Distantly Supervised Relation Extraction via Recursive Hierarchy-Interactive Attention and Entity-Order Perception
Abstract
Wrong-labeling problem and long-tail relations severely affect the performance of distantly supervised relation extraction task. Many studies mitigate the effect of wrong-labeling through selective attention mechanism and handle long-tail relations by introducing relation hierarchies to share knowledge. However, almost all existing studies ignore the fact that, in a sentence, the appearance order of two entities contributes to the understanding of its semantics. Furthermore, they only utilize each relation level of relation hierarchies separately, but do not exploit the heuristic effect between relation levels, i.e., higher-level relations can give useful information to the lower ones. Based on the above, in this paper, we design a novel Recursive Hierarchy-Interactive Attention network (RHIA) to further handle long-tail relations, which models the heuristic effect between relation levels. From the top down, it passes relation-related information layer by layer, which is the most significant difference from existing models, and generates relation-augmented sentence representations for each relation level in a recursive structure. Besides, we introduce a newfangled training objective, called Entity-Order Perception (EOP), to make the sentence encoder retain more entity appearance information. Substantial experiments on the popular New York Times (NYT) dataset are conducted. Compared to prior baselines, our RHIA-EOP achieves state-of-the-art performance in terms of precision-recall (P-R) curves, AUC, Top-N precision and other evaluation metrics. Insightful analysis also demonstrates the necessity and effectiveness of each component of RHIA-EOP.
keywords:
Distant Supervision, Relation Extraction , Relation Hierarchies , Entity Order , Long-tail Relations , Attention1 Introduction
Various large-scale knowledge bases (KBs), including YAGO [1], Freebase [2] and DBpedia [3], are extremely supportive of many sub-tasks in the field of natural language processing (NLP). However, although existing KBs contain a large number of facts, they are still far from complete compared to the real-world facts, which is infinite. To enrich KBs, many methods have been proposed to automatically extract fact triples from unstructured texts, i.e., relation extraction (RE). Among these, supervised approaches are the most commonly used methods and yield relatively high performance. But existing supervised RE systems require massive training data, especially when using neural networks. Furthermore, obtaining high-quality and large-scale training data is very time-consuming and labor-intensive. In this case, distant supervision (DS) is proposed to automatically label training instances by matching KBs to the corpus [4]. It assumes that given a pair of entities, all sentences contain these two entities will express the relation between them in KBs. The assumption is too strong and results in some problems.
First, wrong labeling problem is inevitable and has become a bottleneck limiting models’ performance by introducing noisy supervision signals. For instance, <Phil Amicone, Yonkers>expresses the /people/person/place_of_birth relation in Freebase. So, the sentence “Mayor Phil Amicone of Yonkers and the board of Education have supported Mr. Petrone during the controversy.” will be automatically labeled as a training sentence, even though it does not express this type of relation. To mitigate the impact of noise labels, multi-instance learning (MIL) [5, 6] is proposed to identify a relation label for a sentence-bag containing two common entities. Then, many techniques have been introduced into distantly supervised relation extraction (DSRE) task, such as multiple perspectives’ attention [7, 8, 9], soft-labeling [10], reinforcement learning [11, 12], etc. Among these, the attention mechanism is the most common and successful, so we also extend this technique.
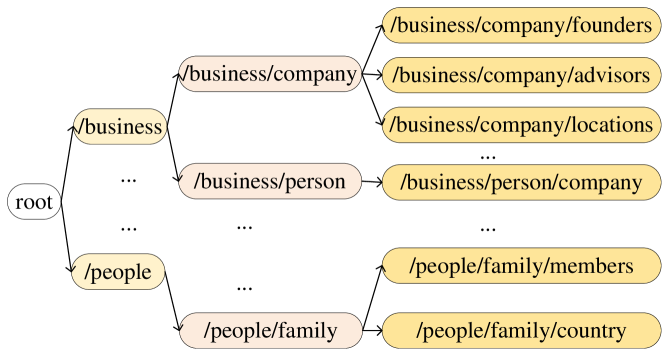
Second, although DS method can generate large-scale training data, it can only cover a limited part of real-world relations and causes long-tail problem. For example, in NYT dataset, nearly 77% of the relations are long-tail. Here a relation is long-tail if the number of corresponding training instances is less 1000. In this case, data imbalance severely limits the performance of RE systems. Recently, some approaches naturally share the knowledge from data-rich relations to long-tail ones by leveraging relation hierarchies [13, 14, 15, 16]. It is based on the observation that although some relations are long-tailed, their ancestor or sibling relations are not. Therefore long-tail relations can benefit from their ancestors or siblings. For example, we select some relations from Freebase and illustrate them in Figure 1. Note that we add a root node to facilitate the narrative. It can be seen that the relation /business/company/founders has two ancestor relations (i.e., /business and /business/company) and several siblings (i.e., /business/company/advisors, /business/company/locations, etc.). And all relations form a taxonomic structure. With it, Han et al. [13] propose a hierarchical attention scheme to generate extra bag-level features for each relation level of relation hierarchies separately. Then Zhang et al. [14] enrich the relation embeddings with TransE [17] and graph convolutional networks [18]. After that, Li et al. [15] propose an attention-based method to enhance sentence representations for each relation level independently, while Yu et al. [16] design a Top-Down classification strategy along the relation hierarchies.
However, the above methods all use each relation level of relation hierarchies independently, i.e., although they use multi-grained relation levels to generate extra features or enrich sentence representations, these levels are discrete, independent and do not affect each other in the calculation. In fact, along the hierarchical relation chains, higher-level relations must be instructive to the lower ones. For example, the sentence “Google was founded by Larry Page and Sergey Brin on September 4, 1998.” expresses the relation /business/company/founders. When classifying along the hierarchical relation chains, if it is identified as /business at the first level, then at the second level, we can select labels only from the child relations of /business. Keep going down until the end of chains, the final label is obtained. During this process, the heuristic effect between relation levels is reflected in layer-by-layer narrowing the scope of the current level’s labels based on the classification probability of previous level. It can also be seen as a continuous refinement from coarse to fine granularity. Distinguishing from existing studies, we aim to implicitly model the heuristic effect through interactions between relation levels, which is one of the most prominent contributions of this paper. Considering further, modeling these interactions is somewhat equivalent to exploiting the taxonomic structure of relations to uncover the correlation of relations, which can improve inter-relational discrimination from the side.
Besides, as we all know, the fact triple is not equal with , therefore the appearance order of two entities is extremely crucial. But during sentence encoding, each feature map generated by CNN/PCNN only retain 1 or 3 maximums along the word sequence through pooling operation. This process ignores the importance of entity order and causes the loss of entity order information, i.e., entity order features are underutilized in the deep learning paradigm.
In this paper, we firstly propose a novel network, named as Recursive Hierarchy-Interactive Attention (RHIA), to fully exploit the relation hierarchies. It assumes that along the hierarchical relation chains, lower-level relations are influenced by the higher-level ones and current known information. Based on this, we leverage a recursive structure along the chains to deliver heuristic information about higher-level relations, and obtain the relation-augmented sentence representations. Then we design a new attention pooling module by using the final hidden state to generate bag-level representations. Besides, to retain more entity-order information in sentence representations, an effective training objective, called Entity-Order Perception (EOP), is introduced. Our key contributions are summarized as follows:
-
1.
