Domain-adaptive Person Re-identification without Cross-camera Paired Samples
Abstract
Existing person re-identification (re-ID) research mainly focuses on pedestrian identity matching across cameras in adjacent areas. However, in reality, it is inevitable to face the problem of pedestrian identity matching across long-distance scenes. The cross-camera pedestrian samples collected from long-distance scenes often have no positive samples. It is extremely challenging to use cross-camera negative samples to achieve cross-region pedestrian identity matching. Therefore, a novel domain-adaptive person re-ID method that focuses on cross-camera consistent discriminative feature learning under the supervision of unpaired samples is proposed. This method mainly includes category synergy co-promotion module (CSCM) and cross-camera consistent feature learning module (CCFLM). In CSCM, a task-specific feature recombination (FRT) mechanism is proposed. This mechanism first groups features according to their contributions to specific tasks. Then an interactive promotion learning (IPL) scheme between feature groups is developed and embedded in this mechanism to enhance feature discriminability. Since the control parameters of the specific task model are reduced after division by task, the generalization ability of the model is improved. In CCFLM, instance-level feature distribution alignment and cross-camera identity consistent learning methods are constructed. Therefore, the supervised model training is achieved under the style supervision of the target domain by exchanging styles between source-domain samples and target-domain samples, and the challenges caused by the lack of cross-camera paired samples are solved by utilizing cross-camera similar samples. In experiments, three challenging datasets are used as target domains, and the effectiveness of the proposed method is demonstrated through four experimental settings.
Index Terms:
Person Re-ID, Domain Adaptation, Long-distance Scenes, Feature Recombination, Distribution Alignment.I Introduction
Person re-ID is a technique used to determine whether pedestrians under non-overlapping cameras have the same identity. Due to its wide application prospect in criminal suspect tracking and missing person search, person re-ID has attracted significant attention from researchers, and a large number of effective methods have been proposed. Among these methods, supervised person re-ID was first proposed[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]. Under the supervision of a large-scale labeled training samples, the recognition performance quickly reaches a certain level with the continuous advancement of deep learning technology. The domain adaptability of the model obtained by this supervised training is poor, and direct deployment to new datasets always results in performance degradation due to the domain shift between source domain and target domain[11, 12, 13]. As the most direct and effective way to solve this problem, large-scale training samples are labeled on the target domain, and the recognition model is supervised for training. However, manually labeling large-scale training samples is extremely time-consuming and laborious[14]. Therefore, fully unsupervised and domain-adaptive person re-ID is proposed.
In general, fully unsupervised methods directly predict pseudo-labels for the training set of the target dataset and utilize the predicted pseudo-labels to supervise model training. Such methods require high reliability of pseudo-labels. If there is a lot of noise in the pseudo-labels, it causes a significant drop in model performance on the target dataset. Domain-adaptive methods mainly use data from source and target domains to train re-ID models. During this process, the source-domain data is labeled while the target-domain data is unlabeled. Source-domain and target-domain data supervise model training by annotated true labels and predicted pseudo-labels, respectively. Therefore, domain adaptative methods are theoretically more stable than fully unsupervised methods, thus attracting the attention of researchers.
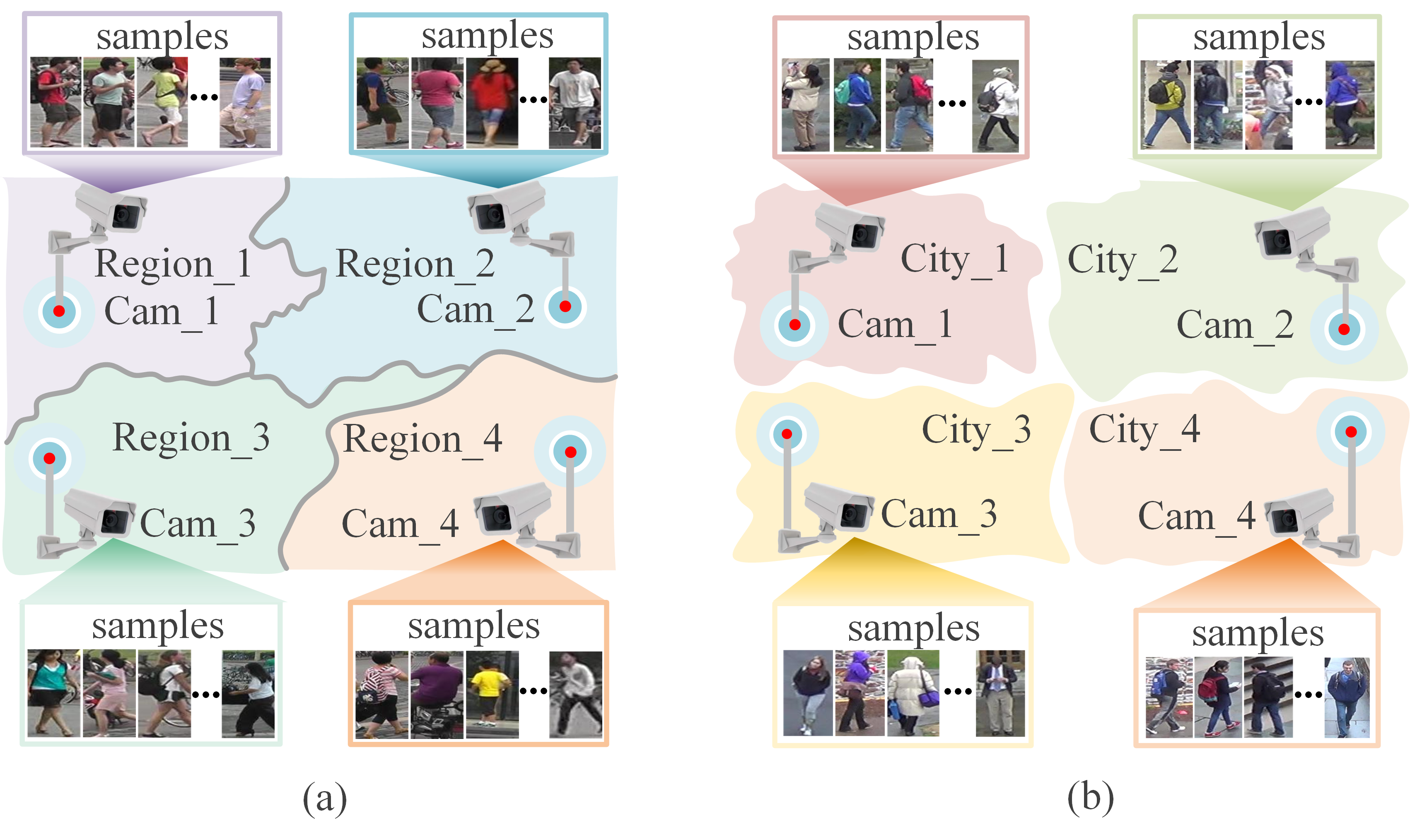
Existing domain-adaptive person re-ID methods mainly address short-distance cross-camera pedestrian matching. This has a positive impact on reducing noisy labels, as pedestrians with the same identity are more likely to appear in short-distance cross-camera views. However, it actually needs to match pedestrian identities across long-distance scenes, as shown in Fig. 1. If pedestrian A appears in the region-1 of a city, which region of the city will he appear in again? This involves the problem of long-distance cross-camera pedestrian identity matching. In such scenes, it is highly likely that cameras across long-distance scenes do not capture pedestrians with the same identity. If existing domain-adaptive person re-ID methods are directly deployed to the long-distance scenes, the original performance drops significantly, because the predicted pseudo-labels are all noisy labels. In view of the lack of cross-camera paired samples, some researchers proposed to predict features from one camera view to another and used the prediction results and original features to form cross-camera sample pairs for supervised model training. However, these methods rely heavily on the quality of prediction results for missing samples across cameras.
To address the above issues, this paper proposes a domain-adaptive person re-ID method without cross-camera paired samples. Unlike existing methods, the proposed method does not need to use pedestrians from a single camera view to generate cross-camera samples or features. It addresses the challenge of missing cross-camera pedestrian sample pairs by improving the domain adaptability of the model on cross-region datasets. Specifically, FRT mechanism is proposed to learn cross-camera discriminative features. This mechanism divides features into two categories according to their contributions in pedestrian identity classification, pedestrian identity-related features and camera identity-related features. This design reduces the features that contribute less to pedestrian identity classification, thereby promoting the role of features that contribute more to pedestrian identity classification. In addition, the control parameters of the model are reduced, which further improves the generalization ability of the model. On this basis, IPL scheme is designed to realize mutual promotion learning between features. This mechanism can not only promote the improvement of feature discriminability but also achieve the separation of camera and pedestrian identity information, reducing the interference of camera information on pedestrian identity-related features.
