Disentangled Contrastive Learning for Learning Robust Textual Representations
Abstract
Although the self-supervised pre-training of transformer models has resulted in the revolutionizing of natural language processing (NLP) applications and the achievement of state-of-the-art results with regard to various benchmarks, this process is still vulnerable to small and imperceptible permutations originating from legitimate inputs. Intuitively, the representations should be similar in the feature space with subtle input permutations, while large variations occur with different meanings. This motivates us to investigate the learning of robust textual representation in a contrastive manner. However, it is non-trivial to obtain opposing semantic instances for textual samples. In this study, we propose a disentangled contrastive learning method that separately optimizes the uniformity and alignment of representations without negative sampling. Specifically, we introduce the concept of momentum representation consistency to align features and leverage power normalization while conforming the uniformity. Our experimental results for the NLP benchmarks demonstrate that our approach can obtain better results compared with the baselines, as well as achieve promising improvements with invariance tests and adversarial attacks. The code is available in https://github.com/zxlzr/DCL.
Keywords:
Natural Language Processing Contrastive Learning Adversarial Attack.1 Introduction
The self-supervised pre-training of transformer models has revolutionized natural language processing (NLP) applications. Such pre-training with language modeling objectives provides a useful initial point for parameters that generalize well to new tasks with fine-tuning. However, there is a significant gap between task performance and model generalizability. Previous approaches have indicated that neural models suffer from poor robustness when encountering randomly permuted contexts [21] and adversarial examples [11, 13].
To address this issue, several studies have attempted to leverage data augmentation or adversarial training into pre-trained language models (LMs) [11], which has indicated promising directions for the improvement of robust textual representation learning. Such methods generally augment textual samples with synonym permutations or back translation and fine-tune downstream tasks on those augmented datasets. Representations learned from instance augmentation approaches have demonstrated expressive power and contributed to the performance improvement of downstream tasks in robust settings. However, the previous augmentation approaches mainly focus on the supervised setting and neglect large amounts of unlabeled data. Moreover, it is still not well understood whether a robust representation has been achieved or if the leveraging of more training samples have contributed to the model robustness.
Specifically, a robust representation should be similar in the feature space with subtle permutations, while large variations occur with different semantic meanings. This motivates us to investigate robust textual representation in a contrastive manner. It is intuitive to utilize data augmentation to generate positive and negative instances for learning robust textual representation via auxiliary contrastive objects. However, it is non-trivial to obtain opposite semantic instances for textual samples. For example, given the sentence, “Obama was born in Honululu,” we are able to retrieve a sentence such as, “Obama was living in Honululu,” or, “Obama was born in Hawaii.” There is no guarantee that these randomly retrieved sentences will have negative semantic meanings that contradict the original sample.
In this study, we propose a novel disentangled contrastive learning (DCL) method for learning robust textual representations. Specifically, we disentangle the contrastive object using two subtasks: feature alignment and feature uniformity [27]. We introduce a unified model architecture to optimize these two sub-tasks jointly. As one component of this system, we introduce momentum representation consistency to align augmented and original representations, which explicitly shortens the distance between similar semantic features that contribute to feature alignment. As another component of this system, we leverage power normalization to enforce the unit quadratic mean for the activations, by which the scattering features within the same batch implicitly contribute to the feature uniformity. Our DCL approach is a unified, unsupervised, and model-agnostic approach, and therefore it is orthogonal to existing approaches. The contributions of this study can be summarized as follows:
-
•
We investigate robust textual representation learning problems and introduce a disentangled contrastive learning approach.
-
•
We introduce a unified model architecture to optimize the sub-tasks of feature alignment and uniformity, as well as providing theoretical intuitions.
-
•
Extensive experimental results related to NLP benchmarks demonstrate the effectiveness of our method in the robust setting; we performed invariance tests and adversarial attacks and verified that our approach could enhance state-of-the-art pre-trained language model methods.
