DO-Conv: Depthwise Over-parameterized Convolutional Layer
Abstract
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.
1 Introduction
Convolutional Neural Networks (CNNs) are capable of expressing highly complicated functions, and have shown great success in addressing many classical computer vision problems, such as image classification, detection and segmentation. It has been widely accepted that increasing the depth of a network by adding linear and non-linear layers together can increase the network’s expressiveness and boost its performance. On the other hand, adding extra linear layers only is not as commonly considered, especially when the additional linear layers result in an over-parameterization111The meaning of “over-parameterization” is overloaded in the community. We opt to use this term and its meaning following [3]. The term is also used in the community for describing the case where the number of parameters in a model exceeds the size of the training dataset, such as that in [2]. — a case where the composition of consecutive linear layers may be represented by a single linear layer with fewer learnable parameters.
Though over-parameterization does not improve the expressiveness of a network, it has been proven as means of accelerating the training of deep linear networks, and shown empirically to speedup the training of deep non-linear networks [3]. These findings suggest that, while much work has been devoted to the quest for novel network architectures, over-parameterization has considerable unexplored potential in benefiting existing architectures.
In this work, we propose to over-parameterize a convolutional layer by augmenting it with an “extra” or “over-parameterizing” component: a depthwise convolution operation, which convolves separately each of the input channels. We refer to this depthwise over-parameterized convolutional layer as DO-Conv, and show that it can not only accelerate the training of various CNNs, but also consistently boost the performance of the converged models.
One notable advantage of over-parameterization, in general, is that the multi-layer composite linear operations used by the over-parameterization can be folded into a compact single layer representation after the training phase. Then, only a single layer is used at inference time, reducing the computation to be exactly equivalent to a conventional layer.
We show with extensive experiments that using DO-Conv boosts the performance of CNNs on many tasks, such as image classification, detection, and segmentation, merely by replacing the conventional convolution with DO-Conv. Since the performance gains are introduced with no increase in inference computations, we advocate DO-Conv as an alternative to the conventional convolutional layer.
2 Related Work
The performance of CNNs is highly correlated with their architectures, and a line of notable architectures have been proposed over the recent years, such as AlexNet [23], VGG [32], GoogLeNet [33], ResNet [15], and MobileNets [18]. Our work is orthogonal to the quest for novel architectures, and can be combined with existing ones to boost their performance.
Convolutional layers are the core building blocks of CNNs. Thus, an improvement of these core building blocks can often lead to boosting the performance of CNNs. Several alternatives to the classical convolutional layer have been proposed, which offer improved feature learning capability and/or efficiency [9, 35, 24, 6]. Our work may be viewed as a contribution along this line.
Arora et al. [3] studied the role of over-parameterization in gradient descent based optimization. They have proven that over-parameterization of fully connected layers can accelerate the training of deep linear networks, and shown empirically that it can also accelerate the training of deep non-linear networks. There are multiple ways to over-parameterize a layer. The kernel of a convolutional layer has both channel and spatial axes, thus the over-parameterization of a convolutional layer can be more versatile than that of a fully connected layer. ExpandNets [13] proposes to over-parameterize the convolution kernel over the input and output channel axes. The advantage of over-parameterization is demonstrated in [13] only on the training of compact CNNs, whose performance is no match to that of the mainstream CNNs. Our method over-parameterizes the convolution kernel over its spatial axes, and the advantage is demonstrated on several commonly used CNN architectures. In ACNet [10] the convolutional layer is replaced with an Asymmetric Convolution Block. This approach is, in essence, an over-parameterization of the convolution kernel over the center row and column of its spatial axes. In fact, ACNet may be viewed as a special case of our over-parameterization approach, which over-parameterizes the entire kernel.
Over-parameterized layers introduce “extra” linear transformations without increasing the expressiveness of the network, and once their parameters have been learned, these “extra” transformations are folded in the inference phase. In this sense, normalization layers, such as batch normalization [19] and weight normalization [29], are quite similar to over-parameterized layers. Normalization layers have been widely used for improving the training of CNNs, while the reason for their success is still being actively studied [31, 4, 21, 20]. It is intriguing to study whether or not the effectiveness of over-parameterization and normalization in CNNs may be attributed to the same underlying reasons.