We take the heuristic effect between relation hierarchies into account, then a novel network, called RHIA, is proposed to model this heuristics. It is the first approach in DSRE to uncover the heuristic effect between relation levels in relation hierarchies.
-
2.
A newfangled training objective, called EOP, is introduced to improve the expressive ability of sentence encoder. It enables the sentence representations to retain more entity-order information.
-
3.
We conduct substantial evaluation on the widely-used benchmark NYT, and receive state-of-the-art performance in multiple metrics. Insightful analysis also verifies the capability and effectiveness of our RHIA-EOP. The code is released at https://github.com/RidongHan/RHIA-EOP.
2 Related work
As an important subtask of natural language processing (NLP), relation extraction (RE) task can be divided into sentence-level extraction [19, 20, 21], document-level extraction [22, 23], few-shot extraction [24], distantly supervised extraction [8, 15, 25, 26], etc. Here we concentrate on the sentence-level distantly supervised relation extraction (DSRE) scenario.
For wrong-labeling problem, some people [5, 6, 27] relax the assumption behind DS and develop multi-instance learning (MIL) framework. After that, many techniques have been applied to DSRE. First, Zeng et al. [28] improve the sentence encoder with Piecewise Convolutional Neural Networks (PCNN), and identify the instance that most likely expresses the corresponding relation in sentence-bag level. Then, Lin et al. [7] design a selective attention among sentences/instances in the sentence level. Inspired by this work, attention models in different aspects are proposed, including word-level attention [8], self-attention [9], bag-level attention [29, 30], feature-level attention [31], segment-level attention [32], etc. Besides, in order to pick out correct training instances to train the model efficiently, reinforcement learning is introduced into DSRE [11, 12]. Since the attention mechanism is the most commonly used and successful, we also extend this technique.
Relation hierarchies contain taxonomic structure of relations. Although some relations are long-tail, their sibling or ancestor relations are not. To handle long-tail relations, existing practices take relation hierarchies into account to share knowledge from higher-level data-sufficient relations to the lower-level long-tail ones, which is intended for long-tail relations to benefit from the training phase of sibling/ancestor relations, i.e., supervised signals come from the relation hierarchies. Han et al. [13] get advanced performance by introducing a hierarchical attention scheme to derive extra bag-level features. Zhang et al. [14] use TransE [17] and graph convolutional network [18] to obtain relation embeddings, and design a novel attention network along relation hierarchies. After that, Li et al. [15] augment the sentence representations with relation embeddings at each level of relation hierarchies to provide more clues to the classifier, while Yu et al. [16] exploit the relation hierarchies to design a top-down classification strategy. Recently, Peng et al. [33] explore the correlation of relations in the relation hierarchies from both global and local perspectives, aiming to make long-tail relations benefit from their sibling or ancestor relations. The shortcoming of these models is that the relation levels are discrete, independent and do not affect each other during the calculation, i.e., the heuristic effect between relation levels is ignored. As stated in the Section 1, higher-level relations are instructive to lower-level ones when classifying. This paper aims to address this flaw, and it is our contribution to differentiating from existing studies. Based on the models of Han et al. [13] and Li et al. [15], although our model also generates extra bag-level features and relation-augmented sentence representations, we further design a recursive interaction method to pass the relation-related heuristic information along the relational hierarchical chains.
3 Our Proposed RE Approach
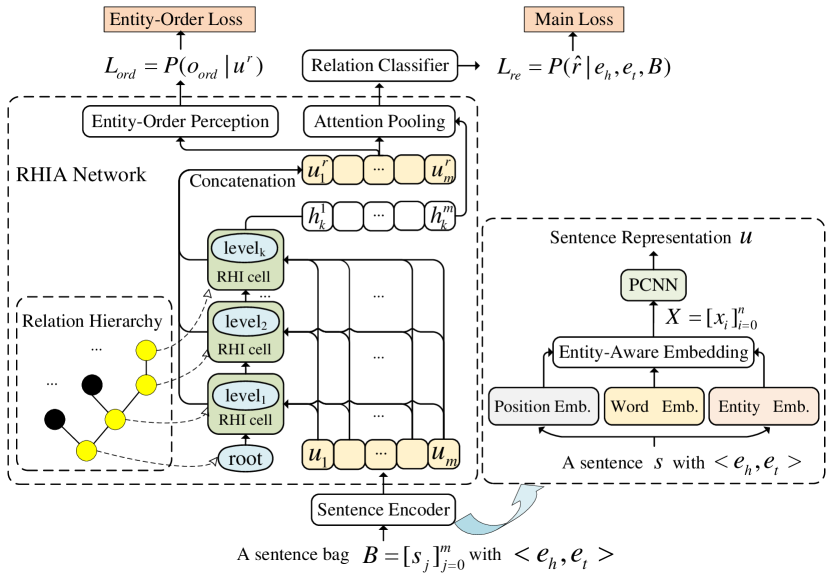
Our model, RE via Recursive Hierarchy-Interactive Attention and Entity-Order Perception (RHIA-EOP), consists of three cascaded components: (1) A sentence encoder based on Entity-Aware Embedding and Piecewise Convolutional Neural Networks (PCNNs). (2) A Recursive Hierarchy-Interactive Attention (RHIA) module for generating more valuable bag representations by fully leveraging relation hierarchies. (3) A relation classifier module with MultiLayer Perceptron (MLP). The overall model inputs a bag of sentences and outputs the relation label in bag level. Figure 2 shows the overall architecture.
3.1 Task Definition
Given a sentence, the goal of relation extraction (RE) is to identify the relation between a pair of entities in this sentence. To facilitate this in distant supervision scenario, we split all sentences into multiple entity-pair bags . Each bag contains some sentences mentioning the same entity pair . Each sentence is a sequence of words, i.e., , and the maximum length is set to . Besides, we have a set of pre-defined relation classes . In this case, the goal of DSRE is to distinguish the relation between two given entities based on an entity-pair bag.
3.2 Sentence Encoder
In this part, three kinds of features are taken into account, including word embedding [34], position embedding [19] and entity embedding [35]. For each sentence in bag 111“sentence” and “instance” are semantically identical., we remove the index for brevity in the following narrative.
Word Embedding
Each sentence is translated into low-dimensional embeddings, i.e., , where denotes the dimension of word embedding.
Position Embedding
Relative position information is very vital to RE task [19], which is defined as the combination of relative distances from each word to entity and entity . Take the sentence “It showed that Sergey Brin, a co-founder of Google, not his partner, Larry Page, who is speaking at the conference.” as an example, the relative distance from co-founder to entity (Google) and entity (Sergey Brin) are -2 and 3, respectively. Then, two low-dimensional vectors, and are converted from these two distances. In this way, we can define position-aware embeddings as , where , , “;” is vector concatenation operation.
