Do Vendi Scores Converge with Finite Samples?
Truncated Vendi Score for Finite-Sample Convergence Guarantees
Abstract
Evaluating the diversity of generative models without reference data poses methodological challenges. The reference-free Vendi [Friedman and Dieng, 2023] and RKE [Jalali et al., 2023] scores address this by quantifying the diversity of generated data using matrix-based entropy measures. Among these two, the Vendi score is typically computed via the eigendecomposition of an kernel matrix constructed from n generated samples. However, the prohibitive computational cost of eigendecomposition for large often limits the number of samples used to fewer than 20,000. In this paper, we investigate the statistical convergence of the Vendi and RKE scores under restricted sample sizes. We numerically demonstrate that, in general, the Vendi score computed with standard sample sizes below 20,000 may not converge to its asymptotic value under infinite sampling. To address this, we introduce the -truncated Vendi score by truncating the eigenspectrum of the kernel matrix, which is provably guaranteed to converge to its population limit with samples. We further show that existing Nyström and FKEA approximation methods converge to the asymptotic limit of the truncated Vendi score. In contrast to the Vendi score, we prove that the RKE score enjoys universal convergence guarantees across all kernel functions. We conduct several numerical experiments to illustrate the concentration of Nyström and FKEA computed Vendi scores around the truncated Vendi score, and we analyze how the truncated Vendi and RKE scores correlate with the diversity of image and text data. The code is available at https://github.com/aziksh-ospanov/truncated-vendi.
1 Introduction
The increasing use of generative artificial intelligence has underscored the need for accurate evaluation of generative models. In practice, users often have access to multiple generative models trained with different training datasets and algorithms, requiring evaluation methods to identify the most suitable model. The feasibility of a model evaluation approach depends on factors such as the required generated sample size, computational cost, and the availability of reference data. Recent studies on evaluating generative models have introduced assessment methods that relax the requirements on data and computational resources.
Specifically, to enable the evaluation of generative models without reference data, the recent literature has focused on reference-free evaluation scores that remain applicable in the absence of reference samples. The Vendi score [Friedman and Dieng, 2023] is one such reference-free metric that quantifies the diversity of generated data using the entropy of a kernel similarity matrix formulated for the generated samples. Given the sorted eigenvalues of the normalized matrix 111In general, we consider the trace-normalized kernel matrix , which given , reduces to . for the kernel similarity matrix of generated samples , the definition of (order-1) Vendi score is as:
| (1) |
Following conventional definitions in information theory, the Vendi score corresponds to the exponential of the Von Neumann entropy of normalized kernel matrix . More generally, Jalali et al. [2023] define the Rényi Kernel Entropy (RKE) score by applying order-2 Rényi entropy to this matrix, which reduces to the inverse-squared Frobenius norm of the normalized kernel matrix:
| (2) |
Although the Vendi and RKE scores do not require reference samples, their computational cost increases rapidly with the number of generated samples . Specifically, calculating the Vendi score for the kernel matrix generally involves an eigendecomposition of , requiring computations. Therefore, the computational load of Vendi score becomes substantial for a large sample size , and the Vendi score is typically evaluated for sample sizes limited to 20,000. In other words, the Vendi score, as defined in Equation (2), would be computationally infeasible to compute with standard processors for sample sizes greater than a few tens of thousands.
Following the above discussion, a key question that arises is whether the Vendi score estimated from restricted sample sizes (i.e. ) has converged to its asymptotic value with infinite samples, which we call the population Vendi. However, the statistical convergence of the Vendi score has not been thoroughly investigated in the literature. In this work, we study the statistical convergence of the Vendi and RKE diversity scores and aim to analyze the concentration of the estimated scores from a limited number of generated samples .
1.1 Our Results on Vendi’s Convergence
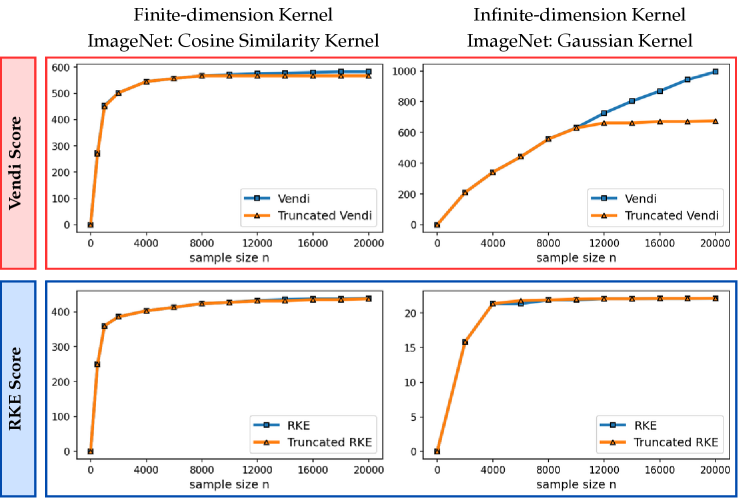
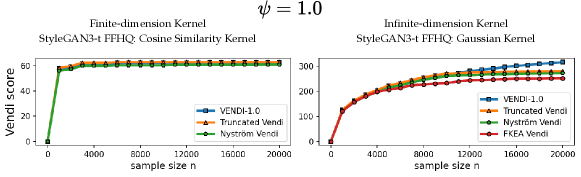
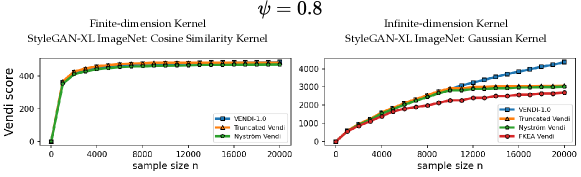
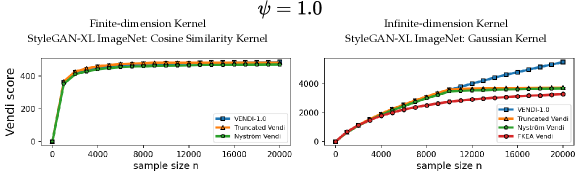
We discuss the answer to the Vendi convergence question for two types of kernel functions: 1) kernel functions with a finite feature dimension, e.g. the cosine similarity and polynomial kernels, 2) kernel functions with an infinite feature map such as Gaussian (RBF) kernels. For kernel functions with a finite feature dimension , we theoretically and numerically show that a sample size is sufficient to guarantee convergence to the population Vendi (asymptotic value when ). For example, the left plot in Figure 1 shows that in the case of the cosine similarity kernel, the Vendi score on randomly selected ImageNet [Deng et al., 2009] samples has almost converged as the sample size reaches 5000, where the dimension (using standard DINOv2 embedding [Oquab et al., 2023]) is 768.
In contrast, our numerical results for kernel functions with an infinite feature map demonstrate that for standard datasets, a sample size bounded by 20,000 could be insufficient for convergence of the Vendi score. For example, the right plot of Figure 1 shows the evolution of the Vendi score with the Gaussian kernel on ImageNet data, and the score continues to grow at a significant rate with 20,000 samples222The heavy computational cost prohibits an empirical evaluation of the sample size required for Vendi’s convergence..
Observing the difference between Vendi score convergence for finite and infinite-dimension kernel functions, a natural question is how to extend the definition of Vendi score from finite to infinite dimension case such that the diversity score would statistically converge in both scenarios. We attempt to address the question by introducing an alternative Vendi statistic, which we call the -truncated Vendi score. The -truncated Vendi score is defined using only the top- eigenvalues of the kernel matrix, where is an integer hyperparameter. This modified score is defined as
where we shift each of the top- eigenvalue by the same constant to ensure they add up to and provide a valid probability model. Observe that for a finite kernel dimension satisfying , the truncated and original Vendi scores take the same value, because the truncation will have no impact on the eigenvalues. On the other hand, under an infinite kernel dimension, the two scores may take different values.
As a main theoretical result, we prove that a sample size is always enough to estimate the -truncated population Vendi from empirical samples, regardless of the finiteness of the kernel feature dimension. This result shows that the -truncated Vendi score provides a statistically converging extension of the Vendi score from the finite kernel dimension to the infinite dimension case. To connect the defined -truncated Vendi score to existing computation methods for the original Vendi score, we show that the existing computationally-efficient methods for computing the Vendi score can be viewed as approximations of our defined -truncated Vendi. Specifically, we show that the Nyström method in [Friedman and Dieng, 2023] and the FKEA method proposed by Ospanov et al. [2024b] provide an estimate of the -truncated Vendi.

