Distributed Quantum Faithful Simulation and Function Computation Using Algebraic Structured Measurements
Abstract
In this work, we consider the task of faithfully simulating a quantum measurement, acting on a joint bipartite quantum state, in a distributed manner. In the distributed setup, the constituent sub-systems of the joint quantum state are measured by two agents, Alice and Bob. A third agent, Charlie receives the measurement outcomes sent by Alice and Bob. Charlie uses local and pairwise shared randomness to compute a bivariate function of the measurement outcomes. The objective of three agents is to faithfully simulate the given distributed quantum measurement acting on the given quantum state while minimizing the communication and shared randomness rates. We demonstrate a new achievable quantum information-theoretic rate-region that exploits the bivariate function using random structured POVMs based on asymptotically good algebraic codes. The algebraic structure of these codes is matched to that of the bivariate function that models the action of Charlie. The conventional approach for this class of problems has been to reconstruct individual measurement outcomes corresponding to Alice and Bob, at Charlie, and then compute the bivariate function. This is achieved using mutually independent approximating POVMs based on random unstructured codes. In the present approach, using algebraic structured POVMs, the computation is performed on the fly, thus obviating the need to reconstruct individual measurement outcomes at Charlie. Using this, we show that a strictly larger rate region can be achieved. The performance limit is characterized using single-letter quantum mutual information quantities. We provide examples to illustrate the information-theoretic gains attained by endowing POVMs with algebraic structure. One of the challenges in analyzing these structured POVMs is that they exhibit only pairwise independence and induce only uniform single-letter distributions. To address this, we use nesting of algebraic codes and develop a covering lemma applicable to pairwise-independent POVM ensembles. Combining these techniques, we provide a multi-party distributed faithful simulation and function computation protocol.
I Introduction
Measurement compression is one of the foremost and fundamental quantum information processing techniques which form the basis of many quantum protocols [1]. One of the seminal works in this regard was by Winter [2], where he performed a novel information theoretic analysis to compress measurements in an asymptotic sense. The measurement compression problem formulated in [2] is as follows. Consider an agent (Alice) who performs a measurement on a quantum state , and sends a set of classical bits to another agent (Bob). Bob intends to faithfully recover the outcomes of Alice’s measurements without having access to , while preserving the correlation with the post-measured state of Alice’s reference. The major contribution of this work (as elaborated in [3]) was in specifying an optimal rate region in terms of classical communication and common randomness needed to faithfully simulate the action of repeated independent measurements performed on many independent copies of the given quantum state.
Wilde et al. [3] extended the measurement compression problem by considering additional resources available to each of the participating parties. One such formulation allows Bob to process the information received from Alice using local private randomness. The authors here also combined the ideas from [2] and [4] to simulate a measurement in presence of quantum side information. In the above problem formulations, authors have derived the results using the prevalent random coding techniques analogous to Shannon’s unstructured random codes [5] involving mutually independent codewords. The point-to-point setup [2, 3] requires randomly generating approximating POVMs and analyzing the error associated with these approximating POVMs, also termed as “covering error”. The key analytical tool that facilitates this is the operator Chernoff bound [6], which crucially exploits the mutual independence of codewords, yielding the quantum covering lemma [7, Lemma 17.2.1].
The measurement compression problem has been studied extensively. Early works on quantifying the information gain of a measurement include [8, 9, 10]. Buscemi et al. [11, 12, 13] later advocated quantum mutual information with respect to a classical-quantum state as the measure to characterize the corresponding information gain. Berta et al. [14] generalized the Winter’s measurement compression theorem by developing a universal measurement compression theorem for arbitrary inputs, and identified the quantum mutual information of a measurement as the information gained by performing the measurement, independent of the input state on which it is performed. They provide a proof based on new “classically coherent state merging protocol” - a variation of the quantum state merging protocol [15, 16], and the post-selection technique for quantum channels [17].
Anshu et al. [18] considered the problem of measurement compression with side information in the one-shot setting. They presented a protocol by proposing a new convex-split lemma for classical-quantum states and employing the position based decoding, and bounded the communication in terms of smooth max and hypothesis testing relative entropies. The original convex-split lemma [19, 20] demanded sub-optimal shared-randomness rate in the one-shot setting, by requiring large amount of additional quantum states in its statement. The authors addressed this by modifying the lemma to only use pairwise independent random variables. This substantially simplified the derandomization required, leading to an exponential reduction in the randomness cost in comparison to [19]. Considering a related problem, Renes and Renner [21] also studied sending of classical messages in the presence of quantum side information in the one-shot setting. For more discussion and results pertaining to one-shot quantum information theory, the reader is directed to [22, 23].
Furthermore, the authors in [24] considered the task of quantifying “relevant information” for the quantum measurements performed in a distributed fashion on bipartite entangled states involving three agents. In this multi-terminal setting, a composite bipartite quantum system is made available to two agents, Alice and Bob, where they have access to the sub-systems and , respectively. Two separate measurements, one for each sub-system, are performed in a distributed fashion with no communication taking place between Alice and Bob. A third party, Charlie, is connected to Alice and Bob via two separate classical links. The objective of the three parties is to simulate the action of repeated independent measurements performed on many independent copies of the given composite state. Further, common randomness at rate is also shared amidst the three parties. This is achieved using random unstructured code ensembles while still using the operator Chernoff bound.
The measurement compression theorem has found its applications in several quantum information processing protocols. Examples include the quantum reverse Shannon theorem [25, 26, 27], local purity distillation protocols [28, 29, 30, 31], and also in the grandmother protocol [1] which is useful in entanglement distillation from noisy quantum states.
An ubiquitous application of distributed systems in current quantum settings arises due to the inherent vulnerability of the large-scale quantum computation systems to noise. The state-of-art systems exhibits technical difficulties in increasing the number of low-noise qubits in a single quantum device. A solution to this is cooperative processing of information separately on spatially segregated units. This necessitates the need for distributed compression protocols to compress efficiently and recover the data. In addition, when one is interested in solely reconstructing functions of the distributively stored quantum data, the rate of communication may be further reduced by employing structured coding techniques. For this, we need to impose further structure on these POVMs. This is to ensure that the joint decoder (Charlie) is able to reconstruct a lower dimensional quantum state with minimal use of the classical communication resource. Hence, structure of the POVM is desired to match with the structure of the function being computed.
The traditional random coding techniques using unstructured code ensembles may not always achieve optimality for distributed multi-terminal settings. For instance, the work by Korner-Marton [32] demonstrated this sub-optimality for the problem of classical distributed lossless compression with the objective of computing the sum of the sources for the binary symmetric case using random linear codes. Traditionally, algebraic-structured codes are used in information coding problems toward achieving computationally efficient (polynomial-time) encoding and decoding algorithms. However, in multi-terminal communication problems, even if computational complexity is a non-issue, random algebraic structured codes outperform random unstructured codes in terms of achieving improved asymptotic rate regions in many cases [33, 34, 35, 36].
