Distributionally Robust Model Predictive Control with Mixture of Gaussian Processes*
Abstract
Despite the success of Gaussian process based Model Predictive Control (MPC) in robotic control, its applicability scope is greatly hindered by multimodal disturbances that are prevalent in real-world settings. Here we propose a novel Mixture of Gaussian Processes based Distributionally Robust MPC (MoGP-DR-MPC) framework for linear time-invariant systems subject to potentially multimodal state-dependent disturbances. This framework utilizes MoGP to automatically determine the number of modes from disturbance data. Using the mean and variance information provided by each mode-specific predictive distribution, it constructs a data-driven state-dependent ambiguity set, which allows for flexible and fine-grained disturbance modeling. Based on this ambiguity set, we impose Distributionally Robust Conditional Value-at-Risk (DR-CVaR) constraints to effectively achieve distributional robustness against errors in the predictive distributions. To address the computational challenge posed by these constraints in the resulting MPC problem, we equivalently reformulate the DR-CVaR constraints into tractable second-order cone constraints. Furthermore, we provide theoretical guarantees on the recursive feasibility and stability of the proposed framework. The enhanced control performance of MoGP-DR-MPC is validated through both numerical experiments and simulations on a quadrotor system, demonstrating notable reductions in closed-loop cost by 17% and 4% respectively compared against Gaussian process based MPC.
I Introduction
Multimodal state-dependent disturbances are pervasive in real-world applications, posing significant challenges to control synthesis because of their inherent complexity and variability. Gaussian Process based Model Predictive Control (GP-MPC) offers an effective approach for controlling systems subject to state-dependent disturbances and its control performance largely depends on the accuracy of the GP model. However, due to the stationary kernels employed in GP, the performance of GP-MPC deteriorates remarkably under multimodal disturbances. Such performance decline underscores the pressing research need for new MPC strategies to tackle the challenges introduced by the heterogeneous modalities.
In the face of unknown disturbances, different strategies have been proposed for GP-MPC. Among them, a robust strategy is to enforce constraint satisfaction under the worst-case scenario to ensure complete safety [1]. For instance, References [2] and [3] used confidence interval bounds and worst-case error bounds, respectively, to tighten constraints. However, such robust methods tend to be overly conservative. An alternative is to integrate GP with stochastic MPC, which employs chance constraints to substantially mitigate conservatism [4]. To expedite the solution process, Reference [5] used probabilistic reachable sets to reformulate chance constraints, while [6] derived a deterministic solution method through online GP-based binary regression. When the underlying distribution is not perfectly known, stochastic GP-MPC methods fall short of guaranteeing the probabilistic constraint satisfaction. To address this issue, Distributionally Robust MPC (DR-MPC) has been proposed and gained tremendous popularity, ensuring robustness over a so-called ambiguity set[7][8]. DR-MPC can also integrate data-driven techniques to extract moment information or approximate distributions, facilitating the construction of the ambiguity set [9][10][11]. Notably, these DR-MPC approaches typically assume that disturbances are independent of system states, overlooking state-dependent scenarios. Drawing upon the capability of DR-MPC to tackle distributional uncertainties, Reference [12] introduced Distributionally Robust Conditional Value-at-Risk (DR-CVaR) constraints into GP-MPC, enhancing safety even when the true distribution deviates from the estimated one. However, according to the existing literature, a critical research gap remains: most existing GP-MPC research primarily focuses on unimodal disturbances, thus enormously limiting their applicability in real-world settings where multimodal state-dependent disturbances are prevalent.
To fill this challenging gap, we propose a Mixture of Gaussian Processes-based Distributionally Robust MPC (MoGP-DR-MPC) framework. To immunize against errors in the predictive distributions, an ambiguity set is constructed based on the structure of modalities and mode-specific predictive distributions. Within this framework, DR-CVaR constraints are employed in the first predicted system state, while subsequent constraints are tightened via an invariant set [13]. We equivalently reformulate the DR-CVaR constraints as second-order cone constraints to facilitate computation for control actions[14], and theoretically provide guarantees for the proposed framework. Its effectiveness and superiority are substantiated through two case studies. The major contributions are summarized as follows:
-
•
We develop a novel DR-MPC framework that delicately integrates MoGP with MPC to enhance control performance in the presence of state-dependent and potentially multimodal disturbances, while ensuring recursive feasibility and stability.
