[name=Theorem,numberwithin=section]thm \declaretheorem[name=Proposition,numberwithin=section]pro
Do not Let Privacy Overbill Utility: Gradient Embedding Perturbation for Private Learning
Abstract
The privacy leakage of the model about the training data can be bounded in the differential privacy mechanism. However, for meaningful privacy parameters, a differentially private model degrades the utility drastically when the model comprises a large number of trainable parameters. In this paper, we propose an algorithm Gradient Embedding Perturbation (GEP) towards training differentially private deep models with decent accuracy. Specifically, in each gradient descent step, GEP first projects individual private gradient into a non-sensitive anchor subspace, producing a low-dimensional gradient embedding and a small-norm residual gradient. Then, GEP perturbs the low-dimensional embedding and the residual gradient separately according to the privacy budget. Such a decomposition permits a small perturbation variance, which greatly helps to break the dimensional barrier of private learning. With GEP, we achieve decent accuracy with reasonable computational cost and modest privacy guarantee for deep models. Especially, with privacy bound , we achieve test accuracy on CIFAR10 and test accuracy on SVHN, significantly improving over existing results.
1 Introduction
Recent works have shown that the trained model may leak/memorize the information of its training set (Fredrikson et al., 2015; Wu et al., 2016; Shokri et al., 2017; Hitaj et al., 2017), which raises privacy issue when the models are trained with sensitive data. Differential privacy (DP) mechanism provides a way to quantitatively measure and upper bound such information leakage. It theoretically ensures that the influence of any individual sample is negligible with the DP parameter or . Moreover, it has been observed that differentially private models can also resist model inversion attack (Carlini et al., 2019), membership inference attack (Rahman et al., 2018; Bernau et al., 2019; Sablayrolles et al., 2019; Yu et al., 2021), gradient matching attack (Zhu et al., 2019), and data poisoning attack (Ma et al., 2019).
One popular way to achieve differentially private machine learning is to perturb the training process with noise (Song et al., 2013; Bassily et al., 2014; Shokri & Shmatikov, 2015; Wu et al., 2017; Fukuchi et al., 2017; Iyengar et al., 2019; Phan et al., 2020). Specifically, gradient perturbation perturbs the gradient at each iteration of (stochastic) gradient descent algorithm and guarantees the privacy of the final model via composition property of DP. It is worthy to note that gradient perturbation does not assume (strongly) convex objective and hence is applicable to various settings (Abadi et al., 2016; Wang et al., 2017; Lee & Kifer, 2018; Jayaraman et al., 2018; Wang & Gu, 2019; Yu et al., 2020). Specifically, for given gradient sensitivity , a general form of gradient perturbation is to add an isotropic Gaussian noise to the gradient independently for each step,
| (1) |
One can set proper variance to make each update differentially private with parameter . It is easy to see that the intensity of the added noise scales linearly with the model dimension . This indicates that as the model becomes larger, the useful signal, i.e., gradient, would be submerged in the added noise (see Figure 2). This dimensional barrier restricts the utility of deep learning models trained with gradient perturbation.
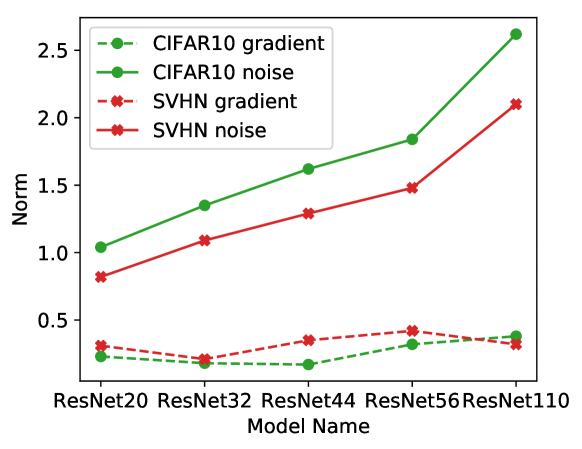
The dimensional barrier is attributed to the fact that the added noise is isotropic while the gradients live on a very low dimensional manifold, which has been observed in (Gur-Ari et al., 2018; Vogels et al., 2019; Gooneratne et al., 2020; Li et al., 2020) and is also verified in Figure 2 for the gradients of a 20-layer ResNet (He et al., 2016). Hence to limit the noise energy, it is natural to think
“Can we reduce the dimension of gradients first and then add the isotropic noise onto a low-dimensional gradient embedding?"
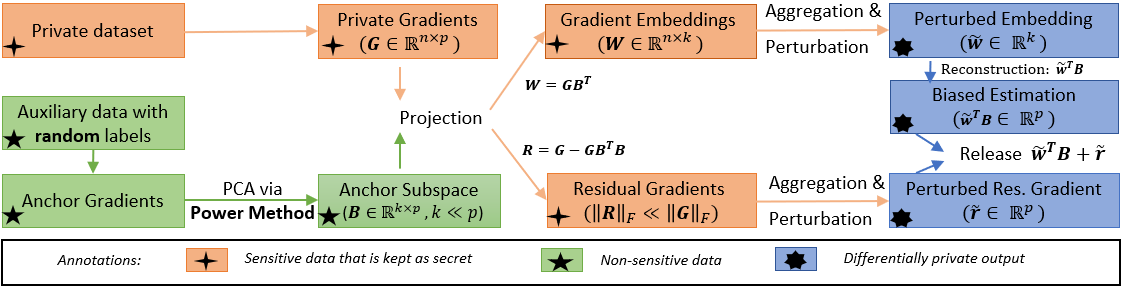
The answer is affirmative. We propose a new algorithm Gradient Embedding Perturbation (GEP), illustrated in Figure 3. Specifically, we first compute anchor gradients on some non-sensitive auxiliary data, and identify an anchor subspace that is spanned by several top principal components of the anchor gradient matrix. Then we project the private gradients into the anchor subspace and obtain low-dimensional gradient embeddings and small-norm residual gradients. Finally, we perturb the gradient embedding and residual gradient separately according to the sensitivities and privacy budget.
We intuitively argue why GEP could reduce the perturbation variance and achieve good utility for large models. First, because the gradient embedding has a very low dimension, the added isotropic noise on embedding has small energy that scales linearly only with the subspace dimension. Second, if the anchor subspace can cover most of the gradient information, the residual gradient, though high dimensional, should have small magnitude, which permits smaller added noise to guarantee the same level privacy because of the reduced sensitivity. Overall, we can use a much lower perturbation compared with the original gradient perturbation to guarantee the same level of privacy.