3 Method
Notation.
We use to denote the -th element of a 3D tensor . A tensor can be reshaped without changing the number of its elements, or their values, e.g., a 4D tensor can be reshaped to a 3D tensor , or , where . For simplicity, we will refer to a tensor and its reshaped version(s) with the same symbol. Furthermore, and refer to the same element of and its reshaped version , respectively.
Conventional convolutional layer.
Given an input feature map, a convolutional layer processes it in a sliding window fashion, applying a set of convolution kernels to a patch of corresponding size, at each window position. For the purposes of our exposition, it is convenient to think of a patch as a 2D tensor , where and are the spatial dimensions of the patch,
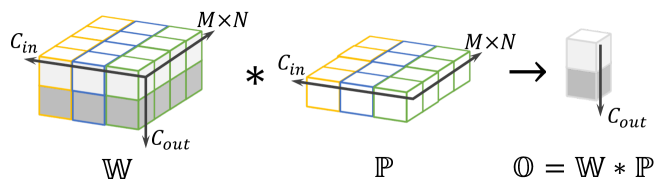
and is the number of channels in the input feature map. The trainable kernels of a convolutional layer222For simplicity, the bias terms are not included in our exposition. can be represented as a 3D tensor , where is the number of channels in the output feature map. The output of a convolution operator is a -dimensional feature :
| (1) |
This is illustrated in Figure 1 (better viewed in color), where , with different input channels in different cube frame colors, with different output channels in different cube face colors, and each element of is produced by a dot-product between one kernel (one horizontal slice of ) and the patch .
Depthwise
convolution.
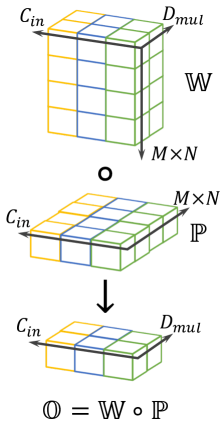
Depthwise convolutional layer.
In a convolutional layer, dot products are computed between each of the kernels and the entire input patch tensor . In contrast, in depthwise convolution, each of the channels of is involved in separate dot-products. Thus, each input patch channel (a -dimensional feature) is transformed into a -dimensional feature. is often referred to as depth multiplier. As depicted in Figure 2, the trainable depthwise convolution kernel can be represented as a 3D tensor . Since each input channel is converted into a -dimensional feature, the output of the depthwise convolution operator is a -dimensional feature :
| (2) |
This is illustrated in Figure 2 (better viewed in color), where , , with different input channels in different cube frame colors, and each element of is computed by the dot product between each vertical column of and the elements in the corresponding channel of (those with the same color).
Depthwise over-parameterized convolutional layer (DO-Conv)
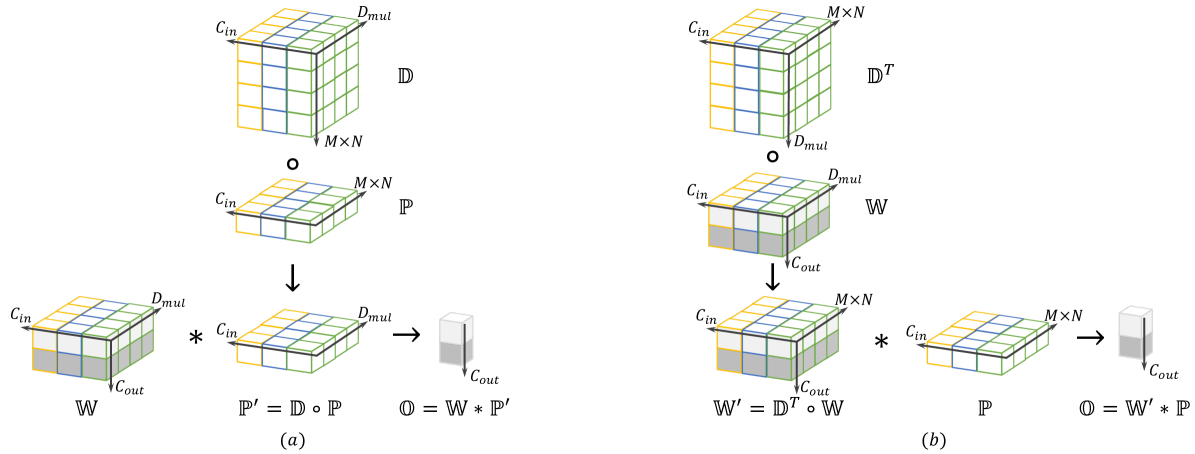
is a composition of a depthwise convolution with trainable kernel and a conventional convolution with trainable kernel , where . Given an input patch , the output of a DO-Conv operator is, the same as that of a convolutional layer, a -dimensional feature . More specifically, as illustrated in Figure 3, the depthwise over-parameterized convolution operator can be applied in two mathematically equivalent ways as:
| (3) | ||||||
| (Fig. 3-a, feature composition) | ||||||
| (Fig. 3-b, kernel composition), | ||||||
where is a transpose of on the first and second axis. Using feature composition, as depicted in Figure 3-a, the depthwise convolution operator first applies the kernel weights to the patch , yielding a transformed feature , and then a conventional convolution operator applies the kernels to , yielding . In contrast, using kernel composition, as depicted in Figure 3-b, the composition of and is achieved through a composite kernel , i.e., a depthwise convolution operator first uses the trainable kernels to transform , yielding , and then a conventional convolution operator is applied between and , yielding .