2 Related Work
Recently, studies have shown that pre-trained models (PTMs) [5] on the large corpus are beneficial for downstream NLP tasks, such as in GLUE, SQuAD, and SNLI. The application scheme of these systems is to fine-tune the pre-trained model using the limited labeled data of specific target tasks. Since training distributions often do not cover all of the test distributions, we would like a supervised classifier or model to perform well on. Therefore, a key challenge in NLP is learning robust textual representations. Previous studies have explored the use of data augmentation and adversarial training to improve the robustness of pre-trained language models. [12] introduced a novel text adversarial training with token-level perturbation to improve the robustness of pre-trained language models. However, supervised instance-level augmentation approaches ignore those unlabeled data and do not guarantee the occurrence of real robustness in the feature space. Our work is motivated by contrastive learning [23], which aims at maximizing the similarity between the encoded query and matched key , while distancing randomly sampled keys . By measuring similarity with a score function , a form of contrastive loss function is considered as:
| (1) |
where and are positive and negative instances, respectively. The score function is usually implemented with the cosine similarity . and are often encoded by a learnable neural encoder (e.g., BERT [5]). Contrastive learning have increasingly attracted attention, which is beneficial for unsupervised or self-supervised learning from computer vision [30, 34, 25, 10, 3] to natural language processing [33, 17, 18, 9, 31, 20].
3 Preliminaries on Learning Robust Textual Representations
Definition 1.Robust textual representation indicates that the representation is vulnerable to small and imperceptible permutations originating from legitimate inputs. Formally, we have the following:
| (2) |
where refers to the random or adversarial permutation of the input text and takes input from and outputs a valid probability distribution for tasks. is the feature encoder, such as BERT. We are interested in deriving methods for pre-training representations that provide guarantees for the movement of inputs such that they are robust to permutations. Therefore, a robust representation should be similar in the feature space with subtle permutations, while large variations are observed for different semantic meanings. Such constraints are related to the well-known contrastive learning [2] schema as follows:
Remark. Robust representation is closely related to regularizing the feature space with the following constraints:
| (3) |
where and are the number of positive and negative instances, respectively, regarding the original input, , and are the positive and negative instances, respectively. Note that we can obtain via off-the-shelf tools such as data augmentation or back-translation. However, it is non-trivial to obtain negative instances for textual samples. Previous approaches [7, 6, 4, 28] regard random sampling of the remaining instances from the corpus as negative instances; however, there is no guarantee that those random instances are semantically irrelevant. Recent semantic-based information retrieval approaches [32] can obtain numerous similar semantic sentences via an approximate nearest neighbor [14], which further indicates that negative sampling for sentences may result in noise. In this study, inspired by the approach utilized by [27], we disentangle the contrast loss with the two following properties:
-
•
Alignment: two samples forming a positive pair should be mapped to nearby features and therefore be (mostly) invariant to unneeded noise factors.
-
•
Uniformity: feature vectors should have an approximately uniform distribution on the unit hypersphere.
| (4) |
The alignment loss can be defined straightforwardly as follows:
| (5) |
Where is the feature encoder and , are positive instance pairs. The uniformity metric refers to optimizing this metric should converge to a uniform distribution. The loss can be defined with the radial basis function (RBF) kernel [27]. Formally, we have:
| (6) |
where is a fixed parameter.
4 Disentangled Contrastive Learning
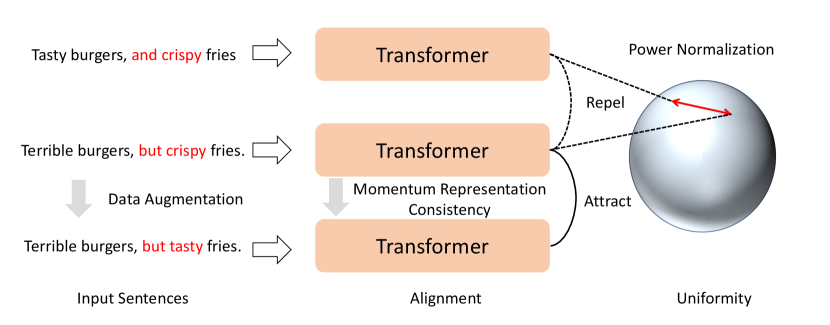
In this section, we present a preliminary study on how to learn robust textual representation via disentangled contrastive learning, as represented in Figure 1.
