of Sciences, 115(25):E5716–E5725, 2018.
- Nurkarim and Wijayanto [2023] W. Nurkarim and A.W. Wijayanto. Building footprint extraction and counting on very high-resolution satellite imagery using object detection deep learning framework. Earth Sci Inform, 2023.
- Perez et al. [2022] Gustavo Perez, Wenlong Zhao, Zezhou Cheng, Maria Carolina T. D. Belotti, Yuting Deng, Victoria F. Simons, Elske Tielens, Jeffrey F. Kelly, Kyle G. Horton, Subhransu Maji, and Daniel Sheldon. Using spatio-temporal information in weather radar data to detect and track communal bird roosts. bioRxiv, 2022. doi: 10.1101/2022.10.28.513761. URL https://www.biorxiv.org/content/early/2022/10/31/2022.10.28.513761.
- Meng et al. [2022] Chenlin Meng, Enci Liu, Willie Neiswanger, Jiaming Song, Marshall Burke, David Lobell, and Stefano Ermon. Is-count: Large-scale object counting from satellite images with covariate-based importance sampling. In Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
- Tuia et al. [2022] Devis Tuia, Benjamin Kellenberger, Sara Beery, Blair R Costelloe, Silvia Zuffi, Benjamin Risse, Alexander Mathis, Mackenzie W Mathis, Frank van Langevelde, Tilo Burghardt, et al. Perspectives in machine learning for wildlife conservation. Nature communications, 13(1):792, 2022.
- Cavender-Bares et al. [2022] Jeannine Cavender-Bares, Fabian D Schneider, Maria João Santos, Amanda Armstrong, Ana Carnaval, Kyla M Dahlin, Lola Fatoyinbo, George C Hurtt, David Schimel, Philip A Townsend, et al. Integrating remote sensing with ecology and evolution to advance biodiversity conservation. Nature Ecology & Evolution, 6(5):506–519, 2022.
- Burke et al. [2021] Marshall Burke, Anne Driscoll, David B Lobell, and Stefano Ermon. Using satellite imagery to understand and promote sustainable development. Science, 371(6535):eabe8628, 2021.
- Leitloff et al. [2010] Jens Leitloff, Stefan Hinz, and Uwe Stilla. Vehicle detection in very high resolution satellite images of city areas. IEEE transactions on Geoscience and remote sensing, 48(7):2795–2806, 2010.
- Van Horn et al. [2018] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The Inaturalist species classification and detection dataset. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- Won [2020] Myounggyu Won. Intelligent traffic monitoring systems for vehicle classification: A survey. IEEE Access, 8:73340–73358, 2020.
- Coifman et al. [1998] Benjamin Coifman, David Beymer, Philip McLauchlan, and Jitendra Malik. A real-time computer vision system for vehicle tracking and traffic surveillance. Transportation Research Part C: Emerging Technologies, 6(4):271–288, 1998.
- Branson et al. [2010] Steve Branson, Catherine Wah, Florian Schroff, Boris Babenko, Peter Welinder, Pietro Perona, and Serge Belongie. Visual recognition with humans in the loop. In European Conference on Computer Vision (ECCV), 2010.
- Wah et al. [2014] Catherine Wah, Grant Van Horn, Steve Branson, Subhransu Maji, Pietro Perona, and Serge Belongie. Similarity comparisons for interactive fine-grained categorization. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
- Settles [2009] Burr Settles. Active learning literature survey. 2009.
- Chapelle et al. [2009] Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews]. IEEE Transactions on Neural Networks, 20(3):542–542, 2009.
- Nguyen et al. [2018] Phuc Nguyen, Deva Ramanan, and Charless Fowlkes. Active testing: An efficient and robust framework for estimating accuracy. In International Conference on Machine Learning (ICML), 2018.
- Kossen et al. [2021] Jannik Kossen, Sebastian Farquhar, Yarin Gal, and Tom Rainforth. Active testing: Sample-efficient model evaluation. In International Conference on Machine Learning, 2021.
- Cochran [1977] William G Cochran. Sampling techniques. John Wiley & Sons, 1977.