Entity embedding
The sequence of entity embeddings is represented as , where , , and are the embeddings of two entities. We employ the same way as Li et al. [15] to obtain the embeddings of entities. Each entity is one entry in the vocabulary of word embedding even if it is usually composed of multiple words. To achieve this, if an entity consists of multiple words, all words are connected with “_” to denote it.
Entity-Aware Embedding
To make better use of the above features, a position-wise gate [35] is used to integrate them, i.e.,
| (1) | |||
| (2) | |||
| (3) |
where “” indicates the element-wise product, , , is a trade-off weight. And is the resulting representation of words for encoding.
Piecewise Convolutional Neural Networks
We select the Piecewise Convolutional Neural Networks (PCNNs) as the sentence encoder [28] because of its high performance and efficiency. Given the input representation , PCNN applies a kernel of window size to slide over , and output feature representation , where and is the number of filters. After that, the feature is firstly divided into three segments based on the position of two entities. And then, the max-pooling operation is employed on each segment, respectively. The results are concatenated as the final sentence representation :
| (4) |
where .
3.3 Recursive Hierarchy-Interactive Attention Network
To fully exploit the taxonomic structure of relations and relation embeddings, an attention network with a recursive structure along the relation hierarchies, called RHIA, is proposed. RHIA consists of several RHI cells. Each cell completes the calculation for one relation level. See Figure 3 for the details of the RHI cell.
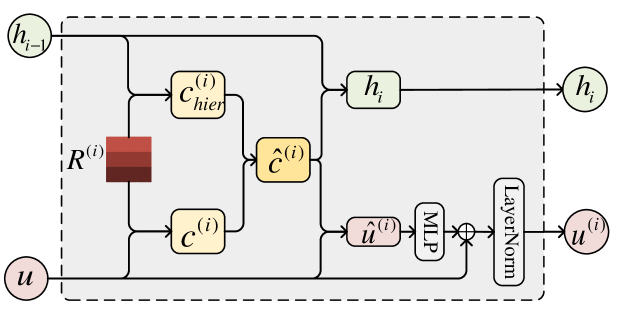
For a bag , the sentence representations are derived via PCNNs encoder. For each relation , its hierarchical chain of relations can be generated, where is the root relation node and is identical to . Connected by the root, all chains compose the relation hierarchies, a kind of tree-like structure. Then, for the -th level of relation hierarchies (), we define a learnable relation embedding matrix , where denotes the number of relations at level .
For a sentence representation 222For convenience, we remove indices in the remaining parts., we aim to augment it with the above relation embeddings for each level, and all levels’ augmented representations are concatenated as the relation-augmented sentence representation . Then an attention-pooling module is employed to generate the bag-level representation. For -th level, it is assumed that the augmented representation of -th level is determined by the input sentence representation and the heuristic information about relations from the higher/previous level .
Based on this, we can build the network in a recursive structure. In details, the sentence-to-relation (sent2rel) attention [15] is employed firstly. The sentence representation and the heuristic information are used as the query to calculate attention scores by dot product with the relation embedding matrix , respectively,
| (5) | |||
| (6) | |||
| (7) | |||
| (8) |
where , is an activation function for the last dimension, and are the relation-aware information.
Since the importance of and are different, then, we leverage an element-wise gate mechanism to integrate the relation-aware information and :
| (9) | |||
| (10) |
where , is the resulting relation-aware representation corresponding to -th level.
After that, to prevent the information loss of the original representation , we leverage an element-wise gate to inject the information of into . In this process, residual connection [36] and layer normalization [37] are also applied. Then, the augmented representation at level is generated,
| (11) | |||
| (12) | |||
| (13) |
where , is a multi-layer perceptron that aims to increase nonlinearity.
Finally, we update to obtain the current heuristic information about relations for the next level’s calculation, which is achieved by merging relation-aware information into with an element-wise gate,
| (14) | |||
| (15) |
where .
During the calculation, is randomly initialized. Along the relation hierarchies, all levels’ augmented representations are generated, i.e., . Then the relation-augmented sentence representation is generated by concatenation operation,
| (16) |
For the bag , all relation-augmented sentence representations can be denoted as . Next, to alleviate wrong labeling problem, we use the attention-pooling [38, 39] to select the correctly labelled sentences from the bag in order to facilitate the generation of an accurate bag-level representation. The attention score for each sentence is calculated from its original representation and its final hidden state (i.e., the -th level’s heuristic information about relations). Then a weighted sum over the bag is employed,
| (17) |
where is the matrix consisting of the final hidden state of all sentences in .
Finally, a softmax classifier based on the MultiLayer Perceptron is used to classify the bag representation ,
| (18) |
where , is the number of pre-defined relations.
3.4 Entity-Order Perception and Training Objectives
To retain more entity-order information, we design a classification sub-task in the multi-task paradigm. Specifically, a MultiLayer Perceptron is employed to bicategorize relation-augmented representations , i.e., whether entity appears before entity or not. That is,
| (19) |
To optimize our model, three objectives are introduced: 1) The main objective is bag-level classification and is defined as minimizing cross-entropy loss,
| (20) |
where is the train set consisting of sentence bags. 2) The hierarchical auxiliary objective is designed to guide RHIA module in choosing appropriate relation embeddings to augment each sentence representation. That is,
| (21) |
where denotes indexing operation. 3) The entity-order perception objective is introduced to take entity-order information into account:
| (22) |
Eventually, these three objectives are integrated into a whole. The final loss function can be represented as:
| (23) |
where , and are weight scores of different losses. is the regularizer.
4 Experiments and Results
Since this paper focuses on the sentence-level distantly supervised relation extraction task, we choose the New York Times (NYT) dataset [5] for evaluation333http://iesl.cs.umass.edu/riedel/ecml/, which is the only widely-adopted distantly supervised relation extraction benchmark and freely available444https://github.com/thunlp/HNRE/tree/master/raw_data. The wrong labeling problem and long-tail problem are extremely serious on it, which is why we choose it. As for other available DS datasets, GIDS [40] has no the long-tail phenomenon; NYT-H [41] is subset variants of NYT, and its test set contains only 9955 sentences, which is so small that the results of our model and baselines are all very high and not comparable; DocRED [42] is designed for document-level relation extraction that require inter-sentence reasoning capability.
The NYT dataset was generated by aligning the corpus with Freebase, and has 53 relations. Among these relation types, there is a special NA class which indicates that no relation exists between two entities. Its train set consists of the corpus from the years 2005-2006, while the test set consists of the rest corpus from year 2007. For its statistics, the number of sentence and entity_pair of train set are 570088 and 293162, respectively, while the values for the test set are 172448 and 96678.
Our RHIA-EOP is programmed using the Pytorch framework and trained on the GeForce GTX 1080 Ti. During the training phase, it takes about 1.5 hours to execute 15-20 epochs before convergence. Besides, following previous work [7], three-fold cross-validation on the train set is used for hyper-parameter selection and the held-out evaluation is applied to conduct the experiments. The evaluation metrics used in this paper include Top-N precision, the precision-recall curve, AUC, Max_F1 and Hits@K.
