DoRA: Domain-Based Self-Supervised Learning Framework for Low-Resource Real Estate Appraisal
Abstract.
The marketplace system connecting demands and supplies has been explored to develop unbiased decision-making in valuing properties. Real estate appraisal serves as one of the high-cost property valuation tasks for financial institutions since it requires domain experts to appraise the estimation based on the corresponding knowledge and the judgment of the market. Existing automated valuation models reducing the subjectivity of domain experts require a large number of transactions for effective evaluation, which is predominantly limited to not only the labeling efforts of transactions but also the generalizability of new developing and rural areas. To learn representations from unlabeled real estate sets, existing self-supervised learning (SSL) for tabular data neglects various important features, and fails to incorporate domain knowledge. In this paper, we propose DoRA, a Domain-based self-supervised learning framework for low-resource Real estate Appraisal. DoRA is pre-trained with an intra-sample geographic prediction as the pretext task based on the metadata of the real estate for equipping the real estate representations with prior domain knowledge. Furthermore, inter-sample contrastive learning is employed to generalize the representations to be robust for limited transactions of downstream tasks. Our benchmark results on three property types of real-world transactions show that DoRA significantly outperforms the SSL baselines for tabular data, the graph-based methods, and the supervised approaches in the few-shot scenarios by at least 7.6% for MAPE, 11.59% for MAE, and 3.34% for HR10%. We expect DoRA to be useful to other financial practitioners with similar marketplace applications who need general models for properties that are newly built and have limited records. The source code is available at https://github.com/wwweiwei/DoRA.
1. Introduction
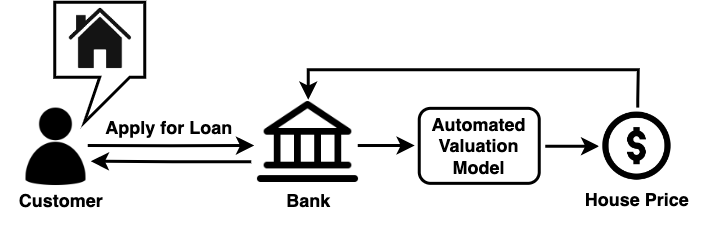
The exploration of property valuations has broad applicability across various domains. Whether it involves developing strategies for mortgage lending, house rental, or security price revaluation, these scenarios can be effectively framed as property valuation systems characterized by intricate and high-cost domain knowledge. In real estate appraisal, appraisers spend several hours estimating an individual property based on their knowledge (Das, 2021), which introduces subjective biases of human estimations due to different understandings of the market (Ahn et al., 2012). Recently, automated valuation models (AVMs) including machine learning (Lin and Chen, 2011; Azimlu et al., 2021) and graph-based approaches (Zhang et al., 2021; Li et al., 2022) have been developed to solve this issue by conducting a price estimation according to the information of real estate, as shown in Figure 1.
However, existing work adopting labeled datasets for supervised learning requires a large number of annotated labels and suffers from the generalization from seen to newly built appraisals. In real-world scenarios, another challenging constraint is that properties are often sparse or newly built in most areas. Beyond annotation costs, endlessly training specialized models on new types of real estate is not scalable in many practical scenarios. Therefore, it is desirable to have a systematic approach to learn generic knowledge from existing unlabeled types of transactions to achieve effective quality with only very few annotated examples. This problem is often defined as few-shot learning. We note that defining low-resource scenarios can be dependent on the goals and expectations of financial institutions and customers. For instance, it can be defined as the number of transactions per city, per property type, or the combination of different factors. In this paper, we aim to tackle the actual application scenarios of few-shot real estate appraisal: rural area, new developing area, and reducing label effort. Therefore, we define low-resource scenarios as the number of transactions per city. However, how to effectively utilize unlabeled records with a high variability of property types remains a challenging problem.
The rapid development of self-supervised learning (SSL) has demonstrated the remarkable power of learning representation by using temporal information in spatial structure in images (He et al., 2020; Chen et al., 2020), and semantic relationships in languages (Mikolov et al., 2013; Devlin et al., 2019). This is beneficial in few-shot scenarios from the generic knowledge of pre-trained models. However, the datasets of real estate appraisal are tabular domains which cannot directly apply these SSL techniques due to the different natures of their compositions (e.g., the 2D structure between pixels and the semantics between words). Thus, several SSL approaches have been proposed to learn the general latent representation of tabular data (Arik and Pfister, 2021; Ucar et al., 2021). Nonetheless, there is no existing approach that is able to integrate expert knowledge into the SSL objective for property estimation. Existing tabular-based SSL methods are feature-agnostic, which does not consider the meaning of the features and regards all features as having the same importance.
In this paper, we propose DoRA, a domain-based self-supervised learning framework to tackle the low-resource scenarios for real estate appraisal. In order to design an upstream task that produces universal representations, a pre-trained stage is introduced by solving the intra-sample domain-based pretext task (i.e., learning the appraiser’s knowledge) from the unlabeled set. In addition, inter-sample contrastive learning is proposed to distinguish the similarities and discrepancies between transactions across towns. In these manners, pre-trained embeddings generate robust representations in a lower dimension that contains more structured and domain-based information to use in the downstream task with only limited data. In the fine-tuning stage, the pre-trained embedders and encoder are reused as a feature extractor for converting downstream transactions with pre-trained embeddings, and the weights are then adjusted based on a few target examples.
To summarize, the contributions of our work are as follows:
-
•
To the best of our knowledge, DoRA is the first work focusing on low-resource real estate appraisal, which not only meets the needs of real-world scenarios but can also be adopted in other property valuations (e.g., house rental).
-
•
The proposed framework is introduced with novel and effective intra- and inter-sample SSL objectives to learn robust geographical knowledge from unlabeled records.
-
•
Extensive experiments were conducted to empirically show that DoRA is effective in few-shot settings compared with existing methods. We also illustrate a developed system of DoRA and the real-world industrial scenarios for cities and towns with extremely limited transactions.