Motivated by this, we consider the quantum distributed faithful measurement simulation problem and present a new achievable rate-region using algebraic structured coding techniques. However, there are two main challenges in using these algebraic structured codes toward an asymptotic analysis in quantum information theory. The first challenge is to be able to induce arbitrary empirical single-letter distributions. For example, if we were to send codewords from a linear code with uniform probability, then the induced empirical distribution of codeword symbols (single-letter distribution on the symbols of the codewords) is uniform. To address this challenge, we use a collection of cosets of a linear code called Unionized Coset Codes (UCCs) [37]. The second challenge is that unlike the random unstructured codes, the codewords generated from a random linear code are only pairwise-independent [38]. This renders the above technique of operator Chernoff bound, or even the covering lemma, unusable. Since our approach relies on the use of UCCs for generating the approximating POVMs, the binning of these POVM elements is performed in a correlated fashion as governed by these structured codes. This is in contrast to the common technique of independent binning. Due to the correlated binning, the pairwise-independence issue gets exacerbated.
We address these challenges using three main ideas summarized as follows:
-
•
Random structured generation of pruned POVMs - We generate a collection of algebraic structured approximating POVMs randomly using the above described UCC technique, and then prune them. This pruning ensures that these POVMs form a positive resolution of identity, and thus eliminates any need for the operator Chernoff inequality. However, such pruning comes at the cost of additional approximating error. To bound the approximating error caused by pruning the POVMs, we develop a new Operator Inequality which provides a handle to convert the pruning error in the form of covering error expression (dealt within the next idea).
-
•
Covering Lemma for Pairwise-Independent Ensemble - Since the traditional covering lemma is based on the Chernoff inequality, we develop an alternative proof for the aforementioned covering lemma [39, Lemma 17.2.1]. This alternative proof is based on the second-order analysis using the operator trace inequalities and hence requires the operators to be only pairwise-independent.
-
•
Multi-partite Packing Lemma - We develop a binning technique for performing computation on the fly so as to achieve a low dimensional reconstruction of a function at the location of Charlie. In an effort towards analysing this binning technique, we develop a multi-partite packing Lemma for the structured POVMs.
Combining these techniques, we provide a multi-party distributed faithful simulation and function computation protocol in a quantum information theoretic setting. We provide a characterization of the asymptotic performance limit of this protocol in terms of a computable single-letter achievable rate-region, which is the main result of the paper (see Theorem 1).
The organization of the paper is as follows. In Section II, we set the notation, state requisite definitions and also provide related results. In Section III.1 we state our main result on the distributed measurement compression and provide the theorem (Theorem 1) characterizing the rate-region. In Section III.2 we provide a new Covering Lemma for pairwise-independent ensembles. Section IV provides useful lemmas. In Section V, we consider the point-to-point setup and provide a theorem characterizing the rate-region using algebraic structured codes. We prove the main result (Theorem 1) in Section VI using the point-to-point result as a building block. Finally, we conclude the paper in Section VII.
II Preliminaries
Notation: Given any natural number , let the finite set be denoted by . Let denote the algebra of all bounded linear operators acting on a finite dimensional Hilbert space . Further, let denote the set of all unit trace positive operators acting on . Let denote the identity operator. The trace distance between two operators and is defined as , where for any operator we define . The von Neumann entropy of a density operator is denoted by . The quantum mutual information for a bipartite density operator is defined as
A positive-operator valued measure (POVM) acting on a Hilbert space is a collection of positive operators in that form a resolution of the identity:
where is a finite set. If instead of the equality above, the inequality holds, then the collection is said to be a sub-POVM. A sub-POVM can be completed to form a POVM, denoted by , by adding the operator to the collection. Let denote a purification of a density operator . Given a POVM acting on , the post-measurement state of the reference together with the classical outputs is represented by
| (1) |
Consider two POVMs and acting on and , respectively. Define With this definition, is a POVM acting on . By denote the -fold tensor product of the POVM with itself. For a prime , we denote the unique finite field of size by , and denote the addition operation over the field by .
Definition 1 (Faithful simulation [3]).
Given a POVM acting on a Hilbert space and a density operator , a sub-POVM acting on is said to be -faithful to with respect to , for , if the following holds:
| (2) |
Lemma 1.
Given a density operator , a sub-POVM acting on for some set , and any Hermitian operator acting on , we have
| (3) |
with equality if , where .
Proof.
The proof is provided in Lemma 3 of [24]. ∎
III Main Results
In this section we present the main results of this paper.
III.1 Simulation of Distributed POVMs using Algebraic-Structured POVMs
Let be a density operator acting on a composite Hilbert Space . Consider two measurements and on sub-systems and , respectively. Imagine again that we have three parties, named Alice, Bob and Charlie, that are trying to collectively simulate the action of a given measurement performed on the state , as shown in Fig. 1. Charlie additionally has access to unlimited private randomness. The problem is defined in the following.
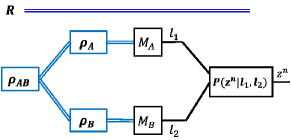
Definition 2.
For a given finite set , and a Hilbert space , a distributed protocol with stochastic processing with parameters
is characterized by
1) a collections of Alice’s sub-POVMs each acting on and with outcomes in a subset satisfying .
2) a collections of Bob’s sub-POVMs each acting on and with outcomes in a subset , satisfying .
3) a collection of Charlie’s classical stochastic maps for all , and .
The overall sub-POVM of this distributed protocol, given by , is characterized by the following operators:
where and are the operators corresponding to the sub-POVMs and , respectively.
In the above definition, determines the amount of classical bits communicated from Alice and Bob to Charlie. The amount of pairwise shared randomness is determined by and . The classical stochastic maps represent the action of Charlie on the received classical bits.
Definition 3.
Given a POVM acting on , and a density operator , a quadruple is said to be achievable, if for all and for all sufficiently large , there exists a distributed protocol with stochastic processing with parameters such that its overall sub-POVM is -faithful to with respect to (see Definition 1), and
The set of all achievable quadruples is called the achievable rate region.
Definition 4 (Joint Measurements).
A POVM , acting on a Hilbert space , is said to have a separable decomposition with stochastic integration given by if there exist POVMs and and a stochastic mapping such that
| (4) |
where , and are finite sets.
The following theorem provides an inner bound to the achievable rate region, which is proved in Section VI. This is one of the main results of this paper.
Theorem 1.
Consider a density operator , and a POVM acting on having a separable decomposition with stochastic integration (as in Definition 4), yielding POVMs and and a stochastic map . Define the auxiliary states
for some orthonormal sets , and , where is a purification of . A quadruple is achievable if there exists a finite field , for a prime , a pair of mappings and , and a stochastic mapping such that
yielding , , and , and the following inequalities are satisfied:
| (5a) | |||
| (5b) | |||
| (5c) | |||
| (5d) | |||
| (5e) | |||
Proof.
A proof is provided in Section VI. ∎
Remark 1.
Note that the rate-region obtained in Theorem 6 of [24] using unstructured random code ensembles, contains the constraint . Hence when
the above theorem gives a lower sum rate constraint. As a result, the rate-region above contains points that are not contained within the rate-region provided in [24]. To illustrate this fact further, consider the following example.
Remark 2.
In the above theorem, we restrict our attention to prime finite fields for ease of exposition. The results can be generalized to arbitrary finite fields in a straight-forward manner.
Example 1.
Suppose the composite state is described using one of the Bell states on as
Since and , Alice and Bob would perceive each of their particles in maximally mixed states and , respectively. Upon receiving the quantum state, the two parties wish to independently measure their states, using identical POVMs and , given by , where , and
Alice and Bob together with Charlie are trying to simulate the action of , using the classical communication and common randomness as the resources available to them, where , and
| (6) |
for and , with . Note that the above POVM admits a separable decomposition as defined in the statement of Theorem 1 with respect to the prime finite field , with and , and
Hence the above theorem can be employed. This gives
where is as defined in the statement of Theorem 1. Since the constraints on , , and are the same as obtained in Theorem 6 of [24]. However, with , the constraint on in the above theorem (5e) is strictly weaker than the constraint obtained using random unstructured codes in Theorem 6 of [24]. Therefore, the rate-region obtained above using random structured codes in Theorem 1 is strictly larger than the rate-region in Theorem 6 of [24].
