[1]\fnmSeyyed Shaho \surAlaviani
[1]\orgdivDepartment of Mechanical Engineering, \orgnameUniversity of Minnesota, \orgaddress\cityMinneapolis, \stateMinnesota, \countryUSA
2]\orgdivDean, Thomas J. Watson College of Engineering and Applied Science, \orgnameBinghamton University, \orgaddress\cityBinghamton, \stateNew York, \countryUSA
Distributed Convex Optimization with State-Dependent (Social) Interactions over Random Networks
Abstract
This paper aims at distributed multi-agent convex optimization where the communications network among the agents are presented by a random sequence of possibly state-dependent weighted graphs. This is the first work to consider both random arbitrary communication networks and state-dependent interactions among agents. The state-dependent weighted random operator of the graph is shown to be quasi-nonexpansive; this property neglects a priori distribution assumption of random communication topologies to be imposed on the operator. Therefore, it contains more general class of random networks with or without asynchronous protocols. A more general mathematical optimization problem than that addressed in the literature is presented, namely minimization of a convex function over the fixed-value point set of a quasi-nonexpansive random operator. A discrete-time algorithm is provided that is able to converge both almost surely and in mean square to the global solution of the optimization problem. Hence, as a special case, it reduces to a totally asynchronous algorithm for the distributed optimization problem. The algorithm is able to converge even if the weighted matrix of the graph is periodic and irreducible under synchronous protocol. Finally, a case study on a network of robots in an automated warehouse is given where there is distribution dependency among random communication graphs.
keywords:
46Exx, 49Mxx, 65Kxx1 Introduction
Distributed multi-agent optimization has been an attractive topic due to its applications in several areas such as power systems, smart buildings, and machine learning to name a few; therefore, several investigators have paid much attention to distributed optimization problems (see Surveys [1]-[4]). Switched dynamical systems are divided into two categories: arbitrary (or state-independent) and state-dependent (see [5] and references therein for details and several examples). Many references, cited in Surveys [1]-[4], have investigated distributed optimization over arbitrary networks.
On the other hand, state-dependent networks have been shown in practical systems such as flocking of birds [6], opinion dynamics [7]-[15], mobile robotic networks [16], wireless networks [17], and predator-prey interaction [18]. For example, an agent in social networks weighs the opinions of others based on how much its opinion is close to theirs (see Section I in the preliminary version, i.e., [31], for more details).
In state-dependent networks, coupling between algorithm analysis and information exchange among agents impose significant challenge because states of agents at each time determine the weights in the communication networks. Hence, distributed algorithms’ design for consensus and optimization over state-dependent networks is still a challenge.
Consensus problem for opinion dynamics has been investigated in [7]-[15]. Existence of consensus in a multi-robot network has been shown in [19]. Distributed consensus [21]-[26] and distributed optimization [20], [27]-[29] over state-dependent networks with time-invariant or time-varying111The underlying communication graph is a priori known in a time-varying arbitrary network at each time , whereas it is a priori unknown in a random arbitrary network. arbitrary graphs have been considered. Hence, the gap in the literature is to consider distributed multi-agent optimization problems with both state-dependent interactions and random arbitrary (see footnote 1) networks.
This paper aims at distributed multi-agent convex optimization over both state-dependent and random arbitrary networks, that has not been addressed in the literature. Assuming doubly stochasticity of weighted matrix of the graph with respect to state variables for each communication network and strong connectivity of the union of the communication networks allows this result to be applicable to periodic and irreducible weighted matrix of the graph in synchronous222In a synchronous protocol, all nodes activate at the same time and perform communication updates. On the other hand, in an asynchronous protocol, each node has its concept of time defined by a local timer, which randomly triggers either by the local timer or by a message from neighboring nodes. The algorithms guaranteed to work with no a priori bound on the time for updates are called totally asynchronous, and those that need the knowledge of a priori bound, known as B-connectivity assumption, are called partially asynchronous (see [32] and [33, Ch. 6-7]). protocol. We show that state-dependent weighted random operator of the graph is quasi-nonexpansive333It has been shown in [30] that state-independent weighted random operator of the graph has nonexpansivity property.; therefore, imposing a priori distribution of random communication topologies in not required. Thus, it contains random arbitrary networks with/without asynchronous protocols for more general class of switched networks. As an extension of the the distributed optimization problem, we provide a more general mathematical optimization problem than that defined in [30], namely minimization of a convex function over the fixed-value point set of a quasi-nonexpansive random operator. Consequently, the reduced optimization problem to distributed optimization includes both state-independent and state-dependent networks over random arbitrary communication graphs with/without asynchronous protocol (see footnote 3). We prove that the discrete-time algorithm proposed in [30] is utilized for quasi-nonexpansive random operators (which include nonexpansive random operators as a special case). The algorithm converges both almost surely and in mean square to the global optimal solution of the optimization problem under suitable assumptions. For the distributed optimization problem, the algorithm reduces to a totally asynchronous algorithm (see footnote 2). It should be noted that the distributed algorithm444We require to clarify that the distributed algorithm in this paper is the randomized version of the algorithm presented in [29]. In [29], the convergence under deterministic arbitrary switching (see footnote 1) is provided, while we prove here its stochastic convergence (both almost sure and mean square) under random arbitrary switching. Furthermore, quasi-nonexpansivity property of the state-dependent weighted operator of the graph (defined in [29]) has not been shown in [29], whereas we show it here. is totally asynchronous but not asynchronous due to synchronized diminishing step size. The algorithm is able to converge even if the weighted matrix of the graph is periodic and irreducible under synchronous protocol. We provide a numerical example where there is distribution dependency among random arbitrary switching graphs and apply the distributed algorithm to validate the results, while no existing references can conclude results (see Example 1). This version provides proofs, mean square convergence of the proposed algorithm, a numerical example, and larger range of a parameter (i.e., ) in the algorithm, that have not been presented in the preliminary version (i.e., [31]).