2. Related Work
Real Estate Appraisal. Previous works defined real estate appraisal as a supervised regression problem, and addressed it with machine learning techniques (Ge et al., 2019; Zhang et al., 2021; Li et al., 2022). To incorporate multi-modal data sources for improving the performance, Zhao et al. (2019) took the visual content of rooms into account using a deep learning framework with XGBoost (Chen and Guestrin, 2016), while Bin et al. (2019) utilized street map images with attention-based neural networks. On the other hand, LUCE was proposed to tackle spatial and temporal sparsity with the lifelong learning heterogeneous information network consisting of graph convolutional networks and long short-term memory networks (Peng et al., 2020). Nonetheless, utilizing unlabeled transactions with high variability for low-resource real estate appraisal remains an unexplored yet challenging problem, which is also beneficial for property valuations. We, therefore, aimed to design a self-supervised learning approach to learn domain representations of transactions from the unlabeled set.
SSL in Tabular Data. Recently, SSL has achieved prominent success in the image (He et al., 2020; Chen et al., 2020), audio (Tagliasacchi et al., 2020), and text (Mikolov et al., 2013; Devlin et al., 2019) research fields. However, these approaches are often difficult to transfer to the tabular domain since tabular data do not have explicit structures to learn the contextualized representations. Therefore, multiple SSL approaches are proposed to learn the relation and latent structure between features in the tabular data domain (Yin et al., 2020; Yoon et al., 2020; Arik and Pfister, 2021; Ucar et al., 2021). However, there is another domain that has not yet been explored: SSL for property valuations, which is mainly comprised of records in tabular format, and requires domain knowledge to evaluate the property objectively. To that end, we have designed a pretext task based on domain knowledge and inter-sample contrastive learning to reinforce the model equipping domain-based contextualized representations of limited transactions for downstream tasks.
3. Preliminaries
3.1. Datasets
Our three datasets (building, apartment, and house) were collected from the Taiwan Real Estate Transaction Platform (Dept of Land Administration, 2023), which contains real estate transactions in Taiwan from 2015 to 2021. It is noted that the dataset of previous work (Li et al., 2022) is a subset of our collected building dataset since the authors adopted only the top 6 largest cities, while we expanded the dataset to all 22 cities and 3 different property types to accommodate more challenging but valuable real-world scenarios, and investigated the robustness of the model, especially for handling limited transactions. Following (Li et al., 2022), 3 months of transactions were used as the testing set (Apr. 2021 to Jun. 2021, 24,142 records), 3 months of transactions were used as the validation set (Jan. 2021 to Mar. 2021, 40,124 records), and the others were used as the training set. We note that most real estate in the training set does not have corresponding prices due to the maintenance of the transaction platform; therefore, we used these unlabeled cases to form the unlabeled set (434,243 records). We also collected two additional types of features to comprehensively describe the real estate from a neighboring and global view: PoI (Point of interest), and economic and geographical features. We summarize these features as follows due to space limitations.
Real Estate Features. Real estate has 39 features, including 16 categorical features and 23 numerical features to represent the metadata, for instance, location, the layout of the real estate, the current condition of the real estate, and household facilities.
PoI Features. The original data is in spatial distribution format. It was collected from a third-party map information company. We designed a PoI converter to transform the data into a tabular format by dividing the facilities into YIMBY (Yes In My Back Yard, i.e., desirable adjacent public facilities) facilities, e.g., park, school, and NIMBY (Not In My Back Yard, i.e., non-desirable adjacent public facilities) facilities, e.g., power station, landfill. Then, the number of PoI of the real estate property was calculated with the Euclidean distance. For instance, the feature YIMBY_100 denotes the number of YIMBY facilities within 100 meters.
Economic and Geographical Features. We added 7 external socio-economic features based on the real estate transaction quarter to represent the global view, including the house price index, unemployment rate, economic growth rate, lending rate, land transactions count, average land price index, and steel price index. We also incorporated the land area and population density by the town name to consider the number of residents and the demand.
3.2. Problem Formulation
As discussed in the Introduction, we randomly sampled 1 and 5 shots for each city from the labeled training set as annotated examples (i.e., support set) to estimate the value of the real estate, and each example consisted of real estate features, PoI features, and economic and geographical features. For instance, there is a total of 110 transactions in the 5-shot setting since the number of cities in Taiwan is 22. We note that one of the cities, Lianjiang, does not have any apartments due to the nature of the city; thus, the apartment dataset only has 105 instances in the 5-shot setting. It is noted that reporting each setting in the paper may not be feasible due to the page limit; therefore, we follow the standard few-shot settings (e.g., (Ma et al., 2022)) to report the overall performance in the experiments.
4. Method
The DoRA framework is illustrated in Figure 2. DoRA takes economic and geographical features, real estate features, and PoI features as inputs. The architecture of DoRA is mainly comprised of the embedder, encoder, and predictors. The training pipeline is decomposed into two phases: Pre-training stage: Train by intra-sample pretext task and inter-sample contrastive learning to learn contextualized representations. Fine-tuning stage: Train with labeled data to predict the values of real estate.
