Domain-shift adaptation via linear transformations
Abstract
A predictor, , learned with data from a source domain (A) might not be accurate on a target domain (B) when their distributions are different. Domain adaptation aims to reduce the negative effects of this distribution mismatch. Here, we analyze the case where , but ; where there are affine transformations of that makes all distributions equivalent. We propose an approach to project the source and target domains into a lower-dimensional, common space, by (1) projecting the domains into the eigenvectors of the empirical covariance matrices of each domain, then (2) finding an orthogonal matrix that minimizes the maximum mean discrepancy between the projections of both domains. For arbitrary affine transformations, there is an inherent unidentifiability problem when performing unsupervised domain adaptation that can be alleviated in the semi-supervised case. We show the effectiveness of our approach in simulated data and in binary digit classification tasks, obtaining improvements up to 48% accuracy when correcting for the domain shift in the data.
1 Introduction
The goal of supervised machine learning is to produce a model that can accurately predict a value, , given a vector input, , corresponding (implicitly) to an unknown function Murphy (2012). In the supervised setting, we learn an approximate , by applying a learning algorithm to a (source) training dataset . We can then apply this by applying it to new instances .
A common assumption is that the source (S) and the target (T) domains follow the same probability distribution–i.e. . When this is not the case, a predictor learned using might not generalize when used on Storkey (2009). The performance on the target domain depends on its performance on the source domain, and on the similarity between the distributions of the domain and target domains Ben-David et al. (2007).
A well known model to explain the discrepancy between distributions is covariate shift, where , but Shimodaira (2000). Other assumptions lead to different models Storkey (2009); Kull and Flach (2014), which motivate algorithms that decrease the negative impact of the discrepancies under different circumstances Csurka (2017); Wen et al. (2014).
Our study focuses on the case where , , and . However, we assume the existence of a function , with parameters and , such that and . This implies that there is a common feature space where the source and target domains follow the same distribution; see Figure 1. This model is called domain-shift Storkey (2009), or covariate observation shift Kull and Flach (2014).
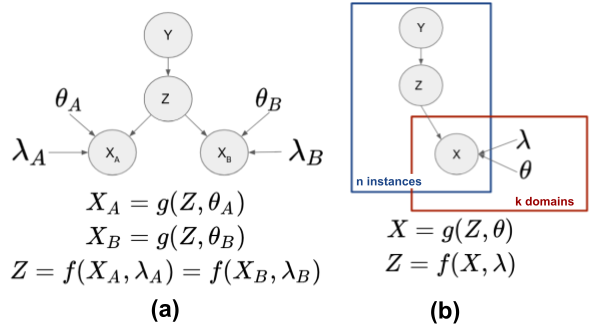
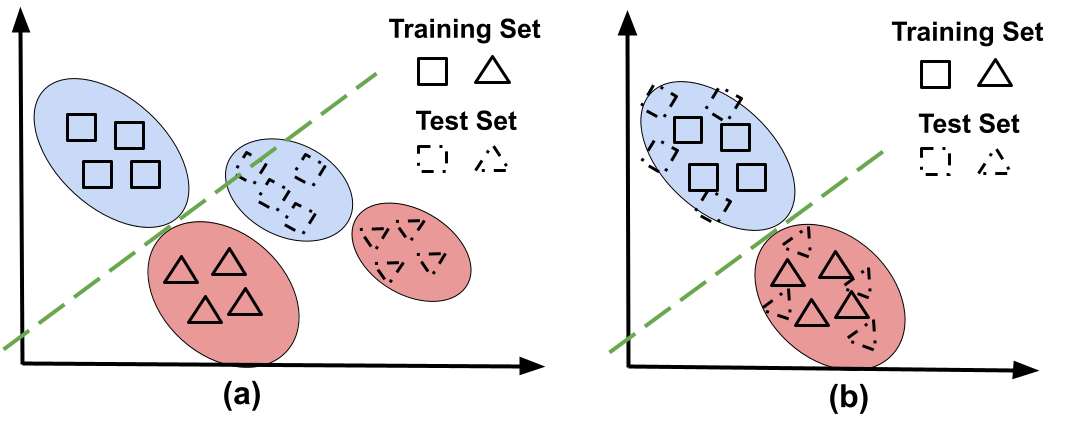
Figure 2(a) exemplifies domain shift. Note that the decision boundary learned from the source domain (shown with solid squares and triangles) has poor performance on the target domain (shown with dashed squares and triangles). Domain-shift adaptation aims to find a common representation that minimizes the divergence between the domains. If successful, the decision function learned during training will have a good performance when doing inference; see Figure 2(b).