This paper is organized as follows. In Section 2, preliminaries on convex analysis and stochastic convergence are given. In Section 3, formulations of the distributed optimization problem and the mathematical optimization are provided. Algorithm and its convergence analysis are presented in Section 4. Finally, a numerical example is given in order to show advantages of the results in Section 5, followed by conclusions and future work in Section 6.
Notations: denotes the set of all real numbers. For any vector and for any matrix where represents the transpose of matrix , represents maximum eigenvalue, and represents largest singular value. Sorted in an increasing order with respect to real parts, represents the second eigenvalue of a matrix . represents the real part of the complex number . For any matrix with , and . represents Identity matrix of size for some where denotes the set of all natural numbers. denotes the gradient of the function . denotes the Kronecker product. represents Cartesian product. denotes Expectation of the random variable .
2 Preliminaries
A vector is said to be a stochastic vector when its components , are non-negative and their sum is equal to 1; a square matrix is said to be a stochastic matrix when each row of is a stochastic vector. A square matrix is said to be doubly stochastic matrix when both and are stochastic matrices.
Let be a real Hilbert space with norm and inner product . An operator is said to be monotone if for all . is -strongly monotone if for all . A differentiable function is -strongly convex if for all . Therefore, a function is -strongly convex if its gradient is -strongly monotone. A convex differentiable function is -strongly smooth if
A mapping is said to be -Lipschitz continuous if there exists a such that for all . Let be a nonempty subset of a Hilbert space and . The point is called a fixed point of if . And, denotes the set of all fixed points of .
Let and denote elements in the sets and , respectively, where . Let be a measurable space (-sigma algebra) and be a nonempty subset of a Hilbert space . A mapping is measurable if for each open subset of . The mapping is a random map if for each fixed , the mapping is measurable, and it is continuous if for each the mapping is continuous.
Definition 1.
A measurable mapping is a random fixed point of the random map if for each .
Definition 2.
[30] If there exists a point such that for all , it is called fixed-value point, and represents the set of all fixed-value points of .
Definition 3.
Let be a nonempty subset of a Hilbert space and be a random map. The map is said to be
1) nonexpansive random operator if for each and for arbitrary we have
| (1) |
2) quasi-nonexpansive random operator if for any we have
where is a random fixed point of (see Definition 1).
Note that if holds in (1), the operator is called (Banach) contraction.
Remark 1.
If a nonexpansive random operator has a random fixed point, then it is a quasi-nonexpansive random operator. From Definitions 2 and 3, if a quasi-nonexpansive random operator has a fixed-value point, say , then we have for any that
| (2) |
Proposition 1.
[34, Th. 1] If is a closed convex subset of a Hilbert space and is quasi-nonexpansive, then is a nonempty closed convex set.
Definition 4.
A sequence of random variables is said to converge
1) pointwise (surely) to if for every ,
2) almost surely to if there exists a subset such that , and for every ,
3) in mean square to if
Lemma 1. [35, Ch. 5] Let . Then
Lemma 2. [36] Let be a sequence of nonnegative real numbers satisfying where , and . Then .
Lemma 3. Let the sequence in a real Hilbert space be bounded for each realization and converge almost surely to . Then the sequence converges in mean square to .
Proof: See the proof of Theorem 2 in [30].
The Cucker-Smale weight [6], which depends on distance between two agents and , is of the form
| (3) |
where and .
3 Problem Formulation
In social networks, an agent weighs the opinions of others based on how close its opinion (or state) and theirs are, that motivates consideration of state-dependent networks. Vehicular platoon can be modeled as both position-dependent (or state-dependent by considering the position as state) and random arbitrary networks, that is a practical example for motivation of this work. Therefore, there are two combined networks: 1) a network induced by states’ weights, and 2) the underlying random arbitrary network (see Section III in the preliminary version, i.e., [31], for details). The combined state-dependent & random arbitrary network is formulated as follows.
A network of nodes labeled by the set is considered. The topology of the interconnections among nodes is not fixed but defined by a set of graphs where is the ordered edge set and where is the set of all possible communication graphs, i.e., . We assume that is a measurable space where is the -algebra on . We write for the labels of agent ’s in/out neighbors at graph so that there is an arc in from vertex to vertex only if agent receives/sends information from/to agent . We write when . It is assumed that there are no communication delay or communication noise in the network.
It should be noted that in our formulation, the in and out neighbors of each agent at each graph are fixed, and we will consider that the weights of links are possibly state-dependent. For instance, an agent pays attention arbitrarily at each time to its friends while it weighs the difference between its opinion and others for decision (see [29, Sec. III] for more details).
We associate for each node a convex cost function which is only observed by node . The objective of each agent is to find a solution of the following optimization problem:
where . Since each node knows only its own , the nodes cannot individually calculate the optimal solution and, therefore, must collaborate to do so.
The above problem can be formulated based on local variables of the agents as
| (4) | ||||||
| subject to |
where , and the constraint set is reached through state-dependent interactions and random (arbitrary) communication graphs. The set
| (5) |
is known as consensus subspace which is a convex set. Note that the Hilbert space considered in this paper for the distributed optimization problem is
We show and for the state-dependent weighted matrix of the fixed graph in a switching network having all possible communication topologies in the set . For instance, if nodes are not activated at some time for communication updates in asynchronous protocol, and/or there are no edges in occuring graph at the time , then .