Example 2.
For the same state as in the above example, consider the following identical POVMs and , where , and
Let the joint measurement that Alice and Bob are trying to simulate be given by
| (7) |
for where is a conditional PMF on with and . Note that depends on the variables only through , the logical OR function. Now, we define the random variables and on the prime finite field with the identity mappings and , while noting that and take values in with . Now with , we identify the mapping as
| (8) |
For this identification, we obtain , which gives the constraint on in the above theorem (5e) strictly weaker than the corresponding constraint obtained using random unstructured codes in Theorem 6 of [24]. Since this is a biting constraint, the above rate-region is strictly larger than the former for this example.
Example 3.
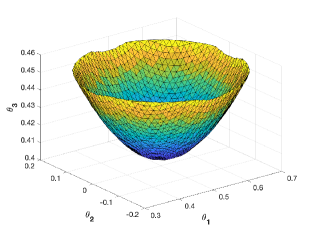
Building upon Example 2, we explore more points in the POVM space such that the above theorem provides constraints (5e) that are strictly weaker than the corresponding constraint obtained in Theorem 6 of [24]. For this, we consider the same state as above and the following identical POVMs and , where , and
for 111The above parametrization is only for illustrative purposes and do not constitute all the two dimensional POVMs.. Figure 2 illustrates the surface where and therefore the region inside the surface has , where the POVMs obtained provides the constraint on in the above theorem (5e) strictly weaker than the corresponding constraint obtained in Theorem 6 of [24].
Remark 3.
Note that for POVMs contained in the above -surface of Example 2, the sum rate constraint is strictly weaker than the corresponding constraint in [24, Theorem 6], and vice-versa outside. One can employ a strategy based on superposition and successive encoding that combines the two coding techniques to yield a unified rate-region.
III.2 Covering Lemma with Change of Measure for Pairwise-Independent Ensemble
The proof of the theorem is based on a construction of algebraic-structured POVM ensemble where the elements are only pairwise independent and not mutually independent. To analyze these POVMs we retreat back to first principles and develop a new one-shot Covering Lemma based on a change of measure technique and a second order analysis. This lemma, which can be of independent interest, is one of the main contributions of this work.
Lemma 2 (Covering Lemma).
Let be an ensemble, with for all , being a finite set, and . Further, suppose we are given a total subspace projector and a collection of codeword subspace projectors which satisfy the following hypotheses
| (9a) | ||||
| (9b) | ||||
| (9c) | ||||
| (9d) | ||||
| (9e) | ||||
for some and . Let be a finite non-negative integer. Additionally, assume that there exists some set containing , with (null operator) and for . Suppose be any distribution on the set such that the distribution is is absolutely continuous with respect to the distribution . Further, assume that for all Let a random covering code be defined as a collection of codewords that are chosen pairwise independently according to the distribution . Then we have
| (10) |
where . Futhermore, for defined as , we have
| (11) |
Proof.
The proof is provided in Appendix A.1 ∎
IV Useful Lemmas
In this section we present a few lemmas which will be used extensively in the sequel.
Definition 5 (Pruning Operators).
Consider an operator acting on Hilbert space We say that a projector prunes with respect to Identity on if is a projector on to the non-negative eigenspace of .
IV.1 Pruning Trace Inequality
Lemma 3.
Consider a random operator acting on a Hilbert space Let be a pruning operator for with respect to , as in Definition 5. Then we have
Proof.
The proof follows by noting that . ∎
Remark 4.
To demonstrate the significance of this inequality, we compare it with the popular Operator Markov Inequality [39]. We know from Operator Markov inequality
One can observe that . Taking expectation, we obtain
Moreover, one can also note that , and expectation gives
Hence we conclude that the new inequality is indeed tighter than the operator Markov inequality.
Lemma 4.
(Pruning Trace Inequality) Consider the above random operator acting on a Hilbert space Further, suppose for . Let be a pruning operator for with respect to , as in Definition 5. Then, we have
Proof.
The proof is provided in Appendix A.2 ∎
V Point-to-point Measurement Compression using Structured Random POVMs
Before presenting the proof of Theorem 1, as a pedagogical first step, we consider the measurement compression problem in the point-to-point setup. This problem was addressed in [2], where the performance limits were derived using unstructured random POVM ensembles. Here, we redrive the performance limit using random algebraic structured POVM ensembles. Since the algebraic structured codes can only induce a uniform distribution, we consider a collection of cosets of a random linear code for this task. The problem setup is described as follows. An agent (Alice) performs a measurement on a quantum state , and sends a set of classical bits to a receiver (Bob). Bob has access to additional private randomness, and he is allowed to use this additional resource to perform any stochastic mapping of the received classical bits. The overall effect on the quantum state can be assumed to be a measurement which is a concatenation of the POVM Alice performs and the stochastic map Bob implements. This problem serves as a building block toward the proof of Theorem 1. Formally, the problem is stated as follows.
V.1 Problem Formulation and Main Result
Definition 6.
For a given finite set , and a Hilbert space , a measurement simulation protocol with parameters
is characterized by
1) a collection of codes , for
, such that , and , a finite set, is called the code alphabet,
2) a collection of Alice’s sub-POVMs each acting on and with outcomes in .
3) a collection of Bob’s classical stochastic maps for all , and .
The overall sub-POVM of this protocol, given by , is characterized by the following operators:
| (12) |
where is the set of operators corresponding to the sub-POVM . Let denote the th codeword of .
In the above definition, characterizes the amount of classical bits communicated from Alice to Bob, and the amount of common randomness is determined by , with being the common randomness bits distributed among the parties. The classical stochastic mappings induced by represents the action of Bob on the received classical bits. In building the code, we use the Unionized Coset Code (UCC) [37] defined below. These codes involve two layers of codes (i) a coarse code and (ii) a fine code. The coarse code is a coset of the linear code and the fine code is the union of several cosets of the linear code.
For a fixed matrix with , and being a prime number, and a vector , define the coset code as
| (13) |
In other words, is a shift of the row space of the matrix . The row space of is a linear code. If the rank of is , then there are codewords in the coset code.
Definition 7.
An UCC is characterized by a pair consisting of a matrix , and a mapping , and the code is the following union: , where is defined in (13).
Definition 8.
Given a finite set , and a Hilbert space , an UCC-based measurement simulation protocol is a pair of measurement simulation protocol and a collection of UCCs with parameters characterized by such that (i) the code alphabet of the protocol (with suitable relabeling), (ii) , , and (iii) for all , we have .
Definition 9.
The UCC grand ensemble is the ensemble of UCCs where , and are chosen randomly, independently and uniformly, where the latter is chosen from the set of all mappings with replacement.
Definition 10.
Given a POVM acting on , and a density operator , a tuple is said to be achievable using the grand UCC ensemble, if for all and for all sufficiently large , there exists an ensemble of UCC-based measurement simulation protocols with parameters (based on the UCC grand ensemble) such that their overall sub-POVM is -faithful to with respect to in the expected sense:
where the expectation is with respect to the ensemble, and
Define as is achievable using the UCC grand ensemble}.