We emphasize several properties of GEP. First, the non-sensitive auxiliary data assumption is weak. In fact, GEP only requires a small number of non-sensitive unlabeled data following a similar feature distribution as the private data, which often exist even for learning on sensitive data. In our experiments, we use a few unlabeled samples from ImageNet to serve as auxiliary data for MNIST, SVHN, and CIFAR-10. This assumption is much weaker than the public data assumption in previous works (Papernot et al., 2017; 2018; Alon et al., 2019; Wang & Zhou, 2020), where the public data should follow exactly the same distribution as the private data. Second, GEP produces an unbiased estimator of the target gradient because of releasing both the perturbed gradient embedding and the perturbed residual gradient, which turns out to be critical for good utility. Third, we use power method to estimate the principal components of anchor gradients, achievable with a few matrix multiplications. The fact that GEP is not sensitive to the choices of subspace dimension further allows a very efficient implementation.
Compared with existing works of differentially private machine learning, our contribution can be summarized as follows: (1) we propose a novel algorithm GEP that achieves good utility for large models with modest differential privacy guarantee; (2) we show that GEP returns an unbiased estimator of target private gradient with much lower perturbation variance than original gradient perturbation; (3) we demonstrate that GEP achieves state-of-the-art utility in differentially private learning with three benchmark datasets. Specifically, for , GEP achieves test accuracy on CIFAR-10 with a ResNet20 model. To the best of our knowledge, GEP is the first algorithm that can achieve such utility with training deep models from scratch for a “single-digit" privacy budget111Abadi et al. (2016) achieve accuracy on CIFAR-10 but they need to pre-train the model on CIFAR-100..
1.1 Related work
Existing works studying differentially private machine learning in high-dimensional setting can be roughly categorized into two sets. One is treating the optimization of the machine learning objective as a whole mechanism and adding noise into this process. The other one is based on the knowledge transfer of machine learning models, which trains a differentially private publishable student model with private signals from teacher models. We review them one by one.
Differentially private convex optimization in high-dimensional setting has been studied extensively over the years (Kifer et al., 2012; Thakurta & Smith, 2013; Talwar et al., 2015; Wang & Xu, 2019; Wang & Gu, 2019). Although these methods demonstrate good utility on some convex settings, their analyses can not be directly applied to non-convex setting. Right before the submission, we note two independent and concurrent works (Zhou et al., 2020; Kairouz et al., 2020) that also leverage the gradient redundancy to reduce the added noise. Specifically, Kairouz et al. (2020) track historical gradients to do dimension reduction for private AdaGrad. Zhou et al. (2020) requires gradients on some public data and then project the noisy gradients into a public subspace at each update. One core difference between these two works and GEP is that we introduce residual gradient perturbation and GEP produces an unbiased estimator of the private gradients, which is essential for achieving the superior utility. Moreover, we weaken the auxiliary data assumption and introduce several designs that significantly boost the efficiency and applicability of GEP.
One recent progress towards training arbitrary models with differential privacy is Private Aggregation of Teacher Ensembles (PATE) (Papernot et al., 2017; 2018; Jordon et al., 2019). PATE first trains independent teacher models on disjoint shards of private data. Then it trains a student model with privacy guarantee by distilling noisy predictions of teacher models on some public samples. In comparison, GEP only requires some non-sensitive data that have similar natural features as the private data while PATE requires the public data follow exactly the same distribution as the private data and in practice it uses a portion of the test data to serve as public data. Moreover, GEP demonstrates better performance than PATE especially for complex datasets, e.g., CIFAR-10, because GEP can train the model with the whole private data rather than a small shard of data.
2 Preliminaries
We introduce some notations and definitions. We use bold lowercase letters, e.g., , and bold capital letters, e.g., , to denote vectors and matrices, respectively. The norm of a vector is denoted by . The spectral norm and the Frobenius norm of a matrix are denoted by and , respectively. A sample consists of feature and label . A dataset is a collection of individual samples. A dataset is said to be a neighboring dataset of if they differ in a single sample, denoted as . Differential privacy ensures that the outputs of an algorithm on neighboring datasets have approximately indistinguishable distributions.
Definition 1 (-DP (Dwork et al., 2006a; b)).
A randomized mechanism guarantees -differential privacy if for any two neighboring input datasets and for any subset of outputs it holds that .
By its definition, -DP controls the maximum influence that any individual sample can produce. One can adjust the privacy parameters to trade off between privacy and utility. Differential privacy is immune to post-processing (Dwork et al., 2014), i.e., any function applied on the output of a differentially private algorithm would not increase the privacy loss as long as it does not have new interaction with the private dataset. Differential privacy also allows composition, i.e., the composition of a series of differentially private mechanisms is also differentially private but with different parameters. Several variants of -DP have been proposed (Bun & Steinke, 2016; Dong et al., 2019) to address certain weakness of -DP, e.g., they achieve better composition property. In this work, we use Rényi differential privacy (Mironov, 2017) to track the privacy loss and then convert it to -DP.
Suppose that there is a private dataset with samples. We want to train a model to learn the mapping in . Specifically, takes as input and outputs a label , and has parameter . The training objective is to minimize an empirical risk , where is a loss function. We further assume that there is an auxiliary dataset that shares similar features as in while could be random.
3 Gradient embedding perturbation
An overview of GEP is given in Figure 3. GEP has three major ingredients: 1) first, estimate an anchor subspace that contains the principal components of some non-sensitive anchor gradients via power method; 2) then, project private gradients into the anchor subspace and produce low-dimensional embeddings of private gradients and residual gradients; 3) finally, perturb gradient embedding and residual gradient separately to establish differential privacy guarantee. In Section 3.1, we present the GEP algorithm in detail. In Section 3.2, we given an analysis on the residual gradients. In Section 3.3, we give a differentially private learning algorithm that updates the model with the output of GEP.
3.1 The GEP algorithm and its privacy analysis
The pseudocode of GEP is presented in Algorithm 1. For convenience, we write a set of gradients and a set of basis vectors as matrices with each row being one gradient/basis vector.