Under the assumption that the mapping from source and target domains to a common representation is an affine function (i.e., and have the form ), we propose an algorithm for unsupervised and semi-supervised domain adaptation. We find the parameters and , which project the data into a common space, by computing the first eigenvectors of the covariance matrices of the probability distributions of each domain, and then finding an orthogonal matrix that minimizes the maximum mean discrepancy between both distributions.
There is an inherent unidentifiability problem with unsupervised domain adaptation. Observe in Figure 3 that, in the absence of labeled data from the source and target domains, it is impossible to distinguish between the different “distribution alignments” presented there. This problem can be alleviated in the semi-supervised case, where few labeled instances allow the distinction between both scenarios.
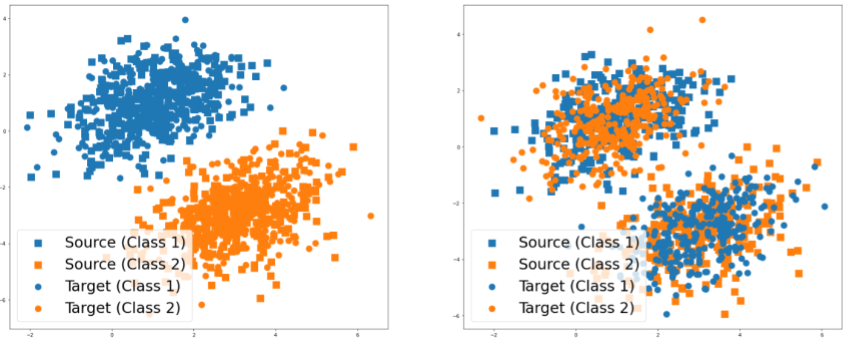
2 Related work
The model presented in Figure 1 is closely related to the probabilistic versions of principal components analysis Tipping and Bishop (1999) and canonical correlation analysis Bach and Jordan (2005). In both cases, and . When the transformation matrix, , is diagonal –i.e., a location-scale transformation– it is possible to perform domain-shift adaptation without the Gaussianity assumption by minimizing the maximum mean discrepancy between both domains Gretton et al. (2012); Zhang et al. (2013). In our study, we allow to be an arbitrary matrix without the Gaussianity assumption. Domain adaptation with arbitrary affine transformation has been explored in the context of mixing small datasets from different domains to increase the size of the training set. While this is often successful, this approach still requires a supervised dataset for each of the different sources Vega and Greiner (2018). Here, our objective is to learn a predictor in the source domain, and then apply it to the target domain in the unsupervised and semi-supervised scenarios.
Recent approaches attempt to minimize the divergence between source and target distributions by using data transformations. CORAL Sun et al. (2016) matches the first two moments of the source and target distributions, while a different line of work uses variants of autoencoders to find a common mapping between source and target data Glorot et al. (2011); Chen et al. (2012, 2015); Louizos et al. (2016). After finding this common feature space, they learned a predictor using only the source data. Their approach achieved better performance when applied to the target dataset, relative to not correcting for domain-shift, in natural language processing tasks.
Adversarial domain adaptation learns the mapping to the common space and the predictor at the same time Ganin et al. (2016); Long et al. (2018); Zhao et al. (2018). It combines a discriminator (which distinguishes instances from the different domains); a predictor (which tries to minimize the prediction error on the labeled instances); and a third function (which maps the instances into a common space). The three functions are optimized together. If successful, the discriminator should be unable to distinguish the domain on an instance (based on its common space encoding), while the predictor should have good performance under the metric of interest Tzeng et al. (2017).
Despite the success of neural networks for domain adaptation in natural language processing and computer vision tasks, it is hard to define what type of problems can be solved with this approach. For example, they might fail when Tachet des Combes et al. (2020). Even when they successfully learn an invariant representation across domains that preserves the predictive power in the source domain, this do not guarantee a successful adaptation. It is possible to have invariant representations and small error in the training set, and still have a large error in the test set Zhao et al. (2019). Therefore, it is important to explicitly determine under which conditions we expect an algorithm to work. Our goal with this paper is to analyze the problem of domain-shift under affine transformations, and to propose an approach for domain adaptation for this scenario.
3 Domain-shift adaptation via linear transformations
Under the assumption that the domain-shift is caused by affine transformations, the equations on Figure 1 become:
| (1) |
Note that the latent variable, , can have a different (lower) dimensionality than the observations and , which in turn can have different dimensionality between themselves. Importantly, we do not assume that we have paired data between the source and target domain. In other words, for a given instance, , we can either observe its representation in the source domain, , or the target domain, , but not both.