Note that the receptive field of DO-Conv is still . This is apparent in Figure 3-b, where the depthwise and conventional convolution kernels are composited to process a single input patch of spatial size . This is perhaps less obvious in the feature composition view (Figure 3-a), where the conventional convolution operator is applied to , while could be greater than . Note, however, that the values of are obtained by transforming an spatial patch.
DO-Conv is an over-parameterization of convolutional layer.
This statement can be easily verified using the kernel composition formulation (Figure 3-b). The linear transformation performed by a convolutional layer can be concisely parameterized by trainable weights. However, in DO-Conv, a linear transformation of equivalent expressiveness is parameterized by two sets of trainable kernel weights: and , where . Thus, even for the case where , the number of parameters is increased by . Note that the condition is necessary, otherwise the composite operator cannot express the same family of linear transformations as in a conventional convolutional layer.
Training and inference of CNNs with DO-Conv.
The interface of DO-Conv is same as that of a convolutional layer, thus DO-Conv layers can easily replace convolutional layers in CNNs. Since the operator defined in Equation 3 is differentiable, both and of DO-Conv can be optimized with the gradient descent based optimizer that is used for training CNNs with convolutional layers. After the training phase, and are folded into , and this single is used for the inference. Since is in the same shape as the kernel of a convolutional layer, the computation of DO-Conv at the inference phase is exactly same as that of a conventional convolutional layer.
Training efficiency and composition choice of DO-Conv.
The two ways for computing DO-Conv are mathematically equivalent, but have different training efficiency. The number of multiply and accumulate operations (MACC), is often used for measuring the amount of computation and serves as an indicator of the efficiency. The MACC cost of feature and kernel composition, when they are applied on an feature map in (assuming ), can be calculated as follows:
| Feature composition | |||
| Kernel composition |
where and are the height and width of the feature map, respectively. Note that is computed once for an entire feature map. The MACC costs of feature and kernel composition depend on the values of the involved hyper-parameters. However, in most cases, since and , kernel composition typically incurs fewer MACC operations than feature composition. Similarly, the memory consumed by in kernel composition is typically smaller than that consumed by in feature composition. Therefore, kernel composition is preferable for the training phase.
DO-Conv and depthwise separable convolutional layer [7].
The feature composition of DO-Conv (Figure 3-a) is equivalent to applying a depthwise convolutional layer on an input feature map, yielding an intermediate feature map in channels, and then applying a convolutional layer on the intermediate feature map. This process is exactly same as that of a depthwise separable convolutional layer, where the convolution is often referred to as pointwise convolution. However, the motivation of DO-Conv and depthwise separable convolution is quite different. Depthwise separable convolution is introduced as an approximation and alternative to a conventional convolution for saving MACC to ease the deployment of CNNs especially on edge devices, thus it requires333In earlier versions of Tensorflow [1], setting in the depthwise separable convolutional layer is considered as an error, though this constraint has been removed since commit 1822073. , and is probably the choice most widely used in practice, for example in Xception [7] and MobileNets [18, 30, 17].