4.1 Feature Alignment with Momentum Representation Consistency
There are multiple ways to align a textual representation. We utilize two transformers with a consistent momentum representation to explicitly guarantee feature alignment [8]. The two networks are defined by a set of weights and . We use the exponential moving average of the parameters to get . Formally, we have:
| (7) |
Given a sentence and its augmentation (e.g, via data augmentation) from the first original network, we may obtain output representations and . Note that previous works [3, 8] indicates that an projection in feature space improve the performance. We then leverage a projection function and -normalize both and to and , respectively. We leverage the mean squared loss as follows:
| (8) |
Additionally, we make the losses symmetrical by feeding to the augmented network and , separately. We optimize with respect to only, but not , via the stop-gradient.
4.2 Feature Uniformity with Power Normalization
To ensure that feature vectors should have an approximately uniform distribution, we can directly optimize the Eq. 6. However, different from computer vision, in the original loss of BRET [5], we have already utilized the next sentence prediction loss. Such a contrastive object has explicitly made the sentence representation scattered in the feature space; thus, the model may quickly collapse without learning. Inspired by [22], we argue that batch normalization can identify the common-mode between examples of a mini-batch and removes it using the other representations in the mini-batch as implicit negative examples. We can, therefore, view batch normalization as a novel method of implementing feature uniformity on embedded representations. Because vanilla batch normalization will lead to significant performance degradation when naively used in NLP, we leverage an enhanced power normalization [24] to guarantee feature uniformity. Specifically, we leverage the unit quadratic mean rather than the mean/variance of running statistics with an approximate backpropagation method to compute the corresponding gradient. Formally, we have the following:
| (9) | ||||
Note that we compute the gradient of the loss regarding the quadratic mean of the batch. In other words, we utilize the running statistics to conduct backpropagation, thus, resulting in bounded gradients, which is necessary for convergence in NLP (see proofs in [24]).
4.3 Implementation Details
We leverage synonyms from WordNet categories to conduct data augmentation for computation efficiency. We combine all the momentum representation consistency and power normalization results in a unified architecture with the mask language model object. We leverage the same architecture of the BERT-base [5]. We first pre-train the model in a large-scale corpus unsupervisedly (e.g., the same corpus and training steps with BERT) and then fine-tune the model using task datasets.
5 Experiment
5.1 Datasets and Setting
| Model | CoLA | SST-2 | MRPC | QQP | MNLI | QNLI | RTE | GLUE | |
|---|---|---|---|---|---|---|---|---|---|
| (m/mm) | Avg | ||||||||
| Normal | BERT | 56.8 | 92.3 | 89.7 | 89.6 | 84.6/85.2 | 91.5 | 69.3 | 82.3 |
| BERT+DA | 58.6 | 93.2 | 86.5 | 86.7 | 84.2/84.4 | 91.1 | 68.9 | 81.7 | |
| DCL | 60.9 | 93.0 | 89.7 | 90.0 | 84.7/84.6 | 91.7 | 69.7 | 83.0 | |
| Robust | BERT | 46.4 | 91.8 | 88.1 | 84.9 | 81.6/82.2 | 89.2 | 67.1 | 78.9 |
| BERT+DA | 53.8 | 92.9 | 85.6 | 85.5 | 83.1/83.4 | 90.7 | 66.3 | 80.1 | |
| DCL | 48.4 | 92.4 | 86.0 | 85.5 | 82.5/82.7 | 89.7 | 68.8 | 79.5 | |
We conducted experiments on three benchmarks: GLUE, SQuAD, SNLI, and DialogRE.