Now we impose Assumptions 1 and 2 below on .
Assumption 1. For each fixed , the weights are continuous, and the state-dependent weighted matrix of the graph is doubly stochastic for all , i.e.,
i)
ii)
Assumption 1 allows us to remove the couple of information exchange with the analysis of our proposed algorithm and to consider random graphs together. The state-dependent weight between any two agents and in Assumption 1 is general and may be a function of distance or other forms of interactions. Note that any network with undirected links and continuous weights satisfies Assumption 1 since the weighted matrix of the graph is symmetric (and thus doubly stochastic).
Assumption 2. The union of the graphs in is strongly connected for all , i.e.,
| (6) |
Assumption 2 guarantees that the information sent from each node is eventually received by every other node. The set defined in (5) (which is the constraint set of (4)) can be obtained from the set
| (7) |
(see [29, Appendices A and B] by setting for the proof). This allows us to reformulate (4) as
| (8) | ||||||
| subject to |
Thus, a solution of (4) can be attained by solving (8) with Assumptions 1 and 2.
The random operator is called state-dependent weighted random operator of the graph (see [30, Def. 8], [29, Def. 4]). From Definition 2 and (7), we have with Assumptions 1 and 2.
Now we show that the random operator with Assumption 1 is quasi-nonexpansive in the Hilbert space . Let . Since and is a stochastic matrix (see Assumption 1) for all , we have . Therefore, we obtain
Since is doubly stochastic by Assumption 1, we have from Lemma 1 (where ) that Hence,
| (9) |
which implies that the random operator is quasi-nonexpansive (see Remark 1).
Problem (8) is a special case of the general class of problem presented in Problem 1 below where . It is to be noted that Problem 3 in [30] is defined for nonexpansive random operator, while we define Problem 1 below for quasi-nonexpansive random operator which contains nonexpansive random operator as a special case (see Remark 1).
Problem 1: Let be a real Hilbert space. Assume that the problem is feasible, namely . Given a convex function and a quasi-nonexpansive random mapping , the problem is to find such that is a fixed-value point of , i.e., we have the following minimization problem
| (10) | ||||||
| subject to |
where is the set of fixed-value points of the random operator (see Definition 2).
Remark 2.
A fixed-value point of a quasi-nonexpansive random mapping is a common fixed point of a family of quasi-nonexpansive non-random mappings for each . From Preposition 1, the fixed point set of a quasi-nonexpansive non-random mapping for each is a convex set. It is well-known that the intersection of convex sets (finite, countable, or uncountable) is convex. Thus, is a convex set, and Problem 1 is a convex optimization problem.
4 Algorithm and Its Convergence
Here, we present that the proposed algorithm in [30] (which works for nonexpansive random operators) is applicable for solving Problem 1 with quasi-nonexpansive random operators. Thus, we propose the following algorithm for solving Problem 1:
| (11) |
where and is a realization of the set at time . The challenge of extending the result in [30] is to use weaker property (2) which is valid for all and , instead of stronger property (1) which is valid for all .
Let be a measurable space where and are defined in Section 3. Consider a probability measure defined on the space where
and is a sigma algebra on such that forms a probability space. We denote a realization in this probability space by . We have the following assumptions.
Assumption 3. is continuously differentiable, -strongly convex, and is -Lipschitz continuous.
Assumption 4. There exists a nonempty subset such that , and each element of occurs infinitely often almost surely.
Assumption 4 is weaker than existing assumptions for random networks as explained in details in Remark 3 below.
Remark 3.
[30] If the sequence is mutually independent with where is the probability of (a particular element) occurring at time , then Assumption 4 is satisfied. Moreover, any ergodic stationary sequences satisfy Assumption 4. Consequently, any time-invariant Markov chain with its unique stationary distribution as the initial distribution satisfies Assumption 4.
4.1 Almost Sure Convergence
Before we give our theorems, we need to extend Lemma 5 in [30] (which is for nonexpansive random operators) to quasi-nonexpansive random operators. Hence, we have the following lemma.
Lemma 4. Let be a real Hilbert space, with a quasi-nonexpansive random operator , , and . Then
(i)
(ii)
(iii) is quasi-nonexpasnive.
Proof. See Appendix A.
We present the main theorem in this paper as follows.
Theorem 2.
Consider Problem 1 with Assumptions 3 and 4. Let and such that
(a)
(b)
Then starting from any initial point, the sequence generated by (11) globally converges almost surely to the unique solution of the problem.
Note that the range of in Theorem 1 in [31] (i.e., the preliminary version of this paper) is which is enlarged to in Theorem 1 above. This is due to the fact that according to definitions of strong convexity and strong smoothness of a differentiable convex function (see also parts (5)-(6) in [43, p. 38]), we always have . Hence, . An advantageous of this enlargement is to have more choice to select the parameter An example of satisfying (a) and (b) in Theorem 1 is where .
Remark 4.
Proof of Theorem 1. We prove Theorem 1 in three steps, i.e.
Step 1: is bounded (see Lemma 5 in Appendix B).
Step 2: converges almost surely to a random variable supported by the feasible set (see Lemma 6 in Appendix C).
Step 3: converges almost surely to the optimal solution (see Lemma 7 in Appendix D).
4.2 Mean Square Convergence
Due to the fact that almost sure convergence in general does not imply mean square convergence and vice versa, we show the mean square convergence of the random sequence generated by Algorithm (11) in the following theorem.
Theorem 3.
Consider Problem 1 with Assumptions 3 and 4. Suppose that and , satisfies (a) and (b) in Theorem 1. Then starting from any initial point, the sequence generated by (11) globally converges in mean square to the unique solution of the problem.