4.1 Experimental Settings
For the initialization of word embeddings, we employ the pre-trained embeddings from Lin et al. [7] 555https://github.com/thunlp/OpenNRE. The relation embedding matrices are initialized randomly as Li et al. [15]. Besides, the dropout strategy [43] is applied to the bag representations to prevent overfitting. During training phase, for optimization, we employ mini-batch SGD [44] with the initial learning rate .
| Parameter | Value |
| word/entity embedding dimension | 50 |
| position embedding dimension | 5 |
| maximum length of sentences | 120 |
| entity-aware smoothness | 0.05 |
| Entity-Aware Embedding dimension | 150 |
| kernel size | 3 |
| hidden dimension of PCNN | 230 |
| learning rate | 0.1 |
| dropout rate | 0.5 |
| number of relation levels | 3 |
| regularization coefficient | 1e-5 |
| weights of loss function | 1, 1, 1 |
The detailed parameter settings are shown in Table 1. For Entity-Aware Embedding module and PCNN module, the parameters keep consistent with those in previous work [15], i.e., . The learning rate and dropout rate are also the same as Han et al. [13]. For parameters of three objective functions, all are consistent with Li et al. [15] except for the weight of . To better exploit Entity-Order Perception, we choose the weight of (i.e., ) from the list . Here we use three-fold cross-validation on the train set. Each value is trained three times since cross-validation, and the best value (i.e., 1) is determined according to the average of AUC.
For the following experiments, we apply the held-out evaluation to evaluate our model. The entire train set is used for the training phase, while the test set is used for evaluation. The results in Section 4.5 are only intended to illustrate the stability of our model, and are not relevant to cross-validation for hyper-parameter selection.
4.2 Baselines
We compare RHIA-EOP with competitive previous baselines that are summarized as follows:
-
1.
PCNN_ATT: Lin et al. [7] propose a selective attention among training sentences to mitigate wrong labeling problem, which is the most classical approach in DSRE task.
-
2.
HNRE: Han et al. [13] design a hierarchical attention network to enrich bag-level representations, which is the first hierarchical relation extraction baseline.
-
3.
ToHRE: Yu et al. [16] introduce a top-down classification strategy and a method to enhance the bag representation in different relation levels.
-
4.
CoRA: Li et al. [15] enhance sentence representations in a collaborative way across all relation levels.
- 5.
- 6.
- 7.
4.3 Model Comparison Results
The comparison results of different models are displayed in Table 2, Table 3 and Figure 4 (a). Note that, the results in Table 2 are obtained using the full test set of the NYT dataset. While the results in Table 3 are obtained using the remaining test set with all single-sentence bags removed as [15], because for each single-sentence bag, the result is the same whether one, two or all sentences are retained for evaluation. Here the single-sentence bag means a bag consisting of only one sentence.
| Approach | P@100 | P@200 | P@300 | P@500 | P@1000 | P@2000 | Mean | AUC | Max_F1 |
|---|---|---|---|---|---|---|---|---|---|
| PCNN_ATT [7] | 78.0 | 72.5 | 71.0 | 67.6 | 54.3 | 40.8 | 64.0 | 0.39 | 0.437 |
| HNRE [13] | 82.0 | 80.5 | 76.0 | 67.8 | 58.3 | 42.1 | 67.8 | 0.42 | 0.455 |
| ToHRE [16] | 91.5 | 82.9 | 79.6 | 74.8 | 63.3 | 48.9 | 73.5 | 0.44 | 0.476 |
| CoRA [15] | 93.0 | 91.0 | 88.0 | 81.2 | 67.6 | 51.4 | 78.7 | 0.53 | 0.525 |
| HNRE w/ Ent. Emb. | 84.7 | 83.1 | 77.3 | 75.5 | 65.6 | 47.9 | 72.4 | 0.47 | 0.467 |
| HNRE w/ Aux. Obj. | 85.0 | 82.5 | 79.3 | 73.9 | 64.2 | 49.8 | 72.5 | 0.49 | 0.485 |