Training depthwise separable convolutional layer with kernel composition.
The equivalence between feature and kernel composition holds not only for (DO-Conv), but also for (depthwise separable convolution). We have shown that for DO-Conv, kernel composition often saves MACC and memory, compared with feature composition. For depthwise separable convolution, it is easy to see that feature composition is more economical. While the MACC is highly correlated with the running speed on edge devices that are often computation capability bounded, this might not be the case on NVIDIA GPUs, as they are more memory access bounded. Depthwise separable convolution has a significantly lower MACC cost than a conventional convolution, but it often runs slower on NVIDIA GPUs, which the CNNs are often trained on. To speedup the training of depthwise separable convolution layers on NVIDIA GPUs, kernel composition can be used, after which feature composition can be used for the deployment on edge devices. This handy trick is not the focus of this paper, but a by-product of the feature and kernel composition equivalence that may greatly interest many deep learning practitioners.
Depthwise over-parameterized depthwise/group convolutional layer (DO-DConv/DO-GConv).
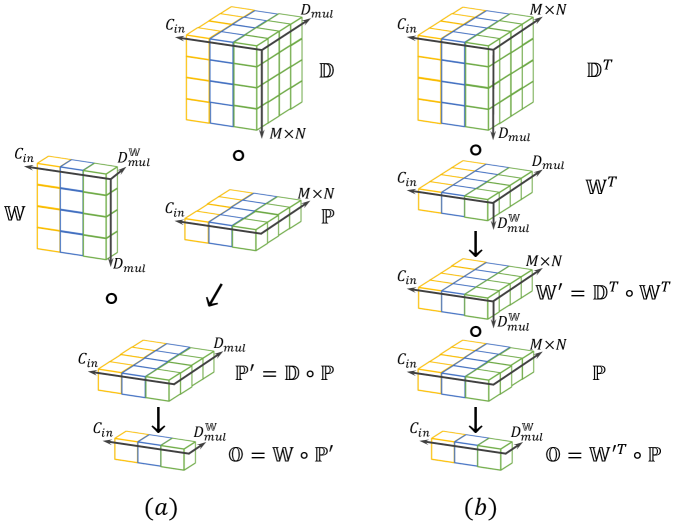
Depthwise over-parameterization can not only be applied over a conventional convolution to yield DO-Conv, but also be applied over a depthwise convolution, which leads to DO-DConv. Following the same principle we used for establishing DO-Conv, as shown in Figure 4, DO-DConv also can be computed in two mathematically equivalent ways as:
| (4) | ||||||
| (Fig. 4-a, feature composition) | ||||||
| (Fig. 4-b, kernel composition) | ||||||
DO-DConv layer can be used as an alternative to depthwise convolutional layer, which is widely used in MobileNets [18, 30, 17]. Same as in DO-Conv, both and are used in the training of DO-DConv, while the folded is used for the inference. Following the same principle used for yielding DO-Conv and DO-DConv, grouped convolutional layer [23], which is a general case of depthwise convolutional layer and is shown to be effective in ResNeXt [34], can be over-parameterized, yielding DO-GConv. We refer to the over-parameterized (depthwise/group) convolutional layer as DO-Conv for simplicity, in cases where there is no ambiguity.
4 Experiments
The choice of and initialization of .
Note that when , the underlying convolution is a pointwise convolution. In this case, there is no spatial patch for the application of the depthwise convolution, thus DO-Conv is not applied. When , the kernel of the underlying convolution is of the same shape as the conventional one, and the over-parameterizing kernel can be viewed as square matrices. We initialize these square matrices to identity , such that in the beginning. In this case, the over-parameterization does not initially change the operation of the original CNN. It also facilitates DO-Conv by reusing the parameters from the pre-trained model. Moreover, since the diagonal elements in could be overly suppressed by regularization, we optimize , where is initialized with zeros, instead of optimizing directly. Unless otherwise noted, we use in our experiments.