If we knew the parameters , and assuming they are non-degenerate, we could do the inverse mapping from the observations and to by solving the following optimization problem:
whose solution (see the Appendix A.1) is given by
| (2) |
Once we map the data from the source and target domains to a common space, we can use the labeled data from the source domain to learn a predictor that we can apply to data from any of both domains (after the appropriate projection into the common space).
3.1 Estimating the transformation parameters
Without loss of generality, we assume that and . Then, given a dataset with instances drawn from the source domain and a dataset with instances drawn from the target domain :
| (3) |
Note that we can compute the empirical estimates , given the datasets and . The empirical estimators of the mean directly give us half of the transformation parameters. For the case of the covariance matrix, we can compute the singular value decomposition:
| (4) | ||||
Since is a positive semi-definite matrix, its eigenvalues are non-negative, which allows us to decompose the diagonal matrix as . By comparing Equations 3 and 4, we can estimate the parameters as:
| (5) |
for any orthogonal matrix, . After substituting the parameter into Equation 2, then applying some algebraic manipulations (see the Appendix A.2) , we observe that:
| (6) |
A consequence of Equation 6 is that matching the empirical mean and covariance matrices of the source and target domain is not enough to correct for domain-shift adaptation: The orthogonal matrix , which represents rotations or reflections, might cause misalignment in the data; see Figure 4(a).
The matrices and , for the source and target domains, respectively, can be computed from the SVD of their empirical covariance matrices, and . Since the objective of domain adaptation is to align the distributions, regardless of the “direction” of the alignment, we arbitrarily set . Then, we find an orthogonal matrix that minimizes the divergence between both probability distributions:
| (7) |
where is an empirical measure of the divergence between the two domains.
3.2 Maximum Mean Discrepancy
A common measure of the divergence between two probability distributions is the Maximum Mean Discrepancy (MMD) Gretton et al. (2012).
Definition 1 (Maximum Mean Discrepancy)
Let p and q be Borel probability measures defined on a domain . Given observations and , drawn independently and identically distributed from p and q, respectively. Let be a class of functions , the MMD is defined as:
Informally, the purpose of the MMD is to determine if two probability distributions, and , are different. The associated algorithm involves taking samples from and , then finding a function that take large values on samples from and small (or negative) values on samples of . The MMD is then the difference between the mean values of the function of the samples.
By defining the class of functions as the unit ball in a reproducing kernel Hilbert space, Gretton et al. (2012) proposed (biased) empirical estimator of the as follows:
| (8) |
where is a valid kernel. In our case, we use the Gaussian kernel .
Equation 8 has two nice properties. (1) It computes an estimation of the MMD with a finite number of instances from each domain. (2) It is a differentiable function, so it can be optimized with iterative methods, such as gradient descent.
3.3 Optimization with orthogonality constraints
For solving the optimization problem with orthogonality constraints presented in Equation 7, we used the Wen and Yin (2013) algorithm (Algorithm 1), which is an iterative method based on the Cayley transform. Their algorithm is similar to gradient descent, but instead of looking for solutions in the Euclidean space, they look for solutions in the Stiefel manifold, which is the set that contains all the orthogonal matrices.
Formally, their proposed algorithm solves:
| (9) |
Input:
Parameter: Learning rate (), Max iterations (M)
Output:
where is a differentiable function. For our purposes, , where and are the projections of and , respectively, using Equation 6 with . is an orthogonal (rotation or reflection) matrix that multiplies .
Algorithm 1 is guaranteed to converge when the learning rate () meets the Armijo-Wolfe conditions Nocedal and Wright (2006). However, it is not guaranteed to find the global minimum of . Similarly to gradient descent approaches, the algorithm might converge to a local minimum. One heuristic to alleviate this problem is to perform multiple restart with different seed points; however, this is still not guaranteed to convergence to the global minimum.
3.4 Unsupervised domain adaptation
For finding the parameters and , we can arbitrarily set in Equation 5, and then use Algorithm 1, with the Maximum Mean Discrepancy, for computing :
| (10) |
where is a dataset that contains the transformed instances using . Finally, we can project the source and target domains to a common representation using Equation 6.
Note that Algorithm 1 requires the gradient of the with respect to the matrix . By applying standard matrix calculus we compute (see Appendix A.3 for details):
| (11) |
Input: . Every row in these matrices represents an instance.
Parameter: Variance of Gaussian kernel ()
Output: . Every row in each matrix represents an instance in the shared space.
