.tifpng.pngconvert #1 \OutputFile \AppendGraphicsExtensions.tif
Distributed Control-Estimation Synthesis for Stochastic Multi-Agent Systems via Virtual Interaction between Non-neighboring Agents
Department of Mechanical Engineering
Ulsan National Institute of Science and Technology
Ulsan, 44919 Repulic of Korea
hojinlee@unist.ac.kr
&
Department of Mechanical Engineering
Ulsan National Institute of Science and Technology
Ulsan, 44919 Repulic of Korea
kwonc@unist.ac.kr
Abstract
This paper considers the optimal distributed control problem for a linear stochastic multi-agent system (MAS). Due to the distributed nature of MAS network, the information available to an individual agent is limited to its vicinity. From the entire MAS aspect, this imposes the structural constraint on the control law, making the optimal control law computationally intractable. This paper attempts to relax such a structural constraint by expanding the neighboring information for each agent to the entire MAS, enabled by the distributed estimation algorithm embedded in each agent. By exploiting the estimated information, each agent is not limited to interact with its neighborhood but further establishing the ‘virtual interactions’ with the non-neighboring agents. Then the optimal distributed MAS control problem is cast as a synthesized control-estimation problem. An iterative optimization procedure is developed to find the control-estimation law, minimizing the global objective cost of MAS.
Keywords Distributed control Distributed estimation Optimal control
1 Introduction
Distributed control within a cooperative multi-agent system (MAS) is the key enabling technology for different networked dynamical systems (Shi and Yan, 2020; Li et al., 2019; Zhu et al., 2020; Morita et al., 2015). Notwithstanding diverse distributed control strategies, their optimality is one of the stumbling blocks due to individual agents’ limited information. In particular, finding the optimal distributed control with network topological constraint is a well-known NP-hard problem (Gupta et al., 2005). To ease this problem, some former studies have focused on a specific form of objective function along with certain MAS network topology conditions under which the optimal distributed control laws can be designed (Ma et al., 2015). More particularly, different techniques have been investigated to design suboptimal distributed control laws for different MAS cooperative tasks (Gupta et al., 2005; Nguyen, 2015; Jiao et al., 2019). In this paper, a new avenue for accomplishing the optimal distributed control of MAS is presented while not requiring the restricted form of the objective function, nor the network topology. The key idea is to expand the available information for each agent by employing the distributed estimation algorithm, and use the expanded information to relax the network topological constraint in a tractable manner. In a nutshell, the main contributions are the following.
-
1.
A synthesized distributed control-estimation framework is proposed based on the authors’ preliminarily developed distributed estimation algorithm (Kwon and Hwang, 2018). The newly proposed framework enables the interactions between non-neighboring agents, namely virtual interactions.
-
2.
With the aid of virtual interactions, a design procedure that solves for the optimal distributed control law of the stochastic MAS over a finite time horizon is developed, which was originally an intractable non-convex problem due to the network topological constraint.
2 Problem Formulation
2.1 Dynamical Model of Stochastic MAS
Consider a stochastic linear multi-agent dynamical system including homogeneous agents whose dynamics is given by:
| (1) |
where and are the state and the control input of the agent, respectively. is a disturbance imposed on the agent, assumed to follow zero-mean white Gaussian distribution with covariance . indicates a discrete-time index. are the system matrices with appropriate dimensions, and are assumed to satisfy the controllability condition. Accordingly, the entire MAS dynamics can be written as
| (2) |
where is the Kronecker product between matrices. The interactions between agents are rendered by inter-agent network topology, described by a graph model consisting of a node set indexing each agent and an edge set indicating the network connectivity between the agents. Each edge denotes that the node can acquire the state information of the node . An adjacency matrix can express the network connectivity of the graph model, where its element if , and otherwise. A degree matrix is defined as where is (weighted) degree of node . The Laplacian matrix , given by , is useful for analysis of the network topology. The set of agents whose state information is available to the agent, i.e., the neighborhood of the agent, is expressed as , and its cardinality is expressed as . Based on the given network topology, the noisy measurement of neighborhood states from the agent’s perspective can be represented as follows (Kwon and Hwang, 2018):
| (3) |
where indicates the availability of the measurement of the agent’s state from the agent such that when , and otherwise. The noise of the measurement from the to the agent is specified as which is assumed to be independent and identically distributed (i.i.d.) Gaussian random variables with zero mean and covariance . Further the measurement and the noise sets of the agent are denoted by and , respectively. Over a finite time horizon , one can rewrite (2) as a static form by stacking up the variables and matrices (Furieri and Kamgarpour, 2020):
| (4) |
where
where and respectively denote the identity and zero matrices of size , and is the block matrix having in the block entry and filled with in other block entries. And , and are the stacked agents’ states and their control inputs over the horizon, where . is the vector containing initial agents’ states and the additive noise. Over the finite time horizon , individual agents interact with their neighbors according to the control law embedded in each agent. Without loss of generality, can be designed by the following output feedback control law (Furieri and Kamgarpour, 2020):
| (5) |
where , , and . The crucial part is the design of the feedback gain, which is denoted by . Here, is an invariant subspace that encodes network topological constraints for distributed MAS imposed by , as well as embeds causal feedback policies by forcing the future response entries to zeros.