- Owen [2013] Art B. Owen. Monte Carlo theory, methods and examples. 2013.
- Winkler [2006] David W. Winkler. Roosts and migrations of swallows. Hornero, 21(2):85–97, 2006.
- Buler et al. [2012] Jeffrey J Buler, Lori A Randall, Joseph P Fleskes, Wylie C Barrow Jr, Tianna Bogart, and Daria Kluver. Mapping wintering waterfowl distributions using weather surveillance radar. PloS one, 7(7):e41571, 2012.
- Horn and Kunz [2008] Jason W Horn and Thomas H Kunz. Analyzing nexrad doppler radar images to assess nightly dispersal patterns and population trends in brazilian free-tailed bats (tadarida brasiliensis). Integrative and Comparative Biology, 48(1):24–39, 2008.
- nex [2023] Next generation weather radar (NEXRAD). National Centers for Environmental Information (NCEI), Feb 2023. URL https://www.ncei.noaa.gov/products/radar/next-generation-weather-radar.
- Rosenberg et al. [2019] Kenneth V. Rosenberg, Adriaan M. Dokter, Peter J. Blancher, John R. Sauer, Adam C. Smith, Paul A. Smith, Jessica C. Stanton, Arvind Panjabi, Laura Helft, Michael Parr, and Peter P. Marra. Decline of the north american avifauna. Science, 366(6461):120–124, 2019. doi: 10.1126/science.aaw1313.
- Sánchez-Bayo and Wyckhuys [2019] Francisco Sánchez-Bayo and Kris AG Wyckhuys. Worldwide decline of the entomofauna: A review of its drivers. Biological conservation, 232:8–27, 2019.
- Chilson et al. [2018] Carmen Chilson, Katherine Avery, Amy McGovern, Eli Bridge, Daniel Sheldon, and Jeffrey Kelly. Automated detection of bird roosts using NEXRAD radar data and convolutional neural networks. Remote Sensing in Ecology and Conservation, 2018.
- Lin et al. [2019] Tsung-Yu Lin, Kevin Winner, Garrett Bernstein, Abhay Mittal, Adriaan M Dokter, Kyle G Horton, Cecilia Nilsson, Benjamin M Van Doren, Andrew Farnsworth, Frank A La Sorte, et al. Mistnet: Measuring historical bird migration in the us using archived weather radar data and convolutional neural networks. Methods in Ecology and Evolution, 10(11):1908–1922, 2019.
- Cheng et al. [2020] Z. Cheng, S. Gabriel, P. Bhambhani, D. Sheldon, S. Maji, A. V, and D. Winkler. Detecting and tracking communal bird roosts in weather radar data. Association for the Advancement of Artificial Intelligence (AAAI), 2020.
- Ren et al. [2015] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 2015.
- Belotti et al. [2023] Maria Carolina TD Belotti, Yuting Deng, Wenlong Zhao, Victoria F Simons, Zezhou Cheng, Gustavo Perez, Elske Tielens, Subhransu Maji, Daniel Sheldon, Jeffrey F Kelly, et al. Long-term analysis of persistence and size of swallow and martin roosts in the us great lakes. Remote Sensing in Ecology and Conservation, 2023.
- Deng et al. [2023] Yuting Deng, Maria Carolina TD Belotti, Wenlong Zhao, Zezhou Cheng, Gustavo Perez, Elske Tielens, Victoria F Simons, Daniel R Sheldon, Subhransu Maji, Jeffrey F Kelly, et al. Quantifying long-term phenological patterns of aerial insectivores roosting in the great lakes region using weather surveillance radar. Global Change Biology, 29(5):1407–1419, 2023.
- Kim and Yoon [2018] KeumJi Kim and SeongHwan Yoon. Assessment of building damage risk by natural disasters in south korea using decision tree analysis. Sustainability, 10(4), 2018. ISSN 2071-1050. doi: 10.3390/su10041072. URL https://www.mdpi.com/2071-1050/10/4/1072.
- Deng and Wang [2022] Liwei Deng and Yue Wang. Post-disaster building damage assessment based on improved u-net. Scientific Reports, 12(1):2045–2322, 2022.