Algorithm 2 shows the procedure to map the source and target domain into a common space in an unsupervised way (The code is publicly available; see Appendix B ). For notation, the source domain (resp., target, shared space) is -dimensional space, (resp. -dimensional, -dimensional; here we assume that . For mapping into this lower dimensional space, we project the data into the first eigenvectors of the empirical covariance matrice (resp. ). The eigenvalues corresponding these eigenvectors are positive, while the other and eigenvalues will be equal to zero.
After mapping both domains to a common space, we can use the labels of the source domain to learn a predictor, and then use it to make predictions in the target domain. Section 4 will show that the Maximum Mean Discrepancy is not convex with respect to the orthogonal matrix , meaning Algorithm 1 might converge to a local minimum. Additionally, in the unsupervised case there is an inherent identifiability problem caused by the missing labels David et al. (2010); Koller and Friedman (2009) – i.e., there are and such that . This can create an “anti-alignment” problem; see Figure 3.
Note than when the “anti-alignment” occurs, the source and target domains have the same marginal probability , but . In other words, a classifier learned on the source domain will have good performance on more data from the same domain; however, it will have very poor performance on the target domain. Zhao et al. (2019) shows that aligning the marginal probability of the covariates, then learning a good predictor on the source domain, is not sufficient for successfully performing domain adaptation.
3.5 Semi-supervised domain adaptation
If we have access to a few labeled instances in the target domain, we might reduce the chance of converging to an “anti-alignment”. Since the MMD is not convex with respect to the rotation matrix , a common strategy is to attempt multiple re-start (with different seed points) of an iterative optimization algorithm. We then choose the one with the lowest cost. In the unsupervised case, the MMD itself is the cost function. For the semi-supervised case, we can first run Algorithm 2 for each seed point, then learn a predictor, using only the labeled data from the source domain. Then, for every alignment generated by each of the seed points, evaluate those predictors on the labeled data of the target domain, and choose the one with the lowest error.
Alternatively, we could incorporate the cross entropy loss of the source and target domains into Equation 10. This approach requires optimizing a weighted linear combination of three terms in the loss function: the MMD, the cross-entropy in the source domain, and the cross-entropy in the target domain. Since this path requires setting these three extra weights, we limited our experiments to the first approach.
4 Experiments and Results
We first show the performance of our approach to perform domain-shift adaptation in a simulated dataset, and then, in a modified version of the MNIST digit classification task.
4.1 Simulated data
For the simulated data we sampled 600 instances to creaet a dataset, , from a mixture of bi-variate Gaussians with parameters , , , . These instances correspond to a common shared space . We then created two random transformation matrices , and two random translation vectors to create the observations. Of course, neither the real parameters, nor the instances in the shared space are visible to our algorithm.
We randomly divided into two disjoint datasets (source domain) and (target domain) with 300 instances each. Then, we created the datasets and . Our algorithm only sees and , which each contain 5-dimensional vectors.
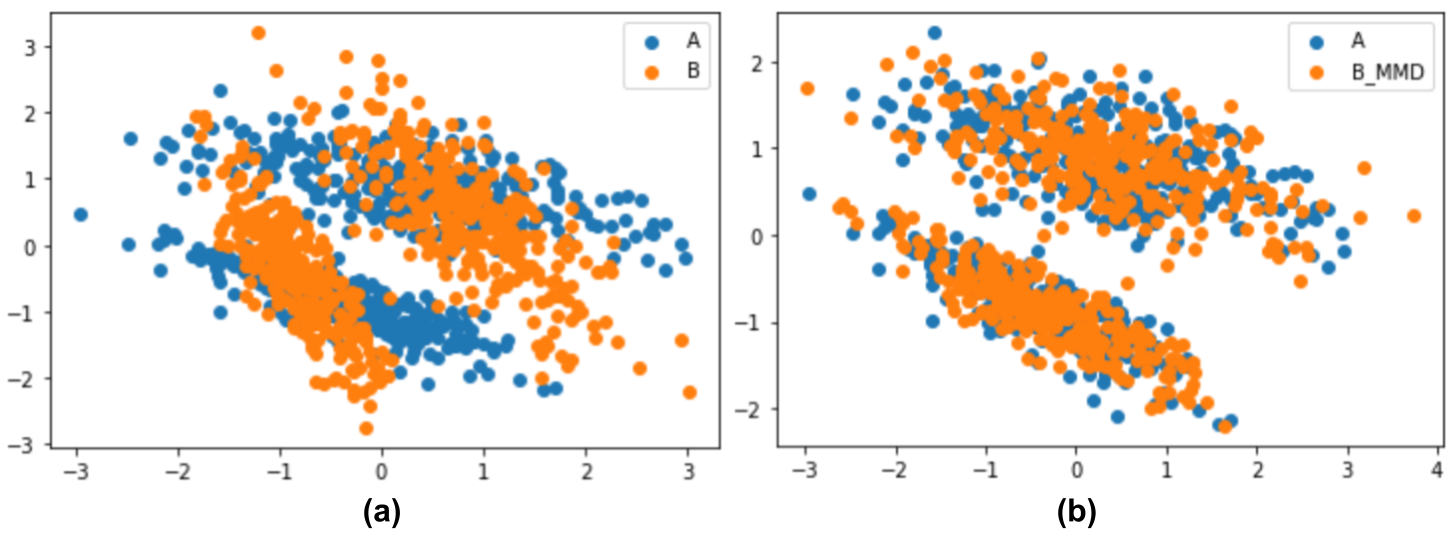
Figure 4(b) shows the result of applying Algorithm 2 to the simulated datasets and . Figure 4(a), on the other hand, shows the effect of ignoring the effect of the orthogonal matrix . In this last case we successfully mapped both datasets into the same lower-dimensional space, and that both datasets have zero mean and an identity covariance matrix; however, they are not aligned. By finding the orthogonal matrix that minimizes the MMD between the source and target datasets we can obtain the correct alignment.