The anchor subspace is constructed as follows. We first compute the gradients of the model on an auxiliary dataset with samples, which is referred to as the anchor gradients . We then use the power method to estimate the principal components of to construct a subspace basis , which is referred to as the anchor subspace. All these matrices are publishable because is non-sensitive. We expect that the anchor subspace can cover most energy of private gradients when the auxiliary data are not far from private data and are reasonably large.
Suppose that the private gradients are . Then, we project the private gradients into the anchor subspace . The projection produces low-dimensional embeddings and residual gradients . The magnitude of residual gradients is usually much smaller than original gradient even when is small because of the gradient redundancy.
Then, we aggregate the gradient embeddings and the residual gradients, respectively. We perturb the aggregated embedding and the aggregated residual gradient respectively to guarantee certain differential privacy. Finally, we release the perturbed embedding and the perturbed residual gradient and construct an unbiased estimator of the private gradient: . This construction process does not resulting in additional privacy loss because of DP’s post-processing property. The privacy analysis of the whole process of GEP is given in Theorem 1.
[] Let and be the sensitivity of and , respectively, the output of Algorithm 1 satisfies -DP for any and if we choose and .
A common practice to control sensitivity is to clip the output with a pre-defined threshold. In our experiments, we use different thresholds and to clip the gradient embeddings and residual gradients, respectively. The privacy loss of GEP consists of two parts: the privacy loss incurred by releasing the perturbed embedding and the privacy loss incurred by releasing the perturbed residual gradient. We compose these two parts via the Rényi differential privacy and convert it to -DP.
We highlight several implementation techniques that make GEP widely applicable and implementable with reasonable computational cost. Firstly, auxiliary non-sensitive data do not have to be the same source as the private data and the auxiliary data can be randomly labeled. This non-sensitive data assumption is very weak and easy to satisfy in practical scenarios. To understand why random label works, a quick example is that for the least squares regression problem the individual gradient is aligned with the feature vector while the label only scales the length but does not change the direction. This auxiliary data assumption avoids conducting principal component analysis (PCA) on private gradients, which requires releasing private high-dimensional basis vectors and hence introduces large privacy loss. Secondly, we use power method (Panju, 2011; Vogels et al., 2019) to approximately estimate the principal components. The new operation we introduce is standard matrix multiplication that enjoys efficient implementation on GPU. The computational complexity of each power iteration is , where is the number of model parameters, is the number of anchor gradients and is the number of subspace basis vectors. Thirdly, we divide the parameters into different groups and compute one orthonormal basis for each group. This further reduces the computational cost. For example, suppose the parameters are divided into two groups with size and the numbers of basis vectors are , the computational complexity of each power iteration is , which is smaller than . In Appendix B, we analyze the additional computational and memory costs of GEP compared to standard gradient perturbation.
Curious readers may wonder if we can use random projection to reduce the dimensionality as Johnson–Lindenstrauss Lemma (Dasgupta & Gupta, 2003) guarantees that one can preserve the pairwise distance between any two points after projecting into a random subspace of much lower dimension. However, preserving the pairwise distance is not sufficient for high quality gradient reconstruction, which is verified by the empirical observation in Appendix C.
3.2 An analysis on the residual gradients of GEP
Let be the target private gradient. For a given anchor subspace , the residual gradients are defined as . We then analyze how large the residual gradients could be. The following argument holds for all time steps and we ignore the time step index for simplicity.
For the ease of discussion, we introduce for to denote the the private gradients and the for to denote the anchor gradients. We use to denote the largest eigenvalue of a given matrix. We assume that the private gradients and the anchor gradients are sampled independently from a distribution . We assume to be the population gradient (uncentered) covariance matrix. We also consider the (uncentered) empirical gradient covariance matrix .
One case is that the population gradient covariance matrix is low-rank . In this case we can argue that the residual gradients are once the number of anchor gradients .
Lemma 3.1.
Assume that the population covariance matrix is with rank and the distribution satisfies for all -flats in with . Let and be the eigendecompositions of and the empirical covariance matrix , respectively, such that and . Then if , we have with probability 1,
| (2) |
Proof.
The proof is based on the non-singularity of covariance matrix. See Appendix D. ∎
We note that -flat is the translate of an -dimensional linear subspace in and the normal distribution satisfies such condition (Eaton & Perlman, 1973; Muirhead, 2009). Therefore, we have seen that for low-rank case of population covariance matrix, the residual gradients are 0 once . In the general case, we measure the expected norm of the residual gradients.
Lemma 3.2.
Assume that and almost surely. Let be the eigendecomposition of the population covariance matrix . Let be the eigendecomposition of the empirical covariance matrix . Then we have with probability ,
| (3) |
where , is a projection operator onto the subspace and the is taken over the randomness of .
Proof.
The proof is an adaptation of Theorem 3.1 in Blanchard et al. (2007). ∎
From Lemma 3.2, we can see the larger the number of anchor gradients and the dimension of the anchor subspace , the smaller the residual gradients. We can choose properly such that the upper bound on the expected residual gradient norm is small. This indicates that we may use a smaller clipping threshold and consequently apply smaller noises with achieving the same privacy guarantee.
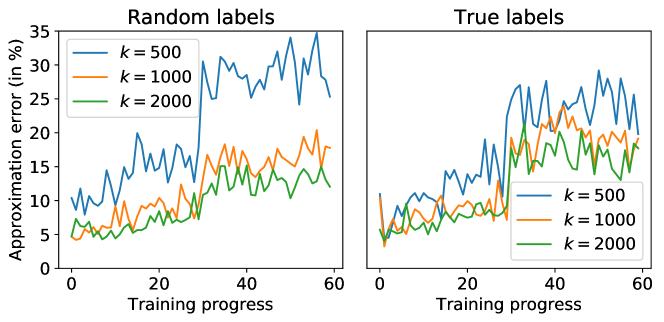
We next empirically examine the projection error by training a -layer ResNet on CIFAR10 dataset. We try two different types of auxiliary data to compute the anchor gradients: 1) samples from the same source as private data with correct labels, i.e., random samples from the test data; 2) samples from different source with random labels, i.e., random samples from ImageNet. The relation between the dimension of anchor subspace and the projection error rate () is presented in Figure 5. We can see that the project error is small and decreases with , and the benefit of increasing diminishes when is large, which is implied by Lemma 3.2. In practice one can only use small or moderate because of the memory constraint. GEP needs to store at least individual gradients and each individual gradient consumes the same amount of memory as the model itself. Moreover, we can see that the projection into anchor subspace of random labeled auxiliary data yields comparable projection error, corroborating our argument that unlabeled auxiliary data are sufficient for finding the anchor subspace.