1.2 Our Results on RKE’s Convergence
For the RKE score, we prove a universal convergence guarantee that holds for every kernel function. The theoretical guarantee shows that the RKE score, and more generally every order- entropy score with , will converge to its population value within error for samples. Our theoretical guarantee also transfers to the truncated version of the RKE score. However, note that the truncation of the eigenspectrum becomes unnecessary in the RKE case, since the score enjoys universal convergence guarantees. Figure 1 shows that using both the cosine-similarity and Gaussian kernel functions, the RKE score nearly converges to its limit value with less than 10000 samples.
Finally, we present the findings of several numerical experiments to validate our theoretical results on the convergence of Vendi, truncated Vendi, and RKE scores. Our numerical results on standard image, text, and video datasets and generative models indicate that in the case of a finite-dimension kernel map, the Vendi score can converge to its asymptotic limit, in which case, as we explained earlier, the Vendi score is identical to the truncated Vendi. On the other hand, in the case of infinite-dimension Gaussian kernel functions, we numerically observe the growth of the score beyond 10,000. Our numerical results further confirm that the scores computed by Nyström method in [Friedman and Dieng, 2023] and the FKEA method [Ospanov et al., 2024b] provide tight estimations of the population truncated Vendi. The following summarizes this work’s contributions:
-
•
Analyzing the statistical convergence of Vendi and RKE diversity scores under restricted sample sizes ,
-
•
Providing numerical evidence on the Vendi score’s lack of convergence for infinite-dimensional kernel functions, e.g. the Gaussian (RBF) kernel,
-
•
Introducing the truncated Vendi score as a statistically converging extension of the Vendi score from finite to infinite dimension kernel functions,
-
•
Demonstrating the universal convergence of the RKE diversity score across all kernel functions.
2 Related Works
Diversity evaluation for generative models Diversity evaluation in generative models can be categorized into two primary types: reference-based and reference-free methods. Reference-based approaches rely on a predefined dataset to assess the diversity of generated data. Metrics such as FID [Heusel et al., 2018], KID and distributed KID [Bińkowski et al., 2018, Wang et al., 2023] measure the distance between the generated data and the reference, while Recall [Sajjadi et al., 2018, Kynkäänniemi et al., 2019] and Coverage [Naeem et al., 2020] evaluate the extent to which the generative model captures existing modes in the reference dataset. Pillutla et al. [2021, 2023] propose MAUVE metric that uses information divergences in a quantized embedding space to measure the gap between generated data and reference distribution. In contrast, the reference-free metrics, Vendi [Friedman and Dieng, 2023] and RKE [Jalali et al., 2023], assign diversity scores based on the eigenvalues of a kernel similarity matrix of the generated data. Jalali et al. [2023] interpret the approach as identifying modes and their frequencies within the generated data followed by entropy calculation for the frequency parameters. The Vendi and RKE scores have been further extended to quantify the diversity of conditional prompt-based generative AI models [Ospanov et al., 2024a, Jalali et al., 2024] and to select generative models in online settings [Rezaei et al., 2024, Hu et al., 2024, 2025]. Also, [Zhang et al., 2024, 2025, Jalali et al., 2025, Gong et al., 2025, Wu et al., 2025] extend the entropic kernel-based scores to measure novelty and embedding dissimilarity. In our work, we specifically focus on the statistical convergence of the vanilla Vendi and RKE scores.
Statistical convergence analysis of kernel matrices’ eigenvalues. The convergence analysis of the eigenvalues of kernel matrices has been studied by several related works. Shawe-Taylor et al. [2005] provide a concentration bound for the eigenvalues of a kernel matrix. We note that the bounds in [Shawe-Taylor et al., 2005] use the expectation of eigenvalues for a random dataset of fixed size as the center vector in the concentration analysis. However, since eigenvalues are non-linear functions of a matrix, this concentration center vector does not match the eigenvalues of the asymptotic kernel matrix as the sample size approaches to infinity. On the other hand, our convergence analysis focuses on the asymptotic eigenvalues with an infinite sample size, which determines the limit value of Vendi scores. In another related work, Bach [2022] discusses a convergence result for the Von-Neumann entropy of kernel matrix. While this result proves a non-asymptotic guarantee on the convergence of the entropy function, the bound may not guarantee convergence at standard sample sizes for computing Vendi scores (less than in practice). In our work, we aim to provide convergence guarantees for the finite-dimension and generally truncated Vendi scores with restricted sample sizes.
Efficient computation of matrix-based entropy. Several strategies have been proposed in the literature to reduce the computational complexity of matrix-based entropy calculations, which involve the computation of matrix eigenvalues—a process that scales cubically with the size of the dataset. Dong et al. [2023] propose an efficient algorithm for approximating matrix-based Renyi’s entropy of arbitrary order , which achieves a reduction in computational complexity down to with . Additionally, kernel matrices can be approximated using low-rank techniques such as incomplete Cholesky decomposition [Fine and Scheinberg, 2001, Bach and Jordan, 2002] or CUR matrix decompositions [Mahoney and Drineas, 2009], which provide substantial computational savings. Pasarkar and Dieng [2024] suggest to leverage Nyström method [Williams and Seeger, 2000] with components, which results in computational complexity. Further reduction in complexity is possible using Random Fourier Features, as suggested by Ospanov et al. [2024b], which allows the computation to scale linearly with as a function of the dataset size. This work focuses on the latter two methods and the population quantities estimated by them.
Impact of embedding spaces on diversity evaluation. In our image-related experiments, we used the DinoV2 embedding [Oquab et al., 2023], as Stein et al. [2023] demonstrate the alignment of this embedding with human evaluations. We note that the kernel function in the Vendi score can be similarly applied to other embeddings, including the standard InceptionV3[Szegedy et al., 2016] and CLIP embeddings [Radford et al., 2021] as suggested by Kynkäänniemi et al. [2022].
3 Preliminaries
Consider a generative model that generates samples from a probability distribution . To conduct a reference-free evaluation of the model, we suppose the evaluator has access to independently generated samples from , denoted by . The assessment task is to estimate the diversity of generative model by measuring the variety of the observed generated data, . In the following subsections, we will discuss kernel functions and their application to define the Vendi and RKE diversity scores.
3.1 Kernel Functions and Matrices
Following the standard definition, is called a kernel function if for every integer and inputs , the following kernel similarity matrix is positive semi-definite (PSD):
| (3) |
Aronszajn’s Theorem [Aronszajn, 1950] shows that this definition is equivalent to the existence of a feature map such that for every we have the following where denotes the standard inner product in the space:
| (4) |
In this work, we study the evaluation using two types of kernel functions: 1) finite-dimension kernels where dimension is finite, 2) infinite-dimension kernels where there is no feature map satisfying (4) with a finite value. A standard example of a finite-dimension kernel is the cosine similarity function where . Also, a widely-used infinite-dimension kernel is the Gaussian (RBF) kernel with bandwidth parameter defined as
| (5) |
Both the mentioned kernel examples belong to normalized kernels which require for every , i.e., the feature map has unit Euclidean norm for every . Given a normalized kernel function, the non-negative eigenvalues of the normalized kernel matrix for points will sum up to , i.e., they form a probability model.
3.2 Matrix-based Entropy Functions and Vendi Score
For a PSD matrix with unit trace , ’s eigenvalues form a probability model. The order- Renyi entropy of matrix is defined using the order- entropy of its eigenvalues as
| (6) |
For the special case , one can consider the Frobenius norm and apply the identity to show . Moreover, for , the above definition reduces to the Shannon entropy of the eigenvalues as [Rényi, 1961].
Jalali et al. [2023] applies the above definition for order to the normalized kernel similarity matrix to define the RKE diversity score (called RKE mode count), which reduces to
| (7) |
For a general entropy order , [Friedman and Dieng, 2023, Pasarkar and Dieng, 2024] apply the matrix-based entropy definition to the normalized kernel matrix and define the order- Vendi score for samples as
| (8) |
Specifically, for order , the above definition results in the standard (order-1) Vendi score in Equation (2).