To further address the challenge caused by the lack of cross-camera positive samples, cross-camera consistent feature learning is implemented within the framework. By exchanging the style of source and target domains, the alignment of instance-level data distribution is achieved, and the supervised model training under the style of the target domain improves the domain adaptability of the model. To enable the model to extract the same pedestrian features across cameras, a cluster-based consistent feature learning method is proposed. This method regards pedestrians with consistent identities across cameras as similar pedestrians and compensates for the impact of missing cross-camera positive samples on model training by reducing the difference of intra-class features. Additionally, identity-inconsistent features are further excluded based on the prior knowledge that pedestrians with the same identity do not exist across long-distance scenes. This ensures that the model can still extract the features of the same identity and exclude the features of different identities without cross-camera positive samples. In summary, this paper has three main contributions as follows.
-
•
A task-specific feature recombination mechanism is proposed. According to the contributions to pedestrian identity classification based on features, the mechanism divides features into two categories related to pedestrian identity and camera identity, and performs interactive promotion learning between the two categories. This not only improves the discriminability of the features, but also improves the generalization of the model.
-
•
Aiming at the problem of missing cross-camera paired samples, an instance-level feature distribution alignment and cross-camera identity consistent feature learning method is proposed. Exchanging source-domain and target-domain camera styles and constraining the category consistency of similar pedestrians across cameras are applied to address the inability to train models supervised with target-domain data.
-
•
The experimental results under four experimental settings on three datasets, i.e., Market-SCT [15], DukeMTMC-SCT (Duke-SCT) [15], and MSMT17-SCT (MSMT-SCT) [16], confirm that the proposed method achieves superior recognition performance compared with existing methods on pedestrian identity matching in long-distance scenes.
The rest of this paper is organized as follows. Section II discusses related work; Section III specifies the proposed method; Section IV shows the experimental results and correspoding analysis; and Section V concludes this paper.
II Related Work
II-A Intra-Camera Supervised Person Re-ID
Due to the strong application prospects, person re-ID across long-distance scenes has received significant attention from researchers in the past two years. In 2020, Zhang et al. [15] first proposed the application requirements of the problems across long-distance scenes and designed a single-camera training method to solve the problem caused by the lack of cross-camera paired samples. This method guarantees the discriminability of features by extracting hard-positive samples in the camera and excluding hard-negative sample pairs within-camera and cross-cameras. In cross-camera person identity matching, mitigating cross-camera intra-class variations is significant for person re-ID. However, this method ignores the impact of the above-mentioned problem on recognition performance. Therefore, Ge et al. [16] proposed a method to predict cross-camera pedestrian features of single-camera pedestrians. The predicted results are combined with the original features to form cross-camera positive sample pairs and used to supervise the model training. This method relies heavily on the predicted cross-camera pedestrian features. If the predictions are not good, it most likely hurts the model performance. To alleviate this problem, Wu et al. [17] proposed a camera-conditioned stable feature generation method, which reduces the impact of unideal features on model performance by improving the quality of generated features. Although this method improves the quality of generated cross-camera sample, the problem of model performance being limited by the quality of generated samples remains unresolved. Different from the above methods, the proposed method belongs to the domain adaptive method. It addresses the challenge of missing cross-camera paired samples by improving model generalization and domain adaptability.
II-B Domain-Adaptive Person Re-ID
The domain-adaptive person re-ID method trains the model through labeled source-domain samples and unlabeled target-domain samples, so that the model has good performance in the target domain. Since this method does not need to label samples in the target domain, which significantly reduces the labor cost of labeling training samples, it has attracted the attention of researchers and proposed a series of effective methods. Existing methods can be roughly classified into three categories, methods based on external model assistance, methods based on domain-adaptive feature extraction, and methods based on pseudo-label prediction. Methods based on external model assistance usually use an external model to assist re-ID models to gain domain adaptability. Commonly used external models include CamStyle transfer model [18], pedestrian pose extraction model [19], etc. In particular, methods such as PT-GAN [20], SPGAN [21], ATNet [22], and CR-GAN [23] all use the CamStyle transfer model to transfer the style of training samples from the source domain to the target domain, so that the model can be trained in a supervised manner on the transferred samples. However, the samples generated after style transfer are prone to corrupt information related to pedestrian identity cues. Utilizing such samples to train a model can easily degrade recognition performance. In pedestrian pose-assisted methods, the pose estimation model is usually used to estimate the pose information of pedestrians in the training set and combined with the generative adversarial mechanism to achieve pedestrian pose-invariant and domain-aligned feature extraction. In addition, to obtain discriminative features with consistent distribution, Yang et al. [24] proposed the part-aware progressive unsupervised domain adaptation person re-ID method. This method utilizes a pedestrian’s pose estimation model to perceive pedestrian body parts. These methods, which rely on external models for data preprocessing, are not conducive to the deployment in real-world scenes.
Methods based on domain-adaptive feature extraction often address the impact of domain discrepancy on recognition performance by learning transferable features. In particular, Yang et al. [25] proposed a patch-based unsupervised learning framework for obtaining transferable discriminative features. This method exploits the similarity between patches to learn features that are transferable across cameras. Wu et al. [26] proposed a camera-aware similarity consistency loss to learn consistent pairwise similarity distributions to address domain shift. Qi et al. [27] proposed an unsupervised camera-aware domain adaptation framework to address domain shift between source and target domains. Zou et al. [28] proposed to purify the target domain representation space through feature disentanglement, thereby enhancing the domain adaptability of the model. Chen et al.[29] used the domain invariance of pedestrian attribute information to improve the performance of visual features in domain-adaptive pedestrian matching. Dong et al. [30] proposed a triple adversarial learning and imaginative reasoning mechanism to obtain domain-adaptive discriminative features. Li et al.[31] proposed a mutual-promotion learning method for feature disentanglement, which achieved the separation of domain-invariant features and domain-related features, improving the performance of the model on the target domain. Although methods based on domain-adaptive feature extraction are effective, their performance is limited due to the underutilization of unlabeled samples from the target domain in model training.
To make full use of unlabeled samples from the target domain in model training, methods based on pseudo-label prediction have been proposed. In particular, Ge et al. [32] proposed an unsupervised mutual mean-teaching (MMT) framework for domain-adaptive person re-ID. The framework improves the accuracy of label prediction through offline refinement of hard pseudo-labels and online refinement of soft pseudo-labels using an alternating training scheme. Yang et al. [33] designed an asymmetric co-teaching framework. The framework suppresses noisy labels through the collaboration of two models. Zhai et al. [34] proposed an augmented discriminative clustering (AD-Cluster) technique to predict pseudo-labels of pedestrians in the target domain. Zeng et al. [35] proposed a hierarchical clustering method with hard-batch triplet loss to improve the quality of pseudo-label prediction. For the problem of model non-convergence in cluster-based pseudo-label prediction methods. Ji et al. [36] proposed an attention-driven two-stage clustering method. To suppress the noise in pseudo-labels, Zhao et al. [37] proposed a noise resistible mutual training (NRMT) mechanism to predict pseudo-labels through interactive instance selection. Shi et al. [38] proposed a reliability exploration with self-ensemble learning (RESL) framework to improve the reliability of pseudo-label prediction in domain-adaptive person re-ID.
To improve the adaptation of the model on the target domain, Chen et al. [39] combined data augmentation methods with a multi-label assignment strategy to decouple semantic features from the source domain. Additionally, a pre-trained model was used to extract various semantic features from the target dataset, and each semantic feature is regarded as a specific domain. The features of each domain are then clustered, and the connections between different clusters are used for self-distillation to generate more reliable pseudo-labels. Li et al. [40] exploited a logical reasoning mechanism that utilizes the logical relationships between samples to refine cross-camera pseudo-labels. When the training set in the target dataset contains a large number of cross-camera positive samples, the above-mentioned methods can predict pseudo-labels relatively reliably. However, across long-distance scenes, the possibility of the same pedestrian appearing under two cameras is extremely low, resulting in the target-domain samples participating in model training being negative samples across cameras.