Comparison protocol.
The performance of a CNN can be affected by a wide range of factors. To demonstrate the effectiveness of DO-Conv, we take several notable CNNs as baselines, and merely replace the non-pointwise convolutional layers with DO-Conv, without any change to other settings. In other words, the replacement is the one and only difference between the baseline and our method. This guarantees that the observed performance change is due to the application of DO-Conv, but not other factors. Furthermore, this also means that no hyper-parameter is tuned to favor DO-Conv. Following this protocol, we demonstrate the effectiveness of DO-Conv on image classification, semantic segmentation and object detection tasks on several benchmark datasets.
4.1 Image Classification
We conducted image classification experiments on CIFAR [22] and ImageNet [28], with a set of notable architectures including ResNet-v1 [15] (including ResNet-v1b, which modifies ResNet-v1 by setting the stride at the layer of a bottleneck block), Plain (same as ResNet-v1, but without skip links), ResNet-v2 [16], ResNeXt [34], MobileNet-v1 [18], -v2 [30] and -v3 [17].
| Network | Plain | ResNet-v1 | ResNet-v2 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Depth | 20 | 20 | 56 | 110 | 164 | 20 | 56 | 110 | 164 | |
| CIFAR | Baseline | 90.88 | 92.03 | 93.47 | 94.00 | 94.65 | 91.83 | 93.26 | 93.72 | 94.69 |
| -10 | DO-Conv | +0.37 | +0.25 | +0.05 | -0.05 | -0.06 | +0.39 | +0.12 | +0.21 | -0.07 |
| CIFAR | Baseline | 66.01 | 67.37 | 70.65 | 72.58 | 75.43 | 67.14 | 70.15 | 72.00 | 75.32 |
| -100 | DO-Conv | +0.27 | +0.31 | +0.25 | +0.01 | +0.03 | +0.54 | +0.63 | +0.22 | +0.07 |
The experiments on CIFAR follow the same settings as those in [15, 16] and the results are shown in Table 1, where the “DO-Conv” rows show the performance change relative to the baselines. All the results on CIFAR dataset reported in this paper are the averaged accuracy of the last five epochs over five runs. We can observe that DO-Conv brings a promising improvement over the baselines on relatively shallower networks.
| Network | Plain | ResNet-v1 | ResNet-v1b | ResNet-v2 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Depth | 18 | 18 | 34 | 50 | 101 | 152 | 18 | 34 | 50 | 101 | 152 | 18 | 34 | 50 | 101 | 152 |
| Reference | - | 70.93 | 74.37 | 77.36 | 78.34 | 79.22 | 70.94 | 74.65 | 77.67 | 79.20 | 79.69 | 71.00 | 74.40 | 77.17 | 78.53 | 79.21 |
| Baseline | 69.97 | 70.87 | 74.49 | 77.32 | 78.16 | 79.34 | 71.08 | 74.35 | 77.56 | 79.14 | 79.60 | 70.80 | 74.76 | 77.17 | 78.56 | 79.24 |
| DO-Conv | +1.01 | +0.82 | +0.49 | +0.08 | +0.46 | +0.07 | +0.71 | +0.77 | +0.44 | +0.25 | +0.1 | +0.64 | +0.22 | +0.31 | +0.11 | +0.14 |
| Network | MobileNet | ResNeXt | ||
| v1 | v2 | v3 | 5032x4d | |
| Reference | 73.28 | 72.04 | 75.32 | 79.32 |
| Baseline | 73.30 | 71.89 | 75.16 | 79.21 |
| DO-D/GConv | +0.03 | +0.16 | +0.14 | +0.40 |
The experiments on ImageNet follow the same settings as those in the model zoo of GluonCV [12]. We implemented DO-Conv into GluonCV (commit bbe4166), such that it is convenient to make sure DO-Conv is the only change over baselines, since all of the other settings are not touched. We base the experiments on GluonCV since it provides not only a wide variety of high performance CNNs, but also the their training procedures. We consider GluonCV highly reproducible, but still, to exclude clutter factors as much as possible, we train these CNNs as baseline ourselves, and compare DO-Conv versions with them, while reporting the performance provided by GluonCV as reference. The results of DO-Conv and DO-DConv/DO-GConv are summarized in Table 2 and Table 3, respectively. It is clear that DO-Conv consistently boosts the performance of various baselines on ImageNet classification.