| HNRE w/ Ent. Emb. w/ Aux. Obj. | 90.1 | 87.0 | 85.7 | 76.8 | 67.3 | 51.7 | 76.4 | 0.52 | 0.525 |
| RHIA-EOP | 95.0 | 94.0 | 89.7 | 85.2 | 71.7 | 53.2 | 81.5 | 0.56 | 0.546 |
| Ablations | |||||||||
| w/o EOP (RHIA) | 93.0 | 89.0 | 88.3 | 81.0 | 70.8 | 52.1 | 79.0 | 0.546 | 0.531 |
| w/o RHIA (EOP) | 96.0 | 93.0 | 88.3 | 81.2 | 70.3 | 51.8 | 80.1 | 0.545 | 0.529 |
| w/o Sent2rel Attention | 93.0 | 92.5 | 89.0 | 82.2 | 71.2 | 53.0 | 80.2 | 0.548 | 0.539 |
| w/o Attention Pooling | 89.0 | 87.0 | 83.3 | 79.6 | 68.9 | 52.0 | 76.6 | 0.534 | 0.531 |
| w/o Gating in Eqs.11-12 | 95.0 | 91.0 | 87.3 | 83.2 | 70.8 | 53.0 | 80.1 | 0.549 | 0.541 |
| w/o Aux. Obj. in Eq.21 | 81.5 | 81.0 | 76.0 | 71.6 | 60.8 | 47.2 | 69.7 | 0.451 | 0.481 |
| w/ uncased BERT-Base | 91.5 | 91.0 | 88.1 | 84.4 | 69.9 | 52.5 | 79.6 | 0.593 | 0.584 |
| One | Two | All | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P@N(%) | 100 | 200 | 300 | Mean | 100 | 200 | 300 | Mean | 100 | 200 | 300 | Mean |
| PCNN_ATT [7] | 73.3 | 69.2 | 60.8 | 67.8 | 77.2 | 71.6 | 66.1 | 71.6 | 76.2 | 73.1 | 67.4 | 72.2 |
| HNRE [13] | 84.0 | 76.0 | 69.7 | 76.6 | 85.0 | 76.0 | 72.7 | 77.9 | 88.0 | 79.5 | 75.3 | 80.9 |
| ToHRE [16] | 87.1 | 81.4 | 75.3 | 81.3 | 89.7 | 83.1 | 78.5 | 83.8 | 92.4 | 86.7 | 81.2 | 86.8 |
| CoRA [15] | 94.0 | 90.5 | 82.0 | 88.8 | 98.0 | 91.0 | 86.3 | 91.8 | 98.0 | 92.5 | 88.3 | 92.9 |
| HNRE w/ Ent. Emb. | 90.2 | 86.5 | 81.3 | 86.0 | 91.3 | 87.2 | 82.4 | 87.0 | 93.1 | 89.0 | 85.8 | 89.3 |
| HNRE w/ Aux. Obj. | 87.7 | 82.0 | 76.8 | 82.2 | 88.0 | 84.4 | 79.2 | 83.9 | 91.0 | 85.5 | 82.7 | 86.4 |
| HNRE w/ Ent. Emb. w/ Aux. Obj. | 93.0 | 85.4 | 81.9 | 86.8 | 94.0 | 90.1 | 84.7 | 89.6 | 94.0 | 90.9 | 87.5 | 90.8 |
| RHIA-EOP | 96.0 | 92.5 | 86.7 | 91.7 | 98.0 | 95.5 | 92.3 | 95.3 | 98.0 | 96.5 | 93.3 | 95.9 |
| Ablations | ||||||||||||
| w/o EOP (RHIA) | 95.0 | 89.5 | 84.0 | 89.5 | 96.0 | 95.0 | 90.3 | 93.8 | 97.0 | 96.5 | 91.0 | 94.8 |
| w/o RHIA (EOP) | 95.0 | 91.0 | 86.7 | 90.9 | 99.0 | 92.0 | 87.7 | 92.9 | 99.0 | 94.5 | 90.0 | 94.5 |
| w/o Sent2rel Attention | 93.3 | 91.0 | 85.0 | 89.8 | 95.0 | 92.0 | 89.3 | 92.1 | 96.0 | 94.0 | 91.7 | 93.9 |
| w/o Attention Pooling | 92.0 | 90.0 | 87.7 | 89.9 | 93.0 | 93.0 | 90.7 | 92.2 | 94.0 | 94.0 | 91.3 | 93.1 |
| w/o Gating in Eqs.11-12 | 95.0 | 92.5 | 86.0 | 91.2 | 96.0 | 94.5 | 90.7 | 93.7 | 96.0 | 95.0 | 93.3 | 94.8 |
| w/o Aux. Obj. in Eq.21 | 83.0 | 81.0 | 74.0 | 79.3 | 89.0 | 83.5 | 78.3 | 83.6 | 89.0 | 85.5 | 80.7 | 85.1 |
| w/ uncased BERT-Base | 94.0 | 90.4 | 85.3 | 89.9 | 95.2 | 93.5 | 90.0 | 92.9 | 96.4 | 93.8 | 91.9 | 94.0 |
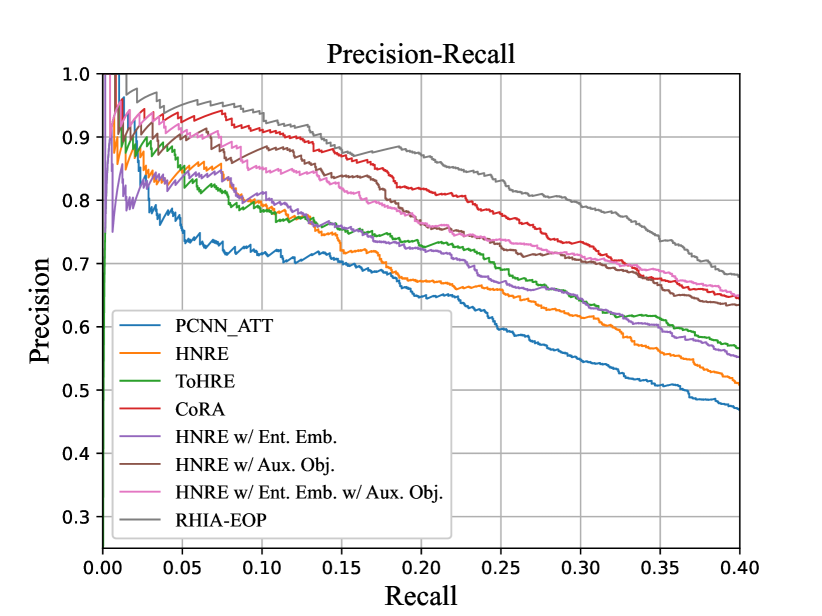
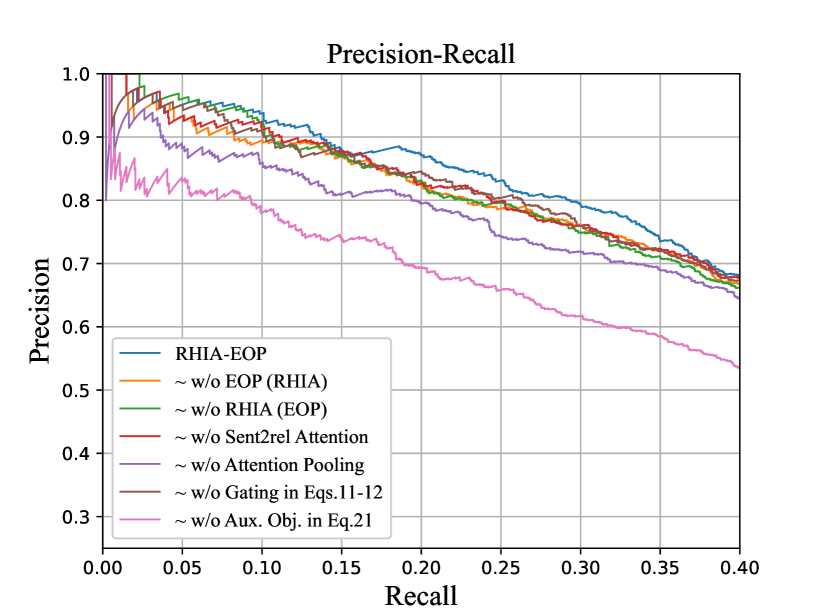
It can be observed that RHIA-EOP significantly outperforms many baseline models in all metrics at the same time. Our approach achieves the AUC of 0.56, which outperforms the strong baseline CoRA (0.53) by 0.03. For Max_F1, we improve baseline approaches by at least 2.1%. For Top-N precision metric, we take relatively more unique values in Table 2, and find that RHIA-EOP sets the best scores on all values. And in another setting, i.e., randomly retaining one, two or all sentence(s) in each bag, RHIA-EOP achieves the best results despite the randomness of retained sentences in Table 3 (Almost all values exceed 90%). Besides, the curve of RHIA-EOP is significantly higher than PCNN_ATT, HNRE, ToHRE and CoRA. The results of setups HNRE w/ Ent. Emb. and HNRE w/ Aux. Obj. indicate that both the Entity-Aware Embedding layer and the hierarchical auxiliary objective bring substantial performance improvements. However, the results of HNRE w/ Ent. Emb. w/ Aux. Obj. are still worse than our RHIA-EOP because the heuristic effects between relation levels and the entity order information are still not considered.