III The Proposed Method
III-A Overview of the Proposed Framework
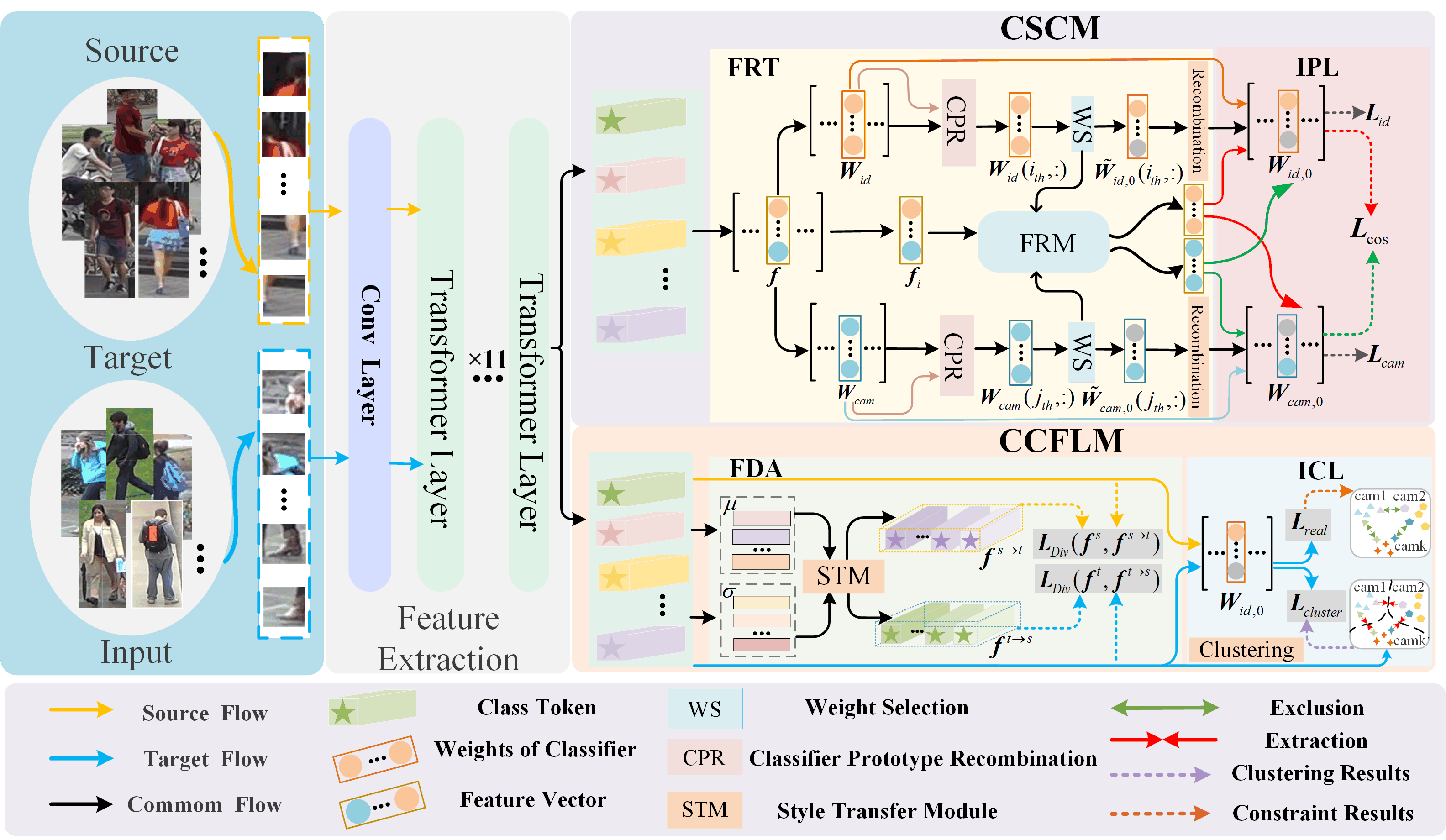
As shown in Fig. 2, the proposed method consists of the feature extraction network , category synergy co-promotion module (CSCM), and cross-camera consistent feature learning module (CCFLM). The is used to extract features from the source-domain and target-domain samples. The CSCM is composed of feature recombination by task (FRT) and interactive promotion learning (IPL). According to the contributions of features to pedestrian and camera identification, FRT divides features into two groups. One group is related to pedestrian identity and the other group is related to camera identity. Then the IPL of features is developed and carried out between the two groups to improve the discriminability of the features. The CCFLM includes the feature distribution alignment (FDA) and cross-camera identity consistent feature learning (ICL) under the supervision of cross-camera unpaired samples. The FDA is mainly used to make the cross-domain features share the same probability distribution. The ICL is mainly used to make the features learned by the model under the supervision of unpaired samples have cross-camera identity consistency.
III-B Feature Extraction Network and Pre-training
Assume that the source-domain data sample set is , where represents the -th sample from , and represent the identity label and camera label of the sample , is the total number of samples in , denotes the total category of pedestrian identity, and and denotes the total number of cameras. Similarly, the training set in the target domain is defined as , where and . In cross-region person re-ID, according to the protocol of [15], it assumes that the training set or domain adaptation in has no paired images across camera views, i.e., for , when . Images of pedestrians with the same identity only appear in a single camera, i.e., , such that when .
In the feature extraction of pedestrian images, the TransReID [41] framework is used as the backbone denoted as . The network consists of 12 transformer layers. In the proposed method, it is necessary to analyze the contribution of extracted features to specific tasks and group them accordingly. Therefore, it is necessary to make have the initial recognition ability. Let be the global token of the -th pedestrian image , and be the -th local token. The feature extraction network can realize pre-training by minimizing Eq.(1).
| (1) |
where and are the cross-entropy loss and triplet loss functions respectively, is the identity classifier, is the total number of pedestrian identities, and is the number of channels of the feature vector. represents the identity label of the -th sample from the source domain, and is the number of source-domain samples in a mini-batch.
Since the pedestrian identity classifier and the camera classifier in the proposed method need to promote each other to realize the separation of pedestrian identity and camera information, it is also necessary to pre-train the camera classifier.
| (2) |
where , is the camera label of , is the camera classifier, and is the number of target-domain samples in a mini-batch.
III-C Category Synergy Co-promotion Module
In the domain-adaptive person re-ID, pedestrian discriminative feature extraction, which is not affected by domain shift, plays a crucial role in improving the domain generalization ability of the model. In multi-classification tasks, different features contribute differently to a specific classification task. If these features can be grouped by their contributions to a specific classification task, it is conductive to enhancing the ability of the network to extract task-specific discriminative features. Therefore, this paper proposes a CSCM. This module is mainly composed of FRT and IPL.
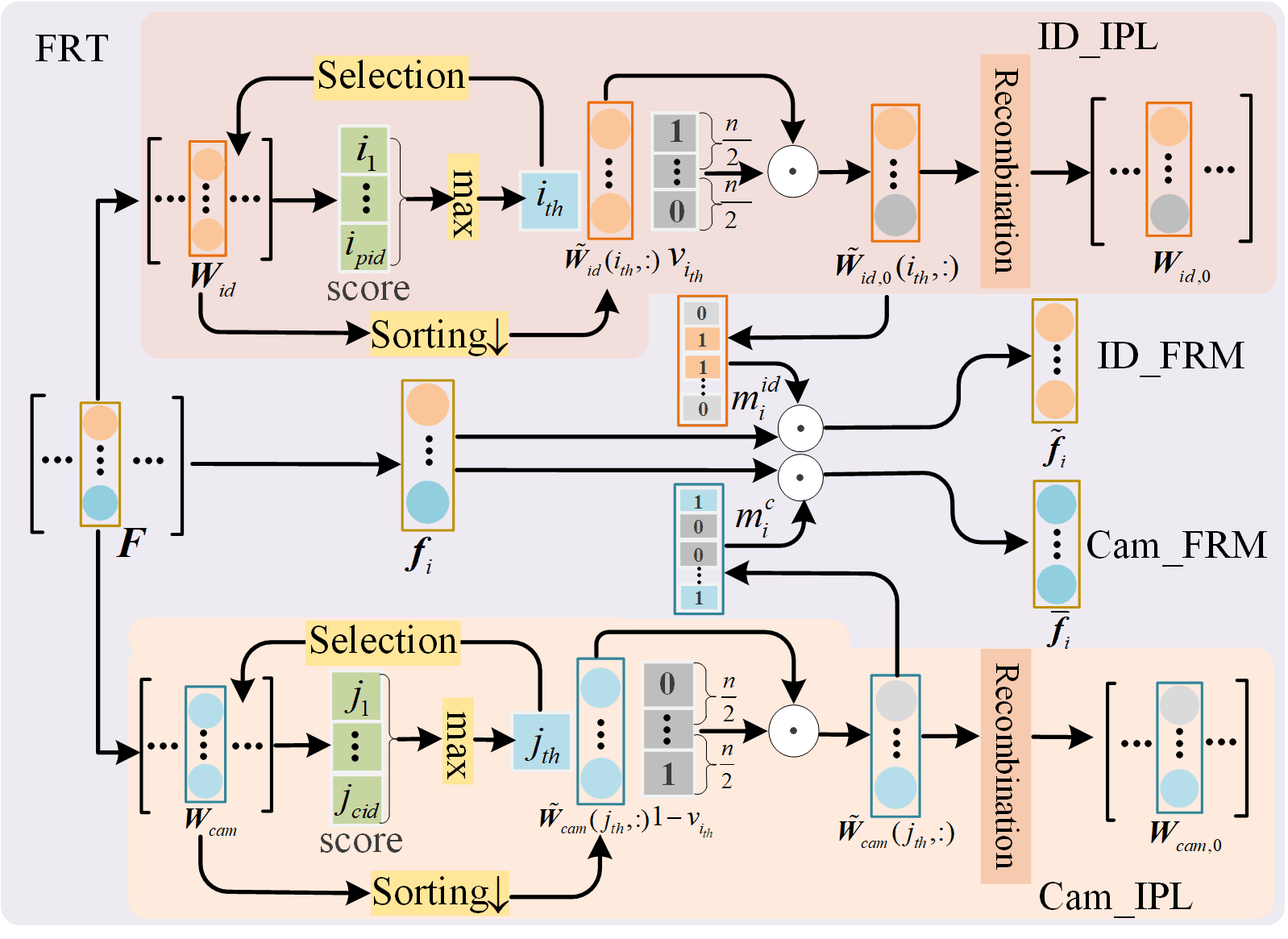
III-C1 Task-specific Feature Recombination
Fig. 3 shows the specific process of FRT. It consists of the feature recombination module by pedestrian identity (ID-FRM) and feature recombination module by camera identity (Cam-FRM). The former is mainly used to improve the discriminability of pedestrian identity-related features, and the latter is mainly used to assist the former in excluding camera-related domain information in features. Assume that the output feature of the source-domain sample passing through the feature extraction network is . The classification result obtained after feeding into the pre-trained pedestrian classifier is given as follows.