3.3 Statistical Analysis of Vendi Score
To derive the population limits of Vendi and RKE scores under infinite sampling, which we call population Vendi and population RKE, respectively, we review the following discussion from [Bach, 2022, Jalali et al., 2023]. First, note that the normalized kernel matrix , whose eigenvalues are used in the definition of Vendi score, can be written as:
| (9) |
where is an matrix whose rows are the feature presentations of samples, i.e., . Therefore, the normalized kernel matrix shares the same non-zero eigenvalues with , where the multiplication order is flipped. Note that is equal to the empirical kernel covariance matrix defined as:
As a result, the empirical covariance matrix and kernel matrix share the same non-zero eigenvalues and therefore have the same matrix-based entropy value for every order : . Therefore, if we consider the population kernel covariance matrix , we can define the population Vendi score as follows.
Definition 1.
Given data distribution , we define the order- population Vendi, , using the matrix-based entropy of the population kernel covariance matrix as
| (10) |
Note that the population RKE score is identical to the population , since RKE and are the same.
4 Statistical Convergence of Vendi and RKE Scores
Given the definitions of the Vendi score and the population Vendi, a relevant question is how many samples are required to accurately estimate the population Vendi using the Vendi score. To address this question, we first prove the following concentration bound on the vector of ordered eigenvalues of the kernel matrix for a normalized kernel function.
Theorem 1.
Consider a normalized kernel function satisfying for every . Let be the vector of sorted eigenvalues of the normalized kernel matrix for independent samples . If we define as the vector of sorted eigenvalues of underlying covariance matrix , then if , the following inequality holds with probability at least :
Note that in calculating the subtraction , we add zero entries to the lower-dimension vector, if the dimension of vectors and do not match.
Proof. We defer the proof to the Appendix.
Theorem 1 results in the following corollary on a dimension-free convergence guarantee for every score with order , including the RKE score (i.e. ).
Corollary 1.
In the setting of Theorem 1, for every and , the following bound holds with probability at least :
Notably, for , we arrive at the following bound on the gap between the empirical and population RKE scores:
Proof. We defer the proof to the Appendix. Therefore, the bound in Corollary 1 holds regardless of the dimension of kernel feature map, indicating that the RKE score enjoys a universal convergence guarantee across all kernel functions. Next, we show that Theorem 1 implies the following corollary on a dimension-dependent convergence guarantee for order- Vendi score with , including standard (order-) Vendi score.
Corollary 2.
In the setting of Theorem 1, consider a finite dimension kernel map where we suppose . (a) For , assuming , the following bound holds with probability at least :
(b) For every and , the following bound holds with probability at least :
Proof. We defer the proof to the Appendix.
Therefore, assuming a finite feature map and given an entropy order , the above results indicate the convergence of the Vendi score to the underlying population Vendi given samples. Observe that this result is consistent with our numerical observations of the convergence of Vendi score using the finite-dimension cosine similarity kernel in Figure 1.
5 Truncated Vendi Score and its Estimation via Proxy Kernels
Corollaries 1, 2 demonstrate that if the Vendi score order is greater than or the kernel feature map dimension is finite, then the Vendi score can converge to the population Vendi with samples. However, the theoretical results do not apply to an order when the kernel map dimension is infinite, e.g. the original order-1 Vendi score [Friedman and Dieng, 2023] with a Gaussian kernel. Our numerical observations indicate that a standard sample size below 20000 could be insufficient for the convergence of order-1 Vendi score (Figure 1). To address this gap, here we define the truncated Vendi score by truncating the eigenspectrum of the kernel matrix, and then show that the existing kernel approximation algorithms for Vendi score concentrate around this modified Vendi score.
Definition 2.
Consider the normalized kernel matrix of samples . Then, for an integer parameter , consider the top- eigenvalues of : . Define and consider the truncated probability sequence :
We define the order- -truncated Vendi score as
Notably, for order , the -truncated Vendi score is:
Remark 1.
The above definition of -truncated Vendi score leads to the definition of -truncated population Vendi , where the mentioned truncation process is applied to the eigenspectrum of the population kernel covariance matrix . Note that the truncated Vendi score is a statistic and function of random samples , whereas the truncated population Vendi is deterministic and a characteristic of the population distribution .
According to Definition 2, we find the probability model with the minimum -norm difference from the -dimensional vector including only the top- eigenvalues. Then, we use the order- entropy of the probability model to define the order- -truncated population Vendi. Our next result shows that this population quantity can be estimated using samples by -truncated Vendi score for every kernel function.
Theorem 2.
Consider the setting in Theorem 1. Then, for every , the difference between the -truncated population Vendi and the empirical -truncated Vendi score of samples is bounded with probability at least :
Proof. We defer the proof to the Appendix. As implied by Theorem 2, the -truncated population Vendi can be estimated using samples, i.e. the truncation parameter plays the role of the bounded dimension of a finite-dimension kernel map. Our next theorem shows that the Nyström method [Friedman and Dieng, 2023] and the FKEA method [Ospanov et al., 2024b] for reducing the computational costs of Vendi scores have a bounded difference with the truncated population Vendi.
Theorem 3.
Consider the setting of Theorem 1. (a) Assume that the kernel function is shift-invariant and the FKEA method with random Fourier features is used to approximate the Vendi score. Then, for every satisfying , with probability at least :
(b) Assume that the Nyström method is applied with parameter for approximating the kernel function. Then, if for some , the kernel matrix ’s th-largest eigenvalue satisfies and , the following holds with probability at least :
Proof. We defer the proof to the Appendix.
6 Numerical Results
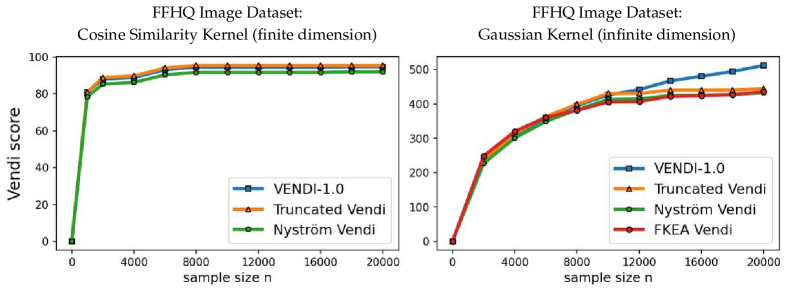
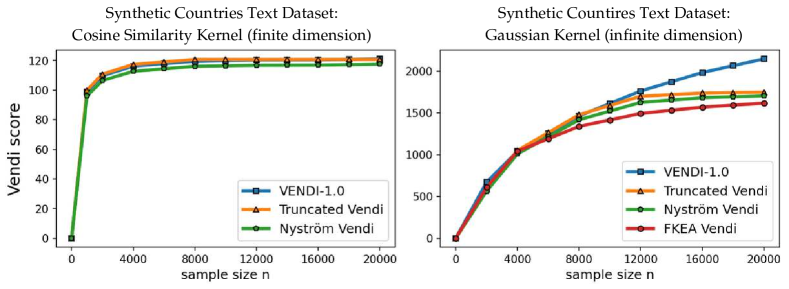
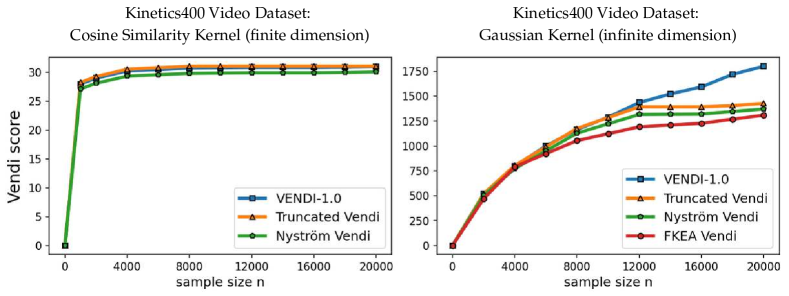
We evaluated the convergence of the Vendi score, the truncated Vendi score, and the proxy Vendi scores using the Nyström method and FKEA in our numerical experiments. We provide a comparative analysis of these scores across different data types and models, including image, text, and video. In our experiments, we considered the cosine similarity kernel as a standard kernel function with a finite-dimension map and the Gaussian (RBF) kernel as a kernel function with an infinite-dimension feature map. In the experiments with Gaussian kernels, we matched the kernel bandwidth parameter with those chosen by [Jalali et al., 2023, Ospanov et al., 2024b] for the same datasets. We used 20,000 number of samples per score computation, consistent with standard practice in the literature. To investigate how computation-cutting methods compare to each other, in the experiments we matched the truncation parameter of our defined -truncated Vendi score with the Nyström method’s hyperparameter on the number of randomly selected rows of kernel matrix and the FKEA’s hyperparameter of the number of random Fourier features. The Vendi and FKEA implementations were adopted from the corresponding references’ GitHub webpages, while the Nyström method was adopted from the scikit-learn Python package.