Remark 5.
The appearance of the modulus in the second constraint needs justification. Note that is the rate of transmission of information from Alice to Bob and is the rate of the common information shared between them. So if is achievable, then it is clear that any is also achievable if and . However is a parameter of the UCC grand ensemble, and there is no natural order on , i.e., it does not naturally follows that is achievable for all .
The following theorem characterizes the achievable rate region which characterizes the asymptotic performance of the UCC grand ensemble.
Theorem 2.
For any density operator and any POVM acting on the Hilbert space , a tuple is achievable using the UCC grand ensemble, i.e., if there exist a POVM , with , and a stochastic map such that
and
| (14) | ||||
| (15) | ||||
| (16) | ||||
| (17) |
where for some orthogonal sets and
Remark 6.
By choosing , we recover the rate region of Wilde et. al [3, Theorem 9].
V.2 Proof of Theorem 2 Using UCC Code Ensemble
As stated earlier, the main objective of proving this theorem is to build a framework for the main theorem of the paper (Theorem 1). In doing so, we observe that the structured POVMs constructed below are only pairwise independent. Since the results in [24] are based on the assumption that approximating POVMs are all mutually independent, the proof below becomes significantly different from [24].
Suppose there exist a POVM and a stochastic map , such that can be decomposed as
| (18) |
We generate the canonical ensemble corresponding to as
| (19) |
Let denote a -typical set associated with the probability distribution induced by corresponding to a random variable . Let denote the -typical projector (as in [7, Def. 15.1.3]) corresponding to the density operator , and denote the strong conditional typical projector (as in [7, Def. 15.2.4]) corresponding to the canonical ensemble . For each , define
| (20) |
and for , with .
V.2.1 Construction of Structured POVMs
We now construct random structured POVM elements. Fix a block length , a positive integer and a finite field with . Without loss of generality, we assume . Furthermore, we assume for all . From now on, we assume that takes values in with this distribution. Let denote the common randomness shared between the encoder and decoder. In building the code, we use the UCCs [37] as defined in Definition 7 .
For every , consider a UCC with parameters . For each , the generator matrix along with the function generates codewords. Each of these codewords are characterized by a triple , where and correspond to the coarse code and the coset indices, respectively. Let denote the codewords associated with the encoder (Alice), generated using the above procedure, where
| (21) |
Now, construct the operators
| (22) |
with being a parameter to be determined. Note that, following the definition of , we have for Having constructed the operators , we normalize these operators, so that they constitute a valid sub-POVM. To do so, we define
Now, we define as the pruning operator for with respect to using Definition 5. Note that, the pruning operator depends on the pair . For ease of analysis, the subspace of is restricted to and hence is a projector onto a subspace of . Using these pruning operators, for each , construct the sub-POVM as
| (23) |
where . Further, using we have and thus is a valid sub-POVM for all . Moreover, the collection is completed using the operators .
V.2.2 Binning of POVMs
The next step is to bin the above constructed sub-POVMs. Since, UCC is a union of several cosets, we associate a bin to each coset, and hence place all the codewords of a coset in the same bin. For each , let denote the th bin. Further, for all , we define
Using these operators, we form the following collection:
Note that if the collection is a sub-POVM for each , then so is the collection , which is due to the relation To complete , we define as 222Note that .. Now, we intend to use the completions as the POVM for the encoder.
V.2.3 Decoder mapping
We create a decoder which, on receiving the classical bits from the encoder, generates a sequence as follows. The decoder first creates a set and a function defined as
| (24) |
where is an arbitrary sequence in . Further, for . Given this and the stochastic processing , we obtain the approximating sub-POVM with the following operators.
The generator matrix and the function are chosen randomly uniformly and independently.
V.2.4 Trace Distance
In what follows, we show that is -faithful to with respect to (according to Definition 1), where can be made arbitrarily small. More precisely, using (18), we show that, where
| (25) |
where the expectation is with respect to the codebook generation.
Step 1: Isolating the effect of error induced by not covering
Consider the second term within , which can be written as
where
Hence, we have where
| (26) |
and . Note that captures the error induced by not covering the state We further bound as
where
To provide a bound for the term , we (i) develop a n-letter version of Lemma 2 and (ii) provide a proposition bounding the term corresponding to , using this n-letter lemma.
Lemma 5.
Let be an ensemble, with for all , for some finite prime . Then, for any , and for any sufficiently small, and any sufficiently large, we have
| (27) |
if , where and , , for some orthogonal set and are as defined in (21), with and generated randomly uniformly and independently.
Proof.
The proof of the lemma is provided in Appendix A.3 ∎
Now we provide the following proposition.
Proposition 1.
For any , any sufficiently small, and any sufficiently large, we have we have , if where is the auxiliary state defined in the theorem.
Proof.
The proof is provided in Appendix B.1. ∎
Now we provide a bound for For that, we first develop another n-letter lemma as follows.
Lemma 6.
For and as defined above, we have
where
| (28) |
and as .
Proof.
The proof is provided in Appendix A.4 ∎
Using the above lemma on gives
Let us first consider . By observing , we bound as
Note that
Now, we use the Pruning Trace Inequality developed in Lemma 4 on , with to obtain
| (29) |
where the second inequality follows from Hólders inequality, and the equality follows by defining as
| (30) |
Similarly, using , can be simplified as
| (31) |
Now we consider and convert it into a similar expression as .
| (32) |
Using the above simplification and the concavity of square-root function we obtain:
The following proposition provides a bound on the above term.
Proposition 2.
For any , any sufficiently small, and any sufficiently large, we have , if , where is the auxiliary state defined in the theorem.
Proof.
The proof is provided in Appendix B.2 ∎
Remark 7.
The term corresponding to the operators that complete the sub-POVMs , i.e., is taken care in . The expression excludes these completing operators.
Step 2: Isolating the effect of error induced by binning
For this, we simplify as
We substitute the above expression into defined in (26), and isolate the effect of binning by adding and subtracting an appropriate term within and applying triangle inequality to obtain where
where is as defined in (24). Note that the term characterizes the error introduced by approximation of the original POVM with the collection of approximating sub-POVM , and the term characterizes the error caused by binning this approximating sub-POVM. In this step, we analyze and prove the following proposition.
Proposition 3.
For any , any sufficiently small, and any sufficiently large, we have , if , where is the auxiliary state defined in the statement of the theorem.
Proof.
The proof is provided in Appendix B.3 ∎
Step 3: Isolating the effect of approximating measurement
In this step, we finally analyze the error induced from employing the approximating measurement, given by the term . We add and subtract appropriate terms
within and use triangle inequality to obtain , where
Now with the intention of employing Lemma 5, we express as
where the equality above is obtained by defining and using the definitions of and , followed by using the triangle inequality for the block diagonal operators, Note that the triangle inequality becomes an equality for such block diagonal operators. By identifying with in Lemma 5 we obtain the following: for all and sufficiently small, and any sufficiently large, , if , where is the auxiliary state defined in the theorem.
Now we consider the term corresponding to , and prove that its expectation is small. Recalling , we get
where the inequality above is obtained by using triangle inequality. Applying the expectation, we get
where we have used the fact that , and the last inequality is obtained by the repeated usage of the Average Gentle Measurement Lemma [7] and setting with as and and for (see (35) in [3] for details). Now, we move on to bounding the last term within , i.e., We start by applying triangle inequality to obtain
| (33) |
Since the above term is exactly same as we obtain the same rate constraints as in to bound i.e., for all and sufficiently small, and any sufficiently large, if .