| Training Stage | Mean IoU.(%) | ||
|---|---|---|---|
| Backbone | Segmentation | PASCAL VOC | Cityscapes |
| Baseline | Baseline | 88.59 | 78.71 |
| Baseline | DO-Conv | +0.25 | +1.45 |
| DO-Conv | DO-Conv | +0.05 | +0.82 |
4.2 Semantic Segmentation
We also conducted semantic segmentation experiments on the PASCAL VOC [11] and the Cityscapes datasets [8] with GluonCV, following the same comparison protocol as that used for the ImageNet classification task. Differently from image classification, the training of a CNN model for image segmentation often has two stages: the “Backbone” and “Segmentation”. The first stage pre-trains a backbone model on the ImageNet classification task, and the second stage fine-tunes the backbone for the segmentation task. DO-Conv can be used in one or both of the stages. We use Deeplabv3 [5] with ResNet-50 and ResNet-100 as the backbones for Cityscapes and PASCAL VOC datasets, respectively, and summarize the results in Table 4. Note that the delta in both the second and third rows are relative to the first row. We can observe that DO-Conv consistently boosts the performance, either when used only in the second stage, or in both stages.
| Training Stage | |||||||
| Backbone | Detection | ||||||
| Baseline | Baseline | 37.9 | 59.5 | 41.2 | 21.4 | 41.4 | 49.6 |
| Baseline | DO-Conv | +0.0 | +0.4 | -0.2 | +0.7 | +0.6 | -1.0 |
| DO-Conv | DO-Conv | +0.3 | +0.4 | +0.3 | +1.0 | +0.3 | +0.0 |
4.3 Object Detection
We evaluated DO-Conv for object detection task on the COCO [26] dataset using Faster R-CNN [27] with ResNet-50 [15] backbone, again with GluonCV, following the same aforementioned comparison protocol. The results are summarized in Table 5. Similarly to segmentation, the detection task has two stages: the “Backbone” and “Detection”. Note that the delta in both the second and third rows are relative to the first row. We can observe that using DO-Conv in the “Detection” stage only does not improve the overall performance. Yet, when it is used in both stages, an obvious improvement is achieved. Remember that no hyper-parameter tuning was done when making these comparisons, and all the experiments stick to the hyper-parameters tuned for the baselines.
4.4 Visualizations
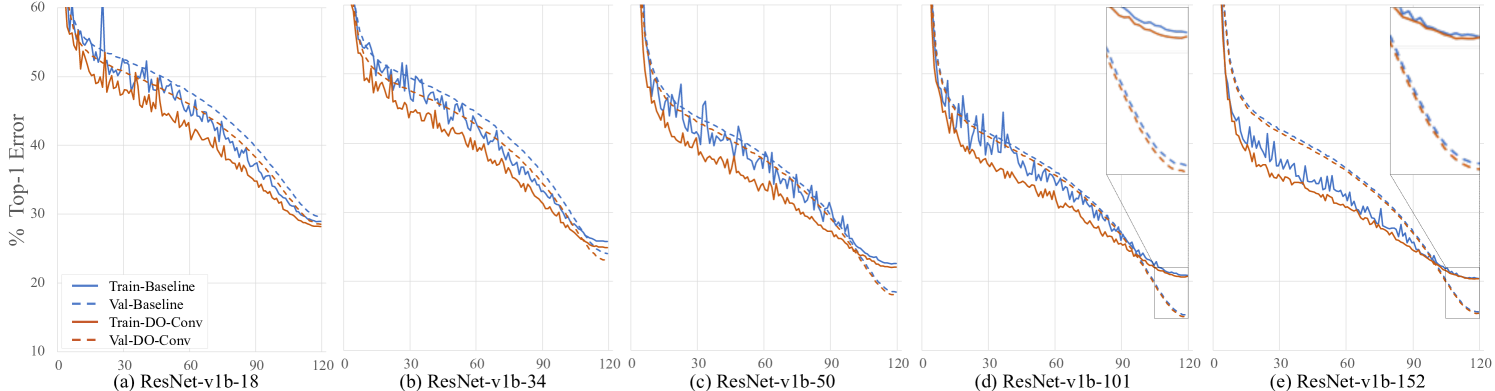
Training dynamics.