6.1 Convergence Analysis of Vendi Scores
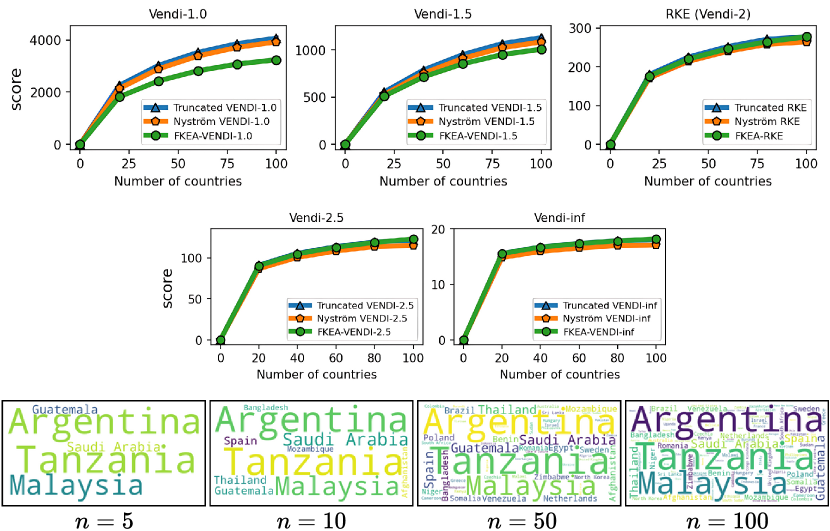
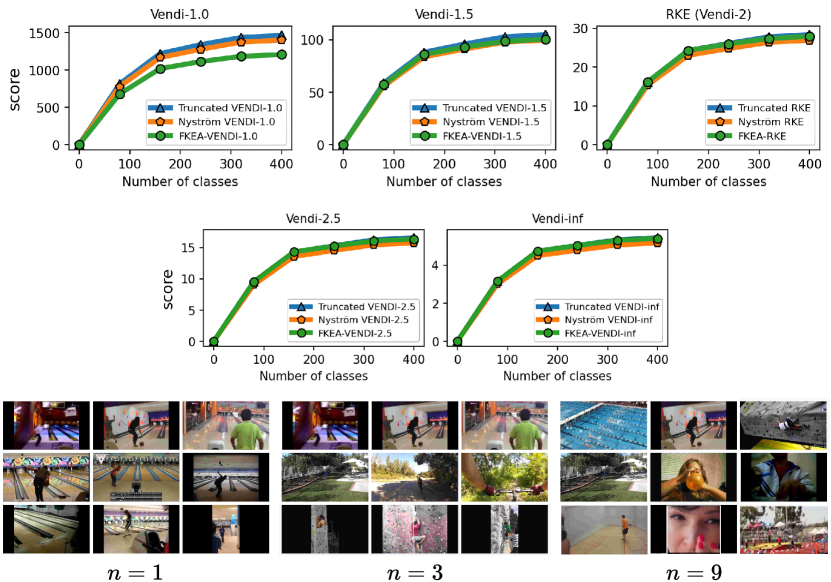
To assess the convergence of the discussed Vendi scores, we conducted experiments on four datasets including ImageNet and FFHQ [Karras et al., 2019] image datasets, a synthetic text dataset with 400k paragraphs generated by GPT-4 about 100 randomly selected countries, and the Kinetics video dataset [Kay et al., 2017]. Our results, presented in Figures 3, 4, and 5, show that for the finite-dimension cosine similarity kernel the Vendi score converges rapidly to the underlying value and the proxy versions including truncated and Nyström Vendi scores were almost identical to the original Vendi score. This observation is consistent with our theoretical results on the convergence of Vendi scores under finite-dimension kernel maps. On the other hand, in the case of infinite dimension Gaussian kernel, we observed that the score did not converge using 20k samples and the score value kept growing with a considerable rate. However, the -truncated Vendi score with converged to its underlying statistic shortly after 10000 samples were used. Consistent with our theoretical result, the proxy Nyström and FKEA estimated scores with their rank hyperparameter matched with also converged to the limit of the truncated Vendi scores. The numerical results show the connection between the truncated Vendi score and the existing kernel methods for approximating the Vendi score.
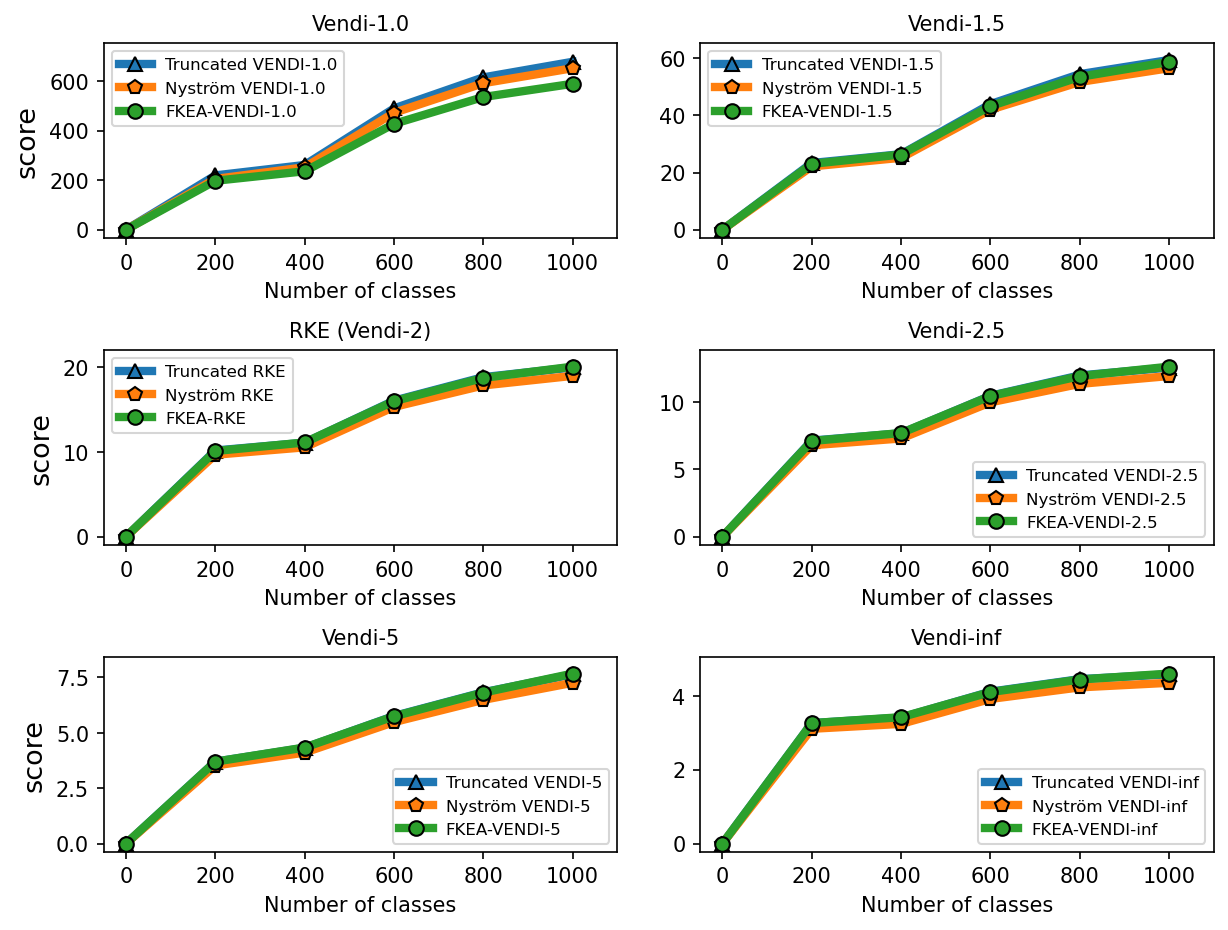
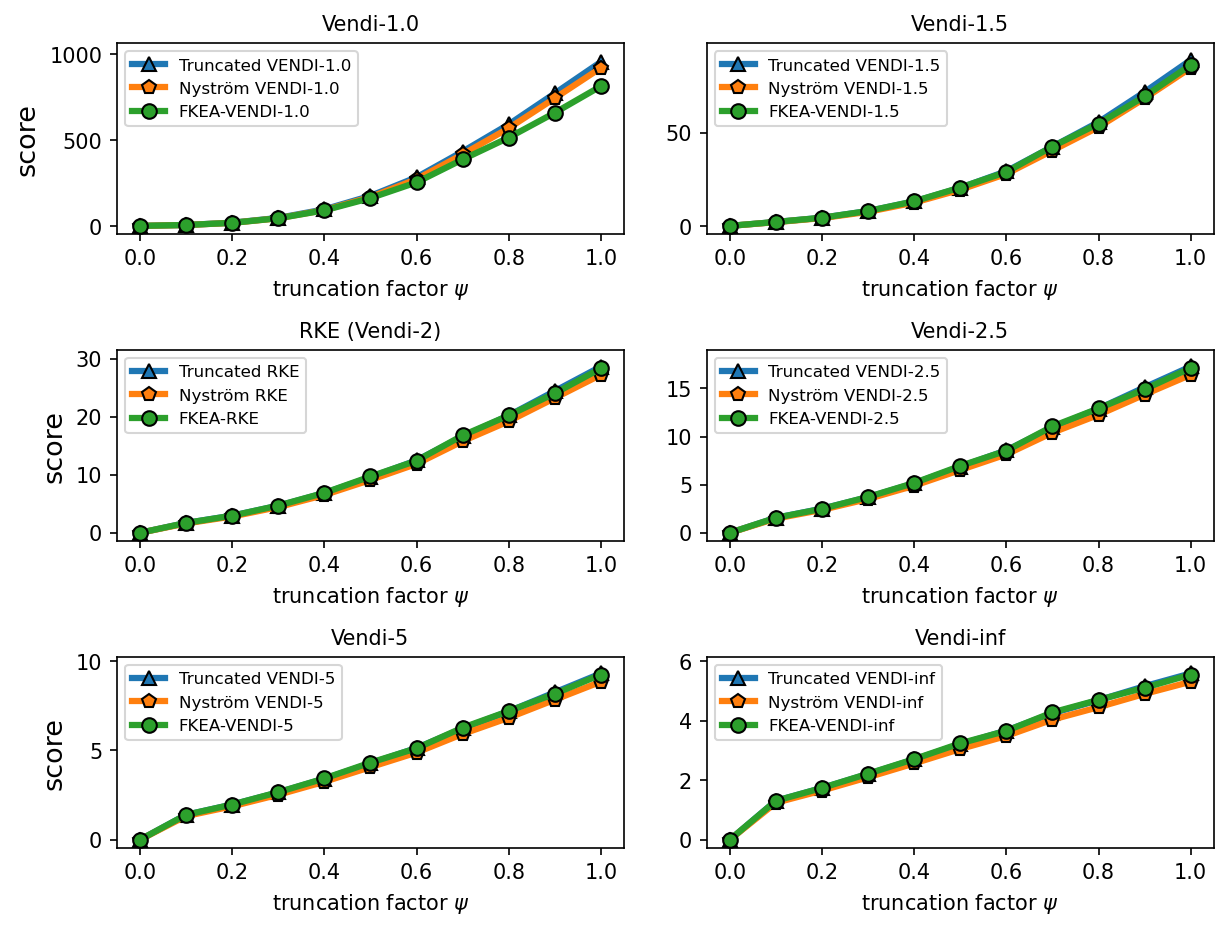
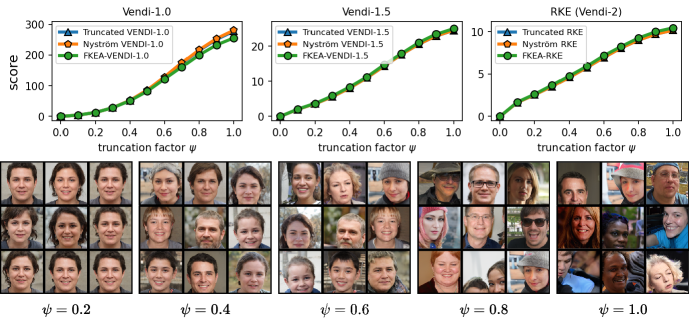
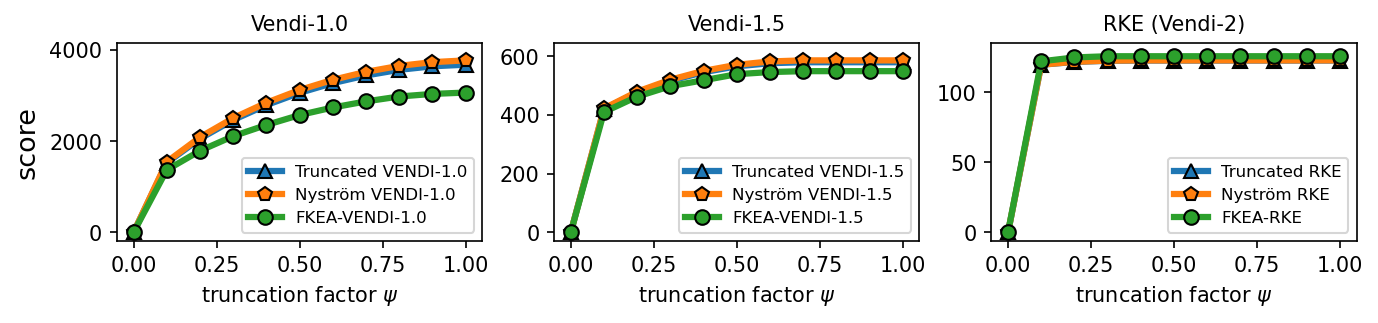
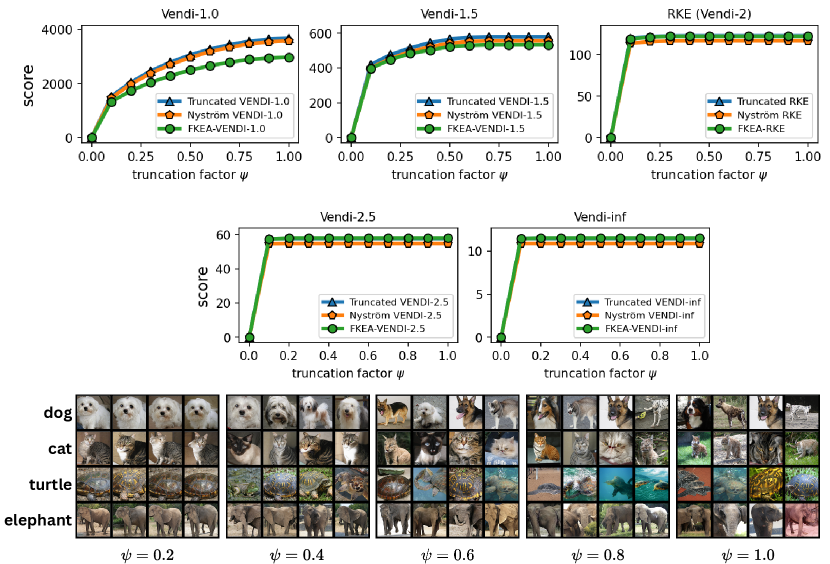