2.2 Optimal MAS Distributed Control Problem
Given the equivalent static form of the stochastic linear MAS dynamics over the time horizon (4), we seek to address the optimal distributed control problem.
Problem 1.
Optimal distributed control law subject to structural constraint (Furieri and Kamgarpour, 2020):
| (6) |
where , and are the associated weight matrices.
Due to the structural constraints imposed on the control input space , Problem 1 is a highly non-convex problem, which is indeed NP-hard and a formidable computational burden (Gupta et al., 2005). To circumvent such a difficulty, we propose a concept of that allows for the interactions between non-neighboring agents, i.e., as depicted in Figure. 1.
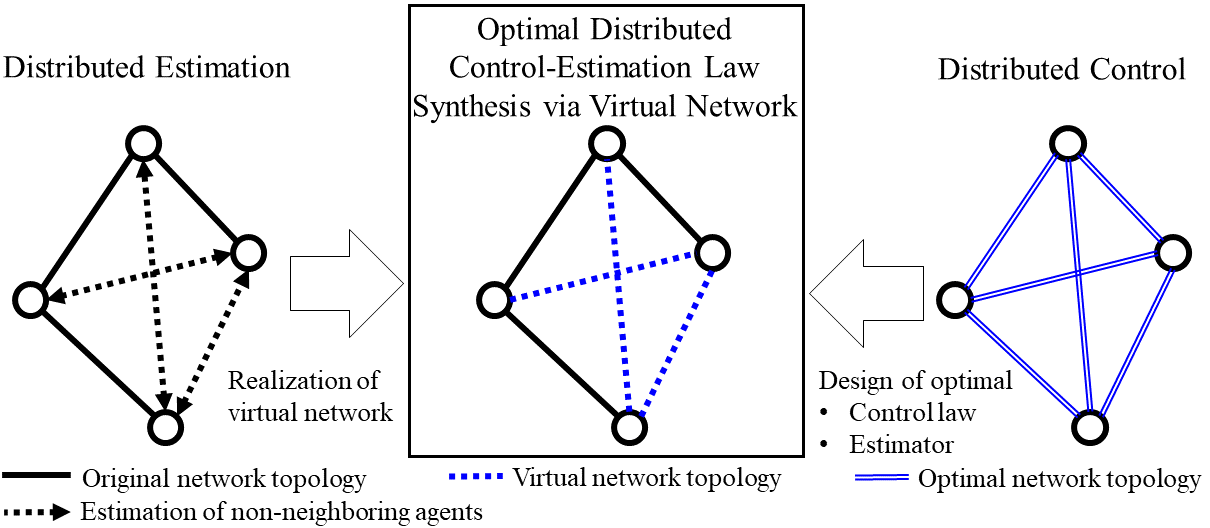
Since the state information of the non-neighboring agent is not available, an appropriate estimator is required for each agent to obtain the estimates of non-neighboring agents’ states. Using the Bayesian approach, Kalman-like filter is adopted for estimation as we consider a linear MAS along with the Gaussian uncertainties.