GLUE [26] is an NLP benchmark aimed at evaluating the performance of downstream tasks of the pre-trained models. Notably, we leverage nine tasks in GLUE, including CoLA, RTE, MRPC, STS, SST, QNLI, QQP, and MNLI-m/mm. We follow the same setup as the original BERT for single sentence and sentence pair classification tasks. We leverage a multi-layer perception with a softmax layer to obtain the predictions.
SQuAD is a reading comprehension dataset constructed from Wikipedia articles. We report results on SQuAD 1.1. Here also, we follow the same setup as the original BERT model and predict an answer span—the start and end indices of the correct answer in the correct context.
SNLI is a collection of 570k human-written English sentence pairs that have been manually labeled for balanced classification with entailment, contradiction, and neutral labels, thereby supporting the task of natural language inference (NLI). We add a linear transformation and a softmax layer to predict the correct label of NLI.
DialogRE is a dialogue-based relation extraction dataset, which contains 1,788 dialogues from a famous American television situation comedy Friends.
To evaluate the robustness of our approach, we also conduct invariance testing with CheckList111https://github.com/marcotcr/checklist.git [21] and adversarial attacks222https://github.com/thunlp/OpenAttack. To generate label-preserving perturbations, we used WordNet categories (e.g., synonyms and antonyms). We selected context-appropriate synonyms as permutation candidates. To generate adversarial samples, we leverage a probability-weighted word saliency (PWWS) [19] method based on synonym replacement. We manually evaluate the quality of the generated instances. We also conduct experiments that apply data augmentation and adversarial training to the BERT model. We utilize PyTorch to implement our model. We use Adam optimizer with a cosine decay learning rate schedule. We set the initial learning rate as 1e-5. We use a batch size of 32 over eight Nvidia 1080Ti GPUs.
5.2 Results and Analysis
Main Results
| Model | F1 | EM | |
|---|---|---|---|
| Normal | BERT | 88.5 | 80.8 |
| BERT+DA | 88.2 | 80.4 | |
| DCL | 88.4 | 81.0 | |
| Robust | BERT | 86.7 | 77.8 |
| BERT+DA | 87.8 | 79.9 | |
| DCL | 86.8 | 78.1 | |
From Table 1 and 2, we can observe the following: 1) Vanilla BERT achieves poor performance in the robust set on both GLUE and SQUAD, which indicates that the previous fine-tuning approach cannot obtain a robust textual representation. This will lead to performance decay with permutations.
2) With data augmentation, BERT can obtain improved performance in the robust set; however, a slight performance decay is observed in the original test set. We argue that data augmentation can obtain better performance by fitting to task-specific data distribution; there is no guarantee that more data will result in robust textual representations.
3) Our DCL approach achieves improved performance in both the original test set and robust set compared with vanilla BERT. Note that our DCL is an unsupervised approach, and we leverage the same training instances with BERT. The performance improvements indicate that our approach can obtain more robust textual representations that enhance the performance of the system.
Adversarial Attack Results
| Model | CoLA | SNLI | DialogRE | |
|---|---|---|---|---|
| Normal | BERT | 56.8 | 91.0 | 63.0 |
| BERT+Adv | 55.0 | 90.9 | 64.3 | |
| DCL | 58.8 | 91.0 | 64.2 | |
| Adversarial | BERT | 47.0 | 87.4 | 59.0 |
| BERT+Adv | 55.1 | 90.3 | 62.9 | |
| DCL | 48.2 | 90.5 | 63.2 | |
From Table 3, we can observe the following: 1) Vanilla BERT achieves a poor performance with adversarial attacks; BERT with adversarial training can obtain a good performance. However, we notice that there exists a performance decay for adversarial training in the original test set. Note that adversarial training methods would lead to standard performance degradation [29], i.e., the degradation of natural examples. 2) Our DCL approach achieves improved performance in the test set with and without an adversarial attack, which further demonstrates that our approach can obtain robust textual representations that are stable for different types of permutations.