To measure RHIA-EOP’s ability to handle long-tail relations, we conduct a model comparison on all long-tail relations, and the results are shown in table 4. Here Hits@K is employed to measure this ability, which indicates whether the ground-label’s probability of a bag ranking in the top-K relations. During the calculation, we use macro average regarding different relations. Very inspiringly, RHIA-EOP achieve the highest results at all values of . These results confirm the heuristic influence of higher-level relations on the lower-level ones and the advantage of relation hierarchies.
| #Instance | <100 | <200 | |||||
|---|---|---|---|---|---|---|---|
| Hits@K | 10 | 15 | 20 | 10 | 15 | 20 | |
| PCNN_ATT [7] | <5.0 | 7.4 | 40.7 | 17.2 | 24.2 | 51.5 | |
| HNRE [13] | 29.6 | 51.9 | 61.1 | 41.4 | 60.6 | 68.2 | |
| ToHRE [16] | 62.9 | 75.9 | 81.4 | 69.7 | 80.3 | 84.8 | |
| CoRA [15] | 66.7 | 72.2 | 87.0 | 72.7 | 77.3 | 89.3 | |
| HNRE w/ Ent. Emb. | 36.4 | 52.2 | 69.6 | 54.5 | 63.6 | 77.8 | |
| HNRE w/ Aux. Obj. | 44.4 | 54.5 | 68.2 | 60.6 | 72.4 | 81.8 | |
| HNRE w/ Ent. Emb. w/ Aux. Obj. | 47.8 | 62.9 | 77.3 | 66.7 | 75.9 | 87.0 | |
| RHIA-EOP | 66.7 | 83.3 | 94.4 | 72.7 | 86.4 | 95.5 | |
| w/ uncased BERT-Base | 55.6 | 66.7 | 72.2 | 63.6 | 77.3 | 81.8 |
In addition, we briefly analyze the computational overhead. Both our RHIA-EOP and the CORA of Li et al. [15] employ multiple attention mechanisms. We further introduce the interaction effects between relation levels and entity order information, and the number of parameters grow from 13M to 18M. It is still much smaller compared to the pre-trained language models since the smallest BERT-Base has 110M parameters). The parameter growth is not really huge (i.e., 5M). The required training time dose not increase dramatically, both models can converge within two hours, while the performance gains are relatively huge and substantial. Therefore, although some computational overhead is added, it is worthwhile.
4.4 Ablation Study
In order to validate the effectiveness of each module in RHIA-EOP and to analyze the sources of performance improvement, we evaluate the following ablation experimental setups:
-
1.
w/o EOP (RHIA): The Entity-Order Perception subtask is removed. It is equivalent to having only the Recursive Hierarchy-Interactive Attention (RHIA) module.
-
2.
w/o RHIA (EOP): The module RHIA is replaced by CoRA [15]. It is equivalent to combining CoRA and EOP.
- 3.
-
4.
w/o Attention Pooling: The attention pooling (i.e., Eq.17) is replaced by average pooling.
- 5.
- 6.
-
7.
w/ uncased BERT-Base: The Entity-Aware Embedding layer is replaced by uncased BERT-Base model.
The results are shown in the bottom of Table 2 and Table3, and Figure 4 (b). And the evaluation results reflect consistent declines in P@N, Max_F1 and AUC. For the two main modules of RHIA-EOP, in Table 2, compared to RHIA-EOP, both RHIA and EOP drop almost 0.015 on AUC, and these two models decrease by 2.5% and 1.4% on the mean of P@N, respectively. While in Table 3, the performance drop is similar obviously, the mean of P@N of RHIA decreases by 2.2%, 1.5% and 1.1%, respectively. For EOP, the values are 0.8%, 2.4% and 1.4%.
To further analyze whether the performance improvement comes from the new attention mechanism or from the full utilization of relation hierarchies, we set up more experimental settings. The setups w/o Sent2rel Attention and w/o Attention Pooling argue for the importance and validity of the attention mechanism. As for the relation hierarchies, firstly, for each level of the relation hierarchies, we construct the corresponding feature representation for each bag and classify it. This is the hierarchical auxiliary objective (i.e., Eq.21). The setup w/o Aux. Obj. in Eq.21 has demonstrated that not using the relation hierarchies leads to a significant performance drop. Secondly, along the relation hierarchies, relational information is propagated in a recursive form (i.e., RHIA). The setup w/o EOP (RHIA) confirms its effectiveness. To sum up, the relation hierarchies are indeed contributing and the attention mechanism is indeed effective.
Interestingly, despite the Pre-trained Language Models (PLMs) are so powerful, the results achieved by the BERT-based implementation are not satisfactory. Except for the values of AUC and Max_F1, the values of all metrics have decreased. The reason may be that BERT cannot highlight two entities as the Entity-Aware Embedding layer does, i.e., it ignores the importance of the entity-pair itself and the position of entities. After all, the essence of DSRE task lies in the classification of entity pairs.
4.5 Statistical Analysis of Multiple training runs
| Metrics | P@N (Mean) | AUC | Max_F1 |
|---|---|---|---|
| Values | 80.82 0.676 | 0.561 0.003 | 0.546 0.009 |
| P@N (Mean) | ONE | TWO | ALL |
|---|---|---|---|
| Values | 91.86 0.873 | 94.36 0.653 | 95.66 0.224 |
We reran our model five times to calculate the respective means and standard deviations in terms of AUC, Max_F1 and the mean of P@N. Here for P@N, the randomness of the selected samples when retaining one/two/all sentence(s) in each bag at random leads to large fluctuations in its value, so we only report the mean and standard deviation of “the mean of P@N”, i.e., P@N (Mean). Detailed results can be found in Table 5 and Table 6. These results demonstrate that the performance gains are stable and convincing.
4.6 Case Study
To visualize the heuristic effect between relation hierarchies, two example sentences from NYT are selected. And then we list/analyze the Top-3 attention scores at all relation levels of these two sentences in Table 7. Our RHIA-EOP, compared to CoRA, better handles the highly unbalanced category (i.e., NA), and gives greater scores to NA for the true instances of NA and less scores to NA for other instances. This capability can also improve the recognition of noisy sentences from the side, and alleviate the wrong labeling problem. These findings demonstrate the effectiveness of RHIA-EOP.
| Relation fact: | <Grameen Bank, /business/company/founders, Muhammad Yunus > | |||||
| Example 1: | Muhammad Yunus, who won the Nobel Peace Prize, last year, demonstrated with, | |||||
| Grameen Bank the power of microfinancing. | ||||||
| Example 2: | On Sunday, though, there was a significant shift of the tectonic plates of Bangladeshi politics, | |||||
| as Muhammad Yunus, the founder of a microfinance empire, known as the Grameen Bank and | ||||||
| the winner of the 2006 Nobel Peace Prize, announced that he would start a new party and step | ||||||
| into the electoral fray. | ||||||
| Example 1 | ||||||
| /business: | 0.422 | NA: | 0.383 | NA: | 0.387 | |
| CoRA | NA: | 0.384 | /business/company: | 0.272 | /business/company/founders: | 0.197 |
| /location: | 0.037 | /business/person: | 0.063 | /business/person/company: | 0.063 | |
| NA: | 0.524 | NA: | 0.612 | NA: | 0.559 | |
| RHIA-EOP | /business: | 0.324 | /business/company: | 0.095 | /business/person/company: | 0.089 |
| /people: | 0.049 | /business/person: | 0.072 | /business/company/founders: | 0.082 | |
| Example 2 | ||||||
| /business: | 0.755 | /business/company: | 0.679 | /business/company/founders: | 0.652 | |
| CoRA | NA: | 0.103 | NA: | 0.089 | NA: | 0.069 |
| /people: | 0.031 | /business/person: | 0.059 | /business/person/company: | 0.057 | |
| /business: | 0.899 | /business/company: | 0.856 | /business/company/founders: | 0.741 | |
| RHIA-EOP | NA: | 0.024 | /business/person: | 0.047 | /business/person/company: | 0.052 |
| /people: | 0.022 | NA: | 0.019 | /business/company/major_shareholders: | 0.044 | |
5 Conclusions
In this paper, we fully exploit the inherent taxonomic structure of relations and design a recursive hierarchy-interactive attention network. In this way, we model the heuristic influence of higher-level relations on the lower-level ones. Furthermore, multiple training objectives are designed to take entity-order information into account. The substantial experiments on the NYT dataset show that RHIA-EOP achieves state-of-the-art performance in multiple metrics, including standard metrics (i.e., AUC, P-R curve, Top-N precision, etc.) and long-tail metrics (i.e., Hits@K). In the future, we plan to consider the interaction between the many sibling relations within the same level and employ our recursive approach to other tasks, such as fine-grained hierarchical text classification. Besides, we will further explore the extension of traditional feature-based methods in the deep learning paradigm.