Definition 1.
The state estimate and its covariance of the MAS using the agent’s measurements are denoted by and , respectively (Kwon and Hwang, 2018), where is the conditional expectation.
The nominal recursive structure of Kalman-like filter is represented by:
| (7) |
where denotes the predicted state estimate from the agent’s perspective. only encodes the neighbor of the agent, that is, where , and are the nonzero column vectors of the matrix . And, represents the estimator gain at time step for estimating the states of the MAS from the agent’s perspective. Once the entire MAS state estimate information becomes available for each agent, one can replace (5) with the estimation-based feedback control law. Accordingly, Problem 1, distributed control law subject to structural constraint, can be reformulated into the problem that simultaneously designs both distributed control and distributed estimator.
Problem 2.
Optimal distributed control-estimation law with virtual interactions:
| (8) |
where , and is the set of estimator gains over the time horizon for the agent.
Remark 1.
It is worth noting that, compared to , is a subspace that only encodes causal feedback policies, not restricted by any network topological constraint.
Albeit Problem 2 can successfully relax the structural constraint on the control law , it is not straightforward to solve as the control law and the state estimation errors mutually affect each other (Kwon and Hwang, 2018). To resolve such complexity, we propose an iterative optimization procedure in a distributed fashion such that: i) divide the primal problem (Problem 2) into the set of sub-problems, each is viewed from an individual agent’s perspective; ii) sequentially design the distributed estimation and control laws for each sub-problem; iii) mix the results from individual sub-problems to approximate the optimal solution to the primal problem. The overall schematic of the proposed distributed control-estimation synthesis is delineated in Figure. 2.
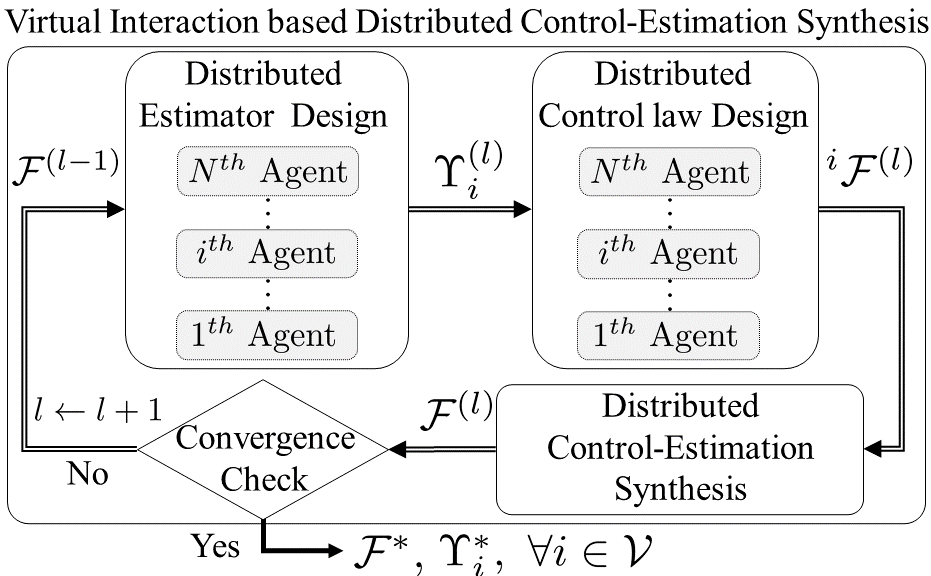
For the iteration, the optimization procedure consists of the following sub-steps. Firstly, distributed estimator design optimizes a set of estimator gains based on the disturbance/noise model, the network topological constraint, and the suboptimal control law resulted from the previous iteration. Then, distributed control law design computes a set of optimal control laws , each from the individual agents’ perspectives, based on the state estimation error information from the designed distributed estimator. Finally, distributed control-estimation synthesis mixes the set of to construct the solution candidate, , for Problem 2. The constructed control law is evaluated to check the convergence and is used for the next iteration. The iteration terminates once the pre-defined stopping criteria are fulfilled, yielding the optimal control-estimation law, denoted by and .