Since , can be made arbitrarily small for sufficiently large n, if and .
V.2.5 Rate Constraints
To sum-up, we showed holds for sufficiently large if the following bounds hold:
| (34a) | ||||
| (34b) | ||||
| (34c) | ||||
| (34d) | ||||
where and , and . Therefore, there exists a distributed protocol with parameters such that its overall POVM is -faithful to with respect to . This completes the proof of the theorem.
VI Proof of Theorem 1
Suppose there exists a finite field , for a prime , a pair of mappings and , and a stochastic mapping such that
yielding , and . This implies that we have POVMs and with and a stochastic map , such that can be decomposed as
| (35) |
where is defined as . The coding strategy used here is based on Unionized Coset Codes, similar to the one employed in the point-to-point proof (Section V.2), but extended to a distributed setting. Further, the structure in these codes provide a method to exploit the structure present in the stochastic processing applied by Charlie on the classical bits received, i.e., . Using this technique, we aim to strictly reduce the rate constraints compared to the ones obtained in Theorem 6 of [24]. Also note that, the results in [24] are based on the assumption that approximating POVMs are all mutually independent. However, since the structured construction of the POVMs only guarantees pairwise independence among the operators of the POVM, the proofs below become significantly different from [24].
We start by generating the canonical ensembles corresponding to and , defined as
| (36) |
With this notation, corresponding to each of the probability distributions, we can associate a -typical set. Let us denote , and as the -typical sets defined for , and , respectively.
Let and denote the -typical projectors (as in [7, Def. 15.1.3]) for marginal density operators and , respectively. Also, for any and , let and denote the strong conditional typical projectors (as in [7, Def. 15.2.4]) for the canonical ensembles and , respectively.
For each and define
and and for and , respectively, with and .
VI.1 Construction of Structured POVMs
In what follows, we construct the random structured POVM elements. Fix a block length , positive integers and , and a finite field . Let denote the common randomness shared between the first encoder and the decoder, and let denote the common randomness shared between the second encoder and the decoder. Let and denote additional pairwise shared randomness used for random coding purposes. This randomness is only used to show the existence of a desired distributed protocol (as defined in Definition 2), and is used only for bounding purposes. We denote , and for . Further, let and be random variables defined on the alphabets and , respectively, where . In building the code, we use the Unionized Coset Codes (UCCs) [37] as defined above in Definition 7.
For every , consider two UCCs and , each with parameters and , respectively. Note that, for every they share the same generator matrix
For each , the generator matrix along with the function and generates and codewords, respectively. Each of these codewords are characterized by a triple , where and corresponds to the coarse code and the fine code indices, respectively, for . Let and denote the codewords associated with Alice and Bob, generated using the above procedure, respectively, where
Now, construct the operators
| (37) |
where
| (38) |
with being a parameter to be determined. Having constructed the operators and , we normalize these operators, so that they constitute a valid sub-POVM. To do so, we first define
where and are defined as
Now, we define and as pruning operators for and with respect to and , respectively (see Definition 5). Note that, these pruning operators, and , depend on the triple . Using these pruning operators, for each and , construct the sub-POVMs and as
| (39) |
where and . Further, using these operators and we have and and thus and are valid sub-POVMs for all and Further, these collections and are completed using the operators and .
VI.2 Binning of POVMs
We next proceed to binning the above constructed collection of sub-POVMs. Since, UCC is already a union of several cosets, we associate a bin to each coset, and hence place all the codewords of a coset in the same bin. For each and , let and denote the and the bins, respectively. Formally, we define the following operators:
for all and . Using these operators, we form the following collection:
| (40) |
Note that if and are sub-POVMs, then so are and , which is due to the relations
| (41) |
To make and complete, we define and as and , respectively333Note that and .. Now, we intend to use the completions and as the POVMs for encoders associated with Alice and Bob, respectively. Also, note that the effect of the binning is in reducing the communication rates from to , where . Now, we move on to describing the decoder.
VI.3 Decoder mapping
We create a decoder that takes as an input a pair of bin numbers and produces a sequence . More precisely, we define a mapping , acting on the outputs of as follows. On observing and the classical indices communicated by the encoder, the decoder constructs and as,
| (42) |
where and is an arbitrary sequence in . Further, for or . Given this, we obtain the sub-POVM with the following operators.
Now, we use the stochastic mapping to define the approximating sub-POVM as
Note that for
UCC Grand Ensemble: The generator matrix and the functions and are chosen randomly uniformly and independently, for and
VI.4 Trace Distance
In what follows, we show that is -faithful to with respect to (according to Definition 1), where can be made arbitrarily small. More precisely, using (35), we show that, where
| (43) |
and the expectation is with respect to the codebook generation.
Step 1: Isolating the effect of error induced by not covering
Consider the second term within , which can be written as
where
Hence, we have
| (44) |
where
| (45) |
and . Note that captures the error induced by not covering the state
Remark 8.
The terms corresponding to the operators that complete the sub-POVMs and , i.e., and are taken care in . The expression excludes these completing operators.
Step 2: Isolating the effect of error induced by binning
We begin by simplifying as
Note that the that appear in the above summation is confined to , however for ease of notation, we do not make this explicit. We substitute the above expression into as in (45), and add and subtract an appropriate term within and apply the triangle inequality to isolate the effect of binning as where
Note that the term characterizes the error introduced by approximation of the original POVM with the collection of approximating sub-POVMs and , and the term characterizes the error caused by binning of these approximating sub-POVMs. In this step, we analyze and prove the following proposition.
Proposition 4 (Mutual Packing).
For any , any sufficiently small, and any sufficiently large, we have , if , , , , , where and are the auxiliary states as defined in the statement of the theorem.
Proof.
The proof is provided in Appendix B.4 ∎
Since averaged over , the quantity can be made arbitrarily small, there must exist a pair such that is small for this pair of . For the rest of the proof, we fix to be this pair. The dependence of functions defined in the sequel on this pair is not made explicit for ease of notation. For the term corresponding to , we prove the following result.
Proposition 5.
For any , any sufficiently small, and any sufficiently large, we have , if and where and are auxiliary states defined in the statement of the theorem.
Proof.
The proof is provided in Appendix B.5. ∎
Step 3: Isolating the effect of Alice’s approximating measurement
In this step, we separately analyze the effect of approximating measurements at the two distributed parties in the term . For that, we split as , where
| (46) |
With this partition, the terms within the trace norm of differ only in the action of Alice’s measurement. And similarly, the terms within the norm of differ only in the action of Bob’s measurement. Showing that these two terms are small forms a major portion of the achievability proof.
Analysis of : To prove is small, we characterize the rate constraints which ensure that an upper bound to can be made to vanish in an expected sense. In addition, this upper bound becomes lucrative in obtaining a single-letter characterization for the rate needed to make the term corresponding to vanish. For this, we define as
| (47) |
By defining and using triangle inequality for block operators (which holds with equality), we add the sub-system to , resulting in the joint system , corresponding to the state as defined in the theorem. Then we approximate the joint system using an approximating sub-POVM producing outputs on the alphabet . To make small for sufficiently large n, we expect the sum of the rate of the approximating sub-POVM and common randomness, i.e., , to be larger than . We prove this in the following.