-
•
We propose an innovative data-driven state-dependent ambiguity set, which closely respects the inherent multimodalities and efficaciously enables the incorporation of fined-grained moment information.
II PROBLEM FORMULATION
We consider the following stochastic linear discrete time-invariant system.
| (1) |
where and denote the system state, control input and disturbance at time , respectively. In particular, unknown disturbance is state-dependent, possibly multimodal and bounded by support , which is represented by a box constraint set . Assume system matrix is known and stabilizable. The system is subject to the probabilistic state constraints and hard input constraints defined as follows.
| (2a) | ||||
| (2b) | ||||
where and . These sets are compact and contain the origin within their interiors. The notation represents the probability and is the prescribed tolerance level that curbs the probability of constraint violation.
Since the underlying distribution is not perfectly known, we propose using a DR-CVaR version of Constraint (2a), which can be defined as
| (3) |
where the superscript represents the -th element of the corresponding vector throughout this paper, and is an ambiguity set derived from historical data using learning techniques presented in the following section. Although Constraint (3) may appear more complex, it admits an exact and convex reformulation that is more tractable in computation than the original chance constraint.
III INFINITE MIXTURE of GPs
To accurately model the state-dependent, potentially multimodal disturbance and derive the corresponding ambiguity set, we adopt an MoGP approach inspired by the Mixture of experts (MoE) framework [15]. This method can naturally incorporate the multimodal structure into the model of .
In MoGP, data points are assigned to local experts via a gating network, with each expert then using the assigned data to train its local GP model. Based on this strategy, the observation likelihood for the MoGP model is given by
where represents the training inputs, denotes the outputs, denotes the parameters of expert , refers to the parameters of the gating network, and represents the indicator variables specifying the corresponding experts. The number of experts is automatically determined from data through maximizing the likelihood.
III-A Gating Network Based on Dirichlet Process
To accommodate the state-dependent property, we tailor the Dirichlet process to serve as an input-dependent gating network. In the standard Dirichlet process with the concentration parameter , the conditional probability of the indicator variable is given by
| (4) |
where represents the number of data points in expert excluding observation , and is the total number of data points. To incorporate input dependence into the gating network, we redefine as follows.
| (5) |
where is a kernel function parametrized by and is the Dirac delta function. Consequently, given a new data point, the conditional distribution of its indicator variable can be obtained by substituting (5) into (4).
III-B Local Gaussian Process
For a local GP expert , let represent the training inputs and denote the corresponding noisy outputs, where . The observation noise is assumed to be i.i.d, following a normal distribution with mean and variance . Each output dimension is modeled independently. For dimension , we define a GP prior with kernel and mean function . Conditioning on the data and , the predictive posterior distribution for the output at a new data point is Gaussian with the following mean and variance.
| (6) | ||||
where .
Based on the above analysis, the predictive distribution of in dimension generated by MoGP can be expressed by combining the conditional distributions of the indicator variables from the gating network with the results from local GP regression, as shown in (7).
| (7) |
where is the number of experts, represents the training dataset, and denotes the weight of the corresponding Gaussian component obtained by Dirichlet process. This formulation effectively captures the potential multimodalities in the latent function. However, errors between the predictive distribution and the true underlying distribution still exists. To mitigate this uncertainty, we construct an ambiguity set in the following section.