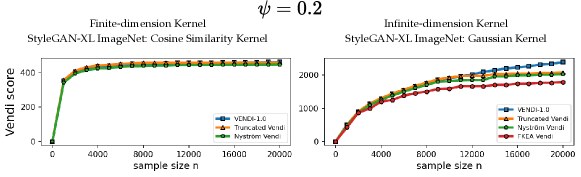
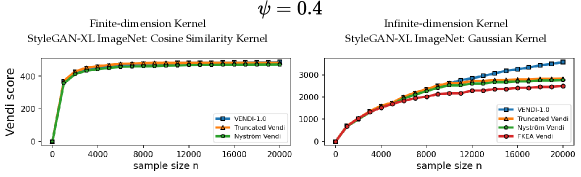
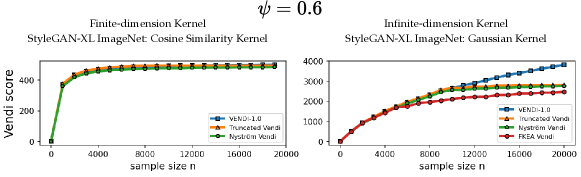
6.2 Correlation between the truncated Vendi score and diversity of data
We performed experiments to test the correlation between the truncated Vendi score and the ground-truth diversity of data. To do this, we applied the truncation technique to the FFHQ-based StyleGAN3 [Karras et al., 2021] model and the ImageNet-based StyleGAN-XL [Sauer et al., 2022] model and simulated generative models with different underlying diversity by varying the truncation technique. Considering the Gaussian kernel, we estimated the -truncated Vendi score with by averaging the estimated -truncated Vendi scores over independent datasets of size 20k where the score seemed to converge to its underlying value. Figures 6, 7 show how the estimated statistic correlates with the truncation parameter for order- Vendi scores with . In all these experiments, the estimated truncated Vendi score correlated with the underlying diversity of the models. In addition, we plot the proxy Nyström and FKEA proxy Vendi values computed using 20000 samples which remain close to the estimated -truncated statistic. These empirical results suggest that the estimated -truncated Vendi score with Gaussian kernel can be used to evaluate the diversity of generated data. Also, the Nyström and FKEA methods were both computationally efficient in estimating the truncated Vendi score from limited generated data. We defer the presentation of the additional numerical results on the convergence of Vendi scores with different orders, kernel functions and embedding spaces to the Appendix.