Quantitative Analysis of Textual Representation
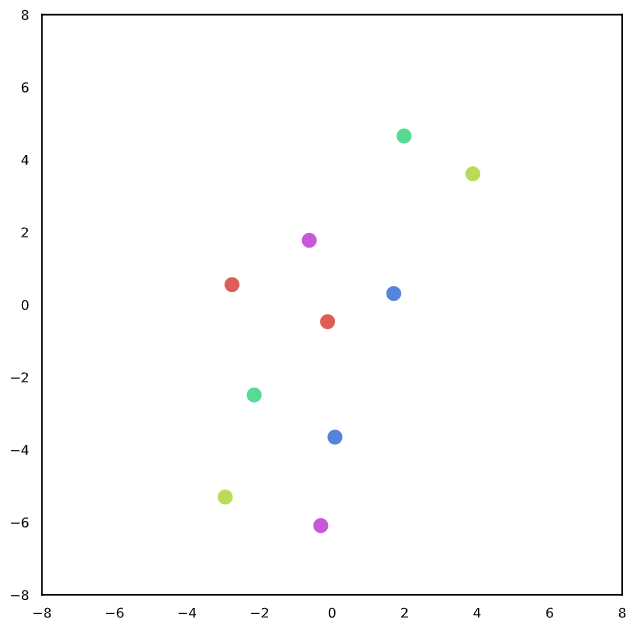
As we hypothesize that power normalization can implicitly contribute to feature uniformity, we conduct further experiments to analyze the effects of normalization [1]. Specifically, we random sample instances and leverage the cosine similarity of the original input projection vectors and the augmented projection vectors. We calculate the average cosine similarity between positive instances (in blue) and random instances (in red) with different strategies, including without normalization (No Norm), batch normalization (BN), and power normalization.
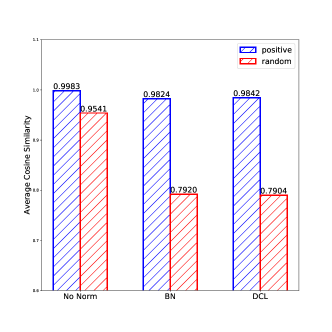
From Figure 3, we observe that with no normalization in or , the feature space is aligned for both positive and negative instances, which shows that there exists a feature collapse for textual representation learning. Considering DCL training (i.e., with power normalization), we notice that the textual representations are relatively more similar between the positive instances (0.9842) than random (negative) ones (0.7904); thus, we can obtain different vectors.
Next, we give an intuitive explanation of preventing feature collapse for textual representation learning. Given an input instance without negative examples, the model may always output the projection vector with . Thus, the model can achieve a perfect prediction through learning a simple identity function, which, in other words, collapse in the feature space. With normalization, the output vector cannot obtain such singular values. Since the outputs will be redistributed regarding the learned mean and standard deviation, we can implicitly learn robust representations.