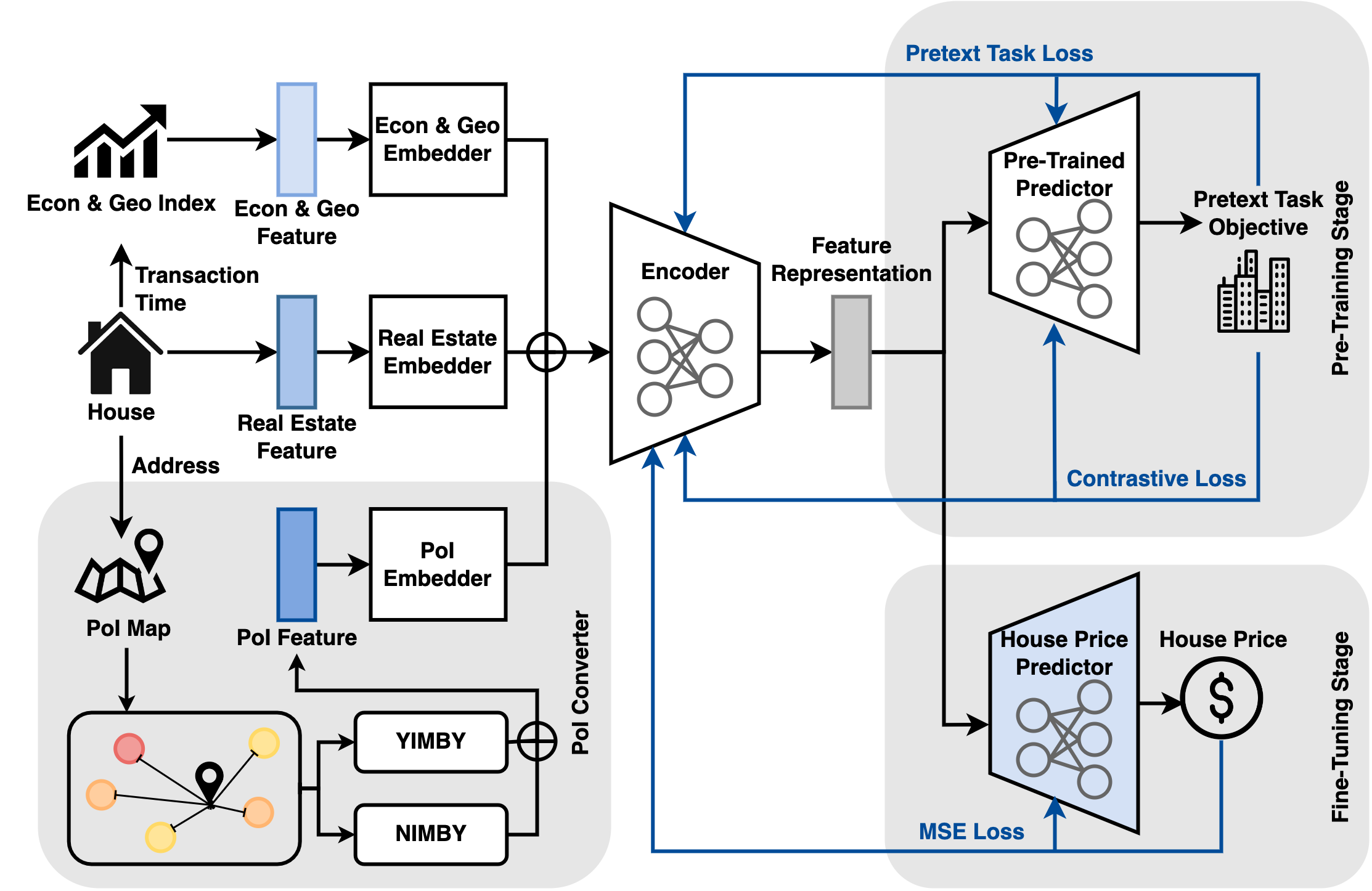
4.1. Model Architecture
Embedder. The heterogeneous input features can be categorized into 4 types: numerical real estate features, categorical real estate features, numerical economic and geographical features, and numerical PoI features. The numerical real estate features of -th real estate are embedded as follows:
| (1) |
where the dimensions of and are and 23, respectively.
To encode categorical real estate features, a naive method is to represent with one-hot encodings, which become sparse for high dimensions of categories and fail to preserve contextual information across features. Thus, each category of real estate features is encoded separately and then concatenated as the categorical real estate embeddings:
| (2) |
| (3) |
where indicates the index of the 16 categorical real estate features, is the concatenation operator, and the dimensions of and are and , respectively.
Similarly, two embedders with the same architecture are employed as the numerical real estate embedder to encode numerical economic and geographical features and PoI features of the -th real estate property, respectively:
| (4) |
| (5) |
where the input dimensions of and are 9 and 16, respectively, and the dimensions of and are and .
The aforementioned embedders are composed of an MLP and a Mish activation function (Misra, 2019) similar to (Li et al., 2022). Afterwards, the embedding of the -th real estate is then concatenated as:
| (6) |
where .
Encoder. To encode the -th embedding of real estate, the encoder is introduced to learn the contextualized feature representation during both the pre-training and fine-tuning stages:
| (7) |
where is a dimension vector. Since existing work on SSL for tabular data mainly focuses on the strategies of pretext tasks (Yoon et al., 2020; Ucar et al., 2021), we also adopt MLPs with layers to align the comparison, where the number of layers of the encoder is optimized to ensure it is able to perform competitive performance of the pretext task (Section 5.2). The output of the encoder can then be used to learn prior knowledge from the pre-training stage and downstream tasks from the fine-tuning stage.
4.2. Pre-Training DoRA
Intra-Sample Pretext Task: Located Town Prediction. To enrich the feature representations from the unlabeled set, an intuitive method for designing the pretext task is to add noise and reconstruct the input, e.g., (Yoon et al., 2020), which treats all features with the same importance but neglects the domain knowledge of the meaning of the features. Inspired by a recent study (Lee et al., 2021) on the conceptual connections of features between pretext and downstream tasks benefiting the downstream tasks, we introduce a domain-based pretext task: predict the located town of the given real estate, which can also be adopted in various geographic-related tasks (e.g., house rental). The input features of the real estate do not include the located town to avoid cheating. In this way, the model is equipped with fine-grained domain knowledge to distinguish what might be the composition of real estate for each city, which benefits downstream tasks with limited transactions.