3 Algorithm Development
This section details out the proposed synthesis procedure of the optimal distributed control-estimation law that can comply with an arbitrary network topology of the stochastic MAS.
3.1 Distributed estimator design
To begin with, the distributed estimation algorithm is optimized by means of estimator gains . As offline design phase, individual estimators can be designed based on the entire MAS model information along with the control law computed from the previous iteration, (, , and ). For brevity, we use to designate in this subsection. Recalling (7), the distributed estimator embedded in the agent calculates , whose performance can be measured by the estimation error.
Definition 2.
is the MAS state estimation error from the agent’s perspective, and its covariance is by Definition 1. Further, stacks all the estimation errors from individual agents’ estimator, and the corresponding covariance is denoted by . Similarly, , , , are defined in terms of the predicted state estimate (Kwon and Hwang, 2018).
Assumption 1.
The initial conditions , and are given to individual agents in order to initiate each of their distributed estimators.
Based on the prior knowledge, the estimation based control input of the agent at time step can be written by:
| (9) |
where is the block matrix which spans from to columns and from to rows of the control law matrix . With (9), the entire MAS dynamics (2) can be expressed by:
| (10) |
where , , and . denotes a block-diagonal matrix with block matrices , and the vector indicates every element equals to . Then the predicted state estimate of the entire MAS from the agent’s perspective is given by:
| (11) |
Subtracting (11) from (10), and concatenating the results for all agents in gives:
| (12) |
Correspondingly, is represented by:
| (13) |
where . Note that the summation terms in the RHS of (13) (e.g., ) imply the correlations of state estimates over time induced by the control law (9). Now, the predicted error, (7) can be rewritten by:
| (14) |
Like the Kalman gain, can be computed in a way minimizing the mean-squared error of the state estimate, i.e., . This is in fact equivalent to minimizing the trace of the posterior covariance matrices, i.e., . By the definition of , we have:
| (15) |
where
| (16) |
Correspondingly, can be updated by:
| (17) |
where , and . Note that, the covariance between the state estimation errors at current and past steps, i.e., and need to be updated using the computed . The cross-covariance between the and the agents’ state estimates is at the off-diagonal block entry, while is at the diagonal block entry of . The detailed expansions of is as follows:
Based on the computed from (16), each agent can update , and , respectively using (14), (15), and (17). This completes the implementation of the distributed estimation algorithm.
Remark 2.
It is noted that computed by each agent is irrespective of agent’s perspective since the same initial condition is given to each agent by Assumption 1.
3.2 Distributed control law design
In this section, the computationally tractable formulation of the optimal distributed control law is derived from the individual agents’ perspectives. The main idea starts with relaxing the structural constraints on by applying the estimator (14) to each agent.
Definition 3.
Let stacks up the time series of the estimation errors from the agent’s perspective, over the time horizon . Given and , one can construct the estimation error covariance over the time horizon , , as well as the cross-covariance between two different agents .
In terms of the time series of the estimation errors, the state estimation based control law over the time horizon can be expressed by:
| (18) |
where . Plugging (18) into (4) yields the objective cost in (8) as follows:
| (19) |
where and denote Euclidean norm and the Frobenius norm, respectively; and , .
Apparently, the objective cost (19) has high-dimensional, highly coupled optimization variables, i.e., , which is our main interest, and , which are the implicit functions of both and . The proposed iterative optimization procedure alleviates these coupling complexities in two aspects. First, akin to the alternating direction method of multipliers (ADMM) technique (Lin et al., 2013), we set constant while optimizing at the iteration, thereby treating as the function of only. Note that is designed over the constant in the distributed estimator design phase of the next iteration. Second, we interpret the global objective cost from the individual agent’s viewpoint, and translate the primal problem (Problem 2) into the agent-wise objective cost. The objective cost, locally seen by the agent’s viewpoint at the iteration, is denoted by which can be constructed using the estimated MAS input instead of (18). is constructed from the agent’s perspective by optimizing the agent-wise objective cost, . Then, the resulting agent-wise optimization problem is represented as follows:
Problem 3.
Optimal distributed control law from agent-wise viewpoint:
| (20) |
where
| (21) |
where , . Note that is computed by Definition 3 at the iteration.