7 Conclusion
In this work, we investigated the statistical convergence behavior of Vendi diversity scores estimated from empirical samples. We highlighted that, due to the high computational complexity of the score for datasets larger than a few tens of thousands of generated data points, the score is often calculated using sample sizes below 10,000. We demonstrated that such restricted sample sizes do not pose a problem for statistical convergence as long as the kernel feature dimension is bounded. However, our numerical results showed a lack of convergence to the population Vendi when using an infinite-dimensional kernel map, such as the Gaussian kernel. To address this gap, we introduced the truncated population Vendi as an alternative target quantity for diversity evaluation. We showed that existing Nyström and FKEA methods for approximating Vendi scores concentrate around this truncated population Vendi. An interesting future direction is to explore the relationship between other kernel approximation techniques and the truncated population Vendi. Also, a comprehensive analysis of the computational-statistical trade-offs involved in estimating the Vendi score is another relevant future direction.
Acknowledgements.
This work is partially supported by a grant from the Research Grants Council of the Hong Kong Special Administrative Region, China, Project 14209920, and is partially supported by CUHK Direct Research Grants with CUHK Project No. 4055164 and 4937054. Finally, the authors thank the anonymous reviewers for their thoughtful feedback and constructive suggestions.References
- Aronszajn [1950] N. Aronszajn. Theory of reproducing kernels. Transactions of the American Mathematical Society, 68(3):337–404, 1950. 10.2307/1990404.
- Bach [2022] Francis Bach. Information Theory with Kernel Methods, August 2022. URL http://arxiv.org/abs/2202.08545. arXiv:2202.08545 [cs, math, stat].
- Bach and Jordan [2002] Francis R Bach and Michael I Jordan. Kernel independent component analysis. In Journal of Machine Learning Research, volume 3, pages 1–48, 2002.
- Bińkowski et al. [2018] Mikołaj Bińkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. In International Conference on Learning Representations, 2018.
- Caron et al. [2020] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. In Advances in Neural Information Processing Systems, volume 33, pages 9912–9924. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/hash/70feb62b69f16e0238f741fab228fec2-Abstract.html.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (CVPR), pages 248–255. IEEE, 2009.
- Dong et al. [2023] Yuxin Dong, Tieliang Gong, Shujian Yu, and Chen Li. Optimal randomized approximations for matrix-based rényi’s entropy. IEEE Transactions on Information Theory, 2023.
- Fine and Scheinberg [2001] Shai Fine and Katya Scheinberg. Efficient svm training using low-rank kernel representations. In Journal of Machine Learning Research (JMLR), pages 243–250, 2001.
- Friedman and Dieng [2023] Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning. In Transactions on Machine Learning Research, 2023.
- Gong et al. [2025] Shizhan Gong, Yankai Jiang, Qi Dou, and Farzan Farnia. Kernel-based unsupervised embedding alignment for enhanced visual representation in vision-language models. arXiv preprint arXiv:2506.02557, 2025.
- Gross [2011] David Gross. Recovering low-rank matrices from few coefficients in any basis. IEEE Transactions on Information Theory, 57(3):1548–1566, 2011.
- Heusel et al. [2018] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2018.
- Hu et al. [2024] Xiaoyan Hu, Ho-fung Leung, and Farzan Farnia. An online learning approach to prompt-based selection of generative models. arXiv preprint arXiv:2410.13287, 2024.
- Hu et al. [2025] Xiaoyan Hu, Ho-fung Leung, and Farzan Farnia. A multi-armed bandit approach to online selection and evaluation of generative models. In International Conference on Artificial Intelligence and Statistics, pages 1864–1872. PMLR, 2025.
- Jalali et al. [2023] Mohammad Jalali, Cheuk Ting Li, and Farzan Farnia. An information-theoretic evaluation of generative models in learning multi-modal distributions. In Advances in Neural Information Processing Systems, volume 36, pages 9931–9943, 2023.
- Jalali et al. [2024] Mohammad Jalali, Azim Ospanov, Amin Gohari, and Farzan Farnia. Conditional vendi score: An information-theoretic approach to diversity evaluation of prompt-based generative models. arXiv preprint arXiv:2411.02817, 2024.
- Jalali et al. [2025] Mohammad Jalali, Bahar Dibaei Nia, and Farzan Farnia. Towards an explainable comparison and alignment of feature embeddings. arXiv preprint arXiv:2506.06231, 2025.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4401–4410, 2019.
- Karras et al. [2021] Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free generative adversarial networks. In Advances in Neural Information Processing Systems, volume 34, pages 852–863. Curran Associates, Inc., 2021.
- Kay et al. [2017] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset, 2017.
- Kohler and Lucchi [2017] Jonas Moritz Kohler and Aurelien Lucchi. Sub-sampled cubic regularization for non-convex optimization. In International Conference on Machine Learning, pages 1895–1904. PMLR, 2017.
- Kynkäänniemi et al. [2019] Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- Kynkäänniemi et al. [2022] Tuomas Kynkäänniemi, Tero Karras, Miika Aittala, Timo Aila, and Jaakko Lehtinen. The Role of ImageNet Classes in Fréchet Inception Distance. September 2022. URL https://openreview.net/forum?id=4oXTQ6m_ws8.
- Mahoney and Drineas [2009] Michael W. Mahoney and Petros Drineas. Cur matrix decompositions for improved data analysis. In Proceedings of the National Academy of Sciences, volume 106, pages 697–702, 2009.
- Naeem et al. [2020] Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of ICML’20, pages 7176–7185. JMLR.org, 2020.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. DINOv2: Learning robust visual features without supervision. In Transactions on Machine Learning Research, 2023. URL https://openreview.net/forum?id=a68SUt6zFt.
- Ospanov et al. [2024a] Azim Ospanov, Mohammad Jalali, and Farzan Farnia. Dissecting clip: Decomposition with a schur complement-based approach. arXiv preprint arXiv:2412.18645, 2024a.
- Ospanov et al. [2024b] Azim Ospanov, Jingwei Zhang, Mohammad Jalali, Xuenan Cao, Andrej Bogdanov, and Farzan Farnia. Towards a scalable reference-free evaluation of generative models. In Advances in Neural Information Processing Systems, volume 38, 2024b.
- Pasarkar and Dieng [2024] Amey Pasarkar and Adji Bousso Dieng. Cousins of the vendi score: A family of similarity-based diversity metrics for science and machine learning. In International Conference on Artificial Intelligence and Statistics. PMLR, 2024.
- Pillutla et al. [2021] Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. MAUVE: Measuring the gap between neural text and human text using divergence frontiers. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=Tqx7nJp7PR.
- Pillutla et al. [2023] Krishna Pillutla, Lang Liu, John Thickstun, Sean Welleck, Swabha Swayamdipta, Rowan Zellers, Sewoong Oh, Yejin Choi, and Zaid Harchaoui. MAUVE Scores for Generative Models: Theory and Practice. JMLR, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In International Conference on Machine Learning, pages 8748–8763. arXiv, February 2021. 10.48550/arXiv.2103.00020. URL http://arxiv.org/abs/2103.00020. arXiv:2103.00020 [cs].
- Rezaei et al. [2024] Parham Rezaei, Farzan Farnia, and Cheuk Ting Li. Be more diverse than the most diverse: Online selection of diverse mixtures of generative models. arXiv preprint arXiv:2412.17622, 2024.
- Rényi [1961] Alfréd Rényi. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, pages 547–561. University of California Press, 1961.