Pre-Trained Predictor. The pre-trained predictor takes the feature representation of the -th real estate property as the input, and predicts the corresponding town with an MLP and the softmax activation function, where the number of is 350:
| (8) |
Pre-Training Loss. During the pre-training stage, the embedders, encoder, and pre-trained predictor are jointly trained in the following optimization problem:
| (9) |
where adjusts the weight between the two losses, is the ground-truth of the located town, and , . is the cross-entropy loss:
| (10) |
where C denotes the number of the unlabeled set.
Inter-Sample Contrastive Learning. Since cross-entropy is sensitive to noisy labels and lessens generalization performance (Zhang and Sabuncu, 2018; Elsayed et al., 2018), we extend contrastive learning (CL) to incorporate label information to consider the similarities and discrepancies between real estate across towns. is defined as:
| (11) |
where is the set of indices of all positive pairs, is the set of all positive and negative pairs, is a temperature parameter, and is the instances (i.e., real estate) in a batch. Positive pairs represent the two instances located in the same town, while negative pairs represent the two instances located in different towns. As a result, is one of the contextualized embeddings that is sampled from the same town within the batch as the positive pairs for CL. By optimizing , embeddings with the same class are closer, and embeddings from different classes are pulled over.
4.3. Fine-Tuning DoRA
House Price Predictor. To train a regressor for the house price prediction, the feature representations of the pre-trained encoder of the -th real estate property are fed into the house price predictor:
| (12) |
where is the estimated price.
Fine-Tuning Loss. To optimize the estimated prices of real estate, the pre-trained embedders, pre-trained encoder, and the house price predictor of DoRA are jointly fine-tuned by minimizing the mean square error loss :
| (13) |
where is the support set and is the -th ground truth price.
5. Experiments
In this section, we attempt to answer the following research questions on three property types of real-world real estate datasets:
| Building | Apartment | House | |||||||||
| Type | Model | MAPE () | MAE () | HR10% () | MAPE () | MAE () | HR10% () | MAPE () | MAE () | HR10% () | |
| STA | HA | 45.360.97 | 12.930.25 | 13.910.09 | 46.202.73 | 16.740.36 | 13.691.19 | 43.400.84 | 7.740.04 | 18.290.19 | |
| SUP | LR | 213.1151.6 | 33.9524.52 | 4.614.42 | 153.319.65 | 34.216.57 | 3.691.68 | 167.640.80 | 27.236.66 | 4.242.94 | |
| XGBoost | 50.4611.12 | 13.223.24 | 11.423.75 | 40.212.47 | 14.172.22 | 16.861.70 | 52.693.32 | 9.771.51 | 13.803.58 | ||
|
41.312.14 | 13.060.74 | 12.501.94 | 40.842.96 | 15.721.27 | 13.562.52 | 37.934.65 | 8.060.47 | 16.201.17 | ||
|
41.682.41 | 12.850.77 | 12.321.49 | 38.341.41 | 14.472.04 | 14.682.88 | 37.000.82 | 7.860.87 | 16.204.04 | ||
| SSL | DAE | 44.670.90 | 12.931.47 | 12.510.68 | 45.170.90 | 14.252.30 | 14.160.44 | 38.402.81 | 6.780.14 | 21.770.84 | |
| SubTab | 39.203.49 | 22.327.30 | 12.963.46 | 37.990.79 | 14.340.45 | 17.440.81 | 41.961.31 | 14.230.86 | 13.772.95 | ||
| Graph | MugRep | 52.2812.03 | 22.743.44 | 11.533.63 | 51.6213.52 | 22.048.52 | 12.221.80 | 51.3810.86 | 21.877.12 | 11.654.69 | |
| ReGram | 41.831.31 | 14.473.65 | 12.773.30 | 42.361.25 | 13.093.31 | 14.900.86 | 39.130.31 | 7.940.27 | 16.941.06 | ||
|
38.772.85 | 11.160.85 | 14.531.24 | 33.731.04 | 10.512.14 | 19.552.25 | 33.591.59 | 6.530.25 | 22.411.72 | ||
| Building | Apartment | House | ||||||||
| Type | Model | MAPE () | MAE () | HR10% () | MAPE () | MAE () | HR10% () | MAPE () | MAE () | HR10% () |
| STA | HA | 45.170.97 | 13.040.24 | 13.780.09 | 46.202.73 | 17.030.19 | 13.691.19 | 45.742.66 | 7.770.04 | 18.470.25 |
| SUP | LR | 99.7434.19 | 17.383.06 | 10.062.46 | 127.097.30 | 30.5915.23 | 8.583.98 | 245.2277.1 | 39.7037.55 | 6.756.11 |
| XGBoost | 34.752.46 | 8.630.82 | 18.764.65 | 39.5311.50 | 11.652.40 | 20.544.53 | 36.298.74 | 7.591.58 | 23.002.64 | |
|
37.711.17 | 11.071.09 | 14.461.63 | 38.663.14 | 14.621.52 | 15.410.85 | 33.740.62 | 7.300.71 | 17.244.37 | |
|
36.772.10 | 10.941.21 | 15.232.91 | 37.553.46 | 13.310.92 | 16.171.83 | 34.541.04 | 7.630.63 | 16.363.91 | |
| SSL | DAE | 43.931.47 | 11.731.51 | 13.731.38 | 43.732.15 | 12.860.88 | 15.621.04 | 39.690.64 | 7.170.89 | 19.963.82 |
| SubTab | 35.290.38 | 14.829.00 | 22.650.19 | 33.481.94 | 10.310.35 | 22.642.06 | 40.602.50 | 11.640.12 | 21.910.28 | |
| Graph | MugRep | 52.1210.32 | 18.061.33 | 9.802.95 | 48.227.87 | 18.503.08 | 11.453.07 | 47.059.25 | 11.704.77 | 14.114.27 |
| ReGram | 40.580.41 | 13.022.50 | 13.211.61 | 41.191.71 | 14.863.33 | 14.210.38 | 37.071.86 | 8.130.39 | 14.826.09 | |
| DoRA (Ours) | 31.850.50 | 7.790.23 | 20.160.64 | 30.270.31 | 9.820.15 | 20.540.52 | 31.660.27 | 6.280.05 | 23.130.10 | |
5.1. Experimental Setup
Implementation Details. The dimensions of , , and are 16, the dimension of is 10, and the dimension of is 256. The number of layers of the encoder is 6 and is designed with hidden dimensions in order. We set weight as 0.7 and temperature as 0.1. For the numerical features, we impute them with standard normalization. In the fine-tuning stage, both DoRA and other baselines use an MLP as the house price predictor. We employ the AdamW optimizer (Loshchilov and Hutter, 2019) using the learning rate of 0.005, and the batch size is 512. During the pre-training stage, we use all property types of unlabeled sets to learn a pre-trained model to enforce the generalizability and then fine-tune based on various property type datasets. The training epochs of the pre-training and fine-tuning stages are 150 and 200, respectively. All of the hyper-parameters in the experiment were tuned based on the validation set. All experiments were repeated 5 times with different random seeds for sampling support sets to reduce the bias of few-shot sampling and to report average metrics with standard deviations for each evaluation metric.