Note that from the triangle inequality, we have Further, we add and subtract appropriate terms within , and again use the triangle inequality to obtain , where
Now we use the following proposition to bound the term corresponding to .
Proposition 6.
For any , any sufficiently small, and any sufficiently large, we have if , where is the auxiliary state defined in the statement of the theorem.
Proof.
The proof of proposition is provided in Appendix B.6. ∎
Now we move on to bounding the term corresponding to We start by applying triangle inequality followed by Lemma 1 on to obtain
| (48) |
Now we use the following proposition to bound the term corresponding to
Proposition 7.
For any , any sufficiently small, and any sufficiently large, we have if , where and are the auxiliary states defined in the statement of the theorem.
Proof.
The proof is provided in Appendix B.7. ∎
Since , hence , and consequently , can be made arbitrarily small for sufficiently large n, if and . Now we move on to bounding .
Step 4: Analyzing the effect of Bob’s approximating measurement
Step 3 ensured that the sub-system is close to a tensor product state in trace-norm. In this step, we approximate the state corresponding to the sub-system using the approximating POVM , producing outputs on the alphabet . We proceed with the following proposition.
Proposition 8.
For any , any sufficiently small, and any sufficiently large, we have , if , , , and where , are the auxiliary states defined in the statement of the theorem.
Proof.
The proof is provided in Appendix B.8. ∎
VI.5 Rate Constraints
To sum-up, we showed holds for sufficiently large if the following bounds hold:
| (49a) | ||||
| (49b) | ||||
| (49c) | ||||
| (49d) | ||||
| (49e) | ||||
| (49f) | ||||
where and . Therefore, there exists a distributed protocol with parameters such that its overall POVM is -faithful to with respect to .
Let us denote the above achievable rate-region by . By doing an exact symmetric analysis, but by replacing the first encoder by a product distribution instead of the second encoder in (as performed in (46)), all the constraints remain the same, except that the constraints on and change as follows
| (50) |
Let us denote the above achievable rate-region by . By time sharing between the any two points of and one can achieve any point in the convex closure of The following lemma gives a symmetric characterization of the closure of convex hull of the union of the above achievable rate-regions.
Lemma 7.
For the above defined rate regions and , we have , where is given by the set of all the quintuples satisfying the following constraints:
| (51) | ||||
| (52) |
Proof.
The proof follows from elementary convex analysis. ∎
Lastly, we complete the proof of the theorem using the following lemma.
Lemma 8.
Proof.
The proof follows from Fourier-Motzkin elimination [40]. ∎
VII Conclusion
We developed a technique of randomly generating structured POVMs using algebraic codes. Using this technique, we demonstrated a new achievable information-theoretic rate-region for the task of faithfully simulating a distributed quantum measurement and function computation. We further devised a Pruning Trace inequality which is a tighter version of the known operator Markov inequality, and a covering lemma which is independent of the operator Chernoff inequality, so as to analyse pairwise-independent POVM elements. Finally, combining these techniques, we demonstrated rate gains for this problem over traditional coding schemes, and provided a multi-party distributed faithful simulation and function computation protocol.
Acknowledgement: We thank Arun Padakandla for his valuable discussion and inputs in developing the proof techniques.
Appendix A Proof of Lemmas
A.1 Proof of Lemma 2
Proof.
We begin by defining the ensemble where for all . Further, let be defined as
By adding an subtracting appropriate terms within the trace norm of and using the triangle inequality we obtain, where
We begin by bounding the term corresponding to and as follows:
| (53) |
where the first two inequalities use the triangle inequality, the third uses the gentle measurement lemma (given the assumption (9a) from the statement of the Lemma) for the first term, and operator Holder’s inequality (Exercise 12.2.1 in [39]) for the second term. The last inequality follows again from the gentle measurement given the assumption (9b). Similarly, for we have
| (54) |
where we use the fact that , and the last inequality uses similar arguments as in (A.1). Finally, we proceed to bound the term corresponding to . Firstly, note that, . This gives
| (55) |
where the first inequality follows from concavity of operator square-root function (Löwner-Heinz theorem, see Theorem in [41]). The last equality uses the fact that codewords of the random code are pairwise independent, and the last inequality follows from monotonicity of the operator square-root function (Theorem in [41]).
Moving on, we now bound the operator within the square root of (A.1) as
where we use the assumption for all . Further since, , we have , which gives
Moreover, using the assumption 9d, i.e., , we get
Thus,
| (56) |
where the second inequality uses the assumption (9e) from the statement of the Lemma. Substituting the simplification obtained in (56) into (A.1) and using the monotonicity of square-root operator, we obtain
| (57) |
where the second inequality uses the assumption (9c). Combining the bounds (A.1), (A.1), and (57) we get the desired result.
∎
A.2 Proof of Lemma 4
Note that if prunes , then also prunes with respect to Using Lemma 3, we obtain
Applying expectation and using the assumption on , we get
A.3 Proof of Lemma 5
We begin by defining as
Further, let and let and denote the -typical projector of and conditional typical projector of respectively. Define for , and otherwise, where Using the triangle inequality we can bound as where
We begin by bounding the term corresponding to as
| (58) |
Now consider the term corresponding to , for which we employ Lemma 2. Toward this, we consider the following identification: with , with , with , with , with , with , with , and for all . Since the collection of random variables are generated using Unionized Coset Codes, we have
Note that for all , where as , and is defined in the statement of the lemma. With these, we check the hypotheses of Lemma 2. Firstly, using the pinching arguments described in [7, Property 15.2.7], we have for all and sufficiently large , satisfying hypothesis (9a). Secondly, (9b) and (9e) are satisfied from the construction of . Next, we consider the hypothesis (9c). We have
where the first inequality above follows from the fact that and using the operator monotonicty of the square-root function (Theorem in [41]). The second inequality follows from the property of the typical projector for some such that as . This gives
Finally, the hypotheses (9d) is satisfied from the property of conditional typical projectors for , where as (see [7, Property 15.2.6]). Next we check the pairwise independence of and . Since these are constructed using randomly and uniformly generated and , we have to be pairwise independent for each (see [37] for details). Therefore, employing Lemma 2 we get
| (59) |
where exp As for , taking expectation and using gives
| (60) |
Combining the bounds from and gives the desired result.
A.4 Proof of Lemma 6
We begin by using the Hólder’s inequality [39, 41] for operator norm, i.e., (), and defining . This gives us
where the equality follows from the fact that and commute, the first inequality follows from the Hólder’s inequality, and the second inequality uses the following bounds
where the second inequality uses Cauchy-Schwarz inequality along with the polar decomposition (see the usage in [39, Lemma 9.4.2]) and the last inequality uses the arguments: (i) is a projector onto a subspace of and (ii) . Further, using the fact that for
it follows that
where the second inequality above follows by defining and using the concavity of the square-root function, the third inequality follows by using the fact that
| (61) |
and defining as above. and the last one follows by first using and then defining and as in the statement of the lemma and using the inequality . This completes the proof.
Appendix B Proof of Propositions
B.1 Proof of Proposition 1
Applying the triangle inequality on gives , where
For the first term , we use Lemma 5, and identify with and . Using this lemma, we obtain the following: For any , and any sufficiently small and any sufficiently large, , if the , where is defined in the statement of the theorem. As for the second term , we use the gentle measurement lemma and bound its expected value as
where the inequality is based on the repeated usage of the average gentle measurement lemma by setting with as and and for (see (35) in [3] for more details).