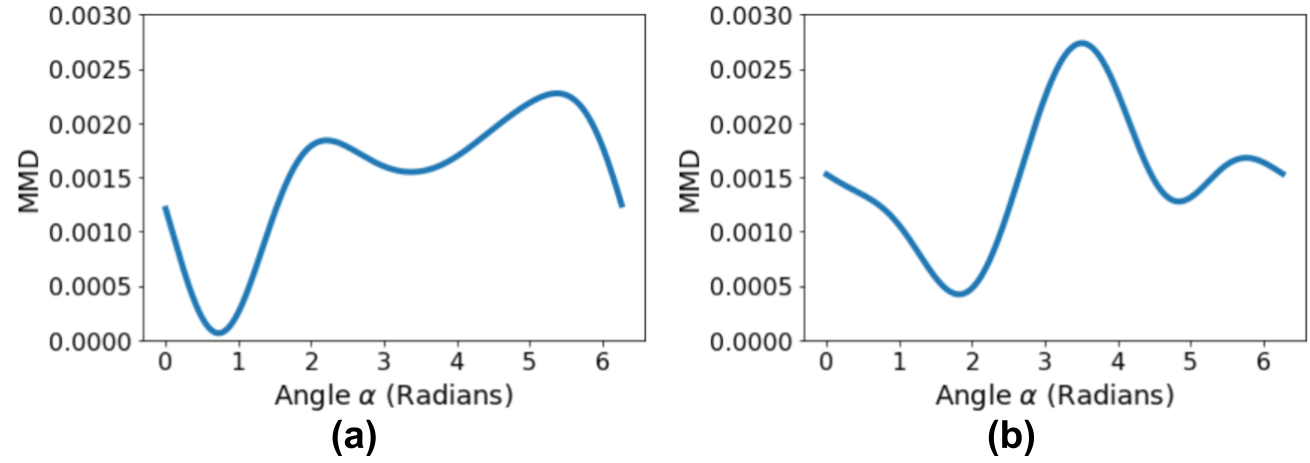
As mentioned in Section 3.4, the maximum mean discrepancy is not convex with respect to the orthogonal matrix . For 2-dimensional spaces, an orthogonal matrix is either a rotation or a reflection Winter (1992). Figure 5 shows the MMD between the projection of into and the rotated (or reflected) projection of into at different angles. Note that we have a total of 4 local minima for the simulated data. The global minimum corresponds to the proper alignment, shown in Figure 4(b). Similar to gradient descent, Algorithm 2 might converge to a local minimum depending on the seed point.
4.2 Binary digit classification
The second experiment is a variation of the digit classification task with the dataset MNIST (source domain) LeCun et al. (1998) and USPS (target domain) Hull (1994). We simplified the task from 10-class digit classification to 45 binary digit classification (0 vs 1, 0 vs 2, … , 8 vs 9).
We first trained a 10-class convolutional neural network on the training data of the source domain (60,000 images) to create image embeddings in a 20-dimensional space. The convolutional neural network contained 4 convolutional layers (32, 128, 256 and 512 filters, respectively), each followed by a MaxPooling layer ( kernel). Then we added a fully connected layer with 20 hidden neurons, and finally the output layer with 10 output neurons. While the output layer used a softmax activation function, the other layers used a rectified linear unit (ReLU) as the activation function; see Appendix B.