| (3) |
where is the probability that belongs to each identity of the source-domain pedestrian. Let be the position index of the largest value among in as follows.
| (4) |
After obtaining , the features are extracted from that make significant contributions to the correct classification of , while excluding the remaining features. In the subsequent training of , the extracted features are encouraged to play a greater role in person identification, so as to implement network augmentation in discriminative feature extraction. Therefore, this paper looks for the vector corresponding to the identity from the identity classifier . For the convenience of subsequent operations, is marked as follows.
| (5) |
To find the top features that contribute significantly to the correct classification, the values in are arranged in order of size as follows.
| (6) |
where represents the descending order operation.
To emphasize the role of features that contribute more to identity classification, this paper proposes to perform link inactivation on features that contribute less to identity classification. Let . after inactivation can be expressed as follows.
| (7) |
where is element-wise dot product.
The value in is put back to the original position of the value in . The classifier is obtained. When traverses all pedestrian identities in the source domain and the target domain, the obtained classifier is denoted as .
To realize the feature discriminability improvement of the corresponding pedestrian image camera category, this paper proposes the following method to construct the deactivated camera classifier .
| (8) |
The constructed in this way can effectively prevent and from using the same features to classify camera and pedestrian identities. This also enables the separation of pedestrian identity information from camera identity information within a feature extraction network framework. To remove camera information from pedestrian identity-related features and improve the domain adaptability of the model, the feature is re-divided into the feature for pedestrian identification and the feature for camera identification.
First, the features of are grouped as follows.
| (9) |
| (10) |
where is a vector composed of 0 and 1.
When the element value at a certain position of is 0, the value at the corresponding position of is also 0. If the element at a certain position of is not 0, the element at the corresponding position of is 1. After the 0 in and are deleted, the recombined features and are obtained. At the same time, the 0 that appears in is deleted due to deactivation, and the obtained pedestrian identity classifier is recorded as . The same operation for camera classifier is used to get the recombined camera classifier .
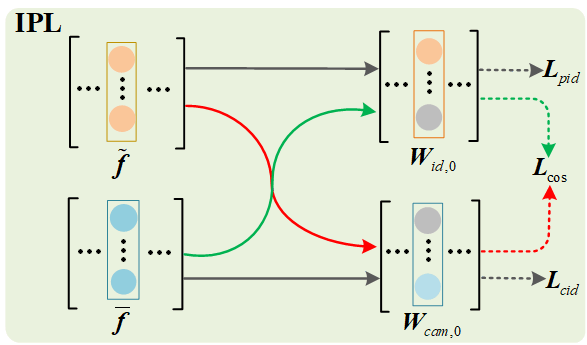
III-C2 Interactive Promotion Module
To further remove the style information of the camera from and the identity information of pedestrians from , the IPL mechanism is proposed. The details of the specific process are shown in Fig. 4. Specifically, the recombined features and are input to the corresponding recombined classifiers and to update , so that the features extracted by can still be classified to the corresponding pedestrian and camera identities after recombination.
| (11) |
In this process, the features that only provide weak contributions are removed. In this case, to ensure that and obtained after recombination using the pre-trained classifier can still correctly classify the recombined and , the discriminability of features and must be improved accordingly. Therefore, minimizing Eq.(11) can improve the ability of to extract discriminative features. In fact, for a specific task, the above method improves the generalization performance of the model by limiting the number of model parameters.
In the IPM, is further updated so that the feature extracted by does not contain camera information, and does not contain pedestrian information. This objective can be achieved by minimizing the loss function as follows.
| (12) |
where , and the value of each element in is , . The value of each element in is . The loss function used in the IPM can be expressed as follows.
| (13) |
III-D Cross-camera Consistency Learning
This paper aims to address the domain-adaptive person re-ID problem due to the lack of cross-camera paired samples. In this setting, there are no pedestrian across cameras with the same identity in the training samples from the target dataset due to the long distance between cameras. Therefore, it is challenging to learn discriminative features across cameras under the supervision of unpaired samples across cameras. This paper addresses the above problem from two aspects, instance-level distribution-consistency learning of source-domain and target-domain features and cross-camera identity consistency learning.
III-D1 Inter-domain Instance-level Distribution Consistency
To make the target-domain samples acquired across long-distance scenes more effectively participate in the model training, an instance-level distribution consistency implementation method is proposed based on the style transfer theory of [42]. Let and be the features of and extracted by . The corresponding mean values are and , respectively. The corresponding variances are and , respectively. Then, after the style is transferred from source domain to target domain, the features can be expressed as follows.
| (14) |
| (15) |
The inconsistency of feature distribution between source-domain data and target-domain data is the main factor causing domain shift. If the source-domain and target-domain sample features have the same distribution, it will be conducive to narrowing the domain shift between the source domain and the target domain. However, diverse factors cause style differences in samples. Eliminating the impact of domain discrepancy on a single sample is challenging, when distribution alignment is directly implemented at the domain level. Therefore, the instance-level distribution-consistency learning is presented. The specific process is given as follows.
| (16) |
| (17) |
| (18) |
where and are the probability distributions of the input features, and is the KL divergence, which is utilized to evaluate the difference between the two distributions. The inter-domain variance is reduced by minimizing Eq.(18) to narrow down the domain distribution between the source and target domains.
In the above process, since the sample style of the target domain is transferred to the source-domain samples, the positive samples across cameras in the target domain are generated, which allows the model to be trained supervised in the style of the target domain. Therefore, the following loss function is used to update .
| (19) |
In the above process, the total loss of obtaining inter-domain distribution consistency can be formulated as follows.
| (20) |
III-D2 Identity Consistency across Cameras
After the above process, the model has a certain domain-adaptive ability in the target domain, but it does not fully consider the difficult sample classification on the target dataset. Therefore, this paper proposes an effective method to solve how isolated camera samples in the target domain participate in model training. However, pedestrians with the same identity across cameras generally do not appear across long-distance scenes. This means that the samples of the same identity across cameras are unavailable to make the model learn identity-consistent features across cameras.
In fact, samples with the same identity across cameras can be regarded as similar ones. If the model can reduce the difference between similar samples, it can also make the distance between the same pedestrian sample features across cameras smaller. Based on this idea, this paper proposes that the similarity between the same identity across cameras can be maximized by clustering the target-domain features and enhancing the similarity of samples within the same class.
Therefore, a cluster-based method for learning identity-consistent features across cameras is developed, aiming at solving the problem of missing positive samples across cameras. Specifically, is symbolized as the -th sample of the target domain, and the identity label of is obtained after clustering. To enable to extract more similar features from pedestrian images with the same identity acquired from different cameras, this paper proposes to minimize the following loss to update .
| (21) |
where is the identity classifier for samples on the target domain.
Minimizing Eq.(21) can make the features of similar samples show a higher similarity. However, hard negative samples with different identities are not considered. Since pedestrian tracking can be applied to quickly obtain the identity information of each tracked pedestrian appeared in a single camera [43, 44], the identity of pedestrians within the same camera views is easy to know. Assume that is the identity label of the sample in a single camera view. The following loss function can be conducted to solve the problem that hard negative samples cannot be distinguished.
| (22) |
| (23) |
where and are the hard negative sample features of in a mini-batch and the hard positive sample features from the same camera respectively. is the threshold. is the identity classifier of pedestrians on the target dataset.