Definition 4.
A subspace is quadratic invariance (QI) with respect to if and only if . And it is trivial to show that is QI with respect to (Lessard and Lall, 2011).
It is well-known fact that QI is a sufficient and necessary condition for the exact convex reformulation (Lessard and Lall, 2011). That is, one can apply an equivalent disturbance-feedback policy to make (21) a convex form, similar to (Furieri and Kamgarpour, 2020).
Definition 5.
Let us introduce the nonlinear mapping as:
| (22) |
and define the cost function in terms of the design parameter (Furieri and Kamgarpour, 2020).
| (23) |
By Theorem in (Furieri and Kamgarpour, 2020), the following convex optimization problem is equivalent to Problem 3.
Problem 4.
Equivalent convex problem to optimal distributed control from agent-wise viewpoint:
| (24) |
By solving (24) using convex programming, one can find the optimal , and the corresponding from the inverse mapping of (22). The same optimization routines (Problem 3 and 4) based on the locally seen cost from the other agents’ perspectives are processed to get the optimal control laws at the iteration step.
3.3 Distributed control-estimation synthesis
The set of optimal control laws from individual agents’ viewpoint, , is mixed to approximate the solution to Problem 2 by the agent-wise mixing strategy proposed as follows:
| (25) |
The basic intuition of the proposed strategy is to exhibit the control law for the agent using the one computed from the sup-optimization problem (Problem 3) from the agent’s perspective. Accordingly, the proposed mixing strategy allows for individual agents to retain distributed controllers to be executed, retaining each of their sub-optimal solutions without interfering with each other.
3.4 Convergence check
The last step of the iteration loop evaluates the designed distributed control law (25), together with the estimator (7). First, let be a set which stores the designed control law, , and the estimator gains, , from each iteration step as follows:
| (26) |
The iteration terminates if: i) the total iteration counts the threshold number ; or ii) the consecutive iteration is converged with respect to the following stopping condition:
| (27) |
where and is the threshold magnitude for the convergence. The objective cost of the corresponding control law is computed by plugging the designed control law, , and the set of distributed estimator gains into (19). The final output of the control-estimation synthesis is given by:
| (28) |
The overall recursive structure of the control-estimation synthesis procedure is summarized in Algorithm 1.
-
a)
Distributed estimator design
It is noted that the algorithm 1 is executed in the offline design phase. Once the distributed control law and the corresponding estimator gains for each agent are designed, each agent is deployed into the distributed online operation using its own prior knowledge. It is worth noting that the majority of the heavy computations occur at the offline design phase. Therefore, when it comes to the online operation, it is not burdensome to the limited on-board resources of each agent. Indeed, the computational complexity of the online operation for the proposed algorithm is scaled by the number of agents, i.e., .
4 Stability Analysis
In this session, the stability analysis of the proposed distributed estimation algorithm in section 3.1 is presented. To begin with, let us consider the control law as static memoryless feedback gain as follows:
| (29) |
where is the block matrix having in the block entry and filled with in other entries. has structural constraints subject to the network topology of MAS specified by the Laplacian . Note that the estimation stability is unrelated to the design of as will be discussed below, and thus readily applicable to memory based feedback control law as in (9). Corresponding to (29), the predicted state estimation errors of the agent can be written as follows:
| (30) |
where
It is noted from the above equation (30) that the estimation error of the individual agent is coupled with the augmented estimation error of the entire MAS, . Then, the following two lemmas are required for proving the stability of the proposed distributed estimation algorithm.
Lemma 1.
Estimation error covariance from the agent, is positive definite and bounded for all if the following system is observable (Kwon and Hwang, 2018):
| (31) |
where is a observer matrix which gathers the measurements from the agent’s perspective, i.e., those that are neighboring agents of the agent. are the nonzero column vectors of the matrix . It is noted that the value of can be decided by the graph of the given network where indicates the availability of measurement of the agent’s state from the agent, i.e., and means .
Proof.
The proof is referred to in the author’s previous work (Kwon and Hwang, 2018).