Qualitative Analysis of Textual Representation
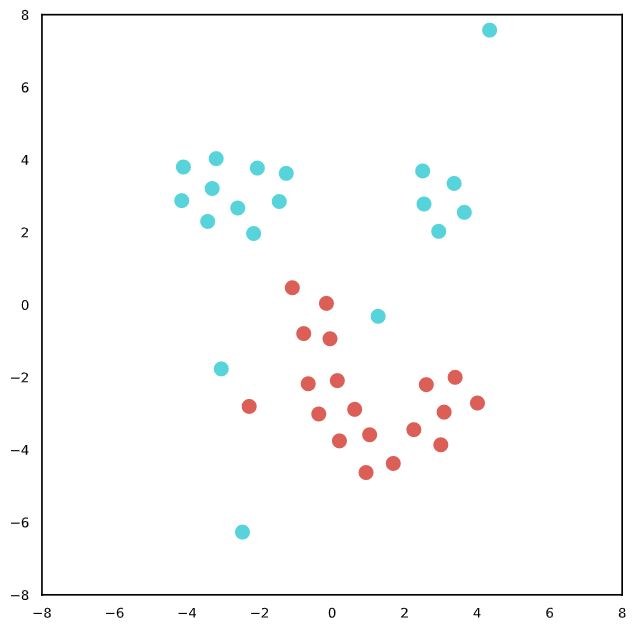
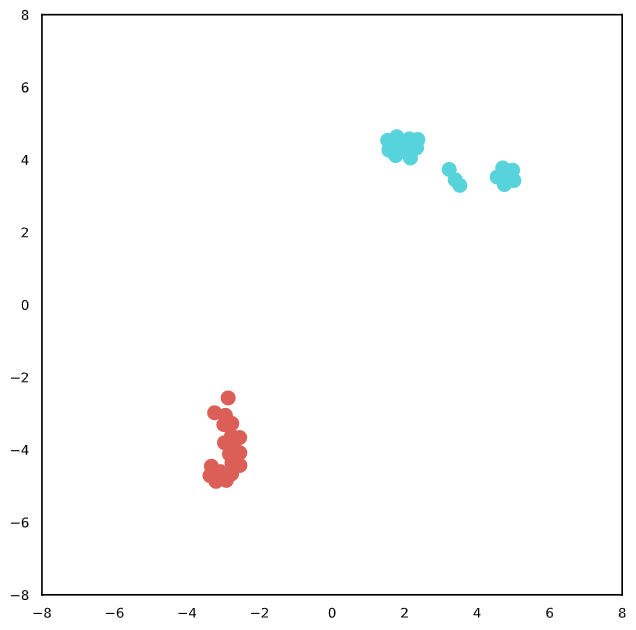
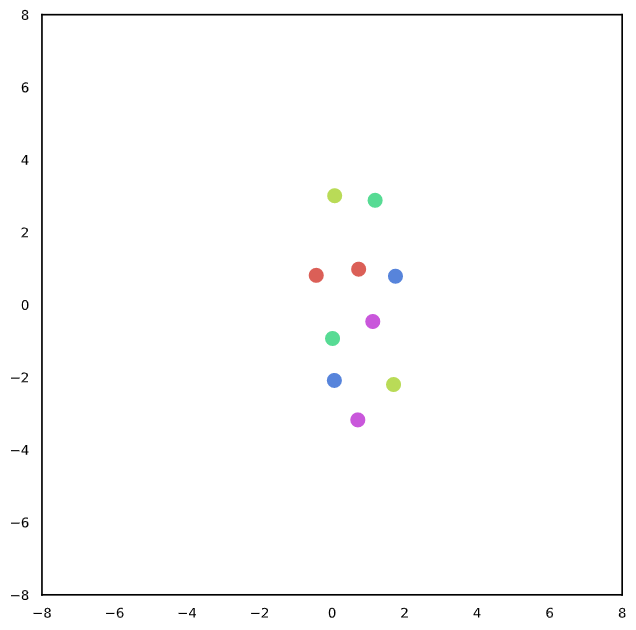
We randomly selected instances to visualize a sentence with T-SNE [15] to better understand the behaviors of textual representations. The different color refers to the different sentence pairs for both random permutation and adversarial attack settings. From Figure 2, it may be observed that our approach can obtain a relatively similar semantic representation with permutations in both invariant tests and adversarial attack settings. Note that we explicitly align the projection of the textual representation with a random permutation, thereby encouraging similar semantic instances to have relatively similar representations.
5.3 Discussion
Robust Representation with Contrastive Learning. Conventional approaches usually try to leverage instance-level augmentation aimed at achieving good performance on a robust set. However, there is no guarantee that robust textual representations will be obtained. Intuitively, directly aligning the representation of input tokens with slight permutations may contribute to robust representations. However, without any negative constraints, the model will easily collapse with a sub-optimal solution. In this study, we observe that power normalization identifies this common mode between examples. In other words, it can remove those trivial samples by using the other representations in the batch as implicit negative instances. We can, therefore, view normalization as an implicitly contrastive learning method.