Proof. From Step 1, Theorem 1, and Lemma 3, one can prove Theorem 2.
4.3 Distributed Optimization
Distributed optimization problem with state-dependent interactions over random arbitrary networks is a special case of Problem 1 (see Section 3). Hence, Algorithm (11) is directly applied to solve (8) in a distributed manner under the consideration that each is -strongly convex and is -Lipschitz. Thus, we give the following corollary of Theorems 1 and 2.
Corollary 1. Consider the optimization (8) with Assumptions 1, 2, and 4. Assume that each is -strongly convex and is -Lipschitz for . Suppose that and satisfies (a) and (b) in Theorem 1. Then starting from any initial point, the sequence generated by the following distributed algorithm based on local information for each agent
| (12) |
globally converges both almost surely and in mean square to the unique solution of the problem.
Algorithm (4.3) is totally asynchronous algorithm (see footnote 2) without requiring a priori distribution or B-connectivity (see footnote 2) of switched graphs. B-connectivity assumption satisfies Assumption 4. The algorithm is not asynchronous due to synchronized diminishing step size . The algorithm still works in the case where state-dependent/state-independent weighted matrix of the graph is periodic and irreducible in synchronous protocol. Detailed properties of Algorithm (4.3) for time-varying (see footnote 1) networks has been studied in [29] and can be induced for random networks (see also footnote 4).
Remark 5.
The convergence rate of a totally asynchronous algorithm in general cannot be established. Determining rate of convergence of (4.3) based on suitable assumptions is left for future work. An asynchronous and totally asynchronous algorithm for distributed optimization over random networks with state-independent interactions has recently been proposed in [37]. As a special case of distributed optimization over state-independent networks, asynchronous and total asynchronous algorithms have been given for average consensus and solving linear algebraic equations in [38] and [39], respectively (see [37, Sec. I] for details).
5 Numerical Example
We give a practical example of distributed optimization with state-dependent interactions of Cucker-Smale form [6] with random (arbitrary) communication links where there are distribution dependencies among random arbitrary switched graphs. We mention that the following example has been solved over time-varying (see footnote 1) networks in [29], while we solve it here over random arbitrary networks, where there are distribution dependency among switched communication graphs, to show the capability of Algorithm (4.3).
Example 1. (Distributed Optimization over Random Arbitrary Networks for an Automated Warehouse): Consider robots on the shop floor in a warehouse. Assigning tasks to robotic agents is modeled as optimization problems in an automated warehouse [40], that are solved by a centralized processor and are neither scalable nor can handle autonomous entities [40]. Moreover, due to large number of robots, the robots must handle tasks in collaborative manner [40] due to computational restriction of a centralized processor. If we assume that the communications among robots are carried out via a wireless network, then the signal power at a receiver is inversely proportional to some power of the distance between transmitter and receiver [41]. Therefore, if we consider the position as the state for each robot, then the weights of the links between robots are state-dependent.
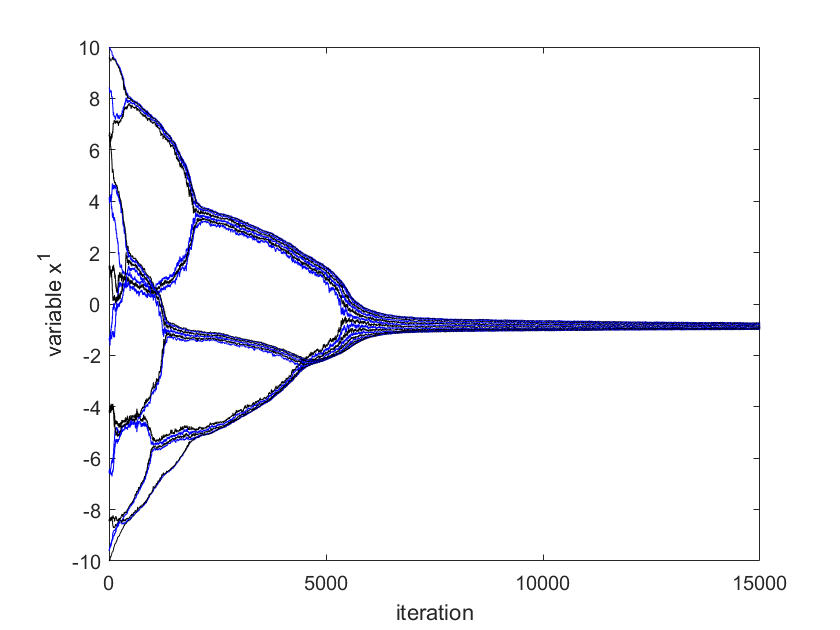
Assume that robots bring some loads from different initial places to a place for delivery. The desired place to put the loads is determined to minimize the pre-defined cost as sum of squared distances to the initial places of the robots as
| (13) |
where is the decision variable, and is the position of the initial place of the load on the two-dimensional shop floor. The above problem is reformulated as the following problem based on the local variables of the agents:
| subject to |
where , and the constraint set is reached via distance-dependent network with random communication graphs.