Evaluation Metrics. Previous work mainly focused on regression metrics for evaluating house price prediction (Zhang et al., 2021; Li et al., 2022). We extended these metrics with hit rate k% (Goodman and Thibodeau, 2003) to measure the accuracy of target properties within a tolerance error percentage k conforming to real-world financial requirements. Therefore, we adopted mean absolute percentage error (MAPE), mean absolute error (MAE), and hit rate 10% (HR10%) to comprehensively evaluate the results.
Baselines. The baselines can be categorized into four groups: 1) Statistics model (STA): Historical Average (HA), 2) Supervised models (SUP): Linear Regression (LR), XGBoost (Chen and Guestrin, 2016), DNN, and DNN with contrastive learning (DNN + CL), 3) Self-supervised models (SSL): DAE (Vincent et al., 2008) and SubTab (Ucar et al., 2021), and 4) Graph-based models (Graph): MugRep (Zhang et al., 2021) and ReGram (Li et al., 2022). The SSL baselines are also pre-trained using the unlabeled set and are then fine-tuned to the house price prediction task.
5.2. Overall Performance
The pre-training performance of DoRA reaches about 0.85 and 0.96 in terms of macro-f1 and micro-f1 scores to ensure that DoRA is capable of detecting the geographic locations of real estate. Table 1 and Table 2 summarize the performance comparisons of various methods with 1-shot and 5-shot scenarios. The best result of each metric is highlighted in boldface and the second best is underlined. Quantitatively, the improvement in DoRA is at least 7.6% for MAPE, 11.59% for MAE, and 3.34% for HR10% on average for the three property types. We make the following observations:
1) DoRA consistently outperforms STA, SUP, SSL, and Graph approaches for the building, apartment, and house datasets with limited transactions, while some SUP models (e.g., XGBoost) are even inferior to the performance compared to the statistics-based method in the 1-shot scenario. Moreover, SUP approaches significantly hinder the performance of all datasets, which indicates that supervised methods require a large amount of labeled data to achieve competitive performance. We can also observe that graph-based methods considering the neighbor’s information to construct a graph perform worse since most rural real estate does not have neighbors. 2) DAE and SubTab perform worse than DoRA in terms of all metrics and different scenarios, which verifies that randomly adding noise to the inputs and regarding all features with the same importance hinder models’ learning of domain-based representations from the unlabeled set. This also points out the attribution of taking advantage of the intra-sample domain-based pretext task in DoRA capable of improving downstream performance. 3) We also notice that adding contrastive loss to the DNN slightly improves some metrics, which implies that contrastive learning enriches representations for the downstream task, even when only applying limited data.
|
|
CL () |
|
MAPE () | |||||||
| Building | Town | + (0.7) | 256 | ✓ | 37.09 | ||||||
| All | Town | + (0.7) | 512 | ✓ | 33.65 | ||||||
| All | Town | + (0.7) | 256 | ✗ | 58.65 | ||||||
| All | Town | - | 256 | ✓ | 37.83 | ||||||
| All | Town | + (0.5) | 256 | ✓ | 36.37 | ||||||
| All | Town | + (0.7) | 256 | ✓ | 31.85 |
| Building | Apartment | House | ||||||||
| Area | Model | MAPE () | MAE () | HR10% () | MAPE () | MAE () | HR10% () | MAPE () | MAE () | HR10% () |
| Nantun District, Taichung | XGBoost | 39.91 | 7.93 | 0.00 | 38.74 | 12.45 | 4.72 | 33.63 | 10.68 | 20.00 |
| DoRA | 15.82 | 2.77 | 40.00 | 21.53 | 10.15 | 16.04 | 22.53 | 9.95 | 35.33 | |
| Wugu District, New Taipei | XGBoost | 54.63 | 11.74 | 16.67 | 65.11 | 16.62 | 0.00 | 162.85 | 28.53 | 0.00 |
| DoRA | 34.77 | 6.20 | 19.67 | 61.58 | 10.61 | 4.46 | 2.55 | 0.44 | 100.00 | |
| Nantou City, Nantou County | XGBoost | 52.69 | 6.86 | 7.69 | 61.58 | 10.61 | 4.46 | 34.86 | 7.52 | 10.14 |
| DoRA | 39.65 | 5.14 | 15.38 | 32.57 | 6.49 | 11.76 | 31.73 | 5.36 | 24.64 | |
5.3. Ablation Study
Model Ablation. We study a comprehensive component ablation with the building dataset in the 5-shot scenario in terms of MAPE. As shown in Table 3, only using the unlabeled set of the corresponding type (building type in row 1) significantly degenerates the downstream performance, which signifies that DoRA is able to leverage the unlabeled set from various types to improve model performance on the house price prediction. Rows 2, 3, 4, and 5 present the sensitivity analysis of different hyper-parameters, which shows that removing contrastive loss and changing the weight of reduce the performance more substantially. In addition, freezing the pre-trained encoder and using the different dimensions of feature representations also negatively impact the house price performance.