Limitations. This work is not without limitations. We only consider the synonym replacement as a data augmentation strategy due to the efficiency of processing a huge amount of data. Other strong data augmentation methods can also be leveraged. Another issue is representation alignment, as there are lots of augmentations. We cannot enumerate all positive pairs for alignments; thus, there is still some room for designing more efficient feature-aligning algorithms. Moreover, as we utilize the square root loss, which is absolutely a Euclidean distance. Recent approaches [16] indicates that Euclidean space may be sub-optimal for textual representations, and we leave this for future works.
6 Conclusion
We investigated robust textual representation learning and proposed a disentangled contrastive learning approach. We introduced feature alignment with a momentum representation consistency and feature uniformity with power normalization. We empirically observed that our approach could obtain an improved performance compared with baselines in NLP benchmarks and achieve a robust performance with invariant tests and adversarial attacks.
7 Acknowledgments
We want to express gratitude to the anonymous reviewers for their hard work and kind comments. This work is funded by NSFC91846204/NSFCU19B2027.
References
- [1] Abe, F., Josh, A.: Understanding self-supervised and contrastive learning with ”bootstrap your own latent” (byol). https://untitled-ai.github.io/understanding-self-supervised-contrastive-learning.html
- [2] Arora, S., Khandeparkar, H., Khodak, M., Plevrakis, O., Saunshi, N.: A theoretical analysis of contrastive unsupervised representation learning. arXiv preprint arXiv:1902.09229 (2019)
- [3] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: Proceedings of Machine Learning and Systems 2020. pp. 10719–10729 (2020)
- [4] Chi, Z., Dong, L., Wei, F., Yang, N., Singhal, S., Wang, W., Song, X., Mao, X.L., Huang, H., Zhou, M.: Infoxlm: An information-theoretic framework for cross-lingual language model pre-training. arXiv preprint arXiv:2007.07834 (2020)
- [5] Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL. pp. 4171–4186. Minneapolis, Minnesota (Jun 2019). https://doi.org/10.18653/v1/N19-1423
- [6] Fang, H., Xie, P.: Cert: Contrastive self-supervised learning for language understanding. arXiv preprint arXiv:2005.12766 (2020)
- [7] Giorgi, J.M., Nitski, O., Bader, G.D., Wang, B.: Declutr: Deep contrastive learning for unsupervised textual representations. arXiv preprint arXiv:2006.03659 (2020)
- [8] Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Doersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., et al.: Bootstrap your own latent: A new approach to self-supervised learning. arXiv preprint arXiv:2006.07733 (2020)
- [9] Gunel, B., Du, J., Conneau, A., Stoyanov, V.: Supervised contrastive learning for pre-trained language model fine-tuning. arXiv preprint arXiv:2011.01403 (2020)
- [10] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.B.: Momentum contrast for unsupervised visual representation learning. CoRR abs/1911.05722 (2019)
- [11] Jin, D., Jin, Z., Tianyi Zhou, J., Szolovits, P.: Is bert really robust? a strong baseline for natural language attack on text classification and entailment. arXiv pp. arXiv–1907 (2019)
- [12] Li, L., Qiu, X.: Textat: Adversarial training for natural language understanding with token-level perturbation. arXiv preprint arXiv:2004.14543 (2020)
- [13] Li, L., Chen, X., Zhang, N., Deng, S., Xie, X., Tan, C., Chen, M., Huang, F., Chen, H.: Normal vs. adversarial: Salience-based analysis of adversarial samples for relation extraction. arXiv preprint arXiv:2104.00312 (2021)
- [14] Liu, T., Moore, A.W., Yang, K., Gray, A.G.: An investigation of practical approximate nearest neighbor algorithms. In: Advances in neural information processing systems. pp. 825–832 (2005)