IV CONTROLLER DESIGN
With the MoGP model for , we design a controller tailored for system (1) in this section. To decouple the impact of disturbances, we decompose the system state into nominal component and error component . The feedback control law is designed as , where is the nominal input and is a feedback gain matrix computed offline, satisfying that is stable. Employing this control law, the corresponding nominal and error dynamics are given below [13].
| (8a) | ||||
| (8b) | ||||
IV-A Ambiguity Set Construction
To formulate the DR-CVaR constraints on system states, we construct a state-dependent ambiguity set that accounts for potential multimodalities by leveraging the MoGP model for in each dimension. Particularly, given a specific system state at time , suppose that the predictive distribution for in dimension , which consists of state-dependent Gaussian components, can be written as
| (9) |
Considering the structure of modalities and independence between each mode, we establish local ambiguity sets using the state-dependent mean and variance information from the Gaussian components in (9). The overall ambiguity set is then constructed as a weighted Minkowski sum of these local ambiguity sets. Explicitly, each local state-dependent ambiguity set is defined below.
| (10) | ||||
where represents the set of positive Borel measure on , and is a positive measure. The proposed ambiguity set is defined as
| (11) |
This construction closely aligns with the potentially multimodal structure, allowing for a more flexible and intricate representation of state-dependent disturbances.
IV-B Constraint Formulation
Define as the step ahead predicted system state based on the current state , while is the given initial state. To ensure recursive feasibility, we adopt a hybrid constraint tightening strategy that combines distributionally robust and worst-case tightening methods.
For , the corresponding DR-CVaR constraint can be expressed as follows [16].
| (12) |
Noting that , since the state-dependent term is the only source of uncertainty, the ambiguity set is essentially a shifted version of the ambiguity set for , denoted as . Hence, it can be defined in the same manner as (11). Based on (11), we consequently prove that Constraint (12) can be equivalently reformulated as second-order cone constraints in the subsequent section.
Given the support set , we define as the minimal Robust Positively Invariant (mRPI) set for the error dynamics in (8b). The remaining system constraints are then guaranteed by the tightened state constraints and input constraints [17]. Additionally, the constraint is required to be satisfied. Finally, we impose the terminal constraint , where is defined in (13).
| (13) |
Based on the above analysis, the formulation of MoGP-DR-MPC at time , denoted as , is written as
| s.t. | (14a) | |||
| (14b) | ||||
| (14e) | ||||
| (14f) | ||||
| (14g) | ||||
| (14h) | ||||
where and are positive definite weight matrices, with determined through the Riccati equation. Obviously, Problem is nonconvex and cannot be solved directly due to the presence of constraint (14e). We then derive its equivalent tractable form in the next section.
IV-C Tractable MPC Formulation
In this section, we demonstrate how to transform the critical and intractable DR-CVaR constraint (14e) into a set of second-order cone constraints using the following theorem.
Theorem 1
For any and , the DR-CVaR constraint (14e) is satisfied if and only if
| (15) | ||||
where is obtained by the following second-order cone program.
| (16) | ||||
| s.t. | ||||
where
Proof:
According to the definition of CVaR, the left side of Constraint (14e) can be rewritten as follows.
| (17) | ||||
| (20) |
where . To simplify the notation, we denote as . Given the initial state , the ambiguity set is defined similarly as (11). Then the worst-case expectation term can be reformulated as follows [14] [18].
| s.t. | (21) |
Obviously, Problem (21) cannot be solved directly, so we take its dual, which is formulated below.
| (22) | ||||
| s.t. | ||||
The semi-infinite constraints in (22) can be transformed into linear matrix inequalities by duality theory and Schur complements [19]. For brevity, the exact form is omitted. Since the resulting matrices are two-dimensional, they can be further rewritten as second-order cone constraints [20]. Thus, Constraint (14e) is equivalent to the following set of constraints.
| (23) | ||||
where
Theorem 1 provides the convex reformulation alternatives of Constraint (14e). It follows that the optimization problem can be reformulated into the convex and tractable form below, which is denoted as .
| s.t. | (24a) | |||
| (24b) | ||||
| (24c) | ||||
| (24d) | ||||
| (24e) | ||||
| (24f) | ||||
If is feasible at time , let and represent its optimal solution. At each time instant, the MoGP-DR-MPC framework solves to obtain the optimal input sequence and only the first element is executed. This process is repeated to perform receding horizon control.
V THEORETICAL PROPERTIES
In this section, we establish the recursive feasibility and stability of MoGP-DR-MPC through the following theorems.
Theorem 2 (Recursive feasibility)
If problem is feasible with state , then is recursively feasible with .