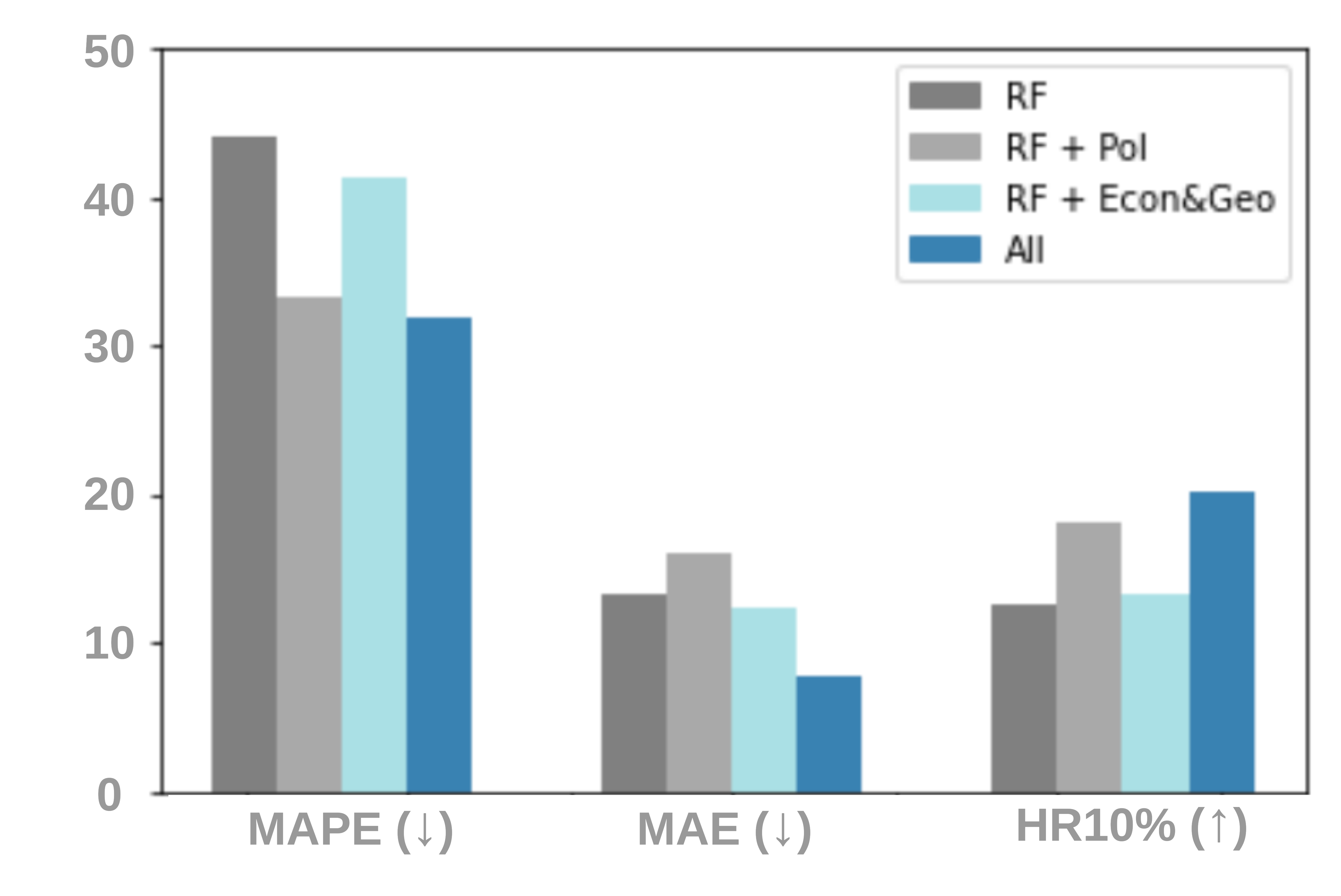
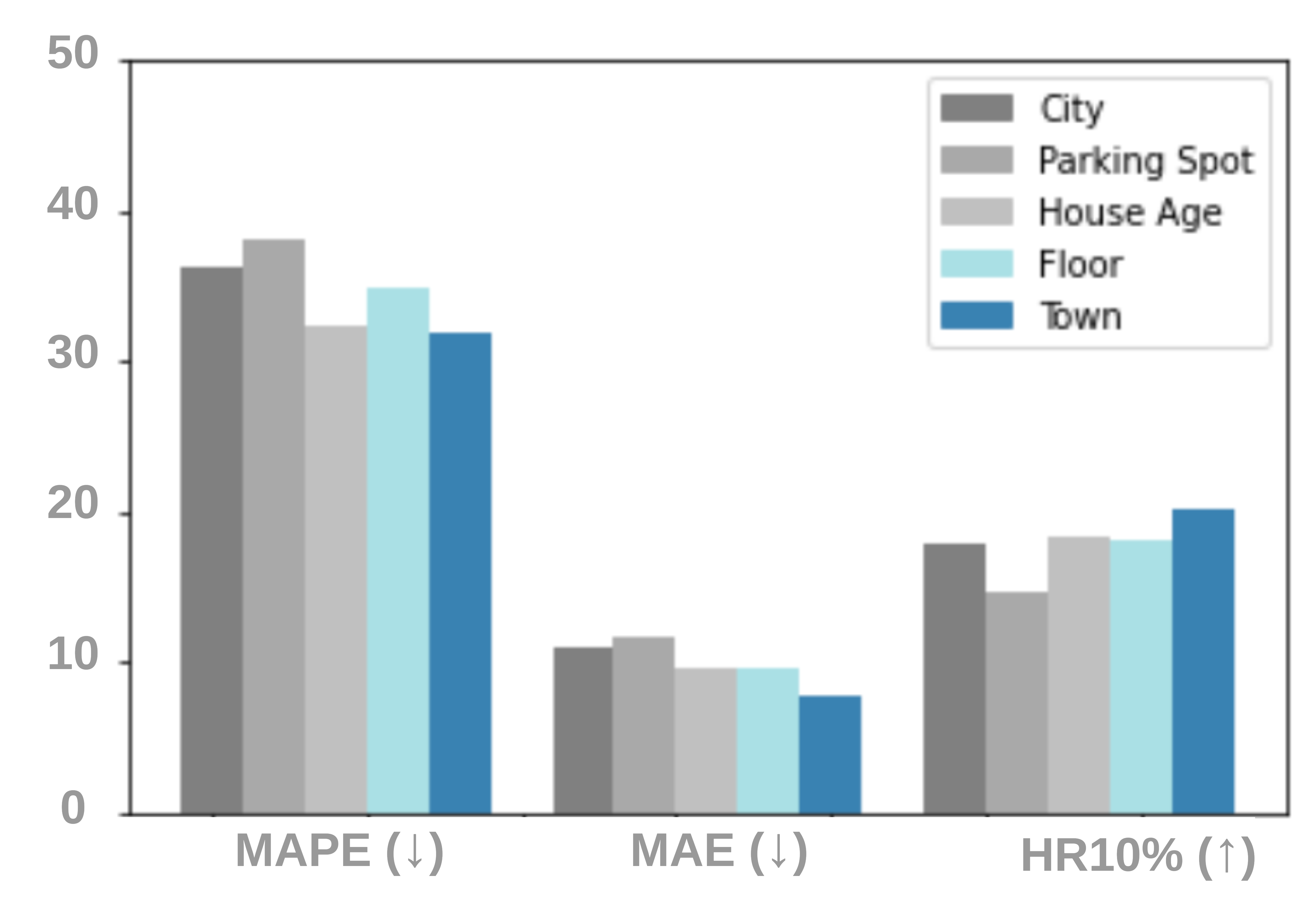
Feature and Pretext Task Ablations. To investigate the relative effects of different feature sources, we evaluate DoRA with full features and its three variants: 1) RF includes only real estate features, which is the basic feature to describe real estate; 2) RF+PoI includes both real estate features and PoI features; 3) RF+Econ&Geo includes both real estate features and economic and geographical features; 4) All includes the complete set of features. Figure 3(a) reports the performance with the building dataset in the 5-shot setting. Removing either PoI features or economic and geographical features leads to inferior performance in terms of all metrics. Moreover, PoI features affect the performance more considerably compared with economic and geographical features, which indicates that the neighboring facilities are critical factors for real estate appraisal. These observations suggest that considering only the metadata of real estate is insufficient for house price prediction, while various sources of describing real estate from a global viewpoint enhance the capability of the model. We also examine various pretext tasks as shown in Figure 3(b), which replaces the original pretext task with another pretext task from the real estate metadata. We can observe that all metrics performance of replacing with different pretext tasks is degraded, which empirically showcases the importance of the pretext task objective.
5.4. Deployment
Deployed System. E.SUN Bank is a commercial bank encouraging AI-driven solutions for businesses in Taiwan. In the past, real estate appraisal tasks were primarily manual, high-cost, and subjective to the appraiser. Moreover, it is challenging to estimate real estate if there are limited historical transactions. To that end, we partnered with the fintech team to deploy automated DoRA to perform an online mortgage calculator platform, which requires real estate appraisal for suggesting the mortgage. In the prototype system, the user is required to enter the information (e.g., address, house age, parking space, etc.) of the property that is to be mortgaged. DoRA will then execute an online real estate appraisal by extracting the PoI features based on the house address as part of the inputs. Afterwards, the appraised price will be incorporated with other internal entities to compute the approximate loan.