- [34] DIUx-xView. Diux-xview/xview2_first_place: 1st place solution for "xview2: Assess building damage" challenge. URL https://github.com/DIUx-xView/xView2_first_place.
- [35] The xview2 ai challenge. URL https://www.ibm.com/cloud/blog/the-xview2-ai-challenge.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015.
- Gupta et al. [2019] Ritwik Gupta, Richard Hosfelt, Sandra Sajeev, Nirav Patel, Bryce Goodman, Jigar Doshi, Eric Heim, Howie Choset, and Matthew Gaston. Creating xBD: A Dataset for Assessing Building Damage from Satellite Imagery. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2019.
- Su et al. [2012] Hao Su, Jia Deng, and Li Fei-Fei. Crowdsourcing annotations for visual object detection. In Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, 2012.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, 2009.
- Hesterberg [1996] Tim C Hesterberg. Estimates and confidence intervals for importance sampling sensitivity analysis. Mathematical and computer modelling, 23(8-9):79–85, 1996.
- Žnidarič [2009] Marko Žnidarič. Asymptotic expansion for inverse moments of binomial and poisson distributions. The Open Mathematics, Statistics and Probability Journal, 1(1), 2009.
- van der Vaart and Wellner [1996] Aad W. van der Vaart and Jon A. Wellner. Weak Convergence and Empirical Processes: With Applications to Statistics. Springer, 1996.
Appendix A Derivations
A.1 IS-Count
Take and , we want . Importance sampling with proposal gives
A.2 DISCount
Take in IS-Count, then
A.3 -DISCount
Proof of Claim 1.
For any we have
In the third line, we used the fact that for any random variable and event (see Lemma 1 below). In the fourth line we used the fact that is conditionally independent of given , since and the latter sum is independent of . In the fifth line we used the fact that because and the terms in the sum are exchangeable. In the sixth line we computed the conditional expectation as follows using the fact that the conditional density of given is equal to :
∎
The unconditional bias of -\discountcan also be analyzed:
Claim 4.
Let . The bias of the -\discountestimator is .
In particular, bias decays exponentially with and quickly becomes negligible, with magnitude at most for and . Further, the bias is easily computable from the detector counts and therefore known prior to sampling, and the event that leads to a biased estimate is observed after sampling. All these factors make bias a very minor concern.111The -\discountestimator can be debiased by dividing by . However, this leads to higher overall error: if , the estimator is unchanged, and conditioned on the event the estimator becomes biased and has higher variance by a factor of .
Proof of Claim 4.
Using Claim 1, we compute the unconditional expectation as
In the final line, is probability that for a single , and is the probability that for all . Rearranging gives the result. ∎
Lemma 1.
for any random variable and event .
Proof.
Observe
∎
A.4 Optimal allocation of samples for \discountto disjoint regions
Proof of Claim 2.
The proof is similar to that of Theorem 5.6 in Cochran [1977]. We prove the claim for ; the proof generalizes to larger in an obvious way. The variance of \discounton is
We want to minimize , which with is proportional to
By the Cauchy-Shwarz inequality, for any ,
If we substitute for any on the left of the inequality and simplify, we see the inequality becomes tight, so the minimum is achieved. We further require , so choose so
∎
A.5 -\discountvariance
Recall that is the probability of a sample landing in under the sampling distribution . Define
to be the variance of the importance weight for .
Claim 5.
Let . The variance of the -\discountestimator is given by
where .
The second term in the variance arise from the possibility that no samples land in ; it decays exponentially in and is negligible compared to the first term. The first term can be compared to the variance of importance sampling with exactly samples allocated to and the proposal distribution , i.e., \discount. Because the sample size is random, the correct scaling factor for -\discountis , which it turns out is asymptotically equivalent to , i.e., \discountwith a sample size of — see Claim 6 below. We find that for a small expected sample size (around 4) there can be up to 30% “excess variance” due to the randomness in the number of samples (see Figure 6), but that this disappears quickly with larger expected sample size.
Claim 6.