Proof:
Given the optimal sequences and , from Constraint (24a), we know that . By the invariant property of , we have for all possible . Define the solution sequence of problem as . We then shift to generate the candidate solution for problem . In particular, .
Theorem 3 (Closed-loop stability)
If the initial problem is feasible, the closed-loop system asymptotically converges to a neighborhood of the origin.
Proof:
Consider at time , the optimal objective value is denoted as . Since candidate solution is feasible, the corresponding objective value is obtained by
Noting that is the solution of Riccati equation, we obtain the following inequality.
| (25) | ||||
Therefore, . Adding this from , we obtain . Then we have and . This gives the convergence of system states. ∎
VI CASE STUDIES
This section presents two case studies to validate the effectiveness of the proposed MoGP-DR-MPC method. Its performance is compared against two baseline methods, namely GP-based DR-MPC (GP-DR-MPC) and robust tube MPC.
VI-A Numerical Experiments
We first conduct numerical experiments on a stochastic system given in (26).
| (26) |
Suppose the constraint sets are and , with a tolerance level of . Disturbance is supported by and is defined using standard four-modal function i.e. Franke function [21] in each dimension. The control objective is to steer the initial state to the origin under the disturbance . Define the stage cost as , where is identity matrix and . The horizon of MPC is set as and we perform 50 closed-loop simulations with a simulation horizon of 30 to showcase the improvement in control performance.
The average closed-loop costs for MoGP-DR-MPC, GP-DR-MPC and robust tube MPC are 66.06, 79.74 and 89.22, respectively. The simulation results indicate that MoGP-DR-MPC reduces the average closed-loop cost by 17% compared with GP-DR-MPC and by 24% compared with robust tube MPC, demonstrating its notable advantage in handling multimodal state-dependent disturbances.
VI-B Simulations on a Quadrotor System
In the second case study, we simulate a trajectory planning and control problem for a planar quadrotor system [22]. The quadrotor starts at and is expected to land at the origin. During its flight, it must remain within the safe region with probability under a multimodal state-dependent wind disturbance, which is common due to varying airflow patterns. The linearized dynamics of the quadrotor system are expressed as follows.
| (27) |