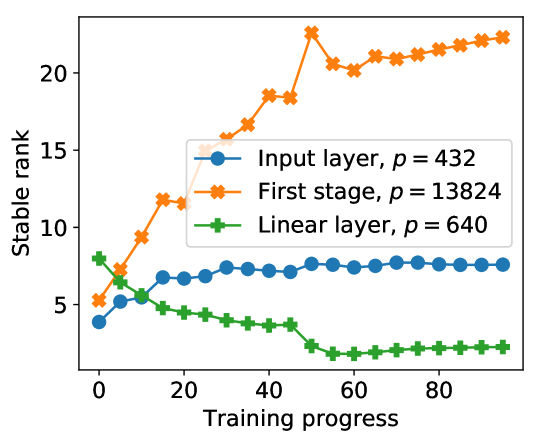
We also verify that the redundancy of residual gradients is small, by plotting the stable rank of residual gradient matrix in Figure 5. The stable rank of residual gradient matrix is an order of magnitude higher than the stable rank of original gradient matrix. This implies that it could be hard to further approximate with low-dimensional embeddings.
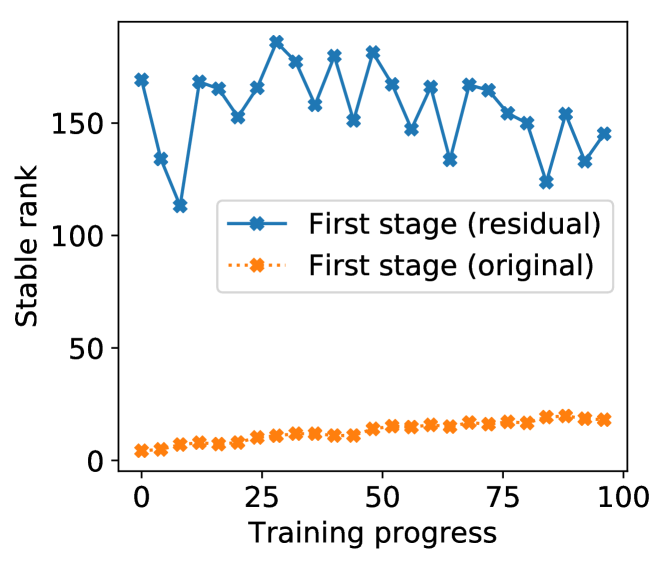
We next compare the GEP with a scheme that simply discards the residual gradients and only outputs the perturbed gradient embedding, i.e., the output is .
Remark 1.
Let be the reconstructed gradient from noisy gradient embedding and be the output of GEP. If ignoring the effect of gradient clipping, we have
| (4) |
where is the aggregated residual gradients, are given in Algorithm 1 and the expectation is over the added random noises.
This indicates that contains a systematic error that makes always deviate from by the residual gradient. This systematic error is the projection error, which is plotted in Figure 5. The systematic error cannot be mitigated by reducing the noise magnitude (e.g., increasing the privacy budget or collecting more private data). We refer to the algorithm releasing directly as Biased-GEP or B-GEP for short, which can be viewed as an efficient implementation of the algorithm in (Zhou et al., 2020). In our experiments, B-GEP can outperform standard gradient perturbation when is large but is inferior to GEP. We note that the above remark is made with ignoring the clipping effect (or set a large clipping threshold). In practice, we do apply clipping for the individual gradients at each time step, which makes the expectations in Remark 1 obscure (Chen et al., 2020b). We note that the claim that is an unbiased estimator of is not that precise when applying gradient clipping.
3.3 Private learning with gradient embedding perturbation
GEP (Algorithm 1) describes how to release one-step gradient with privacy guarantee. In this section, we compose the privacy losses at each step to establish the privacy guarantee for the whole learning process. The differentially private learning process with GEP is given in Algorithm 2 and the privacy analysis is presented in Theorem 2.
[] For any and , the output of Algorithm 2 satisfies -DP if we set .
If the private gradients are randomly sampled from the full batch gradients, the privacy guarantee can be strengthened via the privacy amplification by subsampling theorem of DP (Balle et al., 2018; Wang et al., 2019; Zhu & Wang, 2019; Mironov et al., 2019). Theorem 2 gives the expected excess error of Algorithm 2. Expected excess error measures the distance between the algorithm’s output and the optimal solution in expectation.
[] Suppose the loss is 1-Lipschitz, convex, and -smooth. If , , and , then we have , where and is the sensitivity of residual gradient at step .
The term represents the average projection error over the training process. The previous best expected excess error for gradient perturbation is (Wang et al., 2017). As shown in Lemma 3.1, if the gradients locate in a -dimensional subspace over the training process, and the excess error is , independent of the problem ambient dimension . When the gradients are in general position, i.e., gradient matrix is not exact low-rank, Lemma 3.2 and the empirical result give a hint on how small the residual gradients could be. However, it is hard to get a good bound on and the bound in Theorem 2 does not explicitly improve over previous result. One possible solution is to use a clipping threshold based on the expected residual gradient norm. Then the output gradient becomes biased because of clipping and the utility/privacy guarantees in Theorem 2/2 require new elaborate derivation. We leave this for future work.
4 Experiments
We conduct experiments on MNIST, extended SVHN, and CIFAR-10 datasets. Our implementation is publicly available222https://github.com/dayu11/Gradient-Embedding-Perturbation. The model for MNIST has two convolutional layers with max-pooling and one fully connected layer. The model for SVHN and CIFAR-10 is ResNet20 in He et al. (2016). We replace all batch normalization (Ioffe & Szegedy, 2015) layers with group normalization (Wu & He, 2018) layers because batch normalization mixes the representations of different samples and makes the privacy loss cannot be analyzed accurately. The non-private accuracy for MNIST, SVHN, and CIFAR-10 is 99.1%, 95.9%, and 90.4%, respectively.
We also provide experiments with pre-trained models in Appendix A. Tramèr & Boneh (2020) show that differentially private linear classifier can achieve high accuracy using the features produced by pre-trained models. We examine whether GEP can improve the performance of such private linear classifiers. Notably, using the features produced by a model pre-trained on unlabeled ImageNet, GEP achieves 94.8% validation accuracy on CIFAR10 with .