- Sajjadi et al. [2018] Mehdi S. M. Sajjadi, Olivier Bachem, Mario Lucic, Olivier Bousquet, and Sylvain Gelly. Assessing generative models via precision and recall. In Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018.
- Sauer et al. [2022] Axel Sauer, Katja Schwarz, and Andreas Geiger. Stylegan-xl: Scaling stylegan to large diverse datasets. In ACM SIGGRAPH 2022 Conference Proceedings, volume abs/2201.00273, 2022. URL https://arxiv.org/abs/2201.00273.
- Shawe-Taylor et al. [2005] J. Shawe-Taylor, C.K.I. Williams, N. Cristianini, and J. Kandola. On the eigenspectrum of the gram matrix and the generalization error of kernel-pca. IEEE Transactions on Information Theory, 51(7):2510–2522, 2005. 10.1109/TIT.2005.850052.
- Stein et al. [2023] George Stein, Jesse Cresswell, Rasa Hosseinzadeh, Yi Sui, Brendan Ross, Valentin Villecroze, Zhaoyan Liu, Anthony L Caterini, Eric Taylor, and Gabriel Loaiza-Ganem. Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 3732–3784. Curran Associates, Inc., 2023.
- Szegedy et al. [2016] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Wang et al. [2023] Zixiao Wang, Farzan Farnia, Zhenghao Lin, Yunheng Shen, and Bei Yu. On the distributed evaluation of generative models. arXiv preprint arXiv:2310.11714, 2023.
- Williams and Seeger [2000] Christopher Williams and Matthias Seeger. Using the nyström method to speed up kernel machines. In Advances in neural information processing systems, pages 682–688, 2000.
- Wu et al. [2025] Youqi Wu, Jingwei Zhang, and Farzan Farnia. Fusing cross-modal and uni-modal representations: A kronecker product approach, 2025. URL https://arxiv.org/abs/2506.08645.
- Xu et al. [2015] Zenglin Xu, Rong Jin, Bin Shen, and Shenghuo Zhu. Nystrom approximation for sparse kernel methods: Theoretical analysis and empirical evaluation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015.
- Zhang et al. [2024] Jingwei Zhang, Cheuk Ting Li, and Farzan Farnia. An interpretable evaluation of entropy-based novelty of generative models. arXiv preprint arXiv:2402.17287, 2024.
- Zhang et al. [2025] Jingwei Zhang, Mohammad Jalali, Cheuk Ting Li, and Farzan Farnia. Unveiling differences in generative models: A scalable differential clustering approach. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 8269–8278, 2025.
Supplementary Material
Appendix A Proofs
A.1 Proof of Theorem 1
To prove the theorem, we will use the following lemma followed from [Gross, 2011, Kohler and Lucchi, 2017].
Lemma 1 (Vector Bernstein Inequality [Gross, 2011, Kohler and Lucchi, 2017]).
Suppose that are independent and identically distributed random vectors with zero mean and bounded -norm . Then, for every , the following holds
We apply the above Vector Bernstein Inequality to the random vectors where denotes the Kronecker product. To do this, we define vector for every . Note that is, by definition, a zero-mean vector and also for every we have the following for the normalized kernel function :
Then, the triangle inequality implies that
As a result, the Vector Bernstein Inequality leads to the following for every :
On the other hand, note that is the vectorized version of rank-1 , which shows that the above inequality is equivalent to the following where denotes the Hilbert-Schmidt norm, which will simplify to the Frobenius norm in the finite dimension case,
Subsequently, we can apply the Hoffman-Wielandt inequality which shows that for the sorted eigenvalue vectors of (denoted by in the theorem) and (denoted by in the theorem) we will have , which together with the previous inequality leads to
If we define that implies , we obtain the following for every (since we suppose )
which completes the proof.
A.2 Proof of Corollary 2
The case of . We show that Theorem 1 on the concentration of the eigenvalues will further imply a concentration bound for the logarithm of Vendi-1 score. In the case of (when ), the concentration bound will be formed for the logarithm of the Vendi score, i.e. the Von-Neumann entropy (denoted as ):
Theorem 1 shows that with probability . To convert this concentration bound to a bound on the order-1 entropy (for Vendi-1 score) difference , we leverage the following two lemmas:
Lemma 2.
For every such that , we have
Proof. Let , where . Defining , the first-order optimality condition yields as the local maximum of . Therefore, there are three cases of placement of and on the interval : and appear before maximum point, after maximum point or maximum point is between and . We show that regardless of the placement of and , the above inequality remains true.
-
•
Case 1: . Note that . Since the second-order derivative is negative and the function is monotonically increasing within the interval , the gap between and is maximized when and . This directly leads to the desired bound as follows:
Here, we use the standard limit .
-
•
Case 2: . In this case, we note that is concave yet decreasing over , and so the gap between and will be maximized when and . This leads to:
where the last inequality holds because , and if we define the function , then we have , which is positive over ( is where ), and then negative over , and hence for every .
-
•
Case 3: and . When and lie on the opposite ends from the maximum point, the inequality becomes:
since we pick the side with the largest difference, this difference is upper bounded by either Case 1 or Case 2 because . Therefore, this case is upper-bounded by .
All the three cases of placement of and are upper-bounded by ; Therefore, the claim holds.
Lemma 3.
If for -dimensional vector where , then we have
Proof. We prove the above inequality using the KKT conditions for the following maximization problem, representing a convex optimization problem,
In a concave maximization problem subject to convex constraints, any point that satisfies the KKT conditions is guaranteed to be a global optimum. Let us pick the following solution and slack variables , . The Lagrangian of the above problem:
-
•
Primal Feasibility. The solution satisfies the primal feasibility, since and .
-
•
Dual Feasibility. is feasible because of the assumption implying that for every integer dimension . Note that this implies .
-
•
Complementary Slackness. Since , the condition is satisfied.
-
•
Stationarity. The condition is satisfied as follows:
Since all KKT conditions are satisfied and sufficient for global optimality, is a global optimum of the specified concave maximization problem. We note that this result is also implied by the Schur-concavity property of entropy. Following this result, the specified objective is upper-bounded as follows:
Therefore, the lemma’s proof is complete.
Following the above lemmas, knowing that from Theorem 1 and using the assumption that ensures the upper-bound satisfies , we can apply the above two lemmas to show that with probability :
Note that under a kernel function with finite dimension , the above bound will be .
A.3 Proof of Corollary 1
Considering the -norm definition , we can rewrite the order- Vendi definition as
where is defined in Theorem 1. Similarly, given the definition of we can write
Therefore, for every , the following hold due to the triangle inequality:
As a result, Theorem 1 shows that for every and , the following holds with probability at least
A.4 Proof of Theorem 2
We begin by proving the following lemma showing that the eigenvalues used in the definition of the -truncated Vendi score are the projection of the original eigenvalues onto a -dimensional probability simplex.
Lemma 4.
Consider that satisfies . i.e., the sum of ’s entries equals . Given integer , define vector whose last entries are , i.e., for , and its first entries are defined as where . Then, is the projection of onto the following simplex set and has the minimum -norm distance to this set
Proof. To prove the lemma, first note that , i.e. its first entries are non-negative and add up to , and also its last entries are zero. Then, consider the projection problem discussed in the lemma:
Then, since we know from the assumptions that and , the discussed where together with Lagrangian coefficients (for inequality constraint ) and (for equality constraint) satisfy the KKT conditions. The primal and dual feasibility conditions as well as the complementary slackness clearly hold for these selection of primal and dual variables. Also, the KKT stationarity condition is satisfied as for every we have . Since the optimization problem is a convex optimization task with affine constraints, the KKT conditions are sufficient for optimaility which proves the lemma.
Based on the above lemma, the eigenvalues used to calculate the -truncated Vendi score are the projections of the top- eigenvalues in for the original score onto the -simplex subset of according to the -norm. Similarly, the eigenvalues used to calculate the -truncated population Vendi are the projections of the top- eigenvalues in for the original population Vendi onto the -simplex subset of .
Since -norm is a Hilbert space norm and the -simplex subset is a convex set, we know from the convex analysis that the -distance between the projected points and is upper-bounded by the -distance between the original points and . As a result, Theorem 1 implies that
However, note that the eigenvalue vectors and can be analyzed in a bounded -dimensional space as their entries after index are zero. Therefore, we can apply the proof of Corollary 2 to show that for every and , the following holds with probability at least
To extend the result to a general , we reach the following inequality covering the above result as well as the result of Corollary 1 in one inequality
A.5 Proof of Theorem 3
Proof of Part (a). As defined by Ospanov et al. [2024b], the FKEA method uses the eigenvalues of random Fourier frequencies where for each they consider two features and . Following the definitions, it can be seen that which is approximated by FKEA as . Therefore, if we define kernel matrix as the kernel matrix for , then we will have
where .