We show the train and validation curves of baseline and DO-Conv over 120 epochs with ResNet-v1b in different depths in Figure 5. The hyper-parameters of ResNet in GluonCV are different from those used in the original ResNet work [15]. One notable difference is that the learning rate is gradually decayed to zero at the end of training, and the training converges to a significantly better performance than that reported in [15]. It is clear that the training of DO-Conv not only converges faster, but also converges to lower errors. While faster convergence due to over-parameterization has been reported before [3], to the best of our knowledge, we are the first to report convergence to lower errors on mainstream architectures.

Effect of on .
This is visualized in Figure 6, where is the accumulated absolute difference between and , i.e., . We found that while some s exhibit strong skeleton pattern (major differences on center row and column) as observed in ACNet [10], other s exhibit rather different patterns, such as “Stage2 Conv5” and “Stage3 Conv5” in Figure 6 (B).
4.5 Ablation Studies
DO-Conv in different ResNet stages.
| Stage of ResNet | CIFAR-100 | ImageNet | ||||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | ResNet-v2-20 | ResNet-v1b-50 |
| Baseline | 67.14 | 77.56 | ||||
| +0.17 | +0.17 | |||||
| +0.02 | -0.07 | |||||
| +0.25 | -0.03 | |||||
| +0.29 | +0.02 | |||||
| - | +0.06 | |||||
| +0.10 | -0.11 | |||||
| +0.32 | +0.16 | |||||
| +0.55 | +0.14 | |||||
| - | +0.44 | |||||
We show the results of replacing the convolutional layers in subsets of ResNet stages with DO-Conv in Table 6. For ResNet-v2-20 on CIFAR-100, the accuracy consistently improves when more DO-Conv are used. For ResNet-v1b-50 on ImageNet, the effect is more complicated, as the use of DO-Conv in certain stages may result in a performance drop. The effectiveness of DO-Conv in the first stage is consistent in both cases.
Different initialization of .
| Baseline | 77.56 |
|---|---|
| DO-Conv (random-init) | +0.18 |
| DO-Conv (identity-init) | +0.44 |
The kernels in CNNs are usually randomly initialized when training the networks from scratch. Since the role of the over-parameterization kernel is different than that of other kernels, we opt to initialize it as identity. However, we found that even if it is randomly initialized (with He initialization [14]), it can still boost the performance, though the gain is smaller, compared to identity initialization, as shown in Table 7.
What if ?
| Baseline | 67.14 |
|---|---|
| DO-Conv () | +0.55 |
| DO-Conv () | +0.36 |
| DO-Conv () | +0.47 |
In this case, the matrices of are no longer square, and they are initialized by filling identity matrices as much as possible, while the remaining elements are initialized to zeros. We tested two such settings of and summarized the results in Table 8. We can observe that all three choices of yield an improvement over the baseline. However, the performance using is the best among the three, thus we empirically use .
5 Conclusions and Future work
DO-Conv, a depthwise over-parameterized convolutional layer, is a novel, simple and generic way for boosting the performance of CNNs. Beyond the practical implications of improving training and final accuracy for existing CNNs, without introducing extra computation at the inference phase, we envision that the unveiling of its advantages could also encourage further exploration of over-parameterization as a novel dimension in network architecture design.
In the future, it would be intriguing to get a theoretical understanding of this rather simple means in achieving the surprisingly non-trivial performance improvements on a board range of applications. Furthermore, we would like to expand the scope of applications where these over-parameterized convolution layers may be effective, and learn what hyper-parameters can benefit more from it.
Broader Impact
We believe that the impact of our work is mainly to improve the performance of existing CNN models on a variety of computer vision tasks. It could also assist in developing CNN-based solutions to tasks which have not yet been tackled in this manner. We do not believe that our work has any ethical or social implications beyond those stated above.