B.2 Proof of Proposition 2
To provide a bound for , we individually bound the terms corresponding to and in an expected sense. Let us first consider . To provide a bound for we use Lemma 2 with the following identification: with , with , with , with , with , with , and with .
Firstly, we have for all , where as , which gives
With these, we check the hypotheses of Lemma 2. As for the first hypothesis (9a), using the pinching arguments described in [7, Property 15.2.7], we have for all and sufficiently large . Then the hypotheses (9b) and (9e) are satisfied from the construction of . Next, consider the hypothesis (9c). We have
where the first inequality above follows from using and the operator monotonicty of the square-root function. The second inequality follows from the property of the typical projector for some such that as . This gives
where is as defined in the statement of the theorem. Finally, the hypotheses (9d) is satisfied from the property of conditional typical projectors for , where as Next we check the pairwise independence of and . Since these are constructed using randomly and uniformly generated and , we have to be pairwise independent (see [37] for details). Therefore, employing inequality (11) of Lemma 2, we get
Next, consider and perform the following simplification
| (62) |
where is any state independent of . We again apply Lemma 2 to the above term with the following identification: with , with , with , with , and with Identity operator , and with . With this identification, remains as above, and . Hence, using in inequality (11) of Lemma 2, we obtain
This completes the proof.
B.3 Proof of Proposition 3
We begin using the definition of and applying triangle inequality to to obtain
| (63) |
where the second inequality above uses the following arguments
| (64) |
where the above inequalities follow from the Hólder’s inequality. Finally, the last inequality in (63) follows by defining as
Observe that
which follows from the pairwise independence of the codewords. Using this, we obtain
where as , and is as defined in the statement of the theorem. This completes the proof.
B.4 Proof of Proposition 4
Recalling , we have , where
where and are defined as
We begin by bounding the term corresponding to . Consider the following argument.
where
(a) follows by applying the triangle inequality, and (b) follows from the Lemma 9 given below. Note that in , the average over the entire common information sequence is inside the norm.
Lemma 9.
We have
| (65) |
Proof.
The proof follows from Lemma 2 in [3]. ∎
Next we use Theorem 2 twice with (a) , , , and , and (b) , , , and , and [24, Lemma 5] to yield the following: for any , and any sufficiently small, and any sufficiently large if , , , , where and are defined as in the statement of the theorem. Consequently, we have for all sufficiently large .
In regards to , note that
Using this, we obtain
where as and the above inequality follows from the following lemma (Lemma 10). Hence, if the conditions in the proposition are satisfied.
Lemma 10.
For and as defined above, we have
for some as
Proof.
Firstly, note that
| (66) |
We know, , where as . This implies,
| (67) |
where the second inequality appeals to the fact that . Similarly, using the same arguments above for the operators acting on , we have
| (68) |
where as . Using (i) the simplifications in (67) and (68), and (ii) the fact that for and , in (66), gives
Substituting gives the result.
∎
B.5 Proof of Proposition 5
We bound as , where
Analysis of : We have
| (69) |
where the first inequality uses triangle inequality. The next inequality follows by using Lemma 1 where we use the fact that Finally, the last two inequalities follows again from triangle inequality.
Regarding the first term in (69), using Lemma 5 we claim that for all , and sufficiently small, and any sufficiently large, , if , where are as defined in the statement of the theorem. As for the second term, we use the gentle measurement lemma (as in (76)) and bound its expected value as
where the inequality is based on the repeated usage of the Average Gentle Measurement Lemma and as (see (35) in [3] for more details). Finally, consider the last term. To simplify this term, we appeal to Lemma 6 in Section V.2. This gives us
| (70) |
where
| (71) |
and and .
Further, using the simplification performed in (V.2.4), (V.2.4), and (V.2.4), and the concavity of the square-root function, we obtain,
| (72) |
Using Proposition 2, for any , any sufficiently small, and any sufficiently large, we have if , where , are the auxiliary state defined in the statement of the theorem.
Analysis of : Due to the symmetry in and , the analysis of follows very similar arguments as that of and hence we obtain the following, for any , any sufficiently small, and any sufficiently large, we have if , where , are the auxiliary state defined in the statement of the theorem.
Analysis of : We have
| (73) |
where the inequalities above are obtained by a straight forward substitution and use of triangle inequality. Further, since and , this simplifies the first term in (73) as
Similarly, the second term in (73) simplifies using Lemma 1 as
Using these simplifications, we have
The above expression is similar to the one obtained in the simplification of and hence we can bound using similar constraints as , for sufficiently large .
B.6 Proof of Proposition 6
We start by applying triangle inequality to obtain , where
Now with the intention of employing Lemma 5, we express as
where the equality above is obtained by defining and using the definitions of and , followed by using the triangle inequality for the block diagonal operators. Note that the triangle inequality in this case becomes an equality.
Let us define as
Note that in the above definition of we have and for all . Further, it contains all the elements in product form, and thus can be written as This simplifies as
Using Lemma 5, we claim the following: for any , any sufficiently small, and any sufficiently large, we have , if , where is the auxiliary state defined in the statement of the theorem.
Now we consider the term corresponding to and prove that its expectation with respect to the Alice’s codebook is small. Recalling , we get
where the inequality is obtained by using triangle and the next equality follows from the fact that for all and and using the definition of . By applying expectation of over the Alice’s codebook, we get
where we have used the fact that . To simplify the above equation, we employ Lemma 1 which completely discards the effect of Bob’s measurement. Since , from Lemma 1 we have for every ,
This simplifies as
| (74) |
where the last inequality is obtained by repeated usage of the Average Gentle Measurement Lemma and as (see (35) in [3] for details). This completes the proof.
B.7 Proof of Proposition 7
Noting the similarity between and the term defined in the proof of Theorem 2 (see Section V.2), we begin by further simplifying using Lemma 6. This gives us
| (75) |
where
and , and . Further, using the simplification performed in (V.2.4), (V.2.4), and (V.2.4), and the concavity of the square-root function, we obtain,
where
The proof from here follows from Proposition 2.
B.8 Proof of Proposition 8
We start by adding and subtracting the following terms within
This gives us , where
We start by analyzing . Note that is exactly same as and hence using the same rate constraints as , this term can be bounded. Next, consider . Substitution of gives
where is defined as and the equality uses the triangle inequality for block operators. Now we use Lemma 5 to bound . Let
Note that can be written in tensor product form as . This simplifies as
Application of Lemma 5 gives the following: for any , any sufficiently small, and any sufficiently large, we have if
Now, we move on to consider . Taking expectation with respect gives
where the inequality above is obtained by using the triangle inequality, and the first equality follows from and being generated independently. The last equality follows from the definition of as in (VI.4). Hence, we use the result obtained in bounding Next, we consider .
where the inequalities follow from the definition of and using multiple triangle inequalities. Taking expectation of with respect to , we get
| (76) |
where the second inequality above follows by using Lemma 1 and the fact that and the last inequality follows by applying the Average Gentle Measurement Lemma repeated and as (see (35) in [3] for more details). This completes the proof for the term . Finally, we move onto considering . Simplifying gives
where the first inequality uses traingle inequality and the second inequality uses Lemma 1 to remove the affect of approximating Alice’s POVM on Bob’s approximation, and is defined in (69) in the proof of Proposition 5. Therefore, we have the following: for any , any sufficiently small, and any sufficiently large, we have if . This completes the proof for and hence for all the terms corresponding to .