CRediT authorship contribution statement
Ridong Han: Methodology, Conceptualization, Software, Visualization, Writing, Editing. Tao Peng: Supervision, Funding acquisition, Reviewing, Validation. Jiayu Han: Editing, Reviewing. Hai Cui: Formal analysis, Validation. Lu Liu: Reviewing, Supervision, Validation, Funding acquisition.
Acknowledgment
This work is supported by the National Natural Science Foundation of China under grant No.61872163 and 61806084, Jilin Province Key Scientific and Technological Research and Development Project under grant No.20210201131GX, and Jilin Provincial Education Department Project under grant No.JJKH20190160KJ.
References
- Suchanek et al. [2007] F. M. Suchanek, G. Kasneci, G. Weikum, Yago: a core of semantic knowledge, in: Proceedings of the 16th International Conference on World Wide Web, WWW 2007, ACM, 2007, pp. 697–706. doi:10.1145/1242572.1242667.
- Bollacker et al. [2008] K. D. Bollacker, C. Evans, P. Paritosh, T. Sturge, J. Taylor, Freebase: a collaboratively created graph database for structuring human knowledge, in: Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, ACM, 2008, pp. 1247–1250. doi:10.1145/1376616.1376746.
- Lehmann et al. [2015] J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, C. Bizer, Dbpedia - A large-scale, multilingual knowledge base extracted from wikipedia, Semantic Web 6 (2015) 167–195. doi:10.3233/SW-140134.
- Mintz et al. [2009] M. Mintz, S. Bills, R. Snow, D. Jurafsky, Distant supervision for relation extraction without labeled data, in: Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, ACL 2009, The Association for Computer Linguistics, 2009, pp. 1003–1011.
- Riedel et al. [2010] S. Riedel, L. Yao, A. McCallum, Modeling relations and their mentions without labeled text, in: Machine Learning and Knowledge Discovery in Databases, European Conference, ECML PKDD 2010, volume 6323 of Lecture Notes in Computer Science, Springer, 2010, pp. 148–163. doi:10.1007/978-3-642-15939-8\_10.
- Hoffmann et al. [2011] R. Hoffmann, C. Zhang, X. Ling, L. S. Zettlemoyer, D. S. Weld, Knowledge-based weak supervision for information extraction of overlapping relations, in: Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, The Association for Computer Linguistics, 2011, pp. 541–550.
- Lin et al. [2016] Y. Lin, S. Shen, Z. Liu, H. Luan, M. Sun, Neural relation extraction with selective attention over instances, in: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Association for Computational Linguistics, Berlin, Germany, 2016, pp. 2124–2133. doi:10.18653/v1/P16-1200.
- Qu et al. [2018] J. Qu, D. Ouyang, W. Hua, Y. Ye, X. Li, Distant supervision for neural relation extraction integrated with word attention and property features, Neural Networks 100 (2018) 59–69. doi:10.1016/j.neunet.2018.01.006.
- Du et al. [2018] J. Du, J. Han, A. Way, D. Wan, Multi-level structured self-attentions for distantly supervised relation extraction, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Association for Computational Linguistics, 2018, pp. 2216–2225. doi:10.18653/v1/d18-1245.
- Liu et al. [2017] T. Liu, K. Wang, B. Chang, Z. Sui, A soft-label method for noise-tolerant distantly supervised relation extraction, in: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Association for Computational Linguistics, 2017, pp. 1790–1795. doi:10.18653/v1/d17-1189.
- Xiao et al. [2020] Y. Xiao, C. Tan, Z. Fan, Q. Xu, W. Zhu, Joint entity and relation extraction with a hybrid transformer and reinforcement learning based model, in: Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, AAAI Press, 2020, pp. 9314–9321.
- Yang et al. [2020] J. Yang, Q. Wang, C. Su, X. Wang, Threat intelligence relationship extraction based on distant supervision and reinforcement learning (S), in: Proceedings of the 32nd International Conference on Software Engineering and Knowledge Engineering, SEKE 2020, KSI Research Inc., 2020, pp. 572–576. doi:10.18293/SEKE2020-149.
- Han et al. [2018] X. Han, P. Yu, Z. Liu, M. Sun, P. Li, Hierarchical relation extraction with coarse-to-fine grained attention, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Association for Computational Linguistics, 2018, pp. 2236–2245. doi:10.18653/v1/d18-1247.
- Zhang et al. [2019] N. Zhang, S. Deng, Z. Sun, G. Wang, X. Chen, W. Zhang, H. Chen, Long-tail relation extraction via knowledge graph embeddings and graph convolution networks, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Association for Computational Linguistics, 2019, pp. 3016–3025. doi:10.18653/v1/n19-1306.
- Li et al. [2020] Y. Li, T. Shen, G. Long, J. Jiang, T. Zhou, C. Zhang, Improving long-tail relation extraction with collaborating relation-augmented attention, in: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, International Committee on Computational Linguistics, 2020, pp. 1653–1664. doi:10.18653/v1/2020.coling-main.145.
- Yu et al. [2020] E. Yu, W. Han, Y. Tian, Y. Chang, Tohre: A top-down classification strategy with hierarchical bag representation for distantly supervised relation extraction, in: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, International Committee on Computational Linguistics, 2020, pp. 1665–1676. doi:10.18653/v1/2020.coling-main.146.
- Bordes et al. [2013] A. Bordes, N. Usunier, A. García-Durán, J. Weston, O. Yakhnenko, Translating embeddings for modeling multi-relational data, in: Proceedings of the 27th Annual Conference on Neural Information Processing Systems, NIPS 2013, 2013, pp. 2787–2795.
- Defferrard et al. [2016] M. Defferrard, X. Bresson, P. Vandergheynst, Convolutional neural networks on graphs with fast localized spectral filtering, in: Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, 2016, pp. 3837–3845.
- Zeng et al. [2014] D. Zeng, K. Liu, S. Lai, G. Zhou, J. Zhao, Relation classification via convolutional deep neural network, in: Proceedings of the 25th International Conference on Computational Linguistics, COLING 2014, 2014, pp. 2335–2344.