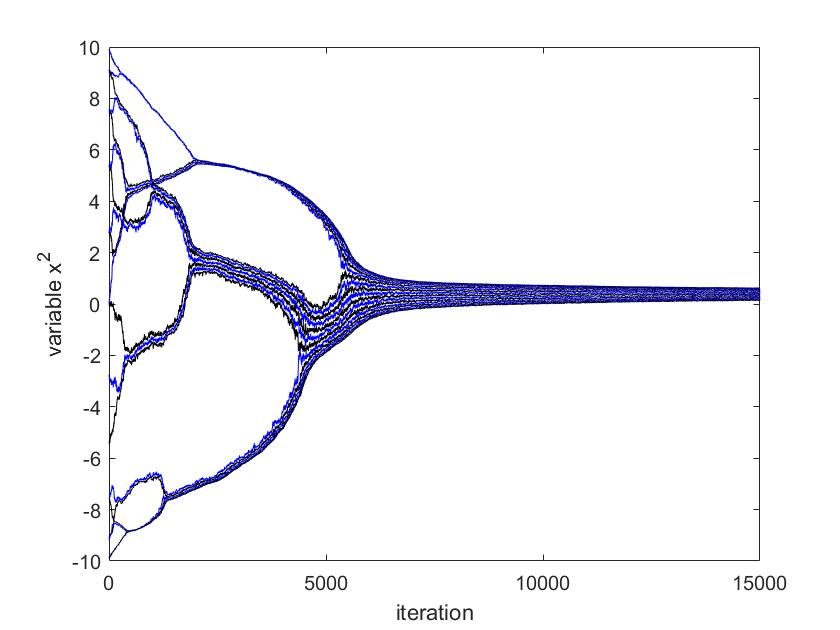
The topology of the underlying undirected graph is assumed to be a line graph, i.e., , for minimal connectivity among robots. Based on weighing property of wireless communication network mentioned eralier, the weight of the link between robots and is modeled to be of Cucker-Smale form (see Section 2)
| (14) |
One can see that the weight of each link at each time is only determined by the states of the agents, and hence no local property is assumed or determined a priori for all in Algorithm (4.3) (see [29] for details). It is easy to check that are 1-strongly convex, and are -Lipschitz continuous.
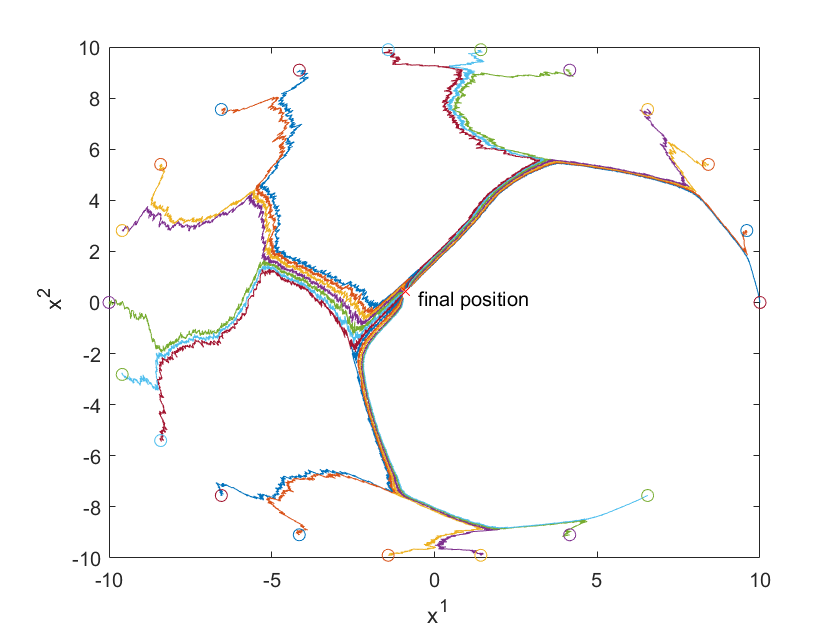
We consider that each link has independent and identically distributed (i.i.d.) Bernoulli distribution with in every -interval, and at the iteration the link that has worked the minimum number of the times in the previous -interval occurs. If some links have the same number of occurrences in the previous -interval, then one is chosen randomly. Here, we have the graphs . Thus the sequence is not independent. It has been shown in [30] that the each graph occurs infinitely often almost surely. Moreover, the union of the graphs is strongly connected for all . Therefore, Assumption 4 is fulfilled. Thus the conditions of Theorems 1 and 2 are satisfied.
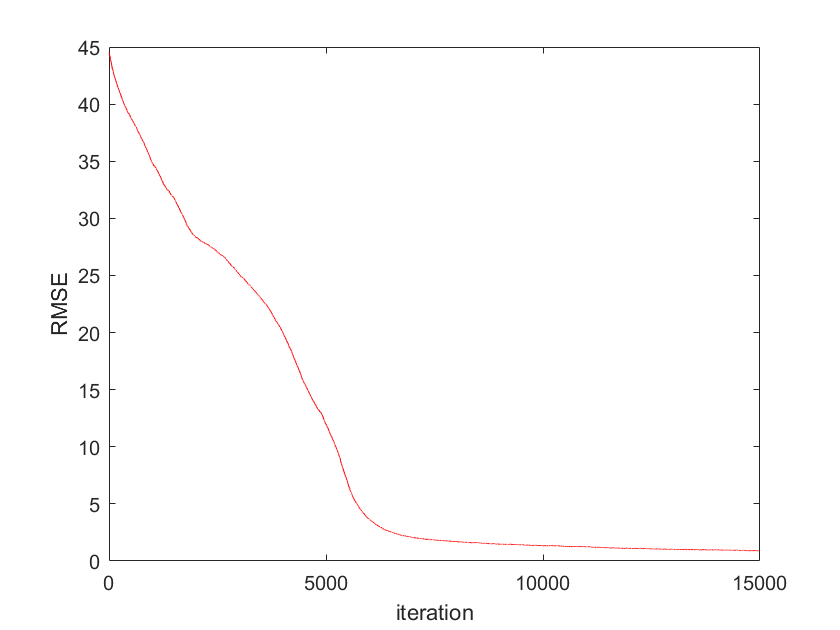
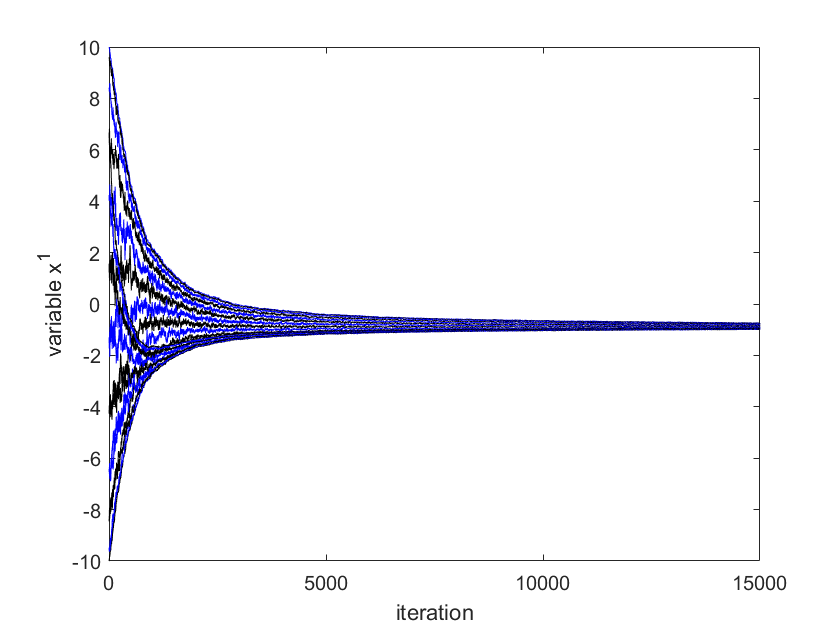
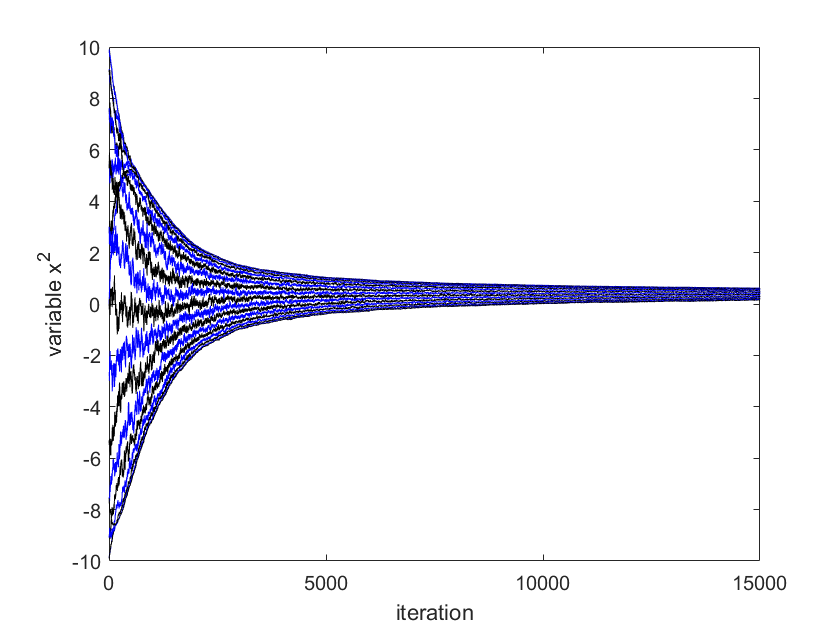
We use for simulation. The initial position of agent is chosen to be . The optimal solution of (13) in centralized way can be computed as mean of and is . The results given by Algorithm (4.3) are shown in Figure 1-4. The error , where is given in Fig. 4. The two-dimensional (2D) plot is shown in Figure 3. Figures 1-4 show that the positions of robotic agents are approaching the solution of the optimization (13) for one realization of random network with distribution dependency. Note that no existing result can solve this problem since the weights of links are both position-dependent and randomly arbitrarily activated.