where is the sampling time and represents the mass of the system. The state vector includes the quadrotor’s positions and velocities in the and directions, while the control input applies forces along these axes. The support set of the wind disturbance is represented by and the safe region is defined by
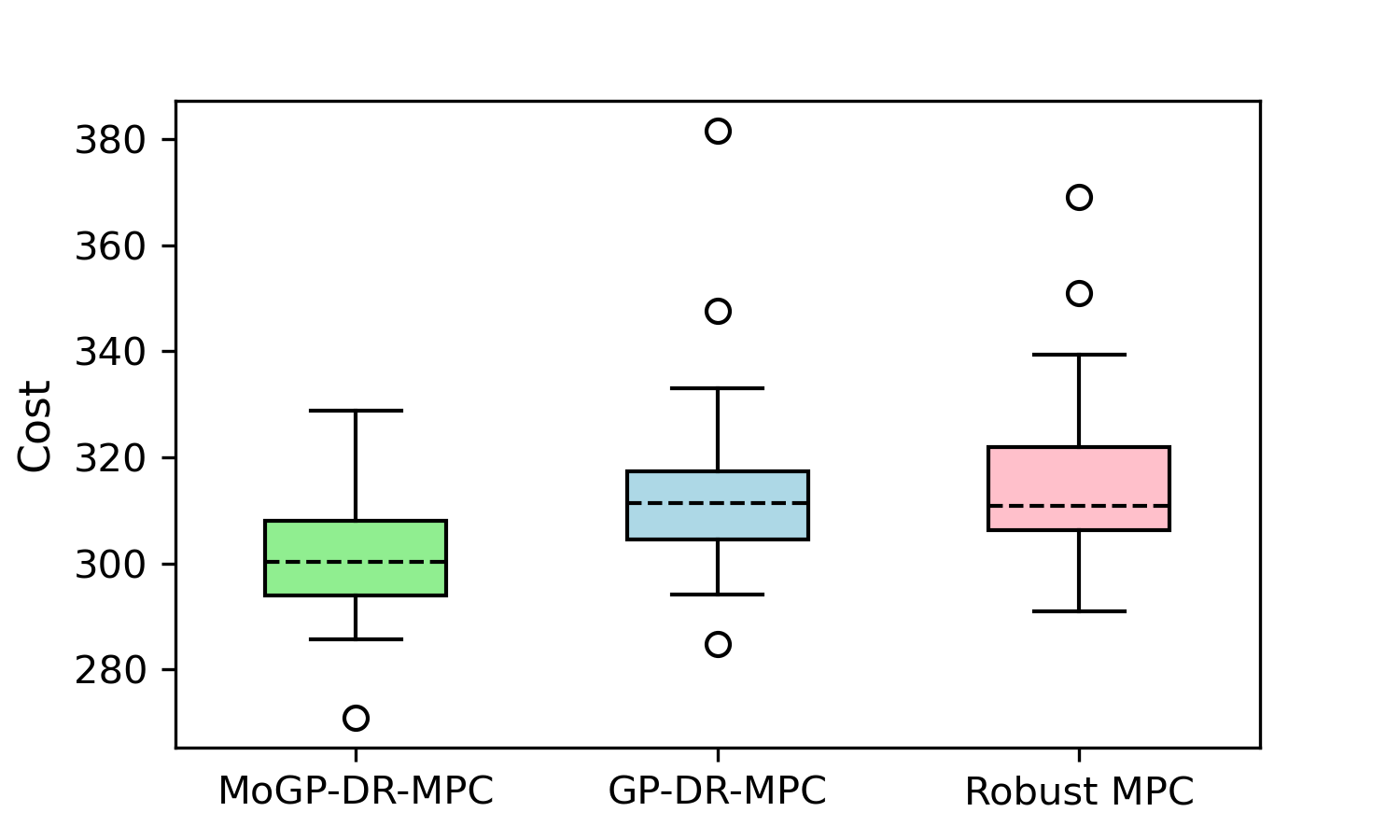
In the simulations, the MPC time horizon is set to five and we evaluate the performance of MoGP-DR-MPC against two baseline approaches. Specifically, we analyze the closed-loop costs under 50 different sequences of disturbance realizations, each with 30 simulation steps. As illustrated in Fig 1, MoGP-DR-MPC achieves an average reduction in closed-loop cost of 4% compared with GP-DR-MPC and 5% compared with robust tube MPC. This corroborates the superior ability of MoGP-DR-MPC to capture the multimodal characteristics of disturbance data, yielding less conservative control performance.
Additionally, because the optimal control problem is convex and the MoGP model is trained offline, the computation time for MoGP-DR-MPC is on par with that of conventional GP-MPC. Fig 2 shows the position trajectories of the quadrotor generated by 30 simulations.
VII CONCLUSIONS
In this paper, we presented a novel MoGP-DR-MPC framework that seamlessly integrated MoGP to effectively control systems with state-dependent multimodal disturbances. Based on the MoGP model, we developed a data-driven state-dependent ambiguity set, which closely aligns with the multimodality structure. We reformulated the DR-CVaR constraints as scalable second-order cone constraints, ensuring computational tractability. The recursive feasibility and closed-loop stability of MoGP-DR-MPC were guranteed through invariant sets. Both numerical experiments and simulations on a quadrotor system verified the effectiveness of the proposed method in coping with multimodal disturbances.
References
- [1] F. Berkenkamp and A. P. Schoellig, “Safe and robust learning control with gaussian processes,” in 2015 European Control Conference (ECC). IEEE, 2015, pp. 2496–2501.
- [2] Y. Wang, C. Ocampo-Martinez, and V. Puig, “Robust model predictive control based on gaussian processes: Application to drinking water networks,” in 2015 European Control Conference (ECC), 2015, pp. 3292–3297.
- [3] A. Rose, M. Pfefferkorn, H. H. Nguyen, and R. Findeisen, “Learning a gaussian process approximation of a model predictive controller with guarantees,” in 2023 62nd IEEE Conference on Decision and Control (CDC). IEEE, 2023, pp. 4094–4099.