References
- [1] Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G.S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jia, Y., Jozefowicz, R., Kaiser, L., Kudlur, M., Levenberg, J., Mané, D., Monga, R., Moore, S., Murray, D., Olah, C., Schuster, M., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viégas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., Zheng, X.: TensorFlow: Large-scale machine learning on heterogeneous systems (2015), http://tensorflow.org/, software available from tensorflow.org
- [2] Allen-Zhu, Z., Li, Y., Song, Z.: A convergence theory for deep learning via over-parameterization. In: International Conference on Machine Learning. pp. 242–252 (2019)
- [3] Arora, S., Cohen, N., Hazan, E.: On the optimization of deep networks: Implicit acceleration by overparameterization. In: 35th International Conference on Machine Learning (2018)
- [4] Bjorck, N., Gomes, C.P., Selman, B., Weinberger, K.Q.: Understanding batch normalization. In: Advances in Neural Information Processing Systems. pp. 7694–7705 (2018)
- [5] Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017)
- [6] Chen, Y., Fan, H., Xu, B., Yan, Z., Kalantidis, Y., Rohrbach, M., Yan, S., Feng, J.: Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 3435–3444 (2019)
- [7] Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1251–1258 (2017)
- [8] Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3213–3223 (2016)
- [9] Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 764–773 (2017)
- [10] Ding, X., Guo, Y., Ding, G., Han, J.: ACNet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 1911–1920 (2019)
- [11] Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision 111(1), 98–136 (2015)
- [12] Guo, J., He, H., He, T., Lausen, L., Li, M., Lin, H., Shi, X., Wang, C., Xie, J., Zha, S., et al.: Gluoncv and gluonnlp: Deep learning in computer vision and natural language processing. Journal of Machine Learning Research 21(23), 1–7 (2020)
- [13] Guo, S., Alvarez, J.M., Salzmann, M.: ExpandNet: Training compact networks by linear expansion. arXiv preprint arXiv:1811.10495 (2018)
- [14] He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 1026–1034 (2015)
- [15] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
- [16] He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: Proceedings of the European Conference on Computer Vision. pp. 630–645. Springer (2016)
- [17] Howard, A., Sandler, M., Chu, G., Chen, L.C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., et al.: Searching for MobileNetv3. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 1314–1324 (2019)
- [18] Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
- [19] Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015)
- [20] Kohler, J., Daneshmand, H., Lucchi, A., Hofmann, T., Zhou, M., Neymeyr, K.: Exponential convergence rates for batch normalization: The power of length-direction decoupling in non-convex optimization. In: The 22nd International Conference on Artificial Intelligence and Statistics. pp. 806–815 (2019)
- [21] Kohler, J.M., Daneshmand, H., Lucchi, A., Zhou, M., Neymeyr, K., Hofmann, T.: Towards a theoretical understanding of batch normalization. arXiv preprint arXiv:1805.10694 (2018)
- [22] Krizhevsky, A.: Learning Multiple Layers of Features from Tiny Images. Master’s thesis, University of Toronto (April 2009)
- [23] Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems. pp. 1097–1105 (2012)
- [24] Li, X., Wang, W., Hu, X., Yang, J.: Selective kernel networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 510–519 (2019)
- [25] Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2980–2988 (2017)
- [26] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Proceedings of the European Conference on Computer Vision. pp. 740–755. Springer (2014)
- [27] Ren, S., He, K., Girshick, R.B., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 39, 1137–1149 (2015)
- [28] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al.: ImageNet large scale visual recognition challenge. International Journal of Computer Vision 115(3), 211–252 (2015)
- [29] Salimans, T., Kingma, D.P.: Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In: Advances in Neural Information Processing Systems. pp. 901–909 (2016)
- [30] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: MobileNetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 4510–4520 (2018)
- [31] Santurkar, S., Tsipras, D., Ilyas, A., Madry, A.: How does batch normalization help optimization? In: Advances in Neural Information Processing Systems. pp. 2483–2493 (2018)
- [32] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: ICLR (2014)
- [33] Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1–9 (2015)
- [34] Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1492–1500 (2017)
- [35] Zhu, X., Hu, H., Lin, S., Dai, J.: Deformable convnets v2: More deformable, better results. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 9308–9316 (2019)