We also simulate the above example with different weights than Cucker-Smale form, i.e.,
6 Conclusions and Future Work
Distributed optimization with both state-dependent interactions and random (arbitrary) networks is considered. It is shown that the state-dependent weighted random operator of the graph is quasi-nonexpansive; thus, it is not required to impose a priori distribution of random communication topologies on switching graphs. A more general optimization problem than that addressed in the literature is provided. A gradient-based discrete-time algorithm using diminishing step size is provided that is able to converge both almost surely and in mean square to the global solution of the optimization problem under suitable assumptions. Moreover, it reduces to a totally asynchronous algorithm for the distributed optimization problem. Relaxing strong convexity assumption of cost functions and/or doubly stochasticity assumption of communication graphs opens problems for future research.
Appendix A
Proof of Lemma 4.
(i) The proof is the same as the proof of part (i) of Lemma 5 in [30].
(ii) We have from quasi-nonexpansivity of for arbitrary that
| (16) |
In a Hilbert space , we have
| (17) |
From (17), we obtain for all and for all that
| (18) |
Substituting (18) for (16) yields
| (19) |
From the definition of (see (11)), substituting for the left hand side of the inequality (19) implies (ii). Thus the proof of part (ii) of Lemma 4 is complete.
(iii) We have from quasi-nonexpansivity of for and arbitrary that
Therefore, is a quasi-nonexpansive random operator, and the proof of part (iii) of Lemma 4 is complete.
Appendix B
Lemma 5. The sequence generated by (11) is bounded with Assumption 3.