To analyze the estimation stability of , we first introduce as a affine mapping matrix and as a lumped noise as follows:
| (32) |
It is noted that it is trivial to compute initial affine transformation matrix which satisfies under the Assumptions 1. On the other hand, follows the Gaussian distribution , where with initial value as . Then, we can show that the augmented estimation error can be mapped to the estimation error from the single agent’s perspective by the following lemma.
Lemma 2.
Suppose the system given in (31) is observable and satisfies the Assumption 1. Then, given the agent dynamics and the estimation based control (29) with control law as , there exists a affine mapping between the estimation error of the agent, , and the augmented MAS estimation error, , as follows:
| (33) |
Proof. The proof can be shown by induction. Let the estimation error at time step satisfies (33). To verify that the (33) is satisfied at the next time step with the definitions of and , the dynamics of the estimation error of the agent is considered. By (33), (30) can be stated as follows:
| (34) |
And the updated estimation error is derived as follows:
| (35) |
By concatenating (35) for all agents , the MAS augmented estimation error, , can be formulated as follows:
| (36) |
Without loss of generality, the matrix is invertible as it governs the estimation error dynamics (35) induced by the stochastic linear dynamical system. This completes the proof of Lemma 2.
Based on the derived affine mapping between and , we are ready to present the stability of the proposed estimation algorithm. As our paper considers the stochastic MAS, the estimation error can be regarded as a super martingale of the Lyapunov functions, which satisfies the following conditions:
| (37) |
| (38) |
where .
Theorem 1.
Proof. Let us define the Lyapunov function of the estimation error of the agent as follows:
| (39) |
As is positive definite and bounded by lemma 1, There exists . Therefore, is a quadratic function which satisfies the condition in (37). Besides, using (34), the conditional expectation is given by
Then, by applying equation (35), can be written as follows:
| (40) |
To satisfies the condition in (38), should be a positive definite matrix. By applying Lemma 2, the predicted estimation error covariance of the agent is derived using (34) as:
| (41) |
Correspondingly, the updated estimation error covariance can be computed as follows:
| (42) |
and using the definition of , can be defined as:
| (43) |
By applying the matrix inversion lemma, (42) is rewritten as:
| (44) |
And using (44), multiplying to the left and the right sides of and applying (43) yields:
| (45) |
where . It is trivial to show that matrix . Recalling denoted in (41), can be rewritten by:
| (46) |
By applying (46), can be redefined as:
| (47) |
After going through tedious conversion using the matrix inversion lemma, (47) can be rewritten as follows:
| (48) |
As and in (48), one can verify , which guarantees the Lyapunov function satisfies (37) and (38). This proves that the estimation error is globally asymptotically stable.
5 Numerical Simulation
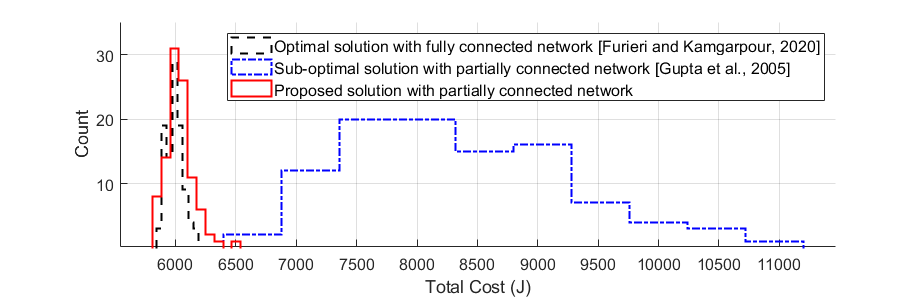
The effectiveness of the proposed algorithm is demonstrated with an illustrative MAS example. The MAS consists of five agents whose dynamics and objective are specified by the following parameter sets: , , , , , and . The MAS network topology is set to be partially connected, the same as the one in (Kwon and Hwang, 2018). To validate the performance of the proposed algorithm, we conduct a comparative analysis with two different scenarios: i) MAS with the fully connected network, which is free from network topological constraint; and ii) MAS with the same (partially connected) network topology where non-neighboring agent information is not available to each agent. For the second case, we test the suboptimal method presented in (Gupta et al., 2005). The simulation results are shown in Figure. 3. By virtue of the virtual interactions between non-neighboring agents, our algorithm outperforms the existing method in the partially connected network, and even matches the fully connected network case despite the network topological constraints.