References
- Devetak et al. [2008] I. Devetak, A. W. Harrow, and A. J. Winter, A resource framework for quantum shannon theory, IEEE Transactions on Information Theory 54, 4587 (2008).
- Winter [2004] A. Winter, ”Extrinsic” and ”intrinsic” data in quantum measurements: asymptotic convex decomposition of positive operator valued measures, Communication in Mathematical Physics 244, 157 (2004).
- Wilde et al. [2012] M. M. Wilde, P. Hayden, F. Buscemi, and M.-H. Hsieh, The information-theoretic costs of simulating quantum measurements, Journal of Physics A: Mathematical and Theoretical 45, 453001 (2012).
- Devetak and Winter [2003] I. Devetak and A. Winter, Classical data compression with quantum side information, Physical Review A 68, 042301 (2003).
- Shannon [1948] C. E. Shannon, A Mathematical Theory of Communication, Bell System Technical Journal 27, 379–423 (July 1948).
- Ahlswede and Winter [2002] R. Ahlswede and A. Winter, Strong converse for identification via quantum channels, IEEE Transactions on Information Theory 48, 569 (2002).
- Wilde [2011] M. M. Wilde, From classical to quantum shannon theory, arXiv preprint arXiv:1106.1445 (2011).
- Groenewold [1971] H. J. Groenewold, A problem of information gain by quantal measurements, International Journal of Theoretical Physics 4, 327 (1971).
- Lindblad [1972] G. Lindblad, An entropy inequality for quantum measurements, Communications in Mathematical Physics 28, 245 (1972).
- Ozawa [1986] M. Ozawa, On information gain by quantum measurements of continuous observables, Journal of mathematical physics 27, 759 (1986).
- Buscemi et al. [2008] F. Buscemi, M. Hayashi, and M. Horodecki, Global information balance in quantum measurements, Physical review letters 100, 210504 (2008).
- Luo [2010] S. Luo, Information conservation and entropy change in quantum measurements, Physical Review A 82, 052103 (2010).
- Shirokov [2011] M. E. Shirokov, Entropy reduction of quantum measurements, Journal of mathematical physics 52, 052202 (2011).
- Berta et al. [2014] M. Berta, J. M. Renes, and M. M. Wilde, Identifying the information gain of a quantum measurement, IEEE Transactions on Information Theory 60, 7987 (2014).
- Horodecki et al. [2005a] M. Horodecki, J. Oppenheim, and A. Winter, Partial quantum information, Nature 436, 673 (2005a).
- Horodecki et al. [2007] M. Horodecki, J. Oppenheim, and A. Winter, Quantum state merging and negative information, Communications in Mathematical Physics 269, 107 (2007).
- Christandl et al. [2009] M. Christandl, R. König, and R. Renner, Postselection technique for quantum channels with applications to quantum cryptography, Physical review letters 102, 020504 (2009).
- Anshu et al. [2019] A. Anshu, R. Jain, and N. A. Warsi, Convex-split and hypothesis testing approach to one-shot quantum measurement compression and randomness extraction, IEEE Transactions on Information Theory 65, 5905 (2019).
- Anshu et al. [2017] A. Anshu, V. K. Devabathini, and R. Jain, Quantum communication using coherent rejection sampling, Physical review letters 119, 120506 (2017).
- Anshu et al. [2014] A. Anshu, V. K. Devabathini, and R. Jain, Quantum message compression with applications, arXiv preprint arXiv:1410.3031 (2014).
- Renes and Renner [2012] J. M. Renes and R. Renner, One-shot classical data compression with quantum side information and the distillation of common randomness or secret keys, IEEE Transactions on Information Theory 58, 1985 (2012).
- Tomamichel [2015] M. Tomamichel, Quantum information processing with finite resources: mathematical foundations, Vol. 5 (Springer, 2015).
- Khatri and Wilde [2020] S. Khatri and M. M. Wilde, Principles of quantum communication theory: A modern approach, arXiv preprint arXiv:2011.04672 (2020).
- Atif et al. [2019] T. A. Atif, M. Heidari, and S. S. Pradhan, Faithful simulation of distributed quantum measurements with applications in distributed rate-distortion theory, arXiv e-prints , arXiv (2019).
- Bennett et al. [2002] C. H. Bennett, P. W. Shor, J. A. Smolin, and A. V. Thapliyal, Entanglement-assisted capacity of a quantum channel and the reverse shannon theorem, IEEE Transactions on Information Theory 48, 2637 (2002).
- Bennett et al. [2009] C. H. Bennett, I. Devetak, A. W. Harrow, P. W. Shor, and A. Winter, Quantum reverse shannon theorem, arXiv preprint arXiv:0912.5537 (2009).
- Berta et al. [2011] M. Berta, M. Christandl, and R. Renner, The quantum reverse shannon theorem based on one-shot information theory, Communications in Mathematical Physics 306, 579 (2011).
- Horodecki et al. [2003] M. Horodecki, K. Horodecki, P. Horodecki, R. Horodecki, J. Oppenheim, A. Sen, U. Sen, et al., Local information as a resource in distributed quantum systems, Physical review letters 90, 100402 (2003).
- Horodecki et al. [2005b] M. Horodecki, P. Horodecki, R. Horodecki, J. Oppenheim, A. Sen, U. Sen, B. Synak-Radtke, et al., Local versus nonlocal information in quantum-information theory: formalism and phenomena, Physical Review A 71, 062307 (2005b).
- Devetak [2005] I. Devetak, Distillation of local purity from quantum states, Physical Review A 71, 062303 (2005).
- Krovi and Devetak [2007] H. Krovi and I. Devetak, Local purity distillation with bounded classical communication, Physical Review A 76, 012321 (2007).
- Korner and Marton [1979] J. Korner and K. Marton, How to encode the modulo-two sum of binary sources (corresp.), IEEE Transactions on Information Theory 25, 219 (1979).
- Krithivasan and Pradhan [2011] D. Krithivasan and S. S. Pradhan, Distributed source coding using abelian group codes: A new achievable rate-distortion region, IEEE Transactions on Information Theory 57, 1495 (2011).
- Nazer and Gastpar [2007] B. Nazer and M. Gastpar, Computation over multiple-access channels, IEEE Trans. on Info. Th. 53, 3498 (2007).
- Philosof and Zamir [2009] T. Philosof and R. Zamir, On the loss of single-letter characterization: The dirty multiple access channel, IEEE Trans. on Info. Th. 55, 2442 (2009).
- Jafarian and Vishwanath [2012] A. Jafarian and S. Vishwanath, Achievable rates for -user Gaussian interference channels, IEEE Transactions on information theory 58, 4367 (2012).
- Pradhan et al. [2021] S. S. Pradhan, A. Padakandla, and F. Shirani, An Algebraic and Probabilistic Framework for Network Information Theory, Vol. 18 (Foundations and Trends in Communications and Information Theory, 2021) pp. 173–376.
- Gallager [1968] R. G. Gallager, Information Theory and Reliable Communication (John Wiley & Sons, New York, 1968).
- Wilde [2013] M. M. Wilde, Quantum information theory (Cambridge University Press, 2013).
- Ziegler [2012] G. M. Ziegler, Lectures on polytopes, Vol. 152 (Springer Science & Business Media, 2012).
- Carlen [2010] E. Carlen, Trace inequalities and quantum entropy: an introductory course, Entropy and the quantum 529, 73 (2010).