- [15] Maaten, L.v.d., Hinton, G.: Visualizing data using t-sne. Journal of machine learning research 9(Nov), 2579–2605 (2008)
- [16] Meng, Y., Zhang, Y., Huang, J., Zhang, Y., Zhang, C., Han, J.: Hierarchical topic mining via joint spherical tree and text embedding. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. pp. 1908–1917 (2020)
- [17] Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems 26. pp. 3111–3119 (2013)
- [18] Mnih, A., Kavukcuoglu, K.: Learning word embeddings efficiently with noise-contrastive estimation. In: Advances in Neural Information Processing Systems 26. pp. 2265–2273 (2013)
- [19] Ren, S., Deng, Y., He, K., Che, W.: Generating natural language adversarial examples through probability weighted word saliency. In: Proceedings of the 57th annual meeting of the association for computational linguistics. pp. 1085–1097 (2019)
- [20] Rethmeier, N., Augenstein, I.: A primer on contrastive pretraining in language processing: Methods, lessons learned and perspectives. arXiv preprint arXiv:2102.12982 (2021)
- [21] Ribeiro, M.T., Wu, T., Guestrin, C., Singh, S.: Beyond accuracy: Behavioral testing of NLP models with checklist. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020. pp. 4902–4912. Association for Computational Linguistics (2020), https://www.aclweb.org/anthology/2020.acl-main.442/
- [22] Santurkar, S., Tsipras, D., Ilyas, A., Madry, A.: How does batch normalization help optimization? In: Advances in Neural Information Processing Systems. pp. 2483–2493 (2018)
- [23] Saunshi, N., Plevrakis, O., Arora, S., Khodak, M., Khandeparkar, H.: A theoretical analysis of contrastive unsupervised representation learning. In: Proceedings of the 36th International Conference on Machine Learning. vol. 97, pp. 5628–5637. PMLR, Long Beach, California, USA (09–15 Jun 2019), http://proceedings.mlr.press/v97/saunshi19a.html
- [24] Shen, S., Yao, Z., Gholami, A., Mahoney, M.W., Keutzer, K.: Powernorm: Rethinking batch normalization in transformers. In: In the proceedings of the International Conference on Machine Learning (ICML) (2020)
- [25] Tian, Y., Krishnan, D., Isola, P.: Contrastive multiview coding. CoRR abs/1906.05849 (2019), http://arxiv.org/abs/1906.05849
- [26] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., Bowman, S.R.: GLUE: A multi-task benchmark and analysis platform for natural language understanding. In: 7th International Conference on Learning Representations, ICLR 2019. OpenReview.net (2019), https://openreview.net/forum?id=rJ4km2R5t7
- [27] Wang, T., Isola, P.: Understanding contrastive representation learning through alignment and uniformity on the hypersphere. arXiv preprint arXiv:2005.10242 (2020)
- [28] Wei, X., Hu, Y., Weng, R., Xing, L., Yu, H., Luo, W.: On learning universal representations across languages. arXiv preprint arXiv:2007.15960 (2020)
- [29] Wen, Y., Li, S., Jia, K.: Towards understanding the regularization of adversarial robustness on neural networks (2019)
- [30] Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018. pp. 3733–3742. IEEE Computer Society (2018)
- [31] Wu, Z., Wang, S., Gu, J., Khabsa, M., Sun, F., Ma, H.: Clear: Contrastive learning for sentence representation. arXiv preprint arXiv:2012.15466 (2020)
- [32] Xiong, L., Xiong, C., Li, Y., Tang, K.F., Liu, J., Bennett, P., Ahmed, J., Overwijk, A.: Approximate nearest neighbor negative contrastive learning for dense text retrieval. arXiv preprint arXiv:2007.00808 (2020)
- [33] Ye, H., Zhang, N., Deng, S., Chen, M., Tan, C., Huang, F., Chen, H.: Contrastive triple extraction with generative transformer. arXiv preprint arXiv:2009.06207 (2020)
- [34] Ye, M., Zhang, X., Yuen, P.C., Chang, S.: Unsupervised embedding learning via invariant and spreading instance feature. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019. pp. 6210–6219. Computer Vision Foundation / IEEE (2019)