To further demonstrate the performance of the proposed algorithm, we have performed additional simulations with respect to the different number of "real" interactions. It is worth noting that the network links between agents yield the “real" interaction while those with no explicit links create the virtual interaction. MAS with five agents has been simulated under different network topology shown in the below Figure. 4.
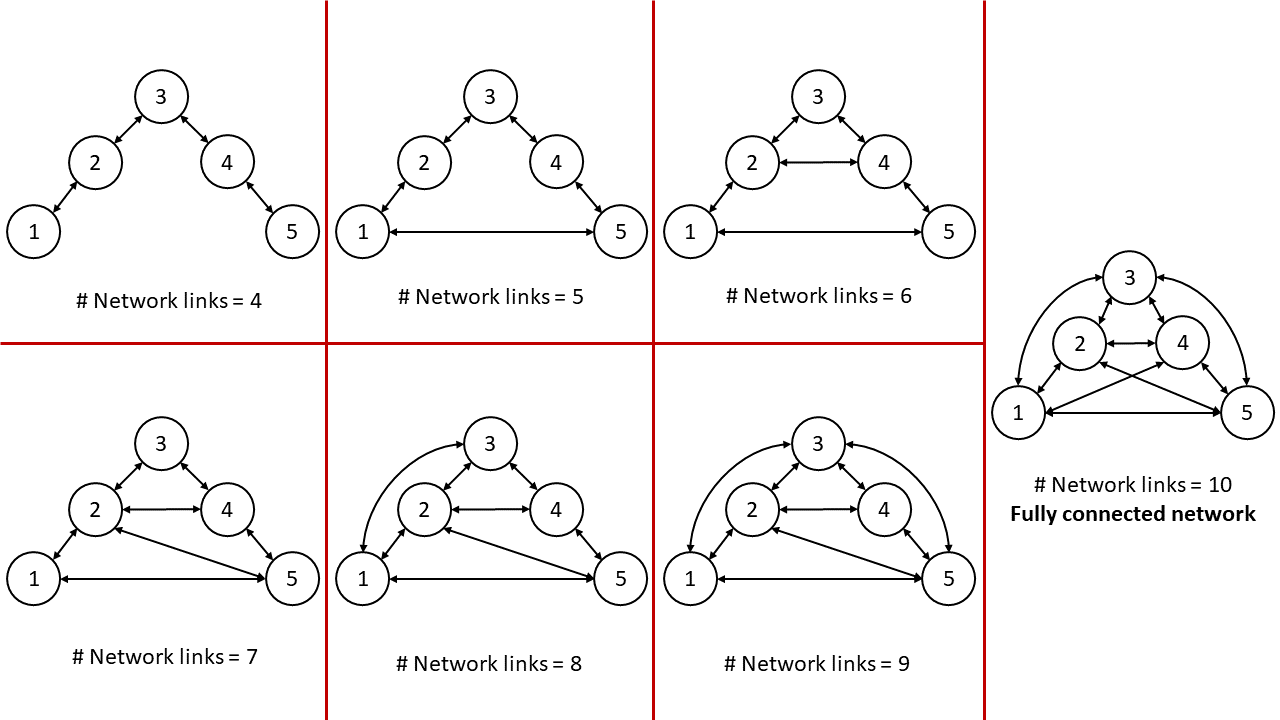
All experiments followed the same setting except the network topology. Apparently, the number of virtual interactions decreases as the number of network links between agents increase whereby we can analyze the effect of ratio between real and virtual interactions. The performance of our proposed method under different network settings is depicted in the below Figure. 5.