In cross-camera identity feature consistency learning, the complete loss function is given as follows.
| (24) |
III-E Algorithm and Optimization
In the training phase, the samples from source domain are used in the first 100 epochs to perform model pre-training by minimizing Eq.(1). The camera classifier is pre-trained by minimizing Eq.(2) in the 100-200 epochs. Feature distribution alignment is achieved by minimizing Eq.(20) in the 200-300 epochs. In the remaining 100 epochs, the learning of consistent features of the same identity across cameras is achieved by minimizing Eq.(24). In the testing phase, is used for feature extraction, and Euclidean distance is performed for pedestrian identity matching. The optimization algorithm is given in Algo. 1.
| Datasets | Cam | Training IDs | Training Imgs | Testing IDs | Testing Imgs | Easy Annotation | Paired data Across Cameras |
| Market-1501 | 6 | 751 | 12,936 | 750 | 15,913 | ✓ | |
| Market-SCT | 6 | 751 | 3,561 | 750 | 15,913 | ✓ | |
| DukeMTMC | 8 | 702 | 16,522 | 1,110 | 17,661 | ✓ | |
| Duke-SCT | 8 | 702 | 5,993 | 1,110 | 17,661 | ✓ | |
| MSMT17 | 15 | 1,041 | 32,621 | 3,060 | 93,820 | ✓ | |
| MSMT-SCT | 15 | 1,041 | 6,694 | 3,060 | 93,820 | ✓ |
| Methods | MarketDuke-SCT | DukeMSMT-SCT | ||||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP | |
| Baseline | 66.8 | 79.5 | 83.2 | 47.9 | 39.0 | 51.5 | 57.9 | 16.3 |
| Baseline+FRT | 69.9 | 82.3 | 86.8 | 52.2 | 43.5 | 56.7 | 62.9 | 20.2 |
| Baseline+FRT+IPL | 78.6 | 87.9 | 90.7 | 63.8 | 44.0 | 57.7 | 63.7 | 20.5 |
| Baseline+FRT+IPL+FDA | 79.4 | 88.6 | 91.1 | 64.1 | 48.1 | 62.0 | 68.0 | 24.6 |
| Baseline+FRT+IPL+FDA+ICL | 83.0 | 91.2 | 93.8 | 69.1 | 56.5 | 69.1 | 74.6 | 31.1 |
IV Experiments
IV-A Datasets and Evaluation Protocol
To verify the effectiveness of the proposed method, this paper uses three datasets specialized for person re-ID across distant scenes, namely Market-SCT [15], DukeMTMC-SCT (Duke-SCT) [15] and MSMT17-SCT (MSMT-SCT) [16] as the target datasets. These three datasets are derived by resetting the datasets Market-1501 (Market) [45], DukeMTMC (Duke) [46], and MSMT17 [47] according to the characteristics of across distant scenes. In Market, Duke, and MSMT17, each pedestrian image in the training set has the corresponding samples with the same identity across cameras. However, in Market-SCT, Duke-SCT, and MSMT17-SCT, the training set only has single-camera pedestrian samples, and there are no samples with the same pedestrian identity across cameras. In person re-ID across long-distance scenes, the datasets Market, Duke, and MSMT17 are used as source-domain data, and Market-SCT, Duke-SCT, and MSMT17-SCT are used as target-domain data. The specific information of different datasets is shown in Table I. In the objective evaluation of algorithm performance, Cumulative Matching Characteristics (CMC) [48] and mean Average Precision (mAP) [45] are used to evaluate the performance of each method under a single query setting.
IV-B Implementation Details
This paper uses the TransReID [41] framework as the backbone of the proposed method. All pedestrian images are resized to 256128 and the batch size is 16. During model training, operations such as horizontal flipping, padding, random cropping, and random erasing are used for data augmentation. The SGD optimizer [49] with a momentum of 0.9, a weight decay rate of , and a learning rate of are used to update the parameters of the encoder . In this process, the learning rate of , , and is . The proposed method is implemented under the PyTorch framework [50], and all experiments are completed on the platform with one NVIDIA GeForce RTX 2080 Ti GPU. The model is trained for a total of 400 epochs. In the first 10 epochs, the learning rate is linearly adjusted by the warm-up strategy [51]. At the 40-th and 70-th epochs, the learning rate decays by 10%.
| Methods | Market-SCT | Duke-SCT | ||||||||
| Source | Rank-1 | Rank-5 | Rank-10 | mAP | Source | Rank-1 | Rank-5 | Rank-10 | mAP | |
| USL | ||||||||||
| MCNL(AAAI’20)[15] | None | 67.0 | 82.8 | 87.9 | 41.6 | None | 67.1 | 80.9 | 84.7 | 45.2 |
| Precise-ICS(WACV’21)[52] | None | 50.0 | 67.5 | 74.8 | 31.2 | None | 41.2 | 57.9 | 64.2 | 25.9 |
| AGW(TPAMI’21)[53] | None | 56.0 | 72.3 | 79.1 | 36.6 | None | 56.5 | 71.0 | 77.7 | 43.9 |
| SimSiam(CVPR’21)[54] | None | 36.2 | 51.9 | 59.1 | 18.0 | None | 28.1 | 43.2 | 51.3 | 19.7 |
| STS(arXiv’21)[55] | None | 21.1 | 34.3 | 41.3 | 8.5 | None | 33.0 | 45.8 | 50.9 | 18.4 |
| ICE(ICCV’21)[56] | None | 29.3 | 41.1 | 47.2 | 13.4 | None | 20.4 | 28.2 | 33.0 | 11.6 |
| CCFP(ACMMM’21)[16] | None | 82.4 | 92.6 | 95.4 | 63.9 | None | 80.3 | 89.0 | 91.9 | 64.5 |
| CCSFG(CVPR’22)[17] | None | 84.0 | 94.3 | 96.2 | 67.7 | None | – | – | – | – |
| PPLR(CVPR’22)[57] | None | 17.9 | 26.1 | 30.9 | 6.0 | None | 15.8 | 22.2 | 26.8 | 8.4 |
| UDA | ||||||||||
| MMT-500(ICLR’20)[32] | Duke | 50.0 | 68.0 | 75.9 | 27.8 | Market | 38.9 | 56.3 | 63.5 | 26.8 |
| MMT-700(ICLR’20)[32] | Duke | 49.1 | 66.9 | 74.3 | 27.7 | Market | 40.9 | 58.1 | 65.5 | 29.2 |
| MMT-900(ICLR’20)[32] | Duke | 51.0 | 70.0 | 76.9 | 28.5 | Market | 42.3 | 59.6 | 67.6 | 30.4 |
| SPCL(NeurIPS’20)[58] | Duke | 11.5 | 23.5 | 30.2 | 4.5 | Market | 12.3 | 19.7 | 24.2 | 5.6 |
| Meb-Net(ECCV’20)[59] | Duke | 54.4 | 71.1 | 78.1 | 30.7 | Market | 41.6 | 58.1 | 64.0 | 27.8 |
| CAC(INS’21)[60] | Duke | 62.1 | 76.6 | 81.1 | 30.6 | Market | 49.6 | 64.0 | 69.8 | 30.0 |
| IDM(ICCV’21)[61] | Duke | 32.3 | 48.3 | 56.1 | 14.3 | Market | 37.9 | 51.2 | 58.4 | 23.6 |
| Dual-Refine(TIP’21)[62] | Duke | 47.7 | 63.4 | 70.1 | 23.3 | Market | 39.8 | 53.4 | 60.2 | 28.1 |
| P2LR(AAAI’22)[63] | Duke | 52.6 | 68.5 | 75.1 | 25.9 | Market | 35.7 | 49.8 | 56.4 | 20.6 |
| DRDL(KBS’22)[31] | Duke | 60.8 | 76.6 | 81.2 | 27.7 | Market | 63.4 | 75.1 | 78.3 | 41.6 |
| Proposed | Duke | 86.3 | 94.4 | 96.7 | 68.3 | Market | 83.0 | 91.2 | 93.8 | 69.1 |
IV-C Ablation Study
The proposed method consists of four core components, feature recombination by task (FRT) and interactive promotion learning (IPL), feature distribution alignment (FDA), and identity consistent learning across cameras with single-camera supervision (ICL). The effectiveness of the above core components is verified on the MarketDuke-SCT and DukeMSMT-SCT. After removing the above four core components from the proposed method, the obtained model is used as the baseline method, and the loss function shown in Eq.(1) is used to train the baseline model. In the ablation experiment, the method after adding FRT to Baseline is denoted as Baseline+FRT, the method after adding IPL to Baseline+FRT is denoted as Baseline+FRT+IPL, the method after adding FDA to Baseline+FRT+IPL is denoted as Baseline+FRT+IPL+FDA, the method of the complete model is denoted as Baseline+FRT+IPL+FDA+ICL.
Effectiveness of FRT. To improve the discriminability of features, this paper groups the features on different channels by task and designs FRT. To verify the effectiveness of FRT, FRT is added to Baseline and the performance of Baseline+FRT is compared with that of Baseline. As shown in Table II, compared with Baseline, the recognition performance obtained by Baseline+FRT on both MarketDuke-SCT and DukeMSMT-SCT is significantly improved. Specifically, after adding FRT, the mAP increases by 4.3% and 3.9% on the MarketDuke-SCT and DukeMSMT-SCT, respectively. Additionally, the recognition accuracy on Rank-1 also improves from 66.8% (39.0%) to 69.9% (43.5%). This indicates that FRT plays a positive role in improving model performance.