We used the output of the fully connected layer with 20 neurons as the image embeddings for both, the training data of the MNIST (60,000 images) and the test data USPS datasets (2,007 images). Then, for each of the 45 binary classification tasks, we compared three scenarios: (1) Baseline: learn the parameters of a logistic regression model using the MNIST dataset, and then test it on the USPS dataset. (2) Use Algorithm 2 to project the MNIST and USPS dataset into a common space of dimension 5. Then learn the parameters of a logistic regression model using only the projected data of the MNIST, and test it on the projected data of the USPS dataset. We chose a “small” dimensionality of the shared space because computing distances in high-dimensional spaces is harder because the instances sparsely populate the input space Friedman et al. (2001). (3) Similar to the second scenario, but now assume that 10% of the data in the USPS dataset is labelled (semi-supervised case).
5 Discussion
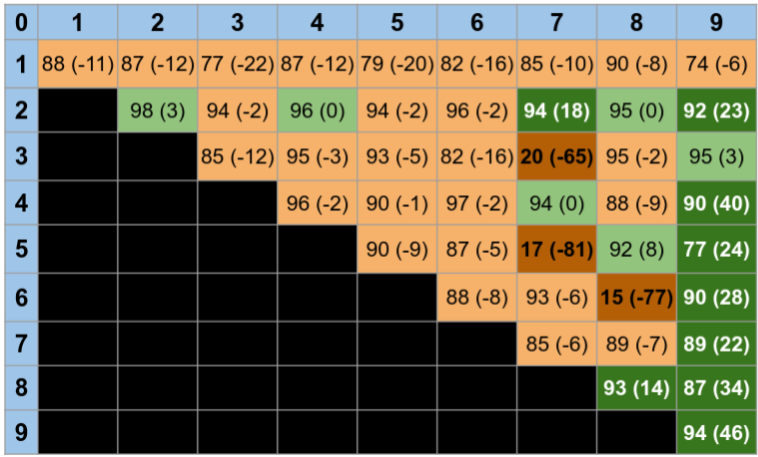
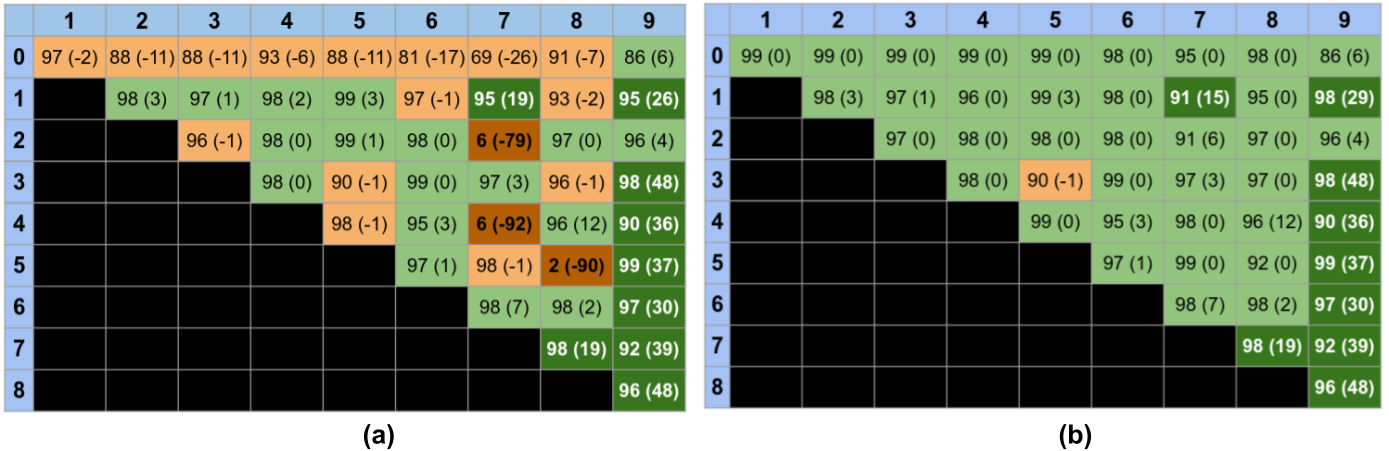
As expected, the results in Figure 6(a) show that even after the reducing the discrepancy between the source and target domain, and learning an accurate classifier on the source domain, this classifier is not guaranteed to generalize to the target domain. All the boxes in orange indicate that applying our algorithm for domain-shift had a lower performance than not doing any transformation at all. Specially interesting are the cases marked in dark orange, where we observe the effect of the “anti-alignment”. On the other hand, when the alignment is done properly, there are very significant improvements in the classification accuracy. Note that for unsupervised domain adaptation there is no way to distinguish between correct and incorrect alignments.