Case Study. As the distribution of transactions for each city is a long-tail distribution, the great majority of the cities only have a few transactions. Therefore, we simulated three cities with extremely limited transactions and compared DoRA with XGBoost. As shown in Table 4, we can observe that DoRA is significantly superior to the baseline for all metrics, particularly in property types where it fails to appraise real estate with 0 hit rate scores. The performance of the house type in Wugu District shows that DoRA appraises effectively while the baseline deteriorates all metrics more substantially. These cases confirm that DoRA is capable of low-resource scenarios due to the incorporation of the unlabeled set. In partnership with the fintech team, such an improvement definitely improves resource utilization and performance of the real estate appraisal.
6. Conclusion
In this work, we propose DoRA, a domain-based SSL framework for low-resource real estate appraisal, which is one of the challenging property valuation tasks due to heavy human efforts. Predicting the geographic location as an intra-sample pretext task reinforces the model learning the domain-based representations of real estate. Moreover, DoRA integrates inter-sample contrastive learning to distinguish the discrepancies between transactions across towns for the robustness of limited examples in downstream tasks. Extensive results on different property types of real-world real estate appraisals demonstrate that DoRA consistently outperforms supervised, graph, and SSL approaches in few-shot scenarios.
Prior to this work, real estate estimations with new and rural transactions were mainly evaluated by appraisers using manual, ad-hoc, intuition-driven methods at E.SUN Bank. Now, fintech teams have adopted DoRA for automatically estimating values of real estate, which saves time and drives objectivity in the business, and empowers the financial institution to plan and adapt dynamically to new information. As our proposed approach was flexibly designed with SSL, we expect DoRA to be useful to other applied scientists in financial marketplaces, especially those whose goal is to perform property valuation with only a few labeled data.
7. Acknowledgments
We would like to thank Fu-Chang Sun, Yi-Hsun Lin, Hsien-Chin Chou, Chih-Chung Sung, and Leo Chyn from E.SUN Bank for sharing data and discussing the findings.