Effectiveness of IPL. IPL is mainly used to remove camera-related information from features, thereby reducing the limitation of the interference information brought by the camera style on person re-ID. According to the experimental results shown in Table II, when IPL is added to Baseline+FRT, the corresponding performance of the model on the MarketDuke-SCT (DukeMSMT-SCT) increases from 69.9% and 52.2% (43.5% and 20.2%) in Rank-1 and mAP to 78.6% and 63.8% (44.0% and 20.5%). This shows that IPL is effective in removing camera information to improve the domain adaptability of the model.
Effectiveness of FDA. To reduce the distribution inconsistency of source-domain and target-domain features caused by domain shift, FDA module is designed to achieve instance-level feature distribution alignment. As shown in Table II, after adding FDA to Baseline+FRT+IPL, the Rank-1 and mAP performance of Baseline+FRT+IPL+FDA on the MarketDuke-SCT (DukeMSMT-SCT) changes from the original 78.6% and 63.8% (44.0% and 20.5%) to 79.4% and 64.1% (48.1% and 24.6%), respectively. This shows that the FDA plays a positive role in improving the domain adaptability of the re-ID model.
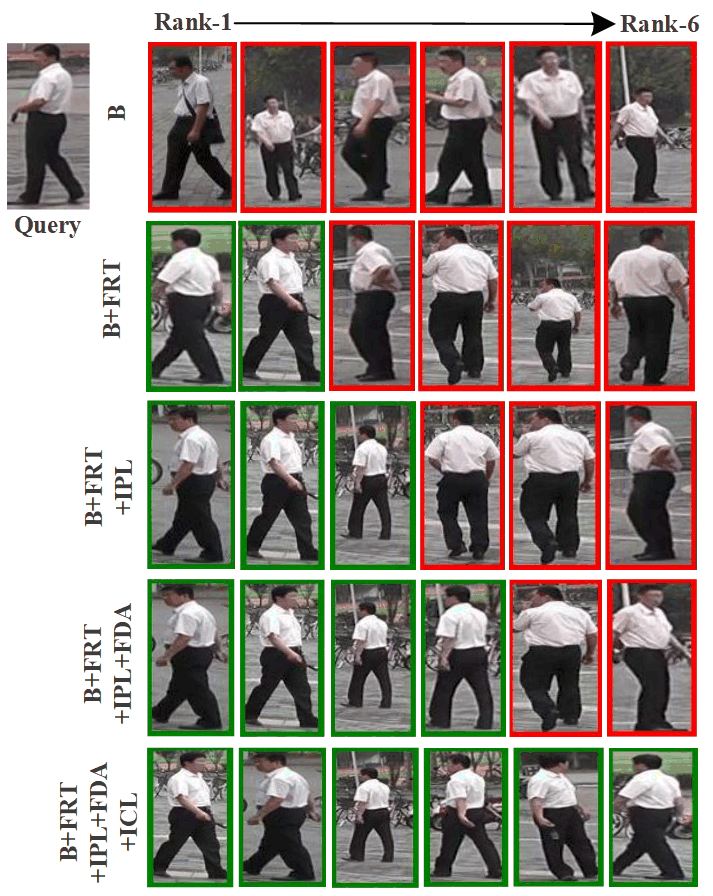
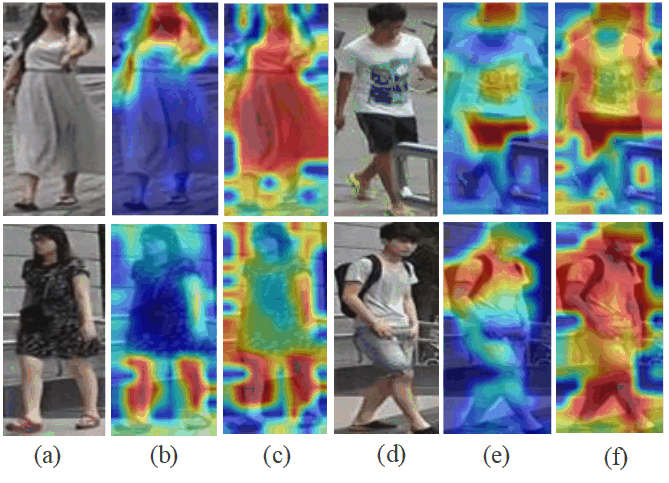
Effectiveness of ICL. The ICL module is introduced to solve the problem of missing cross-camera positive samples. As shown in Table II, compared with Baseline+FRT+IPL+FDA, the corresponding Rank-1 and mAP increase from 79.4% and 64.1% (48.1% and 24.6%) to 83.0% and 69.1% (56.5% and 31.1%) on MarketDuke-SCT (DukeMSMT-SCT) respectively, after the introduction of ICL. The increase rates of Rank-1 and mAP reach 3.6% and 5.0% (8.4% and 6.5%), respectively. This is because ICL enables samples with similar features to show higher similarity. Additionally, it can effectively extend the distance between hard negative samples across cameras, which plays a positive role in pedestrian identity matching. Fig. 5 shows the pedestrian retrieval results after using different modules, from which the contribution of each module is intuitively illustrated. Fig. 6 also qualitatively shows the degree of contribution of the proposed method. Through quantitative and qualitative experiments, the effectiveness of each module in the proposed method has been demonstrated.
IV-D Comparison with State-of-the-Art Methods
Experiments on Market-SCT and Duke-SCT. To verify the effectiveness of the proposed method and its superiority over existing methods, Market-SCT and Duke-SCT are used as the target datasets, and Duke and Market are used as the source-domain datasets respectively. In these experiments, the comparison methods mainly involve both unsupervised learning (USL) and unsupervised domain adaptive (UDA) person re-ID methods. USL methods mainly include MCNL [15], Precise-ICS [52], AGW [53], SimSiam [54], STS [55], ICE [56], CCFP [16], CCSFG [17], and PPLR [57]. UDA methods mainly include MMT-900 [32], SPCL [58], Meb-Net [59], CAC [60], IDM [61], Dual-Refine [62], P2LR [63], and DRDL [31]. The results listed in Table III were obtained by using the codes provided by the corresponding original authors and retraining the corresponding models under the original parameter settings. All comparative experiments only used the optimal preset parameters provided by authors in their papers.
For the USL methods, CCSFG achieves the suboptimal performance on Market-SCT. Its Rank-1 and mAP reach 84.0% and 67.7%, respectively. CCFP also achieves the suboptimal performance on Duke-SCT, with Rank-1 and mAP reaching 80.3% and 64.5%, respectively. In contrast, Rank-1 and mAP obtained by the proposed method are 86.3% and 68.3% (83.0% and 69.1%) respectively on the Market-SCT (Duke-SCT). Compared with the second-best performance, the proposed method improves performance by 2.3% and 0.6% (2.7% and 4.6%) on Market-SCT (Duke-SCT), respectively. This shows that the proposed method has better recognition performance in person re-ID across long-distance scenes than the above-mentioned USL methods. The proposed method belongs to the domain-adaptive recognition methods. Compared with the domain-adaptive methods listed in the Table III, the proposed method also shows better performance. This is mainly because the existing methods are affected by the lack of paired training samples of the target data, which limits their performance on Market-SCT and Duke-SCT.