Evaluated algorithms We use the algorithm in Abadi et al. (2016) as benchmark gradient perturbation approach, referred to as “GP”. We also compare GEP with PATE (Papernot et al., 2017). We run the experiments for PATE using the official implementation. The privacy parameter of PATE is data-dependent and hence cannot be released directly (see Section 3.3 in Papernot et al. (2017)). Nonetheless, we report the results of PATE anyway.
Implementation details At each step, GEP needs to release two vectors: the noisy gradient embedding and the noisy residual gradient. The gradient embeddings have a sensitivity of and the residual gradients have a sensitivity of because of the clipping. The output of GEP can be constructed as follows: (1) normalize the gradient embeddings and residual gradients by and , respectively, (2) concatenate the rescaled vectors, (3) release the concatenated vector via gaussian mechanism with sensitivity , (4) rescale the two components by and . B-GEP only needs to release the normalized noisy gradient embedding. We use the numerical tool in Mironov et al. (2019) to compute the privacy loss. For given privacy budget and sampling probability, is set to be the smallest value such that the privacy budget is allowable to run desired epochs.
All experiments are run on a single Tesla V100 GPU with 16G memory. For ResNet20, the parameters are divided into five groups: input layer, output layer, and three intermediate stages. For a given quota of basis vectors, we allocate it to each group according to the square root of the number of parameters in each group. We compute an orthonormal subspace basis on each group separately. Then we concatenate the projections of all groups to construct gradient embeddings. The number of power iterations is set as as empirical evaluations suggest more iterations do not improve the performance for GEP and B-GEP.
For all datasets, the anchor gradients are computed on random samples from ImageNet. In Appendix C, we examine the influence of choosing different numbers of anchor gradients and different sources of auxiliary data. The selected images are downsampled into size of ( for MNIST) and we label them randomly at each update. For SVHN and CIFAR-10, is chosen from . For MNIST, we halve the size of . We use SGD with momentum 0.9 as the optimizer. Initial learning rate and batchsize are and , respectively. The learning rate is divided by at middle of training. Weight decay is set as . The clipping threshold for is for original gradients and for residual gradients. The number of training epochs for CIFAR-10 and MNIST is 50, 100, 200 for privacy parameter , respectively. The number of training epochs for SVHN is 5, 10, 20 for privacy parameter , respectively. Privacy parameter is for SVHN and for CIFAR-10 and MNIST.
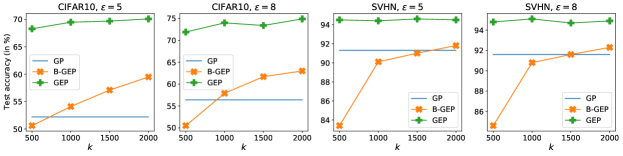
Results The best accuracy with given is in Table 1. For all datasets, GEP achieves considerable improvement over GP in Abadi et al. (2016). Specifically, GEP achieves test accuracy on CIFAR-10 with -DP, outperforming GP by . PATE achieves best accuracy on MNIST but its performance drops as the dataset becomes more complex.
We also plot the relation between accuracy and in Figure 6. GEP is less sensitive to the choice of and outperforms B-GEP for all choices of . The improvement of increasing becomes smaller as becomes larger. We note that the memory cost of choosing large is high because we need to store at least individual gradients to compute anchor subspace.
| Dataset | Algorithm | ||||||
| MNIST | GP | 94.7 | +0.0 | 96.8 | +0.0 | 97.2 | +0.0 |
| PATE | 98.5 | +3.8 | 98.5 | +1.7 | 98.6 | +1.4 | |
| B-GEP | 93.1 | -1.6 | 94.5 | -2.3 | 95.9 | -1.3 | |
| GEP | 96.3 | +1.6 | 97.9 | +1.1 | 98.4 | +1.2 | |
| SVHN | GP | 87.1 | +0.0 | 91.3 | +0.0 | 91.6 | +0.0 |
| PATE | 80.7 | -6.4 | 91.6 | +0.3 | 91.6 | +0.0 | |
| B-GEP | 88.5 | +1.4 | 91.8 | +0.5 | 92.3 | +0.7 | |
| GEP | 92.3 | +5.2 | 94.7 | +3.4 | 95.1 | +3.5 | |
| CIFAR-10 | GP | 43.6 | +0.0 | 52.2 | +0.0 | 56.4333The test accuracy of DP-SGD can be improved to 62% by tuning the hyperparameters. See the implementation in https://github.com/dayu11/Differentially-Private-Deep-Learning. | +0.0 |
| PATE | 34.2 | -9.4 | 41.9 | -10.3 | 43.6 | -12.8 | |
| B-GEP | 50.3 | +6.7 | 59.5 | +7.3 | 63.0 | +6.6 | |
| GEP | 59.7 | +16.1 | 70.1 | +17.9 | 74.9 | +18.5 |
5 Conclusion
In this paper, we propose Gradient Embedding Perturbation (GEP) for learning with differential privacy. GEP leverages the gradient redundancy to reduce the added noise and outputs an unbiased estimator of target gradient. The several key designs of GEP significantly boost the applicability of GEP. Extensive experiments on real world datasets demonstrate the superior utility of GEP.
References
- Abadi et al. (2016) Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In ACM SIGSAC Conference on Computer and Communications Security, 2016.
- Alon et al. (2019) Noga Alon, Raef Bassily, and Shay Moran. Limits of private learning with access to public data. In Advances in Neural Information Processing Systems, 2019.
- Balle et al. (2018) Borja Balle, Gilles Barthe, and Marco Gaboardi. Privacy amplification by subsampling: Tight analyses via couplings and divergences. In Advances in Neural Information Processing Systems, 2018.
- Bassily et al. (2014) Raef Bassily, Adam Smith, and Abhradeep Thakurta. Differentially private empirical risk minimization: Efficient algorithms and tight error bounds. Annual Symposium on Foundations of Computer Science, 2014.
- Bernau et al. (2019) Daniel Bernau, Philip-William Grassal, Jonas Robl, and Florian Kerschbaum. Assessing differentially private deep learning with membership inference. arXiv preprint arXiv:1912.11328, 2019.