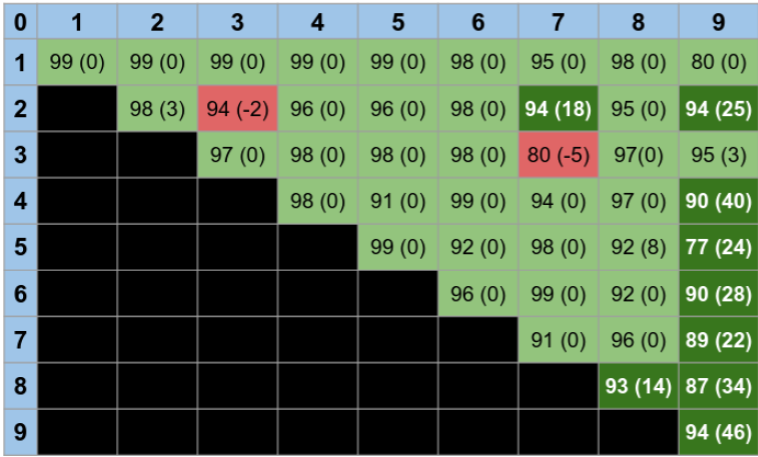
Figure 6(b), on the other hand, shows that we avoid incorrect alignments in the semi-supervised case. Having access to a small set of labelled data allows the algorithm to identify when no domain-shift adaptation is needed (because the classifier already generalizes to the target domain), or detect the “anti-alignments” and choose the proper alignment instead; see the case of 2 vs 7, where an improper alignment occurs in the unsupervised case, but the proper alignment of the semi-supervised case increases the classification accuracy 6%. In the case of proper alignments of the data the accuracy improved in essentially all the cases up to 48%.
The dimensionality of the shared space plays an important role when performing domain-shift adaptation. While Figures 6(a) and 6(b) show the performance obtained in a shared space of dimension 5, Figures 7 and 8 in Appendix C show the performance when the dimension of the shared space is the number of positive eigenvalues in the empirical covariance matrix (13 in our experiments). The performance of the unsupervised domain adaptation degrades significantly, while the semi-supervised approach remain roughly the same. We hypothesize that this decrease in performance is due to the difficulty of reliably estimating metrics on probability distributions in high dimensional spaces with a limited number of instances Friedman et al. (2001).
In summary, we present an algorithm for domain-shift adaptation caused by arbitrary affine transformations. Our approach first projects the data into a shared low-dimensional space using the first eigenvectors of the empirical covariance matrices of the data. Then, it find an orthogonal matrix that minimize the maximum mean discrepancy between the source and target data. For the unsupervised domain adaptation, there is an unavoidable identifiabiliy problem that can be alleviated by having a few labels of the target domain (semi-supervised domain adaptation). When using the correct othogonal matrix, this effectively maps both domains into a shared space where the . In those cases, we can expect that a predictor learned using data from the source domain to generalize to data from a target domain.
References
- Bach and Jordan [2005] Francis R Bach and Michael I Jordan. A probabilistic interpretation of canonical correlation analysis. 2005.
- Ben-David et al. [2007] Shai Ben-David, John Blitzer, Koby Crammer, Fernando Pereira, et al. Analysis of representations for domain adaptation. NeurIPS, 19:137, 2007.
- Chen et al. [2012] Minmin Chen, Zhixiang Xu, Kilian Q Weinberger, and Fei Sha. Marginalized denoising autoencoders for domain adaptation. In ICML, pages 1627–1634, 2012.
- Chen et al. [2015] Minmin Chen, Kilian Q Weinberger, Zhixiang Xu, and Fei Sha. Marginalizing stacked linear denoising autoencoders. JMLR, 16(1):3849–3875, 2015.
- Csurka [2017] Gabriela Csurka. Domain adaptation for visual applications: A comprehensive survey. arXiv preprint arXiv:1702.05374, 2017.
- David et al. [2010] Shai Ben David, Tyler Lu, Teresa Luu, and Dávid Pál. Impossibility theorems for domain adaptation. In AISTATS’10, pages 129–136. JMLR Workshop and Conference Proceedings, 2010.
- Friedman et al. [2001] Jerome Friedman, Trevor Hastie, Robert Tibshirani, et al. The elements of statistical learning, volume 1. Springer series in statistics New York, 2001.
- Ganin et al. [2016] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. JMLR, 17(1):2096–2030, 2016.
- Glorot et al. [2011] Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Domain adaptation for large-scale sentiment classification: A deep learning approach. In ICML, 2011.
- Gretton et al. [2012] Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test. JMLR, 13(1):723–773, 2012.