| Methods | MSMT-SCT | ||||
|---|---|---|---|---|---|
| Source | Rank-1 | Rank-5 | Rank-10 | mAP | |
| USL | |||||
| MCNL(AAAI’20)[15] | None | 26.6 | 40.0 | 46.4 | 10.0 |
| Precise-ICS(WACV’21)[52] | None | 17.2 | 28.4 | 34.3 | 6.7 |
| AGW(TPAMI’21)[53] | None | 23.0 | 33.9 | 40.0 | 11.1 |
| SimSiam(CVPR’21)[54] | None | 2.8 | 5.9 | 8.4 | 1.2 |
| STS(arXiv’21)[55] | None | 13.2 | 21.3 | 25.9 | 4.7 |
| ICE(ICCV’21)[56] | None | 10.6 | 17.6 | 21.5 | 4.0 |
| CCFP(ACMMM’21)[16] | None | 50.1 | 63.3 | 68.8 | 22.2 |
| CCSFG(CVPR’22)[17] | None | 54.6 | 67.7 | 73.1 | 24.6 |
| PPLR(CVPR’22)[57] | None | 5.3 | 9.5 | 12.4 | 2.1 |
| Proposed | Duke | 56.5 | 69.1 | 74.6 | 31.1 |
| Methods | DukeMSMT-SCT | MarketMSMT-SCT | ||||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | Rank-1 | Rank-5 | Rank-10 | mAP | |
| UDA | ||||||||
| MMT-1000(ICLR’20)[32] | 16.1 | 26.1 | 31.5 | 6.5 | 15.8 | 26.0 | 31.5 | 6.4 |
| MMT-2000(ICLR’20)[32] | 15.9 | 25.5 | 30.7 | 6.3 | 16.8 | 26.5 | 32.1 | 6.7 |
| SPCL(NeurIPS’20)[58] | 8.4 | 14.5 | 18.5 | 3.2 | 5.4 | 10.5 | 13.3 | 2.0 |
| Meb-Net(ECCV’20)[59] | 21.7 | 32.6 | 37.9 | 7.4 | 14.5 | 23.4 | 28.5 | 4.9 |
| CAC(INS’21)[60] | 35.6 | 48.0 | 53.7 | 12.6 | 29.0 | 40.6 | 46.3 | 10.6 |
| IDM(ICCV’21)[61] | 11.8 | 18.7 | 23.1 | 4.6 | 11.3 | 18.7 | 22.9 | 4.6 |
| Dual-Refine(TIP’21)[62] | 18.7 | 29.1 | 34.2 | 6.7 | 12.9 | 21.3 | 26.1 | 4.9 |
| P2LR(AAAI’22)[63] | 23.6 | 34.3 | 39.9 | 8.0 | 15.9 | 24.6 | 29.5 | 5.4 |
| DRDL(KBS’22)[31] | 41.9 | 54.3 | 60.0 | 15.6 | 36.0 | 48.0 | 53.4 | 13.6 |
| Proposed | 56.5 | 69.1 | 74.6 | 31.1 | 51.4 | 65.3 | 71.2 | 28.3 |
Experiments on MSMT-SCT. To further prove the effectiveness of the proposed method, MSMT-SCT is used as the target dataset, and both Duke and Market are used as the source-domain datasets to train the model in the second set of experiments. Since MSMT-SCT contains more samples than Market and Duke, DukeMSMT-SCT and MarketMSMT-SCT are more challenging. To verify the superiority of the proposed method over the USL methods, the proposed method is first compared with the USL-based methods, including MCNL [15], Precise-ICS [52], AGW [53], SimSiam [54], STS [55], ICE [56], CCFP [16], CCSFG [17], and PPLR [57], and the experimental results of different methods are shown in Table IV. It can be seen that the proposed method outperforms state-of-the-art USL methods. In addition, compared with the domain-adaptive methods MMT-1000 [32], MMT-2000 [32], SPCL [58], Meb-Net [59], CAC [60], IDM [61], Dual-Refine [62], P2LR [63], and DRDL [31], the proposed method also shows strong competitiveness. As shown in Table V, Rank-1 and mAP obtained by the proposed method reach 56.5% and 31.1% (51.4% and 28.3%) on DukeMSMT-SCT (MarketMSMT-SCT) respectively. Compared with the second-best performance, the proposed method improves performance by 14.6% and 15.5% (15.4% and 14.7%), respectively. This shows that the proposed method has more advantages on the task of spanning from small-size datasets to large-size datasets.
IV-E Parameter Selection and Analysis
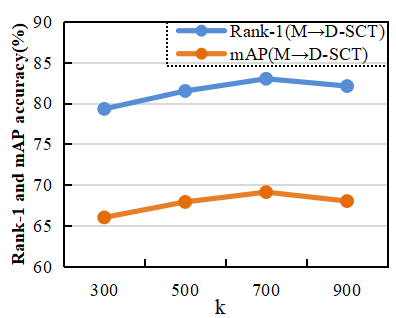
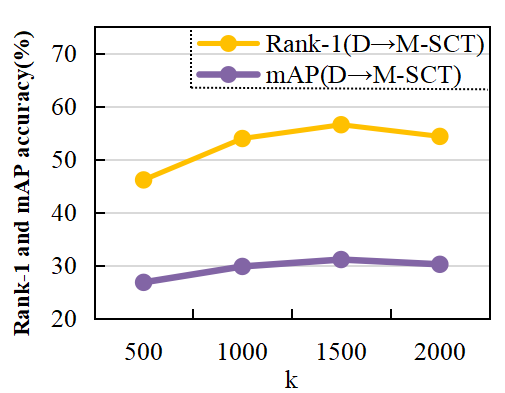
In the proposed method, clustering is adopted to make the features between similar samples have high similarity, so that the model is able to emphasize feature similarity between camera views. Since the optimal solution of hyperparameters cannot be obtained through an optimization method, the optimal hyperparameter values are searched through experiments in this study. Fig. 7 shows the changes in model performance when k takes different values. In the clustering process, the performance of the proposed model is affected, when the number of clusters is too large or too small. When k=700 (k=1,500), the proposed method achieves the best performance on MarketDuke-SCT (DukeMSMT-SCT). Therefore, in the experiments conducted on MarketDuke-SCT, k is set to 700, while in the experiments conducted on DukeMSMT-SCT, k is set to 1,500.
V Conclusion
Aiming at the challenges of person re-ID across long-distance scenes, this paper proposes a domain-adaptive person re-ID method without cross-camera paired samples. This method addresses the above challenges by pedestrian discriminative feature learning, source-domain and target-domain distribution consistency learning, and cross-camera consistency learning. In pedestrian discriminative feature learning, this paper proposes a feature-by-task recombination mechanism. In accordance with the contribution of features to pedestrian identification and camera identification, this mechanism realizes the recombination of features according to tasks, and further model training strengthens the discriminability of recombined features on the corresponding tasks. Furthermore, to achieve the exclusion of feature information from other tasks in specific task-specific features, an interactive promotion learning mechanism is proposed to facilitate feature refinement. Additionally, based on the style transfer theory, this paper achieves the distribution alignment of source-domain and target-domain features. This paper also designs a cross-camera feature consistency learning mechanism to solve the challenge brought by the absence of cross-camera paired samples. A large number of experimental results confirm the effectiveness of the proposed method, and the ablation experiments show the effectiveness of each core component of the proposed model.
References
- [1] Z. Yu, D. Shen, Z. Jin, J. Huang, D. Cai, and X.-S. Hua, “Progressive transfer learning,” IEEE Transactions on Image Processing, vol. 31, pp. 1340–1348, 2022.
- [2] H. Li, J. Xu, Z. Yu, and J. Luo, “Jointly learning commonality and specificity dictionaries for person re-identification,” IEEE Transactions on Image Processing, vol. 29, pp. 7345–7358, 2020.
- [3] H. Li, J. Xu, J. Zhu, D. Tao, and Z. Yu, “Top distance regularized projection and dictionary learning for person re-identification,” Information Sciences, vol. 502, pp. 472–491, 2019.
- [4] D. Tao, Y. Guo, B. Yu, J. Pang, and Z. Yu, “Deep multi-view feature learning for person re-identification,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 10, pp. 2657–2666, 2017.
- [5] Y. Huang, S. Lian, S. Zhang, H. Hu, D. Chen, and T. Su, “Three-dimension transmissible attention network for person re-identification,” IEEE transactions on circuits and systems for video technology, vol. 30, no. 12, pp. 4540–4553, 2020.
- [6] X. Liu, S. Bi, S. Fang, and A. Bouridane, “Bayesian inferred self-attentive aggregation for multi-shot person re-identification,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 10, pp. 3446–3458, 2019.
- [7] C. Shen, G.-J. Qi, R. Jiang, Z. Jin, H. Yong, Y. Chen, and X.-S. Hua, “Sharp attention network via adaptive sampling for person re-identification,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 10, pp. 3016–3027, 2018.
- [8] H. Yao, S. Zhang, R. Hong, Y. Zhang, C. Xu, and Q. Tian, “Deep representation learning with part loss for person re-identification,” IEEE Transactions on Image Processing, vol. 28, no. 6, pp. 2860–2871, 2019.
- [9] L. Wu, R. Hong, Y. Wang, and M. Wang, “Cross-entropy adversarial view adaptation for person re-identification,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 7, pp. 2081–2092, 2019.
- [10] L. Wu, Y. Wang, H. Yin, M. Wang, and L. Shao, “Few-shot deep adversarial learning for video-based person re-identification,” IEEE Transactions on Image Processing, vol. 29, pp. 1233–1245, 2019.
- [11] Y. Luo, T. Liu, D. Tao, and C. Xu, “Decomposition-based transfer distance metric learning for image classification,” IEEE Transactions on Image Processing, vol. 23, no. 9, pp. 3789–3801, 2014.
- [12] Y. Luo, Y. Wen, T. Liu, and D. Tao, “Transferring knowledge fragments for learning distance metric from a heterogeneous domain,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 4, pp. 1013–1026, 2018.
- [13] Y. Luo, H. Hu, Y. Wen, and D. Tao, “Transforming device fingerprinting for wireless security via online multitask metric learning,” IEEE Internet of Things Journal, vol. 7, no. 1, pp. 208–219, 2019.
- [14] H. Tang, C. Yuan, Z. Li, and J. Tang, “Learning attention-guided pyramidal features for few-shot fine-grained recognition,” Pattern Recognition, vol. 130, p. 108792, 2022.