- Blanchard et al. (2007) Gilles Blanchard, Olivier Bousquet, and Laurent Zwald. Statistical properties of kernel principal component analysis. Machine Learning, 66(2-3):259–294, 2007.
- Bun & Steinke (2016) Mark Bun and Thomas Steinke. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Theory of Cryptography Conference, 2016.
- Carlini et al. (2019) Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In USENIX Security Symposium, 2019.
- Chen et al. (2020a) Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. Big self-supervised models are strong semi-supervised learners. arXiv preprint arXiv:2006.10029, 2020a.
- Chen et al. (2020b) Xiangyi Chen, Steven Z Wu, and Mingyi Hong. Understanding gradient clipping in private sgd: A geometric perspective. Advances in Neural Information Processing Systems, 33, 2020b.
- Dasgupta & Gupta (2003) Sanjoy Dasgupta and Anupam Gupta. An elementary proof of a theorem of johnson and lindenstrauss. Random Structures & Algorithms, 2003.
- Dong et al. (2019) Jinshuo Dong, Aaron Roth, and Weijie J Su. Gaussian differential privacy. arXiv preprint arXiv:1905.02383, 2019.
- Dwork et al. (2006a) Cynthia Dwork, Krishnaram Kenthapadi, Frank McSherry, Ilya Mironov, and Moni Naor. Our data, ourselves: Privacy via distributed noise generation. In Annual International Conference on the Theory and Applications of Cryptographic Techniques, 2006a.
- Dwork et al. (2006b) Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. In Theory of cryptography conference, 2006b.
- Dwork et al. (2014) Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 2014.
- Eaton & Perlman (1973) Morris L Eaton and Michael D Perlman. The non-singularity of generalized sample covariance matrices. The Annals of Statistics, pp. 710–717, 1973.
- Fredrikson et al. (2015) Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In ACM SIGSAC Conference on Computer and Communications Security, 2015.
- Fukuchi et al. (2017) Kazuto Fukuchi, Quang Khai Tran, and Jun Sakuma. Differentially private empirical risk minimization with input perturbation. In International Conference on Discovery Science, 2017.
- Gooneratne et al. (2020) Mary Gooneratne, Khe Chai Sim, Petr Zadrazil, Andreas Kabel, Françoise Beaufays, and Giovanni Motta. Low-rank gradient approximation for memory-efficient on-device training of deep neural network. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
- Gur-Ari et al. (2018) Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. arXiv preprint arXiv:1812.04754, 2018.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Conference on Computer Vision and Pattern Recognition, 2020.
- Hitaj et al. (2017) Briland Hitaj, Giuseppe Ateniese, and Fernando Pérez-Cruz. Deep models under the gan: information leakage from collaborative deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017.
- Ioffe & Szegedy (2015) Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, 2015.
- Iyengar et al. (2019) Roger Iyengar, Joseph P Near, Dawn Song, Om Thakkar, Abhradeep Thakurta, and Lun Wang. Towards practical differentially private convex optimization. In IEEE Symposium on Security and Privacy, 2019.
- Jayaraman et al. (2018) Bargav Jayaraman, Lingxiao Wang, David Evans, and Quanquan Gu. Distributed learning without distress: Privacy-preserving empirical risk minimization. In Advances in Neural Information Processing Systems, 2018.
- Jordon et al. (2019) James Jordon, Jinsung Yoon, and Mihaela van der Schaar. Pate-gan: Generating synthetic data with differential privacy guarantees. In International Conference on Learning Representations, 2019.
- Kairouz et al. (2020) Peter Kairouz, Mónica Ribero, Keith Rush, and Abhradeep Thakurta. Dimension independence in unconstrained private erm via adaptive preconditioning. arXiv preprint arXiv:2008.06570, 2020.
- Kifer et al. (2012) Daniel Kifer, Adam Smith, and Abhradeep Thakurta. Private convex empirical risk minimization and high-dimensional regression. In Conference on Learning Theory, 2012.
- Lee & Kifer (2018) Jaewoo Lee and Daniel Kifer. Concentrated differentially private gradient descent with adaptive per-iteration privacy budget. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018.
- Li et al. (2020) Xinyan Li, Qilong Gu, Yingxue Zhou, Tiancong Chen, and Arindam Banerjee. Hessian based analysis of sgd for deep nets: Dynamics and generalization. In SIAM International Conference on Data Mining, 2020.
- Ma et al. (2019) Yuzhe Ma, Xiaojin Zhu, and Justin Hsu. Data poisoning against differentially-private learners: attacks and defenses. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, pp. 4732–4738. AAAI Press, 2019.
- Mironov (2017) Ilya Mironov. Rényi differential privacy. In IEEE Computer Security Foundations Symposium, 2017.
- Mironov et al. (2019) Ilya Mironov, Kunal Talwar, and Li Zhang. Rényi differential privacy of the sampled gaussian mechanism. arXiv, 2019.
- Muirhead (2009) Robb J Muirhead. Aspects of multivariate statistical theory, volume 197. John Wiley & Sons, 2009.
- Panju (2011) Maysum Panju. Iterative methods for computing eigenvalues and eigenvectors. arXiv preprint arXiv:1105.1185, 2011.
- Papernot et al. (2017) Nicolas Papernot, Martín Abadi, Ulfar Erlingsson, Ian Goodfellow, and Kunal Talwar. Semi-supervised knowledge transfer for deep learning from private training data. In International Conference on Learning Representations, 2017.
- Papernot et al. (2018) Nicolas Papernot, Shuang Song, Ilya Mironov, Ananth Raghunathan, Kunal Talwar, and Úlfar Erlingsson. Scalable private learning with pate. In International Conference on Learning Representations, 2018.
- Phan et al. (2020) NhatHai Phan, My T Thai, Han Hu, Ruoming Jin, Tong Sun, and Dejing Dou. Scalable differential privacy with certified robustness in adversarial learning. International Conference on Machine Learning, 2020.
- Rahman et al. (2018) Md Atiqur Rahman, Tanzila Rahman, Robert Laganiere, Noman Mohammed, and Yang Wang. Membership inference attack against differentially private deep learning model. Transactions on Data Privacy, 2018.
- Sablayrolles et al. (2019) Alexandre Sablayrolles, Matthijs Douze, Yann Ollivier, Cordelia Schmid, and Hervé Jégou. White-box vs black-box: Bayes optimal strategies for membership inference. International Conference on Machine Learning, 2019.