- Hull [1994] Jonathan J. Hull. A database for handwritten text recognition research. IEEE Transactions on pattern analysis and machine intelligence, 16(5):550–554, 1994.
- Koller and Friedman [2009] Daphne Koller and Nir Friedman. Probabilistic graphical models: principles and techniques. MIT press, 2009.
- Kull and Flach [2014] Meelis Kull and Peter Flach. Patterns of dataset shift. In First International Workshop on Learning over Multiple Contexts (LMCE) at ECML-PKDD., 2014.
- LeCun et al. [1998] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Long et al. [2018] Mingsheng Long, Zhangjie Cao, Jianmin Wang, and Michael I Jordan. Conditional adversarial domain adaptation. In NeurIPS, pages 1647–1657, 2018.
- Louizos et al. [2016] Christos Louizos, Kevin Swersky, Yujia Li, Max Welling, and Richard S Zemel. The variational fair autoencoder. In ICLR, 2016.
- Murphy [2012] Kevin P Murphy. Machine learning: a probabilistic perspective. MIT press, 2012.
- Nocedal and Wright [2006] Jorge Nocedal and Stephen Wright. Numerical optimization. Springer Science & Business Media, 2006.
- Shimodaira [2000] Hidetoshi Shimodaira. Improving predictive inference under covariate shift by weighting the log-likelihood function. Journal of statistical planning and inference, 90(2):227–244, 2000.
- Storkey [2009] Amos Storkey. When training and test sets are different: characterizing learning transfer. Dataset shift in machine learning, 30:3–28, 2009.
- Sun et al. [2016] Baochen Sun, Jiashi Feng, and Kate Saenko. Return of frustratingly easy domain adaptation. In AAAI, volume 30, 2016.
- Tachet des Combes et al. [2020] Remi Tachet des Combes, Han Zhao, Yu-Xiang Wang, and Geoffrey J Gordon. Domain adaptation with conditional distribution matching and generalized label shift. NeurIPS, 33, 2020.
- Tipping and Bishop [1999] Michael E Tipping and Christopher M Bishop. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(3):611–622, 1999.
- Tzeng et al. [2017] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7167–7176, 2017.
- Vega and Greiner [2018] Roberto Vega and Russ Greiner. Finding effective ways to (machine) learn fmri-based classifiers from multi-site data. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications, pages 32–39. Springer, 2018.
- Wen and Yin [2013] Zaiwen Wen and Wotao Yin. A feasible method for optimization with orthogonality constraints. Mathematical Programming, 142(1):397–434, 2013.
- Wen et al. [2014] Junfeng Wen, Chun-Nam Yu, and Russell Greiner. Robust learning under uncertain test distributions: Relating covariate shift to model misspecification. In ICML, pages 631–639. PMLR, 2014.
- Winter [1992] David J Winter. Matrix algebra. Macmillan, 1992.
- Zhang et al. [2013] Kun Zhang, Bernhard Schölkopf, Krikamol Muandet, and Zhikun Wang. Domain adaptation under target and conditional shift. In ICML, pages 819–827. PMLR, 2013.
- Zhao et al. [2018] Han Zhao, Shanghang Zhang, Guanhang Wu, José MF Moura, Joao P Costeira, and Geoffrey J Gordon. Adversarial multiple source domain adaptation. NeurIPS, 31:8559–8570, 2018.
- Zhao et al. [2019] Han Zhao, Remi Tachet Des Combes, Kun Zhang, and Geoffrey Gordon. On learning invariant representations for domain adaptation. In ICML, pages 7523–7532. PMLR, 2019.
Appendix A Mathematical details
A.1 Proof of Equation 2
Taking the derivative with respect to and making it equal to the zero vector:
Note that the second derivative is always non-negative, so is a minimum.
A.2 Proof of Equation 6
Substituting in , and using that for orthogonal matrices, and for invertible matrices and .:
A.3 Proof of Equation 11
For the case of the Equation 8 using the Gaussian kernel, and since , the gradient of the MMD between and a linear transformation of , , with respect to is:
Appendix B Code availability
The code for reproducing the results presented in this paper is publicly available at https://github.com/rvegaml/DA_Linear. It contains three main elements:
- •
-
•
Simulations.ipynb: A jupyter notebook with the code to reproduce the simulated experiments.
-
•
BinaryDigits.ipynb: A jupyter notebook with the code to reproduce our results with MNIST dataset.
During our experiments, we did not tune any parameter. The CNN was trained for a maximum of 500 epochs, using a learning rate of , and the default parameters of the Adam Optimizer. For the computation of the MMD we used a Gaussian kernel with .
Appendix C Extra figures