Let and be the -\discountand \discountestimators with sample sizes and , respectively. The asymptotic variance of -\discountis given by
This is asymptotically equivalent to \discountwith sample size . That is
Proof of Claim 5.
By the law of total variance,
| (1) |
We will treat each term in Eq. 1 separately. For the first term, from the definition of -\discountwe see
Therefore
In the last line, we used the fact that , so where . The summation for follows from the same fact.
Proof of Claim 6.
By Claim 5 we have
| (2) |
The second limit on the right side is zero, because as (recall that ) and the other factors are bounded. We will show the first limit on the right side is equal to , which will prove the first part of the result. The asymptotic expansion of Žnidarič [2009] (Corollary 3) states that
Using this expansion in the limit gives:
The variance of with sample size is . Setting and using the second to last line above we have
∎
A.6 Control Variates
Recall that with control variates the weight is redefined as
The expectation of the weight given is
Therefore
Therefore
A.7 Confidence Intervals
Proof of Claim 3.
Let be an iid sequence of importance weights for samples in , i.e., for . Each weight has mean and variance . Let . By the central limit theorem,
Recall that where is the average of the importance weights for samples that land in when drawn from all of (for clarity in the proof we add subscripts for sample size to all relevant quantities). It is easy to see that is equal in distribution to where and is independent of the sequence of importance weights — this follows from first choosing the number of samples that land in and then choosing their locations conditioned on being in . From Theorem 3.5.1 of van der Vaart and Wellner [1996] (with and ) it then follows that
Rearranging yields
After dividing by , the result follows from Slutsky’s lemma if , which follows from a similar application of Theorem 3.5.1 of van der Vaart and Wellner [1996]. ∎
Appendix B Counting tasks
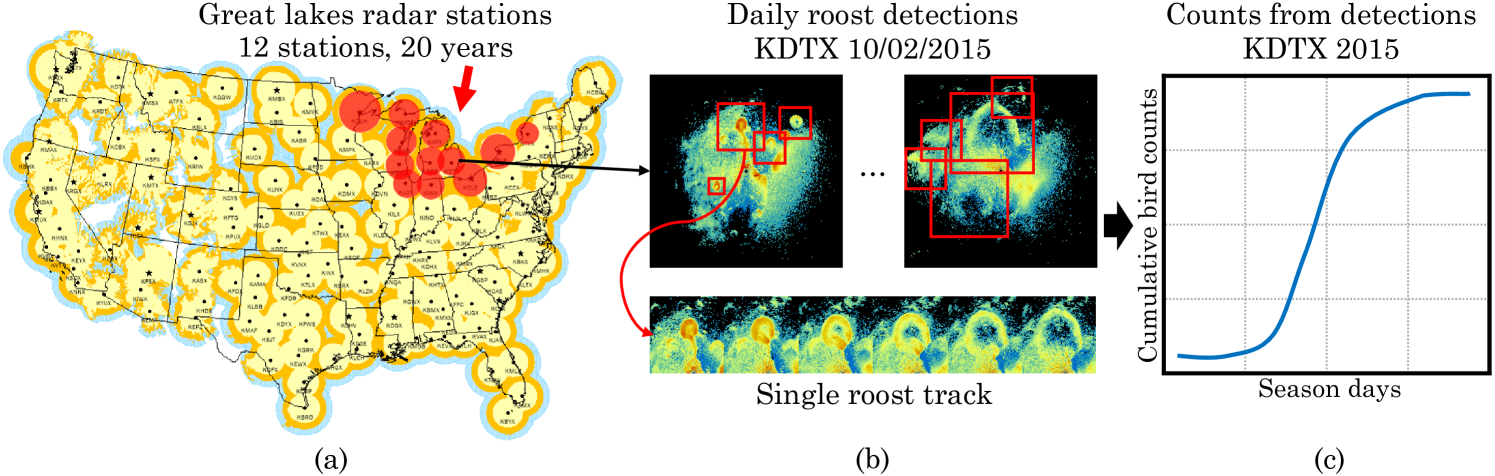

Appendix C Palu Tsunami regions
 |
 |