- Shokri & Shmatikov (2015) Reza Shokri and Vitaly Shmatikov. Privacy-preserving deep learning. In ACM SIGSAC conference on computer and communications security, 2015.
- Shokri et al. (2017) Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In IEEE Symposium on Security and Privacy (SP), 2017.
- Song et al. (2013) Shuang Song, Kamalika Chaudhuri, and Anand D Sarwate. Stochastic gradient descent with differentially private updates. In Global Conference on Signal and Information Processing (GlobalSIP), 2013.
- Talwar et al. (2015) Kunal Talwar, Abhradeep Guha Thakurta, and Li Zhang. Nearly optimal private lasso. In Advances in Neural Information Processing Systems, 2015.
- Thakurta & Smith (2013) Abhradeep Guha Thakurta and Adam Smith. Differentially private feature selection via stability arguments, and the robustness of the lasso. In Conference on Learning Theory, 2013.
- Tramèr & Boneh (2020) Florian Tramèr and Dan Boneh. Differentially private learning needs better features (or much more data). arXiv preprint arXiv:2011.11660, 2020.
- Vogels et al. (2019) Thijs Vogels, Sai Praneeth Karimireddy, and Martin Jaggi. Powersgd: Practical low-rank gradient compression for distributed optimization. In Advances in Neural Information Processing Systems, 2019.
- Wang & Xu (2019) Di Wang and Jinhui Xu. On sparse linear regression in the local differential privacy model. In International Conference on Machine Learning, 2019.
- Wang et al. (2017) Di Wang, Minwei Ye, and Jinhui Xu. Differentially private empirical risk minimization revisited: Faster and more general. In Advances in Neural Information Processing Systems, 2017.
- Wang & Zhou (2020) Jun Wang and Zhi-Hua Zhou. Differentially private learning with small public data. In AAAI, 2020.
- Wang & Gu (2019) Lingxiao Wang and Quanquan Gu. Differentially private iterative gradient hard thresholding for sparse learning. In International Joint Conference on Artificial Intelligence, 2019.
- Wang et al. (2019) Yu-Xiang Wang, Borja Balle, and Shiva Prasad Kasiviswanathan. Subsampled rényi differential privacy and analytical moments accountant. In International Conference on Artificial Intelligence and Statistics, 2019.
- Wu et al. (2016) Xi Wu, Matthew Fredrikson, Somesh Jha, and Jeffrey F Naughton. A methodology for formalizing model-inversion attacks. In IEEE Computer Security Foundations Symposium, 2016.
- Wu et al. (2017) Xi Wu, Fengan Li, Arun Kumar, Kamalika Chaudhuri, Somesh Jha, and Jeffrey Naughton. Bolt-on differential privacy for scalable stochastic gradient descent-based analytics. In ACM International Conference on Management of Data, 2017.
- Wu & He (2018) Yuxin Wu and Kaiming He. Group normalization. In Proceedings of the European conference on computer vision (ECCV), 2018.
- Yu et al. (2020) Da Yu, Huishuai Zhang, Wei Chen, Jian Yin, and Tie-Yan Liu. Gradient perturbation is underrated for differentially private convex optimization. In Proc. of 29th Int. Joint Conf. Artificial Intelligence, 2020.
- Yu et al. (2021) Da Yu, Huishuai Zhang, Wei Chen, Jian Yin, and Tie-Yan Liu. How does data augmentation affect privacy in machine learning? In Proc. of the AAAI Conference on Artificial Intelligence, 2021.
- Zhou et al. (2020) Yingxue Zhou, Zhiwei Steven Wu, and Arindam Banerjee. Bypassing the ambient dimension: Private sgd with gradient subspace identification. arXiv preprint arXiv:2007.03813, 2020.
- Zhu et al. (2019) Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. In Advances in Neural Information Processing Systems, 2019.
- Zhu & Wang (2019) Yuqing Zhu and Yu-Xiang Wang. Poission subsampled rényi differential privacy. In International Conference on Machine Learning, 2019.
Appendix A Experiments with pre-trained models
Recent works have shown that pre-training the models on unlabeled data can be beneficial for subsequent learning tasks (Chen et al., 2020a; He et al., 2020). Tramèr & Boneh (2020) demonstrate that differentially private linear classifier can achieve high accuracy using the features produced by those per-trained models. We show that GEP can also benefit from such pre-trained models.
Inspired by Tramèr & Boneh (2020), we use the output of the penultimate layer of a pre-trained ResNet152 model as feature to train a private linear classifier. The ResNet152 model is pre-trained on unlabeled ImageNet using SimCLR (Chen et al., 2020a). The feature dimension is 4096.
Implementation Details We choose the privacy parameter from . The privacy parameter is . We run all experiments for 5 times and report the average accuracy. The clipping threshold of residual gradients is still one-fifth of the clipping threshold of the original gradients. The dimension of anchor subspace is set as where is the model dimension. We randomly sample samples from the test set as auxiliary data and evaluate performance on the rest test samples. The optimizer is Adam with default momentum coefficients. Other hyper-parameters are listed in Table 2.
| Hyperparameter | Values |
|---|---|
| Learning rate | 0.01, 0.05, 0.1 |
| Running steps | 50, 100, 400 |
| Clipping threshold | 0.01, 0.1, 1 |
Results The experiment results are shown in Table 3. GEP outperforms GP on all values of . With privacy bound , GEP achieves 94.8% validation accuracy on CIFAR10 dataset, improving over the GP baseline by 1.4%. For very strong privacy guarantee (), B-GEP performs on par with GEP because strong privacy guarantee requires large noise and the useful signal in residual gradient is submerged in the added noise. B-GEP benefits less from larger compared to GP or GEP. For and , the performance of B-GEP is worse than the performance of GP. This is because larger can not reduce the systematic error of B-GEP (see Remark 1 in Section 3.2).