Proof. Since the cost function is smooth and strongly convex and the constraint set is nonempty and closed, the problem has a unique solution. Let be the unique solution of the problem. We can write . Therefore, we have
Since is the solution, we have that (see part (i) of Lemma 4). Due to the fact that is a quasi-nonexpansive random operator (see part (iii) of Lemma 4), the above can be written as
| (20) |
Since is -Lipschitz, is -strongly smooth (see [42, Lem. 3.4]). When is -strongly convex and -strongly smooth, the operator where is a contraction (see [43, p. 15] for details). Indeed, there exists a such that
| (21) |
We have that
| (22) |
Therefore, (21) and (22) imply
| (23) |
Substituting (23) for (20) yields
which by induction implies that
that implies , is bounded. Therefore, is bounded for all .
Appendix C
Lemma 6. The sequence generated by (11) converges almost surely to a random variable supported by the feasible set.
Proof. From (11) and , we have
| (24) |
and thus
| (25) |
Due to , we have from part (ii) of Lemma 4 that
| (26) |
We get from (25) and (26) that
| (27) |
or
| (28) |
In a Hilbert space we have for any that
| (29) |
We obtain from (29) that
| (30) |
where . We get from (28) and (30) that
| (31) |
| (32) |
We know that . Since , we have also that . Using these facts and multiplying both sides of (32) by yield
| (33) |
We obtain from (31) and (33) that
| (34) |
We claim that there exists such that the sequence is non-increasing for . We use proof by contradiction and assume that this is not true. Then there exists a subsequence such that which with (34) implies
| (35) |
Since is bounded, is continuous, and , we get from (35) and Theorem 1 (a) that
| (36) |
that is a contradiction. Hence, there exists such that the sequence is non-increasing for . Since is bounded below, it converges for all .
Now we take the limit of both sides of (34) and utilize the convergence of , continuity of , Step 1, , and Theorem 1 (a) to obtain
which implies that converges for each since . Moreover, this together with Assumption 4 implies that converges almost surely to a random variable supported by .
Appendix D
Lemma 7. The sequence generated by (11) converges almost surely to the optimal solution.
Proof. Here we prove that converges almost surely to the optimal solution. Since is the optimal solution, we have
| (37) |
From (17), we have that
| (38) |
We have that ; We get from this fact and (11) that
| (39) |
Furthermore, we have
| (40) |
Substituting (39) and (40) for (38) implies
From (21), quasi-nonexpansivity property of , and Cauchy–Schwarz inequality, we have
| (41) |
We get from (21) that
| (42) |
We obtain from (41), (42), and quasi-nonexpansivity property of that
We obtain from that
or finally
| (43) |
From Step 1, Step 2, (37), and the condition in Theorem 1 (a), we get
| (44) |
Setting in Lemma 2 as
we get from (43), (44), and the condition in Theorem 1 (b) that
Therefore, converges almost surely to .
References
- [1] Jakovetić, D., Bajović, D., Xavier, J., and Moura, J. M. F.: Primal-dual methods for large-scale and distributed convex optimization and data analysis. Proceedings of The IEEE. 108, 1923–1938 (2020)
- [2] Yang, T., Yi, X., Wu, J., Yuan, Y., Wu, D., Meng, Z., Hong, Y., Wang, H., Lin, Z., and Johansson, K. H.: A survey of distributed optimization. Annual Reviews in Control. 47, 278–305 (2019)
- [3] Mazlum, D. K., Dörfler, F., Sandberg, H., Low, S. H., Chakrabarti, S., Baldick, R., and Lavaei, J.: A survey of distributed optimization and control algorithms for electric power systems. IEEE Trans. on Smart Grid. 8, 2941–2962 (2017)
- [4] Nedić, A.: Distributed optimization. Encyclopedia of Systems and Control. 1–12 (2014)
- [5] Liberzon, D.: Switching in Systems and Control. Springer, New York (2003)
- [6] Cucker, F., and Smale, S.: Emergent behavior in flocks. IEEE Trans. Automatic Control. 52, 852–862 (2007)
- [7] Krause, U.: A discrete nonlinear and non-autonomous model of consensus formation. Communications in Difference Equations. Gordon and Breach, Amsterdam. 227–236 (2000)
- [8] Totsch, S., and Tadmor, E.: Heterophilious dynamics enhances consensus. SIAM Review. 56, 577-621 (2014)
- [9] Acemoglu, D., Ozdaglar, A., and Parandehgheibi, A.: Spread of (mis)information in social networks. Games and Economic Behavior. 70, 194–227 (2010)
- [10] Acemoglu, D., and Ozdaglar, A.: Opinion dynamics and learning in social networks. Dynamic Games and Applications. 1, 3–49 (2011)
- [11] Acemoglu, D., Como, G., Fagnani, F., and Ozdaglar, A.: Opinion fluctuations and disagreement in social networks. Mathematics of Operations Research. 38, 1–27 (2013)
- [12] Acemoglu, D., Bimpikis, K., and Ozdaglar, A.: Dynamics of information exchange in endogenous social networks. Theoretical Economics. 9, 41–97 (2014)
- [13] Heyselmann, R., and Krause, U.: Opinion dynamics and bounded confidence moels, analysis, and simulation. J. Artificial Societies and Social Simulation. 5, 1–33 (2002)