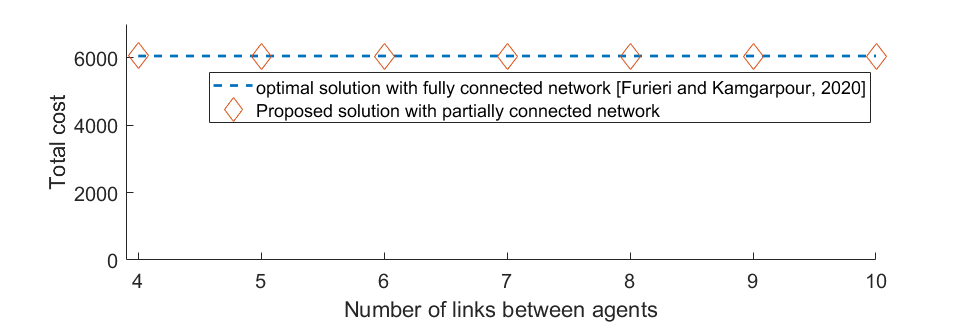
The result shows that the performance of our proposed method does not vary much with respect to the ratio between virtual to real interactions. At the cost of some onboard computational resources to estimate non-neighboring agents, our proposed method provides the clear advantage of having optimal performance with fewer network connections.
6 Conclusions
This paper has proposed a novel design procedure of the optimal distributed control for the linear stochastic MAS, generally subject to network topological constraints. The proposed method gets around the network topological constraint by employing the distributed estimator, whereby each agent can exploit the non-neighboring agent’s information. Future work will include the theoretical performance guarantee of the proposed distributed control-estimation synthesis such as stability analysis, and a further extension to the infinite time horizon case for practical use.
References
- Shi and Yan [2020] Peng Shi and Bing Yan. A survey on intelligent control for multiagent systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020.
- Li et al. [2019] Xianwei Li, Fangzhou Liu, Martin Buss, and Sandra Hirche. Fully distributed consensus control for linear multi-agent systems: A reduced-order adaptive feedback approach. IEEE Transactions on Control of Network Systems, 2019.
- Zhu et al. [2020] Yunru Zhu, Liqi Zhou, Yuanshi Zheng, Jian Liu, and Shiming Chen. Sampled-data based resilient consensus of heterogeneous multiagent systems. International Journal of Robust and Nonlinear Control, 30(17):7370–7381, 2020.
- Morita et al. [2015] Ryosuke Morita, Takayuki Wada, Izumi Masubuchi, Toru Asai, and Yasumasa Fujisaki. Multiagent consensus with noisy communication: stopping rules based on network graphs. IEEE Transactions on Control of Network Systems, 3(4):358–365, 2015.
- Gupta et al. [2005] Vijay Gupta, Babak Hassibi, and Richard M Murray. A sub-optimal algorithm to synthesize control laws for a network of dynamic agents. International Journal of Control, 78(16):1302–1313, 2005.
- Ma et al. [2015] Jingying Ma, Yuanshi Zheng, and Long Wang. Lqr-based optimal topology of leader-following consensus. International Journal of Robust and Nonlinear Control, 25(17):3404–3421, 2015.
- Nguyen [2015] Dinh Hoa Nguyen. A sub-optimal consensus design for multi-agent systems based on hierarchical lqr. Automatica, 55:88–94, 2015.
- Jiao et al. [2019] Junjie Jiao, Harry L Trentelman, and M Kanat Camlibel. A suboptimality approach to distributed linear quadratic optimal control. IEEE Transactions on Automatic Control, 65(3):1218–1225, 2019.
- Kwon and Hwang [2018] Cheolhyeon Kwon and Inseok Hwang. Sensing-based distributed state estimation for cooperative multiagent systems. IEEE Transactions on Automatic Control, 64(6):2368–2382, 2018.
- Furieri and Kamgarpour [2020] Luca Furieri and Maryam Kamgarpour. First order methods for globally optimal distributed controllers beyond quadratic invariance. In 2020 American Control Conference (ACC), pages 4588–4593. IEEE, 2020.
- Lin et al. [2013] Fu Lin, Makan Fardad, and Mihailo R Jovanović. Design of optimal sparse feedback gains via the alternating direction method of multipliers. IEEE Transactions on Automatic Control, 58(9):2426–2431, 2013.
- Lessard and Lall [2011] Laurent Lessard and Sanjay Lall. Quadratic invariance is necessary and sufficient for convexity. In Proceedings of the 2011 American Control Conference, pages 5360–5362. IEEE, 2011.