| Non private | 96.3 | 96.3 | 96.3 | 96.3 |
| GP | 88.2 (0.16) | 91.1 (0.17) | 93.2 (0.19) | 93.4 (0.12) |
| B-GEP | 91.0 (0.07) | 92.9 (0.03) | 93.1 (0.10) | 93.2 (0.08) |
| GEP | 90.9 (0.19) | 93.5 (0.06) | 94.3 (0.09) | 94.8 (0.06) |
Appendix B Complexity Analysis
We provide an analysis of the computational and memory costs of the construction of anchor subspace. The computation of the anchor subspace is the dominant additional cost of GEP compared to conventional gradient perturbation. Notations: , , , and are the dimension of anchor subspace, number of anchor gradients, number of private gradients, and the model dimension, respectively. In order to reduce the computational and memory costs, we divide the parameters into groups and compute one orthonormal basis for each group. We refer to this approach as ‘parameter grouping’. In this section, we assume the parameters and the dimension of the anchor subspace are both divided evenly. Table 4 summarizes the additional costs of GEP with/without parameter grouping. Using parameter grouping can reduce the computational/memory cost significantly.
| Computational Cost | Memory Cost | |
|---|---|---|
| GEP | ||
| GEP+PG |
Appendix C Ablation Study
The influence of choosing different auxiliary datasets. We conduct experiments with different choices of auxiliary datasets. For CIFAR10, we try 2000 random test samples from CIFAR10, 2000 random samples from CIFAR100, and 2000 random samples from ImageNet. When the auxiliary dataset is CIFAR10, we try both correct labels and random labels. For all choices of auxiliary datasets, the test accuracy is evaluated on 8000 test samples of CIFAR10 that are not used as auxiliary data. Other implementation details are the same as in Section 4. The results are shown in Table 5. Surprisingly, using samples from CIFAR10 with correct labels yields the worst accuracy. This may because the model ‘overfits’ the auxiliary data when it has access to correct labels, which makes the anchor subspace contains less information about the private gradients. The best accuracy is achieved using samples from CIFAR10 with random labels, this makes sense because in this case the features of auxiliary data and private data have the same distribution. Using samples from CIFAR100 or ImageNet as auxiliary data has a small influence on the test accuracy.
| Auxiliary Data | Random Label? | Test Accuracy |
|---|---|---|
| CIFAR10 | No | 72.9 (0.31) |
| CIFAR10 | Yes | 75.1 (0.42) |
| CIFAR100 | Yes | 74.7 (0.46) |
| ImageNet | Yes | 74.8 (0.39) |
The influence of the number of anchor gradients. In the main text, the size of auxiliary dataset is . We conduct more experiments with different sizes of auxiliary dataset to examine the influence of . The auxiliary data is randomly sampled from ImageNet. Table 6 reports the test accuracy on CIFAR10 with different choices of . For both B-GEP and GEP, increasing leads to slightly improved performance.
| Algorithm | |||
|---|---|---|---|
| B-GEP | 62.2 (0.26) | 62.6 (0.24) | 63.3 (0.27) |
| GEP | 74.6 (0.41) | 74.8 (0.39) | 75.2 (0.34) |
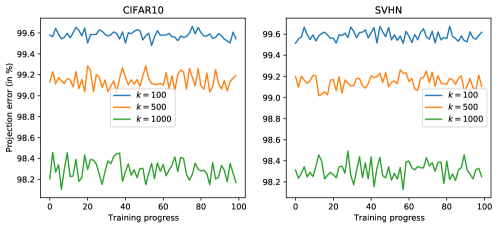
The projection error of random basis vectors. It is tempting to construct the anchor subspace using random basis vectors because Johnson–Lindenstrauss Lemma (Dasgupta & Gupta, 2003) guarantees that one can preserve the pairwise distance between any two points after projecting into a random subspace of much lower dimension. We empirically verify the projection error of Gaussian random basis vectors on CIFAR10 and SVHN. The experiment settings are the same as in Section 4. The projection errors over the training process are plotted in Figure 7. The projection error of random basis vectors is very high () throughout training. This is because preserving the pairwise distance is not sufficient for high quality gradient reconstruction, which requires one to preserve the average ‘distance’ between any individual gradient and all other gradients.
Appendix D Missing Proofs
See 3.1
Proof.
We extend the Theorem 3.2 in Eaton & Perlman (1973) to the low-rank case.
Theorem D.1 (Theorem 3.2 in Eaton & Perlman (1973)).
Let where the are i.i.d. random vectors in , . If for all proper manifolds , then =1.
We note that the subspace spanned by is in the space spanned by by definition. Hence .
Let for . Then is non-singular because of the assumption and Theorem D.1. That is . Therefore , and . Therefore and the subspace spanned by and the subspace spanned by are identical. ∎
See 1
Proof of Theorem 1.
We first introduce some background knowledge of Rényi differential privacy (RDP) (Mironov, 2017). RDP measures the Rényi divergence between two output distributions.
Definition 2 (-RDP).
A randomized mechanism is said to guarantee -RDP if for any neighboring datasets and it holds that
where denotes the Rényi divergence of order .
We next introduce some useful properties of RDP.
Lemma D.2 (Gaussian mechanism of RDP).
Let be the sensitivity, then Gaussian mechanism satisfies -RDP, where .
Lemma D.3 (Composition of RDP).
If , satisfy -RDP and -RDP respectively, then their composition satisfies -RDP.
Lemma D.4 (Conversion from RDP to -DP).
If obeys -RDP, then obeys -DP for all .
Now we proof Theorem 1. Let be the gradient embeddings of two neighboring datasets and be corresponding residual gradients. Without loss of generality, suppose () has one more row than (). For given sensitivity ,
If we set and for some , then Algorithm 1 satisfies -RDP because of Lemma D.2 and D.3. In order to guarantee -DP, we need
| (5) |
Choose and rearrange Eq (5), we need
| (6) |
Then using the constraint on concludes the proof.
∎
See 2
Proof of Theorem 2.
From the proof of Theorem 1, we have each call of GEP satisfies -RDP. Then by the composition property of RDP (Lemma D.3), the output of Algorithm 2 satisfies -RDP. Plugging into Equation 5 and 6 concludes the proof.
∎
See 2
Proof of Theorem 2.
The -smooth condition gives
| (7) |
Based on the update rule of GEP we have
| (8) |
where , are the perturbation noises and is the sensitivity of residual gradients at step .
Take expectation on Eq (7) with respect to the perturbation noises.
| (9) |
Subtract from both sides, we have
| (10) | ||||
The second inequality holds because is convex. Then choose and plug into Eq (10).
| (11) | ||||
Sum over and use convexity, we have
| (12) |
Then substituting and yields the desired bound.
∎