References
- (1)
- Ahn et al. (2012) Jae Joon Ahn, Hyun Woo Byun, Kyong Joo Oh, and Tae Yoon Kim. 2012. Using ridge regression with genetic algorithm to enhance real estate appraisal forecasting. Expert Syst. Appl. 39, 9 (2012), 8369–8379.
- Arik and Pfister (2021) Sercan Ö. Arik and Tomas Pfister. 2021. TabNet: Attentive Interpretable Tabular Learning. In AAAI. AAAI Press, 6679–6687.
- Azimlu et al. (2021) Fateme Azimlu, Shahryar Rahnamayan, and Masoud Makrehchi. 2021. House price prediction using clustering and genetic programming along with conducting a comparative study. In GECCO Companion. ACM, 1809–1816.
- Bin et al. (2019) Junchi Bin, Bryan Gardiner, Zheng Liu, and Eric Li. 2019. Attention-based multi-modal fusion for improved real estate appraisal: a case study in Los Angeles. Multim. Tools Appl. 78, 22 (2019), 31163–31184.
- Chen and Guestrin (2016) Tianqi Chen and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. In KDD. ACM, 785–794.
- Chen et al. (2020) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. 2020. A Simple Framework for Contrastive Learning of Visual Representations. In ICML (Proceedings of Machine Learning Research, Vol. 119). PMLR, 1597–1607.
- Das (2021) Prashant Das. 2021. Machines vs Humans: Real Estate Valuation During Coronavirus. https://hospitalityinsights.ehl.edu/real-estate-valuation-covid-19-crisis.
- Dept of Land Administration (2023) M.O.I. Dept of Land Administration. 2023. Taiwan Real Estate Transaction Platform. https://lvr.land.moi.gov.tw/
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT (1). Association for Computational Linguistics, 4171–4186.
- Elsayed et al. (2018) Gamaleldin F. Elsayed, Dilip Krishnan, Hossein Mobahi, Kevin Regan, and Samy Bengio. 2018. Large Margin Deep Networks for Classification. In NeurIPS. 850–860.
- Ge et al. (2019) Chuancai Ge, Yang Wang, Xike Xie, Hengchang Liu, and Zhengyang Zhou. 2019. An Integrated Model for Urban Subregion House Price Forecasting: A Multi-source Data Perspective. In ICDM. IEEE, 1054–1059.
- Goodman and Thibodeau (2003) Allen C Goodman and Thomas G Thibodeau. 2003. Housing market segmentation and hedonic prediction accuracy. Journal of Housing Economics 12, 3 (2003), 181–201.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. 2020. Momentum Contrast for Unsupervised Visual Representation Learning. In CVPR. Computer Vision Foundation / IEEE, 9726–9735.
- Lee et al. (2021) Jason D. Lee, Qi Lei, Nikunj Saunshi, and Jiacheng Zhuo. 2021. Predicting What You Already Know Helps: Provable Self-Supervised Learning. In NeurIPS. 309–323.
- Li et al. (2022) Chih-Chia Li, Wei-Yao Wang, Wei-Wei Du, and Wen-Chih Peng. 2022. Look Around! A Neighbor Relation Graph Learning Framework for Real Estate Appraisal. CoRR abs/2212.12190 (2022).
- Lin and Chen (2011) Hongyu Lin and Kuentai Chen. 2011. Predicting price of Taiwan real estates by neural networks and support vector regression. In Proc. of the 15th WSEAS Int. Conf. on Syst. 220–225.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In ICLR (Poster). OpenReview.net.
- Ma et al. (2022) Jie Ma, Miguel Ballesteros, Srikanth Doss, Rishita Anubhai, Sunil Mallya, Yaser Al-Onaizan, and Dan Roth. 2022. Label Semantics for Few Shot Named Entity Recognition. In ACL (Findings). Association for Computational Linguistics, 1956–1971.
- Mikolov et al. (2013) Tomás Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. In ICLR (Workshop Poster).
- Misra (2019) Diganta Misra. 2019. Mish: A self regularized non-monotonic activation function. arXiv preprint arXiv:1908.08681 (2019).
- Peng et al. (2020) Hao Peng, Jianxin Li, Zheng Wang, Renyu Yang, Mingzhe Liu, Mingming Zhang, Philip S. Yu, and Lifang He. 2020. Lifelong Property Price Prediction: A Case Study for the Toronto Real Estate Market. CoRR abs/2008.05880 (2020).
- Tagliasacchi et al. (2020) Marco Tagliasacchi, Beat Gfeller, Felix de Chaumont Quitry, and Dominik Roblek. 2020. Pre-Training Audio Representations With Self-Supervision. IEEE Signal Process. Lett. 27 (2020), 600–604.
- Ucar et al. (2021) Talip Ucar, Ehsan Hajiramezanali, and Lindsay Edwards. 2021. SubTab: Subsetting Features of Tabular Data for Self-Supervised Representation Learning. In NeurIPS. 18853–18865.
- Vincent et al. (2008) Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. 2008. Extracting and composing robust features with denoising autoencoders. In ICML (ACM International Conference Proceeding Series, Vol. 307). ACM, 1096–1103.
- Yin et al. (2020) Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In ACL. Association for Computational Linguistics, 8413–8426.
- Yoon et al. (2020) Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. 2020. VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain. In NeurIPS.
- Zhang et al. (2021) Weijia Zhang, Hao Liu, Lijun Zha, Hengshu Zhu, Ji Liu, Dejing Dou, and Hui Xiong. 2021. MugRep: A Multi-Task Hierarchical Graph Representation Learning Framework for Real Estate Appraisal. In KDD. ACM, 3937–3947.
- Zhang and Sabuncu (2018) Zhilu Zhang and Mert R. Sabuncu. 2018. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In NeurIPS. 8792–8802.
- Zhao et al. (2019) Yun Zhao, Girija Chetty, and Dat Tran. 2019. Deep Learning with XGBoost for Real Estate Appraisal. In SSCI. IEEE, 1396–1401.