On the other hand, we note that holds as the kernel function is normalized and hence . Since the Frobenius norm is the -norm of the vectorized version of the matrix, we can apply Vector Bernstein inequality in Lemma 1 to show that for every :
Then, we apply the Hoffman-Wielandt inequality to show that for the sorted eigenvalue vectors of (denoted by ) and (denoted by ) we will have , which together with the previous inequality leads to
Furthermore, as we shown in the proof of Theorem 1 for every
which, by applying the union bound for , together with the previous inequality shows that
Therefore, Lemma 4 implies that
If we define , implying that , then the above inequality shows that
Therefore, if we follow the same steps of the proof of Theorem 2, we can show
Proof of Part (b). To show this theorem, we use Theorem 3 from [Xu et al., 2015], which shows that if the th largest eigenvalue of the kernel matrix satisfies , then given ( is a universal constant), the following spectral norm bound will hold with probability :
Therefore, Weyl’s inequality implies the following for the vector of sorted eigenvalues of , i.e. , and that of , i.e., ,
As a result, considering the subvectors and with the first entries of the vectors, we will have:
Noting that the non-zero entries of are all included in the first- elements, we can apply Lemma 4 which shows that with probability we have
Also, in the proof of Theorem 2, we showed that
Combining the above inequalities using a union bound, shows that with probability at least we have
Hence, repeating the final steps in the proof of Theorem 2, we can prove
Appendix B Additional Numerical Results
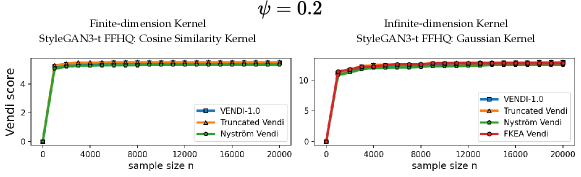
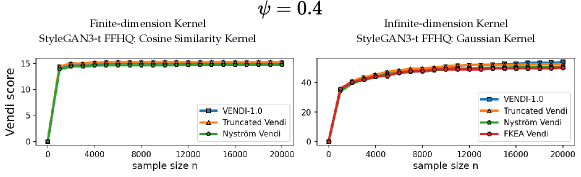
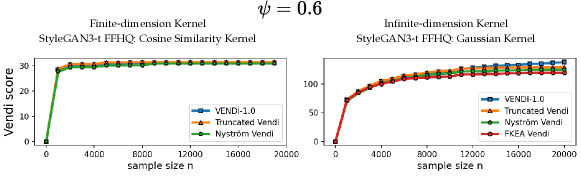
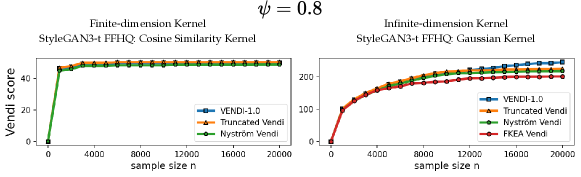
In this section, we present supplementary results concerning the evaluation of diversity and the convergence behavior of different variants of the Vendi score. We extend the convergence experiments discussed in the main text to include the truncated StyleGAN3-t FFHQ dataset (Figure 12) and the StyleGAN-XL ImageNet dataset (Figure 13). Furthermore, we demonstrate that the truncated Vendi statistic effectively captures the diversity characteristics across various data modalities. Specifically, we conducted similar experiments as shown in Figures 7 and 6 on text data (Figure 9) and video data (Figure 11), showcasing the applicability of the metric across different domains.
We observe in Figure 12 that the convergence behavior is illustrated across various values of . The results indicate that, for a fixed bandwidth , the truncated, Nyström, and FKEA variants of the Vendi score converge to the truncated Vendi statistic. As demonstrated in Figure 6 of the main text, this truncated Vendi statistic effectively captures the diversity characteristics inherent in the underlying dataset.
We note that in presence of incremental changes to the diversity of the dataset, finite-dimensional kernels, such as cosine similarity kernel, remain relatively constant. This effect is illustrated in Figure 13, where increase in truncation factor results in incremental change in diversity. This is one of the cases where infinite-dimensional kernel maps with a sensitivity (bandwidth) parameter are useful in controlling how responsive the method should be to the change in diversity.
| VENDI-1.0 | RKE | Vendi-t | FKEA-Vendi | Nystrom-Vendi | Recall | Coverage | |
| 2000 | 239.91 | 13.47 | 239.91 | 228.69 | 239.91 | 0.76 | 0.86 |
| 4000 | 315.35 | 13.51 | 315.35 | 280.68 | 315.35 | 0.81 | 0.87 |
| 6000 | 357.15 | 13.56 | 346.27 | 310.9 | 345.49 | 0.83 | 0.91 |
| 8000 | 392.36 | 13.56 | 354.8 | 329.56 | 357.41 | 0.87 | 0.91 |
| VENDI-1.0 | RKE | Vendi-t | FKEA-Vendi | Nystrom-Vendi | Recall | Coverage | |
| 2000 | 187.17 | 10.65 | 187.17 | 173.06 | 187.18 | 0.78 | 0.85 |
| 4000 | 236.49 | 10.7 | 236.49 | 222.78 | 236.08 | 0.82 | 0.87 |
| 6000 | 264.82 | 10.7 | 258.21 | 236.37 | 257.34 | 0.86 | 0.87 |
| 8000 | 289.08 | 10.71 | 265.84 | 251.59 | 266.23 | 0.86 | 0.86 |
| 10000 | 304.44 | 10.72 | 267.39 | 256.24 | 268.34 | 0.86 | 0.87 |
| Metric | samples | ||||||
| 10000 | 20000 | 30000 | 40000 | 50000 | 60000 | 70000 | |
| Vendi | 97s | 631s | 1868s | - | - | - | - |
| FKEA-Vendi | 19s | 36s | 53s | 71s | 88s | 105s | 124s |
| Nystrom-Vendi | 31s | 44s | 78s | 91s | 112s | 136s | 164s |
B.1 Bandwidth Selection
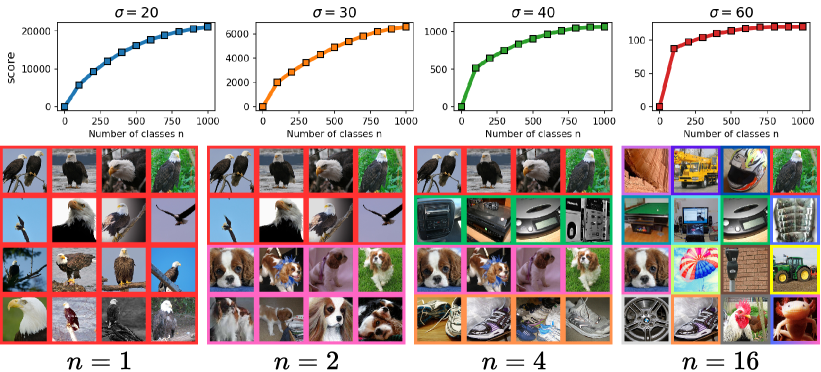
In our experiments, we select the Gaussian kernel bandwidth, , to ensure that the Vendi metric effectively distinguishes the inherent modes within the dataset. The kernel bandwidth directly controls the sensitivity of the metric to the underlying data clusters. As illustrated in Figure 10, varying significantly impacts the diversity computation on the ImageNet dataset. A smaller bandwidth (e.g., ) results in the metric treating redundant samples as distinct modes, artificially inflating the number of clusters, which in turn slows down the convergence of the metric. On the other hand, large bandwidth results in instant convergence of the metric, i.e. in and have almost the same amount of diversity.
Appendix C Selection of Embedding space
To show that proposed truncated Vendi score remains feasible under arbitrary embedding selection, we conducted experiments from Figures 6 and 7. Figures 14, 15, 16 and 17 extend the results to CLIP Radford et al. [2021] and SWaV Caron et al. [2020] embeddings. These experiments demonstrate that FKEA, Nyström and -truncated Vendi correlate with increasing diversity of the evaluated dataset. We emphasize that proposed statistic remains feasible under arbitrary embedding space that is capable of mapping image samples into a latent space.