- [4] E. Bradford, L. Imsland, D. Zhang, and E. A. del Rio Chanona, “Stochastic data-driven model predictive control using gaussian processes,” Computers & Chemical Engineering, vol. 139, p. 106844, 2020.
- [5] L. Hewing, J. Kabzan, and M. N. Zeilinger, “Cautious model predictive control using gaussian process regression,” IEEE Transactions on Control Systems Technology, vol. 28, no. 6, pp. 2736–2743, 2019.
- [6] A. Capone, T. Brüdigam, and S. Hirche, “Online constraint tightening in stochastic model predictive control: A regression approach,” IEEE Transactions on Automatic Control, pp. 1–15, 2024, doi: 10.1109/TAC.2024.3433988.
- [7] B. Li, T. Guan, L. Dai, and G.-R. Duan, “Distributionally robust model predictive control with output feedback,” IEEE Transactions on Automatic Control, vol. 69, no. 5, pp. 3270–3277, 2024.
- [8] K. Kim and I. Yang, “Distributional robustness in minimax linear quadratic control with wasserstein distance,” SIAM Journal on Control and Optimization, vol. 61, no. 2, pp. 458–483, 2023.
- [9] C. Mark and S. Liu, “Recursively feasible data-driven distributionally robust model predictive control with additive disturbances,” IEEE Control Systems Letters, vol. 7, pp. 526–531, 2022.
- [10] G. Pan and T. Faulwasser, “Distributionally robust uncertainty quantification via data-driven stochastic optimal control,” IEEE Control Systems Letters, vol. 7, pp. 3036–3041, 2023.
- [11] F. Micheli, T. Summers, and J. Lygeros, “Data-driven distributionally robust mpc for systems with uncertain dynamics,” in 2022 IEEE 61st Conference on Decision and Control (CDC). IEEE, 2022, pp. 4788–4793.
- [12] A. Hakobyan and I. Yang, “Learning-based distributionally robust motion control with gaussian processes,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 7667–7674.
- [13] F. Li, H. Li, and Y. He, “Adaptive stochastic model predictive control of linear systems using gaussian process regression,” IET Control Theory & Applications, vol. 15, no. 5, pp. 683–693, 2021.
- [14] C. Ning and F. You, “Online learning based risk-averse stochastic mpc of constrained linear uncertain systems,” Automatica, vol. 125, p. 109402, 2021.
- [15] C. Rasmussen and Z. Ghahramani, “Infinite mixtures of gaussian process experts,” Advances in neural information processing systems, vol. 14, 2001.
- [16] B. P. Van Parys, D. Kuhn, P. J. Goulart, and M. Morari, “Distributionally robust control of constrained stochastic systems,” IEEE Transactions on Automatic Control, vol. 61, no. 2, pp. 430–442, 2015.
- [17] D. Q. Mayne, M. M. Seron, and S. V. Raković, “Robust model predictive control of constrained linear systems with bounded disturbances,” Automatica, vol. 41, no. 2, pp. 219–224, 2005.
- [18] G. A. Hanasusanto, D. Kuhn, S. W. Wallace, and S. Zymler, “Distributionally robust multi-item newsvendor problems with multimodal demand distributions,” Mathematical Programming, vol. 152, no. 1, pp. 1–32, 2015.
- [19] S. Boyd and L. Vandenberghe, Convex optimization. Cambridge university press, 2004.
- [20] L. Li, C. Ning, H. Qiu, W. Du, and Z. Dong, “Online data-stream-driven distributionally robust optimal energy management for hydrogen-based multimicrogrids,” IEEE Transactions on Industrial Informatics, vol. 20, no. 3, pp. 4370–4384, 2024.
- [21] R. Franke, A critical comparison of some methods for interpolation of scattered data. Naval Postgraduate School Monterey, CA, 1979.
- [22] Y. K. Nakka, R. C. Foust, E. S. Lupu, D. B. Elliott, I. S. Crowell, S.-J. Chung, and F. Y. Hadaegh, “A six degree-of-freedom spacecraft dynamics simulator for formation control research,” in 2018 AAS/AIAA Astrodynamics Specialist Conference, 2018, pp. 1–20.