- [15] T. Zhang, L. Xie, L. Wei, Y. Zhang, B. Li, and Q. Tian, “Single camera training for person re-identification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12 878–12 885.
- [16] W. Ge, C. Pan, A. Wu, H. Zheng, and W.-S. Zheng, “Cross-camera feature prediction for intra-camera supervised person re-identification across distant scenes,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 3644–3653.
- [17] C. Wu, W. Ge, A. Wu, and X. Chang, “Camera-conditioned stable feature generation for isolated camera supervised person re-identification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 238–20 248.
- [18] Z. Zhong, L. Zheng, Z. Zheng, S. Li, and Y. Yang, “Camera style adaptation for person re-identification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5157–5166.
- [19] C. Su, J. Li, S. Zhang, J. Xing, W. Gao, and Q. Tian, “Pose-driven deep convolutional model for person re-identification,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 3960–3969.
- [20] L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer gan to bridge domain gap for person re-identification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 79–88.
- [21] W. Deng, L. Zheng, Q. Ye, G. Kang, Y. Yang, and J. Jiao, “Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 994–1003.
- [22] J. Liu, Z.-J. Zha, D. Chen, R. Hong, and M. Wang, “Adaptive transfer network for cross-domain person re-identification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 7202–7211.
- [23] Y. Chen, X. Zhu, and S. Gong, “Instance-guided context rendering for cross-domain person re-identification,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 232–242.
- [24] F. Yang, K. Yan, S. Lu, H. Jia, D. Xie, Z. Yu, X. Guo, F. Huang, and W. Gao, “Part-aware progressive unsupervised domain adaptation for person re-identification,” IEEE Transactions on Multimedia, vol. 23, pp. 1681–1695, 2020.
- [25] Q. Yang, H.-X. Yu, A. Wu, and W.-S. Zheng, “Patch-based discriminative feature learning for unsupervised person re-identification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3633–3642.
- [26] A. Wu, W.-S. Zheng, and J.-H. Lai, “Unsupervised person re-identification by camera-aware similarity consistency learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6922–6931.
- [27] L. Qi, L. Wang, J. Huo, L. Zhou, Y. Shi, and Y. Gao, “A novel unsupervised camera-aware domain adaptation framework for person re-identification,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 8080–8089.
- [28] Y. Zou, X. Yang, Z. Yu, B. V. Kumar, and J. Kautz, “Joint disentangling and adaptation for cross-domain person re-identification,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer, 2020, pp. 87–104.
- [29] H. Li, Y. Chen, D. Tao, Z. Yu, and G. Qi, “Attribute-aligned domain-invariant feature learning for unsupervised domain adaptation person re-identification,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 1480–1494, 2020.
- [30] H. Li, N. Dong, Z. Yu, D. Tao, and G. Qi, “Triple adversarial learning and multi-view imaginative reasoning for unsupervised domain adaptation person re-identification,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 5, pp. 2814–2830, 2021.
- [31] H. Li, K. Xu, J. Li, and Z. Yu, “Dual-stream reciprocal disentanglement learning for domain adaptation person re-identification,” Knowledge-Based Systems, vol. 251, p. 109315, 2022.
- [32] Y. Ge, D. Chen, and H. Li, “Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification,” arXiv preprint arXiv:2001.01526, 2020.
- [33] F. Yang, K. Li, Z. Zhong, Z. Luo, X. Sun, H. Cheng, X. Guo, F. Huang, R. Ji, and S. Li, “Asymmetric co-teaching for unsupervised cross-domain person re-identification,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 597–12 604.
- [34] Y. Zhai, S. Lu, Q. Ye, X. Shan, J. Chen, R. Ji, and Y. Tian, “Ad-cluster: Augmented discriminative clustering for domain adaptive person re-identification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9021–9030.
- [35] K. Zeng, M. Ning, Y. Wang, and Y. Guo, “Hierarchical clustering with hard-batch triplet loss for person re-identification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 657–13 665.
- [36] Z. Ji, X. Zou, X. Lin, X. Liu, T. Huang, and S. Wu, “An attention-driven two-stage clustering method for unsupervised person re-identification,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16. Springer, 2020, pp. 20–36.
- [37] F. Zhao, S. Liao, G.-S. Xie, J. Zhao, K. Zhang, and L. Shao, “Unsupervised domain adaptation with noise resistible mutual-training for person re-identification,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16. Springer, 2020, pp. 526–544.
- [38] Z. Li, Y. Shi, H. Ling, J. Chen, Q. Wang, and F. Zhou, “Reliability exploration with self-ensemble learning for domain adaptive person re-identification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 1527–1535.
- [39] F. Chen, N. Wang, J. Tang, P. Yan, and J. Yu, “Unsupervised person re-identification via multi-domain joint learning,” Pattern Recognition, vol. 138, p. 109369, 2023.
- [40] S. Li, F. Li, J. Li, H. Li, B. Zhang, D. Tao, and X. Gao, “Logical relation inference and multiview information interaction for domain adaptation person re-identification,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [41] S. He, H. Luo, P. Wang, F. Wang, H. Li, and W. Jiang, “Transreid: Transformer-based object re-identification,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 013–15 022.
- [42] X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 1501–1510.
- [43] M. Keuper, S. Tang, B. Andres, T. Brox, and B. Schiele, “Motion segmentation & multiple object tracking by correlation co-clustering,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 1, pp. 140–153, 2018.
- [44] W. Luo, B. Stenger, X. Zhao, and T.-K. Kim, “Trajectories as topics: Multi-object tracking by topic discovery,” IEEE Transactions on Image Processing, vol. 28, no. 1, pp. 240–252, 2018.
- [45] L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang, and Q. Tian, “Scalable person re-identification: A benchmark,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1116–1124.
- [46] Z. Zheng, L. Zheng, and Y. Yang, “Unlabeled samples generated by gan improve the person re-identification baseline in vitro,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 3754–3762.
- [47] L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer gan to bridge domain gap for person re-identification,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 79–88.
- [48] X. Wang, G. Doretto, T. Sebastian, J. Rittscher, and P. Tu, “Shape and appearance context modeling,” in 2007 ieee 11th international conference on computer vision. Ieee, 2007, pp. 1–8.
- [49] H. Robbins and S. Monro, “A stochastic approximation method,” The annals of mathematical statistics, pp. 400–407, 1951.
- [50] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019.
- [51] H. Luo, Y. Gu, X. Liao, S. Lai, and W. Jiang, “Bag of tricks and a strong baseline for deep person re-identification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2019, pp. 0–0.
- [52] M. Wang, B. Lai, H. Chen, J. Huang, X. Gong, and X.-S. Hua, “Towards precise intra-camera supervised person re-identification,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 3229–3238.
- [53] M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. Hoi, “Deep learning for person re-identification: A survey and outlook,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 6, pp. 2872–2893, 2021.
- [54] X. Chen and K. He, “Exploring simple siamese representation learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 750–15 758.
- [55] T. Liu, Y. Lin, and B. Du, “Unsupervised person re-identification with stochastic training strategy,” IEEE Transactions on Image Processing, vol. 31, pp. 4240–4250, 2022.
- [56] H. Chen, B. Lagadec, and F. Bremond, “Ice: Inter-instance contrastive encoding for unsupervised person re-identification,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 960–14 969.
- [57] Y. Cho, W. J. Kim, S. Hong, and S.-E. Yoon, “Part-based pseudo label refinement for unsupervised person re-identification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 7308–7318.
- [58] Y. Ge, F. Zhu, D. Chen, R. Zhao et al., “Self-paced contrastive learning with hybrid memory for domain adaptive object re-id,” Advances in Neural Information Processing Systems, vol. 33, pp. 11 309–11 321, 2020.
- [59] Y. Zhai, Q. Ye, S. Lu, M. Jia, R. Ji, and Y. Tian, “Multiple expert brainstorming for domain adaptive person re-identification,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16. Springer, 2020, pp. 594–611.
- [60] H. Li, J. Pang, D. Tao, and Z. Yu, “Cross adversarial consistency self-prediction learning for unsupervised domain adaptation person re-identification,” Information Sciences, vol. 559, pp. 46–60, 2021.
- [61] Y. Dai, J. Liu, Y. Sun, Z. Tong, C. Zhang, and L.-Y. Duan, “Idm: An intermediate domain module for domain adaptive person re-id,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 11 864–11 874.
- [62] Y. Dai, J. Liu, Y. Bai, Z. Tong, and L.-Y. Duan, “Dual-refinement: Joint label and feature refinement for unsupervised domain adaptive person re-identification,” IEEE Transactions on Image Processing, vol. 30, pp. 7815–7829, 2021.
- [63] J. Han, Y.-L. Li, and S. Wang, “Delving into probabilistic uncertainty for unsupervised domain adaptive person re-identification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 1, 2022, pp. 790–798.