- Geng et al. [2020] Z. Geng, G. Chen, Y. Han, G. Lu, F. Li, Semantic relation extraction using sequential and tree-structured LSTM with attention, Inf. Sci. 509 (2020) 183–192. URL: https://doi.org/10.1016/j.ins.2019.09.006. doi:10.1016/j.ins.2019.09.006.
- Chen et al. [2021] Y. Chen, W. Yang, K. Wang, Y. Qin, R. Huang, Q. Zheng, A neuralized feature engineering method for entity relation extraction, Neural Networks 141 (2021) 249–260. URL: https://doi.org/10.1016/j.neunet.2021.04.010. doi:10.1016/j.neunet.2021.04.010.
- Xu et al. [2021] W. Xu, K. Chen, T. Zhao, Document-level relation extraction with reconstruction, in: Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI, 2021, pp. 14167–14175. URL: https://ojs.aaai.org/index.php/AAAI/article/view/17667.
- Huang et al. [2021] Q. Huang, S. Zhu, Y. Feng, Y. Ye, Y. Lai, D. Zhao, Three sentences are all you need: Local path enhanced document relation extraction, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, 2021, pp. 998–1004. URL: https://doi.org/10.18653/v1/2021.acl-short.126. doi:10.18653/v1/2021.acl-short.126.
- Yang et al. [2021] S. Yang, Y. Zhang, G. Niu, Q. Zhao, S. Pu, Entity concept-enhanced few-shot relation extraction, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP, 2021, pp. 987–991. URL: https://doi.org/10.18653/v1/2021.acl-short.124. doi:10.18653/v1/2021.acl-short.124.
- Deng et al. [2021] L. Deng, B. Yang, Z. Kang, S. Yang, S. Wu, A noisy label and negative sample robust loss function for dnn-based distant supervised relation extraction, Neural Networks 139 (2021) 358–370. URL: https://doi.org/10.1016/j.neunet.2021.03.030. doi:10.1016/j.neunet.2021.03.030.
- Zhou et al. [2021] Y. Zhou, L. Pan, C. Bai, S. Luo, Z. Wu, Self-selective attention using correlation between instances for distant supervision relation extraction, Neural Networks 142 (2021) 213–220. URL: https://doi.org/10.1016/j.neunet.2021.04.032. doi:10.1016/j.neunet.2021.04.032.
- Surdeanu et al. [2012] M. Surdeanu, J. Tibshirani, R. Nallapati, C. D. Manning, Multi-instance multi-label learning for relation extraction, in: Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, EMNLP-CoNLL 2012, ACL, 2012, pp. 455–465.
- Zeng et al. [2015] D. Zeng, K. Liu, Y. Chen, J. Zhao, Distant supervision for relation extraction via piecewise convolutional neural networks, in: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, The Association for Computational Linguistics, 2015, pp. 1753–1762. doi:10.18653/v1/d15-1203.
- Yuan et al. [2019] Y. Yuan, L. Liu, S. Tang, Z. Zhang, Y. Zhuang, S. Pu, F. Wu, X. Ren, Cross-relation cross-bag attention for distantly-supervised relation extraction, in: Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, AAAI Press, 2019, pp. 419–426. doi:10.1609/aaai.v33i01.3301419.
- Ye and Ling [2019] Z. Ye, Z. Ling, Distant supervision relation extraction with intra-bag and inter-bag attentions, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Association for Computational Linguistics, 2019, pp. 2810–2819. doi:10.18653/v1/n19-1288.
- Dai et al. [2019] L. Dai, B. Xu, H. Song, Feature-level attention based sentence encoding for neural relation extraction, in: Natural Language Processing and Chinese Computing - 8th CCF International Conference, NLPCC 2019, volume 11838 of Lecture Notes in Computer Science, Springer, 2019, pp. 184–196. doi:10.1007/978-3-030-32233-5\_15.
- Yu et al. [2019] B. Yu, Z. Zhang, T. Liu, B. Wang, S. Li, Q. Li, Beyond word attention: Using segment attention in neural relation extraction, in: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, ijcai.org, 2019, pp. 5401–5407. doi:10.24963/ijcai.2019/750.
- Peng et al. [2022] T. Peng, R. Han, H. Cui, L. Yue, J. Han, L. Liu, Distantly supervised relation extraction using global hierarchy embeddings and local probability constraints, Knowl. Based Syst. 235 (2022) 107637. URL: https://doi.org/10.1016/j.knosys.2021.107637. doi:10.1016/j.knosys.2021.107637.
- Mikolov et al. [2013] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, J. Dean, Distributed representations of words and phrases and their compositionality, in: Proceedings of the 27th Annual Conference on Neural Information Processing Systems , NIPS 2013, 2013, pp. 3111–3119.
- Li et al. [2020] Y. Li, G. Long, T. Shen, T. Zhou, L. Yao, H. Huo, J. Jiang, Self-attention enhanced selective gate with entity-aware embedding for distantly supervised relation extraction, in: Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, AAAI Press, 2020, pp. 8269–8276.
- He et al. [2016] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, IEEE Computer Society, 2016, pp. 770–778. doi:10.1109/CVPR.2016.90.
- Ba et al. [2016] L. J. Ba, J. R. Kiros, G. E. Hinton, Layer normalization, CoRR abs/1607.06450 (2016). arXiv:1607.06450.
- Lin et al. [2017] Z. Lin, M. Feng, C. N. dos Santos, M. Yu, B. Xiang, B. Zhou, Y. Bengio, A structured self-attentive sentence embedding, in: Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, OpenReview.net, 2017.
- Shen et al. [2018] T. Shen, T. Zhou, G. Long, J. Jiang, S. Pan, C. Zhang, Disan: Directional self-attention network for rnn/cnn-free language understanding, in: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, AAAI Press, 2018, pp. 5446–5455.
- Jat et al. [2018] S. Jat, S. Khandelwal, P. P. Talukdar, Improving distantly supervised relation extraction using word and entity based attention, CoRR abs/1804.06987 (2018). arXiv:1804.06987.
- Zhu et al. [2020] T. Zhu, H. Wang, J. Yu, X. Zhou, W. Chen, W. Zhang, M. Zhang, Towards accurate and consistent evaluation: A dataset for distantly-supervised relation extraction, in: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, International Committee on Computational Linguistics, 2020, pp. 6436–6447. doi:10.18653/v1/2020.coling-main.566.
- Yao et al. [2019] Y. Yao, D. Ye, P. Li, X. Han, Y. Lin, Z. Liu, Z. Liu, L. Huang, J. Zhou, M. Sun, Docred: A large-scale document-level relation extraction dataset, in: Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL, 2019, pp. 764–777. URL: https://doi.org/10.18653/v1/p19-1074. doi:10.18653/v1/p19-1074.
- Srivastava et al. [2014] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov, Dropout: a simple way to prevent neural networks from overfitting, J. Mach. Learn. Res. 15 (2014) 1929–1958.
- Cotter et al. [2011] A. Cotter, O. Shamir, N. Srebro, K. Sridharan, Better mini-batch algorithms via accelerated gradient methods, in: Proceedings of the 25th Annual Conference on Neural Information Processing Systems, NIPS 2011, 2011, pp. 1647–1655.