- [14] Blondel, V. D., Hendrickx, J. M., and Tsitsiklis, J. N.: On Krause’s multi-agent consensus model with state-dependent connectivity. IEEE Trans. on Autom. Contr. 54, 2586–2597 (2009)
- [15] Acemoglu, D., Ozdaglar, A., and Yildiz, E.: Diffusion of innovations in social networks. Proc. of 50th IEEE Conf. on Dec. Cont. and Europ. Cont. Conf., Dec. 12-15, Orlando, FL, USA. 2329–2334 (2011)
- [16] Simonetto, A., Kevicsky, T., and Babuška, R.: Constrained distributed algebraic connectivity maximization in robotic networks. Automatica. 49, 1348–1357 (2013)
- [17] Kim, Y., and Mesbahi, M.: On maximizing the second smallest eigenvalue of a state-dependent graph laplacian. IEEE Trans. on Autom. Contr. 51, 116–120 (2006)
- [18] Siljak, D. D.: Dynamic graphs. Nonlin. Analysis: Hybrid Syst. 2, 544–567 (2008)
- [19] Trianni, V., Simone, D. D., Reina, A., and Baronchelli, A.: Emergence of consensus in a multi-robot network: from abstract models to empirical validation. IEEE Robotics and Automation Letters. 1, 348–353 (2016)
- [20] Lobel, I., Ozdaglar, A., and Feiger, D.: Distributed multi-agent optimization with state-dependent communication. Math. Program. Ser. B. 129, 255–284 (2011)
- [21] Jing, G., Zheng, Y., and Wang, L.: Consensus of multiagent systems with distance-dependent communication networks. IEEE Trans. on Neural Networks and Learning Systems. 28, 2712–2726 (2017)
- [22] Jing, G., and Wang, L.: Finite time coordination under state-dependent communication graphs with inherent links. IEEE Trans. on Circuits and Systems-II: Express Briefs. 66, 968–972 (2019)
- [23] Shang, Y.: Constrained consensus in state-dependent directed multiagent networks. IEEE Trans. on Network Science and Engineering. 9, 4416–4425 (2022)
- [24] Sluc̆iak, O., and Rupp, M.: Consensus algorithm with state-dependent weights. IEEE Trans. Signal Processing. 64, 1972–1985 (2016)
- [25] Bogojeska, A., Mirchev, M., Mishkovski, I., and Kocarev, L.: Synchronization and consensus in state-dependent networks. IEEE Trans. on Circuits and Systems-I: Regular Papers. 61, 522–529 (2014)
- [26] Awad, A., Chapman, A., Schoof, E., Narang-Siddarth, A., and Mesbahi, M.: Time-scale separation on networks: consensus, tracking, and state-dependent interactions. IEEE 54th Annual Conf. on Decision and Control, Dec. 15-18, Osaka, Japan. 6172–6177 (2015)
- [27] Shi, G., Johansson, K. H., and Hong, Y.: Reaching an optimal consensus: dynamical systems that compute intersections of convex sets. IEEE Trans. Automatic Control. 58, 610–622 (2013)
- [28] Verma, A., Vasconcelos, M., Mitra, U., and Touri, B.: Maximal dissent: a state-dependent way to agree in distributed convex optimization. IEEE Trans. on Control of Network Systems. 10, 1783–1795 (2023)
- [29] Alaviani, S. Sh., and Elia, N.: Distributed convex optimization with state-dependent (social) interactions and time-varying topologies. IEEE Trans. Signal Processing. 69, 2611-2624 (2021)
- [30] Alaviani, S. Sh., and Elia, N.: Distributed multiagent convex optimization over random digraphs. IEEE Trans. Automatic Control. 65, 986–998 (2020)
- [31] Alaviani, S. Sh., and Kelkar, A. G.: Distributed convex optimization with state-dependent interactions over random networks. Proc. of IEEE Conf. on Decision and Control, Dec. 13-17, Austin, Texas, USA. 3149–3153 (2021)
- [32] Tsitsiklis, J. N.: Problems in decentralized decision making and computation. Ph.D. dissertation. Dep. Elect. Eng. Comp. Sci., MIT, Cambridge, MA (1984)
- [33] Bertsekas, D. P., and Tsitsiklis, J. N.: Parallel and Distributed Computation: Numerical Methods. Prentice Hall, Englewood Cliffs (1989)
- [34] Dotson, W. G.: Fixed points of quasi-nonexpansive mappings. J. Austral. Math. Soc. 13, 167–170 (1972)
- [35] Horn, R. A., and Johnson, C. R.: Matrix Analysis. Cambridge University Press, New York (1985)
- [36] Xu, H. K.: Iterative algorithms for nonlinear operators. J. London Math. Soc. 66, 240-256 (2002)
- [37] Alaviani, S. Sh., and Kelkar, A. G.: Asynchronous Algorithms for Distributed Consensus-Based Optimization and Distributed Resource Allocation over Random Networks. Proc. of Amer. Cont. Conf., June 8-10, Atlanta, GA, USA. 216–221 (2022)
- [38] Alaviani, S. Sh., and Elia, N.: Distributed average consensus over random networks. Proc. of Amer. Cont. Conf., July 10-12, Philadelphia, PA, USA,. 1854–1859 (2019)
- [39] Alaviani, S. Sh., and Elia, N.: A distributed algorithm for solving linear algebraic equations over random networks. IEEE Trans. on Automatic Control. 66, 2399–2406 (2021)
- [40] Kattepur, A., Rath, H. K., Mukherjee, A., and Simha, A.: Distributed optimization framework for Industry 4.0 automated warehouses. EAI Endorsed Transactions on Industrial Networks and Intelligent Systems. 5, 1–10 (2018)
- [41] Pahlavan, K., and Levesque, H.: Wireless Information Networks. Wiley, New York (1995)
- [42] Bubeck, S.: Convex optimization: algorithms and complexity. Foundations and Trends in Machine Learning. 8, 231–357 (2015)
- [43] Ryu, E. K., and Boyd, S.: A primer on monotone operator methods. Appl. Comput. Math. 15, 3–43 (2016)